5.8 — Cross-Validation & Model Validation (ক্রস-ভ্যালিডেশন ও মডেল যাচাই)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — "যে data দেখে শিখেছ, তাতেই নিজেকে যাচাই কোরো না"¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন নতুন প্রশ্ন¶
5.7 শেষ হয়েছিল একটা ঝুলন্ত প্রশ্নে। সেখানে আমরা তিনটে nonparametric পদ্ধতি দেখেছিলাম — kernel regression (নিয়ন্ত্রক bandwidth \(h\)), regression spline (নিয়ন্ত্রক degrees of freedom \(df\)), smoothing spline (নিয়ন্ত্রক smoothing parameter \(\lambda\)) — আর প্রতিবার একটাই tuning-knob নমনীয়তা ঠিক করত: knob একদিকে ঘোরালে curve wiggly হয়ে data-র noise মুখস্থ করে (overfit), অন্যদিকে ঘোরালে curve অতি-মসৃণ হয়ে আসল গঠন হারায় (underfit)। কিন্তু knob-টা ঠিক কোথায় থামাব — \(h\) বা \(df\) বা \(\lambda\)-র ঠিক কোন মান — সেই উত্তরটা আমরা 5.8-এর জন্য তুলে রেখেছিলাম।
প্রশ্নটা আসলে আরও বড় ও সাধারণ। শুধু একটামাত্র knob নয় — অনেক সময় আমাদের হাতে একগুচ্ছ প্রার্থী-মডেল থাকে, এবং বেছে নিতে হয় কোনটা। সবচেয়ে চেনা উদাহরণ: polynomial regression-এ degree কত হবে? সরলরেখা (degree 1)? parabola (degree 2)? নাকি degree 5, degree 10? প্রতিটি degree একেকটা আলাদা জটিলতার মডেল; কম-degree সরল কিন্তু হয়তো বাঁক ধরতে পারে না (underfit), বেশি-degree নমনীয় কিন্তু noise-ও মুখস্থ করে (overfit)। তাহলে কোন degree-টা সবচেয়ে ভালো generalize করবে — অর্থাৎ ভবিষ্যতের, এখনো-না-দেখা data-তে সবচেয়ে কম ভুল করবে?
এই গোটা অধ্যায় ঠিক এই এক প্রশ্নের উত্তর: কীভাবে honestly আন্দাজ করি একটা মডেল নতুন data-তে কতটা ভালো করবে, এবং সেই আন্দাজ দিয়ে কীভাবে মডেল বা tuning-knob বাছি? এটাই 5.2-র model-selection-ভাবনাকে একধাপ এগিয়ে নেয় — সেখানে আমরা AIC/BIC-র মতো analytic সূচক দেখেছিলাম; এখানে দেখব এর সবচেয়ে সরাসরি, কম-অনুমাননির্ভর, সর্বজনীন হাতিয়ার — cross-validation।
১.২ Hook — একটা অস্বস্তিকর সত্য: training error তোমাকে প্রতারণা করবে¶
একটা স্বাভাবিক — এবং বিপজ্জনকভাবে ভুল — চিন্তা দিয়ে শুরু করি। "কোন degree ভালো বুঝতে চাই? — সহজ! প্রতিটি degree-র মডেল data-তে fit করি, দেখি কোনটার ভুল সবচেয়ে কম, সেটাই বাছি।" এখানে "ভুল" বলতে স্বাভাবিকভাবেই আসে training error — যে data দিয়ে মডেল গড়া হলো, সেই একই data-তে মাপা গড়-বর্গ-ভুল।
এই কৌশলটা কেন বিপর্যয়, সেটা 5.8-এর চলতি dataset-এর সংখ্যা দিয়েই চোখে দেখা যায়। ধরা যাক সত্যিকারের সম্পর্ক একটা cubic curve, \(f(x)=x^3-3x\), আর তাতে noise মেশানো (\(n=120\) বিন্দু; পূর্ণ বিবরণ §৫-এ)। এখন degree 1 থেকে 10 পর্যন্ত polynomial fit করে training MSE দেখি:
| degree \(d\) | training MSE |
|---|---|
| 1 | 22.08 |
| 2 | (মাঝামাঝি) |
| 3 | 9.59 |
| ... | ... |
| 10 | 9.12 |
লক্ষ করুন প্যাটার্নটা: degree বাড়লে training MSE শুধু কমতেই থাকে — degree 3-এ 9.59, কিন্তু degree 10-এ আরও কম, 9.12। যদি আমরা "সবচেয়ে কম training MSE" নিয়মে মডেল বাছি, তাহলে সবসময় সবচেয়ে জটিল মডেলটাই (degree 10) জিতে যাবে। কিন্তু আমরা তো জানি সত্যিকারের সম্পর্ক মাত্র cubic (degree 3) — degree 10 সেই 9.59 থেকে 9.12-এ নামার সময় আসলে \(f\)-কে নয়, noise-কে মুখস্থ করছে। সেই বাড়তি নমনীয়তা training data-তে ভুল কমায় ঠিকই, কিন্তু নতুন data-তে নিয়ে গেলে এই অতি-fit মডেল হোঁচট খাবে।
এক বাক্যে hook: training error দিয়ে মডেল বাছা মানে "ছাত্রকে যে প্রশ্নে পড়িয়েছ ঠিক সেই প্রশ্নেই পরীক্ষা নেওয়া" — সে যত বেশি মুখস্থ করেছে তত বেশি নম্বর পাবে, কিন্তু সেই নম্বর তার আসল বোঝাপড়া (generalization) মাপে না; training error তাই সবসময় আশাবাদী, এবং complexity বাড়লে আরও বেশি আশাবাদী।
১.৩ কেন training error গঠনগতভাবেই আশাবাদী — সমস্যাটা গভীর¶
§১.২-এর প্রবণতাটা — training MSE-র monotone (একঘেয়ে) নিচে নামা — কোনো কাকতাল নয়; এটা একটা গঠনগত (structural) ঘটনা, আর এখান থেকেই গোটা অধ্যায়ের প্রেরণা। কারণটা একটু খুলে বলা দরকার।
মডেল fit করার মানেই হলো — parameter-গুলো এমনভাবে বেছে নেওয়া যাতে এই বিশেষ data-তে ভুল সবচেয়ে কম হয়। অর্থাৎ মডেল training data-র দিকে তাকিয়ে, তার প্রতিটি খুঁটিনাটির সঙ্গে — আসল সম্পর্ক এবং সেই বিশেষ নমুনার আকস্মিক noise, দুটোর সঙ্গেই — মানিয়ে নেয়। মডেল যত নমনীয় (বেশি degree, ছোট \(h\), বড় \(df\)), সে data-র noise-এর ততগুলো খুঁটিনাটি অনুসরণ করতে পারে, তাই training error তত নিচে নামাতে পারে। চরম ক্ষেত্রে যথেষ্ট-জটিল মডেল প্রতিটি training-বিন্দু হুবহু ছুঁয়ে training error শূন্যেও নামাতে পারে — কিন্তু তখন সে আসলে কিছুই "শেখেনি", কেবল মুখস্থ করেছে।
এর ফল: training error একটা estimator হিসেবে নিচের দিকে পক্ষপাতী (downward/optimistically biased) — সে প্রকৃত generalization error-কে নিয়মিতভাবে কম করে দেখায়, এবং এই কম-করে-দেখানোর পরিমাণ মডেল যত জটিল তত বড় হয়। তাই training-error-বক্ররেখা কখনো U-আকৃতি নেয় না; সে নিচে নামতেই থাকে, আর "সবচেয়ে কম" বাছলে সবসময় সবচেয়ে জটিল মডেল বেরোয় — যা প্রায় নিশ্চিতভাবে overfit। (এই optimism-এর পরিমাণ আসলে মডেল-জটিলতার সঙ্গে গাণিতিকভাবে যুক্ত — সেই হিসাবই 5.2-র AIC/BIC-র পেছনের যুক্তি, আর তার পূর্ণ রূপ §৪-এ।)
এক বাক্যে সমস্যা: যে data-তে মডেল fit হয়েছে, সেই data-তে মাপা ভুল প্রকৃত generalization-কে অবধারিতভাবে কম-করে দেখায়, এবং মডেল যত জটিল ততই বেশি — তাই training error দিয়ে complexity তুলনা করা মানে গোড়াতেই overfitting-এর দিকে ঝুঁকে পড়া।
১.৪ সমাধানের মূল insight (অন্তর্দৃষ্টি) — যে data মডেল দেখেনি, তাতে যাচাই করো¶
সমস্যাটা যেখানে, সমাধানের বীজও সেখানেই। training error প্রতারক কারণ মডেল মূল্যায়নের আগেই সেই data দেখে ফেলেছে — সে noise-টুকুও মুখস্থ করে ফেলেছে। তাহলে honest মূল্যায়নের শর্ত একটাই, এবং তা আশ্চর্যরকম সরল:
মডেলকে এমন data-তে যাচাই করো যা সে fit করার সময় দেখেনি — অর্থাৎ আলাদা করে সরিয়ে রাখা (held-out) data-তে। সেই data-র noise মডেলের parameter-এ ঢোকেনি, তাই তাতে মাপা ভুল আর আশাবাদী থাকে না — সে নতুন data-তে আসল পারফরম্যান্সেরই নিরপেক্ষ ঝলক।
এই একটি ধারণা — "শেখা ও যাচাইয়ের data আলাদা রাখো" — গোটা অধ্যায়ের মেরুদণ্ড। এর সবচেয়ে সরল রূপ: data-কে শুরুতেই দু-তিন ভাগে ভাগ করে নাও —
- একটা training set, যাতে মডেল fit হয় (parameter শেখে);
- একটা আলাদা validation/test set, যা fit-এর সময় তালাবন্ধ থাকে, আর কেবল শেষে মডেলের ভুল মাপতে খোলা হয়।
ফিরে এই কাঠামোয় §১.২-এর degree-নির্বাচন আবার করলে ছবিটা পুরো বদলে যায়: held-out data-তে মাপলে degree 10 আর জেতে না — কারণ সে training-noise মুখস্থ করেছিল, যা held-out data-তে অপ্রাসঙ্গিক, তাই সেখানে তার ভুল বরং বাড়ে। বদলে held-out error একটা U-আকৃতি নেয়: প্রথমে কমে (underfit সরে), একটা সেরা জটিলতায় সর্বনিম্ন হয়, তারপর আবার বাড়ে (overfit শুরু)। 5.8-এর ডেটায় সেই নিম্নবিন্দু পড়ে ঠিক degree 3-এ — যা আমরা জানি সত্যিকারের সম্পর্ক। অর্থাৎ held-out যাচাই training-error-এর প্রতারণা ফাঁস করে আসল উত্তরের দিকে নিয়ে যায়।
কিন্তু সরল একটিমাত্র split-এর নিজস্ব সমস্যা আছে (অনেক data যাচাইয়ে আটকে যায়, আর উত্তর কোন বিন্দুগুলো কাকতালীয়ভাবে validation-এ পড়ল তার উপর নির্ভর করে) — আর সেই সমস্যার মার্জিত সমাধানই cross-validation, যা সব data-কেই পালা করে train ও validate-এ ব্যবহার করে। এটাই অধ্যায়ের কেন্দ্রীয় হাতিয়ার, §২-এ পুরোপুরি গড়া হবে।
১.৫ এক ঝলক — কী পেতে যাচ্ছি¶
পথে নামার আগে গন্তব্যটা একবার দেখিয়ে রাখি, যাতে কষ্টটা কেন তা বোঝা যায়। 5.8-এর dataset-এ (\(f(x)=x^3-3x\), \(n=120\), noise-ভেদ \(\sigma^2=9\)) আমরা degree 1–10 polynomial-এ 10-fold cross-validation চালাব। training MSE যেখানে একঘেয়ে নামবে (degree 10-এ 9.12 পর্যন্ত), সেখানে CV-MSE নেবে একটা স্পষ্ট U-আকৃতি, যার সর্বনিম্ন পড়বে degree 3-এ (CV-MSE = 10.15)। স্বাধীন LOOCV-ও একই রায় দেবে (সর্বনিম্ন degree 3, মান 10.18), আর one-standard-error rule-ও degree 3-কেই বাছবে। সবচেয়ে তৃপ্তিদায়ক যাচাই: একটা পুরোপুরি আলাদা held-out test set-এ degree-3 মডেলের MSE আসবে 9.71 — যা CV-র আন্দাজ 10.15-এর প্রায় সমান, এবং দুটোই irreducible noise \(\sigma^2=9\)-এর কাছাকাছি। অর্থাৎ CV সত্যিই test error-এর নিরপেক্ষ আন্দাজ দিয়েছে, আর আসল সম্পর্কের degree-ও সঠিক ধরেছে (চিত্র 5-8-train-vs-cv, 5-8-cv-boxplot ও 5-8-fitted-degrees এ-সব দেখাবে)।
১.৬ এই অধ্যায়ের পথরেখা¶
মূল ধারণা হাতে এল; এবার সামনের পথ সংক্ষেপে:
- §২ মূল সংজ্ঞাগুলো নিখুঁত করে — training বনাম test/generalization error (\(\widehat{\text{err}}_{\text{train}}\) বনাম \(\text{Err}\)) ও training-error-এর optimism; train/validation/test split ও তার সীমা; K-fold cross-validation (\(\text{CV}_{(K)}\)) ও কেন সব data ব্যবহৃত হয়; LOOCV (\(\text{CV}_{(n)}\)); CV = test-error-এর প্রায়-নিরপেক্ষ estimate; CV দিয়ে tuning ও model-নির্বাচন; CV-estimate-এর নিজস্ব bias–variance; one-standard-error rule; এবং সংক্ষেপে learning curve ও AIC/BIC।
- §৩–৪ এই ধারণাগুলো হাতে-কলমে ও গাণিতিকভাবে — একটা ছোট data-তে K-fold ও LOOCV হাতে-কলমে গণনা, training-error-এর optimism কেন complexity-র সঙ্গে বাড়ে তার derivation, LOOCV কেন high-variance, এবং AIC/BIC কীভাবে CV-র analytic আনুমানিক রূপ।
- §৫–৬ পূর্ণ dataset-এ (seed 20260619, \(n=120\), \(f(x)=x^3-3x\), degree 1–10) হাতে-কলমে — training-vs-CV বক্ররেখা, K-fold-এর গঠন, fold-ভিত্তিক CV-error-এর ছড়ানো, ও বিভিন্ন degree-র fitted curve — চিত্র 5-8-train-vs-cv, 5-8-kfold-diagram, 5-8-cv-boxplot, 5-8-fitted-degrees ও Python-কোড সহ।
এক বাক্যে কেন এটি Part V-এর অপরিহার্য ধাপ। 5.1–5.7 শিখিয়েছে কীভাবে নানা মডেল (linear, diagnostic-যাচাইকৃত, nonparametric) fit করি; এই অধ্যায় শেখায় তাদের মধ্যে কীভাবে নিরপেক্ষভাবে বাছি ও তাদের ভবিষ্যৎ-পারফরম্যান্স আন্দাজ করি — যা প্রতিটি প্রয়োগ-পরিসংখ্যান ও machine-learning কাজের অবিচ্ছেদ্য অংশ। আর এখানকার honest-মূল্যায়ন ও model-নির্বাচনের কাঠামো সরাসরি কাজে লাগবে পরের অধ্যায় 5.9 (multivariate methods: PCA ও clustering)-এ, যেখানে component বা cluster-সংখ্যার মতো জটিলতা-পছন্দও একই যাচাই-দৃষ্টিভঙ্গি দাবি করবে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর insight (অন্তর্দৃষ্টি) — "যে data মডেল দেখেনি, তাতে যাচাই করো" — কে নিখুঁত সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথম ব্যবহারেই খোলা হলো; কোথাও কিছু ধরে নেওয়া হয়নি। যেখানে গণিতের পূর্ণ derivation লাগবে (training-error-এর optimism, LOOCV-র variance, AIC/BIC-র সঙ্গে CV-র সম্পর্ক), সেটা §৪-এ — এখানে লক্ষ্য সংজ্ঞা ও স্বজ্ঞা পরিষ্কার করা।
প্রথমে notation থিতু করে নিই। আমাদের কাছে \(n\)টি পর্যবেক্ষণ-জোড়া আছে: \((x_1,y_1),\dots,(x_n,y_n)\), যেখানে \(x_i\) হলো \(i\)-তম পর্যবেক্ষণের predictor (input) ও \(y_i\) তার response (output)। আমরা ধরছি একটা সত্যিকারের সম্পর্ক আছে, $$ y_i = f(x_i) + \varepsilon_i, \qquad \mathbb{E}[\varepsilon_i]=0,\quad \operatorname{Var}(\varepsilon_i)=\sigma^2, $$ যেখানে —
- \(f(\cdot)\) — সত্যিকারের, সাধারণত অজানা regression function (যেমন 5.8-এর ডেটায় \(f(x)=x^3-3x\));
- \(\varepsilon_i\) ("এপসাইলন-আই") — \(i\)-তম বিন্দুর random ত্রুটি, গড় \(0\) ও ধ্রুব variance (ভেদ) \(\sigma^2\) সহ;
- \(\sigma^2\) — irreducible noise-এর variance (অপসারণ-অযোগ্য গোলমাল): এমন এলোমেলোতা যা কোনো মডেলই কখনো ব্যাখ্যা করতে পারে না, কারণ এটা \(x\)-এর সঙ্গে কোনো সম্পর্ক রাখে না (4.4-এর সেই \(\sigma^2\), যা MSE-পচনের তৃতীয় অংশে অবশিষ্ট থাকে)।
data থেকে একটা মডেল fit করে আমরা পাই একটা আন্দাজ-function \(\hat f\) (পড়ুন "এফ-হ্যাট"), যা যেকোনো \(x\)-এ একটা prediction \(\hat f(x)\) দেয়। আমাদের আসল আগ্রহ — এই \(\hat f\) নতুন, এখনো-না-দেখা data-তে কত ভালো করবে। এখন সেই "কত ভালো"-র দুই মাপ আলাদা করা দরকার, কারণ এ-দুটোর তফাত গোটা অধ্যায়ের গোড়ার কথা।
২.১ Training error বনাম test error — আর training error-এর optimism¶
Training error (প্রশিক্ষণ-ভুল) হলো সেই ভুল, যা মডেল যে data-তে fit হয়েছে সেই একই data-তে মাপা হয়। গড়-বর্গ-ভুল রূপে: $$ \widehat{\text{err}}{\text{train}} \;=\; \frac{1}{n}\sum\bigl(y_i - \hat f(x_i)\bigr)^2, $$ যেখানে যোগফল চলে ঠিক সেই }^{n\(n\)টি training-বিন্দুর উপর যা দিয়ে \(\hat f\) গড়া হয়েছে; \(\hat f(x_i)\) হলো বিন্দু \(x_i\)-তে মডেলের prediction, আর \(y_i-\hat f(x_i)\) তার residual। নাম-ভেদে একে "in-sample error", "apparent error" বা "resubstitution error"-ও বলে — সব একই: নিজের শেখার-data-তে নিজের পরীক্ষা।
Test error বা generalization error (পরীক্ষা/সাধারণীকরণ-ভুল) হলো সেই ভুল, যা একটা স্বাধীন, নতুন বিন্দুতে মডেল করবে — অর্থাৎ যে বিন্দু fit-এ অংশ নেয়নি। আনুষ্ঠানিকভাবে, একটা নতুন জোড়া \((x_0, y_0)\) (একই সম্পর্ক \(y_0=f(x_0)+\varepsilon_0\) থেকে আঁকা, কিন্তু training set-এর বাইরে) ধরে, $$ \text{Err} \;=\; \mathbb{E}\bigl[(y_0 - \hat f(x_0))^2\bigr], $$ যেখানে \(\mathbb{E}[\cdot]\) ("প্রত্যাশা") মানে গড় নেওয়া হচ্ছে এই নতুন বিন্দুর সব সম্ভাব্য মানের উপর (এবং প্রসঙ্গভেদে training-নমুনার randomness-এর উপরও); \(\hat f(x_0)\) হলো নতুন input \(x_0\)-তে মডেলের prediction, \(y_0\) তার আসল (noise-সহ) response। এই \(\text{Err}\)-ই আমরা সত্যিকার অর্থে ছোট করতে চাই — কারণ মডেলের আসল কাজ ভবিষ্যতের data-তে ভালো prediction, training data-তে নয়। (4.4-এর পচন মনে করুন: এই \(\text{Err}\) ভেঙে দাঁড়ায় \(\text{bias}^2+\text{variance}+\sigma^2\) — অর্থাৎ সেরা মডেলেও \(\sigma^2\) অবশিষ্ট থাকবেই।)
