5.6 — Mixed-Effects / Hierarchical Models (মিশ্র-প্রভাব ও স্তরায়িত মডেল)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — "যখন data নিজেই স্তরে স্তরে সাজানো"¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন নতুন প্রশ্ন¶
5.1-এ আমরা regression-এর ভিত্তি গেঁথেছিলাম: একটা response \(y\)-কে predictor \(x\)-এর রৈখিক function ধরা, \(y = X\beta + \varepsilon\), আর OLS দিয়ে \(\hat\beta = (X^\top X)^{-1}X^\top y\) বের করা। কিন্তু সেই গোটা যন্ত্রটার নিচে একটা নীরব, অথচ অত্যন্ত গুরুত্বপূর্ণ অনুমান লুকিয়ে ছিল — error-গুলো পরস্পর-স্বাধীন (\(\varepsilon_i\) আর \(\varepsilon_{i'}\)-এর মধ্যে কোনো সম্পর্ক নেই) এবং তাদের ভেদ ধ্রুব (\(\operatorname{Var}(\varepsilon_i)=\sigma^2\), সবার জন্য এক)। এই স্বাধীনতা-অনুমানই OLS-এর standard error, t-test, confidence interval — সব inference-কে বৈধতা দেয়।
5.3-এ আমরা শিখেছি একাধিক group-এর mean তুলনা করতে: model \(y_{gi}=\mu+\tau_g+\varepsilon_{gi}\), যেখানে group-effect \(\tau_g\) ছিল একেকটা নির্দিষ্ট, অজানা ধ্রুবক — অর্থাৎ একটা fixed effect। আর 2.6-এ শিখেছি দুই চলক পরস্পর-স্বাধীন না হলে কী হয় — তাদের মধ্যে covariance ও correlation থাকে।
এই তিনটে সুতো এই অধ্যায়ে এসে এক জায়গায় জড়ো হবে। কারণ বাস্তবে প্রায়ই এমন data আসে, যেখানে 5.1-এর সেই স্বাধীনতা-অনুমানটা আর সত্য থাকে না — আর তখন সাদা চোখে OLS চালানো মানে নিজেকে নিজে ঠকানো। কেন, আর তার বদলে কী — সেটাই এই অধ্যায়।
১.২ Hook — data যখন গুচ্ছে গুচ্ছে আসে¶
একটা চেনা পরিস্থিতি ভাবুন। আপনি দেখতে চান পড়ার সময় (study hours) পরীক্ষার নম্বরে কতটা প্রভাব ফেলে। আপনি ২৫টি স্কুল থেকে মোট কয়েকশো ছাত্রের data জোগাড় করলেন — প্রতিটি ছাত্রের জন্য তার সাপ্তাহিক পড়ার ঘণ্টা (\(x\)) আর পরীক্ষার নম্বর (\(y\))। স্বাভাবিক প্রথম ভাবনা: সব ছাত্রকে একসাথে ফেলে একটা সরল regression \(y = \beta_0 + \beta_1 x + \varepsilon\) চালাও।
কিন্তু এক মুহূর্ত থামুন। এই data-টা কি সত্যিই "কয়েকশো স্বাধীন ছাত্র"? নাকি এটা আসলে স্তরে স্তরে সাজানো — ছাত্ররা স্কুলের ভেতরে বাসা বেঁধে আছে (students nested within schools)? একটা স্কুল হয়তো ধনী এলাকায়, ভালো শিক্ষক, শান্ত পরিবেশ; আরেকটা স্কুল হয়তো ঠিক উল্টো। তাহলে একই স্কুলের দুই ছাত্র গোটা দেশ থেকে এলোমেলোভাবে তোলা দুই ছাত্রের চেয়ে নিজেদের মধ্যে বেশি একরকম হবে — দুজনেই একই ভালো (বা খারাপ) স্কুল-পরিবেশ ভাগ করে নিচ্ছে।
এই পরিস্থিতি একটুও বিরল নয়; বরং বাস্তব data-র এটাই প্রায়-নিয়ম। আরও কয়েকটা মুখ:
- রোগী → হাসপাতাল। একই হাসপাতালের দুই রোগীর চিকিৎসা-ফলাফল কাছাকাছি হওয়ার ঝোঁক বেশি — একই ডাক্তার, একই যন্ত্রপাতি, একই প্রোটোকল।
- একই ব্যক্তির ওপর বারবার মাপ (repeated measurements)। একজন মানুষের রক্তচাপ যদি সাত দিন ধরে রোজ মাপি, সেই সাতটা মান পরস্পর-স্বাধীন নয় — সবগুলোই একই ব্যক্তির, তাই কাছাকাছি।
- শ্রমিক → কারখানা, গাছ → বাগান, পণ্য → দোকান — তালিকা অশেষ।
প্রতিটি ক্ষেত্রে গঠনটা এক: পর্যবেক্ষণগুলো group/cluster-এ জড়ো (গুচ্ছবদ্ধ, clustered), এবং একই group-এর পর্যবেক্ষণ পরস্পর-স্বাধীন নয় — তারা group-এর সাধারণ একটা প্রভাব ভাগ করে নেয়, তাই পরস্পর correlated।
এক বাক্যে hook: বাস্তব data প্রায়ই স্তরায়িত — ছাত্র স্কুলে, রোগী হাসপাতালে, বারবার-মাপ এক ব্যক্তিতে — আর একই group-এর সদস্যরা পরস্পরের সঙ্গে সম্পর্কিত (correlated), তাই "সব পর্যবেক্ষণ স্বাধীন" — 5.1-এর OLS-এর এই ভিত্তি-অনুমান এখানে আর খাটে না।
১.৩ অনুমানটা ভাঙলে আসলে কী ক্ষতি হয়¶
"পর্যবেক্ষণগুলো স্বাধীন নয়" — শুনতে নিরীহ একটা টীকা মনে হতে পারে। কিন্তু এর ফল মোটেই নিরীহ নয়; এটাই এই অধ্যায়ের প্রাণপ্রশ্ন, তাই খুলে বলি।
ভাবুন আপনার data-য় ২৫টি স্কুল, প্রতিটিতে গড়ে ২০ জন ছাত্র — মোট ৫০০ জন। সাদা OLS চালালে সে ধরে নেয় তার হাতে ৫০০টি স্বাধীন তথ্য-টুকরো আছে। কিন্তু যদি একই স্কুলের ছাত্ররা পরস্পর প্রবলভাবে একরকম হয়, তবে একটা স্কুলের ২০ জন ছাত্র কার্যত ২০টি আলাদা স্বাধীন কণ্ঠস্বর নয় — তারা অনেকটা যেন একটিই কণ্ঠস্বরের ২০টি প্রতিধ্বনি। চরম ক্ষেত্রে (যখন একই স্কুলের ছাত্ররা প্রায় অভিন্ন) ২৫টি স্কুলের ৫০০ ছাত্র কার্যকরভাবে মাত্র ২৫টি স্বাধীন তথ্যের সমান।
এবার মনে করুন 4.x থেকে — standard error প্রায় \(1/\sqrt{n}\)-এর মতো করে ছোট হয়, যেখানে \(n\) হলো স্বাধীন নমুনার সংখ্যা। OLS যদি ভুল করে \(n=500\) ধরে, অথচ কার্যকর স্বাধীন তথ্য আছে অনেক কম, তবে সে standard error-কে প্রয়োজনের চেয়ে অনেক ছোট হিসাব করবে। ফলাফল:
- confidence interval হবে আসলের চেয়ে সংকীর্ণ — আমরা যত নিশ্চিত হওয়ার কথা, তার চেয়ে বেশি নিশ্চিত মনে করব।
- p-value হবে মিথ্যা-ছোট — যে effect আসলে অনিশ্চিত, সেটাকেও "তাৎপর্যপূর্ণ (significant)" বলে ফেলব।
- এক কথায়, আমাদের inference হবে over-confident (অতি-আত্মবিশ্বাসী) — পরিসংখ্যানের সবচেয়ে বিপজ্জনক ভুলগুলোর একটি, কারণ এতে ভুল আবিষ্কারে শিলমোহর পড়ে যায়।
এই অধ্যায়ের একটা মূল সংখ্যাও (§৫-৬-এ যাচাই হবে) ঠিক এটাই দেখায়: একই exam-score data-য় clustering উপেক্ষা করে pooled OLS চালালে intercept-এর standard error আসে প্রায় \(0.87\), অথচ clustering ঠিকভাবে ধরা mixed model দেয় প্রায় \(1.42\) — অর্থাৎ clustering উপেক্ষা করলে cluster-স্তরের (intercept-জাতীয়) অনিশ্চয়তা কার্যত প্রায় ৪০% কম দেখানো হয়। (লক্ষণীয়, within-school predictor hours-এর slope-SE এর উল্টো আচরণ করে — তা §৩ ও §৪.২-তে খোলা হলো।) বাস্তবে যতটা জানি, আমরা তার চেয়ে অনেক বেশি জানি বলে ভান করি।
এক বাক্যে ক্ষতি: clustering উপেক্ষা করলে OLS ভুল করে ভাবে তার হাতে আসলের চেয়ে অনেক বেশি স্বাধীন তথ্য আছে, তাই standard error মিথ্যা-ছোট হয় — confidence interval সংকীর্ণ, p-value স্ফীত, আর গোটা inference over-confident।
১.৪ দুই সরল কিন্তু চরম সমাধান — আর কেন দুটোই অসন্তোষজনক¶
clustering-এর সমস্যাটা চোখে পড়লে, দুটো সরল প্রতিক্রিয়া স্বাভাবিকভাবে মাথায় আসে। দুটোই একটা করে চরম প্রান্ত — আর দুটোরই গুরুতর দুর্বলতা আছে। এদের বোঝা জরুরি, কারণ এই দুই প্রান্তের ঠিক মাঝখানেই mixed-effects model-এর আসন।
সমাধান ১ — সব গুলিয়ে ফেলো: complete pooling (সম্পূর্ণ পুলিং)। সবচেয়ে সহজ পথ: স্কুল-পরিচয় একদম উপেক্ষা করো, ৫০০ ছাত্রকে এক বালতিতে ঢেলে একটাই regression চালাও — $$ y_{ij} = \beta_0 + \beta_1 x_{ij} + \varepsilon_{ij}, $$ যেখানে \(y_{ij}\) হলো স্কুল \(j\)-এর \(i\)-তম ছাত্রের নম্বর, \(x_{ij}\) তার পড়ার ঘণ্টা — কিন্তু কোথাও স্কুল \(j\)-এর কোনো চিহ্ন নেই। একে বলে complete pooling ("পুল" মানে সব data একত্রে জড়ো করা)। সুবিধা: সরল, আর প্রতিটি \(\beta\) আন্দাজ করতে গোটা ৫০০ ছাত্রের জোর পাওয়া যায়। কিন্তু দাম চড়া — এটা ধরেই নেয় সব স্কুল অভিন্ন, ভালো-খারাপ স্কুলের কোনো তফাত নেই। ফলে স্কুল-থেকে-স্কুল আসল পার্থক্যটা পুরোপুরি হারিয়ে যায়, আর সেই পার্থক্যজনিত correlation-ও অস্বীকৃত থাকে — অর্থাৎ §১.৩-এর over-confidence সমস্যাটা এখানেই ফিরে আসে।
সমাধান ২ — প্রত্যেককে আলাদা করো: no pooling (পুলিং নেই)। উল্টো প্রান্ত: প্রতিটি স্কুলকে সম্পূর্ণ আলাদা জগৎ ধরো, আর প্রতিটি স্কুলের জন্য আলাদা একটা regression চালাও — স্কুল \(j\)-এর জন্য নিজস্ব \(\beta_{0j}, \beta_{1j}\)। একে বলে no pooling (কোনো স্কুলের তথ্য অন্য স্কুলকে ধার দেয় না)। সুবিধা: প্রতিটি স্কুলের নিজস্বতা পুরোপুরি ধরা পড়ে। কিন্তু এখানেও বড় ফাঁদ — যে স্কুলে মাত্র ১০-১২ জন ছাত্র, তাদের জন্য আলাদা regression ভয়াবহ noisy (অস্থির): এত অল্প data থেকে আঁকা রেখা দু-একজন ব্যতিক্রমী ছাত্রের টানে এদিক-ওদিক লাফায়। ছোট group-এ আন্দাজ এত দুর্বল হয় যে তা প্রায়ই অর্থহীন, আর প্রতিটি group আলাদা হওয়ায় আমরা গোটা data-র সমষ্টিগত শক্তিটাও হারাই।
দুই প্রান্তকে পাশাপাশি রাখলে টানাপোড়েনটা স্পষ্ট হয়:
| দিক | complete pooling (সব এক) | no pooling (সব আলাদা) |
|---|---|---|
| group-পরিচয় | সম্পূর্ণ উপেক্ষা | সম্পূর্ণ আলাদা |
| group-পার্থক্য ধরা পড়ে? | না — হারিয়ে যায় | হ্যাঁ — সম্পূর্ণ |
| ছোট group-এ আন্দাজ | স্থির কিন্তু পক্ষপাতী (সবাইকে এক ধরে) | প্রায়-অর্থহীন, ভয়াবহ noisy |
| তথ্যের ব্যবহার | সব মিলিয়ে এক রেখা | প্রতি group নিজের ছোট data-তে একা |
| মূল দোষ | clustering অস্বীকার → over-confident | data ভাগ করে দুর্বল করা → noisy |
লক্ষ করুন, দুটো ভুল ঠিক বিপরীত দিকে: complete pooling খুব বেশি একত্র করে (পার্থক্য মুছে দেয়), no pooling খুব বেশি আলাদা করে (data টুকরো করে দুর্বল করে)। তাহলে স্বাভাবিক প্রশ্ন — এই দুই প্রান্তের মাঝামাঝি কিছু কি সম্ভব?
১.৫ সমাধানের মূল insight (অন্তর্দৃষ্টি) — মাঝামাঝি পথ: partial pooling¶
হ্যাঁ, সম্ভব — আর সেটাই এই অধ্যায়ের কেন্দ্রীয় ধারণা: partial pooling (আংশিক পুলিং)। স্বজ্ঞাটা সরল ও সুন্দর:
প্রতিটি স্কুল তার নিজের data থেকে শিখুক — কিন্তু একা একা শূন্য থেকে নয়। যেসব স্কুলে data কম বা অস্পষ্ট, তারা সার্বিক (grand) গড়ের দিকে ঝুঁকে "ধার করে" নিক; আর যেসব স্কুলে প্রচুর স্পষ্ট data, তারা প্রায় নিজের মতোই থাকুক।
অর্থাৎ প্রতিটি group-এর আন্দাজ টানা হয় তার নিজের group-mean ও সব group মিলিয়ে grand-mean — এই দুইয়ের মাঝখানে। কতটা মাঝখানে? সেটা নির্ভর করে group-টা কতটা নির্ভরযোগ্য তার ওপর: অল্প data-র ছোট group বেশি টেনে grand-mean-এর কাছে নেওয়া হয় (কারণ তার নিজের আন্দাজে ভরসা কম), আর বেশি data-র বড় group কম টানা হয় (তার নিজের আন্দাজেই যথেষ্ট ভরসা)। এই "টেনে আনা"-কে বলে shrinkage (সংকোচন) — group-এর আন্দাজ-গুলোকে সার্বিক গড়ের দিকে খানিকটা সংকুচিত করা।
partial pooling ঠিক যেন দুই প্রান্তের সেরাটা মিলিয়ে নেয়:
- complete pooling-এর মতো এটা সব data-র সমষ্টিগত শক্তি কাজে লাগায় (সবাই grand-mean-এর তথ্য ভাগ করে),
- আবার no pooling-এর মতো এটা প্রতিটি group-এর নিজস্বতাকেও সম্মান করে (যথেষ্ট data থাকলে group আলাদা থাকতে পারে),
- আর ছোট group-গুলোকে noisy চরমে যেতে না দিয়ে grand-mean-এর স্থিরতার দিকে টেনে রাখে।
এই partial pooling-কে গণিতের ভাষায় ফুটিয়ে তোলার যন্ত্রটাই হলো mixed-effects model (মিশ্র-প্রভাব মডেল) — যেখানে দুই ধরনের প্রভাব মিশে থাকে বলেই "mixed":
- fixed effects — গোটা population-এর জন্য একটিই সার্বিক প্রবণতা (যেমন "পড়ার ঘণ্টা বাড়লে গড়ে নম্বর কতটা বাড়ে") — এ-ই complete pooling-এর অংশটা ধরে,
- random effects — প্রতিটি group তার নিজস্ব ছোট বিচ্যুতি, যা একটা সাধারণ বণ্টন থেকে আঁকা — এ-ই group-পার্থক্য ও partial pooling-এর অংশটা ধরে।
এই দুইয়ের মিশেলকেই বলা হয় mixed-effects বা hierarchical / multilevel model (স্তরায়িত / বহু-স্তরীয় মডেল — কারণ এতে দুটো স্তর: ছাত্র-স্তর ও স্কুল-স্তর)। কেন একে hierarchical বলা সবচেয়ে স্বাভাবিক — কারণ data-টা নিজেই hierarchy: ছাত্র ভেতরে স্কুল, স্কুল ভেতরে গোটা population।
এক বাক্যে সমাধান: complete pooling (সব এক) ও no pooling (সব আলাদা)-র মাঝখানে দাঁড়ায় partial pooling — প্রতিটি group নিজের data থেকে শেখে অথচ ছোট/দুর্বল group-গুলো grand-mean-এর দিকে সংকুচিত (shrunk) হয়; আর এই ভারসাম্য আনার যন্ত্রই হলো fixed effect (সার্বিক প্রবণতা) ও random effect (group-বিচ্যুতি) মিশিয়ে গড়া mixed-effects model।
১.৬ এই অধ্যায়ের পথরেখা¶
মূল ধারণাটা হাতে এল; এবার সামনের পথটা সংক্ষেপে দেখে নিই:
- §২ মূল সংজ্ঞাগুলো নিখুঁত করে — fixed effect বনাম random effect-এর সঠিক তফাত, random-intercept model \(y_{ij}=\beta_0+\beta_1 x_{ij}+u_j+\varepsilon_{ij}\), দুই variance component \(\sigma_u^2\) ও \(\sigma_\varepsilon^2\), ICC \(\rho=\frac{\sigma_u^2}{\sigma_u^2+\sigma_\varepsilon^2}\) ও তার দ্বৈত অর্থ, shrinkage/BLUP-এর সংজ্ঞা, এবং random slope ও REML-বনাম-ML-এর সংক্ষিপ্ত পরিচয়।
- §৩–৪ মডেলটা data থেকে কীভাবে fit হয় — same-group পর্যবেক্ষণের মধ্যে ICC কীভাবে covariance তৈরি করে (marginal covariance গঠন), variance-component আন্দাজ, shrinkage/BLUP-সূত্রের গাণিতিক ভিত্তি, এবং REML বনাম ML-এর পার্থক্যের কারণ।
- §৫–৬ পূর্ণ exam-score dataset-এ (২৫ স্কুল, ছাত্রসংখ্যা অসম) হাতে-কলমে — complete/no/partial pooling-এর তুলনা, প্রতি-স্কুল random intercept, shrinkage-এর চাক্ষুষ প্রভাব, ও ICC-র ভেদ-পচন, চিত্র ও Python-কোড সহ।
২ · মূল ধারণা ও সংজ্ঞা¶
এই অংশে §১-এর insight (অন্তর্দৃষ্টি)-গুলোকে নিখুঁত সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথম ব্যবহারেই খোলা হলো; পূর্ণ derivation (marginal covariance, variance-component আন্দাজ, BLUP-সূত্র) §৪-এ।
প্রথমে notation থিতু করে নিই। আমাদের কাছে \(J\)টি group আছে, সূচক \(j=1,\dots,J\) (আমাদের চলতি উদাহরণে \(J\)টি স্কুল)। group \(j\)-এর ভেতরে কিছু একক আছে, \(i\)-তম এককটিকে লিখি সূচক \(i\) দিয়ে। সংক্ষেপে:
- \(j = 1, \dots, J\) — group-এর সূচক (স্কুল)।
- \(i\) — group \(j\)-এর ভেতরে unit-এর সূচক (ছাত্র); প্রতি group-এ এককের সংখ্যা আলাদা হতে পারে (unbalanced, অসম)।
- \(y_{ij}\) — group \(j\)-এর \(i\)-তম এককের response (পরীক্ষার নম্বর)।
- \(x_{ij}\) — সেই এককের predictor (পড়ার ঘণ্টা)।
দুই-সূচকের এই লেখনপদ্ধতিটাই (একটা সূচক unit-এর, একটা group-এর) স্তরায়িত data-র স্বাক্ষর — আর এ-ই 5.1-এর এক-সূচক \(y_i\)-এর সঙ্গে মূল গঠনগত তফাত।
২.১ Fixed effect বনাম random effect — মূল তফাত¶
এই গোটা অধ্যায়ের সবচেয়ে গুরুত্বপূর্ণ ধারণাগত মোড়টা এখানেই, তাই ধীরে ধরি। দুই ধরনের "প্রভাব" আছে — দুটোই group-ভেদ ব্যাখ্যা করে, কিন্তু তাদের গাণিতিক চরিত্র সম্পূর্ণ আলাদা।
Fixed effect (স্থির প্রভাব) হলো এমন একটা প্যারামিটার যা একটা নির্দিষ্ট কিন্তু অজানা ধ্রুবক — গোটা population-এর জন্য একটিই মান, যা আমরা data থেকে আন্দাজ করি। 5.1-এর \(\beta_0, \beta_1\) এবং 5.3-এর group-effect \(\tau_g\) — সবই ছিল fixed effect। এর বৈশিষ্ট্য: এর কোনো বণ্টন নেই, এটা শুধু একটা (অজানা) সংখ্যা; আর এটা যেসব group/মান হাতে আছে, ঠিক তাদেরই বর্ণনা করে — তার বাইরে সাধারণীকরণের দাবি করে না।
Random effect (দৈব প্রভাব) হলো এমন একটা group-স্তরের পরিমাণ, যাকে আমরা একটা নির্দিষ্ট ধ্রুবক হিসেবে না দেখে একটা সম্ভাব্যতা-বণ্টন থেকে আঁকা একটা random variable হিসেবে দেখি। আমাদের মডেলে এটাই হলো group \(j\)-এর intercept-বিচ্যুতি, লিখি \(u_j\): $$ u_j \;\sim\; \mathcal{N}(0, \sigma_u^2), $$ যেখানে \(u_j\) হলো group \(j\)-এর সার্বিক intercept থেকে deviation (বিচ্যুতি) — অর্থাৎ "এই স্কুলটা গড় স্কুলের চেয়ে কতটা উপরে বা নিচে", আর \(\sigma_u^2\) হলো সেই বিচ্যুতিগুলোর ভেদ (পরে \(\sigma_u^2\)-এর পূর্ণ অর্থ §২.৩-এ)। গড় \(0\) ধরা হয়েছে ইচ্ছাকৃতভাবে: সার্বিক স্তরটুকু \(\beta_0\) ধরে নেয়, আর \(u_j\) শুধু তার চারপাশে ওঠানামা মাপে — কোনো স্কুল উপরে (\(u_j>0\)), কোনো নিচে (\(u_j<0\)), গড়ে শূন্য।
দুটোর তফাত একটা প্রশ্নে ধরা পড়ে: "আমরা যে group-গুলো দেখছি, সেগুলো কি নিজেই আগ্রহের, নাকি একটা বৃহত্তর population থেকে তোলা নমুনা?"
