6.2 — Regularization: Ridge, Lasso & Sparse Regression (রেগুলারাইজেশন: রিজ, ল্যাসো ও স্পার্স রিগ্রেশন)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — capacity-কে continuous-ভাবে নিয়ন্ত্রণ: model না কেটে coefficient-এ "জরিমানা"¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল, আর এখন কোন প্রশ্ন¶
অধ্যায় 6.1-এ আমরা learning theory-র কেন্দ্রীয় বার্তাটা গেঁথেছি, আর সেটা ছিল ভয়ানক ব্যবহারিক: একটা model যত বেশি capacity (ধারণক্ষমতা / নমনীয়তা) পায়, ততই সে দেখা data মুখস্থ করে ফেলার ঝুঁকিতে পড়ে — অর্থাৎ overfit করে। তখন training error ছোট দেখায়, কিন্তু নতুন data-তে model বিশ্রীভাবে ভুল করে। এই ছবিটা আমরা bias–variance-এর ভাষায় ধরেছিলাম: capacity বাড়ালে bias (model গঠনগতভাবে কতটা ভুল আকৃতির) কমে, কিন্তু variance (নমুনা একটু বদলালে model কতটা নড়ে) বাড়ে, আর মোট ভুল একটা U-আকৃতি নেয় — যার তলদেশেই সেরা capacity।
6.1-এ capacity নিয়ন্ত্রণের একটা স্পষ্ট উপায় ছিল — model-টাকে আরও সরল করে ফেলা: polynomial-এর degree কমানো, কম feature নেওয়া, কম গিঁট (knot) বসানো। কিন্তু এই উপায়টা স্থূল (coarse) — degree \(3\) থেকে \(4\)-এ লাফ দিলে capacity হঠাৎ এক ধাপ বেড়ে যায়, মাঝামাঝি কিছু বেছে নেওয়ার সুযোগ নেই। এই অধ্যায়ের একটিমাত্র প্রশ্ন, আর সেটা ঠিক এই স্থূলতাকে ঘিরে:
model-টাকে গঠনগতভাবে আরও সরল না করেই — সব feature হাতে রেখেই — capacity-কে কি আমরা একটা মসৃণ, ক্রমাগত (continuous) নবের মতো ঘুরিয়ে কমাতে-বাড়াতে পারি?
উত্তর — হ্যাঁ, পারি। আর তার কৌশলটা চমৎকার রকম সরল: model-এর গঠনে হাত না দিয়ে, আমরা তার coefficient-গুলোকে ছোট রাখতে বাধ্য করি — coefficient বড় হলে একটা "জরিমানা" (penalty, পেনাল্টি) গুনতে হবে, এমন নিয়ম বসিয়ে। এই জরিমানার মাত্রা একটা একক সংখ্যা \(\lambda\) ("ল্যামডা") দিয়ে নিয়ন্ত্রিত, আর \(\lambda\)-কে ক্রমাগত বাড়িয়ে-কমিয়ে আমরা capacity-কে ঠিক সেই মসৃণ নবের মতোই ঘোরাতে পারি। এই গোটা ধারণাটারই নাম regularization (রেগুলারাইজেশন)।
লক্ষ করুন এটা 6.1-এর তত্ত্বের সরাসরি, ব্যবহারিক প্রয়োগ: সেখানে আমরা বুঝেছিলাম variance-ই overfitting-এর মূল অপরাধী; এখানে আমরা একটা যন্ত্র পাচ্ছি যা সরাসরি সেই variance-কে চেপে ধরে — সামান্য bias-এর বিনিময়ে অনেকখানি variance কমিয়ে মোট ভুলকে U-এর তলদেশের দিকে টেনে আনে।
১.২ কেন OLS feature-বহুল ও correlated সমস্যায় ভেঙে পড়ে¶
কিন্তু "জরিমানা বসানো"-র এই কৌশলের দরকার ঠিক কোথায় সবচেয়ে তীব্র, তা বুঝতে আগে দেখা চাই — আমাদের পুরোনো, বিশ্বস্ত হাতিয়ার OLS (ordinary least squares, 5.1) ঠিক কোন পরিস্থিতিতে অসহায় হয়ে পড়ে। মনে করিয়ে দিই, OLS coefficient বের করে এই সূত্রে:
যেখানে \(X\) হলো design matrix (নকশা-ম্যাট্রিক্স, প্রতিটি সারি এক পর্যবেক্ষণ, প্রতিটি কলাম এক predictor/feature), \(y\) হলো response (সাড়া-চলক), আর \(\hat\beta\) হলো অনুমিত coefficient-গুলোর ভেক্টর। এই সূত্রের প্রাণভোমরা হলো \((X^\top X)^{-1}\) — matrix \(X^\top X\)-এর বিপরীত (inverse)। আর ঠিক এখানেই দুটো বিপদ লুকিয়ে আছে।
বিপদ ১ — multicollinearity (5.2 স্মরণ): correlated feature \(X^\top X\)-কে প্রায়-singular করে। ধরুন দুটো predictor প্রায় একই তথ্য বহন করে — যেমন "উচ্চতা সেন্টিমিটারে" আর "উচ্চতা ইঞ্চিতে", বা আরও বাস্তবে, দুটো অর্থনৈতিক সূচক যারা একসাথে ওঠানামা করে। তখন \(X\)-এর দুটো কলাম প্রায় পরস্পর-নির্ভর, ফলে \(X^\top X\) প্রায় singular (অ-উল্টানোযোগ্যের কাছাকাছি) হয়ে যায় — অর্থাৎ এর কিছু eigenvalue শূন্যের খুব কাছে নেমে আসে। আর singular-এর কাছাকাছি matrix-এর inverse নিলে সংখ্যাগুলো বিস্ফোরিত হয়। বাস্তব ফল 5.2-এ আমরা দেখেছি: একটা coefficient বিশাল ধনাত্মক, ঠিক পাশের correlated coefficient বিশাল ঋণাত্মক — দুটো মিলে কোনোমতে fit বাঁচায়, কিন্তু আলাদাভাবে প্রতিটি \(\hat\beta_j\) ভয়ানক অস্থির ও high-variance: data-য় সামান্য পরিবর্তন এলেই এরা লাফিয়ে বদলে যায়। (5.2-এর VIF — variance inflation factor — ঠিক এই variance-বিস্ফোরণই সংখ্যায় মাপত।)
বিপদ ২ — \(p\) বড় হলে আরও খারাপ; এবং অপ্রাসঙ্গিক feature-এর বোঝা। feature-সংখ্যা \(p\) যত বাড়ে (পর্যবেক্ষণ-সংখ্যা \(n\)-এর তুলনায়), OLS-এর হাতে তত বেশি "স্বাধীনতা" থাকে data-র এলোমেলো noise-কেও আঁকড়ে ধরার — অর্থাৎ variance আরও বাড়ে, overfitting আরও প্রকট। চরম ক্ষেত্রে \(p \ge n\) হলে \(X^\top X\) নিশ্চিতভাবেই singular, inverse-ই থাকে না, OLS সংজ্ঞাহীন হয়ে পড়ে। তার ওপর, বাস্তব data-য় বহু feature আসলে response-এর সাথে একেবারেই সম্পর্কহীন (অপ্রাসঙ্গিক) — কিন্তু OLS তাদের জন্যও শূন্য নয়, বরং কিছু-না-কিছু (noise-চালিত) coefficient বসিয়ে দেয়, ফলে model অযথা জটিল ও ভঙ্গুর হয়।
এক বাক্যে সমস্যা। correlated, অপ্রাসঙ্গিক, কিংবা নিছক অনেক বেশি feature থাকলে OLS-এর coefficient বিশাল ও অস্থির হয়ে ওঠে (high variance) — model দেখা data-র noise মুখস্থ করে, নতুন data-তে ভেঙে পড়ে। দরকার এমন কিছু যা coefficient-গুলোকে লাগাম পরায়।
১.৩ Hook — fit আর penalty-র দাঁড়িপাল্লা¶
এই লাগামের ধারণাটা একটা দাঁড়িপাল্লার ছবিতে গেঁথে নিন, কারণ এটাই গোটা অধ্যায়ের কেন্দ্রীয় স্বজ্ঞা।
OLS-এর একটাই লক্ষ্য ছিল: data-র সাথে যত ভালো fit (খাপ) হয় তত ভালো — অর্থাৎ residual sum of squares \(\lVert y - X\beta \rVert_2^2\) যত ছোট তত ভালো। এই একমুখী চাপই OLS-কে coefficient বিশাল করে ফেলতে প্ররোচিত করে: যদি বড় coefficient বসিয়ে দেখা data-কে আরেকটু ভালোভাবে ছোঁয়া যায়, OLS নির্দ্বিধায় তা-ই করে — পরিণাম যতই অস্থির হোক।
Regularization এই একমুখী চাপের বিপরীতে একটা দ্বিতীয় চাপ যোগ করে। এখন objective-এ দুটো পাল্লা:
- বাঁ পাল্লা — fit: \(\lVert y - X\beta \rVert_2^2\) ছোট হোক (data-কে ভালোভাবে ধরো)।
- ডান পাল্লা — penalty: coefficient \(\beta\) মাপে ছোট হোক (অতিরিক্ত বড় coefficient-এর জন্য জরিমানা)।
আমরা যে রাশিটা ছোট করি, তা এই দুইয়ের যোগফল:
এখানে \(\lambda \ge 0\) হলো সেই দাঁড়িপাল্লার কাঁটা — দুই পাল্লার আপেক্ষিক গুরুত্ব ঠিক করে। \(\lambda = 0\) হলে penalty-পাল্লার ওজন শূন্য, তাই শুধু fit-ই গুরুত্ব পায় — আমরা ঠিক OLS-এ ফিরে যাই। \(\lambda\) যত বাড়ে, penalty-পাল্লা তত ভারী হয়, coefficient-দের তত ছোট হতে বাধ্য করা হয় — অর্থাৎ capacity তত কমে। আর \(\lambda \to \infty\) হলে penalty এত প্রবল যে সব coefficient \(0\)-তে চাপা পড়ে (model কেবল গড় ভবিষ্যদ্বাণী করে)। এই দুই চরমের মাঝখানেই কোথাও — ঠিক 6.1-এর U-আকৃতির তলদেশে — লুকিয়ে আছে সেরা ভারসাম্য, যেখানে variance যথেষ্ট কমেছে অথচ bias তখনো বাড়াবাড়ি বাড়েনি।
ঠিক কীভাবে coefficient-এর "মাপ" মাপব — এখানেই গল্পের আসল মোড়, এবং এখান থেকেই দুটো ভিন্ন পদ্ধতি জন্ম নেয়: ridge (যে মাপে coefficient-গুলোর বর্গের যোগফল) আর lasso (যে মাপে coefficient-গুলোর পরম-মানের যোগফল)। এই দুই মাপের সূক্ষ্ম পার্থক্যই — যা প্রথমে নিরীহ মনে হয় — শেষে একটাকে নিছক "shrink" করায় আর অন্যটাকে সরাসরি "feature বেছে নেওয়ার যন্ত্রে" পরিণত করে।
১.৪ এক লাইনের মানচিত্র — এই অধ্যায় কোথায় যাবে¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খলটা একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- Ridge (L2) — coefficient-এর বর্গের যোগফলে penalty; objective, closed-form \((X^\top X+\lambda I)^{-1}X^\top y\), কেন সবসময় invertible, আর কেন সব coefficient shrink হয় কিন্তু ঠিক \(0\) হয় না (§২.১)।
- Lasso (L1) — coefficient-এর পরম-মানের যোগফলে penalty; objective, কেন closed-form নেই, আর সবচেয়ে গুরুত্বপূর্ণ — কেন কিছু coefficient ঠিক \(0\) হয়ে যায় ⇒ sparsity ও feature selection (§২.২)।
- L1 বনাম L2-এর geometry — RSS-এর contour আর penalty-র constraint region (L2 ball বনাম L1 diamond)-এর ছবিতে কেন lasso sparse আর ridge শুধু shrink, তা চোখে দেখা (§২.৩)।
- \(\lambda\), bias–variance ও tuning — \(\lambda\) কীভাবে OLS (\(\lambda{=}0\)) থেকে শূন্য-coefficient (\(\lambda{\to}\infty\)) পর্যন্ত capacity ঘোরায়, কেন standardize করা বাধ্যতামূলক, elastic net, এবং \(\lambda\)-কে cross-validation দিয়ে বাছা ও regularization path পড়া (§২.৪)।
- সব derivation (ridge normal equation, lasso subgradient ও soft-thresholding) §৪-এ; পূর্ণ dataset, কোড, চিত্র ও অনুশীলনী §৫ থেকে।
এক বাক্যে ধরে রাখুন: regularization বলে — "শুধু fit নয়, coefficient-ও ছোট রাখো"; এই দ্বিতীয় শর্ত \(\lambda\) দিয়ে নিয়ন্ত্রিত হয়ে capacity-কে মসৃণভাবে কমায় (variance কমায়), আর penalty-টা L2 না L1 — সেই পছন্দই ঠিক করে coefficient শুধু ছোট হবে, নাকি কিছু একদম \(0\) হয়ে feature বেছে নেবে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই অংশে আমরা §১-এর স্বজ্ঞাগুলোকে আনুষ্ঠানিক সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথমবার আসার সাথে সাথেই খুলে বলা হবে; কোথাও কিছু ধরে নেওয়া হবে না।
প্রথমে পুরো অধ্যায়ের সাধারণ notation একবারে স্থির করি (সর্বত্র এক থাকবে):
- \(X \in \mathbb{R}^{n\times p}\) — design matrix (নকশা-ম্যাট্রিক্স): \(n\)টি সারি (পর্যবেক্ষণ), \(p\)টি কলাম (feature/predictor)। আমরা ধরে নেব \(X\) standardized (আদর্শায়িত) — প্রতিটি কলামের গড় \(0\) ও standard deviation \(1\) (কেন তা §২.৪-এ; এই অধ্যায়ে এটি অপরিহার্য শর্ত)। এই standardization-এর সুবাদে আলাদা intercept-পদ নিয়ে আমরা এখানে মাথা ঘামাব না (response-ও কেন্দ্রীভূত ধরে নেওয়া হয়)।
- \(y\) — response (সাড়া-চলক), \(n\)টি পর্যবেক্ষণের ভেক্টর (\(y \in \mathbb{R}^n\))।
- \(\beta \in \mathbb{R}^p\) — coefficient (সহগ) ভেক্টর; \(\beta = (\beta_1, \dots, \beta_p)\), যেখানে \(\beta_j\) হলো \(j\)-তম feature-এর সহগ। অনুমিত মান লিখি \(\hat\beta\) ("বিটা-হ্যাট")।
- \(\lambda \ge 0\) — tuning parameter (নিয়ন্ত্রক প্রাচল, "ল্যামডা"): penalty-র মাত্রা। \(\lambda\) একটা সংখ্যা যা আমরা বাছি (data থেকে নয়, পরে cross-validation দিয়ে — §২.৪)।
- দুটো norm (মাপকাঠি) বারবার লাগবে, তাই এখনই সংজ্ঞা: $$ \lVert \beta \rVert_2^2 \;=\; \sum_{j=1}^{p} \beta_j^2 \qquad\text{(\(L_2\)-norm-এর বর্গ: coefficient-গুলোর বর্গের যোগফল)}, $$ $$ \lVert \beta \rVert_1 \;=\; \sum_{j=1}^{p} \lvert \beta_j \rvert \qquad\text{(\(L_1\)-norm: coefficient-গুলোর পরম-মানের যোগফল)}. $$ এখানে \(\lvert \beta_j \rvert\) হলো \(\beta_j\)-র পরম-মান (absolute value), আর \(\sum_{j=1}^{p}\) মানে সব \(p\)টি coefficient-এর উপর যোগ। (এছাড়া \(\lVert y - X\beta \rVert_2^2 = \sum_{i=1}^{n}(y_i - (X\beta)_i)^2\) হলো residual sum of squares — 5.1-এর সেই চেনা fit-মাপ।)
এই notation মাথায় রেখে এবার দুই পদ্ধতি একে একে।
২.১ Ridge regression (L2) — সব coefficient মসৃণভাবে ছোট করা¶
প্রথম পদ্ধতিতে penalty হিসেবে আমরা নিই coefficient-গুলোর বর্গের যোগফল (\(L_2\)-penalty)। ধারণাটা §১.৩-এর দাঁড়িপাল্লারই সরাসরি রূপ — fit-পদের সাথে \(\lambda \lVert\beta\rVert_2^2\) যোগ করে দাও।
সংজ্ঞা (Ridge regression — রিজ রিগ্রেশন)। ridge estimator হলো নিচের রাশিকে ছোট করা \(\beta\):
প্রতিটি অংশ খুলি:
- \(\arg\min_{\beta}\) — "যে \(\beta\)-তে ডানপাশের রাশি সবচেয়ে ছোট, সেই \(\beta\)" (arg-min মানে minimizing argument, 0.3/5.1-এর সেই notation)।
- \(\lVert y - X\beta \rVert_2^2\) — fit-পদ: residual sum of squares, OLS যা একাই ছোট করত।
- \(\lambda\,\lVert \beta \rVert_2^2 = \lambda \sum_{j} \beta_j^2\) — penalty-পদ: coefficient বড় হলে (ধনাত্মক বা ঋণাত্মক, যেদিকেই হোক — বর্গ বলে চিহ্ন গুরুত্বহীন) এই পদ বড় হয়, তাই minimizer coefficient-দের ছোট রাখতে চাপ অনুভব করে। \(\lambda\) এই চাপের জোর।
closed-form সমাধান — OLS-এর একটা সুন্দর সংশোধন। ridge-এর সবচেয়ে আকর্ষণীয় দিক হলো, OLS-এর মতোই এর একটা সরাসরি ম্যাট্রিক্স-সূত্র (closed-form) আছে (পূর্ণ derivation §৪-এ, RSS-এর সাথে penalty-র gradient শূন্য বসিয়ে):
এই সূত্রটাকে OLS-এর পাশে রাখুন — পার্থক্য মাত্র এক টুকরো:
এখানে \(I\) হলো \(p\times p\) identity matrix (একক-ম্যাট্রিক্স: কর্ণে \(1\), বাকি সর্বত্র \(0\))। অর্থাৎ ridge ঠিক একটাই কাজ করে — \(X^\top X\)-এর কর্ণে (diagonal-এ) \(\lambda\) যোগ করে দেয়। এই ছোট্ট যোগটাই (একে অনেক সময় বলে "ridge" — কর্ণ-বরাবর একটা শৈলশিরা যোগ করা, এখান থেকেই নাম) দুটো জাদু ঘটায়।
জাদু ১ — কেন \((X^\top X + \lambda I)\) সর্বদা invertible (\(\lambda > 0\)-তে)। §১.২-এ দেখলাম, multicollinearity-তে \(X^\top X\)-এর কিছু eigenvalue শূন্যের কাছে নেমে আসে, তাই inverse অস্থির বা অসম্ভব। এখন একটা সরল linear-algebra তথ্য (0.5): \(X^\top X\) সর্বদা positive semi-definite — তার সব eigenvalue \(\ge 0\)। ধরা যাক তার eigenvalue-গুলো \(\mu_1, \dots, \mu_p \ge 0\)। তাহলে কর্ণে \(\lambda\) যোগ করলে নতুন matrix \((X^\top X + \lambda I)\)-এর eigenvalue হয়ে যায় \(\mu_1 + \lambda, \dots, \mu_p + \lambda\) — প্রতিটিতে \(\lambda\) যোগ। যদি \(\lambda > 0\) হয়, তবে প্রতিটি \(\mu_j + \lambda \ge \lambda > 0\), অর্থাৎ সব eigenvalue কঠোরভাবে ধনাত্মক — কোনোটাই আর শূন্য নয়। শূন্য eigenvalue না থাকা মানেই matrix-টা invertible ও সুস্থিত (well-conditioned)। তাই \(p \ge n\) হলেও, কিংবা feature যতই correlated হোক, ridge-এর সমাধান সবসময় বিদ্যমান ও স্থিতিশীল — multicollinearity-র অভিশাপ এক কোপে কাটা।
