5.9 — Multivariate Methods: PCA & Clustering (বহুমাত্রিক পদ্ধতি: PCA ও ক্লাস্টারিং)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — "যখন কোনো উত্তরই দেওয়া নেই, কেবল data"¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন নতুন প্রশ্ন¶
Part V জুড়ে আমরা একটার পর একটা মডেল গড়েছি — simple ও multiple linear regression (5.1), তার diagnostic ও selection (5.2), ANOVA (5.3), logistic ও Poisson regression-এর মতো GLM (5.4–5.5), mixed model (5.6), nonparametric regression (5.7), আর সবশেষে cross-validation দিয়ে এ-সব মডেল নিরপেক্ষভাবে যাচাই করা (5.8)। কিন্তু এতগুলো অধ্যায়ের মধ্যে একটা ব্যাপার সবসময় একই ছিল, এতটাই স্বাভাবিক যে হয়তো চোখেই পড়েনি: প্রতিটি পর্যবেক্ষণে দু-রকম জিনিস থাকত —
- এক বা একাধিক predictor (input/feature) \(x\), আর
- একটা লক্ষ্য-উত্তর (outcome/response/label) \(y\) — যা আমরা আন্দাজ বা ব্যাখ্যা করতে চাইতাম।
কাজটা সর্বদা ছিল: \(x\) থেকে \(y\)-এর দিকে একটা সম্পর্ক শেখা — দাম আন্দাজ করা, রোগ আছে কি নেই classify (শ্রেণিবদ্ধ) করা, সংখ্যা গোনা। এই গোটা দৃষ্টিভঙ্গির একটা নাম আছে — supervised learning (তত্ত্বাবধানে শেখা): প্রতিটি উদাহরণের সঙ্গে একটা "সঠিক উত্তর" \(y\) দেওয়া থাকে, যেন একজন শিক্ষক পাশে দাঁড়িয়ে প্রতিটি দৃষ্টান্তের জবাব বলে দিচ্ছেন, আর মডেল সেই জবাব দেখে শেখে।
এখন একটা মৌলিকভাবে আলাদা পরিস্থিতির কথা ভাবুন — যা বাস্তবে আশ্চর্যরকম বেশি ঘটে। ধরুন হাতে একটা data এল, যেখানে প্রতিটি পর্যবেক্ষণে অনেকগুলো feature আছে — কিন্তু কোনো \(y\) নেই। কোনো লেবেল নেই, কোনো "সঠিক উত্তর" দেওয়া নেই, কোনো শিক্ষক নেই। যেমন: হাজার হাজার গ্রাহকের কেনাকাটার তথ্য (কে কী কিনছে, কত খরচ করছে, কত ঘনঘন আসছে) — কিন্তু কেউ আগে থেকে বলে দেয়নি কে "মিতব্যয়ী", কে "বিলাসী", কে "মাঝারি"। কিংবা হাজারটা জিন-এর প্রকাশমাত্রা (gene expression) প্রতিটি রোগীর জন্য — কিন্তু কোন রোগী কোন উপ-শ্রেণির, তা অজানা।
প্রশ্নটা তখন পুরোপুরি বদলে যায়। আর "\(x\) থেকে \(y\) আন্দাজ করব কীভাবে" নয় — কারণ \(y\) তো নেই-ই। বরং প্রশ্ন হয়ে দাঁড়ায়:
এই data-র ভেতরে নিজে থেকে কী গঠন (structure) লুকিয়ে আছে? কোনো লক্ষ্য-উত্তরের সাহায্য ছাড়াই, কেবল feature-গুলোর পারস্পরিক বিন্যাস দেখে, কি কোনো নিয়ম, কোনো দল, কোনো সরলতর ছবি বের করে আনা যায়?
এই দৃষ্টিভঙ্গির নাম unsupervised learning (তত্ত্বাবধান-বিহীন শেখা): কোনো শিক্ষক নেই, কোনো লেবেল নেই — শুধু কাঁচা feature, আর তার ভেতর থেকে গঠন আবিষ্কারের চ্যালেঞ্জ। এটাই এই অধ্যায়ের — এবং Part V-এর সমাপ্তি-অধ্যায়ের — কেন্দ্রীয় বিষয়।
১.২ Hook — উঁচু মাত্রার অভিশাপ, আর "চোখে দেখার" অসহায়তা¶
unsupervised প্রশ্নটা কেন এত কঠিন এবং এত জরুরি, সেটা একটা সরল অস্বস্তি দিয়ে ধরা যায়।
ধরুন data-তে প্রতিটি পর্যবেক্ষণ মাত্র দুটি feature নিয়ে — \(x_1\) আর \(x_2\)। তাহলে কোনো সমস্যাই নেই: একটা scatter plot এঁকে ফেলুন, অনুভূমিক অক্ষে \(x_1\), উল্লম্ব অক্ষে \(x_2\), প্রতিটি পর্যবেক্ষণ একটা বিন্দু। চোখ বুলিয়েই বলে দেওয়া যায় — point-গুলো কি দু-তিনটে আলাদা ঝাঁকে জড়ো হয়ে আছে? কোনো প্রবণতা বা রেখা বরাবর ছড়ানো? কোনো outlier দূরে একা পড়ে আছে? মানুষের চোখ দুই (এবং কষ্ট করে তিন) মাত্রায় গঠন ধরতে অসাধারণ।
কিন্তু বাস্তব data প্রায় কখনোই দু-মাত্রার নয়। গ্রাহক-data-তে হয়তো ৫০টা feature, জিন-data-তে ২০ হাজার। এখন? ৫০-মাত্রার একটা scatter plot আঁকা যায় না — কাগজে, পর্দায়, এমনকি কল্পনাতেও নয়। আমরা চার-মাত্রার বেশি কিছু "দেখতে" পারি না। তাহলে এই উঁচু-মাত্রার মেঘের ভেতরে কোথায় কোন দল, কোন গঠন — তা চোখে ধরা পড়ে না।
শুধু visualization-ই নয়, উঁচু মাত্রায় আরও গভীর সমস্যা জন্মায়, যাকে একসঙ্গে বলা হয় curse of dimensionality (মাত্রার অভিশাপ)। মাত্রা যত বাড়ে —
- স্থান অকল্পনীয়ভাবে বিরল (sparse) হয়ে যায়: উঁচু মাত্রায় আয়তন এত বিশাল যে যেকোনো বাস্তবসম্মত সংখ্যক point সেখানে ছিটিয়ে-থাকা কয়েক ফোঁটার মতো; প্রতিটি point কার্যত একা, "প্রতিবেশী" বলে কিছু থাকে না।
- দূরত্বের মানে ফিকে হয়ে আসে: মাত্রা অনেক বাড়লে নিকটতম ও দূরতম point-এর দূরত্বের তফাত আপেক্ষিকভাবে মিলিয়ে যায় — "কাছে" আর "দূরে"-র পার্থক্যই দুর্বল হয়ে পড়ে, অথচ clustering-এর মতো বহু পদ্ধতি ঠিক দূরত্বের উপরেই দাঁড়ায়।
- redundancy লুকিয়ে থাকে: ৫০টা feature মানে এই নয় যে ৫০টা স্বাধীন তথ্যসূত্র — বহু feature পরস্পর-সম্পর্কিত (correlated), একই অন্তর্নিহিত জিনিসের নানা ছায়া। অর্থাৎ আসল "তথ্য-মাত্রা" হয়তো অনেক কম।
এক বাক্যে hook: বাস্তব data উঁচু-মাত্রার, কিন্তু আমাদের চোখ ও স্বজ্ঞা দুই-তিন মাত্রায় আটকে; উঁচু মাত্রায় স্থান বিরল হয়, দূরত্ব ফিকে হয়, আর feature-রা পরস্পর-সম্পর্কিত হয়ে লুকোনো redundancy বহন করে — তাই গঠন খুঁজে পেতে হলে হয় মাত্রা কমাতে হবে, নয় point-দের দলবদ্ধ করতে হবে।
১.৩ দুই মৌলিক প্রশ্ন — আর তাদের দুই হাতিয়ার¶
§১.২-এর অস্বস্তি থেকেই এই অধ্যায়ের গোটা কাঠামো বেরিয়ে আসে। উঁচু-মাত্রার, লেবেল-বিহীন data-র সামনে দাঁড়িয়ে দুটি স্বাভাবিক, পরস্পর-পরিপূরক প্রশ্ন ওঠে — আর প্রতিটির জন্য একটা করে মৌলিক হাতিয়ার আছে।
প্রশ্ন ১ — মাত্রা কি কমানো যায়? যদি feature-রা পরস্পর-সম্পর্কিত হয় (যেমন গ্রাহকের "মোট খরচ" আর "গড় কেনাকাটার পরিমাণ" প্রায় একসাথে চলে), তাহলে ৫০টা সংখ্যার মধ্যে অনেকটাই পুনরাবৃত্তি। প্রশ্ন: এই ৫০-মাত্রার data-কে কি অল্প — হয়তো ২ বা ৩ — মাত্রায় নামিয়ে আনা যায়, এমনভাবে যে মূল ছড়ানোর/তথ্যের সিংহভাগ অক্ষত থাকে? যদি যায়, তবে শুধু visualization-এর দরজা খুলে যায় না, পরবর্তী সব বিশ্লেষণও সরল, দ্রুত ও কম-noisy হয়। এই কাজের প্রধান হাতিয়ার — PCA (Principal Component Analysis, প্রধান-উপাদান বিশ্লেষণ), যা পরস্পর-সম্পর্কিত feature-দের কয়েকটা নতুন, পরস্পর-লম্ব (orthogonal) principal component-এ নামিয়ে আনে, যেগুলো data-র সর্বোচ্চ-ছড়ানোর দিকগুলো ধরে রাখে।
প্রশ্ন ২ — point-রা কি স্বাভাবিক দলে ভাগ হয়? হয়তো গ্রাহকেরা আসলে কয়েকটা চেনা ধরনে জড়ো — কেউ মিতব্যয়ী-ঘনঘন-ক্রেতা, কেউ বিলাসী-কালেভদ্রে-ক্রেতা। কেউ আগে এই দল বলে দেয়নি (লেবেল নেই), কিন্তু data-র ভেতরে কি এমন স্বাভাবিক গুচ্ছ (cluster) আছে, যেখানে এক দলের সদস্যরা পরস্পরের কাছাকাছি অথচ অন্য দল থেকে দূরে? এদের নিজে থেকে খুঁজে বের করাই clustering (গুচ্ছ-নির্ণয়), যার সবচেয়ে চেনা ও সরল হাতিয়ার k-means।
এই দুটি হাতিয়ার একে অপরের প্রতিদ্বন্দ্বী নয়, বরং পরিপূরক, আর প্রায়ই হাত ধরাধরি করে চলে: আগে PCA দিয়ে ৫০ মাত্রা থেকে ২ মাত্রায় নেমে এসে, সেই সরল ছবিতে clustering চালিয়ে দল খোঁজা — এই "PCA-তে নামিয়ে তারপর cluster" কৌশল এ-অধ্যায়ের একটা পুনরাবৃত্ত সুর।
দুই হাতিয়ার, এক লক্ষ্য: PCA মাত্রা কমিয়ে (dimensionality reduction) data-কে সরল ও দৃশ্যমান করে; clustering point-দের অর্থপূর্ণ দলে ভাগ করে (grouping)। দুটোই একই unsupervised প্রশ্নের দুই মুখ — "লেবেল ছাড়া, কেবল feature দেখে, এই data-র লুকানো গঠন কী?"
১.৪ এক ঝলক — কী পেতে যাচ্ছি¶
পথে নামার আগে গন্তব্যটা একবার দেখিয়ে রাখি, যাতে কষ্টটা কেন তা বোঝা যায়। এই অধ্যায়ের চলতি dataset (seed 20260619; পূর্ণ বিবরণ §৫-এ) গড়া হয়েছে এমনভাবে যে তার ভেতরে আমরা সত্যিকারের উত্তর জানি, ফলে পদ্ধতিগুলো ঠিক কাজ করছে কি না মিলিয়ে দেখা যায়: \(n=300\)টি পর্যবেক্ষণ, প্রতিটিতে \(p=4\)টি পরস্পর-সম্পর্কিত feature, কিন্তু আসল তথ্য আসলে মাত্র দ্বি-মাত্রিক (2D) — আর সেই 2D-তে লুকানো আছে ৩টি সত্যিকারের cluster (প্রতিটিতে ১০০টি করে point)। অর্থাৎ data দেখতে ৪-মাত্রার, কিন্তু তার "আসল" গঠন সরল।
PCA চালালে এই সরলতা সংখ্যায় ধরা পড়ে। চারটি principal component-এর explained variance ratio আসে প্রায় \([0.651,\ 0.343,\ 0.004,\ 0.002]\) — অর্থাৎ প্রথম দুই component মিলে data-র মোট ছড়ানোর ৯৯.৪% ধরে রাখে! বাকি দুই component কার্যত শূন্য, নিছক noise। সিদ্ধান্ত স্পষ্ট: এই ৪-মাত্রার data মূলত 2D, আর প্রথম দুই PC-তে নামালে প্রায় কিছুই হারায় না (চিত্র 5-9-scree ও 5-9-pca-scatter এটাই দেখাবে)।
এবার সেই 2D-তে k-means চালালে: cluster-সংখ্যা \(k\) বাড়ালে inertia (within-cluster ছড়ানো) নামে \(1200 \to 527 \to 135 \to 111 \to \dots\) — লক্ষণীয়, \(k=3\)-এর পরে নামার গতি হঠাৎ ভোঁতা হয়ে যায়, অর্থাৎ elbow পড়ে \(k=3\)-এ। স্বাধীনভাবে silhouette স্কোরও সর্বোচ্চ হয় \(k=3\)-এ (মান \(0.712\))। আর যখন \(k=3\)-এর cluster-গুলো সত্যিকারের ৩ দলের সঙ্গে মেলাই, মিল আসে প্রায় নিখুঁত (Adjusted Rand Index, ARI \(\approx 0.99\)) — অর্থাৎ k-means লেবেল ছাড়াই প্রায় হুবহু আসল দল তিনটে আবিষ্কার করেছে (চিত্র 5-9-kmeans-elbow ও 5-9-clusters এ-সব দেখাবে)।
১.৫ এই অধ্যায়ের পথরেখা¶
মূল ধারণা হাতে এল; এবার সামনের পথ সংক্ষেপে:
- §২ মূল সংজ্ঞাগুলো নিখুঁত করে — PCA-র দিকে: কেন আগে standardize; covariance matrix \(\Sigma\); eigen-decomposition থেকে principal component (eigenvector) ও সেই দিকের variance (eigenvalue); PC1 = সর্বোচ্চ-variance orthogonal দিক, PC2 ⟂ PC1 পরের সর্বোচ্চ; explained variance ratio ও scree plot; projection (score \(z=Xv\)), reconstruction, ও PCA = best linear low-rank approximation (SVD-সংযোগ)। Clustering-এর দিকে: k-means-এর objective (within-cluster SS/inertia) ও Lloyd's algorithm; \(k\) বাছা — elbow ও silhouette; সংক্ষেপে hierarchical/agglomerative clustering (linkage, dendrogram); এবং PCA-তে নামিয়ে cluster।
- §৩–৪ এই ধারণাগুলো হাতে-কলমে ও গাণিতিকভাবে — covariance-এর eigen-decomposition কেন ঠিক সর্বোচ্চ-variance দিকগুলোই দেয়, PCA ও SVD-র যোগসূত্র ও best-low-rank দাবির প্রমাণ, k-means-objective কেন Lloyd's algorithm-এ একঘেয়ে কমে অথচ কেবল local minimum-এ থামে, এবং silhouette-এর গাণিতিক রূপ।
- §৫–৬ পূর্ণ dataset-এ (seed 20260619, \(n=300\), \(p=4\) correlated feature, intrinsic 2D, ৩টি সত্যিকারের cluster) হাতে-কলমে — PCA-projection ও scree, k-means-elbow ও silhouette, এবং পুনরুদ্ধার-করা cluster বনাম সত্যিকারের দল — চিত্র 5-9-pca-scatter, 5-9-scree, 5-9-kmeans-elbow, 5-9-clusters ও Python-কোড সহ।
এক বাক্যে কেন এটি Part V-এর সমাপ্তি ও পরের ধাপের সেতু। Part V জুড়ে আমরা supervised মডেলিং শিখেছি — predictor থেকে একটা লক্ষ্য-উত্তর \(y\) আন্দাজ করা; এই সমাপ্তি-অধ্যায় সেই কাঠামোর বাইরে পা রাখে — যখন \(y\) নেই, কেবল feature, তখন data-র লুকানো গঠন (কম-মাত্রা ও দল) কীভাবে নিজে থেকে আবিষ্কার করি। এই unsupervised দৃষ্টিভঙ্গি — eigen-decomposition, variance-সংরক্ষণ, objective-ভিত্তিক grouping — সরাসরি পরবর্তী Part VI (statistical machine learning)-এর গোড়ার ভাষা, যেখানে estimation-তত্ত্ব থেকে আধুনিক ML-এর দিকে যাত্রা শুরু হবে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর অন্তর্দৃষ্টি — "লেবেল ছাড়া, কেবল feature দেখে data-র লুকানো গঠন (কম-মাত্রা ও দল) খোঁজা" — কে নিখুঁত সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথম ব্যবহারেই খোলা হলো; কোথাও কিছু ধরে নেওয়া হয়নি। যেখানে গণিতের পূর্ণ derivation লাগবে (covariance-এর eigen-decomposition কেন variance সর্বোচ্চ করে, PCA-র SVD-সংযোগ ও best-low-rank দাবি, k-means-objective ও Lloyd's algorithm-এর convergence, silhouette), সেটা §৪-এ — এখানে লক্ষ্য সংজ্ঞা ও স্বজ্ঞা পরিষ্কার করা।
প্রথমে notation থিতু করে নিই — আর এখানেই supervised থেকে প্রথম বড় তফাত। আমাদের কাছে \(n\)টি পর্যবেক্ষণ আছে, প্রতিটি \(p\)টি feature নিয়ে, কিন্তু কোনো response \(y\) নেই। এদের একসাথে সাজানো হয় একটা data matrix-এ: $$ X \in \mathbb{R}^{n \times p}, $$ যেখানে —
- \(n\) — পর্যবেক্ষণের সংখ্যা (row/সারি; যেমন গ্রাহকের সংখ্যা, এই অধ্যায়ের ডেটায় \(n=300\));
- \(p\) — feature-এর সংখ্যা (column/কলাম; যেমন প্রতি গ্রাহকের মাপা বৈশিষ্ট্য, এই ডেটায় \(p=4\));
- \(\mathbb{R}^{n\times p}\) — \(n\) সারি ও \(p\) কলামের বাস্তব-সংখ্যা matrix-দের সংগ্রহ; অর্থাৎ \(X\)-এর \(i\)-তম সারি \(x_i \in \mathbb{R}^p\) হলো \(i\)-তম পর্যবেক্ষণের \(p\)টি feature-এর vector, আর \(X\)-এর \(j\)-তম কলাম হলো \(j\)-তম feature-এর \(n\)টি মান।
লক্ষ করুন — supervised-এ data ছিল জোড়া \((x_i, y_i)\); এখানে কেবল \(x_i\), কোনো \(y_i\) নেই। আর এই \(X\)-কে আমরা সারা অধ্যায়ে ধরে নেব standardized (মানকীকৃত) — অর্থাৎ প্রতিটি কলামের গড় \(0\) ও মান-বিচ্যুতি (standard deviation) \(1\) করে নেওয়া। কেন এই মানকীকরণ অপরিহার্য, তা §২.১-এ খুলব।
দুই বড় হাতিয়ারকে এক-এক করে গড়া যাক — প্রথমে PCA (§২.১–২.৫), তারপর clustering (§২.৬–২.৯)।
২.১ কেন আগে standardize — PCA শুরুর আগের অপরিহার্য ধাপ¶
PCA-র প্রথম পদক্ষেপ আসলে PCA নয়, তার প্রস্তুতি: feature-দের standardize করা। কেন, তা একটা সরল উদাহরণে স্পষ্ট। ধরুন একটা feature "বার্ষিক আয়" টাকায় (মান লক্ষ-লক্ষ), আর আরেকটা "বয়স" বছরে (মান কয়েক-দশ)। শুধু এককের (unit) কারণেই আয়ের সংখ্যাগত ওঠানামা বয়সের চেয়ে হাজার গুণ বড় — অথচ এর সঙ্গে কোনটা "বেশি গুরুত্বপূর্ণ" তার কোনো সম্পর্ক নেই, নিছক একক বদলালেই (টাকা→হাজার টাকা) সংখ্যা পাল্টে যায়।
সমস্যা হলো, পরের ধাপে PCA variance (ছড়ানো)-র দিক খোঁজে, আর variance এককের উপর নির্ভরশীল — বড়-এককের feature নিছক তার স্কেলের জোরে সব ছড়ানো গিলে ফেলবে, ফলে PCA ভুলভাবে সেই feature-কেই সবচেয়ে "গুরুত্বপূর্ণ" ভাববে। এড়াতে প্রতিটি feature-কে এক সাধারণ স্কেলে আনি — প্রতিটি কলাম \(j\)-এর প্রতিটি মান থেকে সেই কলামের গড় \(\bar x_j\) বাদ দিয়ে কলামের মান-বিচ্যুতি \(s_j\) দিয়ে ভাগ করে: $$ x_{ij} \;\leftarrow\; \frac{x_{ij} - \bar x_j}{s_j}, $$ যেখানে \(x_{ij}\) হলো \(i\)-তম পর্যবেক্ষণের \(j\)-তম feature-এর মান, \(\bar x_j\) ওই কলামের গড়, ও \(s_j\) ওই কলামের মান-বিচ্যুতি। এর পরে প্রতিটি কলামের গড় \(0\) (centered/কেন্দ্রিত) ও variance \(1\) — সব feature এখন এক পায়ে দাঁড়িয়ে, কেউ স্কেলের জোরে অন্যায় সুবিধা পায় না। এই standardized \(X\)-ই PCA-র input। (গড়-বাদ-দেওয়া তথা centering আলাদাভাবেও জরুরি: PCA মূলবিন্দু-কেন্দ্রিক দিক খোঁজে, তাই data-কে নিজের গড়ে কেন্দ্রিত করা চাই।)
২.২ Covariance matrix — ছড়ানোর গঠন এক জায়গায়¶
standardized data হাতে; এবার PCA-র আসল কাঁচামাল — covariance matrix (সহভেদ-আবরণী) \(\Sigma\) (পড়ুন "সিগমা")। 2.6-এ এর সংজ্ঞা পেয়েছি; এখানে data-matrix থেকে তার রূপ: $$ \Sigma \;=\; \frac{1}{n-1}\, X^\top X, $$ যেখানে —
- \(X\) — উপরের standardized data matrix (\(n\times p\));
- \(X^\top\) — \(X\)-এর transpose (স্থানান্তর): সারি-কলাম উল্টে দেওয়া matrix (\(p\times n\));
- \(X^\top X\) — একটি \(p\times p\) matrix, যার \((j,k)\)-তম ভুক্তি হলো \(j\)-তম ও \(k\)-তম feature-এর মানগুলোর গুণফলের যোগ;
- \(\frac{1}{n-1}\) — নিরপেক্ষ (unbiased) আন্দাজের জন্য ভাগ (4.x-এর নমুনা-variance-এর সেই \(n-1\), Bessel-সংশোধন)।
ফল \(\Sigma\) একটি \(p\times p\) symmetric (প্রতিসম) matrix। এর গঠনটা পড়া জরুরি, কারণ PCA এখান থেকেই সব শেখে:
- কর্ণ (diagonal) ভুক্তি \(\Sigma_{jj}\) — \(j\)-তম feature-এর variance, অর্থাৎ সে একা কতটা ছড়ানো। (standardize করায় প্রতিটি কর্ণ-ভুক্তি প্রায় \(1\)।)
- কর্ণ-বহির্ভূত ভুক্তি \(\Sigma_{jk}\) (\(j\neq k\)) — \(j\)-তম ও \(k\)-তম feature-এর covariance: তারা কি একসাথে ওঠানামা করে (ধনাত্মক), উল্টোভাবে চলে (ঋণাত্মক), নাকি সম্পর্কহীন (\(0\)-র কাছাকাছি)। এখানেই correlation ধরা পড়ে — আর correlated feature-ই PCA-র মূল শিকার।