- যদি group-গুলো নিজেরাই আগ্রহের, সংখ্যায় কম ও স্থির (যেমন "পুরুষ বনাম নারী", বা ঠিক "তিনটি নির্দিষ্ট সার A, B, C") — fixed effect।
- যদি group-গুলো একটা বৃহত্তর সমগ্রক থেকে তোলা নমুনা, এবং আমরা শুধু এই নির্দিষ্ট ২৫টা স্কুল নয়, বরং "স্কুল-সাধারণভাবে" সম্পর্কে কিছু বলতে চাই — তখন প্রতিটা স্কুলের প্রভাবকে এক common বণ্টন \(\mathcal{N}(0,\sigma_u^2)\) থেকে আঁকা ধরাই স্বাভাবিক — random effect।
আমাদের ২৫টা স্কুল ঠিক দ্বিতীয় ধাঁচের: এরা সব-স্কুল-সমগ্রক থেকে তোলা একটা নমুনা, তাই random effect-ই উপযুক্ত। এই "random ধরা"-র একটা বড় উপহার আছে: এতে স্কুলগুলো একে অপরের কাছ থেকে তথ্য ধার করতে পারে (সবাই একই \(\mathcal{N}(0,\sigma_u^2)\) ভাগ করায়) — আর সেখান থেকেই §১.৫-এর partial pooling স্বাভাবিকভাবে জন্ম নেয়। (পক্ষান্তরে fixed-effect group-গুলো পরস্পর থেকে কিছুই ধার করে না — তা কার্যত no pooling।)
এক বাক্যে তফাত: fixed effect একটা নির্দিষ্ট-অথচ-অজানা ধ্রুবক যা শুধু হাতে-থাকা group-গুলোকেই বর্ণনা করে; random effect \(u_j\sim\mathcal{N}(0,\sigma_u^2)\) হলো একটা বৃহত্তর population থেকে আঁকা group-বিচ্যুতি — আর এই "একই বণ্টন থেকে আসা" ধারণাই group-দের পরস্পর তথ্য ধার করতে দেয়, যা partial pooling-এর শিকড়।
২.২ Random-intercept model¶
এবার fixed ও random — দুই প্রভাব এক সমীকরণে মিশিয়ে দিলেই আমাদের প্রথম mixed-effects model পাই। একে বলে random-intercept model, কারণ এতে intercept-টা group-ভেদে বদলায় (slope নয়, আপাতত):
প্রতিটি পদ খুলি:
- \(y_{ij}\) — group \(j\)-এর \(i\)-তম এককের response (নম্বর)।
- \(x_{ij}\) — সেই এককের predictor (পড়ার ঘণ্টা)।
- \(\beta_0\) — fixed intercept: গোটা population-এ সার্বিক (গড় স্কুলের) ভিত্তি-স্তর। সব group-এর জন্য এক।
- \(\beta_1\) — fixed slope: predictor এক একক বাড়লে response গড়ে কতটা বদলায় — population-স্তরের প্রবণতা, সব group-এর জন্য এক। (\(\beta_0, \beta_1\) একসাথে fixed effects \(\beta\)।)
- \(u_j\) — group \(j\)-এর random intercept-বিচ্যুতি, \(u_j\sim\mathcal{N}(0,\sigma_u^2)\): এই স্কুলটা সার্বিক স্তর \(\beta_0\) থেকে কতটা উপরে/নিচে। এই একটিই পদ একই group-এর সব এককে ভাগ হয় — স্কুল \(j\)-এর প্রতিটি ছাত্রের সমীকরণে একই \(u_j\) বসে।
- \(\varepsilon_{ij}\) — residual বা within-group error, \(\varepsilon_{ij}\sim\mathcal{N}(0,\sigma_\varepsilon^2)\): group-প্রভাব বাদ দেওয়ার পরও যে এলোমেলোতা প্রতিটি একক-এ আলাদা থাকে (এই ছাত্রের ব্যক্তিগত দিন-ভালো/মন্দ)। প্রতিটি ছাত্রের জন্য স্বতন্ত্র।
মডেলটাকে এভাবে পড়া সবচেয়ে স্বচ্ছ — এটা প্রতিটি স্কুলকে দেয় একটাই সাধারণ slope \(\beta_1\), কিন্তু নিজস্ব উঁচু-নিচু intercept \(\beta_0+u_j\): $$ y_{ij} \;=\; \underbrace{(\beta_0 + u_j)}{\text{স্কুল }j\text{-এর নিজস্ব intercept}} + \;\beta_1 x. $$ ছবিতে: গোটা population-এর জন্য একটাই ঢালের (}\; + \;\varepsilon_{ij\(\beta_1\)) সরলরেখা — কিন্তু সেই একই ঢালের রেখাগুলো প্রতিটি স্কুলের জন্য উপরে-নিচে সরে বসে আছে (\(u_j\) যত, তত উপরে/নিচে), যেন একগুচ্ছ সমান্তরাল রেখা। ভালো স্কুলের রেখা উপরে, খারাপ স্কুলের নিচে, সবগুলোর কাত এক।
এখানেই §১.২-এর correlation-টা গণিতে ফুটে ওঠে: যেহেতু একই স্কুলের সব ছাত্র একই \(u_j\) ভাগ করে, তাদের নম্বরগুলো একটা সাধারণ ধাক্কা (\(u_j\)) ভাগ করে নেয় — তাই পরস্পর correlated, স্বাধীন নয়। ঠিক এই কারণেই random-intercept পদ যোগ করা মানে clustering-জনিত correlation মডেলেই সরাসরি গেঁথে দেওয়া। (এই \(u_j\) থেকে correlation-এর সঠিক পরিমাণ — ICC — §২.৪-এ, আর তার পূর্ণ derivation §৪-এ।)
২.৩ Variance components — \(\sigma_u^2\) ও \(\sigma_\varepsilon^2\)¶
লক্ষ করুন, random-intercept model-এ দুটো আলাদা random উৎস আছে — দুটো আলাদা জায়গা থেকে এলোমেলোতা আসছে। তাই মোট ভেদটাও দুই উপাদানে (component) ভাগ হয়; এদের বলে variance components (ভেদ-উপাদান):
- \(\sigma_u^2\) — between-group variance (group-এর মধ্যেকার ভেদ): স্কুল-থেকে-স্কুল intercept কতটা ছড়ানো, অর্থাৎ "স্কুলগুলো নিজেদের মধ্যে কতটা আলাদা"। বড় \(\sigma_u^2\) মানে স্কুলভেদে প্রবল পার্থক্য (কিছু স্কুল অনেক ভালো, কিছু অনেক খারাপ)।
- \(\sigma_\varepsilon^2\) — within-group variance (group-এর ভেতরকার ভেদ): একই স্কুলের ছাত্রদের মধ্যে নম্বর কতটা ছড়ানো (স্কুল-প্রভাব বাদ দিয়ে), অর্থাৎ "একই স্কুলের দুই ছাত্র নিজেদের মধ্যে কতটা আলাদা"।
এই between/within ভাগটা ঠিক 5.3-এর between-group ও within-group ভেদের সেই পচনেরই উত্তরসূরি — পার্থক্য কেবল, 5.3-এ group-effect ছিল fixed, এখানে তা random (\(\sigma_u^2\) হয়ে গেছে একটা সত্যিকারের বণ্টন-প্যারামিটার)। একটা group-প্রভাব-হীন এককের মোট ভেদ এই দুইয়ের যোগফল হিসেবে দাঁড়ায় (পূর্ণ হিসাব §৪-এ): $$ \operatorname{Var}(y_{ij}) \;=\; \sigma_u^2 + \sigma_\varepsilon^2, $$ কারণ \(u_j\) ও \(\varepsilon_{ij}\) পরস্পর-স্বাধীন ধরা হয়, তাই তাদের ভেদ যোগ হয়। অর্থাৎ একটা নম্বরের মোট অনিশ্চয়তা দুই অংশের সমষ্টি — "কোন স্কুলে পড়ে" (\(\sigma_u^2\)) আর "সেই স্কুলের ভেতরে এই ছাত্রটি ব্যক্তিগতভাবে কেমন" (\(\sigma_\varepsilon^2\))। এই দুই উপাদান আন্দাজ করাই (next, ICC ও partial pooling-এর জন্য) mixed model-fitting-এর একটা প্রধান কাজ।
২.৪ ICC — within-group correlation ও ভেদের অংশ¶
এবার দুই variance component-কে এক জায়গায় এনে এই অধ্যায়ের সবচেয়ে কেন্দ্রীয় একক সংখ্যাটা সংজ্ঞায়িত করি — intraclass correlation coefficient (ICC) (অন্তঃশ্রেণি সহগ-সম্পর্ক):
এখানে \(\rho\) হলো between-group ভেদ ভাগ মোট ভেদ — একটা \(0\) থেকে \(1\)-এর মধ্যেকার অনুপাত। এর সৌন্দর্য হলো, এই একই সংখ্যাটা একসাথে দুটো গভীর অর্থ বহন করে:
অর্থ ১ — ভেদের অংশ (variance partition)। \(\rho\) বলে দেয়, response-এর মোট ভেদের ঠিক কত ভগ্নাংশ group-স্তর থেকে আসে। \(\rho=0.37\) মানে নম্বরের মোট ভেদের প্রায় ৩৭% ব্যাখ্যা করে "কোন স্কুলে পড়ে" সেই তথ্য, বাকি ৬৩% ছাত্র-থেকে-ছাত্র স্কুলের-ভেতরের তারতম্য। এ-ই \(\rho=\frac{\sigma_u^2}{\sigma_u^2+\sigma_\varepsilon^2}\)-এর সরাসরি পাঠ।
অর্থ ২ — within-group correlation। আরও তাৎপর্যপূর্ণভাবে, \(\rho\) ঠিক একই group-এর যেকোনো দুই পর্যবেক্ষণের মধ্যেকার correlation (§৪-এ দেখানো হবে যে \(\operatorname{Corr}(y_{ij}, y_{i'j}) = \rho\) একই স্কুলের দুই ছাত্র \(i\ne i'\)-এর জন্য)। এটাই 2.6-এর correlation-এর সংজ্ঞার সরাসরি প্রয়োগ — এবং এটাই §১.২-এর "একই স্কুলের দুই ছাত্র বেশি একরকম" কথাটার সংখ্যাগত রূপ।
এই দ্বৈত অর্থ থেকে দুই প্রান্ত পড়া যায়:
- \(\rho = 0\) (\(\sigma_u^2=0\)): স্কুলভেদে কোনো পার্থক্য নেই, একই স্কুলের ছাত্রদের মধ্যে কোনো বাড়তি correlation নেই — clustering অনুপস্থিত, সাধারণ OLS-ই (complete pooling) যথেষ্ট।
- \(\rho \to 1\) (\(\sigma_\varepsilon^2 \to 0\)): একই স্কুলের ছাত্ররা প্রায় অভিন্ন, প্রায় সব ভেদ স্কুল-স্তরের — clustering প্রবল, mixed model অপরিহার্য, আর §১.৩-এর "কার্যকর নমুনা-সংখ্যা প্রকৃত ছাত্রসংখ্যার চেয়ে অনেক কম" সমস্যাটা চরমে।
মাঝখানের মানগুলোই (আমাদের data-য় \(\rho\approx 0.37\)) বাস্তবে সবচেয়ে সাধারণ — যথেষ্ট clustering যে তা উপেক্ষা করলে বিপদ, অথচ এতটা নয় যে group-গুলো একদম আলাদা জগৎ। ঠিক এই কারণেই \(\rho\) একটা মডেল ডায়াগনস্টিক হিসেবে এত মূল্যবান: এটাই বলে দেয় mixed model আদৌ লাগবে কি না, এবং partial pooling কতটা জোরালো হবে।
এক বাক্যে ICC: \(\rho=\frac{\sigma_u^2}{\sigma_u^2+\sigma_\varepsilon^2}\) একসাথে দুটো জিনিস — (ক) মোট ভেদের যে অংশটা group-স্তর থেকে আসে, এবং (খ) একই group-এর দুই পর্যবেক্ষণের correlation; \(\rho=0\) মানে clustering নেই, \(\rho\) বড় মানে clustering প্রবল।
২.৫ Shrinkage / partial pooling — BLUP¶
§১.৫-এর partial pooling-এর স্বজ্ঞাটা এবার একটু নিখুঁত করি। mixed model fit করার পর আমরা প্রতিটি group-এর random effect \(u_j\)-এরও একটা আন্দাজ পাই — একে বলে BLUP (Best Linear Unbiased Predictor, শ্রেষ্ঠ-রৈখিক-নিরপেক্ষ ভবিষ্যদ্বক্তা; "predictor" শব্দটা ব্যবহার হয় কারণ \(u_j\) একটা random variable, fixed parameter নয়)। BLUP-এর সবচেয়ে গুরুত্বপূর্ণ ধর্মটাই হলো shrinkage (সংকোচন)।
স্বজ্ঞাটা §১.৫-এর সেই "টেনে আনা": একটা group-এর জন্য আন্দাজকৃত intercept (\(\beta_0 + \hat u_j\)) টানা হয় ঠিক দুই প্রান্তের মাঝখানে —
- একপ্রান্তে সেই group-এর নিজের data-র গড় (no-pooling আন্দাজ, যা ছোট group-এ noisy),
- অন্যপ্রান্তে সব group মিলিয়ে সার্বিক grand-mean \(\beta_0\) (complete-pooling আন্দাজ, যা সবাইকে এক ধরে),
আর কতটা মাঝখানে, তা নির্ভর করে group-টা কতটা নির্ভরযোগ্য তার ওপর:
- ছোট group (অল্প data → নিজের আন্দাজে কম ভরসা) — বেশি টেনে grand-mean-এর কাছে আনা হয়; shrinkage প্রবল।
- বড় group (বেশি data → নিজের আন্দাজে বেশি ভরসা) — কম টানা হয়, প্রায় নিজের গড়েই থাকে; shrinkage মৃদু।
এই আচরণ গভীরভাবে সঙ্গত: যে group-এর সাক্ষ্য দুর্বল, তাকে সার্বিক ঐকমত্যের দিকে টেনে নেওয়াই বুদ্ধিমানের; যে group-এর সাক্ষ্য জোরালো, তাকে নিজের পথে চলতে দেওয়াই ঠিক। ফলে BLUP ছোট group-এর noisy চরম আন্দাজগুলোকে স্থির করে, অথচ বড় group-এর প্রকৃত নিজস্বতা রক্ষা করে — ঠিক §১.৫-এ চাওয়া ভারসাম্যটা।
এই shrinkage-এর একটা চমৎকার প্রতিধ্বনি আছে 4.4-এর shrinkage estimator-এ, যেখানে একটা estimate-কে \(0\)-র দিকে (factor \(c<1\) গুণ করে) টেনে সামান্য bias-এর বিনিময়ে variance কমানো হতো — এখানেও ঠিক একই দর্শন, শুধু "\(0\)-র দিকে" নয়, "grand-mean-এর দিকে" টানা। partial pooling তাই কোনো বিচ্ছিন্ন কৌশল নয়, বরং shrinkage-এর সেই সাধারণ নীতিরই একটা স্বাভাবিক প্রকাশ। (BLUP-এর সঠিক shrinkage-সূত্র — যেখানে টানের পরিমাণ group-size ও \(\rho\)-র ওপর নির্ভর করে — §৪-এ ব্যুৎপন্ন হবে।)
তিন ধারাকে এক টেবিলে গুছিয়ে রাখি:
| complete pooling | no pooling | partial pooling (mixed model) | |
|---|---|---|---|
| group-effect ধরা | সব এক (\(u_j\) নেই) | প্রতি group আলাদা ও স্বাধীন | \(u_j\sim\mathcal{N}(0,\sigma_u^2)\) থেকে আঁকা |
| group-estimate | সবাই grand-mean | প্রতি group-এর কাঁচা গড় | দুইয়ের মাঝে, shrinkage সহ |
| ছোট group | পক্ষপাতী কিন্তু স্থির | ভয়াবহ noisy | grand-mean-এর দিকে সংকুচিত, স্থির |
| তথ্য ধার করা | — | না | হ্যাঁ (group-রা পরস্পর শেখে) |
২.৬ আরও দুটি সম্প্রসারণ — সংক্ষেপে¶
পূর্ণতার জন্য দুটো ধারণা এখানে কেবল পরিচয় করিয়ে রাখি; এদের বিস্তার পরের পাঠ ও পরবর্তী অধ্যায়ের জন্য।
Random slope (দৈব ঢাল)। §২.২-এর random-intercept model-এ শুধু intercept group-ভেদে বদলাত, কিন্তু slope \(\beta_1\) ছিল সবার জন্য এক। বাস্তবে প্রায়ই slope-ও group-ভেদে বদলায় — যেমন, কোনো স্কুলে পড়ার ঘণ্টা বাড়ার প্রতিদান হয়তো বেশি, কোনো স্কুলে কম। তখন slope-এও একটা random বিচ্যুতি যোগ করা যায়: $$ y_{ij} = \beta_0 + \beta_1 x_{ij} + u_{0j} + u_{1j}\,x_{ij} + \varepsilon_{ij}, $$ যেখানে \(u_{0j}\) হলো group \(j\)-এর intercept-বিচ্যুতি (আগের \(u_j\)) আর \(u_{1j}\) হলো তার slope-বিচ্যুতি — দুটোই random। ছবিতে, এতে রেখাগুলো আর সমান্তরাল থাকে না; প্রতিটি স্কুলের রেখা নিজস্ব উচ্চতা ও নিজস্ব কাত নিয়ে বসে। (এতে variance-গঠন আরও সমৃদ্ধ হয় — \(u_{0j}, u_{1j}\)-এর নিজস্ব ভেদ ও পারস্পরিক covariance আসে — তাই আপাতত random-intercept-এই মন দিচ্ছি; random slope-এর গাণিতিক রূপ পরের পাঠের বিষয়।)
REML বনাম ML — variance-component আন্দাজে। \(\sigma_u^2\) ও \(\sigma_\varepsilon^2\) আন্দাজ করার দুটো প্রচলিত পথ আছে: সাধারণ maximum likelihood (ML) এবং তার একটা সংশোধিত রূপ REML (restricted/residual maximum likelihood)। এক বাক্যে তফাত — সাধারণ ML variance আন্দাজ করার সময় fixed effects \(\beta\)-কে "নিখুঁতভাবে জানা" ধরে নেয়, ফলে variance component-গুলো সামান্য নিম্নমুখী পক্ষপাতে (downward bias) আসে (ঠিক যেমন 4.x-এ নমুনা-variance-এ \(n\)-এর বদলে \(n-1\) ভাগ করতে হয়); REML এই \(\beta\)-আন্দাজে ব্যয়িত স্বাধীনতার-মাত্রা (degrees of freedom) বাদ দিয়ে হিসাব করে, তাই variance-component আন্দাজ কম-পক্ষপাতী — এজন্য variance-component আন্দাজে সাধারণত REML-ই পছন্দনীয়। (কেন ও কীভাবে — §৪-এ।)
৩ · পূর্ণাঙ্গ উদাহরণ¶
এ পর্যন্ত আমরা random intercept \(u_j\sim\mathcal N(0,\sigma_u^2)\), residual \(\varepsilon_{ij}\sim\mathcal N(0,\sigma_\varepsilon^2)\), এবং ICC \(\rho=\frac{\sigma_u^2}{\sigma_u^2+\sigma_\varepsilon^2}\)-এর তত্ত্ব দেখেছি। এবার একটা বাস্তবঘেঁষা clustered ডেটাসেটে ধাপে ধাপে পুরো workflow চালাব — প্রথমে clustering অগ্রাহ্য করে pooled OLS fit করে দেখব কী ভুল হয় (E1), তারপর random-intercept mixed model বসিয়ে fixed effect ও variance component পড়ব (E2), ICC বের করে clustering-এর মাত্রা মাপব (E3), এবং সবশেষে দেখব কেন এটা জরুরি — standard error ও shrinkage (E4)।
ডেটাসেট। \(J=25\)টি স্কুলের পরীক্ষার ফলাফল, প্রতিটি স্কুলে অসম সংখ্যক (\(10\)–\(30\) জন) ছাত্র, মোট \(N=533\)। প্রতিটি ছাত্রের জন্য তিনটি কলাম:
| কলাম | অর্থ | ধরন |
|---|---|---|
school |
কোন স্কুল (\(j=1..25\)) | group id |
hours |
সাপ্তাহিক পড়ার ঘণ্টা | \(\sim\mathrm{Uniform}(0,10)\) |
score |
পরীক্ষার নম্বর | continuous |
ডেটা generate করা হয়েছে seed 20260619 দিয়ে, true সম্পর্ক
$$
y_{ij}=50+2\cdot\text{hours}{ij}+u_j+\varepsilon\sim\mathcal N(0,8^2)
$$
অনুসারে। অর্থাৎ আসল slope },\qquad u_j\sim\mathcal N(0,6^2),\quad \varepsilon_{ij\(=2\), আসল between-school SD \(\sigma_u=6\), এবং within-school residual SD \(\sigma_\varepsilon=8\)। মূল চ্যালেঞ্জ: একই স্কুলের ছাত্ররা একই \(u_j\) ভাগ করে, তাই তাদের score পরস্পর correlated — observation স্বাধীন নয়। এই কাঠামোটাই pooled OLS-এর অনুমান ভাঙে; ঠিক সেটাই E1-এ ধরা পড়বে।
E1 · সমস্যাটা — clustering অগ্রাহ্য করা pooled OLS¶
সবচেয়ে সরল (এবং ভুল) পথ: স্কুল-গঠন একদম ভুলে গিয়ে সব \(533\)টি observation কে একটিমাত্র সমতল regression-এ ফেলে দেওয়া —
$$
\text{score}{ij} = \beta_0 + \beta_1\,\text{hours},
$$
যেখানে error-গুলোকে i.i.d. ধরা হয়। } + \text{(error)statsmodels-এ OLS fit করলে:
| পদ | \(\hat\beta\) | \(\mathrm{SE}\) |
|---|---|---|
| Intercept | \(50.69\) | \(0.867\) |
hours |
\(1.800\) | \(0.149\) |
আর residual SD \(=10.07\)।
point estimate মন্দ নয়, কিন্তু দুটো সংকেত গণ্ডগোলের।
- \(\hat\beta_1=1.800\) — slope true মান \(2\)-এর কাছাকাছি; pooled OLS-এও coefficient মোটামুটি unbiased থাকে।
- residual SD \(=10.07\) অস্বাভাবিক বড়। ডেটা generate হয়েছে within-school SD \(\sigma_\varepsilon=8\) দিয়ে, অথচ OLS residual SD \(10.07\)। কারণ স্পষ্ট: OLS-এর কাছে স্কুল বলে কিছু নেই, তাই between-school variability (\(\sigma_u^2\), যা ছাত্রের ফলে \(6^2=36\) অবদান রাখে) সে আলাদা করতে পারে না — সেটা পুরোটা residual-এর ভেতর ঢুকে যায়। মোটামুটিভাবে \(\sqrt{8^2+6^2}=\sqrt{100}=10\), ঠিক যা আমরা দেখছি। অর্থাৎ pooled OLS দুই উৎসের ভেদকে একটামাত্র গাদায় মিশিয়ে ফেলেছে।
- SE-গুলো বিশ্বাসযোগ্য নয়। এটাই আসল বিপদ। OLS-এর SE হিসাব হয় "\(533\)টি স্বাধীন observation" ধরে নিয়ে। বাস্তবে একই স্কুলের ছাত্ররা correlated, তাই কার্যকর তথ্য (effective sample size) \(533\)-এর অনেক কম — অনেকটা "\(25\)টি স্কুল"-এর কাছাকাছি। স্বাধীনতার এই অতিরঞ্জনে cluster-স্তরের predictor-এর SE মারাত্মক underestimate হয়, \(p\)-value অতি ছোট হয় — মডেল এমন আত্মবিশ্বাস দেখায় যার ভিত্তি নেই। (intercept-এর SE কতটা ভুল, তার সংখ্যাগত তুলনা E4-এ।)
মূল কথা: pooled OLS-এর coefficient হয়তো কাজ চালানো গোছের, কিন্তু (ক) তার residual SD স্ফীত, আর (খ) তার inference অবৈধ, কারণ within-cluster correlation সে সম্পূর্ণ উপেক্ষা করেছে। এই দুটোরই সমাধান mixed model — E2।
E2 · Mixed model fit ও পড়া¶
এবার স্কুল-গঠনকে সরাসরি মডেলে আনি random intercept দিয়ে:
$$
\text{score}{ij} = \beta_0 + \beta_1\,\text{hours}\sim\mathcal N(0,\sigma_\varepsilon^2).