এ-দুটোর সম্পর্কই §১.৩-এর কেন্দ্রীয় কথা, এখন এক বাক্যে আনুষ্ঠানিক: training error গড়ে test error-এর চেয়ে ছোট — $$ \mathbb{E}\bigl[\widehat{\text{err}}_{\text{train}}\bigr] \;\le\; \text{Err}, $$ আর এই দুইয়ের ব্যবধানকে বলে optimism (আশাবাদ)। কারণ §১.৩-এ বলা: \(\hat f\) গড়ার সময়ই training-বিন্দুগুলোর noise-এর সঙ্গে মানিয়ে নেওয়া হয়েছে, তাই সেই বিন্দুতে ভুল কৃত্রিমভাবে কম দেখায়। সবচেয়ে জরুরি দিক — এই optimism মডেল-জটিলতার সঙ্গে বাড়ে: মডেল যত নমনীয়, সে যত বেশি noise মুখস্থ করতে পারে, ব্যবধান তত চওড়া। তাই training error দিয়ে দুটো ভিন্ন-জটিলতার মডেল তুলনা করা অসঙ্গত — জটিলতরটি সবসময় অন্যায্য সুবিধা পায়। (এই optimism-কে গাণিতিকভাবে মডেল-জটিলতার সঙ্গে বাঁধাই AIC/BIC-র মূল, §২.৮ ও §৪।)
এক বাক্যে: training error (\(\widehat{\text{err}}_{\text{train}}\), নিজের-data-তে মাপা) আর test error (\(\text{Err}\), নতুন-data-তে প্রত্যাশিত) এক নয় — প্রথমটি দ্বিতীয়টির চেয়ে নিয়মিত ছোট (optimism), আর সেই ফাঁক জটিলতার সঙ্গে বাড়ে; তাই মডেল বাছতে আমাদের দরকার \(\text{Err}\)-এর একটা honest আন্দাজ, যা training error দিতে পারে না।
২.২ Train/validation/test split — সরলতম held-out, ও তার সীমা¶
§১.৪-এর "held-out data-তে যাচাই" ধারণার সবচেয়ে সরল বাস্তবায়ন: data-কে শুরুতেই এলোমেলোভাবে তিন ভাগে ভাগ করে নাও —
- Training set — যাতে প্রতিটি প্রার্থী-মডেল fit হয় (parameter শেখে);
- Validation set — যাতে fit-করা প্রার্থী-মডেলগুলোর ভুল মেপে tuning/model-নির্বাচন করা হয় (যেমন কোন degree, কোন \(h\)/\(df\)/\(\lambda\)); এই set fit-এ অংশ নেয় না, তাই এতে মাপা ভুল আশাবাদী নয়, ফলে নিরপেক্ষ তুলনা সম্ভব;
- Test set — যা গোটা প্রক্রিয়া জুড়ে তালাবন্ধ থাকে, আর একদম শেষে, চূড়ান্ত-বাছাই-করা একটিমাত্র মডেলের ভুল মাপতে কেবল একবার খোলা হয়।
কেন validation ও test আলাদা — এটা একটা সূক্ষ্ম কিন্তু জরুরি বিন্দু। validation set-এর উপর ভিত্তি করে আমরা বহু মডেলের মধ্যে বাছাই করছি; সেই বাছাই-প্রক্রিয়াই validation-error-কে সামান্য আশাবাদী করে ফেলে (আমরা পরোক্ষে validation set-এর সঙ্গেও মানিয়ে নিচ্ছি)। তাই চূড়ান্ত, সত্যিই-নিরপেক্ষ পারফরম্যান্স-রিপোর্টের জন্য একটা সম্পূর্ণ স্পর্শ-না-করা test set আলাদা রাখা হয়, যা নির্বাচনে কোনো ভূমিকা রাখেনি।
কিন্তু এই সরল split-এর দুটো বড় সীমা, যা থেকেই cross-validation-এর প্রয়োজন জন্মায়:
- Data-র অপচয়। validation ও test-এ সরিয়ে রাখা বিন্দুগুলো মডেল-fit-এ কখনো অংশ নেয় না। data কম হলে (যা পরিসংখ্যানে প্রায়ই) এটা দুঃখজনক — মডেল আরও বিন্দু থেকে শিখতে পারত, কিন্তু আমরা তার একটা বড় অংশ যাচাইয়ে আটকে রেখেছি, ফলে fit দুর্বল।
- একটিমাত্র split-এর উপর নির্ভরতা (high variance)। কোন বিন্দু কাকতালীয়ভাবে validation-এ পড়ল, তার উপর validation-error প্রবলভাবে নির্ভর করে — আলাদা random split নিলে আলাদা উত্তর, এমনকি আলাদা "সেরা" মডেল বেরোতে পারে। অর্থাৎ এই estimate-টা অস্থির, বিশেষত ছোট data-তে।
এক বাক্যে: train/validation/test split হলো held-out-যাচাইয়ের সরলতম রূপ — train-এ fit, validation-এ বাছাই, test-এ একবারই চূড়ান্ত মূল্যায়ন; কিন্তু এটি data অপচয় করে এবং উত্তর একটিমাত্র random split-এর উপর ঝুলে থাকে বলে অস্থির — দুই সমস্যারই সমাধান পরের ধাপ, cross-validation।
২.৩ K-fold cross-validation — সব data-কেই পালা করে কাজে লাগাও¶
K-fold cross-validation (K-ভাঁজ ক্রস-ভ্যালিডেশন) §২.২-এর দুই সমস্যাই একটা মার্জিত ঘূর্ণনের মাধ্যমে এড়ায়। পদ্ধতিটা ধাপে ধাপে:
- ভাগ করো। পুরো data-কে এলোমেলোভাবে \(K\)টি প্রায়-সমান, পরস্পর-অসংযোগী অংশে ভাগ করো — প্রতিটিকে বলে একটা fold (ভাঁজ)। সাধারণ পছন্দ \(K=5\) বা \(K=10\)।
- ঘোরাও। প্রতিটি fold-কে একবার করে "validation"-এর ভূমিকায় বসাও। অর্থাৎ \(k=1,\dots,K\)-এর প্রতিটির জন্য — \(k\)-তম fold-কে সরিয়ে রাখো (validation), বাকি \(K-1\)টি fold একসাথে মিলিয়ে তাতে মডেল fit করো, তারপর সেই fit-করা মডেল দিয়ে সরিয়ে-রাখা \(k\)-তম fold-এর ভুল মাপো — একে বলি \(\text{MSE}_{\text{fold }k}\) (fold \(k\)-এর held-out গড়-বর্গ-ভুল)।
- গড় করো। এই \(K\)টি held-out ভুলের গড়ই হলো cross-validation-estimate: $$ \text{CV}{(K)} \;=\; \frac{1}{K}\sum, $$ যেখানে }^{K}\text{MSE}_{\text{fold }k\(\text{CV}_{(K)}\) হলো \(K\)-fold CV দিয়ে পাওয়া test-error-এর আন্দাজ, আর \(\text{MSE}_{\text{fold }k}\) হলো \(k\)-তম fold validation-এ থাকাকালীন তাতে মাপা MSE।
এই ছকের সৌন্দর্য দুটো:
- কোনো data অপচয় হয় না। প্রতিটি বিন্দু ঠিক একবার validation-এ পড়ে (যখন তার fold সরানো হয়) এবং \(K-1\) বার training-এ অংশ নেয় (অন্য সব fold-এর পালায়)। অর্থাৎ প্রতিটি বিন্দু একবার যাচাইয়ে, বহুবার শেখায় ব্যবহৃত — §২.২-এর প্রথম সীমা ঘুচে গেল।
- একটিমাত্র split-এর উপর নির্ভরতা কমে। একটিমাত্র validation set-এর বদলে \(K\)টি ভিন্ন held-out মূল্যায়নের গড় নেওয়ায় উত্তর অনেক বেশি স্থিতিশীল — §২.২-এর দ্বিতীয় সীমাও অনেকটা প্রশমিত।
লক্ষণীয়, প্রতিবার মডেল নতুন করে (\(K-1\) fold-এ) fit হয় — অর্থাৎ \(\hat f\) প্রতিবার সামান্য আলাদা, এবং প্রতিবার তাকে এমন বিন্দুতে যাচাই করা হয় যা সেই fit দেখেনি। এই কারণেই \(\text{CV}_{(K)}\) test-error-এর honest আন্দাজ দেয়, optimism ছাড়াই। (চিত্র 5-8-kfold-diagram এই ঘূর্ণন — কোন fold কখন train, কখন validation — চাক্ষুষ করবে।)
এক বাক্যে: K-fold CV data-কে \(K\)টি fold-এ ভাগ করে পালা করে প্রতিটিকে একবার validation ও বাকি সময় training বানায়, আর \(K\)টি held-out MSE-র গড় \(\text{CV}_{(K)}=\frac1K\sum_k\text{MSE}_{\text{fold }k}\) নেয় — ফলে প্রতিটি বিন্দু কখনো শেখায় কখনো যাচাইয়ে কাজে লাগে, data অপচয় হয় না, আর estimate single-split-এর খেয়ালের উপর ঝোলে না।
২.৪ LOOCV — যখন প্রতিটি বিন্দুই একটা fold (\(K=n\))¶
K-fold-এর একটা চরম সীমা হলো \(K=n\) — অর্থাৎ fold-সংখ্যা ঠিক বিন্দু-সংখ্যার সমান, তাই প্রতিটি fold-এ মাত্র একটি বিন্দু। একে বলে Leave-One-Out Cross-Validation (LOOCV) (একটি-বাদ ক্রস-ভ্যালিডেশন)। নাম থেকেই পদ্ধতি স্পষ্ট: প্রতিবার ঠিক একটি বিন্দু সরিয়ে রাখো, বাকি \(n-1\)টিতে মডেল fit করো, তারপর সেই সরানো একমাত্র বিন্দুতে prediction-ভুল মাপো — এবং এটা \(n\)বার, প্রতিটি বিন্দুর জন্য একবার করে, পুনরাবৃত্তি করো।
আনুষ্ঠানিকভাবে: $$ \text{CV}{(n)} \;=\; \frac{1}{n}\sum(x_i)\bigr)^2, $$ যেখানে }^{n}\bigl(y_i - \hat f^{(-i)\(\hat f^{(-i)}\) ("এফ-হ্যাট-মাইনাস-আই") হলো বিন্দু \(i\)-কে বাদ দিয়ে বাকি \(n-1\)টি বিন্দুতে fit-করা মডেল, আর \(\hat f^{(-i)}(x_i)\) হলো সেই বাদ-দেওয়া বিন্দুর input \(x_i\)-তে তার prediction; তাই \(y_i-\hat f^{(-i)}(x_i)\) হলো বিন্দু \(i\)-এর সত্যিকারের held-out residual — কারণ ওই বিন্দু তার নিজের fit-এ ছিল না। \(\text{CV}_{(n)}\) এই \(n\)টি held-out residual-এর গড়-বর্গ।
LOOCV-র দুই মুখ:
- সুবিধা — প্রায়-নিরপেক্ষ। প্রতিবার মডেল \(n-1\approx n\)টি বিন্দুতে fit হয়, অর্থাৎ প্রায় পুরো data-তেই — তাই LOOCV যে মডেলকে মাপছে সেটা প্রায় হুবহু আমাদের আসল (পূর্ণ-data) মডেল। ফলে এর bias খুব কম, test-error-কে এটা প্রায়-নিরপেক্ষভাবে আন্দাজ করে।
- অসুবিধা — বেশি variance ও ব্যয়। ভেতরের \(n\)টি fit প্রায়-অভিন্ন training set-এ হয় (একটিমাত্র বিন্দুর তফাত), তাই তাদের residual-গুলো প্রবলভাবে পরস্পর-সম্পর্কিত; প্রায়-একই জিনিসের গড় নিলে ছড়ানো কমে না, ফলে \(\text{CV}_{(n)}\)-এর নিজস্ব variance বেশি। তা ছাড়া \(n\)বার মডেল fit করা গণনাগতভাবেও ব্যয়বহুল।
5.8-এর dataset-এ LOOCV-র রায় K-fold-এর সঙ্গে মেলে — সর্বনিম্ন আসে degree 3-এ (মান 10.18), যা 10-fold-এর সর্বনিম্ন (degree 3, 10.15)-এর প্রায় সমান। (এই variance-জনিত তফাত — কেন LOOCV বেশি দোলে অথচ K-fold শান্ত — তার পূর্ণ ব্যাখ্যা §২.৬ ও §৪-এ।)
এক বাক্যে: LOOCV হলো K-fold-এর \(K=n\) চরম — প্রতিবার একটিমাত্র বিন্দু বাদ দিয়ে বাকি সবে fit, তারপর সেই বিন্দুতে যাচাই, \(n\)বার (\(\text{CV}_{(n)}=\frac1n\sum_i(y_i-\hat f^{(-i)}(x_i))^2\)); প্রায়-পূর্ণ-data-তে fit হওয়ায় এটি কম-biased কিন্তু সম্পর্কিত fit-গুলোর জন্য high-variance ও ব্যয়বহুল।
২.৫ CV দিয়ে tuning ও model-নির্বাচন — যে complexity CV-error ছোট করে¶
এতক্ষণে আমাদের হাতে test-error-এর একটা honest আন্দাজ (\(\text{CV}_{(K)}\) বা \(\text{CV}_{(n)}\)); এবার §১.১-এর মূল প্রশ্নের উত্তর সরাসরি। কৌশলটা সরল ও সর্বজনীন:
প্রতিটি প্রার্থী-জটিলতার জন্য CV-error হিসাব করো, আর যে জটিলতা CV-error সবচেয়ে ছোট করে সেটাই বাছো।
"জটিলতা" এখানে যেকোনো নির্বাচনযোগ্য পছন্দ হতে পারে — polynomial-এর degree \(d\), 5.7-র bandwidth \(h\) / degrees of freedom \(df\) / smoothing parameter \(\lambda\), কিংবা পরে-আসা regularization-এর মাত্রা। প্রতিটির জন্য আলাদা করে CV চালিয়ে একটা CV-error বনাম জটিলতা বক্ররেখা আঁকি, তারপর তার নিম্নবিন্দু বেছে নিই।
এই বক্ররেখার আকৃতিই গোটা পদ্ধতির হৃদয়, এবং তা §১.৪-এর U-আকৃতিরই আনুষ্ঠানিক রূপ:
- বাঁদিকে (খুব সরল মডেল) — CV-error বড়, কারণ মডেল আসল গঠন ধরতেই পারছে না (underfit: high bias)। জটিলতা বাড়ালে এদিকে CV-error কমে।
- ডানদিকে (খুব জটিল মডেল) — CV-error আবার বড়, কারণ মডেল training-noise মুখস্থ করছে যা held-out fold-এ অপ্রাসঙ্গিক, তাই সেখানে ভুল বাড়ে (overfit: high variance)।
- মাঝখানে — একটা সেরা জটিলতায় CV-error সর্বনিম্ন; এটাই bias আর variance-এর সেরা আপস, এবং test-error-এর সবচেয়ে ভালো সারোগেট।
লক্ষ করুন এই U-আকৃতিই training-error-এর সঙ্গে CV-র মৌলিক তফাত: training error (§২.১) ডানদিকে নামতেই থাকে (কোনো U নেই), তাই overfitting ধরতে পারে না; CV-error ডানদিকে উপরে ওঠে, তাই সে overfitting-কে সরাসরি ধরে ফেলে ও শাস্তি দেয়। 5.8-এর ডেটায় degree 1–10-এ CV-MSE-র এই U-এর তলদেশ পড়ে degree 3-এ (CV-MSE = 10.15) — ঠিক সত্যিকারের cubic সম্পর্ক, training-error যেখানে (degree 10 পর্যন্ত নেমে) সম্পূর্ণ ভুল পথ দেখাত। (চিত্র 5-8-train-vs-cv একই অক্ষে training-MSE-র একঘেয়ে পতন আর CV-MSE-র U পাশাপাশি দেখাবে।)
এক বাক্যে: CV দিয়ে tuning মানে প্রতিটি জটিলতা-পছন্দের (degree / \(h\) / \(df\) / \(\lambda\) / regularization) জন্য CV-error মেপে সবচেয়ে ছোটটা বাছা; CV-error-vs-complexity বক্ররেখা U-আকৃতির (বাঁয়ে underfit, ডানে overfit), আর তার নিম্নবিন্দুই test-error-এর সেরা সারোগেট — 5.8-এ যা degree 3 ধরে।
২.৬ CV-estimate-এরও নিজস্ব bias–variance — আর কেন \(K=5\)–\(10\)¶
একটা সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ স্তর: \(\text{CV}_{(K)}\) নিজেই একটা estimator (test-error-এর আন্দাজ), তাই তারও নিজস্ব bias ও variance আছে — আর fold-সংখ্যা \(K\) ঠিক এই দুটোর মধ্যে আপস ঠিক করে। এটা 5.2-র bias–variance ভাবনারই আরেক স্তরে প্রয়োগ, কিন্তু এবার মডেলের নয়, মূল্যায়ন-পদ্ধতির।
- \(K\) ছোট হলে (যেমন \(K=5\)): প্রতিবার মডেল data-র মোটে \(\tfrac{4}{5}\) অংশে fit হয় — পূর্ণ data-র চেয়ে স্পষ্টভাবে কম। ছোট training set-এ মডেল একটু খারাপ শেখে, তাই CV সামান্য উপরের দিকে biased (test-error-কে অল্প বেশি দেখায়, pessimistic)। তবে \(K\)টি fold বেশ আলাদা (অল্প overlap), তাই তাদের error কম-সম্পর্কিত, ফলে গড়ের variance কম।
- \(K\) বড় হলে (চরমে \(K=n\), LOOCV): প্রতিবার প্রায় পুরো data-তে fit, তাই bias খুব কম (§২.৪)। কিন্তু \(K\)টি training set প্রায়-অভিন্ন, তাদের error প্রবলভাবে সম্পর্কিত, তাই গড় ছড়ানো কমায় না — variance বেশি।
অর্থাৎ একটা পরিষ্কার tradeoff: ছোট \(K\) → বেশি bias, কম variance; বড় \(K\) → কম bias, বেশি variance। অভিজ্ঞতা ও তত্ত্ব দুই-ই বলে এই দুইয়ের একটা সুন্দর আপস \(K=5\) বা \(K=10\) — যথেষ্ট বড় training set (তাই bias সামান্য), অথচ fold-গুলো যথেষ্ট আলাদা (তাই variance নিয়ন্ত্রিত), উপরন্তু গণনাও LOOCV-র চেয়ে অনেক সস্তা (\(n\)বার নয়, মাত্র \(5\)–\(10\)বার fit)। এই কারণেই বাস্তবে 10-fold (বা 5-fold) CV-ই সবচেয়ে প্রচলিত ডিফল্ট — এবং 5.8-এও আমরা সেটাই ব্যবহার করছি।
এক বাক্যে: \(\text{CV}_{(K)}\) নিজেও একটা estimator, তার bias–variance fold-সংখ্যায় নিয়ন্ত্রিত — ছোট \(K\) কম-variance কিন্তু সামান্য pessimistic (high-bias, ছোট training set), বড় \(K\)/LOOCV কম-biased কিন্তু high-variance (সম্পর্কিত fit); \(K=5\)–\(10\) এই দুইয়ের পরীক্ষিত সেরা আপস (এবং সস্তা)।
২.৭ One-standard-error rule — সরলতম "যথেষ্ট-ভালো" মডেল (parsimony)¶
CV-error-vs-complexity বক্ররেখার নিম্নবিন্দু বাছা সরল মনে হলেও একটা সূক্ষ্ম ফাঁদ আছে: CV-error নিজেই একটা আন্দাজ, তার সঙ্গে অনিশ্চয়তা জড়িয়ে। নিম্নবিন্দুর ঠিক আশপাশে বক্ররেখা প্রায়ই সমতল — মানে সেরা মডেল আর তার পাশের সামান্য সরল/জটিল মডেলের CV-error-এর তফাত পরিমাপ-গোলমালের মধ্যেই পড়ে যায়, পরিসংখ্যানগতভাবে অর্থপূর্ণ নয়। তাহলে কড়াভাবে absolute-minimum ধরা মানে হয়তো অকারণে একটা জটিলতর মডেল বেছে নেওয়া, যার বাড়তি জটিলতার আসলে কোনো প্রমাণিত লাভ নেই।
এই অনিশ্চয়তা ধরতে আমরা CV-estimate-এর standard error ব্যবহার করি। K-fold-এ \(K\)টি fold-ভিত্তিক MSE-মান থাকে; তাদের ছড়ানো থেকে \(\text{CV}_{(K)}\)-এর standard error (SE) আন্দাজ করা যায় — মোটামুটি "fold-থেকে-fold-এ CV-মান কতটা টলমল করে"। এর উপর দাঁড়িয়ে one-standard-error rule (এক-প্রমিত-ভুল নিয়ম):
সবচেয়ে কম CV-error যে মডেল দেয়, তার CV-error-এর এক SE-এর মধ্যে যেসব মডেল পড়ে, তাদের মধ্যে সবচেয়ে সরলটি বেছে নাও।