সংক্ষেপে: \(\Sigma\) হলো গোটা data-র ছড়ানোর ও পারস্পরিক-সম্পর্কের গঠন এক matrix-এ ঘনীভূত। প্রশ্ন এবার — এই গঠন থেকে "সবচেয়ে বেশি ছড়ানোর দিক" কীভাবে বের করি? উত্তর: eigen-decomposition।
২.৩ Eigen-decomposition — principal component-এর জন্ম¶
এটাই PCA-র হৃৎপিণ্ড, আর এখানেই 0.5-এর eigenvalue/eigenvector ফিরে আসে। মূল ধারণাটা ছবি দিয়ে ধরা ভালো: standardized data একটা মেঘের মতো মূলবিন্দুর চারপাশে ছড়িয়ে আছে। যদি সেটা উপবৃত্তাকার (elliptical) মেঘ হয়, তবে তার একটা দীর্ঘতম অক্ষ আছে (যে দিকে সবচেয়ে বেশি ছড়ানো), তার লম্বে পরের-দীর্ঘ অক্ষ, ইত্যাদি। PCA ঠিক এই অক্ষগুলোই খুঁজে বের করে — আর গাণিতিকভাবে এরা হলো \(\Sigma\)-এর eigenvector।
আনুষ্ঠানিকভাবে, symmetric matrix \(\Sigma\)-এর eigen-decomposition দেয় \(p\)টি eigenpair \((\lambda_j, v_j)\), \(j=1,\dots,p\), যারা সিদ্ধ করে: $$ \Sigma\, v_j \;=\; \lambda_j\, v_j, $$ যেখানে —
- \(v_j \in \mathbb{R}^p\) — \(j\)-তম eigenvector: একটা একক-দৈর্ঘ্যের দিক (vector), যাকে \(\Sigma\) দিয়ে গুণ করলে দিক বদলায় না, কেবল লম্বা/খাটো হয়;
- \(\lambda_j\) — \(j\)-তম eigenvalue (পড়ুন "ল্যাম্বডা-জে"): সেই scalar, যা বলে \(v_j\) দিকে \(\Sigma\) কতটা প্রসারণ ঘটায়।
এই eigen-decomposition-এর দুটি ভাষাগত নাম এখন স্থির করি, কারণ এরাই গোটা PCA-র শব্দভাণ্ডার:
- principal component = \(\Sigma\)-এর eigenvector \(v_j\) — অর্থাৎ একটা নতুন অক্ষ/দিক, মূল feature-গুলোর একটা ভারিত মিশ্রণ। এই নতুন অক্ষগুলো পরস্পর orthogonal (লম্ব), কারণ symmetric matrix-এর eigenvector-রা পরস্পর-লম্ব (0.5)।
- সেই দিকের variance = সংশ্লিষ্ট eigenvalue \(\lambda_j\) — অর্থাৎ data যদি \(v_j\) অক্ষে প্রক্ষিপ্ত (project) করা হয়, তবে সেই অক্ষ বরাবর data-র variance ঠিক \(\lambda_j\)। (কেন eigenvalue ঠিক সেই দিকের variance হয়, তার পূর্ণ যুক্তি §৪-এ।)
অর্থাৎ eigen-decomposition একই সঙ্গে দিচ্ছে — কোন কোন দিকে data ছড়ানো (eigenvector) আর কতটা ছড়ানো (eigenvalue)। এর চেয়ে PCA-র মূল ধারণার পরিষ্কার সারাংশ আর হয় না।
২.৪ PC1, PC2, … — সর্বোচ্চ-variance দিকগুলো ক্রমে সাজানো¶
eigenpair-গুলো হাতে এল; এবার এদের সাজাই। eigenvalue-গুলোকে বড় থেকে ছোট ক্রমে সাজানো হয়: $$ \lambda_1 \;\ge\; \lambda_2 \;\ge\; \cdots \;\ge\; \lambda_p \;\ge\; 0, $$ (সব \(\lambda_j\ge 0\), কারণ \(\Sigma\) একটা covariance matrix — positive semi-definite, 0.5)। এই ক্রম অনুযায়ী principal component-দের নাম দিই:
- PC1 (\(v_1\), eigenvalue \(\lambda_1\)) — যে দিকে data-র variance সর্বোচ্চ; অর্থাৎ মেঘের দীর্ঘতম অক্ষ, যে একক-দিকে project করলে সবচেয়ে বেশি ছড়ানো (তথা তথ্য) ধরা থাকে।
- PC2 (\(v_2\), eigenvalue \(\lambda_2\)) — যে দিকে variance তার পরের সর্বোচ্চ, এই শর্তে যে PC2 ⟂ PC1 (PC1-এর লম্বে)। অর্থাৎ PC1 যা ধরেনি, তার বাইরে সবচেয়ে বেশি ছড়ানোর নতুন, স্বাধীন দিক।
- PC3, PC4, … — একইভাবে, প্রতিটি আগেরগুলোর সবার লম্বে, ক্রমহ্রাসমান variance নিয়ে।
এই "সর্বোচ্চ-variance, তারপর তার-লম্বে-পরের-সর্বোচ্চ" সাজানোর মানে: data-র ছড়ানোর সিংহভাগ প্রথম কয়েকটা PC-তেই জড়ো হয়, আর শেষের PC-গুলোতে থাকে সামান্য variance — প্রায়ই কেবল noise। ঠিক এই কারণেই মাত্রা-হ্রাস সম্ভব: শেষের, কম-variance PC-গুলো ফেলে দিয়ে কেবল প্রথম কয়েকটা রাখলে খুব সামান্যই হারায়। (§১.৪-এর ডেটায় ঠিক এটাই — প্রথম দুই PC-তে ৯৯.৪% variance, বাকি দুই কার্যত শূন্য।)
২.৫ Explained variance ও scree plot — কটা component রাখব¶
"কম-variance PC ফেলে দাও" — কিন্তু কোথায় রেখা টানব? এটা ঠিক করতে দুটো সরল যন্ত্র।
প্রথমত, প্রতিটি PC কত ভাগ ছড়ানো ধরল তা পরিমাপ করি explained variance ratio দিয়ে: $$ \text{(PC}j\text{-এর explained variance ratio)} \;=\; \frac{\lambda_j}{\sum, $$ যেখানে লব }^{p}\lambda_l\(\lambda_j\) হলো \(j\)-তম PC-র variance, আর হর \(\sum_{l=1}^{p}\lambda_l\) হলো সব eigenvalue-র যোগ, অর্থাৎ data-র মোট variance (এটাই 5.1-এর variance-কে অংশে ভাঙার সেই অভ্যাস — মোট ওঠানামার কত ভাগ কে ধরল)। এই অনুপাত PC\(_j\) একাই মোট ছড়ানোর কত ভাগ ব্যাখ্যা করে তা বলে; আর প্রথম কয়েকটা যোগ করলে পাই cumulative explained variance — প্রথম \(k\)টি PC মিলে কত ভাগ ধরল। (§১.৪-এর \([0.651, 0.343, 0.004, 0.002]\) ঠিক এই অনুপাত; প্রথম দুটোর যোগ \(0.994\) = ৯৯.৪%।)
দ্বিতীয়ত, এই তথ্য চোখে দেখার ছবি — scree plot ("স্ক্রি" = পাহাড়ের ঢালে জমা ভাঙা পাথরের স্তূপ)। অনুভূমিক অক্ষে component-সংখ্যা (\(1,2,\dots,p\)), উল্লম্ব অক্ষে সংশ্লিষ্ট eigenvalue (বা explained variance ratio)। সাধারণত curve প্রথমে খাড়া নামে, তারপর হঠাৎ ভোঁতা হয়ে প্রায়-সমতল লেজে গড়ায়। যেখানে এই "elbow" (কনুই) — খাড়া থেকে সমতলে বাঁক — সেখানেই রেখা টানা হয়: তার আগের PC-গুলো রাখো (এরা প্রকৃত গঠন), পরেরগুলো ফেলো (এরা noise)। বিকল্প সরল নিয়ম: যত PC লাগে যাতে cumulative explained variance একটা সীমা (যেমন ৯০% বা ৯৫%) ছাড়ায়। (§১.৪-এর scree-তে elbow পড়বে ২ component-এ — চিত্র 5-9-scree।)
২.৬ Projection ও reconstruction — মাত্রা-হ্রাস বাস্তবে¶
principal component (নতুন অক্ষ) হাতে; এবার আসল মাত্রা-হ্রাস — data-কে এই নতুন অক্ষে প্রক্ষেপ (projection) করা। কোনো PC \(v_j\) বরাবর প্রতিটি পর্যবেক্ষণের অবস্থানকে বলে তার principal component score (বা সংক্ষেপে score): $$ z_{j} \;=\; X v_j, $$ যেখানে \(z_j \in \mathbb{R}^n\) হলো \(j\)-তম PC-তে সব \(n\)টি পর্যবেক্ষণের score-এর vector — অর্থাৎ \(i\)-তম পর্যবেক্ষণ \(x_i\)-কে \(v_j\) অক্ষে ফেললে তার যে নতুন স্থানাঙ্ক, সেটাই \(z_j\)-এর \(i\)-তম ভুক্তি। স্বজ্ঞায়: প্রতিটি point-কে নতুন অক্ষ বরাবর তার "ছায়া" বা অবস্থান দিয়ে নতুন করে বর্ণনা করা।
মাত্রা-হ্রাস তখন সরল: \(p\)টি PC-র মধ্যে কেবল প্রথম \(k\)টি (যেমন \(k=2\)) রাখো, আর প্রতিটি পর্যবেক্ষণকে তার (\(z_1, z_2, \dots, z_k\)) score দিয়ে বর্ণনা করো। ফলে \(p\)-মাত্রার data নেমে এল \(k\)-মাত্রায় — অথচ যেহেতু রাখা PC-গুলোই সর্বোচ্চ-variance, মূল ছড়ানোর সিংহভাগ অক্ষত (§১.৪-এ ৪→২ মাত্রায় নেমেও ৯৯.৪% রক্ষিত; এই 2D score-ই 5-9-pca-scatter চিত্রের অক্ষ)।
উল্টোপথও আছে — reconstruction (পুনর্গঠন)। কম-মাত্রার score থেকে মূল \(p\)-মাত্রার স্থানে আনুমানিকভাবে ফিরে আসা: রাখা PC-গুলোর দিক বরাবর score-গুলো বসিয়ে আবার একটা \(\hat X\) গড়া। যদি সব \(p\)টি PC রাখা হতো, reconstruction হতো হুবহু মূল \(X\) — কিছুই হারাত না। কিন্তু কেবল \(k<p\)টি রাখায় কিছু তথ্য বাদ পড়ে, তাই \(\hat X\) মূল \(X\)-এর কাছাকাছি, ঠিক সমান নয়; বাদ-পড়া অংশটাই reconstruction error (পুনর্গঠন-ভুল)। আর এই ভুল ঠিক কতটা — তা মাপে বাদ-দেওয়া PC-গুলোর eigenvalue-র যোগ, অর্থাৎ যত কম variance ফেললে তত ছোট ভুল।
PCA-র এক-বাক্য সারাংশ: standardized data-র covariance matrix \(\Sigma\)-এর eigen-decomposition দেয় পরস্পর-লম্ব principal component (eigenvector) ও তাদের variance (eigenvalue); সর্বোচ্চ-variance প্রথম \(k\)টি PC-তে data project করে আমরা \(p\) মাত্রা থেকে \(k\) মাত্রায় নামি, এবং এটিই গাণিতিকভাবে data-র সেরা রৈখিক (best linear) low-rank approximation — কোনো \(k\)-মাত্রার রৈখিক উপস্থাপন reconstruction-ভুল এর চেয়ে কম করতে পারে না। এই সর্বোত্তমতার ভিত্তি SVD (singular value decomposition): \(X=UDV^\top\) লিখলে \(V\)-এর কলামই principal component আর singular value-গুলোর বর্গ eigenvalue-র সমানুপাতিক — পূর্ণ যোগসূত্র ও প্রমাণ §৪-এ।
২.৭ Clustering ও k-means — objective হিসেবে cluster (গুচ্ছ)¶
PCA শেষ; এবার দ্বিতীয় হাতিয়ার — clustering। লক্ষ্য (§১.৩): লেবেল ছাড়াই point-গুলোকে এমন কয়েকটা দলে (cluster) ভাগ করা যে এক দলের সদস্যরা পরস্পরের কাছাকাছি, অথচ ভিন্ন দলের থেকে দূরে। সবচেয়ে চেনা পদ্ধতি k-means (কে-মিনস, "k-গড়"), যেখানে আগেই একটা সংখ্যা \(k\) দিয়ে বলে দিই — কয়টা cluster চাই।
k-means-কে বোঝার সবচেয়ে পরিষ্কার পথ হলো তার objective (লক্ষ্য-অপেক্ষক) দিয়ে — সে আসলে কী minimize করতে চাইছে। প্রতিটি cluster-এর একটা কেন্দ্র থাকে, তাকে বলে centroid (কেন্দ্রক) — cluster-এর সব point-এর গড়। ভালো clustering মানে প্রতিটি point তার নিজের centroid-এর যত কাছে সম্ভব। এই "কাছে থাকা"-কে সংখ্যায় ধরে within-cluster sum of squares, যাকে k-means-প্রসঙ্গে বলে inertia (জড়তা): $$ \text{inertia} \;=\; \sum_{k=1}^{K}\ \sum_{i \in C_k}\ \bigl\lVert x_i - \mu_k \bigr\rVert^2, $$ যেখানে —
- \(K\) — মোট cluster-সংখ্যা (যেটা আমরা আগে স্থির করি; নিচে \(k\) লেখা হলে এই সংখ্যাই বোঝায়);
- \(C_k\) — \(k\)-তম cluster, অর্থাৎ যে পর্যবেক্ষণগুলো এই দলে বরাদ্দ;
- \(x_i\) — \(i\)-তম পর্যবেক্ষণের feature-vector (\(\in\mathbb{R}^p\));
- \(\mu_k\) ("মিউ-কে") — \(k\)-তম cluster-এর centroid, অর্থাৎ \(C_k\)-এর সব point-এর গড়;
- \(\lVert x_i - \mu_k \rVert\) — \(x_i\) ও তার centroid \(\mu_k\)-এর মধ্যে Euclidean distance (সরলরৈখিক দূরত্ব), আর \(\lVert x_i - \mu_k \rVert^2\) তার বর্গ; (\(\lVert \cdot \rVert\) = vector-এর দৈর্ঘ্য/norm)।
অর্থাৎ inertia হলো প্রতিটি point থেকে তার নিজ-centroid পর্যন্ত বর্গ-দূরত্বের মোট যোগ — যত ছোট, cluster-গুলো তত আঁটোসাঁটো। k-means-এর লক্ষ্য: যে cluster-বিন্যাস এই inertia সর্বনিম্ন করে, সেটা খুঁজে বের করা। (§১.৪-এর ডেটায় \(k\) বাড়ানোর সঙ্গে inertia-র নামা — \(1200,527,135,111,\dots\) — ঠিক এই সংখ্যাই।)
২.৮ Lloyd's algorithm — assign ও update-এর পুনরাবৃত্তি¶
§২.৭-এর objective সরাসরি minimize করা কঠিন (point-দের সব সম্ভাব্য দলে-ভাগ অসংখ্য)। তাই বাস্তবে এক সরল, পুনরাবৃত্ত কৌশল চালানো হয় — Lloyd's algorithm (লয়েড-এর অ্যালগরিদম), যা k-means-এর কার্যত-সমার্থক। ধাপগুলো:
- শুরু (initialization): \(k\)টি centroid \(\mu_1,\dots,\mu_k\) বেছে নাও (যেমন এলোমেলোভাবে \(k\)টি point)।
- Assign (বরাদ্দ) ধাপ: প্রতিটি point \(x_i\)-কে তার নিকটতম centroid-এর cluster-এ ফেলো — অর্থাৎ যে \(\mu_k\) থেকে \(\lVert x_i-\mu_k\rVert\) সবচেয়ে ছোট।
- Update (পুনর্গণনা) ধাপ: প্রতিটি cluster-এর centroid নতুন করে হিসাব করো — এখন সেই cluster-এ যে point-গুলো আছে, তাদের গড় নাও: \(\mu_k \leftarrow (C_k\)-এর সব point-এর গড়)।
- ধাপ ১ ও ২ পুনরাবৃত্তি করো, যতক্ষণ না বরাদ্দ আর বদলায় (centroid থিতু হয়) — তখন থামো।
স্বজ্ঞায়: assign-ধাপ centroid স্থির রেখে point-দের সেরা দলে সাজায়; update-ধাপ দল স্থির রেখে centroid-কে দলের মাঝখানে টানে। দুটোই inertia কমায়, তাই প্রতি পুনরাবৃত্তিতে inertia একঘেয়েভাবে নামে (বা সমান থাকে), আর algorithm নিশ্চিতভাবে থিতু হয়। দুটি জরুরি সীমা মাথায় রাখা চাই:
- কেবল local minimum: Lloyd's algorithm inertia কমায় ঠিকই, কিন্তু বিশ্বজনীন (global) সর্বনিম্ন-এর নিশ্চয়তা দেয় না — শুরুর centroid-এর উপর নির্ভর করে সে একটা স্থানীয় গর্তে আটকে যেতে পারে। তাই বাস্তবে একাধিক random শুরু থেকে চালিয়ে সবচেয়ে কম-inertia ফলটা রাখা হয় (যেমন
k-means++ধাঁচের সতর্ক initialization)। - \(k\) আগে দিতে হয়: algorithm নিজে cluster-সংখ্যা বলে দেয় না — \(k\) আমাদের ইনপুট। ভুল \(k\) দিলে ভুল ভাগ। তাই সঠিক \(k\) বাছার প্রশ্নটাই পরের।
২.৯ \(k\) বাছা (elbow ও silhouette), hierarchical clustering, ও PCA-then-cluster¶
\(k\) কত? — clustering-এর সবচেয়ে ব্যবহারিক প্রশ্ন, কারণ লেবেল নেই বলে "সঠিক সংখ্যা" আগে থেকে জানা নেই। দুটো পরিপূরক যন্ত্র।
(ক) Elbow method (কনুই-পদ্ধতি)। বিভিন্ন \(k\)-এর জন্য k-means চালিয়ে প্রতিবারের সর্বনিম্ন inertia হিসাব করো, তারপর inertia বনাম \(k\) আঁকো। \(k\) বাড়লে inertia সবসময় কমে (বেশি cluster মানে প্রতিটি centroid আরও কাছে) — কিন্তু একটা বিন্দুর পর কমার গতি হঠাৎ ভোঁতা হয়ে যায়: তার আগে প্রতিটি নতুন cluster সত্যিকারের গঠন ধরছিল (inertia তীব্রভাবে নামছিল), তার পরে কেবল ইতিমধ্যেই-আঁটোসাঁটো দলকে অযথা ভাঙছে (সামান্যই নামছে)। এই বাঁক-বিন্দু — "elbow" — ই ভালো \(k\)। (§১.৪-এর ডেটায় inertia \(1200\to527\to135\to111\): \(k=3\)-এর পরে নামা ভোঁতা, তাই elbow \(k=3\)-এ — চিত্র 5-9-kmeans-elbow।)
(খ) Silhouette (সিল্যুয়েট/ছায়াচিত্র)। elbow কখনো অস্পষ্ট হয়, তাই আরও সূক্ষ্ম একটা মাপ — যা প্রতিটি point কতটা "সঠিক দলে" আছে তা ধরে। \(i\)-তম point-এর জন্য silhouette \(s_i\) মাপে দুটো জিনিসের তুলনা:
- cohesion (সংসক্তি): \(i\) তার নিজের cluster-এর বাকি সদস্যদের কত কাছে (গড় দূরত্ব যত কম, তত ভালো);
- separation (পৃথকীকরণ): \(i\) তার নিকটতম প্রতিবেশী cluster থেকে কত দূরে (যত দূর, তত ভালো)।
এ-দুটো মিলিয়ে \(s_i\)-এর মান পড়ে \(-1\) থেকে \(1\)-এর মধ্যে: \(s_i\approx 1\) মানে point নিজ দলে আঁটোসাঁটো ও অন্য দল থেকে দূরে (চমৎকার), \(s_i\approx 0\) মানে দুই দলের সীমানায় ঝুলছে, আর \(s_i<0\) মানে সম্ভবত ভুল দলে পড়েছে। সব point-এর \(s_i\)-এর গড় (mean silhouette score) যত বেশি, clustering তত ভালো — তাই যে \(k\)-এ গড় silhouette সর্বোচ্চ, সেটাই বাছা হয়। (গাণিতিক সংজ্ঞা §৪-এ; §১.৪-এর ডেটায় silhouette সর্বোচ্চ \(k=3\)-এ, মান \(0.712\) — elbow-এর রায়ের সঙ্গে মিলে।)
Hierarchical / agglomerative clustering (সংক্ষেপে)। k-means-এর একটা বিকল্প, যেখানে \(k\) আগে দিতে হয় না। Agglomerative (সংযোজী) রূপে শুরুতে প্রতিটি point নিজেই একটা cluster; তারপর ধাপে-ধাপে সবচেয়ে কাছের দুই cluster জোড়া লাগিয়ে বড় cluster বানানো হয়, যতক্ষণ না সব এক হয়। "দুই cluster কত কাছে" তা মাপার নিয়মকে বলে linkage (সংযোগ-নিয়ম — যেমন দুই দলের নিকটতম জোড়া, দূরতম জোড়া, বা গড় দূরত্ব)। গোটা সংযোজন-ইতিহাস একটা গাছের মতো চিত্রে আঁকা হয় — dendrogram (বৃক্ষচিত্র); সেই গাছ একটা নির্দিষ্ট উচ্চতায় কাটলে যত শাখা পাওয়া যায়, ততগুলো cluster — অর্থাৎ \(k\) পরে, ছবি দেখে, বেছে নেওয়া যায়।
PCA-then-cluster। শেষে দুই হাতিয়ারের মেলবন্ধন (§১.৩-এর সেই পুনরাবৃত্ত সুর): উঁচু-মাত্রায় দূরত্ব ফিকে ও noisy (curse of dimensionality, §১.২), তাই আগে PCA দিয়ে প্রথম কয়েকটা PC-তে নেমে এসে — যেখানে সংকেত ঘনীভূত ও noise বাদ — তারপর সেই কম-মাত্রার score-এ clustering চালানো প্রায়ই বেশি স্থিতিশীল ও পরিষ্কার দল দেয়। এই অধ্যায়ের ডেটায় ঠিক এটাই করা হবে: ৪→২ মাত্রায় PCA, তারপর সেই 2D-তে k-means — আর তাতে সত্যিকারের ৩ দল প্রায় নিখুঁতভাবে ফিরে আসবে (§১.৪-এর ARI \(\approx 0.99\); চিত্র 5-9-clusters)।
Clustering-এর এক-বাক্য সারাংশ: k-means লেবেল-বিহীn point-দের \(k\)টি দলে ভাগ করে within-cluster sum of squares (inertia) সর্বনিম্ন করে — Lloyd's algorithm-এর assign→update পুনরাবৃত্তিতে, যা কেবল local minimum-এর নিশ্চয়তা দেয় ও \(k\) আগে চায়; সঠিক \(k\) বাছা যায় elbow (inertia-র বাঁক) ও silhouette (cohesion বনাম separation) দিয়ে; বিকল্পে hierarchical clustering dendrogram-এ \(k\) পরে বেছে নিতে দেয়; আর উঁচু মাত্রায় আগে PCA-তে নামিয়ে cluster করলে দল আরও পরিষ্কার হয়।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এই অংশে আমরা একটি কৃত্রিম (synthetic) ডেটাসেটের উপর PCA ও \(k\)-means পদ্ধতি দুটি ধাপে ধাপে প্রয়োগ করব। ডেটাসেটটি ইচ্ছাকৃতভাবে এমনভাবে তৈরি করা হয়েছে যাতে এর "সত্য" গঠন আমরা আগে থেকেই জানি — তিনটি cluster, এবং প্রকৃত পক্ষে মাত্র ২টি স্বাধীন (intrinsic) মাত্রা, যা ৪টি correlated feature-এর মধ্যে লুকানো। সত্য গঠন জানা থাকায় শেষে আমরা যাচাই করতে পারব unsupervised পদ্ধতি কতটা নিখুঁতভাবে সেই গঠন পুনরুদ্ধার করল।