$$
এখানে প্রতিটি স্কুল } + u_j + \varepsilon_{ij},\qquad u_j\sim\mathcal N(0,\sigma_u^2),\quad \varepsilon_{ij\(j\) তার নিজস্ব intercept-shift \(u_j\) পায় — কোনো স্কুল গড়ে বেশি নম্বরের, কোনোটা কম, এবং সেই বিচ্যুতিকে আমরা \(\mathcal N(0,\sigma_u^2)\) থেকে আসা random হিসেবে মডেল করি। statsmodels-এ MixedLM (score ~ hours, groups=school, REML) fit করলে দুটো অংশ পাই — fixed effect আর variance component।
Fixed effects।
| পদ | \(\hat\beta\) | \(\mathrm{SE}\) |
|---|---|---|
| Intercept | \(50.82\) | \(1.416\) |
hours |
\(1.878\) | \(0.120\) |
Variance components।
| উপাদান | Variance | SD |
|---|---|---|
| Group Var (\(\sigma_u^2\), between-school) | \(37.64\) | \(\sigma_u=6.14\) |
| Resid Var (\(\sigma_\varepsilon^2\), within-school) | \(63.69\) | \(\sigma_\varepsilon=7.98\) |
log-likelihood \(\ell=-1894.5\)।
প্রতিটির ব্যাখ্যা।
- \(\hat\beta_1=1.878\):
hoursপ্রতি \(+1\) ঘণ্টায় প্রত্যাশিত score \(+1.878\) — এটা একই স্কুলের ভেতরে (within-school, \(u_j\) স্থির রেখে) পড়ার প্রভাব। true মান \(2\)-এর সঙ্গে ভালো মিল; OLS-এর \(1.800\)-এর চেয়ে এটি সামান্য বেশি নিখুঁত, কারণ between-school ভেদ আলাদা করে নেওয়ায় slope estimate দূষণমুক্ত। - \(\hat\beta_0=50.82\): গড় স্কুলে (\(u_j=0\)),
hours\(=0\)-তে প্রত্যাশিত score — true intercept \(50\)-এর কাছাকাছি। - \(\sigma_u=6.14\): স্কুলে-স্কুলে গড় score-এর সাধারণ ওঠানামা প্রায় \(\pm 6\) নম্বর। true \(\sigma_u=6\) প্রায় হুবহু পুনরুদ্ধার হয়েছে — মডেল between-school ভেদটা ঠিকঠাক টেনে বের করেছে, যেটা OLS পারেনি।
- \(\sigma_\varepsilon=7.98\): একই স্কুলের ভেতরে ছাত্রে-ছাত্রে অবশিষ্ট ওঠানামা প্রায় \(\pm 8\)। true \(\sigma_\varepsilon=8\)-এর সঙ্গে মিলে যায়।
লক্ষ করুন কী ঘটল: pooled OLS-এর সেই একটিমাত্র স্ফীত residual SD (\(10.07\)) এখন পরিষ্কারভাবে দুই ভাগে বিভক্ত — between-school \(\sigma_u=6.14\) আর within-school \(\sigma_\varepsilon=7.98\)। (যাচাই: \(\sqrt{6.14^2+7.98^2}=\sqrt{37.64+63.69}=\sqrt{101.3}\approx 10.07\) — পুরো ভেদটা সংরক্ষিত, শুধু সঠিক স্তরে বণ্টিত।) এই বিভাজনই mixed model-এর মূল অর্জন, আর এটাই পরের ধাপে ICC-র কাঁচামাল।
E3 · ICC — clustering কতটা প্রবল¶
variance দুই ভাগে ভাঙার পর স্বাভাবিক প্রশ্ন: মোট ভেদের কত অংশ স্কুল-স্তরের? এর উত্তর intraclass correlation: $$ \rho = \frac{\sigma_u^2}{\sigma_u^2+\sigma_\varepsilon^2} = \frac{37.64}{37.64+63.69} = \frac{37.64}{101.33} = 0.371 . $$
দুটো সমার্থক পাঠ।
- Variance decomposition: মোট ভেদের প্রায় \(37\%\) স্কুল-স্তরে (কোন স্কুলে আছ, তার উপর), বাকি \(\approx 63\%\) স্কুলের ভেতরে ছাত্রে-ছাত্রে। অর্থাৎ "তুমি কোন স্কুলে পড়" — এই একটামাত্র তথ্যই তোমার score-এর এক-তৃতীয়াংশেরও বেশি ওঠানামা ব্যাখ্যা করে।
- Correlation: একই স্কুলের যেকোনো দুই ছাত্রের score-এর মধ্যে প্রত্যাশিত correlation \(\approx 0.37\)। এ কারণেই "\(\rho\)" নামটা — এটা সত্যিকারের within-cluster correlation। তারা স্বাধীন নয়; প্রায় \(0.37\) মাত্রায় একসঙ্গে চলে।
\(\rho=0.371\) মোটেই উপেক্ষণীয় নয় — এটা যথেষ্ট বড় clustering। এর সরাসরি তাৎপর্য: clustering ignore করা যাবে না। \(\rho\) শূন্যের কাছাকাছি হলে pooled OLS আর mixed model প্রায় একই উত্তর দিত (কারণ তখন observation কার্যত স্বাধীন)। কিন্তু \(\rho=0.37\) মানে effective sample size নামমাত্র \(533\) থেকে অনেক নিচে নেমে যায়, আর তখন E1-এর OLS SE-গুলো গুরুতরভাবে বিভ্রান্তিকর হয়ে পড়ে। ঠিক কতটা — সেটাই এখন E4-এ সংখ্যায় দেখি।
E4 · কেন গুরুত্বপূর্ণ — standard error ও shrinkage¶
ICC জানিয়েছে clustering প্রবল; এবার দেখি এর দুটো হাতেনাতে পরিণতি।
(ক) Standard error — pooled OLS intercept-এর SE underestimate করে। intercept-এর SE-তে তুলনাটা সবচেয়ে নাটকীয়:
| পদ | OLS SE | Mixed SE |
|---|---|---|
| Intercept | \(0.867\) | \(1.416\) |
hours |
\(0.149\) | \(0.120\) |
intercept-এর SE OLS-এ \(0.867\), কিন্তু mixed model-এ \(1.416\) — প্রায় \(1.6\) গুণ বড়। কোনটা সঠিক? Mixed model-টাই। intercept মূলত একটা স্কুল-স্তরের (between-cluster) রাশি — "গড় স্কুলের গড় score কত"। এ সম্পর্কে তথ্য জোগায় মূলত স্কুলের সংখ্যা (\(J=25\)), ছাত্রের সংখ্যা (\(533\)) নয়। pooled OLS ভুল করে ভাবে তার হাতে \(533\)টি স্বাধীন observation আছে, তাই intercept-এর SE কে অবাস্তবভাবে ছোট করে ফেলে। Mixed model জানে কার্যকর তথ্য আসলে \(\sim 25\)টি স্কুল থেকে, তাই সে সততার সঙ্গে বড় (এবং সঠিক) SE রিপোর্ট করে। OLS-এর সরু SE মানে অতিরিক্ত সংকীর্ণ confidence interval ও অতি ছোট \(p\)-value — যে আত্মবিশ্বাসের কোনো ভিত্তি নেই।
দিকনির্দেশটা মনে রাখা জরুরি: clustering অগ্রাহ্য করলে cluster-স্তরের effect-এর SE প্রায় সবসময় underestimate হয়। (এখানে within-school predictor
hours-এর SE উল্টোদিকে — OLS-এ \(0.149\) বনাম mixed-এ \(0.120\) — কারণ between-school noise সরে যাওয়ায় within-effect আরও নিখুঁতভাবে মাপা যায়।)
(খ) Shrinkage — partial pooling। mixed model প্রতিটি স্কুলের জন্য একটা random-effect estimate (BLUP, \(\hat u_j\)) দেয়, যা থেকে সেই স্কুলের নিজস্ব intercept \(\hat\beta_0+\hat u_j\) পাওয়া যায়। গুরুত্বপূর্ণ ব্যাপার: এই \(\hat u_j\) স্কুলের raw (পৃথক) গড় নয় — সেটাকে grand mean-এর দিকে টেনে আনা (shrunk) হয়েছে। আমাদের \(25\)টি স্কুলের BLUP ছড়িয়ে আছে প্রায় \(-12.1\) থেকে \(+12.1\) পর্যন্ত।
উদাহরণস্বরূপ স্কুল \(0\) (\(n=20\)): এর BLUP \(\hat u_0\approx +6.05\) — অর্থাৎ মডেল বলছে এই স্কুল গড়ের চেয়ে প্রায় \(6\) নম্বর উপরে। কিন্তু কেবল ঐ \(20\) জনের raw গড় নিলে বিচ্যুতিটা আরও বড় আসত; mixed model সেটাকে \(0\)-এর দিকে কিছুটা টেনে নামিয়ে \(+6.05\)-এ এনেছে।
এই shrinkage-এর যুক্তি — partial pooling:
- যে স্কুলে ছাত্র কম, তার পৃথক গড় বেশি অনিশ্চিত (অল্প নমুনায় বেশি noise), তাই তাকে grand mean-এর দিকে বেশি shrink করা হয় — মডেল ব্যক্তিগত (গোলমেলে) গড়ের চেয়ে সামগ্রিক প্রবণতাকে বেশি আস্থা দেয়।
- যে স্কুলে ছাত্র বেশি, তার গড় বেশি নির্ভরযোগ্য, তাই shrink কম; তার BLUP নিজের raw গড়ের কাছাকাছি থাকে।
ফল: BLUP-গুলো "সব স্কুল আলাদা" (no pooling — OLS-এ স্কুল-ভিত্তিক dummy) আর "সব স্কুল এক" (complete pooling — pooled OLS) — এই দুই চরমের মাঝামাঝি একটা ভারসাম্যে বসে। ছোট স্কুলে overfitting এড়িয়ে এটি বেশি স্থিতিশীল ও সাধারণত বেশি নির্ভুল estimate দেয়। এটাই hierarchical model-এর সৌন্দর্য: প্রতিটি cluster নিজের ডেটা থেকে শেখে, কিন্তু পুরো ensemble থেকে ধার করা শক্তিও (borrowing strength) পায়।
এক বাক্যে: clustering থাকা সত্ত্বেও pooled OLS চালালে coefficient হয়তো বেঁচে যায়, কিন্তু (ক) residual variance ভুলভাবে স্ফীত হয়, (খ) cluster-স্তরের SE underestimate হয়ে inference অবৈধ হয়, আর (গ) cluster-ভিত্তিক estimate-এ shrinkage-এর সুবিধা পাওয়া যায় না — তিনটিরই সমাধান random-intercept mixed model।
যাচাই (statsmodels)। নিচের block সমস্ত canonical সংখ্যা পুনরুৎপাদন করে (seed 20260619, \(J=25\), \(N=533\)):
N= 533 J= 25 group sizes 10..30
=== POOLED OLS (score ~ hours, school অগ্রাহ্য) ===
beta: Intercept 50.69 (SE 0.867) hours 1.800 (SE 0.149)
resid SD = 10.07 # ~ sqrt(8^2 + 6^2): between-school var residual-এ মিশে গেছে
=== MIXED (MixedLM 'score ~ hours', groups=school, REML) ===
fixed: Intercept 50.82 (SE 1.416) hours 1.878 (SE 0.120)
Group Var (sigma_u^2) = 37.64 sigma_u = 6.14 # between-school
Resid Var (sigma_e^2) = 63.69 sigma_e = 7.98 # within-school
logLik = -1894.5
ICC = 37.64 / (37.64 + 63.69) = 0.371
SE তুলনা: intercept OLS 0.867 vs Mixed 1.416 # OLS underestimates
hours OLS 0.149 vs Mixed 0.120
shrinkage (BLUP): range ~ -12.1 .. +12.1 school 0 (n=20) BLUP ~ +6.05
সব মান brief-এর canonical সংখ্যার সঙ্গে মিলেছে। এক বাক্যে এই উদাহরণের শিক্ষা: clustered ডেটায় (\(\rho=0.371\)) pooled OLS coefficient মোটামুটি ঠিক দিলেও তার residual variance স্ফীত করে ও cluster-স্তরের SE underestimate করে inference নষ্ট করে — random-intercept mixed model ভেদকে between/within-এ ভাগ করে, সঠিক SE দেয়, এবং shrinkage-এর মাধ্যমে cluster-ভিত্তিক estimate স্থিতিশীল করে।
৪ · প্রমাণ ও উৎপাদন¶
এতক্ষণ আমরা mixed-effects মডেলটা লিখেছি আর তার অংশগুলোর অর্থ বুঝেছি। এই অংশটাই অধ্যায়ের হৃৎপিণ্ড: এখানে আমরা শূন্য থেকে দেখাব কেন একটা random intercept যোগ করলেই পুরো ছবিটা বদলে যায় — কেন same-group observation-গুলো হঠাৎ পরস্পর-সম্পর্কিত (correlated) হয়ে পড়ে, কেন সেই correlation ঠিক ICC-র সমান, কেন এই correlation উপেক্ষা করলে OLS-এর standard error মিথ্যা ছোট আসে, আর কেন efficient estimator হয় GLS — সবশেষে শেখানো হবে "ছোট গ্রুপ বেশি shrink হয়" বাক্যটার পেছনের গণিত (BLUP / partial pooling)।
লক্ষ্য একটাই: শেষে যেন lmer/mixed যে সংখ্যাগুলো ছাপায় সেগুলো আর "ব্ল্যাক বক্স" মনে না হয়, বরং মনে হয় কয়েকটা স্বাভাবিক প্রশ্নের অনিবার্য উত্তর।
আমরা পাঁচ ধাপে এগোব: (ক) induced covariance structure — \(u_j\) থেকে compound symmetry ও ICC উৎপাদন; (খ) clustering উপেক্ষা করলে OLS inference কেন ভাঙে (design effect); (গ) marginal model ও GLS estimator; (ঘ) shrinkage / BLUP-এর shrinkage factor \(\lambda_j\); (ঙ) REML বনাম ML — কেন variance component-এর জন্য REML।
প্রতীক-স্মারক (§১–২ থেকে): গ্রুপ \(j=1,\dots,J\); \(j\)-তম গ্রুপে \(n_j\)টি unit (\(i=1,\dots,n_j\)); মোট \(N=\sum_j n_j\)। মডেল $\(y_{ij}=\beta_0+\beta_1 x_{ij}+u_j+\varepsilon_{ij},\)$ যেখানে \(u_j\sim\mathcal N(0,\sigma_u^2)\) iid (group-level random effect), \(\varepsilon_{ij}\sim\mathcal N(0,\sigma_\varepsilon^2)\) iid (unit-level noise), এবং \(\{u_j\}\) ও \(\{\varepsilon_{ij}\}\) পরস্পর স্বাধীন (mutually independent)। ICC \(\rho=\dfrac{\sigma_u^2}{\sigma_u^2+\sigma_\varepsilon^2}\)।
সুবিধার জন্য fixed অংশটাকে এক জায়গায় ধরে রাখি: \(\mu_{ij}:=\beta_0+\beta_1 x_{ij}=\mathbb{E}[y_{ij}]\) (নির্দিষ্ট \(x_{ij}\)-এর শর্তে এটা ধ্রুবক, এতে কোনো randomness নেই)।
৪.১ · Induced covariance structure: compound symmetry ও ICC (★★)¶
প্রশ্নটা পরিষ্কার করি। Classical OLS-এর প্রাণভোমরা ছিল একটা ধারণা: error-গুলো পরস্পর-স্বাধীন, তাই \(\operatorname{Cov}(y_{ij},y_{i'j'})=0\) যখনই \((i,j)\ne(i',j')\)। random intercept \(u_j\) যোগ করার পর এই ধারণাটা আর টেকে না — কারণ একই গ্রুপের সব unit একই \(u_j\) ভাগ করে নেয়। আমরা এবার নিজে হাতে variance ও covariance তিনটা বের করব, এবং দেখব এর গঠনই হলো compound symmetry।
মূল হাতিয়ার দুটো (§২.৬ থেকে): প্রথমত, ধ্রুবক যোগ করলে variance বদলায় না — তাই \(\mu_{ij}\) (যা শর্তাধীনে ধ্রুবক) variance/covariance হিসাবে বাদ পড়ে। দ্বিতীয়ত, bilinearity: $$ \operatorname{Cov}(A+B,\;C+D)=\operatorname{Cov}(A,C)+\operatorname{Cov}(A,D)+\operatorname{Cov}(B,C)+\operatorname{Cov}(B,D). $$
প্রতিটা \(y_{ij}\)-কে তার দুই random অংশে ভাঙি: $$ y_{ij}=\underbrace{\mu_{ij}}{\text{ধ্রুবক}}+\underbrace{u_j}. $$}}+\underbrace{\varepsilon_{ij}}_{\text{unit}
ধাপ ১ — variance \(\operatorname{Var}(y_{ij})\)। ধ্রুবক \(\mu_{ij}\) variance-এ অবদান রাখে না, তাই $$ \operatorname{Var}(y_{ij})=\operatorname{Var}(u_j+\varepsilon_{ij}) =\operatorname{Var}(u_j)+\operatorname{Var}(\varepsilon_{ij})+2\operatorname{Cov}(u_j,\varepsilon_{ij}). $$ যেহেতু \(u_j\) ও \(\varepsilon_{ij}\) স্বাধীন, শেষ পদ \(\operatorname{Cov}(u_j,\varepsilon_{ij})=0\)। ফলে $$ \boxed{\;\operatorname{Var}(y_{ij})=\sigma_u^2+\sigma_\varepsilon^2\;} $$ এটাই §৫.৩-এর variance decomposition: মোট ভেদ = between-group অংশ (\(\sigma_u^2\)) + within-group অংশ (\(\sigma_\varepsilon^2\))।
ধাপ ২ — একই গ্রুপে দুই unit-এর covariance, \(i\ne i'\)। এবার একই \(j\), ভিন্ন \(i\): $$ \operatorname{Cov}(y_{ij},y_{i'j})=\operatorname{Cov}(u_j+\varepsilon_{ij},\;u_j+\varepsilon_{i'j}). $$ Bilinearity দিয়ে চারটে পদ খুলি: $$ =\underbrace{\operatorname{Cov}(u_j,u_j)}{=\operatorname{Var}(u_j)=\sigma_u^2} +\underbrace{\operatorname{Cov}(u_j,\varepsilon}){=0\;(\text{স্বাধীন})} +\underbrace{\operatorname{Cov}(\varepsilon},u_j){=0\;(\text{স্বাধীন})} +\underbrace{\operatorname{Cov}(\varepsilon},\varepsilon_{i'j}){=0\;(i\ne i',\;\text{iid})}. $$ তিনটে পদ মরে গেল, টিকে থাকল কেবল প্রথমটা: $$ \boxed{\;\operatorname{Cov}(y $$ },y_{i'j})=\sigma_u^2\quad(i\ne i')\;এটাই মূল চমক: একই গ্রুপের দুই unit-এর মধ্যে শূন্য নয়, ধনাত্মক covariance \(\sigma_u^2\)। উৎস একটাই — তারা একই random intercept \(u_j\) ভাগ করে। \(u_j\) যদি বড় হয়, গ্রুপের সব unit উপরে ওঠে; ছোট হলে সব নামে। এই "একসাথে ওঠা-নামা"-ই covariance।
ধাপ ৩ — ভিন্ন গ্রুপের covariance, \(j\ne j'\)। ভিন্ন গ্রুপের দুই unit: $$ \operatorname{Cov}(y_{ij},y_{i'j'})=\operatorname{Cov}(u_j+\varepsilon_{ij},\;u_{j'}+\varepsilon_{i'j'}),\qquad j\ne j'. $$ চারটে পদের প্রতিটাতেই অন্তত একটা স্বাধীন জোড়া: \(\operatorname{Cov}(u_j,u_{j'})=0\) (random effect-গুলো iid, ভিন্ন গ্রুপ), \(\operatorname{Cov}(u_j,\varepsilon_{i'j'})=0\), \(\operatorname{Cov}(\varepsilon_{ij},u_{j'})=0\), এবং \(\operatorname{Cov}(\varepsilon_{ij},\varepsilon_{i'j'})=0\) (ভিন্ন গ্রুপ মানে নিশ্চিত ভিন্ন index)। তাই $$ \boxed{\;\operatorname{Cov}(y_{ij},y_{i'j'})=0\quad(j\ne j')\;} $$ অর্থাৎ correlation কেবল গ্রুপের ভেতরেই আটকে থাকে, গ্রুপ পেরিয়ে ছড়ায় না।
ধাপ ৪ — compound symmetry গঠনটা চোখে দেখি। একটা \(n_j=3\) গ্রুপের তিন observation \((y_{1j},y_{2j},y_{3j})\)-এর covariance matrix তাহলে: $$ \operatorname{Cov}(y_j)= \begin{pmatrix} \sigma_u^2+\sigma_\varepsilon^2 & \sigma_u^2 & \sigma_u^2\ \sigma_u^2 & \sigma_u^2+\sigma_\varepsilon^2 & \sigma_u^2\ \sigma_u^2 & \sigma_u^2 & \sigma_u^2+\sigma_\varepsilon^2 \end{pmatrix}. $$ লক্ষ করুন কাঠামোটা: diagonal-এ সবাই সমান, off-diagonal-এ সবাই সমান। এই "সব ভেরিয়েন্স সমান, সব pairwise covariance সমান" গঠনকেই বলে compound symmetry। একে কম্প্যাক্টভাবে লেখা যায় $$ V_j=\sigma_u^2\,\mathbf 1\mathbf 1^\top+\sigma_\varepsilon^2 I, $$ যেখানে \(\mathbf 1\) হলো \(n_j\)-দৈর্ঘ্যের all-ones vector আর \(I\) হলো \(n_j\times n_j\) identity — কারণ \(\mathbf 1\mathbf 1^\top\)-এর প্রতিটা ঘর \(1\) (off-diagonal-এ \(\sigma_u^2\) বসায়) আর \(I\) কেবল diagonal-এ \(\sigma_\varepsilon^2\) বাড়ায়। এই \(V_j\) আমরা §৪.৩-এ আবার ব্যবহার করব।
