6.5 — Decision Trees, Bagging & Random Forests (ডিসিশন ট্রি, ব্যাগিং ও র্যান্ডম ফরেস্ট)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — রেখার ভাষা ছেড়ে হ্যাঁ/না-প্রশ্নের গাছে¶
১.১ আগের অধ্যায় কোথায় রেখে এসেছিল — আর কোন নতুন ভাষা¶
এ পর্যন্ত — 6.3-এর LDA/QDA/Naive Bayes/k-NN থেকে 6.4-এর support vector machine পর্যন্ত — আমাদের প্রতিটি classifier-এর decision boundary (সিদ্ধান্ত-সীমানা, যে পৃষ্ঠ feature-space-কে শ্রেণি-অঞ্চলে ভাগ করে) ছিল মূলত একই গোত্রের: একটা রেখা, বক্ররেখা, বা hyperplane (অধিসমতল)। SVM তো সরাসরি একটা রৈখিক স্কোর \(w^\top x+b\) গড়ে boundary \(w^\top x+b=0\) টানত (এখানে \(x\in\mathbb{R}^p\) হলো \(p\)টি বৈশিষ্ট্যের একটা feature vector, \(w\in\mathbb{R}^p\) একটা weight vector, \(b\in\mathbb{R}\) একটা ধ্রুবক); LDA মসৃণ density model করে boundary বের করত; k-NN প্রতিবেশীর ভোটে। ভিন্ন ভিন্ন পথ, কিন্তু সবার শেষে boundary-টা ছিল feature-গুলোর একটা মসৃণ, সাধারণত রৈখিক বা মৃদু-বক্র সমন্বয়।
এই অধ্যায়ে আমরা boundary গড়ার একটা সম্পূর্ণ ভিন্ন ভাষা শিখব — যেখানে কোনো \(w^\top x+b\) নেই, কোনো density নেই, কোনো দূরত্ব নেই। বদলে আছে কেবল একগুচ্ছ সরল হ্যাঁ/না প্রশ্ন, প্রতিটি একটামাত্র feature নিয়ে:
"feature \(j\)-এর মান কি একটা সীমা \(t\)-এর বেশি? — হ্যাঁ হলে এদিকে যাও, না হলে ওদিকে।"
এমন প্রশ্নের একটা শৃঙ্খল — একটা প্রশ্নের উত্তর অনুযায়ী পরের প্রশ্ন — সাজালে তৈরি হয় একটা গাছ (tree): শিকড় থেকে শুরু করে শাখায়-শাখায় নামতে নামতে শেষে একটা পাতায় পৌঁছনো, আর সেই পাতাই বলে দেয় শ্রেণি। এই নিয়ম-ভিত্তিক যন্ত্রের নাম decision tree (ডিসিশন ট্রি / সিদ্ধান্ত-বৃক্ষ)।
এক বাক্যে উত্তরণ। 6.4 পর্যন্ত boundary ছিল রেখা/বক্ররেখা/hyperplane — feature-গুলোর একটা মসৃণ সমন্বয়; এই অধ্যায়ে boundary গড়ে ওঠে একগুচ্ছ সরল হ্যাঁ/না প্রশ্নের গাছ থেকে, যেখানে প্রতিটি প্রশ্ন একটামাত্র feature-কে একটা সীমার সঙ্গে তুলনা করে।
১.২ Hook — কুড়ি প্রশ্নের খেলা, আর আয়তে-কাটা মানচিত্র¶
ছোটবেলার "কুড়ি প্রশ্ন" খেলাটা মনে করুন: একজন একটা জিনিস ভাবে, আর আপনি কেবল হ্যাঁ/না প্রশ্ন করে সেটা বের করেন — "এটা কি জীবন্ত? হ্যাঁ। এটা কি চার পায়ে হাঁটে? না। এটা কি ওড়ে?..."। প্রতিটি উত্তর সম্ভাবনার জগৎটাকে অর্ধেক করে দেয়, আর কয়েকটা ভালো প্রশ্নেই আপনি উত্তরে পৌঁছে যান। decision tree ঠিক এই খেলাটাই খেলে — শুধু প্রশ্নগুলো হয় data-র feature নিয়ে, আর প্রতিটা প্রশ্ন বাছা হয় যত বেশি সম্ভব শ্রেণি আলাদা করে দেওয়ার লক্ষ্যে।
এবার এই খেলার একটা জ্যামিতিক ছবি আঁকি, কারণ সেখানেই এই অধ্যায়ের আসল স্বাদ। ধরা যাক দুটো feature — \(x_1\) (অনুভূমিক অক্ষ) ও \(x_2\) (উল্লম্ব অক্ষ) — নিয়ে একটা সমতল। প্রথম প্রশ্ন "\(x_1 > 5\)?" আসলে সমতলটায় একটা উল্লম্ব রেখা \(x_1 = 5\) টেনে দেয়, আর space-কে বাঁ-ডান দুই ভাগে কাটে। এরপর ডান ভাগে যদি প্রশ্ন করি "\(x_2 > 3\)?", সেটা শুধু ওই ডান অংশেই একটা অনুভূমিক রেখা \(x_2 = 3\) টানে। এভাবে প্রতিটি প্রশ্ন একটামাত্র অক্ষের সমান্তরাল একটা কোপ — তাই গাছের গড়া boundary সবসময় axis-aligned (অক্ষ-সমান্তরাল), আর গোটা feature-space শেষমেশ ভাগ হয়ে যায় একগুচ্ছ আয়তাকার অঞ্চলে (অক্ষ-সমান্তরাল বাক্স)। প্রতিটি আয়তের ভেতরে গাছ একটামাত্র শ্রেণি-রায় দেয়।
এই অধ্যায়ের একটা চিত্রে (নাম: 6-5-tree-diagram) এই গাছটাই আঁকা — প্রশ্ন-নোড আর পাতা সমেত একটা প্রবাহচিত্র, যেখানে প্রতিটি internal node একটা হ্যাঁ/না প্রশ্ন আর প্রতিটি পাতা একটা শ্রেণি-রায়। মনে রাখবেন, গাছের প্রতিটি পাতা আসলে feature-space-এর একটা আয়তাকার অঞ্চলের সঙ্গেই সমার্থক — এই দুই রূপ একই জিনিসের দুই ছবি।
এক বাক্যে hook। একটা decision tree হলো feature নিয়ে কুড়ি-প্রশ্নের খেলা — প্রতিটি হ্যাঁ/না প্রশ্ন একটা অক্ষ-সমান্তরাল কোপে feature-space-কে কাটে, আর গাছটা শেষে গোটা space-কে আয়তাকার অঞ্চলে ভাগ করে, প্রতিটি অঞ্চলে একটা শ্রেণি-রায় বসিয়ে।
১.৩ গাছের শক্তি — আর গাছের অভিশাপ¶
এই সরল ছবিটার দুটো মুখ আছে, আর দুটোই এই অধ্যায়ের গল্প বোঝার জন্য জরুরি।
শক্তি — সরলতা ও interpretability। গাছের সবচেয়ে আকর্ষণীয় গুণ: এটা মানুষ-পাঠযোগ্য (interpretable)। একটা গাছকে আপনি সরাসরি একটা "যদি-তবে" নিয়মের তালিকা হিসেবে পড়তে পারেন — "যদি আয় > ৫০ হাজার এবং বয়স < ৩০, তবে শ্রেণি A"। কোনো রহস্যময় ওজন বা উচ্চ-মাত্রিক রূপান্তর নেই; প্রতিটি সিদ্ধান্তের পেছনের যুক্তি চোখের সামনে। তাছাড়া গাছ feature-এর scale নিয়ে মাথা ঘামায় না (কারণ এটা কেবল "বেশি না কম" দেখে, প্রকৃত মান নয়), categorical ও সংখ্যাগত feature একসঙ্গে সামলায়, আর সহজেই অরৈখিক ও পারস্পরিক-ক্রিয়াশীল সম্পর্ক ধরে। এই স্বচ্ছতার জন্যই গাছ এত জনপ্রিয়।
অভিশাপ — একটা গাছ data মুখস্থ করে। কিন্তু এই নমনীয়তারই একটা চড়া মূল্য আছে। প্রশ্ন করতে থাকলে — গাছ গভীর (deep) করতে থাকলে — শেষে প্রতিটি আয়ত এত ছোট হয়ে যায় যে তার ভেতরে হয়তো একটা-দুটো training-বিন্দু পড়ে, আর গাছ সেই বিন্দুগুলোকে নিখুঁতভাবে আলাদা করে ফেলে। অর্থাৎ গাছ training-data-কে কার্যত মুখস্থ করে — এটাই 6.1-এর চেনা overfitting (অতিরিক্ত-ফিট)। এর পরিসংখ্যানিক রূপ: একটা গভীর গাছের bias কম (সে প্রায় যেকোনো জটিল pattern ধরতে পারে), কিন্তু variance বিশাল — training-data-তে এক চিমটে পরিবর্তন হলেই (একটা বিন্দু সরে গেলে, বা অন্য একটা bootstrap-নমুনা নিলে) গোটা গাছের গঠন আমূল বদলে যেতে পারে। গাছ তাই কুখ্যাতভাবে অস্থির (unstable): একই সমস্যায় সামান্য ভিন্ন data দিলে আপনি প্রায়-অচেনা একটা গাছ পেতে পারেন।
(সংখ্যায় এই অস্থিরতা পরে চোখে দেখা যাবে: এই অধ্যায়ের dataset-এ একটা পূর্ণ-বৃদ্ধি-পাওয়া গাছ — গভীরতা ১০, ৫১টা পাতা — test-নির্ভুলতায় মোটে \(0.733\)-এ আটকে যায়, অথচ training-এ প্রায় নিখুঁত; আর bootstrap-নমুনা বদলে বদলে গাছ লাগালে তার নির্ভুলতার মান প্রায় \(0.040\) standard deviation-এ এদিক-ওদিক দোলে — এই বড় দোলাটাই high variance-এর সরাসরি সাক্ষী।)
এক বাক্যে। একটা গাছ একই সঙ্গে সবচেয়ে সরল-ও-interpretable এবং সবচেয়ে অস্থির model — গভীর গাছ data মুখস্থ করে (low bias) কিন্তু training সামান্য বদলালেই আমূল পাল্টে যায় (high variance, 6.1)।
১.৪ মূল insight (অন্তর্দৃষ্টি) — একটা গাছ নয়, একটা জঙ্গল¶
তাহলে কি গাছের interpretability-র লোভে আমাদের high variance মেনে নিতে হবে? — এখানেই এই অধ্যায়ের কেন্দ্রীয়, আশ্চর্যরকম সহজ ধারণাটা আসে: একটা গাছ অস্থির হলে, বহু গাছকে একসাথে কাজে লাগাও।
স্বজ্ঞাটা একটা ভিড়-জ্ঞানের (wisdom of the crowd) ছবি দিয়ে ধরা যায়। একজন বিশেষজ্ঞকে একটা কঠিন সংখ্যা আন্দাজ করতে বললে তার উত্তর হয়তো অনেকটা এদিক-ওদিক হতে পারে (high variance)। কিন্তু আপনি যদি অনেক মোটামুটি-স্বাধীন লোককে একই প্রশ্ন করে তাদের উত্তরের গড় নেন, তবে আশ্চর্যজনকভাবে সেই গড় প্রায়ই যেকোনো একক উত্তরের চেয়ে অনেক বেশি নির্ভরযোগ্য হয় — কারণ একেকজনের ভুল একেক দিকে, আর গড় নিলে সেই বিপরীতমুখী ভুলগুলো পরস্পরকে বাতিল করে দেয়। ঠিক এই নীতিটাই গাছে প্রয়োগ করা হয়: বহু গাছ লাগাও, প্রত্যেকে আলাদা ভুল করুক, তারপর তাদের ভোট নাও (classification) বা গড় নাও (regression) — আলাদা আলাদা ভুল গড়ে গিয়ে বাতিল হয়, আর যা টিকে থাকে সেটা আসল সংকেত। এই "বহু model মিলিয়ে একটা ভালো model" বানানোর সাধারণ ধারণার নাম ensemble (সমষ্টি / সংঘ)।
কিন্তু একটা সূক্ষ্ম প্রশ্ন থেকে যায়: একই training-data-তে গাছ লাগালে তো প্রতিবার একই গাছ পাব — তখন "বহু আলাদা গাছ" আসবে কোথা থেকে? এখানেই Part IV-এর একটা পুরোনো হাতিয়ার ঠিক জায়গায় খাপ খেয়ে যায় — bootstrap (4.9)। মনে করুন bootstrap কী করত: একই data থেকে with replacement (পুনঃস্থাপনসহ) বারবার তুলে একটু-একটু আলাদা নকল-নমুনা (resample) বানাত। ঠিক সেই কৌশলে আমরা \(B\)টি আলাদা bootstrap-নমুনা বানাই, প্রতিটায় একটা করে গাছ লাগাই — ফলে \(B\)টা ভিন্ন গাছ পাই, যাদের ভুলও ভিন্ন। তাদের ভোট/গড় নেওয়াই হলো bagging (bootstrap aggregating)। আর এর উপর আরেকটা ছোট চাল যোগ করলে গাছগুলো আরও বেশি স্বাধীন হয় — সেটাই random forest (এলোমেলো অরণ্য), যা §১.৫-এ ও বিশদে §২-এ আসছে।
এক বাক্যে insight (অন্তর্দৃষ্টি)। একটা অস্থির গাছের high variance-এর দাওয়াই হলো ensemble — bootstrap (4.9) দিয়ে বহু আলাদা গাছ বানিয়ে তাদের ভোট/গড় নেওয়া, যাতে গাছে-গাছে আলাদা ভুল গড়ে বাতিল হয়ে যায় আর variance নেমে আসে।
১.৫ এই অধ্যায়ের পথরেখা¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খল একবারে দেখে নিই, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- Decision tree (CART) (§২.১–২.২) — recursive binary split, অঞ্চল \(R_m\), প্রতিটি পাতায় majority/গড় দিয়ে রায়; axis-aligned boundary।
- Impurity ও split-নির্বাচন (§২.৩) — Gini \(G_m\) ও entropy \(H_m\) দিয়ে 'node কতটা মিশ্র' মাপা, আর information gain \(\Delta\) সর্বোচ্চ করে best split বাছা (greedy)।
- Depth, pruning ও কেন গাছ high-variance (§২.৪) — complexity-নিয়ন্ত্রণ, এবং কেন গভীর গাছ low-bias/high-variance/unstable।
- Bagging ও OOB (§২.৫) — bootstrap-এ \(B\)টি গাছ, \(\hat f_{\text{bag}}=\frac1B\sum_b\hat f_b\)/majority vote; কেন variance কমে; OOB error দিয়ে বিনামূল্যে validation।
- Random forest ও feature importance (§২.৬) — প্রতি-split random feature subset ⇒ correlation \(\rho\) কমে ⇒ variance আরও নামে; feature importance।
- Bias–variance ছবি (§২.৭) — single গাছ বনাম ensemble।
- সব derivation — variance-of-average সূত্র \(\rho\sigma^2+\frac{1-\rho}{B}\sigma^2\), Gini-বনাম-entropy, OOB-র ~৩৭% হিসাব — §৪-এ; পূর্ণ dataset, কোড, চিত্র ও অনুশীলনী §৫ থেকে।
এক বাক্যে কেন এটি এখানে। 6.4 boundary-কে গড়ত একটা মসৃণ রৈখিক/kernel নীতিতে; এই অধ্যায় boundary গড়ার একটা সম্পূর্ণ ভিন্ন, নিয়ম-ভিত্তিক ঘরানা (decision tree) আনে, তারপর তার high variance-কে ensemble (bagging ও random forest) দিয়ে কেটে দেয়; পরের অধ্যায় 6.6 (boosting) ensemble-এর আরেকটা ঘরানা আনবে, যেখানে গাছগুলো সমান্তরালে নয়, একে অপরের ভুল শুধরে ক্রমান্বয়ে গড়ে ওঠে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর insight (অন্তর্দৃষ্টি) — "হ্যাঁ/না প্রশ্নের গাছ feature-space-কে আয়তে কাটে; একটা গাছ অস্থির, তাই বহু গাছের ensemble নাও" — কে নিখুঁত সংজ্ঞায় রূপ দেব। প্রতিটি প্রতীক প্রথম ব্যবহারেই খোলা হলো; কোথাও কিছু ধরে নেওয়া হয়নি। যেখানে গণিতের পূর্ণ derivation লাগবে (বিশেষত averaging কীভাবে variance কমায় ও OOB কেন ~৩৭%), সেটা §৪-এ — এখানে লক্ষ্য সংজ্ঞা ও স্বজ্ঞা পরিষ্কার করা।
প্রথমে কিছু সাধারণ চিহ্ন স্থির করে নিই, যা গোটা অধ্যায়ে অপরিবর্তিত থাকবে। আমাদের কাছে \(n\)টি লেবেল-করা পর্যবেক্ষণ আছে: \((x_1,y_1),\dots,(x_n,y_n)\), যেখানে \(x_i\in\mathbb{R}^p\) হলো \(i\)-তম পর্যবেক্ষণের feature vector (\(p\)টি সংখ্যাগত বৈশিষ্ট্যের তালিকা, \(i=1,\dots,n\)), আর \(y_i\) হলো তার শ্রেণি-লেবেল। শ্রেণিবিন্যাসে (classification) \(y_i\) একটা সসীম শ্রেণি-সেট থেকে আসে, যাকে আমরা লিখব \(c\in\{1,\dots,K\}\) (\(K\)টি সম্ভাব্য শ্রেণি); regression-এ \(y_i\in\mathbb{R}\) একটা সংখ্যা। মূল আলোচনা classification ঘিরে, তবে গাছ ও ensemble দুই ক্ষেত্রেই কাজ করে — পার্থক্য কেবল পাতায় রায়টা majority না গড়, আর impurity-মাপটা Gini/entropy না variance।
২.১ Decision tree — recursive binary split ও অঞ্চল \(R_m\)¶
§১.২-এর কুড়ি-প্রশ্নের ছবিটাকে এবার আনুষ্ঠানিক করি।
সংজ্ঞা (Decision tree — সিদ্ধান্ত-বৃক্ষ; এখানে CART সংস্করণ)। একটা decision tree হলো feature-space \(\mathbb{R}^p\)-কে ভাগ করার একটা নিয়ম, যা গড়ে ওঠে পরপর binary split (দ্বিমুখী বিভাজন) দিয়ে। এখানে যে সংস্করণটা আমরা দেখব তার নাম CART (Classification And Regression Trees — শ্রেণিবিন্যাস ও সমাশ্রয়ণ বৃক্ষ), যেখানে প্রতিটি split-এর প্রশ্ন সবসময় এই সরল রূপের:
যেখানে \(x_j\) হলো একটা বিন্দুর \(j\)-তম feature (\(j\in\{1,\dots,p\}\)), আর \(t\in\mathbb{R}\) একটা threshold (সীমা/দ্বারমান)। উত্তর "হ্যাঁ" (\(x_j>t\)) হলে বিন্দুটা একদিকে যায়, "না" (\(x_j\le t\)) হলে অন্যদিকে — তাই প্রতিটি প্রশ্ন বর্তমান অঞ্চলকে ঠিক দুই টুকরো করে।
গাছের পরিভাষাটা একবার গুছিয়ে নিই (চিত্র 6-5-tree-diagram এই শব্দগুলোই দেখাবে):
- root node (মূল-নোড) — গাছের একদম উপরের নোড, যেখান থেকে প্রথম প্রশ্ন শুরু; এটা গোটা feature-space-কে প্রতিনিধিত্ব করে।
- internal node (অভ্যন্তরীণ নোড) — যে নোডে একটা প্রশ্ন "\(x_j>t\)?" বসে আছে, আর সেখান থেকে দুটো শাখা (branch) নেমে গেছে।
- leaf / terminal node (পাতা / প্রান্ত-নোড) — যে নোডে আর প্রশ্ন নেই; এখানেই শ্রেণি-রায় বসে। প্রতিটি পাতা feature-space-এর একটা নির্দিষ্ট আয়তাকার অঞ্চলের সঙ্গে এক-এক-মিলে যায়।
সাধারণভাবে যেকোনো নোডকে আমরা সূচক \(m\) দিয়ে চিহ্নিত করি, আর সেই নোড feature-space-এ যে অঞ্চলটা দখল করে তাকে লিখি \(R_m\) ("region \(m\)", \(m\)-তম অঞ্চল)। মূল কথাটা §১.২-এর জ্যামিতি থেকে: যেহেতু প্রতিটি split একটামাত্র অক্ষের সমান্তরাল (কেবল একটা feature \(x_j\)-কে একটা সংখ্যা \(t\)-র সঙ্গে তুলনা), প্রতিটি অঞ্চল \(R_m\) সবসময় একটা axis-aligned (অক্ষ-সমান্তরাল) আয়তাকার বাক্স — কখনো তির্যক নয়। শিকড় থেকে একটা পাতায় নামার পথটা আসলে পরপর কয়েকটা "\(x_j>t\)" শর্তের একটা তালিকা, আর সেই শর্তগুলোর ছেদই (intersection) ওই পাতার আয়ত \(R_m\)।
recursive (পুনরাবৃত্ত) গঠন। "recursive binary split" কথাটার অর্থ: গাছ তৈরি হয় ধাপে ধাপে, একই কাজ বারবার করে। শুরুতে গোটা space একটামাত্র অঞ্চল (root)। একটা split বসিয়ে তাকে দুই ভাগ করো; তারপর প্রতিটি ভাগকে আবার একই নিয়মে আলাদাভাবে ভাগ করো; এভাবে চলতে থাকো যতক্ষণ না কোনো থামার-শর্ত (stopping rule — যেমন গভীরতা-সীমা বা ন্যূনতম-বিন্দু, §২.৪) পূরণ হয়। প্রতিটি ভাগ স্বাধীনভাবে নিজের পথে গভীর হয়, তাই গাছটা ভারসাম্যহীন (একদিক গভীর, অন্যদিক অগভীর) হতে পারে — data যেমন চায়।
২.২ গাছের prediction — পাতায় majority/গড়¶
গাছ তো space-কে অঞ্চলে ভাগ করল; এবার একটা নতুন বিন্দু \(x\) এলে সে শ্রেণি বলে কীভাবে? সহজ: \(x\)-কে শিকড় থেকে শুরু করে প্রতিটা প্রশ্নের উত্তর অনুযায়ী নামিয়ে নাও, যতক্ষণ না সে একটা পাতায় (অঞ্চল \(R_m\)-এ) পৌঁছয়; তারপর ওই অঞ্চলে training-data যা বলেছিল, সেটাই রায়। আনুষ্ঠানিকভাবে:
প্রথমে একটা নোড \(m\)-এ (অঞ্চল \(R_m\)-এ) শ্রেণিগুলোর অনুপাত মাপি। ধরা যাক \(R_m\)-এর ভেতরে যে training-বিন্দুগুলো পড়েছে তাদের মধ্যে \(c\) শ্রেণির ভগ্নাংশ:
প্রতিটি প্রতীক খুলি:
- \(\hat p_{mc}\) ("p-hat-\(m\)-\(c\)") — নোড \(m\)-এ \(c\) শ্রেণির class proportion (শ্রেণি-অনুপাত): ওই অঞ্চলের কত ভাগ training-বিন্দু \(c\) শ্রেণির। টুপি (hat) চিহ্নটা মনে করায় এটা data থেকে গোনা একটা estimate।
- \(N_m\) — অঞ্চল \(R_m\)-এ পড়া training-বিন্দুর মোট সংখ্যা।
- \(\sum_{i:\,x_i\in R_m}\) — কেবল ওই অঞ্চলে পড়া বিন্দুগুলোর উপর যোগফল।
- \(\mathbb{1}(y_i=c)\) — একটা indicator (নির্দেশক): শর্ত সত্য (\(y_i=c\)) হলে \(1\), নাহলে \(0\)। তাই যোগফলটা গোনে অঞ্চলে কতগুলো বিন্দু \(c\) শ্রেণির।
লক্ষ করুন প্রতিটি নোডে \(\sum_{c=1}^K \hat p_{mc}=1\) (সব শ্রেণির ভগ্নাংশ মিলে এক)। এবার prediction:
- classification-এ নোড \(m\)-এর রায় হলো সেই শ্রেণি যার অনুপাত সর্বোচ্চ — majority vote (সংখ্যাগরিষ্ঠের রায়): $$ \hat y(x) \;=\; \arg\max_{c}\ \hat p_{mc}, \qquad x\in R_m, $$ যেখানে \(\arg\max_c\) মানে "যে \(c\)-তে রাশিটা সর্বোচ্চ, সেই \(c\)"। অর্থাৎ অঞ্চলে যে শ্রেণি বেশি, নতুন বিন্দুকে সেই শ্রেণিই দেওয়া হয়।
- regression-এ (\(y\in\mathbb{R}\)) রায় হলো অঞ্চলের training-\(y\)-গুলোর গড়: \(\hat y(x)=\frac{1}{N_m}\sum_{i:\,x_i\in R_m} y_i\)।
কথায়: গাছ feature-space-কে আয়তে ভাগ করে রাখে, আর প্রতিটি আয়তের ভেতরে একটামাত্র ধ্রুবক রায় দেয় — শ্রেণির ক্ষেত্রে সংখ্যাগরিষ্ঠ শ্রেণি, সংখ্যার ক্ষেত্রে গড়। এ কারণেই গাছের boundary ধাপে-ধাপে-কাটা (piecewise-constant): এক আয়তের মধ্যে রায় একই, আয়তের সীমা পেরোলেই হঠাৎ বদলে যায়।
২.৩ Impurity ও best split — Gini, entropy, ও information gain¶
এখন গাছ-নির্মাণের আসল প্রশ্ন: প্রতিটা নোডে কোন feature \(j\) আর কোন threshold \(t\) দিয়ে কাটব? অসংখ্য সম্ভাব্য "\(x_j>t\)" আছে — কোনটা ভালো? স্বজ্ঞা §১.২ থেকেই স্পষ্ট: ভালো split সেটা, যা কেটে দেওয়ার পর দুই পাশের অঞ্চল যতটা সম্ভব এক-শ্রেণির (বিশুদ্ধ) হয়ে যায়। তাই আগে দরকার "একটা নোড কতটা মিশ্র / অবিশুদ্ধ" তা মাপার একটা সংখ্যা — তার নাম impurity (অবিশুদ্ধতা)।
সংজ্ঞা (Gini impurity — জিনি-অবিশুদ্ধতা)। নোড \(m\)-এর Gini impurity:
এখানে \(\hat p_{mc}\) হলো §২.২-এর সেই শ্রেণি-অনুপাত। স্বজ্ঞা: \(\hat p_{mc}(1-\hat p_{mc})\) রাশিটা \(c\) শ্রেণির জন্য একটা "মিশ্রণ-পরিমাপ" — যদি \(c\) শ্রেণি অঞ্চলে প্রায় অনুপস্থিত (\(\hat p_{mc}\approx 0\)) বা প্রায় একচেটিয়া (\(\hat p_{mc}\approx 1\)) হয়, তবে এটা \(\approx 0\); আর \(\hat p_{mc}=0.5\)-এ এটা সর্বোচ্চ। সব শ্রেণির উপর যোগ করলে \(G_m\) ছোট হয় যখন একটা শ্রেণি প্রায় পুরো অঞ্চল দখল করে (বিশুদ্ধ নোড, \(G_m=0\)), আর বড় হয় যখন শ্রেণিগুলো সমান-সমান মিশে থাকে। (একটা সমান্তরাল স্বজ্ঞা: \(G_m\) হলো ওই অঞ্চল থেকে এলোমেলোভাবে দুটো বিন্দু তুললে তারা ভিন্ন শ্রেণির হওয়ার সম্ভাবনা — মিশ্রণ যত বেশি, এই সম্ভাবনা তত বড়।)