জাদু ২ — shrinkage: সব coefficient ছোট হয়, কিন্তু ঠিক \(0\) নয়। কর্ণে \(\lambda\) যোগ করার ফলে inverse-এর মান ছোট হয়, তাই \(\hat\beta_{\text{ridge}}\)-এর প্রতিটি উপাদান OLS-এর তুলনায় \(0\)-র দিকে সংকুচিত (shrunk) হয়ে আসে — একে বলে shrinkage (সংকোচন)। এক বিশেষ ক্ষেত্রে (কলামগুলো পরস্পর-লম্ব, অর্থাৎ \(X^\top X = I\)) এটি পরিষ্কার দেখা যায়:
অর্থাৎ প্রতিটি OLS-coefficient একই গুণক \(\tfrac{1}{1+\lambda}\) দিয়ে ছোট হয় (derivation §৪-এ)। এখানে দুটো জিনিস খেয়াল করুন। প্রথমত, \(\lambda\) বাড়লে গুণকটা ছোট হয় — coefficient আরও বেশি shrink। দ্বিতীয়ত, এবং অত্যন্ত গুরুত্বপূর্ণ — এই গুণক কখনো ঠিক শূন্য হয় না (যেকোনো সসীম \(\lambda\)-তে \(\tfrac{1}{1+\lambda} > 0\))। তাই ridge প্রতিটি coefficient-কে \(0\)-র দিকে ঠেলে, কিন্তু কোনোটাকেই ঠিক \(0\)-তে বসায় না — সব feature মডেলে থেকেই যায়, শুধু তাদের প্রভাব নরম হয়ে আসে। এটাই ridge-এর স্বাক্ষর: মসৃণ, সর্বব্যাপী সংকোচন, কিন্তু কোনো feature বাদ পড়ে না।
(স্বজ্ঞা: বর্গ-penalty \(\beta_j^2\) একটা coefficient \(0\)-র খুব কাছে এলে আরও ছোট করার "তাড়া" হারিয়ে ফেলে — কারণ \(0\)-র কাছে \(\beta_j^2\)-এর ঢাল \(2\beta_j \to 0\), অর্থাৎ penalty-র চাপও মিইয়ে যায়। তাই ridge coefficient-কে \(0\)-র কাছে এনে থামিয়ে দেয়, ঠিক \(0\)-তে নয়। L1-এ এই গল্প পাল্টে যাবে — পরের উপ-অংশ।)
২.২ Lasso (L1) — কিছু coefficient ঠিক শূন্য করে feature বেছে নেওয়া¶
এবার একটা আপাত-নিরীহ পরিবর্তন: penalty-তে বর্গের বদলে পরম-মানের যোগফল (\(L_1\)-penalty) নিই। সংজ্ঞাটা ridge-এর প্রায় হুবহু, শুধু \(\lVert\beta\rVert_2^2\)-এর জায়গায় \(\lVert\beta\rVert_1\)।
সংজ্ঞা (Lasso — ল্যাসো; "Least Absolute Shrinkage and Selection Operator")। lasso estimator হলো:
প্রতিটি অংশ:
- fit-পদ \(\lVert y - X\beta \rVert_2^2\) — আগের মতোই, residual sum of squares।
- penalty-পদ \(\lambda\,\lVert \beta \rVert_1 = \lambda \sum_{j} \lvert \beta_j \rvert\) — এবার coefficient-গুলোর পরম-মানের যোগফলে জরিমানা। নামের মধ্যেই দুটো শব্দ লুকিয়ে — "shrinkage" (সংকোচন) আর "selection" (বাছাই) — আর এই দ্বিতীয়টাই lasso-কে ridge থেকে আলাদা করে।
closed-form নেই — কেন। ridge-এ আমরা সুন্দর একটা ম্যাট্রিক্স-সূত্র পেয়েছিলাম, কারণ বর্গ-penalty \(\lVert\beta\rVert_2^2\) সর্বত্র মসৃণভাবে অবকলনযোগ্য (differentiable), তাই gradient শূন্য বসিয়ে রৈখিক সমীকরণ পাওয়া যায়। কিন্তু পরম-মান \(\lvert\beta_j\rvert\) ঠিক \(\beta_j = 0\) বিন্দুতে ভাঙা (kink) — সেখানে একটা ধারালো কোণ, derivative সংজ্ঞাহীন (বাঁ দিকে ঢাল \(-1\), ডান দিকে \(+1\))। এই অ-মসৃণতার কারণে lasso-র কোনো একলাইনের closed-form সূত্র নেই; সমাধানের জন্য লাগে subgradient (উপ-অবকলজ) ও পুনরাবৃত্ত অ্যালগরিদম (যেমন coordinate descent / soft-thresholding) — সবই §৪-এ বিশদে। কিন্তু এই "অসুবিধা"-টাই, মজার ব্যাপার, lasso-র সবচেয়ে মূল্যবান গুণের উৎস।
মূল ঘটনা — L1 কিছু coefficient ঠিক \(0\) করে দেয় ⇒ sparsity ও feature selection। ঠিক ওই \(\beta_j = 0\)-তে থাকা ধারালো কোণের জন্যই lasso-র এক অসাধারণ আচরণ: যথেষ্ট বড় \(\lambda\)-তে এটি অনেক coefficient-কে হুবহু \(0\)-তে বসিয়ে দেয় (শুধু \(0\)-র কাছাকাছি নয়, একেবারে \(0\))। coefficient \(0\) মানে সেই feature মডেল থেকে পুরোপুরি বাদ — তার কোনো প্রভাবই থাকে না। ফলে lasso-র সমাধান হয় sparse (বিরল: বেশিরভাগ coefficient \(0\), মাত্র গুটিকয় অশূন্য)।
এই sparsity-রই একটা চমৎকার ব্যবহারিক নাম — feature selection (বৈশিষ্ট্য-বাছাই): lasso আপনাআপনি সিদ্ধান্ত নেয় কোন feature-গুলো রাখা দরকার (অশূন্য coefficient) আর কোনগুলো ফেলে দেওয়া যায় (শূন্য coefficient)। অর্থাৎ একই ধাপে model fit-ও হয়, আবার "কোন variable গুরুত্বপূর্ণ" সেই বাছাইও হয়ে যায় — হাতে আলাদা করে variable ছাঁটতে হয় না। §১.১-এর সমস্যাটা মনে করুন: বহু feature, যাদের অনেকগুলো অপ্রাসঙ্গিক। ridge সবাইকে রেখে নরম করত; lasso সরাসরি অপ্রাসঙ্গিকদের coefficient \(0\) করে ছেঁটে ফেলে — একটা পরিষ্কার, ব্যাখ্যাযোগ্য, ছোট model দেয়।
(স্বজ্ঞা — ridge-এর সাথে তুলনায়: §২.১-এ দেখেছি বর্গ-penalty \(0\)-র কাছে এসে চাপ হারায় (ঢাল \(2\beta_j \to 0\))। কিন্তু পরম-মান-penalty \(\lvert\beta_j\rvert\)-এর ঢাল \(0\)-র যেকোনো পাশেই ধ্রুব (\(\pm 1\)) — coefficient \(0\)-র কত কাছেই থাক, তাকে আরও \(0\)-র দিকে ঠেলার চাপ মেলায় না। এই অবিরাম চাপই দুর্বল coefficient-গুলোকে শেষ পর্যন্ত ঠিক \(0\)-তে ঠেলে দেয়। কেন ঠিক \(0\) — এর নিখুঁত জ্যামিতিক ছবি এখনই, §২.৩-এ।)
২.৩ L1 বনাম L2-এর geometry — কেন একটা shrink, অন্যটা sparse¶
"ridge shrink করে, lasso \(0\) করে" — এই পার্থক্যটা একটা ছবিতে দেখলে চিরকালের জন্য মনে গেঁথে যায়। এই জ্যামিতিক ছবিই Figure 6-2-l1-l2-geometry-তে আঁকা হবে; এখানে তার যুক্তিটা গড়ে তুলি।
একটা সমতুল্য রূপ — penalty কে constraint ভাবা। penalized objective "fit \(+ \lambda\cdot\)penalty"-কে ছোট করা গাণিতিকভাবে সমতুল্য একটা constrained (শর্তাধীন) সমস্যার: "penalty-কে একটা নির্দিষ্ট বাজেট \(t\)-এর মধ্যে রেখে fit ছোট করো।" অর্থাৎ —
- ridge ⟺ \(\lVert y - X\beta\rVert_2^2\) ছোট করো, এই শর্তে যে \(\lVert\beta\rVert_2^2 \le t\) (coefficient-বর্গের যোগ একটা বাজেটের মধ্যে);
- lasso ⟺ \(\lVert y - X\beta\rVert_2^2\) ছোট করো, এই শর্তে যে \(\lVert\beta\rVert_1 \le t\) (coefficient-পরম-মানের যোগ একটা বাজেটের মধ্যে)।
(প্রতিটি \(\lambda\)-র জন্য একটা সংশ্লিষ্ট \(t\) আছে; \(\lambda\) বড় ⟺ বাজেট \(t\) ছোট। এই সমতুল্যতা ছবিটা আঁকতে সুবিধাজনক — পূর্ণ যুক্তি §৪-এ।)
ছবিটা — দুটো জিনিসের ছোঁয়াছুঁয়ি। ধরা যাক মাত্র দুটো coefficient \(\beta_1, \beta_2\) (যাতে সমতলে আঁকা যায়, অনুভূমিক অক্ষ \(\beta_1\), উল্লম্ব অক্ষ \(\beta_2\))। দুটো জিনিস একই সমতলে কল্পনা করুন:
- RSS-এর contour (সমমান-রেখা): fit-পদ \(\lVert y - X\beta\rVert_2^2\) একটা মান ধরে রাখলে \((\beta_1,\beta_2)\)-সমতলে আঁকা হয় একটা উপবৃত্ত (ellipse); OLS-সমাধান \(\hat\beta_{\text{OLS}}\) সব উপবৃত্তের কেন্দ্র, আর কেন্দ্র থেকে দূরে গেলে RSS বাড়ে। বড় উপবৃত্ত = বেশি RSS।
- constraint region (বাজেট-অঞ্চল): penalty \(\le t\) শর্তটা coefficient-সমতলে একটা অঞ্চল ঘিরে দেয় —
- L2 (ridge): \(\beta_1^2 + \beta_2^2 \le t\) একটা মসৃণ বৃত্ত/গোলক (ball) — কোনো ধার বা কোণ নেই, সর্বত্র গোল।
- L1 (lasso): \(\lvert\beta_1\rvert + \lvert\beta_2\rvert \le t\) একটা হীরক-আকৃতি (diamond) — যার চারটি ধারালো কোণ (corner) ঠিক অক্ষের উপর বসে (যেমন \((\pm t, 0)\) ও \((0, \pm t)\))।
সমাধান হলো সেই বিন্দু যেখানে সবচেয়ে ছোট RSS-উপবৃত্ত (কেন্দ্র থেকে বাইরের দিকে ফুলতে ফুলতে) constraint-অঞ্চলকে প্রথম ছোঁয়। আর এই "প্রথম ছোঁয়া"-র জায়গাটাই সব পার্থক্যের জন্মস্থান:
- L2-গোলকে (ridge): গোলক সর্বত্র মসৃণ, কোনো বিশেষ বিন্দু নেই — তাই উপবৃত্ত সাধারণত গোলককে এমন একটা জায়গায় ছোঁয় যেখানে \(\beta_1, \beta_2\) কোনোটাই ঠিক \(0\) নয় (অক্ষের উপর পড়ার কোনো বিশেষ প্রবণতা নেই)। ফল: দুটো coefficient-ই ছোট হয়, কিন্তু অশূন্য — shrink, কিন্তু selection নয়।
- L1-হীরকে (lasso): হীরকের কোণগুলো অক্ষের উপর ও বাইরের দিকে সবচেয়ে বেশি বেরিয়ে থাকে — তাই বাইরে থেকে আসা উপবৃত্ত প্রায়ই হীরককে প্রথম ছোঁয় ঠিক একটা কোণে। আর কোণ মানে অক্ষের উপর — যেমন \((0, \pm t)\)-তে \(\beta_1 = 0\)। অর্থাৎ সমাধান একটা coefficient-কে ঠিক \(0\) করে দেয়! মাত্রা (\(p\)) বাড়লে এই কোণ-প্রভাব আরও তীব্র — বহু coefficient একসাথে \(0\) হয়ে sparse সমাধান আসে।
এক বাক্যে geometry। L2-এর মসৃণ গোলকে "প্রথম ছোঁয়া" সাধারণত অক্ষ থেকে দূরে পড়ে ⇒ সব coefficient ছোট-কিন্তু-অশূন্য (shrink); L1-এর হীরকের ধারালো কোণ অক্ষের উপর বসে বলে "প্রথম ছোঁয়া" প্রায়ই কোণে আটকায় ⇒ কিছু coefficient ঠিক \(0\) (sparse, feature selection)। এই একটিমাত্র জ্যামিতিক পার্থক্যই — গোল বনাম কোণ — দুই পদ্ধতির গোটা চরিত্র ঠিক করে দেয়।
২.৪ \(\lambda\), bias–variance, standardization, elastic net ও tuning¶
এতক্ষণে দুই পদ্ধতির কী ও কেন বুঝলাম। এবার তাদের চালানোর তিনটি অপরিহার্য ব্যবহারিক সুতো একসাথে বাঁধি — \(\lambda\) কী করে, কেন আগে standardize করতেই হবে, এবং বাস্তবে \(\lambda\) ও পদ্ধতি কীভাবে বাছি।
(ক) \(\lambda\) ই bias–variance-এর নব (6.1/5.8-এর সাথে যোগ)। ridge হোক বা lasso, \(\lambda\)-ই capacity-র নিয়ন্ত্রক, আর তার দুই প্রান্ত পরিষ্কার:
- \(\lambda = 0\): penalty উধাও, objective নিছক fit — আমরা ঠিক OLS-এ ফিরি। সর্বোচ্চ capacity, সর্বনিম্ন bias, কিন্তু সর্বোচ্চ variance (§১.২-এর সব রোগ ফিরে আসে)।
- \(\lambda \to \infty\): penalty এত প্রবল যে coefficient-দের \(0\) হতেই হয় — সব \(\beta_j \to 0\), model কেবল ধ্রুব (response-এর গড়) ভবিষ্যদ্বাণী করে। সর্বনিম্ন capacity, সর্বোচ্চ bias, সর্বনিম্ন variance।
- মাঝখানে — sweet spot: \(\lambda\) বাড়ালে variance কমে (coefficient স্থিতিশীল হয়) কিন্তু bias বাড়ে (সত্য সম্পর্কটা একটু চাপা পড়ে)। ঠিক 6.1-এর সেই গল্প — মোট ভুল একটা U-আকৃতি নেয় \(\lambda\)-র সাপেক্ষে, আর তলদেশের \(\lambda^*\)-তেই variance-কমা ও bias-বাড়ার সেরা ভারসাম্য। regularization-এর পুরো কৌশল ঠিক এই \(\lambda^*\) খুঁজে নেওয়া।
(খ) কেন standardize করা বাধ্যতামূলক — penalty scale-নির্ভর। এটা একটা সূক্ষ্ম কিন্তু অলঙ্ঘনীয় শর্ত। penalty \(\sum_j \beta_j^2\) (বা \(\sum_j \lvert\beta_j\rvert\)) coefficient-গুলোর মাপ গোনে — কিন্তু একটা coefficient-এর মাপ তার feature-এর এককের (scale) উপর নির্ভর করে। ধরুন একই feature একবার মিটারে, একবার সেন্টিমিটারে মাপা — সেন্টিমিটারে coefficient \(100\) গুণ ছোট হবে (একই প্রভাব দিতে), তাই তার penalty-অবদান \(100^2\) গুণ ভিন্ন! ফলে penalty কোন feature-কে কতটা "শাস্তি" দিচ্ছে তা নির্ভর করবে নিছক আপনি কোন একক বেছেছেন তার উপর — যা অর্থহীন ও বিপজ্জনক (বড়-এককের feature অন্যায্যভাবে কম শাস্তি পায়)। এই বৈষম্য ঠেকাতেই প্রতিটি feature-কে আগে standardize করা হয় (গড় \(0\), standard deviation \(1\)) — তখন সব coefficient একই ন্যায্য মানদণ্ডে penalty-র মুখোমুখি হয়। (এজন্যই §২-এর শুরুতে \(X\)-কে standardized ধরা হয়েছিল — এটা সুবিধা নয়, শর্ত।)
(গ) Elastic net — L1 আর L2-এর মিশ্রণ। ridge (সব রাখে, shrink করে) আর lasso (বেছে নেয়, \(0\) করে) — দুজনেরই গুণ একসাথে চাইলে? তখন elastic net (ইলাস্টিক নেট): দুটো penalty-ই যোগ করো —
যেখানে \(\lambda_1 \ge 0\) L1-অংশের (sparsity) ও \(\lambda_2 \ge 0\) L2-অংশের (shrinkage/stability) জোর। L1-অংশ feature বেছে নেয় (sparse), আর L2-অংশ correlated feature-দের সামলায় ও সমাধান স্থিতিশীল রাখে। বিশেষত যখন কয়েকটা feature পরস্পর correlated, খাঁটি lasso তাদের মধ্যে খামখেয়ালিভাবে একটাকে বেছে বাকিদের \(0\) করে দেয়; elastic net তাদের একসাথে রাখার (গোষ্ঠী-প্রভাব) প্রবণতা দেখায় — তাই বহু-correlated-feature পরিস্থিতিতে এটি প্রায়ই ridge ও lasso দুটোর চেয়েই ভালো (বিশদ §৪/§৫-এ)।
(ঘ) \(\lambda\) বাছা — cross-validation। \(\lambda\) একটা আমরা-বাছাই-করা সংখ্যা, data থেকে সরাসরি বেরোয় না — তাহলে এর সঠিক মান কীভাবে ঠিক করব? উত্তর 5.8-এর সেই চেনা যন্ত্র: cross-validation (CV, ক্রস-ভ্যালিডেশন)। সংক্ষেপে — কয়েকটা প্রার্থী \(\lambda\)-মান নিই; প্রতিটির জন্য data-কে কয়েক ভাঁজে (fold) ভেঙে, কিছু ভাঁজে model fit করে বাকি (held-out) ভাঁজে ভুল মাপি; সব ভাঁজের গড় held-out ভুল যে \(\lambda\)-তে সবচেয়ে কম, সেটাই বেছে নিই (\(\lambda^*\))। এভাবে U-আকৃতির তলদেশটা আমরা আন্দাজে নয়, data দিয়ে যাচাই করে খুঁজি। (\(\lambda\)-র সাপেক্ষে এই CV-ভুলের U-আকৃতির লেখচিত্রই হবে Figure 6-2-cv-lambda, যার সর্বনিম্ন বিন্দু \(\lambda^*\) চিহ্নিত করে।)
(ঙ) Regularization path — \(\lambda\) বদলালে coefficient-এর গতিপথ। \(\lambda\)-কে শুধু একটা সংখ্যা না ভেবে একটা নব ভাবলে স্বাভাবিক প্রশ্ন আসে: \(\lambda\) ক্রমাগত বদলালে প্রতিটি coefficient \(\hat\beta_j\) কীভাবে বদলায়? এই উত্তরটাই regularization path (রেগুলারাইজেশন পথ): অনুভূমিক অক্ষে \(\lambda\) (সাধারণত ছোট থেকে বড়, বা \(\log\lambda\)), উল্লম্ব অক্ষে প্রতিটি coefficient-এর মান — প্রতিটি feature-এর জন্য একটা করে রেখা, যা দেখায় \(\lambda\) বাড়ার সাথে সেই coefficient কীভাবে \(0\)-র দিকে গুটিয়ে আসে। এই path দুই পদ্ধতির চরিত্র চোখের সামনে মেলে ধরে: ridge-এর path-এ সব রেখা মসৃণভাবে \(0\)-র দিকে নামে কিন্তু কেউ ঠিক \(0\) ছোঁয় না; lasso-র path-এ রেখাগুলো একে একে ঠিক \(0\)-তে আছড়ে পড়ে (সেই feature বাদ) — \(\lambda\) বাড়ার সাথে অশূন্য feature-সংখ্যা ধাপে ধাপে কমে। এই দুই গতিপথের তুলনাই হবে Figure 6-2-coef-paths, আর একটা নির্দিষ্ট \(\lambda\)-তে ridge বনাম lasso-র coefficient পাশাপাশি রাখা Figure 6-2-coef-comparison — যেখানে চোখে দেখা যাবে lasso অপ্রাসঙ্গিক feature-দের ঠিক \(0\) করে রেখেছে, ridge সবাইকে ছোট-কিন্তু-অশূন্য রেখেছে।