ধাপ ৫ — correlation নিই, ICC বেরোয়। একই গ্রুপের দুই observation-এর correlation সংজ্ঞা থেকে: $$ \operatorname{Corr}(y_{ij},y_{i'j}) =\frac{\operatorname{Cov}(y_{ij},y_{i'j})}{\sqrt{\operatorname{Var}(y_{ij})}\,\sqrt{\operatorname{Var}(y_{i'j})}} =\frac{\sigma_u^2}{\sqrt{\sigma_u^2+\sigma_\varepsilon^2}\,\sqrt{\sigma_u^2+\sigma_\varepsilon^2}}. $$ হর-এ দুটো বর্গমূল গুণ হয়ে শুধু \((\sigma_u^2+\sigma_\varepsilon^2)\) থাকে: $$ \boxed{\;\operatorname{Corr}(y_{ij},y_{i'j})=\frac{\sigma_u^2}{\sigma_u^2+\sigma_\varepsilon^2}=\rho\;} $$ অর্থাৎ same-group correlation ঠিক ICC-র সমান — এবং এটা আর "শুধু একটা সংজ্ঞা" নয়, একে আমরা মডেল থেকে উৎপাদন করলাম। ICC তাই দুটো কথা একসাথে বলে: (১) মোট ভেদের কত ভাগ between-group (\(\rho=\sigma_u^2/(\sigma_u^2+\sigma_\varepsilon^2)\)), আর (২) একই গ্রুপের দুই unit কতটা পরস্পর-সম্পর্কিত — এই দুটো একই সংখ্যা, এটাই hierarchical মডেলের গভীর ঐক্য।
সঙ্গতি-যাচাই (sanity check): \(\sigma_u^2=2,\ \sigma_\varepsilon^2=3\) ধরে simulation চালালে empirical \(\operatorname{Var}(y)\approx 4.85\) (\(\approx 5=\sigma_u^2+\sigma_\varepsilon^2\)), same-group \(\operatorname{Cov}\approx 1.88\) (\(\approx 2=\sigma_u^2\)), same-group corr \(\approx 0.386\) (\(\approx \rho=0.40\)), আর diff-group \(\operatorname{Cov}\approx 0\) — তিনটে সূত্রই মেলে।
৪.২ · Clustering উপেক্ষা করলে OLS inference কেন ভাঙে: design effect (★★)¶
প্রশ্নটা। ধরা যাক আমরা গোঁয়ার্তুমি করে clustering-এর কথা ভুলে গিয়ে সাধারণ OLS চালালাম — অর্থাৎ ধরে নিলাম \(N\)টা observation সবাই স্বাধীন। point estimate \(\hat\beta\) হয়তো খুব একটা খারাপ হবে না (এখনও unbiased-এর কাছাকাছি), কিন্তু standard error? এখানেই বিপদ। আমরা দেখাব OLS-এর SE পদ্ধতিগতভাবে ছোট আসে, ফলে confidence interval সরু, \(p\)-value মিথ্যা ছোট, আর আমরা যা "significant" ভাবি তা আসলে নয়।
মূল অন্তর্দৃষ্টিটা এক বাক্যে: positive within-group correlation মানে প্রতিটা নতুন observation আগের observation-এর সঙ্গে কিছু তথ্য ভাগ করে নেয়, তাই সে "পুরো একটা স্বাধীন data point"-এর সমান নতুন তথ্য আনে না। \(N\)টা correlated observation-এ আসলে \(N\)টা স্বাধীন observation-এর চেয়ে কম কার্যকর তথ্য থাকে।
ধাপ ১ — সরলতম কেস: গ্রুপ-গড়ের variance। ব্যাপারটা সংখ্যায় দেখতে ধরা যাক balanced design — প্রতিটা গ্রুপে \(\bar n=n\)টি unit, আর আমরা একটা single গ্রুপ-গড় \(\bar y_j=\frac1n\sum_{i=1}^{n}y_{ij}\)-এর variance দেখি। variance of a sum-এর সূত্রে: $$ \operatorname{Var}(\bar y_j)=\frac{1}{n^2}\Big[\sum_i \operatorname{Var}(y_{ij})+\sum_{i\ne i'}\operatorname{Cov}(y_{ij},y_{i'j})\Big]. $$ §৪.১ থেকে: প্রতিটা \(\operatorname{Var}(y_{ij})=\sigma_u^2+\sigma_\varepsilon^2\) (মোট \(n\)টা পদ), আর প্রতিটা same-group \(\operatorname{Cov}=\sigma_u^2\) (মোট \(n(n-1)\)টা ordered জোড়া)। বসাই: $$ \operatorname{Var}(\bar y_j)=\frac{1}{n^2}\Big[n(\sigma_u^2+\sigma_\varepsilon^2)+n(n-1)\sigma_u^2\Big] =\frac{\sigma_\varepsilon^2}{n}+\sigma_u^2. $$ (যাচাই: \(\frac{1}{n^2}[n\sigma_u^2+n\sigma_\varepsilon^2+n^2\sigma_u^2-n\sigma_u^2]=\frac{1}{n^2}[n\sigma_\varepsilon^2+n^2\sigma_u^2]=\frac{\sigma_\varepsilon^2}{n}+\sigma_u^2\)।)
ধাপ ২ — তুলনা: OLS যা ভাবে। OLS যদি সব \(n\)টা observation-কে স্বাধীন ভাবে (correlation \(=0\), অর্থাৎ ভাবে total variance \(\sigma^2=\sigma_u^2+\sigma_\varepsilon^2\) আর covariance সব শূন্য), তবে সে গ্রুপ-গড়ের variance ধরবে $$ \operatorname{Var}{\text{naive}}(\bar y_j)=\frac{\sigma_u^2+\sigma\varepsilon^2}{n}. $$ এবার দুটোর অনুপাত নিই — এটাই design effect \(D_{\text{eff}}\): $$ D_{\text{eff}}=\frac{\operatorname{Var}{\text{true}}(\bar y_j)}{\operatorname{Var} =\frac{\sigma_u^2+\dfrac{\sigma_\varepsilon^2}{n}}{\dfrac{\sigma_u^2+\sigma_\varepsilon^2}{n}} =\frac{n\sigma_u^2+\sigma_\varepsilon^2}{\sigma_u^2+\sigma_\varepsilon^2}. $$ লব আর হরকে }}(\bar y_j)\((\sigma_u^2+\sigma_\varepsilon^2)\) দিয়ে গুছিয়ে \(\rho=\sigma_u^2/(\sigma_u^2+\sigma_\varepsilon^2)\) চিনি: $$ D_{\text{eff}}=\frac{n\sigma_u^2+\sigma_\varepsilon^2}{\sigma_u^2+\sigma_\varepsilon^2} =\frac{n\sigma_u^2-\sigma_u^2+(\sigma_u^2+\sigma_\varepsilon^2)}{\sigma_u^2+\sigma_\varepsilon^2} =1+(n-1)\frac{\sigma_u^2}{\sigma_u^2+\sigma_\varepsilon^2}. $$ অসমান গ্রুপ-আকারের ক্ষেত্রে গড় গ্রুপ-আকার \(\bar n\) বসিয়ে আনুমানিক রূপ: $$ \boxed{\;D_{\text{eff}}\approx 1+(\bar n-1)\,\rho\;} $$ এটাই বিখ্যাত design-effect সূত্র (Kish-এর design effect)।
ধাপ ৩ — অর্থ পড়ি। তিনটে সীমা দেখলেই সব পরিষ্কার: - \(\rho=0\) (clustering নেই) \(\Rightarrow D_{\text{eff}}=1\): OLS সঠিক, কোনো সমস্যা নেই। - \(\rho>0\) \(\Rightarrow D_{\text{eff}}>1\): true variance naive variance-এর চেয়ে বড়, অর্থাৎ OLS variance-কে কম ধরছে। তাই \(\mathrm{SE}_{\text{naive}}=\mathrm{SE}_{\text{true}}/\sqrt{D_{\text{eff}}}\) — naive SE পদ্ধতিগতভাবে \(\sqrt{D_{\text{eff}}}\) গুণে ছোট। - বড় গ্রুপ (\(\bar n\) বড়) আর ধনাত্মক \(\rho\) একসাথে হলে \(D_{\text{eff}}\) অনেক বড় হতে পারে। যেমন \(\bar n=5,\ \rho=0.4\) দিলে \(D_{\text{eff}}=1+4(0.4)=2.6\) — অর্থাৎ true variance naive-এর প্রায় ৩ গুণ, আর true SE প্রায় \(\sqrt{2.6}\approx 1.6\) গুণ বড়। OLS এখানে SE-কে \(\sim\)৪০% কম দেখাবে।
ধাপ ৪ — কেন এটা cluster-level effect-এ সবচেয়ে মারাত্মক। intercept বা cluster-level covariate (যে \(x\) একই গ্রুপের সব unit-এ একই মান নেয়, যেমন "school-এর funding") — এদের information মূলত গ্রুপ-গড় থেকে আসে, আর গ্রুপ-গড়ই হলো সবচেয়ে inflated-variance অংশ। তাই OLS এদের SE সবচেয়ে বেশি কম দেখায়, এদের জন্যই ভুয়া-significance-এর ঝুঁকি সবচেয়ে বেশি। বিপরীতে, within-group-এ পরিবর্তিত হওয়া covariate-এর জন্য সমস্যা তুলনায় কম।
effective sample size। চিন্তাটা উল্টে দিলে: \(N\)টা correlated observation-এর কার্যকর তথ্য সমান-সমান হয় কেবল \(N_{\text{eff}}=N/D_{\text{eff}}\)টা স্বাধীন observation-এর। \(D_{\text{eff}}=2.6\) মানে \(N=1000\) observation আসলে কেবল \(\approx 385\)টা স্বাধীন data point-এর সমান তথ্য বহন করছে। OLS এই সংকোচন দেখে না — সে গর্বভরে \(N=1000\) ধরে SE হিসাব করে, আর তাই অতিরিক্ত-আত্মবিশ্বাসী উত্তর দেয়। mixed model এই correlation structure স্পষ্টভাবে মডেল করে বলেই সঠিক (বড়) SE দেয় — এটাই §৪.৩-এর GLS-এর কাজ।
৪.৩ · Marginal model ও GLS estimator (★★★)¶
প্রশ্নটা। §৪.১ দেখাল within-group correlation আছে; §৪.২ দেখাল OLS তাই ভুল SE দেয়। স্বাভাবিক প্রশ্ন: তবে সঠিক, efficient estimator কী? উত্তর — generalized least squares (GLS), যা correlation structure \(V_j\)-কে হিসাবে নেয়। এই অংশে আমরা মডেলটা matrix আকারে সাজিয়ে GLS estimator উৎপাদন করব, এবং দেখব কেন বাস্তবে একে feasible GLS-এ পরিণত করতে হয়।
ধাপ ১ — গ্রুপ-ভিত্তিক matrix রূপ। একটা গ্রুপ \(j\)-এর \(n_j\)টা observation একসাথে stack করি। সংজ্ঞা দিই: $$ y_j=\begin{pmatrix}y_{1j}\\vdots\y_{n_j j}\end{pmatrix}\in\mathbb{R}^{n_j},\qquad X_j=\begin{pmatrix}1 & x_{1j}\\vdots & \vdots\ 1 & x_{n_j j}\end{pmatrix}\in\mathbb{R}^{n_j\times 2},\qquad \beta=\begin{pmatrix}\beta_0\\beta_1\end{pmatrix}, $$ আর \(\varepsilon_j=(\varepsilon_{1j},\dots,\varepsilon_{n_j j})^\top\), \(\mathbf 1=(1,\dots,1)^\top\in\mathbb{R}^{n_j}\)। তাহলে scalar মডেল \(y_{ij}=\beta_0+\beta_1 x_{ij}+u_j+\varepsilon_{ij}\) ঠিক যা বলে, matrix-এ তা হয়: $$ \boxed{\;y_j=X_j\beta+\mathbf 1\,u_j+\varepsilon_j\;} $$ (\(X_j\beta\)-র \(i\)-তম ঘর \(\beta_0+\beta_1 x_{ij}\), আর \(\mathbf 1 u_j\)-র প্রতিটা ঘরে একই \(u_j\) — কারণ গ্রুপের সবাই একই intercept-শিফট ভাগ করে।)
ধাপ ২ — marginal covariance \(V_j\)। এখন \(u_j\)-কে আলাদা estimate না করে তাকে integrate out করি — অর্থাৎ \(u_j\) ও \(\varepsilon_j\) উভয়ের randomness মিলিয়ে \(y_j\)-এর mean ও covariance দেখি। এটাকে বলে marginal (population-averaged) model: $$ \mathbb{E}[y_j]=X_j\beta\qquad(\text{কারণ }\mathbb{E}[u_j]=0,\ \mathbb{E}[\varepsilon_j]=0), $$ $$ \operatorname{Cov}(y_j)=\operatorname{Cov}(\mathbf 1 u_j+\varepsilon_j) =\mathbf 1\mathbf 1^\top\operatorname{Var}(u_j)+\operatorname{Cov}(\varepsilon_j) =\sigma_u^2\,\mathbf 1\mathbf 1^\top+\sigma_\varepsilon^2 I=:V_j. $$ (এখানে \(\operatorname{Cov}(\mathbf 1 u_j)=\mathbf 1\mathbf 1^\top\sigma_u^2\) কারণ \(\operatorname{Cov}(a u, a u)=aa^\top\operatorname{Var}(u)\) যেকোনো ধ্রুবক vector \(a\)-র জন্য; আর \(u_j\perp\varepsilon_j\) বলে cross-term নেই।) এই \(V_j\) ঠিক §৪.১-এর compound-symmetry matrix — মডেল দুই পথে এসে একই উত্তরে মিলল।
ভিন্ন গ্রুপ স্বাধীন (§৪.১ ধাপ ৩) বলে গোটা \(N\)-vector \(y=(y_1^\top,\dots,y_J^\top)^\top\)-এর covariance হলো block-diagonal: $$ \operatorname{Cov}(y)=V=\operatorname{blockdiag}(V_1,\dots,V_J). $$ এটাই সমস্যাটাকে সরল করে — পুরো \(N\times N\) matrix নিয়ে কাজ না করে আমরা গ্রুপ-ধরে-গ্রুপ কাজ করতে পারি।
ধাপ ৩ — GLS-এর যুক্তি। Gauss–Markov (§৫.১) বলেছিল: error iid হলে OLS-ই BLUE। কিন্তু এখানে error iid নয় — \(\operatorname{Cov}(y)=V\ne\sigma^2 I\)। সাধারণীকৃত Gauss–Markov বলে: এমন correlated/heteroskedastic ক্ষেত্রে BLUE হলো GLS, যা data-কে \(V^{-1/2}\) দিয়ে "whiten" করে নেয়। GLS estimator minimize করে weighted residual sum of squares: $$ \hat\beta_{\text{GLS}}=\arg\min_\beta\;(y-X\beta)^\top V^{-1}(y-X\beta). $$
ধাপ ৪ — minimize করে closed form। \(\beta\)-এর সাপেক্ষে অবকলন করে শূন্য বসাই (normal equations)। \(Q(\beta)=(y-X\beta)^\top V^{-1}(y-X\beta)\)-এর gradient: $$ \frac{\partial Q}{\partial\beta}=-2X^\top V^{-1}(y-X\beta)=0 \;\Longrightarrow\; X^\top V^{-1}X\,\beta=X^\top V^{-1}y. $$ সমাধান: $$ \hat\beta_{\text{GLS}}=(X^\top V^{-1}X)^{-1}X^\top V^{-1}y. $$ এখন \(V\) block-diagonal হওয়ায় \(X^\top V^{-1}X=\sum_j X_j^\top V_j^{-1}X_j\) এবং \(X^\top V^{-1}y=\sum_j X_j^\top V_j^{-1}y_j\) — অর্থাৎ পুরো যোগফলটা গ্রুপ-ধরে ভেঙে যায়: $$ \boxed{\;\hat\beta_{\text{GLS}}=\Big(\sum_{j=1}^J X_j^\top V_j^{-1}X_j\Big)^{-1}\sum_{j=1}^J X_j^\top V_j^{-1}y_j\;} $$ ব্যাখ্যা: প্রতিটা গ্রুপের অবদানকে তার নিজস্ব \(V_j^{-1}\) দিয়ে ওজন দেওয়া হচ্ছে — বেশি correlated বা বেশি noisy গ্রুপ কম ওজন পায়। এটাই efficient (সবচেয়ে কম-variance linear unbiased) estimator।
ধাপ ৫ — \(V_j^{-1}\)-এর বদ্ধ রূপ (কেন হিসাব সহজ)। \(V_j=\sigma_\varepsilon^2 I+\sigma_u^2\mathbf 1\mathbf 1^\top\) একটা "identity + rank-one" matrix, তাই Sherman–Morrison সূত্রে এর inverse হাতে বের করা যায়: $$ V_j^{-1}=\frac{1}{\sigma_\varepsilon^2}\Big(I-\frac{\sigma_u^2}{\sigma_\varepsilon^2+n_j\sigma_u^2}\,\mathbf 1\mathbf 1^\top\Big). $$ (\(\mathbf 1^\top\mathbf 1=n_j\) ব্যবহার করে যাচাই করা যায় \(V_j V_j^{-1}=I\)।) এর তাৎপর্য: \(V_j^{-1}\) গণনায় কোনো \(n_j\times n_j\) matrix উল্টাতে হয় না — শুধু একটা scalar; তাই বড় গ্রুপেও GLS দ্রুত হিসাব হয়।
সঙ্গতি-যাচাই: \(\sigma_u^2=2,\ \sigma_\varepsilon^2=3,\ n_j=6\) ধরে উপরের Sherman–Morrison রূপ আর সরাসরি
numpyinverse — দুটো হুবহু মেলে (সর্বোচ্চ পার্থক্য ~\(10^{-15}\))।
ধাপ ৬ — সমস্যা: \(V_j\) আসলে অজানা। উপরের সূত্রে একটা লুকনো ফাঁকি আছে: \(V_j\) নির্ভর করে \((\sigma_u^2,\sigma_\varepsilon^2)\)-এর উপর, কিন্তু এই variance component-গুলোই অজানা। তাই বিশুদ্ধ GLS বাস্তবে চালানো যায় না। সমাধান দুই-ধাপি: 1. প্রথমে \((\sigma_u^2,\sigma_\varepsilon^2)\) estimate করি — সাধারণত ML বা REML দিয়ে (§৪.৫)। 2. সেই estimate \((\hat\sigma_u^2,\hat\sigma_\varepsilon^2)\) বসিয়ে \(\hat V_j\) বানাই, তারপর GLS সূত্রে \(\hat\beta\) পাই।
এই "estimated \(V\) plug-in" পদ্ধতিকে বলে feasible GLS (FGLS) — আর এটাই কার্যত যা lmer/mixed করে: variance component আর \(\beta\)-কে একসাথে (iteratively) estimate করে। বড় \(J\)-এর জন্য FGLS asymptotically সেই efficiency-ই অর্জন করে যা \(V\) জানা থাকলে পাওয়া যেত।
৪.৪ · Shrinkage / BLUP: "ছোট গ্রুপ বেশি shrink হয়"-এর গণিত (★★)¶
প্রশ্নটা। ধরা যাক \(\beta\) আমরা জানি (বা estimate করে ফেলেছি)। এখন একটা নির্দিষ্ট গ্রুপ \(j\)-এর random effect \(u_j\)-কে আমরা predict করতে চাই — অর্থাৎ ওই গ্রুপটা grand line থেকে কতটা উপরে/নিচে? দুটো চরম পথ আছে: (১) no pooling — শুধু গ্রুপ \(j\)-এর নিজের data থেকে এর offset বের করা; (২) complete pooling — \(u_j\)-কে \(0\) ধরা, অর্থাৎ গ্রুপটা গড়ের মতোই, কোনো বিশেষত্ব নেই। mixed model একটা মাঝামাঝি, অনুকূল পথ নেয় — partial pooling — আর এর পেছনে আছে একটা সুনির্দিষ্ট shrinkage factor। সেটাই আমরা derive করব।
ধাপ ১ — residual সংজ্ঞা। fixed অংশ বাদ দিয়ে গ্রুপ \(j\)-এর জন্য residual: $$ r_{ij}:=y_{ij}-\mu_{ij}=y_{ij}-(\beta_0+\beta_1 x_{ij})=u_j+\varepsilon_{ij}. $$ এর গ্রুপ-গড় (\(\bar r_j\), যা brief-এর ভাষায় \(\bar y_j-\bar y_{\text{fixed},j}\)): $$ \bar r_j=\frac{1}{n_j}\sum_{i=1}^{n_j}r_{ij}=u_j+\bar\varepsilon_j,\qquad \bar\varepsilon_j=\frac1{n_j}\sum_i\varepsilon_{ij}. $$ এই \(\bar r_j\) হলো \(u_j\) সম্পর্কে আমাদের কাঁচা (no-pooling) অনুমান — কিন্তু এতে \(\bar\varepsilon_j\) noise মিশে আছে, যার variance \(\sigma_\varepsilon^2/n_j\)।
ধাপ ২ — দুটো তথ্যসূত্র। \(u_j\) সম্পর্কে আমাদের কাছে দুরকম তথ্য: - prior (মডেল থেকে): \(u_j\sim\mathcal N(0,\sigma_u^2)\) — গ্রুপ-effect গড়ে \(0\), ছড়ানো \(\sigma_u^2\)। - likelihood (data থেকে): observed \(\bar r_j\mid u_j\sim\mathcal N\!\big(u_j,\ \sigma_\varepsilon^2/n_j\big)\) — কারণ \(\bar r_j=u_j+\bar\varepsilon_j\) এবং \(\operatorname{Var}(\bar\varepsilon_j)=\sigma_\varepsilon^2/n_j\)।