সংজ্ঞা (Entropy — এনট্রপি / তথ্য-অবিশুদ্ধতা)। আরেকটা প্রচলিত impurity-মাপ, যা তথ্য-তত্ত্ব (information theory) থেকে আসে:
এখানে \(\log\) সাধারণত base-2 (তখন একক "bit") বা প্রাকৃতিক লগ; ধরা হয় \(0\log 0 = 0\) (limit-অর্থে)। \(H_m\)-ও ঠিক একই আচরণ করে: বিশুদ্ধ নোডে (একটা \(\hat p_{mc}=1\), বাকি সব \(0\)) \(H_m=0\), আর শ্রেণিগুলো সমান-সমান হলে \(H_m\) সর্বোচ্চ। স্বজ্ঞা: entropy হলো "অঞ্চলের একটা বিন্দুর শ্রেণি জানতে গড়ে কতটা চমক/তথ্য লাগে" — সব এক-শ্রেণি হলে কোনো চমক নেই (\(H=0\)), পুরো মিশ্র হলে চমক সর্বাধিক। (Gini ও entropy কার্যত একই রকম split বাছে; এদের সূক্ষ্ম পার্থক্য ও তুলনা §৪-এ।)
Split বাছার নীতি — information gain। এবার মূল যন্ত্র। একটা split একটা অভিভাবক-নোড \(m\)-কে দুই সন্তান-নোড — বাঁ (\(m_L\)) ও ডান (\(m_R\)) — এ ভাগ করে। আমরা চাই split-এর পর অবিশুদ্ধতা যতটা সম্ভব কমুক। কিন্তু দুই সন্তানের impurity-কে কেবল যোগ করলে হবে না — যে সন্তানে বেশি বিন্দু, তার বেশি গুরুত্ব পাওয়া উচিত। তাই আমরা সন্তানদের impurity-র একটা ভারিত গড় (weighted average) নিই, ভার হলো প্রতিটি সন্তানে পড়া বিন্দুর অনুপাত। এই কমে-যাওয়াটাকে বলে information gain (তথ্য-অর্জন):
প্রতিটি প্রতীক খুলি:
- \(\Delta\) ("ডেল্টা") — এই split থেকে পাওয়া information gain: অভিভাবকের impurity থেকে সন্তানদের ভারিত-গড় impurity বাদ দিলে যতটা impurity কমল।
- \(I_m\) — নোড \(m\)-এর impurity, যেখানে \(I\) মানে আপনার বেছে নেওয়া মাপ — হয় Gini \(G_m\), নয় entropy \(H_m\) (regression-এ অঞ্চলের \(y\)-গুলোর variance)।
- \(N_m, N_{m_L}, N_{m_R}\) — যথাক্রমে অভিভাবক, বাঁ-সন্তান ও ডান-সন্তানে পড়া training-বিন্দুর সংখ্যা; স্বভাবতই \(N_{m_L}+N_{m_R}=N_m\)।
- \(\frac{N_{m_L}}{N_m}, \frac{N_{m_R}}{N_m}\) — দুই সন্তানের ভার (কত ভাগ বিন্দু কোন দিকে গেল)।
split-নির্বাচনের নিয়মটা এবার এক বাক্যে: সম্ভাব্য সব \((j,t)\) জোড়ার মধ্যে সেইটা বাছো যা \(\Delta\) সর্বোচ্চ করে — অর্থাৎ যে কোপ অবিশুদ্ধতা সবচেয়ে বেশি কমায়। কারণ \(I_m\) স্থির (অভিভাবকের), \(\Delta\) সর্বোচ্চ করা মানে সন্তানদের ভারিত-গড় impurity সর্বনিম্ন করা — সবচেয়ে বিশুদ্ধ দুই টুকরো পাওয়া।
Greedy (লোভী) প্রকৃতি — একটা জরুরি সতর্কতা। গাছ এই best split-টা বাছে কেবল এই মুহূর্তের কথা ভেবে — অর্থাৎ এই এক ধাপে impurity সবচেয়ে কমে, তা-ই; ভবিষ্যতে নিচের split-গুলো কী হবে তা হিসাবে নেয় না। এই "প্রতি ধাপে স্থানীয়ভাবে সেরা" নীতিকে বলে greedy (লোভী)। এটা দ্রুত ও ব্যবহারিক, কিন্তু বিশ্ব-সেরা (globally optimal) গাছের নিশ্চয়তা দেয় না — হয়তো এখন একটু খারাপ একটা split পরে অনেক ভালো গাছে নিয়ে যেত, কিন্তু greedy পদ্ধতি তা দেখে না। (পূর্ণ-সেরা গাছ খোঁজা গণনাগতভাবে কার্যত অসম্ভব, তাই এই greedy আপস সর্বজনীন।)
২.৪ Depth, pruning, ও কেন গাছ high-variance¶
§১.৩-এর "অভিশাপ"-টাকে এবার একটু গুছিয়ে দেখি, কারণ এটাই ensemble-এ যাওয়ার পুরো কারণ।
কখন থামবে — গাছের complexity। recursive split চলতেই থাকতে পারে যতক্ষণ না প্রতিটি পাতায় একটামাত্র শ্রেণি (বা একটামাত্র বিন্দু) থাকে — তখন training-নির্ভুলতা প্রায় ১০০%। এমন পূর্ণ-বৃদ্ধি-পাওয়া (fully grown) গাছ অতি-গভীর ও অতি-বিস্তৃত, আর সে training-data মুখস্থ করে ফেলে (overfit, 6.1)। তাই বাস্তবে গাছের complexity নিয়ন্ত্রণ করতে হয়, দুই প্রধান উপায়ে:
- depth-সীমা ও থামার-শর্ত (pre-pruning / আগেই ছাঁটা) — গাছের সর্বোচ্চ গভীরতা (depth — শিকড় থেকে পাতা পর্যন্ত প্রশ্নের সংখ্যা) বেঁধে দাও, বা নিয়ম করো "একটা নোডে ন্যূনতম এতগুলো বিন্দু না থাকলে আর ভাগ কোরো না"। এতে গাছ ছোট থাকে, প্রতিটি পাতায় অনেক বিন্দু — তাই কম মুখস্থ, বেশি generalization (সাধারণীকরণ)।
- pruning (ছাঁটাই / post-pruning) — প্রথমে একটা বড় গাছ গড়ে তারপর সেই শাখাগুলো কেটে ফেলা যেগুলো test-performance-এ তেমন কিছু যোগ করে না (সাধারণত একটা penalty-যুক্ত মানদণ্ডে — গাছ যত বড়, তত শাস্তি)। ফল: একটা ছোট গাছ যা generalization (সাধারণীকরণ)-এ ভালো।
দুই উপায়ই আসলে একই bias–variance ভারসাম্যের দুই হাতল: গাছ যত গভীর, bias তত কম কিন্তু variance তত বেশি; যত অগভীর, bias তত বেশি কিন্তু variance তত কম। (সংখ্যায়: এই অধ্যায়ের dataset-এ একটা গভীরতা-সীমিত গাছ — গভীরতা ৩ — test-নির্ভুলতা \(0.794\)-এ তোলে, অথচ পূর্ণ গভীরতা-১০ গাছ মোটে \(0.733\)-এ আটকে যায়; অর্থাৎ গাছটাকে একটু ছোট করে দিলেই overfitting কমে নির্ভুলতা বাড়ে।)
কেন গাছ এত high-variance — মূল কথা। এখানে variance-এর অর্থ 6.1-এর সেই অর্থেই: training-data সামান্য বদলালে শেখা model কতটা বদলায়। গাছের ক্ষেত্রে এটা চরম, এবং তার একটা কাঠামোগত কারণ আছে। গাছ গড়া হয় greedy ভাবে, ধাপে ধাপে — আর উপরের দিকের একটা split যদি সামান্য বদলায় (কারণ data একটু আলাদা, তাই হয়তো অন্য একটা feature বা threshold এবার \(\Delta\) সর্বোচ্চ করল), তবে তার নিচের গোটা subtree সম্পূর্ণ ভিন্নভাবে গড়ে ওঠে — ভুলটা ক্রমে বড় হতে হতে গোটা গাছ পাল্টে দেয়। তাই একটা গাছ অত্যন্ত অস্থির (unstable): একই সমস্যায় দুটো আলাদা bootstrap-নমুনা দিলে আপনি প্রায়-অচেনা দুটো গাছ পেতে পারেন, যদিও তাদের গড় নির্ভুলতা কাছাকাছি।
(এই অস্থিরতা §৫-এ সংখ্যায় দেখানো হবে: একই dataset-এর বহু bootstrap-নমুনায় পূর্ণ গাছ লাগিয়ে test-নির্ভুলতা মাপলে সেই মানগুলোর standard deviation প্রায় \(0.040\) — অর্থাৎ কেবল data-র নকল-নমুনা বদলেই নির্ভুলতা ±৪ শতাংশ-বিন্দু এদিক-ওদিক দোলে। এই বড় দোলাই high variance-এর সরাসরি মাপ, এবং পরবর্তী ensemble ঠিক এই দোলাটাই কমাতে চায়।)
এক বাক্যে। একটা গাছের complexity (depth/pruning) bias–variance ঠিক করে — গভীর গাছ low-bias কিন্তু high-variance ও unstable, কারণ greedy-গঠনে উপরের একটা split বদলালে নিচের গোটা subtree পাল্টে যায়; এই অস্থিরতাই ensemble-এর প্রেরণা।
২.৫ Bagging — bootstrap-এ বহু গাছ, আর OOB error¶
§১.৪-এর "ভিড়-জ্ঞান" স্বজ্ঞাকে এবার আনুষ্ঠানিক করি। ধারণা: একটা গাছ high-variance হলে, বহু গাছের গড় নিয়ে সেই variance কমাও। কিন্তু আলাদা গাছ পেতে আলাদা data লাগে — আর সেটা জোগায় bootstrap (4.9)।
সংজ্ঞা (Bagging — bootstrap aggregating)। bagging (নামটা "bootstrap aggregating" থেকে) তিন ধাপে কাজ করে:
ধাপ ১ — \(B\)টি bootstrap-নমুনা বানাও। মূল training-set \(\{(x_1,y_1),\dots,(x_n,y_n)\}\) থেকে with replacement (পুনঃস্থাপনসহ) আবার \(n\)টি বিন্দু তুলে একটা resample বানাও; এটা \(B\) বার করো, পাও \(B\)টি bootstrap-নমুনা (প্রতিটায় কিছু বিন্দু একাধিকবার, কিছু একেবারেই নেই — 4.9-এর সেই চেনা ছবি)। এখানে \(B\) হলো গাছের সংখ্যা (যেমন \(B=300\))।
ধাপ ২ — প্রতিটায় একটা গাছ লাগাও। \(b\)-তম bootstrap-নমুনায় একটা decision tree লাগিয়ে পাও \(\hat f_b\) — এটা \(b\)-তম গাছের prediction-function (\(b=1,\dots,B\))। লক্ষ করো, প্রতিটি গাছ একটু-আলাদা data দেখে, তাই \(B\)টা গাছ ভিন্ন হয়, আর তাদের ভুলও ভিন্ন। (এখানে সাধারণত গাছগুলোকে গভীর/অছাঁটা রাখা হয় — কারণ আমরা চাই low bias; high variance-টা পরের গড়ই সামলাবে।)
ধাপ ৩ — সমষ্টি করো (aggregate)। নতুন \(x\)-এর জন্য সব গাছের রায় একত্র করো:
- regression-এ — সরল গড়: $$ \boxed{\ \hat f_{\text{bag}}(x) \;=\; \frac{1}{B}\sum_{b=1}^{B}\hat f_b(x)\ } $$ যেখানে \(\hat f_{\text{bag}}(x)\) হলো bagged model-এর prediction, আর \(\frac1B\sum_{b=1}^B\) হলো \(B\)টা গাছের রায়ের গড়।
- classification-এ — majority vote (সংখ্যাগরিষ্ঠ ভোট): \(B\)টা গাছ যে শ্রেণিতে সবচেয়ে বেশি ভোট দেয়, সেটাই চূড়ান্ত রায়।
কেন variance কমে — স্বজ্ঞা। মূল গণিত §৪-এ, কিন্তু স্বজ্ঞাটা §১.৪-এর সেই ভিড়-জ্ঞান: প্রতিটা গাছের prediction-এ একটা এলোমেলো ভুল (variance) আছে, কিন্তু গাছগুলো যদি স্বাধীনভাবে ভুল করে, তবে গড় নিলে সেই বিপরীতমুখী ভুলগুলো বেশিরভাগ বাতিল হয়ে যায়। গড়ের bias প্রায় একই থাকে (প্রতিটা গাছই গড়ে ঠিক জায়গায় তাক করে), কিন্তু এদিক-ওদিকের দোলা — variance — অনেক কমে। ফল: bagged ensemble একটা একক গাছের চেয়ে অনেক বেশি স্থির ও নির্ভুল। (সংখ্যায়: এই অধ্যায়ের dataset-এ \(300\)টা গাছের bagging নির্ভুলতা তুলে দেয় \(0.822\)-এ — একটা পূর্ণ গাছের \(0.733\) থেকে স্পষ্ট লাফ, যদিও মূল উপাদান সেই একই অস্থির গাছ।)
OOB error — বিনামূল্যে validation। bagging-এর একটা চমৎকার উপহার আছে, যা bootstrap-এর গঠন থেকেই বিনামূল্যে আসে। লক্ষ করো, একটা গাছ যে bootstrap-নমুনায় train হয়, সেখানে মূল data-র সব বিন্দু থাকে না — গড়ে প্রায় এক-তৃতীয়াংশ (~৩৭%) বিন্দু বাদ পড়ে যায় (কেন ঠিক ৩৭%, তার হিসাব §৪-এ)। একটা নির্দিষ্ট বিন্দু \((x_i,y_i)\)-এর দৃষ্টিকোণ থেকে, যেসব গাছের bootstrap-নমুনায় সে পড়েনি, সেই গাছগুলোর কাছে সে একদম না-দেখা (out-of-bag, OOB) — অর্থাৎ তাদের জন্য সে একটা বৈধ test-বিন্দু।
সংজ্ঞা (OOB error — out-of-bag error)। প্রতিটি training-বিন্দু \((x_i,y_i)\)-এর জন্য কেবল সেই গাছগুলোর ভোট নাও যাদের bootstrap-নমুনায় \(i\) পড়েনি (তার OOB-গাছগুলো), সেই ভোট থেকে \(i\)-এর একটা prediction বানাও, আর তা আসল \(y_i\)-এর সঙ্গে মেলাও। সব বিন্দুর উপর এই না-মেলার হারই OOB error — একটা test-error-এর আন্দাজ, আলাদা validation-set বা cross-validation ছাড়াই। কারণ প্রতিটি বিন্দু কেবল সেইসব গাছ দিয়ে যাচাই হচ্ছে যারা তাকে training-এ দেখেনি, তাই এটা সৎ (honest) মূল্যায়ন — bagging/forest-এর একটা বড় ব্যবহারিক সুবিধা।
২.৬ Random forest — decorrelation, OOB, ও feature importance¶
bagging variance কমায় ঠিকই, কিন্তু একটা সীমা আছে: bootstrap-নমুনাগুলো একই মূল data থেকে আসে, তাই গাছগুলো পুরোপুরি স্বাধীন নয় — তারা পরস্পর-সম্পর্কিত (correlated)। বিশেষত যদি একটা feature খুব শক্তিশালী হয়, তবে প্রায় প্রতিটা গাছই উপরের দিকে সেই একই feature দিয়ে split করবে, ফলে গাছগুলো একে-অন্যের মতো দেখতে হবে — আর §১.৪-এর ভিড়-জ্ঞান বলে, সম্পর্কিত ভুল গড়ে নিলে তত ভালোভাবে বাতিল হয় না। তাই variance-হ্রাসও আটকে যায়। random forest ঠিক এই সমস্যাটার সমাধান।
সংজ্ঞা (Random forest — এলোমেলো অরণ্য)। একটা random forest হলো bagging-করা decision tree-র একটা ensemble, যাতে একটা বাড়তি এলোমেলোপনা যোগ করা হয়: প্রতিটি split-এ, সব \(p\)টা feature বিবেচনা না করে, এলোমেলোভাবে বাছা একটা ছোট feature-উপসেট (random feature subset) থেকেই best split খোঁজা হয়। সাধারণত প্রতিটি split-এ এলোমেলোভাবে \(m_{\text{try}}\)টা feature বাছা হয় (classification-এ চেনা পছন্দ \(m_{\text{try}}\approx\sqrt{p}\)), আর কেবল সেই \(m_{\text{try}}\)টার মধ্যেই §২.৩-এর information-gain নিয়মে split বাছা হয়। প্রতিটা split-এ আবার নতুন করে এলোমেলো উপসেট।
কেন এটা কাজ করে — decorrelation। এই ছোট চালটার একটাই উদ্দেশ্য: গাছগুলোকে পরস্পর-অসম্পর্কিত (decorrelated) করা। যেহেতু প্রতিটা split-এ শক্তিশালী feature-টা হয়তো বাছা উপসেটে নাও থাকতে পারে, ভিন্ন ভিন্ন গাছ ভিন্ন ভিন্ন feature-কে উপরে তুলে আনে — তাই গাছগুলো একে-অন্যের মতো কম দেখতে হয়, তাদের ভুলের মধ্যে correlation \(\rho\) ("rho") কমে যায়। আর কেন কম correlation মানে কম variance, তার সঠিক রূপ §৪-এ derive করা variance-of-average সূত্র:
প্রতিটি প্রতীক খুলি:
- \(\sigma^2\) — একটা একক গাছের prediction-এর variance (এক গাছ কতটা দোলে)।
- \(\rho\) — যেকোনো দুটো গাছের prediction-এর মধ্যে correlation (পারস্পরিক সম্পর্ক): \(\rho=1\) মানে গাছগুলো হুবহু এক, \(\rho=0\) মানে সম্পূর্ণ স্বাধীন।
- \(B\) — গাছের সংখ্যা।
সূত্রটা যা বলে তা গভীর: \(B\to\infty\) করলে দ্বিতীয় পদ \(\frac{1-\rho}{B}\sigma^2\to 0\) — অর্থাৎ আরও গাছ যোগ করে variance-এর এই অংশটা শূন্যে নামানো যায়। কিন্তু প্রথম পদ \(\rho\sigma^2\) থেকেই যায়, যত গাছই লাগাও — এটা গাছের মধ্যেকার correlation-এর জন্য একটা মেঝে (floor)। bagging কেবল দ্বিতীয় পদটা কমায়; কিন্তু random forest \(\rho\)-কেও কমিয়ে ওই মেঝেটাকেই নামিয়ে দেয় — তাই random forest সাধারণত bagging-এর চেয়ে কম variance, বেশি নির্ভুল। (সংখ্যায়: এই dataset-এ \(300\)-গাছের random forest নির্ভুলতা \(0.839\) — bagging-এর \(0.822\)-এর চেয়েও ভালো; আর গাছের সংখ্যা বাড়ার সঙ্গে নির্ভুলতা কীভাবে দ্রুত থিতু হয় তা স্পষ্ট: ১ গাছে \(0.711\), ৫-এ \(0.806\), ২৫-এ \(0.844\), ৩০০-তে \(0.839\) — অর্থাৎ কয়েক ডজন গাছেই বেশিরভাগ লাভ এসে যায়, এটাই চিত্র 6-5-ensemble-accuracy-তে দেখা যাবে।)
random forest-ও bagging-এর মতোই OOB error দেয় (প্রতিটা গাছ যে বিন্দুগুলো দেখেনি, তা দিয়ে বিনামূল্যে যাচাই — §২.৫)। সংখ্যায়, এই dataset-এ forest-এর OOB-নির্ভুলতা \(0.848\) — যা আলাদা test-set-এর \(0.839\)-এর খুব কাছাকাছি, অর্থাৎ OOB একটা নির্ভরযোগ্য test-error-আন্দাজ।
Feature importance — কোন feature কত কাজে লাগল। ensemble interpretability-কে অনেকটা ফিরিয়ে আনে একটা সরল ধারণায়: feature importance (বৈশিষ্ট্য-গুরুত্ব)। স্বজ্ঞা — যে feature বারবার, গাছে-গাছে, বড় বড় split-এ ব্যবহৃত হয়ে অনেক impurity কমায়, সে নিশ্চয়ই গুরুত্বপূর্ণ। আনুষ্ঠানিকভাবে, একটা feature \(j\)-এর importance মাপা হয় সব গাছ মিলে, যেসব split-এ \(j\) ব্যবহৃত হয়েছে, সেখানে অর্জিত মোট information gain \(\Delta\)-র যোগফল (বিন্দু-সংখ্যা দিয়ে ভারিত) দিয়ে — অর্থাৎ "\(j\) সব মিলিয়ে কত অবিশুদ্ধতা কমাল"। যে feature বেশি impurity কমায়, তার importance বেশি। এটা একটা মূল্যবান হাতিয়ার: কোন feature-গুলো আসলে predictive আর কোনগুলো নিছক noise, তা চোখে দেখা যায়। (সংখ্যায়: এই dataset-এ যে কটা informative feature ইচ্ছাকৃতভাবে রাখা হয়েছিল সেগুলোর importance সবচেয়ে উঁচু, আর যে feature-গুলো নিছক noise তাদের importance প্রায় শূন্যে নেমে যায় — random forest নিজে থেকেই আসল-feature ও noise-feature আলাদা করে চিনে নেয়, যা চিত্র 6-5-feature-importance-তে দেখা যাবে।)
২.৭ Bias–variance — একটা গাছ বনাম ensemble¶
পুরো অধ্যায়ের গল্পটা এবার 6.1-এর bias–variance কাঠামোয় এক ছবিতে গেঁথে নিই — কারণ এটাই বুঝিয়ে দেয় ensemble ঠিক কী জিতে নেয়, আর কী জেতে না।
মনে করুন test-error-কে মোটামুটি তিন ভাগে ভাঙা যায় (6.1): \(\text{error} \approx \text{bias}^2 + \text{variance} + \text{(অপরিবর্তনীয় noise)}\)। এই ভাঙনে:
- একটা গভীর গাছ — low bias, high variance। গাছ এত নমনীয় যে গড়ে সে সত্য pattern-টা ভালোই ধরে (bias কম), কিন্তু training সামান্য বদলালেই আমূল পাল্টে যায় (variance বিশাল, §২.৪)। তাই গাছের মোট error-এর সিংহভাগই আসে variance থেকে।
- ensemble — সেই bias রেখেই variance কাটে। এখানেই মূল কৌশল। bagging ও random forest bias-কে প্রায় ছোঁয় না — প্রতিটা গাছ যেহেতু নিজে low-bias, তাদের গড়ও low-bias থাকে। বদলে তারা আক্রমণ করে variance-এর উপর: বহু গাছের গড়/ভোট নিয়ে এদিক-ওদিকের দোলা বাতিল করে দেয় (§২.৫), আর random forest গাছগুলো decorrelate করে সেই variance আরও নিচে নামায় (§২.৬)। ফল: একই (কম) bias, কিন্তু অনেক কম variance — তাই মোট error পড়ে যায়।
এই একটা বাক্যেই গোটা অধ্যায়ের সারমর্ম ধরা — আমরা গাছের সবচেয়ে খারাপ গুণটা (high variance) ensemble দিয়ে কেটে ফেলি, অথচ তার সবচেয়ে ভালো গুণটা (low bias, নমনীয়তা) ধরে রাখি। এ কারণেই random forest একই সঙ্গে একটা একক গাছের মতো নমনীয়, অথচ অনেক বেশি স্থির ও নির্ভুল — যা এই অধ্যায়ের canonical সংখ্যাগুলোতেই (একক গাছ \(0.733\) → random forest \(0.839\)/OOB \(0.848\)) স্পষ্ট।
এক বাক্যে। একটা গাছ low-bias কিন্তু high-variance; ensemble (bagging ও random forest) সেই bias প্রায় অপরিবর্তিত রেখে কেবল variance-অংশটাই কেটে দেয় — averaging দিয়ে দোলা বাতিল করে, এবং forest-এ গাছ decorrelate করে আরও — তাই মোট error কমে।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এই অংশে চারটি ক্রমবর্ধমান উদাহরণের মধ্য দিয়ে এই অধ্যায়ের কেন্দ্রীয় গল্পটা হাতে-কলমে দেখা হবে — কীভাবে একটা একক decision tree-এর high variance সমস্যা ধাপে ধাপে averaging আর randomization দিয়ে কমে আসে। প্রথমে দেখব একটা single tree কীভাবে training data মুখস্থ করে overfit করে, এবং একই tree resample বদলালে কতটা অস্থির হয় (E1); তারপর সেই অস্থিরতা bagging কীভাবে গড় করে কমায় (E2); এরপর random forest কীভাবে feature-subset randomization দিয়ে আরও এগিয়ে যায় এবং বিনামূল্যে OOB validation দেয় (E3); সবশেষে tree-সংখ্যার প্রভাব, feature importance র্যাঙ্কিং, এবং সব পদ্ধতির একটা সারাংশ টেবিল (E4)। প্রতিটি সংখ্যা scikit-learn দিয়ে নিচে যাচাই করা।
সব উদাহরণে একই synthetic dataset ব্যবহার করা হবে — make_classification-এর ২০টি feature, যার মধ্যে মাত্র ৬টি informative, ২টি redundant, আর বাকি ১২টি প্রায় বিশুদ্ধ noise। শ্রেণি দুটো কিছুটা overlap করে (class_sep=0.8) এবং ৫% label ইচ্ছাকৃতভাবে উল্টে দেওয়া (flip_y=0.05) — অর্থাৎ এটা এমন একটা "কঠিন" সমস্যা যেখানে কোনো একক tree সহজে memorize করে ফেলবে:
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier
X, y = make_classification(
