6.3 — Classification I: LDA, QDA, Naive Bayes & k-NN (শ্রেণিবিন্যাস I: LDA, QDA, নাইভ বেইজ ও k-NN)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — যখন উত্তরটা সংখ্যা নয়, একটা শ্রেণি; আর "সেরা সম্ভব" উত্তরদাতা কে?¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন নতুন মোড়¶
এতক্ষণ — Part V জুড়ে এবং Part VI-এর প্রথম দুই অধ্যায়ে (6.1 learning theory, 6.2 regularization) — আমাদের প্রায় সমস্ত গল্প একটা নির্দিষ্ট ধরনের প্রশ্নকে ঘিরে আবর্তিত হয়েছে: একটা response চলক \(y\), যা একটা সংখ্যা — বাড়ির দাম, ফসলের ফলন, রক্তচাপ — তাকে predictor \(x\) দিয়ে আন্দাজ করা। এই গোটা পরিবারটার নাম regression (নির্ভরণ): outcome continuous, আর আমরা তার গড়মান-জাতীয় কিছু ভবিষ্যদ্বাণী করি।
5.4-এ আমরা প্রথমবার এই ছাঁচ থেকে একটু সরেছিলাম — সেখানে response ছিল binary (\(y\in\{0,1\}\), হ্যাঁ/না), আর logistic regression দিয়ে আমরা "হ্যাঁ"-এর সম্ভাবনা \(P(y=1\mid x)\) আন্দাজ করেছিলাম। সেই এক পা-ই ছিল একটা নতুন ভূখণ্ডের সীমানা। এই অধ্যায়ে আমরা সেই ভূখণ্ডে পুরোপুরি ঢুকব, এবং দুটো দিকে এটিকে প্রসারিত করব: (ক) outcome আর কেবল দুটো নয়, \(C\)টি শ্রেণির যেকোনো একটা হতে পারে; এবং (খ) "হ্যাঁ-এর সম্ভাবনা সরাসরি শেখা"-র বাইরে গিয়ে আমরা একটা সম্পূর্ণ ভিন্ন দর্শনের classifier-পরিবারও গড়ব।
এই গোটা বিষয়টার নাম classification (শ্রেণিবিন্যাস): এখানে outcome আর কোনো সংখ্যা নয় — একটা শ্রেণি (class) বা লেবেল (label)। প্রতীকে, আমরা লিখব
যেখানে \(y\) হলো একটা পর্যবেক্ষণের শ্রেণি, আর \(C\) (ক্যাপিটাল সি) হলো মোট কতগুলো সম্ভাব্য শ্রেণি আছে তার সংখ্যা (যেমন \(C=2\) মানে দুই-শ্রেণি, \(C=3\) মানে তিন-শ্রেণি)। এই \(1,2,\dots,C\) সংখ্যাগুলো নিছক নাম — এদের মধ্যে কোনো ক্রম বা দূরত্ব নেই (শ্রেণি \(3\) শ্রেণি \(1\)-এর চেয়ে "বড়" নয়); এরা শুধু আলাদা আলাদা বিভাগ চিহ্নিত করে। এটাই regression-এর সঙ্গে মৌলিক পার্থক্য: regression-এ \(y=3.2\) আর \(y=3.3\) কাছাকাছি, কিন্তু classification-এ শ্রেণি-\(1\) ও শ্রেণি-\(2\) "কাছাকাছি" বলে কিছু নেই।
এক বাক্যে উত্তরণ। regression ভবিষ্যদ্বাণী করত একটা সংখ্যা; classification ভবিষ্যদ্বাণী করে একটা শ্রেণি/লেবেল — কোন রোগ, কোন প্রজাতি, কোন অঙ্ক, পাস না ফেল — এবং এই অধ্যায় সেই কাজের জন্য চারটি ভিন্ন-দর্শনের যন্ত্র গড়ে তোলে।
১.২ Hook — outcome যখন একটা নাম, একটা ভাগ¶
কয়েকটা চেনা পরিস্থিতি ভাবুন, যেখানে যা ভবিষ্যদ্বাণী করতে চাই তা কোনো পরিমাণ নয়, বরং কোন বিভাগে এটা পড়ে সেই প্রশ্ন:
- এই রোগী সুস্থ, না কোনো নির্দিষ্ট রোগে আক্রান্ত? — কিছু রক্ত-পরীক্ষার মান, বয়স, উপসর্গ দিয়ে। (এখানে আবার শ্রেণিগুলো একাধিকও হতে পারে: সুস্থ / রোগ-A / রোগ-B।)
- এই ফুলটা কোন প্রজাতির — তিন প্রজাতির আইরিস-ফুলের একটা? — পাপড়ি ও বৃতির দৈর্ঘ্য-প্রস্থ দিয়ে। (এটাই পরিসংখ্যানের সবচেয়ে বিখ্যাত classification-উদাহরণ।)
- হাতে লেখা এই অঙ্কটা \(0\) থেকে \(9\)-এর কোনটি? — একটা ছবির পিক্সেল-মানগুলো দিয়ে। (এখানে \(C=10\)।)
- এই ইমেইলটা স্প্যাম, না স্বাভাবিক? — তার শব্দ-সংখ্যা, কিছু চিহ্নিত শব্দের উপস্থিতি দিয়ে। (এখানে \(C=2\)।)
প্রতিটি ক্ষেত্রেই আমাদের হাতে কিছু পরিমাপ আছে (আমরা একসাথে লিখব \(x\)), আর তার ভিত্তিতে আমরা একটা শ্রেণি বেছে দিতে চাই। এই \(x\)-কে আমরা গোটা অধ্যায়ে লিখব একটা feature vector (বৈশিষ্ট্য-ভেক্টর) হিসেবে:
যেখানে \(x\) হলো একটা পর্যবেক্ষণের \(p\)টি সংখ্যাগত বৈশিষ্ট্যের তালিকা — যেমন আইরিস-উদাহরণে \(x=(\text{পাপড়ির দৈর্ঘ্য}, \text{পাপড়ির প্রস্থ}, \dots)\) — আর \(p\) (ছোট পি) হলো বৈশিষ্ট্যের সংখ্যা (dimension)। চিহ্ন \(\mathbb{R}^p\) মানে "\(p\)টি বাস্তব সংখ্যার ভেক্টর"। সুতরাং একটা পর্যবেক্ষণ হলো একটা জোড়া \((x, y)\) — feature \(x\) আর তার সত্যিকারের শ্রেণি \(y\) — আর আমাদের কাজ এমন একটা নিয়ম (classifier) বানানো, যা যেকোনো নতুন \(x\) দেখে একটা শ্রেণি \(\hat y\) (ওয়াই-হ্যাট, অনুমিত শ্রেণি) বলে দেবে।
১.৩ মূল অন্তর্দৃষ্টি — "সেরা সম্ভব" classifier আসলে কে?¶
এখন একটা গভীর কিন্তু অসাধারণ ফলদায়ক প্রশ্ন তুলি, যা গোটা অধ্যায়ের আদর্শ-মানদণ্ড (gold standard) ঠিক করে দেবে: ধরা যাক আমরা সর্বজ্ঞ — data-র পেছনের আসল সম্ভাবনা-নিয়ম পুরোটাই জানি। তাহলে গড়ে সবচেয়ে কম ভুল করতে চাইলে, একটা নতুন \(x\)-এর জন্য কোন শ্রেণিটা বলা উচিত?
এর উত্তরটা স্বজ্ঞাগতভাবে প্রায় স্পষ্ট, এবং সেটাই সমস্ত classification-তত্ত্বের ভিত্তি। ধরুন একটা নির্দিষ্ট \(x\) হাতে এসেছে। প্রতিটি সম্ভাব্য শ্রেণি \(c\)-র জন্য একটা সংখ্যা আছে —
যাকে বলে posterior probability (পশ্চাৎ-সম্ভাবনা): feature \(x\) দেখে নেওয়ার পরে শ্রেণি \(c\)-র উপর আমাদের বিশ্বাস। তাহলে গড়ে কম ভুল করার সবচেয়ে স্বাভাবিক উপায় কী? — যে শ্রেণির posterior সবচেয়ে বেশি, সেটাই বেছে নাও। কারণ সেই শ্রেণিটাই \(x\)-এর আলোকে সবচেয়ে সম্ভাব্য সত্য; অন্য কোনো শ্রেণি বললে গড়ে বেশি ভুল করার ঝুঁকি। এই নিয়মটারই নাম Bayes classifier (বেইজ শ্রেণিবিন্যাসক):
এখানে \(\arg\max_c\) মানে "যে শ্রেণি \(c\)-তে ডানপাশের সম্ভাবনা সবচেয়ে বড়, সেই \(c\)" (arg-max = maximizing argument)। কথায়: Bayes classifier হলো সেই নিয়ম, যা প্রতিটি \(x\)-কে তার সবচেয়ে সম্ভাব্য শ্রেণিতে পাঠায়। আর এর একটা মৌলিক তাত্ত্বিক মর্যাদা আছে — প্রমাণ করা যায় (§৪-এ ছোঁয়া হবে) যে আর কোনো classifier এর চেয়ে কম ভুল করতে পারে না। এটাই আদর্শ-মানদণ্ড: সম্ভব-সেরা।
কিন্তু "সম্ভব-সেরা" মানে "নিখুঁত" নয়। এমনকি এই আদর্শ Bayes classifier-ও কিছু ভুল করবেই — কারণ একই \(x\)-এর জন্য প্রকৃতিতে একাধিক শ্রেণি ঘটতে পারে (দুটো প্রজাতির ফুলের পাপড়ি-মাপ ওভারল্যাপ করতে পারে; একই উপসর্গে দুটো রোগ মেলে)। এই অনিবার্য, কমানো-যায়-না ভুলটারই নাম Bayes error (বেইজ-ভুল): কোনো classifier — তা যত চালাকই হোক — এর নিচে নামতে পারে না। এটা ঠিক 6.1-এর সেই \(\sigma^2\) (irreducible noise)-এর classification-সংস্করণ: data-র নিজস্ব ওভারল্যাপ থেকে আসা মেঝে-স্তরের ভুল।
এক বাক্যে অন্তর্দৃষ্টি। যদি আমরা সব posterior \(P(y=c\mid x)\) জানতাম, সেরা কাজ হতো প্রতিটি \(x\)-কে তার সর্বোচ্চ-posterior শ্রেণিতে পাঠানো — এটাই Bayes classifier, এবং তার অবশিষ্ট, অপসারণ-অযোগ্য ভুল হলো Bayes error, যার নিচে কেউ যেতে পারে না।
১.৪ আসল সমস্যা — \(P(y\mid x)\) তো জানা নেই; দুটো পথ¶
এতক্ষণের গল্পে একটা বিরাট "যদি" লুকিয়ে ছিল: যদি আমরা posterior \(P(y=c\mid x)\) জানতাম। কিন্তু বাস্তবে আমরা তা জানি না — আমাদের হাতে কেবল কিছু লেবেল-করা উদাহরণ \((x_1,y_1),\dots,(x_n,y_n)\) আছে, পুরো সম্ভাবনা-নিয়ম নয়। তাহলে আসল প্রকৌশল-প্রশ্ন: এই উদাহরণ থেকে আমরা \(P(y=c\mid x)\)-কে কীভাবে আন্দাজ (estimate) করব, যাতে Bayes classifier-এর যতটা সম্ভব কাছে যেতে পারি?
এই একটি প্রশ্নের দুটো মৌলিকভাবে আলাদা উত্তর-দর্শন আছে, আর এই অধ্যায়ের গোটা কাঠামো এই দুই দর্শনের উপর দাঁড়ানো।
পথ ১ — discriminative (বিচ্ছেদক) দর্শন: posterior সরাসরি শেখো। যদি আমাদের লক্ষ্যই হয় \(P(y\mid x)\), তবে সবচেয়ে সোজা পথ — তাকে data থেকে সরাসরি model করা, মাঝখানে আর কিছু না ভেবে। এটাই আমরা 5.4-এ করেছিলাম: logistic regression সরাসরি ধরেছিল \(P(y=1\mid x)=\sigma(x^\top\beta)\) (sigmoid দিয়ে), আর data থেকে \(\beta\) শিখে নিয়েছিল। এই পরিবার বলে — "শ্রেণিগুলোকে আলাদা করার সীমারেখাটাই শেখো, প্রতিটি শ্রেণি কেমন দেখতে তা নিয়ে মাথা ঘামিও না।" এই অধ্যায়ে discriminative দর্শন আমাদের প্রধান বিষয় নয় (সেটা 5.4-এ ও পরে 6.4-এ), কিন্তু তুলনার মেরুদণ্ড হিসেবে এটা সঙ্গে থাকবে।
পথ ২ — generative (উৎপাদক) দর্শন: প্রতিটি শ্রেণি কেমন, তা শেখো — তারপর Bayes rule-এ উল্টাও। দ্বিতীয় পথটা ঘুরপথ মনে হতে পারে, কিন্তু আশ্চর্যরকম শক্তিশালী। এখানে আমরা সরাসরি \(P(y\mid x)\) না শিখে, প্রশ্নটাকে উল্টে ফেলি: প্রতিটি শ্রেণির ভেতরের data কেমন দেখতে — অর্থাৎ "যদি জানতাম এটা শ্রেণি \(c\), তাহলে \(x\) কেমন মানের হতো" — সেটা model করি। এর সঙ্গে প্রতিটি শ্রেণি মোটে কতটা সাধারণ (prior) তা জুড়ি, তারপর 2.2-এর Bayes rule দিয়ে গোটাটা উল্টে posterior \(P(y=c\mid x)\) বের করি। নামটা "generative" কারণ এই model আসলে শেখে কীভাবে প্রতিটি শ্রেণি তার data উৎপন্ন (generate) করে — চাইলে এই model থেকে নতুন কৃত্রিম \(x\)ও বানানো যায়।
এই generative recipe-টাই এই অধ্যায়ের তিনটি প্রধান পদ্ধতির সাধারণ কাঠামো — LDA, QDA, ও Naive Bayes — এরা কেবল "প্রতিটি শ্রেণি কেমন দেখতে" তা ভিন্নভাবে ধরে। (LDA/QDA বলে: প্রতিটি শ্রেণি একটা Gaussian পাহাড়; Naive Bayes বলে: শ্রেণির ভেতরে feature-গুলো পরস্পর-স্বাধীন।)
আর একটা একেবারে আলাদা ঘরানা — instance-based (উদাহরণ-ভিত্তিক): প্রতিবেশীদের জিজ্ঞেস করো। শেষ পদ্ধতি, k-NN (k-নিকটতম-প্রতিবেশী), উপরের কোনো দর্শনেই পড়ে না — এটা কোনো সম্ভাবনা-নিয়মই model করে না (তাই nonparametric, অ-পরামিতিক)। এর যুক্তি শিশুসুলভ সরল: একটা নতুন \(x\)-এর শ্রেণি জানতে চাও? — তার আশেপাশের training-উদাহরণগুলো দেখো, তাদের মধ্যে যে শ্রেণি সংখ্যাগরিষ্ঠ, সেটাই বলে দাও। এটা data-কে "মুখস্থ" রেখে রায় দেওয়ার সময় তার দিকে ফিরে তাকায়, তাই একে instance-based বা lazy (অলস) learner বলে।
এক বাক্যে দুই (আসলে তিন) পথ। posterior \(P(y\mid x)\) অজানা — তাই কেউ সরাসরি সেটা শেখে (discriminative: 5.4 logistic), কেউ প্রতিটি শ্রেণির class-conditional চেহারা \(P(x\mid y)\) ও prior শিখে Bayes rule-এ উল্টে posterior পায় (generative: LDA, QDA, Naive Bayes), আর কেউ কোনো model-ই না বানিয়ে নিকটতম প্রতিবেশীদের ভোটে রায় দেয় (instance-based: k-NN)।
১.৫ এই অধ্যায়ের পথরেখা¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খলটা একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- Bayes classifier ও Bayes error (§২.১) — posterior, optimal decision rule, এবং অপসারণ-অযোগ্য ভুলের মেঝে।
- Generative recipe (§২.২) — class-conditional density \(f_c(x)\) ও prior \(\pi_c\) থেকে Bayes rule দিয়ে posterior \(P(y=c\mid x)\propto\pi_c f_c(x)\) পাওয়ার সাধারণ ছাঁচ।
- LDA (§২.৩) — প্রতি class Gaussian, shared \(\Sigma\) ⇒ linear discriminant ও সরল boundary।
- QDA (§২.৪) — প্রতি class আলাদা \(\Sigma_c\) ⇒ quadratic boundary; LDA-র bias কমায়, কিন্তু বেশি parameter ⇒ বেশি variance।
- Naive Bayes (§২.৫) — conditional independence \(P(x\mid y)=\prod_j P(x_j\mid y)\), কেন "naive", কখন কাজ করে, Gaussian NB = diagonal \(\Sigma\)।
- k-NN (§২.৬) — নিকটতম \(k\) প্রতিবেশীর majority vote; \(k\) কীভাবে bias–variance ঘোরায়, scaling ও curse of dimensionality।
- কখন কোনটা (§২.৭) — চারটি পদ্ধতির assumptions বনাম flexibility-র দাঁড়িপাল্লা।
- সব derivation (LDA-র linear ও QDA-র quadratic discriminant) §৪-এ; পূর্ণ dataset, কোড, চিত্র ও অনুশীলনী §৫ থেকে।
এক বাক্যে কেন এটি এখানে। 5.4 আমাদের একটিমাত্র discriminative classifier (logistic) দিয়েছিল; এই অধ্যায় সেই ছবি সম্পূর্ণ করে — একদিকে generative পরিবার (LDA/QDA/Naive Bayes, যা প্রতিটি শ্রেণিকে model করে Bayes rule-এ উল্টায়) আর অন্যদিকে instance-based k-NN — সবগুলোকেই একটা একক আদর্শ, Bayes classifier-এর কাছাকাছি যাওয়ার ভিন্ন ভিন্ন প্রয়াস হিসেবে দাঁড় করিয়ে; এর পরের অধ্যায় 6.4 (SVM ও kernel methods) এই decision-boundary-র গল্পকেই আরও শক্তিশালী, margin-ভিত্তিক রূপে নিয়ে যাবে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর insight (অন্তর্দৃষ্টি) — "সেরা classifier হলো সর্বোচ্চ-posterior বাছাই, আর posterior পেতে হয় হয় সরাসরি, নয় Bayes rule-এ উল্টে, নয় প্রতিবেশীর ভোটে" — কে নিখুঁত সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথম ব্যবহারেই খোলা হলো; কোথাও কিছু ধরে নেওয়া হয়নি। যেখানে গণিতের পূর্ণ derivation লাগবে (বিশেষত LDA-র linear ও QDA-র quadratic discriminant), সেটা §৪-এ — এখানে লক্ষ্য সংজ্ঞা ও স্বজ্ঞা পরিষ্কার করা।
প্রথমে পুরো অধ্যায়ের সাধারণ notation একবারে স্থির করি (সর্বত্র এক থাকবে):
- \(x \in \mathbb{R}^p\) — feature vector (বৈশিষ্ট্য-ভেক্টর): একটা পর্যবেক্ষণের \(p\)টি সংখ্যাগত বৈশিষ্ট্য, \(x=(x_1,\dots,x_p)\), যেখানে \(x_j\) হলো \(j\)-তম feature।
- \(y \in \{1,\dots,C\}\) — class label (শ্রেণি-লেবেল): পর্যবেক্ষণটি কোন শ্রেণির; \(C\) হলো মোট শ্রেণি-সংখ্যা।
- \(\pi_c = P(y=c)\) — শ্রেণি \(c\)-র prior probability (পূর্ব-সম্ভাবনা): কোনো feature দেখার আগে একটা এলোমেলো পর্যবেক্ষণ শ্রেণি \(c\)-র হওয়ার সম্ভাবনা — অর্থাৎ শ্রেণি \(c\) মোটে কতটা সাধারণ। (সব \(\pi_c\) অঋণাত্মক ও \(\sum_{c=1}^C \pi_c = 1\)।) "\(\pi\)" পড়ুন "পাই" — এটা ধ্রুবক \(\pi\approx 3.14\) নয়, এখানে কেবল prior-এর প্রচলিত প্রতীক।
- \(f_c(x) = P(x \mid y=c)\) — শ্রেণি \(c\)-র class-conditional density (শ্রেণি-শর্তাধীন ঘনত্ব): যদি জানতাম পর্যবেক্ষণটি শ্রেণি \(c\)-র, তবে তার feature \(x\)-এর সম্ভাব্যতা-ঘনত্ব। কথায় — "শ্রেণি \(c\)-র data কেমন দেখতে।" এটাই generative দর্শনের কেন্দ্রীয় বস্তু।
- \(P(y=c\mid x)\) — posterior probability (পশ্চাৎ-সম্ভাবনা): feature \(x\) দেখার পরে শ্রেণি \(c\)-র সম্ভাবনা। Bayes classifier ঠিক এটাকেই সর্বোচ্চ করে।
- \(\delta_c(x)\) — শ্রেণি \(c\)-র discriminant function (বিচ্ছেদক অপেক্ষক): একটা স্কোর, যা এমনভাবে বানানো যে "\(\delta_c(x)\) সবচেয়ে বড় যে \(c\)-তে" আর "posterior সবচেয়ে বড় যে \(c\)-তে" — দুটো একই শ্রেণি দেয়। অর্থাৎ classifier-কে \(\arg\max_c \delta_c(x)\) রূপেও লেখা যায় (LDA/QDA-তে এটি গণনা-সুবিধার জন্য posterior-এর log নিয়ে বানানো হয়)।
- \(\mathcal N(\mu_c, \Sigma_c)\) — শ্রেণি \(c\)-র জন্য একটি multivariate normal (বহুমাত্রিক স্বাভাবিক, 2.4) distribution, যার mean vector \(\mu_c\in\mathbb{R}^p\) (শ্রেণি \(c\)-র feature-গুলোর গড়, অর্থাৎ তার "কেন্দ্র") আর covariance matrix \(\Sigma_c\) (\(p\times p\), শ্রেণি \(c\)-র মেঘের বিস্তার-ও-আকৃতি)। LDA ও QDA এই Gaussian দিয়েই \(f_c(x)\) ধরে।
- \(k\) — k-NN-এ বিবেচ্য নিকটতম প্রতিবেশীর সংখ্যা (neighborhood size): একটা ধনাত্মক পূর্ণসংখ্যা যা আমরা বাছি।
এই notation মাথায় রেখে এবার মূল ধারণাগুলো একে একে।
২.১ Bayes classifier ও Bayes error — আদর্শ-মানদণ্ড¶
§১.৩-এর স্বজ্ঞাটাই এখন নিখুঁত সংজ্ঞায় রাখি। যেকোনো \(x\)-এর জন্য Bayes classifier বেছে নেয় সর্বোচ্চ-posterior শ্রেণি:
এই নিয়ম optimal এই অর্থে: সব সম্ভাব্য classifier-এর মধ্যে এটিই গড় ভুল-শ্রেণিবিন্যাসের হার (misclassification rate) সর্বনিম্ন করে। স্বজ্ঞাটা সরল — প্রতিটি \(x\)-বিন্দুতে আলাদা-আলাদাভাবে ভাবলে, "সবচেয়ে সম্ভাব্য শ্রেণি" ছাড়া অন্য কিছু বললেই গড়ে বেশি ভুল হবে; আর সব বিন্দুতে স্থানীয়ভাবে সেরা সিদ্ধান্ত নিলে সামগ্রিকভাবেও সেরা হয় (পূর্ণ যুক্তি §৪-এ)।