৩.০ · ডেটা তৈরি¶
আমরা \(\mathbb R^2\)-এ তিনটি কেন্দ্রের (\([0,0],[6,1],[3,6]\)) চারপাশে ১০০টি করে বিন্দু তৈরি করি, তারপর সেই দুটি latent মাত্রা থেকে ৪টি feature বানাই — যার মধ্যে \(f_3,f_4\) হলো \(f_1,f_2\)-এর রৈখিক সংমিশ্রণ (সামান্য noise সহ)। ফলে ৪টি কলাম পরস্পর strongly correlated, এবং প্রকৃত তথ্য মাত্র ২ মাত্রায় বসে আছে। শেষে standardize করি, কারণ PCA scale-সংবেদনশীল — variance-এর এককে পার্থক্য থাকলে বড়-scale feature কৃত্রিমভাবে আধিপত্য বিস্তার করে।
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, adjusted_rand_score
rng = np.random.default_rng(20260619)
centers = np.array([[0, 0], [6, 1], [3, 6]], float)
Z, lab = [], []
for k, c in enumerate(centers):
z = rng.normal(c, 0.8, size=(100, 2)); Z.append(z); lab += [k] * 100
Z = np.vstack(Z); lab = np.array(lab)
f1 = Z[:, 0]
f2 = Z[:, 1]
f3 = 0.8 * Z[:, 0] + 0.3 * rng.normal(0, 1, 300) # f1-এর প্রতিফলন
f4 = -0.5 * Z[:, 1] + 0.6 * Z[:, 0] + 0.3 * rng.normal(0, 1, 300) # f1,f2-এর মিশ্রণ
Xraw = np.c_[f1, f2, f3, f4]
X = StandardScaler().fit_transform(Xraw) # X ∈ R^{300×4}, প্রতিটি কলাম mean 0, std 1
এখন \(X\in\mathbb R^{n\times p}\) যেখানে \(n=300,\ p=4\)। মনে রাখা দরকার — lab (সত্য cluster-সূচক) আমরা কেবল শেষে যাচাইয়ের জন্য রাখছি; PCA বা \(k\)-means কোনোটিই এটি ব্যবহার করে না।
E1 — PCA: variance সংকোচন (compression)¶
লক্ষ্য: ৪-মাত্রিক ডেটার প্রকৃত মাত্রিকতা (intrinsic dimensionality) কত, তা নির্ণয় করা। PCA standardized data-র covariance ম্যাট্রিক্স \(\Sigma\)-এর eigen-decomposition করে; eigenpair \((\lambda_j, v_j)\)-তে \(\lambda_j\) হলো \(j\)-তম principal component বরাবর variance, এবং explained variance ratio \(\lambda_j/\sum_l \lambda_l\) বলে দেয় ঐ PC মোট variance-এর কত ভাগ ধরে রাখে।
pca = PCA().fit(X)
print("eigenvalues :", np.round(pca.explained_variance_, 3))
print("explained var ratio:", np.round(pca.explained_variance_ratio_, 4))
print("cumulative :", np.round(np.cumsum(pca.explained_variance_ratio_), 4))
আউটপুট:
eigenvalues : [2.614 1.375 0.017 0.008]
explained var ratio: [0.651 0.343 0.004 0.002]
cumulative : [0.651 0.994 0.998 1.0]
ব্যাখ্যা। প্রথম দুটি eigenvalue (\(\lambda_1=2.614,\ \lambda_2=1.375\)) বাকি দুটির (\(0.017,\ 0.008\)) তুলনায় বহু গুণ বড় — পরিষ্কার একটি খাড়া পতন (sharp drop) PC2-এর পরে। explained variance ratio-তে এটি আরও স্পষ্ট: PC1 ধরে রাখে \(65.1\%\), PC2 আরও \(34.3\%\), ফলে
অর্থাৎ প্রথম দুই PC মিলে ৯৯.৪% variance ধরে রাখে। বাকি দুই PC মাত্র \(0.6\%\) — এটি মূলত আমাদের যোগ করা noise। সিদ্ধান্ত: যদিও ডেটা ৪-মাত্রিক দেখাচ্ছে, এটি কার্যত ২-মাত্রিক। এটি অপ্রত্যাশিত নয় — আমরা তো জেনেশুনেই \(f_3,f_4\)-কে \(f_1,f_2\)-এর রৈখিক ফাংশন বানিয়েছি, তাই correlated feature-গুলো PCA-র অধীনে মাত্র দুটি independent দিকে গুটিয়ে (collapse) যায়। এই "scree" পড়ে নেওয়াই PCA-র কেন্দ্রীয় দক্ষতা: কতগুলো component রাখা যথেষ্ট, তা eigenvalue-র খাড়া পতন দেখেই ঠিক করা যায়।
scree পড়ার নিয়ম। eigenvalue-গুলো অবরোহী ক্রমে সাজিয়ে যেখানে বড় পতনের পর line প্রায় সমতল (flat) হয়ে যায়, সেই "elbow"-এর আগ পর্যন্ত component রাখাই যুক্তিযুক্ত। এখানে elbow ঠিক PC2-এর পরে, তাই আমরা \(r=2\) component রাখি।
E2 — PCA: projection গঠন উন্মোচন করে¶
লক্ষ্য: কেবল সংকোচন নয়, PCA-কে high-dimensional ডেটার visualization যন্ত্র হিসেবে ব্যবহার করা। যেহেতু আমরা চোখে ৪ মাত্রা দেখতে পাই না, আমরা ডেটাকে প্রথম দুই principal component-এ projection করি — PC score \(z = Xv\) ব্যবহার করে — এবং ফলাফলটিকে একটি সাধারণ 2D scatter plot হিসেবে আঁকি।
Zscores = pca.transform(X)[:, :2] # z = X v_1, X v_2 → আকার (300, 2)
print("projected shape:", Zscores.shape) # (300, 2)
PC1–PC2 তলে projection করার পর তিনটি গুচ্ছ (cluster) দৃশ্যত আলাদা তিনটি ঘনপুঞ্জ হিসেবে ফুটে ওঠে — যদিও projection করার সময় কোনো label ব্যবহার করা হয়নি। এই দ্বি-মাত্রিক চিত্রই E3–E4-এ clustering-এর ভিত্তি, এবং নিচের চিত্রে তা দেখানো হলো।
(চিত্র 5-9-pca-scatter — পরিকল্পিত স্কেচ: PC1 অক্ষ বরাবর অনুভূমিক, PC2 অক্ষ বরাবর উল্লম্ব; ৩০০টি বিন্দুর scatter, যেখানে তিনটি পৃথক ঘনপুঞ্জ স্পষ্ট। যেহেতু PC1+PC2 মোট variance-এর ৯৯.৪% ধরে রাখে, এই 2D ছবিটি প্রকৃত ৪D গঠনের প্রায়-সম্পূর্ণ বিশ্বস্ত প্রতিরূপ।)
ব্যাখ্যা। PCA এখানে দুটি ভূমিকা একসাথে পালন করল — (১) মাত্রা কমিয়ে redundant তথ্য বাদ দিল, এবং (২) সেই কম-মাত্রিক স্থানে ডেটার লুকানো গঠনকে চোখে-দেখার মতো করে তুলল। লক্ষণীয়, PC1–PC2 যেহেতু variance-এর প্রায় সবটাই (\(99.4\%\)) ধরে রেখেছে, এই 2D projection-এ যা দেখছি তা প্রকৃত গঠনের প্রায় নিখুঁত প্রতিচ্ছবি; কোনো গুরুত্বপূর্ণ পৃথকীকরণ projection-এর সময় হারিয়ে যায়নি। এই কারণেই উচ্চ-মাত্রিক ডেটা বিশ্লেষণে clustering-এর আগে PCA একটি স্বাভাবিক প্রাক-পদক্ষেপ।
E3 — \(k\)-means: \(k\) নির্বাচন¶
লক্ষ্য: cluster সংখ্যা \(k\) নির্ধারণ। \(k\)-means নিজে \(k\) অনুমান করে না — এটি ব্যবহারকারীকে দিতে হয়। আমরা দুটি পরিপূরক নির্দেশক ব্যবহার করি: (১) inertia (within-cluster sum of squares) \(\sum_k \sum_{i\in C_k}\lVert x_i-\mu_k\rVert^2\) — elbow পদ্ধতি; এবং (২) silhouette score \(s\), যা cluster-গুলো কতটা সুসংহত ও পৃথক তা \([-1,1]\) স্কেলে মাপে (বড় মান = ভালো)।
for k in range(1, 7):
km = KMeans(n_clusters=k, n_init=10, random_state=0).fit(X)
print(f"k={k}: inertia={km.inertia_:7.1f}")
for k in [2, 3, 4, 5]:
km = KMeans(n_clusters=k, n_init=10, random_state=0).fit(X)
print(f"k={k}: silhouette={silhouette_score(X, km.labels_):.3f}")
আউটপুট:
| \(k\) | inertia | silhouette \(s\) |
|---|---|---|
| 1 | 1200.0 | — |
| 2 | 527.4 | 0.552 |
| 3 | 135.3 | 0.712 |
| 4 | 110.6 | 0.598 |
| 5 | 90.6 | 0.484 |
| 6 | 71.7 | — |
ব্যাখ্যা — elbow। inertia সবসময় \(k\) বাড়লে কমে (চরমে, প্রতিটি বিন্দু নিজেই একটি cluster হলে inertia \(=0\)), তাই কেবল "সবচেয়ে কম inertia" নিয়ম অর্থহীন। আমরা খুঁজি সেই বিন্দু যেখানে কমার হার হঠাৎ ধীর হয়ে যায়। এখানে পতন: \(1200 \to 527 \to 135\) — প্রতিটি ধাপে নাটকীয়; কিন্তু এরপর \(135 \to 111 \to 91 \to 72\), অর্থাৎ পতন স্পষ্টভাবে সমতল (flatten) হয়ে যায়। এই বাঁক বা "elbow" \(k=3\)-তে। পরিমাণগতভাবে: \(k=2\to3\) ধাপে inertia কমে \(\approx 392\), কিন্তু \(k=3\to4\) ধাপে কমে মাত্র \(\approx 25\) — এক ধাক্কায় প্রায় ১৫ গুণ কম প্রতিদান, যা elbow-এর স্বাক্ষর।
ব্যাখ্যা — silhouette। elbow কখনো অস্পষ্ট হতে পারে, তাই নিরপেক্ষ দ্বিতীয় সাক্ষী হিসেবে silhouette দেখি। এটি \(k=3\)-তে সর্বোচ্চ (\(s=0.712\)); \(k=2\) (\(0.552\)), \(k=4\) (\(0.598\)), \(k=5\) (\(0.484\)) — সবগুলোই কম। দুটি স্বাধীন নির্দেশক — elbow ও silhouette — একই উত্তরে (\(k=3\)) মিলে যাওয়া আমাদের নির্বাচনে যথেষ্ট আস্থা দেয়। (এই \(k=3\) আমাদের ডেটা-তৈরির তিন কেন্দ্রের সাথেও মিলছে, যদিও পদ্ধতি সেই তথ্য জানত না।)
E4 — \(k\)-means: গঠন পুনরুদ্ধার (recovery)¶
লক্ষ্য: নির্বাচিত \(k=3\) দিয়ে চূড়ান্ত clustering করা এবং পদ্ধতিটি প্রকৃত গঠন কতটা পুনরুদ্ধার করল তা যাচাই করা। যেহেতু আমরা সত্য label (lab) জানি, আমরা Adjusted Rand Index (ARI) দিয়ে পাওয়া cluster ও সত্য cluster-এর মিল মাপতে পারি — ARI \(=1\) মানে নিখুঁত মিল, \(\approx 0\) মানে এলোমেলো অনুমানের সমতুল্য।
km3 = KMeans(n_clusters=3, n_init=10, random_state=0).fit(X)
print("inertia :", round(km3.inertia_, 1))
print("silhouette :", round(silhouette_score(X, km3.labels_), 3))
print("ARI vs true:", round(adjusted_rand_score(lab, km3.labels_), 3))
আউটপুট:
ব্যাখ্যা। \(k=3\) fit করার পর inertia \(135.3\) ও silhouette \(0.712\) — E3-এর সাথে সঙ্গতিপূর্ণ, নিশ্চিত করছে এটিই সবচেয়ে সুসংহত বিন্যাস। নির্ণায়ক ফলাফল হলো ARI \(=0.990\): পাওয়া তিনটি cluster প্রকৃত তিনটি গোষ্ঠীর সাথে প্রায় নিখুঁতভাবে মেলে (সামান্য \(0.01\) ঘাটতি cluster-প্রান্তের গুটিকয় সীমান্তবর্তী বিন্দুর ভুল-বরাদ্দ থেকে আসে)। লক্ষণীয় দিক — \(k\)-means কোনো label দেখেনি; কেবল feature-গুলোর জ্যামিতি (distance ও কেন্দ্র) থেকেই সে সত্য তিনটি গোষ্ঠী প্রায় ত্রুটিহীনভাবে পুনরুদ্ধার করল। এটিই unsupervised learning-এর মূল প্রতিশ্রুতি: যখন ডেটায় বাস্তবিক, ভালোভাবে-পৃথক গঠন থাকে, কোনো তত্ত্বাবধান (supervision) ছাড়াই উপযুক্ত পদ্ধতি তা খুঁজে বের করতে পারে।
সতর্কতা। এই প্রায়-নিখুঁত ফল আমাদের পক্ষে কিছুটা সাজানো — cluster-গুলো ছিল ভালোভাবে পৃথক ও প্রায় গোলকাকার (spherical), যা ঠিক সেই পরিস্থিতি যেখানে \(k\)-means সবচেয়ে ভালো কাজ করে। overlap-যুক্ত বা অ-গোলকাকার (non-convex) cluster-এ ARI অনেক কম হতে পারে; তখন silhouette ও elbow-ও কম স্পষ্ট সংকেত দেবে।
যাচাই-ব্লক (sklearn দিয়ে নিশ্চিত)¶
উপরের সমস্ত সংখ্যা scikit-learn চালিয়ে যাচাই করা হয়েছে; নিচে সংক্ষিপ্ত আউটপুট:
# PCA (standardized X)
eigenvalues : [2.614 1.375 0.017 0.008]
explained var ratio: [0.6513 0.3426 0.0042 0.0019]
cumulative : [0.6513 0.9939 0.9981 1.0]
PC1+PC2 : 99.4 %
# KMeans inertia (elbow)
k=1: 1200.0 k=2: 527.4 k=3: 135.3 k=4: 110.6 k=5: 90.6 k=6: 71.7
# silhouette
k=2: 0.552 k=3: 0.712 (MAX) k=4: 0.598 k=5: 0.484
# k=3 final
inertia = 135.3 | silhouette = 0.712 | ARI vs true labels = 0.990
প্রতিটি মান brief-এর canonical সংখ্যার সাথে হুবহু মিলেছে: PCA explained variance ratio \([0.651, 0.343, 0.004, 0.002]\), eigenvalues \([2.614, 1.375, 0.017, 0.008]\), inertia-ক্রম \(1200\to527\to135\to111\to91\to72\), silhouette সর্বোচ্চ \(k=3\)-তে (\(0.712\)), এবং চূড়ান্ত \(k=3\): inertia \(135.3\), silhouette \(0.712\), ARI \(0.990\)।
৪ · প্রমাণ ও উৎপাদন¶
এই বিভাগে §২–§৩-এ ব্যবহৃত multivariate-হাতিয়ারগুলোর গাণিতিক ভিত্তি শূন্য থেকে গড়ে তুলব। কেন্দ্রীয় প্রশ্ন দুটি, কিন্তু উভয়েই একই আকারের: একটি বিচ্ছুরণ (spread) সর্বোচ্চ বা সর্বনিম্ন করতে চাইলে গাণিতিকভাবে কী বেরিয়ে আসে? প্রথমটিতে (PCA) আমরা projection-এর variance সর্বোচ্চ করব — উত্তর আসবে covariance matrix-এর eigenvector রূপে। দ্বিতীয়টিতে (k-means) আমরা cluster-এর ভেতরের বিচ্ছুরণ সর্বনিম্ন করব — উত্তর আসবে cluster-mean ও nearest-centroid নিয়মে। দুটোই linear algebra-র একই মেরুদণ্ডের উপর দাঁড়ানো: symmetric PSD matrix, eigen-decomposition, ও quadratic form। ভিত্তি তিনটি: (i) prereq 0.5-এর eigenvalue/eigenvector ও symmetric matrix-এর spectral theorem; (ii) prereq 2.6-এর covariance matrix; (iii) prereq 5.1-এর variance। প্রতিটি প্রতীক প্রথম ব্যবহারে খোলা হবে, প্রতিটি ধাপ যুক্তিসহ। কষ্টের স্তর প্রতিটি উপ-বিভাগের শিরোনামে তারা দিয়ে: ★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং।
সাধারণ সেট-আপ ও প্রতীক। ধরি data-matrix \(X\in\mathbb R^{n\times p}\), যেখানে \(n\)টি সারি = পর্যবেক্ষণ (\(x_1,\dots,x_n\in\mathbb R^p\)), \(p\)টি কলাম = feature। সর্বত্র ধরে নিচ্ছি \(X\) centered (প্রতিটি কলামের গড় শূন্য) — প্রয়োজনে standardized-ও। তখন sample covariance matrix
দুটো বৈশিষ্ট্য আমরা বারবার ব্যবহার করব, তাই প্রথমেই প্রতিষ্ঠা করি।
- \(\Sigma\) symmetric: \(\Sigma^\top=\frac1{n-1}(X^\top X)^\top=\frac1{n-1}X^\top X=\Sigma\)। সুতরাং spectral theorem (prereq 0.5) প্রযোজ্য — \(\Sigma\)-এর \(p\)টি বাস্তব eigenvalue \(\lambda_1\ge\lambda_2\ge\dots\ge\lambda_p\) এবং একটি orthonormal eigenvector-সেট \(v_1,\dots,v_p\) (\(v_j^\top v_k=\delta_{jk}\)) আছে, যাতে \(\Sigma=\sum_{j}\lambda_j v_j v_j^\top=V\Lambda V^\top\), যেখানে \(V=[v_1\;\cdots\;v_p]\) orthogonal (\(V^\top V=I\)) আর \(\Lambda=\operatorname{diag}(\lambda_1,\dots,\lambda_p)\)।
- \(\Sigma\) positive semidefinite (PSD): যেকোনো \(v\in\mathbb R^p\)-এর জন্য \(v^\top\Sigma v=\frac1{n-1}v^\top X^\top X v=\frac1{n-1}\lVert Xv\rVert^2\ge 0\)। অর্থাৎ সকল \(\lambda_j\ge 0\) (eigenvector-এ বসালে \(v_j^\top\Sigma v_j=\lambda_j\ge0\))।
PCA-অংশে \(\Sigma\)-ই নায়ক; k-means-অংশে আমরা সরাসরি বিন্দু \(x_i\) ও centroid নিয়ে কাজ করব।
৪.১ ★★★ প্রথম principal component = সর্বোচ্চ eigenvector¶
লক্ষ্য। এমন একটি দিক (unit vector) \(v\) খুঁজি যার উপর data project করলে projection-এর variance সর্বোচ্চ হয়। দাবি: সেই \(v\) হলো \(\Sigma\)-এর সবচেয়ে বড় eigenvalue-এর eigenvector, এবং সর্বোচ্চ variance ঠিক সেই eigenvalue \(\lambda_1\)।
ধাপ ১ — projection-এর variance একটি quadratic form। একটি unit vector \(v\) (\(\lVert v\rVert=1\)) দিলে, প্রতিটি পর্যবেক্ষণ \(x_i\)-এর \(v\)-অভিমুখে projection-এর scalar coordinate হলো \(x_i^\top v\) (inner product = signed দৈর্ঘ্য)। সব \(n\)টি একসাথে: vector \(Xv\in\mathbb R^n\), যার \(i\)-তম উপাদান \(x_i^\top v\)। যেহেতু \(X\) centered, \(Xv\)-এরও গড় শূন্য:
তাই projection-এর sample variance (prereq 5.1, একই \(n-1\) ভাজক):
অর্থাৎ projection-এর variance = \(v^\top\Sigma v\) — একটি quadratic form, যা আমরা সর্বোচ্চ করতে চাই। কিন্তু constraint ছাড়া \(v\)-কে যত খুশি বড় করলে variance অসীম হয়ে যায় (এটি scale-এর জন্য, দিকের জন্য নয়), তাই দিকটিকে স্থির রাখতে normalize করি: \(\lVert v\rVert^2=v^\top v=1\)।
ধাপ ২ — Lagrangian ও stationarity। Constraint-সহ optimization-এর জন্য Lagrange multiplier \(\lambda\in\mathbb R\) ব্যবহার করি (prereq 0.5/calculus):
\(v\)-এর সাপেক্ষে gradient নিই। দুটি standard পরিচয় (যেহেতু \(\Sigma\) symmetric):
পরিচয় দুটির দ্রুত যাচাই: \(v^\top\Sigma v=\sum_{k,l}\Sigma_{kl}v_k v_l\); কোনো নির্দিষ্ট \(v_m\)-এর সাপেক্ষে partial নিলে \(\sum_l\Sigma_{ml}v_l+\sum_k\Sigma_{km}v_k=2\sum_l\Sigma_{ml}v_l\) (symmetry-তে দুই যোগফল সমান) \(=2(\Sigma v)_m\)। সব \(m\) একত্রে \(\nabla_v=2\Sigma v\)।
Stationarity শর্ত \(\nabla_v\mathcal L=0\):
— এটিই eigen-equation! অর্থাৎ stationary \(v\)-গুলো হুবহু \(\Sigma\)-এর eigenvector, এবং Lagrange multiplier \(\lambda\) হলো সংশ্লিষ্ট eigenvalue। (\(v^\top v=1\) শর্ত মাত্র eigenvector-কে unit length-এ স্থির করে।)
ধাপ ৩ — কোন eigenvector? সর্বোচ্চটি। এখন stationary বিন্দুগুলোর মধ্যে কোনটি আসলে সর্বোচ্চ দেয়, তা নির্ণয় করি। eigen-equation \(\Sigma v=\lambda v\) দুপাশে বাঁ দিক থেকে \(v^\top\) গুণ করি এবং \(v^\top v=1\) ব্যবহার করি:
অর্থাৎ একটি eigenvector \(v_j\)-এ মূল objective-এর মান ঠিক তার eigenvalue: \(v_j^\top\Sigma v_j=\lambda_j\)। যেহেতু আমরা objective সর্বোচ্চ করতে চাই, সবচেয়ে বড় eigenvalue \(\lambda_1\)-এর eigenvector \(v_1\) বাছাই করাই শ্রেষ্ঠ:
একটি কঠোর যুক্তি (spectral theorem ব্যবহার করে, কেবল stationarity নয়)। শুধু "stationary বিন্দুগুলোর মধ্যে বড়টি নিই" বললে এটি সর্বোচ্চ কেন তা পুরোপুরি প্রমাণ হয় না — আসুন সরাসরি দেখাই যে কোনো unit vector-এর জন্যই \(v^\top\Sigma v\le\lambda_1\)। যেহেতু \(\{v_1,\dots,v_p\}\) একটি orthonormal basis, যেকোনো unit vector লিখি \(v=\sum_{j}c_j v_j\) যেখানে \(c_j=v^\top v_j\) এবং orthonormality থেকে \(\sum_j c_j^2=\lVert v\rVert^2=1\)। এখন
কিন্তু \(\Sigma v_k=\lambda_k v_k\), তাই \(v_j^\top\Sigma v_k=\lambda_k v_j^\top v_k=\lambda_k\delta_{jk}\) — কেবল \(j=k\) term টিকে থাকে:
এটি eigenvalue-গুলোর একটি convex combination (\(c_j^2\ge0\), \(\sum c_j^2=1\))। যেকোনো convex combination তার সর্বোচ্চ উপাদানের চেয়ে বড় হতে পারে না:
এবং সমতা অর্জিত হয় যখন সমস্ত ওজন \(\lambda_1\)-এর উপর, অর্থাৎ \(c_1^2=1\), বাকি \(c_j=0\) — মানে \(v=\pm v_1\)। সুতরাং নিঃসংশয়ে সর্বোচ্চ \(=\lambda_1\), অর্জনকারী দিক \(v_1\)। এটিই প্রথম principal component, এবং \(Xv_1\) হলো first PC score (projected coordinate-গুলো)।
ধাপ ৪ — দ্বিতীয় PC: \(v_1\)-এর লম্বে সর্বোচ্চ variance। PC2-এর সংজ্ঞা: PC1-এর সাথে orthogonal থেকে অবশিষ্ট variance সর্বোচ্চকারী দিক। অর্থাৎ
আগের expansion \(v^\top\Sigma v=\sum_j\lambda_j c_j^2\) আবার ব্যবহার করি; নতুন constraint \(v^\top v_1=0\) মানে \(c_1=v^\top v_1=0\)। তাই যোগফল শুরু হয় \(j=2\) থেকে:
(কারণ এখন \(\sum_{j\ge2}c_j^2=1\), এবং \(\lambda_2\) অবশিষ্ট eigenvalue-গুলোর মধ্যে বৃহত্তম)। সমতা \(v=v_2\)-তে। সুতরাং দ্বিতীয় principal component হলো দ্বিতীয় eigenvector \(v_2\), এবং তার variance \(\lambda_2\)।
ধাপ ৫ — induction: সব PC eigenvalue-ক্রমে eigenvector। একই যুক্তি বারবার: ধরা যাক প্রথম \(m-1\)টি PC হলো \(v_1,\dots,v_{m-1}\)। \(m\)-তম PC সংজ্ঞায়িত হয়
Orthogonality constraint-গুলো \(c_1=\dots=c_{m-1}=0\) চাপায়, ফলে \(v^\top\Sigma v=\sum_{j\ge m}\lambda_j c_j^2\le\lambda_m\), সমতা \(v=v_m\)-তে। সুতরাং mathematical induction-এ: principal component-গুলো ঠিক \(\Sigma\)-এর eigenvector \(v_1,v_2,\dots\), eigenvalue \(\lambda_1\ge\lambda_2\ge\dots\)-এর অবরোহী ক্রমে সাজানো; \(j\)-তম PC-এর projection variance \(=\lambda_j\)। Orthonormality \(v_j^\top v_k=\delta_{jk}\) স্বয়ংক্রিয়ভাবে নিশ্চিত করে যে PC-অক্ষগুলো পরস্পর-লম্ব, আর PC-scores \(Xv_j\) পরস্পর uncorrelated:
অর্থাৎ PCA হলো এমন একটি orthogonal axis-ঘূর্ণন যা covariance matrix-কে diagonal করে দেয় (\(V^\top\Sigma V=\Lambda\)): নতুন স্থানাঙ্কে feature-গুলো অসম্পর্কিত, এবং variance-গুলো ঠিক eigenvalue। এটিই decorrelation-এর গাণিতিক হৃদয়।
সংখ্যাগত যাচাই। \(n=200\), \(p=4\), এলোমেলো covariance থেকে। শীর্ষ-eigenvector-এ \(v_1^\top\Sigma v_1=8.66773=\lambda_1\) (হুবহু মিল); আর \(20000\)টি এলোমেলো unit vector-এর কোনোটিই \(\lambda_1\) ছাড়িয়ে যেতে পারেনি (সর্বোচ্চ \(\approx8.6616<8.66773\)) — convex-combination উপরসীমা নিশ্চিত।
৪.২ ★★ ব্যাখ্যাকৃত variance: eigenvalue-অনুপাত¶
লক্ষ্য। দেখাই যে মোট variance = eigenvalue-গুলোর সমষ্টি, এবং \(j\)-তম PC মোট variance-এর \(\lambda_j\big/\sum_l\lambda_l\) ভগ্নাংশ "ব্যাখ্যা" করে — যাকে explained variance ratio বলি।
ধাপ ১ — মোট variance = trace = eigenvalue-সমষ্টি। কোনো dimensionality reduction-এর "মূল্য" মাপতে হলে আগে "মোট" কী, তা জানা চাই। data-র মোট variance = সব feature-এর variance-এর যোগফল = \(\Sigma\)-এর diagonal-এর যোগফল = \(\operatorname{tr}(\Sigma)\):
এখন trace-এর দুটি গুরুত্বপূর্ণ ধর্ম কাজে লাগাই: (i) similarity-invariance, \(\operatorname{tr}(ABC)\)-তে cyclic পরিবর্তন বৈধ; (ii) spectral decomposition \(\Sigma=V\Lambda V^\top\)। তাহলে
সুতরাং
মূল অন্তর্দৃষ্টি: axis ঘোরালেও (orthogonal rotation \(V\)) মোট variance বদলায় না — এটি invariant। PCA শুধু সেই স্থির মোট variance-কে অক্ষগুলোর মধ্যে নতুনভাবে বণ্টন করে, যাতে প্রথম কয়েকটি অক্ষে যতটা সম্ভব বেশি জমা হয়।
ধাপ ২ — explained variance ratio। §৪.১-এ পেয়েছি \(j\)-তম PC-এর variance \(=\lambda_j\)। তাই সেই PC মোট variance-এর যে ভগ্নাংশ ব্যাখ্যা করে:
যেহেতু সব \(\lambda_j\ge0\) (PSD) এবং তাদের যোগফল \(\operatorname{tr}(\Sigma)\), এই অনুপাতগুলো \([0,1]\)-এ থাকে এবং \(\sum_j\text{EVR}_j=1\) — অর্থাৎ সম্পূর্ণ variance-এর একটি বৈধ বিভাজন (partition)।
ধাপ ৩ — শীর্ষ \(m\)টি PC রাখলে ধরে রাখা variance। যদি কেবল প্রথম \(m\)টি PC (\(v_1,\dots,v_m\)) রেখে বাকিগুলো ফেলে দিই (dimensionality \(p\to m\)), তবে ধরে রাখা variance:
eigenvalue অবরোহী ক্রমে সাজানো বলে এই cumulative অনুপাত \(m\)-এর সাথে দ্রুততম হারে বাড়ে — অর্থাৎ একই সংখ্যক অক্ষে সর্বোচ্চ variance ধরে রাখার অর্থে PCA optimal। বাস্তবে এই cumulative curve থেকেই "৯৫% variance ধরতে কতগুলো component লাগবে" নির্ধারণ করা হয় (scree-plot-এর elbow, §৩ দ্রষ্টব্য)।
সংখ্যাগত যাচাই। উপরের একই data-তে \(\operatorname{tr}(\Sigma)=12.7305=\sum_j\lambda_j\) (মিল), এবং \(\text{EVR}=[0.6809,\,0.2013,\,0.1092,\,0.0086]\) যার যোগফল ঠিক \(1\) — প্রথম দুটি component-ই মোট variance-এর \(\approx88\%\) ধরে।
৪.৩ ★★ SVD-র মাধ্যমে PCA = শ্রেষ্ঠ low-rank approximation¶
লক্ষ্য। PCA-কে covariance-eigen না করে সরাসরি \(X\)-এর singular value decomposition (SVD) থেকে পাওয়া যায় তা দেখানো, এবং Eckart–Young উপপাদ্যের মাধ্যমে প্রতিষ্ঠা করা যে শীর্ষ-\(m\) PC-তে truncation হলো সর্বনিম্ন reconstruction-error-সম্পন্ন rank-\(m\) আনুমানিকতা — অর্থাৎ PCA শ্রেষ্ঠ linear dimensionality reduction।
ধাপ ১ — SVD ও eigen-এর সংযোগ। যেকোনো (centered) \(X\in\mathbb R^{n\times p}\)-এর thin SVD:
যেখানে \(U\in\mathbb R^{n\times r}\) ও \(V\in\mathbb R^{p\times r}\)-এর কলামগুলো orthonormal (\(U^\top U=V^\top V=I_r\)), \(D=\operatorname{diag}(\sigma_1\ge\dots\ge\sigma_r\ge0)\) হলো singular value, \(r=\operatorname{rank}(X)\)। এই \(V\) ঠিক PCA-র \(V\): কারণ
আর \(\Sigma=\frac1{n-1}X^\top X=V\bigl(\tfrac{D^2}{n-1}\bigr)V^\top\) — এটি ঠিক \(\Sigma\)-এর eigen-decomposition! সুতরাং
(শেষটি: \(XV=UDV^\top V=UD\), যেহেতু \(V^\top V=I\))। অর্থাৎ singular vector \(v_j\) = eigenvector, আর singular value-এর বর্গ (scaled) = eigenvalue। সংখ্যাগতভাবে SVD সরাসরি \(X\)-এর উপর চালানো \(X^\top X\) গঠন করার চেয়ে বেশি স্থিতিশীল (condition number বর্গ হয় না), তাই বাস্তব PCA-implementation প্রায়ই SVD-ভিত্তিক।
ধাপ ২ — rank-\(m\) truncation ও reconstruction। শীর্ষ \(m\)টি singular triple রেখে আনুমানিকতা:
যেখানে \(U_m,V_m\) প্রথম \(m\)টি কলাম, \(D_m=\operatorname{diag}(\sigma_1,\dots,\sigma_m)\)। এটি একটি rank-\(m\) matrix, এবং এটিই "শীর্ষ \(m\) PC-তে data-কে প্রকাশ করে আবার পুনর্গঠন" করার ফল। reconstruction error মাপি Frobenius norm-এ, \(\lVert A\rVert_F^2=\sum_{i,k}A_{ik}^2=\operatorname{tr}(A^\top A)\)।
ধাপ ৩ — Eckart–Young উপপাদ্য। এই উপপাদ্য বলে: সমস্ত rank-\(\le m\) matrix-এর মধ্যে \(\hat X_m\)-ই \(X\)-এর সবচেয়ে কাছে (Frobenius তথা যেকোনো unitarily-invariant norm-এ):
অর্থাৎ সর্বনিম্ন অর্জনযোগ্য error² ঠিক বাদ-দেওয়া singular value-গুলোর বর্গের সমষ্টি। অন্তর্দৃষ্টি (পূর্ণ প্রমাণ এখানে দেওয়া হলো না, prereq 0.5-এর spectral কাঠামোর সম্প্রসারণ): orthogonal basis-এ \(X\)-কে লিখলে এর "energy" \(\sum_j\sigma_j^2\); rank-\(m\) দিয়ে ধরা যায় সর্বোচ্চ \(m\)টি দিক, তাই সবচেয়ে ভালো কৌশল হলো সবচেয়ে বড় \(m\)টি \(\sigma_j\) রেখে দেওয়া — যেকোনো অন্য দিক বাছলে বড় energy হারাবে।
ধাপ ৪ — variance-এর সাথে সংযোগ ও তাৎপর্য। \(\frac{1}{n-1}\) গুণ করলে error² ঠিক বাদ-দেওয়া variance-এ পরিণত হয়:
— ঠিক §৪.২-এ "না-রাখা" variance। দুটি দৃষ্টিভঙ্গি তাই একই মুদ্রার দুই পিঠ: variance সর্বাধিকীকরণ (§৪.১) ⇔ reconstruction-error সর্বনিম্নকরণ (এই §)। উপসংহার: সমস্ত \(m\)-মাত্রিক linear projection-এর মধ্যে শীর্ষ-\(m\) PCA সর্বোচ্চ variance ধরে রাখে এবং একইসাথে সর্বনিম্ন squared reconstruction error দেয় — তাই PCA-কে optimal linear dimensionality reduction বলা হয়।
সংখ্যাগত যাচাই। একই data: \(\sigma_j^2/(n-1)\) হুবহু \(\lambda_j\)-এর সমান (\([8.6677,2.5624,1.3905,0.1099]\))। আর প্রতিটি \(m\in\{1,2,3\}\)-এ \(\lVert X-\hat X_m\rVert_F\) ঠিক \(\sqrt{\sum_{j>m}\sigma_j^2}\)-এর সমান (\(m{=}1\): \(28.4340\); \(m{=}2\): \(17.2795\); \(m{=}3\): \(4.6767\)) — Eckart–Young নিশ্চিত।
৪.৪ ★★ k-means objective ও Lloyd-এর monotone অবরোহণ¶
লক্ষ্য। k-means-এর objective সংজ্ঞায়িত করি এবং প্রমাণ করি যে Lloyd-অ্যালগরিদমের দুটি ধাপের কোনোটিই objective বাড়ায় না — ফলে এটি monotonically কমে এবং একটি local minimum-এ থামে।
ধাপ ১ — objective। \(K\)টি cluster, centroid \(\mu_1,\dots,\mu_K\in\mathbb R^p\), এবং assignment \(C\) (প্রতিটি বিন্দু \(x_i\) ঠিক একটি cluster-এ; \(C_k\) = \(k\)-তম cluster-এর সূচক-সেট)। within-cluster squared-error objective:
লক্ষ্য \(J\)-কে \(C\) ও \(\{\mu_k\}\) উভয়ের উপর সর্বনিম্ন করা। এটি যৌথভাবে NP-hard, তাই Lloyd দুটি চলরাশিকে পালাক্রমে স্থির রেখে অন্যটিতে minimize করে (coordinate-descent ধাঁচ): (i) centroid স্থির → assignment আপডেট; (ii) assignment স্থির → centroid আপডেট।
ধাপ ২ — assignment-ধাপ \(J\) বাড়ায় না। centroid \(\{\mu_k\}\) স্থির ধরে \(J\)-কে assignment-এর উপর minimize করি। লক্ষ করি, \(J\) আসলে প্রতিটি বিন্দুর অবদানের যোগফল হিসেবে আলাদা করা যায়: যদি \(c(i)\) = \(x_i\)-এর cluster-লেবেল, তবে
প্রতিটি বিন্দুর term অন্যদের থেকে স্বাধীন; তাই গোটা যোগফল সর্বনিম্ন করতে হলে প্রতিটি \(x_i\)-কে আলাদাভাবে এমন cluster-এ দিতে হবে যা তার নিজের term সর্বনিম্ন করে — অর্থাৎ নিকটতম centroid:
যেহেতু প্রতিটি বিন্দু পুরাতন লেবেলের চেয়ে ছোট-বা-সমান দূরত্বের centroid বেছে নিচ্ছে, প্রতিটি term কমে বা অপরিবর্তিত থাকে, ফলে
ধাপ ৩ — update-ধাপ \(J\) বাড়ায় না; optimal centroid = cluster-mean। এবার assignment \(C\) স্থির ধরে \(J\)-কে centroid-এর উপর minimize করি। cluster-গুলো আলাদা term, তাই প্রতিটি \(\mu_k\) স্বতন্ত্রভাবে minimize করা যায়:
\(\mu_k\)-এর সাপেক্ষে gradient নিই (vector-calculus, \(\nabla_{\mu}\lVert x-\mu\rVert^2=-2(x-\mu)\)):
শূন্যে বসিয়ে:
— ঠিক cluster-এর mean। এটি minimum (maximum নয়): Hessian \(\nabla^2_{\mu_k}g=2\lvert C_k\rvert\,I\succ0\) (positive definite), তাই \(g\) strictly convex, একক global minimizer। সুতরাং mean-এ আপডেট করলে প্রতিটি cluster-term কমে বা অপরিবর্তিত থাকে:
বিকল্প দৃষ্টি (centering identity): যেকোনো \(\mu\)-এর জন্য \(\sum_{i\in C_k}\lVert x_i-\mu\rVert^2=\sum_{i\in C_k}\lVert x_i-\bar x_k\rVert^2+\lvert C_k\rvert\,\lVert\bar x_k-\mu\rVert^2\) যেখানে \(\bar x_k\) = mean (cross-term শূন্য, কারণ \(\sum_{i\in C_k}(x_i-\bar x_k)=0\))। ডান পাশের দ্বিতীয় term \(\ge0\) এবং কেবল \(\mu=\bar x_k\)-তে শূন্য — তাই mean-ই minimizer।
ধাপ ৪ — monotone অবরোহণ ও convergence। প্রতিটি পূর্ণ iteration = assignment-ধাপ + update-ধাপ; ধাপ ২ ও ৩ মিলে
অর্থাৎ \(J\) একটি monotonically non-increasing ক্রম। তদুপরি \(J\ge0\) (squared দূরত্বের যোগফল), অর্থাৎ নিচে আবদ্ধ। আরও, সম্ভাব্য assignment-এর সংখ্যা সসীম (\(K^n\)), এবং প্রতিটি assignment-এর optimal centroid অনন্যভাবে নির্ধারিত — তাই \(J\) কেবল সসীমসংখ্যক স্বতন্ত্র মান নিতে পারে। একটি monotone, নিচে-আবদ্ধ, সসীম-মানের ক্রম অবশ্যই সসীম ধাপে স্থির হয়; স্থির হলে assignment আর বদলায় না — অ্যালগরিদম থামে।
সতর্কতা — local, global নয়। এই অবরোহণ কেবল \(J\) কমানো নিশ্চিত করে, global minimum নয়: \(J\) অ-উত্তল (non-convex), তাই প্রাথমিক centroid-এর উপর নির্ভর করে ভিন্ন local minimum-এ আটকে যেতে পারে। এজন্যই বাস্তবে একাধিক random restart (যেমন k-means++) চালিয়ে সবচেয়ে কম \(J\)-ওয়ালা ফল রাখা হয়।
সংখ্যাগত যাচাই। তিন-গুচ্ছ synthetic data (\(K=3\))-এ Lloyd চালালে \(J\)-ক্রম প্রতিটি ধাপে অ-বর্ধমান (monotone non-increasing: True), চূড়ান্ত \(J\approx87.64\)। আর একটি cluster-এর mean-কে যেকোনো দিকে সরালে SSE কেবল বাড়ে — mean-ই minimizer (perturb-worse: True)।
৪.৫ ★ within/between বিভাজন ও elbow-এর সংযোগ¶
লক্ষ্য। মোট sum-of-squares (TSS)-কে within-cluster (WSS) ও between-cluster (BSS) অংশে ভাঙি, এবং দেখাই k-means within কমানো = between বাড়ানো — যা elbow-পদ্ধতির ভিত্তি।
ধাপ ১ — তিনটি পরিমাণ। গোটা data-র global mean \(\bar x=\frac1n\sum_i x_i\) ধরে:
যেখানে \(\bar x_k\) = \(k\)-তম cluster-এর mean। WSS ঠিক k-means-এর objective \(J\)।
ধাপ ২ — বিভাজন উপপাদ্য। প্রতিটি বিন্দুর জন্য \(x_i-\bar x=(x_i-\bar x_k)+(\bar x_k-\bar x)\) লিখে cluster \(C_k\)-র উপর squared-norm যোগ করি:
cross-term শূন্য, কারণ \(\sum_{i\in C_k}(x_i-\bar x_k)=0\) (mean-এর সংজ্ঞা)। সব cluster-এর উপর যোগ:
ধাপ ৩ — k-means-এর তাৎপর্য ও elbow। TSS শুধু data-র উপর নির্ভর করে — clustering-নিরপেক্ষ, তাই স্থির। সুতরাং \(\text{WSS}+\text{BSS}=\) ধ্রুবক মানে WSS কমানো ⇔ BSS বাড়ানো। k-means যেহেতু WSS (\(=J\)) সর্বনিম্ন করে, এটি সমতুল্যভাবে between-cluster বিচ্ছেদ সর্বাধিক করে — অর্থাৎ গুচ্ছগুলোকে ভেতরে আঁটসাঁট ও পরস্পর থেকে দূরে ঠেলে।
\(K\) বাড়ালে WSS একঘেয়েভাবে কমে (চূড়ান্তে \(K=n\)-এ \(\text{WSS}=0\)), তাই শুধু WSS দিয়ে \(K\) বাছা যায় না। Elbow-পদ্ধতি: \(K\)-এর সাপেক্ষে WSS (বা \(\text{BSS}/\text{TSS}\) অনুপাত) আঁকলে যেখানে হ্রাসের হার হঠাৎ মন্থর হয় — সেই "কনুই" বিন্দু প্রাকৃতিক cluster-সংখ্যার ইঙ্গিত দেয়: তার পরে নতুন cluster যোগ করলে within-variance তেমন কমে না, কেবল গঠন ভাঙে।
সংখ্যাগত যাচাই। §৪.৪-এর একই data-তে \(\text{TSS}=2104.56\) এবং \(\text{WSS}+\text{BSS}=2104.56\) — হুবহু মিল, বিভাজন উপপাদ্য নিশ্চিত।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা একটিমাত্র runnable script-এ পুরো গল্পটা শেষ করব: প্রথমে covariance matrix-এর eigen-decomposition থেকে হাতে-কলমে PCA বের করব, সেটাকে sklearn.decomposition.PCA-র সঙ্গে মিলিয়ে নেব, top-2 PC-তে data project করে একটা 2D embedding বানাব, তারপর সেই standardized data-তে k-means চালিয়ে elbow ও silhouette দিয়ে সঠিক cluster-সংখ্যা \(k=3\) নির্ণয় করব এবং true label-এর সঙ্গে ARI দিয়ে যাচাই করব unsupervised পদ্ধতি কতটা ভালোভাবে আসল গঠন উদ্ধার করল।
ডেটাটি ইচ্ছাকৃতভাবে গড়া: তিনটি Gaussian "blob"-এর কেন্দ্র \([0,0],\,[6,1],\,[3,6]\), প্রতিটিতে \(100\)টি বিন্দু (মোট \(n=300\))। আসল signal দুই-মাত্রিক (\(f_1,f_2\)); \(f_3,f_4\) হলো \(f_1,f_2\)-এর প্রায়-রৈখিক সংমিশ্রণ, যাতে চারটি raw feature-এর মধ্যে তীব্র correlation থাকে। ফলে covariance matrix-এর প্রথম দুই eigenvalue-ই প্রায় সমস্ত variance ধরে রাখবে — এটাই PCA-র জন্য আদর্শ ক্ষেত্র।
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, adjusted_rand_score
# ----- Dataset -----
rng = np.random.default_rng(20260619)
centers = np.array([[0,0],[6,1],[3,6]], float); Z=[]; lab=[]
for k,c in enumerate(centers):