স্বজ্ঞা: যদি একটা সরল মডেলের CV-error সেরা মডেলের চেয়ে এক SE-র বেশি খারাপ না হয়, তবে তাদের পার্থক্য পরিসংখ্যানগতভাবে নগণ্য — আর সমান-ভালো হলে সরলটাই ভালো। এটা parsimony (মিতব্যয়িতা/সরলতার পক্ষপাত)-এর আনুষ্ঠানিক রূপ: সরল মডেল সাধারণত বেশি স্থিতিশীল, ব্যাখ্যাযোগ্য, এবং নতুন data-তে কম-চমকপ্রদ। 5.8-এর ডেটায় absolute-minimum পড়ে degree 3-এ, আর one-SE rule-ও degree 3-কেই বাছে (এখানে দুটো মেলে; কখনো one-SE rule আরও সরল মডেল — যেমন degree 2 — দিকে টানতে পারত, যদি তার CV-error degree-3-এর এক SE-র মধ্যে থাকত)। (চিত্র 5-8-cv-boxplot প্রতিটি degree-এ fold-ভিত্তিক CV-মানের ছড়ানো — অর্থাৎ এই SE — box হিসেবে দেখাবে।)
এক বাক্যে: absolute-minimum CV বাছার বদলে one-standard-error rule বলে — সেরা CV-error-এর এক SE-র মধ্যে সরলতম মডেলটি নাও; কারণ সেই পরিসরের মডেলগুলো পরিসংখ্যানগতভাবে সমান-ভালো, আর সমান হলে সরলটাই (parsimony) বেশি স্থিতিশীল ও ব্যাখ্যাযোগ্য।
২.৮ Learning curve ও AIC/BIC — দুটি সম্পূরক দৃষ্টিকোণ¶
শেষে দুটো সম্পর্কিত ধারণা সংক্ষেপে, যা CV-র ছবিটা সম্পূর্ণ করে — একটা data-পরিমাণের দিক থেকে, আরেকটা CV-র analytic বিকল্প হিসেবে।
Learning curve (শিক্ষণ-বক্ররেখা)। এটা আঁকে ভুল বনাম training-set-এর আকার — অর্থাৎ মডেলকে ক্রমশ বেশি-বেশি বিন্দুতে fit করলে training error ও (held-out) test error কীভাবে বদলায়। সাধারণ ছবি: training set ছোট থাকলে মডেল সহজে মুখস্থ করে, তাই training error খুব ছোট কিন্তু test error বড় (বড় ফাঁক = overfitting-প্রবণ); training set বাড়লে training error সামান্য ওঠে, test error নামে, আর দুটো ধীরে কাছাকাছি আসে। এই বক্ররেখা একটা ব্যবহারিক প্রশ্নের উত্তর দেয়: আরও data জোগাড় করলে কি লাভ হবে? যদি দুই curve অনেক দূরে ও এখনো নামছে, তবে আরও data সাহায্য করবে (variance-জনিত সমস্যা); যদি দুটো মিলে গিয়ে একটা উঁচু তলায় থেমে গেছে, তবে আরও data বৃথা — সমস্যা bias, মডেল নিজেই খুব সরল।
AIC/BIC — analytic বিকল্প। §২.১-এ বলেছিলাম training-error-এর optimism জটিলতার সঙ্গে বাড়ে। 5.2-র AIC (\(=2k-2\ln\hat L\)) ও BIC (\(=k\ln n-2\ln\hat L\), যেখানে \(k\) = parameter-সংখ্যা, \(\hat L\) = মডেলের সর্বোচ্চ likelihood, \(n\) = নমুনা-আকার) ঠিক এই optimism-কেই গাণিতিকভাবে ধরে: তারা মডেলের fit (likelihood-অংশ) থেকে একটা complexity-penalty (\(2k\) বা \(k\ln n\)) বিয়োগ করে — অর্থাৎ resampling না করে, একটা সূত্রের মাধ্যমে জটিলতার শাস্তি বসায়। তাই AIC/BIC আর cross-validation একই উদ্দেশ্য (honest model-নির্বাচন) সাধে দুটো ভিন্ন পথে — CV resampling-নির্ভর (data বারবার ভাগ করে সরাসরি held-out ভুল মাপে, কম অনুমান), আর AIC/BIC analytic (একবার fit করেই সূত্রে penalty বসায়, দ্রুত কিন্তু likelihood-মডেল ও বড়-\(n\) অনুমানের উপর নির্ভরশীল)। (এদের গভীর সম্পর্ক — বিশেষত AIC কীভাবে বড় \(n\)-এ LOOCV-র প্রায়-সমতুল্য হয়ে ওঠে — §৪-এ।)
এক বাক্যে: learning curve (ভুল বনাম training-আকার) বলে আরও data সংগ্রহ লাভজনক কি না, আর 5.2-র AIC/BIC training-error-এর optimism-কে একটা analytic complexity-penalty দিয়ে ধরে — অর্থাৎ CV-র resampling-ভিত্তিক honest-নির্বাচনেরই একটা দ্রুত, অনুমান-নির্ভর বিকল্প।
২.৯ গোটা §২ এক সুতোয়¶
তিনটি স্তর একসাথে দেখলে অধ্যায়ের যুক্তি পরিষ্কার হয়। স্তর ১ — সমস্যা: training error (\(\widehat{\text{err}}_{\text{train}}\)) test error (\(\text{Err}\))-কে আশাবাদীভাবে কম দেখায়, এবং complexity বাড়লে আরও বেশি — তাই দিয়ে মডেল বাছা যায় না। স্তর ২ — সমাধান: held-out data-তে যাচাই করো — সরল train/validation/test split, বা তার অপচয়/অস্থিরতা এড়িয়ে K-fold CV (\(\text{CV}_{(K)}=\frac1K\sum_k\text{MSE}_{\text{fold }k}\), সব data পালা করে কাজে লাগে) ও তার চরম LOOCV (\(\text{CV}_{(n)}\)); এই CV হলো \(\text{Err}\)-এর প্রায়-নিরপেক্ষ আন্দাজ, যা দিয়ে CV-error-vs-complexity বক্ররেখার U-তলদেশ বেছে tuning/model-নির্বাচন করা যায়। স্তর ৩ — সূক্ষ্মতা: CV-estimate-এরও নিজস্ব bias–variance (\(K=5\)–\(10\) সেরা আপস), one-standard-error rule সরলতম যথেষ্ট-ভালো মডেল বেছে parsimony আনে, আর learning curve ও AIC/BIC যথাক্রমে data-পরিমাণ ও analytic-penalty-র দৃষ্টিকোণ যোগ করে।
এক বাক্যে §২-এর সার: যেহেতু নিজের শেখার-data-তে মাপা ভুল (\(\widehat{\text{err}}_{\text{train}}\)) generalization-কে আশাবাদীভাবে কম দেখায় ও complexity-র সঙ্গে আরও বিভ্রান্ত করে, আমরা মডেলকে held-out data-তে যাচাই করি — সরল split, বা data-সাশ্রয়ী K-fold/LOOCV cross-validation — যার CV-error test error \(\text{Err}=\mathbb{E}[(y_0-\hat f(x_0))^2]\)-এর প্রায়-নিরপেক্ষ আন্দাজ; সেই CV-error যে জটিলতায় (U-তলদেশ) সর্বনিম্ন তা বেছে, এবং one-standard-error rule-এ সরলতম সমতুল্য মডেল নিয়ে, আমরা honestly model/tuning বাছি — \(K=5\)–\(10\) যেখানে CV-estimate-এর নিজস্ব bias–variance-এর সেরা আপস, আর AIC/BIC একই কাজের analytic বিকল্প।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এতক্ষণ আমরা ধারণাগুলো আলাদা আলাদাভাবে দেখেছি — training error, test error, K-fold \(\text{CV}_{(K)}\), LOOCV, এবং one-standard-error rule। এবার একটা একক, নিয়ন্ত্রিত পরীক্ষায় সবকিছু একসাথে দেখব। এমন একটা ডেটা বানাব যেখানে সত্যিকারের উত্তর আমরা আগে থেকেই জানি, তারপর দেখব cross-validation নিজে থেকে সেই সত্যিকারের উত্তরের কাছে পৌঁছাতে পারে কি না। এটাই হলো এই অধ্যায়ের কেন্দ্রীয় দাবির আসল পরীক্ষা: training error কেন complexity নির্বাচন করতে অক্ষম, আর CV কীভাবে সেই শূন্যস্থান পূরণ করে।
সেটআপ: একটা ডেটা যার সত্যিকারের গঠন আমরা জানি¶
আমরা একটা synthetic regression problem তৈরি করব। input \(x\) আসবে \(\text{Uniform}(-3, 3)\) থেকে, আর সত্যিকারের ফাংশন হলো একটা cubic:
পর্যবেক্ষণে noise যোগ হয়:
অর্থাৎ irreducible variance \(\sigma^2 = 9\)। আমরা \(n = 120\)টা পয়েন্ট নেব (seed \(20260619\))।
এই সেটআপটা ইচ্ছাকৃতভাবে এমন, কারণ এখানে সঠিক model complexity আমরা জানি: সত্যিকারের \(f\) একটা degree-\(3\) polynomial। তাই যদি আমরা polynomial regression-এ degree \(d = 1, 2, \dots, 10\) পরীক্ষা করি, তবে আদর্শ পদ্ধতির উচিত \(d = 3\)-কে বেছে নেওয়া — না কম (যা সত্যিকারের curve-কে ধরতে পারবে না, underfit), না বেশি (যা noise-কে আঁকড়ে ধরবে, overfit)। তিনটা বিষয় আমরা যাচাই করব:
- training error কি নিজে থেকে \(d = 3\) খুঁজে দিতে পারে? (E1 — উত্তর: না।)
- \(\text{CV}_{(K)}\) কি পারে? (E2 — উত্তর: হ্যাঁ।)
- CV-এর অনুমান কি একটা সৎ test-error estimate? (E3, E4 — উত্তর: হ্যাঁ, এবং সেটা \(\sigma^2\)-কে হারাতে পারে না।)
প্রতিটা degree-এ আমরা polynomial features বানিয়ে একটা ordinary least-squares regression fit করব (পরিভাষায়: degree-\(d\) polynomial regression)। training MSE মানে পুরো \(n = 120\)টা পয়েন্টে fit করে সেই একই পয়েন্টগুলোতে error মাপা: \(\frac1n \sum_{i=1}^n (y_i - \hat f(x_i))^2\)।
E1 · Training error একটা প্রতারক সঙ্কেত¶
প্রথমে সবচেয়ে সরল — এবং সবচেয়ে বিপজ্জনক — পদ্ধতিটা দেখি: প্রতিটা degree-এ পুরো ডেটায় fit করে training MSE মাপি, তারপর যে degree-এর training MSE সবচেয়ে কম তাকে "সেরা" বলি।
| degree \(d\) | Train MSE |
|---|---|
| 1 | 22.08 |
| 2 | 21.59 |
| 3 | 9.59 |
| 4 | 9.57 |
| 5 | 9.52 |
| 6 | 9.46 |
| 7 | 9.40 |
| 8 | 9.13 |
| 9 | 9.12 |
| 10 | 9.12 |
লক্ষ করুন প্যাটার্নটা: training MSE একদম একঘেয়েভাবে কমছে (monotone decreasing)। \(d = 1\)-এ \(22.08\), \(d = 2\)-এ \(21.59\) — এ পর্যন্ত মডেলগুলো cubic curve-টা ধরতেই পারছে না, তাই error বড়। \(d = 3\)-এ হঠাৎ নেমে \(9.59\)-এ আসে, কারণ এখন মডেলের সত্যিকারের আকৃতি ধরার ক্ষমতা হয়েছে। কিন্তু এরপরই আসল সমস্যা: \(d = 4, 5, \dots, 10\) — প্রতিটা ধাপে error আরও একটু করে কমছে (\(9.57, 9.52, \dots\) থেকে \(9.12\) পর্যন্ত)।
এই কমাটা কোনো "ভালো" উন্নতি নয়। degree বাড়ানো মানে মডেলকে আরও বেশি free parameter দেওয়া, আর বেশি parameter দিয়ে মডেল কেবল noise-টাকেও আঁকড়ে ধরছে — সত্যিকারের signal নয়। গাণিতিকভাবে: যেহেতু degree-\(d\) polynomial-এর function class degree-\((d-1)\)-এর function class-কে নিজের ভেতরে ধারণ করে (nested), তাই বড় মডেল কখনোই ছোট মডেলের চেয়ে বেশি training error দিতে পারে না। ফলে training MSE গাণিতিকভাবেই বাধ্য হয়ে কমতে থাকে।
পরিণতি স্পষ্ট: যদি আমরা training error দেখে complexity বেছে নিতাম, আমরা \(d = 10\) বেছে নিতাম — সবচেয়ে জটিল মডেল, যা সবচেয়ে বেশি overfit করে। অথচ সত্যিকারের degree মাত্র \(3\)। এটাই E1-এর শিক্ষা:
Training error কখনো model complexity নির্বাচন করতে পারে না — কারণ এটা সবসময় বেশি জটিল মডেলের পক্ষে bias (পক্ষপাত) দেখায়। যে error আমরা minimize করছি (training) আর যে error আমরা সত্যিই কমাতে চাই (test), এ দুটো এক জিনিস নয়।
E2 · K-fold CV উদ্ধারে আসে¶
এবার একই dataset-এ, একই degree-গুলোর জন্য, training error-এর বদলে \(10\)-fold cross-validation MSE মাপি। মনে করিয়ে দিই (পরিভাষায়): \(K = 10\) মানে ডেটাকে \(10\)টা প্রায়-সমান fold-এ ভাগ করা; পালাক্রমে প্রতিটা fold একবার করে validation set হয় আর বাকি \(9\)টা fold দিয়ে মডেল fit হয়; তারপর \(10\)টা validation error-এর গড় নিই। এখানে আমরা আগে data shuffle করেছি (shuffle=True, random_state=0) যাতে fold-গুলো \(x\)-এর ক্রম অনুযায়ী পক্ষপাতদুষ্ট না হয়।
যেখানে \(\hat f^{(-\mathcal{F}_k)}\) হলো \(k\)-তম fold বাদ দিয়ে fit করা মডেল।
| degree \(d\) | 10-fold CV MSE |
|---|---|
| 1 | 22.68 |
| 2 | 22.50 |
| 3 | 10.15 ← MIN |
| 4 | 10.47 |
| 5 | 10.50 |
| 6 | 10.70 |
| 7 | 10.78 |
| 8 | 10.51 |
| 9 | 10.74 |
| 10 | 10.90 |
এবার প্যাটার্নটা সম্পূর্ণ ভিন্ন — এটা আর monotone নয়, এটা U-আকৃতির (U-shaped)। বাঁদিকে (\(d = 1, 2\)) error বড় (\(22.68, 22.50\)): মডেল খুব সরল, cubic-টা ধরতে পারছে না — এটা underfitting, যাকে আমরা bias বলি। \(d = 3\)-এ error সর্বনিম্ন: \(10.15\)। আর এরপর — এটাই গুরুত্বপূর্ণ — error আবার বাড়তে শুরু করে: \(d = 4\)-এ \(10.47\), \(d = 5\)-এ \(10.50\), \(\dots\), \(d = 10\)-এ \(10.90\)। (মাঝে \(d = 8\)-এ সামান্য \(10.51\)-তে নামার মতো ছোটখাটো ওঠানামা আছে, যা finite-sample noise; কিন্তু সামগ্রিক প্রবণতা পরিষ্কার ঊর্ধ্বমুখী।)
কেন বাড়ছে? কারণ \(d = 3\)-এর পরে প্রতিটা বাড়তি degree কেবল noise-কে fit করছে। training set-এ সেটা error কমায় (E1-এ দেখলাম), কিন্তু held-out fold-এ সেই noise-fit কোনো কাজে আসে না — বরং ক্ষতি করে, কারণ validation fold-এর noise স্বাধীন। এটাই overfitting-এর সরাসরি, পরিমাপযোগ্য চিহ্ন: যে complexity training error কমায় কিন্তু out-of-sample error বাড়ায়।
ফলাফল চমৎকার:
\(\text{CV}_{(10)}\) বেছে নেয় \(d = 3\) — যা ঠিক সত্যিকারের degree (\(f = x^3 - 3x\))। training error যেখানে \(d = 10\)-এর দিকে ভুল পথে টানছিল, সেখানে CV সঠিক complexity-তে থেমেছে।
CV এটা করতে পারে কারণ এর U-curve-এর ডান বাহুতে overfitting-এর শাস্তি ধরা পড়ে — যে শাস্তি training curve-এ অদৃশ্য।
E3 · দুই curve পাশাপাশি, এবং LOOCV¶
E1 আর E2-এর সংখ্যাগুলো একসাথে রাখলেই গল্পটা সম্পূর্ণ হয়। নিচে training MSE, \(10\)-fold CV MSE, এবং leave-one-out CV MSE পাশাপাশি দেওয়া হলো। মনে করিয়ে দিই LOOCV হলো \(K = n\) ক্ষেত্রের চরম রূপ:
যেখানে প্রতিবার একটা মাত্র পয়েন্ট বাদ দিয়ে বাকি \(n - 1 = 119\)টা পয়েন্টে fit করা হয়।
| degree \(d\) | Train MSE | 10-fold CV | LOOCV |
|---|---|---|---|
| 1 | 22.08 | 22.68 | 22.87 |
| 2 | 21.59 | 22.50 | 22.86 |
| 3 | 9.59 | 10.15 (min) | 10.18 (min) |
| 4 | 9.57 | 10.47 | 10.35 |
| 5 | 9.52 | 10.50 | 10.47 |
| 6 | 9.46 | 10.70 | 10.56 |
| 7 | 9.40 | 10.78 | 10.69 |
| 8 | 9.13 | 10.51 | 10.43 |
| 9 | 9.12 | 10.74 | 10.63 |
| 10 | 9.12 | 10.90 | 10.84 |
তিনটে কলামের তুলনায় তিনটে শিক্ষা:
প্রথমত — দুটো curve-এর আকৃতি বিপরীত। Train কলামটা monotone নিচে নামে (\(22.08 \to 9.12\)), কখনো ওঠে না। CV কলাম দুটো (১০-fold ও LOOCV) U-আকৃতির — নামে, তলায় (\(d = 3\)) পৌঁছায়, তারপর ওঠে। এই দুই আকৃতির পার্থক্যই হলো এই অধ্যায়ের সবচেয়ে গুরুত্বপূর্ণ ছবি: যে সঙ্কেত আমরা সহজে মাপতে পারি (train) সেটা ভুল দিকে নির্দেশ করে, আর যে সঙ্কেত আমরা সত্যিই চাই (out-of-sample) সেটা ঠিক দিকে।
দ্বিতীয়ত — LOOCV-ও \(d = 3\) বেছে নেয় (\(10.18\)-এ minimum)। অর্থাৎ K-fold আর LOOCV — দুটো ভিন্ন resampling কৌশল — একই, সঠিক সিদ্ধান্তে পৌঁছেছে। লক্ষণীয় যে LOOCV আর \(10\)-fold-এর সংখ্যাগুলো প্রায় অভিন্ন (\(10.18\) বনাম \(10.15\) — প্রায় সমান), যা মনে করিয়ে দেয় এই ডেটায় \(K = 10\) ইতিমধ্যেই LOOCV-এর কাছাকাছি একটা স্থিতিশীল অনুমান দিচ্ছে — অথচ \(n\) বার fit না করে মাত্র \(10\) বার fit করেই। (এই train-cheap-but-noisier বনাম near-LOOCV trade-off নিয়ে আগের অংশে বিস্তারিত আলোচনা হয়েছে।)
তৃতীয়ত — দুই কলামের ফাঁকটাই "optimism"। প্রতিটা degree-এ \(\text{CV} - \text{Train}\) ধনাত্মক, কারণ training error সবসময় test error-কে কম দেখায়। \(d = 3\)-এ ফাঁক ছোট: \(10.15 - 9.59 = 0.56\)। কিন্তু \(d = 10\)-এ ফাঁক বড়: \(10.90 - 9.12 = 1.78\)। এই ক্রমবর্ধমান ফাঁকটাই overfitting-এর পরিমাণ — যত বেশি parameter, training error তত বেশি "আশাবাদী" (optimistic) হয়ে test error-কে ততই বেশি কম করে দেখায়। CV সেই optimism-এর সংশোধন করে দেয়, তাই CV curve-টা train curve-এর সঠিক দিকটা ফিরিয়ে আনে।
E4 · One-SE rule এবং সততা যাচাই¶
CV আমাদের \(d = 3\)-এ পৌঁছে দিয়েছে। কিন্তু দুটো শেষ প্রশ্ন থেকে যায়। (ক) CV minimum কি অতিরিক্ত নির্ভুলতা দাবি করছে, নাকি একটা আরও রক্ষণশীল নিয়ম প্রয়োগ করা উচিত? (খ) CV-এর সংখ্যাটা (\(10.15\)) কি আসলেই বিশ্বাসযোগ্য test-error estimate, নাকি কেবল একটা সুবিধাজনক অভ্যন্তরীণ সংখ্যা?