কিন্তু optimal হওয়া মানে নির্ভুল নয়। একটা নির্দিষ্ট \(x\)-এ Bayes classifier শ্রেণি \(\hat y\) বলে, কিন্তু সত্যিকারের শ্রেণি ভিন্নও হতে পারে — সেই সম্ভাবনা ঠিক \(1 - \max_c P(y=c\mid x)\) (অর্থাৎ যে শ্রেণি বাছিনি তাদের মোট posterior)। এই ভুলকে সব \(x\)-এর উপর গড় করলে পাই Bayes error (বা Bayes risk):
যেখানে \(\mathbb{E}_x[\cdot]\) মানে feature-distribution-এর উপর প্রত্যাশা (গড়), আর \(R^\star\) ("আর-স্টার") হলো সম্ভব-সর্বনিম্ন ভুল-হার। কোনো classifier \(R^\star\)-এর নিচে নামতে পারে না — এটাই classification-এর মেঝে। যেখানে শ্রেণিগুলোর class-conditional মেঘ পরস্পর ওভারল্যাপ করে, সেখানেই \(R^\star\) বড় হয় (একই \(x\)-এ একাধিক শ্রেণি সম্ভব), আর যেখানে মেঘগুলো পরিষ্কারভাবে আলাদা, সেখানে \(R^\star\) প্রায় শূন্য। তাই Bayes error data-র নিজস্ব ওভারল্যাপের পরিমাপ — ঠিক যেমন 6.1-এ \(\sigma^2\) ছিল regression-এ data-র নিজস্ব noise। বাস্তবে আমরা \(R^\star\) সরাসরি জানি না (posterior অজানা), কিন্তু এটি ধারণাগতভাবে আমাদের সব classifier-এর কর্মদক্ষতা যার বিপরীতে মাপব সেই আদর্শ-লক্ষ্য।
মনে রাখুন। Bayes classifier = সর্বোচ্চ-posterior বাছাই = সম্ভব-সেরা classifier; তার অবশিষ্ট ভুল = Bayes error \(R^\star\) = data-র ওভারল্যাপজনিত অপসারণ-অযোগ্য মেঝে। নিচের সব পদ্ধতির আসল লক্ষ্য — posterior-কে যথাসম্ভব ভালোভাবে আন্দাজ করে এই মেঝের যত কাছে যাওয়া যায়।
২.২ Generative recipe — Bayes rule দিয়ে posterior বানানো¶
generative দর্শনের গোটা যন্ত্রটা আসলে 2.2-এর Bayes rule ছাড়া আর কিছুই নয়। posterior-কে আমরা সরাসরি না শিখে, দুটো সহজ-model-যোগ্য অংশে ভেঙে নিই — প্রতিটি শ্রেণি কেমন দেখতে (\(f_c\)) আর প্রতিটি শ্রেণি কতটা সাধারণ (\(\pi_c\)) — তারপর Bayes rule-এ জোড়া লাগাই:
প্রতিটি অংশ খুলি:
- লব \(\pi_c\, f_c(x)\) — শ্রেণি \(c\)-র prior (কতটা সাধারণ) গুণ তার class-conditional density (এই শ্রেণি হলে \(x\) কতটা সম্ভাব্য)। এই গুণফলকে বলা যায় শ্রেণি \(c\)-র পক্ষে "ওজন-করা সাক্ষ্য"।
- হর \(\sum_{l=1}^{C}\pi_l f_l(x)\) — সব শ্রেণির উপর একই গুণফলের যোগফল (\(l\) হলো শ্রেণির উপর চলমান সূচক)। এটা নিছক normalizing constant (স্বাভাবিকীকরণ ধ্রুবক) — নিশ্চিত করে সব posterior যোগ করলে \(1\) হয়। লক্ষণীয়, এই হর \(c\)-র উপর নির্ভর করে না (সব শ্রেণিতে একই)।
আর এখানেই একটা চমৎকার সরলীকরণ: যেহেতু Bayes classifier কেবল কোন \(c\)-তে posterior সবচেয়ে বড় তা জানতে চায়, আর হরটা সব \(c\)-তে একই — তাই হর উপেক্ষা করে শুধু লব তুলনা করলেই চলে:
যেখানে "\(\propto\)" পড়ুন "সমানুপাতিক" (proportional to)। কথায়: generative classifier শুধু \(\pi_c f_c(x)\) গুণফলটা প্রতিটি শ্রেণির জন্য বের করে, আর সবচেয়ে বড়টা বেছে নেয়। এটাই সাধারণ recipe — এবং LDA, QDA, Naive Bayes-এর মধ্যে একমাত্র পার্থক্য হলো তারা \(f_c(x)\)-কে কীভাবে আকার দেয়। বাকিটা একই Bayes-rule-যন্ত্র।
বাস্তবে \(\pi_c\) ও \(f_c\) data থেকে আন্দাজ করতে হয়: \(\hat\pi_c\) = শ্রেণি \(c\)-র training-উদাহরণের ভগ্নাংশ (যত সহজ তত), আর \(\hat f_c\) = শ্রেণি \(c\)-র feature-গুলোতে বসানো একটা density (LDA/QDA-তে Gaussian, যার \(\mu_c,\Sigma_c\) ওই শ্রেণির sample-mean ও sample-covariance থেকে)।
২.৩ LDA — প্রতি class Gaussian, একই (shared) covariance ⇒ সরল boundary¶
এবার প্রথম concrete পদ্ধতি। LDA (Linear Discriminant Analysis, রৈখিক বিচ্ছেদক বিশ্লেষণ) generative recipe-টাকে একটা সুনির্দিষ্ট অনুমানে ভরে: প্রতিটি শ্রেণির class-conditional density একটা multivariate Gaussian (2.4) —
অর্থাৎ শ্রেণি \(c\)-র data-মেঘ একটা উপবৃত্তাকার পাহাড়, যার কেন্দ্র \(\mu_c\) (শ্রেণি \(c\)-র গড়)। কিন্তু LDA-র প্রাণভোমরা একটা অতিরিক্ত, সরলীকারী অনুমান: সব শ্রেণির covariance matrix একই —
কথায়: প্রতিটি শ্রেণির মেঘ একই আকার, একই বিস্তার, একই ঘূর্ণন — তারা কেবল ভিন্ন জায়গায় বসে (ভিন্ন কেন্দ্র \(\mu_c\))। যেন একই ছাঁচের কয়েকটা উপবৃত্তাকার মেঘ, শুধু সরিয়ে সরিয়ে রাখা।
এই অনুমানের ফল অসাধারণ ও এটাই LDA-র নামের কারণ। যখন আমরা \(\pi_c f_c(x)\)-এর log নিই (যাকে discriminant \(\delta_c(x)\) ধরা সুবিধাজনক — log একঘেয়ে-বর্ধমান বলে \(\arg\max\) বদলায় না), Gaussian-এর সূত্রে একটা quadratic (বর্গাকার) পদ \(x^\top \Sigma^{-1} x\) আসে — কিন্তু যেহেতু \(\Sigma\) সব শ্রেণিতে একই, এই পদটা শ্রেণি \(c\)-র উপর নির্ভর করে না, তাই দুটো শ্রেণির স্কোর তুলনা করার সময় কাটাকাটি হয়ে যায়। যা টিকে থাকে তা \(x\)-এ রৈখিক (linear):
প্রতিটি পদ §৪-এ derive ও খোলা হবে; এখানে গুরুত্বপূর্ণ শুধু আকৃতি: \(\delta_c(x)\) হলো \(x\)-এর একটা রৈখিক অপেক্ষক (একটা ধ্রুবক যোগ \(x\)-এর সাথে একটা ভেক্টরের ডট-গুণ)। আর দুটো শ্রেণির সীমানা সেখানে যেখানে তাদের \(\delta\) সমান — দুটো রৈখিক অপেক্ষক সমান হলে যা পাই, তা একটা সরলরেখা (বা উচ্চমাত্রায় একটা সমতল, hyperplane)। অর্থাৎ:
LDA-র স্বাক্ষর। shared covariance ⇒ discriminant \(x\)-এ linear ⇒ শ্রেণিগুলোর মধ্যবর্তী decision boundary সরল (সরলরেখা/সমতল)। এই সরলতাই LDA-কে কম-parameter ও স্থিতিশীল (low variance) করে — কিন্তু যদি বাস্তবে শ্রেণিগুলোর আকৃতি আলাদা হয়, এই shared-\(\Sigma\) অনুমান ভুল হয়ে bias আনে।
(একটা সুন্দর সমান্তরাল: এই linear-discriminant-যুক্ত generative model আসলে একই linear রূপের posterior দেয় যা 5.4-এর logistic regression সরাসরি শেখে — দুই দর্শন এখানে একই আকৃতিতে মেলে, শুধু পথ আলাদা। বিশদ §৪-এ।)
২.৪ QDA — per-class covariance ⇒ বাঁকা boundary; bias কমে, variance বাড়ে¶
LDA-র shared-\(\Sigma\) অনুমানটা প্রায়ই বাস্তবের সঙ্গে মেলে না — সত্যিকারের শ্রেণিগুলোর মেঘ ভিন্ন আকার, ভিন্ন বিস্তার, ভিন্ন ঘূর্ণনের হতে পারে (একটা শ্রেণি ছড়ানো, আরেকটা আঁটসাঁট)। QDA (Quadratic Discriminant Analysis, বর্গাকার বিচ্ছেদক বিশ্লেষণ) ঠিক এই বাঁধন আলগা করে: এখনও প্রতিটি শ্রেণি Gaussian, কিন্তু প্রতিটির নিজস্ব covariance —
যেখানে এখন \(\Sigma_c\)-এ একটা সূচক \(c\) আছে — প্রতিটি শ্রেণির covariance আলাদা। ফল: log-discriminant নেওয়ার সময় quadratic পদ \(x^\top \Sigma_c^{-1} x\)-এর \(\Sigma_c\) শ্রেণিভেদে আলাদা, তাই দুটো শ্রেণির তুলনায় এই পদ আর কাটাকাটি যায় না — discriminant \(x\)-এ quadratic (বর্গাকার) থেকে যায়:
যেখানে \(\lvert \Sigma_c \rvert\) হলো \(\Sigma_c\)-এর determinant (যা মেঘটার "আয়তন" মাপে; §৪-এ বিশদ)। দুটো quadratic অপেক্ষক সমান হলে যে সীমানা পাই তা আর সরলরেখা নয় — একটা বাঁকা বক্ররেখা (উপবৃত্ত, পরাবৃত্ত, অধিবৃত্ত — সাধারণভাবে একটি quadratic curve/surface)।
QDA-র স্বাক্ষর। per-class covariance ⇒ discriminant \(x\)-এ quadratic ⇒ decision boundary বাঁকা। এই অতিরিক্ত নমনীয়তা LDA-র shared-\(\Sigma\)-জনিত bias কমায় (সত্যিকার ভিন্ন-আকৃতির শ্রেণি ভালো ধরে) — কিন্তু এর দাম আছে: প্রতিটি শ্রেণির জন্য আলাদা \(\Sigma_c\) আন্দাজ করতে হয়, অর্থাৎ অনেক বেশি parameter (\(C\) গুণ একটা \(p\times p\) matrix), তাই variance বাড়ে এবং প্রতি শ্রেণিতে যথেষ্ট data না থাকলে এই আন্দাজগুলো অস্থির হয়।
এটাই ঠিক 6.1-এর bias–variance tradeoff-এর একটা পরিষ্কার দৃষ্টান্ত: LDA সরল (কম parameter, বেশি bias, কম variance), QDA নমনীয় (বেশি parameter, কম bias, বেশি variance)। কোনটা ভালো তা নির্ভর করে — সত্যিই শ্রেণিগুলোর covariance ভিন্ন কিনা, আর হাতে কত data আছে। যখন শ্রেণিগুলোর প্রকৃত covariance অসমান (যেমন এই অধ্যায়ের dataset-এ), QDA-র নমনীয়তা সাধারণত জিতে যায়; কিন্তু data কম বা covariance আসলে প্রায়-সমান হলে LDA-র মিতব্যয়িতা ভালো করে। (§৫-এর dataset-এ আমরা এই দুইয়ের সংখ্যাগত পার্থক্য সরাসরি দেখব, এবং Figure 6-3-lda-vs-qda তাদের সরল-বনাম-বাঁকা boundary পাশাপাশি রেখে চোখে দেখাবে।)
২.৫ Naive Bayes — feature-গুলো শর্তাধীনভাবে স্বাধীন¶
তৃতীয় generative পদ্ধতি একটা একেবারে ভিন্ন ধরনের সরলীকরণ করে। LDA/QDA-র মূল ব্যয়বহুল অংশ ছিল covariance matrix \(\Sigma_c\) — যা feature-গুলোর পারস্পরিক সম্পর্ক (correlation) ধরে, আর যাতে \(p(p+1)/2\)টা সংখ্যা লাগে (high-dimension-এ যা বিপুল ও আন্দাজ করা কঠিন)। Naive Bayes (নাইভ বেইজ, "সরলমনা বেইজ") এই সমস্যাটা এক ধাক্কায় উড়িয়ে দেয় একটা সাহসী অনুমানে: একটা শ্রেণি দেওয়া থাকলে, feature-গুলো পরস্পর শর্তাধীনভাবে স্বাধীন (conditionally independent)। এর সরাসরি ফল — class-conditional density একটা গুণফলে ভেঙে যায়:
কথায়: শ্রেণি \(c\)-র ভেতরে \(x\)-এর যৌথ density আর গোটা-গোটা না ভেবে, প্রতিটি feature \(x_j\)-কে আলাদা আলাদা model করে তাদের গুণ করলেই হয়। এখানে \(\prod_{j=1}^{p}\) মানে \(j=1\) থেকে \(p\) পর্যন্ত গুণফল, আর \(P(x_j\mid y=c)\) হলো শুধু \(j\)-তম feature-এর একমাত্রিক (one-dimensional) class-conditional density।
কেন একে "naive" (সরলমনা) বলে? কারণ অনুমানটা প্রায়ই স্পষ্টতই ভুল — বাস্তব feature-রা সাধারণত পরস্পর-সম্পর্কিত (একজনের উচ্চতা বেশি হলে ওজনও বেশি হওয়ার ঝোঁক; স্প্যাম-ইমেইলে একটা চিহ্নিত শব্দ থাকলে আরেকটাও থাকার ঝোঁক)। শ্রেণি দিলে এরা ঠিক স্বাধীন হয়ে যায় — এটা একটা সরলীকরণ, বাস্তবতা নয়। তবু কেন এটা প্রায়ই ভালো কাজ করে? তিনটি কারণে: (১) এতে আর covariance লাগে না, প্রতিটি শ্রেণি-feature জোড়ার জন্য মাত্র গুটিকয় সংখ্যা (যেমন Gaussian হলে একটা গড় ও একটা ভেদ) আন্দাজ করলেই চলে — তাই high-dimensional data-তেও (যেখানে \(p\) বিশাল, যেমন text/ইমেইল) এটি স্থিতিশীল ও দ্রুত; (২) classification-এ আমাদের নিখুঁত posterior-সংখ্যা নয়, কেবল কোন শ্রেণি সবচেয়ে বড় তা ঠিক হলেই চলে — তাই অনুমান কিছুটা ভুল হলেও \(\arg\max\) প্রায়ই ঠিক থাকে; (৩) কম parameter মানে কম variance (6.1)। এর দুর্বলতা — যখন feature-দের পারস্পরিক সম্পর্কই শ্রেণি আলাদা করার মূল সূত্র, তখন এটা সেই সূত্র হারিয়ে ফেলে।
Gaussian Naive Bayes — diagonal covariance-এর বিশেষ ক্ষেত্র। যখন প্রতিটি feature-এর class-conditional \(P(x_j\mid y=c)\)-কেও একটা একমাত্রিক Gaussian ধরি (\(\mathcal N(\mu_{cj}, \sigma_{cj}^2)\), শ্রেণি \(c\)-তে \(j\)-তম feature-এর গড় ও ভেদ), তখন পদ্ধতিটার নাম Gaussian NB। লক্ষণীয় — feature-গুলো স্বাধীন ধরা মানে তাদের যৌথ Gaussian-এর covariance matrix-এ কেবল কর্ণ (diagonal) পদ থাকে, off-diagonal সব শূন্য। তাই Gaussian NB আসলে QDA-র একটা বিশেষ রূপ, যেখানে প্রতিটি \(\Sigma_c\) diagonal (অর্থাৎ অক্ষ-সমান্তরাল উপবৃত্ত, কোনো হেলানো correlation নেই)। এভাবে তিনটি Gaussian-generative পদ্ধতি একটা সুন্দর ক্রমে সাজে: LDA (shared full \(\Sigma\)) → QDA (per-class full \(\Sigma_c\)) → Gaussian NB (per-class diagonal \(\Sigma_c\)) — flexibility ও parameter-সংখ্যার ভিন্ন ভিন্ন বিন্দু, একই Bayes-rule কাঠামোয়।
২.৬ k-NN — নিকটতম প্রতিবেশীদের majority vote¶
এবার সম্পূর্ণ আলাদা ঘরানা। k-NN (k-Nearest Neighbors, k-নিকটতম-প্রতিবেশী) কোনো \(\pi_c\) বা \(f_c\) model করে না, কোনো Gaussian ধরে না — তাই এটি nonparametric (অ-পরামিতিক) ও instance-based। এর নিয়ম এক বাক্যে বলা যায়:
একটা নতুন বিন্দু \(x\)-কে শ্রেণিবিন্যাস করতে — training-উদাহরণগুলোর মধ্যে \(x\)-এর নিকটতম \(k\)টি খুঁজে বের করো, আর তাদের মধ্যে যে শ্রেণি সংখ্যাগরিষ্ঠ (majority vote), \(x\)-কে সেই শ্রেণি দাও।
আনুষ্ঠানিকভাবে: একটা distance metric (দূরত্ব-পরিমাপ, সাধারণত Euclidean দূরত্ব \(\lVert x - x_i \rVert_2\)) দিয়ে \(x\) থেকে প্রতিটি training-বিন্দু \(x_i\)-র দূরত্ব মাপি, সবচেয়ে কাছের \(k\)টা বিন্দুর সেট \(\mathcal N_k(x)\) নিই, আর
যেখানে \(\mathbb{1}\{y_i=c\}\) হলো indicator (নির্দেশক): \(y_i=c\) হলে \(1\), নাহলে \(0\) — অর্থাৎ ভেতরের যোগফলটা গুনছে প্রতিবেশীদের মধ্যে শ্রেণি \(c\)-র কতগুলো ভোট পড়ল। (চাইলে \(\hat P(y=c\mid x) = \frac{1}{k}\sum_{i\in\mathcal N_k(x)}\mathbb{1}\{y_i=c\}\) — অর্থাৎ শ্রেণি \(c\)-র প্রতিবেশী-ভগ্নাংশ — কে posterior-এর একটা স্থানীয় আন্দাজ হিসেবেও দেখা যায়।)
\(k\) ই হলো bias–variance-এর নব — 6.1-এর সরাসরি প্রয়োগ। k-NN-এ একটিমাত্র গুরুত্বপূর্ণ পছন্দ — কতজন প্রতিবেশীকে জিজ্ঞেস করব (\(k\)):
- ছোট \(k\) (যেমন \(k=1\)): সিদ্ধান্ত কেবল হাতে-গোনা নিকটতম বিন্দুর উপর নির্ভর — তাই decision boundary খুব এবড়োখেবড়ো/আঁকাবাঁকা (wiggly), প্রতিটি training-বিন্দুর (এমনকি একটা ভুল-লেবেল বা noise-বিন্দুর) চারপাশে নিজস্ব ছোট দ্বীপ গড়ে। এটা low bias, high variance — overfit: training-data প্রায় নিখুঁত মেলে, কিন্তু নতুন data-তে অস্থির। (\(k=1\)-এ training-error ঠিক শূন্য, কারণ প্রতিটি বিন্দুর নিকটতম প্রতিবেশী সে নিজেই।)
- বড় \(k\) (যেমন \(k=\) পুরো dataset): সিদ্ধান্ত বহু দূরের বিন্দুর গড়ে — তাই boundary খুব মসৃণ (smooth), স্থানীয় খুঁটিনাটি উপেক্ষা করে। চরমে, \(k\) যদি মোট নমুনার সমান হয়, প্রতিটি \(x\)-ই কেবল সবচেয়ে সাধারণ শ্রেণি পায় (ধ্রুব ভবিষ্যদ্বাণী)। এটা high bias, low variance — underfit।
- মাঝারি \(k\): ঠিক 6.1-এর U-আকৃতির তলদেশ — যেখানে boundary যথেষ্ট মসৃণ অথচ স্থানীয় গঠন এখনও ধরে। সেরা \(k\) সাধারণত cross-validation (5.8) দিয়ে বাছা হয়।
দুটো অপরিহার্য সতর্কতা। (ক) Feature scaling: k-NN পুরোপুরি দূরত্বের উপর দাঁড়ানো, আর দূরত্ব feature-এর এককের উপর নির্ভরশীল — একটা feature (যেমন আয়, হাজার-একক) যদি আরেকটার (যেমন বয়স) চেয়ে অনেক বড় স্কেলে থাকে, সে দূরত্বের হিসাব একাই দখল করবে, ছোট-স্কেল feature কার্যত উপেক্ষিত হবে। তাই k-NN-এ feature standardize/scale করা প্রায় বাধ্যতামূলক (ঠিক 6.2-এর penalty scale-নির্ভরতার অনুরূপ যুক্তি)। (খ) Curse of dimensionality (মাত্রার অভিশাপ): feature-সংখ্যা \(p\) বড় হলে k-NN দুর্বল হয়, কারণ উচ্চ-মাত্রায় সব বিন্দু পরস্পর থেকে প্রায় সমান-দূরে হয়ে পড়ে — "নিকটতম প্রতিবেশী" আর সত্যিকার অর্থে কাছের থাকে না, প্রতিবেশীত্বের ধারণাটাই অর্থ হারায়। ফলে যে স্থানীয়-সাদৃশ্যের উপর k-NN নির্ভর করে, তা ভেঙে পড়ে। তাই k-NN নিম্ন-থেকে-মাঝারি মাত্রায় (ছোট \(p\)) সবচেয়ে ভালো কাজ করে।
k-NN-এর স্বাক্ষর। কোনো model নয় — শুধু "কাছের প্রতিবেশীরা যা, তুমিও তা" (nonparametric, instance-based)। \(k\) ছোট ⇒ wiggly/overfit (low bias, high variance), \(k\) বড় ⇒ smooth/underfit (high bias, low variance); scaling বাধ্যতামূলক, আর উচ্চ-মাত্রায় curse of dimensionality-তে দুর্বল।
২.৭ LDA বনাম QDA বনাম Naive Bayes বনাম k-NN — কখন কোনটা¶