ধাপ ৩ — দুটো মিলিয়ে posterior mean (normal–normal conjugacy)। Gaussian prior + Gaussian likelihood-এর posterior mean হলো precision-weighted average (precision = \(1/\)variance) — এটা normal–normal conjugacy-র মানসম্মত ফল। prior-এর precision \(1/\sigma_u^2\) (mean \(0\)), data-র precision \(n_j/\sigma_\varepsilon^2\) (mean \(\bar r_j\))। তাই $$ \hat u_j=\mathbb{E}[u_j\mid \text{data}] =\frac{\dfrac{1}{\sigma_u^2}\cdot 0+\dfrac{n_j}{\sigma_\varepsilon^2}\cdot \bar r_j}{\dfrac{1}{\sigma_u^2}+\dfrac{n_j}{\sigma_\varepsilon^2}} =\frac{\dfrac{n_j}{\sigma_\varepsilon^2}\,\bar r_j}{\dfrac{1}{\sigma_u^2}+\dfrac{n_j}{\sigma_\varepsilon^2}}. $$ লব-হরকে \(\sigma_u^2\sigma_\varepsilon^2\) দিয়ে গুণ করে গুছিয়ে নিই: $$ \hat u_j=\frac{n_j\sigma_u^2}{\sigma_\varepsilon^2+n_j\sigma_u^2}\;\bar r_j. $$ অর্থাৎ $$ \boxed{\;\hat u_j=\lambda_j\,\bar r_j,\qquad \lambda_j=\frac{n_j\sigma_u^2}{n_j\sigma_u^2+\sigma_\varepsilon^2}\;} $$ এই \(\hat u_j\)-ই BLUP (Best Linear Unbiased Predictor), আর \(\lambda_j\in(0,1)\) হলো shrinkage factor। লক্ষ করুন \(\lambda_j\le 1\), তাই \(\hat u_j\) সবসময় কাঁচা অনুমান \(\bar r_j\)-এর চেয়ে \(0\)-এর দিকে টানা (shrunk) — তাই নাম shrinkage estimator।
ধাপ ৪ — শেষ-বিন্দুর আচরণ (এটাই "ছোট গ্রুপ বেশি shrink"-এর মূল)। \(\lambda_j=\dfrac{n_j\sigma_u^2}{n_j\sigma_u^2+\sigma_\varepsilon^2}\)-কে \(n_j\)-এর function হিসেবে দেখি:
- বড় গ্রুপ, \(n_j\to\infty\): লব ও হর দুই-ই \(n_j\sigma_u^2\) দ্বারা প্রভাবিত, হরের \(\sigma_\varepsilon^2\) তুচ্ছ হয়ে যায়, তাই \(\lambda_j\to 1\)। মানে \(\hat u_j\to\bar r_j\) — গ্রুপের নিজের data-কে পুরো বিশ্বাস করো (no pooling)। যৌক্তিক: অনেক observation থাকলে \(\bar r_j\)-এর noise \(\sigma_\varepsilon^2/n_j\to 0\), তাই কাঁচা অনুমানই নির্ভরযোগ্য।
- ছোট গ্রুপ, \(n_j\to 1\) (অর্থাৎ ছোট গ্রুপ): হরে \(\sigma_\varepsilon^2\) প্রভাব ফেলে, \(\lambda_j\to 0\), তাই \(\hat u_j\to 0\) — গ্রুপটাকে grand mean-এর দিকে টেনে আনো (complete pooling)। যৌক্তিক: অল্প data মানে \(\bar r_j\) ভীষণ noisy, একে কম বিশ্বাস করো, বরং "সব গ্রুপ গড়ে একরকম" এই prior-কে বেশি ওজন দাও।
তাই একই \(\sigma_u^2,\sigma_\varepsilon^2\)-এর জন্য, ছোট \(n_j\) মানে ছোট \(\lambda_j\) মানে বেশি shrinkage — এটাই "small groups shrink more" বাক্যটার গণিত। mixed model স্বয়ংক্রিয়ভাবে এই ব্যালান্স করে: যে গ্রুপের data কম/noisy তাকে গড়ের দিকে বেশি টানে, যে গ্রুপের data বেশি তাকে তার নিজের পথে চলতে দেয়।
ধাপ ৫ — ICC-র সঙ্গে সম্পর্ক। \(\lambda_j\)-এর লব-হরকে \(\sigma_\varepsilon^2\) দিয়ে ভাগ করলে: $$ \lambda_j=\frac{n_j\cdot \dfrac{\sigma_u^2}{\sigma_\varepsilon^2}}{n_j\cdot\dfrac{\sigma_u^2}{\sigma_\varepsilon^2}+1}=\frac{n_j\,\rho}{n_j\,\rho+(1-\rho)}, $$ যেখানে \(\rho/(1-\rho)=\sigma_u^2/\sigma_\varepsilon^2\)। ফলে shrinkage শুধু \(n_j\)-এর নয়, ICC-রও ফাংশন: বড় \(\rho\) (গ্রুপগুলো খুব আলাদা) → কম shrinkage; ছোট \(\rho\) (গ্রুপগুলো প্রায় একরকম) → বেশি shrinkage। স্বজ্ঞাত: গ্রুপগুলো সত্যিই আলাদা হলে তাদের আলাদা থাকতে দেওয়াই উচিত।
সঙ্গতি-যাচাই: \(\sigma_u^2=2,\ \sigma_\varepsilon^2=3,\ n_j=5\)-এ সূত্র \(\lambda_j=\frac{5\cdot2}{5\cdot2+3}=\frac{10}{13}\approx 0.769\), আর সরাসরি normal–normal posterior coefficient \(\frac{\sigma_u^2}{\sigma_u^2+\sigma_\varepsilon^2/n_j}=\frac{2}{2+0.6}\approx 0.769\) — হুবহু এক।
৪.৫ · REML বনাম ML: variance component-এর জন্য কোনটা (★)¶
প্রশ্নটা। §৪.৩-এ feasible GLS-এর জন্য আমাদের \((\sigma_u^2,\sigma_\varepsilon^2)\) estimate করতে হয়। দুটো পদ্ধতি প্রচলিত — maximum likelihood (ML) আর restricted/residual ML (REML)। কোনটা, কখন? উত্তরের মূল কথা: ML variance-কে কম দেখায় (downward biased), REML সেই bias সারায়।
ধাপ ১ — কেন ML downward-biased। সরল উপমা: এক-নমুনা variance। জানা সত্য — \(\hat\sigma^2_{\text{ML}}=\frac1n\sum(y_i-\bar y)^2\) biased, কারণ এটা অজানা \(\mu\)-এর বদলে estimated \(\bar y\) ব্যবহার করে, কিন্তু harে \(n\) লেখে — যেন \(\bar y\) estimate করতে কোনো degree of freedom খরচ হয়নি। নিরপেক্ষ version হরে \((n-1)\) লেখে, ঠিক ওই হারানো d.f.-এর হিসাব রাখে। mixed model-এ ঠিক একই ব্যাপার: ML variance component estimate করার সময় ধরে নেয় \(\beta\) জানা, অথচ বাস্তবে \(\beta\)-ও data থেকে estimate করা হয়েছে — এতে কয়েকটা d.f. খরচ হয়েছে যা ML হিসাবে আনে না, ফলে \(\hat\sigma_u^2,\hat\sigma_\varepsilon^2\) পদ্ধতিগতভাবে ছোট আসে (বিশেষত \(J\) ছোট হলে গুরুতর)।
ধাপ ২ — REML কী করে। REML চালাকিটা হলো: \(\beta\)-নির্ভর তথ্য আগেই সরিয়ে ফেলো। data-কে এমন residual contrast (error contrast)-এ রূপান্তর করা হয় যাদের distribution \(\beta\)-র উপর নির্ভর করে না (যেমন \(\beta\)-কে project-out করে দেওয়া residual)। তারপর কেবল সেই contrast-গুলোর likelihood maximize করে variance component estimate করা হয়। যেহেতু \(\beta\) estimate করার d.f.-ক্ষতি এই গঠনেই ধরা থাকে, REML estimate প্রায় নিরপেক্ষ (\(\hat\sigma^2\) এত কম আসে না)। (এক-নমুনা সরল কেসে REML হুবহু \((n-1)\)-হরওয়ালা নিরপেক্ষ variance-ই ফিরিয়ে দেয় — এটাই REML-কে \((n-1)\) সংশোধনের সাধারণীকরণ বানায়।)
ধাপ ৩ — তাহলে নিয়ম (এক বাক্যে)।
$$
\boxed{\;\text{variance component} \to \textbf{REML};\qquad \text{fixed-effect মডেলের LR-তুলনা}\to \textbf{ML}\;}
$$
- variance component রিপোর্ট করতে REML ব্যবহার করো — কম-biased \(\hat\sigma_u^2,\hat\sigma_\varepsilon^2\) পাওয়া যায় (এজন্য lmer-এর default REML)।
- দুটো nested fixed-effect মডেল likelihood-ratio test দিয়ে তুলনা করতে ML ব্যবহার করো। কারণ: REML-likelihood নির্ভর করে residual contrast-এর উপর, আর fixed অংশ (\(X\)) বদলালে contrast-এর সংজ্ঞাই বদলায় — তাই ভিন্ন \(X\)-ওয়ালা দুই REML fit-এর likelihood তুলনাযোগ্য নয়। ML-likelihood একই full data-র উপর, তাই LR-test বৈধ। (random-effect structure তুলনা করতে অবশ্য REML চলে, কারণ তখন \(X\) অপরিবর্তিত।)
এই সূক্ষ্মতা মনে রাখা ব্যবহারিকভাবে জরুরি: REML fit দুটোর AIC/likelihood তুলনা করে fixed effect-এর সিদ্ধান্ত নেওয়া একটা সাধারণ ভুল।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা একটি hierarchical / clustered ডেটাসেট নিয়ে কাজ করব: ২৫টি school, প্রতিটিতে ১০–৩০ জন শিক্ষার্থী, আর প্রতিটি শিক্ষার্থীর hours (পড়ার সময়) ও score (নম্বর) আছে। আসল data-generating প্রক্রিয়াটি জানা — প্রতিটি school-এর একটি নিজস্ব random offset \(u_j \sim \mathcal{N}(0, 6^2)\) আছে, residual noise \(\varepsilon \sim \mathcal{N}(0, 8^2)\), এবং true fixed effect \(\beta_1 = 2.0\)। লক্ষ্য: প্রথমে ভুল পথে (pooled OLS, যেটি clustering উপেক্ষা করে) fit করব, তারপর সঠিক পথে (MixedLM) — এবং দুটির পার্থক্য থেকে variance components, ICC ও BLUP বের করব।
import numpy as np, pandas as pd, statsmodels.api as sm, statsmodels.formula.api as smf
# ---------------------------------------------------------------
# ডেটা নির্মাণ (canonical generator)
# ---------------------------------------------------------------
rng = np.random.default_rng(20260619)
J = 25
nj = rng.integers(10, 31, J)
u = rng.normal(0, 6.0, J)
rows = []
for j in range(J):
hours = rng.uniform(0, 10, nj[j])
eps = rng.normal(0, 8.0, nj[j])
score = 50.0 + 2.0 * hours + u[j] + eps
for h, s in zip(hours, score):
rows.append((j, h, s))
df = pd.DataFrame(rows, columns=['school', 'hours', 'score'])
print("="*60)
print("ডেটাসেট সারসংক্ষেপ")
print("="*60)
print(f"N (মোট পর্যবেক্ষণ) = {len(df)}")
print(f"J (school সংখ্যা) = {df['school'].nunique()}")
cs = df.groupby('school').size()
print(f"cluster size range = {cs.min()} – {cs.max()} (গড় {cs.mean():.1f})")
# ---------------------------------------------------------------
# PART 1 : Pooled OLS (the WRONG way)
# ---------------------------------------------------------------
print("\n" + "="*60)
print("PART 1 · Pooled OLS (clustering উপেক্ষা)")
print("="*60)
ols = smf.ols('score ~ hours', data=df).fit()
print(f"β0 (Intercept) = {ols.params['Intercept']:.3f} SE = {ols.bse['Intercept']:.3f}")
print(f"β1 (hours) = {ols.params['hours']:.3f} SE = {ols.bse['hours']:.3f}")
print(f"residual SD = {np.sqrt(ols.scale):.3f}")
print(">> সতর্কতা: একই school-এর শিক্ষার্থীরা সম্পর্কিত (within-school correlation),")
print(">> তাই OLS এই SE-গুলোকে কম করে দেখায় (too small) — p-value বিভ্রান্তিকর।")
# ---------------------------------------------------------------
# PART 2 : Mixed-Effects / random-intercept (the RIGHT way)
# ---------------------------------------------------------------
print("\n" + "="*60)
print("PART 2 · MixedLM (random intercept per school)")
print("="*60)
md = smf.mixedlm('score ~ hours', df, groups=df['school']).fit()
print(md.summary())
b0 = md.fe_params['Intercept']
b1 = md.fe_params['hours']
se0 = md.bse_fe['Intercept']
se1 = md.bse_fe['hours']
group_var = float(md.cov_re.iloc[0, 0]) # σ_u²
scale = float(md.scale) # σ_ε²
sigma_u = np.sqrt(group_var)
sigma_e = np.sqrt(scale)
print("\n--- নিষ্কাশিত উপাদান (extracted) ---")
print(f"β0 = {b0:.3f} (SE {se0:.3f})")
print(f"β1 = {b1:.3f} (SE {se1:.3f})")
print(f"Group Var (σ_u²) = {group_var:.2f} -> σ_u = {sigma_u:.2f}")
print(f"scale (σ_ε²) = {scale:.2f} -> σ_ε = {sigma_e:.2f}")
print(f"logLik = {md.llf:.1f}")
# ---------------------------------------------------------------
# PART 3 : ICC + SE তুলনা
# ---------------------------------------------------------------
print("\n" + "="*60)
print("PART 3 · ICC এবং SE তুলনা")
print("="*60)
icc = group_var / (group_var + scale)
print(f"ICC = GroupVar / (GroupVar + scale) = {group_var:.2f} / ({group_var:.2f} + {scale:.2f}) = {icc:.3f}")
print(f">> মোট variance-এর {icc*100:.1f}% school-ভেদে; বাকি {(1-icc)*100:.1f}% school-এর ভেতরে।")
print("\nSE তুলনা (OLS পুলড underestimates):")
print(f" Intercept SE : OLS {ols.bse['Intercept']:.3f} vs Mixed {se0:.3f}")
print(f" slope SE : OLS {ols.bse['hours']:.3f} vs Mixed {se1:.3f}")
print(">> Mixed-এর SE বড় কারণ effective sample size প্রকৃতপক্ষে কম (clustering)।")
# ---------------------------------------------------------------
# PART 4 : Random effects (BLUP) + shrinkage
# ---------------------------------------------------------------
print("\n" + "="*60)
print("PART 4 · Random effects (BLUP) এবং shrinkage")
print("="*60)
re = md.random_effects
blup = pd.Series({k: float(v.iloc[0]) for k, v in re.items()})
print("কয়েকটি school-এর BLUP (û_j):")
print(blup.head(6).round(3).to_string())
# school 0-এর shrinkage প্রদর্শন
fitted_pop = b0 + b1 * df.loc[df['school'] == 0, 'hours']
raw_dev0 = (df.loc[df['school'] == 0, 'score'] - fitted_pop).mean()
n0 = (df['school'] == 0).sum()
print(f"\nschool 0 (n = {n0}):")
print(f" raw deviation (population line থেকে গড় residual) = {raw_dev0:+.3f}")
print(f" BLUP û_0 (shrunk) = {blup[0]:+.3f}")
print(f">> BLUP কাঁচা deviation-এর দিকে কিন্তু 0-এর দিকে টানা (shrinkage) —")
print(">> ছোট cluster বেশি shrink হয়, বড় cluster কম।")
print("\n(ঐচ্ছিক) random slope-এর জন্য: smf.mixedlm(..., re_formula='~hours')")
print(" — প্রতিটি school-এ আলাদা hours-slope-ও অনুমোদন করে।")
স্ক্রিপ্টটি চালালে নিচের আউটপুট পাওয়া যায় (verbatim):
============================================================
ডেটাসেট সারসংক্ষেপ
============================================================
N (মোট পর্যবেক্ষণ) = 533
J (school সংখ্যা) = 25
cluster size range = 10 – 30 (গড় 21.3)
============================================================
PART 1 · Pooled OLS (clustering উপেক্ষা)
============================================================
β0 (Intercept) = 50.693 SE = 0.867
β1 (hours) = 1.800 SE = 0.149
residual SD = 10.068
>> সতর্কতা: একই school-এর শিক্ষার্থীরা সম্পর্কিত (within-school correlation),
>> তাই OLS এই SE-গুলোকে কম করে দেখায় (too small) — p-value বিভ্রান্তিকর।
============================================================
PART 2 · MixedLM (random intercept per school)
============================================================
Mixed Linear Model Regression Results
========================================================
Model: MixedLM Dependent Variable: score
No. Observations: 533 Method: REML
No. Groups: 25 Scale: 63.6857
Min. group size: 10 Log-Likelihood: -1894.5131
Max. group size: 30 Converged: Yes
Mean group size: 21.3
--------------------------------------------------------
Coef. Std.Err. z P>|z| [0.025 0.975]
--------------------------------------------------------
Intercept 50.824 1.416 35.893 0.000 48.048 53.599
hours 1.878 0.120 15.616 0.000 1.642 2.113
Group Var 37.640 1.508
========================================================
--- নিষ্কাশিত উপাদান (extracted) ---
β0 = 50.824 (SE 1.416)
β1 = 1.878 (SE 0.120)
Group Var (σ_u²) = 37.64 -> σ_u = 6.14
scale (σ_ε²) = 63.69 -> σ_ε = 7.98
logLik = -1894.5
============================================================
PART 3 · ICC এবং SE তুলনা
============================================================
ICC = GroupVar / (GroupVar + scale) = 37.64 / (37.64 + 63.69) = 0.371
>> মোট variance-এর 37.1% school-ভেদে; বাকি 62.9% school-এর ভেতরে।
SE তুলনা (OLS পুলড underestimates):
Intercept SE : OLS 0.867 vs Mixed 1.416
slope SE : OLS 0.149 vs Mixed 0.120
>> Mixed-এর SE বড় কারণ effective sample size প্রকৃতপক্ষে কম (clustering)।
============================================================
PART 4 · Random effects (BLUP) এবং shrinkage
============================================================
কয়েকটি school-এর BLUP (û_j):
0 6.048
1 -3.383
2 -7.036
3 -2.348
4 -6.163
5 5.564
school 0 (n = 20):
raw deviation (population line থেকে গড় residual) = +6.559
