6.9 — Anomaly Detection, Semi-Supervised & Online Learning (অ্যানোমালি শনাক্তকরণ, আধা-তত্ত্বাবধান ও অনলাইন লার্নিং)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি) — যখন আদর্শ-পরিস্থিতি ভেঙে পড়ে¶
১.১ Part VI কী ধরে নিয়ে এসেছিল — আর কোন তিনটি নীরব অনুমান¶
পুরো Part VI জুড়ে — 6.1-এর bias–variance থেকে 6.3-এর classification, 6.5-এর random forest, 6.7-এর Gaussian mixture, 6.8-এর manifold learning পর্যন্ত — আমরা একটা নির্দিষ্ট, আরামদায়ক জগৎ ধরে নিয়েছি, প্রায় না-ভেবেই। সেই জগতের তিনটি নীরব অনুমান এক জায়গায় লিখে রাখা যাক, কারণ এই অধ্যায়ের গোটা গল্প হলো এই তিনটিকে একে একে ভেঙে দেখা:
- Data পরিষ্কারভাবে labeled — প্রতিটি training-বিন্দুর সঙ্গে তার সঠিক উত্তর \(y_i\) দেওয়া আছে। classifier শেখানো মানেই ছিল \((x_i,y_i)\) জোড়া থেকে শেখা।
- Data একবারেই গোটাটা হাতে — পুরো dataset \(\{x_1,\dots,x_n\}\) আমাদের কাছে, একসাথে, মেমরিতে; আমরা যতবার খুশি তার উপর দিয়ে যেতে পারি (যেমন random forest-এর প্রতিটি গাছ পুরো data দেখে, EM-এর প্রতিটি iteration সব বিন্দুর উপর দিয়ে যায়)।
- প্রতিটি class-এ যথেষ্ট নমুনা — শ্রেণিগুলো মোটামুটি ভারসাম্যপূর্ণ, প্রতিটিতে শেখার মতো যথেষ্ট উদাহরণ আছে।
এই তিনটি অনুমান যখন সত্যি, Part VI-এর হাতিয়ারগুলো চমৎকার কাজ করে। কিন্তু বাস্তবে এদের যেকোনোটাই — কখনো সবগুলোই — ভেঙে পড়তে পারে। আর প্রতিটি ভাঙনের সঙ্গে জন্ম নেয় একটা গোটা উপ-ক্ষেত্র (subfield), যার নিজস্ব ধারণা ও পদ্ধতি আছে। এই শেষ অধ্যায়টা সেই তিনটি ভাঙনের একটা জরিপ (survey) — গভীর গণিত নয়, বরং প্রতিটির মূল স্বজ্ঞা, পরিসংখ্যানিক ভিত্তি, আর "কখন কোনটা" বোঝা।
এক বাক্যে উত্তরণ। Part VI ধরে নিয়েছিল data পরিষ্কারভাবে labeled, একবারে গোটাটা হাতে, ও প্রতিটি class-এ যথেষ্ট নমুনা; এই অধ্যায় সেই তিনটি অনুমানের তিনটি ভাঙন জরিপ করে — যথাক্রমে semi-supervised (label কম), online/streaming (data একবারে নয়), আর anomaly detection (একটা শ্রেণি অতি-বিরল)।
১.২ Hook — তিনটি বাস্তব দৃশ্য, যেখানে চেনা কাঠামো খাটে না¶
ধারণাগুলো ঠিক কোথায় কামড় বসায়, তা তিনটি ছোট দৃশ্যে দেখা যাক — প্রতিটি একটা frontier-এর প্রবেশদ্বার।
দৃশ্য ১ — ক্রেডিট-কার্ড জালিয়াতি (একটা শ্রেণি প্রায় নেই)। একটা ব্যাংকের লেনদেনের খাতা ভাবুন: লক্ষ লক্ষ লেনদেন, যার মধ্যে হয়তো ০.১% জালিয়াতি (fraud)। এখানে চেনা classifier-এর সমস্যা দ্বিগুণ। প্রথমত, fraud-এর উদাহরণ এত কম যে "fraud বনাম স্বাভাবিক" শেখানোর মতো ভারসাম্যপূর্ণ data-ই নেই। দ্বিতীয়ত — আরও গভীর — আমরা আসলে দুই শ্রেণি আলাদা করতে চাই না; আমরা চাই "স্বাভাবিক"-এর একটা ছবি গড়ে যা তার বাইরে পড়ে তাকে চিহ্নিত করতে, কারণ আগামীকালের জালিয়াতি হয়তো আজকের কোনো উদাহরণের মতোই নয়। এটাই anomaly detection — সংখ্যাগরিষ্ঠ "স্বাভাবিক"-কে চিনে, তার থেকে যা বিচ্যুত তাকে ধরা।
দৃশ্য ২ — চিকিৎসা-চিত্র লেবেল করা (label ব্যয়বহুল, data সস্তা)। ভাবুন এক লক্ষ MRI scan আছে, কিন্তু প্রতিটিতে "টিউমার আছে/নেই" লেবেল বসাতে একজন বিশেষজ্ঞ রেডিওলজিস্টের সময় লাগে — তাই হয়তো মাত্র ৫০০টা scan labeled, বাকি ৯৯,৫০০ unlabeled পড়ে আছে। কেবল ৫০০ উদাহরণে একটা শক্তিশালী classifier শেখা কঠিন। প্রশ্ন: ওই বিপুল unlabeled scan-গুলো কি কোনোভাবে কাজে লাগানো যায়, যদিও তাদের উত্তর জানা নেই? এটাই semi-supervised learning-এর কেন্দ্রীয় প্রশ্ন।
দৃশ্য ৩ — সেন্সর-প্রবাহ বা শেয়ারবাজার (data থামে না)। ভাবুন একটা কারখানার যন্ত্রে বসানো সেন্সর প্রতি সেকেন্ডে একটা করে পরিমাপ পাঠাচ্ছে — অবিরাম, বছরের পর বছর। পুরো ইতিহাস মেমরিতে ধরে রাখা অসম্ভব, আর model-টাকে চলতে চলতে শিখতে ও হালনাগাদ হতে হবে; তদুপরি যন্ত্রটা পুরোনো হলে তার "স্বাভাবিক" আচরণই বদলে যায়, তাই গতকালের model আজ বাসি। এটাই online/streaming learning — data প্রবাহ হিসেবে আসে, model এক-পাসে শেখে ও বদলায়।
এক বাক্যে hook। জালিয়াতি (একটা শ্রেণি প্রায় নেই → anomaly detection), অল্প-labeled MRI (label ব্যয়বহুল → semi-supervised), আর অবিরাম সেন্সর-প্রবাহ (data থামে না → online learning) — তিনটি বাস্তব দৃশ্য যেখানে Part VI-এর আদর্শ-কাঠামো সরাসরি খাটে না।