n_samples=600, n_features=20, n_informative=6, n_redundant=2,
n_repeated=0, n_classes=2, class_sep=0.8, flip_y=0.05,
random_state=20260619)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=0, stratify=y)
# 420 train / 180 test, label y ∈ {0, 1}
৩.১ E1 — একটা single tree overfit করে, এবং সে unstable¶
প্রথমে কোনো depth-সীমা ছাড়াই একটা সম্পূর্ণ decision tree বাড়তে দিই — অর্থাৎ গাছকে যতদূর সম্ভব নিচে নামতে দিই যতক্ষণ না প্রতিটি leaf প্রায় বিশুদ্ধ (\(G_m \to 0\)) হয়:
full = DecisionTreeClassifier(random_state=0).fit(X_train, y_train)
print(round(full.score(X_test, y_test), 3), # 0.733
full.get_depth(), # 10
full.get_n_leaves()) # 51
ফলাফল: গাছটা depth 10 পর্যন্ত নেমে 51টি leaf তৈরি করেছে, অথচ test accuracy মাত্র 0.733। এই ৫১টি leaf আসলে training-এর ৪২০টি বিন্দুকে ছোট ছোট খোপে ভাগ করে ফেলেছে — গাছটা training data কার্যত মুখস্থ করেছে (training accuracy এখানে প্রায় ১.০)। কিন্তু flip_y=0.05-এর কারণে training-এর কিছু label নিজেই ভুল; সেই noise-ও গাছ আলাদা leaf বানিয়ে "শিখে" ফেলেছে। এটাই classic overfitting — গাছ signal আর noise-এর পার্থক্য করতে পারেনি, ফলে নতুন data-তে generalization দুর্বল।
সমাধানের প্রথম চেষ্টা: গাছের গভীরতা সীমিত করে দেওয়া (pre-pruning), যাতে সে noise-এর জন্য আলাদা leaf বানাতে না পারে। max_depth কমিয়ে দেখি:
for d in [3, 5, 8]:
m = DecisionTreeClassifier(max_depth=d, random_state=0).fit(X_train, y_train)
print(d, round(m.score(X_test, y_test), 3))
# 3 0.794
# 5 0.794
# 8 0.756
মাত্র depth=3-এ test accuracy লাফিয়ে 0.794-এ উঠে গেছে — full tree-এর 0.733 থেকে অনেক ভালো! অর্থাৎ অগভীর, "কম-ক্ষমতাসম্পন্ন" একটা গাছ এখানে বেশি গভীর গাছের চেয়ে ভালো generalize করছে, কারণ সে noise মুখস্থ করার সুযোগই পায়নি। depth বাড়াতে বাড়াতে (depth=8 → 0.756) accuracy আবার নামছে — এটাই bias-variance trade-off-এর গাছ-সংস্করণ: খুব অগভীর = high bias (underfit), খুব গভীর = high variance (overfit), মাঝামাঝি কোথাও sweet spot।
কিন্তু depth tune করেও মূল সমস্যা যায় না — single tree মূলগতভাবে অস্থির (high variance)। একটা গাছ training data-র ক্ষুদ্র পরিবর্তনেও আমূল বদলে যেতে পারে, কারণ root-এর কাছে একটা split সামান্য বদলালে তার নিচের পুরো subtree বদলে যায়। এটা পরিমাপ করতে training set থেকে ২০টা bootstrap resample নিই (প্রতিবার একই আকারের নমুনা, replacement সহ), প্রতিটায় একটা full tree ফিট করি, এবং একই fixed test set-এ accuracy দেখি:
np.random.seed(66)
rng = np.random.RandomState(66)
n, accs = X_train.shape[0], []
for b in range(20):
idx = rng.randint(0, n, n) # bootstrap resample
m = DecisionTreeClassifier().fit(X_train[idx], y_train[idx])
accs.append(m.score(X_test, y_test))
print(round(np.mean(accs), 3), round(np.std(accs), 3)) # 0.752 0.040
২০টা গাছের accuracy-র গড় 0.752, কিন্তু standard deviation 0.040 — অর্থাৎ data সামান্য বদলালেই (একই distribution থেকেই নেওয়া resample) accuracy ±৪ শতাংশ-বিন্দু এদিক-ওদিক দুলছে। এই দোলাটাই variance। প্রতিটা resample আলাদা গাছ জন্ম দেয়, আর তাদের ভুলগুলো আলাদা আলাদা জায়গায়। একটা একক গাছ বেছে নিলে আপনি কার্যত এই ২০টা গাছের একটাকে এলোমেলোভাবে তুলে নিচ্ছেন — ভাগ্য ভালো হলে 0.79, খারাপ হলে 0.71।
এখান থেকেই পরের পদক্ষেপের অনুপ্রেরণা: যেহেতু আলাদা গাছগুলোর ভুল আলাদা জায়গায় ছড়ানো, তাহলে অনেকগুলো গাছের গড় নিলে কি সেই ভুলগুলো একে অপরকে বাতিল করে দেবে?
single-tree accuracy over 20 bootstrap resamples (mean = 0.752)
0.71 ●
0.72 ● ●
0.73 ● ● ●
0.74 ● ● ●
0.75 ─────────────────●●●─────────── mean = 0.752
0.76 ● ● ●
0.77 ● ● ●
0.78 ● ●
0.79 ●
└──────────────────────────── 20 trees, sd = 0.040 (HIGH variance)
↑ same data distribution, yet each tree lands differently
৩.২ E2 — Bagging variance কমায়¶
E1-এ দেখা গেল আলাদা bootstrap গাছগুলোর ভুল এলোমেলোভাবে ছড়ানো। Bagging (bootstrap aggregating) ঠিক এই পর্যবেক্ষণটাকে কাজে লাগায়: \(B\)টা bootstrap resample-এ \(B\)টা গাছ ফিট করো, তারপর তাদের prediction গড় করো —
(classification-এ এই "গড়" মানে majority vote, অথবা class-probability-র গড়)। মূল insight (অন্তর্দৃষ্টি) আসে variance-এর গণিত থেকে: যদি \(B\)টা random variable-এর প্রত্যেকের variance \(\sigma^2\) হয় এবং তারা পরস্পর স্বাধীন হয়, তাহলে তাদের গড়ের variance নেমে আসে \(\sigma^2/B\)-তে। ভুলগুলো random ও uncorrelated হলে গড় নেওয়ার সময় একে অপরকে বাতিল করে, কিন্তু সঠিক signal (যা সব গাছে common) টিকে থাকে।
লক্ষণীয় — bagging প্রতিটা গাছকে ইচ্ছাকৃতভাবে deep ও unpruned রাখে। একক unpruned গাছের bias কম কিন্তু variance বেশি; সেই variance-টাই averaging সামলে নেবে। তাই এখানে আমরা depth সীমিত করি না:
bag = BaggingClassifier(
estimator=DecisionTreeClassifier(random_state=0),
n_estimators=300, random_state=0).fit(X_train, y_train)
print(round(bag.score(X_test, y_test), 3)) # 0.822
৩০০টা bootstrap গাছ গড় করে test accuracy 0.822 — single full tree-এর 0.733 তো বটেই, এমনকি সবচেয়ে ভালো depth-tuned single tree-এর 0.794 ছাড়িয়ে গেছে। আর E1-এর সেই ±0.040 দোলা? সেটাও কার্যত মিলিয়ে গেছে — ৩০০টা গাছের গড় হিসেবে \(\hat f_{\text{bag}}\) একটা স্থিতিশীল, পুনরুৎপাদনযোগ্য predictor।
মূল কথাটা মনে রাখা জরুরি: bagging প্রতিটা গাছকে আরও ভালো বানায় না — বরং অনেকগুলো অস্থির গাছকে একত্রে স্থিতিশীল করে। প্রতিটা গাছ এককভাবে এখনও 0.75-এর আশেপাশেই দোলে; কিন্তু তাদের গড় 0.82-তে গিয়ে স্থির হয়, কারণ uncorrelated errors averaging-এ বাতিল হয়ে যায়।
single tree (depth-tuned) ████████████████████░░░░░ 0.794
single full tree ██████████████████░░░░░░░ 0.733
bagging (300 trees) ██████████████████████░░░ 0.822 ◀── averaging wins
└────────────────────────┘
0.70 0.85 test accuracy
৩.৩ E3 — Random forest: decorrelation + বিনামূল্যে validation¶
Bagging-এর একটা সূক্ষ্ম সীমাবদ্ধতা আছে। variance কমানোর সূত্র \(\sigma^2/B\) তখনই খাটে যখন গাছগুলো পরস্পর স্বাধীন। কিন্তু bagging-এর সব গাছ একই training set-এর resample থেকেই আসে, তাই তারা পরস্পর correlated — বিশেষত যদি কোনো একটা feature খুব strong predictor হয়, প্রায় প্রতিটা গাছ root-এ সেই একই feature-এ split করবে, ফলে গাছগুলো একে অপরের মতো দেখতে হবে। গড়ের প্রকৃত variance তখন
— যেখানে \(\rho\) হলো গাছ-জোড়ার গড় correlation। \(B \to \infty\) নিলেও দ্বিতীয় পদটা শূন্য হয়, কিন্তু প্রথম পদ \(\rho\sigma^2\) থেকে যায়। অর্থাৎ correlation \(\rho\)-ই হলো আসল বাধা — শুধু গাছ বাড়িয়ে একে পেরোনো যায় না; \(\rho\) নিজেই কমাতে হবে।
Random forest ঠিক এই কাজটা করে একটা চমৎকার সরল কৌশলে: প্রতিটা split-এ পুরো ২০টা feature বিবেচনা না করে, এলোমেলোভাবে বাছাই করা একটা subset (সাধারণত \(\sqrt{p} \approx \sqrt{20} \approx 4\)টা feature) থেকে সেরা split খোঁজা হয়। এর ফলে কোনো একটা dominant feature সব গাছের root দখল করতে পারে না — কখনো সে subset-এ থাকে, কখনো থাকে না — ফলে গাছগুলো decorrelated হয় (\(\rho\) কমে), আর তখন averaging আরও কার্যকরভাবে variance কমায়।
rf = RandomForestClassifier(
n_estimators=300, oob_score=True, random_state=0).fit(X_train, y_train)
print(round(rf.score(X_test, y_test), 3), # 0.839
round(rf.oob_score_, 3)) # 0.848
Test accuracy 0.839 — bagging-এর 0.822-কেও ছাড়িয়ে গেছে। পার্থক্যটা শুধু feature-subset randomization থেকে: bagging আর random forest দুটোই ৩০০টা bootstrap গাছ গড় করে, কিন্তু RF-এর গাছগুলো কম correlated, তাই তাদের গড়ের variance আরও কম, এবং accuracy আরও বেশি।
দ্বিতীয় সংখ্যাটা — OOB accuracy 0.848 — সমান গুরুত্বপূর্ণ। প্রতিটা bootstrap resample-এ training-এর প্রায় এক-তৃতীয়াংশ বিন্দু বাদ পড়ে যায় (out-of-bag): গড়ে কোনো একটা বিন্দু একটা গাছের bootstrap-এ থাকার সম্ভাবনা \(1-(1-1/n)^n \approx 1 - e^{-1} \approx 0.632\), অর্থাৎ ~৩৬.৮% গাছ সেই বিন্দুটা কখনো দেখেনি। প্রতিটা training বিন্দুর জন্য কেবল সেই "না-দেখা" গাছগুলোর vote দিয়ে prediction করে যে accuracy পাওয়া যায়, সেটাই OOB error — কার্যত একটা বিনামূল্যের cross-validation।
লক্ষ করুন OOB 0.848 ≈ test 0.839 — এত কাছাকাছি যে এটা নিশ্চিত করে OOB একটা বিশ্বস্ত validation estimate দিচ্ছে। এর বাস্তব তাৎপর্য বিরাট: random forest-এ আলাদা একটা validation/holdout set আলাদা করে রাখার দরকারই নেই — model fit করার সময়ই OOB থেকে generalization performance "বিনামূল্যে" পাওয়া যায়, পুরো data training-এ ব্যবহার করেও।
test acc OOB acc
single full tree 0.733 ██████████░░░░░
bagging (300) 0.822 ████████████████░░░
random forest(300) 0.839 █████████████████░░ 0.848 ◀── OOB ≈ test
└──────────────────┘ (free validation,
0.70 0.86 no separate holdout)
decorrelated trees (random feature subset) → lower ρ → lower ensemble variance
৩.৪ E4 — গাছের সংখ্যা ও feature importance¶
গাছের সংখ্যা বাড়ালে কী হয়? random forest-এ n_estimators বাড়ালে কখনো overfit হয় না — accuracy শুধু একটা সীমার দিকে স্থির হয়ে যায় (plateau)। কারণটা E2-এর averaging সূত্রেই নিহিত: আরও গাছ মানে গড়ের variance-এর \((1-\rho)\sigma^2/B\) পদটা আরও ছোট, কিন্তু bias বা \(\rho\sigma^2\) পদ অপরিবর্তিত — তাই performance খারাপ হওয়ার কোনো কারণ নেই, শুধু আর উন্নতিও থামে। এটা যাচাই করি:
for ne in [1, 5, 25, 100, 300]:
m = RandomForestClassifier(n_estimators=ne, random_state=0).fit(X_train, y_train)
print(ne, round(m.score(X_test, y_test), 3))
# 1 0.711
# 5 0.806
# 25 0.844
# 100 0.833
# 300 0.839
মাত্র ১টা গাছ (যা কার্যত একটা একক randomized tree) দেয় 0.711 — single full tree-এর চেয়েও দুর্বল। কিন্তু ৫টা গাছেই লাফিয়ে 0.806, ২৫টা-তে 0.844, এবং তারপর ১০০ (0.833) ও ৩০০ (0.839)-এর আশেপাশে দোলাটা স্থির। অর্থাৎ প্রথম কয়েক ডজন গাছেই বেশিরভাগ লাভ আসে; এরপর আরও গাছ যোগ করলে কোনো ক্ষতি নেই, কিন্তু লাভও সামান্য — শুধু estimate-টা মসৃণ ও পুনরুৎপাদনযোগ্য হয়। (২৫ ও ৩০০-এর মধ্যে ছোট উঠানামা random forest-এর অবশিষ্ট randomness-এরই প্রতিফলন, কোনো প্রকৃত প্রবণতা নয়।)
RF test accuracy vs. number of trees
0.85 │ ●━━━━━━━━━━━●━━━━━━━━━━━━━━━━━━● ← plateau
0.84 │ ●(25) (100) (300)
0.83 │
0.82 │
0.81 │ ●(5)
0.80 │ ╱
0.75 │ ╱
0.71 │ ●(1)
└───┼────┼────┼─────────┼──────────────────┼── n_estimators
1 5 25 100 300
more trees never hurt — accuracy just stabilizes (variance ↓)
Feature importance। Random forest শুধু prediction দেয় না — কোন feature গুরুত্বপূর্ণ তারও একটা স্বয়ংক্রিয় র্যাঙ্কিং দেয়। প্রতিটা split যতটা impurity (Gini \(G_m\)) কমায়, সেই কমার পরিমাণ সব গাছ জুড়ে সংশ্লিষ্ট feature-এর হিসাবে যোগ করা হয়; বেশি impurity কমানো feature মানে বেশি গুরুত্বপূর্ণ। যেহেতু আমাদের dataset-এ মাত্র ৬টা feature informative, আশা করা যায় forest সেগুলোকেই উপরে তুলবে:
imp = rf.feature_importances_
order = np.argsort(imp)[::-1]
for i in order[:6]:
print(i, round(imp[i], 3))
# 4 0.164
# 6 0.132
# 15 0.087
# 11 0.080
# 14 0.060
# 1 0.058
দুটো feature স্পষ্টভাবে আধিপত্য করছে — idx 4 (0.164) ও idx 6 (0.132) — এই দুটো মিলে মোট importance-এর প্রায় ৩০%। বাকি informative feature-গুলো (idx 15, 11, 14, 1) মাঝারি মান নিয়ে অনুসরণ করছে, আর ১২টা noise feature-এর importance প্রায় শূন্যের কাছাকাছি নেমে যায়। এটাই random forest-এর একটা বড় ব্যবহারিক সুবিধা: কোনো আলাদা পরিশ্রম ছাড়াই এটা automatic feature ranking দেয় — কোন feature signal বহন করে আর কোনগুলো শুধু noise, তা চিহ্নিত করে দেয়, যা feature selection বা ডেটা বোঝার ক্ষেত্রে অমূল্য।
RF feature importance (top 6 of 20; the 12 noise features ≈ 0)
idx 4 ████████████████████████████████ 0.164
idx 6 ██████████████████████████ 0.132
idx 15 █████████████████ 0.087
idx 11 ████████████████ 0.080
idx 14 ████████████ 0.060
idx 1 ███████████ 0.058
└────────────────────────────────┘
informative features rise; noise features sink to ~0
সারাংশ টেবিল। এই অধ্যায়ের পুরো অগ্রগতিটা একসাথে দেখা যাক — একক অস্থির গাছ থেকে decorrelated ensemble পর্যন্ত:
| পদ্ধতি | সংক্ষিপ্ত বর্ণনা | test accuracy | মূল বৈশিষ্ট্য |
|---|---|---|---|
| Single full tree | depth 10, 51 leaves, unpruned | 0.733 | training data মুখস্থ করে (overfit) |
Single tree, max_depth=3 |
pre-pruned, অগভীর | 0.794 | কম capacity → ভালো generalization |
| Single tree (variance) | ২০ bootstrap-এ মান | 0.752 ± 0.040 | high variance — অস্থির |
| Bagging (300 trees) | bootstrap গাছের গড় | 0.822 | uncorrelated errors বাতিল → variance ↓ |
| Random forest (300) | bagging + random feature subset | 0.839 | decorrelation (\(\rho\) ↓) → আরও কম variance |
| RF — OOB estimate | না-দেখা গাছের vote | 0.848 | বিনামূল্যে validation, holdout লাগে না |
টেবিলটা নিচ থেকে উপরে এই অধ্যায়ের মূল বার্তা ফুটিয়ে তোলে: একটা single decision tree interpretable কিন্তু high-variance ও overfit-প্রবণ; bootstrap averaging (bagging) সেই variance কমায়; আর random feature-subset (random forest) গাছগুলোকে decorrelate করে variance আরও কমিয়ে সর্বোচ্চ accuracy দেয় — উপরন্তু OOB-র মাধ্যমে বিনামূল্যে একটা নির্ভরযোগ্য validation estimate-ও দেয়।
যাচাই (scikit-learn, seed 20260619)। উপরের সব সংখ্যা নিচের একক স্ক্রিপ্টে পুনরুৎপাদনযোগ্য।
train/test: 420 180 full tree acc: 0.733 depth: 10 leaves: 51 max_depth=3: 0.794 | max_depth=5: 0.794 | max_depth=8: 0.756 single-tree, 20 bootstraps: mean 0.752, sd 0.040 (high variance) bagging(300) acc: 0.822 random forest(300): test 0.839, OOB 0.848 RF by n_estimators: 1→0.711, 5→0.806, 25→0.844, 100→0.833, 300→0.839 RF top importances: idx4 0.164, idx6 0.132, idx15 0.087, idx11 0.080, idx14 0.060, idx1 0.058single tree → bagging → random forest: প্রতিটি ধাপে test accuracy বাড়ে (0.733 → 0.822 → 0.839), যা variance-হ্রাসের তত্ত্বকে সংখ্যায় নিশ্চিত করে; আর OOB (0.848) ≈ test (0.839) দেখায় OOB একটা বিশ্বস্ত validation।
৪ · প্রমাণ ও উৎপাদন¶
এই অংশে decision tree আর ensemble পদ্ধতিগুলোর গাণিতিক ভিত্তি ধাপে ধাপে গড়ে তুলি। তিনটি প্রশ্নের উত্তর খুঁজব: একটা গাছ কীভাবে split বেছে নেয় (impurity), একগুচ্ছ গাছ গড় করলে কেন variance কমে (bagging-এর হৃদয়), আর random forest কী করে সেই variance আরও নামিয়ে আনে (correlation কমিয়ে)। শেষে দুটো প্রায়-বিনা-খরচের যন্ত্র — OOB error estimate আর feature importance।
৪.১ ★★ Impurity ও split criterion¶
একটা classification tree-এর প্রতিটা leaf এক একটা region \(R_m\)-কে একটামাত্র শ্রেণিতে ম্যাপ করতে চায়। তাই কোনো node \(m\) "কতটা বিশুদ্ধ" তা মাপার দরকার — অর্থাৎ ওই node-এ পড়া training point-গুলোর label কতটা একরকম। Class-proportion-গুলো হলো
যেখানে \(N_m\) হলো node \(m\)-এ থাকা point-সংখ্যা আর \(c\) শ্রেণি index। দুটো জনপ্রিয় impurity measure:
দুটোই "mixedness" মাপে — সমজাতীয় বা pure node-এ মান \(0\), আর সবচেয়ে mixed (uniform) node-এ সর্বোচ্চ। এই দুই দাবি প্রমাণ করি।
দাবি ১ — purity-তে \(G_m=H_m=0\). Node pure মানে কোনো এক শ্রেণি \(c^\star\)-এর জন্য \(\hat p_{mc^\star}=1\) আর বাকি সবের জন্য \(\hat p_{mc}=0\)। তাহলে Gini-র প্রতিটা পদ শূন্য: যে পদে \(\hat p_{mc}=0\) সেটা স্পষ্টতই \(0\), আর \(c^\star\) পদে \(1\cdot(1-1)=0\)। সুতরাং \(G_m=0\)। Entropy-তে \(\hat p_{mc}\log_2\hat p_{mc}\) পদে \(\hat p_{mc}=1\) দিলে \(1\cdot\log_2 1=0\); আর \(\hat p_{mc}\to 0\) হলে \(\lim_{p\to0^+}p\log_2 p=0\) (convention অনুযায়ী \(0\log_2 0:=0\))। সুতরাং \(H_m=0\)। \(\;\blacksquare\)
দাবি ২ — uniform distribution-এ সর্বোচ্চ। ধরা যাক \(K\)টা শ্রেণি। Gini-কে \(G_m=\sum_c\hat p_{mc}-\sum_c\hat p_{mc}^2=1-\sum_c\hat p_{mc}^2\) লিখলে \(G_m\) সর্বোচ্চ হয় যখন \(\sum_c\hat p_{mc}^2\) সর্বনিম্ন, constraint \(\sum_c\hat p_{mc}=1\)-এর অধীনে। Lagrangian
Constraint বসিয়ে \(\hat p_{mc}=1/K\) — অর্থাৎ uniform। তখন \(\sum_c\hat p_{mc}^2=K\cdot(1/K)^2=1/K\), ফলে \(G_m^{\max}=1-1/K\)। Entropy-র জন্য একই Lagrange যুক্তিতে (অথবা concavity থেকে) সর্বোচ্চ আসে uniform-এ, \(H_m^{\max}=\log_2 K\)। দুই extreme-এর মাঝে — uniform-এ চূড়া, pure-এ শূন্য — অর্থাৎ এরা সত্যিই "কতটা ছড়ানো" তার পরিমাপ। \(\;\blacksquare\)
দুই-শ্রেণির (\(K=2\)) ক্ষেত্রে যদি \(\hat p_{m1}=p,\ \hat p_{m2}=1-p\), তবে
দুটোই \(p=\tfrac12\)-তে চূড়া (\(G_m=0.5,\ H_m=1\)) আর \(p\in\{0,1\}\)-এ শূন্য — নিচের চিত্রের মতো ঘণ্টা-আকৃতি।
impurity
1.0 | . . . . . <- H_m (entropy), peak 1.0
| . .