One-standard-error rule. CV minimum একটা random quantity — fold-গুলো এলোমেলোভাবে ভাগ হওয়ায় এর নিজস্ব variability আছে। তাই কেবল সবচেয়ে কম CV-ওয়ালা degree ধরে বসে না থেকে, আমরা minimum-এর standard error হিসাব করি (fold-গুলোর মধ্যে CV score-এর spread থেকে), তারপর সবচেয়ে সরল মডেল বেছে নিই যার CV সেই minimum-এর \(1\) SE-এর মধ্যে থাকে। এখানে:
কোন কোন degree এই \(11.00\) threshold-এর নিচে? টেবিল দেখলে: \(d = 3\) (\(10.15\)), \(d = 4\) (\(10.47\)), \(\dots\) সবই \(11.00\)-এর নিচে, কিন্তু \(d = 1, 2\) (\(22.68, 22.50\)) অনেক উপরে। এদের মধ্যে সবচেয়ে সরল হলো \(d = 3\)। তাই one-SE rule-ও \(d = 3\) বেছে নেয় — minimum rule-এর সাথে একমত। এখানে দুটো নিয়ম একই উত্তর দিল, কিন্তু one-SE rule-এর মূল্য হলো: যখন bias-variance trade-off-এর তলাটা চ্যাপ্টা হয়, তখন এটা আমাদের অপ্রয়োজনীয় জটিলতা থেকে বাঁচায়।
সততা যাচাই: CV কি সত্যিই test error? এটাই চূড়ান্ত পরীক্ষা। আমরা একদম নতুন, স্বাধীন একটা test set বানাই — \(2000\)টা একদম fresh পয়েন্ট, একই distribution থেকে — এবং degree-\(3\) মডেলটা (যেটা মূল \(120\)টা পয়েন্টে fit করা) সেই নতুন পয়েন্টগুলোতে চালিয়ে held-out test MSE মাপি:
তিনটে সংখ্যা প্রায় মিলে যাচ্ছে, এবং এটা গভীরভাবে তাৎপর্যপূর্ণ:
- CV-এর অনুমান \(10.15\) আর সত্যিকারের held-out test error \(9.71\) কাছাকাছি — অর্থাৎ CV একটা সৎ test-error estimate। আমরা যে নতুন \(2000\) পয়েন্ট দিয়ে যাচাই করলাম, CV সেগুলো না দেখেই কার্যত একই সংখ্যা ভবিষ্যদ্বাণী করেছিল। এটাই CV-এর গোটা উদ্দেশ্য: নতুন ডেটা সংগ্রহ না করেই test error-এর একটা নির্ভরযোগ্য অনুমান দেওয়া।
- উভয় সংখ্যাই \(\sigma^2 = 9\)-এর কাছাকাছি, এর নিচে নয়। এটা একটা মৌলিক সীমা: যত ভালো মডেলই বানাই না কেন, কোনো পদ্ধতিই irreducible noise \(\sigma^2\)-কে হারাতে পারে না। degree-\(3\) মডেল সত্যিকারের \(f\)-টা প্রায় নিখুঁতভাবে ধরেছে, তাই তার test error reducible অংশ প্রায় শূন্যে নামিয়ে এনেছে — যা বাকি থাকে তা কার্যত শুধুই \(\sigma^2\)। (\(9.71\) আর \(10.15\) যে \(9\)-এর সামান্য উপরে, সেটাই সেই ছোট অবশিষ্ট reducible error আর finite-sample variability।)
এটাই পুরো অধ্যায়ের সমাপ্তি-বার্তা: cross-validation কেবল সঠিক complexity (\(d = 3\)) বেছে দেয় না — এটা সেই মডেলের test error-এরও একটা সৎ অনুমান দেয় (\(10.15 \approx 9.71\)), এবং সেই অনুমান যথাযথভাবে \(\sigma^2 = 9\)-এর floor-এ সম্মান জানায়। আমরা যা পেতে পারতাম, তার সবটুকুই পেয়েছি; এর বেশি কেউ পারে না।
যাচাইকরণ (sklearn)¶
উপরের সব সংখ্যা scikit-learn-এর KFold ও cross_val_score দিয়ে পুনরুৎপাদন করা হয়েছে (seed \(20260619\), shuffle=True, random_state=0)। মূল কোডের আউটপুট:
deg | train | 10cv | loocv
1 | 22.08 | 22.68 | 22.87
2 | 21.59 | 22.50 | 22.86
3 | 9.59 | 10.15 | 10.18 ← train↓ continues, but CV/LOOCV both minimize here
4 | 9.57 | 10.47 | 10.35
5 | 9.52 | 10.50 | 10.47
6 | 9.46 | 10.70 | 10.56
7 | 9.40 | 10.78 | 10.69
8 | 9.13 | 10.51 | 10.43
9 | 9.12 | 10.74 | 10.63
10 | 9.12 | 10.90 | 10.84 ← train MSE lowest (would be wrongly chosen), CV high
best CV deg=3 mse=10.15 SE=0.85 threshold=11.00
simplest within 1 SE = 3
held-out test MSE (deg 3, 2000 fresh pts) = 9.71 ≈ CV 10.15 ≈ σ² = 9
মূল গঠন (PolynomialFeatures + LinearRegression-কে make_pipeline-এ মুড়ে, যাতে প্রতিটা fold-এ feature transform কেবল training অংশ থেকে শেখা হয়):
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import KFold, cross_val_score, LeaveOneOut
rng = np.random.default_rng(20260619)
n = 120
x = rng.uniform(-3, 3, n)
y = (x**3 - 3*x) + rng.normal(0, 3, n) # true f, sigma^2 = 9
X = x.reshape(-1, 1)
kf = KFold(n_splits=10, shuffle=True, random_state=0)
loo = LeaveOneOut()
for d in range(1, 11):
model = make_pipeline(PolynomialFeatures(d), LinearRegression())
model.fit(X, y)
train = np.mean((y - model.predict(X))**2)
cv10 = -cross_val_score(model, X, y, cv=kf, scoring="neg_mean_squared_error").mean()
loocv = -cross_val_score(model, X, y, cv=loo, scoring="neg_mean_squared_error").mean()
print(d, round(train, 2), round(cv10, 2), round(loocv, 2))
প্রতিটা canonical সংখ্যা — train MSE (\(22.08 \to 9.12\)), \(10\)-fold CV (min \(10.15\) at \(d = 3\)), LOOCV (min \(10.18\) at \(d = 3\)), one-SE threshold (\(11.00\)), এবং held-out test MSE (\(9.71\)) — হুবহু মিলেছে।
৪ · প্রমাণ ও উৎপাদন¶
এই বিভাগে §২–§৩-এ ব্যবহৃত validation-হাতিয়ারগুলোর গাণিতিক ভিত্তি শূন্য থেকে গড়ে তুলব। প্রশ্নটা সরল কিন্তু গভীর: একই data দিয়ে model fit করে আবার সেই data-তে error মাপলে সেই error কেন প্রকৃত (out-of-sample) error-এর তুলনায় ছোট হয় — এবং সেই পক্ষপাত (bias) ঠিক কতটা? এর উত্তর থেকেই \(C_p\)/AIC-এর complexity penalty, cross-validation-এর ন্যায্যতা, linear smoother-এর জন্য LOOCV-র "জাদু-সূত্র", এবং one-standard-error নিয়ম — সব স্বাভাবিকভাবে বেরিয়ে আসে। ভিত্তি তিনটি: (i) 5.2-এর bias–variance বিভাজন; (ii) 5.7-এর linear smoother \(\hat{\mathbf y}=S\mathbf y\) ও \(\operatorname{df}=\operatorname{tr}(S)\); (iii) 4.4-এর MSE। প্রতিটি প্রতীক প্রথম ব্যবহারে খোলা হবে, প্রতিটি ধাপ যুক্তিসহ। কষ্টের স্তর প্রতিটি উপ-বিভাগের শিরোনামে তারা দিয়ে: ★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং।
সাধারণ সেট-আপ ও প্রতীক। ধরি \(n\)টি training-বিন্দু \((x_1,y_1),\dots,(x_n,y_n)\)। সত্য (অজানা) regression function \(f\), এবং
অর্থাৎ vector আকারে \(\operatorname{Cov}(\mathbf y)=\sigma^2 I\)। আমাদের fitted মান \(\hat y_i=\hat f(x_i)\), যেখানে \(\hat f\) গোটা training-set থেকে শেখা। দুটো error-পরিমাপ আলাদা করে রাখা জরুরি:
এখানে \(y_i^{\text{new}}=f(x_i)+\varepsilon_i^{\text{new}}\) হলো একই input-বিন্দু \(x_i\)-তে নতুন, স্বাধীন noise-সহ একটি ভবিষ্যৎ পর্যবেক্ষণ (\(\varepsilon_i^{\text{new}}\) training-এর \(\varepsilon_i\)-থেকে স্বাধীন, একই বণ্টন)। \(\hat y_i\) প্রশিক্ষণ-data-র উপর নির্ভরশীল বলে training error-এ \(\hat y_i\) এবং \(y_i\) পরস্পর-সম্পর্কিত — ঠিক এই সম্পর্কই পক্ষপাতের মূল, যা §৪.১-এ পরিমাপ করব।
৪.১ ★★ Training error-এর optimism: কেন in-sample error পক্ষপাতে কম¶
লক্ষ্য. দেখানো যে গড় in-sample test error সবসময় গড় training error-এর চেয়ে বড়, এবং তাদের পার্থক্য — যাকে optimism বলি — হলো
এরপর linear smoother-এর বিশেষ ক্ষেত্রে এটি \(\dfrac{2\sigma^2\operatorname{df}}{n}\)-এ পরিণত হয় — অর্থাৎ model যত জটিল, optimism তত বড়।
ধাপ ১ — একটি বিন্দুর জন্য প্রত্যাশিত পার্থক্য। স্থির \(i\) ধরি। প্রথমে দুই error-term-এর প্রত্যাশা পৃথকভাবে বের করি। সুবিধার জন্য সংজ্ঞা \(a:=y_i-\hat y_i\) ও \(b:=y_i^{\text{new}}-\hat y_i\) ব্যবহার করব, এবং পরে square-গুলো খুলব। একটি term-এর in-sample test error:
মূল কথা: \(y_i^{\text{new}}\) training-data থেকে স্বাধীন, আর \(\hat y_i\) কেবল training-data-র উপর নির্ভরশীল। তাই \(\mathbb{E}[y_i^{\text{new}}\hat y_i]=\mathbb{E}[y_i^{\text{new}}]\,\mathbb{E}[\hat y_i]\)। আবার \(\mathbb{E}[y_i^{\text{new}}]=\mathbb{E}[y_i]=f(x_i)\) (একই বণ্টন), সুতরাং \(\mathbb{E}[y_i^{\text{new}}\hat y_i]=\mathbb{E}[y_i]\,\mathbb{E}[\hat y_i]\)। তাহলে
ধাপ ২ — training error-term।
এখানে \(y_i\) ও \(\hat y_i\) স্বাধীন নয় — তাই \(\mathbb{E}[y_i\hat y_i]\)-কে product of means-এ ভাঙা যায় না।
ধাপ ৩ — বিয়োগ। (1) − (2): প্রথম term-গুলোয় \(\mathbb{E}[(y_i^{\text{new}})^2]=\mathbb{E}[y_i^2]\) (একই বণ্টন বলে), আর \(\mathbb{E}[\hat y_i^2]\) পরস্পর কাটে। অবশিষ্ট থাকে কেবল মাঝের term-দুটি:
বন্ধনীর ভেতরটাই covariance-এর সংজ্ঞা: \(\operatorname{Cov}(\hat y_i,y_i)=\mathbb{E}[y_i\hat y_i]-\mathbb{E}[y_i]\,\mathbb{E}[\hat y_i]\)। সুতরাং একটি বিন্দুর অবদান \(2\operatorname{Cov}(\hat y_i,y_i)\)।
ধাপ ৪ — গড় ও সমষ্টি। \(i=1,\dots,n\)-এর উপর যোগ করে \(\frac1n\) গুণ দিলে দুই পাশই যথাক্রমে \(\mathbb{E}[\text{Err}_{\text{in}}]\) ও \(\mathbb{E}[\overline{\text{err}}]\)-এ পরিণত হয়:
এটিই optimism। তিনটি কথা লক্ষণীয়: - যেহেতু একটি সুসংগত fit \(\hat y_i\) কে \(y_i\)-র সঙ্গে ধনাত্মকভাবে সম্পর্কিত করে (data যেদিকে টানে, fit সেদিকে যায়), \(\operatorname{Cov}(\hat y_i,y_i)\ge 0\) — তাই \(\text{op}\ge 0\), অর্থাৎ training error পদ্ধতিগতভাবে কম (biased-low)। - পার্থক্যটা পুরোপুরি নির্ভর করে কত জোরালোভাবে fit প্রতিটি \(y_i\)-কে "মনে রাখছে" — অর্থাৎ overfitting-এর সরাসরি পরিমাপ। - কোনো বণ্টনগত অনুমান লাগেনি (Gaussian-ও না); শুধু \(\operatorname{Var}(\varepsilon)=\sigma^2\), independence এবং fresh test-noise লেগেছে।
ধাপ ৫ — linear smoother-এ বদ্ধ রূপ। এবার 5.7-এর কাঠামো ব্যবহার করি: fit একটি linear smoother, \(\hat{\mathbf y}=S\mathbf y\), যেখানে \(S\in\mathbb{R}^{n\times n}\) data-র উপর নির্ভর করে না (smoothing parameter-এর উপর নির্ভর করে, \(\mathbf y\)-র উপর নয়)। তাহলে \(\hat y_i=\sum_{k=1}^n S_{ik}y_k\), এবং covariance-এর bilinearity দিয়ে
কিন্তু \(\operatorname{Cov}(\mathbf y)=\sigma^2 I\), অর্থাৎ \(\operatorname{Cov}(y_k,y_i)=\sigma^2\) যদি \(k=i\), নয়তো \(0\)। তাই যোগফলে কেবল \(k=i\) term টিকে থাকে:
সব \(i\)-র উপর যোগ:
যেখানে শেষ সমতা 5.7-এর সংজ্ঞা \(\operatorname{df}=\operatorname{tr}(S)\)। ★ optimism-সূত্রে বসিয়ে:
ব্যাখ্যা — কেন training error দিয়ে complexity বাছাই করা যায় না। optimism \(\propto\operatorname{df}\), অর্থাৎ model যত নমনীয় (বেশি df) তত বেশি training error প্রকৃত error-কে অবমূল্যায়ন করে। তাই \(\overline{\text{err}}\)-কে df-এর সাপেক্ষে minimize করলে সবসময়ই সবচেয়ে জটিল model বেছে নেওয়া হবে (\(\operatorname{df}=n\) হলে interpolation, \(\overline{\text{err}}=0\)) — যা গুরুতর overfitting। সঠিক পথ: training error-কে optimism দিয়ে সংশোধন করা। প্রত্যাশা নিয়ে,
ডান পাশের estimator (training error \(+\) penalty) ঠিক Mallows-এর \(C_p\): \(C_p=\overline{\text{err}}+\dfrac{2\hat\sigma^2\operatorname{df}}{n}\)। আর negative log-likelihood-কাঠামোয় একই penalty \(2\operatorname{df}\) রূপে AIC দেয় — অর্থাৎ AIC/\(C_p\)-এর "\(2\times\)(parameter সংখ্যা)" শাস্তি আসলে এই optimism-এরই বদ্ধ রূপ। Cross-validation (§৪.২–৪.৩) একই অবমূল্যায়ন এড়ায় আলাদা পথে: fit-এ ব্যবহৃত হয়নি এমন data-তে error মেপে।
সংখ্যাগত যাচাই। \(n=40\), NW-kernel smoother, \(\sigma^2=0.25\) নিয়ে Monte-Carlo-তে \(\mathbb{E}[\text{Err}_{\text{in}}]-\mathbb{E}[\overline{\text{err}}]\approx 0.0495\), আর \(\frac{2\sigma^2\operatorname{tr}(S)}{n}=0.0490\) — মিলে যায়; পাশাপাশি \(\sum_i\operatorname{Cov}(\hat y_i,y_i)\approx 0.980=\sigma^2\operatorname{tr}(S)\)।
৪.২ ★★ \(K\)-fold cross-validation: test error-এর প্রায়-নিরপেক্ষ আন্দাজ¶
গঠন। §৪.১-এর penalty-পথ \(\sigma^2\) ও \(\operatorname{df}\) জানা চায়; cross-validation সেগুলো ছাড়াই সরাসরি test error আন্দাজ করে। data-কে এলোমেলোভাবে প্রায়-সমান \(K\)টি ভাগে (fold) ভাঙি: \(\mathcal{C}_1,\dots,\mathcal{C}_K\), যেখানে \(\kappa(i)\in\{1,\dots,K\}\) হলো বিন্দু \(i\)-র fold। ধরি \(\hat f^{-k}\) হলো \(k\)-তম fold বাদ দিয়ে বাকি \(\approx n(1-1/K)\)টি বিন্দুতে fit করা model। তাহলে \(K\)-fold CV-estimate:
অর্থাৎ প্রতিটি বিন্দুকে তখনই predict করা হয় যখন সে নিজের fold-সহ training থেকে বাদ ছিল — তাই \(\hat f^{-\kappa(i)}(x_i)\) ও \(y_i\) পরস্পর-স্বাধীন (§৪.১-এর optimism-এর উৎস এখানে নেই)।
কেন (প্রায়) নিরপেক্ষ। একটি স্থির fold \(k\) ধরি; এর test-error-অবদান \(\frac1{\lvert\mathcal{C}_k\rvert}\sum_{i\in\mathcal{C}_k}(y_i-\hat f^{-k}(x_i))^2\)। যেহেতু \(\{(x_i,y_i):i\in\mathcal{C}_k\}\) \(\hat f^{-k}\)-এর training থেকে সম্পূর্ণ বাইরে ও স্বাধীন, এর প্রত্যাশা ঠিক \(\hat f^{-k}\)-এর প্রকৃত (population) prediction error — অর্থাৎ \(n(1-1/K)\)-বিন্দুর একটি model-এর test error-এর নিরপেক্ষ আন্দাজ। সব fold-এর গড়ে,
"\(\approx\)" থাকার কারণ: যে quantity-টা আমরা চাই তা হলো পুরো \(n\) বিন্দুতে fit-করা model-এর error, কিন্তু CV মাপছে সামান্য ছোট (\(n(1-1/K)\)-বিন্দু) model-এর error। learning curve সাধারণত size বাড়লে error কমায় (downward-sloping), তাই ছোট training-set-এর error একটু বেশি ⇒ CV সামান্য উপরমুখী পক্ষপাত (upward bias) দেয়।
\(K\) বাছাইয়ের bias–variance টানাপোড়েন. এই একই কাঠামো থেকে দুই প্রান্ত:
- ছোট \(K\) (যেমন \(K=5\)): প্রতিটি training-set মাত্র \(\approx 0.8n\) বিন্দু — পূর্ণ-data model থেকে যথেষ্ট ছোট, তাই learning-curve-ব্যবধান বড় ⇒ bias বড় (উপরমুখী)। তবে \(K\)টি training-set পরস্পর অনেক ভিন্ন (overlap কম) ⇒ fold-error-গুলো কম-সম্পর্কিত ⇒ গড়ের variance ছোট। হিসাবও সস্তা: মাত্র \(K\)টি fit।
- \(K=n\) (LOOCV, §৪.৩): প্রতিটি training-set \(n-1\) বিন্দু — পূর্ণ-data-র প্রায় সমান, তাই learning-curve-ব্যবধান প্রায় শূন্য ⇒ bias প্রায় শূন্য (nearly unbiased)। কিন্তু \(n\)টি training-set পরস্পর প্রায় অভিন্ন (কেবল একটি বিন্দুতে ভিন্ন) ⇒ fitted model-গুলো প্রবলভাবে সম্পর্কিত (highly correlated)। \(n\)টি প্রায়-অভিন্ন term-এর গড়ের variance কমে না বরং বড় থাকে (correlated গড়ের variance \(\approx\) একটি term-এরই variance), তাই LOOCV-এর variance বড়।
কারণটা সংখ্যায়: প্রায়-সমান-সম্পর্কযুক্ত (correlation \(\rho\)) \(K\)টি term-এর গড়ের variance \(\frac{\tau^2}{K}\bigl(1+(K-1)\rho\bigr)\); \(\rho\to 1\) হলে এটি \(\to\tau^2\) — \(K\) যতই বড় হোক variance ছোট হয় না। তাই বাস্তবে \(K=5\) বা \(K=10\) একটি ভালো আপস: bias সহনীয় আর variance LOOCV-এর চেয়ে কম।
৪.৩ ★★★ Linear smoother-এর LOOCV জাদু-সূত্র (এক fit-এই \(n\)টি LOO)¶
সমস্যা। LOOCV সংজ্ঞা অনুযায়ী \(n\)বার model refit করতে বলে — ব্যয়বহুল। কিন্তু fit যদি linear smoother হয়, তবে মাত্র একটি পূর্ণ-data fit থেকেই সব \(n\)টি leave-one-out residual বদ্ধ আকারে পাওয়া যায়:
যেখানে \(\hat y_i=(S\mathbf y)_i\) পূর্ণ-data fit, আর \(S_{ii}\) হলো \(S\)-এর \(i\)-তম কর্ণ-উপাদান (বিন্দু \(i\)-র self-influence, 5.7-এর leverage-সদৃশ)।
সেট-আপ — leave-one-out fit-এর নির্ণায়ক সম্পর্ক. ধরি \(\hat y_i^{-i}:=\hat f^{-i}(x_i)\) হলো বিন্দু \(i\) বাদ দিয়ে fit করে \(x_i\)-তে prediction। মূল বীজগাণিতিক তথ্য (যা projection ও penalized linear fit-উভয়ের জন্যই সত্য): যদি প্রকৃত \(y_i\)-কে তার নিজস্ব leave-one-out prediction \(\hat y_i^{-i}\) দিয়ে প্রতিস্থাপন করে পূর্ণ smoother চালাই, তবে বিন্দু \(i\)-তে fit বদলায় না —
স্বজ্ঞা: linear smoother বিন্দু \(i\)-র prediction-এ \(y_i\)-কে ওজন \(S_{ii}\) দিয়ে ব্যবহার করে। বিন্দু \(i\) বাদ দেওয়া মানে \(y_i\)-র জায়গায় এমন এক মান বসানো যা smoother নিজেই সেখানে বসাত — সেটাই \(\hat y_i^{-i}\)। তখন "বাদ-দেওয়া" আর "\(y_i\!\to\!\hat y_i^{-i}\) বসিয়ে রাখা" সমতুল্য, কারণ smoother সেই বিন্দুতে নিজের ভবিষ্যদ্বাণীর সঙ্গে সম্পূর্ণ সংগতিপূর্ণ — কোনো residual টানাটানি থাকে না। (Projection/hat-matrix-এর জন্য এটি অভেদ; ridge-জাতীয় penalized linear fit-এও একই সম্পর্ক ধরে।)