১.৩ মূল ধারণা — তিন frontier, এক সাধারণ সুর¶
তিনটি frontier আলাদা দেখালেও তাদের একটা সাধারণ সুর আছে: প্রতিটিই আগের অধ্যায়ের গঠন-জ্ঞান পুনর্ব্যবহার করে, শুধু প্রশ্নটা পাল্টে দিয়ে। এক-এক বাক্যে তিনটির ছবি এখানে; পুরো সংজ্ঞা §২-এ।
Frontier ১ — Anomaly detection (বিরল বিন্দু খোঁজা)। ধারণাটা: একটা anomaly score \(s(x)\) বানাও, যা প্রতিটি বিন্দুকে একটা সংখ্যা দেয় — যত বড়, তত বেশি "অস্বাভাবিক" — তারপর সবচেয়ে উঁচু-score বিন্দুগুলোকে anomaly বলে চিহ্নিত করো। চারটি ভিন্ন ঘরানা চারভাবে \(s(x)\) সংজ্ঞায়িত করে: statistical (কেন্দ্র থেকে Mahalanobis দূরত্ব — 2.4), density/distance (প্রতিবেশীর তুলনায় স্থানীয় ঘনত্ব কম কিনা — 6.8-এর kNN), isolation (random split-এ কত সহজে বিন্দুটা একা হয়ে পড়ে — 6.5-এর গাছ), আর boundary (inlier-অঞ্চলটাকে একটা সীমা দিয়ে ঘিরে, বাইরের সব anomaly)।
Frontier ২ — Semi-supervised learning (unlabeled কাজে লাগানো)। মূল insight (অন্তর্দৃষ্টি): unlabeled data-তে label না থাকলেও তাদের জ্যামিতিক গঠন আছে — তারা কোথায় গুচ্ছ বাঁধে, কোন low-D পৃষ্ঠে বসে, কে কার পাশে। যদি আমরা ধরে নিই একই গুচ্ছ/পৃষ্ঠের বিন্দুর label একই (cluster/manifold অনুমান), তবে অল্প কয়েকটা label সেই গঠন বরাবর "ছড়িয়ে" বহু unlabeled বিন্দুকে label দিতে পারে — ঠিক যেন কয়েক ফোঁটা রং একটা সংযুক্ত নকশায় ছড়িয়ে পড়ে। 6.7-এর cluster ও 6.8-এর manifold/neighbor-graph এখানে সরাসরি কাজে লাগে।
Frontier ৩ — Online/streaming learning (এক-পাসে শেখা)। ধারণা: পুরো data-র উপর বারবার যাওয়ার বদলে, প্রতিটি নতুন বিন্দু আসামাত্র model-এর parameter \(\theta\)-তে একটামাত্র ছোট সংশোধন করো — \(\theta_{t+1}=\theta_t-\eta_t\nabla\ell_t\), অর্থাৎ এই এক বিন্দুতে যতটা ভুল হলো তার gradient-এর দিকে এক ধাপ। এটা মূলত stochastic gradient descent-কে (4.x-এ দেখা) একটা চলমান প্রবাহে প্রয়োগ — এক-পাস, কম-মেমরি — সঙ্গে বাড়তি সতর্কতা যে বণ্টন নিজেই সময়ের সঙ্গে বদলাতে পারে (concept drift)।
এক বাক্যে। তিনটি frontier-ই আগের অধ্যায়ের গঠন-জ্ঞান পুনর্ব্যবহার করে প্রশ্ন পাল্টে দেয় — anomaly detection একটা score \(s(x)\) দিয়ে বিরল বিন্দু খোঁজে, semi-supervised জ্যামিতিক গঠন বরাবর অল্প label ছড়ায়, আর online learning প্রতিটি নতুন বিন্দুতে \(\theta\)-কে এক ধাপ হালনাগাদ করে।
১.৪ একটা সতর্কতা — কেন anomaly detection-এ accuracy মিথ্যা বলে¶
এই অধ্যায়ের একটা ফাঁদ আগেভাগে দাগিয়ে রাখা দরকার, কারণ এটাই anomaly detection-এর মূল্যায়নের প্রাণ — আর এটা না বুঝলে ফলাফল ভয়ংকরভাবে ভুল পড়া হয়।
ভাবুন একটা dataset যেখানে ৯৫% বিন্দু inlier (স্বাভাবিক) আর ৫% outlier (anomaly)। এখন একটা অলস "model" বানাই যা প্রতিটি বিন্দুকেই নির্বিচারে "স্বাভাবিক" বলে — একটাও anomaly ধরে না। এর accuracy কত? পুরো ৯৫% — কারণ ৯৫% বিন্দু সত্যিই স্বাভাবিক, আর সেগুলো ঠিক বলা হলো। কিন্তু এই model সম্পূর্ণ অকেজো: যে বিরল ৫% খুঁজতে গোটা ব্যবস্থাটা গড়া, তার একটাও সে ধরল না। এখানেই শিক্ষা: তীব্র class imbalance-এ (একটা শ্রেণি অতি-বিরল) accuracy একটা প্রতারক মাপকাঠি — উঁচু accuracy মানেই ভালো কাজ নয়।
তাহলে কী দিয়ে মাপব? — সেই মাপকাঠি যা বিরল শ্রেণির উপর সরাসরি নজর রাখে (6.3): precision (যাদের anomaly বললাম, তাদের কত ভগ্নাংশ সত্যিই anomaly — মিথ্যা সংকেত কত কম), recall (সত্যিকার anomaly-গুলোর কত ভগ্নাংশ ধরা পড়ল — ফাঁকি কত কম), আর সবচেয়ে গুরুত্বপূর্ণ — ROC AUC, যা score \(s(x)\)-এর threshold না বেছেই বলে দেয় model কতটা ভালোভাবে anomaly-কে inlier থেকে আলাদা ক্রমে সাজায় (\(0.5\) = এলোমেলো আন্দাজ, \(1.0\) = নিখুঁত আলাদাকরণ)। এই অধ্যায়ের সংখ্যায় তা স্পষ্ট হবে: একই dataset-এ Isolation Forest, LOF ও Mahalanobis-ভিত্তিক EllipticEnvelope-এর ROC AUC 1.000 (নিখুঁত), আর One-Class SVM-এর 0.941 — accuracy দিয়ে এই পার্থক্য কখনোই ধরা পড়ত না।
এক বাক্যে। তীব্র class-imbalance-এ accuracy প্রতারক (সবাইকে 'স্বাভাবিক' বললেও উঁচু থাকে) — তাই anomaly detection-এ লাগে precision, recall ও ROC AUC, যা বিরল শ্রেণির উপর সরাসরি নজর রাখে।
১.৫ এই অধ্যায়ের পথরেখা¶