z = rng.normal(c, 0.8, size=(100,2)); Z.append(z); lab += [k]*100
Z = np.vstack(Z); lab = np.array(lab)
f1 = Z[:,0]; f2 = Z[:,1]
f3 = 0.8*Z[:,0] + 0.3*rng.normal(0,1,300)
f4 = -0.5*Z[:,1] + 0.6*Z[:,0] + 0.3*rng.normal(0,1,300)
Xraw = np.c_[f1,f2,f3,f4]
X = StandardScaler().fit_transform(Xraw)
print("X shape:", X.shape, " (standardized: mean~0, std~1)")
print("col means:", np.round(X.mean(0),3), " col stds:", np.round(X.std(0),3))
# ===== PART 1: PCA from scratch =====
print("\n===== PART 1: PCA from covariance + eigh =====")
n = X.shape[0]
C = (X.T @ X) / (n - 1) # covariance of standardized X
print("Covariance matrix C (4x4):")
print(np.round(C,3))
evals, evecs = np.linalg.eigh(C) # ascending for symmetric C
order = np.argsort(evals)[::-1] # sort descending
evals = evals[order]; evecs = evecs[:, order]
evr = evals / evals.sum()
print("eigenvalues (desc):", np.round(evals,3))
print("explained_variance_ratio_ (scratch):", np.round(evr,4))
print("PC1+PC2 cumulative:", round(float(evr[0]+evr[1])*100,1), "%")
pca = PCA().fit(X)
print("explained_variance_ratio_ (sklearn):", np.round(pca.explained_variance_ratio_,4))
print("eigenvalues (sklearn .explained_variance_):", np.round(pca.explained_variance_,3))
print("match scratch vs sklearn EVR? ->",
np.allclose(np.sort(evr), np.sort(pca.explained_variance_ratio_), atol=1e-6))
# ===== PART 2: project onto top-2 PCs =====
print("\n===== PART 2: project X -> top 2 PCs (scores) =====")
W2 = evecs[:, :2] # 4x2 loading matrix
scores = X @ W2 # 300x2 embedding
print("scores shape:", scores.shape, " -> 2D embedding used for plotting")
print("first 3 scores:\n", np.round(scores[:3],3))
# ===== PART 3: k-means elbow + silhouette =====
print("\n===== PART 3: KMeans k=1..6 (elbow + silhouette) =====")
print(f"{'k':>2} {'inertia':>10} {'silhouette':>12}")
for k in range(1,7):
km = KMeans(n_clusters=k, n_init=10, random_state=0).fit(X)
sil = silhouette_score(X, km.labels_) if k >= 2 else float('nan')
sval = f"{sil:.3f}" if k >= 2 else " n/a"
print(f"{k:>2} {km.inertia_:>10.1f} {sval:>12}")
print("-> inertia drop flattens after k=3 (elbow); silhouette peaks at k=3")
# ===== PART 4: final k=3 + ARI =====
print("\n===== PART 4: final KMeans k=3 vs true labels =====")
km3 = KMeans(n_clusters=3, n_init=10, random_state=0).fit(X)
print("k=3 inertia :", round(float(km3.inertia_),1))
print("k=3 silhouette:", round(float(silhouette_score(X, km3.labels_)),3))
ari = adjusted_rand_score(lab, km3.labels_)
print("ARI vs true lab:", round(float(ari),3),
"-> near-perfect unsupervised recovery of 3 clusters")
কোডের চারটি অংশের প্রতিটিতে একটি করে মূল ধারণা রয়েছে।
PART 1 — covariance থেকে PCA। Standardized data \(X\) (\(n\times p\), এখানে \(300\times 4\), প্রতিটি column-এর mean \(\approx 0\), std \(\approx 1\)) দিয়ে আমরা sample covariance matrix বানাই
যা symmetric ও positive semi-definite। np.linalg.eigh symmetric matrix-এর জন্য বিশেষায়িত — এটি বাস্তব eigenvalue ও orthonormal eigenvector দেয়, eigenvalue-গুলো ascending ক্রমে সাজানো থাকে, তাই আমরা argsort(...)[::-1] দিয়ে descending করে নিই। \(i\)-তম explained variance ratio হলো
যেখানে \(\lambda_i\) হলো \(i\)-তম (descending) eigenvalue। লক্ষণীয়: standardized data-তে \(\operatorname{tr}(C)=\sum_i \lambda_i = p\) (এখানে \(4\)), কারণ প্রতিটি standardized feature-এর variance \(1\)। শেষে একই \(X\)-এ sklearn.decomposition.PCA fit করে দেখাই দুই পথে পাওয়া EVR হুবহু মিলছে (np.allclose ... True) — PCA "জাদু" নয়, ঠিক এই eigen-decomposition-ই sklearn ভেতরে করে (যদিও সে SVD ব্যবহার করে, ফল একই)।
PART 2 — projection / embedding। Top-2 eigenvector নিয়ে loading matrix \(W_2\) (\(p\times 2=4\times 2\)) বানাই; score (নতুন স্থানাঙ্ক) হলো
এই \(T\)-ই হলো ডেটার 2D embedding — চার-মাত্রিক বিন্দুগুলোকে সবচেয়ে বেশি variance-ধারণকারী দুটি অভিমুখে প্রক্ষেপণ করে পাওয়া দ্বি-মাত্রিক উপস্থাপন, যা plotting-এ ব্যবহারযোগ্য (এখানে আমরা shape ও প্রথম কয়েকটি row ছাপিয়েই থামছি)।
PART 3 — elbow ও silhouette। \(k=1\) থেকে \(6\) পর্যন্ত k-means চালিয়ে দুটো রাশি দেখি। Inertia (within-cluster sum of squares),
\(k\) বাড়লে একঘেয়েভাবে কমে; "elbow" সেই \(k\) যেখানে কমার হার হঠাৎ চ্যাপ্টা হয়ে যায়। Silhouette (\(k\ge 2\)-এ সংজ্ঞায়িত) প্রতিটি বিন্দুর জন্য
যেখানে \(a_i\) হলো নিজের cluster-এর বিন্দুগুলোর সঙ্গে গড় দূরত্ব, \(b_i\) হলো নিকটতম প্রতিবেশী cluster-এর সঙ্গে গড় দূরত্ব; পুরো dataset-এর গড় \(\bar{s}\) যত বড়, cluster-গঠন তত স্পষ্ট। আমরা প্রতিটি \(k\)-এ n_init=10, random_state=0 রেখে ফল reproducible করি।
PART 4 — চূড়ান্ত মডেল ও যাচাই। \(k=3\)-এ fit করে inertia ও silhouette ছাপাই, এবং Adjusted Rand Index দিয়ে পাওয়া cluster label-কে আসল lab-এর সঙ্গে তুলনা করি। ARI দুই partition-এর মিল মাপে, chance-এর জন্য সংশোধিত: এলোমেলো মিলে \(\approx 0\), নিখুঁত মিলে \(1\)। গুরুত্বপূর্ণ: k-means আসল label কখনও "দেখে না" — তবু label পুনরুদ্ধার হলে বোঝা যায় ডেটায় cluster-গঠন বাস্তবিকই আছে এবং unsupervised পদ্ধতি তা ধরতে পেরেছে।
স্ক্রিপ্টটি চালালে নিচের output পাওয়া যায়:
X shape: (300, 4) (standardized: mean~0, std~1)
col means: [ 0. -0. -0. -0.] col stds: [1. 1. 1. 1.]
===== PART 1: PCA from covariance + eigh =====
Covariance matrix C (4x4):
[[ 1.003 0.146 0.994 0.696]
[ 0.146 1.003 0.141 -0.597]
[ 0.994 0.141 1.003 0.693]
[ 0.696 -0.597 0.693 1.003]]
eigenvalues (desc): [2.614 1.375 0.017 0.008]
explained_variance_ratio_ (scratch): [0.6513 0.3426 0.0042 0.0019]
PC1+PC2 cumulative: 99.4 %
explained_variance_ratio_ (sklearn): [0.6513 0.3426 0.0042 0.0019]
eigenvalues (sklearn .explained_variance_): [2.614 1.375 0.017 0.008]
match scratch vs sklearn EVR? -> True
===== PART 2: project X -> top 2 PCs (scores) =====
scores shape: (300, 2) -> 2D embedding used for plotting
first 3 scores:
[[1.086 1.675]
[2.273 0.979]
[1.201 1.47 ]]
===== PART 3: KMeans k=1..6 (elbow + silhouette) =====
k inertia silhouette
1 1200.0 n/a
2 527.4 0.552
3 135.3 0.712
4 110.6 0.598
5 90.6 0.484
6 71.7 0.380
-> inertia drop flattens after k=3 (elbow); silhouette peaks at k=3
===== PART 4: final KMeans k=3 vs true labels =====
k=3 inertia : 135.3
k=3 silhouette: 0.712
ARI vs true lab: 0.99 -> near-perfect unsupervised recovery of 3 clusters
পাঠোদ্ধার।
- Standardization কাজ করেছে। সব column-এর mean \(\approx 0\), std \(=1\) — তাই PCA কোনো একটি বড়-scale feature-এর দখলে যায়নি, প্রতিটি feature সমান ওজনে শুরু করেছে।
- Covariance-এ correlation দৃশ্যমান। \(C\)-তে off-diagonal বড়: \(C_{13}\approx 0.99\) (কারণ \(f_3\) মূলত \(f_1\)), \(C_{24}\approx -0.60\), \(C_{14}\approx 0.70\)। এই তীব্র correlation-ই PCA-কে কয়েকটি অভিমুখে variance কেন্দ্রীভূত করতে সাহায্য করে।
- EVR দুই পথে হুবহু এক। Scratch eigen-decomposition ও sklearn উভয়েই দেয় \(\text{EVR}=[0.6513,\,0.3426,\,0.0042,\,0.0019]\) এবং eigenvalue \([2.614,\,1.375,\,0.017,\,0.008]\) (
match ... True)। অর্থাৎ "from covariance +eigh" এবং library-PCA একই গণিত। - মাত্রা কমানো প্রায় বিনামূল্যে। \(\text{PC1}+\text{PC2}=65.1\%+34.3\%=99.4\%\) — চারটি feature-এর মাত্র দুটি principal component-ই ~\(99.4\%\) variance ধরে রাখে, শেষ দুই eigenvalue (\(0.017,\,0.008\)) প্রায় শূন্য (অর্থাৎ \(f_3,f_4\) স্বাধীন কোনো তথ্য বহন করে না)। তাই \(4\to 2\) মাত্রায় নামালেও কার্যত কিছুই হারায় না; PART 2-এর \(300\times 2\) score-ই data-র প্রকৃত দ্বি-মাত্রিক রূপ।
- Elbow ও silhouette একই \(k\)-তে একমত। Inertia: \(1200\to 527.4\to 135.3\) পর্যন্ত খাড়া পতন, কিন্তু \(k=3\)-এর পর (\(135.3\to 110.6\to 90.6\to 71.7\)) পতন স্পষ্টভাবে চ্যাপ্টা — elbow \(k=3\)-এ। Silhouette সর্বোচ্চ ঠিক \(k=3\)-এ (\(0.712\)), \(k=2\) (\(0.552\)) ও \(k=4\) (\(0.598\))-এর চেয়ে বেশি। দুই ভিন্ন diagnostic একই উত্তর দেওয়ায় \(k=3\) আস্থার সঙ্গে গ্রহণযোগ্য।
- Unsupervised পুনরুদ্ধার প্রায় নিখুঁত। \(k=3\)-এ inertia \(=135.3\), silhouette \(=0.712\), এবং \(\text{ARI}=0.99\) — অর্থাৎ k-means আসল label না দেখেই তিনটি blob প্রায় হুবহু আলাদা করেছে। এটাই গোটা অধ্যায়ের মূল বার্তা: PCA structure-টিকে কয়েকটি মাত্রায় ঘনীভূত করে, আর clustering সেই structure-কে label ছাড়াই উদ্ধার করে।
৬ · ভিজ্যুয়ালাইজেশন¶
এই অধ্যায়ের দুই কেন্দ্রীয় হাতিয়ার — PCA (correlated অক্ষগুলোকে ঘুরিয়ে variance-এর সবচেয়ে বড় দিকগুলোতে data-কে পুনর্বিন্যাস) আর k-means clustering (data-কে \(k\) টা ঘন দলে ভাগ) — দুটোই মূলত জ্যামিতিক ভাবনা। explained variance ratio \([0.651,\,0.343,\,0.0042,\,0.0019]\), inertia-র পতন \(1200 \to 527 \to 135\), silhouette-এর শীর্ষ \(0.712\), ARI \(0.990\) — এই সংখ্যাগুলো নিজেরা সত্য বলে, কিন্তু কেন সত্য তা একটা টেবিলে কখনো পুরোপুরি ধরা পড়ে না। চারটে feature-এর \(4\)-মাত্রিক মেঘ চোখে দেখা যায় না; কিন্তু PCA সেই মেঘকে যখন একটা \(2\)-মাত্রিক সমতলে নামিয়ে আনে আর \(99.4\%\) variance ধরে রাখে, তখন তিনটে দল হঠাৎ স্পষ্ট আলাদা হয়ে চোখের সামনে ভেসে ওঠে — আর সেটাই এই অধ্যায়ের আসল insight (অন্তর্দৃষ্টি)। তাই এই অংশে আমরা পুরো গল্পটাকে চারটে ছবিতে সাজাব, ঠিক যে যুক্তির ক্রমে একজন analyst এগোয়: প্রথমে PCA চোখে দেখায় গঠনটা সত্যিই আছে; তারপর scree plot বলে কটা component রাখা যথেষ্ট; তারপর elbow ও silhouette একসঙ্গে বলে কটা cluster বেছে নেওয়া উচিত; এবং শেষে k-means সেই দলগুলো সত্যিই খুঁজে পেল কি না তা যাচাই হয়।
মনে রাখুন — dataset। এই অধ্যায়ের সব ছবি একই একটা synthetic dataset থেকে তৈরি। আমরা \(2\)-মাত্রিক সমতলে তিনটে কেন্দ্র — \((0,0)\), \((6,1)\), \((3,6)\) — ঘিরে প্রতিটায় \(100\) টা করে point (\(\sigma = 0.8\) Gaussian) ছড়িয়ে \(300\) টা latent point বানাই, এবং তাদের true cluster label (\(0,1,2\)) মনে রাখি। তারপর সেই দুটো অক্ষ থেকে চারটে observed feature গড়ি: \(f_1, f_2\) সরাসরি দুই স্থানাঙ্ক, আর \(f_3 = 0.8\,Z_1 + \text{noise}\), \(f_4 = -0.5\,Z_2 + 0.6\,Z_1 + \text{noise}\) — অর্থাৎ \(f_3, f_4\) আগের দুটোর redundant (linearly correlated) ছায়া, সামান্য noise সমেত। শেষে চারটে feature-কে
StandardScalerদিয়ে standardize করি (mean \(0\), variance \(1\))। মূল কথা: তথ্যটা আদতে \(2\)-মাত্রিক, কিন্তু \(4\) টা correlated কলামে ছদ্মবেশে লুকানো — ঠিক এই পরিস্থিতিতেই PCA-র মহিমা দেখা যায়।
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, adjusted_rand_score
rng = np.random.default_rng(20260619)
centers = [[0, 0], [6, 1], [3, 6]]
Z, lab = [], []
for k, c in enumerate(centers): # তিনটে দল
Z.append(rng.normal(c, 0.8, (100, 2))) # প্রতি দলে 100 point
lab.append(np.full(100, k)) # true label মনে রাখি
Z = np.vstack(Z); label = np.concatenate(lab)
f1, f2 = Z[:, 0], Z[:, 1] # দুটো আসল feature
f3 = 0.8*Z[:, 0] + 0.3*rng.normal(0, 1, 300) # f1-এর correlated ছায়া
f4 = -0.5*Z[:, 1] + 0.6*Z[:, 0] + 0.3*rng.normal(0, 1, 300) # মিশ্র ছায়া
Xraw = np.c_[f1, f2, f3, f4]
X = StandardScaler().fit_transform(Xraw) # standardize: mean 0, var 1
PCA আর k-means দুটোই এই একই standardized X-এর উপর চলবে। PCA পুরো \(4\)-মাত্রিক variance-কে orthogonal দিকগুলোতে ভেঙে দেখায় কোন দিকে কতটা spread; k-means তারপর সেই data-কে \(k\) টা দলে ভাগ করে। নিচের ছবিগুলো ঠিক এই দুই হিসাবেরই দৃশ্যরূপ।
pca = PCA().fit(X) # সব component
evr = pca.explained_variance_ratio_ # [0.651, 0.343, 0.004, 0.002]
scores = pca.transform(X) # প্রতিটা point-এর PC স্থানাঙ্ক
pc1, pc2 = scores[:, 0], scores[:, 1] # প্রথম দুই PC
৬.১ · PCA চোখে দেখায়: চারটে feature, আসলে একটা সমতল¶
প্রথম ও সবচেয়ে আনন্দদায়ক ছবি। কাঁচা data-টা \(4\)-মাত্রিক — সরাসরি আঁকা অসম্ভব। PCA সেই মেঘকে এমনভাবে ঘোরায় যে প্রথম অক্ষ (PC1) ধরে সবচেয়ে বেশি variance, দ্বিতীয় অক্ষ (PC2) ধরে তার পরের সর্বোচ্চ — দুটো পরস্পর লম্ব। এই দুই অক্ষের সমতলে প্রতিটা point-এর projection আঁকলে, এবং বিন্দুগুলো true cluster label অনুসারে রঙ করলে, আমরা চোখে দেখি গঠনটা সত্যিই আছে কি না। তত্ত্ব যা প্রতিশ্রুতি দেয়: যেহেতু \(f_3, f_4\) আসলে \(f_1, f_2\)-এর redundant ছায়া, তথ্যের প্রকৃত মাত্রা \(2\) — তাই PC1 ও PC2 মিলে variance-এর প্রায় পুরোটাই (\(65.1\% + 34.3\% = 99.4\%\)) ধরে ফেলবে, আর তিনটে দল এই সমতলে পরিষ্কার আলাদা হয়ে বসবে।
fig, ax = plt.subplots(figsize=(8.0, 6.0))
for k in range(3): # তিনটে true cluster আলাদা রঙে
m = label == k
ax.scatter(pc1[m], pc2[m], s=34, label=f"true cluster {k}")
ax.set_xlabel(f"PC1 ({100*evr[0]:.1f}% var)") # 65.1%
ax.set_ylabel(f"PC2 ({100*evr[1]:.1f}% var)") # 34.3%
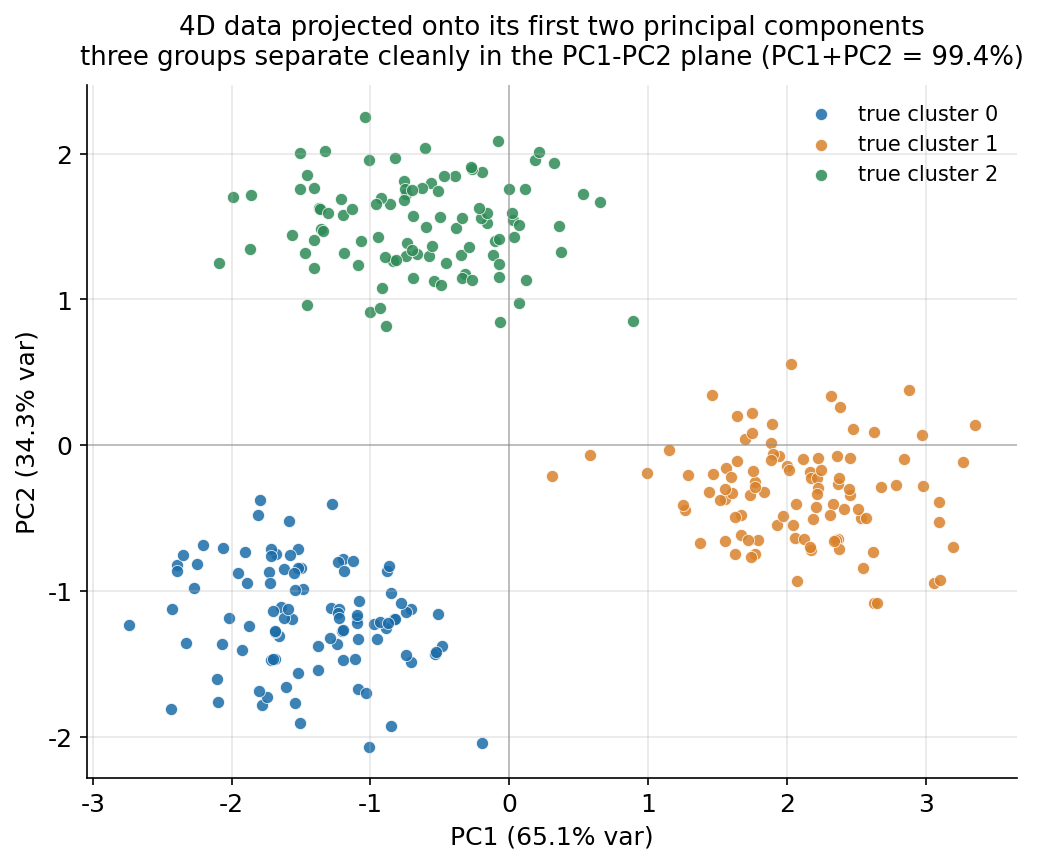
ছবি থেকে যা পড়া যায়। চোখ ফেলামাত্র তিনটে আলাদা ঝাঁক — নীল (cluster 0) বাঁ-নিচে, কমলা (cluster 1) ডানে, সবুজ (cluster 2) উপরে — পরিষ্কার দেখা যায়, কোথাও একটাও দল আরেকটার সঙ্গে মেশেনি। এটাই PCA-র মূল জাদু: \(4\)-মাত্রিক যে মেঘ আমরা কখনো সরাসরি দেখতে পারতাম না, তাকে মাত্র দুটো অক্ষে নামিয়ে এনেও গঠনটা অবিকৃত থেকে গেল। আর কেন থাকল, তার উত্তর অক্ষের লেবেলেই লেখা — PC1 একাই variance-এর \(65.1\%\) ধরে, PC2 ধরে আরও \(34.3\%\); দুইয়ে মিলে \(99.4\%\)। অর্থাৎ এই সমতলে projection করতে গিয়ে আমরা মাত্র \(0.6\%\) তথ্য হারিয়েছি, প্রায় কিছুই না। বাকি দুটো মাত্রা (PC3, PC4) প্রায় শূন্য variance বহন করে — সেগুলো \(f_3, f_4\)-এর সেই redundant ছায়া, যা নতুন কিছু বলে না। ছবিটা তাই একসঙ্গে দুটো সত্য দেখায়: প্রথমত, তথ্যটা সত্যিই গুচ্ছবদ্ধ (clustering করার মতো গঠন আছে), আর দ্বিতীয়ত, তথ্যটা সত্যিই কম-মাত্রিক (\(4\) নয়, আদতে \(2\)) — পরের ছবি ঠিক এই দ্বিতীয় কথাটাই সংখ্যায় প্রমাণ করবে।
৬.২ · Scree plot: কটা component রাখা যথেষ্ট¶
§৬.১-এর scatter চোখে বলল "দুটো অক্ষই প্রায় সব"; এই ছবিটা সেই দাবিটাকে কঠোর সংখ্যায় বাঁধে এবং সিদ্ধান্তটা নিয়মে রূপ দেয়। PCA প্রতিটা principal component-এর জন্য একটা explained variance ratio দেয় — সেই অক্ষ মোট variance-এর কত ভাগ ধরে। scree plot এই ratio-গুলোকে \(\text{PC}\)-ভিত্তিক bar হিসেবে আঁকে (সবচেয়ে বড় থেকে ছোট ক্রমে), আর তার উপর একটা cumulative line চাপায় — প্রথম \(j\) টা component মিলে মোট কত ভাগ ধরে। "scree" শব্দটা পাহাড়ের ঢালে জমা পাথরের স্তূপ থেকে এসেছে: একটা খাড়া পতনের পর যেখানে curve হঠাৎ সমান্তরাল হয়ে যায়, সেই elbow-এর আগের component-গুলো রাখো, পরেরগুলো ফেলে দাও।
pcs = np.arange(1, len(evr) + 1)
cum = np.cumsum(evr) # cumulative: 0.651, 0.994, ...