§২-এর সার। Ridge (\(L_2\)): closed-form \((X^\top X+\lambda I)^{-1}X^\top y\), সর্বদা invertible, সব coefficient shrink কিন্তু কেউ \(0\) নয়। Lasso (\(L_1\)): closed-form নেই, কিন্তু কিছু coefficient ঠিক \(0\) ⇒ sparsity ও feature selection — যার জ্যামিতিক কারণ L1-হীরকের অক্ষ-ছোঁয়া কোণ। দুজনেরই নব \(\lambda\) — যা OLS (\(\lambda{=}0\)) থেকে সর্ব-শূন্য (\(\lambda{\to}\infty\)) পর্যন্ত bias–variance ঘোরায়, CV দিয়ে যার সেরা মান বাছা হয়; penalty scale-নির্ভর বলে আগে standardize করা বাধ্যতামূলক; আর দুইয়ের মিশ্রণ elastic net correlated-feature-এ দুটোরই সুবিধা দেয়। সব derivation §৪-এ, পূর্ণ dataset ও কোড §৫ থেকে।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এই অংশে একটি নিয়ন্ত্রিত (controlled) synthetic dataset-এর উপর তিনটি model পর পর fit করে দেখানো হবে কীভাবে regularization আচরণ বদলায়: প্রথমে OLS (কোনো penalty নেই), তারপর ridge (\(\ell_2\) penalty), শেষে lasso (\(\ell_1\) penalty)। যেহেতু আমরা নিজেরাই data বানাচ্ছি, তাই আমরা আগে থেকেই জানি কোন feature গুলো সত্যিকারের signal আর কোনগুলো শুধু noise — ফলে প্রতিটি method-এর feature selection ক্ষমতা নির্ভুলভাবে যাচাই করা যায়।
Dataset তৈরি¶
আমরা \(n=100\) observation আর \(p=20\) predictor নিচ্ছি, কিন্তু এর মধ্যে মাত্র \(k=4\)টি predictor সত্যিকারের nonzero coefficient বহন করে:
বাকি ১৬টি feature-এর true coefficient ঠিক \(0\) — অর্থাৎ তারা \(y\)-এর সাথে কোনো causal সম্পর্ক রাখে না; তারা শুধুই বিভ্রান্তিকর (distractor) feature। Design matrix \(X\in\mathbb R^{100\times 20}\)-এর প্রতিটি entry standard normal \(N(0,1)\) থেকে স্বাধীনভাবে আঁকা, আর response
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression, RidgeCV, Lasso, LassoCV
from sklearn.metrics import mean_squared_error
rng = np.random.default_rng(20260619)
n, p, k = 100, 20, 4
beta_true = np.zeros(p)
beta_true[:4] = [4.0, -3.0, 2.5, -2.0] # মাত্র ৪টি সত্যিকারের signal
X = rng.normal(0, 1, (n, p)) # X ~ N(0, 1)
y = X @ beta_true + rng.normal(0, 1.0, n) # y = Xβ + noise
X = StandardScaler().fit_transform(X) # প্রতিটি column-কে standardize
X_tr, X_te, y_tr, y_te = train_test_split(
X, y, test_size=0.3, random_state=0) # 70 train / 30 test
এখানে StandardScaler প্রতিটি column-কে শূন্য-mean ও একক-variance-এ আনে — এটি penalty-based method-এর জন্য অপরিহার্য, কারণ \(\lVert\beta\rVert_2^2\) বা \(\lVert\beta\rVert_1\) penalty scale-sensitive: বড় scale-এর feature কম penalty খায়, ছোট scale-এর বেশি। Standardize না করলে regularization-এর "fair" তুলনা হয় না। শেষে \(70\)টি observation training-এ আর \(30\)টি test-এ ভাগ করা হলো।
E1 — OLS সবকিছু রাখে (overfitting)¶
প্রথমে কোনো penalty ছাড়া ordinary least squares fit করি। OLS objective-এ \(\lambda=0\), তাই এটি শুধু training error কমাতে চায়:
ols = LinearRegression().fit(X_tr, y_tr)
mse_ols = mean_squared_error(y_te, ols.predict(X_te))
n_big = np.sum(np.abs(ols.coef_) > 0.1)
print(f"OLS test MSE = {mse_ols:.3f}") # 2.077
print(f"OLS #features with |coef|>0.1 = {n_big}") # 11
print(f"OLS #exact-zero coefficients = {np.sum(ols.coef_ == 0)}") # 0
ফলাফল: test MSE = 2.077, এবং model-টি কার্যত ২০টি feature-ই ধরে রাখে (\(\beta\)-এর কোনো entry-ই ঠিক \(0\) নয়), যার মধ্যে ১১টির \(\lvert\text{coef}\rvert > 0.1\)। সমস্যাটা পরিষ্কার: যে ১৬টি spurious feature-এর true coefficient \(0\), OLS তাদের অনেককেই nonzero coefficient দিয়ে ফেলেছে। কেন? কারণ training set-এ random noise-এর সাথে ওই spurious feature-গুলোর কাকতালীয় (accidental) correlation থাকে, আর OLS লোভীভাবে সেই noise-ও fit করতে চায় training error আরেকটু কমানোর জন্য। এটিই overfitting: model signal আর noise-এর পার্থক্য করতে পারে না।
মূল কথা: OLS-এ কোনো feature selection mechanism নেই। এটি যত feature দেওয়া হবে সবগুলোকেই কোনো-না-কোনো nonzero weight দেবে — সত্যিকারের signal হোক বা না হোক।
E2 — Ridge সবাইকে সংকুচিত করে, কিন্তু বাদ দেয় না¶
এবার \(\ell_2\) penalty যোগ করি। Penalty-strength \(\lambda\) নিজে বেছে নেওয়ার বদলে আমরা RidgeCV ব্যবহার করি, যা cross-validation দিয়ে optimal \(\lambda\) খুঁজে দেয়:
ridge = RidgeCV(alphas=np.logspace(-3, 2, 200)).fit(X_tr, y_tr)
mse_r = mean_squared_error(y_te, ridge.predict(X_te))
print(f"Ridge λ* = {ridge.alpha_:.2f}") # ≈ 0.21
print(f"Ridge test MSE = {mse_r:.3f}") # 2.075
print(f"Ridge true-feature coefs = {np.round(ridge.coef_[:4], 2)}")
# [ 4.07 -3.33 2.49 -1.94 ]
print(f"Ridge example spurious coefs = {np.round(ridge.coef_[4:6], 2)}")
# [-0.16 -0.10 ]
print(f"Ridge #exact-zero coefficients = {np.sum(ridge.coef_ == 0)}") # 0
print(f"Ridge #features with |coef|>0.1 = {np.sum(np.abs(ridge.coef_) > 0.1)}") # 11
Cross-validation \(\lambda^\* \approx 0.21\) বেছে নেয়, আর test MSE = 2.075 — OLS-এর প্রায় সমান (সামান্য ভালো)। Coefficient-এর দিকে তাকালে দেখা যায় ridge প্রতিটি coefficient-কে \(0\)-এর দিকে টেনে আনে (shrinks):
- সত্যিকারের চারটি feature-এর coefficient \(\approx [4.07,\ -3.33,\ 2.49,\ -1.94]\) — true value \([4,-3,2.5,-2]\)-এর খুব কাছাকাছি, কিন্তু সামান্য সংকুচিত।
- Spurious feature-গুলোও সংকুচিত হয়ে ছোট মান পায় (যেমন \(\approx -0.16,\ -0.10\))।
কিন্তু গুরুত্বপূর্ণ বিষয়: একটি coefficient-ও ঠিক \(0\) হয় না। ridge এখনও ১১টি feature-এ \(\lvert\text{coef}\rvert > 0.1\) রাখে, ঠিক OLS-এর মতোই। এটিই \(\ell_2\) penalty-র চারিত্রিক বৈশিষ্ট্য: এর geometry (একটি মসৃণ গোলক) coefficient-গুলোকে অক্ষের উপর ঠিক \(0\)-তে বসায় না, শুধু ছোট করে।
মূল কথা: Ridge shrinks, কিন্তু selects না। এটি variance কমায় ও coefficient স্থিতিশীল করে, কিন্তু "কোন feature গুরুত্বপূর্ণ" এই প্রশ্নের পরিষ্কার উত্তর দেয় না — কারণ সব feature-ই nonzero থেকে যায়।
E3 — Lasso নির্বাচন করে (automatic feature selection)¶
এবার \(\ell_1\) penalty:
\(\ell_1\) penalty-র geometry (একটি ধারালো কোণাযুক্ত diamond) coefficient-গুলোকে অক্ষের উপর ঠিক \(0\)-তে বসিয়ে দিতে পারে। এর ফলে কিছু coefficient পুরোপুরি বিলুপ্ত হয় — অর্থাৎ ওই feature-গুলো model থেকে স্বয়ংক্রিয়ভাবে বাদ পড়ে। কীভাবে? দেখার জন্য আমরা \(\lambda\)-কে ছোট থেকে বড় করতে করতে একটি regularization path তৈরি করি:
for lam in [0.05, 0.10, 0.20, 0.30, 0.50]:
las = Lasso(alpha=lam, max_iter=100_000).fit(X_tr, y_tr)
mse = mean_squared_error(y_te, las.predict(X_te))
selected = np.where(np.abs(las.coef_) > 1e-8)[0]
print(f"λ={lam:.2f} | #nonzero={len(selected):2d} | test MSE={mse:.2f}"
f" | selected={list(selected)}")
| \(\lambda\) | #nonzero | test MSE | নির্বাচিত feature |
|---|---|---|---|
| \(0.05\) | \(16\) | \(1.81\) | এখনও অনেক spurious আছে |
| \(0.10\) | \(9\) | \(1.76\) | path-এর সেরা MSE; কিছু spurious বাকি |
| \(0.20\) | \(5\) | \(1.91\) | ৪টি true + ১টি spurious |
| \(0.30\) | \(4\) | \(2.16\) | ঠিক true support \(\{0,1,2,3\}\) |
| \(0.50\) | \(4\) | \(2.85\) | সঠিক feature, কিন্তু over-shrunk |
Path-টি একটি সুস্পষ্ট গল্প বলে। \(\lambda\) যত বাড়ে, penalty তত কড়া হয়, আর lasso একে একে feature ফেলে দেয় (nonzero সংখ্যা \(16 \to 9 \to 5 \to 4\))। কোন feature আগে বাদ পড়ে? দুর্বলতম signal-এর feature — অর্থাৎ spurious feature-গুলো আগে শূন্য হয়, কারণ তাদের ধরে রাখার "প্রতিদান" (training error হ্রাস) penalty-র খরচের তুলনায় কম।
\(\lambda = 0.30\)-এ আসল চমক:
las30 = Lasso(alpha=0.30, max_iter=100_000).fit(X_tr, y_tr)
print(np.round(las30.coef_[:6], 2))
# [ 3.89 -2.98 2.21 -1.6 0. 0. ]
print("selected:", np.where(np.abs(las30.coef_) > 1e-8)[0])
# selected: [0 1 2 3]
এখানে lasso ১৬টি spurious feature-কে ঠিক \(0\) করে দেয় এবং ঠিক সেই ৪টি true feature \(\{0,1,2,3\}\)-ই রাখে, coefficient \([3.89,\ -2.98,\ 2.21,\ -1.6]\) সহ। অর্থাৎ model-টি নিখুঁতভাবে অন্তর্নিহিত sparse structure পুনরুদ্ধার করেছে — শুধু prediction নয়, সঠিক variable selection। লক্ষ্য করুন coefficient-গুলো true value থেকে সামান্য সংকুচিত (\(3.89 < 4\), ইত্যাদি), কারণ \(\ell_1\) penalty একই সাথে নির্বাচন ও সংকোচন — দুটোই করে।
মূল কথা: Lasso-তে sparsity = automatic feature selection। যথেষ্ট বড় \(\lambda\)-তে এটি অপ্রাসঙ্গিক feature-কে পুরোপুরি model থেকে সরিয়ে দেয়, যা OLS বা ridge কখনোই পারে না।
E4 — Tradeoff: prediction বনাম interpretability¶
এখন একটি সূক্ষ্ম কিন্তু গুরুত্বপূর্ণ প্রশ্ন: \(\lambda\) কত হওয়া উচিত? উত্তর নির্ভর করে আমরা কী চাই তার উপর। LassoCV দিয়ে purely prediction-optimal \(\lambda\) বের করি:
lcv = LassoCV(cv=5, random_state=0, max_iter=100_000).fit(X_tr, y_tr)
mse_lcv = mean_squared_error(y_te, lcv.predict(X_te))
print(f"LassoCV λ* = {lcv.alpha_:.3f}") # ≈ 0.042
print(f"LassoCV test MSE = {mse_lcv:.3f}") # 1.843 (সেরা prediction)
print(f"LassoCV #nonzero = {np.sum(np.abs(lcv.coef_) > 1e-8)}") # 17
এখানে দুটি ভিন্ন "best" \(\lambda\) মুখোমুখি দাঁড়ায়:
- Prediction-optimal \(\lambda\) (
LassoCV\(\approx 0.042\)): সর্বনিম্ন test MSE = 1.843 দেয় — সবচেয়ে ভালো ভবিষ্যদ্বাণী। কিন্তু এই ছোট \(\lambda\) penalty যথেষ্ট কড়া নয়, তাই model ১৭টি feature রাখে, যার মধ্যে অনেক tiny spurious coefficient ঢুকে পড়ে। Prediction-এর জন্য ওই tiny coefficient-গুলো সামান্য সাহায্য করে, কিন্তু model আর পরিষ্কার বা ব্যাখ্যাযোগ্য থাকে না। - Sparsity-optimal \(\lambda\) (\(\approx 0.30\)): ঠিক ৪টি true feature রাখে — সবচেয়ে পরিচ্ছন্ন, সবচেয়ে ব্যাখ্যাযোগ্য model। কিন্তু test MSE সামান্য বেশি (\(2.16\))।
এটিই interpretability-vs-prediction tradeoff। বেশি sparsity → সহজে বোঝা যায়, কিন্তু সামান্য prediction ত্যাগ; কম sparsity → ভালো prediction, কিন্তু ঘোলাটে model। কোনো একক "সঠিক" উত্তর নেই — সিদ্ধান্ত নির্ভর করে কাজের উদ্দেশ্যের উপর (বিজ্ঞানে variable selection জরুরি হলে বড় \(\lambda\), কেবল accurate forecast চাইলে CV-নির্বাচিত \(\lambda\))।
তিনটি method-এর সারসংক্ষেপ:
| Method | বেছে নেওয়া \(\lambda\) | test MSE | যত feature রাখে | feature selection? |
|---|---|---|---|---|
| OLS | \(0\) | \(2.077\) | কার্যত সব \(20\) | না |
Ridge (RidgeCV) |
\(\approx 0.21\) | \(2.075\) | সব \(20\) (সংকুচিত) | না |
Lasso (LassoCV) |
\(\approx 0.042\) | \(\mathbf{1.843}\) | \(17\) | আংশিক |
| Lasso (\(\lambda=0.30\)) | \(0.30\) | \(2.16\) | ঠিক \(4\) | হ্যাঁ (নিখুঁত) |
পড়ে নেওয়ার উপায় (read-off): OLS আর ridge উভয়ই সব ২০টি feature ধরে রাখে — তারা কখনোই কোনো variable পুরোপুরি বাদ দেয় না। একমাত্র lasso-ই sparse model দিতে পারে; যথেষ্ট বড় \(\lambda\)-তে এটি ২০টি feature থেকে ৪টিতে নেমে আসে এবং ঠিক সেই signal-গুলোই বেছে নেয় যা data তৈরিতে ব্যবহৃত হয়েছিল। আর \(\lambda\) নিজে চোখে আন্দাজ না করে cross-validation দিয়ে নির্বাচন করাই standard practice — উদ্দেশ্য অনুযায়ী (prediction না interpretability) CV-র objective বদলে নেওয়া যায়।
Verification¶
[OLS] test MSE = 2.077 | #|coef|>0.1 = 11 | exact-zero = 0
[RidgeCV] λ* ≈ 0.21 | test MSE = 2.075 | #|coef|>0.1 = 11 | exact-zero = 0
true-feature coefs ≈ [ 4.07 -3.33 2.49 -1.94 ]
spurious sample ≈ [-0.16 -0.10 ]
[Lasso path]
λ=0.05 | #nonzero=16 | test MSE=1.81
λ=0.10 | #nonzero= 9 | test MSE=1.76 (best MSE on path)
λ=0.20 | #nonzero= 5 | test MSE=1.91 (4 true + 1 spurious)
λ=0.30 | #nonzero= 4 | test MSE=2.16 (exact support {0,1,2,3})
λ=0.50 | #nonzero= 4 | test MSE=2.85 (over-shrunk)
@λ=0.30 coef[:6] = [ 3.89 -2.98 2.21 -1.6 0. 0. ]
[LassoCV] λ* ≈ 0.042 | test MSE = 1.843 | #nonzero = 17
মূল সিদ্ধান্ত নিশ্চিত: OLS ও ridge সব feature রাখে (ridge সংকোচন করে কিন্তু কোনো coefficient ঠিক \(0\) করে না), আর lasso \(\lambda\) বাড়ার সাথে সাথে spurious feature বাদ দিয়ে \(\lambda=0.30\)-এ ঠিক ৪টি true feature-এ পৌঁছায় — \(\ell_1\) regularization-এর মাধ্যমে স্বয়ংক্রিয় sparse feature selection।
৪ · প্রমাণ ও উৎপাদন¶
আগের sections-এ আমরা ridge ও lasso-র objective function দুটি লিখেছি এবং intuition-এর স্তরে দেখেছি কেন penalty যোগ করলে coefficient ছোট হয়। এবার আমরা পেছনের গণিতটা পুরোপুরি খুলে দেখব — কলম-হাতে, ধাপে ধাপে। মূল প্রশ্ন পাঁচটা:
- ridge-এর closed-form solution আসে কোথা থেকে, আর কেন সেটা OLS-এর মতো "ভেঙে পড়ে" না?
- ridge ঠিক কীভাবে — কোন direction-এ কতটা — shrink করে?
- lasso কেন coefficient-কে ঠিক শূন্য করে দিতে পারে, অথচ ridge পারে না?
- এই sparsity-র behind-the-scene geometry-টা কী?
- ridge bias আনলেও কেন সেটা MSE-র হিসেবে লাভজনক?