পুরো অধ্যায়ের যুক্তি-শৃঙ্খল একনজরে, যাতে প্রতিটি অংশ কেন আসছে তা পরিষ্কার থাকে:
- Anomaly detection (§২ক) — anomaly score \(s(x)\), contamination \(\nu\), আর চার ঘরানা (Mahalanobis/EllipticEnvelope, LOF, Isolation Forest, One-Class SVM); imbalance-সচেতন মূল্যায়ন (precision/recall/AUC)।
- Semi-supervised learning (§২খ) — labeled set \(L\) ও unlabeled set \(U\), তিনটি অনুমান (cluster/manifold/smoothness), আর দুই পদ্ধতি (self-training, label propagation/spreading)।
- Online/streaming learning (§২গ) — incremental update \(\theta_{t+1}=\theta_t-\eta_t\nabla\ell_t\) (
partial_fit), concept drift, regret, one-pass। - সব derivation — Mahalanobis কেন χ²-threshold দেয়, LOF-এর local-density-অনুপাত, label spreading-এর graph-যুক্তি, SGD-update — §৪-এ; পূর্ণ dataset, কোড, চিত্র ও অনুশীলনী §৫–৬-এ।
এক বাক্যে কেন এটি এখানে। Part VI-এর প্রতিটি অধ্যায় ধরে নিয়েছিল data পরিষ্কার-labeled, একবারে-হাতে, class-ভারসাম্যপূর্ণ; এই সমাপ্তি-অধ্যায় সেই তিনটি অনুমানের ভাঙন — anomaly detection, semi-supervised ও online learning — জরিপ করে Part VI-এর statistical ML যাত্রা শেষ করে; এর পরের Part VII একটা সম্পূর্ণ ভিন্ন স্তরে নামে — measure-theoretic probability, যেখানে সম্ভাব্যতার ভিত্তিটাই কঠোর গাণিতিক কাঠামোয় পুনর্নির্মাণ করা হবে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে §১-এর তিনটি insight (অন্তর্দৃষ্টি) — "বিরল বিন্দু খোঁজা, unlabeled গঠন কাজে লাগানো, এক-পাসে শেখা" — কে নিখুঁত সংজ্ঞায় রূপ দেব, তিনটি অংশে: (ক) anomaly detection, (খ) semi-supervised learning, (গ) online/streaming learning। প্রতিটি প্রতীক প্রথম ব্যবহারেই খোলা হলো; কোথাও কিছু ধরে নেওয়া হয়নি। যেহেতু এটা একটা survey, এখানে লক্ষ্য সংজ্ঞা ও স্বজ্ঞা পরিষ্কার করা; যেখানে গণিতের পূর্ণ derivation লাগবে (বিশেষত Mahalanobis-এর χ²-threshold, LOF-এর local-density-অনুপাত, label spreading-এর graph-যুক্তি ও SGD-update), সেটা §৪-এ।
কিছু সাধারণ চিহ্ন প্রথমে স্থির করে নিই। আমাদের কাছে \(n\)টি পর্যবেক্ষণ আছে: \(x_1,\dots,x_n\), যেখানে \(x_i\in\mathbb{R}^p\) হলো \(i\)-তম পর্যবেক্ষণের feature vector (\(p\)টি সংখ্যাগত বৈশিষ্ট্যের তালিকা; \(i,j\) বিন্দুর সূচক)। anomaly detection-এ মূল বস্তু একটা anomaly score \(s(x)\in\mathbb{R}\) — প্রতিটি বিন্দুকে একটা সংখ্যা, যেখানে বড় মান = বেশি অস্বাভাবিক (কিছু পদ্ধতিতে উল্টোটা, তখন চিহ্ন বদলে নেওয়া হয়)। semi-supervised-এ data দুই ভাগে: labeled set \(L=\{(x_i,y_i)\}\) (যাদের উত্তর \(y_i\) জানা) আর unlabeled set \(U=\{x_i\}\) (যাদের উত্তর অজানা), সাধারণত \(\lvert L\rvert \ll \lvert U\rvert\)। online learning-এ data আসে একটা প্রবাহ হিসেবে — সময় \(t=1,2,\dots\)-এ একটা করে \(x_t\) — আর model একটা parameter-ভেক্টর \(\theta_t\) দিয়ে বর্ণিত, যা প্রতি ধাপে হালনাগাদ হয়।
(ক) Anomaly / Outlier Detection — বিরল বিন্দু খোঁজার চারটি ভাষা¶
প্রথম frontier: কীভাবে সংখ্যাগরিষ্ঠ "স্বাভাবিক" বিন্দু থেকে বিরল "অস্বাভাবিক" বিন্দু আলাদা করি।
সংজ্ঞা (anomaly / outlier)। একটা anomaly (অ্যানোমালি) বা outlier (বহিরাগত বিন্দু) হলো এমন একটা পর্যবেক্ষণ যা data-র সংখ্যাগরিষ্ঠ অংশকে যে প্রক্রিয়া তৈরি করেছে (the generating process) তার থেকে স্পষ্টভাবে আলাদা প্রক্রিয়া থেকে এসেছে বলে মনে হয় — তাই এটা বিরল ও বাকিদের ধরন থেকে বিচ্যুত। মূল কথাটা আপেক্ষিক: একটা বিন্দু নিজে থেকে anomaly নয়, বরং সংখ্যাগরিষ্ঠ "স্বাভাবিক" বিন্দুদের সাপেক্ষে। লক্ষ্য তাই প্রতিটি বিন্দুকে একটা anomaly score \(s(x)\) দেওয়া, আর যাদের \(s\) সবচেয়ে বেশি (সবচেয়ে অস্বাভাবিক) তাদের চিহ্নিত করা।
সংজ্ঞা (contamination \(\nu\))। কিন্তু "সবচেয়ে বেশি \(s\)" বললে কতগুলো? এখানেই আসে contamination (দূষণ-মাত্রা) \(\nu\in(0,1)\) — data-তে anomaly-র প্রত্যাশিত ভগ্নাংশ সম্পর্কে আমাদের আগাম-আন্দাজ (যেমন \(\nu=0.05\) মানে "ধরে নিচ্ছি ~৫% বিন্দু anomaly")। ব্যবহারিকভাবে \(\nu\) একটা threshold ঠিক করে: score-গুলো সাজিয়ে উপরের \(\nu\)-ভগ্নাংশ বিন্দুকে anomaly বলা হয়, বাকিদের inlier। (এই অধ্যায়ের dataset-এ সত্যিকার অনুপাত ৫%, আর আমরা \(\nu=0.05\) দিই — তাই \(n=300\)-এর মধ্যে ঠিক ১৫টা বিন্দু anomaly-চিহ্নিত হয়।) এবার চারটি ঘরানা — প্রতিটি \(s(x)\)-কে ভিন্নভাবে সংজ্ঞায়িত করে, অর্থাৎ "অস্বাভাবিকতা"র ভিন্ন সংজ্ঞা ধরে।