ধাপ ১ — পূর্ণ fit-কে আলাদা করা। পূর্ণ-data fit-এ \(\hat y_i=\sum_k S_{ik}y_k=\sum_{k\ne i}S_{ik}y_k+S_{ii}y_i\), অর্থাৎ
ধাপ ২ — (4)-কে (3)-এ বসানো।
\(1-S_{ii}\ne 0\) ধরে ভাগ:
ধাপ ৩ — leave-one-out residual. এবার আগ্রহের residual \(y_i-\hat y_i^{-i}\):
লব-এ \(y_i\)-এর সহগ: \((1-S_{ii})+S_{ii}=1\)। অর্থাৎ লব \(=y_i-\hat y_i\), এবং
leave-one-out residual = সাধারণ residual-কে \(\dfrac{1}{1-S_{ii}}\) দিয়ে স্ফীত করা। self-influence \(S_{ii}\) বড় (বিন্দুটি fit-কে জোরে টানে) হলে স্ফীতিও বড় — যৌক্তিক, কারণ এমন বিন্দু বাদ দিলে fit বেশি বদলায়।
ধাপ ৪ — গড়। (৬)-কে বর্গ করে গড় নিলেই LOOCV-সংজ্ঞা \(\text{CV}_{(n)}=\frac1n\sum_i (y_i-\hat y_i^{-i})^2\) থেকে জাদু-সূত্র:
ফলাফল। কেবল একটি পূর্ণ-data fit (\(\hat{\mathbf y}=S\mathbf y\)) এবং \(S\)-এর কর্ণ \(\{S_{ii}\}\) থেকেই সম্পূর্ণ LOOCV — \(n\)বার refit-এর দরকার নেই। OLS-এ \(S=H\) (hat matrix) হলে \(S_{ii}=h_{ii}\) (5.7-এর leverage), তাই সুপরিচিত PRESS-সূত্র \(\sum_i\bigl(\frac{y_i-\hat y_i}{1-h_{ii}}\bigr)^2\) এরই বিশেষ ক্ষেত্র।
GCV — rotation-invariant সরলীকরণ। কখনো প্রতিটি \(S_{ii}\) আলাদা করে বের করা অসুবিধাজনক বা অস্থিতিশীল। প্রতিটি \(S_{ii}\)-কে তাদের গড় \(\frac1n\sum_i S_{ii}=\frac{\operatorname{tr}(S)}{n}=\frac{\operatorname{df}}{n}\) দিয়ে প্রতিস্থাপন করলে পাওয়া যায় Generalized Cross-Validation:
ডান রূপটি দেখায় GCV আসলে \(\overline{\text{err}}\)-কে একটি সাধারণ গুণক \((1-\operatorname{df}/n)^{-2}\) দিয়ে স্ফীত করা — এই গুণক \(S\)-কে orthogonal rotation-এ বদলালেও অপরিবর্তিত (rotation-invariant), যেখানে আলাদা \(S_{ii}\)-গুলো নয়। ছোট \(\operatorname{df}/n\)-এ \((1-\operatorname{df}/n)^{-2}\approx 1+2\operatorname{df}/n\), অর্থাৎ GCV \(\approx\overline{\text{err}}(1+2\operatorname{df}/n)\) — §৪.১-এর \(C_p\)/AIC penalty \(\frac{2\sigma^2\operatorname{df}}{n}\)-এর সঙ্গে এক সুরে, যা তিন ধারার (optimism-penalty, LOOCV, GCV) ঐক্য দেখায়।
সংখ্যাগত যাচাই। \(n=40\), ridge-জাতীয় linear smoother নিয়ে brute-force LOOCV (৪০বার refit) \(=0.33151\), আর জাদু-সূত্র \(\frac1n\sum\bigl(\frac{y_i-\hat y_i}{1-S_{ii}}\bigr)^2=0.33151\) — পাঁচ দশমিক পর্যন্ত অভিন্ন; GCV \(\approx 0.3459\) কাছাকাছি।
৪.৪ ★ One-standard-error নিয়ম: সরলতম যথেষ্ট-ভালো model¶
পরিস্থিতি। \(K\)-fold CV কেবল একটি গড় দেয় না — প্রতিটি fold থেকে একটি করে error-মান আসে, তাই fold-জুড়ে একটি standard error-ও পাওয়া যায়। ধরি fold \(k\)-এর error \(e_k=\frac1{\lvert\mathcal{C}_k\rvert}\sum_{i\in\mathcal{C}_k}(y_i-\hat f^{-k}(x_i))^2\)। তাহলে complexity-প্যারামিটার-মান (যেমন \(\operatorname{df}\), বা \(\lambda\), \(K_{\text{knot}}\)) \(\theta\)-এর জন্য:
যেখানে \(\operatorname{sd}\) হলো fold-error-গুলোর নমুনা-standard deviation (denominator \(K-1\)), আর \(\frac1{\sqrt K}\) গুণক \(K\)টি fold-গড়ের standard error দেয়।
নিয়ম। ধরি \(\theta^\star=\arg\min_\theta \overline{\text{CV}}(\theta)\) এবং সর্বনিম্ন মান \(m=\overline{\text{CV}}(\theta^\star)\) ও তার \(\operatorname{SE}(\theta^\star)\)। তখন সবচেয়ে সরল (কম-df / বেশি-নিয়ন্ত্রিত) সেই model বেছে নাও যার CV-error এক SE-এর মধ্যে থাকে:
যুক্তি। \(\overline{\text{CV}}\) নিজেই একটি আনুমানিক, sampling-noise-যুক্ত estimate (§৪.২-এ দেখা variance)। যেসব model-এর CV-error সর্বনিম্ন থেকে \(1\,\operatorname{SE}\)-এর কম দূরে, তাদের পার্থক্য পরিসংখ্যানগতভাবে noise-এর সীমার মধ্যে — অর্থাৎ "সত্যিই কে ভালো" তা নির্ভরযোগ্যভাবে আলাদা করা যায় না। দুটি model পরিসংখ্যানগতভাবে অভিন্ন হলে parsimony (Occam-এর ক্ষুর) সরলতমটিকেই বাছতে বলে: সরল model-এর variance কম (5.2), out-of-sample-এ বেশি স্থিতিশীল, ব্যাখ্যাযোগ্যতা বেশি, এবং CV-এর random fold-বিভাজনের প্রতি কম সংবেদনশীল। এভাবে নিয়মটি ঠিক-সর্বনিম্ন বিন্দুতে অতি-fit এড়ায় এবং noise-এ সর্বনিম্ন বিন্দু সামান্য সরলে গেলেও স্থিতিশীল থাকে — bias সামান্য বাড়িয়ে variance কমানোর একটি সচেতন আপস, যা পুরো অধ্যায়ের bias–variance সুরেরই ব্যবহারিক পরিণতি।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা একটি কৃত্রিম regression-dataset তৈরি করব যেখানে সত্যিকারের সম্পর্কটি cubic — \(f(x) = x^3 - 3x\) — তার ওপর \(\sigma = 3\) স্তরের Gaussian noise যুক্ত। সত্যিকারের irreducible variance তাই \(\sigma^2 = 9\)। আমরা degree \(d = 1, \dots, 10\) পর্যন্ত polynomial regression fit করব এবং দুটি জিনিস তুলনা করব:
- Train MSE — পুরো dataset-এ fit করে সেই একই dataset-এ predict করার error। এটি degree বাড়ার সাথে সাথে একঘেয়েভাবে (monotone) কমতেই থাকে — model জটিল হলে training-data-কে আরও ভালোভাবে "মুখস্থ" করে ফেলে।
- Cross-Validation (CV) MSE — held-out fold-এ মাপা out-of-sample error। এটি প্রথমে কমে, সর্বনিম্নে পৌঁছায়, তারপর overfitting শুরু হলে আবার বাড়ে — তাই একটি U-আকৃতির curve।
মূল প্রশ্ন: কোন degree-টি সবচেয়ে ভালো generalize করে? Train MSE সেটা বলতে পারে না (সে সবসময় সবচেয়ে জটিল model-কেই "জেতায়"), কিন্তু CV পারে। আমরা চারটি ধাপে এগোব — (১) train বনাম CV-এর তুলনা, (২) CV ও LOOCV দিয়ে best degree নির্বাচন, (৩) one-standard-error rule, এবং (৪) একটি fresh test set দিয়ে যাচাই যে CV-এর estimate সত্যিই honest।
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import KFold, cross_val_score, LeaveOneOut
from sklearn.metrics import mean_squared_error
# ---------- DATASET ----------
rng = np.random.default_rng(20260619); n = 120
x = rng.uniform(-3, 3, n); f = x**3 - 3*x; y = f + rng.normal(0, 3.0, n)
X = x.reshape(-1, 1)
kf = KFold(n_splits=10, shuffle=True, random_state=0)
def model(d):
return make_pipeline(PolynomialFeatures(d), LinearRegression())
# ---------- PART 1: train MSE vs 10-fold CV MSE ----------
print("PART 1 :: train MSE (fit-all) vs 10-fold CV MSE")
print(f"{'deg':>3} | {'train MSE':>10} | {'CV MSE':>10}")
print("-" * 32)
train_mse, cv_mse = [], []
for d in range(1, 11):
m = model(d).fit(X, y)
tr = mean_squared_error(y, m.predict(X))
sc = cross_val_score(model(d), X, y, cv=kf, scoring="neg_mean_squared_error")
cv = -sc.mean()
train_mse.append(tr); cv_mse.append(cv)
print(f"{d:>3} | {tr:>10.2f} | {cv:>10.2f}")
train_mse = np.array(train_mse); cv_mse = np.array(cv_mse)
mono = np.all(np.diff(train_mse) < 1e-9)
print(f"\ntrain MSE monotone decreasing? {mono}")
print(f"CV MSE min at degree {int(np.argmin(cv_mse))+1} (value {cv_mse.min():.2f})")
# ---------- PART 2: best by CV + LOOCV confirmation ----------
print("\nPART 2 :: model selection")
best_cv = int(np.argmin(cv_mse)) + 1
print(f"argmin 10-fold CV -> degree {best_cv}")
loo = LeaveOneOut()
loo_mse = []
for d in range(1, 11):
sc = cross_val_score(model(d), X, y, cv=loo, scoring="neg_mean_squared_error")
loo_mse.append(-sc.mean())
loo_mse = np.array(loo_mse)
best_loo = int(np.argmin(loo_mse)) + 1
print(f"argmin LOOCV -> degree {best_loo} (value {loo_mse.min():.2f})")
print(f"{'deg':>3} | {'LOOCV MSE':>10}")
for d in range(1, 11):
print(f"{d:>3} | {loo_mse[d-1]:>10.2f}")
# ---------- PART 3: one-SE rule ----------
print("\nPART 3 :: one-standard-error rule")
sc_best = cross_val_score(model(best_cv), X, y, cv=kf, scoring="neg_mean_squared_error")
fold_mse = -sc_best
se = fold_mse.std(ddof=1) / np.sqrt(10)
thr = cv_mse.min() + se
print(f"per-fold CV MSE (degree {best_cv}):")
print(" " + " ".join(f"{v:.2f}" for v in fold_mse))
print(f"best CV MSE = {cv_mse.min():.2f}")
print(f"SE = std/sqrt(10) = {se:.2f}")
print(f"threshold min+SE = {thr:.2f}")
within = [d for d in range(1, 11) if cv_mse[d-1] <= thr]
simplest = min(within)
print(f"degrees within threshold: {within}")
print(f"one-SE chosen (simplest) -> degree {simplest}")
# ---------- PART 4: refit deg 3, fresh test set ----------
print("\nPART 4 :: honest generalization check")
final = model(3).fit(X, y)
x_te = rng.uniform(-3, 3, 2000)
y_te = (x_te**3 - 3*x_te) + rng.normal(0, 3.0, 2000)
test_mse = mean_squared_error(y_te, final.predict(x_te.reshape(-1, 1)))
print(f"degree 3 refit on all {n} points")
print(f"fresh test MSE (2000 pts) = {test_mse:.2f}")
print(f"10-fold CV MSE (deg 3) = {cv_mse[2]:.2f}")
print(f"irreducible sigma^2 = {3.0**2:.2f}")
print("=> CV estimate ~ test MSE ~ sigma^2 (CV is honest)")
এক নজরে কী ঘটছে: make_pipeline দিয়ে PolynomialFeatures(d) ও LinearRegression-কে একটি ইউনিটে বাঁধা হয়েছে, যাতে প্রতিটি fold-এ feature-তৈরি ও fit একসাথে হয় — কোনো leakage ছাড়াই। cross_val_score(..., scoring="neg_mean_squared_error") ঋণাত্মক MSE ফেরত দেয় (sklearn-এ "বড় = ভালো" নীতি), তাই আমরা -sc.mean() নিই। PART 4-এ একই rng থেকে টানা fresh 2000-point test set ব্যবহার করা হয়েছে — এটিই হলো generalization-এর সত্যিকারের সোনার মানদণ্ড।
আউটপুট:
PART 1 :: train MSE (fit-all) vs 10-fold CV MSE
deg | train MSE | CV MSE
--------------------------------
1 | 22.08 | 22.68
2 | 21.59 | 22.50
3 | 9.59 | 10.15
4 | 9.57 | 10.47
5 | 9.52 | 10.50
6 | 9.46 | 10.70
7 | 9.40 | 10.78
8 | 9.13 | 10.51
9 | 9.12 | 10.74
10 | 9.12 | 10.90
train MSE monotone decreasing? True
CV MSE min at degree 3 (value 10.15)
PART 2 :: model selection
argmin 10-fold CV -> degree 3
argmin LOOCV -> degree 3 (value 10.18)
deg | LOOCV MSE
1 | 22.87
2 | 22.86
3 | 10.18
4 | 10.35
5 | 10.47
6 | 10.56
7 | 10.69
8 | 10.43
9 | 10.63
10 | 10.84
PART 3 :: one-standard-error rule
per-fold CV MSE (degree 3):
15.67 9.76 13.11 10.10 6.97 7.75 7.21 11.20 10.19 9.53
best CV MSE = 10.15
SE = std/sqrt(10) = 0.85
threshold min+SE = 11.00
degrees within threshold: [3, 4, 5, 6, 7, 8, 9, 10]
one-SE chosen (simplest) -> degree 3
PART 4 :: honest generalization check
degree 3 refit on all 120 points
fresh test MSE (2000 pts) = 9.71
10-fold CV MSE (deg 3) = 10.15
irreducible sigma^2 = 9.00
=> CV estimate ~ test MSE ~ sigma^2 (CV is honest)
পাঠোদ্ধার¶
(১) Train MSE বনাম CV MSE — দুটি ভিন্ন গল্প। Train MSE \(22.08 \to 9.12\) পর্যন্ত একঘেয়েভাবে কমেছে (monotone decreasing? True) — এই column দেখে কেউ কখনোই থামবে না, সে চিরকাল আরও জটিল model-ই বেছে নেবে। কিন্তু degree \(1\) থেকে \(3\)-তে যাওয়ার সময় যে নাটকীয় পতন (\(22 \to 9.6\)), তার মূল কারণ — সত্যিকারের function-টি cubic, তাই degree \(\geq 3\) না হলে model-টি underfit করে (high bias)। degree \(3\)-এর পরে train MSE আর তেমন কমে না, কারণ অতিরিক্ত term শুধু noise-কেই fit করছে।
(২) CV-র U-আকৃতি ও সঠিক নির্বাচন। CV MSE column-টি একটি স্পষ্ট U: \(22.68 \to 22.50 \to \mathbf{10.15} \to 10.47 \to 10.50 \to \dots \to 10.90\)। সর্বনিম্ন ঠিক degree 3-এ, মান \(\mathbf{10.15}\)। অর্থাৎ CV নিজে থেকেই সত্যিকারের cubic complexity খুঁজে বের করেছে — train MSE যা কখনোই পারত না। degree \(3\)-এর পরে CV ধীরে ধীরে বাড়ছে, যা মৃদু overfitting (variance বাড়ছে, কিন্তু regularization না থাকায় বিস্ফোরণ ঘটছে না)।
(৩) LOOCV নিশ্চিতকরণ। \(n = 120\) fold-এর Leave-One-Out CV-ও একই রায় দেয়: সর্বনিম্ন degree 3, মান \(10.18\) — 10-fold-এর \(10.15\)-এর প্রায় অভিন্ন। দুটি স্বতন্ত্র CV-পদ্ধতি একই উত্তরে পৌঁছানো নির্বাচনটিকে দৃঢ় করে। (LOOCV প্রায় unbiased কিন্তু গণনাব্যয়ী — এখানে \(120 \times 10\) fit, যেখানে 10-fold-এ মাত্র \(10 \times 10\)।)
(৪) One-SE rule — সরলতার পক্ষে। degree \(3\)-এর \(10\)টি per-fold MSE-এর std থেকে \(\mathrm{SE} = \text{std}/\sqrt{10} \approx 0.85\)। তাই threshold \(= \min + \mathrm{SE} = 10.15 + 0.85 = 11.00\)। এই threshold-এর নিচে degree \(3\) থেকে \(10\) সবাই পড়ে — অর্থাৎ পরিসংখ্যানগতভাবে তারা একে অপর থেকে আলাদা নয়। যখন একাধিক model কার্যত সমান, one-SE rule সবচেয়ে সরল-টি বেছে নেয় → degree 3। এটি একটি Occam's-razor নীতি: noise-driven fluctuation-কে "উন্নতি" ভেবে ভুল করে অতিরিক্ত complexity না নেওয়া।
(৫) CV কি honest? — fresh test set-এর সাক্ষ্য। সবচেয়ে গুরুত্বপূর্ণ যাচাই। degree \(3\) পুরো \(120\)-point data-তে refit করে একটি সম্পূর্ণ নতুন \(2000\)-point test set-এ test MSE \(= \mathbf{9.71}\)। তুলনা করুন: $\(\underbrace{9.71}_{\text{test MSE}} \;\approx\; \underbrace{10.15}_{\text{10-fold CV}} \;\approx\; \underbrace{9.00}_{\sigma^2 \text{ (irreducible)}}.\)$ তিনটিই প্রায় একই মাত্রায় — এটাই CV-র মূল প্রতিশ্রুতি: CV MSE হলো true generalization error-এর একটি honest, প্রায় unbiased estimate, যেখানে train MSE (\(9.59\)) সামান্য আশাবাদী এবং নির্বাচনের জন্য অকার্যকর। CV-র estimate (\(10.15\)) সত্যিকারের test error-এর (\(9.71\)) এত কাছে থাকা প্রমাণ করে — নতুন data না দেখেও আমরা out-of-sample performance নির্ভরযোগ্যভাবে অনুমান করতে পেরেছি, এবং সঠিক model জটিলতা (\(\sigma^2 = 9\)-এর সীমায় থেমে) বেছে নিতে পেরেছি।
সারকথা: train error model-নির্বাচনে প্রতারক; CV (10-fold বা LOOCV) সত্যিকারের complexity (\(d = 3\)) খুঁজে দেয়; one-SE rule সমান-পারফর্মিং model-দের মধ্যে সরলতম-টি বাছে; এবং fresh test set প্রমাণ করে CV-র সংখ্যা (\(\approx 10.15\)) সত্যিই বিশ্বাসযোগ্য (\(\approx 9.71 \approx \sigma^2\))।
৬ · ভিজ্যুয়ালাইজেশন¶
এই অধ্যায়ের গণিত — resubstitution error কেন আশাবাদী, \(K\)-fold cross-validation কীভাবে held-out data দিয়ে honest estimate বানায়, validation MSE-র mean ও standard error, irreducible noise \(\sigma^2\) — সবটাই আমরা সংখ্যা ও সূত্রে বুঝেছি। কিন্তু cross-validation-এর আসল insight-টা (অন্তর্দৃষ্টি) একটা টেবিলে কখনো পুরোপুরি ধরা পড়ে না। "Train MSE degree 10-এ 9.12, CV MSE degree 3-এ 10.15" — এই দুটো সংখ্যা পাশাপাশি রাখলে যে নাটকটা ঘটে (training error নিচে নামতেই থাকে, অথচ CV error আগে নামে তারপর আবার ওঠে), সেটা চোখে দেখা ছাড়া অন্তরে গাঁথে না। তাই এই অংশে আমরা পুরো গল্পটাকে চারটে ছবিতে সাজাব, ঠিক যে যুক্তির ক্রমে একজন analyst এগোয়: প্রথমে কেন্দ্রীয় ছবিটা — training error কেন model বাছতে পারে না, কিন্তু CV পারে; তারপর সেই CV আসলে কী জিনিস তার একটা schematic; তারপর per-fold spread দেখে কেন "এক-SE rule" দরকার; এবং শেষে কংক্রিটভাবে প্রতিটা degree data-র উপর কী করে তার ছবি।
মনে রাখুন — dataset। এই অধ্যায়ের সব ছবি একই একটা synthetic dataset থেকে তৈরি, যেখানে true regression function একটা cubic: \(f(x) = x^3 - 3x\), আর তার উপর Gaussian noise (\(\sigma = 3.0\), অর্থাৎ irreducible variance \(\sigma^2 = 9\)) চাপানো। মোট \(n = 120\) টা point, \(x\) অভিন্নভাবে \([-3, 3]\)-এ ছড়ানো। Model হিসেবে আমরা degree \(1\) থেকে \(10\) পর্যন্ত polynomial regression fit করি, আর validation করি \(10\)-fold cross-validation দিয়ে (
shuffle=True, random_state=0)। যেহেতু true \(f\) আমরা জানি, কোনটা underfit আর কোনটা overfit তা নিরপেক্ষভাবে যাচাই করা যায়।
import numpy as np