0.5 | . ___ . <- G_m (Gini), peak 0.5
| . __-- --__ .
| _-- --_
0.0 +----+----+----+----+----+----+--> p = p_{m1}
0 0.5 1.0
(pure) (uniform) (pure)
Split criterion — information gain. একটা split node \(m\)-কে দুই child \(m_L\) আর \(m_R\)-এ ভাগ করে, যাদের ওজন (point-ভগ্নাংশ)
কোন split ভালো? যেটা child-গুলোকে যত বেশি সম্ভব বিশুদ্ধ করে — অর্থাৎ যেটা impurity-র weighted average সবচেয়ে নামায়। এই হ্রাসকে বলে information gain:
(entropy দিয়ে চালালে এটাকেই বলে information gain তার আসল অর্থে)। Greedy CART algorithm প্রতিটা node-এ সব feature \(j\) আর সব threshold \(t\)-এর ওপর scan করে \(\Delta\)-কে maximize করে; তারপর প্রতিটা child-এ recursively একই কাজ করে, যতক্ষণ না কোনো stopping rule (যেমন node pure, বা \(N_m\) ন্যূনতম সীমার নিচে, বা সর্বোচ্চ depth) আঘাত করে। গুরুত্বপূর্ণ: এটা greedy — প্রতিটা পদক্ষেপে স্থানীয়ভাবে সেরা split নেয়, globally optimal tree খোঁজে না (সেটা NP-hard)।
child-impurity-র weighted average নেওয়াটা জরুরি, নাহলে সংখ্যায় ছোট কিন্তু আবর্জনা-ভরা child শাস্তি না পেয়ে পার পেয়ে যেত। \(w_L,w_R\) ওজন ঠিক ততটাই গুরুত্ব দেয় যতটা প্রতিটা child-এ data আছে।
Worked mini-example (2-class). ধরা যাক parent node \(m\)-এ \(60\)টা point: শ্রেণি \(0\)-তে \(30\)টা, শ্রেণি \(1\)-তে \(30\)টা — অর্থাৎ পুরোপুরি mixed। তাহলে
একটা candidate split দুই child দেয়:
- \(m_L\): শ্রেণি \(0\)-তে \(25\), শ্রেণি \(1\)-তে \(5\) (মোট \(N_{m_L}=30\)),
- \(m_R\): শ্রেণি \(0\)-তে \(5\), শ্রেণি \(1\)-তে \(25\) (মোট \(N_{m_R}=30\))।
Child impurity:
আর symmetric হওয়ায় \(G_{m_R}=\tfrac{5}{18}\approx 0.2778\)। ওজন \(w_L=w_R=\tfrac{30}{60}=\tfrac12\), তাই
সুতরাং information gain
Positive gain — split-টা node-কে আরও বিশুদ্ধ করছে, তাই গ্রহণযোগ্য। (একই split-এ entropy দিয়ে চললে: \(H_m=1\), \(H_{m_L}=H_{m_R}=-\tfrac{25}{30}\log_2\tfrac{25}{30}-\tfrac{5}{30}\log_2\tfrac{5}{30}\approx 0.6500\), তাই \(\Delta_H\approx 1-0.6500=0.3500\) — একই গল্প, ভিন্ন স্কেল।)
৪.২ ★★★ গড় কেন variance কমায় — bagging-এর হৃদয়¶
একটা পূর্ণ-বৃদ্ধ (deep) tree হলো low-bias, high-variance estimator: training set-এ সামান্য পরিবর্তন এলে পুরো গাছ বদলে যায় (§৬.১-এর bias–variance ভাষায়, এর variance term বড়)। Bagging (bootstrap aggregating)-এর মূল ধারণা: একই রকম অনেকগুলো এমন estimator-এর গড় নিলে bias না বাড়িয়ে variance কমানো যায়। এখন গাণিতিকভাবে দেখাই ঠিক কতটা কমে।
ধরা যাক আমাদের কাছে \(B\)টা estimator \(\hat f_1,\dots,\hat f_B\) আছে (যেমন \(B\)টা bootstrap sample-এ ফিট করা \(B\)টা গাছ, একটা নির্দিষ্ট test point \(x\)-এ মূল্যায়িত)। ধরে নিই এরা identically distributed:
অর্থাৎ প্রতিটার variance এক \(\sigma^2\), আর যেকোনো জোড়ার pairwise correlation এক \(\rho\)। তাহলে যেকোনো জোড়ার covariance
Bagged estimator হলো গড় \(\bar f=\frac1B\sum_{b=1}^{B}\hat f_b\)। এর variance হিসাব করি variance-of-a-sum সূত্র খুলে:
ডবল-যোগফলটাকে diagonal (\(b=b'\)) আর off-diagonal (\(b\neq b'\)) পদে ভাঙি।
- Diagonal: \(B\)টা পদ, প্রতিটা \(\operatorname{Cov}(\hat f_b,\hat f_b)=\operatorname{Var}(\hat f_b)=\sigma^2\) ⟹ মোট \(B\sigma^2\)।
- Off-diagonal: \(B^2-B=B(B-1)\)টা পদ, প্রতিটা \(\rho\sigma^2\) ⟹ মোট \(B(B-1)\rho\sigma^2\)।
বসিয়ে:
এবার দ্বিতীয় পদটা গুছিয়ে লিখি: \(\frac{B-1}{B}=1-\frac1B\), তাই
\(\frac{\sigma^2}{B}\) আর \(-\frac{\rho\sigma^2}{B}\)-কে একত্র করে \(\frac{(1-\rho)}{B}\sigma^2\):
এই পরিচয়টাই bagging-এর গোটা গল্প ধরে রাখে। দুটো পদকে আলাদা করে পড়ি:
- প্রথম পদ \(\rho\sigma^2\) — \(B\)-এর ওপর নির্ভর করে না। যত গাছই যোগ করি, এই অংশ থেকেই যায়। এটা estimator-গুলোর মধ্যেকার correlation-এর floor।
- দ্বিতীয় পদ \(\frac{1-\rho}{B}\sigma^2\) — এটা \(B\)-এর সাথে ক্ষয় পায়। \(B\to\infty\) হলে
অর্থাৎ গড় নেওয়া estimator-গুলোর uncorrelated অংশটাকে মেরে ফেলে, কিন্তু correlated অংশ (\(\rho\sigma^2\)) অক্ষত থাকে। এটাই কেন আরও বেশি গাছ যোগ করলে এক সময় আর লাভ হয় না — variance একটা মেঝেতে এসে থামে, যে মেঝে ঠিক করে \(\rho\)।
দুটো প্রান্ত যাচাই: যদি গাছগুলো পুরোপুরি uncorrelated হতো (\(\rho=0\)), তবে \(\operatorname{Var}(\bar f)=\sigma^2/B\to 0\) — গড় নিলেই variance শূন্যের দিকে যেত (classical \(\sigma^2/B\) আইন)। উল্টোদিকে যদি একদম একরকম হতো (\(\rho=1\)), তবে \(\operatorname{Var}(\bar f)=\sigma^2\) — গড় নিয়ে কিছুই লাভ হতো না। বাস্তব gap এই দুইয়ের মাঝে।
Bias বদলায় না। গড় নেওয়া কেন bias বাড়ায় না? Expectation linear, আর প্রতিটা \(\hat f_b\) identically distributed (\(\mathbb E[\hat f_b]=\mathbb E[\hat f]\)):
সুতরাং ensemble-এর expected prediction একক গাছের সমান — bias একই থাকে, শুধু variance নামে। এই কারণেই bagging high-variance, low-bias শিক্ষার্থীদের (যেমন deep, unpruned tree) সবচেয়ে বেশি সাহায্য করে: bias এমনিতেই কম, তাই variance কমালেই মোট error (bias\(^2\) + variance + noise) কমে। উল্টোদিকে high-bias, low-variance মডেল (যেমন linear fit) bagging-এ তেমন লাভ পায় না — সেখানে variance এমনিতেই ছোট।
এক সংখ্যাসূচক যাচাই: \(\sigma^2=4,\ \rho=0.3,\ B=8\) নিলে সূত্র দেয় \(0.3\cdot4+\frac{0.7}{8}\cdot4=1.2+0.35=1.55\); multivariate-normal simulation-এ গড়ের empirical variance \(\approx 1.55\) — মিলে যায়।
৪.৩ ★★ Random forest কীভাবে \(\rho\) নামায়¶
§৪.২ আমাদের লক্ষ্য পরিষ্কার করে দিল: floor \(\rho\sigma^2\) কমাতে হলে \(\rho\) কমাতে হবে। কিন্তু সাধারণ bagged গাছগুলো বেশ correlated থাকে — কেন? কারণ একই dataset-এর একটা feature যদি খুব strong predictor হয়, প্রায় প্রতিটা bootstrap sample-এই সেই feature root-এর কাছে split হিসেবে বেছে নেওয়া হয়। ফলে গাছগুলো গঠনে একে অপরের মতো হয়ে যায়, তাদের prediction-ও correlated — অর্থাৎ \(\rho\) বড়, floor উঁচু।
Random forest-এর সমাধান চমৎকার রকম সরল: bootstrap তো করবই, কিন্তু প্রতিটা split-এ সব \(p\)টা feature বিবেচনা না করে এলোমেলোভাবে একটা ছোট উপসেট \(m\) (\(m<p\)) feature বেছে নিয়ে শুধু তাদের মধ্যেই সেরা split খুঁজব। এর ফল:
- কোনো একটা গাছ যে strong feature-এ split করবে, তা random — কখনো সেই feature subset-এ থাকবে না, তখন গাছকে বিকল্প feature ব্যবহার করতে হবে।
- ফলে গাছগুলো গঠনে একে অপরের থেকে আরও বেশি আলাদা (decorrelated) হয় ⟹ pairwise correlation \(\rho\) কমে ⟹ floor \(\rho\sigma^2\) নামে ⟹ ensemble variance plain bagging-এর চেয়ে কম।
এটাই random forest-কে plain bagged tree-এর চেয়ে শক্তিশালী করে: একই \(\sigma^2\), কিন্তু ছোট \(\rho\), তাই \(\lim_{B\to\infty}\operatorname{Var}=\rho\sigma^2\) ছোট।
\(m\)-এর rule of thumb. সাধারণ heuristic:
যেখানে \(p\) মোট feature-সংখ্যা। (\(m=p\) নিলে random forest ঠিক plain bagging-এ ফিরে যায় — তখন কোনো feature-randomization নেই।) সাধারণত \(m\) একটা tunable hyperparameter; ছোট \(m\) ⟹ গাছগুলো বেশি decorrelated কিন্তু প্রতিটা split-এ কম তথ্য।
একটা trade-off আছে। \(m\) ছোট করলে প্রতিটা split-এ সেরা feature না-ও পাওয়া যেতে পারে, তাই প্রতিটা গাছ আলাদাভাবে সামান্য দুর্বল — অর্থাৎ bias একটু বাড়ে। কিন্তু \(\rho\)-হ্রাস থেকে আসা variance-লাভ সাধারণত এই সামান্য bias-বৃদ্ধিকে ছাপিয়ে যায়, তাই মোট test error কমে। বিনিময়টা প্রায় সবসময় random forest-এর পক্ষে।
Var(ensemble) as B grows (floor = rho * sigma^2)
Var
| * single tree variance sigma^2
| \
| \___ plain bagging -> floor rho_bag * sigma^2 (higher rho)
| \____________________________________________
| \
| \__ random forest -> floor rho_rf * sigma^2 (lower rho)
| \______________________________________
+-------------------------------------------------> B
small m -> smaller rho -> lower floor
৪.৪ ★★ Out-of-bag (OOB) error estimate¶
Bagging-এ প্রতিটা গাছ একটা bootstrap sample-এ প্রশিক্ষিত — অর্থাৎ মূল \(n\)টা point থেকে \(n\)বার with-replacement টানা। স্বাভাবিকভাবেই কিছু point কোনো একটা bootstrap sample-এ একবারও আসে না; সেই গাছের সাপেক্ষে ওরা out-of-bag (OOB)। এই "না-দেখা" point-গুলো প্রায় বিনা খরচে একটা validation set জুগিয়ে দেয়। এখন বের করি একটা নির্দিষ্ট point ঠিক কত ভাগ গাছের কাছে OOB থাকে।
একটা bootstrap টানে প্রতিবার \(n\)টা point থেকে সমসম্ভাবনায় একটা বাছা হয়, তাই কোনো নির্দিষ্ট point \(i\) একবারে বাছা না-হওয়ার সম্ভাবনা \(1-\frac1n\)। \(n\)টা স্বাধীন টান (with replacement) হওয়ায় পুরো sample-এ \(i\) একবারও না-আসার সম্ভাবনা
\(n\) বড় হলে এর সীমা বের করি। মানসূত্র \(\lim_{n\to\infty}\big(1+\frac{x}{n}\big)^{n}=e^{x}\) ব্যবহার করি \(x=-1\) সহ:
(চাইলে log নিয়েও দেখা যায়: \(\ln\big(1-\frac1n\big)^n=n\ln\!\big(1-\frac1n\big)=n\big(-\frac1n-\frac{1}{2n^2}-\cdots\big)\to -1\), তাই সীমা \(e^{-1}\)।) সংখ্যায়: \(n=100\)-তে মান \(\approx 0.366\), \(n=1000\)-তে \(\approx 0.3677\) — দ্রুত \(0.368\)-এ থিতু হয়।
ব্যাখ্যা। তাহলে প্রতিটা point প্রায় \(37\%\) গাছের কাছে OOB, আর \(\approx 63\%\) গাছের training-এ ছিল। এর সুবিধা নেওয়ার নিয়ম: প্রতিটা training point \(x_i\)-এর জন্য prediction তৈরি করো শুধু সেই গাছগুলো দিয়ে যারা \(x_i\)-কে দেখেনি (যাদের সাপেক্ষে এটা OOB) — তারপর এই OOB-prediction-গুলোকে আসল label-এর সাথে মিলিয়ে error হিসাব করো। যেহেতু প্রতিটা point এমন গাছ দিয়ে predict হচ্ছে যারা ওকে train-এ দেখেনি, এই OOB error কার্যত একটা প্রায়-নিরপেক্ষ (almost unbiased) test-error estimate দেয় — আলাদা hold-out set বা cross-validation ছাড়াই, বিনামূল্যে। বড় \(B\)-তে (point-পিছু গড়ে \(\approx 0.368\,B\)টা গাছ ভোট দেয়) এটি cross-validation-এর কাছাকাছি নির্ভরযোগ্য হয়।
৪.৫ ★ Feature importance¶
Forest তো এতগুলো গাছের সমষ্টি — কোন feature আসলে বেশি কাজে লাগছে তা জানতে চাই। স্বাভাবিক পরিমাপ: একটা feature যতবার split-এর জন্য ব্যবহৃত হয়েছে, প্রতিবার সে যত impurity-decrease (\(\Delta\), §৪.১) ঘটিয়েছে, তার যোগফল — গোটা forest-এর সব গাছের সব split জুড়ে।
আনুষ্ঠানিকভাবে, feature \(j\)-এর গুরুত্ব
যেখানে \(\Delta_m\) ওই node-এর information gain আর \(w_m\) ওই node-এ পৌঁছানো point-ভগ্নাংশ (যাতে root-এর কাছের বড় split বেশি ওজন পায়)। সব feature-এর ওপর এই মানগুলোকে normalize করা হয় (যোগফল \(1\) বা সর্বোচ্চ \(100\) ধরে), যাতে আপেক্ষিকভাবে তুলনা করা যায়।
স্বজ্ঞা সরল: একটা predictive feature বারবার বড় impurity-drop ঘটায়, তাই তার মোট অবদান বড় — গুরুত্ব উঁচু। বিপরীতে একটা noise feature কদাচিৎ কোনো split-এ লাভজনক হয় (random forest-এর feature-subsampling থাকা সত্ত্বেও তার gain গড়ে নগণ্য), তাই তার গুরুত্ব \(\approx 0\)। এভাবে forest শুধু prediction দেয় না, কোন feature-গুলো সেই prediction চালাচ্ছে তার একটা সস্তা ranking-ও উপহার দেয়।
৫ · কোড ল্যাব (Python)¶
এই অধ্যায়ের তত্ত্বকে এক জায়গায় বেঁধে দেখার জন্য একটিই runnable script ব্যবহার করা হবে। ডেটাসেট সিন্থেটিক — make_classification দিয়ে তৈরি, যেখানে \(20\)টি feature-এর মধ্যে মাত্র \(6\)টি সত্যিকারের informative, \(2\)টি redundant (informative-গুলোর linear combination), আর বাকি \(12\)টি বিশুদ্ধ noise। তাই এখানে আমরা একই সঙ্গে দুটো জিনিস যাচাই করতে পারব: একটি single deep tree কীভাবে overfit করে এবং অস্থির (high variance) হয়, আর bagging ও random forest কীভাবে সেই variance কমিয়ে test accuracy বাড়ায়। শেষে feature_importances_ দেখে যাচাই করব মডেল সত্যিই signal feature-গুলোকে আলাদা করতে পারছে কিনা, noise-গুলোকে প্রায় \(0\) ওজন দিচ্ছে কিনা।