ঘরানা ১ — statistical (Mahalanobis দূরত্ব ও robust covariance)। স্বজ্ঞা: যদি স্বাভাবিক data একটা multivariate Gaussian-এর (2.4) মতো একটা কেন্দ্রের চারপাশে উপবৃত্তাকার মেঘ গড়ে, তবে যে বিন্দু সেই কেন্দ্র থেকে যত দূরে, তত বেশি অস্বাভাবিক। কিন্তু "দূরত্ব" এখানে সাধারণ Euclidean নয় — কারণ মেঘটা কোনো দিকে বেশি ছড়ানো, কোনো দিকে কম, এমনকি কাত হতে পারে। তাই ব্যবহৃত হয় Mahalanobis distance (2.4): $$ D_M(x) \;=\; \sqrt{(x-\mu)^\top \Sigma^{-1} (x-\mu)}, $$ যেখানে \(\mu\in\mathbb{R}^p\) হলো data-র কেন্দ্র (mean vector), \(\Sigma\) হলো covariance matrix (\(p\times p\), যা ছড়ানো ও correlation ধরে), আর \(\Sigma^{-1}\) তার বিপরীত — এই \(\Sigma^{-1}\)-ই দূরত্বকে প্রতিটি দিকে ছড়ানোর অনুপাতে "মাপ-সংশোধন" করে, তাই উপবৃত্তের সমান-ঘনত্ব রেখা বরাবর \(D_M\) সমান। anomaly score সরাসরি \(s(x)=D_M(x)\) (বা \(D_M^2\))। একটা সূক্ষ্ম কিন্তু জরুরি মোচড়: \(\mu\) ও \(\Sigma\) যদি সাধারণ গড় ও covariance দিয়ে হিসাব করি, তবে outlier-গুলোই সেই হিসাবকে টেনে বিকৃত করে দেয় (কেন্দ্র সরে যায়, \(\Sigma\) ফুলে ওঠে) — তাই ব্যবহৃত হয় robust covariance: outlier-প্রতিরোধী একটা estimator (scikit-learn-এর EllipticEnvelope যা ব্যবহার করে), যা data-র "মূল ভর"-কে ঘিরে \(\mu,\Sigma\) আন্দাজ করে, outlier-দের প্রভাব এড়িয়ে। (কেন \(D_M^2\) একটা χ² বণ্টন মানে, আর সেখান থেকে threshold কীভাবে আসে — §৪।)
ঘরানা ২ — density/distance (Local Outlier Factor, LOF)। Mahalanobis একটা একক global কেন্দ্র ও আকার ধরে — কিন্তু data যদি কয়েকটা ভিন্ন-ঘনত্বের গুচ্ছে থাকে? একটা বিন্দু একটা ঘন গুচ্ছের ধারে হয়তো স্বাভাবিক, অথচ একই বিন্দু একটা পাতলা গুচ্ছের কেন্দ্রে অস্বাভাবিক — সব নির্ভর করে স্থানীয় প্রতিবেশের উপর। Local Outlier Factor (LOF) ঠিক এই স্থানীয়তা ধরে: একটা বিন্দুর চারপাশের local density (স্থানীয় ঘনত্ব) তার প্রতিবেশীদের local density-র তুলনায় কতটা কম, তা মাপে — অর্থাৎ একটা অনুপাত। স্বজ্ঞা: outlier হলো সেই বিন্দু যার চারপাশ তার প্রতিবেশীদের চারপাশের চেয়ে অনেক বেশি ফাঁকা। কাজটা শুরু হয় প্রতিটি বিন্দুর k-nearest-neighbour (kNN) (6.8) বের করে — কে কার কাছের প্রতিবেশী — তারপর সেই প্রতিবেশ-দূরত্ব থেকে স্থানীয় ঘনত্ব ও তার অনুপাত হিসাব করে। LOF \(\approx 1\) মানে প্রতিবেশীদের মতোই ঘনত্ব (স্বাভাবিক), LOF \(\gg 1\) মানে অনেক বেশি ফাঁকা (outlier); তাই \(s(x)\) হলো এই LOF মান। (পূর্ণ local-density-অনুপাতের সংজ্ঞা §৪।)
ঘরানা ৩ — isolation (Isolation Forest)। তৃতীয় ঘরানা একটা চমৎকার উল্টো-ভাবনা থেকে আসে, আর সরাসরি 6.5-এর গাছের ভাষায় কথা বলে — কিন্তু label আলাদা করতে নয়, বিন্দু আলাদা (isolate) করতে। ধারণা: যদি বারবার একটা random feature ও সেই feature-এর পরিসরে একটা random threshold বেছে data-কে কোপাতে থাকি (random binary split), তবে একটা outlier খুব অল্প কয়েকটা কোপেই একা হয়ে পড়বে — কারণ সে তো এমনিতেই ফাঁকা জায়গায় বসে, তাকে আলাদা করতে কম বেড়া লাগে; অন্যদিকে একটা ঘন-ভিড়ের ভেতরের সাধারণ বিন্দুকে একা করতে অনেক কোপ লাগে। Isolation Forest এমন বহু random গাছ বানায় (6.5-এর ensemble-চেতনা), আর প্রতিটি বিন্দুর জন্য মাপে গড়ে কত গভীরে (কত কোপে) সে আলাদা হয় — এই গড় path length যত ছোট, বিন্দুটা তত বেশি anomalous। তাই \(s(x)\) বানানো হয় গড় path length থেকে (ছোট গভীরতা ⇒ উঁচু score)। সৌন্দর্য: কোনো দূরত্ব বা ঘনত্ব সরাসরি হিসাব করতে হয় না, আর উঁচু-মাত্রায়/বড় data-তে এটি দ্রুত।