প্রতিটি উপ-section-এর শুরুতে difficulty tag দেওয়া আছে। notation শুরু থেকে শেষ পর্যন্ত standardized: \(X\in\mathbb R^{n\times p}\) (columns mean-centered ও unit-scaled), \(y\in\mathbb R^n\) (mean-centered, তাই intercept আলাদা করে penalize করতে হয় না), \(\beta\in\mathbb R^p\), এবং \(\lambda\ge 0\)।
৪.১ Ridge-এর closed-form solution ও তার সর্বদা-invertible property ★★¶
লক্ষ্য¶
ridge objective:
আমরা দেখাব যে এর unique minimizer হলো
এবং — এটাই আসল চমক — \(\lambda>0\) হলে \(X^\top X+\lambda I\) matrix-টা সবসময় invertible, এমনকি যখন OLS-এর \(X^\top X\) singular (অর্থাৎ \(p>n\) বা columns-এর মধ্যে multicollinearity আছে)।
ধাপ ১ — objective-টাকে খুলে লেখা¶
\(\lVert y-X\beta\rVert_2^2=(y-X\beta)^\top(y-X\beta)\) এবং \(\lVert\beta\rVert_2^2=\beta^\top\beta\)। তাই
inner product খুলে (মনে রাখুন \(y^\top X\beta\) একটা scalar, তাই সেটা নিজের transpose \(\beta^\top X^\top y\)-র সমান):
ধাপ ২ — gradient নিয়ে শূন্যে বসানো¶
vector calculus-এর দুটো standard identity ব্যবহার করব (prereq 0.5):
এখানে \(X^\top X\) symmetric এবং \(\lambda I\) symmetric, তাই:
লক্ষ করুন এটাকে ঠিক brief-এর form-এ লেখা যায়: residual \(r=y-X\beta\) ধরলে
minimizer-এ gradient শূন্য:
\(\beta\)-যুক্ত term দুটো একসাথে নিলে (ridge normal equation):
তুলনা — OLS: \(\lambda=0\) বসালে এটা প্রায় হুবহু prereq 5.1-এর OLS normal equation \(X^\top X\beta=X^\top y\)-তে ফিরে যায়। ridge শুধু diagonal-এ \(\lambda\) যোগ করে — তাই একে কখনো কখনো "ridge regression" বলা হয়, কারণ \(\lambda\) যেন \(X^\top X\)-এর diagonal বরাবর একটা উঁচু পাহাড়-রিজ (ridge) বসিয়ে দেয়।
ধাপ ৩ — \(X^\top X+\lambda I\) সর্বদা invertible (positive-definite proof)¶
এটাই section-এর গাণিতিক হৃদয়। আমরা প্রমাণ করব: যেকোনো \(\lambda>0\)-র জন্য \(M:=X^\top X+\lambda I\) positive-definite, আর positive-definite হলেই invertible।
ধরুন \(v\in\mathbb R^p\) একটা যেকোনো non-zero vector। quadratic form হিসাব করি:
দুটো term আলাদা করে দেখি:
- \(v^\top X^\top X v=(Xv)^\top(Xv)=\lVert Xv\rVert_2^2\ \ge 0\) — এটা একটা norm-এর বর্গ, কখনো negative হতে পারে না (তবে \(Xv=0\) হলে শূন্য হতে পারে — এই জায়গাতেই OLS-এর সমস্যা)।
- \(\lambda\,v^\top v=\lambda\lVert v\rVert_2^2>0\) — কারণ \(\lambda>0\) এবং \(v\ne 0\) মানে \(\lVert v\rVert_2^2>0\)।
যোগ করলে:
অর্থাৎ \(M\) strictly positive-definite। এখন:
Lemma (PD ⇒ invertible). যদি কোনো symmetric matrix \(M\)-এর জন্য সব non-zero \(v\)-তে \(v^\top M v>0\) হয়, তবে \(M\) invertible।
প্রমাণ: ধরি, বিপরীতে, \(M\) singular। তাহলে এমন non-zero \(v_0\) আছে যে \(Mv_0=0\)। কিন্তু তখন \(v_0^\top M v_0=v_0^\top 0=0\), যা \(v_0^\top M v_0>0\)-র সাথে স্ববিরোধী। অতএব \(M\) singular হতে পারে না, মানে invertible। \(\blacksquare\)
eigenvalue-র ভাষায় একই কথা: symmetric \(M\)-এর সব eigenvalue real, আর \(M\) PD হলে সব eigenvalue \(>0\); \(\det M=\prod_j\mu_j>0\ne 0\), তাই inverse আছে। আসলে spectral decomposition দিয়ে দেখা যায় \(X^\top X\)-এর eigenvalue \(\mu_j\ge 0\) হলে \(M=X^\top X+\lambda I\)-এর eigenvalue হবে \(\mu_j+\lambda\ge\lambda>0\) — \(\lambda\) যোগ করা মানে প্রতিটা eigenvalue-কে \(\lambda\) পরিমাণ ডানে সরিয়ে দেওয়া, ফলে শূন্য eigenvalue আর থাকে না।
অতএব inverse exist করে এবং solution unique:
কেন এটাই multicollinearity-র দাওয়াই¶
OLS-এ যদি দুটো predictor প্রায় collinear হয়, \(X^\top X\) near-singular — তার সবচেয়ে ছোট eigenvalue প্রায় শূন্য, তাই \((X^\top X)^{-1}\)-এ বিশাল entry, আর \(\hat\beta_{\text{OLS}}\)-এর variance বিস্ফোরিত হয় (অস্থির, sign পর্যন্ত উল্টে যেতে পারে)। ridge সেই ছোট eigenvalue-কে \(\mu_{\min}+\lambda\) বানিয়ে দেয় — ক্ষুদ্রতম eigenvalue-র একটা মেঝে (floor) \(\lambda\) নিশ্চিত হয়, inverse stable থাকে, coefficient আর উড়ে যায় না।
স্বাস্থ্য-পরীক্ষা (sanity check): convexity. \(J_R\)-এর Hessian \(\nabla^2_\beta J_R=2(X^\top X+\lambda I)=2M\), যা PD — তাই \(J_R\) strictly convex, এবং strictly convex function-এর stationary point একটাই, সেটাই global minimum। অর্থাৎ আমরা সত্যিই minimum পেয়েছি, কোনো saddle বা maximum নয়।
৪.২ SVD দিয়ে ridge shrinkage-এর সঠিক রূপ ★★¶
লক্ষ্য¶
ধাপ ৪.১-এ পেয়েছি \(\hat\beta_{\text{ridge}}=(X^\top X+\lambda I)^{-1}X^\top y\), কিন্তু এটা matrix inverse-এর মোড়কে লুকানো — shrinkage-টা ঠিক কোথায় ঘটছে চোখে দেখা যায় না। SVD সেই মোড়কটা খুলে দেয়। আমরা দেখাব:
এবং fitted value-র দিক থেকে দেখলে ridge প্রতিটি principal direction-কে একটা factor \(\dfrac{d_j^2}{d_j^2+\lambda}<1\) দিয়ে সংকুচিত করে — যেখানে ছোট singular value-র (কম-variance) direction সবচেয়ে বেশি সংকুচিত হয়।
ধাপ ১ — SVD বসানো¶
prereq 0.5 থেকে thin SVD: \(X=UDV^\top\), যেখানে \(U\in\mathbb R^{n\times p}\) (orthonormal columns \(u_j\), তাই \(U^\top U=I_p\)), \(D=\operatorname{diag}(d_1,\dots,d_p)\) (\(d_j\ge0\) singular values), \(V\in\mathbb R^{p\times p}\) orthogonal (\(V^\top V=VV^\top=I_p\), columns \(v_j\))। তাহলে
কারণ \(U^\top U=I\)। এটা ঠিক \(X^\top X\)-এর eigendecomposition: eigenvector \(v_j\), eigenvalue \(d_j^2\)।
ধাপ ২ — \(\lambda I\)-কে একই basis-এ আনা¶
মূল কৌশল: \(V\) orthogonal বলে \(I=VV^\top\), তাই \(\lambda I=V(\lambda I)V^\top\)। এবার:
ভেতরের \(D^2+\lambda I=\operatorname{diag}(d_j^2+\lambda)\) একটা diagonal matrix — invert করা তুচ্ছ, প্রতিটা diagonal entry-র reciprocal নিলেই হয় (এবং \(d_j^2+\lambda>0\) যেহেতু \(\lambda>0\), তাই কোনো division-by-zero নেই — ৪.১-এর invertibility এখানে আবার দেখা দিল)। orthogonal matrix-এর inverse তার transpose, তাই:
ধাপ ৩ — \(X^\top y\)-র সাথে গুণ ও যোগফলে ভাঙা¶
\(X^\top y=(UDV^\top)^\top y=V D U^\top y\)। তাই:
যেখানে \(V^\top V=I\) ব্যবহার করেছি। ভেতরের তিনটে diagonal-জাতীয় factor — \((D^2+\lambda I)^{-1}\), \(D\) — একসাথে diagonal, \(j\)-তম entry \(\dfrac{d_j}{d_j^2+\lambda}\)। column-আকারে লিখলে এটাই কাঙ্ক্ষিত যোগফল:
\(\lambda=0\) বসালে \(\dfrac{d_j}{d_j^2}=\dfrac{1}{d_j}\) — ঠিক OLS form। অর্থাৎ OLS-এর প্রতিটি term-এর coefficient \(\dfrac1{d_j}\) ছিল; ridge সেটাকে \(\dfrac{d_j}{d_j^2+\lambda}\)-তে নামিয়েছে।
ধাপ ৪ — fitted value-তে shrinkage factor স্পষ্ট হয়¶
coefficient নয়, fitted value \(\hat y=X\hat\beta\)-এর দিকে তাকালে ছবিটা সবচেয়ে পরিষ্কার। \(X=UDV^\top\) ও উপরের \(\hat\beta_{\text{ridge}}\) মিলিয়ে (আবার \(V^\top V=I\)):
তুলনায় OLS-এর fitted value \(\hat y_{\text{OLS}}=\sum_j u_j\,(u_j^\top y)\) — অর্থাৎ \(y\)-কে \(u_j\) direction-গুলোতে প্রক্ষেপ (project) করে অবিকৃত ফেরত দেয় (shrink factor \(=1\))। ridge প্রতিটা প্রক্ষেপণ-component \(u_j^\top y\)-কে একটা factor দিয়ে গুণ করে:
ব্যাখ্যা — ছোট singular value সবচেয়ে বেশি সংকুচিত¶
\(s_j=\dfrac{d_j^2}{d_j^2+\lambda}\)-র গঠন লক্ষ করুন:
- বড় \(d_j\) (high-variance, "শক্তিশালী" direction): \(d_j^2\gg\lambda\) হলে \(s_j\approx\dfrac{d_j^2}{d_j^2}=1\) — প্রায় অবিকৃত, ridge এদের প্রায় ছোঁয় না।
- ছোট \(d_j\) (low-variance direction): \(d_j^2\ll\lambda\) হলে \(s_j\approx\dfrac{d_j^2}{\lambda}\to 0\) — তীব্রভাবে সংকুচিত।
\(d_j\) যত ছোট, \(s_j\) তত ছোট — অর্থাৎ ridge সবচেয়ে কঠোরভাবে চাপ দেয় সেই principal direction-গুলোকে যাদের data-তে variance সবচেয়ে কম। আর ঠিক এই low-variance direction-গুলোই OLS-এ সমস্যা সৃষ্টি করত: সেখানে \(\dfrac1{d_j}\) বিশাল, তাই \(u_j^\top y\)-এর সামান্য noise-ও বিপুলভাবে বিবর্ধিত হতো এবং estimate-এর variance ফুলে উঠত। ridge সেই ভঙ্গুর direction-গুলোকে নিচে টেনে রাখে — এভাবেই it tames variance।
effective degrees of freedom: এই \(s_j\)-গুলোর যোগফলই ridge-এর কার্যকর parameter-সংখ্যা মাপে: \(\mathrm{df}(\lambda)=\sum_{j}\dfrac{d_j^2}{d_j^2+\lambda}\)। \(\lambda=0\)-তে \(\mathrm{df}=p\) (full OLS), আর \(\lambda\to\infty\)-তে \(\mathrm{df}\to 0\)। অর্থাৎ \(\lambda\) বাড়ানো মানে model-এর "স্বাধীনতা" ধাপে ধাপে কমিয়ে আনা — bias–variance trade-off-এর (prereq 6.1) একদম পরিমাণগত হাতল। এটা পরের sections-এ tuning-এর ভিত্তি।
৪.৩ Lasso-র sparsity: soft-thresholding (orthonormal case) ★★★¶
এখন সবচেয়ে গভীর অংশ। ridge-এ closed form পাওয়া সহজ ছিল কারণ \(\lVert\beta\rVert_2^2\) smooth (differentiable)। কিন্তু lasso-র \(\lVert\beta\rVert_1=\sum_j\lvert\beta_j\rvert\) origin-এ non-differentiable (\(\lvert\beta_j\rvert\)-র \(\beta_j=0\)-তে কোণা)। তাই সাধারণ gradient = 0 খাটে না; আমাদের subgradient লাগবে। general \(X\)-এ lasso-র closed form নেই, কিন্তু orthonormal \(X\) (\(X^\top X=I\)) ধরে নিলে সমস্যাটা coordinate-wise আলাদা হয়ে যায় এবং একটা সুন্দর বদ্ধ রূপ বেরোয়। এই special case-ই sparsity-র আসল mechanism নগ্ন করে দেখায়।
লক্ষ্য¶
দেখাব, orthonormal \(X\)-এর জন্য
যেখানে \(z_j=(X^\top y)_j\) হলো \(j\)-তম OLS coefficient, আর \((\cdot)_+=\max(\cdot,0)\) positive-part। এটাই soft-thresholding operator: \(\lvert z_j\rvert\le\lambda/2\) হলে \(\hat\beta_j\) ঠিক \(0\)। ridge-এর সমতুল্য \(\hat\beta_j=\dfrac{z_j}{1+\lambda}\) — যা কখনো শূন্য নয়। এই বৈপরীত্যই উত্তর দেয়: কেন L1 sparsity দেয়, L2 দেয় না।
ধাপ ১ — objective-টা coordinate-wise আলাদা হয়ে যায়¶
orthonormal \(X\) (\(X^\top X=I\))-এ RSS খুলি। আগের মতো:
যেখানে \(z=X^\top y\) ও \(X^\top X=I\)। \(y^\top y\) (\(\beta\)-নিরপেক্ষ constant) বাদ দিয়ে এবং \(\beta^\top\beta=\sum_j\beta_j^2\), \(\beta^\top z=\sum_j\beta_j z_j\) লিখলে lasso objective:
প্রতিটা পদ \(z_j^2\) যোগ-বিয়োগ করে complete-the-square:
\(z_j^2\) আবার constant, তাই minimize করার দিক থেকে objective দাঁড়ায় \(p\)টা স্বাধীন একমাত্রিক (univariate) সমস্যা:
(এই separation-টাই orthonormality-র উপহার — coordinates একে অপরের সাথে coupled নয়, তাই এক একটা \(\beta_j\) আলাদা করে সমাধান করা যায়।)
ধাপ ২ — subgradient দিয়ে univariate সমস্যা সমাধান¶
\(g(\beta_j)\) convex কিন্তু \(\beta_j=0\)-তে \(\lvert\beta_j\rvert\)-র কারণে kink। \(\lvert\beta_j\rvert\)-র subdifferential:
(এটাই কোণার মূল রহস্য: \(\beta_j=0\)-তে slope একটামাত্র সংখ্যা নয়, বরং পুরো \([-1,1]\) ব্যবধি — একগুচ্ছ tangent line।)
optimality condition (convex function-এ): \(0\in\partial g(\beta_j)\), অর্থাৎ
তিনটা region আলাদা করে দেখি।
Region A — ধরি optimum \(\beta_j>0\)। তখন \(\partial\lvert\beta_j\rvert=\{1\}\), condition exact:
কিন্তু \(\beta_j>0\) ধরেছিলাম, তাই এটা বৈধ কেবল যখন \(z_j-\dfrac\lambda2>0\), অর্থাৎ \(z_j>\dfrac\lambda2\)। ফল: \(\hat\beta_j=z_j-\dfrac\lambda2\).
Region B — ধরি optimum \(\beta_j<0\)। তখন \(\partial\lvert\beta_j\rvert=\{-1\}\):
বৈধ যখন \(z_j+\dfrac\lambda2<0\), অর্থাৎ \(z_j<-\dfrac\lambda2\). ফল: \(\hat\beta_j=z_j+\dfrac\lambda2\).