স্ক্রিপ্টটি চারটি অংশে বিভক্ত:
- PART 1 — একটি unpruned
DecisionTreeClassifier; এর test accuracy,get_depth(),get_n_leaves()ছাপানো হয়, তারপরmax_depth ∈ {3,5,8}দিয়ে depth সীমিত করলে accuracy কেমন বদলায় দেখা হয়। সবশেষে \(20\)টি bootstrap resample-এর উপর একই deep tree train করে test accuracy-র mean ও standard deviation ছাপিয়ে variance-টা সংখ্যায় দেখানো হয়। - PART 2 —
BaggingClassifier-এ \(300\)টি deep tree একত্র করে averaging-এর প্রভাব দেখা হয়। - PART 3 —
RandomForestClassifier(feature subsampling + bootstrap), OOB estimate, এবংn_estimatorsবাড়ালে accuracy কীভাবে stabilise করে তার sweep। - PART 4 — random forest-এর
feature_importances_থেকে top-6 feature ও noise feature-দের গড় importance।
import numpy as np
from sklearn.datasets import make_classification
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = make_classification(
n_samples=600, n_features=20, n_informative=6, n_redundant=2,
n_repeated=0, n_classes=2, class_sep=0.8, flip_y=0.05,
random_state=20260619)
Xtr, Xte, ytr, yte = train_test_split(
X, y, test_size=0.3, random_state=0, stratify=y)
# ---------------------------------------------------------------
print("=" * 60)
print("PART 1 : single Decision Tree (overfitting & variance)")
print("=" * 60)
full = DecisionTreeClassifier(random_state=0).fit(Xtr, ytr)
print(f"full tree : test acc = {accuracy_score(yte, full.predict(Xte)):.3f}")
print(f" : get_depth() = {full.get_depth()}")
print(f" : get_n_leaves() = {full.get_n_leaves()}")
for d in (3, 5, 8):
t = DecisionTreeClassifier(max_depth=d, random_state=0).fit(Xtr, ytr)
print(f"max_depth={d} : test acc = {accuracy_score(yte, t.predict(Xte)):.3f}")
# একই deep tree-কে 20টি bootstrap resample-এ train করে অস্থিরতা মাপা
np.random.seed(66)
rng = np.random.RandomState(66)
n = Xtr.shape[0]
accs = []
for b in range(20):
idx = rng.randint(0, n, n) # n টি নমুনা, replacement-সহ
tb = DecisionTreeClassifier().fit(Xtr[idx], ytr[idx])
accs.append(accuracy_score(yte, tb.predict(Xte)))
accs = np.array(accs)
print(f"20 full trees on bootstrap resamples : "
f"mean={accs.mean():.3f} sd={accs.std():.3f}")
# ---------------------------------------------------------------
print("\n" + "=" * 60)
print("PART 2 : Bagging (averaging tames the variance)")
print("=" * 60)
bag = BaggingClassifier(DecisionTreeClassifier(random_state=0),
n_estimators=300, random_state=0).fit(Xtr, ytr)
print(f"Bagging(300) : test acc = {accuracy_score(yte, bag.predict(Xte)):.3f}")
# ---------------------------------------------------------------
print("\n" + "=" * 60)
print("PART 3 : Random Forest (feature subsampling + OOB)")
print("=" * 60)
rf = RandomForestClassifier(n_estimators=300, oob_score=True,
random_state=0).fit(Xtr, ytr)
print(f"RandomForest(300) : test acc = {accuracy_score(yte, rf.predict(Xte)):.3f}")
print(f"RandomForest(300) : oob_score_ = {rf.oob_score_:.3f}")
print("n_estimators sweep (test acc):")
for m in (1, 5, 25, 100, 300):
r = RandomForestClassifier(n_estimators=m, random_state=0).fit(Xtr, ytr)
print(f" n_estimators={m:>3} -> {accuracy_score(yte, r.predict(Xte)):.3f}")
# ---------------------------------------------------------------
print("\n" + "=" * 60)
print("PART 4 : feature importances (signal vs noise)")
print("=" * 60)
imp = rf.feature_importances_
order = np.argsort(imp)[::-1]
print("top-6 features:")
for rank, j in enumerate(order[:6], 1):
print(f" #{rank} idx {j:>2} importance = {imp[j]:.3f}")
noise = imp[order[6:]]
print(f"other 14 features : mean importance = {noise.mean():.3f} "
f"(max = {noise.max():.3f})")
স্ক্রিপ্টটি চালালে নিচের output পাওয়া যায় (verbatim):
============================================================
PART 1 : single Decision Tree (overfitting & variance)
============================================================
full tree : test acc = 0.733
: get_depth() = 10
: get_n_leaves() = 51
max_depth=3 : test acc = 0.794
max_depth=5 : test acc = 0.794
max_depth=8 : test acc = 0.756
20 full trees on bootstrap resamples : mean=0.752 sd=0.040
============================================================
PART 2 : Bagging (averaging tames the variance)
============================================================
Bagging(300) : test acc = 0.822
============================================================
PART 3 : Random Forest (feature subsampling + OOB)
============================================================
RandomForest(300) : test acc = 0.839
RandomForest(300) : oob_score_ = 0.848
n_estimators sweep (test acc):
n_estimators= 1 -> 0.711
n_estimators= 5 -> 0.806
n_estimators= 25 -> 0.844
n_estimators=100 -> 0.833
n_estimators=300 -> 0.839
============================================================
PART 4 : feature importances (signal vs noise)
============================================================
top-6 features:
#1 idx 4 importance = 0.164
#2 idx 6 importance = 0.132
#3 idx 15 importance = 0.087
#4 idx 11 importance = 0.080
#5 idx 14 importance = 0.060
#6 idx 1 importance = 0.058
other 14 features : mean importance = 0.030 (max = 0.057)
পাঠোদ্ধার¶
PART 1 — একটি deep tree overfit করে এবং অস্থির। Unpruned tree-টি training data-কে প্রায় নিখুঁতভাবে মুখস্থ করে: depth পৌঁছায় \(10\)-এ আর leaf-সংখ্যা \(51\) — অর্থাৎ \(420\)টি training নমুনার জন্য গড়ে প্রতি leaf-এ মাত্র \(\sim 8\)টি নমুনা পড়ে। এই অতিরিক্ত নমনীয়তার মাশুল test set-এ: accuracy মাত্র \(0.733\)। উল্টোদিকে depth \(3\)-এ আটকে দিলে accuracy লাফিয়ে \(0.794\)-এ ওঠে, যদিও মডেলটি অনেক simpler। এটিই pruning-এর মূল বার্তা — গভীরতা বাড়ালেই generalisation ভালো হয় না; বরং একটা optimum-এর পর variance বেড়ে test performance পড়তে থাকে। depth \(3 \to 5 \to 8\) যেতে যেতে accuracy \(0.794 \to 0.794 \to 0.756\) — অর্থাৎ মডেল যত গভীর, তত বেশি overfit।
variance-টা চোখে দেখা যায় bootstrap পরীক্ষায়। একই deep tree-কে \(20\)টি ভিন্ন resample-এর উপর train করলে test accuracy ঘোরাফেরা করে গড় \(0.752\)-এর আশেপাশে, standard deviation \(0.040\)। অর্থাৎ training data সামান্য বদলালেই গাছের গঠন ও তার prediction অনেকটা বদলে যায়। উচ্চ variance এই মডেলের জন্মগত দুর্বলতা — আর ঠিক এই দুর্বলতাই ensemble পরবর্তী অংশগুলোতে নিরাময় করবে।
PART 2 — Bagging variance কমায়। \(300\)টি deep tree (প্রতিটি আলাদা bootstrap resample-এ train) মিলিয়ে majority vote নিলে test accuracy দাঁড়ায় \(0.822\) — একক গাছের \(0.733\) থেকে \(\sim 9\) percentage point উন্নতি। এখানে কোনো গাছকে আর pruning করা হয়নি; প্রতিটি member ব্যক্তিগতভাবে high-variance, কিন্তু \(B\)টি প্রায়-স্বাধীন estimator-এর গড় নিলে variance প্রায় \(1/B\) গুণে নামে। স্বজ্ঞাটি সরল — যদি প্রতিটি গাছের prediction-এর variance \(\sigma^2\) আর গাছগুলোর মধ্যে গড় correlation \(\rho\) হয়, তবে \(B\)টি গাছের গড়ের variance $$ \rho\,\sigma^2 + \frac{1-\rho}{B}\,\sigma^2 , $$ যা \(B\) বড় হলে \(\rho\,\sigma^2\)-এ গিয়ে স্থির হয়। তাই \(\rho\) যত কম, ensemble তত বেশি লাভবান।
PART 3 — Random Forest সেই correlation আরও ভাঙে এবং OOB free validation দেয়। প্রতিটি split-এ feature-গুলোর একটা random উপসেট বিবেচনা করে random forest গাছগুলোর মধ্যকার correlation \(\rho\) কমিয়ে দেয় — উপরের সূত্রের \(\rho\,\sigma^2\) পদটিই ছোট হয়। ফলাফল bagging-এর চেয়েও ভালো: test accuracy \(0.839\)। আরও আকর্ষণীয় হলো oob_score_ = 0.848: প্রতিটি গাছের bootstrap-এ যে নমুনাগুলো বাদ পড়ে (গড়ে \(\sim 37\%\)), সেগুলোর উপর prediction জুড়ে দিয়ে এই estimate পাওয়া — অর্থাৎ আলাদা validation set খরচ না করেই একটা honest generalisation মাপ। এখানে OOB (\(0.848\)) test accuracy (\(0.839\))-র কাছাকাছি, যা দেখায় OOB একটি নির্ভরযোগ্য প্রক্সি।
n_estimators sweep stabilisation-এর গল্পটা স্পষ্ট করে: \(1\)টি গাছে accuracy মাত্র \(0.711\) (কার্যত একটা single random tree, তাই খারাপ ও অস্থির), \(5\)-এ \(0.806\), \(25\)-এ \(0.844\), তারপর \(100 \to 300\) যেতে \(0.833 \to 0.839\) — অর্থাৎ একটা স্তরে পৌঁছে accuracy আর তেমন বাড়ে না, কেবল একটা সংকীর্ণ ব্যান্ডে স্থির হয়। বার্তাটি ব্যবহারিক: বেশি গাছ মানেই overfit নয় (random forest গাছ বাড়ালে overfit করে না), কিন্তু একটা পর্যাপ্ত সংখ্যার পর কেবল computation খরচ বাড়ে, accuracy নয়।
PART 4 — importance signal-কে noise থেকে আলাদা করে। Random forest-এর impurity-based feature_importances_ সবচেয়ে বেশি ওজন দেয় idx \(4\) (\(0.164\)) ও idx \(6\) (\(0.132\))-কে, তারপর idx \(15\) (\(0.087\)), idx \(11\) (\(0.080\))। এই top feature-গুলো ঠিক সেই informative/redundant signal যেগুলো make_classification ক্লাস-পার্থক্য তৈরিতে ব্যবহার করেছিল। অন্যদিকে বাকি \(14\)টি feature-এর গড় importance মাত্র \(0.030\) এবং সর্বোচ্চও \(0.057\)-এর বেশি নয় — অর্থাৎ pure-noise feature-গুলো প্রায় শূন্য গুরুত্ব পায়। মডেল কার্যত নিজে থেকেই feature selection করে ফেলেছে: \(20\)টির মধ্যে মুষ্টিমেয় কয়েকটি column-ই তার সিদ্ধান্তের ভিত্তি, বাকিগুলো প্রায় উপেক্ষিত।
সারমর্ম: একটি single deep tree এখানে test accuracy \(0.733\)-এ overfit করে এবং bootstrap-এ standard deviation \(0.040\) নিয়ে অস্থির; bagging সেই variance কমিয়ে \(0.822\)-এ আনে; আর random forest — feature subsampling-এর মাধ্যমে correlation আরও ভেঙে — test accuracy \(0.839\) ও OOB estimate \(0.848\) অর্জন করে, পাশাপাশি importance-এর মাধ্যমে signal feature-গুলোকে স্বচ্ছভাবে চিহ্নিত করে।
৬ · ভিজ্যুয়ালাইজেশন¶
আগের অংশগুলোতে আমরা decision tree, bagging আর random forest-এর গণিত একে একে দেখেছি — একটি tree কীভাবে greedy ভাবে impurity (Gini/entropy) কমিয়ে data-কে অক্ষ-সমান্তরাল (axis-aligned) আয়তাকার অঞ্চলে কাটে, কেন একা একটি গভীর tree high-variance ও overfit-প্রবণ, bagging কীভাবে bootstrap নমুনার ওপর বহু tree গড় করে সেই variance কমায়, আর random forest কীভাবে প্রতিটি split-এ feature-এর random subset বেছে tree-গুলোর মধ্যকার correlation আরও ভেঙে দেয়। কিন্তু এই ধারণাগুলোর আসল চেহারা — একটি interpretable tree দেখতে কেমন, একা tree-র সীমানা কতটা খাঁজকাটা আর forest-এর সীমানা কতটা মসৃণ, ensemble সংখ্যাগত দিক দিয়ে একক tree-র চেয়ে ঠিক কতখানি এগিয়ে যায়, আর forest শেষমেশ কোন feature-গুলোকে গুরুত্বপূর্ণ বলে চিহ্নিত করে — এসব সমীকরণে যতটা ধরা পড়ে, ছবিতে দেখলে তার চেয়ে অনেক বেশি স্পষ্ট হয়। এই অংশে আমরা চারটি ছবি তৈরি করব, যেগুলো একসাথে "একক tree থেকে শুরু করে ensemble পর্যন্ত" গোটা গল্পটা চোখের সামনে মেলে ধরে।