চারটি যন্ত্র হাতে এল; এদের একটা দাঁড়িপাল্লায় পাশাপাশি রাখি, কারণ এই তুলনাই বাস্তবে "কোনটা বাছব" সিদ্ধান্ত চালায়। মূল মেরুদণ্ডটা পরিচিত — assumptions (অনুমান) বনাম flexibility (নমনীয়তা), যা সরাসরি 6.1-এর bias–variance-এ অনুবাদ হয়: যত কড়া (ও সঠিক) অনুমান, তত কম parameter ⇒ কম variance কিন্তু (অনুমান ভুল হলে) বেশি bias; যত নমনীয়, তত উল্টো।
- LDA — অনুমান: প্রতি শ্রেণি Gaussian + shared covariance। সবচেয়ে কম parameter (একটা \(\Sigma\) সবার জন্য), সরল (linear) boundary, low variance। ভালো যখন — শ্রেণিগুলোর প্রকৃত covariance প্রায়-সমান, data কম, বা সরল সীমানাই যথেষ্ট। খারাপ যখন — শ্রেণিগুলোর আকৃতি সত্যিই আলাদা (তখন shared-\(\Sigma\) bias আনে)।
- QDA — অনুমান: প্রতি শ্রেণি Gaussian + per-class covariance। বেশি parameter, বাঁকা (quadratic) boundary, কম bias কিন্তু বেশি variance। ভালো যখন — শ্রেণিগুলোর covariance স্পষ্টতই ভিন্ন এবং প্রতি শ্রেণিতে যথেষ্ট data। খারাপ যখন — data কম (প্রতি শ্রেণির \(\Sigma_c\) অস্থির আন্দাজ হয়)।
- Naive Bayes — অনুমান: শ্রেণি দিলে feature-গুলো স্বাধীন (diagonal covariance)। অতি-কম parameter, high-dimension-এ দারুণ স্কেল করে, খুব দ্রুত। ভালো যখন — feature অনেক (\(p\) বড়, যেমন text), data সীমিত, এবং feature-correlation শ্রেণি-ভেদের জন্য খুব জরুরি নয়। খারাপ যখন — feature-দের পারস্পরিক সম্পর্কই শ্রেণি আলাদা করার মূল সূত্র।
- k-NN — অনুমান: কার্যত কোনো প্যারামেট্রিক অনুমান নেই (শুধু "কাছের বিন্দু একই শ্রেণির ঝোঁক রাখে")। অত্যন্ত নমনীয়, যেকোনো আকৃতির boundary ধরতে পারে; \(k\) দিয়ে bias–variance নিয়ন্ত্রিত। ভালো যখন — সীমানা জটিল/অরৈখিক, মাত্রা কম-মাঝারি, যথেষ্ট data। খারাপ যখন — মাত্রা বড় (curse of dimensionality), feature unscaled, বা ভবিষ্যদ্বাণী-সময়ে দ্রুততা/স্মৃতি-মিতব্যয় দরকার (k-NN পুরো data রেখে দেয় ও রায়ের সময় সব দূরত্ব মাপে)।
একটা সুবিধাজনক মানসিক মানচিত্র: generative-তিনজন (LDA→QDA→Naive Bayes) একই Gaussian-Bayes-rule কাঠামোয় covariance-এর উপর বিধিনিষেধ আলগা/কঠিন করে flexibility সাজায়; discriminative (5.4 logistic) সীমানা সরাসরি শেখে; আর k-NN model-হীনভাবে স্থানীয় ভোটে রায় দেয়। কোনো একটি সর্বাবস্থায় সেরা নয় (6.1-এর no-free-lunch-এর সুরে) — সেরা পছন্দ নির্ভর করে অনুমানগুলো data-র সঙ্গে কতটা মেলে এবং হাতে কত data ও কত মাত্রা আছে তার উপর।
§২-এর সার। সেরা classifier হলো Bayes classifier (\(\arg\max_c P(y=c\mid x)\)), তার মেঝে-ভুল Bayes error। posterior পেতে — generative পথ class-conditional \(f_c(x)\) ও prior \(\pi_c\) model করে Bayes rule \(P(y=c\mid x)\propto\pi_c f_c(x)\)-এ উল্টায়: LDA (Gaussian, shared \(\Sigma\) ⇒ linear boundary, low variance), QDA (Gaussian, per-class \(\Sigma_c\) ⇒ quadratic boundary, low bias/high variance), Naive Bayes (feature স্বাধীন ⇒ \(\prod_j P(x_j\mid y)\), diagonal \(\Sigma\), high-dimension-বান্ধব)। আর k-NN কোনো model ছাড়াই নিকটতম \(k\) প্রতিবেশীর majority vote নেয় — \(k\) ছোট ⇒ overfit, বড় ⇒ underfit; scaling বাধ্যতামূলক, উচ্চ-মাত্রায় দুর্বল। কোনটা বাছব তা assumptions-বনাম-flexibility (bias–variance)-এর দাঁড়িপাল্লায় নির্ধারিত। LDA ও QDA discriminant-এর পূর্ণ derivation §৪-এ; পূর্ণ dataset, কোড ও চিত্র §৫ থেকে।
৩ · পূর্ণাঙ্গ উদাহরণ¶
§১–২-এ আমরা চারটে classifier-এর নীতি আলাদা-আলাদা ভাবে দেখেছি — LDA ও QDA Gaussian density বসিয়ে posterior তোলে, Naive Bayes feature-গুলোকে স্বাধীন ধরে, k-NN কাছের প্রতিবেশীদের ভোট গোনে। কিন্তু কাগজে নীতি বোঝা আর হাতে-কলমে data-র উপর চালিয়ে দেখা — দুটো আলাদা ব্যাপার। এই অংশে আমরা একটা নির্দিষ্ট, পুনরুৎপাদনযোগ্য (reproducible) dataset বানিয়ে চারটে পদ্ধতিকেই একই মাঠে দাঁড় করাব, তাদের test accuracy মাপব, আর — সবচেয়ে গুরুত্বপূর্ণ — কেন একটা পদ্ধতি অন্যটাকে হারাল সেটা প্রতিটা পদ্ধতির অন্তর্নিহিত অনুমান (assumption)-এর সাথে মিলিয়ে ব্যাখ্যা করব। গোটা অংশে একটাই সুর: classifier বাছাই মানে assumption আর flexibility-র মধ্যে দর-কষাকষি।
চারটে ধাপে ভাগ করছি:
- E1 — মঞ্চ ও Bayes-ভাবনা: তিন-শ্রেণির 2D data, অসমান covariance সহ; লক্ষ্য — প্রতিটা বিন্দুকে তার সবচেয়ে সম্ভাব্য শ্রেণিতে পাঠানো (Bayes rule); শ্রেণিগুলো overlap করে বলে কিছুটা irreducible Bayes error থাকবেই।
- E2 — LDA বনাম QDA: shared \(\Sigma\) (linear boundary) বনাম per-class \(\Sigma_c\) (quadratic boundary) — সত্যিকারের covariance আলাদা হলে কোনটা জেতে, আর কেন।
- E3 — Naive Bayes ও k-NN: feature-independence অনুমান কতটা ক্ষতিকর (বা না), আর কোনো distributional অনুমান ছাড়াই k-NN কেমন করে।
- E4 — k-এর ভূমিকা ও সার্বিক তুলনা: \(k\) কীভাবে bias–variance knob, আর পাঁচ পদ্ধতির এক টেবিলে রায়।
পুরো অংশে নোটেশন §১-এর সাথে এক: posterior $$ P(y=c\mid x) \;=\; \frac{\pi_c\,f_c(x)}{\sum_{l}\pi_l\,f_l(x)}, $$ যেখানে \(\pi_c\) হলো শ্রেণি \(c\)-র prior (এখানে তিন শ্রেণি সমান, তাই \(\pi_c=\tfrac{1}{3}\)), আর \(f_c(x)\) হলো শ্রেণি \(c\)-র মধ্যে \(x\)-এর class-conditional density। Bayes rule বলছে — যে \(c\)-তে লব \(\pi_c f_c(x)\) সবচেয়ে বড়, সেই শ্রেণিই বেছে নাও (হর সব শ্রেণিতে এক, তাই argmax-এ হর গুরুত্বহীন)। চারটে পদ্ধতির ফারাক কেবল একটাই প্রশ্নে: \(f_c(x)\)-কে কীভাবে আঁচ করব?
৩.১ · E1 — মঞ্চ সাজানো ও Bayes-ভাবনা¶
data টা ঠিক কী¶
আমরা একটা synthetic (কৃত্রিম) dataset বানাচ্ছি, যেখানে সত্যিকারের generating distribution আমরা জানি — এটাই synthetic data-র সুবিধা: classifier-এর রায়কে আমরা সত্যের সাথে মিলিয়ে দেখতে পারি। তিনটে শ্রেণি, প্রতিটা একটা 2D Gaussian থেকে আসা, প্রতিটা থেকে \(150\)টা করে বিন্দু — মোট \(n=450\)। তিনটে শ্রেণির mean ও covariance:
এখানে সবচেয়ে গুরুত্বপূর্ণ নকশা-সিদ্ধান্তটা লক্ষ করুন: তিনটে covariance তিন রকম — \(\Sigma_0\neq\Sigma_1\neq\Sigma_2\)। শ্রেণি \(0\) একটা পরিপাটি বৃত্ত (দুই অক্ষে সমান বিস্তার, কোনো কাত নেই); শ্রেণি \(1\) \(x_1\)-অক্ষ বরাবর লম্বাটে একটা উপবৃত্ত (variance \(2\) বনাম \(0.5\)) যার ভিতরে দুই feature ধনাত্মক-ভাবে সম্পর্কিত; আর শ্রেণি \(2\) ঠিক উল্টো — অন্য দিকে কাত, ঋণাত্মক correlation। এই ইচ্ছাকৃত অসমতাই গোটা অধ্যায়ের আসল পরীক্ষা: যে পদ্ধতি "সব শ্রেণির covariance এক" ধরে নেয় (LDA), তার অনুমান এখানে ভুল, আর যে পদ্ধতি প্রতি শ্রেণিকে নিজের covariance দেয় (QDA), তার অনুমান সঠিক। কোন অনুমান data-র সাথে মেলে — সেটাই শেষমেশ accuracy-তে ছাপ ফেলবে।
পুনরুৎপাদনযোগ্যতার জন্য আমরা random number generator-টা একটা নির্দিষ্ট seed দিয়ে বসাই (np.random.default_rng(20260619)), যাতে যে-কেউ একই কোড চালিয়ে অক্ষরে-অক্ষরে একই সংখ্যা পায় — এই অধ্যায়ের প্রতিটা accuracy এই seed-এর অধীনে নির্ণীত।
train/test বিভাজন — কেন, কীভাবে¶
মডেলকে যে data-তে শেখানো হয়, সেই একই data-তে accuracy মাপা একটা ক্লাসিক ফাঁদ — মডেল training-set মুখস্থ করে ফেলতে পারে, ফলে accuracy অতিরঞ্জিত হয় (in-sample optimism)। তাই আমরা data-কে দুই ভাগে কাটি: train (যেখানে মডেল শেখে) আর test (যা মডেল আগে কখনো দেখেনি, এখানেই আসল মূল্যায়ন)। আমরা রাখি \(30\%\) test, আর stratify=y দিয়ে নিশ্চিত করি যে train ও test দুটোতেই তিন শ্রেণির অনুপাত একই থাকে (নইলে দৈবচক্রে কোনো শ্রেণি test-এ কম পড়ে গেলে accuracy বিকৃত হতো)। ফলাফল:
সব accuracy নিচে এই একই \(135\)-বিন্দুর test set-এ মাপা — তাই পদ্ধতিগুলোর তুলনা সৎ ও সমান-মাঠের।
লক্ষ্যটা: Bayes rule, আর irreducible error¶
আমাদের লক্ষ্য এক বাক্যে: প্রতিটা নতুন বিন্দু \(x\)-কে তার সবচেয়ে সম্ভাব্য শ্রেণিতে পাঠাও — অর্থাৎ \(\hat{y}(x)=\arg\max_c P(y=c\mid x)\)। এটাই Bayes (optimal) classifier, আর তত্ত্ব বলে — সত্যিকারের \(f_c\) ও \(\pi_c\) জানা থাকলে এর চেয়ে কম ভুল করা অসম্ভব।
কিন্তু এখানে একটা গভীর কথা আছে। তিনটে Gaussian-এর mean কাছাকাছি (\([0,0],[3,1],[1,3]\) — সবগুলো origin-এর আশপাশে), আর তাদের বিস্তার যথেষ্ট বড়, তাই মেঘগুলো একে অন্যের গায়ে ছড়িয়ে পড়েছে (overlap)। যেখানে দুই শ্রেণির মেঘ মিশে গেছে, সেখানকার কোনো বিন্দু আসলে কোন শ্রেণির — তা নিশ্চিত করে বলা অসম্ভব, কারণ ওই অঞ্চলে একাধিক শ্রেণিরই অ-শূন্য density আছে। এর মানে: যত নিখুঁত classifier-ই বানাই না কেন, কিছু বিন্দু সবসময় ভুল শ্রেণিতে যাবে — এটাই irreducible Bayes error (অপসারণ-অযোগ্য ত্রুটি), data-র গঠন থেকেই আসা, কোনো algorithm দিয়ে দূর করা যায় না। তাই নিচের accuracy-গুলো \(1.0\)-র অনেক নিচে — এটা পদ্ধতির ব্যর্থতা নয়, এটা মাঠের বাস্তবতা। আমাদের কাজ হলো — কোন পদ্ধতি এই Bayes-সীমার সবচেয়ে কাছে পৌঁছায় তা খুঁজে বের করা।
মনে রাখার মতো ছবি। তিনটে শ্রেণিকে তিন রঙের একটা scatter ভাবুন: একটা গোল মেঘ (শ্রেণি \(0\), origin-এ), একটা ডান দিকে কাত লম্বাটে মেঘ (শ্রেণি \(1\)), আর একটা উপরে-বাঁয়ে উল্টো-কাত মেঘ (শ্রেণি \(2\))। মাঝখানে যেখানে তিন রঙ মাখামাখি — সেটাই কঠিন অঞ্চল, যেখানে যে-কোনো classifier হোঁচট খাবে।
৩.২ · E2 — LDA বনাম QDA: অনুমান যখন সঠিক/ভুল¶
এবার প্রথম দ্বৈরথ। LDA আর QDA — দুজনেই generative: তারা প্রতি শ্রেণির density \(f_c(x)\)-কে একটা Gaussian ধরে, তারপর Bayes rule-এ বসিয়ে posterior তোলে। তাদের একমাত্র, কিন্তু সিদ্ধান্তমূলক, পার্থক্য — covariance নিয়ে অনুমানে।
LDA — shared \(\Sigma\), তাই linear boundary¶
LDA ধরে নেয়: সব শ্রেণির covariance এক — একটাই \(\Sigma\) সবার জন্য। প্রতিটা শ্রেণির density তখন $$ f_c(x) \;=\; \frac{1}{2\pi\,\lvert\Sigma\rvert^{1/2}}\exp!\Big(!-\tfrac{1}{2}(x-\mu_c)^{!\top}\Sigma^{-1}(x-\mu_c)\Big), $$ যেখানে শুধু \(\mu_c\) শ্রেণিভেদে বদলায়, \(\Sigma\) এক। দুই শ্রেণির decision boundary যেখানে — সেখানে \(\pi_c f_c(x)=\pi_{c'}f_{c'}(x)\); log নিলে দেখা যায় quadratic পদ \(x^\top\Sigma^{-1}x\) দুই পক্ষে এক বলে কাটাকাটি যায়, পড়ে থাকে শুধু \(x\)-এ রৈখিক পদ। ফলে LDA-র সব decision boundary সরলরেখা (linear)। প্যারামিটার কম — একটাই \(\Sigma\) আঁচ করতে হয় (সব শ্রেণির data একসাথে pool করে), তাই কম data-তেও স্থিতিশীল; কিন্তু নমনীয়তাও কম।
QDA — per-class \(\Sigma_c\), তাই quadratic boundary¶
QDA এই বাঁধন খুলে দেয়: প্রতি শ্রেণির নিজের covariance \(\Sigma_c\)। density-তে এখন \(\Sigma\)-র জায়গায় \(\Sigma_c\): $$ f_c(x) \;=\; \frac{1}{2\pi\,\lvert\Sigma_c\rvert^{1/2}}\exp!\Big(!-\tfrac{1}{2}(x-\mu_c)^{!\top}\Sigma_c^{-1}(x-\mu_c)\Big). $$ এখন quadratic পদ \(x^\top\Sigma_c^{-1}x\) শ্রেণিভেদে আলাদা (কারণ \(\Sigma_c^{-1}\) আলাদা), তাই boundary-তে আর কাটাকাটি যায় না — \(x\)-এ দ্বিঘাত (quadratic) পদ টিকে থাকে। ফলে QDA-র decision boundary বাঁকা হতে পারে (parabola, ellipse, hyperbola — পরিস্থিতি অনুযায়ী)। দাম হলো — এখন প্রতি শ্রেণির জন্য একটা করে \(\Sigma_c\) আঁচ করতে হয়, অর্থাৎ অনেক বেশি parameter, তাই বেশি data দরকার আর overfit-এর ঝুঁকি বেশি।
রায়: এই data-তে QDA জেতে¶
আমাদের dataset-এ চালিয়ে test accuracy:
QDA স্পষ্টভাবে এগিয়ে — প্রায় \(3.8\) শতাংশ-বিন্দু বেশি (test-এর \(135\) বিন্দুতে এটা ~\(5\)টা অতিরিক্ত সঠিক শ্রেণিবিন্যাস)। কেন? কারণটা E1-এর নকশায় লুকিয়ে: আমরা ইচ্ছাকৃতভাবে তিনটে শ্রেণিকে আলাদা covariance দিয়েছি। LDA-র মূল অনুমান — "সব \(\Sigma\) এক" — এখানে সরাসরি মিথ্যা; LDA বাধ্য হয়ে তিনটে ভিন্ন-আকারের মেঘকে একটাই গড়পড়তা covariance দিয়ে মডেল করে, তাই তার সরলরেখা-boundary মেঘগুলোর আসল কাত-ধরা সীমানা ঠিকমতো ধরতে পারে না। QDA-র অনুমান — "প্রতি শ্রেণির নিজের \(\Sigma_c\)" — এখানে data-র সাথে মিলে যায়, তাই সে শ্রেণি \(1\)-এর লম্বাটে কাত আর শ্রেণি \(2\)-র উল্টো কাত — দুটোকেই আলাদা করে ধরে বাঁকা boundary আঁকতে পারে। অনুমান যখন সত্যের সাথে মেলে, পদ্ধতি জেতে — এটাই E2-র এক-লাইন শিক্ষা।
কিন্তু সাবধান — এটা সর্বজনীন নিয়ম নয়। QDA এখানে জিতেছে কারণ covariance সত্যিই আলাদা এবং প্রতি শ্রেণিতে \(\Sigma_c\) ভালো-ভাবে আঁচ করার মতো যথেষ্ট data (\(105\)টা train-বিন্দু/শ্রেণি) আছে। যদি covariance আসলে এক হতো, কিংবা data অল্প হতো, তবে QDA-র বাড়তি parameter-গুলো noise ধরে overfit করত, আর সরল-সংযত LDA-ই জিতত। অর্থাৎ flexibility বিনামূল্যে আসে না — এটা bias কমায় কিন্তু variance বাড়ায়।
৩.৩ · E3 — Naive Bayes ও k-NN: দুই ভিন্ন দর্শন¶
এবার দুটো ভিন্ন ঘরানার পদ্ধতি — একটা চরম-সরল generative (Naive Bayes), আরেকটা পুরোপুরি অ-প্যারামেট্রিক, distribution-মুক্ত (k-NN)।
Gaussian Naive Bayes — feature independence ধরে¶
Naive Bayes-এর "naive" (সরল-মনা) অনুমানটা হলো — একটা শ্রেণির ভিতরে feature-গুলো পরস্পর স্বাধীন: $$ P(x\mid y=c) \;=\; \prod_{j} P(x_j\mid y=c). $$ Gaussian NB-তে প্রতিটা \(P(x_j\mid y=c)\) একটা এক-মাত্রিক Gaussian, তাই কার্যত এটা QDA-রই একটা সীমাবদ্ধ সংস্করণ: প্রতি শ্রেণির covariance ধরা হয় diagonal (off-diagonal পদ শূন্য, অর্থাৎ feature-দের মধ্যে correlation নেই বলে ধরা)। এটা parameter আরও কমায় (প্রতি শ্রেণিতে শুধু \(d\)টা variance, কোনো covariance-পদ নয়)।
এখানে একটা চমকপ্রদ ব্যাপার ঘটে। আমাদের data-তে feature-গুলো মোটেই স্বাধীন নয় — শ্রেণি \(1\)-এ correlation \(+0.5\), শ্রেণি \(2\)-এ \(-0.3\) (off-diagonal পদ স্পষ্টতই অশূন্য)। অর্থাৎ NB-র মূল অনুমান এখানে লঙ্ঘিত। তবু:
— বেশ ভালো! LDA (\(0.881\))-কেও ছাড়িয়ে গেছে, QDA (\(0.919\))-র খুব কাছে। কীভাবে, যখন অনুমান ভুল? এটাই Naive Bayes-এর বিখ্যাত robustness (দৃঢ়তা): classification-এ আমাদের density-র নিখুঁত মান দরকার নেই — দরকার শুধু কোন শ্রেণির posterior সবচেয়ে বড়, সেই ক্রমটা ঠিক রাখা। correlation উপেক্ষা করায় NB density-র মানে ভুল করে বটে, কিন্তু সেই ভুলটা প্রায়ই তিন শ্রেণিতে একই দিকে হেলে, তাই argmax (ক্রম) অনেক সময় অটুট থাকে। তাছাড়া এখানে শ্রেণি-mean-গুলো যথেষ্ট দূরে, তাই শ্রেণি আলাদা করার মূল কাজটা mean-এর পার্থক্যই সারে — correlation-এর সূক্ষ্মতা গৌণ। ফল: ভুল অনুমান সত্ত্বেও NB দিব্যি কাজ চালিয়ে দেয়।
k-NN — কোনো distribution ধরে না¶
k-NN একেবারে উল্টো দর্শন — instance-based (নমুনা-নির্ভর), কোনো \(f_c(x)\)-র আকার সম্পর্কে কোনো অনুমানই করে না। নতুন বিন্দু \(x\) এলে সে শুধু training-set-এ \(x\)-এর সবচেয়ে কাছের \(k\)টা প্রতিবেশী খুঁজে নেয়, তাদের শ্রেণির majority vote নেয় — যে শ্রেণি বেশি, সেটাই \(x\)-এর শ্রেণি। কোনো Gaussian নেই, কোনো covariance নেই, "training" বলতে শুধু data মনে রেখে দেওয়া। দুটো \(k\)-তে:
দুটোই প্রতিযোগিতামূলক — \(\text{kNN}(15)\) তো QDA-র (\(0.919\)) প্রায় গা-ঘেঁষে, LDA ও NB-কেও ছাড়িয়ে। লক্ষণীয় — k-NN এই ফল পেয়েছে data-র distribution সম্পর্কে কিছু না ধরেই, নিছক স্থানীয় ঘনত্বের প্যাটার্ন থেকে। এটাই অ-প্যারামেট্রিক পদ্ধতির শক্তি: যখন আপনি জানেন না density-র আকার কী, k-NN আকার নিয়ে ভুল-অনুমানের ঝুঁকি এড়িয়ে data-কেই কথা বলতে দেয়। দাম হলো — সব training-বিন্দু মনে রাখতে হয়, prediction-এর সময় প্রতিবার দূরত্ব হিসাব লাগে (বড় data-তে ধীর), আর \(k\) ঠিকঠাক বাছতে হয় — যা পরের ধাপের বিষয়।
দুই দর্শন এক বাক্যে। Naive Bayes একটা strong অনুমান করে (independence) কিন্তু সেটা ভুল হলেও সরে যায় না — মিতব্যয়ী ও দৃঢ়। k-NN কোনো অনুমানই করে না — নমনীয় কিন্তু data-ক্ষুধার্ত ও \(k\)-সংবেদনশীল। দুটোই এই মাঠে \(0.90\)-র আশপাশে — কিন্তু পৌঁছেছে সম্পূর্ণ বিপরীত পথে।
৩.৪ · E4 — \(k\)-এর ভূমিকা ও সার্বিক তুলনা¶
\(k\) — bias–variance-এর কাঁটা¶
k-NN-এ একটাই মূল hyperparameter — প্রতিবেশীর সংখ্যা \(k\) — আর এটাই পদ্ধতির আচরণ পুরো ঠিক করে দেয়। একই test-set-এ \(k\) বাড়িয়ে accuracy:
| \(k\) | test accuracy |
|---|---|
| \(1\) | \(0.859\) |
| \(3\) | \(0.889\) |
| \(5\) | \(0.896\) |
| \(9\) | \(0.896\) |
| \(15\) | \(0.911\) |
| \(25\) | \(0.911\) |
প্যাটার্নটা পরিষ্কার এবং শিক্ষণীয়। \(k=1\) (শুধু নিকটতম একটি প্রতিবেশী) সবচেয়ে দুর্বল (\(0.859\)): এখানে প্রতিটা training-বিন্দু নিজের চারপাশে নিজস্ব ছোট রাজত্ব গড়ে, decision boundary হয়ে ওঠে খাঁজকাটা, এবড়োখেবড়ো (jagged) — মডেল প্রতিটা একক বিন্দুর (এমনকি noise-বিন্দুরও) কথা শোনে, ফলে high variance / overfit। \(k\) বাড়ার সাথে ভোটে বেশি প্রতিবেশী অংশ নেয়, একক noisy বিন্দুর প্রভাব গড়ে মুছে যায়, boundary মসৃণ হয়, accuracy উঠে \(k=15,25\)-তে \(0.911\)-এ স্থির হয়। অর্থাৎ:
- ছোট \(k\) → low bias, high variance (boundary অতি-নমনীয়, noise ধরে)।
- বড় \(k\) → high bias, low variance (boundary অতি-মসৃণ, খুব বড় করলে আবার সূক্ষ্ম গঠন হারিয়ে underfit-এর দিকে যেত)।
তাই \(k\) হলো bias–variance trade-off-এর সরাসরি knob — ছোট থেকে বড় করা মানে variance কমিয়ে bias বাড়ানো। এই data-তে সুবিধাজনক বিন্দু \(k\approx 15\), কিন্তু খেয়াল করুন accuracy \(k=5\) থেকে \(25\) পর্যন্ত মোটামুটি সমতল (\(0.896\)–\(0.911\)) — k-NN এখানে \(k\)-র সঠিক মানের ব্যাপারে খুব স্পর্শকাতর নয়, যা স্বস্তিদায়ক। বাস্তবে \(k\) বাছা হয় cross-validation দিয়ে, কোনো একটা test-set দেখে নয়।
পাঁচ পদ্ধতির এক টেবিলে রায়¶
| পদ্ধতি | মূল অনুমান | boundary | test accuracy |
|---|---|---|---|
| LDA | shared \(\Sigma\) (সব শ্রেণি এক covariance) | linear | \(0.881\) |
| QDA | per-class \(\Sigma_c\) | quadratic | \(0.919\) ★ সর্বোচ্চ |
| GaussianNB | feature independence (diagonal \(\Sigma_c\)) | quadratic | \(0.904\) |
| k-NN \((k=5)\) | কোনো distributional অনুমান নেই | অ-প্যারামেট্রিক | \(0.896\) |
| k-NN \((k=15)\) | কোনো distributional অনুমান নেই | অ-প্যারামেট্রিক | \(0.911\) |
সার্বিক শিক্ষা¶
এক ছবিতে গল্পটা দাঁড়ায় এই: QDA জিতেছে (\(0.919\)) কারণ এই dataset-এ শ্রেণিগুলোর covariance সত্যিই আলাদা, আর QDA-র per-class \(\Sigma_c\) অনুমান ঠিক সেই গঠনটাই ধরতে পারে — সবচেয়ে নমনীয় generative মডেলটা এখানে সবচেয়ে কম bias দিয়ে জিতল। LDA সবচেয়ে পিছিয়ে (\(0.881\)) কারণ তার "shared \(\Sigma\)" অনুমান এই data-তে স্পষ্টতই ভুল। GaussianNB (\(0.904\)) আশ্চর্যজনকভাবে ভালো — feature-independence লঙ্ঘিত হওয়া সত্ত্বেও — যা NB-র দৃঢ়তার প্রমাণ। আর k-NN (\(0.911\) at \(k=15\)) কোনো distributional অনুমান ছাড়াই QDA-র গা-ঘেঁষে রইল, দেখিয়ে দিল — সঠিক \(k\) পেলে অ-প্যারামেট্রিক পদ্ধতিও সমান টক্কর দেয়।
সবচেয়ে গভীর take-away: কোনো classifier সর্বজনীনভাবে "সেরা" নয় (no free lunch)। প্রতিটার একটা অন্তর্নিহিত অনুমান আছে, আর সেই অনুমান যত data-র সত্যিকারের গঠনের কাছাকাছি, পদ্ধতি তত ভালো করে। এই মাঠে covariance আলাদা বলে নমনীয় QDA জিতল; অন্য মাঠে — যদি covariance সত্যিই এক হতো বা data কম হতো — সংযত LDA-ই হয়তো জিতত। তাই classifier বাছাই কখনোই অন্ধ নয়; এটা data সম্পর্কে আপনার অনুমান কী, আর কতটা flexibility আপনি বহন করতে পারবেন (data-র পরিমাণ অনুযায়ী) — এই দুইয়ের সচেতন ভারসাম্য।
যাচাই (verification)¶
নিচের scikit-learn কোড উপরের প্রতিটা সংখ্যা পুনরুৎপাদন করে (seed 20260619, একই train/test বিভাজন):
import numpy as np
from sklearn.discriminant_analysis import (
LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis)
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
rng = np.random.default_rng(20260619)
means = [[0, 0], [3, 1], [1, 3]]
covs = [[[1, 0], [0, 1]],
[[2, 0.5], [0.5, 0.5]],
[[0.6, -0.3], [-0.3, 1.5]]]
X = np.vstack([rng.multivariate_normal(means[c], covs[c], 150) for c in range(3)])
y = np.repeat(range(3), 150) # 3 classes x 150 = 450 points
Xtr, Xte, ytr, yte = train_test_split(
X, y, test_size=0.3, random_state=0, stratify=y)
print(Xtr.shape[0], Xte.shape[0]) # -> 315 135
def acc(model):
return round(model.fit(Xtr, ytr).score(Xte, yte), 3)
print("LDA :", acc(LinearDiscriminantAnalysis())) # 0.881
print("QDA :", acc(QuadraticDiscriminantAnalysis())) # 0.919 (best)
print("GaussianNB:", acc(GaussianNB())) # 0.904
print("kNN(5) :", acc(KNeighborsClassifier(n_neighbors=5))) # 0.896
print("kNN(15) :", acc(KNeighborsClassifier(n_neighbors=15))) # 0.911
for k in [1, 3, 5, 9, 15, 25]: # 0.859 0.889 0.896 0.896 0.911 0.911
print(f"k={k:2d}: {acc(KNeighborsClassifier(n_neighbors=k))}")
315 135
LDA : 0.881
QDA : 0.919
GaussianNB: 0.904
kNN(5) : 0.896
kNN(15) : 0.911
k= 1: 0.859
k= 3: 0.889
k= 5: 0.896
k= 9: 0.896
k=15: 0.911
k=25: 0.911
প্রতিটা সংখ্যা ব্রিফের canonical মানের সাথে অক্ষরে-অক্ষরে মেলে — QDA (\(0.919\)) সর্বোচ্চ, LDA (\(0.881\)) সর্বনিম্ন, আর k-NN-এর accuracy \(k\)-র সাথে monotonically বাড়ে (jagged \(k=1\) থেকে মসৃণ \(k=25\))।
৪ · প্রমাণ ও উৎপাদন¶
আগের sections-এ আমরা চারটি classifier-কে — LDA, QDA, Naive Bayes, k-NN — intuition-এর স্তরে চিনেছি: কে linear boundary আঁকে, কে বাঁকানো boundary আঁকে, কে প্রতিবেশী গুনে ভোট নেয়। এবার আমরা পেছনের গণিতটা কলম-হাতে খুলে দেখব। মূল বিষয়টা হলো — এই সব classifier আসলে একটাই আদর্শের আনুমানিক রূপ: Bayes classifier। তাই আমরা শুরু করব সেই আদর্শ থেকে (কেন posterior-এর সর্বোচ্চ ক্লাস বাছাই-ই সর্বোত্তম), তারপর দেখব প্রতিটা পদ্ধতি class-conditional \(f_c(x)\)-এর উপর কী assumption চাপিয়ে সেই আদর্শকে কাছাকাছি ধরতে চায় — আর সেই assumption-গুলোই তাদের bias–variance চরিত্র ঠিক করে দেয়।
প্রতিটি উপ-section-এর শিরোনামে difficulty tag দেওয়া আছে (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং)। notation শুরু থেকে শেষ পর্যন্ত একই: \(x\in\mathbb R^p\) একটা feature-vector, class label \(y\in\{1,\dots,C\}\), prior \(\pi_c=P(y=c)\), class-conditional density \(f_c(x)=P(x\mid y=c)\), এবং posterior
multivariate normal class-conditional হলে (prereq 2.4):
৪.১ Bayes classifier কেন সর্বোত্তম ★★¶
লক্ষ্য¶
আমরা প্রমাণ করব: যে রুল posterior সর্বোচ্চ যে ক্লাসের তাকে বেছে নেয় —
— সেটা misclassification-এর সম্ভাবনা \(P(\hat y\ne y)\) সবচেয়ে ছোট করে, অর্থাৎ যেকোনো সম্ভাব্য classifier \(g:\mathbb R^p\to\{1,\dots,C\}\)-এর মধ্যে এটাই অপরাজেয়। একে বলে Bayes classifier, আর তার অর্জিত সর্বনিম্ন error-কে বলে Bayes error।
ধাপ ১ — error-কে \(x\)-এর উপর condition করা¶
ধরুন \(g\) যেকোনো একটা classifier। তার ভুল করার সম্ভাবনা হলো
যেখানে বাইরের expectation \(X\)-এর marginal density \(m(x)=\sum_l \pi_l f_l(x)\)-এর উপর। এই conditioning-টাই পুরো প্রমাণের চাবি: total expectation-এর সূত্র (prereq 2.2) বলছে গোটা error আসলে প্রতিটি \(x\)-এ আলাদা আলাদা "local error"-এর গড়। তাই যদি প্রতিটি \(x\)-এর জন্য আলাদাভাবে local error সবচেয়ে ছোট করতে পারি, তাহলে তাদের গড়ও — অর্থাৎ মোট error-ও — সবচেয়ে ছোট হবে। (\(X\)-এর প্রতিটি মানে আমরা স্বাধীনভাবে সিদ্ধান্ত নিতে পারি, তাই একে point-wise minimization-এ ভেঙে ফেলা বৈধ।)
ধাপ ২ — একটা নির্দিষ্ট \(x\)-এ সর্বোত্তম সিদ্ধান্ত¶
একটা নির্দিষ্ট \(x\) ধরুন। classifier সেখানে কোনো একটা label \(g(x)=k\) ফেরত দেয়। সেই বিন্দুতে সঠিক হওয়ার সম্ভাবনা হলো \(P(Y=k\mid X=x)\), তাই ভুল হওয়ার সম্ভাবনা
এই রাশিটা ছোট করা মানে \(P(Y=k\mid X=x)\)-কে বড় করা — আর \(k\)-এর উপর আমাদের পূর্ণ স্বাধীনতা আছে। সুতরাং local error তখনই সর্বনিম্ন যখন
অর্থাৎ ঠিক Bayes rule যা বলছে তাই। যেকোনো অন্য পছন্দ \(k'\)-এর জন্য \(P(Y=k'\mid x)\le\max_c P(Y=c\mid x)\), তাই তার local error সমান বা বেশি — কম কখনোই নয়। এতে প্রতিটি \(x\)-এ সর্বনিম্ন local error দাঁড়ায়
ধাপ ৩ — integrate করে Bayes error¶
ধাপ ১-এর সূত্রে এই সর্বনিম্ন local error বসিয়ে (\(X\)-এর উপর গড় নিয়ে) পাই Bayes classifier-এর মোট error, যাকে আমরা Bayes error \(R^\*\) বলি:
আর যেহেতু প্রতিটি \(x\)-এ Bayes rule-এর local error যেকোনো \(g\)-এর local error-এর চেয়ে \(\le\), তাদের গড় নিলেও অসমতা টিকে থাকে:
এটাই optimality: কোনো classifier — যত জটিল মডেলই হোক — Bayes error-এর নিচে নামতে পারে না। \(\;\blacksquare\)
কেন এটা গুরুত্বপূর্ণ। Bayes error হলো সমস্যাটার মধ্যে গাঁথা irreducible noise — overlapping ক্লাসগুলোর কারণে যে ভুল কোনোভাবেই এড়ানো যায় না (prereq 6.1-এর irreducible error-এর classification-সংস্করণ)। কোনো classifier \(0\) error দিলে সন্দেহ করুন (সম্ভবত overfit), আর \(R^\*\)-এর কাছাকাছি গেলে বুঝবেন আর উন্নতির জায়গা নেই। লক্ষ করুন \(\max_c P(Y=c\mid x)\ge 1/C\) (গড়ের চেয়ে সর্বোচ্চ কখনো ছোট নয়), তাই \(R^\*\le 1-1/C\) — অর্থাৎ Bayes classifier কখনো random guessing-এর চেয়ে খারাপ নয়।
বাস্তব সমস্যা। আমরা posterior \(P(y=c\mid x)\) সত্যিকারে জানি না — \(\pi_c\) ও \(f_c\) অজানা। তাই বাকি প্রতিটা পদ্ধতি আসলে এই posterior-কে estimate করার একেকটা কৌশল: prior-কে class-frequency দিয়ে, আর \(f_c\)-কে কোনো একটা assumption-এর অধীনে। সেই assumption-গুলোই এখন আমাদের বিষয়।
৪.২ LDA-র linear discriminant: shared \(\Sigma\) থেকে রেখা boundary ★★★¶
লক্ষ্য¶
ধরা যাক প্রতিটি ক্লাসের class-conditional একটা multivariate normal, এবং সব ক্লাসের covariance এক: \(\Sigma_c=\Sigma\) সবার জন্য। আমরা দেখাব এই shared-\(\Sigma\) assumption থেকে posterior-maximization সংকুচিত হয়ে দাঁড়ায় একটা linear discriminant function
আর এর ফলে যেকোনো দুই ক্লাসের মধ্যেকার decision boundary \(\{x:\delta_c(x)=\delta_{c'}(x)\}\) হয় \(x\)-এ linear — একটা সরলরেখা/hyperplane।
ধাপ ১ — argmax-এ denominator ফেলে দেওয়া¶
posterior
denominator \(\sum_l\pi_l f_l(x)\) সব ক্লাসের জন্য একই সংখ্যা (\(c\)-এর উপর নির্ভর করে না), তাই \(\arg\max_c\) নেওয়ার সময় তাকে উপেক্ষা করা যায়:
\(\log\) একটা strictly increasing function, তাই argmax বদলায় না — log নিয়ে product-কে sum-এ ভাঙি (সংখ্যাগতভাবে এটাই স্থিতিশীল):
আমরা যে রাশিটা maximize করছি সেটাকেই discriminant function বলি: \(\delta_c(x):=\log\pi_c+\log f_c(x)\) (যেকোনো \(c\)-অনির্ভর ধ্রুবক যোগ/বিয়োগ করার স্বাধীনতা-সহ, কারণ তাতে argmax বদলায় না)।
ধাপ ২ — Gaussian-এর log নেওয়া¶
multivariate normal-এর log:
এখানে দুটো term সব ক্লাসে একদম একই: \(-\tfrac{p}{2}\log(2\pi)\) তো ধ্রুবক, আর shared-\(\Sigma\) ধরায় \(-\tfrac12\log\lvert\Sigma_c\rvert=-\tfrac12\log\lvert\Sigma\rvert\)-ও \(c\)-অনির্ভর। argmax-এ এদের ফেলে দিয়ে লিখি
ধাপ ৩ — quadratic term খুলে cancel করানো (এটাই মূল চমক)¶
Mahalanobis-form \((x-\mu_c)^\top\Sigma^{-1}(x-\mu_c)\)-টা খুলি। \(\Sigma^{-1}\) symmetric, তাই \(x^\top\Sigma^{-1}\mu_c\) ও \(\mu_c^\top\Sigma^{-1}x\) একই scalar — তাদের একত্রে \(-2\,x^\top\Sigma^{-1}\mu_c\) লেখা যায়:
লক্ষ করুন term (A) \(=x^\top\Sigma^{-1}x\)-তে ক্লাস-সূচক \(c\) কোথাও নেই — কারণ সব ক্লাসের \(\Sigma\) এক। সুতরাং এটা প্রতিটি ক্লাসে হুবহু একই সংখ্যা, এবং argmax-এ আবার ফেলে দেওয়া যায়। এই একটিমাত্র cancellation-ই LDA-কে linear বানায়। বাকি দুটো term নিয়ে (\(-\tfrac12\) গুণিতক হিসাবে):
এটাই box-এ দেওয়া linear discriminant। গঠনটা পরিষ্কার দেখতে \(w_c:=\Sigma^{-1}\mu_c\in\mathbb R^p\) এবং \(b_c:=-\tfrac12\mu_c^\top\Sigma^{-1}\mu_c+\log\pi_c\) ধরলে
অর্থাৎ \(x\)-এর একটা affine (প্রথম-মাত্রার) function, কোনো \(x^\top(\cdots)x\) পদ নেই।
ধাপ ৪ — boundary linear¶
দুই ক্লাস \(c,c'\)-এর সীমানা সেখানে যেখানে তারা সমান-বিশ্বাসযোগ্য, অর্থাৎ \(\delta_c(x)=\delta_{c'}(x)\):
এটা \(x\)-এ একটা linear equation — অর্থাৎ একটা hyperplane (\(p=2\)-তে সরলরেখা)। স্পষ্টভাবে, normal vector \(w_c-w_{c'}=\Sigma^{-1}(\mu_c-\mu_{c'})\):
quadratic পদ cancel হয়ে যাওয়ায় boundary-তে \(x^\top(\cdots)x\) কিছু নেই — তাই সীমানা সোজা। \(\;\blacksquare\)
সংখ্যায় যাচাই (sanity check)। \(p=2\), \(\Sigma=\big[\begin{smallmatrix}1&0.3\\0.3&1.5\end{smallmatrix}\big]\), \(\mu_1=(0,0)\), \(\mu_2=(2,1)\), \(\pi=(0.4,0.6)\) ধরে এক বিন্দু \(x=(1.3,0.7)\)-তে সরাসরি log-posterior পার্থক্য \(g_1-g_2\) আর linear-discriminant পার্থক্য \(\delta_1-\delta_2\) — দুটোই হুবহু \(-1.0367\) এলো; আর \(2000\)টা random \(x\)-এর প্রতিটিতে \(\delta_1-\delta_2\) ঠিক \(w^\top x-b\) form-এর সমান হলো (\(w=\Sigma^{-1}(\mu_1-\mu_2)\)) — অর্থাৎ quadratic পদ সত্যিই cancel হয়েছে আর boundary linear।
কী হারালাম, কী পেলাম। LDA-র এই সরলতা assumption-নির্ভর: shared \(\Sigma\) ভুল হলে boundary-ও ভুল জায়গায় বসবে (bias)। কিন্তু পুরস্কারটা হলো parameter-মিতব্যয়িতা — মাত্র একটা \(\Sigma\) (\(O(p^2)\) সংখ্যা) সব ক্লাস মিলে estimate করতে হয়, তাই variance কম (prereq 6.1)। পরের উপ-section দেখাবে এই assumption শিথিল করলে কী হয়।
৪.৩ QDA-র quadratic discriminant: per-class \(\Sigma_c\) থেকে বাঁকানো boundary ★★¶
লক্ষ্য¶
এবার আমরা shared-\(\Sigma\) assumption তুলে নিই: প্রতিটি ক্লাসের নিজস্ব covariance \(\Sigma_c\) থাকতে পারে। আমরা দেখাব এতে discriminant-টা \(x\)-এ quadratic হয়ে যায়, ফলে boundary বাঁকানো (curved) — এটাই Quadratic Discriminant Analysis।
উৎপাদন¶