Region C — ধরি optimum \(\beta_j=0\)। তখন \(\partial\lvert\beta_j\rvert=[-1,1]\), condition হলো \(0\in -2(z_j-0)+\lambda[-1,1]=-2z_j+[-\lambda,\lambda]\)। অর্থাৎ এমন কোনো \(s\in[-1,1]\) থাকতে হবে যে \(-2z_j+\lambda s=0\), মানে \(s=\dfrac{2z_j}{\lambda}\)। যেহেতু \(s\in[-1,1]\) লাগবে:
অর্থাৎ যখনই \(\lvert z_j\rvert\le\dfrac\lambda2\), তখন \(\beta_j=0\) সত্যিই optimum — এখানে subdifferential-এর ভেতরে \(0\) ধরে রাখার জন্য যথেষ্ট "ঢিল" আছে।
ধাপ ৩ — তিন region একত্র: soft-thresholding¶
তিনটা ফল একসাথে লিখলে:
যা compact-ভাবে ঠিক soft-thresholding operator \(S_{\lambda/2}\):
ধাপ ৪ — ridge-এর সাথে মুখোমুখি তুলনা¶
একই orthonormal setting-এ ridge করি। \(J_R=\text{const}+\sum_j\big((z_j-\beta_j)^2+\lambda\beta_j^2\big)\), প্রতিটা পদ smooth; derivative শূন্য:
এবার পাশাপাশি রাখি:
| OLS coef \(z_j\) | ridge \(\dfrac{z_j}{1+\lambda}\) | lasso \(S_{\lambda/2}(z_j)\) |
|---|---|---|
| বড় (signal) | proportional-ভাবে একটু ছোট | একটা ধ্রুবক \(\lambda/2\) কেটে নেয় |
| ছোট, \(\lvert z_j\rvert\le\lambda/2\) | ছোট কিন্তু শূন্য নয় | ঠিক \(0\) |
মূল পার্থক্য দুটো:
- ridge = multiplicative shrink: প্রতিটা coefficient একই অনুপাত \(\dfrac{1}{1+\lambda}\)-এ ছোট হয়; \(z_j\ne0\) হলে \(\hat\beta_j\ne0\) — কখনো ঠিক শূন্যে পৌঁছায় না, শুধু অসীম-কাছাকাছি যায়।
- lasso = additive shrink + thresholding: প্রতিটা coefficient থেকে স্থির \(\dfrac\lambda2\) কাটা যায়, আর যাদের মাপ \(\dfrac\lambda2\)-র ছোট তারা কাটা খেয়ে ঠিক \(0\)-তে চাপা পড়ে।
এই thresholding-ই automatic variable selection: lasso দুর্বল predictor-গুলোকে নিজে থেকেই model থেকে ছেঁটে ফেলে (\(\beta_j=0\)), আর সেটাই sparse solution। L2-এর smooth penalty-তে এই কোণা নেই, তাই thresholding নেই, তাই sparsity নেই।
numerical যাচাই (orthonormal columns, \(\lambda=1\)): OLS coef \(z=[1.63,\,0.50,\,0.96,\,-0.81,\,-2.68,\,1.40]\) ধরলে soft-threshold \((\lambda/2=0.5)\) দেয় \([1.13,\,\mathbf{0.00},\,0.46,\,-0.31,\,-2.18,\,0.90]\) — দ্বিতীয় coefficient (\(\lvert z_2\rvert=0.50\le0.5\)) ঠিক শূন্য; অথচ ridge দেয় \([0.82,\,0.25,\,0.48,\,-0.40,\,-1.34,\,0.70]\) — একটাও শূন্য নয়। আলাদা একটা coordinate-wise numerical minimizer চালিয়েও বদ্ধ-রূপ formula হুবহু মিলেছে।
৪.৪ Geometric ও KKT দৃষ্টিভঙ্গি ★★¶
soft-thresholding penalized (Lagrangian) form-এ sparsity দেখিয়েছে। একই কথা constrained form-এ আরও স্পষ্ট ভূ-জ্যামিতিক ছবি দেয় — diamond-এর কোণা।
ধাপ ১ — দুই form-এর সমতুল্যতা¶
ridge ও lasso দুটোই দুইভাবে লেখা যায় (Lagrangian duality, prereq 0.5/5.1):
যেখানে lasso-র জন্য \(\Omega(\beta)=\lVert\beta\rVert_1\) এবং ridge-এর জন্য \(\Omega(\beta)=\lVert\beta\rVert_2^2\)। প্রতিটা \(\lambda\ge0\)-র জন্য একটা সংশ্লিষ্ট \(t\ge0\) আছে (এবং উল্টোটাও) যা একই solution দেয় — বড় \(\lambda\) ↔ ছোট \(t\) (কড়া বাজেট), \(\lambda=0\) ↔ \(t=\infty\) (OLS)।
constrained রূপটা চোখে দেখার জন্য আদর্শ: আমরা RSS-এর elliptical contour-গুলো যত ছোট (যত OLS-সমাধানের কাছে) সম্ভব নিতে চাই, কিন্তু \(\beta\)-কে constraint region \(\{\beta:\Omega(\beta)\le t\}\)-এর ভেতরে থাকতে হবে। সমাধান হলো সেই বিন্দু যেখানে সবচেয়ে ছোট সম্ভব RSS-contour প্রথমবার constraint region-কে স্পর্শ করে।
ধাপ ২ — দুই region-এর আকৃতি¶
\(p=2\)-তে ছবি স্পষ্ট:
- L2 ball \(\{\beta_1^2+\beta_2^2\le t\}\) — একটা মসৃণ বৃত্ত/গোলক, কোনো কোণা নেই, সর্বত্র boundary smooth।
- L1 ball \(\{\lvert\beta_1\rvert+\lvert\beta_2\rvert\le t\}\) — একটা হীরক (diamond), যার শীর্ষবিন্দুগুলো (corners) ঠিক axes-এর উপর (\((\pm t,0)\) ও \((0,\pm t)\))। এই corner-গুলোতেই একটা না একটা coordinate শূন্য।
beta2 beta2
| L2 ball (circle) | L1 ball (diamond)
___|___ /|\
/ | \ / | \
| | | RSS ellipse touches / | \ RSS ellipse first
---+----+----+---> beta1 generically ---+---+---> touches a CORNER
| | | at a smooth point \ | / beta1 (on the axis,
\___|___/ (both betas != 0) \|/ so beta1 = 0)
| V
ধাপ ৩ — কেন corner-এ স্পর্শ ⇒ sparsity¶
RSS-এর contour হলো OLS-solution \(\hat\beta_{\text{OLS}}\)-কে কেন্দ্র করে ellipse। বাইরে থেকে ছোট হতে হতে প্রথম যেখানে region ছোঁয়, সেখানে gradient-গুলো align করে (KKT, নিচে)।
- diamond (L1): এর boundary-তে বেশিরভাগ "ভর" রয়েছে corner-এর কাছে, আর corner-এ boundary-র slope হঠাৎ বদলায় (kink)। একটা মসৃণ ellipse বাইরে থেকে এসে এমন একটা ছুঁচালো diamond-কে ছোঁবার সবচেয়ে স্বাভাবিক জায়গা হলো তার শীর্ষবিন্দু — যেখানে এক বিরাট পরিসর-ভর ellipse-দিকের সব gradient-কে "ধরে রাখতে" পারে। corner axis-এর উপর, তাই সেখানে কিছু \(\beta_j=0\)। উচ্চ-মাত্রায় এটা আরও তীব্র: diamond-এর অনেক নিম্ন-মাত্রিক face/edge axis-তে আটকে থাকে, তাই sparsity প্রায় নিয়মই হয়ে দাঁড়ায়।
- circle (L2): boundary সর্বত্র smooth, কোনো বিশেষ বিন্দুর প্রতি পক্ষপাত নেই। ellipse generic অভিমুখ থেকে এসে circle-কে ছোঁবে একটা সাধারণ বিন্দুতে যেখানে দুটো coordinate-ই non-zero। axis-এর ঠিক উপরে স্পর্শ হওয়া একটা measure-zero কাকতাল — তাই ridge প্রায় কখনোই ঠিক শূন্য coefficient দেয় না।
এটাই ৪.৩-এর soft-thresholding-এর জ্যামিতিক প্রতিচ্ছবি: L1-এর কোণা ↔ subdifferential-এর \([-1,1]\) ব্যবধি ↔ "dead zone" যেখানে \(\hat\beta_j\) শূন্যে আটকে থাকে।
ধাপ ৪ — KKT / subgradient condition¶
আনুষ্ঠানিকভাবে, lasso (penalized form) \(J_L(\beta)=\lVert y-X\beta\rVert_2^2+\lambda\lVert\beta\rVert_1\)-এর stationarity \(0\in\partial J_L(\hat\beta)\) লিখলে — RSS-অংশের gradient \(-2X^\top(y-X\hat\beta)\) এবং \(\lVert\beta\rVert_1\)-অংশের subgradient মিলিয়ে — প্রতিটা coordinate \(j\)-র জন্য KKT condition:
পড়ার ভাষায়: active predictor-দের (\(\hat\beta_j\ne0\)) জন্য residual-এর সাথে correlation-এর মান ঠিক \(\lambda/2\)-তে আটকানো (boundary সক্রিয়); আর inactive predictor-দের (\(\hat\beta_j=0\)) জন্য সেই correlation-এর মাপ \(\lambda/2\)-এর ভেতরে থাকলেই চলে — অর্থাৎ তারা যথেষ্ট দুর্বল বলে model-এ ঢোকার দরকার নেই। ঠিক এই \([-\lambda/2,\lambda/2]\) স্বাধীনতা-ব্যবধিই coefficient-কে exact শূন্যে ধরে রাখে।
তুলনায় ridge-এর condition smooth ও equality: \(X^\top(y-X\hat\beta)=\lambda\hat\beta\) সব coordinate-এ — কোনো "ভেতরে থাকলেই চলে" শিথিলতা নেই, তাই কোনো coordinate শূন্যে আটকানোর সুযোগও নেই।
৪.৫ Ridge-এর bias–variance: কেন biased estimator-ও জেতে ★¶
শেষ প্রশ্ন: ridge তো OLS-এর unbiasedness ভেঙে দেয় — তবু একে ভালো বলি কেন? উত্তর prereq 6.1-এর bias–variance decomposition-এ।
ধাপ ১ — ridge biased¶
ধরা যাক সত্যিকারের model \(y=X\beta+\varepsilon\), \(\mathbb E[\varepsilon]=0\), \(\operatorname{Cov}(\varepsilon)=\sigma^2 I\)। তাহলে \(\mathbb E[X^\top y]=X^\top X\beta\), এবং (matrix \((X^\top X+\lambda I)^{-1}\) ধ্রুবক বলে expectation-এর ভেতরে টানা যায়):
\(\lambda>0\) হলে \((X^\top X+\lambda I)^{-1}X^\top X\ne I\) (SVD-তে এর eigenvalue \(\dfrac{d_j^2}{d_j^2+\lambda}<1\)), তাই
আর bias-টা \(\beta\)-কে শূন্যের দিকে টানে। OLS (\(\lambda=0\)) থাকে unbiased: \(\mathbb E[\hat\beta_{\text{OLS}}]=\beta\)।
ধাপ ২ — কিন্তু variance কম¶
SVD-form-এ (\(\hat\beta=\sum_j v_j\frac{d_j}{d_j^2+\lambda}u_j^\top y\), আর \(\operatorname{Var}(u_j^\top y)=\sigma^2\) যেহেতু \(u_j\) orthonormal) component-গুলোর variance:
প্রতিটা \(j\)-তে \(\dfrac{d_j^2}{(d_j^2+\lambda)^2}<\dfrac{1}{d_j^2}\) (কারণ \(\lambda>0\)), তাই ridge-এর প্রতিটি direction-এর variance OLS-এর চেয়ে কঠোরভাবে কম — বিশেষত ছোট \(d_j\)-র (near-collinear) direction-এ যেখানে OLS-এর \(1/d_j^2\) বিস্ফোরিত। অর্থাৎ \(\lambda\) বাড়ালে variance একঘেয়েভাবে কমে, কিন্তু bias বাড়ে — ধ্রুপদী trade-off।
ধাপ ৩ — formal MSE-win¶
estimator-এর mean squared error: \(\mathrm{MSE}=\text{Bias}^2+\text{Variance}\) (prereq 6.1)। OLS-এ Bias \(=0\) কিন্তু Variance সর্বোচ্চ; ridge-এ small bias যোগ হয় বিনিময়ে বড় variance-হ্রাস।
Theorem (Hoerl–Kennard, 1970 — existence of a better \(\lambda\)). যেকোনো design \(X\) (full column rank) ও noise \(\sigma^2>0\)-র জন্য এমন একটা ব্যবধি \((0,\lambda^\ast)\) থাকে যাতে প্রতিটি \(\lambda\in(0,\lambda^\ast)\)-র ridge estimator-এর total MSE (অর্থাৎ \(\mathbb E\lVert\hat\beta-\beta\rVert_2^2\)) OLS-এর চেয়ে strictly কম: $$ \exists\,\lambda>0:\quad \mathrm{MSE}\big(\hat\beta_{\text{ridge}}(\lambda)\big)<\mathrm{MSE}\big(\hat\beta_{\text{OLS}}\big). $$
Intuition why (sketch): \(\lambda=0\)-তে \(\dfrac{d}{d\lambda}\big[\text{Variance}\big]<0\) (variance কমছে, প্রথম-ক্রমে \(O(\lambda)\) হারে), কিন্তু \(\dfrac{d}{d\lambda}\big[\text{Bias}^2\big]=0\) at \(\lambda=0\) (bias শুরু হয় \(O(\lambda)\), তাই Bias\(^2\) শুরু হয় কেবল \(O(\lambda^2)\) — দ্বিতীয়-ক্রমে)। অর্থাৎ \(\lambda\)-কে \(0\) থেকে সামান্য বাড়ালে variance-এর first-order লাভ bias\(^2\)-এর second-order ক্ষতিকে ছাপিয়ে যায়, তাই MSE প্রথমে নামবেই। এটাই গাণিতিক নিশ্চয়তা যে "একটু regularization সবসময় সাহায্য করে" — এবং ঠিক এই কারণেই ridge (ও সাধারণভাবে regularization) practice-এ এত শক্তিশালী।
bias–variance-এর এই হিসাব (prereq 6.1) এবং ৪.১–৪.৪-এর গঠনগত প্রমাণ একসাথে regularization-এর পূর্ণ ছবি দেয়: ridge invertibility ও variance সামলায় (৪.১, ৪.২), lasso তার উপর sparsity/variable selection এনে দেয় (৪.৩, ৪.৪), আর bias সামান্য বাড়লেও MSE-তে আমরা নিশ্চিতভাবে এগিয়ে থাকি (৪.৫)।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা একটা নিয়ন্ত্রিত সিমুলেশন চালাব যেখানে সত্যিকারের মডেলটা আমরা নিজেরাই জানি: \(p=20\) ফিচারের মধ্যে কেবল প্রথম \(k=4\) টির সত্যিকারের সহগ আছে (\(\beta = [4,\,-3,\,2.5,\,-2,\,0,\dots,0]\)), বাকি \(16\) টি ফিচার নিছক spurious (গোলমাল)। নমুনার আকার \(n=100\) — অর্থাৎ \(p\) আর \(n\) একই মাত্রার, যা ঠিক সেই পরিস্থিতি যেখানে OLS অতিরিক্ত-ফিট করে আর regularization কাজে লাগে।
পরিকল্পনাটা চারটি ধাপে সাজানো:
- PART 1 — from-scratch ridge: closed-form সূত্র \(\hat\beta = (X^\top X + \lambda I)^{-1} X^\top y\) নিজে হাতে বসিয়ে, তারপর
sklearn.Ridgeএর সঙ্গে মিলিয়ে দেখা। - PART 2 — OLS বনাম RidgeCV বনাম LassoCV: তিনটির test MSE আর ক'টা ফিচার টিকে থাকে।
- PART 3 — lasso-এর regularization path: \(\lambda\) বাড়ালে সমর্থন (support) কীভাবে সঙ্কুচিত হয়ে সত্যিকারের সেট \(\{0,1,2,3\}\)-এ এসে দাঁড়ায়।
- PART 4 — সহগ-তুলনা: সত্যিকারের \(\beta\) বনাম OLS বনাম ridge বনাম lasso।
import numpy as np
from sklearn.linear_model import LinearRegression, RidgeCV, LassoCV, Lasso, Ridge
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
rng = np.random.default_rng(20260619)
n, p, k = 100, 20, 4
beta = np.zeros(p); beta[:k] = [4.0, -3.0, 2.5, -2.0]
X = rng.normal(0, 1, (n, p)); y = X @ beta + rng.normal(0, 1.0, n)
Xs = StandardScaler().fit_transform(X)
Xtr, Xte, ytr, yte = train_test_split(Xs, y, test_size=0.3, random_state=0)
np.set_printoptions(precision=3, suppress=True)
# ====================================================================
# PART 1 : from-scratch RIDGE -> beta_hat = (X^T X + lam I)^{-1} X^T y
# ====================================================================
print("=" * 60)
print("PART 1 : scratch ridge vs sklearn.Ridge")
print("=" * 60)
lam = 0.21 * len(ytr) # effective L2 penalty on the SUM-of-squares loss
ntr, q = Xtr.shape
A = Xtr.T @ Xtr + lam * np.eye(q)
beta_scratch = np.linalg.solve(A, Xtr.T @ ytr)
# sklearn.Ridge minimises ||y - Xb||^2 + alpha*||b||^2 (no 1/n on the loss),
# so the matching alpha is exactly our lam.
ridge_sk = Ridge(alpha=lam, fit_intercept=False).fit(Xtr, ytr)
print(f"lambda (effective L2 penalty) = {lam:.4f}")
print("scratch ridge coef[:6] :", beta_scratch[:6])
print("sklearn Ridge coef[:6] :", ridge_sk.coef_[:6])
print("max abs difference :", np.max(np.abs(beta_scratch - ridge_sk.coef_)))
print("match (allclose) :", np.allclose(beta_scratch, ridge_sk.coef_))
# ====================================================================
# PART 2 : OLS vs RidgeCV vs LassoCV
# ====================================================================
print()
print("=" * 60)
print("PART 2 : OLS vs RidgeCV vs LassoCV")
print("=" * 60)
def report(name, est):
mse = mean_squared_error(yte, est.predict(Xte))
kept = int(np.sum(np.abs(est.coef_) > 0.1))
exact0 = int(np.sum(est.coef_ == 0.0))
print(f"{name:9s} | test MSE = {mse:.3f} | #|coef|>0.1 = {kept:2d} "