ছবিগুলো দুটি নিয়ন্ত্রিত dataset-এর ওপর দাঁড়িয়ে। প্রথমটি — যেটি accuracy ও feature importance মাপতে ব্যবহৃত — একটি 20-feature synthetic classification সমস্যা: ৬০০টি observation, দুই class, যার মধ্যে মাত্র ৬টি feature প্রকৃত-অর্থে informative ও আরও ২টি redundant, বাকিগুলো মূলত noise; class_sep=0.8 ও flip_y=0.05 রাখায় সমস্যাটা মাঝারি-কঠিন (class-গুলো সম্পূর্ণ আলাদা নয়, আর ৫% label ইচ্ছাকৃতভাবে উল্টে দেওয়া)। এই high-dimensional, অনেক noise-feature-যুক্ত পরিবেশই হলো সেই জায়গা যেখানে একক tree হোঁচট খায় আর ensemble জ্বলে ওঠে। দ্বিতীয় dataset-টি দৃশ্যায়নের সুবিধার জন্য — মাত্র দুই মাত্রার make_moons (৪০০ বিন্দু, noise=0.3), যার অর্ধচন্দ্রাকার, পরস্পর-জড়ানো দুই class কোনো একটিমাত্র সরলরেখায় ভাগ করা যায় না — ঠিক তাই এটি tree বনাম forest-এর decision boundary-র আকৃতি পাশাপাশি দেখানোর আদর্শ পটভূমি।
import numpy as np
from sklearn.datasets import make_classification, make_moons
from sklearn.model_selection import train_test_split
# ---- main dataset: 20 features, only 6 informative + 2 redundant ----
X, y = make_classification(n_samples=600, n_features=20, n_informative=6,
n_redundant=2, n_repeated=0, n_classes=2,
class_sep=0.8, flip_y=0.05, random_state=20260619)
Xtr, Xte, ytr, yte = train_test_split(X, y, test_size=0.3,
random_state=0, stratify=y)
# ---- 2D dataset for the decision-boundary picture ----
Xm, ym = make_moons(n_samples=400, noise=0.3, random_state=20260619)
Xm_tr, Xm_te, ym_tr, ym_te = train_test_split(Xm, ym, test_size=0.3, random_state=0)
এই setup-এর সুবিধা হলো একই train/test split-এ আমরা চারটি model — full tree, একটি pruned (depth-3) tree, bagging (৩০০ tree) ও random forest (৩০০ tree) — সরাসরি তুলনা করতে পারব, এবং random forest-এর out-of-bag (OOB) estimate-ও পাব আলাদা test set ছাড়াই। আমরা আগে থেকেই অনুমান করতে পারি — full tree (যে training data মুখস্থ করে ফেলে) সবচেয়ে দুর্বল, depth-3 tree (যা সংক্ষিপ্ত হওয়ায় variance কম) কিছুটা ভালো, আর দুটি ensemble সবার ওপরে। ছবিগুলো ঠিক এই অনুমানটাই ধাপে ধাপে প্রমাণ করে দেখাবে।
৬.১ · একটি interpretable decision tree¶
প্রথম ছবিটি দেখায় decision tree-র সবচেয়ে আকর্ষণীয় গুণ — তার স্বচ্ছতা (interpretability)। দৃশ্যমানতার জন্য আমরা 2D make_moons data-তে একটি max_depth=3 tree fit করেছি এবং sklearn.tree.plot_tree দিয়ে তার সম্পূর্ণ গঠন এঁকেছি। প্রতিটি internal node-এ লেখা থাকে একটি সরল শর্ত (feature <= threshold), সেই node-এর Gini impurity, কতগুলো training sample সেখানে এসে পৌঁছেছে (samples), আর প্রতিটি class-এ তাদের ভাগ (value)। প্রতিটি leaf হলো একটি চূড়ান্ত সিদ্ধান্ত-কুঠুরি, যার রঙ বলে দেয় সংখ্যাগরিষ্ঠ class কোনটি — রঙ যত গাঢ়, leaf তত "বিশুদ্ধ" (pure)।
from sklearn.tree import DecisionTreeClassifier, plot_tree
small = DecisionTreeClassifier(max_depth=3, random_state=0).fit(Xm_tr, ym_tr)
plot_tree(small, feature_names=["x1", "x2"],
class_names=["class 0", "class 1"],
filled=True, rounded=True) # color = majority class
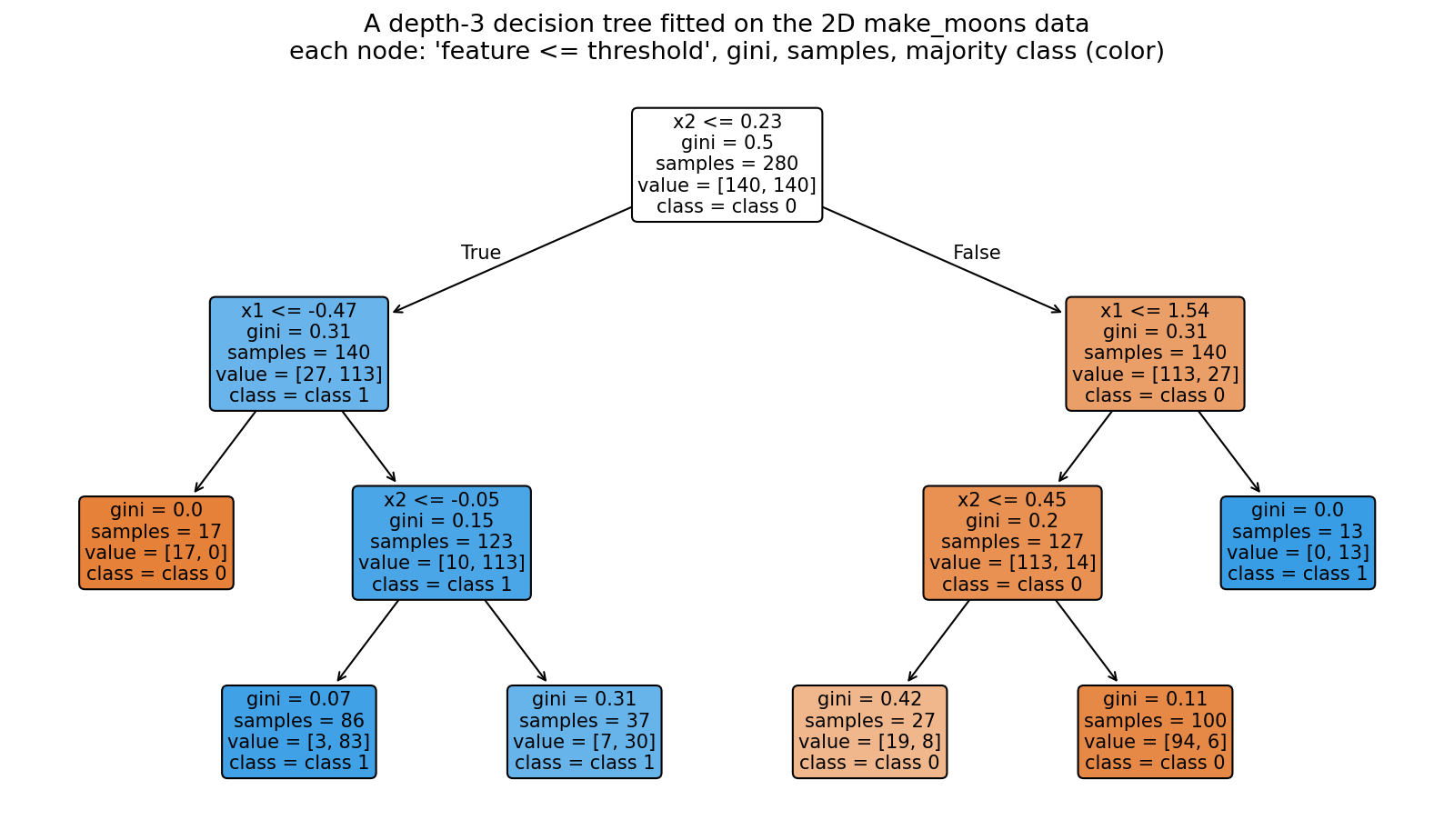
এই একটি ছবিই decision tree-র কেন্দ্রীয় সৌন্দর্যটি ধরে ফেলে: model-টি আসলে কিছু নেস্টেড "yes/no" প্রশ্নের একটি প্রবাহচিত্র (flowchart) ছাড়া কিছুই নয়। root থেকে শুরু করুন — first split জিজ্ঞেস করছে "\(x_2 \le 0.23\)?"; উত্তর হ্যাঁ হলে বাঁ-শাখায়, না হলে ডান-শাখায়; প্রতিটি পরবর্তী node আরেকটি একক-feature প্রশ্ন যোগ করে, আর তিন স্তর পরে আপনি একটি leaf-এ পৌঁছে যান যেখানে class ঘোষণা করা হয়। লক্ষ করুন Gini impurity কীভাবে উপর থেকে নিচে কমতে থাকে — root-এ এটি প্রায় \(0.5\) (data সেখানে দুই class-এ প্রায় সমান-মিশ্রিত), কিন্তু প্রতিটি ভালো split দু-পাশের অঞ্চলকে আরও একরঙা করে তোলে, তাই গভীর node-গুলোতে Gini কমে আসে এবং leaf-গুলো গাঢ়, বিশুদ্ধ রঙ ধারণ করে। এই কাঠামো একজন মানুষ অনায়াসে পড়তে ও ব্যাখ্যা করতে পারে — "যদি \(x_2\) ছোট এবং \(x_1\) বড় হয়, তবে class 1" — আর ঠিক এই কারণেই tree-কে বলা হয় white-box model: এর সিদ্ধান্তের যুক্তি সম্পূর্ণ দৃশ্যমান।
কিন্তু এখানেই লুকিয়ে আছে tree-র দুর্বলতার বীজ। প্রতিটি split যেহেতু একটিমাত্র feature-এ একটি threshold বসায়, তাই decision boundary সর্বদা অক্ষ-সমান্তরাল (axis-aligned) — অর্থাৎ আয়তাকার ধাপে গঠিত, কখনও তির্যক নয়। আর depth যদি বাড়তে দেওয়া হয়, tree প্রতিটি training বিন্দুর চারপাশে আরও সূক্ষ্ম আয়তক্ষেত্র কেটে শেষমেশ data-কে প্রায় মুখস্থ করে ফেলতে পারে। এই depth-3 tree-টি ইচ্ছাকৃতভাবে ছোট রাখা — পড়ার যোগ্য রাখতে — কিন্তু পরের ছবিতে আমরা দেখব একটি পূর্ণ-বর্ধিত (unpruned) tree-কে ছেড়ে দিলে তার সীমানা কতটা অস্থির ও খাঁজকাটা হয়ে ওঠে।
৬.২ · একক tree বনাম forest: variance কমে যাওয়া চোখে দেখা¶
দ্বিতীয় ছবিটি ensemble-এর মূল যুক্তিটি — গড় করলে variance কমে — সরাসরি চাক্ষুষ করে। একই 2D make_moons data-তে বাঁ panel-এ একটি একক, পূর্ণ-বর্ধিত decision tree-র decision boundary, আর ডান panel-এ একটি ৩০০-tree random forest-এর boundary, পাশাপাশি। দুটিকে এক করে দেখলেই বোঝা যায় কেন বহু tree-র গড় একটি tree-র চেয়ে নির্ভরযোগ্য।
from sklearn.ensemble import RandomForestClassifier
tree2d = DecisionTreeClassifier(random_state=0).fit(Xm_tr, ym_tr) # one full tree
rf2d = RandomForestClassifier(n_estimators=300,
random_state=0).fit(Xm_tr, ym_tr) # 300 trees
# প্রতিটি model-কে একটি ঘন mesh-grid-এ predict করিয়ে region আঁকা হয়
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=REGION_CMAP, alpha=0.85) # filled regions
ax.contour(xx, yy, Z, levels=[0.5], colors="#333333") # the boundary
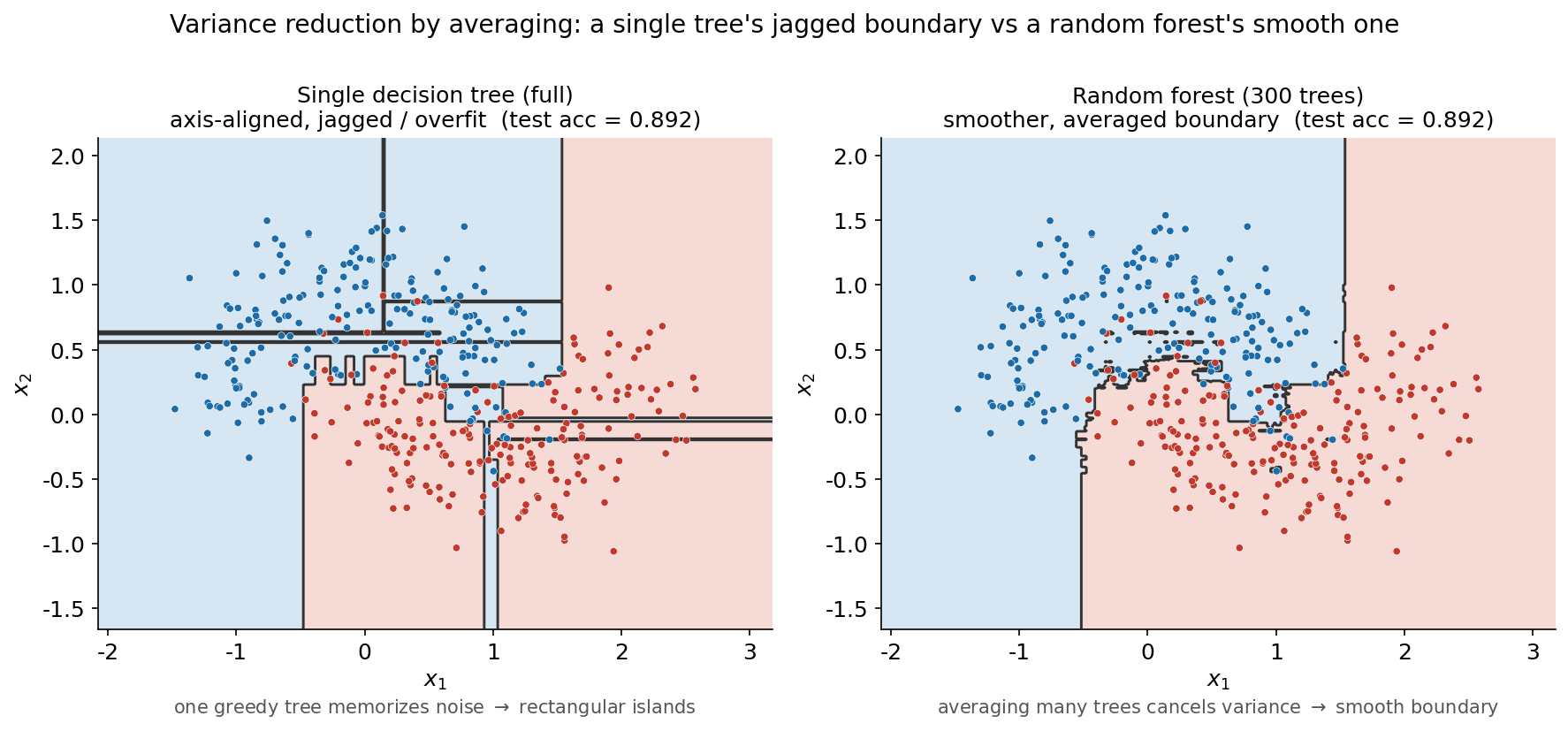
বাঁ panel-এ একক tree-র সীমানাটি লক্ষ করুন — এটি একগুচ্ছ খাড়া-ও-আনুভূমিক ধাপের সমষ্টি, কারণ আমরা ৬.১-এ দেখেছি প্রতিটি split অক্ষ-সমান্তরাল। আরও খারাপ, পূর্ণ tree-টি training data-র প্রতিটি বিন্দুকে সঠিক করতে গিয়ে noise-অঞ্চলেও ছোট-ছোট বিচ্ছিন্ন আয়তাকার দ্বীপ কেটে ফেলেছে — যেমন নীল এলাকার ভেতরে একটি লাল কুঠুরি বা উল্টোটা। এটি ক্লাসিক overfitting: model দুই class-এর প্রকৃত অর্ধচন্দ্রাকার গঠন শেখার বদলে এই নির্দিষ্ট training নমুনার দৈবচয়িত ওঠানামাও মুখস্থ করে ফেলেছে। data সামান্য বদলালে — অন্য একটি bootstrap নমুনা নিলে — এই দ্বীপগুলো সম্পূর্ণ জায়গা বদলে ফেলত; অর্থাৎ tree-টি high-variance।
ডান panel-এ random forest ঠিক এই সমস্যাটাই সারিয়ে তোলে। এখানে ৩০০টি tree, প্রতিটি ভিন্ন bootstrap নমুনায় ও প্রতিটি split-এ feature-এর random subset দেখে প্রশিক্ষিত — তাই প্রতিটি tree আলাদা-আলাদা খাঁজ ও দ্বীপ তৈরি করে। কিন্তু যখন এদের prediction গড় করা হয় (সংখ্যাগরিষ্ঠ ভোটে), তখন এলোমেলো, পরস্পর-অসংলগ্ন খাঁজগুলো একে অপরকে কাটাকাটি করে মুছে যায়, পড়ে থাকে কেবল সেই সীমানা যেটির ব্যাপারে অধিকাংশ tree একমত — আর সেটিই অর্ধচন্দ্রের প্রকৃত আকৃতির অনেক কাছাকাছি, মসৃণ একটি বক্ররেখা। এটিই ensemble-এর গাণিতিক হৃদয়: স্বতন্ত্র, কম-correlated কিছু high-variance predictor-কে গড় করলে তাদের গড়ের variance অনেক কমে যায়, অথচ bias প্রায় একই থাকে। 2D-তে দুই model-এর test accuracy কাছাকাছি হলেও (এই সহজ, কম-মাত্রিক সমস্যায় একক tree-ও মন্দ করে না), boundary-র চরিত্রের পার্থক্যই আসল শিক্ষা — আর পরের ছবিতে আমরা দেখব উচ্চ-মাত্রিক, noise-ভরা data-তে এই variance-হ্রাস কীভাবে সরাসরি accuracy-র বড় লাফে অনুবাদ হয়।
৬.৩ · single tree থেকে ensemble: accuracy-র সিঁড়ি¶
তৃতীয় ছবিটি আমাদের 2D খেলাঘর থেকে বেরিয়ে মূল 20-feature dataset-এ ফিরে আসে এবং পুরো গল্পটাকে সংখ্যায় বাঁধে। এটি চারটি model-এর test accuracy-র একটি bar chart — full tree, depth-3 tree, bagging (৩০০) ও random forest (৩০০) — যেখানে দুটি ensemble আলাদা রঙে (সবুজ) চিহ্নিত। random forest-এর bar-এর ওপর একটি লাল হীরা ও বিন্দুরেখায় তার OOB score আলাদাভাবে দেখানো, আর একটি inset-এ random forest-এর accuracy কীভাবে tree-সংখ্যার সাথে বাড়ে তার বক্ররেখা।
from sklearn.ensemble import BaggingClassifier
full_tree = DecisionTreeClassifier(random_state=0).fit(Xtr, ytr)
d3_tree = DecisionTreeClassifier(max_depth=3, random_state=0).fit(Xtr, ytr)
bag = BaggingClassifier(DecisionTreeClassifier(random_state=0),
n_estimators=300, random_state=0).fit(Xtr, ytr)
rf = RandomForestClassifier(n_estimators=300, oob_score=True,
random_state=0).fit(Xtr, ytr)
accs = [accuracy_score(yte, m.predict(Xte)) # 0.733, 0.794, 0.822, 0.839
for m in (full_tree, d3_tree, bag, rf)]
print(rf.oob_score_) # 0.848 (no test set needed)
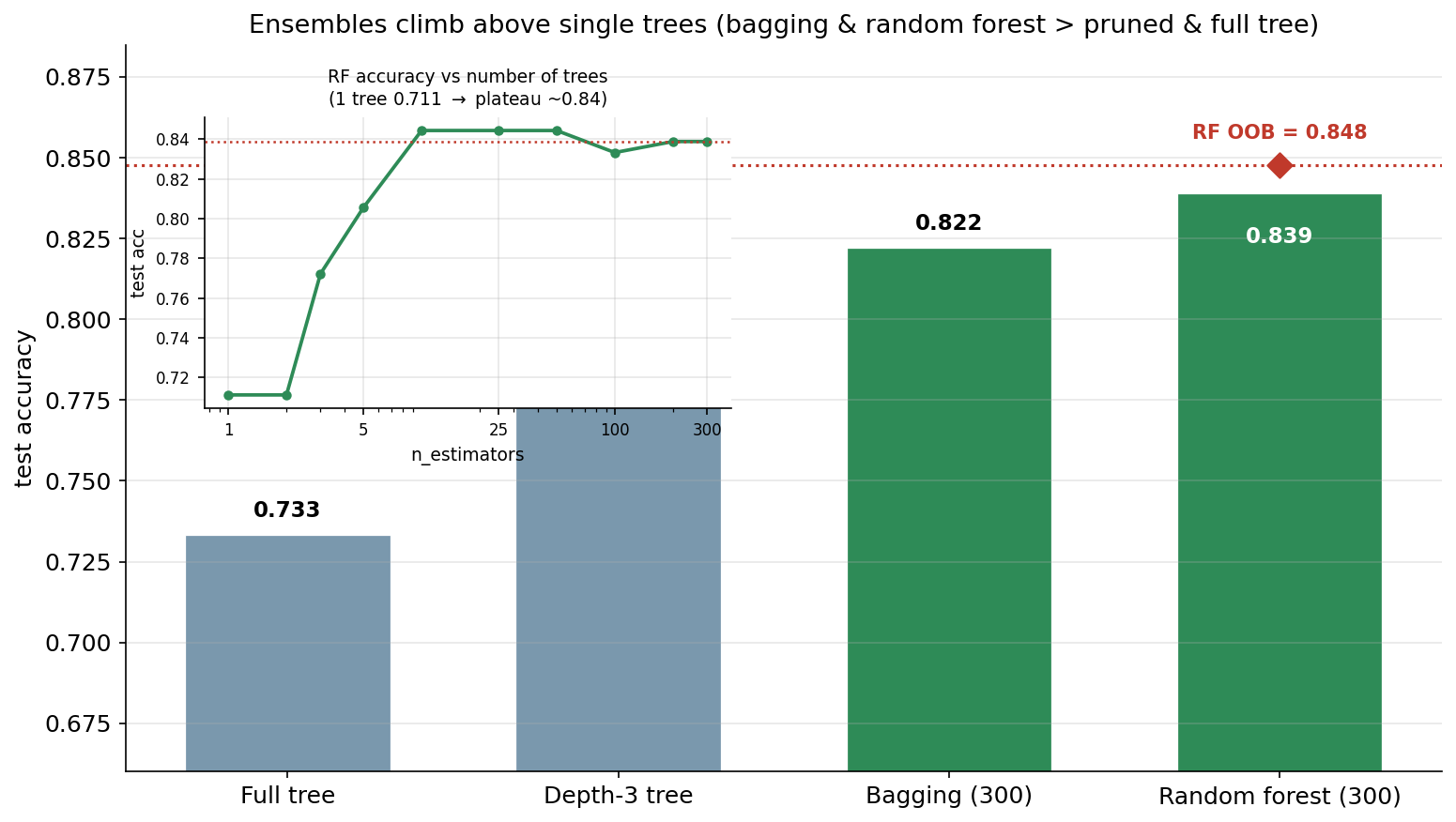
bar-গুলো বাঁ থেকে ডানে একটি পরিষ্কার সিঁড়ি তৈরি করে, যা এই অধ্যায়ের কেন্দ্রীয় বার্তাটি সংখ্যায় বলে দেয়। সবচেয়ে বাঁয়ে full tree, মাত্র 0.733 — সবচেয়ে দুর্বল। কারণটি ৬.২-তে দেখা সেই overfitting: এই উচ্চ-মাত্রিক, noise-ভরা data-তে একটি অনিয়ন্ত্রিত tree (এখানে গভীরতা ১০, ৫১টি leaf!) training set প্রায় মুখস্থ করে ফেলে, ফলে নতুন data-তে হোঁচট খায়। তার ঠিক ডানে depth-3 tree, 0.794 — মজার ব্যাপার, গাছটিকে ছোট করেই (pruning করে) accuracy বেড়েছে! এটি প্রথম দেখায় স্ববিরোধী মনে হলেও আসলে bias–variance ভারসাম্যের সরাসরি ফল: depth সীমিত রাখলে tree কম noise মুখস্থ করে, তাই variance কমে এবং generalization ভালো হয়। কিন্তু একটি একক tree, যত ভালোভাবেই ছাঁটা হোক, এখানে এক সীমার বেশি এগোতে পারে না।
আসল লাফটা আসে ensemble-এ। Bagging (০.৮২২) ৩০০টি unpruned tree-কে ভিন্ন bootstrap নমুনায় প্রশিক্ষণ দিয়ে গড় করে — প্রতিটি tree একা high-variance, কিন্তু গড়ের variance অনেক কম, তাই accuracy depth-3 tree-কেও ছাড়িয়ে যায়। Random forest (০.৮৩৯) আরও এক ধাপ এগিয়ে: bagging-এর মতোই গড় করে, কিন্তু প্রতিটি split-এ feature-এর কেবল একটি random subset বিবেচনা করে, যা tree-গুলোকে পরস্পর থেকে আরও de-correlate করে। কম-correlated predictor গড় করলে variance আরও বেশি কমে — তাই forest সাধারণত bagging-কেও সামান্য পেছনে ফেলে, যেমন এখানে। তীরচিহ্নিত লাল হীরা — OOB = 0.848 — random forest-এর একটি বিশেষ উপহার: যেহেতু প্রতিটি bootstrap নমুনায় গড়ে ~৩৭% observation বাদ পড়ে, সেই "out-of-bag" বিন্দুগুলোকে test set হিসেবে ব্যবহার করে কোনো আলাদা hold-out ছাড়াই performance আন্দাজ করা যায়; এখানে OOB (0.848) test accuracy-র (0.839) খুব কাছাকাছি, যা নিশ্চিত করে দুটিই বিশ্বাসযোগ্য।
inset-টি ensemble-এর আরেকটি গুরুত্বপূর্ণ বৈশিষ্ট্য দেখায় — কতগুলো tree যথেষ্ট? বক্ররেখাটি বলে: একটিমাত্র tree-তে random forest কার্যত একটি একক tree-র মতোই দুর্বল (০.৭১১), কিন্তু tree-সংখ্যা বাড়ার সাথে accuracy দ্রুত ওঠে — ৫ tree-তে ০.৮০৬, ২৫ tree-তে ০.৮৪৪ — এবং এরপর প্রায় সমতল (plateau) হয়ে যায়, ৩০০ tree-তেও ≈০.৮৪-এর আশপাশেই থাকে। অর্থাৎ tree যোগ করলে performance আর খারাপ হয় না (overfitting বাড়ে না), কিন্তু একটি সীমার পর বাড়তি tree কেবল computation খরচ — উপকার নগণ্য। এটি একটি ব্যবহারিক নির্দেশনা: কয়েকশো tree সাধারণত যথেষ্ট, এর বেশি বাড়ানো অপচয়।
৬.৪ · forest কোন feature-গুলোকে গুরুত্ব দেয়¶
শেষ ছবিটি random forest-এর আরেকটি মূল্যবান উপজাত — feature importance — দৃশ্যমান করে। একই ৩০০-tree forest-এর feature_importances_ (Gini-ভিত্তিক, অর্থাৎ প্রতিটি feature গড়ে কত impurity কমাল তার ওপর নির্ভর করে) ২০টি feature-এর জন্য সাজানো একটি অনুভূমিক bar chart-এ দেখানো — সবচেয়ে গুরুত্বপূর্ণ feature উপরে। কয়েকটি প্রকৃত-informative feature সবুজে, আর বাকি দীর্ঘ লেজ ধূসরে।
rf = RandomForestClassifier(n_estimators=300, random_state=0).fit(Xtr, ytr)
imp = rf.feature_importances_ # one nonneg value per feature, sums to 1
order = np.argsort(imp) # ascending -> biggest at top of barh
ax.barh(range(20), imp[order]) # feat 4: 0.164, feat 6: 0.132, ...