ঘরানা ৪ — boundary (One-Class SVM)। চতুর্থ ঘরানা একটা ভিন্ন প্রশ্ন করে: দুই শ্রেণি আলাদা না করে, শুধু "স্বাভাবিক" বিন্দুগুলোকে ঘিরে একটা boundary (সীমানা) আঁকো — তার ভেতরে যা পড়ে inlier, বাইরে যা পড়ে anomaly। এটাই One-Class SVM (এক-শ্রেণির support vector machine, 6.4-এর SVM-এর এক-শ্রেণির রূপ): এটি feature-space-এ (kernel দিয়ে, 6.4) এমন একটা compact অঞ্চল শেখে যা সিংহভাগ data-কে ভেতরে রাখে, আর সেই অঞ্চলের সীমানা থেকে একটা বিন্দু ভেতরে না বাইরে — সেটাই তার anomaly-রায়; সীমানা থেকে দূরত্ব দিয়ে \(s(x)\) বানানো যায়। এটি শক্তিশালী কিন্তু kernel ও parameter-সংবেদনশীল, আর এই অধ্যায়ের dataset-এ এর ROC AUC 0.941 — অন্য তিনটির 1.000-এর চেয়ে সামান্য কম, যা মনে করায় কোনো একক পদ্ধতিই সর্বজয়ী নয়।
এক বাক্যে। চারটি anomaly-ঘরানা "অস্বাভাবিকতা"কে চারভাবে সংজ্ঞায়িত করে — statistical (কেন্দ্র থেকে Mahalanobis \(D_M\) দূরত্ব, robust covariance), density/distance (LOF — প্রতিবেশীর তুলনায় স্থানীয় ঘনত্ব কম), isolation (Isolation Forest — random split-এ অল্প গভীরতায় আলাদা), boundary (One-Class SVM — inlier-অঞ্চল ঘিরে) — আর contamination \(\nu\) score-কে label-এ রূপ দেয়।
মূল্যায়নের চ্যালেঞ্জ — কেন AUC, accuracy নয় (পুনরাবৃত্তি, এবার সংজ্ঞায়)। §১.৪-এ দেখা সতর্কতাটা এখানে আনুষ্ঠানিক করি, কারণ এটাই anomaly detection-এর মূল্যায়নের ভিত্তি। যেহেতু inlier:outlier অনুপাত চরম-অসম (এখানে 95:5), accuracy (সঠিক-শ্রেণিকৃত ভগ্নাংশ) প্রতারক — "সব inlier" বললেই ৯৫%। তাই বিরল শ্রেণির উপর সরাসরি নজর-রাখা মাপকাঠি লাগে (6.3): precision \(=\dfrac{\text{সঠিকভাবে-ধরা anomaly}}{\text{মোট anomaly-চিহ্নিত}}\) (মিথ্যা সংকেত কত কম), recall \(=\dfrac{\text{সঠিকভাবে-ধরা anomaly}}{\text{মোট সত্যিকার anomaly}}\) (ফাঁকি কত কম), আর ROC AUC — receiver-operating-characteristic বক্ররেখার নিচের ক্ষেত্রফল — যা threshold \(\nu\) না বেছেই মাপে score \(s(x)\) কতটা ভালোভাবে anomaly-কে inlier থেকে আলাদা ক্রমে সাজায় (\(0.5\) এলোমেলো, \(1.0\) নিখুঁত)। এই অধ্যায়ের canonical সংখ্যা: একই dataset-এ ROC AUC — Isolation Forest 1.000, LOF 1.000, Mahalanobis-ভিত্তিক EllipticEnvelope 1.000, One-Class SVM 0.941; আর Isolation Forest \(\nu=0.05\)-এ ঠিক ১৫টা বিন্দু flag করে, precision 1.00 ও recall 1.00 (১৫টা সত্যিকার outlier-এর সবগুলোই ধরা, একটাও মিথ্যা নয়) — accuracy এই সূক্ষ্ম পার্থক্যগুলোর কিছুই দেখাত না।
(খ) Semi-Supervised Learning — unlabeled data কীভাবে সাহায্য করে¶
দ্বিতীয় frontier: যখন labeled কম কিন্তু unlabeled প্রচুর — কীভাবে সেই unlabeled data কাজে লাগাই।
সংজ্ঞা (semi-supervised learning)। Semi-supervised learning (আধা-তত্ত্বাবধানে শেখা) হলো সেই কাঠামো যেখানে training data দুই অংশে: একটা ছোট labeled set \(L=\{(x_i,y_i)\}_{i=1}^{n_L}\) (যাদের সঠিক উত্তর \(y_i\) জানা) আর একটা বড় unlabeled set \(U=\{x_i\}_{i=1}^{n_U}\) (যাদের উত্তর অজানা), সাধারণত \(n_L \ll n_U\)। লক্ষ্য — supervised learning-এর মতোই একটা classifier শেখা, কিন্তু \(L\)-এর পাশাপাশি \(U\)-কেও কাজে লাগিয়ে, যাতে কেবল \(L\) দিয়ে শেখার চেয়ে ভালো ফল হয়। (এই অধ্যায়ের dataset: make_moons — দুটো অর্ধচন্দ্রাকৃতি গুচ্ছ, \(n=300\), noise 0.15 — যার মধ্যে মাত্র ~১০% বিন্দু labeled, বাকি unlabeled।)
মূল প্রশ্ন ও তিনটি অনুমান। কিন্তু এখানে একটা গভীর ধাঁধা: unlabeled বিন্দুতে তো label-ই নেই — তবে তারা classifier শেখাতে কীভাবে সাহায্য করবে? উত্তর হলো, label না থাকলেও unlabeled বিন্দুরা data-র জ্যামিতিক গঠন ফাঁস করে দেয় — তারা কোথায় ঘন গুচ্ছ বাঁধে, কোন low-D পৃষ্ঠে বসে, কোথায় ফাঁকা। এই গঠন তখনই কাজে লাগে যখন আমরা label আর গঠনের মধ্যে একটা সংযোগ ধরে নিই — তিনটি ক্লাসিক অনুমানের যেকোনো একটা:
- cluster assumption (গুচ্ছ-অনুমান) — একই গুচ্ছের (cluster) বিন্দুরা সম্ভবত একই label বহন করে; অর্থাৎ decision boundary ঘন অঞ্চলের ভেতর দিয়ে নয়, বরং ফাঁকা জায়গা দিয়ে যায়। (unlabeled বিন্দু গুচ্ছগুলো কোথায় তা দেখিয়ে দেয়, তাই boundary কোথায় বসবে তা স্পষ্ট হয়।)
- manifold assumption (ম্যানিফোল্ড-অনুমান, 6.8) — data একটা low-D বাঁকা পৃষ্ঠে (manifold) বসে, আর সেই পৃষ্ঠ বরাবর কাছাকাছি বিন্দুর label একই; তাই label মাপতে হবে পৃষ্ঠ বরাবর দূরত্বে, ambient Euclidean-এ নয়।