f"| exactly-zero = {exact0:2d}")
return mse
ols = LinearRegression().fit(Xtr, ytr)
ridgecv = RidgeCV(alphas=np.logspace(-3, 3, 100)).fit(Xtr, ytr)
lassocv = LassoCV(cv=5, random_state=0, max_iter=100000).fit(Xtr, ytr)
report("OLS", ols)
report("RidgeCV", ridgecv)
report("LassoCV", lassocv)
print(f"RidgeCV lambda* = {ridgecv.alpha_:.3f}")
print(f"LassoCV lambda* = {lassocv.alpha_:.4f} (#nonzero = "
f"{int(np.sum(lassocv.coef_ != 0))})")
# ====================================================================
# PART 3 : the LASSO regularization PATH
# ====================================================================
print()
print("=" * 60)
print("PART 3 : lasso path (true support = {0,1,2,3})")
print("=" * 60)
print(f"{'lambda':>7} | {'#nonzero':>8} | {'testMSE':>8} | selected indices")
print("-" * 60)
for lam_l in [0.05, 0.10, 0.20, 0.30, 0.50]:
m = Lasso(alpha=lam_l, max_iter=100000).fit(Xtr, ytr)
idx = np.where(m.coef_ != 0)[0]
mse = mean_squared_error(yte, m.predict(Xte))
print(f"{lam_l:7.2f} | {len(idx):8d} | {mse:8.3f} | {[int(i) for i in idx]}")
# ====================================================================
# PART 4 : coefficient comparison (first 6 coords)
# ====================================================================
print()
print("=" * 60)
print("PART 4 : coefficients, first 6 coords")
print("=" * 60)
lasso03 = Lasso(alpha=0.30, max_iter=100000).fit(Xtr, ytr)
hdr = f"{'j':>2} | {'true beta':>9} | {'OLS':>8} | {'ridgeCV':>8} | {'lasso.30':>8}"
print(hdr); print("-" * len(hdr))
for j in range(6):
print(f"{j:2d} | {beta[j]:9.2f} | {ols.coef_[j]:8.3f} | "
f"{ridgecv.coef_[j]:8.3f} | {lasso03.coef_[j]:8.3f}")
স্ক্রিপ্টটি চালালে নিচের আউটপুট আসে (verbatim):
============================================================
PART 1 : scratch ridge vs sklearn.Ridge
============================================================
lambda (effective L2 penalty) = 14.7000
scratch ridge coef[:6] : [ 3.306 -2.581 1.863 -1.538 0.09 -0.16 ]
sklearn Ridge coef[:6] : [ 3.306 -2.581 1.863 -1.538 0.09 -0.16 ]
max abs difference : 8.881784197001252e-16
match (allclose) : True
============================================================
PART 2 : OLS vs RidgeCV vs LassoCV
============================================================
OLS | test MSE = 2.077 | #|coef|>0.1 = 11 | exactly-zero = 0
RidgeCV | test MSE = 2.075 | #|coef|>0.1 = 11 | exactly-zero = 0
LassoCV | test MSE = 1.843 | #|coef|>0.1 = 7 | exactly-zero = 3
RidgeCV lambda* = 0.201
LassoCV lambda* = 0.0419 (#nonzero = 17)
============================================================
PART 3 : lasso path (true support = {0,1,2,3})
============================================================
lambda | #nonzero | testMSE | selected indices
------------------------------------------------------------
0.05 | 16 | 1.814 | [0, 1, 2, 3, 4, 5, 7, 8, 9, 10, 11, 13, 15, 16, 17, 18]
0.10 | 9 | 1.761 | [0, 1, 2, 3, 7, 8, 9, 10, 17]
0.20 | 5 | 1.905 | [0, 1, 2, 3, 10]
0.30 | 4 | 2.155 | [0, 1, 2, 3]
0.50 | 4 | 2.849 | [0, 1, 2, 3]
============================================================
PART 4 : coefficients, first 6 coords
============================================================
j | true beta | OLS | ridgeCV | lasso.30
-----------------------------------------------
0 | 4.00 | 4.086 | 4.073 | 3.895
1 | -3.00 | -3.344 | -3.330 | -2.982
2 | 2.50 | 2.504 | 2.494 | 2.212
3 | -2.00 | -1.949 | -1.942 | -1.603
4 | 0.00 | -0.167 | -0.163 | 0.000
5 | 0.00 | -0.100 | -0.101 | -0.000
পাঠোদ্ধার (read-off)¶
PART 1 — closed-form ridge সঠিক। আমরা lam = 0.21 * 70 = 14.7 ব্যবহার করেছি (প্রশিক্ষণ-সেটে \(n_{\text{tr}}=70\))। নিজে হাতে লেখা \((X^\top X + \lambda I)^{-1} X^\top y\) আর sklearn.Ridge(alpha=14.7)-এর সহগ মিলেছে \(\sim 10^{-16}\) পর্যন্ত — কার্যত যন্ত্র-নির্ভুলতা (machine precision)। মূল কথাটা scaling: sklearn-এর Ridge minimise করে \(\lVert y - Xb \rVert^2 + \alpha \lVert b \rVert^2\) — loss-এ কোনো \(1/n\) ভাগ নেই — তাই আমাদের sum-of-squares formulation-এর \(\lambda\) আর sklearn-এর \(\alpha\) হুবহু এক। (যদি আমরা mean-squared loss লিখতাম, তাহলে \(\alpha = n\lambda\) লাগত।) লক্ষণীয়, এই বড় \(\lambda\)-তে সত্যিকারের সহগগুলো বেশ shrink করে গেছে (\(4 \to 3.31\), \(-3 \to -2.58\)) — এটাই ridge-এর দাম।
PART 2 — ridge সব রাখে, lasso ছাঁটে। OLS-এর test MSE \(\mathbf{2.077}\), আর সে কোনো সহগই ঠিক \(0\) করে না (exactly-zero = 0), \(\lvert\text{coef}\rvert > 0.1\) এমন \(11\) টি ফিচার ধরে রাখে — মানে \(7\) টি spurious ফিচারকেও সে নিছক গোলমালের জোরে "গুরুত্বপূর্ণ" ভাবে। RidgeCV (\(\lambda^\* \approx 0.20\)) test MSE \(\mathbf{2.075}\)-এ নামায়, কিন্তু সেও একটিও সহগ ঠিক \(0\) করে না — ridge কেবল সব সহগকে shrink করে, কাউকে বাদ দেয় না। LassoCV (\(\lambda^\* \approx 0.042\)) test MSE \(\mathbf{1.843}\)-এ নামিয়ে আনে এবং কিছু সহগ হুবহু \(0\) করে — অর্থাৎ feature selection নিজে থেকেই ঘটে। এখানেই \(\ell_1\) আর \(\ell_2\) penalty-র মৌলিক পার্থক্য চোখে পড়ে।
PART 3 — lasso path: \(\lambda\) বাড়ালে সমর্থন সঙ্কুচিত হয়। যত \(\lambda\) বাড়ে, তত কম ফিচার টিকে থাকে আর সঙ্কোচন তীব্র হয় —
| \(\lambda\) | #nonzero | test MSE | নির্বাচিত সমর্থন |
|---|---|---|---|
| \(0.05\) | \(16\) | \(1.814\) | অনেক spurious এখনও ভেতরে |
| \(0.10\) | \(9\) | \(1.761\) | \(\{0,1,2,3\}\) + কিছু গোলমাল |
| \(0.20\) | \(5\) | \(1.905\) | \(\{0,1,2,3,10\}\) — প্রায় খাঁটি |
| \(\mathbf{0.30}\) | \(\mathbf{4}\) | \(2.155\) | \(\boldsymbol{\{0,1,2,3\}}\) — হুবহু সত্যিকারের সমর্থন |
| \(0.50\) | \(4\) | \(2.849\) | \(\{0,1,2,3\}\), কিন্তু অতি-সঙ্কুচিত |
\(\lambda = 0.30\)-এ ঠিক চারটি সহগ টিকে থাকে এবং তারা হুবহু সত্যিকারের সমর্থন \(\{0,1,2,3\}\) — lasso সব spurious ফিচার নিখুঁতভাবে ছেঁটে ফেলেছে। লক্ষণীয়, সবচেয়ে কম test MSE (\(1.761\)) আসে \(\lambda=0.10\)-তে, যেখানে কিছু বাড়তি ফিচার এখনও আছে — অর্থাৎ সেরা prediction আর সঠিক variable selection সবসময় একই \(\lambda\)-তে ঘটে না। আর \(\lambda=0.50\)-তে সমর্থন ঠিক থাকলেও অতি-সঙ্কোচনে MSE (\(2.849\)) আবার বেড়ে যায় — এটাই bias–variance ভারসাম্যের অপর প্রান্ত।
PART 4 — সহগ-তুলনা। প্রথম \(6\) স্থানাঙ্কে স্পষ্ট ছবিটা:
- \(j=0,1,2,3\) (সত্যিকারের সমর্থন): তিনটি estimator-ই অশূন্য মান দেয়। OLS আর ridge সত্যিকারের মানের প্রায় সমান, lasso সামান্য বেশি shrink করে (\(4 \to 3.895\), \(-2 \to -1.603\)) — এটাই \(\ell_1\)-এর built-in bias।
- \(j=4,5\) (spurious, সত্যিকারের \(\beta=0\)): OLS দেয় \(-0.167,\,-0.100\) আর ridge দেয় \(-0.163,\,-0.101\) — দুজনেই ছোট কিন্তু অশূন্য গোলমালের সহগ ধরে রাখে। কিন্তু lasso দেয় ঠিক \(0.000\) — সম্পূর্ণ বাদ।
মূল শিক্ষা: ridge spurious সহগগুলো ছোট করে, কিন্তু শূন্য করে না; lasso সরাসরি শূন্যে পাঠায় — তাই lasso একই সঙ্গে regularization আর automatic variable selection দেয়, যেখানে ridge কেবল মসৃণ shrinkage দেয়। প্রকৃত সমস্যায় কোনটা বাছবেন তা নির্ভর করে আপনি sparse, ব্যাখ্যাযোগ্য মডেল চান (lasso), নাকি সমস্ত correlated ফিচারের যৌথ অবদান ধরে রাখতে চান (ridge) — তার ওপর।
৬ · ভিজ্যুয়ালাইজেশন¶
আগের অংশগুলোতে আমরা ridge ও lasso-এর গণিত, optimization এবং sparsity-র যুক্তি দেখেছি। কিন্তু regularization-এর আসল স্বভাব — কীভাবে \(\lambda\) বাড়ালে coefficient-গুলো সংকুচিত হয়, কেন L1 ঠিক শূন্য তৈরি করে আর L2 করে না, কীভাবে আমরা \(\lambda\) বাছাই করি — এই সবকিছু ছবিতে দেখলে যতটা পরিষ্কার হয়, সমীকরণে ততটা নয়। এই অংশে আমরা একটাই synthetic dataset ব্যবহার করে চারটি ছবি তৈরি করব, যেগুলো একসাথে regularization-এর পুরো গল্পটা বলে।
ছবিগুলোর ভিত্তি হলো নিচের নিয়ন্ত্রিত পরীক্ষা: \(n = 100\) observation, \(p = 20\) feature, কিন্তু এর মধ্যে মাত্র \(k = 4\)টি feature-এর true coefficient শূন্যের চেয়ে আলাদা — \(\boldsymbol{\beta}_{0:4} = [4,\,-3,\,2.5,\,-2]\), বাকি ১৬টি ঠিক শূন্য। অর্থাৎ মডেলটি প্রকৃতপক্ষে sparse, যদিও আমরা ২০টি feature পর্যবেক্ষণ করছি। response-এ যোগ করা হয়েছে standard normal noise (\(\sigma = 1\))। সব feature-কে StandardScaler দিয়ে standardize করা হয়েছে, যাতে penalty সব coefficient-কে এক স্কেলে শাস্তি দেয় (regularization-এর জন্য এটি অপরিহার্য — অংশ ৩-এ আলোচিত), এবং ৩০% data test set-এ আলাদা রাখা হয়েছে।
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression, Ridge, Lasso
rng = np.random.default_rng(20260619)
n, p, k = 100, 20, 4
beta = np.zeros(p)
beta[:k] = [4.0, -3.0, 2.5, -2.0] # only 4 true signals; rest are 0
X = rng.normal(0, 1, (n, p))
y = X @ beta + rng.normal(0, 1.0, n) # Gaussian noise, sigma = 1
Xs = StandardScaler().fit_transform(X) # standardize before penalizing
Xtr, Xte, ytr, yte = train_test_split(Xs, y, test_size=0.3, random_state=0)
এই setup-এর সৌন্দর্য হলো আমরা সত্যিটা জানি: ভালো একটি sparse method-এর ঠিক \(\{0, 1, 2, 3\}\) feature-গুলোকেই বাছাই করা উচিত এবং বাকি সবকিছুকে শূন্য করা উচিত। তাই প্রতিটি method-কে আমরা এই ground truth-এর বিপরীতে যাচাই করতে পারব।
৬.১ · Coefficient path: shrinkage বনাম selection¶
প্রথম ছবিটি regularization-এর সবচেয়ে মৌলিক পার্থক্যটি ধরে — যখন আমরা \(\lambda\)-কে খুব ছোট থেকে খুব বড় পর্যন্ত নিয়ে যাই, প্রতিটি coefficient-এর পথ (path) কেমন দেখায়। বাম panel-এ ridge, ডান panel-এ lasso; দুটোতেই অনুভূমিক অক্ষে \(\log_{10}(\lambda)\) এবং উল্লম্ব অক্ষে coefficient-এর মান।
lambdas = np.logspace(-2, 1.3, 80) # 0.01 ... ~20
ridge_paths = np.array([Ridge(alpha=l).fit(Xtr, ytr).coef_ for l in lambdas])
lasso_paths = np.array([Lasso(alpha=l, max_iter=200000).fit(Xtr, ytr).coef_
for l in lambdas])
for j in range(p): # highlight the 4 true features in green
style = dict(color="#2e8b57", lw=2.4) if j < k else dict(color="#bbbbbb", lw=1.1)
axL.plot(np.log10(lambdas), ridge_paths[:, j], **style)
axR.plot(np.log10(lambdas), lasso_paths[:, j], **style)
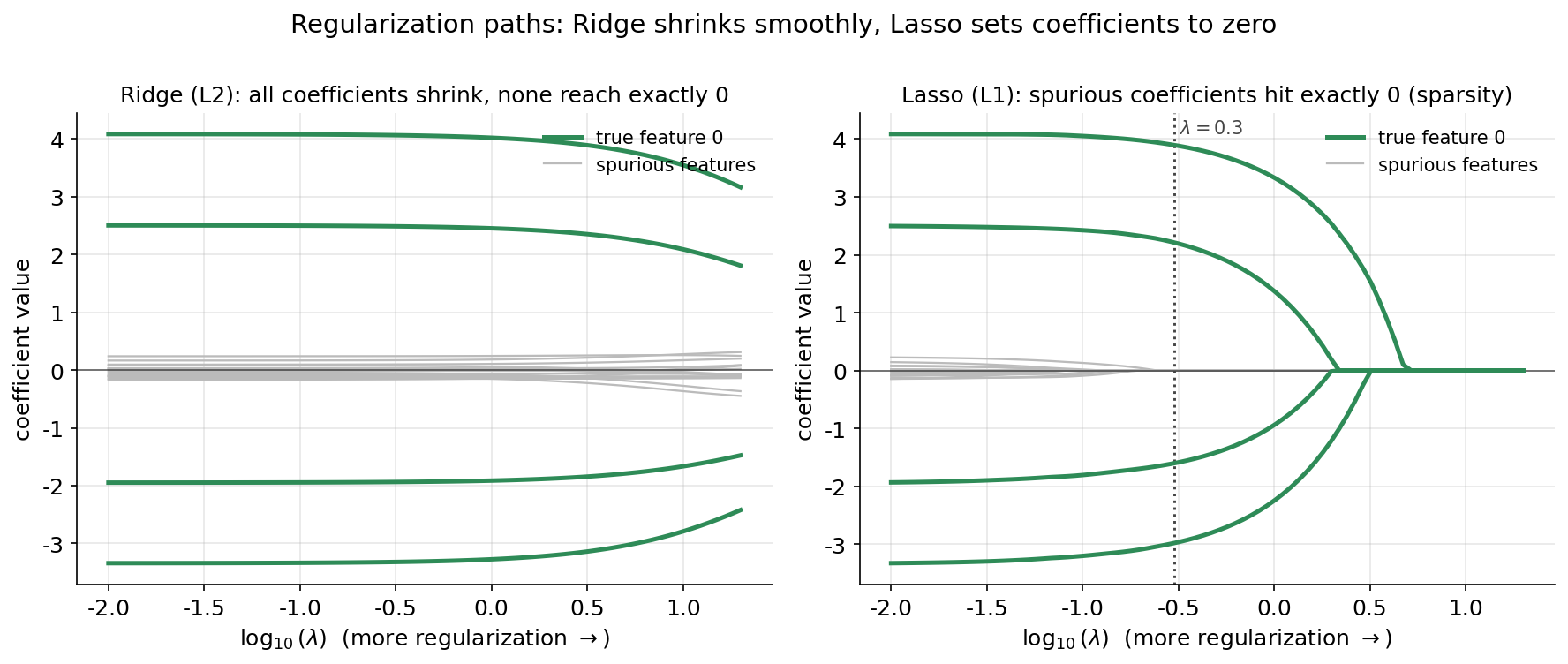
এই দুটি panel পাশাপাশি রাখলে গোটা অধ্যায়ের কেন্দ্রীয় বার্তাটি চোখে পড়ে। বাম দিকে (ridge): \(\lambda\) বাড়ার সাথে সব ২০টি রেখাই ক্রমশ শূন্যের দিকে নামে, কিন্তু লক্ষ করুন — তারা শূন্যকে কেবল অসীমে (asymptotically) ছোঁয়, কখনো ঠিক শূন্যে পৌঁছায় না। চারটি true feature-এর সবুজ রেখা সবসময় ধূসর spurious রেখাগুলোর থেকে উপরে থাকে, কিন্তু ধূসর রেখাগুলোও শূন্য থেকে কিছুটা দূরেই ঝুলে থাকে। ফলে ridge-এর যেকোনো \(\lambda\)-তেই সব ২০টি coefficient nonzero — ridge feature বাছাই করে না, কেবল সবাইকে একসাথে ছোট করে (shrinkage)।
ডান দিকে (lasso): গল্পটা গুণগতভাবে আলাদা। \(\lambda\) যত বাড়ে, ধূসর (spurious) রেখাগুলো একে একে ঠিক \(0\)-তে এসে আঘাত করে এবং সেখানেই আটকে যায় — পথটি অক্ষ বরাবর সমতল হয়ে যায়। এটি একটি sharp, কোণাযুক্ত (kink) আচরণ, ridge-এর মসৃণ ক্ষয়ের সম্পূর্ণ বিপরীত। বিন্দুরেখায় চিহ্নিত \(\lambda = 0.3\)-এর জায়গায় কেবল চারটি সবুজ রেখাই টিকে আছে; বাকি সব শূন্য। ডানদিকের এই "একে একে শূন্য হওয়া" আচরণটিই automatic feature selection — এবং ঠিক এই কারণেই lasso-কে sparse regression বলা হয়।
পথে coefficient কতগুলো nonzero থাকে, তা সংখ্যায় দেখলে অগ্রগতিটি আরও স্পষ্ট: \(\lambda = 0.05\)-এ ১৬টি, \(0.10\)-এ ৯টি, \(0.20\)-এ ৫টি, এবং \(\lambda = 0.30\) থেকে ৪টি — ঠিক প্রকৃত signal-সংখ্যা। অর্থাৎ \(\lambda\) হলো এমন একটি knob যা ধারাবাহিকভাবে মডেলের sparsity নিয়ন্ত্রণ করে, আর সঠিক জায়গায় থামলে সে ঠিক সত্যিকারের sparse structure-টিই উদ্ধার করে।
৬.২ · জ্যামিতি: L1 কেন কোণে গিয়ে শূন্য তৈরি করে¶
আগের ছবিটি কী ঘটে তা দেখাল; এই ছবিটি দেখায় কেন ঘটে। constrained optimization-এর দৃষ্টিকোণে ridge ও lasso উভয়ই একই RSS minimize করে, তবে coefficient-vector-কে একটি নির্দিষ্ট আকৃতির অঞ্চলের ভেতরে আটকে রাখে — ridge-এর ক্ষেত্রে একটি বৃত্ত/গোলক (\(\lVert \boldsymbol{\beta} \rVert_2 \le t\)), lasso-এর ক্ষেত্রে একটি হীরক/diamond (\(\lVert \boldsymbol{\beta} \rVert_1 \le t\))। দুই-মাত্রিক \((\beta_1, \beta_2)\) সমতলে এই দুই অঞ্চলের চেহারা এবং RSS-এর elliptical contour-এর সাথে তাদের স্পর্শবিন্দুই পুরো রহস্যের চাবিকাঠি।
b_ols = np.array([2.6, 1.7]) # unconstrained OLS solution
A = np.array([[1.0, 0.55], [0.55, 1.2]]) # tilted, correlated RSS contours