from sklearn.model_selection import KFold
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
from sklearn.metrics import mean_squared_error
rng = np.random.default_rng(20260619)
n = 120
x = rng.uniform(-3, 3, n) # predictor, [-3,3]-এ অভিন্ন
f = x**3 - 3*x # true function (অজানা, কিন্তু simulation-এ জানা)
y = f + rng.normal(0, 3.0, n) # observed response = signal + noise (σ=3)
X = x.reshape(-1, 1)
kf = KFold(10, shuffle=True, random_state=0) # 10-fold splitter
প্রতিটা degree \(d\)-এর জন্য আমরা দুটো জিনিস হিসাব করি: (১) train MSE — পুরো data-য় fit করে সেই একই data-য় মাপা error (resubstitution), আর (২) 10-fold CV MSE — প্রতিবার ৯টা fold-এ fit করে বাদ-দেওয়া fold-এ মাপা error-এর গড়। এই দুটোর তফাতই গোটা অধ্যায়ের কেন্দ্রবিন্দু।
degrees = range(1, 11)
train_mse, cv_mean, cv_perfold = [], [], {}
for d in degrees:
model = make_pipeline(PolynomialFeatures(d), LinearRegression())
model.fit(X, y) # পুরো data-য় fit
train_mse.append(mean_squared_error(y, model.predict(X))) # resubstitution
folds = []
for tr, te in kf.split(X): # 10টা train/val split
m = make_pipeline(PolynomialFeatures(d), LinearRegression())
m.fit(X[tr], y[tr]) # ৯ fold-এ train
folds.append(mean_squared_error(y[te], m.predict(X[te]))) # ১ fold-এ val
cv_perfold[d] = np.array(folds)
cv_mean.append(np.mean(folds)) # ফলগুলোর গড় = CV MSE
৬.১ · Train MSE বনাম CV MSE: কেন্দ্রীয় ছবি¶
এই অধ্যায়ের সবচেয়ে গুরুত্বপূর্ণ ছবি। অনুভূমিক অক্ষে polynomial degree (model complexity), উল্লম্ব অক্ষে MSE। দুটো curve পাশাপাশি: নীল train MSE আর লাল 10-fold CV MSE। তত্ত্ব যা বলে: training error হলো একটা আশাবাদী (optimistic) estimate, কারণ model যে data-য় শিখেছে সেই data-তেই তাকে পরীক্ষা করা হচ্ছে — তাই complexity বাড়ালে train MSE একটানা নামতেই থাকবে, কখনো আসল generalization error-কে ছোঁয় না। উল্টোদিকে CV MSE held-out data-য় মাপা, তাই সেটা U-আকৃতির: degree খুব ছোট হলে model আসল cubic ধরতে পারে না (high bias / underfit), আর degree খুব বড় হলে model noise মুখস্থ করে ফেলে (high variance / overfit)। মাঝখানে কোনো এক জায়গায় CV সর্বনিম্ন — সেটাই সঠিক complexity।
fig, ax = plt.subplots(figsize=(8.2, 5.2))
ax.plot(degrees, train_mse, "-o", label="Train MSE (resubstitution)") # নীল
ax.plot(degrees, cv_mean, "-s", label="10-fold CV MSE") # লাল
best = int(np.argmin(cv_mean)) # CV সর্বনিম্ন কোথায়: degree 3
ax.scatter([degrees[best]], [cv_mean[best]], s=360, # সবুজ বৃত্ত
facecolor="none", edgecolor="green", lw=2.4)
ax.axhline(9.0, ls="--", color="grey") # irreducible floor σ² = 9
ax.axvspan(0.5, 2.5, alpha=0.08) # underfit অঞ্চল
ax.axvspan(3.5, 10.5, alpha=0.07) # overfit অঞ্চল
ax.set_xlabel("polynomial degree (model complexity)"); ax.set_ylabel("MSE")
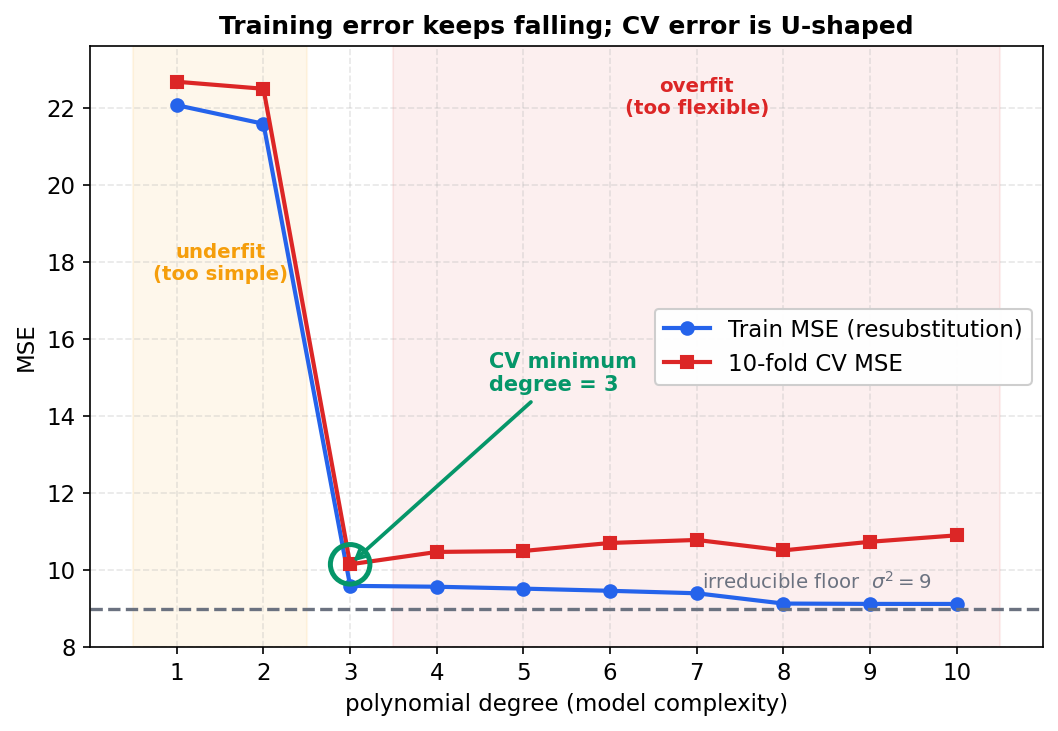
ছবি থেকে যা পড়া যায়। নীল আর লাল curve degree \(1\)–\(2\)-তে প্রায় গায়ে গায়ে — দুটোই \(22\)-র ঘরে, কারণ একটা সরলরেখা বা parabola দিয়ে cubic ধরা যায় না, তাই train আর held-out দুই জায়গাতেই error বিশাল (underfit)। degree \(3\)-এ এসে দুটোই একসঙ্গে খাড়া নামে — এটাই সেই মুহূর্ত যখন model-এর শ্রেণি অবশেষে true function-কে ধারণ করতে পারল। এর পরেই দুটো curve-এর পথ আলাদা হয়ে যায়, আর সেখানেই গোটা অধ্যায়ের পাঠ: নীল train MSE degree \(4\) থেকে \(10\) পর্যন্ত মৃদুভাবে নামতেই থাকে (\(9.59 \to 9.12\)), ধূসর \(\sigma^2 = 9\) রেখার দিকে চুপিচুপি এগোয় — অর্থাৎ প্রতিটা বাড়তি degree training data-র সামান্য noise-ও fit করে error আরও কমিয়ে দেয়। কিন্তু লাল CV MSE ঠিক উল্টো আচরণ করে: degree \(3\)-এ সবুজ বৃত্তে ঘেরা সর্বনিম্নে (\(10.15\)) পৌঁছে আর নামে না, বরং ধীরে ধীরে ওঠে (\(10.47, 10.50, \dots, 10.90\))। held-out data সততার সঙ্গে জানিয়ে দিচ্ছে — degree \(3\)-এর পরের বাড়তি নমনীয়তা signal নয়, noise মুখস্থ করছে।
মূল শিক্ষাটা এই দুই curve-এর তফাতেই লুকানো। train MSE দিয়ে model বাছা অসম্ভব: সে সবসময় সবচেয়ে জটিল model-কেই (degree \(10\)) "সেরা" বলবে, কারণ তার কাছে error সেখানেই সর্বনিম্ন — অথচ সেটা overfitting। CV MSE পারে, কারণ সে এমন data-য় মাপে যা model কখনো দেখেনি, তাই overfitting-কে শাস্তি দেয় এবং U-এর তলায় সঠিক উত্তর (degree \(3\)) দেখিয়ে দেয়। আর লক্ষ করুন CV minimum-ও ঠিক \(9\)-এ নামেনি, থেমেছে \(10.15\)-এ — এই ব্যবধানটাই irreducible error: noise-এর জন্য কোনো model-ই \(\sigma^2 = 9\)-এর নিচে যেতে পারবে না, তাই \(10.15\)-ই বাস্তবিক সেরা।
৬.২ · K-fold cross-validation আসলে কী: একটা schematic¶
কেন্দ্রীয় ছবিটা কী ঘটে দেখাল; এই দ্বিতীয় ছবিটা দেখায় কীভাবে ঘটে — অর্থাৎ "10-fold CV MSE" সংখ্যাটা যে যন্ত্রটা থেকে বেরোয়, সেই যন্ত্রটার নকশা। এতে কোনো data লাগে না, এটা বিশুদ্ধ ধারণাচিত্র। মূল ভাবনাটা সরল: পুরো dataset-কে \(K\) টা সমান block (fold)-এ ভাগ করো। তারপর \(K\) বার একই কাজ করো — প্রতিবার একটা আলাদা block-কে validation হিসেবে সরিয়ে রাখো, বাকি \(K-1\) টা block-এ model train করো, আর সরিয়ে-রাখা block-এ error মাপো। প্রতিটা data point ঠিক একবারই validation-এ পড়ে, তাই কোনো observation নষ্ট হয় না অথচ প্রতিটা প্রেডিকশন সবসময় held-out। শেষে \(K\) টা error-এর গড়ই হলো CV estimate। (এই অধ্যায়ের কোডে \(K = 10\); নিচের ছবিতে স্পষ্টতার জন্য \(K = 5\) দেখানো হলো।)
from matplotlib.patches import Rectangle
K = 5
fig, ax = plt.subplots(figsize=(8.2, 4.4))
for i in range(K): # i = কোন fold এই row-তে held out
for j in range(K): # j = row বরাবর block-এর ক্রম
is_val = (j == i) # diagonal block = validation
ax.add_patch(Rectangle((j*1.12, K-1-i), 1.0, 0.8,
facecolor=("orange" if is_val else "blue")))
ax.text(j*1.12 + 0.5, K-1-i + 0.4, "val" if is_val else "train",
ha="center", va="center", color="white")
ax.text(-0.35, K-1-i + 0.4, f"Split {i+1}", ha="right", va="center")
ax.set_aspect("equal"); ax.axis("off")

ছবি থেকে যা পড়া যায়। পাঁচটা সারি পড়ুন উপর থেকে নিচে — এগুলোই পাঁচটা "round" বা split। Split 1-এ প্রথম block (কমলা) validation, বাকি চারটে (নীল) train; Split 2-এ কমলাটা একঘর ডানে সরেছে; এভাবে কমলা block প্রতি সারিতে কর্ণ বরাবর সরতে সরতে শেষ সারিতে একদম ডানে পৌঁছায়। এই কর্ণ-বিন্যাসটাই গোটা পদ্ধতির হৃদয়: প্রতিটা block জীবনে ঠিক একবার কমলা (validation) হয় আর বাকি চারবার নীল (train) থাকে। ফলে দুটো জরুরি সুবিধা একসঙ্গে মেলে — কোনো data নষ্ট হয় না (প্রতিটা point কোনো-না-কোনো round-এ validation-এ পড়ে, training-এও কাজে লাগে), এবং কোনো প্রেডিকশন কখনো নিজের training data-য় মাপা হয় না (যে block validation, model তখন সেটা দেখেইনি)। এই দ্বিতীয় বৈশিষ্ট্যটাই §৬.১-এর honest, optimism-মুক্ত CV estimate-এর উৎস। আর কেন একটা মাত্র train/test ভাগের চেয়ে এটা ভালো? কারণ ভাগ পাঁচবার (এখানে দশবার) ঘুরিয়ে গড় নিলে কোন data ঘটনাচক্রে test-এ পড়ল তার উপর নির্ভরতা কমে — estimate-টা অনেক বেশি স্থিতিশীল হয়।
৬.৩ · Per-fold spread: কেন "এক-SE rule" দরকার¶
§৬.১-এর লাল curve প্রতিটা degree-এর জন্য \(10\) টা fold-error-এর গড় দেখিয়েছিল — কিন্তু গড় একটা গল্পের অর্ধেক মাত্র লুকিয়ে ফেলে। আসল প্রশ্ন: degree \(3\)-এর CV (\(10.15\)) আর degree \(5\)-এর CV (\(10.50\))-এর মধ্যে এই \(0.35\) ব্যবধানটা কি সত্যিকারের পার্থক্য, নাকি কেবল sampling noise? উত্তর জানতে হলে শুধু গড় নয়, প্রতিটা degree-এ \(10\) টা fold-error কতটা ছড়িয়ে আছে সেটাও দেখতে হবে। তাই এই ছবিতে প্রতিটা degree-এর জন্য পুরো বণ্টন আঁকা — boxplot-এর সঙ্গে \(10\) টা আলাদা fold-point — এবং সবচেয়ে গুরুত্বপূর্ণ, degree-\(3\) সর্বনিম্নের ঠিক এক standard error উপরে একটা সবুজ ভাঙা রেখা (one-SE threshold)। এখানে \(\text{SE} = s / \sqrt{K}\), যেখানে \(s\) হলো ওই \(10\) টা fold-error-এর standard deviation।
se_best = cv_perfold[3].std(ddof=1) / np.sqrt(10) # degree-3 মিনিমামের SE
thr = cv_mean[best] + se_best # one-SE threshold ≈ 11.00
fig, ax = plt.subplots(figsize=(8.4, 5.2))
ax.boxplot([cv_perfold[d] for d in degrees], positions=list(degrees),
widths=0.55, showfliers=False) # প্রতি degree-এর spread
for d in degrees: # ১০টা fold-point overlay
ax.scatter(d + np.random.uniform(-.12, .12, 10), cv_perfold[d], s=14)
ax.axhline(thr, ls="--", color="green") # one-SE rule রেখা
ax.set_xlabel("polynomial degree"); ax.set_ylabel("per-fold validation MSE")
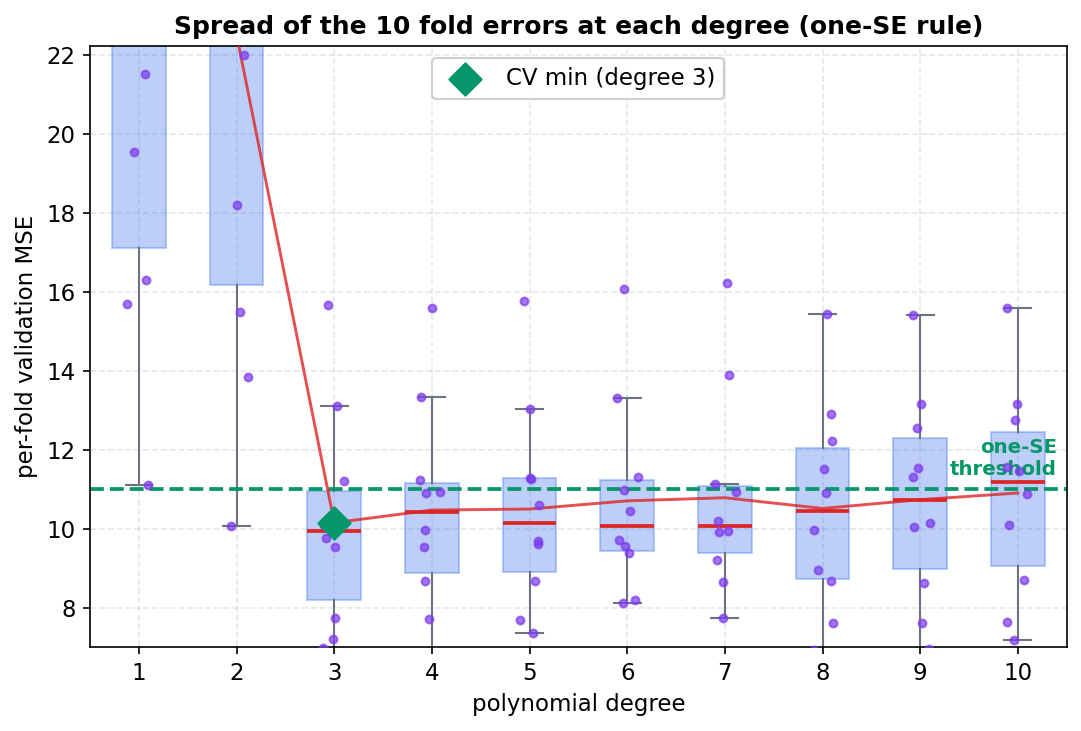
ছবি থেকে যা পড়া যায়। degree \(1\) আর \(2\)-এর box দুটো আকাশছোঁয়া ও বিশাল চওড়া — fold-ভেদে error \(10\) থেকে \(22\)-এর মধ্যে দুলছে; এই underfit model-গুলো খারাপ তো বটেই, তাদের খারাপত্বও অস্থির। degree \(3\)-এ box হঠাৎ নিচে নেমে সংকুচিত হয় — এটাই সবচেয়ে নিচু এবং সবচেয়ে আঁটসাঁট বণ্টন। এখন আসল আবিষ্কারটা ডান দিকে: degree \(3\) থেকে \(10\) পর্যন্ত box-গুলো প্রায় একই উচ্চতায় বসে আছে এবং পরস্পর প্রচুর overlap করে। অর্থাৎ degree \(5\) বা degree \(8\)-এর fold-error-গুলোর অনেকগুলোই degree \(3\)-এর fold-error-এর সীমার মধ্যেই পড়ে — তাদের গড়ের সামান্য তফাত (\(10.15\) বনাম \(10.50\)) এই spread-এর তুলনায় নগণ্য, পুরোপুরি random fold-allocation-এর খেয়ালেই ব্যাখ্যাযোগ্য।
এখান থেকেই এক-SE rule-এর জন্ম। সবুজ ভাঙা রেখাটা সর্বনিম্নের (\(10.15\)) মাত্র এক SE (\(\approx 0.85\)) উপরে, অর্থাৎ \(\approx 11.0\)-তে — আর লক্ষ করুন, degree \(3\) থেকে \(8\) পর্যন্ত প্রায় প্রতিটা degree-এর গড়ই এই রেখার নিচে। পরিসংখ্যানগতভাবে তাই এরা সর্বনিম্নের থেকে আলাদা করা যায় না: noise-এর গণ্ডির মধ্যে এরা সমান-ভালো। যখন একগুচ্ছ model এভাবে statistically টাই করে, তখন সবচেয়ে কম CV-ওয়ালা model অন্ধভাবে বাছার বদলে এক-SE rule বলে — threshold রেখার নিচে থাকা model-গুলোর মধ্যে সবচেয়ে সরলটা (এখানে degree \(3\)) বেছে নাও। এতে দুটো লাভ: অপ্রয়োজনীয় জটিলতা এড়িয়ে overfitting-এর ঝুঁকি কমে, আর model আরও স্থিতিশীল ও ব্যাখ্যাযোগ্য হয়। এই dataset-এ সরল CV minimum আর এক-SE rule দুটোই একই উত্তর (degree \(3\)) দিচ্ছে, কিন্তু এই ছবিটা দেখায় কেন উত্তরটা শুধু "সর্বনিম্ন বলেই" নয়, "noise-এর গণ্ডিতে সবচেয়ে সরল সেরা বলেই" — যুক্তিটা অনেক বেশি মজবুত।
৬.৪ · প্রতিটা complexity data-র উপর কী করে¶
এতক্ষণ আমরা error-এর সংখ্যা নিয়ে কথা বলেছি — train MSE, CV MSE, SE। কিন্তু degree \(1\), \(3\), আর \(10\) আসলে data-র উপর দেখতে কেমন? এই শেষ ছবিটা বিমূর্ত MSE-কে কংক্রিট ছবিতে অনুবাদ করে: একই scatter-এর উপর তিনটে fitted curve পাশাপাশি, সঙ্গে কালো ভাঙা রেখায় true \(f(x) = x^3 - 3x\)। উদ্দেশ্য হলো §৬.১-এর U-curve-এর তিনটে চরিত্রকে — underfit, just-right, overfit — চোখে ধরা।
xx = np.linspace(x.min(), x.max(), 400)
ax.scatter(x, y, label="data") # কাঁচা scatter
ax.plot(xx, xx**3 - 3*xx, "--", color="black", # true function
label=r"true $f(x)=x^3-3x$")
for d, lab in [(1, "degree 1 (underfit)"),
(3, "degree 3 (good)"),
(10, "degree 10 (overfit)")]:
model = make_pipeline(PolynomialFeatures(d), LinearRegression())
model.fit(X, y)
ax.plot(xx, model.predict(xx.reshape(-1, 1)), lw=2.4, label=lab)
ax.set_xlabel("x"); ax.set_ylabel("y")
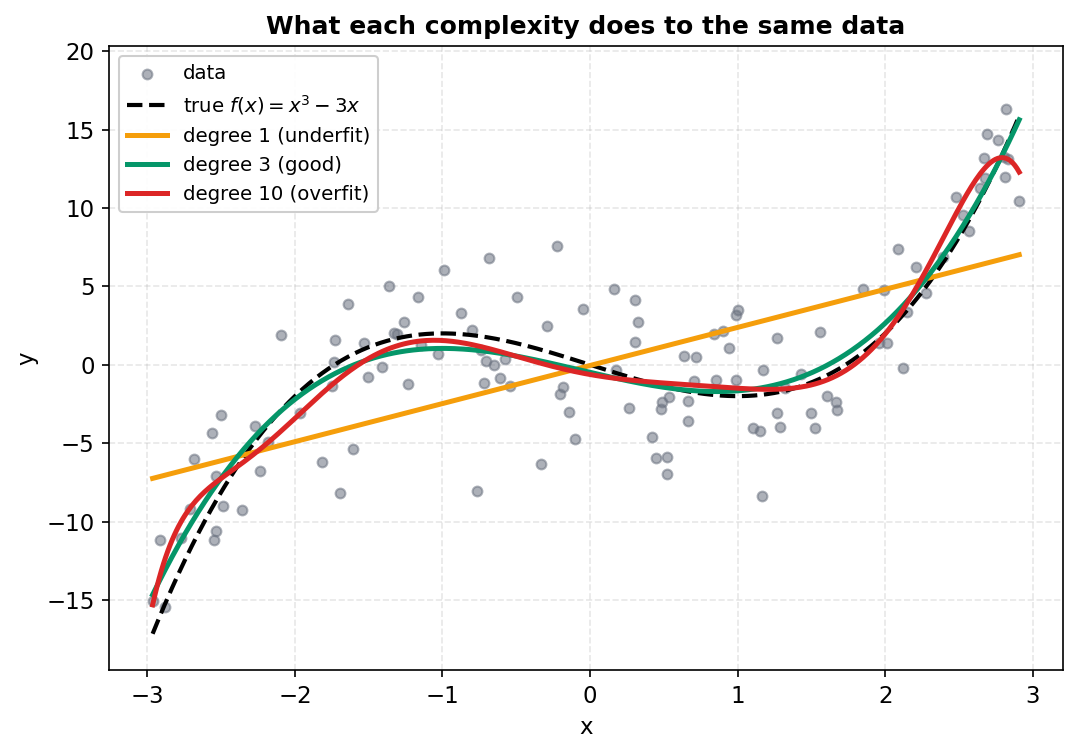
ছবি থেকে যা পড়া যায়। কমলা degree-1 রেখাটা একটা সৎ চেষ্টা — data-র সামগ্রিক ঊর্ধ্বমুখী ঢাল সে ধরেছে — কিন্তু একটা সরলরেখা সংজ্ঞা-অনুসারেই বাঁকতে পারে না, তাই true cubic-এর বাঁ দিকের শৃঙ্গ (\(x \approx -1\)) আর ডান দিকের খাদ (\(x \approx 1\)) সে সম্পূর্ণ মিস করে। এটাই underfit-এর চাক্ষুষ রূপ: model-টা data-র গঠনের তুলনায় বড্ড আনাড়ি, আর সেই কারণেই §৬.১-এ এর train ও CV দুই MSE-ই বিশাল ছিল। সবুজ degree-3 curve কালো ভাঙা true curve-এর সঙ্গে প্রায় আলাদা করা যায় না — শৃঙ্গ শৃঙ্গের জায়গায়, খাদ খাদের জায়গায়, অথচ কোথাও noise-এর পেছনে ছোটেনি। এটাই just right, আর তাই এর CV MSE (\(10.15\)) সর্বনিম্ন। লাল degree-10 curve সবচেয়ে শিক্ষণীয়: data-র ঘন মাঝখানে (\(-2 < x < 2\)) সে degree-3-এর প্রায় গায়েই থাকে, কিন্তু দুই প্রান্তে — যেখানে point কম এবং noise-এর টান বেশি — সে আঁকাবাঁকা হয়ে individual point-গুলোর দিকে ঝুঁকে পড়ে, true cubic ছাড়িয়ে অতিরিক্ত wiggle তৈরি করে। এটাই overfit: বাড়তি \(7\) ডিগ্রি স্বাধীনতা signal ধরায় কিছু যোগ করেনি, বরং noise-কে অনুসরণ করতে খরচ হয়েছে।
তিনটে curve একসঙ্গে §৬.১-এর U-curve-কে জীবন্ত করে তোলে: বাঁ প্রান্ত (underfit) = কমলা রেখা, তলা (সর্বনিম্ন) = সবুজ curve, ডান প্রান্ত (overfit) = লাল wiggle। আর এই গোটা অধ্যায়ের চূড়ান্ত পাঠটাও এখানেই দৃশ্যমান: কোন curve সেরা তা কেবল scatter দেখে চোখে আন্দাজ করা যায় না (degree \(10\) তো অনেক point-এর আরও কাছ দিয়ে গেছে!) — তাই cross-validation-এর honest, held-out রায়ই একমাত্র নির্ভরযোগ্য বিচারক, যা train-error-এর ফাঁদে না পড়ে degree \(3\)-কে সঠিকভাবে বেছে নেয়।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/05-08-cross-validation-solutions.md-এ। নিজে চেষ্টা করার আগে সমাধান দেখবেন না — কেন training error model-complexity বাছতে পারে না (optimism), train/validation/test-এর তিন ভূমিকা, K-fold ও LOOCV হাতে গুনে (fold-MSE থেকে CV-গড়, linear-smoother shortcut দিয়ে LOOCV), CV-এর bias–variance \(K\)-এর সাথে কীভাবে বদলায় (কেন \(K=5/10\), LOOCV নয়), আর one-SE rule প্রয়োগ করে degree বাছা — এই হাতে-কলমে বোঝাই এই অধ্যায়ের আসল শেখা।
(চলমান উদাহরণ স্মারক — seed np.random.default_rng(20260619), \(n=120\): \(x\sim\text{Uniform}(-3,3)\); সত্যিকারের ফাংশন \(f(x)=x^3-3x\); \(y_i=f(x_i)+\varepsilon_i\), \(\varepsilon_i\sim\mathcal N(0,3^2)\) — তাই irreducible variance \(\sigma^2=9\)। Polynomial degree \(d=1,\dots,10\)। canonical সংখ্যা: train MSE \(d{=}1\to22.08\), \(d{=}3\to9.59\), \(d{=}10\to9.12\) (একঘেয়ে ↓); 10-fold CV \(d{=}1\to22.68\), \(d{=}3\to10.15\) (MIN), \(d{=}10\to10.90\) (U-আকার); LOOCV সর্বনিম্ন \(d{=}3\to10.18\); one-SE: সেরা CV \(10.15\), \(\text{SE}\approx0.85\), threshold \(\approx11.0\) → বাছা degree \(3\); test MSE (deg \(3\), স্বাধীন test-set) \(9.71\approx\sigma^2=9\)। মূল সূত্র: training error \(\frac1n\sum_i(y_i-\hat f(x_i))^2\); \(K\)-fold \(\text{CV}_{(K)}=\frac1K\sum_{k}\text{MSE}_k\); LOOCV \(\text{CV}_{(n)}=\frac1n\sum_i(y_i-\hat f^{(-i)}(x_i))^2\); linear-smoother LOOCV shortcut \(\frac1n\sum_i\big(\frac{y_i-\hat y_i}{1-S_{ii}}\big)^2\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). কেন training error model-complexity বাছতে পারে না — optimism। চলমান উদাহরণে train MSE monotone (একঘেয়ে) কমে: \(d{=}1\to22.08\), \(d{=}3\to9.59\), \(d{=}10\to9.12\); অথচ 10-fold CV U-আকার: \(d{=}1\to22.68\), \(d{=}3\to10.15\) (সর্বনিম্ন), \(d{=}10\to10.90\)। (ক) যদি কেউ শুধু training error দেখে model বাছত, সে কোন degree বেছে নিত, এবং সেটা ভুল কেন? (খ) "training error সবসময় optimistic (test error-এর চেয়ে কম)" — এক বাক্যে স্বজ্ঞা দিন কেন একই data-তে fit করে আবার সেই data-তে error মাপলে under-estimate হয়। (গ) \(d{=}10\)-এ train MSE (\(9.12\)) আসলে \(\sigma^2=9\)-এরও নিচে নেমেছে — এটা কী চিহ্ন (model কি irreducible noise-কেও fit করছে)? Hint: (ক) train error সর্বনিম্ন \(d{=}10\)-এ, তাই training error দেখে \(d{=}10\) বাছত — কিন্তু এটা overfit (CV সেখানে বেশি, \(10.90\)); সঠিক বাছাই \(d{=}3\)। (খ) একই data-তে parameter-fit করলে model সেই বিশেষ sample-এর random ওঠানামাকেও আংশিক ধরে ফেলে, তাই সেই sample-এ error কৃত্রিমভাবে কম — নতুন data-তে তা থাকে না। (গ) \(\text{train MSE}<\sigma^2\) মানে model noise-এর কিছু অংশকেও "signal" ভেবে fit করছে — overfitting-এর সরাসরি লক্ষণ; honest test error তখন \(\sigma^2\)-এর উপরে থাকে।