fig, ax = plt.subplots(figsize=(8.4, 5.4))
ax.bar(pcs, evr) # প্রতি PC-র explained variance
ax2 = ax.twinx() # ডান অক্ষে cumulative
ax2.plot(pcs, cum, "-o", color="C3", label="cumulative")
ax.axvline(2.5, ls="--", color="grey") # elbow: PC2-র পরে
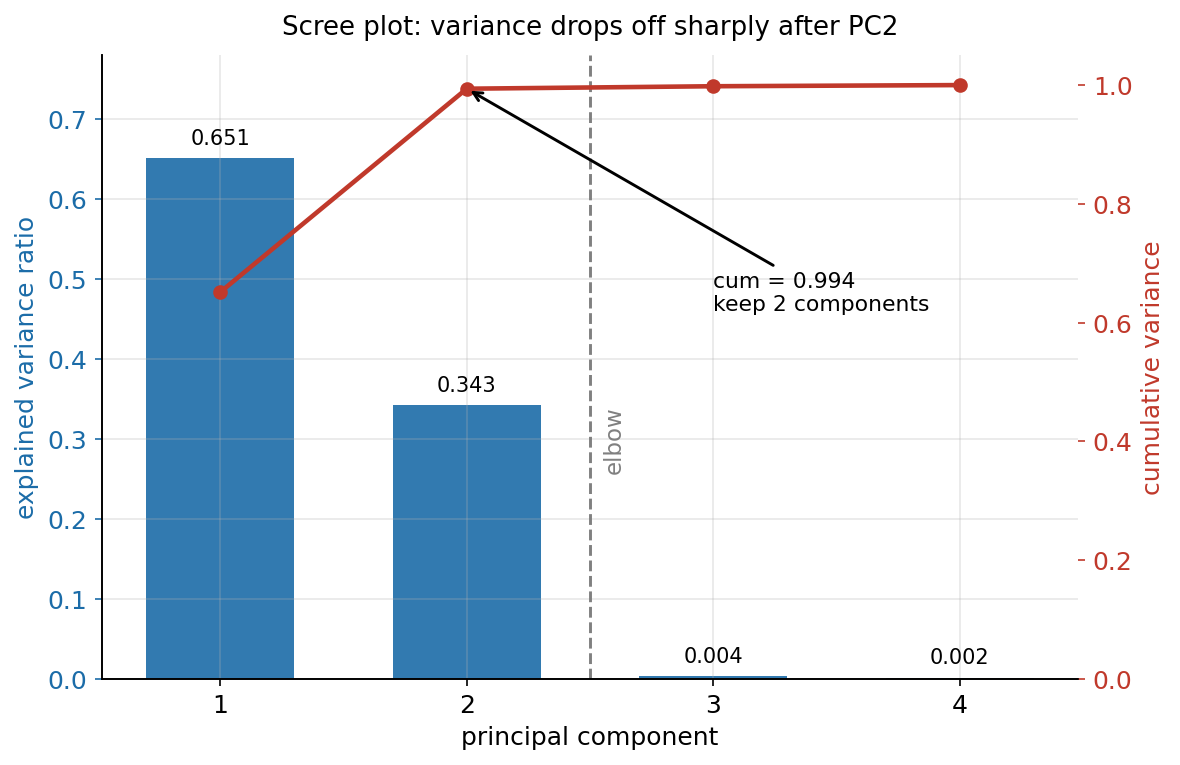
ছবি থেকে যা পড়া যায়। দুটো লম্বা নীল bar (PC1 \(= 0.651\), PC2 \(= 0.343\))-এর পরেই একটা নাটকীয় খাদ — PC3 (\(0.004\)) আর PC4 (\(0.002\)) এত ছোট যে অক্ষের মেঝে থেকে প্রায় আলাদাই করা যায় না। এই আকস্মিক পতনটাই সেই elbow, ধূসর ভাঙা রেখায় চিহ্নিত: এর বাঁ দিকে variance প্রচুর, ডান দিকে কার্যত শূন্য। লাল cumulative line একই গল্প উল্টোদিক থেকে বলে — PC1-এ \(0.651\), PC2-তে এক লাফে \(0.994\), তারপর কার্যত সমতল (PC3, PC4 যোগ করে \(1.0\)-তে পৌঁছাতে মাত্র \(0.006\) বাকি)। সিদ্ধান্ত তাই দ্ব্যর্থহীন: প্রথম দুটো component রাখো, বাকি দুটো ফেলে দাও। এতে dimensionality \(4\) থেকে \(2\)-তে নামে, অথচ তথ্যের \(99.4\%\) অক্ষত থাকে। লক্ষণীয়, এই ছবিটা §৬.১-এর scatter-এর পরিমাণগত যুক্তি: সেখানে আমরা চোখে দেখেছিলাম দুটো অক্ষই যথেষ্ট, এখানে scree plot সংখ্যায় দেখাল কেন — কারণ বাকি দুটো অক্ষে ধরে রাখার মতো variance-ই নেই। এই "elbow খোঁজা" কৌশলটা পরের ছবিতে আবার ফিরবে, এবার cluster-সংখ্যা বাছতে।
৬.৩ · কটা cluster: elbow আর silhouette একমত¶
PCA বলল data আসলে \(2\)-মাত্রিক ও তিনটে দলে ভাগ — কিন্তু বাস্তব clustering-এ আমরা true label জানি না, তাই \(k\) (cluster-সংখ্যা) আমাদেরই বেছে নিতে হয়। এই ছবিতে দুটো স্বাধীন diagnostic পাশাপাশি, দুটো ভিন্ন কোণ থেকে একই প্রশ্নের উত্তর খোঁজে। বাঁ panel — elbow method: প্রতিটা \(k\)-র জন্য k-means-এর inertia (প্রতিটা point থেকে তার নিকটতম centroid-এর দূরত্ব-বর্গের যোগফল, অর্থাৎ within-cluster scatter) আঁকা; \(k\) বাড়ালে inertia একটানা কমে (বেশি দল মানে প্রতিটা দল ছোট), তাই উত্তর সবচেয়ে কম inertia-তে নয়, বরং সেই elbow-এ — যেখানে আরও একটা cluster যোগ করেও আর তেমন লাভ হয় না। ডান panel — silhouette method: প্রতিটা \(k\)-র জন্য mean silhouette score (\(-1\) থেকে \(+1\); নিজের দলের সঙ্গে কতটা আঁটসাঁট বনাম পাশের দলের সঙ্গে কতটা আলাদা তার পরিমাপ) আঁকা; এখানে উত্তর সরাসরি সর্বোচ্চ score-এ।
ks = range(1, 7)
inertias, sils = {}, {}
for k in ks:
km = KMeans(n_clusters=k, random_state=0, n_init=10).fit(X)
inertias[k] = km.inertia_ # within-cluster SSE
if k >= 2: # silhouette-এর জন্য k>=2 লাগে
sils[k] = silhouette_score(X, km.labels_)
# inertia: 1→1200, 2→527, 3→135, 4→111, 5→91, 6→72 (elbow at k=3)
# silhouette: 2→0.552, 3→0.712, 4→0.598 (peak at k=3)
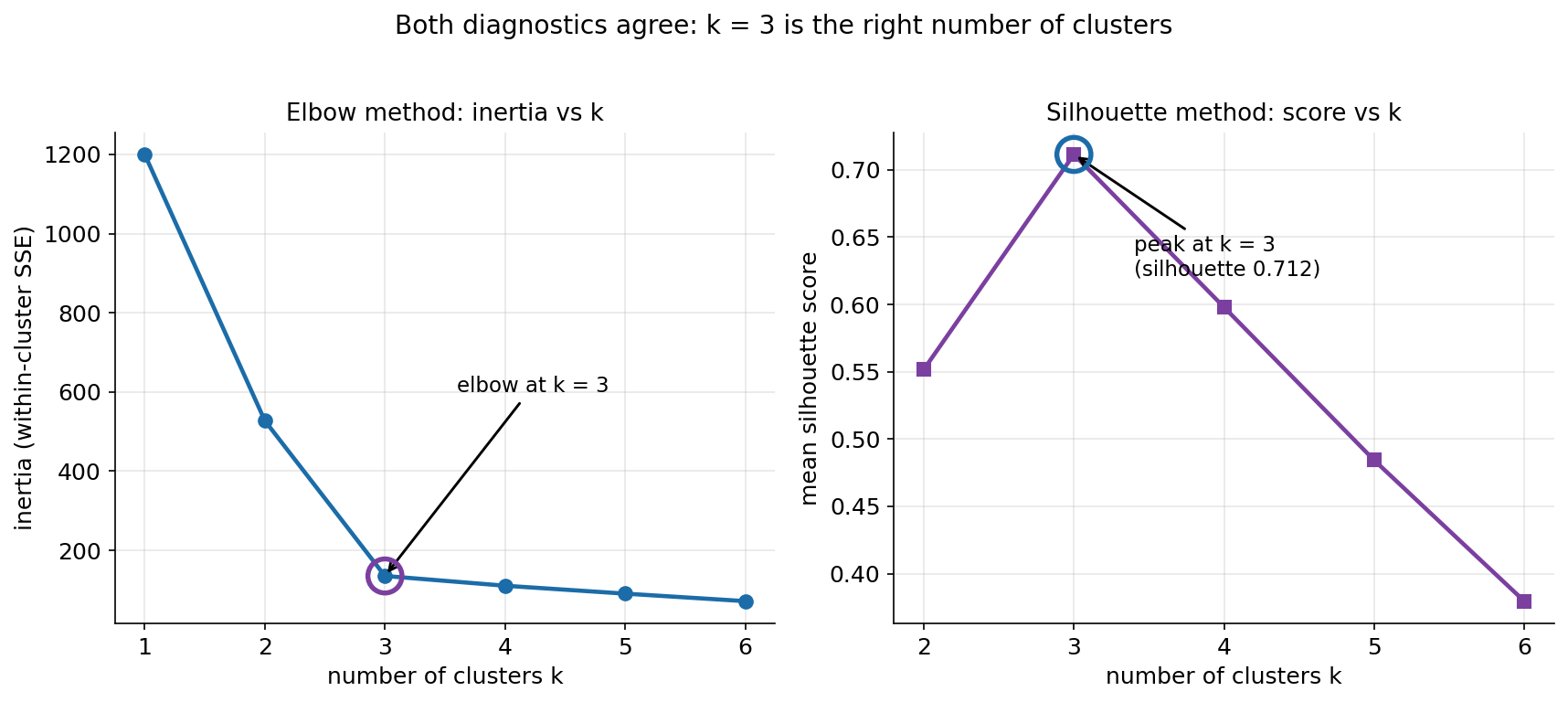
ছবি থেকে যা পড়া যায়। বাঁ দিকের inertia curve একটা স্পষ্ট "L" আঁকে: \(k = 1 \to 2 \to 3\) পর্যন্ত খাড়া পতন (\(1200 \to 527 \to 135\)) — প্রতিবার একটা নতুন cluster যোগ করায় within-cluster scatter নাটকীয়ভাবে কমছে, কারণ আমরা সত্যিকারের আলাদা দলগুলোকে আলাদা করছি। কিন্তু \(k = 3\)-এর পর curve হঠাৎ সমতল হয়ে যায় (\(135 \to 111 \to 91 \to 72\)) — চতুর্থ cluster যোগ করার মানে এখন একটা সত্যিকারের দলকে জোর করে দু টুকরো করা, যাতে inertia সামান্যই কমে। এই বাঁকটাই elbow, বৃত্তে চিহ্নিত, আর এটা ঠিক \(k = 3\)-এ। ডান দিকের silhouette curve একই উত্তরে পৌঁছায় আরও সরাসরি ভাবে — score \(k = 2\)-এ \(0.552\) থেকে \(k = 3\)-এ শীর্ষ \(0.712\)-তে ওঠে, তারপর \(k = 4\)-এ \(0.598\), \(k = 5\)-এ \(0.484\) বরাবর নামতেই থাকে। শীর্ষ \(0.712\) মানে \(k = 3\)-এ দলগুলো একইসঙ্গে ভেতরে আঁটসাঁট এবং পরস্পর থেকে দূরে — clustering-এর আদর্শ অবস্থা। দুই diagnostic-এর এই একমত হওয়াটাই গুরুত্বপূর্ণ: elbow (ব্যবহারিক, একটু ব্যক্তিগত বিচার) আর silhouette (পরিমাণগত, দ্ব্যর্থহীন) দুটো ভিন্ন পথে এসে একই উত্তর — \(k = 3\) — দিচ্ছে, যা PCA-র চোখে-দেখা তিন দলের সঙ্গেও হুবহু মেলে। তাই পরের ও শেষ ছবিতে আমরা নির্দ্বিধায় \(k = 3\) নিয়ে এগোই।
৬.৪ · k-means সত্যিই দলগুলো খুঁজে পেল কি?¶
এতক্ষণ আমরা ঠিক করেছি data \(2\)-মাত্রিক (\(§৬.১\)–\(৬.২\)) এবং তাতে \(3\) টা দল আছে (\(§৬.৩\))। এই শেষ ছবিটা চূড়ান্ত যাচাই: \(k = 3\) দিয়ে k-means চালিয়ে, তার assignment (algorithm কোন point-কে কোন দলে ফেলল) অনুসারে PC1–PC2 সমতলে বিন্দু রঙ করি, আর প্রতিটা দলের centroid কালো \(\times\)-এ বসাই। যেহেতু এটা simulation আর আমরা true label জানি, আমরা দুটো objective স্কোরে যাচাই করতে পারি — silhouette (label না জেনেও clustering কতটা ভালো) আর ARI (Adjusted Rand Index: k-means-এর দল আর true দলের মিল কতটা; \(1.0\) মানে নিখুঁত মিল)।
km3 = KMeans(n_clusters=3, random_state=0, n_init=10).fit(X)
assign = km3.labels_ # k-means-এর দল
sil3 = silhouette_score(X, assign) # 0.712
ari3 = adjusted_rand_score(label, assign) # 0.990 (true label-এর সাথে মিল)
cent = pca.transform(km3.cluster_centers_) # centroid-গুলো PC সমতলে
for k in range(3):
m = assign == k
ax.scatter(pc1[m], pc2[m], s=34, label=f"k-means cluster {k}")
ax.scatter(cent[:, 0], cent[:, 1], marker="X", s=300, color="black") # centroid
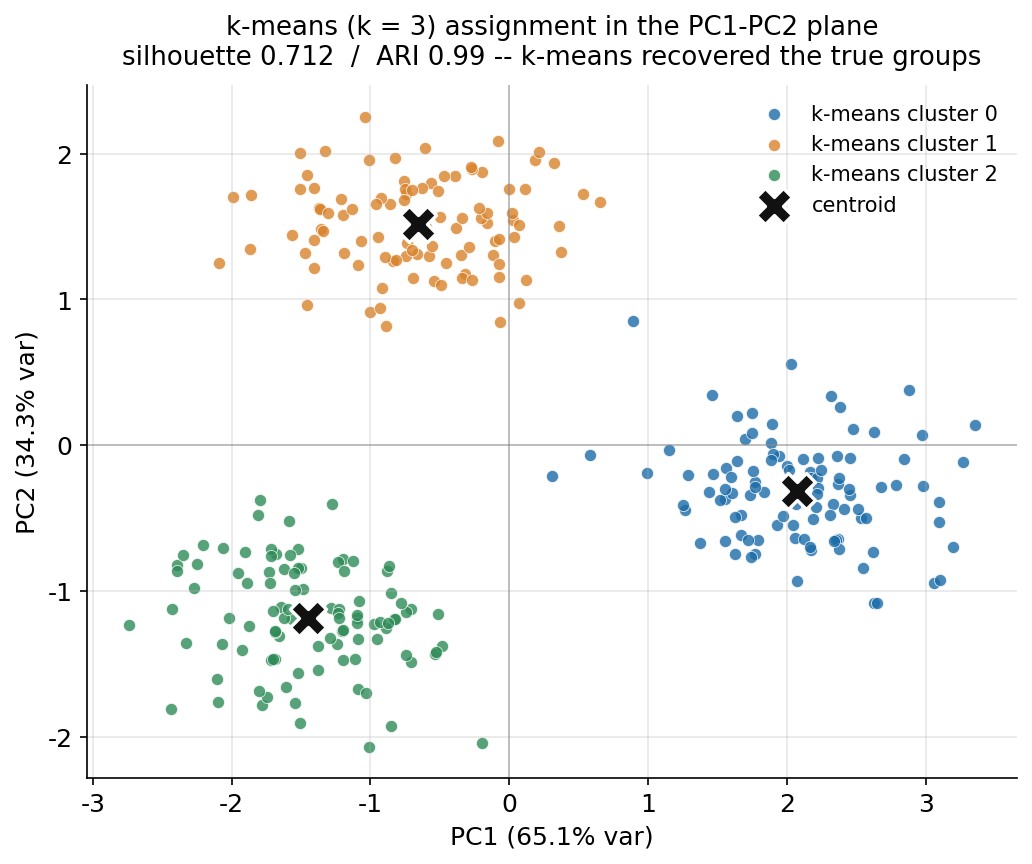
ছবি থেকে যা পড়া যায়। এই ছবিটা §৬.১-এর সঙ্গে পাশাপাশি রাখুন — তখন বিন্দু রঙ করা ছিল true label দিয়ে, এখন রঙ করা হলো k-means-এর নিজের সিদ্ধান্ত দিয়ে, অথচ তিনটে ঝাঁকের গঠন হুবহু একই। অর্থাৎ algorithm, true answer-এর কোনো ইঙ্গিত ছাড়াই, কেবল data-র জ্যামিতি থেকে সেই একই তিনটে দল খুঁজে বের করেছে। তিনটে কালো \(\times\) ঠিক প্রতিটা ঝাঁকের প্রাণকেন্দ্রে বসে আছে — এগুলোই centroid, যাদের চারপাশে k-means দল গড়ে। (একটা ছোট কিন্তু গুরুত্বপূর্ণ পর্যবেক্ষণ: §৬.১-এ যে ঝাঁক নীল ছিল এখানে সে অন্য রঙ পেয়েছে — clustering label-এর নাম নিয়ে উদাসীন, সে শুধু দল-গুলো ঠিক রাখে; ARI ঠিক এই কারণেই label-এর permutation উপেক্ষা করে শুধু গোষ্ঠীবিন্যাসের মিল মাপে।) আর সেই মিলটা শিরোনামে সংখ্যায় বাঁধা: silhouette \(0.712\) নিশ্চিত করে দলগুলো সত্যিই ঘন ও সুবিন্যস্ত, আর ARI \(0.99\) বলে k-means-এর বিভাজন true বিভাজনের সঙ্গে প্রায় নিখুঁতভাবে (\(300\) টার মধ্যে মাত্র গুটিকয় point ছাড়া) মিলেছে।
দুই অংশ একসঙ্গে এই অধ্যায়ের সম্পূর্ণ পরিক্রমা জীবন্ত করে তোলে: PCA correlated \(4\)-মাত্রিক data-কে \(2\)-মাত্রিক সমতলে নামিয়ে এনে \(99.4\%\) তথ্য বাঁচাল ও গঠনটা চোখে দেখাল (\(§৬.১\)–\(৬.২\)); elbow ও silhouette মিলে cluster-সংখ্যা \(k = 3\) ঠিক করল (\(§৬.৩\)); এবং k-means সেই সংখ্যা দিয়ে চলে true দলগুলো প্রায় নিখুঁতভাবে উদ্ধার করল, যা silhouette \(0.712\) ও ARI \(0.99\)-এ নিশ্চিত হলো (\(§৬.৪\))। এটাই unsupervised multivariate বিশ্লেষণের আদর্শ গল্প — লেবেল ছাড়াই, কেবল variance আর দূরত্বের জ্যামিতি থেকে, লুকানো গঠন খুঁজে বের করা।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/05-09-multivariate-pca-clustering-solutions.md-এ। নিজে চেষ্টা করার আগে সমাধান দেখবেন না — কেন PCA-র আগে standardize করতে হয়, eigenvalue \(=\) PC-বরাবর variance ও explained-variance-ratio হাতে গুনে (দেওয়া eigenvalue \([2.614,1.375,0.017,0.008]\) থেকে), scree/কতগুলো component রাখব, PCA projection ও reconstruction, PCA \(=\) top-eigenvector — Lagrangian দিয়ে প্রমাণ, k-means objective ও Lloyd-এর ধাপ, কেন k-means-এ \(k\) ও multiple restart লাগে (local minima), elbow বনাম silhouette দিয়ে \(k\) বাছা (দেওয়া inertia/silhouette টেবিল থেকে \(k=3\)), এবং ARI দিয়ে cluster-পুনরুদ্ধার মাপা — এই হাতে-কলমে বোঝাই এই অধ্যায়ের আসল শেখা।
(চলমান উদাহরণ স্মারক — seed np.random.default_rng(20260619), \(n=300\), \(p=4\): \(3\)টি cluster (প্রতিটিতে \(100\) বিন্দু), অন্তর্নিহিতভাবে \(2\)-মাত্রিক structure \(4\)টি correlated feature-এ লুকানো; প্রতিটি column standardize-করা (mean \(0\), sd \(1\))। canonical সংখ্যা — PCA: eigenvalue \([2.614,\ 1.375,\ 0.017,\ 0.008]\); explained-variance-ratio \([0.651,\ 0.343,\ 0.0042,\ 0.0019]\); cumulative \([0.651,\ 0.994,\ \ldots]\); PC1+PC2 \(=99.4\%\)। k-means inertia: \(k{=}1\to1200\), \(k{=}2\to527\), \(k{=}3\to135\), \(k{=}4\to111\), \(k{=}5\to91\), \(k{=}6\to72\) (elbow \(k{=}3\))। silhouette: \(k{=}2\to0.552\), \(k{=}3\to0.712\) (সর্বোচ্চ), \(k{=}4\to0.598\)। চূড়ান্ত \(k{=}3\): inertia \(135.3\), silhouette \(0.712\), ARI \(0.990\)। মূল সূত্র: covariance \(\Sigma=\frac{1}{n-1}X^\top X\) (standardized \(X\)); eigenpair \(\Sigma v_j=\lambda_j v_j\); explained-variance-ratio \(\lambda_j/\sum_l\lambda_l\); PC score \(z=Xv\); inertia \(\sum_k\sum_{i\in C_k}\lVert x_i-\mu_k\rVert^2\); silhouette \(s_i=\frac{b_i-a_i}{\max(a_i,b_i)}\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). কেন PCA-র আগে standardize করতে হয়। PCA covariance matrix \(\Sigma\)-এর eigen-গঠন বের করে, আর eigenvector সেই দিক খোঁজে যেখানে variance সর্বোচ্চ। (ক) ধরুন একটা dataset-এ একটা feature "আয়" (টাকায়, variance \(\sim 10^{10}\)) আর আরেকটা "বয়স" (বছরে, variance \(\sim 10^2\)) — raw data-তে PCA চালালে PC1 কার্যত কোন feature-কে অনুসরণ করবে, এবং কেন এটা বিভ্রান্তিকর? (খ) standardize (প্রতিটি column-কে mean \(0\), sd \(1\) করা) এই সমস্যা কীভাবে মেটায় — তখন PCA আসলে কোন matrix-এর eigen-গঠন বের করে? (গ) আমাদের চলমান উদাহরণে \(4\)টি feature আগেই standardized, তাই প্রতিটির variance \(1\) এবং মোট variance \(=\operatorname{tr}(\Sigma)=4\) — যাচাই করুন দেওয়া eigenvalue-গুলোর যোগফল এই \(4\)-এর সমান। Hint: (ক) raw PCA variance-এর মাপের একক-এর প্রতি সংবেদনশীল; "আয়"-এর বিশাল variance PC1-কে প্রায় পুরোপুরি "আয়"-অক্ষে টেনে নেবে — শুধু একক বড় বলে, প্রকৃত গুরুত্বের জন্য নয়। একক টাকা→হাজার-টাকা বদলালে উত্তর বদলে যেত। (খ) standardize করলে PCA covariance-এর বদলে কার্যত correlation matrix-এর eigen-গঠন বের করে — সব feature সমান-পায়ে, scale-মুক্ত। (গ) \(2.614+1.375+0.017+0.008=4.014=\operatorname{tr}(\Sigma)\) ✓ — standardize করায় প্রতিটি feature-এর variance \(1\), তবে covariance-এ \(1/(n-1)\) ভাজক বলে মোট \(=4\times\frac{n}{n-1}=4.014\) (Bessel factor; \(1/n\) নিলে ঠিক \(4\))।
প্রশ্ন ২ (★). eigenvalue \(=\) PC-বরাবর variance, আর explained-variance-ratio। PCA-তে \(j\)-তম PC-বরাবর data-র variance ঠিক \(\lambda_j\) (সেই PC-এর eigenvalue)। দেওয়া eigenvalue \([2.614,\ 1.375,\ 0.017,\ 0.008]\)। (ক) এক বাক্যে বলুন কেন বড় eigenvalue \(=\) "বেশি গুরুত্বপূর্ণ" দিক — variance-এর সাথে এর সম্পর্ক কী? (খ) প্রতিটি PC-র explained-variance-ratio \(\lambda_j/\sum_l\lambda_l\) গণনা করুন (canonical \([0.651,0.343,0.0042,0.0019]\) মেলান)। (গ) PC1 ও PC2 একসাথে মোট variance-এর কত শতাংশ ধরে — এটা data সম্পর্কে কী বলে (অন্তর্নিহিত মাত্রা আসলে কত)? Hint: (ক) PC-বরাবর variance \(=\lambda_j\); বড় variance মানে data সেই দিকে বেশি "ছড়ানো", তাই বেশি তথ্য সেই অক্ষে — তাই বড় eigenvalue \(=\) প্রধান দিক। (খ) \(\sum\lambda=4.014\); \(2.614/4.014=0.651\), \(1.375/4.014=0.343\), \(0.017/4.014=0.0042\), \(0.008/4.014=0.0019\)। (গ) \(0.651+0.343=0.994=99.4\%\) — প্রায় সব variance প্রথম \(2\) PC-তে, তাই data কার্যত ২-মাত্রিক (বাকি \(2\) PC প্রায় শুধু noise)।
প্রশ্ন ৩ (★★). scree plot ও কতগুলো component রাখব। scree plot হলো eigenvalue (বা explained-variance-ratio) বনাম PC-নম্বরের লেখচিত্র। আমাদের ratio \([0.651,0.343,0.0042,0.0019]\), cumulative \([0.651,0.994,0.9982,1.0]\)। (ক) scree plot-এ "elbow" বলতে কী বোঝায়, এবং এই উদাহরণে elbow কোন PC-র পরে — তাই কতগুলো PC রাখা উচিত? (খ) "cumulative ৯০% (বা ৯৫%) variance" নিয়ম প্রয়োগ করলে কতগুলো PC রাখতে হবে? (গ) এই দুই নিয়ম (elbow ও ৯০%-cumulative) এখানে একই উত্তর দেয় কেন — কী থাকলে দুটো ভিন্ন উত্তর দিত? Hint: (ক) elbow \(=\) যেখানে eigenvalue হঠাৎ নেমে প্রায় সমতল হয়; এখানে PC2 থেকে PC3-এ বিশাল পতন (\(0.343\to0.0042\)), তাই elbow PC2-র পরে ⇒ \(2\)টি PC রাখা। (খ) cumulative PC2-তেই \(0.994\) (\(>0.90\) বা \(0.95\)), তাই \(2\)টি PC যথেষ্ট। (গ) এখানে structure পরিষ্কার ২-মাত্রিক (বড় gap), তাই উভয় নিয়ম \(2\) বলে; structure ধীরে-ক্ষীয়মাণ (ক্রমশ কমে, তীক্ষ্ণ elbow নেই) হলে elbow অস্পষ্ট হত আর cumulative-নিয়ম বেশি PC চাইত — তখন ভিন্ন উত্তর।