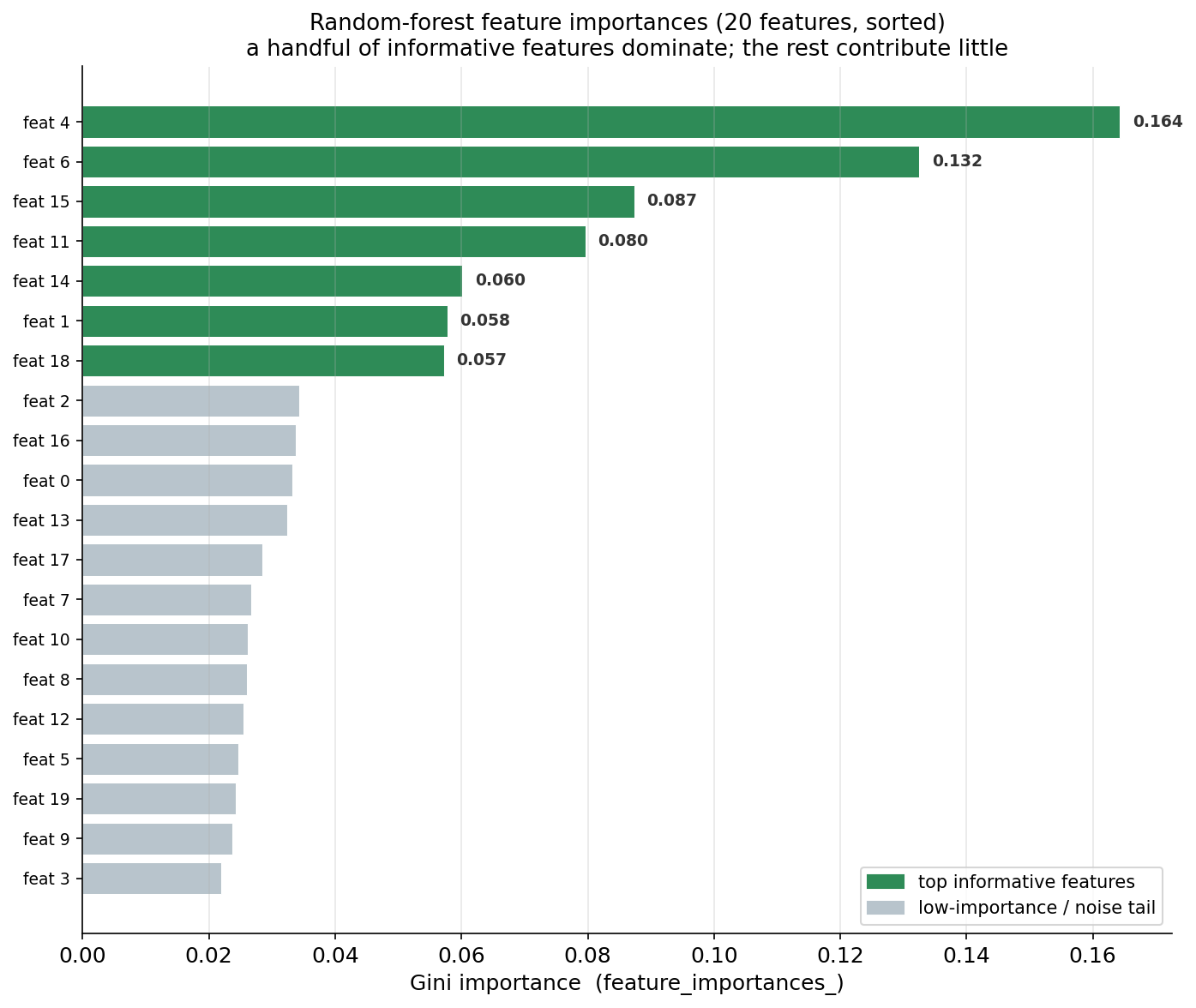
এই chart-টি random forest-এর একটি চমৎকার ব্যবহারিক ক্ষমতা প্রদর্শন করে: এটি নিজে থেকেই বলে দেয় কোন feature-গুলো সিদ্ধান্তে আসলে কাজে লাগছে। শীর্ষে — feat 4 (≈ 0.164) ও feat 6 (≈ 0.132) — সবচেয়ে দীর্ঘ দুটি bar, এরা একাই মোট importance-এর প্রায় ৩০% বহন করছে; এরপর feat 15, feat 11, feat 14 ও feat 1 মাঝারি গুরুত্বে নেমে আসছে। গুরুত্বপূর্ণ ব্যাপার হলো — আমরা data তৈরি করেছিলাম মাত্র ৬টি informative (+২টি redundant) feature দিয়ে, আর forest কোনো পূর্ব-জ্ঞান ছাড়াই ঠিক সেই গুটিকয় feature-কেই শীর্ষে তুলে এনেছে। এর নিচে বাকি feature-গুলো একটি দীর্ঘ, প্রায়-সমান ধূসর লেজ তৈরি করে — এদের গুরুত্ব অনেক কম, কারণ এরা মূলত noise বা দুর্বল-প্রাসঙ্গিক, আর forest সঠিকভাবেই এদের ওপর কম নির্ভর করে।
এই ক্ষমতার দুটি বাস্তব প্রয়োগ। প্রথমত, feature selection: যদি কোনো dataset-এ শত শত feature থাকে, random forest একবার fit করে এই ranking দেখে আপনি দ্রুত বুঝতে পারেন কোন মুষ্টিমেয় feature ধরে রাখলেই প্রায় সমান performance পাওয়া যাবে — model হালকা ও দ্রুত হবে। দ্বিতীয়ত, ব্যাখ্যা (interpretation): যদিও একটি forest একক tree-র মতো সম্পূর্ণ white-box নয় (৩০০টি tree একসাথে পড়া অসম্ভব), এই importance ranking একধরনের সারসংক্ষেপ-স্বচ্ছতা ফিরিয়ে দেয় — "model মূলত feat 4 ও feat 6-এর ওপর সিদ্ধান্ত নিচ্ছে" — যা domain বিশেষজ্ঞের সাথে আলোচনায় অমূল্য। তবে একটি সতর্কতা স্মরণে রাখা ভালো: Gini-ভিত্তিক importance উচ্চ-cardinality বা পরস্পর-correlated feature-এর দিকে কিছুটা পক্ষপাতদুষ্ট হতে পারে, এবং দুটি redundant feature একে অপরের গুরুত্ব ভাগ করে নিলে কারও individual importance কম দেখাতে পারে — তাই গুরুত্বপূর্ণ সিদ্ধান্তে permutation importance-এর মতো বিকল্প পদ্ধতির সাথে মিলিয়ে দেখা শ্রেয়।
সারসংক্ষেপ¶
চারটি ছবি একসাথে "একক tree থেকে ensemble পর্যন্ত" পুরো যাত্রাটি মেলে ধরে। Tree diagram (৬.১) দেখাল decision tree আসলে নেস্টেড yes/no প্রশ্নের একটি স্বচ্ছ flowchart — interpretable, কিন্তু অক্ষ-সমান্তরাল ও overfit-প্রবণ। Single tree বনাম forest (৬.২) সেই overfitting চাক্ষুষ করল: একক tree-র খাঁজকাটা, দ্বীপ-ভরা, high-variance সীমানার বিপরীতে forest-এর মসৃণ সীমানা — যা বহু tree গড় করায় এলোমেলো খাঁজগুলো কাটাকাটি হয়ে যাওয়ার সরাসরি ফল। Accuracy-র সিঁড়ি (৬.৩) এই variance-হ্রাসকে সংখ্যায় বাঁধল: full tree 0.733 → depth-3 tree 0.794 → bagging 0.822 → random forest 0.839 (OOB 0.848), এবং inset দেখাল forest-এর accuracy কয়েকশো tree-তে plateau করে। শেষে feature importance (৬.৪) প্রকাশ করল forest নিজে থেকেই গুটিকয় প্রকৃত-informative feature (feat 4, 6, …) চিনে নেয় — যা feature selection ও ব্যাখ্যায় কাজে লাগে। সম্মিলিত শিক্ষা: একটি tree সরল ও বোধগম্য কিন্তু অস্থির; bootstrap ও randomness দিয়ে বহু tree গড় করলেই সেই অস্থিরতা ভেঙে শক্তিশালী, নির্ভরযোগ্য classifier তৈরি হয়। এই ছবিগুলো তৈরির সম্পূর্ণ, পুনরুৎপাদনযোগ্য কোড আছে _code/figs_6-5.py-তে।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/06-05-trees-bagging-random-forests-solutions.md-এ। নিজে চেষ্টা করার আগে সমাধান দেখবেন না — একটা node কীভাবে split হয় (Gini/entropy হাতে গুনে, যে split সর্বোচ্চ information gain দেয় সেটা বাছা), কেন একটা single tree overfit করে/high variance, bagging কীভাবে variance কমায় (\(\rho\sigma^2+\frac{1-\rho}{B}\sigma^2\) হাতে গুনে), কেন random forest bagging-এর চেয়েও \(\rho\) কমায় (feature subsampling, \(m=\sqrt{p}\)), OOB কেন \(\approx37\%\) (\(e^{-1}\approx0.368\) থেকে) ও কেন OOB free test-error estimate, feature importance পড়া, আরও tree কখনো ক্ষতি করে না (n_estimators টেবিল), এবং tree বনাম ensemble-এর bias–variance — এই হাতে-কলমে বোঝাই এই অধ্যায়ের আসল শেখা।
(চলমান উদাহরণ স্মারক — seed 20260619, make_classification(n=600, n_features=20, n_informative=6, n_redundant=2), \(70/30\) split (\(420\) train, \(180\) test)। canonical test accuracy: full (unpruned) tree \(0.733\) (depth \(10\), \(51\) leaf; bootstrap sd \(0.040\)); depth-\(3\) tree \(0.794\); bagging (\(B{=}300\)) \(0.822\); random forest (\(B{=}300\)) \(0.839\), OOB \(0.848\)। RF, n_estimators বাড়ালে: \(1\to0.711\), \(5\to0.806\), \(25\to0.844\), \(300\to0.839\)। feature importance (RF): idx4 \(0.164\), idx6 \(0.132\), idx15 \(0.087\)। মূল notation: Gini \(G_m=\sum_c\hat p_{mc}(1-\hat p_{mc})\); entropy \(H_m=-\sum_c\hat p_{mc}\log_2\hat p_{mc}\); information gain \(\Delta=I_{\text{parent}}-\sum_{\text{child}}\frac{N_{\text{child}}}{N}I_{\text{child}}\); bagging \(\hat f_{\text{bag}}=\frac1B\sum_b\hat f_b\); \(B\)টি গাছের গড়ের variance \(\rho\sigma^2+\frac{1-\rho}{B}\sigma^2\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). একটা tree কীভাবে কাজ করে — recursive partitioning। decision tree feature-space-কে বারবার দুই ভাগে কেটে (axis-aligned split, যেমন "\(x_j\le t\)?") আয়তাকার অঞ্চলে ভাগ করে, এবং প্রতিটি অঞ্চল (leaf)-এ একটাই prediction দেয়। (ক) একটা leaf-এ classification-এ prediction কী হয় (সেই leaf-এ পড়া training-বিন্দুদের কোন সংখ্যা), আর regression-এ কী হয়? (খ) "axis-aligned split" বলতে কী বোঝায়, এবং কেন একটা single tree-এর decision boundary সিঁড়ির মতো (staircase) দেখায়, মসৃণ তির্যক রেখা নয়? (গ) এক বাক্যে বলুন কেন tree interpretable — root থেকে leaf পর্যন্ত পথটা কীসের সমান। Hint: (ক) leaf-এ classification-এ majority class (সবচেয়ে বেশি-সংখ্যক শ্রেণি), regression-এ সেই leaf-এর training-বিন্দুদের response-গড়। (খ) প্রতিটি split কেবল একটা feature-অক্ষের সমকোণে কাটে (\(x_j\le t\)), তাই boundary সবসময় অক্ষের সমান্তরাল টুকরো — তির্যক সীমা ধরতে অনেকগুলো ধাপ লাগে, ফলে সিঁড়ি। (গ) প্রতিটি root→leaf পথ হলো এক সারি if-then শর্তের সংযোগ ("\(x_4\le0.2\) এবং \(x_6>1.1\) ⇒ class 1") — মানুষ পড়তে পারে এমন নিয়ম।
প্রশ্ন ২ (★). impurity কী মাপছে — Gini বনাম entropy। একটা node \(m\)-এ শ্রেণি-অনুপাত \(\hat p_{mc}\); Gini \(G_m=\sum_c\hat p_{mc}(1-\hat p_{mc})\), entropy \(H_m=-\sum_c\hat p_{mc}\log_2\hat p_{mc}\)। (ক) একটা pure node (সব বিন্দু একই শ্রেণি) ও একটা সর্বোচ্চ-মিশ্র binary node (\(50\)–\(50\))-এ \(G\) ও \(H\)-এর মান কত — তাই দুটোই কোন দিকে যায় যত node বিশুদ্ধ হয়? (খ) tree split বাছার সময় impurity কী করতে চায় (parent-এর চেয়ে children-এ impurity বাড়ে না কমে)? (গ) Gini আর entropy প্রায় সবসময় একই split বাছে কেন, এবং Gini default হয় কোন ব্যবহারিক কারণে? Hint: (ক) pure node: \(G=0\), \(H=0\) (সর্বনিম্ন); \(50\)–\(50\) binary: \(G=2(0.5)(0.5)=0.5\), \(H=-2(0.5)\log_2 0.5=1\) (সর্বোচ্চ)। যত বিশুদ্ধ, তত \(0\)-এর দিকে। (খ) impurity কমাতে চায় — split বাছা হয় যেটা children-এ weighted impurity সবচেয়ে কমায় (information gain সর্বোচ্চ)। (গ) দুই measure একই monotone আচরণ (বিশুদ্ধতায় \(0\), মিশ্রতায় বড়), তাই বাছাই প্রায় অভিন্ন; Gini-তে log লাগে না বলে গণনায় একটু সস্তা — তাই CART-এ default।
প্রশ্ন ৩ (★★). কেন একটা single (deep) tree overfit করে — high variance। চলমান উদাহরণে unpruned tree depth \(10\), \(51\) leaf পর্যন্ত বাড়ে এবং test accuracy মাত্র \(0.733\), অথচ একই গাছ training-এ প্রায় নিখুঁত। (ক) কেন গভীর গাছ training-data-তে প্রায় \(100\%\) ঠিক করে — leaf-সংখ্যা বাড়লে কী ঘটে? (খ) "high variance" বলতে এখানে কী বোঝায় — চলমান উদাহরণে full tree-এর test accuracy-র bootstrap sd \(0.040\) এই variance-এর কোন প্রমাণ? (গ) depth-\(3\)-এ ছেঁটে দিলে accuracy বেড়ে \(0.794\) হয় — এটা bias–variance ভাষায় কী ঘটনা (depth কমালে কোনটা বাড়ে, কোনটা কমে, আর কেন net লাভ)? Hint: (ক) leaf যত বেশি, প্রতিটি leaf তত কম-বিন্দু ধরে; চরমে প্রতি leaf-এ ১টা বিন্দু হলে গাছ training-label হুবহু মুখস্থ করে — noise সমেত। (খ) high variance = training-set সামান্য বদলালে গাছের গঠন ও prediction অনেক বদলায়; \(420\) বিন্দু resample করে বারবার গাছ গড়লে test accuracy \(\pm0.04\) ঘুরে বেড়ায় — এই অস্থিরতাই variance-এর সরাসরি পরিমাপ। (গ) depth \(10\to3\) করলে capacity কমে: variance অনেক কমে, bias সামান্য বাড়ে; এখানে variance-পতন bias-বৃদ্ধিকে ছাপিয়ে যায়, তাই net test accuracy \(0.733\to0.794\) বাড়ে — pruning-এর মূল যুক্তি (৬.১-এর bias–variance tradeoff)।
প্রশ্ন ৪ (★★). bagging কীভাবে variance কমায় — গড়ের জাদু। bagging \(B\)টি bootstrap-নমুনায় গাছ গড়ে গড় করে: \(\hat f_{\text{bag}}=\frac1B\sum_b\hat f_b\)। (ক) যদি \(B\)টি estimator হত পরস্পর-স্বাধীন, প্রতিটির variance \(\sigma^2\), তবে গড়ের variance কত — তাই \(B\to\infty\)-এ কী হত? (খ) বাস্তবে গাছগুলো স্বাধীন নয় (একই data-র bootstrap, তাই correlated, correlation \(\rho\)); তখন গড়ের variance \(\rho\sigma^2+\frac{1-\rho}{B}\sigma^2\) — \(B\to\infty\)-এ এটা কোথায় থামে, এবং কোন পদটা \(B\) বাড়িয়ে দূর করা যায় না? (গ) তাই bagging-এর মূল সীমাবদ্ধতা কী — শুধু গাছ বাড়িয়ে variance-কে \(0\)-এ নামানো যায় না কেন, এবং এই বাধাই পরের কৌশল (random forest)-এর প্রেরণা? Hint: (ক) স্বাধীন হলে variance \(=\sigma^2/B\), তাই \(B\to\infty\)-এ \(0\) — গড় করলে noise মুছে যায়। (খ) correlated হলে \(B\to\infty\)-এ variance \(\to\rho\sigma^2\) (floor); \(\frac{1-\rho}{B}\sigma^2\) পদটা \(B\)-তে \(0\)-এ যায়, কিন্তু \(\rho\sigma^2\) পদ \(B\)-নিরপেক্ষ, কখনো যায় না। (গ) bagging-এর floor \(\rho\sigma^2\) — গাছগুলো বেশি correlated (\(\rho\) বড়) হলে যত গাছই হোক variance এই floor-এর নিচে নামে না; তাই variance আরও কমাতে হলে \(\rho\) কমাতে হবে — random forest ঠিক সেটাই করে।
প্রশ্ন ৫ (★★). random forest কেন bagging-এর চেয়ে ভালো — \(\rho\) কমানো। RF প্রতিটি split-এ সব \(p\)টি feature নয়, এলোমেলোভাবে বাছা একটা উপসেট (\(m=\sqrt{p}\)টি feature) থেকেই সেরা split খোঁজে। (ক) এই feature-subsampling গাছগুলোর pairwise correlation \(\rho\)-এর উপর কী প্রভাব ফেলে, এবং কেন (একটা খুব-শক্তিশালী feature থাকলে সব bagged গাছ কী করত)? (খ) variance-সূত্র \(\rho\sigma^2+\frac{1-\rho}{B}\sigma^2\)-এ \(\rho\) ছোট হলে floor (\(\rho\sigma^2\)) কী হয় — তাই RF-এর variance-floor কেন bagging-এর চেয়ে নিচু? (গ) চলমান উদাহরণে bagging \(0.822\) কিন্তু RF \(0.839\) — এই \(0.017\) উন্নতি এই decorrelation-যুক্তির সাথে কীভাবে সঙ্গতিপূর্ণ? \(p=20\)-এ default \(m=\sqrt{20}\approx4\)। Hint: (ক) feature-subsampling প্রতিটি গাছকে আলাদা feature-সেট ব্যবহার করতে বাধ্য করে, তাই গাছগুলো একে অন্যের চেয়ে আলাদা হয় ⇒ \(\rho\) কমে। subsampling না থাকলে (bagging) একটা প্রভাবশালী feature প্রায় সব গাছের root-এ বসত, ফলে গাছগুলো একই রকম (correlated)। (খ) \(\rho\) ছোট ⇒ floor \(\rho\sigma^2\) ছোট ⇒ \(B\) বাড়ালে variance আরও নিচে নামতে পারে — RF-এর floor bagging-এর floor-এর নিচে। (গ) কম \(\rho\) মানে গড় করার পর কম residual variance ⇒ test accuracy bagging-এর \(0.822\) থেকে RF-এর \(0.839\)-এ ওঠে; এটাই decorrelation-লাভ।
প্রশ্ন ৬ (★★). OOB — bootstrap-এর free validation set। bootstrap নমুনা \(n\)টি বিন্দু with replacement তোলে, তাই কিছু বিন্দু কোনো নির্দিষ্ট নমুনায় ঢোকেই না — এরা ওই গাছের out-of-bag (OOB)। (ক) একটা নির্দিষ্ট বিন্দু একটা size-\(n\) bootstrap-নমুনায় ঢুকবে না তার সম্ভাবনা \((1-\frac1n)^n\); \(n\to\infty\)-এ এটা কোন সংখ্যায় যায়, এবং তাই গড়ে প্রতিটি গাছের জন্য কত শতাংশ বিন্দু OOB? (খ) এই OOB বিন্দুগুলো ওই গাছ দেখেনি, তাই তাদের উপর prediction কেন একটা honest (unbiased-প্রায়) test estimate দেয়? (গ) চলমান উদাহরণে OOB accuracy \(0.848\) আর held-out test accuracy \(0.839\) — এত কাছাকাছি কেন, এবং এর ব্যবহারিক সুবিধা কী (আলাদা validation set/CV ছাড়াই কী পাওয়া যায়)? Hint: (ক) \((1-\frac1n)^n\to e^{-1}\approx0.368\); তাই প্রতিটি গাছের জন্য গড়ে \(\approx36.8\%\) (\(\approx37\%\)) বিন্দু OOB (বাকি \(\approx63\%\) in-bag)। (\(n=600\)-এ মান \(0.368\)।) (খ) প্রতিটি বিন্দুর জন্য কেবল সেই গাছগুলোর ভোট নেওয়া হয় যারা তাকে training-এ দেখেনি — তাই তার নিজের prediction-এ data-leak নেই, test-error-এর মতো নিরপেক্ষ। (গ) দুটোই একই (অদেখা) data-র উপর error মাপছে, তাই কাছাকাছি (\(0.848\) বনাম \(0.839\)); সুবিধা — OOB বিনামূল্যে (training-এর পার্শ্বফল), আলাদা validation set বা \(k\)-fold CV-র খরচ ছাড়াই model-মূল্যায়ন ও hyperparameter-tuning সম্ভব।
প্রশ্ন ৭ (★★). feature importance — কে গুরুত্বপূর্ণ, আর সাবধানতা। RF প্রতিটি feature-এর importance মাপে: সেই feature-এ করা সব split-এ মোট impurity-হ্রাস (সব গাছ জুড়ে গড়), তারপর normalize (যোগফল \(1\))। চলমান উদাহরণে শীর্ষ তিন: idx4 \(0.164\), idx6 \(0.132\), idx15 \(0.087\)। (ক) idx4-এর importance \(0.164\) মানে কী — এটা কি বলছে idx4 একাই accuracy-র \(16.4\%\), না অন্য কিছু? (খ) data-তে \(6\)টি informative feature আছে; importance-র এই ক্রম কীভাবে সেই informative feature-গুলো চেনার সাথে সঙ্গতিপূর্ণ, আর redundant feature-দের কী হওয়ার কথা? (গ) impurity-based importance-এর একটা পরিচিত পক্ষপাত বলুন — কোন ধরনের feature-কে এটা অযথা বেশি গুরুত্ব দেয়, এবং তখন বিকল্প (permutation importance) কেন ভালো? Hint: (ক) \(0.164\) = মোট impurity-হ্রাসের ভগ্নাংশ যা idx4-এর split-গুলো থেকে এসেছে (সব importance-এর যোগ \(1\)) — আপেক্ষিক অবদান, সরাসরি accuracy-শতাংশ নয়। (খ) informative feature-রা বেশি impurity কমায় বলে বড় importance পায় (idx4, idx6 শীর্ষে); pure-redundant বা noise feature-রা কম কমায়, তাই নিচে — তবে redundant feature informative-এর correlated বলে কিছু importance "চুরি" করতে পারে (দুজনে ভাগ করে নেয়)। (গ) impurity-importance high-cardinality / অনেক-split-সম্ভব (continuous, many-level) feature-কে inflate করে — আকস্মিকভাবেই বেশি split-সুযোগ পায়; permutation importance feature-মান এলোমেলো করে accuracy-পতন মেপে এই পক্ষপাত এড়ায়।
প্রশ্ন ৮ (★★). আরও tree কখনো ক্ষতি করে না — কিন্তু gain স্যাচুরেট করে। চলমান উদাহরণে RF, n_estimators বাড়ালে test accuracy: \(1\to0.711\), \(5\to0.806\), \(25\to0.844\), \(300\to0.839\)। (ক) \(1\to25\) গাছে accuracy দ্রুত বাড়ে (\(0.711\to0.844\)) কেন — variance-সূত্রের কোন পদ এ সময় দ্রুত নামছে? (খ) \(25\to300\)-এ accuracy কার্যত সমতল (\(0.844\) ও \(0.839\), পার্থক্যটা নমুনা-ওঠানামা) — কেন আরও গাছ যোগ করলে আর তেমন উন্নতি হয় না (কোন পদ floor-এ পৌঁছেছে)? (গ) তবু "আরও গাছ overfit করায় না" কেন — boosting-এর বিপরীতে RF-এ গাছ বাড়ানো কেন নিরাপদ (variance শুধু কমে বা স্থির, bias প্রায় অপরিবর্তিত)? Hint: (ক) শুরুতে \(\frac{1-\rho}{B}\sigma^2\) পদ (\(B\)-তে \(1/B\) হারে) দ্রুত কমে — অল্প গাছে গড় করলেই variance অনেকটা পড়ে। (খ) \(B\) বড় হলে \(\frac{1-\rho}{B}\sigma^2\to0\), variance floor \(\rho\sigma^2\)-এ পৌঁছে যায় — তখন আরও গাছ যোগ করলে variance প্রায় কমে না, accuracy সমতল (\(0.844\approx0.839\), পার্থক্য random)। (গ) প্রতিটি গাছ স্বাধীন bootstrap+feature-subset-এ গড়া; গড় করা কেবল variance কমায়, কখনো bias বাড়ায় না এবং বেশি গাছ মানে শুধু গড়ে আরও বিন্দু — তাই n_estimators একটা "যত-বেশি-তত-ভালো (বা সমান)" knob, tuning-ঝুঁকিহীন (কেবল গণনা-খরচ বাড়ে)।
খ · গণনামূলক (computational)¶
প্রশ্ন ৯ (★). একটা node-এ Gini ও entropy হাতে গুনুন। একটা node-এ \(10\)টি বিন্দু: \(6\)টি class A, \(4\)টি class B। (ক) শ্রেণি-অনুপাত \(\hat p_A,\hat p_B\) বের করে Gini \(G=\sum_c\hat p_c(1-\hat p_c)\) গণনা করুন। (খ) entropy \(H=-\sum_c\hat p_c\log_2\hat p_c\) গণনা করুন। (গ) একই node যদি \(9\)A–\(1\)B হত, \(G\) আগের চেয়ে বড় না ছোট হত (গণনা করে দেখান) — এটা impurity-র অর্থের সাথে কীভাবে মেলে? Hint: (ক) \(\hat p_A=0.6,\hat p_B=0.4\); \(G=0.6(0.4)+0.4(0.6)=0.24+0.24=\mathbf{0.48}\)। (খ) \(H=-(0.6\log_2 0.6+0.4\log_2 0.4)=-(0.6(-0.737)+0.4(-1.322))=0.442+0.529=\mathbf{0.971}\)। (গ) \(9\)A–\(1\)B: \(G=0.9(0.1)+0.1(0.9)=0.18<0.48\) — node বেশি বিশুদ্ধ (এক শ্রেণির প্রাধান্য), তাই impurity কম, যৌক্তিক।
প্রশ্ন ১০ (★★). সেরা split বাছুন — information gain তুলনা। parent node: \(10\) বিন্দু, \(6\)A–\(4\)B (তাই \(G_{\text{parent}}=0.48\), \(H_{\text{parent}}=0.971\) — প্রশ্ন ৯ থেকে)। দুটো প্রার্থী split: - Split 1: বাঁ child \([4\text{A},0\text{B}]\) (\(4\) বিন্দু), ডান child \([2\text{A},4\text{B}]\) (\(6\) বিন্দু)। - Split 2: বাঁ child \([3\text{A},1\text{B}]\) (\(4\) বিন্দু), ডান child \([3\text{A},3\text{B}]\) (\(6\) বিন্দু)।