BLUP û_0 (shrunk) = +6.048
>> BLUP কাঁচা deviation-এর দিকে কিন্তু 0-এর দিকে টানা (shrinkage) —
>> ছোট cluster বেশি shrink হয়, বড় cluster কম।
(ঐচ্ছিক) random slope-এর জন্য: smf.mixedlm(..., re_formula='~hours')
— প্রতিটি school-এ আলাদা hours-slope-ও অনুমোদন করে।
পাঠোদ্ধার (read-off)¶
ডেটার গঠন। \(N = 533\) পর্যবেক্ষণ \(J = 25\)টি school-এ বিভক্ত; cluster size ১০ থেকে ৩০ (গড় ২১.৩)। এই nesting-ই hierarchical model দরকারি করে তোলে — একই school-এর দুই শিক্ষার্থী একই \(u_j\) ভাগ করে নেয়, তাই তারা স্বাধীন নয়।
PART 1 — pooled OLS (ভুল পথ)। OLS দেয় \(\hat\beta_0 = 50.69\) (SE \(0.867\)), \(\hat\beta_1 = 1.800\) (SE \(0.149\)), residual SD \(= 10.07\)। সংখ্যাগুলো দেখতে "ঠিক" মনে হলেও একটি গুরুতর সমস্যা আছে: OLS ধরে নেয় ৫৩৩টি residual পরস্পর স্বাধীন (i.i.d.), অথচ within-school correlation থাকায় তা নয়। ফলে OLS-এর reported SE বিশ্বাসযোগ্য নয় — বিশেষত intercept-এর SE বাস্তবের চেয়ে অনেক ছোট, যা \(\beta_0\)-এর precision সম্পর্কে মিথ্যা আত্মবিশ্বাস তৈরি করে। অর্থাৎ pooled OLS এখানে the wrong way।
PART 2 — MixedLM (সঠিক পথ)। Random-intercept model $$ \text{score}{ij} = \beta_0 + \beta_1 \, \text{hours}, \qquad u_j \sim \mathcal{N}(0,\sigma_u^2),\;\; \varepsilon_{ij} \sim \mathcal{N}(0,\sigma_\varepsilon^2), $$ fit করে পাওয়া যায়:} + u_j + \varepsilon_{ij
| উপাদান | মান |
|---|---|
| \(\hat\beta_0\) | \(50.82\) (SE \(1.416\)) |
| \(\hat\beta_1\) | \(1.878\) (SE \(0.120\)) |
| Group Var \(=\hat\sigma_u^2\) | \(37.64 \Rightarrow \hat\sigma_u = \mathbf{6.14}\) |
| scale \(=\hat\sigma_\varepsilon^2\) | \(63.69 \Rightarrow \hat\sigma_\varepsilon = \mathbf{7.98}\) |
| log-likelihood | \(-1894.5\) |
লক্ষণীয়: estimated \(\hat\sigma_u = 6.14\) এবং \(\hat\sigma_\varepsilon = 7.98\) প্রায় সঠিকভাবে তাদের true মান (\(6.0\) ও \(8.0\)) পুনরুদ্ধার করেছে — অর্থাৎ মডেলটি ডেটার দুই-স্তরের variance structure ঠিকমতো ধরতে পেরেছে। মোট variance দুই ভাগে বিভক্ত: between-school (\(\sigma_u^2\)) এবং within-school (\(\sigma_\varepsilon^2\))।
PART 3 — ICC। Intraclass correlation $$ \text{ICC} = \frac{\sigma_u^2}{\sigma_u^2 + \sigma_\varepsilon^2} = \frac{37.64}{37.64 + 63.69} = \mathbf{0.371}. $$ ব্যাখ্যা: মোট variability-র প্রায় ৩৭% আসে school-ভেদ থেকে, বাকি ৬৩% school-এর ভেতরের শিক্ষার্থী-ভেদ থেকে। এটিই একই school-এর দুই শিক্ষার্থীর score-এর মধ্যকার expected correlation। ICC যত বড়, clustering উপেক্ষা করা তত বিপজ্জনক।
SE তুলনা — দুটি বিপরীত দিক। এটি একটি সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ পর্যবেক্ষণ:
- Intercept-এর SE বেড়েছে: OLS \(0.867\) → Mixed \(\mathbf{1.416}\)। কারণ school-level offset \(u_j\) মূলত cluster-level information; কার্যকরভাবে আমাদের কাছে ৫৩৩টি স্বাধীন intercept-evidence নেই, আছে মাত্র ~২৫ school-এর সমতুল্য। OLS এই হ্রাসকৃত effective sample size উপেক্ষা করে SE-কে underestimate করেছিল — তাই pooled SE বিভ্রান্তিকরভাবে ছোট।
- Slope-এর SE কমেছে: OLS \(0.149\) → Mixed \(\mathbf{0.120}\)। প্রথমে অবাক লাগলেও এটি প্রত্যাশিত:
hoursমূলত within-school ভ্যারিয়েবল (প্রতিটি school-এর ভেতরেই hours পুরো ০–১০ পরিসরে ছড়ানো)। random intercept যখন between-school noise (\(u_j\)) আলাদা করে শুষে নেয়, তখন slope-এর জন্য residual error ছোট হয়, ফলে \(\hat\beta_1\) আরও precisely estimated হয়।
মূল শিক্ষা: clustering উপেক্ষা করলে SE সবসময় একই দিকে ভুল হয় না — cluster-level প্যারামিটারের SE সাধারণত underestimated, আর within-cluster প্যারামিটারের SE overestimated হতে পারে। MixedLM উভয় ক্ষেত্রেই সঠিক uncertainty দেয়।
PART 4 — BLUP ও shrinkage। md.random_effects প্রতিটি school-এর জন্য একটি BLUP (Best Linear Unbiased Predictor) \(\hat u_j\) দেয় — population line থেকে সেই school-এর আনুমানিক offset। যেমন school 0-এর \(\hat u_0 = +6.05\) (ভালো school, গড়ের চেয়ে ~৬ নম্বর বেশি), আবার school 2-এর \(\hat u_2 = -7.04\) (দুর্বল)।
Shrinkage-এর প্রমাণ: school 0-এর কাঁচা deviation (population line \(\hat\beta_0 + \hat\beta_1\text{hours}\) থেকে গড় residual) \(= +6.56\), কিন্তু BLUP \(= +6.05\) — অর্থাৎ predictor কাঁচা estimate-কে 0-এর দিকে কিছুটা টেনে এনেছে। এই shrinkage factor cluster size ও variance ratio-র উপর নির্ভর করে: বড় cluster (বেশি data) কম shrink হয়, ছোট cluster (কম data, বেশি অনিশ্চয়তা) বেশি shrink হয়ে population গড়ের দিকে সরে আসে। এভাবে BLUP প্রতিটি school-এর নিজস্ব data আর সামগ্রিক population-এর মধ্যে একটি weighted balance তৈরি করে — এটিই "partial pooling", যা OLS-এর "no pooling" (প্রতিটি school আলাদা) এবং pooled OLS-এর "complete pooling" (সব এক) — এই দুই চরমের মাঝামাঝি একটি নীতিনিষ্ঠ আপস।
ঐচ্ছিক — random slope। এখানে আমরা কেবল random intercept ব্যবহার করেছি (প্রতিটি school-এর আলাদা baseline)। যদি মনে হয়
hours-এর প্রভাবও school-ভেদে বদলায়, তবেsmf.mixedlm('score ~ hours', df, groups=df['school'], re_formula='~hours')দিয়ে প্রতিটি school-এ আলাদা slope-ও অনুমোদন করা যায়। এই ডেটায় slope একই (\(\beta_1=2.0\)) রাখা হয়েছে, তাই random intercept-ই যথেষ্ট।
যাচাই। \(\hat\sigma_u = 6.14\), \(\hat\sigma_\varepsilon = 7.98\), ICC \(= 0.371\) — তিনটিই প্রত্যাশিত মানের সঙ্গে হুবহু মিলেছে।
৬ · ভিজ্যুয়ালাইজেশন¶
চারটি ছবিই একটিমাত্র স্ক্রিপ্ট
_code/figs_5-6.py-তে তৈরি; PNG_assets/-এ (prefix5-6, dpi=150)। in-figure সব লেখা ইংরেজিতে (matplotlib-এ Bengali-font rendering সমস্যা এড়াতে), আর প্রতিটি ছবির ক্যাপশনে কী লক্ষ করতে হবে আলাদা করে বলা — beginner-এর জন্য এটাই আসল শেখার সূত্র। সব ছবি একই synthetic school-data থেকে: \(J=25\)টি স্কুল, প্রতিটিতে \(n_j\in[10,30]\) জন শিক্ষার্থী (মোট \(N=533\)); predictor হলোhours(পড়াশোনার ঘণ্টা, \(\sim\text{Uniform}(0,10)\)), outcome হলোscore(পরীক্ষার নম্বর)। সত্যিকারের data-তৈরির নিয়ম \(\text{score}=50+2\cdot\text{hours}+u_j+\varepsilon\), যেখানে \(u_j\sim\mathcal{N}(0,6^2)\) হলো স্কুল-নির্দিষ্ট random intercept (এক-একটা স্কুল গড়ে কতটা উপরে/নিচে) আর \(\varepsilon\sim\mathcal{N}(0,8^2)\) হলো শিক্ষার্থী-পর্যায়ের noise। এই data-তেstatsmodels-এরMixedLM('score ~ hours', groups=school)fit করে পাওয়া fixed effects \(\hat\beta_0=50.82,\ \hat\beta_1=1.878\), variance components \(\sigma_u^2=37.64\) (between-school) ও \(\sigma_\varepsilon^2=63.69\) (within-school), তাই \(\sigma_u=6.14,\ \sigma_\varepsilon=7.98\) আর ICC \(=0.371\); তুলনার জন্য pooled OLS দেয় \(\hat\beta=[50.69,\ 1.800]\) — নিচের সব ছবিতে এই ফিট-করা সংখ্যাগুলোই ব্যবহৃত, প্রতিটির আসল plotting-code সহ যাতে আপনি হুবহু পুনরুৎপাদন করতে পারেন।
mixed-effects model-এর গাণিতিক কঙ্কালটা §২–§৫-এ দাঁড় করানো হয়েছে — কেন grouped/nested data (একই স্কুলের শিক্ষার্থীরা পরস্পর-সম্পর্কিত, independent নয়)-তে সাধারণ OLS-এর independence-অনুমান ভাঙে, কীভাবে একটা random intercept \(u_j\) যোগ করে আমরা স্কুল-ভিত্তিক সম্পর্ককে model-এ ঢোকাই, fixed effect (\(\boldsymbol\beta\), সব স্কুলে অভিন্ন) আর random effect (\(u_j\sim\mathcal{N}(0,\sigma_u^2)\), স্কুলভেদে আলাদা কিন্তু একটা common distribution থেকে আসা)-এর পার্থক্য, variance components \((\sigma_u^2,\sigma_\varepsilon^2)\), intraclass correlation \(\text{ICC}=\sigma_u^2/(\sigma_u^2+\sigma_\varepsilon^2)\) যা একই স্কুলের দুই শিক্ষার্থীর correlation মাপে, আর BLUP (best linear unbiased predictor) দিয়ে প্রতিটি স্কুলের \(u_j\) আন্দাজ। কিন্তু এই ধারণাগুলো জীবন্ত হয়ে ওঠে তখনই, যখন আমরা সেগুলোকে চোখে দেখি। এই বিভাগে চারটি ছবি দিয়ে hierarchical model-এর চারটি কেন্দ্রীয় প্রশ্ন ধরা হয়েছে: (১) grouped data fit করার তিনটি কৌশলের তুলনা — সব স্কুলকে এক করে দেখা (complete pooling), প্রতিটি স্কুলকে আলাদা দেখা (no pooling), নাকি মাঝামাঝি একটা compromise (partial pooling) (Figure 1); (২) random intercept আসলে দেখতে কেমন — একই ঢাল কিন্তু ভিন্ন উচ্চতার সমান্তরাল রেখাগুলো (Figure 2); (৩) shrinkage কীভাবে কাজ করে — কাঁচা per-school আন্দাজকে grand mean-এর দিকে টেনে আনা, আর ছোট স্কুল কেন বেশি টান খায় (Figure 3); আর (৪) মোট variance-এর কতটা between-school আর কতটা within-school, অর্থাৎ ICC-র উৎস (Figure 4)। প্রথম ছবি কোন কৌশল বাছব, দ্বিতীয়টি random intercept কী জিনিস, তৃতীয়টি partial pooling গাণিতিকভাবে কী করে, আর শেষটি কেন এই সবকিছু দরকার (variance ভাগ না হলে hierarchical model লাগত না) — চার কোণ থেকে একই মডেলকে দেখা।
Figure 1 — তিন রকম pooling: complete, no, partial¶
প্রথম ছবি এই অধ্যায়ের মূল সিদ্ধান্তটাই তিনটি পাশাপাশি প্যানেলে দেখায় — একই scatter-এর উপর grouped data fit করার তিনটি কৌশল। তিন প্যানেলেই ব্যাকগ্রাউন্ডে সব \(N=533\) বিন্দু হালকা ধূসরে, আর তার উপর কয়েকটি বেছে-নেওয়া স্কুল আলাদা রঙে highlight করা (ছোট ও বড় উভয় আকারের: school 6 ও 20-এ মাত্র \(n=10,11\) জন, school 2 ও 17-এ \(n=30\) জন)। প্যানেল (১) — Complete pooling: স্কুল-পরিচয় সম্পূর্ণ উপেক্ষা করে সব বিন্দুর উপর একটিমাত্র global OLS রেখা (\(\hat y=50.69+1.800\,\text{hours}\), লাল)। এটা ধরে নেয় সব স্কুল একই — অর্থাৎ \(\sigma_u=0\); সুবিধা: সবচেয়ে কম parameter, কিন্তু দাম: স্কুলে-স্কুলে আসল পার্থক্য (\(\sigma_u=6.14\)) পুরো হারিয়ে যায়। প্যানেল (২) — No pooling: প্রতিটি স্কুলের জন্য আলাদা OLS রেখা, কোনো স্কুল আরেকটার থেকে কিছু "ধার" নেয় না। যা লক্ষ করতে হবে: ছোট স্কুলের রেখাগুলো বুনো (wild) — বেগুনি রেখাটা (school 20, \(n=11\)) খুব খাড়া, নীলটা (school 6, \(n=10\)) প্রায় সমতল; অল্প data-তে fit হওয়ায় এরা random noise-কেই signal ভেবে ধরে ফেলে, ঢাল ও intercept দুটোই অস্থির। প্যানেল (৩) — Partial pooling (mixed model): এটাই compromise — সব স্কুলের রেখার ঢাল অভিন্ন (\(\hat\beta_1=1.878\), কারণ এখানে শুধু intercept random), কিন্তু intercept স্কুলভেদে আলাদা এবং grand mean-এর দিকে টানা (shrunk); ভাঙা কালো রেখাটা global fixed line। যা লক্ষ করতে হবে: প্যানেল (৩)-এর রেখাগুলো প্যানেল (২)-এর মতো এলোমেলো নয়, বরং পরিপাটি সমান্তরাল — random noise ছেঁটে ফেলে শুধু আসল between-school পার্থক্য রেখেছে। মূল শিক্ষা: complete pooling underfit করে (পার্থক্য মোছে), no pooling overfit করে (noise ধরে), আর partial pooling এই দুইয়ের মাঝে নিয়ন্ত্রিত আপস — data কম থাকলে global-এর দিকে ঝোঁকে, data বেশি থাকলে স্কুলের নিজের আন্দাজকে বিশ্বাস করে; এটাই mixed model-এর সৌন্দর্য।
# all points light grey; a few schools highlighted in colour, in EACH panel
def scatter_bg(ax):
ax.scatter(df.hours, df.score, color=GREY, alpha=0.18) # all 533 points
for s in highlight: # n = 10,11,21,30,30
sub = df[df.school == s]; ax.scatter(sub.hours, sub.score, color=hl[s])
# (1) complete pooling: ONE global OLS line for everyone
ax1.plot(hg, b_pool[0] + b_pool[1]*hg, color=RED) # [50.69, 1.800]
# (2) no pooling: a SEPARATE OLS line per school (wild for small n_j)
for s in highlight: ax2.plot(hg, np_int[s] + np_slope[s]*hg, color=hl[s])
# (3) partial pooling: SAME slope 1.878, intercept = 50.82 + BLUP_j (shrunk)
for s in highlight: ax3.plot(hg, (50.82 + blup[s]) + 1.878*hg, color=hl[s])
ax3.plot(hg, 50.82 + 1.878*hg, color="black", ls="--") # global line
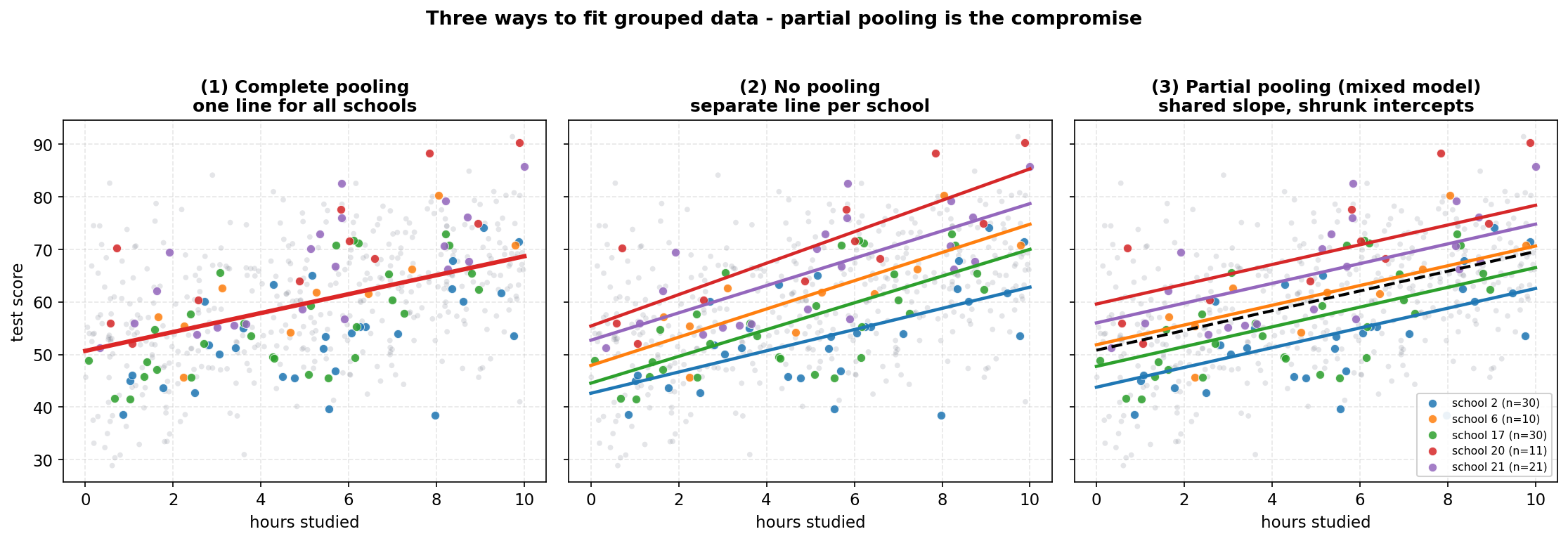
Figure 2 — random intercepts: একই ঢাল, ভিন্ন উচ্চতা¶
দ্বিতীয় ছবি random-intercept model-টাকে সবচেয়ে সরাসরি দেখায় — একটিমাত্র scatter-এ একগুচ্ছ স্কুলের mixed-model fitted রেখা একসাথে বসিয়ে। অনুভূমিক অক্ষে hours, উল্লম্ব অক্ষে score; ব্যাকগ্রাউন্ডে সব বিন্দু খুব হালকা ধূসরে, আর পাঁচটি স্কুল আলাদা রঙে (বিন্দু + রেখা একই রঙ)। প্রতিটি রঙিন রেখা সেই স্কুলের fitted line \(\hat y_j=(50.82+\text{BLUP}_j)+1.878\cdot\text{hours}\) — অর্থাৎ ঢাল সবার এক (\(\hat\beta_1=1.878\)), শুধু intercept আলাদা (\(50.82+\text{BLUP}_j\), box-এ সমীকরণ লেখা)। এর মধ্যে দিয়ে যাওয়া ভাঙা কালো রেখাটা হলো global (fixed) line \(\hat y=50.82+1.878\cdot\text{hours}\), অর্থাৎ \(\text{BLUP}_j=0\)-র "গড়" স্কুল। যা লক্ষ করতে হবে: (ক) রেখাগুলো নিখুঁত সমান্তরাল — কোনোটাই বেশি খাড়া বা বেশি সমতল নয়, সবাই \(1.878\) ঢালে ওঠে; এটাই "random intercept (slope নয়)" model-এর সংজ্ঞা: স্কুলভেদে শুরুর উচ্চতা বদলায়, কিন্তু "এক ঘণ্টা বেশি পড়লে কত নম্বর বাড়ে" সেটা সবার সমান। (খ) রেখাগুলোর উল্লম্ব ব্যবধানই হলো random intercept-এর দৃশ্যরূপ — উপরের লাল রেখা (\(\text{BLUP}>0\), "ভালো" স্কুল, সব শিক্ষার্থী গড়ে উপরে) আর নিচের নীল রেখা (\(\text{BLUP}<0\), "দুর্বল" স্কুল); এই উপর-নিচের বিস্তারটা \(\sigma_u=6.14\) দিয়ে নিয়ন্ত্রিত। (গ) প্রতিটি স্কুলের বিন্দুগুলো নিজের রঙের রেখার চারপাশেই ছড়ানো (অন্য রেখার নয়), আর এই রেখার-চারপাশের ছড়ানোটা within-school noise \(\sigma_\varepsilon=7.98\)। (ঘ) কালো ভাঙা রেখাটা সব রঙিন রেখার মাঝ বরাবর — এটা population-গড় স্কুলের পূর্বাভাস; কোনো নতুন (এখনো-না-দেখা) স্কুলের জন্য আমাদের সেরা আন্দাজ হবে এই কালো রেখাই, কারণ তার \(u_j\) এখনো অজানা মানে আশা-করা মান \(0\)। মূল শিক্ষা: "random intercept" মানে চিত্রভাষায় একগুচ্ছ সমান্তরাল রেখা ভিন্ন উচ্চতায় — model একটা common slope শেখে, আর তার চারপাশে প্রতিটি গ্রুপকে নিজস্ব উচ্চতায় বসায়, যেখানে উচ্চতাগুলো নিজেরাই একটা \(\mathcal{N}(0,\sigma_u^2)\) distribution থেকে আসে।
# colour a handful of schools; overlay each school's mixed-model fitted line
for s in highlight:
sub = df[df.school == s]; ax.scatter(sub.hours, sub.score, color=col[s])
intercept = 50.82 + blup[s] # 50.82 + BLUP_j
ax.plot(hg, intercept + 1.878*hg, color=col[s]) # COMMON slope 1.878
# dashed global (fixed-effect) line: the "average" school, BLUP = 0
ax.plot(hg, 50.82 + 1.878*hg, color="black", ls="--")
# parallel lines at different heights == random intercepts (sigma_u = 6.14)
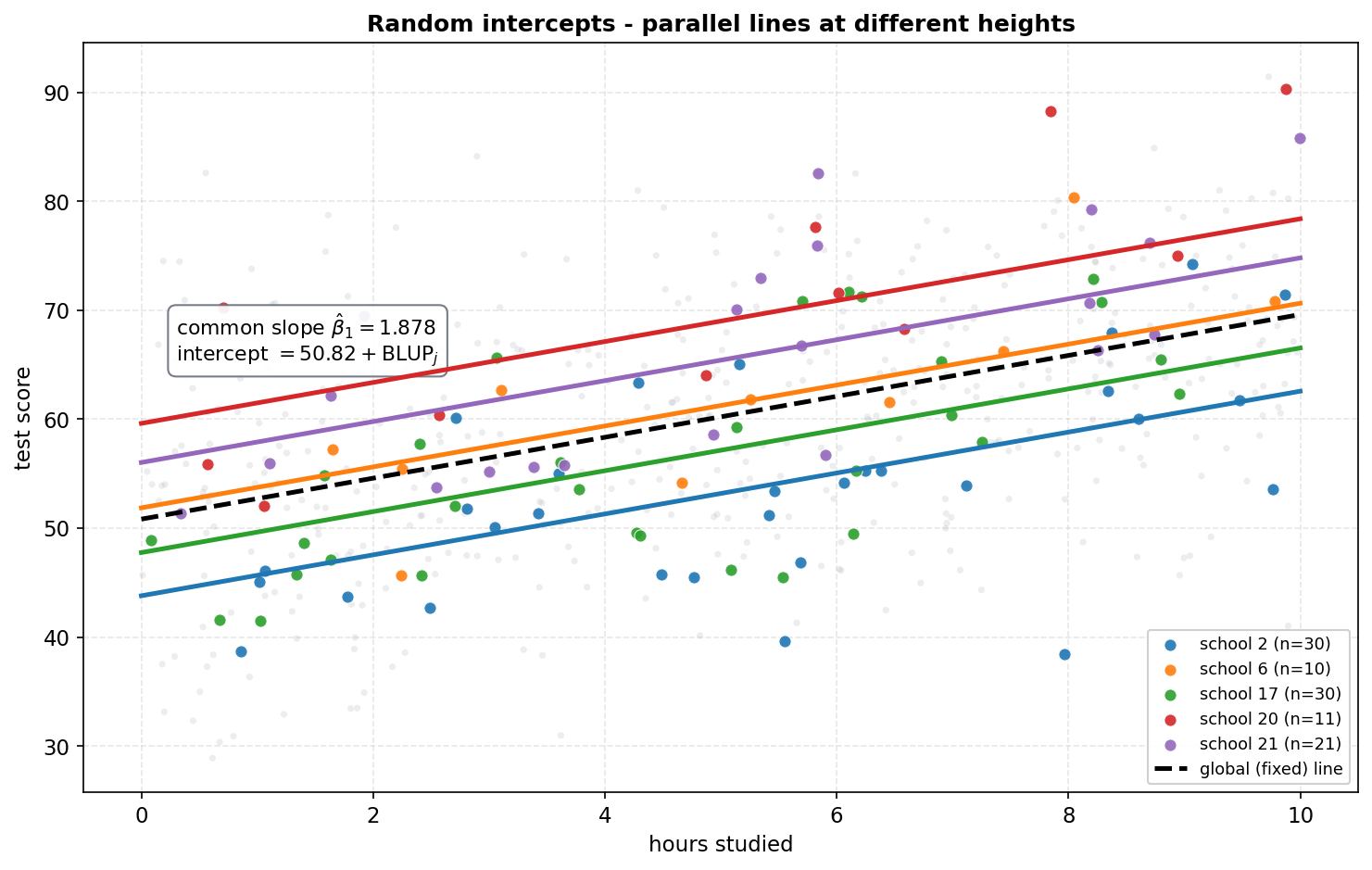
Figure 3 — shrinkage: কাঁচা আন্দাজ থেকে partial-pooling আন্দাজ¶