- smoothness assumption (মসৃণতা-অনুমান) — যদি দুটি বিন্দু একটা ঘন অঞ্চলে কাছাকাছি হয়, তাদের label-ও কাছাকাছি (একই) হওয়া উচিত; অর্থাৎ label-ফাংশন ঘন অঞ্চলে মসৃণভাবে বদলায়, হঠাৎ লাফায় না।
এই তিনটি আসলে একই সুরের তিন রূপ — গঠনে যা কাছে/একসাথে, label-এও তা একসাথে — আর এরাই unlabeled data-কে অর্থবহ করে তোলে। এবার দুটি প্রধান পদ্ধতি।
পদ্ধতি ১ — self-training (স্ব-প্রশিক্ষণ)। সবচেয়ে সরল ধারণা, প্রায় স্পষ্ট: প্রথমে কেবল \(L\) দিয়ে একটা classifier শেখাও; তারপর সেই classifier দিয়ে \(U\)-এর বিন্দুগুলো predict করো; যেগুলোর প্রেডিকশন সবচেয়ে আত্মবিশ্বাসী (high-confidence), সেগুলোকে তাদের predicted label সহ \(L\)-এ যোগ করে নাও ("pseudo-label"); এই বর্ধিত \(L\) দিয়ে আবার শেখাও — আর এভাবে বারবার। স্বজ্ঞা: model তার নিজের সবচেয়ে নিশ্চিত অনুমানগুলোকে নতুন সত্য ধরে ক্রমে নিজের জ্ঞান বাড়ায়। ঝুঁকি স্পষ্ট — একটা ভুল-কিন্তু-আত্মবিশ্বাসী pseudo-label নিজেকে আরও পোক্ত করে ভুল ছড়াতে পারে; তাই confidence-threshold সাবধানে বাছতে হয়।
পদ্ধতি ২ — label propagation / label spreading (graph-এ label ছড়ানো)। আরও মার্জিত ও এই অধ্যায়ের কেন্দ্রীয় পদ্ধতি, যা smoothness/manifold অনুমানকে সরাসরি রূপ দেয়। ধারণাটা একটা graph-এর ছবিতে: প্রতিটি বিন্দু (labeled ও unlabeled, উভয়ই) একটা node, আর কাছাকাছি বিন্দুদের মধ্যে একটা edge টানা হয় (যেমন kNN দিয়ে, 6.8) — যত কাছে, edge তত "ভারী" (শক্তিশালী সংযোগ)। শুরুতে কেবল \(L\)-এর node-গুলোর label জানা; তারপর সেই জানা label edge বরাবর প্রতিবেশীতে "চুঁইয়ে" (propagate/spread) পড়ে — যেন কয়েক ফোঁটা রং একটা সংযুক্ত জালে ছড়িয়ে পড়ছে, ঘন-সংযুক্ত প্রতিবেশীরা একই রঙে রাঙা হয়ে যাচ্ছে। প্রক্রিয়াটা থিতু হলে প্রতিটি unlabeled node একটা label পায় — যা মূলত "graph বরাবর কোন জানা label-এর সবচেয়ে কাছে" তা-ই। (label spreading হলো এরই একটা স্থিতিশীল রূপ, যা noise-এ কম সংবেদনশীল; পূর্ণ graph-যুক্তি ও সমীকরণ §৪।)
কেন এটা কাজ করে — canonical সংখ্যায়। make_moons-এর দুই অর্ধচন্দ্র ঠিক সেই পরিস্থিতি যেখানে unlabeled data নাটকীয়ভাবে সাহায্য করে: চাঁদ দুটো পরস্পর-জড়ানো, তাই মাত্র গুটিকয় labeled বিন্দু থেকে সঠিক বাঁকা boundary শেখা কঠিন — কেবল labeled data-তে (২১০টার মধ্যে ২২টা labeled) একটা supervised classifier test-নির্ভুলতায় আটকে যায় 0.833-এ। কিন্তু unlabeled বিন্দুরা দুই চাঁদের আকৃতি পুরোটা দেখিয়ে দেয়, তাই label সেই আকৃতি বরাবর ছড়ালে — LabelSpreading (unlabeled কাজে লাগিয়ে) test-নির্ভুলতা লাফিয়ে 0.989-এ ওঠে। এই \(0.833 \to 0.989\) উল্লম্ফনই semi-supervised learning-এর প্রতিশ্রুতির সরাসরি সাক্ষী।
এক বাক্যে। Semi-supervised learning অল্প labeled \(L\) ও প্রচুর unlabeled \(U\) থেকে শেখে — unlabeled data-র জ্যামিতিক গঠন কাজে লাগায় cluster/manifold/smoothness অনুমানের মাধ্যমে; প্রধান পদ্ধতি self-training (আত্মবিশ্বাসী pseudo-label) ও label propagation/spreading (neighbor-graph-এ label ছড়ানো) — make_moons-এ যা 0.833 থেকে 0.989-এ নির্ভুলতা তোলে।
(গ) Online / Streaming Learning — প্রবাহের সঙ্গে শেখা¶
তৃতীয় frontier: যখন data একবারে নয়, একটা থামহীন প্রবাহ হিসেবে আসে — কীভাবে চলতে চলতে শিখি।
সংজ্ঞা (online / streaming learning)। Online learning (অনলাইন শেখা) বা streaming learning হলো সেই কাঠামো যেখানে data একসাথে গোটাটা পাওয়া যায় না, বরং একটা প্রবাহ (stream) হিসেবে আসে — সময় \(t=1,2,3,\dots\)-এ একটা করে (বা ছোট ছোট mini-batch-এ) বিন্দু \(x_t\) — এবং model-কে প্রতিটি নতুন বিন্দু দেখে তখনই হালনাগাদ হতে হয়, পুরো ইতিহাস মেমরিতে না রেখে। এর বিপরীত হলো batch learning, যা Part VI জুড়ে আমরা ধরে এসেছি: পুরো dataset একসাথে নিয়ে, তার উপর বারবার (বহু epoch) যেয়ে শেখা। online learning-এ আদর্শ হলো one-pass — প্রতিটি বিন্দু কেবল একবার দেখা, তারপর সম্ভব হলে ফেলে দেওয়া।
সংজ্ঞা (incremental update)। এটি সম্ভব করার গাণিতিক হাতিয়ার হলো incremental (ক্রমবর্ধমান) update: model-টা একটা parameter-ভেক্টর \(\theta_t\) দিয়ে বর্ণিত (যেমন একটা রৈখিক classifier-এর ওজন), আর প্রতিটি নতুন বিন্দুতে এক ধাপ সংশোধন —
$$
\theta_{t+1} \;=\; \theta_t - \eta_t\,\nabla \ell_t,