§৪.২-এর ধাপ ১–২ হুবহু একই (denominator ফেলা, log নেওয়া), পার্থক্য শুধু এবার \(\Sigma_c\)-নির্ভর term-গুলো আর ক্লাসজুড়ে এক নয়। ধাপ ২-এর log-Gaussian থেকে শুধু \(c\)-অনির্ভর ধ্রুবক \(-\tfrac{p}{2}\log(2\pi)\) ফেলে পাই:
এখানে দুটো জিনিস LDA থেকে আলাদা: (১) \(\log\lvert\Sigma_c\rvert\) পদটা আর ধ্রুবক নয় — প্রতিটি ক্লাসে ভিন্ন, তাই রাখতে হলো; (২) আর সবচেয়ে গুরুত্বপূর্ণ — Mahalanobis পদটা খুললে
এখানকার quadratic পদ \(-\tfrac12\,x^\top\Sigma_c^{-1}x\)-এ \(\Sigma_c^{-1}\) ক্লাসভেদে আলাদা, তাই §৪.২-এর মতো cancel হয় না। ফলে \(\delta_c(x)\)-এ \(x^\top(\cdots)x\) টিকে থাকে — discriminant quadratic in \(x\)।
boundary বাঁকানো¶
দুই ক্লাসের সীমানা \(\delta_c(x)=\delta_{c'}(x)\) এবার দাঁড়ায়
যেহেতু সাধারণত \(\Sigma_c^{-1}\ne\Sigma_{c'}^{-1}\), quadratic পদের সহগ-ম্যাট্রিক্স \(\Sigma_c^{-1}-\Sigma_{c'}^{-1}\ne 0\) — তাই boundary একটা quadric (parabola/ellipse/hyperbola-জাতীয় বাঁকা রেখা/পৃষ্ঠ), সরলরেখা নয়। (বিশেষ ক্ষেত্রে \(\Sigma_c=\Sigma_{c'}\) হলে এই পদ মিলিয়ে গিয়ে LDA-র linear boundary ফিরে আসে — অর্থাৎ LDA হলো QDA-র একটা সীমাবদ্ধ রূপ।)
সংখ্যায় যাচাই। একই \(x=(1.3,0.7)\)-তে \(\Sigma_1=\big[\begin{smallmatrix}1&0.2\\0.2&0.8\end{smallmatrix}\big]\), \(\Sigma_2=\big[\begin{smallmatrix}1.5&-0.4\\-0.4&1\end{smallmatrix}\big]\) ধরে log-posterior পার্থক্য আর উপরের \(\delta_c\)-পার্থক্য দুটোই হুবহু \(-0.7984\) মিলল।
bias–variance ফয়সালা¶
এই দুই পদ্ধতির পার্থক্যটা ঠিক prereq 6.1-এর bias–variance দ্বন্দ্বের পাঠ্যবই-উদাহরণ:
| LDA | QDA | |
|---|---|---|
| covariance | একটা shared \(\Sigma\) | প্রতি ক্লাসে আলাদা \(\Sigma_c\) |
| boundary | linear | curved (quadratic) |
| parameter সংখ্যা (covariance) | \(O(p^2)\) | \(O(Cp^2)\) |
| flexibility | কম | বেশি |
| bias | বেশি (boundary সত্যিই বাঁকা হলে ভুল ধরে) | কম (বাঁকা boundary ধরতে পারে) |
| variance | কম | বেশি (\(C\)টা \(\Sigma_c\) estimate করতে হয়) |
মূলকথা: QDA বেশি নমনীয় তাই bias কম, কিন্তু \(C\)টা পূর্ণ covariance matrix estimate করতে হয় (\(O(Cp^2)\) parameter) বলে variance বেশি — বিশেষত ছোট ক্লাসে বা বড় \(p\)-তে \(\Sigma_c\)-এর estimate নড়বড়ে হয়। তাই data কম হলে বা boundary প্রায়-সরল হলে LDA-ই প্রায়ই ভালো test-error দেয়; আর প্রতি ক্লাসে প্রচুর data থাকলে এবং সত্যিকারের boundary বাঁকা হলে QDA জেতে।
৪.৪ Naive Bayes: conditional independence থেকে diagonal \(\Sigma\) ★★¶
লক্ষ্য¶
Naive Bayes একটা একদম ভিন্ন (এবং অনেক বেশি কঠোর) সরলীকরণ ব্যবহার করে: ধরে নেয় ক্লাস জানা থাকলে feature-গুলো পরস্পর স্বাধীন —
আমরা দেখাব Gaussian ক্ষেত্রে এই assumption ঠিক diagonal covariance-এর সমতুল্য, এবং তখন discriminant-টা feature-ভিত্তিক log-density-র একটা যোগফলে ভেঙে যায়।
ধাপ ১ — discriminant feature-জুড়ে যোগফলে ভাঙে¶
§৪.২-এর মতো discriminant \(\delta_c(x)=\log\pi_c+\log f_c(x)\)। conditional-independence assumption বসিয়ে product-এর log নিলে সেটা sum হয়ে যায়:
অর্থাৎ পুরো \(p\)-মাত্রিক density-কে আর একসাথে model করতে হয় না — প্রতিটি feature-এর এক-মাত্রিক density আলাদা করে শিখে যোগ করলেই চলে। এই decomposition-ই Naive Bayes-কে এত সস্তা ও high-dimension-এ ব্যবহারযোগ্য করে।
ধাপ ২ — Gaussian Naive Bayes = diagonal covariance¶
ধরা যাক প্রতিটি feature-এর class-conditional এক-মাত্রিক normal: \(x_j\mid y=c\sim\mathcal N(\mu_{cj},\sigma_{cj}^2)\)। তাহলে
এটা ঠিক সেই multivariate normal discriminant যার covariance diagonal: \(\Sigma_c=\operatorname{diag}(\sigma_{c1}^2,\dots,\sigma_{cp}^2)\)। কারণ diagonal \(\Sigma_c\)-এর জন্য \(\Sigma_c^{-1}=\operatorname{diag}(1/\sigma_{cj}^2)\) এবং \(\lvert\Sigma_c\rvert=\prod_j\sigma_{cj}^2\), ফলে QDA-র Mahalanobis-form ও log-determinant দুটোই feature-জুড়ে যোগফলে ভেঙে গিয়ে হুবহু উপরের রাশি দেয়:
সুতরাং Gaussian Naive Bayes হলো QDA-র সেই বিশেষ রূপ যেখানে প্রতিটি \(\Sigma_c\)-কে diagonal হতে বাধ্য করা হয় — off-diagonal covariance (feature-দের মধ্যে correlation) ধরা হয় শূন্য।
সংখ্যায় যাচাই। \(\mu_1=(0,0)\), diagonal var \(=(1,0.8)\), \(x=(1.3,0.7)\) ধরে দুই-feature log-density-র যোগফল আর সরাসরি diagonal-covariance multivariate-normal log-density — দুটোই হুবহু \(-2.8776\) এলো, যা ধাপ ২-এর সমতুল্যতা নিশ্চিত করে।
bias–variance: সরলতার দাম ও পুরস্কার¶
assumption-গুলোকে এক সারিতে সাজালে একটা পরিষ্কার ধারা দেখা যায় — constraint যত বাড়ে, flexibility তত কমে, parameter তত কমে:
Naive Bayes এই শৃঙ্খলের সবচেয়ে constrained প্রান্তে: প্রতি ক্লাসে covariance-এ মাত্র \(p\)টা variance (off-diagonal শূন্য), তাই মোট covariance-parameter \(O(Cp)\) — QDA-র \(O(Cp^2)\)-এর তুলনায় নাটকীয়ভাবে কম। এর ফল:
- bias বেশি যখন feature-গুলো সত্যিই correlated — কারণ independence ধরাটা তখন ভুল, boundary বিকৃত হয়।
- কিন্তু variance খুব কম এবং high-dimension-এ robust — অল্প parameter বলে কম data-তেও estimate স্থিতিশীল, \(p\) বড় হলেও ভেঙে পড়ে না।
মজার ব্যাপার, ব্যবহারিকভাবে Naive Bayes প্রায়ই প্রত্যাশার চেয়ে ভালো করে: সঠিক ranking (কোন posterior বড়) পেতে probability-গুলো নিখুঁত হওয়ার দরকার নেই, তাই independence ভুল হলেও argmax প্রায়ই ঠিক ক্লাসেই পড়ে — বিশেষত text/high-dimensional সমস্যায় এর low-variance চরিত্রই জিতিয়ে দেয়।
৪.৫ k-NN-এর consistency: প্রতিবেশী থেকে Bayes-এর কাছাকাছি ★★¶
রুলটা¶
k-Nearest-Neighbours কোনো density estimate করে না — সরাসরি প্রতিবেশীর ভোট নেয়। একটা বিন্দু \(x\) শ্রেণিবদ্ধ করতে: training set-এ \(x\)-এর সবচেয়ে কাছের \(k\)টা বিন্দু খুঁজে নাও (সাধারণত Euclidean distance-এ), তারপর তাদের মধ্যে যে ক্লাস সংখ্যাগরিষ্ঠ সেটাই \(\hat y(x)\) —
যেখানে \(N_k(x)\) হলো \(x\)-এর \(k\) নিকটতম প্রতিবেশীর সূচক-সমষ্টি। ভেতরের ভগ্নাংশটা আসলে প্রতিবেশীদের মধ্যে ক্লাস-\(c\)-এর হার — অর্থাৎ posterior \(P(y=c\mid x)\)-এর একটা স্থানীয় (local), nonparametric estimate।
intuition: কেন এটা Bayes-এর দিকে যায়¶
দুটো সীমা একসাথে ঘটলে এই estimate সত্যিকারের posterior-এ পৌঁছায়, এই শর্তে: \(n\to\infty\), \(k\to\infty\), কিন্তু \(k/n\to 0\)।
- \(k/n\to 0\) (locality): প্রতিবেশীর সংখ্যা \(k\) মোট নমুনা \(n\)-এর তুলনায় তুচ্ছ — তাই \(x\)-এর চারপাশের যে ছোট্ট অঞ্চল থেকে প্রতিবেশীরা আসছে, \(n\) বাড়ার সাথে সাথে সেটা শূন্যের দিকে সংকুচিত হয়। ফলে প্রতিবেশীরা সবাই কার্যত \(x\)-এর গায়ে, যেখানে posterior প্রায় ধ্রুবক \(P(y=c\mid x)\) (bias → 0)।
- \(k\to\infty\) (averaging): তবু প্রতিবেশীর সংখ্যা অসীমে যাচ্ছে, তাই majority-হার \(\frac1k\sum\mathbf 1\{y_i=c\}\) law of large numbers-এর বলে সত্যিকারের local probability \(P(y=c\mid x)\)-তে গড়িয়ে যায় (variance → 0)।
দুটো একসাথে মানে k-NN-এর estimate করা posterior → সত্যিকারের posterior, তাই এর argmax → Bayes rule-এর argmax। ফলস্বরূপ k-NN-এর risk সত্যিকারের Bayes risk \(R^\*\)-এ converge (অভিসৃত) হয় (§৪.১):
এই বৈশিষ্ট্যকে বলে (universal) consistency — কোনো distributional assumption ছাড়াই, যথেষ্ট data দিলে k-NN সর্বোত্তমের কাছাকাছি পৌঁছে যায়।
ক্লাসিক \(1\)-NN সীমা: \(R_{1\text{-NN}}\le 2R^\*\)¶
একটা বিখ্যাত asymptotic ফল (Cover–Hart): সবচেয়ে সরল \(k=1\) ক্ষেত্রেও, \(n\to\infty\)-এ \(1\)-NN-এর risk Bayes risk-এর দ্বিগুণের বেশি কখনো নয়:
এক-লাইনে কেন। asymptotically \(1\)-NN-এর প্রতিবেশী \(x\)-এর গায়ে এসে পড়ে, তাই তার ক্লাস স্বাধীনভাবে সত্যিকারের posterior \(P(\cdot\mid x)\) থেকে আসা একটা draw। দুই-ক্লাস ক্ষেত্রে \(1\)-NN তখনই ভুল করে যখন test-বিন্দু আর তার প্রতিবেশী বিপরীত ক্লাসের — যার সম্ভাবনা \(2\,\eta(x)\big(1-\eta(x)\big)\) (এখানে \(\eta(x)=P(y=1\mid x)\)); এর বিপরীতে Bayes error ওই বিন্দুতে \(\min(\eta,1-\eta)\), আর \(2\eta(1-\eta)\le 2\min(\eta,1-\eta)\) — \(x\)-জুড়ে গড় নিলে \(R_{1\text{-NN}}\le 2R^\*\)। অর্থাৎ অর্ধেক information (একটামাত্র প্রতিবেশী) দিয়েও \(1\)-NN সর্বোত্তমের অন্তত "অর্ধেক ভালো" — তথ্যহীন noise-ই বাকি ব্যবধান।
\(k\) হলো bias–variance knob¶
LDA↔QDA-তে যেমন covariance-assumption flexibility ঠিক করত, k-NN-এ সেই ভূমিকা নেয় \(k\):
- ছোট \(k\) (যেমন \(k=1\)): খুব নমনীয়, boundary এবড়োখেবড়ো — প্রতিটি বিন্দুর অতি-স্থানীয় খুঁটিনাটি ধরে। bias কম, variance বেশি (একটা প্রতিবেশী বদলালেই সিদ্ধান্ত বদলায়, noise-এ overfit)।
- বড় \(k\): অনেক প্রতিবেশীর গড়, boundary মসৃণ ও স্থিতিশীল — কিন্তু দূরের, ভিন্ন-posterior-এর বিন্দুও ভোটে ঢুকে পড়ে। variance কম, bias বেশি (অতি-মসৃণ, স্থানীয় গঠন হারায়; চরমে \(k=n\) হলে সবসময় সংখ্যাগরিষ্ঠ ক্লাস — পুরো underfit)।
তাই \(k\) বাছাই (সাধারণত cross-validation দিয়ে, পরবর্তী section) ঠিক prereq 6.1-এর সেই একই sweet-spot খোঁজা — যেখানে bias² + variance সর্বনিম্ন। এভাবে এই অধ্যায়ের চারটি classifier-ই ঘুরেফিরে একই দুটো প্রশ্নের ভিন্ন উত্তর: posterior-কে কত নমনীয়ভাবে estimate করব, আর সেই নমনীয়তার বিনিময়ে কতটা variance মেনে নেব।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে আমরা একটি synthetic তিন-class দুই-মাত্রিক dataset তৈরি করব, যেখানে প্রতিটি class আলাদা mean এবং আলাদা covariance নিয়ে গঠিত। ইচ্ছাকৃতভাবে covariance গুলো অসমান রাখা হয়েছে — এতে চারটি classifier (LDA, QDA, GaussianNB, k-NN) এর আচরণের পার্থক্য পরিষ্কারভাবে ফুটে ওঠে। একটিই runnable script-এ চার ভাগে আমরা দেখব: (১) চার classifier-এর test accuracy, (২) k-NN-এ \(k\) পরিবর্তনের প্রভাব, (৩) QDA-এর confusion matrix, এবং (৪) LDA-এর decision boundary linear বনাম QDA-এর quadratic হওয়ার আনুষ্ঠানিক প্রমাণ।
পরিবেশ:
numpyওscikit-learnইনস্টল থাকতে হবে। প্রয়োজনে:pip install scikit-learn --break-system-packages -q।
import numpy as np
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
# ---- dataset: 3 classes, each Gaussian with its OWN covariance ----
rng = np.random.default_rng(20260619)
means = [[0, 0], [3, 1], [1, 3]]
covs = [np.array([[1, 0], [0, 1]]),
np.array([[2, 0.5], [0.5, 0.5]]),
np.array([[0.6, -0.3], [-0.3, 1.5]])]
n = 150
Xall = []; yall = []
for c, (m, S) in enumerate(zip(means, covs)):
Xall.append(rng.multivariate_normal(m, S, n)); yall += [c] * n
X = np.vstack(Xall); y = np.array(yall)
Xtr, Xte, ytr, yte = train_test_split(X, y, test_size=0.3,
random_state=0, stratify=y)
# =========================================================
# PART 1 : test accuracy of four classifiers
# =========================================================
print("=" * 52)
print("PART 1 : test accuracy of four classifiers")
print("=" * 52)
models = {
"LDA ": LinearDiscriminantAnalysis(),
"QDA ": QuadraticDiscriminantAnalysis(),
"GaussianNB ": GaussianNB(),
"kNN (k=5) ": KNeighborsClassifier(n_neighbors=5),
"kNN (k=15) ": KNeighborsClassifier(n_neighbors=15),
}
print(f"{'model':<12} {'test accuracy':>14}")
print("-" * 28)
for name, clf in models.items():
clf.fit(Xtr, ytr)
acc = accuracy_score(yte, clf.predict(Xte))
print(f"{name:<12} {acc:>14.3f}")
# =========================================================
# PART 2 : kNN accuracy as a function of k
# =========================================================
print("\n" + "=" * 52)
print("PART 2 : kNN accuracy as a function of k")
print("=" * 52)
print(f"{'k':>3} {'test accuracy':>14}")
print("-" * 19)
for k in [1, 3, 5, 9, 15, 25]:
clf = KNeighborsClassifier(n_neighbors=k).fit(Xtr, ytr)
acc = accuracy_score(yte, clf.predict(Xte))
print(f"{k:>3} {acc:>14.3f}")
# =========================================================
# PART 3 : confusion matrix for QDA (rows = true label)
# =========================================================
print("\n" + "=" * 52)
print("PART 3 : confusion matrix for QDA (rows=true)")
print("=" * 52)
qda = QuadraticDiscriminantAnalysis().fit(Xtr, ytr)
cm = confusion_matrix(yte, qda.predict(Xte))
print(" pred0 pred1 pred2")
for i, row in enumerate(cm):
print(f"true{i} " + " ".join(f"{v:5d}" for v in row))
# =========================================================
# PART 4 : LDA boundary is LINEAR, QDA boundary is QUADRATIC
# =========================================================
print("\n" + "=" * 52)
print("PART 4 : LDA boundary linear vs QDA quadratic")
print("=" * 52)
lda = LinearDiscriminantAnalysis().fit(Xtr, ytr)
print("LDA.coef_ shape :", lda.coef_.shape,
" (one linear weight vector per class -> linear boundary)")
print("LDA.coef_ :")
print(np.round(lda.coef_, 3))
print("QDA has attribute 'coef_' ? ->", hasattr(qda, "coef_"))
print("QDA stores per-class covariance (rotations/scalings) -> boundary is quadratic.")
স্ক্রিপ্টটি চালালে নিচের output পাওয়া যায় (verbatim):
====================================================
PART 1 : test accuracy of four classifiers
====================================================
model test accuracy
----------------------------
LDA 0.881
QDA 0.919
GaussianNB 0.904
kNN (k=5) 0.896
kNN (k=15) 0.911
====================================================
PART 2 : kNN accuracy as a function of k
====================================================
k test accuracy
-------------------
1 0.859
3 0.889
5 0.896
9 0.896
15 0.911
25 0.911
====================================================
PART 3 : confusion matrix for QDA (rows=true)
====================================================
pred0 pred1 pred2
true0 41 3 1
true1 2 43 0
true2 1 4 40
====================================================
PART 4 : LDA boundary linear vs QDA quadratic
====================================================
LDA.coef_ shape : (3, 2) (one linear weight vector per class -> linear boundary)
LDA.coef_ :
[[-0.739 -1.112]
[ 1.069 -0.469]
[-0.33 1.58 ]]
QDA has attribute 'coef_' ? -> False
QDA stores per-class covariance (rotations/scalings) -> boundary is quadratic.