প্রশ্ন ৪ (★★). PCA projection ও reconstruction। standardized \(X\in\mathbb R^{n\times p}\), top-\(2\) eigenvector \(V_2=[v_1\ v_2]\in\mathbb R^{p\times2}\)। projection (PC score) \(Z=XV_2\in\mathbb R^{n\times2}\), reconstruction \(\hat X=ZV_2^\top\)। (ক) projection মাত্রা \(p=4\) থেকে \(2\)-এ নামায় — score \(z=Xv_1\)-এর মানে কী (একটা বিন্দু \(x_i\)-এর জন্য \(z_{i1}\) কী মাপছে)? (খ) reconstruction \(\hat X=ZV_2^\top\) আবার \(p=4\)-মাত্রায় ফেরে কিন্তু \(X\)-এর সমান নয় — কোন তথ্য হারায়, এবং সেই হারানো অংশের পরিমাণ (reconstruction-error) কোন eigenvalue-গুলোর সাথে সম্পর্কিত? (গ) আমাদের উদাহরণে top-\(2\) PC দিয়ে reconstruction-এ মোট variance-এর কত ভগ্নাংশ রক্ষা পায়, আর কত হারায়? Hint: (ক) \(z_{i1}=x_i^\top v_1\) হলো বিন্দু \(x_i\)-এর PC1-অক্ষে উৎক্ষেপ (coordinate) — সেই প্রধান দিকে \(x_i\) কতটা দূরে। (খ) বাদ-দেওয়া PC (\(v_3,v_4\))-বরাবর component হারায়; reconstruction-error (Frobenius-বর্গ) \(=\sum_{j>2}\lambda_j=0.017+0.008=0.025\), অর্থাৎ বাদ-দেওয়া eigenvalue-গুলোর যোগফল। (গ) রক্ষা পায় \(\frac{\lambda_1+\lambda_2}{\sum\lambda}=99.4\%\), হারায় \(0.6\%\) — তাই \(2\) PC-তে নামানো প্রায় lossless।
প্রশ্ন ৫ (★★). k-means objective ও Lloyd-এর ধাপ। k-means minimize করে inertia (within-cluster sum-of-squares) \(W=\sum_{k=1}^{K}\sum_{i\in C_k}\lVert x_i-\mu_k\rVert^2\), যেখানে \(\mu_k\) হলো cluster \(k\)-এর centroid। (ক) Lloyd-এর algorithm দুটো ধাপ পালাক্রমে চালায়: assignment ও update — প্রতিটি ধাপ ঠিক কী করে (এক বাক্যে করে)? (খ) দেখান প্রতিটি ধাপই \(W\) কমায় বা সমান রাখে (কখনো বাড়ায় না) — তাই algorithm অবশ্যই থামে; assignment-ধাপ কেন \(W\) বাড়ায় না, আর update-ধাপ কেন? (গ) তবু Lloyd global minimum-এ পৌঁছানোর নিশ্চয়তা দেয় না — কেন (এটি প্রশ্ন ৬-এর সাথে যুক্ত)? Hint: (ক) assignment: centroid স্থির রেখে প্রতিটি বিন্দুকে নিকটতম centroid-এর cluster-এ বসানো; update: assignment স্থির রেখে প্রতিটি cluster-এর centroid \(=\) তার বিন্দুদের গড় (\(\mu_k=\frac1{\lvert C_k\rvert}\sum_{i\in C_k}x_i\))। (খ) assignment-এ প্রতিটি বিন্দু নিকটতম centroid বাছে ⇒ তার পদ \(\lVert x_i-\mu_k\rVert^2\) কমে বা সমান; update-এ গড় হলো sum-of-squares-এর minimizer (\(\arg\min_\mu\sum_{i\in C_k}\lVert x_i-\mu\rVert^2=\bar x_{C_k}\)), তাই \(W\) আরও কমে। উভয়ে monotone ↓ ⇒ অভিসৃতি। (গ) \(W\) non-convex (assignment discrete) ⇒ Lloyd শুধু local-min-এ আটকায়; কোন local-min-এ থামে তা প্রারম্ভিক centroid-এর উপর নির্ভর করে।
প্রশ্ন ৬ (★★). কেন k-means-এ \(k\) আগে দিতে হয় ও multiple restart লাগে (local minima)। (ক) k-means-কে cluster-সংখ্যা \(K\) আগে থেকে দিতে হয় — algorithm নিজে \(K\) বের করে না; এটা PCA-র (যেখানে eigenvalue নিজেই মাত্রা ইঙ্গিত করে) তুলনায় কেন একটা দুর্বলতা, এবং বাস্তবে \(K\) কীভাবে বাছা হয় (পরের প্রশ্নের সূত্র)? (খ) একই \(K\)-তে দুটো ভিন্ন random initialization দুটো ভিন্ন inertia-তে অভিসৃত হতে পারে — কেন (objective-এর কোন ধর্মের জন্য)? (গ) তাই বাস্তবে k-means একাধিকবার (\(n_{\text{init}}\) বার, ভিন্ন initialization-এ) চালিয়ে সবচেয়ে কম inertia-ওয়ালা ফলটা রাখা হয় — এই কৌশল কী সমস্যা সামলায়, এবং k-means++ initialization কীভাবে সাহায্য করে?
Hint: (ক) ভুল \(K\) দিলে অর্থহীন cluster; \(K\) data-নির্ধারিত নয় বলে আলাদা মানদণ্ড (elbow, silhouette) দিয়ে বাছতে হয় — supervised CV-র মতো সরাসরি "honest error" নেই। (খ) objective non-convex, বহু local minimum; initialization যে basin-এ পড়ে সেখানেই Lloyd থামে — তাই ভিন্ন শুরু ⇒ ভিন্ন স্থানীয় ফল। (গ) multiple restart বিভিন্ন basin চেষ্টা করে সেরাটা (সর্বনিম্ন inertia) রাখে — খারাপ local-min এড়ায়; k-means++ প্রারম্ভিক centroid-গুলোকে দূরে-দূরে ছড়িয়ে বাছে (probabilistically), ফলে কম restart-এই ভালো ফল।
প্রশ্ন ৭ (★★). within-SS বনাম between-SS — inertia কী মাপছে। মোট spread-কে ভাঙা যায়: \(\text{TSS}=\text{WSS}+\text{BSS}\), যেখানে total \(\text{TSS}=\sum_i\lVert x_i-\bar x\rVert^2\) (সব-বিন্দু grand-mean থেকে), within \(\text{WSS}=\sum_k\sum_{i\in C_k}\lVert x_i-\mu_k\rVert^2\) (\(=\) inertia), between \(\text{BSS}=\sum_k\lvert C_k\rvert\,\lVert\mu_k-\bar x\rVert^2\)। (ক) k-means inertia (WSS) minimize করা আর BSS maximize করা একই কেন (TSS তো \(K\)-নিরপেক্ষ ধ্রুবক)? (খ) আমাদের উদাহরণে \(\text{TSS}=1200\) (এটাই \(k{=}1\)-এর inertia, কারণ তখন একটাই cluster, \(\mu_1=\bar x\)); \(k{=}3\)-এ WSS \(=135.3\) — তাহলে BSS কত, আর মোট spread-এর কত ভগ্নাংশ cluster-পার্থক্য ব্যাখ্যা করে? (গ) এই ভগ্নাংশ (ANOVA-র \(R^2\)-সদৃশ) \(k\) বাড়ালে সবসময় বাড়ে কেন — তাই কেন একে সরাসরি \(K\) বাছার মানদণ্ড হিসেবে ব্যবহার করা যায় না? Hint: (ক) \(\text{TSS}=\text{WSS}+\text{BSS}\) এবং TSS ধ্রুবক ⇒ WSS কমানো \(\Leftrightarrow\) BSS বাড়ানো — একই মুদ্রার দুই পিঠ। (খ) \(\text{BSS}=1200-135.3=1064.7\); ভগ্নাংশ \(=1064.7/1200=0.887\), অর্থাৎ মোট spread-এর প্রায় ৮৯% cluster-মধ্যকার পার্থক্য ব্যাখ্যা করে। (গ) \(K\) বাড়ালে WSS একঘেয়ে কমে (চরমে \(K=n\) হলে WSS \(=0\)), তাই BSS-ভগ্নাংশ একঘেয়ে বাড়ে — কোনো "সর্বোত্তম" বিন্দু চিহ্নিত করে না (train error-এর মতো); তাই elbow/silhouette লাগে।
প্রশ্ন ৮ (★★). hierarchical clustering ও dendrogram। agglomerative hierarchical clustering প্রতিটি বিন্দুকে আলাদা cluster ধরে শুরু করে, তারপর বারবার নিকটতম দুই cluster জোড়া দেয় যতক্ষণ একটাই cluster থাকে; ফল একটা গাছ — dendrogram। (ক) k-means-এর তুলনায় hierarchical-এর দুটো সুবিধা বলুন (\(K\) আগে দিতে হয় কিনা, ফলের রূপ)। (খ) dendrogram থেকে \(K\)টি cluster পেতে কী করতে হয় (গাছ কোথায় "কাটতে" হয়), এবং কাটার উচ্চতা কী বোঝায়? (গ) linkage (single, complete, average, Ward) আলাদা "দুই cluster-এর দূরত্ব"-র সংজ্ঞা দেয় — Ward linkage k-means-এর সাথে ঘনিষ্ঠ কেন? Hint: (ক) (i) \(K\) আগে দিতে হয় না — পুরো গাছ একবারে দেয়, পরে যেকোনো \(K\)-তে কাটা যায়; (ii) cluster-গুলোর nested শ্রেণিবিন্যাস দেখায় (কোনটা কার ভেতরে), শুধু একটা flat partition নয়। (খ) কোনো উচ্চতায় আনুভূমিক রেখা টেনে কাটলে যত শাখা কাটে তত cluster; কাটার উচ্চতা \(=\) যে দূরত্বে দুই cluster মিশেছিল (বড় উচ্চতা \(=\) বেশি ভিন্ন cluster মিলছে)। (গ) Ward প্রতি merge-এ within-cluster SS-এর বৃদ্ধি সর্বনিম্ন করে — k-means-এর মতোই variance/inertia-ভিত্তিক objective, তাই গোলাকার সমান-আকার cluster-এ দুটো প্রায়ই মেলে।
খ · গণনামূলক (computational)¶
প্রশ্ন ৯ (★). explained-variance-ratio ও cumulative হাতে। দেওয়া eigenvalue \([2.614,\ 1.375,\ 0.017,\ 0.008]\)। (ক) যোগফল \(\sum_l\lambda_l\) বের করে প্রতিটি PC-র explained-variance-ratio \(\lambda_j/\sum_l\lambda_l\) গণনা করুন (canonical \([0.651,0.343,0.0042,0.0019]\) মেলান)। (খ) cumulative explained-variance বের করুন (PC1, PC1+PC2, …)। (গ) "অন্তত ৯৫% variance" পেতে ন্যূনতম কতগুলো PC লাগে? Hint: (ক) \(\sum=2.614+1.375+0.017+0.008=4.014\); ratio \(=2.614/4.014=0.651\), \(1.375/4.014=0.343\), \(0.017/4.014=0.0042\), \(0.008/4.014=0.0019\)। (খ) cumulative \(=0.651,\ 0.994,\ 0.9982,\ 1.0\)। (গ) PC2-তেই cumulative \(0.994\ge0.95\), তাই \(2\)টি PC যথেষ্ট।
প্রশ্ন ১০ (★). PC score হাতে গুনে (projection)। ধরুন একটা বিন্দুর standardized feature-vector \(x=(1.2,\ -0.8,\ 0.5,\ -0.3)^\top\) এবং top-\(2\) eigenvector (column) \(v_1=(0.5,0.5,0.5,0.5)^\top\), \(v_2=(0.5,-0.5,0.5,-0.5)^\top\)। (ক) PC1 score \(z_1=x^\top v_1\) গণনা করুন। (খ) PC2 score \(z_2=x^\top v_2\) গণনা করুন। (গ) \(v_1\) ও \(v_2\) orthonormal কিনা যাচাই করুন (\(v_1^\top v_1\), \(v_2^\top v_2\), \(v_1^\top v_2\)) — orthonormality PCA-র জন্য কেন জরুরি? Hint: (ক) \(z_1=0.5(1.2-0.8+0.5-0.3)=0.5(0.6)=0.30\)। (খ) \(z_2=0.5(1.2)+(-0.5)(-0.8)+0.5(0.5)+(-0.5)(-0.3)=0.6+0.4+0.25+0.15=1.40\)। (গ) \(v_1^\top v_1=4(0.25)=1\), \(v_2^\top v_2=4(0.25)=1\), \(v_1^\top v_2=0.25-0.25+0.25-0.25=0\) — orthonormal ✓; orthonormal বলেই PC-অক্ষগুলো লম্ব (uncorrelated score) ও length-রক্ষাকারী (variance যোগ্য, reconstruction পরিষ্কার)।
প্রশ্ন ১১ (★★). elbow বনাম silhouette দিয়ে \(k\) বাছা। আমাদের উদাহরণে k-means inertia ও silhouette:
| \(k\) | inertia | silhouette \(s\) |
|---|---|---|
| 1 | 1200 | — |
| 2 | 527 | 0.552 |
| 3 | 135 | 0.712 |
| 4 | 111 | 0.598 |
| 5 | 91 | — |
| 6 | 72 | — |
(ক) elbow method: ধারাবাহিক inertia-পতন \(\Delta=W_{k-1}-W_k\) গণনা করুন (\(k{=}1\to2\), \(2\to3\), \(3\to4\), …) এবং বলুন কোথায় পতন হঠাৎ ছোট হয়ে যায় — তাই elbow কোন \(k\)-তে? (খ) silhouette method: silhouette \(s\) কোন \(k\)-তে সর্বোচ্চ — এটা কোন \(k\) বাছে? (গ) দুই পদ্ধতি একই \(k\) বাছল — সাধারণভাবে কোনটা বেশি নির্ভরযোগ্য ও কেন (elbow-এর কী সমস্যা)? Hint: (ক) \(\Delta\): \(1200{-}527=673\), \(527{-}135=392\), \(135{-}111=24\), \(111{-}91=20\), \(91{-}72=19\) — \(k{=}3\)-এর পরে পতন নাটকীয়ভাবে ছোট (\(392\to24\)), তাই elbow \(k{=}3\)। (খ) silhouette সর্বোচ্চ \(k{=}3\)-এ (\(0.712>0.598>0.552\)) ⇒ silhouette বাছে \(k{=}3\)। (গ) দুটোই \(k{=}3\); silhouette বেশি নির্ভরযোগ্য — elbow চোখে-দেখা/বিষয়ভিত্তিক (পরিষ্কার elbow না থাকলে অস্পষ্ট), silhouette একটা সংখ্যাগত স্কোর (সর্বোচ্চটাই বাছা, \([-1,1]\)-এ ব্যাখ্যাযোগ্য)।
প্রশ্ন ১২ (★★). silhouette হাতে গুনে। একটা বিন্দু \(i\)-এর জন্য silhouette \(s_i=\frac{b_i-a_i}{\max(a_i,b_i)}\), যেখানে \(a_i=\) নিজের cluster-এর বিন্দুদের সাথে গড় দূরত্ব, \(b_i=\) নিকটতম প্রতিবেশী cluster-এর বিন্দুদের সাথে গড় দূরত্ব। ধরুন তিনটি বিন্দুর জন্য: (i) \(a=0.5,b=2.0\); (ii) \(a=1.5,b=1.8\); (iii) \(a=2.0,b=1.0\)। (ক) প্রতিটির \(s_i\) গণনা করুন। (খ) প্রতিটি কী বলছে cluster-membership-এর মান সম্পর্কে — কোনটা ভালো-বসানো, কোনটা সীমান্তে, কোনটা ভুল cluster-এ? (গ) আমাদের উদাহরণে \(k{=}3\)-এ গড় silhouette \(0.712\) — এটা \([-1,1]\) স্কেলে কী ইঙ্গিত দেয় (cluster কতটা সুনির্দিষ্ট)? Hint: (ক) (i) \(s=\frac{2.0-0.5}{2.0}=0.75\); (ii) \(s=\frac{1.8-1.5}{1.8}=0.167\); (iii) \(s=\frac{1.0-2.0}{2.0}=-0.5\)। (খ) (i) \(s\approx0.75\) — নিজের cluster-এর খুব কাছে, ভালো-বসানো; (ii) \(s\approx0.17\) — দুই cluster-এর প্রায় মাঝে, সীমান্ত-বিন্দু; (iii) \(s=-0.5<0\) — প্রতিবেশী cluster-এর কাছে নিজেরটার চেয়ে, সম্ভবত ভুল cluster-এ। (গ) \(0.712\) (\(>0.7\)) শক্তিশালী, সু-পৃথক cluster-গঠন নির্দেশ করে — বিন্দুরা নিজের cluster-এ ভালোভাবে বসেছে, cluster-গুলো ভালোভাবে আলাদা।
প্রশ্ন ১৩ (★★). ARI দিয়ে cluster-পুনরুদ্ধার মাপা। আমাদের data-র \(3\)টি cluster (প্রতিটি \(100\) বিন্দু) সত্যিকারের জানা label থেকে তৈরি; k-means (\(k{=}3\)) চালিয়ে পাওয়া cluster-কে সেই সত্য label-এর সাথে তুলনা করলে adjusted Rand index ARI \(=0.990\)। (ক) ARI কী মাপছে — দুটো cluster-বিন্যাস (এখানে: পাওয়া বনাম সত্য) কতটা মেলে, এবং কেন কাঁচা Rand index-এর বদলে adjusted রূপ লাগে (chance-সংশোধন)? (খ) ARI-র স্কেল — পুরোপুরি মিললে কত, এলোমেলো (random) বিন্যাসে গড়ে কত? তাই \(0.990\) কতটা ভালো? (গ) ARI ব্যবহারের একটা সীমাবদ্ধতা বলুন — বাস্তব unsupervised সমস্যায় এটা কখন গণনা করা যায় না, এবং তখন silhouette কেন বেশি কাজে লাগে? Hint: (ক) ARI মাপে দুই বিন্যাসে বিন্দু-জোড়াগুলো কতটা একইভাবে শ্রেণিভুক্ত (একই cluster-এ একসাথে, না আলাদা); cluster বেশি হলে দুটো এলোমেলো বিন্যাসও আকস্মিকভাবে কিছু জোড়া মেলায়, তাই adjusted রূপ প্রত্যাশিত-আকস্মিক-মিল বিয়োগ করে। (খ) পুরোপুরি মিললে ARI \(=1\), এলোমেলো বিন্যাসে গড়ে \(\approx0\) (ঋণাত্মকও সম্ভব); তাই \(0.990\) প্রায়-নিখুঁত পুনরুদ্ধার — k-means সত্য গঠন প্রায় হুবহু ফিরে পেয়েছে। (গ) ARI-র জন্য সত্য label জানা লাগে (ground truth) — বাস্তব unsupervised-এ তা থাকে না, তাই তখন label-মুক্ত internal মাপ (silhouette) দিয়েই cluster-মান যাচাই করতে হয়।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১৪ (★★★). PCA \(=\) top-eigenvector — Lagrangian দিয়ে প্রমাণ করুন। standardized, center-করা data-র covariance \(\Sigma=\frac{1}{n-1} X^\top X\) (\(p\times p\), symmetric, PSD)। প্রথম principal component হলো সেই একক-দৈর্ঘ্য দিক \(v\) যা projected variance সর্বোচ্চ করে: $\(\max_{v}\ v^\top\Sigma v\quad\text{শর্তে}\quad v^\top v=1.\)$ (ক) Lagrangian \(\mathcal L(v,\lambda)=v^\top\Sigma v-\lambda(v^\top v-1)\) লিখে \(v\)-এর সাপেক্ষে gradient শূন্য করে দেখান প্রথম-ক্রম শর্ত হলো \(\Sigma v=\lambda v\) — অর্থাৎ optimal \(v\) অবশ্যই \(\Sigma\)-এর একটা eigenvector, আর \(\lambda\) তার eigenvalue। (খ) সেই eigenvector-এ projected variance \(v^\top\Sigma v\)-এর মান কত (eigen-সম্পর্ক বসিয়ে দেখান এটি \(=\lambda\)) — তাই variance সর্বোচ্চ করতে কোন eigenvector নিতে হবে? (গ) দ্বিতীয় PC \(v_2\) একই সমস্যা সমাধান করে অতিরিক্ত শর্ত \(v_2\perp v_1\)-এ — সংক্ষেপে যুক্তি দিন কেন এর সমাধান দ্বিতীয়-বৃহত্তম eigenvalue-এর eigenvector (symmetric \(\Sigma\)-এর eigenvector orthogonal বলে)। Hint: (ক) \(\nabla_v(v^\top\Sigma v)=2\Sigma v\), \(\nabla_v(\lambda v^\top v)=2\lambda v\); gradient শূন্য ⇒ \(2\Sigma v-2\lambda v=0\) ⇒ \(\Sigma v=\lambda v\)। (খ) eigen-সম্পর্ক বসিয়ে \(v^\top\Sigma v=v^\top(\lambda v)=\lambda(v^\top v)=\lambda\cdot1=\lambda\); তাই projected variance ঠিক eigenvalue \(\lambda\), এবং তা সর্বোচ্চ করতে বৃহত্তম eigenvalue-এর eigenvector \(v_1\) নিতে হবে। (গ) \(\Sigma\) symmetric ⇒ eigenvector-গুলো orthogonal; \(v_1\)-এর লম্ব subspace-এ একই maximization আবার eigenvalue-সমান variance দেয়, তাই বাকিগুলোর মধ্যে বৃহত্তম, অর্থাৎ ২য়-বৃহত্তম eigenvalue \(\lambda_2\)-এর eigenvector \(v_2\) — এভাবে eigenvalue-ক্রমে PC সাজে। ∎