$$
যেখানে \(\theta_t\) হলো \(t\)-তম ধাপের প্যারামিটার, \(\ell_t\) হলো কেবল এই একটা বিন্দু \(x_t\)-তে গণিত loss (ক্ষতি), \(\nabla\ell_t\) তার gradient (কোন দিকে \(\theta\) নাড়ালে এই বিন্দুর ভুল কমে), আর \(\eta_t>0\) হলো learning rate (পদক্ষেপের মাপ, যা সাধারণত \(t\)-এর সঙ্গে কমে)। স্বজ্ঞা: প্রতিটি নতুন উদাহরণ যতটুকু "ভুল" দেখাল, ঠিক ততটুকু সংশোধনের দিকে একটা ছোট পা ফেলা — পুরো data-র উপর gradient না নিয়ে, কেবল হাতের বিন্দুতে। এটি আসলে stochastic gradient descent (SGD)-কে একটা চলমান প্রবাহে প্রয়োগ; scikit-learn-এ এটি partial_fit method দিয়ে রূপ পায় (পুরো fit নয় — প্রতিবার এক টুকরো data দিয়ে model-কে একটু এগিয়ে দেওয়া)। (পূর্ণ SGD-update ও learning-rate-এর ভূমিকা §৪।)
সংজ্ঞা (concept drift)। online learning-এর সবচেয়ে স্বতন্ত্র বিপদ হলো concept drift (ধারণা-প্রবাহ/সরণ) — সময়ের সঙ্গে data-র অন্তর্নিহিত distribution (বণ্টন) নিজেই বদলে যাওয়া, তাই একসময়ের সঠিক model পরে বাসি হয়ে পড়া। ব্যাখ্যা: batch learning ধরে নেয় data একটা স্থির (stationary) বণ্টন থেকে আসছে; কিন্তু একটা থামহীন প্রবাহে — যন্ত্র পুরোনো হচ্ছে, গ্রাহকের রুচি পাল্টাচ্ছে, জালিয়াতির ধরন বদলাচ্ছে — সেই বণ্টন \(P(x,y)\) ধীরে বা হঠাৎ সরে যেতে পারে। তাই online learner-কে কেবল শিখলেই চলে না, পুরোনোকে ভুলে নতুনের সঙ্গে মানিয়ে নিতেও হয় (যেমন সাম্প্রতিক data-কে বেশি ওজন দেওয়া, বা drift টের পেলে নিজেকে নতুন করে গড়া)।
সংজ্ঞা (regret — কার্যকারিতা মাপার ধারণা)। batch learning-এ আমরা test-set-এ নির্ভুলতা মাপি; কিন্তু একটা প্রবাহে "test-set" বলে আলাদা কিছু নেই — তাহলে online learner কতটা ভালো তা মাপি কীভাবে? একটা স্বাভাবিক ধারণা হলো regret (অনুতাপ): learner প্রবাহ-জুড়ে যত ভুল/loss জমাল, আর একটা আদর্শ স্থির model (যে গোটা প্রবাহ আগে থেকে দেখে সেরা একক \(\theta\) বেছে নিত) যত loss করত — এই দুইয়ের পার্থক্য। অর্থাৎ "চলতে-চলতে শিখে আমি সেই-আদর্শ- পশ্চাৎদৃষ্টি-model-এর তুলনায় মোট কতটা বেশি ভুগলাম।" একটা ভালো online learner-এর লক্ষ্য — regret যেন ধাপ-সংখ্যা \(T\)-এর তুলনায় ধীরে বাড়ে (গড়-regret \(\to 0\)), অর্থাৎ যথেষ্ট data দেখার পর সে কার্যত সেই-আদর্শ-model-এর মতোই ভালো করে। (regret-bound-এর পরিসংখ্যানিক ধারণা §৪-এ ছোঁয়া হবে।)
এক বাক্যে। Online/streaming learning-এ data একটা থামহীন প্রবাহ হিসেবে আসে, তাই model incremental ভাবে এক-পাসে হালনাগাদ হয় (\(\theta_{t+1}=\theta_t-\eta_t\nabla\ell_t\), SGD-র
partial_fit); মূল বিপদ concept drift (বণ্টন বদলে model বাসি), আর কার্যকারিতা মাপা হয় regret দিয়ে — আদর্শ স্থির model-এর তুলনায় জমা-ভুলের পার্থক্য।
৩ · পূর্ণাঙ্গ উদাহরণ¶
এই অধ্যায়ের তিনটি frontier — anomaly detection, semi-supervised learning, এবং online learning — কে আমরা চারটি concrete experiment-এ ধরব। প্রতিটি experiment একই দুটি synthetic dataset-এর উপর চলে (seed 20260619), যাতে সংখ্যাগুলো পুনরুৎপাদনযোগ্য (reproducible) হয়। প্রথম দুটি experiment (E1, E2) anomaly detection নিয়ে; তৃতীয়টি (E3) দেখায় unlabeled data কীভাবে সাহায্য করে; চতুর্থটি (E4) streaming/online learning-এর একটি ঝলক দিয়ে পুরো survey-টি গুটিয়ে আনে।
দুটি dataset সংক্ষেপে:
- ANOMALY dataset — একটি correlated Gaussian "মেঘ" (cloud) থেকে \(285\)টি inlier, যার mean \([0,0]\) আর covariance \(\bigl[\begin{smallmatrix}1 & 0.5\\ 0.5 & 1\end{smallmatrix}\bigr]\)। এর বাইরে একটি বলয় (ring) — radius \(r\in[5,8]\), কোণ \(\theta\in[0,2\pi)\) — থেকে \(15\)টি outlier: \(\mathbf{x}_i=(r_i\cos\theta_i,\, r_i\sin\theta_i)\)। মোট \(n=300\), আর ground-truth label \(y^{\text{true}}=[\underbrace{0,\dots,0}_{285},\underbrace{1,\dots,1}_{15}]\)। contamination অর্থাৎ outlier-অনুপাত \(\nu = 15/300 = 0.05\)।
- SEMI-SUP dataset —
make_moonsথেকে দুটি interleaving অর্ধচন্দ্র (two-moons), \(300\)টি বিন্দু, noise \(0.15\)। stratified split-এ \(210\) train / \(90\) test। train-এর মধ্যে মাত্র \(22\)টি বিন্দুর label আমরা "জানি" (≈ \(10\%\)); বাকি \(188\)টিকে unlabeled (\(-1\)) হিসেবে রাখা হয়।