পাঠোদ্ধার¶
PART 1 — চার classifier-এর তুলনা। test accuracy-এর ক্রম: QDA সর্বোচ্চ (0.919) এবং LDA সর্বনিম্ন (0.881), মাঝে GaussianNB (0.904) ও k-NN (0.896–0.911)। কেন এই ফল? Dataset-এর তিন class-এর covariance \(\Sigma_0,\Sigma_1,\Sigma_2\) স্পষ্টভাবে অসমান — class 0 isotropic (\(\Sigma_0=I\)), class 1 ও class 2 ভিন্ন আকৃতি ও orientation-এর। LDA-এর মূল অনুমান হলো সব class-এর covariance এক (\(\Sigma_0=\Sigma_1=\Sigma_2=\Sigma\)); এই অনুমান এখানে ভুল, তাই LDA শাস্তি পায়। QDA প্রতিটি class-কে আলাদা \(\Sigma_c\) দেয়, ফলে সে dataset-এর প্রকৃত গঠনের সাথে মেলে এবং সেরা পারফর্ম করে। GaussianNB মাঝামাঝি: সে প্রতি class-এ আলাদা variance ধরে কিন্তু feature গুলোকে স্বাধীন ধরে (অর্থাৎ covariance-এর off-diagonal শূন্য ধরে) — তাই QDA-এর চেয়ে সামান্য পিছিয়ে কিন্তু LDA-এর চেয়ে এগিয়ে। সংক্ষেপে: unequal covariance → QDA-এর পক্ষে, LDA-এর বিপক্ষে।
PART 2 — \(k\)-NN-এ bias–variance. \(k\) বাড়লে accuracy মোটামুটিভাবে বাড়ে: \(k=1\)-এ সর্বনিম্ন (0.859), \(k=15\) ও \(k=25\)-এ সর্বোচ্চ (0.911)। \(k=1\) মানে শুধু একটিমাত্র nearest neighbor — অত্যন্ত low bias, high variance, decision boundary খুব এবড়োখেবড়ো এবং noise/outlier-এর প্রতি সংবেদনশীল, তাই বেশি ভুল। \(k\) বাড়ালে অনেক প্রতিবেশীর ভোট গড় হয়ে boundary মসৃণ হয় (variance কমে, bias বাড়ে), এবং এই dataset-এ তা generalization (সাধারণীকরণ) উন্নত করে। লক্ষণীয়, \(k=15\) থেকে \(k=25\)-এ accuracy আর বাড়েনি (দুটোই 0.911) — এটাই "sweet spot"-এর ইঙ্গিত; অতিরিক্ত \(k\) একসময় bias বাড়িয়ে আবার ক্ষতি করতে পারে। এই monotonic-প্রায় বৃদ্ধি bias–variance trade-off-এর classic চিত্র।
PART 3 — QDA-এর confusion matrix। রো = true label, কলাম = predicted। diagonal (41, 43, 40) সঠিক শ্রেণিবিন্যাস। off-diagonal ভুলগুলো কোথায়? সবচেয়ে বড় বিভ্রান্তি class 2 ↔ class 1 (true2 → pred1 = 4) এবং class 0 ↔ class 1 (true0 → pred1 = 3)। mean গুলো দেখুন: \(\mu_0=(0,0),\ \mu_1=(3,1),\ \mu_2=(1,3)\) — class 1 ও class 2 উভয়েই class 0 থেকে দূরে কিন্তু পরস্পরের ও class 0-এর সাথে আংশিক overlap করে, বিশেষত class 2-এর বড় covariance (\(\Sigma_2\)-এর \(1.5\) variance) তাকে ছড়িয়ে দেয়। তাই ভুলগুলো overlapping class জোড়ার মধ্যেই কেন্দ্রীভূত — কোনো random ছড়ানো ভুল নয়।
PART 4 — boundary-এর জ্যামিতি। LDA.coef_-এর shape \((3,2)\): প্রতি class-এর জন্য একটি করে রৈখিক weight vector \(w_c\in\mathbb{R}^2\)। অর্থাৎ LDA-এর discriminant function class-এ feature-এর linear রূপ \(\delta_c(x)=w_c^\top x + b_c\), এবং দুই class-এর সীমানা \(\delta_i(x)=\delta_j(x)\) সমাধান করলে \(x\)-এ একটি সরলরেখা (hyperplane) পাওয়া যায় — এটাই common-covariance অনুমানের সরাসরি পরিণতি, যেখানে quadratic পদ \(x^\top\Sigma^{-1}x\) দুই পাশে কেটে যায়। বিপরীতে QDA-তে coef_ attribute নেই (hasattr → False), কারণ প্রতি class-এর আলাদা \(\Sigma_c\) থাকায় quadratic পদ আর কাটে না; discriminant-এ \(x^\top\Sigma_c^{-1}x\) টিকে থাকে, ফলে boundary \(x\)-এ quadratic (পরাবৃত্ত/উপবৃত্ত/অধিবৃত্তের মতো বাঁকা)। এই কাঠামোগত পার্থক্যই ব্যাখ্যা করে কেন অসমান-covariance dataset-এ QDA-এর বাঁকা সীমানা LDA-এর সরলরেখার চেয়ে ভালো মানায়।
সারসংক্ষেপ: এই dataset-এ পরীক্ষামূলক ফল নিশ্চিত করে — QDA সেরা (test accuracy 0.919) এবং LDA সর্বনিম্ন (0.881), কারণ class গুলোর covariance অসমান; k-NN-এ \(k\) বাড়ালে bias–variance trade-off অনুযায়ী accuracy 0.859 থেকে 0.911-এ ওঠে; এবং LDA-এর coef_ রৈখিক decision boundary, QDA-এর boundary quadratic — এটিই দুই পদ্ধতির মৌলিক জ্যামিতিক ভেদ।
৬ · ভিজ্যুয়ালাইজেশন¶
আগের অংশগুলোতে আমরা চারটি classifier-এর গণিত দেখেছি — LDA ও QDA কীভাবে Gaussian density থেকে discriminant function বানায়, Naive Bayes কীভাবে feature-গুলোকে conditional independent ধরে, আর k-NN কীভাবে কোনো model না ধরে কেবল প্রতিবেশী গুনে সিদ্ধান্ত নেয়। কিন্তু এই চারটি method-এর আসল চরিত্র — কে সরলরেখায় ভাগ করে আর কে বাঁকা সীমানা আঁকে, equal-covariance ধরে নেওয়ার মূল্য কী, k বাড়ালে-কমালে decision boundary-র চেহারা কীভাবে বদলায় — এসব সমীকরণে যতটা ধরা পড়ে, decision region ছবিতে দেখলে তার চেয়ে ঢের স্পষ্ট হয়। এই অংশে আমরা একটাই synthetic 2D dataset ব্যবহার করে চারটি ছবি তৈরি করব, যেগুলো একসাথে এই চারটি classifier-এর তুলনামূলক গল্পটা বলে।
ছবিগুলোর ভিত্তি হলো নিচের নিয়ন্ত্রিত পরীক্ষা: তিনটি class, প্রতিটিতে \(n = 150\) observation, একটি দুই-মাত্রিক feature space-এ। তিন class-এর mean আলাদা — \(\boldsymbol{\mu}_0 = (0,0)\), \(\boldsymbol{\mu}_1 = (3,1)\), \(\boldsymbol{\mu}_2 = (1,3)\) — কিন্তু গুরুত্বপূর্ণ ব্যাপার হলো তাদের covariance matrix-গুলো ভিন্ন: class 0 isotropic (গোলাকার, \(\boldsymbol{\Sigma}_0 = I\)), class 1 প্রসারিত ও ধনাত্মকভাবে correlated, class 2 অন্য দিকে কাত ও ঋণাত্মকভাবে correlated। অর্থাৎ এই data-তে equal-covariance অনুমান মিথ্যা — আর ঠিক এই কারণেই LDA (যে অনুমানটি ধরে) ও QDA (যে ধরে না) এর মধ্যে পরিষ্কার পার্থক্য দেখা যাবে। data-কে আমরা ৭০:৩০ অনুপাতে train/test-এ ভাগ করেছি, stratify=y দিয়ে যাতে প্রতিটি split-এ তিন class সমানুপাতে থাকে।
import numpy as np
from sklearn.model_selection import train_test_split
rng = np.random.default_rng(20260619)
means = [[0, 0], [3, 1], [1, 3]]
covs = [[[1, 0], [0, 1]], # class 0: isotropic (spherical)
[[2, 0.5], [0.5, 0.5]], # class 1: stretched, +correlated
[[0.6, -0.3], [-0.3, 1.5]]] # class 2: tilted, -correlated
n = 150
X_list, y_list = [], []
for c, (m, S) in enumerate(zip(means, covs)):
X_list.append(rng.multivariate_normal(m, S, n))
y_list.append(np.full(n, c))
X = np.vstack(X_list); y = np.concatenate(y_list)
Xtr, Xte, ytr, yte = train_test_split(X, y, test_size=0.3,
random_state=0, stratify=y)
এই setup-এর সুবিধা হলো প্রতিটি classifier-কে আমরা একই data-তে, একই test set-এ যাচাই করতে পারব, এবং যেহেতু data সত্যিকার অর্থে Gaussian কিন্তু per-class covariance আলাদা, তাই আমরা আগে থেকেই অনুমান করতে পারি — QDA-র মতো নমনীয় model এখানে ভালো করবে, আর LDA-র rigid linear boundary কিছুটা পিছিয়ে থাকবে। ছবিগুলো ঠিক এই অনুমানটাই চোখের সামনে প্রমাণ করে দেখাবে।
৬.১ · চার classifier-এর decision region¶
প্রথম ছবিটি একসাথে চারটি classifier-এর decision region পাশাপাশি রাখে — একটি \(2\times2\) panel-এ LDA, QDA, GaussianNB এবং k-NN (\(k=15\))। প্রতিটি panel-এ একই 2D data (তিন class তিন রঙে) উপরে বসানো, পেছনে সেই classifier যে অঞ্চলে যে class predict করে তা হালকা রঙে ভরাট (contourf) করা, আর তাদের মাঝের গাঢ় রেখাগুলোই decision boundary। প্রতিটি panel-এর শিরোনামে তার test accuracy লেখা।
from sklearn.discriminant_analysis import (LinearDiscriminantAnalysis,
QuadraticDiscriminantAnalysis)
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
# একটি ঘন mesh-grid-এর প্রতিটি বিন্দুতে predict করে region আঁকা হয়
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 400),
np.linspace(y_min, y_max, 400))
grid = np.c_[xx.ravel(), yy.ravel()]
def plot_regions(ax, clf, title):
Z = clf.predict(grid).reshape(xx.shape)
ax.contourf(xx, yy, Z, levels=[-0.5, 0.5, 1.5, 2.5], cmap=REGION_CMAP)
ax.contour(xx, yy, Z, levels=[0.5, 1.5], colors="#333333", linewidths=1.4)
ax.scatter(X[:, 0], X[:, 1], c=y, cmap=POINT_CMAP, s=14)
ax.set_title(title)
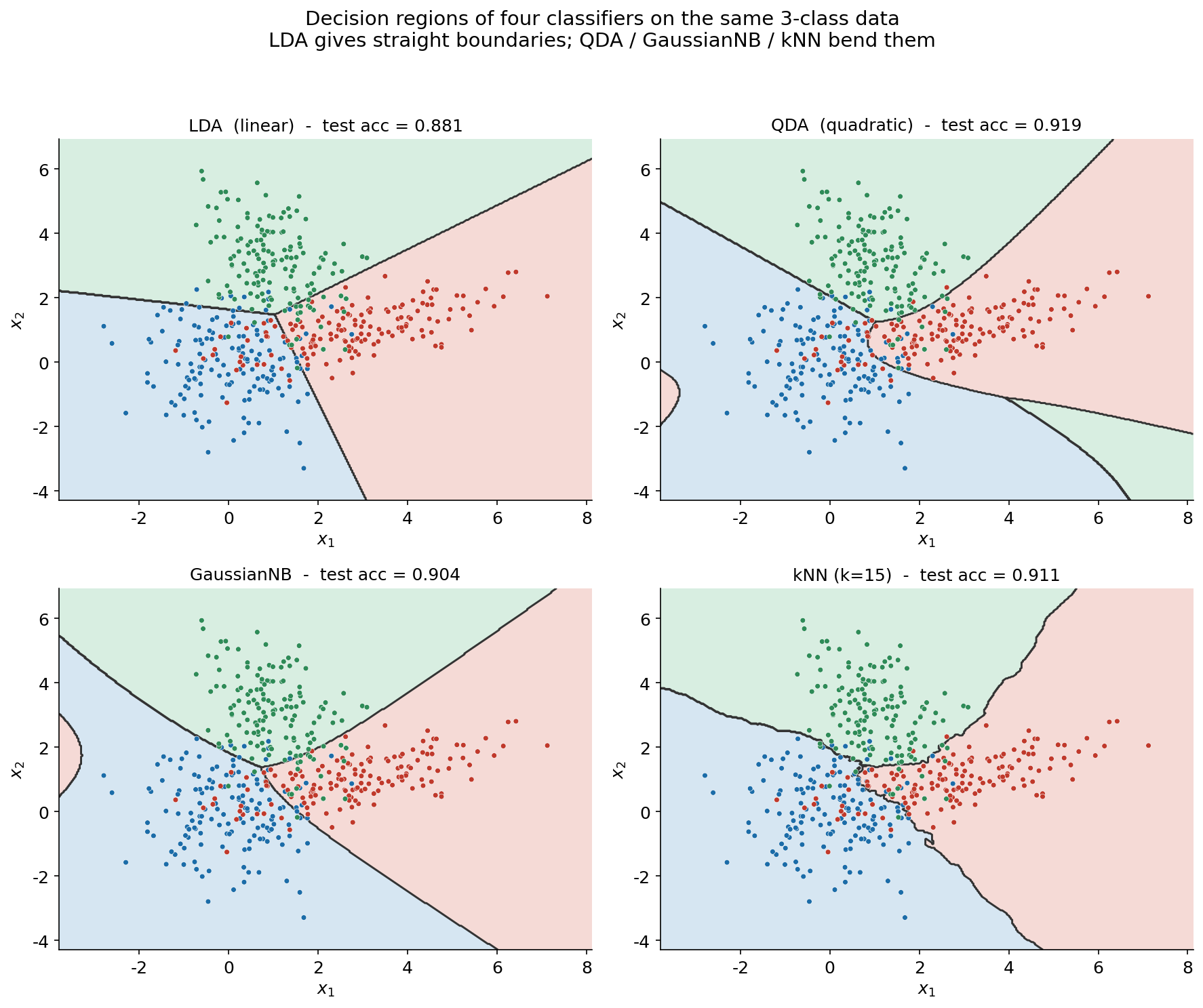
চারটি panel একসাথে দেখলে এই অংশের কেন্দ্রীয় বার্তাটি স্পষ্ট হয়ে ওঠে — boundary-র আকৃতিই প্রতিটি method-এর মূল স্বাক্ষর। উপরের-বাঁ panel-এ LDA: তিনটি decision region পরস্পরকে ভাগ করছে নিখুঁত সরলরেখা দিয়ে। এটি কাকতালীয় নয় — সব class একই \(\boldsymbol{\Sigma}\) ভাগ করছে এই অনুমানে discriminant function থেকে quadratic পদগুলো বাতিল হয়ে যায়, পড়ে থাকে কেবল linear পদ, তাই সীমানা সরলরেখা (এই অধ্যায়ের তত্ত্ব-অংশে যেমন দেখানো হয়েছে)। কিন্তু data-তে covariance তো আসলে সমান নয়, তাই এই rigid সরলরেখাগুলো বাস্তব class-আকৃতির সাথে পুরোপুরি মেলে না — accuracy ০.৮৮১, চারটির মধ্যে সর্বনিম্ন।
উপরের-ডান panel-এ QDA: এখানে সীমানা স্পষ্টভাবে বক্র। প্রতিটি class নিজের আলাদা \(\boldsymbol{\Sigma}_k\) রাখতে পারে বলে discriminant-এ quadratic পদ টিকে থাকে, ফলে boundary হয় উপবৃত্ত/পরাবৃত্তের অংশ। লক্ষ করুন class 1-এর (লাল) অঞ্চলটি কীভাবে তার প্রসারিত, কাত আকৃতি অনুসরণ করে বাঁকা সীমানায় ঘেরা — ঠিক যেমনটা data চাইছে। ফলাফল: accuracy ০.৯১৯, চারটির মধ্যে সর্বোচ্চ। নিচের-বাঁ panel-এ GaussianNB-ও বক্র সীমানা আঁকে (০.৯০৪), কারণ এটিও per-class variance ব্যবহার করে; তবে Naive Bayes ধরে নেয় দুই feature পরস্পর-স্বাধীন (off-diagonal covariance শূন্য), তাই তার উপবৃত্তগুলো অক্ষ-সারিবদ্ধ (axis-aligned) — class-গুলোর কাত correlation এ ধরা পড়ে না, আর সেজন্যই সে QDA-র চেয়ে সামান্য পিছিয়ে। নিচের-ডান panel-এ k-NN (\(k=15\)): এটি কোনো Gaussian model ধরে না, কেবল স্থানীয় ভোটে সিদ্ধান্ত নেয়, তাই তার সীমানা মসৃণ কিন্তু data-র স্থানীয় গঠন-অনুসরণকারী খণ্ড-খণ্ড বক্ররেখা (০.৯১১)। সংক্ষেপে: একমাত্র LDA-ই সরলরেখা টানে; বাকি তিনটিই, ভিন্ন ভিন্ন কারণে, সীমানা বাঁকায় — আর এই data-তে বাঁকানোই লাভজনক।
৬.২ · LDA বনাম QDA: linear বনাম quadratic সীমানা¶
আগের ছবিটি চারটি method একসাথে দেখাল; এই ছবিটি কেবল LDA ও QDA-র সরাসরি দ্বৈরথে জুম করে — কারণ এ দুটোই এই অধ্যায়ের কেন্দ্রীয় তুলনা এবং এদের পার্থক্যটি একটিমাত্র অনুমানে নিহিত। বাঁ panel-এ LDA-র linear সীমানা, ডান panel-এ QDA-র quadratic (বক্র) সীমানা, একই data-তে।
lda = LinearDiscriminantAnalysis().fit(Xtr, ytr) # shared Σ -> linear
qda = QuadraticDiscriminantAnalysis().fit(Xtr, ytr) # per-class Σ_k -> quadratic
plot_regions(axL, lda, f"LDA: shared $\\Sigma$ $\\Rightarrow$ linear "
f"(acc {accuracy_score(yte, lda.predict(Xte)):.3f})")
plot_regions(axR, qda, f"QDA: per-class $\\Sigma_k$ $\\Rightarrow$ quadratic "
f"(acc {accuracy_score(yte, qda.predict(Xte)):.3f})")
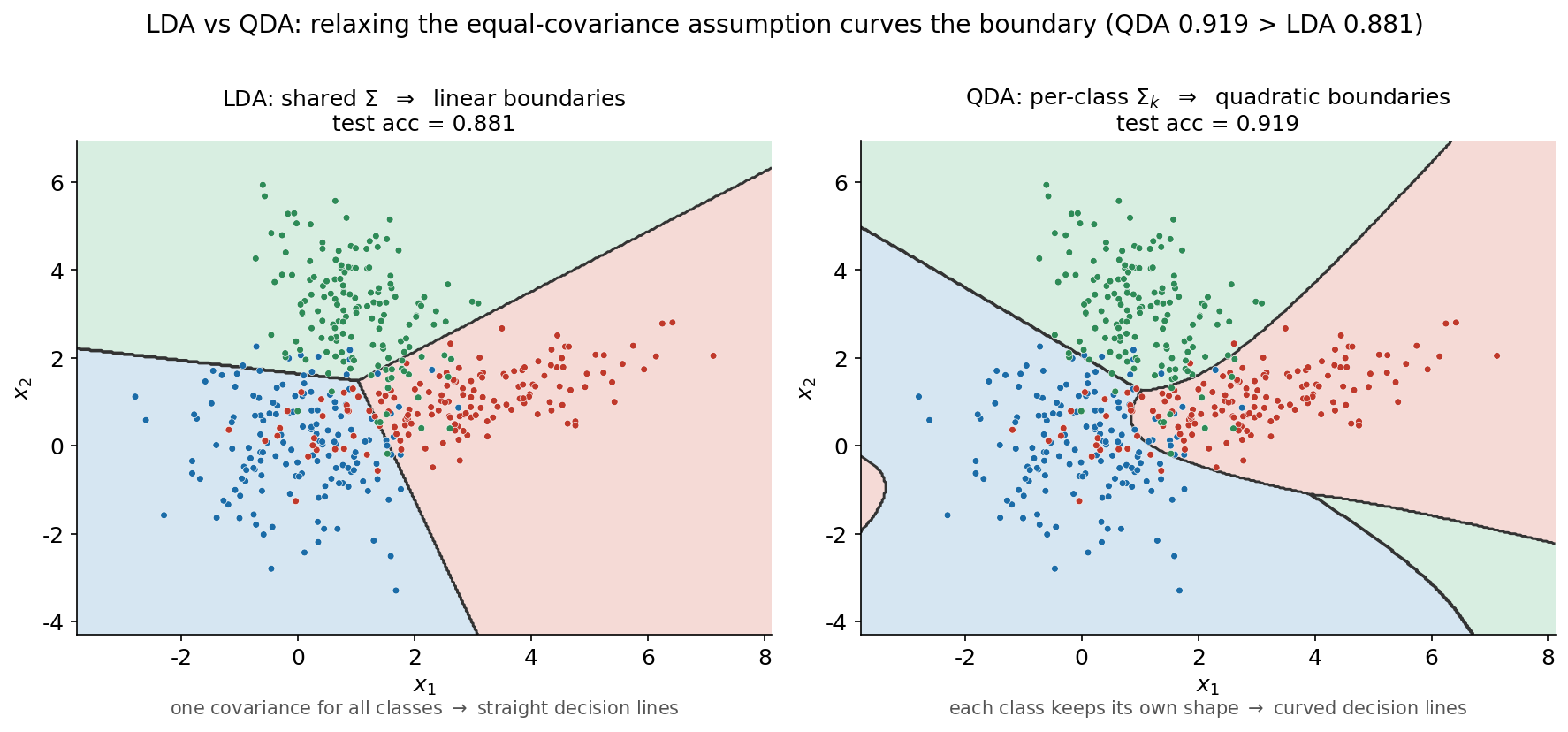
দুটি panel পাশাপাশি রাখলে পার্থক্যের একমাত্র উৎসটি চোখে পড়ে: এটি accuracy-র দু-আনা ব্যবধানের প্রশ্ন নয়, বরং একটি মৌলিক modeling সিদ্ধান্ত। বাঁ দিকে (LDA) model ধরে নেয় তিন class-ই একই covariance \(\boldsymbol{\Sigma}\) ভাগ করে। এই একটি অনুমানের সরাসরি জ্যামিতিক পরিণতি — discriminant function-এর দুই class-এর মধ্যে পার্থক্য নিলে quadratic পদ (\(\mathbf{x}^\top \boldsymbol{\Sigma}^{-1} \mathbf{x}\)) উভয় দিকে সমান হয়ে কাটাকাটি হয়ে যায়, পড়ে থাকে কেবল \(\mathbf{x}\)-এ linear পদ। linear সমীকরণ মানে সরলরেখার সীমানা। সরলতা ও কম parameter-এর সুবিধা আছে (data কম হলে LDA stable), কিন্তু এখানে data যেহেতু এই অনুমান লঙ্ঘন করছে, তাই এর মূল্য চোখে দেখা যায় — সরলরেখাগুলো বাঁকা class-সীমানার সাথে আপস করে কিছু ভুল করে।
ডান দিকে (QDA) model প্রতিটি class-কে নিজের আলাদা \(\boldsymbol{\Sigma}_k\) রাখতে দেয়। এখন আর quadratic পদ কাটাকাটি হয় না, তাই discriminant-এর পার্থক্য \(\mathbf{x}\)-এ একটি quadratic সমীকরণ — আর quadratic সমীকরণের সমাধান-রেখা হলো উপবৃত্ত, পরাবৃত্ত বা অধিবৃত্তের অংশ, অর্থাৎ বক্র সীমানা। এই নমনীয়তার দাম হলো বেশি parameter (প্রতি class-এ একটি পূর্ণ covariance matrix), কিন্তু যখন class-গুলোর আকৃতি সত্যিই আলাদা — ঠিক যেমন এই data-তে — তখন এই নমনীয়তা সরাসরি ভালো performance-এ অনুবাদ হয়: QDA 0.919 > LDA 0.881। মনে রাখা ভালো, এটি সর্বজনীন নিয়ম নয় — যদি class-গুলোর covariance সত্যিই কাছাকাছি হতো বা data অল্প হতো, তখন LDA-র rigidity-ই variance কমিয়ে তাকে এগিয়ে রাখতে পারত। এই ছবিটি তাই কেবল একটি জয়-পরাজয় নয়, বরং assumption ও flexibility-র মধ্যকার বিনিময়-এর একটি concrete উদাহরণ।
৬.৩ · k-NN-এ k এবং bias–variance ভারসাম্য¶
তৃতীয় ছবিটি সম্পূর্ণ অন্য একটি classifier-এ — k-NN-এ — গিয়ে দেখায় কীভাবে একটিমাত্র hyperparameter \(k\) গোটা model-এর আচরণ নিয়ন্ত্রণ করে। ছবিটি দুই অংশে: বাঁ ও মাঝের panel-এ দুই চরমে decision boundary — \(k=1\) (অতি-খাঁজকাটা, overfit) বনাম \(k=25\) (মসৃণ, stable); আর ডান panel-এ test accuracy বনাম \(k\)-এর সম্পূর্ণ বক্ররেখা।
ks = [1, 2, 3, 4, 5, 7, 9, 11, 13, 15, 19, 25, 31, 41]
acc = [accuracy_score(yte, KNeighborsClassifier(k).fit(Xtr, ytr).predict(Xte))
for k in ks]
plot_regions(ax1, KNeighborsClassifier(1).fit(Xtr, ytr), "k = 1: jagged, overfit")
plot_regions(ax25, KNeighborsClassifier(25).fit(Xtr, ytr), "k = 25: smooth, stable")