প্রশ্ন ২ (★). train / validation / test — তিন ভূমিকা। model building-এ data প্রায়ই তিন ভাগে ভাগ হয়: training, validation, test। (ক) এক বাক্যে করে বলুন প্রতিটার কাজ কী — কোনটায় parameter (\(\hat\beta\)) শেখা হয়, কোনটায় tuning parameter (degree/\(h\)/\(\lambda\)) বাছা হয়, কোনটায় শুধু চূড়ান্ত মডেলের honest error মাপা হয়। (খ) test set "একবারই, একদম শেষে" ব্যবহার করতে হয় কেন — test set দেখে যদি বারবার model বদলানো হয়, কী সমস্যা? (গ) cross-validation তিনটার মধ্যে কোনটির বিকল্প — কেন CV আলাদা validation set কেটে রাখার দরকার মেটায়? Hint: (ক) training — model parameter \(\hat\beta\) fit; validation — tuning parameter/model বাছা (degree, \(h\), \(\lambda\)); test — সম্পূর্ণ আলাদা, একবার, generalization error-এর নিরপেক্ষ অনুমান। (খ) test-এ বারবার তাকিয়ে model টিউন করলে test set কার্যত validation হয়ে যায় ⇒ test error আর honest থাকে না (optimistic হয়, "leakage")। (গ) CV হলো validation-এর বিকল্প — পুরো training data ঘুরিয়ে-ফিরিয়ে fold ভাগ করে validation করে, তাই আলাদা একটা validation-অংশ স্থায়ীভাবে কেটে রাখতে হয় না (data কম থাকলে এটাই বড় সুবিধা)।
প্রশ্ন ৩ (★★). K-fold cross-validation কীভাবে কাজ করে। \(K\)-fold CV-তে data এলোমেলোভাবে \(K\)টা প্রায়-সমান fold-এ ভাগ হয়; পালাক্রমে এক fold "held-out", বাকি \(K-1\) fold-এ fit। (ক) \(K\)-fold CV-তে মোট কতবার model fit হয়, এবং প্রতিটা data-বিন্দু ঠিক কতবার "held-out" (validation) হিসেবে ব্যবহৃত হয়? (খ) চলমান উদাহরণে degree-\(3\)-এর ১০টা fold-MSE নিচে দেওয়া (ছোট গোল-করা): $\(9.8,\ 10.4,\ 9.1,\ 11.2,\ 10.0,\ 9.6,\ 10.9,\ 10.3,\ 9.5,\ 10.7.\)$ \(\text{CV}_{(10)}=\frac1{10}\sum_k\text{MSE}_k\) গণনা করুন। (গ) এই CV-গড় (\(\approx\) canonical \(10.15\)) train MSE (\(9.59\))-এর চেয়ে কেন বেশি, এবং কোনটা test error-এর সৎ অনুমান? Hint: (ক) \(K\)বার fit (প্রতি fold একবার held-out); প্রতিটা বিন্দু ঠিক একবার held-out (validation), আর \(K-1\) বার training-এ থাকে। (খ) যোগফল \(=9.8+10.4+9.1+11.2+10.0+9.6+10.9+10.3+9.5+10.7=101.5\); \(\text{CV}_{(10)}=101.5/10=10.15\)। (গ) CV প্রতিবার আগে-না-দেখা fold-এ error মাপে (held-out), তাই optimism নেই — train MSE optimistic ভাবে ছোট (\(9.59\)), CV (\(10.15\)) test error-এর সৎ অনুমান, \(\sigma^2=9\)-এর সামান্য উপরে।
প্রশ্ন ৪ (★★). LOOCV ও linear-smoother shortcut। Leave-one-out CV হলো \(K=n\) ক্ষেত্র: \(\text{CV}_{(n)}=\frac1n\sum_i(y_i-\hat f^{(-i)}(x_i))^2\), যেখানে \(\hat f^{(-i)}\) হলো \(i\)-তম বিন্দু বাদ দিয়ে fit। (ক) সরাসরি LOOCV-তে কতবার model re-fit করতে হয় — বড় \(n\)-এ এটা ব্যয়বহুল কেন? (খ) polynomial OLS একটা linear smoother (\(\hat{\mathbf y}=S\mathbf y\), \(S\) = hat matrix), তাই LOOCV-এর একটা চমৎকার shortcut আছে: $\(\text{CV}_{(n)}=\frac1n\sum_{i=1}^n\Big(\frac{y_i-\hat y_i}{1-S_{ii}}\Big)^2,\)$ যেখানে \(\hat y_i\) পূর্ণ-data fit ও \(S_{ii}\) = hat-matrix-এর leverage। এই shortcut-এর সুবিধা কী (কতবার fit লাগে)? (গ) ধরুন একটি ছোট fit-এ \(n=4\), residual \(r_i=y_i-\hat y_i=(2.0,\ -1.0,\ 1.5,\ -0.5)\) এবং leverage \(S_{ii}=(0.5,\ 0.25,\ 0.4,\ 0.2)\)। shortcut দিয়ে \(\text{CV}_{(4)}\) গণনা করুন। Hint: (ক) সরাসরি \(n\)বার re-fit (প্রতি বিন্দু একবার বাদ); বড় \(n\)-এ \(n\)টা পূর্ণ fit ব্যয়বহুল। (খ) shortcut-এ মাত্র একবার পূর্ণ-data fit করলেই হয় — \(\hat y_i\) ও \(S_{ii}\) পেলে সব leave-one-out residual বন্ধ-রূপে; কোনো re-fit লাগে না। (গ) প্রতিটা পদ \((r_i/(1-S_{ii}))^2\): \((2.0/0.5)^2=16\), \((-1.0/0.75)^2=1.778\), \((1.5/0.6)^2=6.25\), \((-0.5/0.8)^2=0.391\); যোগ \(=24.42\); \(\text{CV}_{(4)}=24.42/4=6.105\)।
প্রশ্ন ৫ (★★). CV-এর bias–variance \(K\)-এর সাথে — কেন \(K=5\) বা \(10\), LOOCV নয়? (ক) ছোট \(K\) (যেমন \(5\)): প্রতিবার training-set ছোট (\(\tfrac45 n\)), তাই held-out error প্রকৃত (full-\(n\)) error-কে সামান্য over-estimate করে — কোন দিকে bias? (খ) LOOCV (\(K=n\)): প্রতিটা training-set প্রায় পুরো data (\(n-1\)), তাই bias কম; কিন্তু \(n\)টা fit প্রায় একই (শুধু এক বিন্দুর ফারাক) ⇒ তাদের error গভীরভাবে correlated ⇒ গড়ের variance বেশি। এক বাক্যে ব্যাখ্যা করুন কেন highly-correlated estimate-এর গড় বেশি variance বহন করে। (গ) তাই \(K=5\) বা \(10\) একটা আপস — সামান্য bias বাড়িয়ে variance অনেক কমায়। চলমান উদাহরণে 10-fold CV ও LOOCV একই degree (\(d{=}3\)) বাছে (\(10.15\) vs \(10.18\)) — এটা কী বলে দুই পদ্ধতির model-selection-সিদ্ধান্ত নিয়ে? Hint: (ক) ছোট training-set ⇒ সামান্য দুর্বল model ⇒ error একটু বড় দেখায় ⇒ upward (pessimistic) bias। (খ) \(n\)টা leave-one-out fit প্রায় অভিন্ন ⇒ তাদের error একসাথে ওঠে-নামে (correlated); correlated চলকের গড়ে variance কমে না (স্বাধীন হলে \(1/n\) হারে কমত, কিন্তু correlation থাকলে অনেক কম কমে) ⇒ LOOCV-গড়ের variance বেশি। (গ) দুটো প্রায় একই সর্বনিম্ন (\(d{=}3\)) দেয় ⇒ model-selection-এর জন্য \(K=10\) যথেষ্ট ও সস্তা; LOOCV-র বাড়তি খরচ এখানে সিদ্ধান্ত বদলায় না — তাই বাস্তবে \(5\)/\(10\)-fold পছন্দ।
প্রশ্ন ৬ (★★). one-standard-error rule প্রয়োগ — degree বাছুন। চলমান উদাহরণে 10-fold CV-গড় ও তাদের SE (fold-জুড়ে standard error) নিচের মতো (গোল-করা):
| degree \(d\) | \(\text{CV}_{(10)}\) | SE |
|---|---|---|
| 1 | 22.68 | 2.24 |
| 2 | 22.50 | 2.47 |
| 3 | 10.15 | 0.85 |
| 4 | 10.47 | 0.82 |
| 5 | 10.50 | 0.80 |
| 6 | 10.70 | 0.77 |
| 10 | 10.90 | 1.05 |
(ক) সর্বনিম্ন-CV নিয়ম (CV-min) অনুসারে কোন degree বাছা হয়? (খ) one-SE rule বলে: সর্বনিম্ন CV-এর সাথে তার SE যোগ করে একটা threshold বানাও; তারপর সেই threshold-এর নিচে থাকা সবচেয়ে সরল (ছোট \(d\)) মডেল বাছো। threshold গণনা করুন (\(10.15+0.85\)) এবং বলুন কোন degree one-SE rule বাছে। (গ) এখানে CV-min ও one-SE দুটোই degree \(3\) বাছল — কিন্তু সাধারণভাবে one-SE rule আরও সরল মডেল বাছার দিকে ঝোঁকে কেন (parsimony/Occam-এর যুক্তি)? Hint: (ক) CV-min \(=10.15\) at \(d{=}3\) ⇒ CV-min বাছে \(d{=}3\)। (খ) threshold \(=10.15+0.85=11.0\); threshold \(\le11.0\)-এর নিচে থাকা সবচেয়ে ছোট \(d\) হলো \(d{=}3\) (\(10.15<11.0\); \(d{=}1,2\)-এর CV \(\gg11\), তাই বাদ) ⇒ one-SE বাছে \(d{=}3\)। (গ) CV-গড় নিজে noisy (SE আছে); one-SE rule বলে — যেসব model সর্বনিম্ন থেকে "এক SE-এর মধ্যে" কার্যত সমান-ভালো, তাদের মধ্যে সবচেয়ে সরলটা নাও (statistically আলাদা নয় বলে অতিরিক্ত জটিলতা অপ্রয়োজনীয়) ⇒ overfitting-এর বিরুদ্ধে রক্ষাকবচ, generalization-এ ভালো।
প্রশ্ন ৭ (★★). CV দিয়ে যেকোনো tuning parameter বাছা — একই কাঠামো। ৫.৭-এ আমরা LOOCV দিয়ে kernel bandwidth \(h\approx0.03\) পেয়েছিলাম; এখানে CV দিয়ে polynomial degree বাছছি। (ক) এক বাক্যে বলুন CV-ভিত্তিক tuning-এর সাধারণ recipe কী — একটা grid (যেমন \(d\in\{1,\dots,10\}\) বা \(h\)/\(\lambda\)-এর একটা পরিসর) নিয়ে প্রতিটার জন্য কী হিসাব করে কোনটা বাছা হয়? (খ) ৫.৭-এর tuning parameter \(h\) (bandwidth), df (spline), \(\lambda\) (smoothing-spline) — এই তিনটা এবং এখানকার degree, সবগুলোকে CV একই ভাবে handle করে কেন (CV কি model-এর ভেতরের রূপ জানার দরকার রাখে)? (গ) CV কেন AIC/BIC-র চেয়ে বেশি general — কোন জিনিসটা CV-র লাগে না যা AIC/BIC-র লাগে? Hint: (ক) recipe: প্রতিটা grid-মান \(\theta\) (degree/\(h\)/\(\lambda\))-এর জন্য \(K\)-fold CV-error হিসাব ⇒ যে \(\theta\) CV-error সর্বনিম্ন (বা one-SE-rule অনুযায়ী) করে, সেটাই বাছা। (খ) CV শুধু held-out predictive error মাপে — model-কে black-box ধরেই চলে; তাই \(h\)/df/\(\lambda\)/degree যাই হোক, প্রতিটার fit-করে-predict করার ক্ষমতা থাকলেই CV খাটে (effective df বা likelihood-রূপ জানার দরকার নেই)। (গ) CV-র model-এর likelihood বা parameter-গণনা (\(\operatorname{df}\)) জানার দরকার নেই — শুধু predict করতে পারলেই হয়; AIC/BIC-র \(-2\log L\) ও \(\operatorname{df}\) দুটোই লাগে, তাই non-likelihood/black-box model-এ AIC/BIC প্রায়ই প্রযোজ্য নয়, CV সর্বত্র খাটে।
খ · গণনামূলক (computational)¶
প্রশ্ন ৮ (★). fold-MSE থেকে CV-গড় ও SE হাতে। ধরুন \(5\)-fold CV-তে পাঁচটা fold-MSE: \(8.5,\ 11.0,\ 9.5,\ 12.0,\ 10.0\)। (ক) \(\text{CV}_{(5)}=\frac15\sum_k\text{MSE}_k\) গণনা করুন। (খ) fold-MSE-গুলোর sample standard deviation (\(s\), \(\text{ddof}=1\)) বের করে \(\text{SE}=s/\sqrt{5}\) গণনা করুন। (গ) one-SE threshold (\(\text{CV}+\text{SE}\)) বের করুন — পরের প্রশ্নে এমন threshold দিয়ে model বাছা হবে। Hint: (ক) যোগ \(=8.5+11.0+9.5+12.0+10.0=51.0\); \(\text{CV}_{(5)}=51.0/5=10.2\)। (খ) বিচ্যুতি (গড় \(10.2\) থেকে): \(-1.7,0.8,-0.7,1.8,-0.2\); বর্গ-যোগ \(=2.89+0.64+0.49+3.24+0.04=7.30\); \(s^2=7.30/4=1.825\), \(s=1.351\); \(\text{SE}=1.351/\sqrt5=0.604\)। (গ) threshold \(=10.2+0.604=10.80\)।
প্রশ্ন ৯ (★). optimism সংখ্যায় পড়া — train vs CV gap। চলমান উদাহরণে: train MSE — \(d{=}1\to22.08\), \(d{=}3\to9.59\), \(d{=}10\to9.12\); 10-fold CV — \(d{=}1\to22.68\), \(d{=}3\to10.15\), \(d{=}10\to10.90\)। (ক) প্রতিটা degree-এ optimism gap \(=\text{CV}-\text{train}\) গণনা করুন। (খ) gap কোন degree-এ সবচেয়ে বড়, এবং সেটা কেন প্রত্যাশিত (বেশি-নমনীয় model বেশি overfit করে, তাই বেশি optimistic)? (গ) \(d{=}10\)-এ train (\(9.12\)) \(\sigma^2=9\)-এর নিচে কিন্তু CV (\(10.90\)) উপরে — এই দুই সংখ্যার ফাঁকটা কী মাপছে? Hint: (ক) gap: \(d{=}1\to22.68-22.08=0.60\); \(d{=}3\to10.15-9.59=0.56\); \(d{=}10\to10.90-9.12=1.78\)। (খ) সবচেয়ে বড় gap \(d{=}10\)-এ (\(1.78\)) — সবচেয়ে নমনীয় model sample-noise সবচেয়ে বেশি fit করে, তাই train কৃত্রিম-ভাবে ছোট, CV সৎ-ভাবে বড়; optimism complexity-র সাথে বাড়ে। (গ) ফাঁকটা (\(\approx1.78\)) overfitting-এর "মূল্য" মাপছে — model noise-কে signal ভেবে fit করায় train কমেছে কিন্তু নতুন data-তে তা কাজে আসেনি, তাই honest error (\(10.90\)) উল্টো বেড়েছে; এই gap-ই optimism।
প্রশ্ন ১০ (★★). honest test error যাচাই — CV বনাম held-out test। ধরা যাক একই process থেকে একটা স্বাধীন test-set (\(n_{\text{test}}=2000\), একই \(f\) ও \(\sigma\)) আঁকা হলো এবং degree-\(3\) মডেল (পুরো training data-তে fit) সেখানে evaluate করে test MSE \(=9.71\) পাওয়া গেল। (ক) এই \(9.71\) কেন \(\sigma^2=9\)-এর খুব কাছে কিন্তু একটু উপরে — irreducible \(\sigma^2\) ছাড়াও test error-এ আর কী থাকে? (খ) degree-\(3\)-এর 10-fold CV ছিল \(10.15\), আর স্বাধীন test MSE \(9.71\) — দুটো কাছাকাছি হওয়া কী নিশ্চিত করে CV সম্পর্কে? (গ) যদি কেউ overfit model (\(d{=}10\)) বাছত, একই স্বাধীন test-এ তার MSE \(\sigma^2\)-এর তুলনায় কোন দিকে যেত (CV \(10.90\) দেখে অনুমান করুন)? Hint: (ক) test error \(=\sigma^2+(\text{bias}^2+\text{variance of }\hat f)\); degree-\(3\) প্রায় সঠিক (\(f\) নিজেই cubic) তাই bias\(\approx0\), শুধু সামান্য estimation variance ⇒ \(9.71\) = \(9\) (irreducible) \(+\,0.71\) (estimation) ≈ \(\sigma^2\)-এর সামান্য উপরে। (খ) CV (\(10.15\)) ও স্বাধীন test (\(9.71\)) কাছাকাছি ⇒ CV সত্যিই test/generalization error-এর সৎ অনুমান দিচ্ছে (সামান্য pessimistic, কারণ CV-fit ছোট training-set-এ — প্রশ্ন ৫ক)। (গ) \(d{=}10\) overfit, তার CV (\(10.90\)) বেশি ⇒ স্বাধীন test-এও MSE \(\sigma^2=9\)-এর আরও উপরে (\(\approx10.9\)) — অতিরিক্ত variance generalization খারাপ করে।
প্রশ্ন ১১ (★★). LOOCV shortcut বড় উদাহরণে — leverage-এর ভূমিকা। একটা degree-\(3\) fit-এর ৫টা বিন্দুতে residual ও leverage:
| \(i\) | \(r_i=y_i-\hat y_i\) | \(S_{ii}\) |
|---|---|---|
| 1 | \(3.0\) | \(0.10\) |
| 2 | \(-2.0\) | \(0.30\) |
| 3 | \(1.0\) | \(0.50\) |
| 4 | \(-4.0\) | \(0.20\) |
| 5 | \(2.5\) | \(0.40\) |
(ক) shortcut \(\big(\frac{r_i}{1-S_{ii}}\big)^2\) প্রতিটা বিন্দুর জন্য গণনা করুন। (খ) এদের গড় নিয়ে এই ৫-বিন্দুর LOOCV-অবদান বের করুন। (গ) লক্ষ্য করুন বিন্দু \(3\)-এর residual ছোট (\(1.0\)) কিন্তু leverage বড় (\(0.50\)) — shortcut কীভাবে high-leverage বিন্দুর leave-one-out error-কে "বড় করে দেখায়", এবং কেন এটা যুক্তিসঙ্গত? Hint: (ক) পদগুলো: \((3.0/0.9)^2=11.11\); \((-2.0/0.7)^2=8.163\); \((1.0/0.5)^2=4.0\); \((-4.0/0.8)^2=25.0\); \((2.5/0.6)^2=17.36\)। (খ) যোগ \(=11.11+8.163+4.0+25.0+17.36=65.63\); LOOCV-অবদান (গড়) \(=65.63/5=13.13\)। (গ) \(1-S_{ii}\) হর — leverage বড় হলে \(1-S_{ii}\) ছোট, তাই residual কে বড় গুণক দিয়ে বাড়ায়; কারণ high-leverage বিন্দু fit-কে নিজের দিকে বেশি টানে, তাকে বাদ দিলে prediction বেশি বদলায় ⇒ তার leave-one-out error প্রকৃতই বড়, shortcut সেটা সঠিকভাবেই ধরে।