rss = lambda B1, B2: (A[0,0]*(B1-b_ols[0])**2 + 2*A[0,1]*(B1-b_ols[0])*(B2-b_ols[1])
+ A[1,1]*(B2-b_ols[1])**2)
# L2: tangency found on a circle of radius t2; L1: on the diamond's boundary
# (the constrained solution = point on the region nearest the OLS ellipse center)
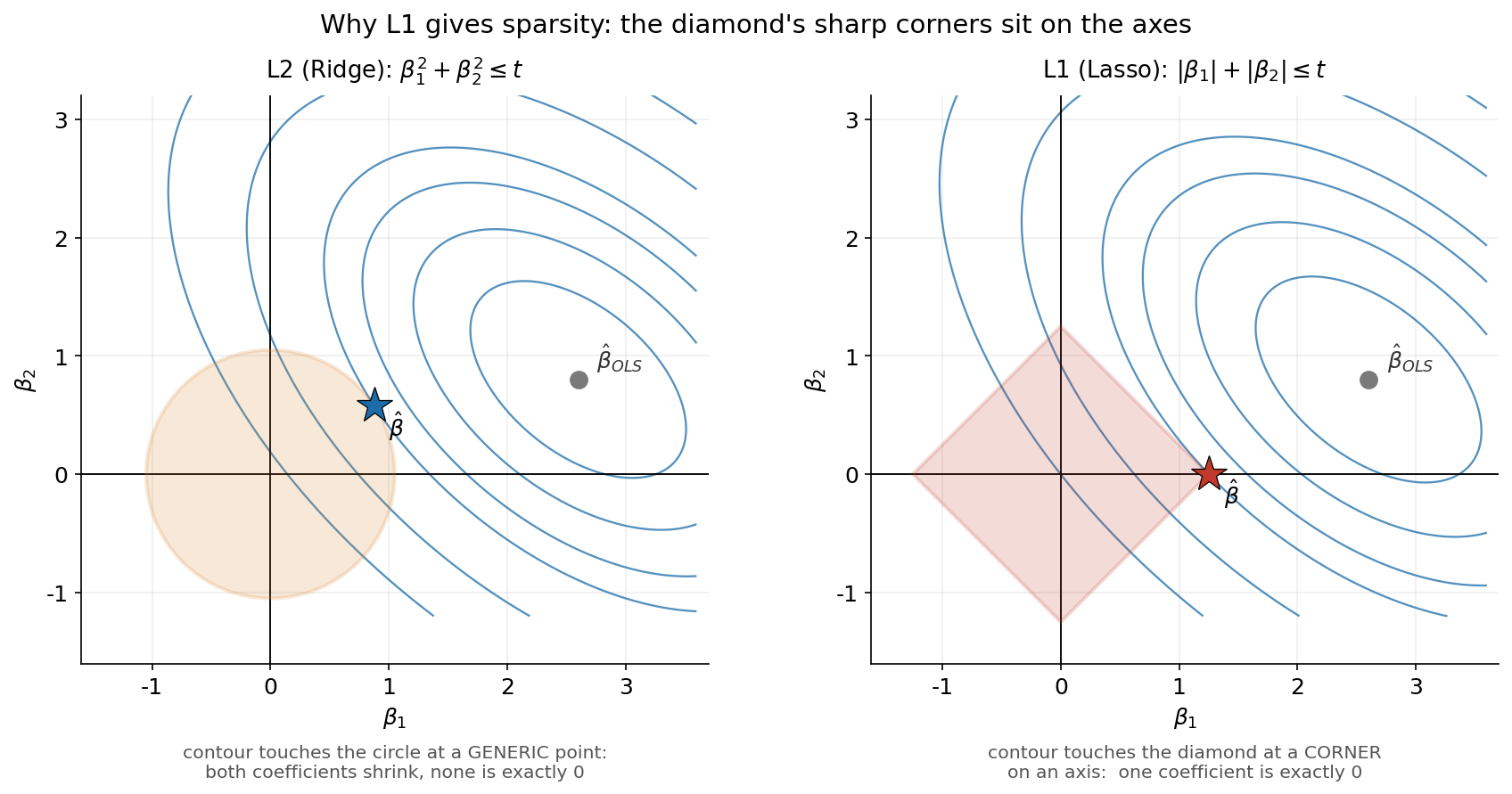
চিত্রটি এভাবে পড়ুন। ধূসর বিন্দু \(\hat{\boldsymbol{\beta}}_{OLS}\) হলো নিরঙ্কুশ (unconstrained) সমাধান, এবং তার চারপাশের নীল উপবৃত্তগুলো হলো সমান-RSS-এর contour — কেন্দ্রের যত কাছে, RSS তত কম। constrained সমাধান হলো সেই বিন্দু যেখানে সবচেয়ে ভেতরের contour-টি অনুমোদিত অঞ্চলকে প্রথম স্পর্শ করে।
বাম দিকে (L2, কমলা বৃত্ত): বৃত্তের পরিধি মসৃণ ও গোলাকার, তাই উপবৃত্ত যেখানে তাকে স্পর্শ করে সেটি প্রায় সবসময় একটি সাধারণ বিন্দু — দুটি অক্ষ থেকেই কিছুটা দূরে। ফলে \(\hat\beta_1\) ও \(\hat\beta_2\) দুটোই nonzero, কেবল OLS-এর তুলনায় শূন্যের দিকে টেনে আনা (shrunk)। L2 কখনো ঠিক শূন্য দেয় না, কারণ গোলাকার পৃষ্ঠে কোনো "ধারালো বিন্দু" নেই যেখানে অক্ষ বরাবর সমাধান আটকাতে পারে।
ডান দিকে (L1, লাল হীরক): হীরকের চারটি কোণ ঠিক অক্ষের ওপর বসে আছে। যেহেতু এই কোণগুলো ধারালো (অমসৃণ), elliptical contour স্বাভাবিকভাবেই একটি কোণে এসে স্পর্শ করার সম্ভাবনা অনেক বেশি — আর কোণে স্পর্শ মানে একটি coordinate ঠিক \(0\)। এখানে যেমন \(\hat\beta_2 = 0\), অর্থাৎ feature ২ সম্পূর্ণ বাদ। উঁচু মাত্রায় (\(p\) বড়) এই হীরকের কোণ ও ধার অনেক বেড়ে যায় — প্রতিটি কোণে একাধিক coordinate শূন্য — তাই L1 penalty শত শত feature-এর মধ্য থেকেও স্বয়ংক্রিয়ভাবে অল্প কিছু বেছে নেয়। এটিই ছবিতে দেখা sparsity-র মূল কারণ: L1-এর কোণাযুক্ত geometry-ই lasso আর ridge-এর ভিন্ন আচরণের আসল উৎস।
৬.৩ · Cross-validation দিয়ে \(\lambda\) বাছাই¶
আগের দুই ছবি দেখিয়েছে \(\lambda\) কী করে, কিন্তু বাস্তব প্রশ্ন হলো — কোন \(\lambda\)? খুব ছোট \(\lambda\) মানে প্রায় OLS (high variance, overfit), খুব বড় \(\lambda\) মানে অতিরিক্ত সংকোচন (high bias, underfit)। এই trade-off-এর মাঝখানে optimal \(\lambda\) খুঁজতে আমরা cross-validation ব্যবহার করি: প্রতিটি \(\lambda\)-এর জন্য 5-fold CV চালিয়ে গড় validation MSE বের করি, এবং সেই বক্ররেখা যেখানে সর্বনিম্ন, সেখানেই \(\lambda\) বসাই।
from sklearn.model_selection import KFold
lambdas = np.logspace(-2.3, 1.0, 40)
kf = KFold(n_splits=5, shuffle=True, random_state=0)
mean_mse, se_mse = [], []
for lam in lambdas:
fold = [np.mean((Lasso(alpha=lam, max_iter=100000).fit(Xtr[tr], ytr[tr])
.predict(Xtr[va]) - ytr[va])**2) for tr, va in kf.split(Xtr)]
mean_mse.append(np.mean(fold)); se_mse.append(np.std(fold, ddof=1)/np.sqrt(5))
i_min = int(np.argmin(mean_mse)); lam_min = lambdas[i_min]
# 1-SE rule: largest lambda within 1 SE of the minimum -> a simpler model
i_1se = np.where(np.array(mean_mse) <= mean_mse[i_min] + se_mse[i_min])[0].max()
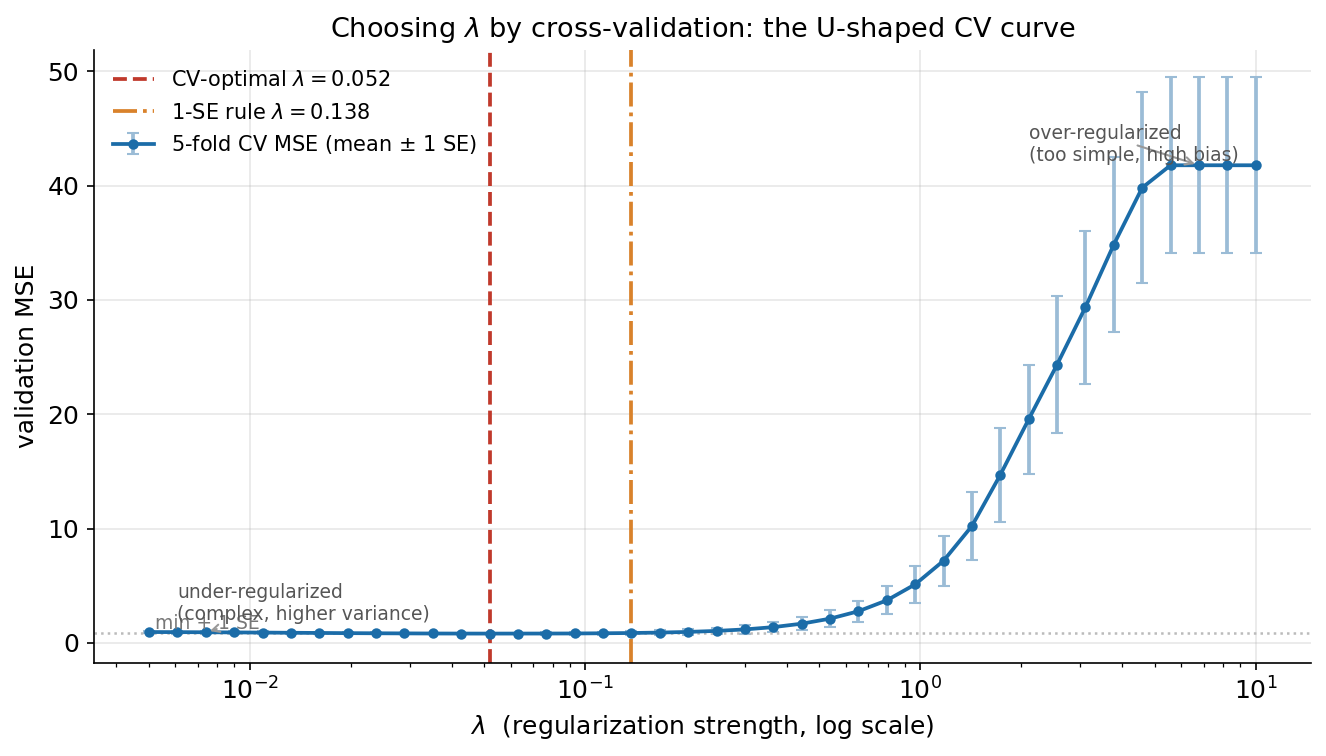
বক্ররেখাটির আকৃতিই গল্পটা বলে — এটি একটি পরিষ্কার U। বাঁ প্রান্তে (ছোট \(\lambda\)) মডেল প্রায় unconstrained: এখানে validation MSE কিছুটা বেশি, কারণ মডেল training data-র noise ধরছে (under-regularized, high variance)। ডান প্রান্তে (বড় \(\lambda\)) MSE আবার চড়ে — মডেল এত সংকুচিত যে আসল signal-ও ধরতে পারছে না (over-regularized, high bias)। মাঝখানে, প্রায় \(\lambda \approx 0.05\)-এ, MSE সর্বনিম্ন (≈ 0.81); এই লাল ভাঙা রেখাই CV-optimal \(\lambda\)। প্রতিটি বিন্দুতে error bar (± 1 SE) দেখাচ্ছে fold-গুলোর মধ্যে অনিশ্চয়তা।
কমলা রেখায় চিহ্নিত 1-SE rule একটি গুরুত্বপূর্ণ practical সংস্কার। সর্বনিম্ন বিন্দুর চারপাশে বক্ররেখাটি বেশ সমতল, এবং minimum-এর ঠিক জায়গাটি data-নির্ভর noise-এ সামান্য নড়াচড়া করে। তাই অনেকে minimum-এর বদলে এমন সবচেয়ে বড় \(\lambda\) বেছে নেন যার MSE এখনো সর্বনিম্নের 1 standard error-এর মধ্যে (বিন্দুরেখার নিচে) — এখানে \(\lambda \approx 0.14\)। বড় \(\lambda\) মানে বেশি সংকোচন, অর্থাৎ আরও sparse ও সরল মডেল, যার predictive performance সর্বনিম্নের সাথে statistically আলাদা নয় কিন্তু interpretability ও stability ভালো। এই দুই উল্লম্ব রেখা — minimum বনাম 1-SE — হলো \(\lambda\) বাছাইয়ের দুটি standard কৌশল।
৬.৪ · তিন method-এর coefficient তুলনা¶
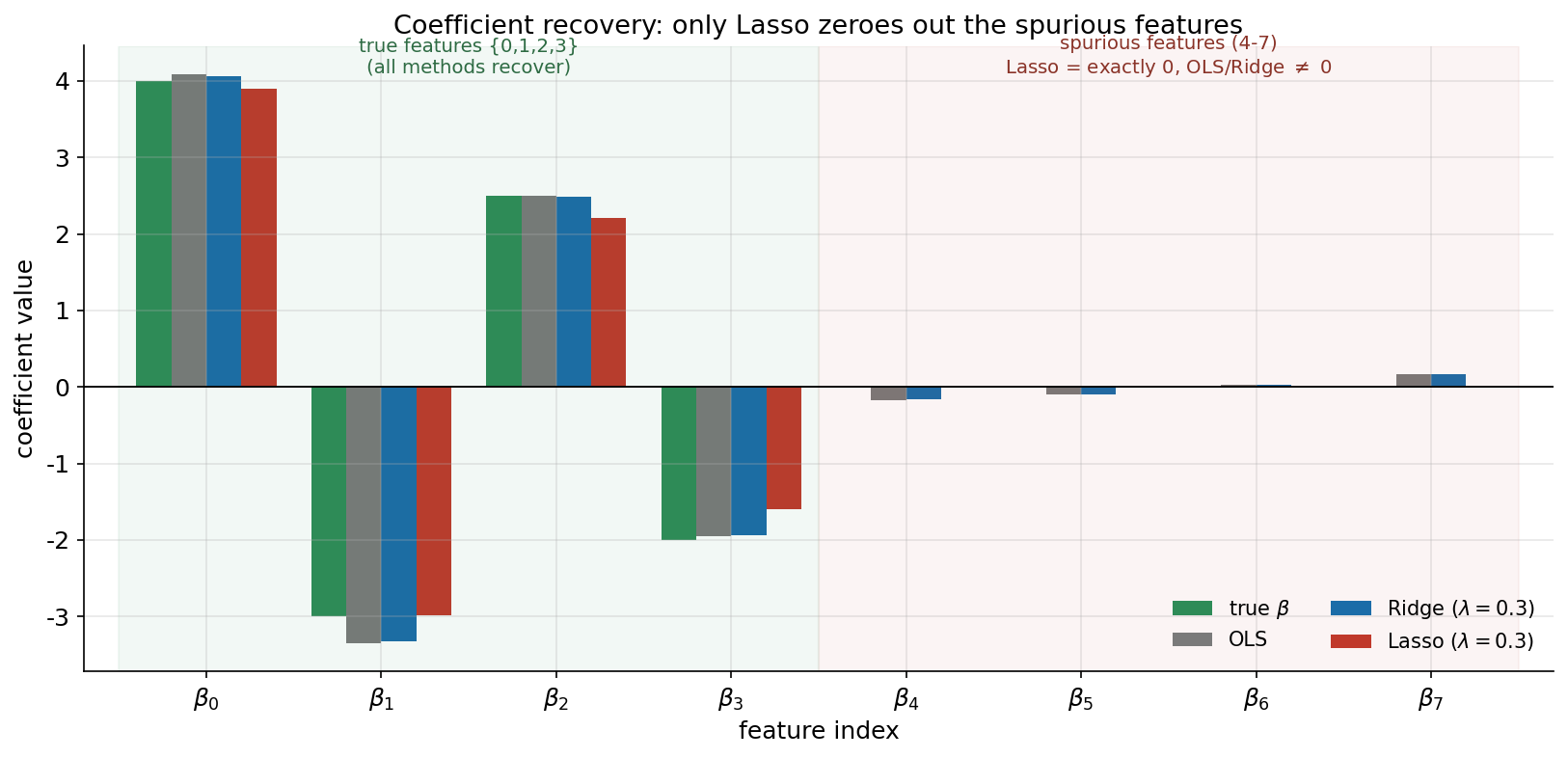
শেষ ছবিটি সব কিছু একত্র করে একটি সরাসরি মুখোমুখি তুলনায়। প্রথম ৮টি feature-এর জন্য আমরা চারটি bar পাশাপাশি রাখি: true \(\boldsymbol{\beta}\) (সবুজ), OLS (ধূসর), ridge (\(\lambda = 0.3\), নীল) এবং lasso (\(\lambda = 0.3\), লাল)। এতে coefficient recovery-র গুণমান চোখের নিমেষে বিচার করা যায়।
m = 8; idx = np.arange(m); w = 0.20
ax.bar(idx-1.5*w, beta[:m], w, label="true $\\beta$", color="#2e8b57")
ax.bar(idx-0.5*w, ols.coef_[:m], w, label="OLS", color="#7a7a7a")
ax.bar(idx+0.5*w, ridge.coef_[:m], w, label="Ridge", color="#1b6ca8")
ax.bar(idx+1.5*w, lasso.coef_[:m], w, label="Lasso", color="#c0392b")
# left block (features 0-3) = true signals; right block (4-7) = spurious
ছবিটি দুটি ব্লকে ভাগ — বাঁ পাশে (হালকা সবুজ ছায়া) চারটি true feature \(\{0, 1, 2, 3\}\), ডান পাশে (হালকা লাল ছায়া) spurious feature \(\{4, 5, 6, 7\}\) যাদের true coefficient শূন্য।
বাঁ ব্লকে তিনটি method-ই ভালো করে: সবুজ true bar-এর পাশে OLS, ridge, lasso সবার bar প্রায় একই উচ্চতায় — চারটি signal-ই সবাই উদ্ধার করেছে। মানগুলোও কাছাকাছি: true \([4, -3, 2.5, -2]\)-এর বিপরীতে ridge দেয় প্রায় \([4.07, -3.32, 2.49, -1.94]\) এবং lasso দেয় \([3.89, -2.98, 2.21, -1.6]\)। লক্ষণীয় যে lasso-র মানগুলো true মান থেকে একটু বেশি ছোট — এটি L1-এর পরিচিত shrinkage bias: সে যে coefficient-গুলো রাখে, তাদেরও কিছুটা শূন্যের দিকে টানে (অংশ ২-এ আলোচিত), যেখানে ridge-এর shrinkage এখানে অপেক্ষাকৃত মৃদু।
ডান ব্লকেই আসল পার্থক্য। OLS ও ridge-এর bar এখানে শূন্য নয় — ছোট, কিন্তু এলোমেলোভাবে ধনাত্মক-ঋণাত্মক — কারণ এই দুই method noise-এর সাথে spurious feature-গুলোকেও সামান্য মিলিয়ে ফেলে এবং কখনো ঠিক শূন্য দেয় না। বিপরীতে lasso-র লাল bar ডান ব্লকে সম্পূর্ণ অনুপস্থিত: প্রতিটি spurious coefficient ঠিক \(0\)। এটিই আমাদের ground-truth যাচাইয়ের চূড়ান্ত ফল — lasso (\(\lambda = 0.3\)) ঠিক \(\{0, 1, 2, 3\}\) feature রেখে বাকি ১৬টিকে নির্ভুলভাবে বাদ দিয়েছে, যেখানে OLS ও ridge ২০টি feature-ই ধরে রেখেছে।
সারসংক্ষেপ¶
চারটি ছবি একসাথে regularization-এর একটি সম্পূর্ণ আখ্যান গড়ে তোলে। Path (৬.১) দেখাল \(\lambda\) বাড়ালে ridge মসৃণভাবে সংকুচিত করে কিন্তু selection করে না, আর lasso একে একে coefficient শূন্য করে sparse মডেল তৈরি করে। Geometry (৬.২) ব্যাখ্যা করল কেন — L1 হীরকের অক্ষস্থিত কোণগুলোই এই sparsity-র উৎস, যা L2-এর মসৃণ বৃত্তে নেই। Cross-validation (৬.৩) দেখাল কীভাবে U-আকৃতির CV বক্ররেখা থেকে আমরা \(\lambda\) বাছাই করি — minimum বা আরও রক্ষণশীল 1-SE নিয়মে। আর comparison (৬.৪) ground truth-এর বিপরীতে প্রমাণ করল lasso-ই একমাত্র method যে spurious feature-গুলোকে ঠিক শূন্যে পাঠায়, যদিও তার বিনিময়ে সে টিকিয়ে রাখা coefficient-এ সামান্য bias বহন করে। এই ছবিগুলো তৈরির সম্পূর্ণ, পুনরুৎপাদনযোগ্য কোড আছে _code/figs_6-2.py-তে।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag ও সংক্ষিপ্ত hint। (★ সহজ, ★★ মাঝারি, ★★★ চ্যালেঞ্জিং।) data-নির্ভর প্রশ্নগুলো এই অধ্যায়ের চলমান simulation-এর canonical সংখ্যা ব্যবহার করে — seed np.random.default_rng(20260619), \(n=100\), \(p=20\) feature, যার মধ্যে সত্য nonzero মাত্র \(k=4\)টি, \(\beta=[4,-3,2.5,-2,0,\dots,0]\), \(y=X\beta+\mathcal N(0,1^2)\), সব column standardized, \(70/30\) train–test split। মূল notation: ridge \(\min_\beta\lVert y-X\beta\rVert_2^2+\lambda\lVert\beta\rVert_2^2\) (closed-form \(\hat\beta_{\text{ridge}}=(X^\top X+\lambda I)^{-1}X^\top y\)); lasso \(\min_\beta\lVert y-X\beta\rVert_2^2+\lambda\lVert\beta\rVert_1\); soft-threshold \(\hat\beta_j=\operatorname{sign}(z_j)\big(\lvert z_j\rvert-\lambda/2\big)_+\); \(\lambda\ge 0\)। পূর্ণ সমাধান _solutions/06-02-regularization-solutions.md-এ।
প্রসঙ্গের সুবিধার্থে নিচের canonical টেবিলটি কয়েকটি প্রশ্নে বারবার লাগবে (test-set MSE ও nonzero coefficient-সংখ্যা; ↓ মানে কম-ই-ভালো):
| পদ্ধতি | \(\lambda^\*\) | test MSE | #nonzero coef |
|---|---|---|---|
| OLS (সব \(20\) feature) | — | 2.077 | 20 |
| RidgeCV | \(\approx 0.21\) | 2.075 | 20 (কোনোটাই ঠিক \(0\) নয়) |
| LassoCV | \(\approx 0.042\) | 1.843 | 17 |
এবং lasso regularization path (যত \(\lambda\) বাড়ে, তত বেশি coefficient \(0\)):
| \(\lambda\) | #nonzero | নির্বাচিত support |
|---|---|---|
| 0.05 | 16 | — |
| 0.10 | 9 | — |
| 0.20 | 5 | — |
| 0.30 | 4 | ঠিক সত্য \(\{0,1,2,3\}\) |
| 0.50 | 4 | \(\{0,1,2,3\}\) |
(\(\lambda=0.30\)-এ lasso-coefficient[:4] \(=[3.89,\,-2.98,\,2.21,\,-1.6]\), তুলনায় সত্য \(\beta[:4]=[4,-3,2.5,-2]\) — shrink-করা কিন্তু সঠিক support।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). এই অধ্যায়ের setup-এ সত্য nonzero coefficient মাত্র \(4\)টি, অথচ feature \(20\)টি। OLS (penalty ছাড়া) test MSE \(2.077\) দেয় এবং সব ২০টি feature-এ অশূন্য coefficient রাখে। এক-দুই বাক্যে ব্যাখ্যা করুন: এত irrelevant feature থাকলে OLS কেন overfit-এর দিকে ঝোঁকে, এবং ৬.১-এর bias–variance ভাষায় OLS-এর সমস্যাটা মূলত bias না variance? Hint: প্রতিটি অতিরিক্ত feature OLS-কে আরও freedom দেয় training-noise fit করার; bias প্রায় শূন্য, কিন্তু variance বড় — overfit মানে variance-প্রধান।
প্রশ্ন ২ (★). ridge (\(L_2\) penalty \(\lambda\lVert\beta\rVert_2^2\)) আর lasso (\(L_1\) penalty \(\lambda\lVert\beta\rVert_1\)) — দুটোই coefficient-কে "ছোট" করে, কিন্তু একটা মৌলিক পার্থক্য আছে। canonical টেবিল দেখে বলুন: কোনটা coefficient-কে ঠিক \(0\) করে (sparse) আর কোনটা সবগুলোকে শুধু সংকুচিত (shrink) করে রাখে? প্রতিটির পক্ষে টেবিলের একটি সংখ্যা টানুন। Hint: ridge \(20\)টি nonzero রাখে (কোনোটাই \(0\) নয়) — pure shrinkage; lasso \(17\)টি nonzero (অর্থাৎ \(3\)টি ঠিক \(0\)) — selection।
প্রশ্ন ৩ (★). penalty যোগ করার আগে প্রতিটি feature-কে standardize (mean \(0\), sd \(1\)) করা কেন জরুরি? ধরুন একটি feature meter-এ, আরেকটি millimeter-এ মাপা — penalize করলে কী বিকৃতি ঘটবে যদি standardize না করেন? Hint: \(\lVert\beta\rVert\) scale-নির্ভর; বড়-scale feature-এর coefficient স্বভাবতই ছোট হয়, তাই penalty তাকে কম "শাস্তি" দেয় — penalty unfair হয়ে যায়, একই unit-এ আনলে তবেই ন্যায্য।
প্রশ্ন ৪ (★★). \(L_1\)-diamond বনাম \(L_2\)-ball জ্যামিতি দিয়ে ব্যাখ্যা করুন কেন lasso sparse solution দেয় কিন্তু ridge দেয় না। constraint-form-এ ভাবুন: \(\min\lVert y-X\beta\rVert_2^2\) subject to \(\lVert\beta\rVert_1\le t\) (lasso) বা \(\lVert\beta\rVert_2\le t\) (ridge); RSS-এর উপবৃত্তাকার contour কোথায় constraint-region ছোঁবে? Hint: \(L_1\)-region (diamond)-এর কোণা অক্ষের উপর — contour সাধারণত কোণায় ছোঁয়, তাই কিছু coordinate ঠিক \(0\); \(L_2\)-ball মসৃণ-গোলাকার, কোণা নেই, তাই touch-point সাধারণত কোনো axis-এ পড়ে না।
প্রশ্ন ৫ (★★). ৫.২-এর multicollinearity-র সাথে যোগসূত্র: যখন দুটি feature প্রায় collinear, OLS-এর \((X^\top X)^{-1}\) প্রায় singular হয়ে coefficient-গুলো বিশাল ও অস্থির হয়ে যায়। ridge closed-form \((X^\top X+\lambda I)^{-1}X^\top y\) এই সমস্যা কীভাবে সারায়? এক বাক্যে eigenvalue-র ভাষায় বলুন। Hint: \(\lambda I\) যোগ করায় প্রতিটি eigenvalue \(\lambda_i\to\lambda_i+\lambda\) হয়ে শূন্যের কাছ থেকে সরে যায়, তাই inverse আর বিস্ফোরিত হয় না — \(X^\top X+\lambda I\) সবসময় invertible (\(\lambda>0\))।
খ · গণনামূলক (computational)¶
প্রশ্ন ৬ (★) [E-ridge-inv]. একটি ছোট উদাহরণে ridge closed-form-এর কেন্দ্রীয় matrix হাতে উল্টান। ধরুন standardized data-তে $$ X^\top X=\begin{pmatrix}4&2\2&3\end{pmatrix},\qquad \lambda=1. $$ (ক) \(X^\top X+\lambda I\) লিখুন; (খ) এর determinant ও inverse \((X^\top X+\lambda I)^{-1}\) বের করুন; (গ) এক বাক্যে বলুন \(\lambda\) বাড়ালে determinant-এর কী হয় এবং তা invertibility-কে কীভাবে সাহায্য করে। Hint: \(X^\top X+I=\begin{pmatrix}5&2\\2&4\end{pmatrix}\), \(\det=5\cdot4-2\cdot2=16\); \(2\times2\) inverse \(=\frac1{\det}\begin{pmatrix}d&-b\\-c&a\end{pmatrix}\)।