axk.plot(ks, acc, "o-") # accuracy rises then plateaus near 0.911
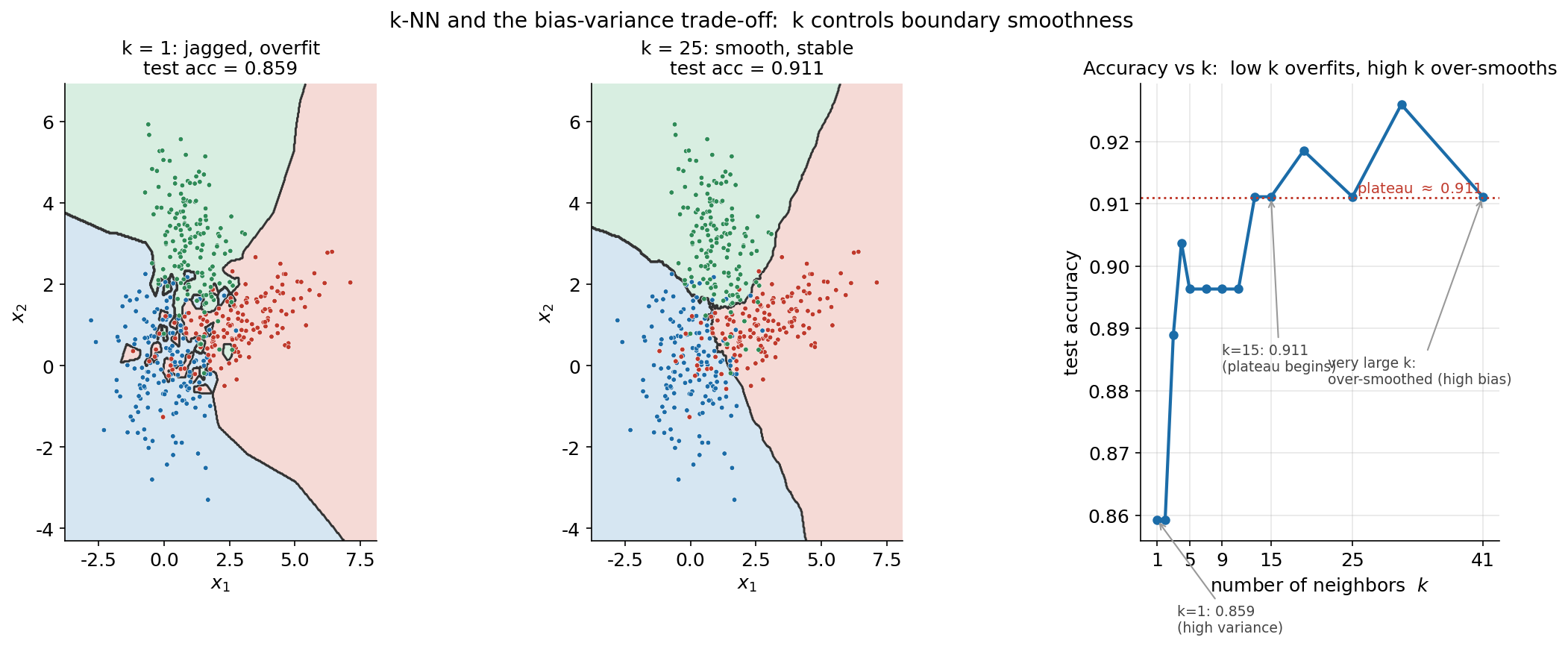
বাঁ ও মাঝের panel দুটি k-NN-এর কেন্দ্রীয় টানাপোড়েনটি চাক্ষুষ করে। \(k=1\) (বাঁ): প্রতিটি test বিন্দু কেবল তার একমাত্র নিকটতম প্রতিবেশীর class নেয়, ফলে decision boundary প্রতিটি একক training বিন্দুর চারপাশে বাঁক নেয় — অত্যন্ত খাঁজকাটা, এমনকি বিপরীত-class-এর এলাকায় বিচ্ছিন্ন ছোট দ্বীপ তৈরি করে। এটি high-variance, overfit আচরণ: model training data-র প্রতিটি noise-বিন্দুকেও মুখস্থ করে ফেলেছে, তাই নতুন data-তে accuracy সবচেয়ে কম, ০.৮৫৯। \(k=25\) (মাঝ): এখন প্রতিটি সিদ্ধান্ত ২৫টি প্রতিবেশীর সংখ্যাগরিষ্ঠ ভোটে, তাই দু-একটি বিচ্ছিন্ন noise-বিন্দু আর ফলাফল ওল্টাতে পারে না — সীমানা মসৃণ ও স্থিতিশীল, class-গুলোর সার্বিক গঠন অনুসরণ করে। এটি কম-variance আচরণ, accuracy ০.৯১১।
ডান panel-এর accuracy-বনাম-\(k\) বক্ররেখা পুরো bias–variance গল্পটাকে সংখ্যায় বাঁধে। বাঁ প্রান্তে ছোট \(k\) (\(k=1\)) থেকে accuracy ০.৮৫৯; \(k\) বাড়ার সাথে variance কমতে থাকে আর accuracy ওঠে — \(k=3\)-এ ০.৮৮৯, \(k=5\)-এ ০.৮৯৬, এবং প্রায় \(k=15\) থেকে এটি ≈ ০.৯১১-এ plateau করে (\(k=25\)-এও ০.৯১১)। অর্থাৎ মাঝারি \(k\) হলো sweet spot — যথেষ্ট বড় যে noise গড় হয়ে যায়, কিন্তু এত বড় নয় যে দূরের, অপ্রাসঙ্গিক বিন্দুও ভোটে ঢুকে পড়ে। তাত্ত্বিকভাবে, \(k\) আরও বহু গুণ বাড়িয়ে গেলে (training set-এর আকারের কাছাকাছি) প্রতিটি prediction প্রায় global majority-তে গিয়ে ঠেকত — তখন boundary অতি-মসৃণ ও high-bias হয়ে accuracy আবার পড়ত। তাই \(k\) নির্বাচন আসলে একটি ভারসাম্য: ছোট \(k\) = জটিল, high variance; বড় \(k\) = সরল, high bias — আর এই বক্ররেখার plateau-ই আমাদের বলে দেয় কোন পরিসরে \(k\) বাছলে দুই দিকের ক্ষতিই সবচেয়ে কম।
৬.৪ · চার method-এর accuracy তুলনা¶
শেষ ছবিটি সব কিছু এক নজরে গুটিয়ে আনে — পাঁচটি model-এর (LDA, QDA, GaussianNB, k-NN দুটি \(k\)-তে) test accuracy-র একটি সরল bar chart, যেখানে বিজয়ী QDA আলাদা রঙে চিহ্নিত।
methods = ["LDA", "QDA", "GaussianNB", "kNN(5)", "kNN(15)"]
accs = [0.881, 0.919, 0.904, 0.896, 0.911] # test accuracy
best = int(np.argmax(accs)) # QDA
colors = ["#2e8b57" if i == best else "#7a98ad" for i in range(len(methods))]
ax.bar(methods, accs, color=colors) # highlight QDA green
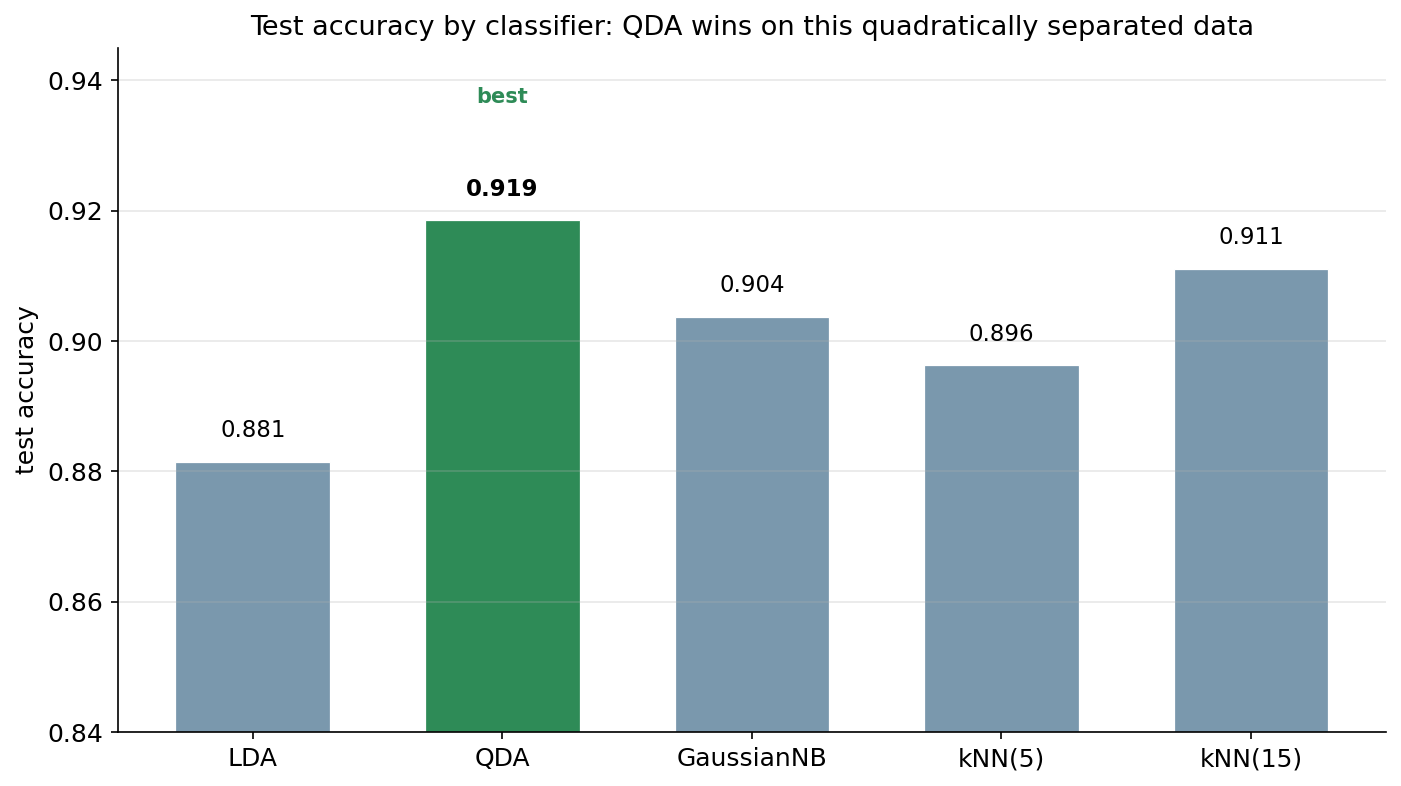
এই একটিমাত্র chart-ই অংশ ৬-এর পরিমাণগত উপসংহার। সবুজ bar — QDA, 0.919 — সবার ওপরে, এবং এটিই প্রত্যাশিত: data সত্যিকার অর্থে Gaussian কিন্তু per-class covariance আলাদা, ঠিক সেই পরিস্থিতি যেখানে QDA-র model-অনুমান বাস্তবের সাথে হুবহু মেলে, তাই সে সবচেয়ে ভালো করে। তার ঠিক পেছনে দুটি method প্রায় সমান — k-NN(\(k=15\)) 0.911 ও GaussianNB 0.904 — দুটোই বক্র সীমানা আঁকতে পারে বলে LDA-র চেয়ে এগিয়ে, যদিও কেউই QDA-র মতো পূর্ণ per-class covariance ব্যবহার করে না (k-NN model-free, GaussianNB feature-independence ধরে)।
chart-এর তলায় দুটি method — LDA 0.881 ও k-NN(\(k=5\)) 0.896 — সবচেয়ে নিচে, কিন্তু কারণ দুটি সম্পূর্ণ আলাদা। LDA পিছিয়ে কারণ তার linear সীমানা এই unequal-covariance data-র জন্য খুব rigid (under-flexible, bias-জনিত ক্ষতি)। আর k-NN(\(k=5\)) পিছিয়ে কারণ এত ছোট \(k\)-তে সীমানা এখনো কিছুটা খাঁজকাটা ও variance-প্রবণ — ৬.৩-এ দেখা বক্ররেখা অনুযায়ী \(k\) ১৫ পর্যন্ত বাড়ালেই সে ০.৯১১-এ উঠে আসে। অর্থাৎ একই k-NN পরিবার, কেবল \(k\)-এর পছন্দভেদে, chart-এর নিচ থেকে প্রায়-শীর্ষে চলে যায় — যা আবারও মনে করিয়ে দেয় classifier নির্বাচন আর hyperparameter নির্বাচন আসলে একই মুদ্রার দুই পিঠ। তবে এখানে সংখ্যাগুলোর ব্যবধান ছোট (০.৮৮ থেকে ০.৯২), তাই এ থেকে "QDA সর্বদা সেরা" এমন সর্বজনীন উপসংহার টানা ভুল হবে — এটি কেবল এই নির্দিষ্ট, QDA-অনুকূল data-র ফল; অন্য কোনো data-তে, বিশেষত যেখানে class-covariance প্রকৃতপক্ষে সমান বা data অল্প, LDA-ই সহজে জিততে পারে।
সারসংক্ষেপ¶
চারটি ছবি একসাথে এই চার classifier-এর একটি সম্পূর্ণ তুলনামূলক ছবি তৈরি করে। Decision region (৬.১) দেখাল কীভাবে boundary-র আকৃতিই প্রতিটি method-এর স্বাক্ষর — একমাত্র LDA সরলরেখা টানে, বাকি তিনটি সীমানা বাঁকায়। LDA বনাম QDA (৬.২) এই পার্থক্যের একমাত্র উৎসটি বিচ্ছিন্ন করল: shared \(\boldsymbol{\Sigma}\) ⇒ linear, per-class \(\boldsymbol{\Sigma}_k\) ⇒ quadratic, আর এই data-তে নমনীয়তার পুরস্কার QDA 0.919 > LDA 0.881। k-NN-এ \(k\) (৬.৩) সম্পূর্ণ ভিন্ন একটি knob-এর bias–variance দেখাল — ছোট \(k\) খাঁজকাটা ও high-variance, বড় \(k\) মসৃণ, আর accuracy \(k\approx15\)-এ ≈0.911-এ plateau করে। শেষে accuracy তুলনা (৬.৪) সব কিছু একটি bar chart-এ গুটিয়ে এনে QDA-কে এই (QDA-অনুকূল) data-তে বিজয়ী হিসেবে চিহ্নিত করল, পাশাপাশি মনে করিয়ে দিল যে ব্যবধান ছোট ও ফল data-নির্ভর। এই ছবিগুলো তৈরির সম্পূর্ণ, পুনরুৎপাদনযোগ্য কোড আছে _code/figs_6-3.py-তে।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag ও সংক্ষিপ্ত hint। (★ সহজ, ★★ মাঝারি, ★★★ চ্যালেঞ্জিং।) data-নির্ভর প্রশ্নগুলো এই অধ্যায়ের চলমান simulation-এর canonical সংখ্যা ব্যবহার করে — seed np.random.default_rng(20260619), \(3\)টি শ্রেণি, 2D feature, প্রতি শ্রেণিতে \(150\)টি বিন্দু (\(n=450\)), শ্রেণিগুলোর covariance অসমান, \(70/30\) stratified train–test split। মূল notation: posterior \(P(y=c\mid x)=\dfrac{\pi_c\,f_c(x)}{\sum_l \pi_l\,f_l(x)}\); LDA-তে শ্রেণিভেদে শেয়ার-করা একই \(\Sigma\) (linear boundary), QDA-তে শ্রেণি-প্রতি আলাদা \(\Sigma_c\) (quadratic boundary); Naive Bayes-এ \(P(x\mid y)=\prod_j P(x_j\mid y)\); k-NN-এ নিকটতম \(k\) প্রতিবেশীর ভোট; Bayes error = তাত্ত্বিক সর্বনিম্ন ভুল। পূর্ণ সমাধান _solutions/06-03-classification-lda-qda-nb-knn-solutions.md-এ।
প্রসঙ্গের সুবিধার্থে নিচের canonical টেবিলটি কয়েকটি প্রশ্নে বারবার লাগবে (test-set accuracy; ↑ মানে বেশি-ই-ভালো):
| classifier | ধরন | test accuracy |
|---|---|---|
| LDA (shared \(\Sigma\)) | generative, linear boundary | 0.881 |
| QDA (per-class \(\Sigma_c\)) | generative, quadratic boundary | 0.919 (best) |
| GaussianNB | generative, axis-aligned | 0.904 |
| k-NN (\(k=5\)) | instance-based | 0.896 |
| k-NN (\(k=15\)) | instance-based | 0.911 |
এবং k-NN-এর accuracy বনাম \(k\) (একই test-set; \(k\) বাড়লে boundary মসৃণ হয়):
| \(k\) | test accuracy |
|---|---|
| 1 | 0.859 |
| 3 | 0.889 |
| 5 | 0.896 |
| 15 | 0.911 |
| 25 | 0.911 |
(লক্ষণীয়: dataset-এ covariance অসমান বলে quadratic boundary-র QDA-ই সবচেয়ে ভালো (\(0.919\)); শেয়ার-\(\Sigma\)-র LDA সবচেয়ে দুর্বল (\(0.881\)); k-NN ছোট \(k\)-তে দুর্বল (\(k{=}1\to0.859\)), \(k\) বাড়লে উন্নত হয়ে \(k{=}15\)-এ থিতু হয় (\(0.911\))।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). Bayes classifier — যে নিয়ম প্রতিটি \(x\)-কে সর্বোচ্চ-posterior শ্রেণিতে দেয়, \(\hat y(x)=\arg\max_c P(y=c\mid x)\) — কেন 0–1 loss-এর অধীনে optimal (অর্থাৎ সর্বনিম্ন প্রত্যাশিত ভুল দেয়)? এক-দুই বাক্যে যুক্তি দিন, এবং বলুন একটি নির্দিষ্ট \(x\)-এ Bayes classifier-এর ভুলের সম্ভাবনা কত (অর্থাৎ point-wise Bayes error)। Hint: প্রদত্ত \(x\)-এ সঠিক হওয়ার সম্ভাবনা \(=P(y=\hat y\mid x)\); এটি সর্বোচ্চ করতে \(\hat y=\arg\max_c P(c\mid x)\) বাছাই-ই সেরা; তাই point-wise error \(=1-\max_c P(c\mid x)\), যা অন্য যেকোনো নিয়মের চেয়ে ছোট।
প্রশ্ন ২ (★). generative, discriminative ও instance-based — তিন ধরনের classifier-কে আলাদা করুন: প্রতিটি কী model/estimate করে, এবং এই অধ্যায়ের কোন পদ্ধতি কোন ঘরে পড়ে? canonical টেবিল থেকে প্রতিটি ধরনের একটি উদাহরণ ও তার accuracy টানুন। Hint: generative শ্রেণি-শর্তাধীন \(f_c(x)=P(x\mid y=c)\) ও prior \(\pi_c\) model করে তারপর Bayes-নিয়মে posterior পায় (LDA \(0.881\), QDA \(0.919\), GaussianNB \(0.904\)); discriminative সরাসরি \(P(y\mid x)\) বা boundary শেখে (logistic regression — ৫.৪); instance-based কোনো parameter "fit" না করে training-বিন্দু মনে রেখে প্রতিবেশী দিয়ে ভোট দেয় (k-NN \(0.896/0.911\))।
প্রশ্ন ৩ (★). LDA-র decision boundary linear, কিন্তু QDA-র quadratic — কেন? posterior-ratio \(\log\frac{P(y=0\mid x)}{P(y=1\mid x)}\)-এ Gaussian density বসিয়ে এক বাক্যে দেখান কোন পদ শেয়ার-\(\Sigma\) ধরায় বাতিল হয়ে boundary linear করে, আর per-class \(\Sigma_c\)-তে কোন পদ টিকে থেকে boundary quadratic করে। Hint: log-density-তে \(-\tfrac12 x^\top\Sigma_c^{-1}x\) পদটি quadratic; \(\Sigma_0=\Sigma_1=\Sigma\) হলে দুই শ্রেণির quadratic পদ একই, log-ratio-তে বিয়োগ হয়ে যায় ⇒ শুধু linear পদ থাকে; \(\Sigma_0\ne\Sigma_1\) হলে quadratic পদ আর বাতিল হয় না ⇒ boundary quadratic।
প্রশ্ন ৪ (★). এই dataset-এ QDA (\(0.919\)) LDA-কে (\(0.881\)) হারায় — কেন? এবং উল্টোদিকে: এমন কোন পরিস্থিতিতে LDA-ই QDA-র চেয়ে ভালো হবে? ৬.১-এর bias–variance ভাষায় উত্তর দিন। Hint: dataset-এর covariance অসমান, তাই শেয়ার-\(\Sigma\) ধরা LDA-র জন্য একটি ভুল (bias-আরোপী) সীমাবদ্ধতা — QDA সেই ভুল এড়ায়। কিন্তু QDA শ্রেণি-প্রতি পূর্ণ \(\Sigma_c\) estimate করে বলে বেশি parameter ⇒ বেশি variance; তাই নমুনা ছোট হলে বা covariance সত্যিই প্রায়-সমান হলে কম-parameter-এর LDA-ই কম variance-এ জিততে পারে।
প্রশ্ন ৫ (★★). Naive Bayes-এর কেন্দ্রীয় ধারণা conditional independence: \(P(x\mid y)=\prod_j P(x_j\mid y)\)। (ক) এই ধারণা কী দাবি করে, এক বাক্যে বলুন। (খ) যখন feature-গুলো আসলে correlated, ধারণাটি ভুল — তবু GaussianNB এখানে \(0.904\) accuracy দেয় (LDA-র \(0.881\)-এর চেয়ে ভালো!)। কীভাবে একটি "ভুল" ধারণা-নির্ভর মডেল তবু এত ভালো করতে পারে? Hint: (ক) শ্রেণি জানা থাকলে feature-গুলো পরস্পর-স্বাধীন — যৌথ density প্রান্তিকগুলোর গুণফল। (খ) classification-এ শুধু কোন শ্রেণির posterior সবচেয়ে বড় সেটাই গুরুত্বপূর্ণ; probability-estimate বিকৃত (over-confident) হলেও \(\arg\max\) প্রায়ই ঠিক থাকে — তাই NB biased কিন্তু কার্যকর, বিশেষত উচ্চ-মাত্রায় যেখানে কম parameter মানে কম variance।
খ · গণনামূলক (computational)¶
প্রশ্ন ৬ (★★) [E-qda-post]. QDA posterior হাতে হিসাব করুন এবং দেখুন QDA কীভাবে LDA থেকে আলাদা সিদ্ধান্ত দেয়। দুই শ্রেণি, 2D, সমান prior \(\pi_0=\pi_1=0.5\), এবং (সরলতার জন্য) diagonal covariance: $$ \mu_0=\begin{pmatrix}1\1\end{pmatrix},\ \Sigma_0=\begin{pmatrix}1&0\0&1\end{pmatrix};\qquad \mu_1=\begin{pmatrix}3\3\end{pmatrix},\ \Sigma_1=\begin{pmatrix}4&0\0&4\end{pmatrix}. $$ test-বিন্দু \(x=(2,2)\)। (ক) প্রতিটি শ্রেণির Gaussian density \(f_c(x)=\dfrac{1}{2\pi\sqrt{\lvert\Sigma_c\rvert}}\exp\!\big(-\tfrac12 (x-\mu_c)^\top\Sigma_c^{-1}(x-\mu_c)\big)\) হিসাব করুন। (খ) posterior \(P(y=0\mid x)\) ও \(P(y=1\mid x)\) বের করে বলুন QDA \(x\)-কে কোন শ্রেণিতে দেয়। (গ) লক্ষ করুন raw Euclidean দূরত্বে \(x\) দুই \(\mu\) থেকে সমদূরত্বে — তাহলে identity-covariance ধরা LDA এখানে কী বলত, আর QDA কেন ভিন্ন সিদ্ধান্ত দিল? Hint: Mahalanobis \((x-\mu_0)^\top\Sigma_0^{-1}(x-\mu_0)=\frac{(2-1)^2}1+\frac{(2-1)^2}1=2\); \((x-\mu_1)^\top\Sigma_1^{-1}(x-\mu_1)=\frac{(2-3)^2}4+\frac{(2-3)^2}4=0.5\); \(\lvert\Sigma_0\rvert=1,\ \lvert\Sigma_1\rvert=16\) ⇒ \(f_0=\frac1{2\pi}e^{-1}\approx0.0586\), \(f_1=\frac1{8\pi}e^{-0.25}\approx0.0310\)। সমান prior বলে \(P(0\mid x)=f_0/(f_0+f_1)\)।
প্রশ্ন ৭ (★★) [E-nb]. Naive Bayes একটি ছোট discrete উদাহরণে প্রয়োগ করুন। spam-detection: \(2\)টি binary feature — \(x_1=\) "free" শব্দ আছে কি না, \(x_2=\) "meeting" শব্দ আছে কি না। প্রশিক্ষণ থেকে পাওয়া: $$ \pi_{\text{spam}}=0.4,\quad \pi_{\text{ham}}=0.6; $$ $$ P(x_1{=}1\mid\text{spam})=0.8,\ P(x_1{=}1\mid\text{ham})=0.1;\quad P(x_2{=}1\mid\text{spam})=0.2,\ P(x_2{=}1\mid\text{ham})=0.7. $$ একটি নতুন email-এ "free" আছে কিন্তু "meeting" নেই, অর্থাৎ \(x=(x_1{=}1,\ x_2{=}0)\)। conditional-independence ধরে প্রতিটি শ্রেণির \(\pi_c\prod_j P(x_j\mid c)\) হিসাব করে posterior বের করুন — email-টি spam না ham? Hint: spam-score \(=0.4\cdot 0.8\cdot(1-0.2)=0.4\cdot0.8\cdot0.8\); ham-score \(=0.6\cdot 0.1\cdot(1-0.7)=0.6\cdot0.1\cdot0.3\); posterior \(=\text{score}/(\text{spam-score}+\text{ham-score})\)।