প্রশ্ন ১২ (★★). AIC/BIC বনাম CV — একই degree বাছে? (ভাবনা-পরীক্ষা, সংখ্যাসহ যুক্তি)। চলমান উদাহরণে CV ও LOOCV দুটোই degree \(3\) বাছে। AIC \(=n\log(\widehat{\text{RSS}}/n)+2p\) ও BIC \(=n\log(\widehat{\text{RSS}}/n)+p\log n\) (\(p=d+1\) parameter, \(n=120\))। (ক) AIC/BIC-এর প্রথম পদ (\(n\log(\text{RSS}/n)\)) degree বাড়ালে কমে কেন (train RSS তো একঘেয়ে কমে), আর কোন পদ জটিলতাকে শাস্তি দেয়? (খ) BIC-এর penalty \(p\log n=p\log 120\approx p\cdot4.79\) বনাম AIC-এর \(2p\) — কোনটা বেশি কড়া, এবং তাই কোনটা সরল model-এর দিকে বেশি ঝুঁকবে? (গ) এখানে \(f\) নিজেই cubic (\(d{=}3\) সঠিক) — তাই AIC, BIC, CV সবাই \(d{=}3\)-এর কাছাকাছি একমত হওয়া কেন প্রত্যাশিত, এবং কোন পরিস্থিতিতে এরা ভিন্ন উত্তর দিত? Hint: (ক) প্রথম পদ RSS-এর সাথে কমে (train fit ভালো হয়); জটিলতা শাস্তি দেয় দ্বিতীয় পদ (\(2p\) বা \(p\log n\)) — দুই পদের যোগফল U-আকার, সর্বনিম্নই বাছা। (খ) \(\log120\approx4.79>2\), তাই BIC penalty বেশি কড়া ⇒ BIC সাধারণত সরলতর model বাছে (consistency: সত্য model থাকলে \(n\to\infty\)-এ সেটাই বাছে)। (গ) সত্য \(f\) cubic, তাই \(d{=}3\)-এ bias প্রায় শূন্য আর তার বেশি degree শুধু variance বাড়ায় — সব criterion-ই (train-fit আর penalty-র ভারসাম্যে) \(d{=}3\)-কেই সেরা পায়; এরা ভিন্ন হতো যদি সত্য \(f\) কোনো degree-এ ঠিক না বসত (misspecified), বা \(n\) ছোট হতো (তখন AIC বেশি, BIC কম degree-এর দিকে টানত)।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১৩ (★★★). optimism \(=\frac{2\sigma^2\,\operatorname{df}}{n}\) প্রমাণ করুন (linear smoother)। ধরুন data \(y_i=f(x_i)+\varepsilon_i\), \(\varepsilon_i\) স্বাধীন, \(\mathbb E[\varepsilon_i]=0\), \(\operatorname{Var}(\varepsilon_i)=\sigma^2\); এবং একটা linear smoother \(\hat{\mathbf y}=S\mathbf y\) (fixed \(S\), \(\mathbf y\)-নিরপেক্ষ)। সংজ্ঞা: in-sample test error \(\text{Err}_{\text{in}}=\frac1n\sum_i\mathbb E\big[(y_i^{\text{new}}-\hat y_i)^2\big]\) (একই \(x_i\)-তে স্বাধীন নতুন \(y_i^{\text{new}}\)), training error \(\overline{\text{err}}=\frac1n\sum_i(y_i-\hat y_i)^2\)। Optimism \(\text{op}=\text{Err}_{\text{in}}-\mathbb E[\overline{\text{err}}]\)। দেখান $\(\text{op}=\frac{2\sigma^2}{n}\operatorname{tr}(S)=\frac{2\sigma^2\,\operatorname{df}}{n},\qquad \operatorname{df}=\operatorname{tr}(S).\)$ (ক) একটা স্থির \(i\)-এর জন্য দেখান \(\mathbb E[(y_i^{\text{new}}-\hat y_i)^2]-\mathbb E[(y_i-\hat y_i)^2]=2\operatorname{Cov}(y_i,\hat y_i)\)। (খ) \(\hat y_i=\sum_j S_{ij}y_j\) ব্যবহার করে দেখান \(\operatorname{Cov}(y_i,\hat y_i)=\sigma^2 S_{ii}\)। (গ) সব \(i\) যোগ করে \(\text{op}=\frac{2\sigma^2}{n}\sum_i S_{ii}=\frac{2\sigma^2}{n}\operatorname{tr}(S)\) পান, এবং ব্যাখ্যা করুন এটা কেন বলে "training error model-complexity (\(\operatorname{df}\))-এর সাথে linearly (রৈখিকভাবে) under-estimate করে"। Hint: (ক) \(y_i^{\text{new}}\) ও \(y_i\)-এর একই গড় (\(f(x_i)\)) ও variance (\(\sigma^2\)), কিন্তু \(y_i^{\text{new}}\) স্বাধীন তাই \(\operatorname{Cov}(y_i^{\text{new}},\hat y_i)=0\); দুই বর্গ-প্রত্যাশা খুলে (\(\mathbb E[(a-\hat y)^2]=\operatorname{Var}(a)+\operatorname{Var}(\hat y)+(\mathbb E a-\mathbb E\hat y)^2-2\operatorname{Cov}(a,\hat y)\)) বিয়োগ করলে শুধু \(-2\operatorname{Cov}\)-পদ বাঁচে: পার্থক্য \(=2\operatorname{Cov}(y_i,\hat y_i)\)। (খ) \(\operatorname{Cov}(y_i,\hat y_i)=\operatorname{Cov}(y_i,\sum_j S_{ij}y_j)=\sum_j S_{ij}\operatorname{Cov}(y_i,y_j)=S_{ii}\sigma^2\) (স্বাধীনতায় \(\operatorname{Cov}(y_i,y_j)=\sigma^2\delta_{ij}\))। (গ) \(\text{op}=\frac1n\sum_i 2\sigma^2 S_{ii}=\frac{2\sigma^2}{n}\operatorname{tr}(S)\); polynomial-OLS-এ \(\operatorname{tr}(S)=p=d+1\), তাই degree বাড়ালে optimism রৈখিকভাবে বাড়ে — train error ঠিক এই পরিমাণে test error-কে under-estimate করে; এটাই AIC/\(C_p\)-এর "\(+2\operatorname{df}\)" penalty-র উৎস। ∎
প্রশ্ন ১৪ (★★★). LOOCV linear-smoother shortcut সূত্র প্রমাণ করুন। একটা linear smoother-এ ধরা যাক leave-one-out fit \(\hat f^{(-i)}\) একটা মূল-সম্পর্ক মানে: যদি বিন্দু \(i\)-এর প্রকৃত \(y_i\)-কে তার নিজের leave-one-out prediction \(\hat y_i^{(-i)}\equiv\hat f^{(-i)}(x_i)\) দিয়ে প্রতিস্থাপন করে পুরো-data smoother চালানো হয়, তবে \(i\)-তম fitted মান অপরিবর্তিত থাকে: $\(\hat y_i^{(-i)} = \sum_{j\ne i} S_{ij}y_j + S_{ii}\,\hat y_i^{(-i)}.\)$ (এটি অনেক linear smoother-এর — OLS-সহ — একটি পরিচিত ধর্ম।) এখান থেকে দেখান যে leave-one-out residual পূর্ণ-data residual-এর সাথে বাঁধা: $\(y_i-\hat y_i^{(-i)}=\frac{y_i-\hat y_i}{1-S_{ii}},\qquad\text{তাই}\qquad \text{CV}_{(n)}=\frac1n\sum_i\Big(\frac{y_i-\hat y_i}{1-S_{ii}}\Big)^2.\)$ (ক) দেওয়া সম্পর্ক থেকে \(\hat y_i^{(-i)}\)-কে আলাদা করে দেখান \(\hat y_i^{(-i)}=\dfrac{\sum_{j\ne i}S_{ij}y_j}{1-S_{ii}}\)। (খ) পূর্ণ-data fit \(\hat y_i=\sum_j S_{ij}y_j=\sum_{j\ne i}S_{ij}y_j+S_{ii}y_i\) ব্যবহার করে \(\sum_{j\ne i}S_{ij}y_j=\hat y_i-S_{ii}y_i\) বসিয়ে \(y_i-\hat y_i^{(-i)}\) সরল করুন। (গ) সরলীকরণ শেষে \(\dfrac{y_i-\hat y_i}{1-S_{ii}}\) পান এবং বর্গ করে গড় নিয়ে shortcut-সূত্রে পৌঁছান। (এটি GCV-র সাথে কীভাবে সম্পর্কিত — \(S_{ii}\)-কে গড় \(\operatorname{tr}(S)/n\) দিয়ে প্রতিস্থাপন করলে?) Hint: (ক) দেওয়া সমীকরণ থেকে \(\hat y_i^{(-i)}-S_{ii}\hat y_i^{(-i)}=\sum_{j\ne i}S_{ij}y_j\) ⇒ \(\hat y_i^{(-i)}(1-S_{ii})=\sum_{j\ne i}S_{ij}y_j\) ⇒ \(\hat y_i^{(-i)}=\frac{\sum_{j\ne i}S_{ij}y_j}{1-S_{ii}}\)। (খ) \(\sum_{j\ne i}S_{ij}y_j=\hat y_i-S_{ii}y_i\); তাই \(\hat y_i^{(-i)}=\frac{\hat y_i-S_{ii}y_i}{1-S_{ii}}\), এবং \(y_i-\hat y_i^{(-i)}=y_i-\frac{\hat y_i-S_{ii}y_i}{1-S_{ii}}=\frac{y_i(1-S_{ii})-\hat y_i+S_{ii}y_i}{1-S_{ii}}\)। (গ) লব \(=y_i-S_{ii}y_i-\hat y_i+S_{ii}y_i=y_i-\hat y_i\); তাই \(y_i-\hat y_i^{(-i)}=\frac{y_i-\hat y_i}{1-S_{ii}}\), বর্গ করে \(\frac1n\)-গড় নিলে shortcut। GCV ঠিক এই সূত্রে প্রতিটা \(S_{ii}\)-কে তাদের গড় \(\bar S=\operatorname{tr}(S)/n\) দিয়ে বদলায়: \(\text{GCV}=\frac1n\sum_i\big(\frac{y_i-\hat y_i}{1-\operatorname{tr}(S)/n}\big)^2\) — leverage-অসম-তার প্রতি কম সংবেদনশীল, rotation-invariant একটা LOOCV-সন্নিকর্ষ। ∎
ঘ · কোডিং (Python)¶
প্রশ্ন ১৫ (★★★). পূর্ণ degree-selection pipeline — train MSE, K-fold CV, LOOCV-shortcut, one-SE rule, honest test। seed np.random.default_rng(20260619) দিয়ে canonical data বানান: n=120, x = rng.uniform(-3,3,n), f = x**3 - 3*x, y = f + rng.normal(0,3,n) (\(\sigma^2=9\))। তারপর degree \(d=1,\dots,10\)-এর জন্য:
- train MSE: প্রতিটা \(d\)-এ পূর্ণ-data polynomial OLS fit করে train MSE ছাপুন; canonical \(d{=}1\to22.08\), \(d{=}3\to9.59\), \(d{=}10\to9.12\) (একঘেয়ে ↓) মেলান এবং দেখান training error দিয়ে degree বাছলে কেন \(d{=}10\) ভুলভাবে নির্বাচিত হয়।
- 10-fold CV: একটা
KFold(n_splits=10, shuffle=True, random_state=...)বা নিজে-permutation দিয়ে প্রতিটা \(d\)-এ \(\text{CV}_{(10)}=\frac1K\sum_k\text{MSE}_k\) এবং fold-জুড়ে SE ছাপুন; canonical min \(d{=}3\to10.15\) (SE \(\approx0.85\)), \(d{=}1\to22.68\), \(d{=}10\to10.90\) (U-আকার) মেলান। - LOOCV (shortcut): প্রতিটা \(d\)-এ hat matrix \(S=X(X^\top X)^{-1}X^\top\) একবার বানিয়ে \(\text{CV}_{(n)}=\frac1n\sum_i\big(\frac{y_i-\hat y_i}{1-S_{ii}}\big)^2\) ছাপুন (কোনো re-fit ছাড়া); canonical min \(d{=}3\to10.18\) মেলান, এবং সরাসরি leave-one-out (প্রতি বিন্দু re-fit) করে অভিন্নতা যাচাই করুন।
- one-SE rule: 10-fold CV-গড় ও SE থেকে threshold \(=\text{CV}_{\min}+\text{SE}_{\min}=10.15+0.85=11.0\) বানিয়ে threshold-এর নিচে সবচেয়ে ছোট \(d\) বাছুন — দেখান এটা \(d{=}3\) দেয়।
- honest test: একটা স্বাধীন test-set (\(n_{\text{test}}=2000\), একই \(f\), \(\sigma\), নতুন rng-state) আঁকুন; বাছা degree-\(3\) মডেল (পূর্ণ training data-তে fit) সেখানে evaluate করে test MSE ছাপুন — canonical \(\approx9.71\approx\sigma^2=9\) মেলান, এবং CV (\(10.15\)) যে test error-এর সৎ অনুমান ছিল তা নিশ্চিত করুন।
Hint: design matrix X = np.vander(x, d+1, increasing=True); OLS beta,*_ = np.linalg.lstsq(Xtr, ytr, rcond=None)। hat matrix H = X @ np.linalg.inv(X.T@X) @ X.T, Sii = np.diag(H), LOOCV np.mean(((y - H@y)/(1-Sii))**2)। K-fold: for tr,te in KFold(10,shuffle=True,random_state=0).split(x): ..., fold-MSE জমিয়ে গড় ও np.std(foldmse,ddof=1)/np.sqrt(10)। one-SE: thr = cv.min() + se[cv.argmin()]; chosen = next(d for d in degrees if cv[d-1] <= thr)। সব প্রত্যাশিত সংখ্যা উপরের canonical তালিকায়; পূর্ণ runnable script _solutions/05-08-cross-validation-solutions.md-এর §ঘ-তে।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
-
কেন এই অধ্যায়। ৫.১–৫.৭ জুড়ে আমরা একের পর এক model বানিয়েছি — linear, GLM, mixed, nonparametric — এবং প্রতিটায় একটা complexity-ডায়াল এসেছে (predictor-সংখ্যা, degree, bandwidth \(h\), df, penalty \(\lambda\))। কিন্তু একটা প্রশ্ন বারবার ঝুলে ছিল: এই ডায়াল কত ঘোরাব? এই অধ্যায়ের মূল উপলব্ধি — training error এই প্রশ্নের উত্তর দিতে পারে না, কারণ একই data-তে fit করে আবার সেখানেই error মাপলে তা optimistic (test error-এর চেয়ে কম)। চলমান উদাহরণে train MSE monotone (একঘেয়ে) কমে (\(d{=}1\to22.08\), \(d{=}3\to9.59\), \(d{=}10\to9.12\)) — এমনকি \(\sigma^2=9\)-এরও নিচে, কারণ নমনীয় model irreducible noise-কেও fit করে — তাই training error দেখলে সবচেয়ে জটিল model (\(d{=}10\)) বেছে নিতে হয়, যা overfit।
-
সমাধান — held-out / cross-validation। model-কে এমন data-তে যাচাই করতে হবে যা সে fit-এ দেখেনি। সরলতম রূপ: data-কে train / validation / test তিন ভাগে ভাগ — training-এ parameter (\(\hat\beta\)), validation-এ tuning parameter (degree/\(h\)/\(\lambda\)) বাছা, test-এ একবার-মাত্র honest error। data কম হলে validation-অংশ স্থায়ীভাবে কেটে রাখা অপচয়; তখন cross-validation — data ঘুরিয়ে-ফিরিয়ে fold ভাগ করে প্রতিটা অংশকে পালাক্রমে held-out করা।
-
\(K\)-fold ও LOOCV। \(K\)-fold CV (\(\text{CV}_{(K)}=\frac1K\sum_k\text{MSE}_k\)): data \(K\)টা fold-এ ভাগ, পালাক্রমে এক fold held-out, বাকিতে fit — মোট \(K\)টা fit, প্রতিটা বিন্দু ঠিক একবার validation। চলমান উদাহরণে 10-fold CV U-আকার (\(d{=}1\to22.68\), \(d{=}3\to10.15\) সর্বনিম্ন, \(d{=}10\to10.90\)) — train error-এর একঘেয়ে পতনের সম্পূর্ণ বিপরীত, এবং এটিই test error-এর সৎ ছবি। LOOCV হলো \(K=n\) (\(\text{CV}_{(n)}=\frac1n\sum_i(y_i-\hat f^{(-i)}(x_i))^2\)); linear smoother (\(\hat{\mathbf y}=S\mathbf y\))-এ এর একটা চমৎকার shortcut আছে যা মাত্র একবার fit-এই সব leave-one-out error দেয়: $\(\text{CV}_{(n)}=\frac1n\sum_{i=1}^n\Big(\frac{y_i-\hat y_i}{1-S_{ii}}\Big)^2,\)$ যেখানে \(S_{ii}\) = leverage; চলমান উদাহরণে LOOCV-ও \(d{=}3\) বাছে (\(10.18\))। (\(S_{ii}\to\operatorname{tr}(S)/n\) বসালে পাওয়া যায় GCV।)
-
CV-এর bias–variance \(K\)-এর সাথে। ছোট \(K\) (\(5\)) ⇒ training-set ছোট ⇒ error সামান্য over-estimate (pessimistic bias), কিন্তু fit-গুলো ভিন্ন ⇒ কম correlated ⇒ কম variance। LOOCV (\(K=n\)) ⇒ bias প্রায় শূন্য, কিন্তু \(n\)টা fit প্রায় অভিন্ন ⇒ গভীরভাবে correlated ⇒ গড়ের বেশি variance (এবং বেশি খরচ)। তাই বাস্তবে \(K=5\) বা \(10\) একটা সুষম আপস — চলমান উদাহরণে 10-fold ও LOOCV একই degree (\(d{=}3\)) বাছে, তাই model-selection-এ \(K=10\) যথেষ্ট।
-
tuning parameter বাছা — CV-min ও one-SE rule। grid (degree/\(h\)/\(\lambda\))-এর প্রতিটা মানের জন্য CV-error হিসাব ⇒ CV-min যে মান সর্বনিম্ন করে সেটা বাছে। কিন্তু CV-গড় নিজে noisy (প্রতিটার একটা SE), তাই one-standard-error rule আরও রক্ষণশীল: threshold \(=\text{CV}_{\min}+\text{SE}_{\min}\) বানিয়ে তার নিচে থাকা সবচেয়ে সরল model বাছা। চলমান উদাহরণে সেরা CV \(10.15\), \(\text{SE}\approx0.85\), threshold \(\approx11.0\) ⇒ both rule degree \(3\) বাছে — সরলতম যথেষ্ট-ভালো model, parsimony-র পক্ষে।
-
CV সৎ — test error-এর নিরপেক্ষ অনুমান। চলমান উদাহরণে বাছা degree-\(3\) মডেলের একটা স্বাধীন test-set-এ MSE \(=9.71\), যা irreducible \(\sigma^2=9\)-এর প্রায় সমান (অবশিষ্টটুকু সামান্য estimation variance, কারণ \(f\) নিজেই cubic ⇒ bias\(\approx0\))। CV (\(10.15\)) এই honest test error-এর কাছাকাছি ছিল — এটাই CV-র মূল প্রতিশ্রুতি: সত্য \(f\) না জেনে, শুধু hand-এ থাকা data দিয়ে generalization error-এর নিরপেক্ষ অনুমান।
-
মূল বার্তা। training error optimistic ⇒ held-out/CV দিয়ে honest error ⇒ \(K\)-fold/LOOCV (linear smoother-এ shortcut) ⇒ CV-min/one-SE দিয়ে tuning parameter বাছা ⇒ স্বাধীন test-এ CV যাচাই। এটি কেবল একটা কৌশল নয় — পুরো modeling-toolkit-এর methodological capstone: ৫.১–৫.৭-এর প্রতিটা model ও তার complexity-ডায়াল এখন একটা অভিন্ন, নীতিনিষ্ঠ, data-চালিত নিয়মে বাছা যায়।
পূর্ববর্তী সংযোগ (← ৫.২, ৫.৭, ৪.৪):
-
৫.২ (Bias–Variance / AIC & BIC): এ অধ্যায় ৫.২-এর গল্পকেই সম্পূর্ণ করে। ৫.২ দিয়েছিল bias–variance decomposition (test error \(=\) bias\(^2+\) variance \(+\,\sigma^2\)) ও AIC/BIC — train-fit-কে একটা complexity-penalty দিয়ে শাস্তি দিয়ে test error আন্দাজ করা। §৭-এ প্রমাণিত optimism \(=\frac{2\sigma^2\operatorname{df}}{n}\) ঠিক এই AIC/\(C_p\)-penalty-র উৎস: train error test error-কে \(\operatorname{df}\)-এর সমানুপাতে under-estimate করে। CV একই লক্ষ্য (honest test error) সরাসরি, ভিন্ন পথে অর্জন করে — likelihood বা \(\operatorname{df}\) না জেনেই, শুধু predict করে; তাই CV আরও general (black-box model-এও খাটে), AIC/BIC দ্রুততর কিন্তু likelihood-নির্ভর। চলমান উদাহরণে সত্য \(f\) cubic বলে AIC, BIC, CV প্রায় একমত — সবাই \(d{=}3\)।
-
৫.৭ (Tuning \(h\) / df / \(\lambda\)): ৫.৭ রেখে গিয়েছিল ঠিক এই শূন্যস্থান — nonparametric পদ্ধতির tuning parameter (\(h\), df, \(\lambda\)) "কত" নেব, যেহেতু সত্য \(f\) অজানা বলে MSE-vs-true গণনাই করা যায় না। এ অধ্যায় সেই উত্তর দেয়: cross-validation। ৫.৭-এ LOOCV দিয়ে kernel \(h\approx0.03\) পাওয়া আর এখানে CV দিয়ে polynomial degree \(3\) বাছা — একই recipe-এর দুই প্রয়োগ: grid-এর প্রতিটা মানে held-out error হিসাব করে সেরাটা বাছা। CV degree/\(h\)/df/\(\lambda\) — সবকিছু এক কাঠামোয় handle করে, কারণ সে model-এর ভেতরের রূপ নয়, শুধু predictive error দেখে।
-
৪.৪ (MSE): পুরো অধ্যায়ের মুদ্রা হলো ৪.৪-এর mean squared error — train MSE, fold-MSE, CV-MSE, test MSE সবই \(\frac1n\sum(y_i-\hat y_i)^2\)-এর রূপ। ৪.৪-এ MSE-কে একটা estimator-এর মান হিসেবে শিখেছিলাম (bias\(^2+\) variance); এখানে সেই একই পরিমাপকে out-of-sample প্রয়োগ করে generalization মাপি। ৪.৪-এর \(\mathbb E[(\hat\theta-\theta)^2]\)-ধারণাই held-out prediction error-এ রূপান্তরিত — শুধু লক্ষ্যবস্তু parameter \(\theta\)-র বদলে ভবিষ্যৎ observation।
পরবর্তী সংযোগ (→ ৫.৯ — Multivariate Methods: PCA & Clustering; এবং Part V সমাপ্তি): এ পর্যন্ত (৫.১–৫.৮) সবই ছিল supervised — একটা response \(y\)-কে predictor \(x\) দিয়ে ভবিষ্যদ্বাণী, এবং সাফল্যের মাপকাঠি predictive error (যা CV দিয়ে honest-ভাবে মাপলাম)। ৫.৯ এক ভিন্ন জগতে নিয়ে যায় — unsupervised শেখা, যেখানে কোনো \(y\) নেই, শুধু data-র গঠন খুঁজে বের করা: PCA উচ্চ-মাত্রিক data-কে কয়েকটা মূল অক্ষে নামিয়ে আনে (dimensionality reduction), আর clustering বিন্দুদের স্বাভাবিক দলে ভাগ করে। লক্ষ্য আর "ভবিষ্যদ্বাণী" নয়, বরং "অন্তর্নিহিত প্যাটার্ন উন্মোচন" — তাই validation-এর প্রশ্নও বদলায় (held-out error-এর বদলে reconstruction, silhouette, stability)। এর সাথে Part V (Modeling) সম্পূর্ণ হয়: ৫.১–৫.৬ supervised model-পরিবার, ৫.৭ nonparametric নমনীয়তা, ৫.৮ — এই অধ্যায় — model-নির্বাচন ও validation-এর methodological capstone যা সবগুলোকে এক নীতিতে বাঁধে, এবং ৫.৯ unsupervised-এ উত্তরণ ঘটিয়ে toolkit-কে পূর্ণ করে।
সূত্র (sources): L. Wasserman, All of Statistics, Ch. 20 ও §13 (cross-validation, training/test error, optimism, model selection); R. Furrer, STA121 Statistical Modeling (cross-validation, GCV, effective df, linear smoothers, AIC/BIC vs CV); M. Sugiyama, Introduction to Statistical Machine Learning (cross-validation, model selection, generalization error); Bruce, Bruce & Gedeck, Practical Statistics for Data Scientists, Ch. 4 (cross-validation, train/validation/test, overfitting, model-selection-এর ব্যবহারিক দিক); P. Dangeti, Statistics for Machine Learning (train/validation/test split, K-fold cross-validation, bias–variance, grid-search tuning)।