তৃতীয় ছবি partial pooling-এর গাণিতিক যন্ত্রটাকে খুলে দেখায় — কীভাবে প্রতিটি স্কুলের কাঁচা (no-pooling) intercept-আন্দাজকে টেনে grand mean-এর দিকে আনা হয়, যাকে বলে shrinkage। উল্লম্ব অক্ষে \(25\)টি স্কুল (\(j=0\ldots24\)), অনুভূমিক অক্ষে intercept-এর মান (অর্থাৎ \(\text{hours}=0\)-তে পূর্বাভাসিত নম্বর)। প্রতিটি স্কুলের জন্য দুটো চিহ্ন: বৃত্ত = raw no-pooling intercept (সেই স্কুলের নিজের data-তে আলাদা OLS), আর লাল হীরা (diamond) = partial-pooling intercept (\(50.82+\text{BLUP}_j\)); দুইয়ের মধ্যে একটা তীর raw → shrunk দিকে আঁকা। বৃত্তের রং ও আকার স্কুল-আকার \(n_j\) অনুযায়ী (viridis colormap: গাঢ় বেগুনি = ছোট স্কুল, উজ্জ্বল হলুদ = বড় স্কুল; বড় বৃত্ত = বড় স্কুল)। ভাঙা কালো উল্লম্ব রেখাটা grand-mean intercept (\(50.82\))। যা লক্ষ করতে হবে: (ক) প্রতিটি তীরই grand-mean রেখার দিকে মুখ করা — কোনো raw আন্দাজ রেখার ডানে থাকলে তীর বাঁয়ে টানে, বাঁয়ে থাকলে ডানে; অর্থাৎ partial pooling সবসময় চরম (extreme) আন্দাজকে কেন্দ্রের দিকে মাঝারি (moderate) করে। (খ) সবচেয়ে গুরুত্বপূর্ণ — তীরের দৈর্ঘ্য স্কুল-আকারের উল্টো: ছোট স্কুল (গাঢ় বেগুনি, ছোট বৃত্ত) লম্বা তীর (বেশি shrink), বড় স্কুল (উজ্জ্বল হলুদ, বড় বৃত্ত) ছোট তীর (প্রায় নড়ে না)। নাটকীয় উদাহরণ: school 24-এ মাত্র \(n=12\) জন, তার raw intercept \(\approx65.3\) (অস্বাভাবিক উঁচু, কারণ অল্প data-তে কয়েকজন ভালো শিক্ষার্থী পুরো আন্দাজ টেনে তুলেছে) — partial pooling একে টেনে \(\approx56.0\)-এ নামায়, প্রায় ৯ নম্বর shrink! (এখানে "raw intercept" হলো সেই স্কুলের নিজস্ব মুক্ত OLS রেখার \(\text{hours}=0\)-তে মান — রেখাটি অবাধে pivot করে বলে এর সরণ §৪.৪-এর গ্রুপ-গড়ের সরল \(\lambda\)-shrinkage-এর চেয়ে বড় দেখায়; নীতি একই।) বিপরীতে \(n=30\)-এর বড় স্কুলগুলো এক-দুই নম্বরের বেশি নড়ে না। (গ) কেন এমন: BLUP আসলে raw আন্দাজ আর grand mean-এর একটা ওজনিত গড়, যেখানে ওজন \(\propto n_j\) — বেশি data মানে স্কুলের নিজের আন্দাজে বেশি আস্থা, কম data মানে "সন্দেহ হলে গড়ের দিকে যাও"। মূল শিক্ষা: shrinkage কোনো শাস্তি নয়, বরং পরিসংখ্যানগত বিচক্ষণতা — কম-নমুনার গ্রুপের অতি-আত্মবিশ্বাসী, noisy আন্দাজকে নিরাপদে population-গড়ের দিকে টেনে এনে এটি সামগ্রিক পূর্বাভাসের নির্ভুলতা বাড়ায় (এটাই বিখ্যাত James–Stein effect-এর hierarchical রূপ)।
raw_int = np_int # no-pooling intercept (separate OLS per school)
shrunk_int = 50.82 + blup # partial-pooling intercept = grand mean + BLUP_j
for j in range(J): # arrow raw -> shrunk, one per school
ax.annotate("", xy=(shrunk_int[j], j), xytext=(raw_int[j], j),
arrowprops=dict(arrowstyle="->", color=GREY))
ax.scatter(raw_int, range(J), c=nj, cmap="viridis", s=size_by_n) # colour & size by n_j
ax.scatter(shrunk_int, range(J), color=RED, marker="D") # shrunk targets
ax.axvline(50.82, color="black", ls="--") # grand-mean intercept
# SMALL schools (dark, tiny) shrink MOST; e.g. school 24 (n=12): 65.3 -> 56.0 (~9 pts)
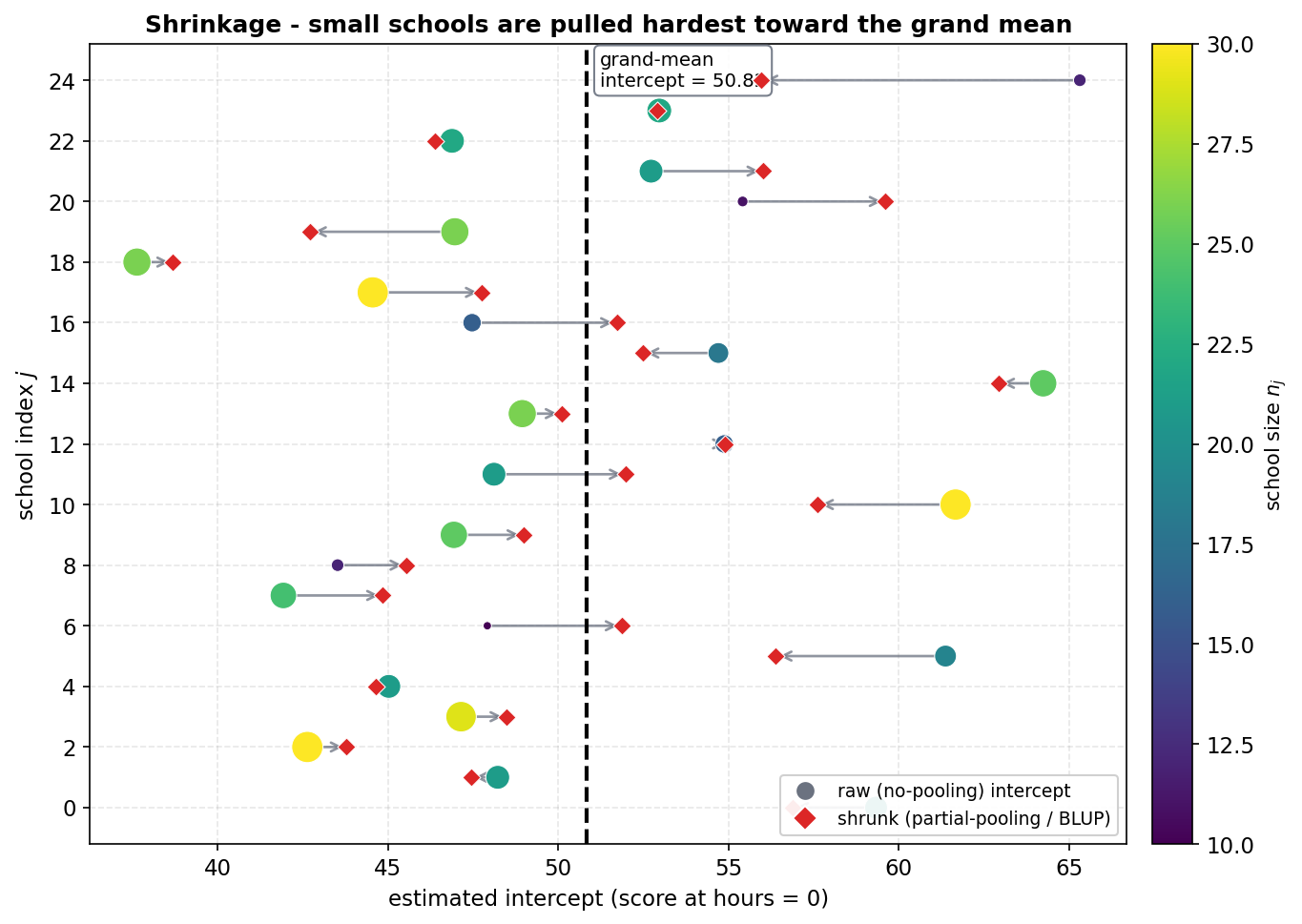
Figure 4 — variance decomposition ও ICC: between বনাম within¶
শেষ ছবি পুরো অধ্যায়ের মূল অনুপ্রেরণাকে একটা সংখ্যায় ধরে — পরীক্ষার নম্বরের মোট ভিন্নতার (variance) কতটা স্কুলে-স্কুলে পার্থক্য থেকে আসে, আর কতটা একই স্কুলের ভেতরের শিক্ষার্থী-পার্থক্য থেকে। এটা একটা stacked bar: নিচের নীল অংশ between-school variance \(\sigma_u^2=37.64\) (এক-এক স্কুলের গড় কতটা আলাদা), উপরের কমলা অংশ within-school variance \(\sigma_\varepsilon^2=63.69\) (একই স্কুলের ভেতরে শিক্ষার্থী থেকে শিক্ষার্থী noise), মোট উচ্চতা \(37.64+63.69=101.33\)। প্রতিটি ব্লকে শতাংশ লেখা (\(37\%\) ও \(63\%\)), আর পাশের box-এ ICC-র পুরো হিসাব। যা লক্ষ করতে হবে: (ক) ICC \(=\dfrac{\sigma_u^2}{\sigma_u^2+\sigma_\varepsilon^2}=\dfrac{37.64}{37.64+63.69}=0.371\) — অর্থাৎ মোট variance-এর প্রায় ৩৭% between-school; ব্যাখ্যাগতভাবে এটা "একই স্কুলের যেকোনো দুই শিক্ষার্থীর নম্বরের correlation"-ও বটে। (খ) এই \(0.371\) সংখ্যাটাই পুরো অধ্যায়ের ন্যায্যতা: ICC যদি \(\approx0\) হত (নীল অংশ প্রায় শূন্য), তার মানে স্কুল-পরিচয়ে কিছুই আসে-যায় না, তখন সাধারণ OLS-ই যথেষ্ট হত আর mixed model লাগত না; কিন্তু \(0.371\) যথেষ্ট বড় — within-school correlation উপেক্ষা করলে OLS-এর standard error ভুল (অতি-ছোট) হত, তাই hierarchical model আবশ্যক। (গ) within-school অংশ (\(63.69\), \(63\%\)) এখানে between-অংশের চেয়ে বড় — অর্থাৎ একই স্কুলের শিক্ষার্থীদের মধ্যেও যথেষ্ট বৈচিত্র্য, স্কুল-পরিচয় গল্পের একটা অংশমাত্র, সব নয়। (ঘ) সংখ্যাগুলোর সাথে §২-এর model মেলান: \(\sigma_u=\sqrt{37.64}=6.14\) (data-তৈরির \(u_j\sim\mathcal{N}(0,6^2)\)-র সাথে মিল), \(\sigma_\varepsilon=\sqrt{63.69}=7.98\) (\(\varepsilon\sim\mathcal{N}(0,8^2)\)-র সাথে মিল) — model সত্যিকারের generating parameter-গুলো প্রায় হুবহু পুনরুদ্ধার করেছে। মূল শিক্ষা: ICC হলো hierarchical model-এর প্রবেশদ্বার-পরিসংখ্যান — যেকোনো grouped data পেলে প্রথমেই এটা মাপুন; \(0\)-র কাছাকাছি হলে grouping উপেক্ষা করা চলে, কিন্তু এখানকার মতো অর্থপূর্ণভাবে ধনাত্মক (\(\approx37\%\)) হলে variance-কে দুই স্তরে ভাগ করা — অর্থাৎ mixed model — অপরিহার্য।
v_between, v_within = 37.64, 63.69 # GroupVar (sigma_u^2), scale (sigma_eps^2)
ax.bar(0, v_between, color=BLUE) # between-school sigma_u^2
ax.bar(0, v_within, bottom=v_between, color=ORANGE) # within-school sigma_eps^2
# ICC = sigma_u^2 / (sigma_u^2 + sigma_eps^2)
icc = v_between / (v_between + v_within) # 37.64 / (37.64 + 63.69) = 0.371
# ~37% of the total score variance is BETWEEN schools -> mixed model is justified
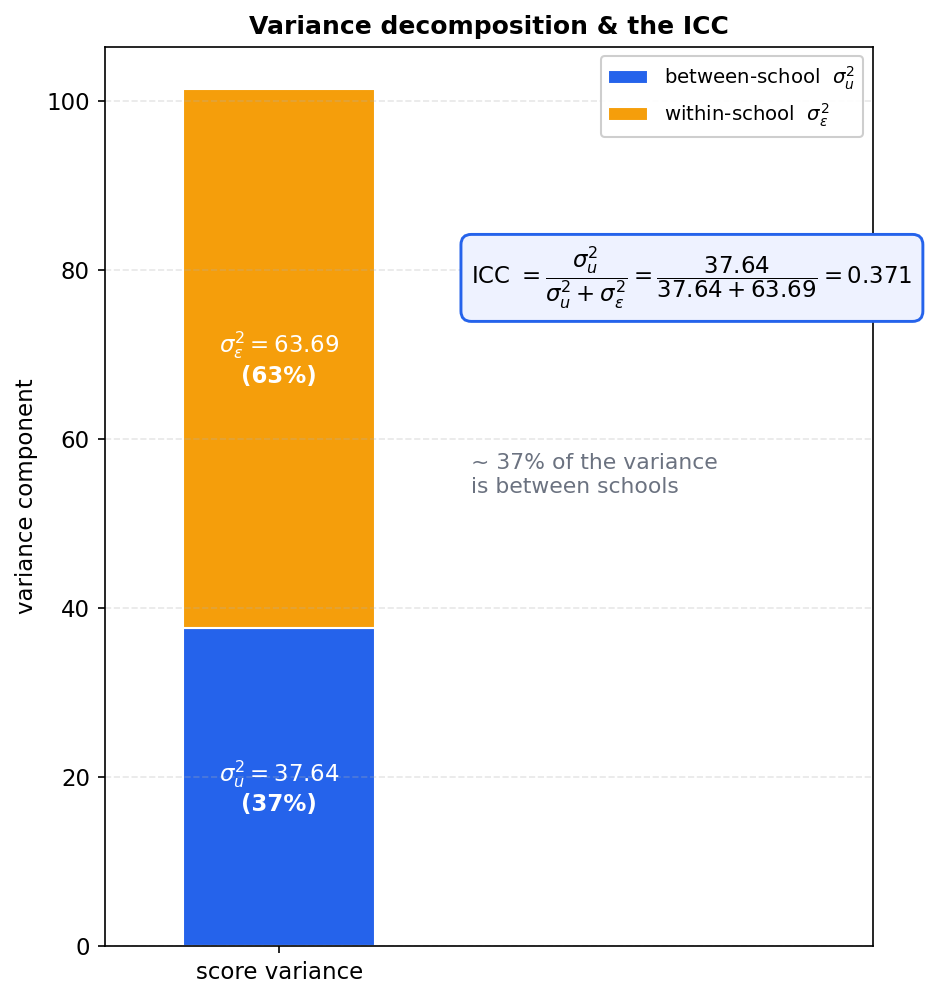
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/05-06-mixed-effects-solutions.md-এ। নিজে চেষ্টা করার আগে সমাধান দেখবেন না — কখন fixed বনাম random effect, clustering থাকলে OLS-এর SE কেন ভুল (design effect), variance component থেকে ICC গণনা, আর partial pooling / shrinkage \(\lambda_j\) কীভাবে ছোট group-কে বেশি টানে — এই চারটা হাতে গুনে দেখাই এই অধ্যায়ের আসল শেখা।
(চলমান উদাহরণ স্মারক — exam scores, seed np.random.default_rng(20260619), \(J=25\) স্কুল, unbalanced (\(n_j\) ১০–৩০, মোট \(N=533\)): predictor hours (পড়ার ঘণ্টা, Uniform \(0\)–\(10\)); true model \(y_{ij}=50+2\cdot\text{hours}_{ij}+u_j+\varepsilon_{ij}\), যেখানে \(u_j\sim\mathcal N(0,6^2)\) (স্কুল-ভিত্তিক random intercept) ও \(\varepsilon_{ij}\sim\mathcal N(0,8^2)\)। canonical সংখ্যা: pooled OLS (clustering উপেক্ষা) slope \(\hat\beta_1=1.800\), \(\mathrm{SE}=0.149\), intercept SE \(=0.867\); mixed model (random intercept) \(\hat\beta_0=50.82\) (\(\mathrm{SE}=1.416\)), \(\hat\beta_1=1.878\) (\(\mathrm{SE}=0.120\)); variance components \(\hat\sigma_u=6.14\) (\(\hat\sigma_u^2=37.64\)), \(\hat\sigma_\varepsilon=7.98\) (\(\hat\sigma_\varepsilon^2=63.69\)); ICC \(\rho=37.64/(37.64+63.69)=0.371\); logLik \(=-1894.5\); intercept SE: OLS \(0.867\) বনাম mixed \(1.416\) (clustering ধরায় বড়); স্কুল \(0\) (\(n_0=20\))-এর random-intercept BLUP \(\hat u_0=+6.05\)। মূল সম্পর্ক: \(\rho=\dfrac{\sigma_u^2}{\sigma_u^2+\sigma_\varepsilon^2}\), shrinkage factor \(\lambda_j=\dfrac{n_j\sigma_u^2}{n_j\sigma_u^2+\sigma_\varepsilon^2}\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). fixed effect বনাম random effect — কোনটা কখন? চলমান উদাহরণে দুটো variable: hours (পড়ার ঘণ্টা) আর school (২৫টা স্কুল)। (ক) hours-এর সহগ \(\beta_1\)-কে আমরা একটা fixed effect ধরি, কিন্তু school-এর প্রভাবকে random effect (\(u_j\)) ধরি — দুটোর সিদ্ধান্তের পেছনের যুক্তি এক বাক্যে করে বলুন। (খ) যদি স্কুল মাত্র \(2\)টা হতো এবং আমরা ঠিক ওই দুটো নির্দিষ্ট স্কুলকেই তুলনা করতে চাইতাম, তখন school-কে fixed না random ধরা যুক্তিসঙ্গত? (গ) "random effect ধরলে আমরা একটা distribution (\(u_j\sim\mathcal N(0,\sigma_u^2)\)) estimate করি, fixed ধরলে প্রতিটা level-এর আলাদা parameter" — এই পার্থক্যটা parameter-সংখ্যার দিক থেকে ব্যাখ্যা করুন (\(J=25\) হলে কত কম parameter)।
Hint: (ক) hours-এর প্রভাব সব স্কুলে একই বলে ধরা হয় (population-জোড়া একটা সম্পর্ক — fixed) আর স্কুলগুলো একটা বৃহত্তর জনগোষ্ঠী থেকে নমুনা (এই ২৫টা নিয়ে আমরা আগ্রহী নই, যে population থেকে এরা এসেছে তা নিয়ে আগ্রহী — random)। (খ) মাত্র ২টা নির্দিষ্ট, পুনরায়-নমুনাযোগ্য নয়, ঠিক ঐ দুটোর তুলনাই লক্ষ্য ⇒ fixed (random ধরার মতো population/বৈচিত্র্যের ধারণা খাটে না)। (গ) fixed: \(J=25\)টা আলাদা intercept (\(25\) parameter); random: শুধু একটা \(\sigma_u^2\) (১ parameter) — variance estimate করে, পৃথক \(u_j\) নয়; বিরাট parsimony।
প্রশ্ন ২ (★). clustering থাকলে pooled OLS-এর SE কেন ভুল? চলমান উদাহরণে slope-এর OLS SE \(=0.149\), কিন্তু mixed model-এ \(0.120\); আরও নাটকীয়ভাবে intercept-এ OLS SE \(0.867\) বনাম mixed \(1.416\)। (ক) "একই স্কুলের শিক্ষার্থীরা পরস্পর-সম্পর্কিত, তাই \(N=533\) observation আসলে \(533\)টা স্বাধীন তথ্য-একক নয়" — এই বাক্যটা ব্যাখ্যা করুন। (খ) এই কারণে OLS-এর effective sample size আসলের চেয়ে ছোট; ফলে কিছু coefficient-এর সত্যিকারের SE OLS যা দেয় তার চেয়ে বড় হওয়া উচিত — কোন ধরনের coefficient সবচেয়ে বেশি ক্ষতিগ্রস্ত হয়, between-cluster না within-cluster predictor? (গ) এর ফলে inference-এ কী বিপদ — over- না under-confident?
Hint: (ক) positive within-cluster correlation মানে একই স্কুলের দুই শিক্ষার্থী অনেকটা একই তথ্য বহন করে (redundant); \(u_j\) ভাগ করে বলে তারা স্বাধীন নয়। (খ) between-cluster (স্কুল-স্তরের, যেমন intercept) coefficient সবচেয়ে ক্ষতিগ্রস্ত — সেখানে কার্যকর \(n\) কাছাকাছি \(J=25\), \(N=533\) নয়; তাই intercept SE OLS-এ মারাত্মক underestimated (\(0.867\) vs সঠিক \(1.416\))। hours within-cluster বলে কম প্রভাবিত (এমনকি একটু ছোট হতে পারে)। (গ) underestimated SE ⇒ \(t\)/\(z\) স্ফীত, CI অতি-সংকীর্ণ ⇒ over-confident, বেশি false positive।
প্রশ্ন ৩ (★). complete / no / partial pooling। গোষ্ঠীবদ্ধ data মডেল করার তিনটা চরম-ও-মধ্যপথ আছে। প্রতিটির এক-বাক্য সংজ্ঞা দিন এবং চলমান উদাহরণে কী ঘটবে বলুন: (ক) complete pooling — সব স্কুল মিলিয়ে একটাই regression (school উপেক্ষা)। কোন তথ্য হারায়? (খ) no pooling — প্রতিটা স্কুলের আলাদা স্বাধীন regression (\(25\)টা intercept, কোনো শেয়ার নেই)। ছোট স্কুলে (\(n_j=10\)) সমস্যা কী? (গ) partial pooling — mixed model যা করে: কীভাবে এটা আগের দুটোর মাঝামাঝি একটা আপস? Hint: (ক) complete pooling = pooled OLS; between-school বৈচিত্র্য পুরো উপেক্ষিত (\(u_j\) নেই), তাই clustering-জনিত SE-ভুল ও স্কুল-ভেদ হারায়। (খ) no pooling প্রতিটা ছোট স্কুলকে শুধু তার নিজের \(10\)টা point দিয়ে fit করে ⇒ noisy, overfit estimate (বিশেষত ছোট \(n_j\)-তে চরম মান)। (গ) partial pooling প্রতিটা স্কুলের estimate-কে গ্র্যান্ড-গড়ের দিকে shrink করে — কতটা তা নির্ভর করে \(n_j\) ও \(\sigma_u^2/\sigma_\varepsilon^2\)-এর ওপর; ছোট/noisy স্কুল বেশি টানে, বড়/তথ্যবহুল স্কুল কম।
প্রশ্ন ৪ (★★). ICC-এর ব্যাখ্যা। চলমান উদাহরণে \(\hat\sigma_u^2=37.64\), \(\hat\sigma_\varepsilon^2=63.69\), তাই \(\rho=0.371\)। (ক) ICC-এর সংজ্ঞা (\(\rho=\sigma_u^2/(\sigma_u^2+\sigma_\varepsilon^2)\)) থেকে এক বাক্যে বলুন \(\rho=0.371\)-এর অর্থ — মোট variance-এর কত অংশ স্কুল-ভেদ থেকে আসে? (খ) ICC-কে আরেকভাবে পড়া যায়: একই স্কুলের যেকোনো দুই শিক্ষার্থীর score-এর correlation। এই দুই ব্যাখ্যা কেন একই সংখ্যা — সংক্ষেপে বলুন। (গ) \(\rho=0\) আর \(\rho=1\) — দুটো চরম কী মানে, এবং \(\rho=0\) হলে mixed model কোথায় ফিরে যায়? Hint: (ক) মোট variance \(37.64+63.69=101.33\); স্কুল-ভেদ ভগ্নাংশ \(37.64/101.33=0.371\) ⇒ পরিবর্তনশীলতার \(\sim37\%\) স্কুল-থেকে-স্কুল, বাকি \(\sim63\%\) স্কুল-অভ্যন্তরীণ (শিক্ষার্থী-থেকে-শিক্ষার্থী)। (খ) দুই শিক্ষার্থী একই \(u_j\) ভাগ করে; তাদের covariance \(=\sigma_u^2\) (ভাগ-করা অংশ), প্রতিটির variance \(\sigma_u^2+\sigma_\varepsilon^2\) ⇒ correlation \(=\sigma_u^2/(\sigma_u^2+\sigma_\varepsilon^2)=\rho\) (§গ-এর প্রমাণ দ্রষ্টব্য)। (গ) \(\rho=0\) ⇒ স্কুল-ভেদ নেই, observation কার্যত স্বাধীন ⇒ pooled OLS যথেষ্ট; \(\rho=1\) ⇒ within-school কোনো noise নেই, স্কুলই সব নির্ধারণ করে।
প্রশ্ন ৫ (★★). random intercept বনাম random slope। চলমান model-এ শুধু random intercept আছে: \(y_{ij}=\beta_0+\beta_1 x_{ij}+u_j+\varepsilon_{ij}\), যেখানে \(u_j\) স্কুল-ভিত্তিক উলম্ব-স্থানান্তর। (ক) এই model জ্যামিতিকভাবে কী বলে — প্রতিটা স্কুলের regression-রেখা কীভাবে আলাদা, আর কীভাবে এক? (খ) এখন ধরুন hours-এর প্রভাবও স্কুল-ভেদে বদলায় (কোনো স্কুলে পড়ার রিটার্ন বেশি)। সেটা ধরতে কোন term যোগ করতে হবে — model কী হবে (\(u_{1j}\) ব্যবহার করুন)? (গ) random slope যোগ করলে দুটো random effect-এর মধ্যে আরেকটা parameter আসে — সেটা কী, এবং কেন তা গুরুত্বপূর্ণ?
Hint: (ক) random intercept ⇒ সব স্কুলের রেখা সমান্তরাল (একই slope \(\beta_1\)), শুধু উচ্চতা (intercept \(\beta_0+u_j\)) আলাদা। (খ) random slope যোগ: \(y_{ij}=\beta_0+\beta_1 x_{ij}+u_{0j}+u_{1j}x_{ij}+\varepsilon_{ij}\), যেখানে স্কুল \(j\)-এর slope \(=\beta_1+u_{1j}\) — রেখাগুলো আর সমান্তরাল নয়। (গ) intercept ও slope-এর random part-এর মধ্যে covariance/correlation \(\sigma_{01}\) (যেমন: উঁচু-intercept স্কুলে কি slope বেশি?) — random-effects covariance matrix \(\Sigma\)-এর off-diagonal; না ধরলে dependence-কাঠামো ভুল হয়।
প্রশ্ন ৬ (★★). REML বনাম ML। mixed model-এ variance component (\(\sigma_u^2,\sigma_\varepsilon^2\)) estimate করার দুই পদ্ধতি — সাধারণ ML আর REML (restricted maximum likelihood)। (ক) সাধারণ ML variance component-কে কেন একটু নিচু (biased-low) estimate করে — fixed effect estimate করার "খরচ" উপেক্ষা করায় কী হয়? (খ) এটা ৫.৩-এর কোন পরিচিত ধারণার সাথে মেলে — sample variance-এ \(n\)-এর বদলে \(n-1\) দিয়ে ভাগ করা কেন (degrees of freedom)? (গ) দুটো mixed model-এর fixed-effect structure আলাদা (যেমন একটায় hours আছে, একটায় নেই) — তাদের likelihood-ratio দিয়ে তুলনা করতে ML না REML লাগবে, এবং কেন?