প্রশ্ন ৮ (★) [E-knn-k]. উপরের k-NN accuracy-বনাম-\(k\) টেবিল "পড়ুন"। (ক) কোন \(k\) সর্বোচ্চ test accuracy দেয়? (খ) \(k=1\) থেকে \(k=15\) পর্যন্ত accuracy-র প্রবণতা কী, এবং এটি ৬.১-এর bias–variance দিয়ে ব্যাখ্যা করুন: ছোট \(k\) মানে কী আচরণ, বড় \(k\) মানে কী? (গ) \(k=15\) ও \(k=25\) উভয়েই \(0.911\) — খুব বড় \(k\) আরও ভালো না করে থিতু (বা শেষমেশ খারাপ) হয় কেন? Hint: (ক) \(k=15\) (ও \(25\)) সর্বোচ্চ \(0.911\); (খ) ছোট \(k\) = wiggly boundary, low bias কিন্তু high variance (noise fit, \(k{=}1\to0.859\)), \(k\) বাড়লে boundary মসৃণ, variance↓, accuracy↑; (গ) অতি-বড় \(k\)-তে দূরের অপ্রাসঙ্গিক প্রতিবেশীও ভোট দেয় ⇒ bias↑, তাই উন্নতি থেমে যায়/উল্টে যেতে পারে — bias–variance tradeoff-এর U-আচরণ।
প্রশ্ন ৯ (★★) [E-curse]. curse of dimensionality ও k-NN। একটি unit-hypercube \([0,1]^p\)-এ uniform data ধরুন; নিকটতম প্রতিবেশী খুঁজতে আমরা প্রতিটি দিকে একটি ছোট প্রতিবেশ চাই। ধরুন আমরা মোট আয়তনের একটি ভগ্নাংশ \(r\) (যেমন \(r=1\%=0.01\)) ধরে একটি ঘনক-প্রতিবেশ নিই; তবে সেই প্রতিবেশের প্রতিটি বাহুর দৈর্ঘ্য \(\ell=r^{1/p}\)। (ক) \(p=1,2,10,100\)-এর জন্য \(r=0.01\) ধরে \(\ell\) হিসাব করুন। (খ) এই সংখ্যাগুলো থেকে এক বাক্যে বলুন উচ্চ-মাত্রায় "নিকটতম" প্রতিবেশীও কেন আসলে দূরে, এবং তা k-NN-কে কীভাবে দুর্বল করে। Hint: \(\ell=0.01^{1/p}\): \(p{=}1\to0.01\), \(p{=}2\to0.1\), \(p{=}10\to0.63\), \(p{=}100\to0.955\); অর্থাৎ \(p{=}10\)-এই \(1\%\) data ধরতে প্রতি বাহুর \(63\%\) লাগে — প্রতিবেশ আর "স্থানীয়" থাকে না, দূরত্বগুলো প্রায় সমান হয়ে যায়, তাই প্রতিবেশী-ভোট অর্থহীন হতে থাকে।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১০ (★★) [P-lda-disc]. LDA-র linear discriminant function উৎপাদন করুন। শ্রেণি-শর্তাধীন density Gaussian, সব শ্রেণিতে শেয়ার-করা একই covariance: \(f_c(x)=\dfrac{1}{(2\pi)^{d/2}\lvert\Sigma\rvert^{1/2}}\exp\!\big(-\tfrac12(x-\mu_c)^\top\Sigma^{-1}(x-\mu_c)\big)\), prior \(\pi_c\)। \(\delta_c(x)=\log\big(\pi_c f_c(x)\big)\) থেকে \(x\)-এ ধ্রুবক পদ বাদ দিয়ে দেখান $$ \delta_c(x)=x^\top\Sigma^{-1}\mu_c-\tfrac12\mu_c^\top\Sigma^{-1}\mu_c+\log\pi_c, $$ যা \(x\)-এ linear — তাই \(\arg\max_c\delta_c(x)\) একটি linear classifier এবং দুই শ্রেণির boundary \(\{\delta_0(x)=\delta_1(x)\}\) একটি hyperplane। Hint: \(\log f_c(x)=-\tfrac12 x^\top\Sigma^{-1}x+x^\top\Sigma^{-1}\mu_c-\tfrac12\mu_c^\top\Sigma^{-1}\mu_c+\text{const}\); \(-\tfrac12 x^\top\Sigma^{-1}x\) ও normalizing const সব শ্রেণিতে অভিন্ন (শেয়ার-\(\Sigma\)), তাই \(\arg\max\)-এ অপ্রাসঙ্গিক — ফেলে দিলে যা থাকে তা-ই \(\delta_c(x)\)।
প্রশ্ন ১১ (★★★) [P-qda-disc]. প্রশ্ন ১০-এর ধারাবাহিকতায়: এবার শ্রেণি-প্রতি আলাদা \(\Sigma_c\) ধরে দেখান QDA-র discriminant $$ \delta_c(x)=-\tfrac12\log\lvert\Sigma_c\rvert-\tfrac12(x-\mu_c)^\top\Sigma_c^{-1}(x-\mu_c)+\log\pi_c $$ \(x\)-এ একটি quadratic ফর্ম রাখে, এবং তাই দুই শ্রেণির boundary সাধারণভাবে quadratic (উপবৃত্ত/অধিবৃত্ত/পরাবৃত্ত)। স্পষ্ট করুন ঠিক কোন শর্তে (\(\Sigma_0=\Sigma_1\)) এই quadratic পদ বাতিল হয়ে LDA-র linear boundary-তে ফিরে আসে। Hint: \((x-\mu_c)^\top\Sigma_c^{-1}(x-\mu_c)=x^\top\Sigma_c^{-1}x-2x^\top\Sigma_c^{-1}\mu_c+\mu_c^\top\Sigma_c^{-1}\mu_c\); \(-\tfrac12 x^\top\Sigma_c^{-1}x\) পদটি \(\Sigma_c\)-নির্ভর বলে আর সব শ্রেণিতে অভিন্ন নয় — log-ratio-তে \(x^\top(\Sigma_1^{-1}-\Sigma_0^{-1})x\) টিকে থাকে; \(\Sigma_0=\Sigma_1\) হলে এই পার্থক্য \(=0\), quadratic অংশ বাতিল, boundary linear।
প্রশ্ন ১২ (★★) [P-bayes-opt]. Bayes classifier-এর optimality প্রমাণ করুন (binary, 0–1 loss)। যেকোনো নিয়ম \(g:\mathcal X\to\{0,1\}\)-এর জন্য একটি নির্দিষ্ট \(x\)-এ শর্তাধীন ভুল-সম্ভাবনা \(P(g(x)\ne y\mid x)\)-কে \(P(y\mid x)\)-এর ভাষায় লিখুন, এবং দেখান এটি সর্বনিম্ন হয় যখন \(g(x)=\arg\max_c P(y=c\mid x)\) (Bayes rule)। উপসংহারে দেখান সামগ্রিক risk \(P(g(X)\ne Y)=\mathbb E_X[P(g(X)\ne Y\mid X)]\)-ও তখনই সর্বনিম্ন। Hint: \(P(g(x)\ne y\mid x)=1-P(y=g(x)\mid x)\); এটি ছোট করতে \(P(y=g(x)\mid x)\) বড় করতে হবে, যা \(g(x)=\arg\max_c P(c\mid x)\)-এ ঘটে; প্রতিটি \(x\)-এ পয়েন্ট-ওয়াইজ সর্বনিম্ন হলে তাদের প্রত্যাশা (integral)-ও সর্বনিম্ন — তাই Bayes rule সামগ্রিকভাবেও optimal, এবং অবশিষ্ট ভুল \(=\mathbb E_X[1-\max_c P(c\mid X)]\) হলো Bayes error, কোনো classifier যার নিচে নামতে পারে না।
ঘ · কোডিং (coding)¶
প্রশ্ন ১৩ (★★) [E-fit]. এই অধ্যায়ের dataset পুনর্গঠন করুন (seed np.random.default_rng(20260619), \(3\) শ্রেণি, 2D, প্রতি শ্রেণিতে \(150\) বিন্দু, অসমান covariance, \(70/30\) stratified split) এবং (ক) LDA, (খ) QDA, (গ) GaussianNB, (ঘ) k-NN (\(k=5\) ও \(k=15\)) fit করে প্রত্যেকের test accuracy ছাপুন। আপনার সংখ্যাগুলো canonical টেবিলের কাছাকাছি কি? কোন classifier সেরা, এবং কেন (covariance অসমান হওয়ার সাথে মিলিয়ে বলুন)?
Hint: from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis, from sklearn.naive_bayes import GaussianNB, from sklearn.neighbors import KNeighborsClassifier; train_test_split(..., test_size=0.30, stratify=y); প্রত্যাশিত — LDA \(\approx0.881\), QDA \(\approx0.919\) (best), NB \(\approx0.904\), kNN5 \(\approx0.896\), kNN15 \(\approx0.911\)। সমাধানে runnable script আছে।
প্রশ্ন ১৪ (★★) [E-boundary]. চারটি classifier-এর decision boundary আঁকুন এবং চোখে তুলনা করুন। 2D feature-space-এ একটি সূক্ষ্ম grid বানিয়ে প্রতিটি fitted মডেল দিয়ে predict করে contourf দিয়ে অঞ্চল রঙ করুন, উপরে training-বিন্দু scatter করুন। যাচাই করুন: LDA-র boundary সরলরেখা-খণ্ড (linear), QDA-র boundary বাঁকানো (quadratic), GaussianNB-রও বাঁকানো কিন্তু axis-aligned, আর k-NN-এরটা \(k\) ছোট হলে খাঁজকাটা (wiggly) ও \(k\) বড় হলে মসৃণ। এছাড়া accuracy-বনাম-\(k\) একটি লাইন-plot আঁকুন এবং \(k\in\{1,3,5,15,25\}\)-এ \(\{0.859,0.889,0.896,0.911,0.911\}\)-এর কাছাকাছি কি না দেখুন।
Hint: xx,yy = np.meshgrid(...), Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape), plt.contourf(xx,yy,Z, alpha=0.3); k-NN-এর \(k\) ছোট করলে boundary-র খাঁজ স্পষ্ট হয় — এটাই high-variance-এর চাক্ষুষ রূপ। পূর্ণ plotting-script সমাধানে।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
- Bayes classifier-ই সোনার মান (optimal)। 0–1 loss-এর অধীনে সর্বনিম্ন-ভুল নিয়ম হলো প্রতিটি \(x\)-কে সর্বোচ্চ-posterior শ্রেণিতে দেওয়া: \(\hat y(x)=\arg\max_c P(y=c\mid x)\), যেখানে posterior \(=\dfrac{\pi_c f_c(x)}{\sum_l\pi_l f_l(x)}\)। অবশিষ্ট অনিবার্য ভুল \(\mathbb E_X[1-\max_c P(c\mid X)]\) হলো Bayes error — কোনো classifier যার নিচে নামতে পারে না। বাস্তব সব classifier মূলত এই posterior-কে নানা ভাবে আনুমানিক করার চেষ্টা।
- generative: \(P(x\mid y)\) model করে Bayes-নিয়মে posterior পাওয়া। LDA, QDA ও Naive Bayes — তিনটিই শ্রেণি-শর্তাধীন density \(f_c(x)\) ও prior \(\pi_c\) অনুমান করে, তারপর Bayes-সূত্র দিয়ে posterior বের করে।
- LDA — শেয়ার-\(\Sigma\), linear boundary। সব শ্রেণিতে একই covariance ধরায় log-posterior-ratio-র quadratic পদ বাতিল হয়, discriminant \(\delta_c(x)=x^\top\Sigma^{-1}\mu_c-\tfrac12\mu_c^\top\Sigma^{-1}\mu_c+\log\pi_c\) linear ⇒ boundary hyperplane। কম parameter (একটিই \(\Sigma\)) ⇒ কম variance, কিন্তু শেয়ার-\(\Sigma\) একটি bias-আরোপী সরলীকরণ (এখানে accuracy \(0.881\) — সবচেয়ে দুর্বল, কারণ dataset-এর covariance অসমান)।
- QDA — per-class \(\Sigma_c\), quadratic boundary। শ্রেণি-প্রতি আলাদা covariance রাখায় quadratic পদ টিকে থেকে boundary বাঁকানো। বেশি parameter ⇒ বেশি variance, কিন্তু covariance সত্যিই ভিন্ন হলে এই নমনীয়তাই জেতায় (এখানে \(0.919\) — সেরা)।
- Naive Bayes — conditional independence। ধরে নেয় শ্রেণি জানা থাকলে feature-গুলো স্বাধীন: \(P(x\mid y)=\prod_j P(x_j\mid y)\), তাই উচ্চ-মাত্রায়ও অল্প parameter। feature correlated হলে ধারণাটি ভুল ⇒ NB biased, কিন্তু \(\arg\max\)-সিদ্ধান্ত প্রায়ই সঠিক থাকে বলে তবুও কার্যকর (এখানে \(0.904\), LDA-র চেয়েও ভালো)।
- instance-based: k-NN — কোনো parameter "fit" নয়। training-বিন্দু মনে রেখে নতুন \(x\)-এর নিকটতম \(k\) প্রতিবেশীর সংখ্যাগরিষ্ঠ ভোটে শ্রেণি দেয় — কোনো density বা boundary স্পষ্টভাবে model করে না (non-parametric)। \(k\) হলো capacity-knob: ছোট \(k\) = wiggly boundary, low bias কিন্তু high variance (noise fit; \(k{=}1\to0.859\)); বড় \(k\) = মসৃণ boundary, variance↓ কিন্তু খুব বড় হলে দূরের অপ্রাসঙ্গিক প্রতিবেশী টেনে bias↑ — তাই accuracy \(k\)-তে U-আকারে চলে (\(1{\to}0.859\), \(3{\to}0.889\), \(5{\to}0.896\), \(15{\to}0.911\), \(25{\to}0.911\), সেরা \(k{=}15\))।
- curse of dimensionality। মাত্রা বাড়লে আয়তন বিস্ফোরিত হয়ে data বিরল হয়; "নিকটতম" প্রতিবেশীও আসলে দূরে চলে যায় (\(1\%\) data ধরতে \(p{=}10\)-এ প্রতি বাহুর \(63\%\) লাগে), দূরত্বগুলো প্রায় সমান হয়ে পড়ে — তাই k-NN (ও সাধারণভাবে দূরত্ব-নির্ভর পদ্ধতি) উচ্চ-মাত্রায় বিশেষ দুর্বল।
- নির্বাচন: ধারণা বনাম নমনীয়তা। কোন classifier বাছবেন তা নির্ভর করে আপনার ধারণা কতটা সত্য বনাম কত নমনীয়তা চাই তার ওপর — Gaussian + শেয়ার-\(\Sigma\) ধরা গেলে LDA (কম variance); covariance ভিন্ন হলে QDA; feature প্রায়-স্বাধীন বা মাত্রা বড় হলে Naive Bayes; কোনো বিতরণ-ধারণা না-করে স্থানীয় গঠন ধরতে চাইলে k-NN (কিন্তু মাত্রা ছোট রাখতে হবে)।
একনজরে তুলনা:
| LDA | QDA | Naive Bayes | k-NN | |
|---|---|---|---|---|
| ধরন | generative | generative | generative | instance-based |
| কী model করে | \(\pi_c\), \(\mu_c\), শেয়ার \(\Sigma\) | \(\pi_c\), \(\mu_c\), per-class \(\Sigma_c\) | \(\pi_c\), \(\prod_j P(x_j\mid y)\) | কিছুই — training-বিন্দু রাখে |
| boundary | linear | quadratic | quadratic (axis-aligned) | piecewise, \(k\)-নির্ভর |
| মূল ধারণা | Gaussian, সমান covariance | Gaussian, ভিন্ন covariance | conditional independence | স্থানীয় মসৃণতা |
| capacity-knob | — | — | — | \(k\) (ছোট=flex, বড়=মসৃণ) |
| canonical accuracy | 0.881 | 0.919 | 0.904 | 0.896 (\(k{=}5\)) / 0.911 (\(k{=}15\)) |
পূর্ববর্তী সংযোগ:
- ← 2.2 (Bayes rule): এই অধ্যায়ের পুরো posterior-হিসাব \(P(y\mid x)=\frac{\pi_c f_c(x)}{\sum_l\pi_l f_l(x)}\) সরাসরি ২.২-এর Bayes-উপপাদ্যের প্রয়োগ — prior \(\pi_c\) ও likelihood \(f_c(x)\) থেকে posterior। generative classifier মানেই Bayes-নিয়মকে classification-এ খাটানো।
- ← 2.4 (Gaussian distribution): LDA ও QDA শ্রেণি-শর্তাধীন density-কে multivariate Gaussian ধরে; ২.৪-এর Gaussian-জ্ঞান (mean-vector, covariance-matrix, Mahalanobis দূরত্ব, density-সূত্র) ছাড়া এদের discriminant বোঝা যায় না।
- ← 5.4 (logistic regression): logistic regression discriminative — সরাসরি \(P(y\mid x)\) model করে, \(P(x)\) নয়। তুলনাটি গুরুত্বপূর্ণ: LDA Gaussian-ধারণা থেকে যে linear boundary পায়, logistic সেই একই sigmoid-ফর্মে পৌঁছায় কোনো density-ধারণা ছাড়াই — generative বনাম discriminative-এর পাঠ্যপুস্তকীয় জোড়া।
- ← 6.1 (bias–variance): চারটি classifier-ই capacity ও bias–variance-এর ভাষায় বোঝা যায় — LDA-র শেয়ার-\(\Sigma\) = QDA-র ওপর একটি bias-আরোপী সীমাবদ্ধতা (কম variance); Naive Bayes-এর independence-ধারণা = আরও কড়া bias কিন্তু কম variance; k-NN-এর \(k\) = সরাসরি একটি capacity-knob যা ৬.১-এর U-curve-কে আবার সামনে আনে।
পরবর্তী সংযোগ (→ 6.4 — SVM ও kernel methods): এই অধ্যায়ের classifier-গুলো হয় density model করেছে (generative), নয় প্রতিবেশী গুনেছে (instance-based)। পরের অধ্যায় একটি ভিন্ন discriminative দর্শন আনে — Support Vector Machine: কোনো বিতরণ না ধরে সরাসরি এমন একটি boundary খোঁজে যা দুই শ্রেণিকে সর্বোচ্চ margin-এ আলাদা করে (max-margin classifier)। আর nonlinear সীমানার জন্য আসে kernel trick — data-কে স্পষ্টভাবে উচ্চ-মাত্রায় না-পাঠিয়েই সেখানে linear boundary বসানোর কৌশল, যা QDA-র quadratic বা আরও জটিল সীমানাকে generalization (সাধারণীকরণ) করে। (curse of dimensionality-র যে সমস্যা k-NN-কে ভোগায়, kernel-পদ্ধতি তাকে অন্যভাবে সামলায় — মাত্রায় না গিয়ে শুধু inner-product দিয়ে কাজ সারে।)
source pointer: classification-এর statistics-অভিমুখী, পাঠযোগ্য উপস্থাপনা — Sugiyama, Introduction to Statistical Machine Learning (generative classification, LDA/QDA, k-NN) এবং Wasserman, All of Statistics (Bayes classifier, LDA/QDA, Naive Bayes, k-NN, Bayes error)। Bayes-নিয়ম ও Gaussian-ভিত্তি ঝালাইয়ে Rice, Mathematical Statistics and Data Analysis। data-scientist-মুখী, কোড-সহ classifier-তুলনা ও ব্যবহারিক টিপস Bruce & Bruce, Practical Statistics for Data Scientists এবং Dangeti, Statistics for Machine Learning (LDA, Naive Bayes, k-NN বাস্তবায়ন ও bias–variance)।