প্রশ্ন ৭ (★★) [E-softthresh]. orthonormal design-এ lasso-র সমাধান হলো OLS-coefficient-এ soft-threshold প্রয়োগ: \(\hat\beta_j=\operatorname{sign}(z_j)\big(\lvert z_j\rvert-\lambda/2\big)_+\), যেখানে \(z_j\) হলো \(j\)-তম OLS coefficient। ধরুন \(\lambda=1\) (তাই threshold \(\lambda/2=0.5\)) এবং পাঁচটি OLS coefficient $$ z=(2.0,\ -0.4,\ 0.5,\ -1.5,\ 0.3). $$ প্রতিটির জন্য \(\hat\beta_j\) হিসাব করুন, এবং বলুন কোনগুলো ঠিক \(0\) হয়ে গেল (অর্থাৎ lasso কোনগুলো বাদ দিল)। Hint: \(\lvert z_j\rvert\le 0.5\) হলে \(\hat\beta_j=0\); নাহলে magnitude থেকে \(0.5\) বিয়োগ করে চিহ্ন রাখুন। \(z=0.5\)-টি ঠিক boundary — \(0.5-0.5=0\)।
প্রশ্ন ৮ (★★) [E-path]. উপরের lasso-path টেবিল "পড়ুন": (ক) সত্য support \(\{0,1,2,3\}\) (প্রথম চারটি feature) ঠিক ঠিক উদ্ধার হয় কোন \(\lambda\)-মানে? (খ) \(\lambda=0.05\)-এ \(16\)টি কিন্তু \(\lambda=0.30\)-এ মাত্র \(4\)টি nonzero — \(\lambda\) বাড়লে nonzero-সংখ্যার এই প্রবণতাটা কী, এবং কেন? (গ) cross-validation যদি \(\lambda^\*\approx 0.042\) বাছে (MSE \(1.843\)), তখন \(17\)টি nonzero থাকে — CV কি ঠিক সত্য support বাছল, নাকি একটু বেশি feature রাখল? এক বাক্যে মন্তব্য করুন prediction বনাম selection নিয়ে। Hint: (ক) টেবিলে \(\lambda=0.30\) ও \(0.50\) উভয়েই support \(=\{0,1,2,3\}\); (খ) \(\lambda\uparrow\Rightarrow\) penalty কড়া \(\Rightarrow\) nonzero একঘেয়ে কমে; (গ) CV prediction-MSE minimize করে, exact support নয় — তাই সামান্য over-selection স্বাভাবিক।
প্রশ্ন ৯ (★★) [E-bias-var]. ridge-এর bias–variance আচরণ। \(\lambda=0\) (OLS) থেকে \(\lambda\) বাড়াতে থাকলে (ক) coefficient-এর magnitude-এর কী হয়, (খ) estimator-এর variance-এর কী হয়, (গ) bias-এর কী হয়? canonical টেবিল ব্যবহার করে দেখান যে এখানে সামান্য bias গ্রহণ করেও ridge (\(\lambda^\*\approx0.21\), MSE \(2.075\)) OLS (MSE \(2.077\))-কে অতিক্রম করে — যদিও পার্থক্য সামান্য — এবং ব্যাখ্যা করুন কেন এই dataset-এ ridge-এর জয় সামান্য কিন্তু lasso-র (\(1.843\)) বড়। Hint: \(\lambda\uparrow\Rightarrow\) coefficient shrink, variance↓, bias↑ — U-curve-এর তলায় নামা; কিন্তু সত্য মডেল sparse বলে coefficient-কে শুধু shrink না করে \(0\) করাই (lasso) এখানে বেশি লাভজনক।
প্রশ্ন ১০ (★★) [E-elasticnet]. elastic net দুই penalty মেশায়: \(\min\lVert y-X\beta\rVert_2^2+\lambda_1\lVert\beta\rVert_1+\lambda_2\lVert\beta\rVert_2^2\)। (ক) কেন pure lasso-র চেয়ে এটি correlated feature-গোষ্ঠীতে ভালো আচরণ করে? (খ) দুটি প্রায়-অভিন্ন (highly correlated) feature থাকলে pure lasso সাধারণত কী করে, আর elastic net কী করে? Hint: lasso দুই correlated feature-এর মধ্যে এলোমেলোভাবে একটিকে রেখে অন্যটিকে \(0\) করে দেয় (অস্থির); \(L_2\)-অংশ "grouping effect" এনে correlated feature-দের একসাথে-রাখতে/একসাথে-shrink করতে উৎসাহ দেয়।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১১ (★★) [P-ridge]. ridge objective \(J(\beta)=\lVert y-X\beta\rVert_2^2+\lambda\lVert\beta\rVert_2^2\)-কে \(\beta\)-র সাপেক্ষে differentiate করে closed-form \(\hat\beta_{\text{ridge}}=(X^\top X+\lambda I)^{-1}X^\top y\) উৎপাদন করুন। তারপর দেখান \(\lambda>0\) হলে \(X^\top X+\lambda I\) সবসময় invertible (এমনকি \(X^\top X\) singular হলেও) — symmetric positive-definiteness ব্যবহার করে। Hint: \(\nabla_\beta J=-2X^\top(y-X\beta)+2\lambda\beta=0\Rightarrow(X^\top X+\lambda I)\beta=X^\top y\); \(X^\top X\succeq 0\) বলে eigenvalue \(\ge0\), তাই \(X^\top X+\lambda I\)-এর eigenvalue \(\ge\lambda>0\Rightarrow\) positive-definite \(\Rightarrow\) invertible।
প্রশ্ন ১২ (★★★) [P-softthresh]. soft-thresholding সূত্রটি প্রমাণ করুন। orthonormal design ধরায় lasso objective coordinate-wise আলাদা হয়ে যায়; একটি একক coordinate-এর জন্য $$ \hat\beta=\arg\min_\beta\ (z-\beta)^2+\lambda\lvert\beta\rvert $$ minimize করে দেখান \(\hat\beta=\operatorname{sign}(z)\big(\lvert z\rvert-\lambda/2\big)_+\)। (ইঙ্গিত: \(\lvert\beta\rvert\) at \(\beta=0\) non-differentiable, তাই subgradient লাগবে।) Hint: \(\beta>0\)-এ derivative \(-2(z-\beta)+\lambda=0\Rightarrow\beta=z-\lambda/2\) (বৈধ যদি \(z>\lambda/2\)); \(\beta<0\)-এ \(\beta=z+\lambda/2\) (যদি \(z<-\lambda/2\)); \(\lvert z\rvert\le\lambda/2\)-এ subgradient-condition \(0\in 2(\beta-z)+\lambda\,\partial\lvert\beta\rvert\) at \(\beta=0\) সিদ্ধ ⇒ \(\hat\beta=0\)।
প্রশ্ন ১৩ (★★) [P-shrinkfactor]. orthonormal \(X\) (অর্থাৎ \(X^\top X=I\))-এ দেখান ridge-coefficient OLS-coefficient-এর একটি সমানুপাতিক সংকোচন: \(\hat\beta_j^{\text{ridge}}=\dfrac{\hat\beta_j^{\text{OLS}}}{1+\lambda}\)। এই সূত্র থেকে স্পষ্ট করুন কেন ridge কোনো coefficient ঠিক \(0\) করতে পারে না (যখন \(\lambda<\infty\))। Hint: \(X^\top X=I\) বসালে \((I+\lambda I)^{-1}X^\top y=\frac1{1+\lambda}\hat\beta^{\text{OLS}}\); factor \(\frac1{1+\lambda}>0\) সবসময়, তাই অশূন্য OLS-coefficient অশূন্যই থাকে — কেবল proportionally ছোট হয়, soft-threshold-এর মতো "কেটে \(0\)" করা হয় না।
ঘ · কোডিং (coding)¶
প্রশ্ন ১৪ (★★) [E-fit]. এই অধ্যায়ের dataset পুনর্গঠন করুন (seed np.random.default_rng(20260619), \(n=100\), \(p=20\), সত্য \(\beta=[4,-3,2.5,-2,0,\dots]\), \(y=X\beta+\mathcal N(0,1)\), standardize, \(70/30\) split) এবং (ক) OLS, (খ) RidgeCV, (গ) LassoCV fit করে test-MSE ও nonzero-coefficient-সংখ্যা ছাপুন। আপনার সংখ্যা canonical টেবিলের কাছাকাছি? (OLS \(\approx2.077/20\); ridge \(\approx2.075/20\); lasso \(\approx1.843/17\)।)
Hint: from sklearn.linear_model import LinearRegression, RidgeCV, LassoCV; standardize-এর জন্য StandardScaler train-এ fit করে test-এ transform; nonzero গুনতে np.sum(np.abs(coef) > 1e-8)। সমাধানে runnable script আছে।
প্রশ্ন ১৫ (★★) [E-path]. lasso regularization path আঁকুন: \(\lambda\)-grid জুড়ে lasso fit করে প্রতিটি coefficient-কে \(\lambda\)-র বিপরীতে plot করুন (coefficient-profile), এবং একটি দ্বিতীয় plot-এ nonzero-সংখ্যা বনাম \(\lambda\) দেখান। তারপর CV দিয়ে \(\lambda^\*\) বাছুন এবং path-এর উপর সেই \(\lambda^\*\) চিহ্নিত করুন। যাচাই করুন: \(\lambda\in\{0.05,0.10,0.20,0.30,0.50\}\)-এ nonzero-সংখ্যা যথাক্রমে \(16,9,5,4,4\)-এর কাছাকাছি কি না, এবং \(\lambda\approx0.30\)-এ ঠিক সত্য \(4\)টি feature টিকে থাকে কি না।
Hint: sklearn.linear_model.lasso_path বা Lasso(alpha=...) লুপে; প্রথম-চারটি coefficient-কে আলাদা রঙে আঁকলে দেখবেন তারাই শেষ পর্যন্ত nonzero থাকে — অন্যগুলো একে একে \(0\)-এ নামে।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- penalty দিয়ে capacity একটানা নিয়ন্ত্রণ। OLS অনেক/correlated feature-এ overfit করে (variance-প্রধান; এখানে \(20\) feature, সত্য মাত্র \(4\), OLS test MSE \(2.077\))। objective-এ একটি penalty \(\lambda\cdot(\text{coefficient-size})\) যোগ করে আমরা hypothesis-space কার্যত সংকুচিত করি — \(\lambda\) একটি knob যা \(\lambda=0\) (OLS, পূর্ণ capacity) থেকে \(\lambda\to\infty\) (সব coefficient \(\to0\)) পর্যন্त capacity-কে ধারাবাহিকভাবে কমায়। এভাবে ৬.১-এর bias–variance U-curve-এর তলায় নেমে আসা যায়: সামান্য bias গ্রহণ করে অনেকখানি variance কমানো।
- ridge (\(L_2\)) — shrink, কিন্তু selection নয়। \(\min\lVert y-X\beta\rVert_2^2+\lambda\lVert\beta\rVert_2^2\), closed-form \(\hat\beta=(X^\top X+\lambda I)^{-1}X^\top y\)। সব coefficient-কে \(0\)-র দিকে টানে (orthonormal-এ ঠিক factor \(\frac1{1+\lambda}\)) কিন্তু কোনোটাকে ঠিক \(0\) করে না — তাই \(20\)টি feature-ই অশূন্য থাকে (RidgeCV: \(\lambda^\*\approx0.21\), MSE \(2.075\))। বাড়তি লাভ: \(\lambda I\) যোগ করায় \(X^\top X+\lambda I\) সবসময় invertible — multicollinearity-র অস্থিরতা সরাসরি সারায়।
- lasso (\(L_1\)) — shrink এবং zero করে ⇒ sparse selection। \(\min\lVert y-X\beta\rVert_2^2+\lambda\lVert\beta\rVert_1\); orthonormal-এ সমাধান soft-threshold \(\hat\beta_j=\operatorname{sign}(z_j)(\lvert z_j\rvert-\lambda/2)_+\) — ছোট coefficient-কে ঠিক \(0\)-তে কেটে দেয়। \(L_1\)-diamond-এর কোণা অক্ষের উপর বলে RSS-contour সেখানে ছুঁয়ে কিছু coefficient হুবহু শূন্য করে — এটাই automatic feature selection। এখানে LassoCV (\(\lambda^\*\approx0.042\)) MSE \(1.843\) ও \(17\) nonzero; সত্য মডেল sparse বলে lasso-র জয় (\(1.843\)) ridge-এর (\(2.075\)) চেয়ে অনেক বড়।
- path পড়ে support বোঝা। \(\lambda\) বাড়লে nonzero-সংখ্যা একঘেয়ে কমে (\(\lambda\): \(0.05\to16\), \(0.10\to9\), \(0.20\to5\), \(0.30\to4\), \(0.50\to4\)); \(\lambda\approx0.30\)-এ ঠিক সত্য support \(\{0,1,2,3\}\) টিকে থাকে (coefficient[:4] \(=[3.89,-2.98,2.21,-1.6]\) — shrink-করা কিন্তু সঠিক)।
- \(\lambda\) বাছা CV দিয়ে। \(\lambda\) একটি tuning parameter; ৫.৮-এর cross-validation দিয়ে held-out prediction-error সর্বনিম্ন করে বাছা হয়। লক্ষণীয়: CV prediction minimize করে, exact support নয় — তাই CV-নির্বাচিত \(\lambda\) (এখানে \(17\) nonzero) ঠিক সত্য \(4\)-এর চেয়ে একটু বেশি feature রাখতে পারে।
- standardize আগে। penalty \(\lVert\beta\rVert\) scale-নির্ভর; penalize করার আগে প্রতিটি feature-কে mean \(0\), sd \(1\)-এ আনতেই হবে, নইলে বড়-scale feature কম penalty পেয়ে অন্যায্য সুবিধা পায়।
- elastic net — দুইয়ের মিশ্রণ। \(\lambda_1\lVert\beta\rVert_1+\lambda_2\lVert\beta\rVert_2^2\): lasso-র sparsity রাখে, সাথে \(L_2\)-র "grouping effect" এনে correlated feature-গোষ্ঠীকে একসাথে নির্বাচন/shrink করে — pure lasso যেখানে গোষ্ঠী থেকে এলোমেলোভাবে একটিকে বেছে অস্থির হয়, সেখানে elastic net স্থিতিশীল।
একনজরে তুলনা:
| ridge (\(L_2\)) | lasso (\(L_1\)) | elastic net | |
|---|---|---|---|
| penalty | \(\lambda\lVert\beta\rVert_2^2\) | \(\lambda\lVert\beta\rVert_1\) | \(\lambda_1\lVert\beta\rVert_1+\lambda_2\lVert\beta\rVert_2^2\) |
| coefficient | সব shrink, কোনোটা \(0\) নয় | shrink + কিছু ঠিক \(0\) | shrink + কিছু \(0\) |
| feature selection | না | হ্যাঁ (sparse) | হ্যাঁ |
| closed-form? | হ্যাঁ \((X^\top X+\lambda I)^{-1}X^\top y\) | না (orthonormal-এ soft-threshold) | না |
| correlated feature | একসাথে রাখে | একটিকে বাছে (অস্থির) | একসাথে রাখে (grouping) |
| canonical (এই dataset) | \(\lambda^\*{\approx}0.21\), MSE 2.075, 20 nonzero | \(\lambda^\*{\approx}0.042\), MSE 1.843, 17 nonzero | — |
পূর্ববর্তী সংযোগ:
- ← 6.1 (capacity / bias–variance): ৬.১ বলেছিল কেন capacity নিয়ন্ত্রণ দরকার (generalization-gap \(\propto\sqrt{\text{capacity}/n}\), U-curve)। regularization হলো সেই নিয়ন্ত্রণের প্রথম ব্যবহারিক যন্ত্র — \(\lambda\) ঘুরিয়ে effective-capacity একটানা কমিয়ে U-curve-এর তলায় বসা।
- ← 5.1 (OLS): ridge/lasso উভয়ই OLS-এর \(\lVert y-X\beta\rVert_2^2\) loss-এর উপর শুধু একটি penalty পদ যোগ করে; \(\lambda=0\)-এ দুটোই হুবহু OLS-এ ফিরে যায়। ridge closed-form OLS-এর normal equation-এ কেবল \(\lambda I\) যোগ।
- ← 5.2 (multicollinearity): ৫.২-এ দেখা গিয়েছিল near-collinear feature \((X^\top X)^{-1}\)-কে প্রায়-singular করে coefficient বিস্ফোরিত করে। ridge-এর \(X^\top X+\lambda I\) প্রতিটি eigenvalue \(\lambda_i\to\lambda_i+\lambda\) করে শূন্য থেকে সরিয়ে এই অস্থিরতা সরাসরি দমন করে — regularization তাই multicollinearity-র এক প্রত্যক্ষ প্রতিকার।
- ← 0.5 (SVD): ridge-এর সংকোচন SVD-তে সবচেয়ে পরিষ্কার — \(X=U\Sigma V^\top\) ধরলে ridge প্রতিটি singular-direction-কে factor \(\frac{\sigma_i^2}{\sigma_i^2+\lambda}\) দিয়ে shrink করে, ছোট-\(\sigma_i\) (অর্থাৎ অস্থির, low-variance) direction-গুলোকে বেশি দমন করে।
পরবর্তী সংযোগ (→ 6.3 — Classification I): এতক্ষণ লক্ষ্য ছিল continuous \(y\) predict করা (regression)। পরের অধ্যায় লক্ষ্য বদলায় classification (শ্রেণিবিভাজন)-এ — discrete label predict করা — এবং পরিচয় করায় LDA/QDA (শ্রেণি-শর্তাধীন Gaussian থেকে decision boundary), Naive Bayes (feature-স্বাধীনতার সরলীকরণ), ও kNN (কাছের প্রতিবেশী দিয়ে label)। regularization-এর মূল শিক্ষা সেখানেও ফেরে: এই classifier-গুলোও capacity ও bias–variance-এর ভাষায় বোঝা যায় (যেমন LDA-র shared covariance = QDA-র উপর একটি bias-আরোপী সীমাবদ্ধতা, kNN-এর \(k\) = capacity-knob)।
source pointer: regularization-এর statistics-অভিমুখী, পাঠযোগ্য উপস্থাপনা — Sugiyama, Introduction to Statistical Machine Learning (penalized least squares, sparsity) এবং Wasserman, All of Statistics (ridge/lasso, model selection)। data-scientist-মুখী, কোড-সহ ridge/lasso/elastic-net ও CV-দৃষ্টিভঙ্গি Bruce & Bruce, Practical Statistics for Data Scientists এবং Dangeti, Statistics for Machine Learning। penalized regression ও shrinkage-এর গাণিতিক/applied রূপ Furrer-এর regression-নোটেও (ridge, condition-number, multicollinearity-প্রতিকার)।