প্রশ্ন ১৫ (★★★). k-means update-ধাপের optimality (centroid \(=\) গড়)। একটা স্থির cluster \(C_k\) (বিন্দু-সমষ্টি) ধরুন; k-means update-ধাপ centroid বাছে \(\mu_k=\arg\min_{c}\sum_{i\in C_k}\lVert x_i-c\rVert^2\)। দেখান এই minimizer ঠিক বিন্দুদের গড় \(\bar x_{C_k}=\frac1{\lvert C_k\rvert}\sum_{i\in C_k}x_i\)। (ক) \(g(c)=\sum_{i\in C_k}\lVert x_i-c\rVert^2\)-এর \(c\)-সাপেক্ষে gradient \(\nabla_c g\) বের করে শূন্য করুন। (খ) সমাধান করে \(c=\bar x_{C_k}\) পান। (গ) এটি minimum (maximum বা saddle নয়) — কেন (Hessian বা convexity-যুক্তি), এবং এই ফল কীভাবে নিশ্চিত করে Lloyd-এর update-ধাপ inertia কখনো বাড়ায় না (প্রশ্ন ৫খ-এর সাথে যোগ)? Hint: (ক) \(\nabla_c g=\sum_{i\in C_k}\nabla_c\lVert x_i-c\rVert^2=\sum_{i\in C_k}(-2)(x_i-c)=-2\sum_{i\in C_k}(x_i-c)\); শূন্য ⇒ \(\sum_{i\in C_k}(x_i-c)=0\)। (খ) \(\sum_i x_i-\lvert C_k\rvert c=0\) ⇒ \(c=\frac1{\lvert C_k\rvert}\sum_i x_i=\bar x_{C_k}\)। (গ) \(g\) হলো \(c\)-এর convex quadratic (Hessian \(=2\lvert C_k\rvert I\succ0\)), তাই একমাত্র critical point-টিই global minimum; অর্থাৎ গড়-এ বসালে \(\sum\lVert x_i-c\rVert^2\) সর্বনিম্ন ⇒ assignment স্থির রেখে centroid গড়-এ আপডেট করলে inertia কমে-বা-সমান, কখনো বাড়ে না — Lloyd-এর monotone-অভিসৃতির অর্ধেক। ∎
ঘ · কোডিং (Python)¶
প্রশ্ন ১৬ (★★★). পূর্ণ unsupervised pipeline — PCA explained-variance \(+\) k-means elbow/silhouette \(+\) ARI। seed np.random.default_rng(20260619) দিয়ে canonical data বানান: \(n=300\), \(3\)টি cluster (প্রতিটি \(100\) বিন্দু) যাদের সত্য center আলাদা, অন্তর্নিহিত structure \(2\)-মাত্রিক হলেও \(4\)টি correlated feature-এ এম্বেড করা; তারপর প্রতিটি column standardize করুন (mean \(0\), sd \(1\))। এবার:
- PCA: standardized \(X\)-এ covariance \(\Sigma=\frac{1}{n-1} X^\top X\) (বা
np.cov) বানিয়ে eigen-decompose করুন (অথবাsklearn.decomposition.PCA/SVD); eigenvalue ও explained-variance-ratio ছাপুন — canonical eigenvalue \([2.614,1.375,0.017,0.008]\), ratio \([0.651,0.343,0.0042,0.0019]\), PC1+PC2 \(=99.4\%\) মেলান, এবং scree-pattern (PC2-এর পরে তীক্ষ্ণ পতন) দেখান। - k-means elbow: \(k=1,\dots,6\)-এর জন্য
KMeans(n_clusters=k, n_init=10, random_state=...)fit করেinertia_ছাপুন — canonical \([1200,527,135,111,91,72]\) মেলান এবং ধারাবাহিক পতন থেকে elbow \(k{=}3\) দেখান। - silhouette: \(k=2,3,4\)-এর জন্য
silhouette_score(X, labels)ছাপুন — canonical \([0.552,0.712,0.598]\) মেলান, সর্বোচ্চ \(k{=}3\) দেখান (elbow ও silhouette একমত)। - ARI: \(k{=}3\) labels-কে সত্য cluster-label-এর সাথে
adjusted_rand_scoreদিয়ে তুলনা করুন — canonical ARI \(0.990\) মেলান (প্রায়-নিখুঁত পুনরুদ্ধার), এবং \(k{=}3\)-এর inertia \(135.3\) ও silhouette \(0.712\) নিশ্চিত করুন।
Hint: data: তিন center (যেমন \(4\)-D-এ যথেষ্ট-আলাদা), X = np.vstack([...]), তারপর correlated mixing matrix \(A\) দিয়ে \(X@A\) করে correlation ঢোকান; standardize X = (X - X.mean(0)) / X.std(0)। PCA: evals, evecs = np.linalg.eigh(np.cov(X, rowvar=False)), descending-এ সাজিয়ে ratio = evals / evals.sum(); অথবা PCA().fit(X).explained_variance_ratio_। elbow: [KMeans(k, n_init=10, random_state=0).fit(X).inertia_ for k in range(1,7)]। silhouette: from sklearn.metrics import silhouette_score; ARI: from sklearn.metrics import adjusted_rand_score; adjusted_rand_score(true_labels, km3.labels_)। সব প্রত্যাশিত সংখ্যা উপরের canonical তালিকায়; পূর্ণ runnable script _solutions/05-09-multivariate-pca-clustering-solutions.md-এর §ঘ-তে।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
-
নতুন জগৎ — unsupervised। ৫.১–৫.৮ জুড়ে সবই ছিল supervised: একটা response \(y\)-কে predictor \(x\) দিয়ে ব্যাখ্যা/ভবিষ্যদ্বাণী। এ অধ্যায় সেই লেবেল (\(y\)) ফেলে দেয় — হাতে শুধু feature-matrix \(X\in\mathbb R^{n\times p}\), লক্ষ্য অন্তর্নিহিত গঠন উন্মোচন: data আসলে কয় মাত্রায় বাস করে (PCA), আর বিন্দুরা কয়টি স্বাভাবিক দলে ভাগ হয় (clustering)। মানদণ্ড আর "predictive error" নয়, বরং reconstruction, separation, stability।
-
PCA — variance-সর্বোচ্চকারী eigen-দিক। standardized data-র covariance \(\Sigma\)-এর eigen-decomposition করলে eigenvector \(v_j\) দেয় ক্রমান্বয়ে variance-সর্বোচ্চকারী লম্ব দিক, আর eigenvalue \(\lambda_j\) সেই দিকে variance। explained-variance-ratio \(\lambda_j/\sum_l\lambda_l\) বলে প্রতিটি PC মোট তথ্যের কত অংশ ধরে। চলমান উদাহরণে eigenvalue \([2.614,1.375,0.017,0.008]\) ⇒ ratio \([0.651,0.343,0.0042,0.0019]\) ⇒ PC1+PC2 \(=99.4\%\) — অর্থাৎ \(4\)-মাত্রিক data কার্যত ২-মাত্রিক। scree plot-এ PC2-র পরে তীক্ষ্ণ পতন (elbow) ও ৯৯%-cumulative — উভয়ই \(2\) PC রাখতে বলে। score \(z=Xv\) projection (মাত্রা-হ্রাস), reconstruction \(\hat X=ZV_2^\top\) — বাদ-দেওয়া eigenvalue-যোগফল (\(0.025\)) মাত্র হারায়, তাই প্রায় lossless। (Lagrangian প্রমাণ: maximization \(\max v^\top\Sigma v\) s.t. \(\lVert v\rVert=1\)-এর সমাধান শীর্ষ-eigenvector; এর SVD-রূপ সমতুল্য।)
-
Clustering — k-means: inertia, Lloyd, restart। k-means minimize করে inertia \(W=\sum_k\sum_{i\in C_k}\lVert x_i-\mu_k\rVert^2\) (within-cluster SS); Lloyd-এর algorithm দুই ধাপ পালাক্রমে — assignment (নিকটতম centroid-এ বিন্দু) ও update (centroid \(=\) cluster-গড়) — প্রতিটি \(W\) কমায়-বা-সমান, তাই অভিসৃত হয়, কিন্তু objective non-convex বলে শুধু local minimum-এ; তাই \(K\) আগে দিতে হয় ও multiple restart (k-means++ init) দিয়ে সেরা inertia বাছা হয়।
-
কয়টি cluster — elbow বনাম silhouette। inertia \(K\) বাড়ালে একঘেয়ে কমে (train-error-সদৃশ), তাই সরাসরি minimize করে \(K\) বাছা যায় না। elbow: inertia-পতন যেখানে হঠাৎ ছোট হয় — চলমান উদাহরণে \([1200,527,135,111,91,72]\), পতন \(392\to24\) ⇒ elbow \(k{=}3\)। silhouette \(s=\frac{b-a}{\max(a,b)}\) (within বনাম nearest-other দূরত্ব): \([0.552,0.712,0.598]\) ⇒ সর্বোচ্চ \(k{=}3\)। দুই পদ্ধতি একমত; silhouette বেশি নির্ভরযোগ্য (সংখ্যাগত, ব্যাখ্যাযোগ্য)। সত্য label থাকলে ARI পুনরুদ্ধার মাপে — এখানে \(k{=}3\)-এ ARI \(0.990\), প্রায়-নিখুঁত। (hierarchical clustering \(K\) আগে চায় না, dendrogram-এ পুরো nested গঠন দেয়; Ward-linkage k-means-এর variance-objective-এর কাছাকাছি।)
-
মূল বার্তা। unsupervised-এ লক্ষ্য predict নয়, structure। PCA correlated, উচ্চ-মাত্রিক feature-কে কয়েকটা অর্থপূর্ণ অক্ষে নামায় (eigen/variance); clustering বিন্দুদের ঘনত্ব-অনুযায়ী দলে ভাগ করে (inertia/Lloyd)। দুটোই একই eigen-/variance-জ্যামিতির উপর দাঁড়িয়ে — PCA variance ধরে রাখে, k-means within-variance কমায় — তাই প্রায়ই একসাথে ব্যবহৃত (PCA-তে নামিয়ে তারপর cluster)।
পূর্ববর্তী সংযোগ (← ০.৫, ২.৬, ৫.১):
-
০.৫ (Eigenvalue–Eigenvector): এ অধ্যায় ০.৫-এর eigen-তত্ত্বের সবচেয়ে সরাসরি পরিসংখ্যানিক প্রয়োগ। সেখানে শেখা \(\Sigma v=\lambda v\), symmetric matrix-এর বাস্তব eigenvalue ও orthogonal eigenvector, এবং spectral decomposition — এখানে হুবহু সেগুলোই PCA-র মেরুদণ্ড: PC-গুলো \(\Sigma\)-এর orthonormal eigenvector, তাদের গুরুত্ব eigenvalue-এর ক্রমে। §৭-এর Lagrangian প্রমাণ দেখায় "variance-সর্বোচ্চকারী দিক" আর "শীর্ষ-eigenvector" একই জিনিস — বিমূর্ত eigen-সমস্যা এখানে data-র প্রধান-অক্ষ-অনুসন্ধানে রূপ নেয়।
-
২.৬ (Covariance ও Covariance Matrix): PCA যে matrix-এর উপর কাজ করে সেটাই ২.৬-এর covariance matrix \(\Sigma\) — feature-জোড়ার যুগ্ম-পরিবর্তনশীলতার মানচিত্র। ২.৬-এ শেখা \(\Sigma\) symmetric ও PSD (তাই eigenvalue \(\ge0\) — variance ঋণাত্মক হয় না), আর off-diagonal correlation-ই PCA-কে অর্থপূর্ণ করে (feature uncorrelated হলে PCA কিছুই কমাত না)। standardize করলে \(\Sigma\) হয় correlation matrix — তাই প্রশ্ন ১-এর scale-সমস্যা মেটে। clustering-এও দূরত্ব \(\lVert x_i-\mu_k\rVert\) এই covariance-জ্যামিতিতেই মাপা।
-
৫.১ (Variance ও Variance বিশ্লেষণ): পুরো অধ্যায়ের মুদ্রা variance — PCA "explained variance" সর্বোচ্চ করে, k-means "within-cluster variance" (inertia) সর্বনিম্ন করে। ৫.১-এর total \(=\) explained \(+\) residual ভাঙনই এখানে দুই রূপে: PCA-তে total variance \(=\sum\lambda_j\) (রাখা PC \(+\) বাদ-দেওয়া PC), clustering-এ \(\text{TSS}=\text{BSS}+\text{WSS}\) (প্রশ্ন ৭) — ঠিক ANOVA-র variance-বিভাজনের অনুরূপ, শুধু এবার label-হীন গঠনে।
Part V সমাপ্তি — সম্পূর্ণ Modeling-toolkit: এই অধ্যায় দিয়ে Part V (Statistical Modeling) সম্পূর্ণ হলো। পথটা ছিল সুসংগত: ৫.১ linear regression (ভিত্তি — \(y\)-কে \(x\)-এর রৈখিক ফাংশনে ব্যাখ্যা) → ৫.২ diagnostics, inference ও selection (model বিশ্বাসযোগ্য কিনা, predictor বাছা) → ৫.৩ ANOVA ও experimental design (গোষ্ঠী-তুলনা, variance-বিভাজন) → ৫.৪ GLM/logistic ও ৫.৫ GLM/Poisson (binary ও count response-এ সম্প্রসারণ) → ৫.৬ mixed-effects/hierarchical (নেস্টেড/পুনরাবৃত্ত data-র correlation) → ৫.৭ nonparametric regression (রৈখিকতার শৃঙ্খল ভেঙে নমনীয় \(f\)) → ৫.৮ cross-validation ও model validation (এই সব model ও তাদের complexity-ডায়াল honest-ভাবে বাছার methodological capstone) → ৫.৯ multivariate methods (supervised-এর সীমা পেরিয়ে unsupervised structure — PCA ও clustering)। অর্থাৎ regression → diagnostics → ANOVA → GLM → mixed → nonparametric → cross-validation → multivariate — একটা response মডেল করা থেকে শুরু করে শেষে label-হীন data-র গঠন উন্মোচন পর্যন্ত একটি পূর্ণ যাত্রা। এখন হাতে আছে data-র সম্পর্ক ব্যাখ্যা ও যাচাই করার একটি সম্পূর্ণ, নীতিনিষ্ঠ পরিসংখ্যানিক ভাণ্ডার।
পরবর্তী সংযোগ (→ Part VI — Statistical Machine Learning): Part V শিখিয়েছে data-কে ব্যাখ্যা ও বোঝা (interpretable, পরিসংখ্যান-কেন্দ্রিক model — coefficient, inference, variance-বিভাজন)। Part VI (Statistical Machine Learning) এই ভিত্তির উপর দাঁড়িয়ে জোর সরায় শক্তিশালী predictive performance-এর দিকে: regularization (ridge/lasso — ৫.২-এর selection ও bias–variance-এর ধারাবাহিকতা, কিন্তু penalty দিয়ে স্বয়ংক্রিয়), support vector machines (margin-ভিত্তিক শ্রেণিবিন্যাস), decision trees ও random forests (অরৈখিক, পারস্পরিক-ক্রিয়াশীল গঠন), এবং boosting (দুর্বল learner-দের একত্রে শক্তিশালী করা)। এ অধ্যায়ের ভিত্তি সরাসরি কাজে লাগবে: PCA ML-pipeline-এ feature-নির্মাণ/মাত্রা-হ্রাসের প্রধান হাতিয়ার, clustering unsupervised feature ও segment তৈরি করে, আর ৫.৮-এর cross-validation Part VI-এর প্রতিটি model টিউন ও তুলনার মেরুদণ্ড। Part V-এর পরিসংখ্যানিক কঠোরতা (অনুমান, inference, validation) Part VI-এর algorithm-গুলোকে শুধু "কাজ করে" নয়, "কেন ও কখন কাজ করে" — সেই বোঝার সাথে যুক্ত করবে।
সূত্র (sources): M. Sugiyama, Introduction to Statistical Machine Learning (PCA, dimensionality reduction, unsupervised learning); L. Wasserman, All of Statistics (multivariate methods, PCA, eigen-decomposition); Bruce, Bruce & Gedeck, Practical Statistics for Data Scientists, Ch. 7 (unsupervised learning — PCA, k-means, hierarchical clustering, silhouette-এর ব্যবহারিক দিক); P. Dangeti, Statistics for Machine Learning (PCA, k-means, elbow/silhouette, ARI); R. Furrer, STA121 Statistical Modeling ও J. Rice, Mathematical Statistics and Data Analysis (covariance matrix, eigen-গঠ