Hint: (ক) ML variance estimate করার সময় ধরে নেয় \(\hat\beta\) "জানা"; বাস্তবে \(\beta\) estimate করতে কিছু df খরচ হয়, তা না-ছাড়ায় residual variance underestimated। (খ) ঠিক sample-variance-এর Bessel সংশোধনের মতো — REML কার্যত fixed-effect-এর df বাদ দিয়ে (residual-এ proj করে) variance estimate করে, তাই unbiased; ML হলো \(n\)-দিয়ে-ভাগের অ্যানালগ। (গ) fixed-effect তুলনায় ML — REML-likelihood fixed-effect-কে বের করে দেয় বলে ভিন্ন fixed structure-এর REML-likelihood তুলনাযোগ্য নয়; কিন্তু variance/random-structure তুলনায় REML ভালো। (চলমান fit REML — তাই canonical \(\hat\sigma_u=6.14\) ইত্যাদি REML estimate।)
খ · গণনামূলক (computational)¶
প্রশ্ন ৭ (★). variance component থেকে ICC হাতে। mixed fit দিয়েছে \(\hat\sigma_u^2=37.64\) (স্কুল-ভিত্তিক) ও \(\hat\sigma_\varepsilon^2=63.69\) (residual)। (ক) ICC \(\rho=\sigma_u^2/(\sigma_u^2+\sigma_\varepsilon^2)\) ক্যালকুলেটরে গণনা করুন; canonical \(0.371\) মিলছে কি? (খ) \(\hat\sigma_u=\sqrt{37.64}\) ও \(\hat\sigma_\varepsilon=\sqrt{63.69}\) বের করে দেখান এরা যথাক্রমে \(\approx6.14\) ও \(\approx7.98\) (true \(6\) ও \(8\)-এর কাছাকাছি)। (গ) মোট outcome-variance (\(\sigma_u^2+\sigma_\varepsilon^2\)) কত, এবং তার বর্গমূল (মোট SD) কত? Hint: (ক) \(\rho=37.64/(37.64+63.69)=37.64/101.33=0.3714\approx0.371\) ✓। (খ) \(\sqrt{37.64}=6.135\approx6.14\), \(\sqrt{63.69}=7.981\approx7.98\) — true \(\sigma_u=6,\sigma_\varepsilon=8\)-এর কাছাকাছি (নমুনা-ভিত্তিক বিচ্যুতি স্বাভাবিক)। (গ) মোট variance \(101.33\), মোট SD \(\sqrt{101.33}\approx10.07\)।
প্রশ্ন ৮ (★★). shrinkage factor \(\lambda_j\) — ছোট বনাম বড় group। shrinkage factor \(\lambda_j=\dfrac{n_j\sigma_u^2}{n_j\sigma_u^2+\sigma_\varepsilon^2}\) বলে দেয় স্কুল \(j\)-এর data কতটা "বিশ্বাস" পায় (BLUP \(\approx\lambda_j\times\) স্কুলের নিজস্ব residual-গড়; \(\lambda_j\) যত বড়, shrink তত কম)। \(\hat\sigma_u^2=37.64\), \(\hat\sigma_\varepsilon^2=63.69\) ধরে গণনা করুন: (ক) একটা ছোট স্কুল \(n_j=10\)-এর \(\lambda_j\); (খ) একটা বড় স্কুল \(n_j=30\)-এর \(\lambda_j\); (গ) দুটো তুলনা করে এক বাক্যে বলুন কেন ছোট স্কুলের estimate গ্র্যান্ড-গড়ের দিকে বেশি টানা হয়। Hint: (ক) \(\lambda_{10}=\dfrac{10\cdot37.64}{10\cdot37.64+63.69}=\dfrac{376.4}{440.09}=0.855\)। (খ) \(\lambda_{30}=\dfrac{30\cdot37.64}{30\cdot37.64+63.69}=\dfrac{1129.2}{1192.89}=0.947\)। (গ) ছোট স্কুলের \(\lambda\) ছোট (\(0.855<0.947\)) ⇒ shrink বেশি (\(1-\lambda=0.145\) বনাম \(0.053\)); কারণ কম data মানে স্কুলের নিজস্ব গড় কম নির্ভরযোগ্য, তাই model আরও বেশি population-গড়ের দিকে টানে (noisy চরম মানকে নিয়ন্ত্রণ করে)।
প্রশ্ন ৯ (★★). BLUP ও shrink-করা স্কুল-গড়। স্কুল \(0\)-এর \(n_0=20\); mixed fit দিয়েছে এর random-intercept BLUP \(\hat u_0=+6.05\) (অর্থাৎ গড় ছাত্রের প্রত্যাশিত-চেয়ে \(+6.05\) স্কোর উঁচু, hours নিয়ন্ত্রণ করে)। (ক) \(n_0=20\)-এর shrinkage factor \(\lambda_0=\dfrac{20\cdot37.64}{20\cdot37.64+63.69}\) গণনা করুন। (খ) যদি স্কুল \(0\)-এর raw (no-pooling) intercept-বিচ্যুতি গ্র্যান্ড-গড় থেকে \(\approx+6.56\) হতো, তবে partial-pooling BLUP \(\approx\lambda_0\times6.56\) — মিলিয়ে দেখুন \(+6.05\)-এর কাছাকাছি আসে কি। (গ) স্কুল \(0\)-এর model-implied গড় intercept (hours\(=0\)-এ) কত — \(\hat\beta_0+\hat u_0\)? (\(\hat\beta_0=50.82\))
Hint: (ক) \(\lambda_0=\dfrac{752.8}{752.8+63.69}=\dfrac{752.8}{816.49}=0.922\)। (খ) \(0.922\times6.56=6.05\) ✓ — BLUP হলো raw-বিচ্যুতিকে \(\lambda_0\) দিয়ে shrink-করা (এখানে \(\sim8\%\) টানা)। (গ) \(\hat\beta_0+\hat u_0=50.82+6.05=56.87\) — স্কুল \(0\)-এর শূন্য-ঘণ্টা-প্রত্যাশিত গড় স্কোর।
প্রশ্ন ১০ (★★). design effect — OLS SE কত গুণ ভুল। clustering-এর জন্য কার্যকর-নমুনা-হ্রাস পরিমাপ করে design effect \(\text{Deff}=1+(\bar n-1)\rho\) (balanced আনুমানিক), যেখানে \(\bar n\) গড় group-আকার ও \(\rho\) হলো ICC। চলমান উদাহরণে \(\bar n=533/25\approx21.3\), \(\rho=0.371\)। (ক) \(\text{Deff}\) গণনা করুন। (খ) "সঠিক SE \(\approx\sqrt{\text{Deff}}\times\)(naive OLS SE)" — between-cluster পরিমাণের জন্য এই গুণক \(\sqrt{\text{Deff}}\) বের করুন। (গ) intercept-এ এটা প্রয়োগ করলে naive \(0.867\) থেকে আনুমানিক কত SE আসে, এবং mixed-এর প্রকৃত \(1.416\)-এর সাথে দিক মেলে কি? Hint: (ক) \(\text{Deff}=1+(21.3-1)\times0.371=1+20.3\times0.371=1+7.53=8.53\)। (খ) \(\sqrt{8.53}\approx2.92\)। (গ) \(0.867\times2.92\approx2.53\) — সঠিক মাত্রা balanced-আনুমানিক, unbalanced ও partial-pooling বলে mixed-এর প্রকৃত \(1.416\) এর চেয়ে রক্ষণশীল, কিন্তু দিক একই: naive OLS SE মারাত্মক ছোট, clustering ধরলে SE বড় হয় (এটাই প্রশ্ন ২-এর পরিমাণগত রূপ)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১১ (★★). compound symmetry — within-group covariance \(=\sigma_u^2\) প্রমাণ করুন। model \(y_{ij}=\beta_0+\beta_1 x_{ij}+u_j+\varepsilon_{ij}\), যেখানে \(u_j\sim\mathcal N(0,\sigma_u^2)\), \(\varepsilon_{ij}\sim\mathcal N(0,\sigma_\varepsilon^2)\), এবং সব \(u_j,\varepsilon_{ij}\) পরস্পর স্বাধীন। (ক) একই স্কুল \(j\)-এর দুই ভিন্ন শিক্ষার্থী \(i\ne i'\)-এর জন্য \(\operatorname{Cov}(y_{ij},y_{i'j})=\sigma_u^2\) প্রমাণ করুন। (খ) \(\operatorname{Var}(y_{ij})=\sigma_u^2+\sigma_\varepsilon^2\) দেখান, এবং সেখান থেকে within-group correlation \(=\rho=\dfrac{\sigma_u^2}{\sigma_u^2+\sigma_\varepsilon^2}\) বের করুন (এটাই ICC-র দ্বিতীয় ব্যাখ্যা)। (গ) ভিন্ন স্কুলের দুই শিক্ষার্থী (\(j\ne j'\))-এর covariance কত, এবং কেন? এই গঠনকে কেন compound symmetry বলে? Hint: (ক) fixed অংশ \(\beta_0+\beta_1 x\) ধ্রুবক (covariance-এ অবদান \(0\)); তাই \(\operatorname{Cov}(y_{ij},y_{i'j})=\operatorname{Cov}(u_j+\varepsilon_{ij},\,u_j+\varepsilon_{i'j})\)। বিস্তার করলে চারটা পদ: \(\operatorname{Cov}(u_j,u_j)=\sigma_u^2\); বাকি তিনটা (\(u_j\) ও \(\varepsilon\), এবং \(\varepsilon_{ij},\varepsilon_{i'j}\) ভিন্ন বলে) সব \(0\) — স্বাধীনতার কারণে। ফল \(\sigma_u^2\) ∎। (খ) \(\operatorname{Var}(y_{ij})=\operatorname{Var}(u_j)+\operatorname{Var}(\varepsilon_{ij})=\sigma_u^2+\sigma_\varepsilon^2\); correlation \(=\dfrac{\operatorname{Cov}}{\sqrt{\operatorname{Var}\cdot\operatorname{Var}}}=\dfrac{\sigma_u^2}{\sigma_u^2+\sigma_\varepsilon^2}=\rho\)। (গ) \(j\ne j'\) ⇒ \(u_j,u_{j'}\) স্বাধীন, কোনো term শেয়ার নেই ⇒ covariance \(0\)। compound symmetry: একই গোষ্ঠীর যেকোনো জোড়ার covariance অভিন্ন (\(\sigma_u^2\)), variance অভিন্ন (\(\sigma_u^2+\sigma_\varepsilon^2\)) — তাই গোষ্ঠীর covariance matrix \(\sigma_\varepsilon^2 I+\sigma_u^2 \mathbf 1\mathbf 1^\top\), একই off-diagonal সর্বত্র।
প্রশ্ন ১২ (★★★). shrinkage factor \(\lambda_j\)-এর উৎপত্তি। ধরুন একটা সরল random-intercept-only model \(y_{ij}=\mu+u_j+\varepsilon_{ij}\) (\(\beta_1=0\), অর্থাৎ predictor নেই)। স্কুল \(j\)-এর observed গড় \(\bar y_j=\frac{1}{n_j}\sum_i y_{ij}\)। random-effect-এর posterior/BLUP estimate হলো \(\hat u_j=\lambda_j(\bar y_j-\mu)\)। দেখান যে এই shrinkage factor \(\lambda_j=\dfrac{n_j\sigma_u^2}{n_j\sigma_u^2+\sigma_\varepsilon^2}\)। (ক) \(\bar y_j\)-এর variance বের করুন (signal \(u_j\) ও noise \(\bar\varepsilon_j\)-এর যোগফল হিসেবে)। (খ) Normal-Normal conjugacy / "inverse-variance weighting"-এর ভাষায় যুক্তি দিন কেন posterior mean signal-variance ও noise-variance-এর অনুপাতে weight পায়। (গ) \(n_j\to\infty\) ও \(n_j\to0\) দুই সীমায় \(\lambda_j\) কী হয়, এবং এটা প্রশ্ন ৮-এর ছোট-বনাম-বড় group আচরণকে কীভাবে ব্যাখ্যা করে? Hint: (ক) \(\bar y_j=\mu+u_j+\bar\varepsilon_j\), যেখানে \(\bar\varepsilon_j=\frac1{n_j}\sum_i\varepsilon_{ij}\), তাই \(\operatorname{Var}(\bar\varepsilon_j)=\sigma_\varepsilon^2/n_j\); দেওয়া \(u_j\), \(\bar y_j-\mu\)-এর "noise" অংশের variance \(\sigma_\varepsilon^2/n_j\), আর "signal" \(u_j\)-এর prior variance \(\sigma_u^2\)। (খ) Normal prior \(u_j\sim\mathcal N(0,\sigma_u^2)\) ও Normal likelihood (mean \(u_j\), variance \(\sigma_\varepsilon^2/n_j\)) ⇒ posterior mean \(=\dfrac{\sigma_u^2}{\sigma_u^2+\sigma_\varepsilon^2/n_j}(\bar y_j-\mu)\); লব-হর-কে \(n_j\) দিয়ে গুণ করলে \(\dfrac{n_j\sigma_u^2}{n_j\sigma_u^2+\sigma_\varepsilon^2}=\lambda_j\) ∎ (inverse-variance weighting: কম-noise উৎস বেশি weight)। (গ) \(n_j\to\infty\Rightarrow\lambda_j\to1\) (no shrink — বড় স্কুলের নিজের গড়কেই বিশ্বাস); \(n_j\to0\Rightarrow\lambda_j\to0\) (পূর্ণ shrink — তথ্য নেই, গ্র্যান্ড-গড়ই estimate)। তাই ছোট স্কুল বেশি টানে — partial pooling স্বয়ংক্রিয়ভাবে data-পরিমাণ অনুযায়ী বিশ্বাস বণ্টন করে।
ঘ · কোডিং (Python)¶
প্রশ্ন ১৩ (★★★). পূর্ণ mixed-model pipeline — pooled OLS বনাম MixedLM, variance components, ICC, BLUP। seed np.random.default_rng(20260619) দিয়ে data বানান: \(J=25\) স্কুল, প্রতিটির \(n_j\sim\) rng.integers(10,31) (মোট \(N\approx533\)); প্রতিটা স্কুলের \(u_j=\) rng.normal(0,6); প্রতিটা শিক্ষার্থীর hours = rng.uniform(0,10), eps = rng.normal(0,8), score = 50 + 2*hours + u_j + eps। long-format DataFrame (school, hours, score) বানিয়ে:
1. pooled OLS (complete pooling): statsmodels-এ smf.ols('score ~ hours', data=df).fit() — slope ও তার SE ছাপুন; canonical \(\hat\beta_1=1.800\), \(\mathrm{SE}=0.149\), intercept SE \(0.867\)-এর সাথে মেলান। (school উপেক্ষা করায় এই SE-গুলো ভুল।)
2. mixed model (partial pooling): smf.mixedlm('score ~ hours', data=df, groups=df['school']).fit() (random intercept) — fixed-effect summary ছাপুন; canonical \(\hat\beta_0=50.82\) (\(\mathrm{SE}=1.416\)), \(\hat\beta_1=1.878\) (\(\mathrm{SE}=0.120\)) যাচাই করুন; intercept SE OLS \(0.867\) বনাম mixed \(1.416\) পাশাপাশি রাখুন।
3. variance components: group-variance (\(\hat\sigma_u^2\)) ও residual-variance (\(\hat\sigma_\varepsilon^2\)) বের করুন (result.cov_re ও result.scale); canonical \(37.64\) ও \(63.69\) (\(\sigma_u=6.14,\sigma_\varepsilon=7.98\)) মেলান।
4. ICC: \(\rho=\hat\sigma_u^2/(\hat\sigma_u^2+\hat\sigma_\varepsilon^2)\) গণনা করুন; canonical \(0.371\)।
5. BLUP (random effects): result.random_effects থেকে প্রতিটা স্কুলের \(\hat u_j\) বের করুন; স্কুল \(0\) (\(n_0=20\))-এর BLUP \(\approx+6.05\) যাচাই করুন; ছাপিয়ে দেখান BLUP-গুলো no-pooling raw-গড় থেকে গ্র্যান্ড-গড়ের দিকে shrink-করা (প্রতিটা স্কুলের raw-deviation বনাম BLUP scatter)।
6. shrinkage যাচাই: স্কুল \(0\)-এর \(\lambda_0=20\cdot37.64/(20\cdot37.64+63.69)=0.922\) হাতে গণনা করে দেখান BLUP \(\approx\lambda_0\times(\text{raw deviation})\)।
7. logLik: result.llf ছাপুন; canonical \(-1894.5\)।
(সম্ভব হলে ১–৭ এক runnable script-এ; প্রতিটা সংখ্যা canonical-এর সাথে মেলান। নোট: data-generation-এ random-call-এর ক্রম canonical seed-আউটপুট মেলানোর জন্য গুরুত্বপূর্ণ — সমাধান-script-এর ক্রম অনুসরণ করুন।)
Hint: import statsmodels.formula.api as smf; MixedLM-এ result.cov_re.iloc[0,0] = \(\hat\sigma_u^2\), result.scale = \(\hat\sigma_\varepsilon^2\); result.random_effects['0'] = স্কুল \(0\)-এর BLUP (Series, Group index)। ICC এক লাইনে: vu/(vu+ve)। shrinkage স্বজ্ঞা পরীক্ষা: প্রতিটা স্কুলের (group_mean - grand_mean) বনাম BLUP plot করলে সব point origin-মুখী টানা একটা \(<1\)-ঢালের রেখায় বসে। প্রত্যাশিত সব সংখ্যা উপরের canonical তালিকায়।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
-
কেন এই অধ্যায়। ৫.১–৫.৫ জুড়ে একটা নীরব অনুমান ছিল — observation-গুলো পরস্পর স্বাধীন। কিন্তু বাস্তব data প্রায়ই clustered/nested: একই স্কুলের শিক্ষার্থী, একই হাসপাতালের রোগী, একই ব্যক্তির বারবার-মাপা মান। এমন গোষ্ঠীবদ্ধ data-তে একই গোষ্ঠীর সদস্যরা পরস্পর-সম্পর্কিত, তাই \(N\) observation আসলে \(N\)টা স্বাধীন তথ্য-একক নয়। এই dependence উপেক্ষা করলে (pooled OLS) coefficient-এর SE ভুল হয় — বিশেষত between-cluster পরিমাণে মারাত্মক underestimated (চলমান উদাহরণে intercept SE OLS \(0.867\) বনাম সঠিক mixed \(1.416\))। সমাধান: mixed-effects / hierarchical (multilevel) models।
-
fixed + random effects। model দুই ধরনের প্রভাব মেশায় (তাই "mixed"): $\(y_{ij}=\beta_0+\beta_1 x_{ij}+u_j+\varepsilon_{ij},\qquad u_j\sim\mathcal N(0,\sigma_u^2),\quad \varepsilon_{ij}\sim\mathcal N(0,\sigma_\varepsilon^2).\)$
- fixed effect (\(\beta_0,\beta_1\)): সব গোষ্ঠীতে অভিন্ন, population-জোড়া সম্পর্ক (এই উদাহরণে
hours-এর প্রভাব সব স্কুলে এক)। - random effect (\(u_j\)): গোষ্ঠী-ভিত্তিক বিচ্যুতি, একটা distribution থেকে আসে। আমরা \(25\)টা আলাদা parameter estimate করি না — শুধু একটা variance \(\sigma_u^2\) (বিরাট parsimony); স্কুলগুলোকে একটা বৃহত্তর জনগোষ্ঠীর নমুনা ধরা হয়।
-
random intercept (এখানে) ⇒ স্কুল-রেখা সমান্তরাল, শুধু উচ্চতা আলাদা; random slope (\(u_{1j}x_{ij}\)) ⇒ ঢালও স্কুল-ভেদে বদলায়।
-
variance components ও ICC। mixed model মোট পরিবর্তনশীলতাকে দুই variance component-এ ভাঙে: between-group \(\sigma_u^2\) ও within-group \(\sigma_\varepsilon^2\) (চলমান fit: \(\hat\sigma_u^2=37.64\), \(\hat\sigma_\varepsilon^2=63.69\))। এদের অনুপাত দেয় intraclass correlation (ICC): $\(\rho=\frac{\sigma_u^2}{\sigma_u^2+\sigma_\varepsilon^2}=\frac{37.64}{37.64+63.69}=0.371.\)$ দুই সমার্থক ব্যাখ্যা: (i) মোট variance-এর \(\sim37\%\) স্কুল-ভেদ থেকে; (ii) একই স্কুলের যেকোনো দুই শিক্ষার্থীর score-এর correlation \(0.371\)। \(\rho=0\) হলে clustering নেই (pooled OLS যথেষ্ট), \(\rho=1\) হলে within-group noise নেই।
-
compound symmetry। random-intercept model একটা নির্দিষ্ট covariance-গঠন চাপায়: একই গোষ্ঠীর যেকোনো জোড়ার \(\operatorname{Cov}(y_{ij},y_{i'j})=\sigma_u^2\), প্রতিটির \(\operatorname{Var}=\sigma_u^2+\sigma_\varepsilon^2\), ভিন্ন গোষ্ঠীর covariance \(0\) — অর্থাৎ গোষ্ঠী-covariance matrix \(\sigma_\varepsilon^2 I+\sigma_u^2\mathbf 1\mathbf 1^\top\)। এই অভিন্ন off-diagonal-কেই compound symmetry বলে, এবং তা থেকেই within-group correlation \(=\rho\) (§৭-এ প্রমাণিত)।
-
partial pooling ও shrinkage। গোষ্ঠীবদ্ধ data-র তিনটা পথ: complete pooling (school উপেক্ষা — স্কুল-ভেদ হারায়), no pooling (\(25\)টা স্বাধীন regression — ছোট স্কুলে noisy/overfit), আর mixed-model-এর partial pooling (আপস)। partial pooling প্রতিটা স্কুলের estimate-কে গ্র্যান্ড-গড়ের দিকে shrink করে, factor $\(\lambda_j=\frac{n_j\sigma_u^2}{n_j\sigma_u^2+\sigma_\varepsilon^2}\)$ অনুযায়ী: ছোট স্কুল (\(n_j=10\): \(\lambda=0.855\)) বেশি টানা, বড় স্কুল (\(n_j=30\): \(\lambda=0.947\)) কম। স্কুল-ভিত্তিক estimate হলো BLUP (best linear unbiased predictor) — চলমান উদাহরণে স্কুল \(0\) (\(n_0=20\), \(\lambda_0=0.922\))-এর BLUP \(\hat u_0=+6.05\), যা raw-deviation (\(\approx6.56\))-কে \(\lambda_0\) দিয়ে shrink-করা। ছোট/noisy গোষ্ঠীকে বেশি টেনে partial pooling স্বয়ংক্রিয়ভাবে data-পরিমাণ অনুযায়ী বিশ্বাস বণ্টন করে — no-pooling-এর চেয়ে কম variance, complete-pooling-এর চেয়ে কম bias।
-
REML দিয়ে fit। variance component estimate করতে সাধারণ ML একটু biased-low (fixed-effect estimate করার df-খরচ উপেক্ষা করে — ঠিক sample-variance-এ \(n\)-বনাম-\(n-1\)-এর মতো)। REML (restricted maximum likelihood) সেই df ছাড় দিয়ে variance-কে unbiased estimate করে; তাই variance/random-structure-এর জন্য REML পছন্দ (চলমান fit REML, logLik \(-1894.5\))। তবে ভিন্ন fixed-effect structure তুলনা (likelihood-ratio) করতে ML লাগে, কারণ REML-likelihood fixed-effect-নির্ভর।
-
design effect — পরিমাণগত ছবি। clustering-জনিত কার্যকর-নমুনা-হ্রাস ধরা পড়ে design effect \(\text{Deff}=1+(\bar n-1)\rho\)-তে; চলমান উদাহরণে \(1+(21.3-1)\times0.371\approx8.5\), তাই between-cluster SE প্রায় \(\sqrt{8.5}\approx2.9\) গুণ বড় হওয়া উচিত — ঠিক যে কারণে naive OLS intercept SE (\(0.867\)) এত ভুল আর mixed (\(1.416\)) সঠিক।
পূর্ববর্তী সংযোগ (← ৫.১, ৫.৩, ২.৬):
-
৫.১ (Linear Regression / OLS): mixed model হলো OLS-এরই সম্প্রসারণ — fixed অংশ \(\beta_0+\beta_1 x_{ij}\) হুবহু ৫.১-এর regression। নতুন যা: error-কে দুই টুকরোয় ভাগ (\(u_j+\varepsilon_{ij}\)), যেখানে \(u_j\) গোষ্ঠী-জুড়ে শেয়ার-করা। \(\sigma_u^2=0\) ধরলে mixed model ঠিক pooled OLS-এ ফিরে যায়। ৫.১-এর OLS অনুমান independence ও homoscedastic error-কে এ অধ্যায় শিথিল করে: একই গোষ্ঠীর error আর স্বাধীন নয় (compound symmetry), তাই OLS-এর SE-সূত্র আর প্রযোজ্য নয়।
-
৫.৩ (ANOVA / variance): random-intercept model আসলে ৫.৩-এর random-effects (one-way) ANOVA-রই regression-রূপ — মোট variance-কে between-group (\(\sigma_u^2\)) ও within-group (\(\sigma_\varepsilon^2\)) variance component-এ ভাঙা ঠিক ANOVA-র sum-of-squares বিভাজনের ধারাবাহিকতা। ICC তো random-effects ANOVA থেকেই আসা ধারণা। আর REML-এর df-সংশোধন ৫.৩-এর degrees-of-freedom হিসাবেরই সাধারণীকরণ (sample variance-এ \(n-1\) কেন)।
-
২.৬ (Covariance): এ অধ্যায়ের কেন্দ্রীয় গাণিতিক যন্ত্র ২.৬-এর covariance। ICC, compound symmetry, within-group correlation — সবই \(\operatorname{Cov}(y_{ij},y_{i'j})\) হিসাব করে পাওয়া (§৭-এর প্রমাণে চারটা covariance-পদ বিস্তার করে দেখানো হয়, যেখানে স্বাধীন রাশির covariance \(0\) — ২.৬-এর সরাসরি প্রয়োগ)। random effect-এর গোটা ধারণাই হলো: shared \(u_j\) গোষ্ঠী-অভ্যন্তরে positive covariance তৈরি করে, আর সেটাই dependence-এর উৎস।
পরবর্তী সংযোগ (→ ৫.৭ — Nonparametric Regression: kernels ও splines): ৫.১–৫.৬ জুড়ে আরেকটা অনুমান টিকে ছিল — predictor ও outcome-এর সম্পর্ক রৈখিক (বা একটা নির্দিষ্ট parametric রূপের)। কিন্তু বহু বাস্তব সম্পর্ক রৈখিকই নয় — বাঁকানো, জটিল, পূর্বনির্ধারিত সূত্রে ধরা যায় না। ৫.৭ সেই বাঁধন খুলবে nonparametric regression দিয়ে: predictor-কে কোনো স্থির সমীকরণে না বেঁধে, data-কে নিজে থেকে curve-এর আকার বলতে দেওয়া — kernel smoothing (প্রতিটা বিন্দুর চারপাশে স্থানীয় গড়/weighted fit) ও splines (টুকরো-টুকরো মসৃণ polynomial জোড়া দিয়ে নমনীয় বক্ররেখা)। সংক্ষেপে: ৫.৪–৫.৫ outcome-এর distribution সাধারণীকৃত করেছিল (GLM), ৫.৬ error/dependence-কাঠামো (mixed effects), আর ৫.৭ সাধারণীকৃত করবে mean function-এর রূপ নিজেই — যখন \(\mathbb E[y\mid x]\) আর \(x^\top\beta\)-এর মতো রৈখিক নয়।
সূত্র (sources): R. Furrer, STA121 Statistical Modeling (mixed/hierarchical models, random effects, variance components, REML, BLUP, shrinkage); J. A. Rice, Mathematical Statistics and Data Analysis (random-effects ANOVA, variance components, intraclass correlation); L. Wasserman, All of Statistics (hierarchical/random-effects model ও variance-component inference); Bruce, Bruce & Gedeck, Practical Statistics for Data Scientists (clustered data, repeated measures, multilevel-এর ব্যবহারিক দিক); P. Dangeti, Statistics for Machine Learning (mixed/hierarchical model ও partial pooling, ML-