(ক) প্রতিটি child-এর Gini গণনা করুন, তারপর weighted child-Gini \(\sum_{\text{child}}\frac{N_{\text{child}}}{N}G_{\text{child}}\) এবং Gini-gain \(\Delta=G_{\text{parent}}-(\text{weighted child Gini})\) — দুই split-এর জন্য। (খ) entropy দিয়ে একই করে information gain \(\Delta=H_{\text{parent}}-\sum\frac{N_{\text{child}}}{N}H_{\text{child}}\) বের করুন। (গ) কোন split বাছা হবে, এবং কেন — দুই impurity-measure একই উত্তর দিল কি? Hint: (ক) Split 1: \(G_L=0\) (pure), \(G_R=2(2/6)(4/6)=0.444\); weighted \(=\frac4{10}(0)+\frac6{10}(0.444)=0.267\); \(\Delta_{\text{Gini}}=0.48-0.267=\mathbf{0.213}\)। Split 2: \(G_L=2(3/4)(1/4)=0.375\), \(G_R=2(0.5)(0.5)=0.5\); weighted \(=\frac4{10}(0.375)+\frac6{10}(0.5)=0.45\); \(\Delta_{\text{Gini}}=0.48-0.45=\mathbf{0.03}\)। (খ) Split 1: \(H_L=0\), \(H_R=-(\frac26\log_2\frac26+\frac46\log_2\frac46)=0.918\); weighted \(=0.6(0.918)=0.551\); \(\text{IG}=0.971-0.551=\mathbf{0.42}\)। Split 2: \(H_L=0.811\), \(H_R=1\); weighted \(=0.4(0.811)+0.6(1)=0.924\); \(\text{IG}=0.971-0.924=\mathbf{0.046}\)। (গ) Split 1 বাছা হবে — উভয় measure-এ gain অনেক বড় (\(0.213\gg0.03\), \(0.42\gg0.046\)), কারণ Split 1 একটা pure child বানায়; দুই measure একমত।
প্রশ্ন ১১ (★★). bagging variance-সূত্র হাতে গুনুন। ধরুন প্রতিটি গাছের variance \(\sigma^2=1\), pairwise correlation \(\rho=0.5\)। গড়ের variance \(V(B)=\rho\sigma^2+\frac{1-\rho}{B}\sigma^2\)। (ক) \(B=1,10,100\)-এর জন্য \(V\) গণনা করুন। (খ) \(B\to\infty\)-এ \(V\) কোন মানে যায় (floor)? এই floor-এর কত শতাংশের মধ্যে পৌঁছাতে \(B=100\) যথেষ্ট কিনা দেখান। (গ) এখন random forest-এর মতো \(\rho=0.05\) ধরুন (decorrelation-এর পর); \(B=100\)-এ \(V\) ও floor কত — bagging (\(\rho=0.5\))-এর তুলনায় কতটা কম variance? Hint: (ক) \(V(1)=0.5(1)+\frac{0.5}{1}(1)=\mathbf{1.0}\); \(V(10)=0.5+\frac{0.5}{10}=\mathbf{0.55}\); \(V(100)=0.5+\frac{0.5}{100}=\mathbf{0.505}\)। (খ) floor \(=\rho\sigma^2=\mathbf{0.5}\); \(V(100)=0.505\) — floor-এর \(1\%\)-এর মধ্যে, তাই \(B=100\) প্রায় floor-এ পৌঁছে দেয় (আরও গাছে সামান্যই লাভ)। (গ) \(\rho=0.05\): floor \(=\mathbf{0.05}\), \(V(100)=0.05+\frac{0.95}{100}=\mathbf{0.0595}\) — bagging-এর \(0.505\)-এর তুলনায় প্রায় \(1/8.5\) গুণ variance; \(\rho\) কমানোর শক্তি এখানেই স্পষ্ট (RF-এর সারমর্ম)।
প্রশ্ন ১২ (★★). OOB-অনুপাত ও \(\sqrt{p}\) হাতে। (ক) size-\(n\) bootstrap-এ একটা নির্দিষ্ট বিন্দু বাদ পড়ার সম্ভাবনা \((1-\frac1n)^n\); \(n=5,\ 100,\ 600\)-এর জন্য মান বের করে দেখান এটা দ্রুত \(e^{-1}\approx0.368\)-এ স্থির হয় — তাই প্রতিটি গাছে গড়ে কত শতাংশ OOB? (খ) চলমান উদাহরণে \(n_{\text{train}}=420\); in-bag গড়ে কত বিন্দু, OOB গড়ে কত? (গ) \(p=20\) feature-এ classification RF-এর default \(m=\sqrt{p}\); এই \(m\) গণনা করুন, এবং বলুন \(m=p\) নিলে RF আসলে কীসে পরিণত হয়। Hint: (ক) \((1-\frac15)^5=0.328\), \((1-\frac1{100})^{100}=0.366\), \((1-\frac1{600})^{600}=0.368\) — দ্রুত \(e^{-1}=0.368\)-এ; তাই প্রতিটি গাছে \(\approx36.8\%\) (\(\approx37\%\)) বিন্দু OOB। (খ) OOB \(\approx0.368\times420\approx155\) বিন্দু; in-bag (স্বতন্ত্র) \(\approx0.632\times420\approx265\) বিন্দু। (গ) \(m=\sqrt{20}\approx4.47\to4\) feature প্রতি split-এ; \(m=p=20\) নিলে প্রতিটি split সব feature দেখে — তখন আর feature-subsampling নেই, RF bagging-এ পরিণত হয় (গাছগুলো আবার বেশি correlated)।
প্রশ্ন ১৩ (★★). n_estimators টেবিল পড়া ও ensemble-লাভ পরিমাপ। চলমান উদাহরণের সংখ্যা:
| মডেল | test accuracy |
|---|---|
| single full tree (depth 10) | 0.733 |
| single tree depth 3 | 0.794 |
| RF, \(B=1\) | 0.711 |
| RF, \(B=5\) | 0.806 |
| RF, \(B=25\) | 0.844 |
| bagging, \(B=300\) | 0.822 |
| RF, \(B=300\) | 0.839 |
| RF OOB (\(B=300\)) | 0.848 |
(ক) \(B=1\)-এর RF (\(0.711\)) কেন single full tree (\(0.733\))-এর চেয়েও খারাপ — একটা গাছ হলে RF আর tree-এর মধ্যে কী পার্থক্য থাকে যা accuracy কমায়? (খ) single best tree (depth-3, \(0.794\)) থেকে RF-\(300\) (\(0.839\)) পর্যন্ত মোট লাভ কত, এবং এর মধ্যে কতটা bagging থেকে (\(0.794\to0.822\)) আর কতটা decorrelation থেকে (\(0.822\to0.839\))? (গ) OOB (\(0.848\)) test (\(0.839\))-এর চেয়ে সামান্য বেশি — এটা কি OOB-কে অবিশ্বাস্য করে, না দুটোই একই সত্য-accuracy-র চারপাশে নমুনা-ওঠানামা — কোন canonical সংখ্যা (full tree-এর sd) এই ওঠানামার মাপ দেয়? Hint: (ক) \(B=1\)-এ RF একটাই গাছ, কিন্তু সেটা single bootstrap-নমুনায় + প্রতি split-এ মাত্র \(m=\sqrt{p}\) feature দেখে গড়া — কম data, কম feature-পছন্দ ⇒ একটা সাধারণ full tree-এর চেয়েও দুর্বল; গড় করার লাভ এখনো শুরুই হয়নি। (খ) মোট \(0.839-0.794=\mathbf{0.045}\); bagging-অংশ \(0.822-0.794=0.028\) (variance-হ্রাস গড় করে), decorrelation-অংশ \(0.839-0.822=0.017\) (\(\rho\) কমিয়ে)। (গ) অবিশ্বাস্য নয় — \(0.848\) ও \(0.839\) একই সত্য-হারের চারপাশে; full tree-এর bootstrap sd \(0.040\) দেখায় এ ধরনের accuracy-পরিমাপে \(\pm0.04\) ওঠানামা স্বাভাবিক, তাই \(0.009\) ব্যবধান তুচ্ছ।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১৪ (★★★). \(B\)টি correlated estimator-এর গড়ের variance — সূত্রটি প্রমাণ করুন। ধরুন \(\hat f_1,\dots,\hat f_B\) প্রতিটির variance \(\operatorname{Var}(\hat f_b)=\sigma^2\) এবং যেকোনো ভিন্ন জোড়ার \(\operatorname{Corr}(\hat f_b,\hat f_{b'})=\rho\) (তাই \(\operatorname{Cov}(\hat f_b,\hat f_{b'})=\rho\sigma^2\) for \(b\ne b'\))। গড় \(\hat f_{\text{bag}}=\frac1B\sum_{b=1}^B\hat f_b\)। (ক) \(\operatorname{Var}\!\left(\frac1B\sum_b\hat f_b\right)=\frac1{B^2}\sum_{b}\sum_{b'}\operatorname{Cov}(\hat f_b,\hat f_{b'})\) — এই দ্বৈত-যোগকে diagonal (\(b=b'\)) ও off-diagonal (\(b\ne b'\)) পদে ভাঙুন এবং প্রতিটির সংখ্যা গুনুন। (খ) বসিয়ে দেখান \(\operatorname{Var}(\hat f_{\text{bag}})=\rho\sigma^2+\frac{1-\rho}{B}\sigma^2\)। (গ) \(B\to\infty\)-সীমা নিন এবং ব্যাখ্যা করুন কেন \(\rho>0\) হলে variance শূন্যে যায় না — random forest কোন পদটা আক্রমণ করে? Hint: (ক) diagonal পদ \(B\)টি, প্রতিটি \(=\sigma^2\); off-diagonal পদ \(B(B-1)\)টি, প্রতিটি \(=\rho\sigma^2\)। (খ) যোগফল \(=B\sigma^2+B(B-1)\rho\sigma^2\); \(\frac1{B^2}\) গুণ করে \(\frac{\sigma^2}{B}+\frac{(B-1)}{B}\rho\sigma^2=\frac{\sigma^2}{B}+\rho\sigma^2-\frac{\rho\sigma^2}{B}=\rho\sigma^2+\frac{1-\rho}{B}\sigma^2\) ∎। (গ) \(B\to\infty\): দ্বিতীয় পদ \(\to0\), থাকে \(\rho\sigma^2\) — একটা ধনাত্মক floor যা \(B\)-নিরপেক্ষ; গড় করা কেবল "স্বাধীন" অংশ মুছে, "ভাগাভাগি-করা" correlation মোছে না। random forest \(\rho\) নিজেই কমিয়ে (feature-subsampling) এই floor নামায়।
প্রশ্ন ১৫ (★★★). leaf-prediction majority/গড় কেন optimal। একটা leaf-এ পড়া training-বিন্দুদের ধরুন; tree সেই leaf-এর সব বিন্দুকে একটাই মান \(c\) দেয়। (ক) Regression: squared loss \(\sum_{i\in\text{leaf}}(y_i-c)^2\) minimize করে দেখান optimal \(c=\bar y_{\text{leaf}}\) (leaf-এর response-গড়) — \(c\)-সাপেক্ষে derivative শূন্য করে। (খ) Classification (0–1 loss): যদি leaf-এ সব বিন্দুকে একই class \(c\) দিতে হয়, ভুল-গণনা \(\sum_{i\in\text{leaf}}\mathbf 1[y_i\ne c]\) minimize করতে কোন \(c\) বাছতে হবে — দেখান এটা majority class। (গ) এই দুই ফল একসাথে কেন স্বজ্ঞাত — একটা leaf-এর ভেতরে আর কোনো feature-তথ্য নেই বলে "সেরা একক উত্তর" আসলে কীসের সমান? Hint: (ক) \(\frac{d}{dc}\sum_i(y_i-c)^2=-2\sum_i(y_i-c)=0\Rightarrow\sum_i(y_i-c)=0\Rightarrow c=\frac1{N}\sum_i y_i=\bar y_{\text{leaf}}\); convex (second derivative \(2N>0\)), তাই minimum। (খ) প্রতিটি \(c\)-এর জন্য ভুল-গণনা \(=N-(\text{class }c\text{-এর সংখ্যা})\); এটা সর্বনিম্ন হয় যখন "class \(c\)-এর সংখ্যা" সর্বোচ্চ, অর্থাৎ \(c=\) সর্বাধিক-সংখ্যক শ্রেণি (majority)। (গ) leaf-এর মধ্যে কোনো splitting-feature বাকি নেই, তাই সব বিন্দু "একইরকম"; তখন সেরা একক উত্তর = কেন্দ্রীয় প্রবণতা — regression-এ গড় (mean), classification-এ mode (majority) — উভয়ই respective loss-এর minimizer।
ঘ · কোডিং (Python)¶
প্রশ্ন ১৬ (★★★). পূর্ণ pipeline — tree → pruning → bagging → random forest → OOB → importance। seed-সূচক 20260619 দিয়ে canonical dataset বানান: make_classification(n_samples=600, n_features=20, n_informative=6, n_redundant=2, random_state=20260619), তারপর \(70/30\) train–test split (random_state=0, \(420\) train / \(180\) test)। এবার:
- single tree:
DecisionTreeClassifier(random_state=...)(unpruned) fit করে test accuracy,get_depth(),get_n_leaves()ছাপুন — canonical \(0.733\), depth \(10\), \(51\) leaf মেলান। তারপরmax_depth=3-এ আবার fit করে \(0.794\) মেলান (pruning-লাভ)। - bagging:
BaggingClassifier(estimator=DecisionTreeClassifier(), n_estimators=300, random_state=...)fit করে test accuracy ছাপুন — canonical \(0.822\)। - random forest:
RandomForestClassifier(n_estimators=300, oob_score=True, random_state=...)fit করে test accuracy ওoob_score_ছাপুন — canonical test \(0.839\), OOB \(0.848\)। - n_estimators curve: \(B\in\{1,5,25,300\}\)-এর জন্য RF fit করে test accuracy ছাপুন — canonical \(0.711,0.806,0.844,0.839\) মেলান (gain স্যাচুরেট করে দেখান)।
- feature importance: RF-এর
feature_importances_থেকে শীর্ষ ৩ feature ও মান ছাপুন — canonical idx4 \(0.164\), idx6 \(0.132\), idx15 \(0.087\) মেলান। - bootstrap sd (ঐচ্ছিক): full tree-কে \(20\)টি bootstrap-resample-এ train করে test accuracy-র sd বের করুন — canonical \(\approx0.040\), যা single tree-এর high variance-এর সরাসরি প্রমাণ।
Hint: from sklearn.datasets import make_classification; from sklearn.model_selection import train_test_split; from sklearn.tree import DecisionTreeClassifier; from sklearn.ensemble import BaggingClassifier, RandomForestClassifier; from sklearn.metrics import accuracy_score। সব estimator-এ একই random_state=20260619 দিন যাতে সংখ্যা পুনরুৎপাদনযোগ্য হয়; importance: np.argsort(rf.feature_importances_)[::-1][:3]। সব প্রত্যাশিত সংখ্যা উপরের canonical তালিকায়; পূর্ণ runnable script _solutions/06-05-trees-bagging-random-forests-solutions.md-এর §ঘ-তে।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
-
Decision tree — recursive impurity-হ্রাসকারী split। একটা tree feature-space-কে বারবার axis-aligned split ("\(x_j\le t\)?") দিয়ে আয়তাকার অঞ্চলে কাটে, প্রতিবার সেই split বাছে যা children-এ impurity (Gini \(G_m=\sum_c\hat p_{mc}(1-\hat p_{mc})\) বা entropy \(H_m=-\sum_c\hat p_{mc}\log_2\hat p_{mc}\)) সবচেয়ে কমায় — অর্থাৎ information gain \(\Delta\) সর্বোচ্চ; প্রতিটি leaf majority class (বা regression-গড়) দেয়। গাছ interpretable (root→leaf পথ = if-then নিয়ম), কিন্তু গভীর হলে training-noise মুখস্থ করে — high variance/overfit। চলমান উদাহরণে unpruned গাছ (depth \(10\), \(51\) leaf) test-এ মাত্র \(0.733\) (bootstrap sd \(0.040\) — অস্থিরতার প্রমাণ); depth-\(3\)-এ ছেঁটে \(0.794\) (bias সামান্য বাড়ে, variance অনেক কমে — net লাভ)।
-
Bagging — bootstrap-গাছ গড় করে variance কমানো। একই data-র \(B\)টি bootstrap-নমুনায় গাছ গড়ে গড় করা: \(\hat f_{\text{bag}}=\frac1B\sum_b\hat f_b\)। \(B\)টি (correlated, correlation \(\rho\)) গাছের গড়ের variance \(\rho\sigma^2+\frac{1-\rho}{B}\sigma^2\) — \(B\) বাড়ালে দ্বিতীয় পদ মরে, কিন্তু একটা floor \(\rho\sigma^2\) থেকে যায় যা গাছ বাড়িয়ে দূর হয় না। তাই bagging variance কমায় (\(0.794\to\mathbf{0.822}\)) কিন্তু \(\rho\)-bottleneck-এ আটকায়।
-
Random forest — feature subsampling-এ decorrelation। প্রতিটি split-এ সব \(p\) নয়, এলোমেলো \(m=\sqrt{p}\)টি feature থেকে সেরা split — এতে গাছগুলো একে অন্যের চেয়ে আলাদা হয়, \(\rho\) কমে, তাই variance-floor \(\rho\sigma^2\) আরও নিচে নামে। চলমান উদাহরণে RF \(0.839\) (bagging-এর \(0.822\) থেকে decorrelation-লাভ \(+0.017\))। n_estimators বাড়ালে gain স্যাচুরেট (\(1\to0.711\), \(5\to0.806\), \(25\to0.844\), \(300\to0.839\)) — আরও গাছ কখনো ক্ষতি করে না, কেবল floor-এ থামে।
-
OOB — বিনামূল্যে validation। প্রতিটি bootstrap-গাছে গড়ে \(\approx37\%\) বিন্দু out-of-bag (\((1-\frac1n)^n\to e^{-1}\approx0.368\)); এদের উপর prediction একটা honest test-estimate দেয় — আলাদা validation set/CV ছাড়াই। চলমান উদাহরণে OOB \(0.848\) ≈ test \(0.839\) (পার্থক্য নমুনা-ওঠানামা, sd \(0.040\)-এর মধ্যে)।
-
Feature importance। প্রতিটি feature-এর split-গুলোতে মোট impurity-হ্রাস (normalize করে যোগফল \(1\)) — কোন feature সিদ্ধান্তে বেশি অবদান রাখে তার আপেক্ষিক মাপ; চলমান উদাহরণে idx4 \(0.164\), idx6 \(0.132\), idx15 \(0.087\) (informative feature-রা শীর্ষে)। তবে impurity-importance high-cardinality feature-কে পক্ষপাত করে — তখন permutation importance নিরাপদ।
-
মূল বার্তা। একটা tree নমনীয় ও interpretable কিন্তু high-variance; একে গড় করো (bagging) → variance কমে; গড়-করা গাছগুলোকে decorrelate করো (random forest, feature-subsampling) → variance আরও কমে; OOB এ সবের মূল্যায়ন বিনামূল্যে দেয়, feature importance ব্যাখ্যা দেয়। অর্থাৎ দুর্বল-কিন্তু-নমনীয় একক learner-কে সমান্তরালে বহুবার গড় করে শক্তিশালী, low-variance predictor বানানোই এ অধ্যায়ের মূল ধারণা (ensemble)।
পূর্ববর্তী সংযোগ (← ৬.১, ৬.৩, ৪.৯):
-
৬.১ (bias–variance ও learning theory): এ অধ্যায় ৬.১-এর bias–variance tradeoff-এর একটা প্রাণবন্ত প্রয়োগ। একটা deep tree = low bias, high variance (capacity বেশি, noise মুখস্থ); pruning (depth \(10\to3\)) variance কমায় bias-এর সামান্য মূল্যে — ঠিক ৬.১-এর "complexity-ডায়াল"। আর গোটা ensemble-গল্পটাই একটা বিশুদ্ধ variance-হ্রাস কৌশল: bagging ও RF bias প্রায় অপরিবর্তিত রেখে (প্রতিটি গাছ low-bias) কেবল variance আক্রমণ করে — \(\rho\sigma^2+\frac{1-\rho}{B}\sigma^2\) সূত্রটাই ৬.১-এর variance-পদের সরাসরি, পরিমাণগত রূপ।
-
৬.৩ (Classification I): ৬.৩-এ শ্রেণিবিন্যাসের গঠন (feature \(x\in\mathbb R^p\), label \(y\), classifier \(\hat y(x)\), decision boundary, 0–1 loss) প্রতিষ্ঠিত হয়েছিল — tree ও forest ঠিক সেই কাঠামোতেই আরেকটা classifier-পরিবার, তবে boundary-টা এখন axis-aligned সিঁড়ি (LDA-র রৈখিক বা k-NN-এর স্থানীয় boundary-র বিপরীতে)। leaf-এর majority-vote ও 0–1 loss-এ majority-optimality (§৭) সরাসরি ৬.৩-এর Bayes-classifier-স্বজ্ঞার উপর দাঁড়ায়; আর RF প্রায়শই LDA/QDA/k-NN-এর চেয়ে ভালো accuracy দেয় কারণ সে nonlinear, feature-মিথস্ক্রিয়া স্বয়ংক্রিয়ভাবে ধরে।
-
৪.৯ (bootstrap): bagging ও OOB-র গোটা যন্ত্রটাই ৪.৯-এর bootstrap-এর সরাসরি ফসল। ৪.৯-এ শিখেছিলাম with-replacement resample করে statistic-এর distribution আঁকা; এখানে সেই একই resample-এ আস্ত গাছ গড়া হয় (bagging = bootstrap aggregating), আর ৪.৯-এর "কোন বিন্দু নমুনায় ঢুকল না" ধারণাটাই OOB হয়ে ওঠে — \((1-\frac1n)^n\to e^{-1}\) গণনাটি সরাসরি bootstrap-এর। অর্থাৎ ৪.৯ ছিল inference-এর হাতিয়ার; এখানে সেটাই prediction-এর variance-হ্রাসে রূপান্তরিত।
পরবর্তী সংযোগ (→ ৬.৬ — Boosting: AdaBoost ও gradient boosting): এ অধ্যায়ের ensemble-দর্শন ছিল সমান্তরাল — অনেকগুলো স্বাধীন, low-bias/high-variance গাছ একসাথে গড় করে variance কমানো (গাছগুলো একে অন্যকে চেনে না)। ৬.৬ একটা আমূল ভিন্ন ensemble-দর্শন আনে: boosting, যেখানে গাছগুলো ক্রমিকভাবে (sequentially) গড়া হয় — প্রতিটি নতুন (সাধারণত অগভীর, high-bias/low-variance) গাছ আগের গাছগুলোর ভুল সংশোধন করতে শেখে। AdaBoost ভুল-শ্রেণিবদ্ধ বিন্দুদের ওজন বাড়িয়ে পরের গাছকে সেদিকে মন দিতে বাধ্য করে; gradient boosting প্রতিটি ধাপে loss-এর residual/gradient-এ গাছ fit করে। ফলে boosting মূলত bias কমায় (RF যেখানে variance কমায়) — দুই কৌশল bias–variance-এর দুই বিপরীত প্রান্ত আক্রমণ করে, এবং এই বৈসাদৃশ্যই (parallel-averaging বনাম sequential-correcting) দুই অধ্যায়কে এক সুতোয় বাঁধে।
সূত্র (sources): P. Dangeti, Statistics for Machine Learning (decision tree, bagging, random forest, feature importance, OOB-এর প্রয়োগমুখী আলোচনা ও Python); Bruce, Bruce & Gedeck, Practical Statistics for Data Scientists, Ch. 6 (tree, bagging, random forest, variable importance, OOB-এর ব্যবহারিক দৃষ্টিভঙ্গি); M. Sugiyama, Introduction to Statistical Machine Learning (ensemble ও variance-হ্রাসের তাত্ত্বিক ভিত্তি); L. Wasserman, All of Statistics, Ch. 22 (trees ও classification-এর সংক্ষিপ্ত পরিসংখ্যানিক উপস্থাপন)।