E1 — চার রকম anomaly detector, একই ring¶
Anomaly detection-এর কেন্দ্রীয় ধারণা: প্রতিটি বিন্দুকে একটি anomaly score \(s(x)\) দেওয়া হয় — যত বড় \(s(x)\), তত বেশি "অস্বাভাবিক"। এখানে আমরা চারটি ভিন্ন কৌশলের detector চালাই, যাদের ভেতরের যুক্তি (mechanism) সম্পূর্ণ আলাদা:
| Detector | কী মাপে (mechanism) | score \(s(x)\) |
|---|---|---|
| Isolation Forest | random partition-এ একটি বিন্দুকে একা (isolate) করতে কত কম গভীরতা লাগে | \(-\,\)average isolation depth |
| Local Outlier Factor (LOF) | প্রতিবেশীদের তুলনায় local density (স্থানীয় ঘনত্ব) কত কম | \(-\,\)negative outlier factor |
| One-Class SVM | শেখা boundary থেকে কতটা বাইরে | \(-\,\)signed distance to boundary |
| Elliptic Envelope | কেন্দ্র থেকে Mahalanobis দূরত্ব \(D_M(x)\) | \(D_M(x)=\sqrt{(x-\mu)^\top\Sigma^{-1}(x-\mu)}\) |
মান নির্ণয়ের জন্য score-গুলোকে ground-truth label-এর বিরুদ্ধে ROC AUC দিয়ে যাচাই করি — AUC মানে: এলোমেলোভাবে নেওয়া একটি সত্যিকারের outlier-কে একটি inlier-এর চেয়ে বেশি score দেওয়ার সম্ভাবনা। AUC \(=1.000\) মানে নিখুঁত আলাদাকরণ (separation), \(0.5\) মানে এলোমেলো অনুমানের সমান।
ফলাফল:
| Detector | ROC AUC |
|---|---|
| Isolation Forest | 1.000 |
| Local Outlier Factor | 1.000 |
| One-Class SVM | 0.941 |
| Elliptic Envelope (\(D_M\)) | 1.000 |
চারটি detector-ই বলয়ের outlier-গুলো প্রায়-নিখুঁতভাবে ধরে ফেলেছে। কেন এত সহজ? কারণ outlier-রা ভৌমিকভাবে (geometrically) inlier-মেঘ থেকে স্পষ্টভাবে বিচ্ছিন্ন — কেন্দ্রীয় cloud-এর effective ব্যাসার্ধ \(\sim 2\text{–}3\), কিন্তু বলয় বসে আছে \(r\in[5,8]\)-এ, মাঝখানে একটি প্রশস্ত ফাঁকা বলয়। ফলে isolation depth (Isolation Forest), local density (LOF), আর Mahalanobis দূরত্ব (Elliptic Envelope) — তিন signal-ই outlier-দের জন্য চরম মান নেয়, AUC ঠেকে \(1.000\)-তে। One-Class SVM সামান্য পিছিয়ে (\(0.941\)): এর RBF boundary inlier-মেঘের লেজে (tails) কিছু সাধারণ বিন্দুকেও সীমার বাইরে ফেলে দেয়, তাই ranking-এ অল্প কিছু inlier কয়েকটি outlier-এর সমান বা সামান্য বেশি score পায় — তবে AUC \(0.941\) এখনও খুবই শক্তিশালী।
মূল শিক্ষা: যখন anomaly-রা সত্যিই "দূরে" থাকে, তখন detector-এর internal যুক্তি যাই হোক — tree-based isolation, density, boundary, বা distribution-based distance — সবগুলোই কাজ করে। আসল চ্যালেঞ্জ শুরু হয় তখন, যখন anomaly আর normal-এর সীমানা ঝাপসা; সেখানে mechanism-ভেদে ফল ভিন্ন হয়, আর সঠিক detector বাছাই গুরুত্বপূর্ণ হয়ে ওঠে।
E2 — flagged set-এ precision ও recall (এবং accuracy কেন বিভ্রান্তিকর)¶
AUC পুরো ranking-এর গুণমান বলে, কিন্তু বাস্তবে একসময় একটি সিদ্ধান্ত নিতেই হয়: কোন বিন্দুগুলোকে আসলে "anomaly" বলে flag করব? Isolation Forest-কে আমরা contamination \(\nu=0.05\) দিয়ে চালাই, অর্থাৎ মডেলকে বলি "ধরে নাও প্রায় \(5\%\) বিন্দু outlier"। মডেল তখন score-এর threshold এমনভাবে বসায় যাতে ঠিক \(0.05\times 300 = 15\)টি বিন্দু flagged হয়।
confusion-এর হিসাব:
ফলাফল — flag হওয়া \(15\)টি বিন্দু ঠিক সেই \(15\)টি সত্যিকারের outlier:
| Metric | মান | অর্থ |
|---|---|---|
| flagged | \(15\) | যতগুলো alarm বাজানো হলো |
| precision | \(1.00\) | প্রতিটি alarm সত্যি (\(FP=0\), কোনো false alarm নেই) |
| recall | \(1.00\) | একটিও outlier মিস হয়নি (\(FN=0\)) |
অর্থাৎ \(TP=15,\ FP=0,\ FN=0\) — নিখুঁত।
কিন্তু এখানে accuracy ব্যবহার করলে কেন বিপদ? ভাবুন একটি বোকা মডেল, যে কিছুই flag করে না — সবাইকে "normal" বলে দেয়। তার accuracy হবে:
কাগজে-কলমে চমৎকার \(95\%\)! অথচ সেই মডেল একটিও anomaly ধরেনি — recall \(=0\), এবং anomaly detection-এর গোটা উদ্দেশ্যই ব্যর্থ। এটাই class-imbalance-এর ফাঁদ: যখন একটি শ্রেণি (\(95\%\) inlier) আরেকটিকে (\(5\%\) outlier) চূড়ান্তভাবে ছাপিয়ে যায়, তখন accuracy সংখ্যাটি "majority-কে অন্ধভাবে অনুমান করা"-র পুরস্কার দেয়, কিন্তু আমরা যা সত্যিই খুঁজছি (বিরল ঘটনা) তা সম্পর্কে কিছুই বলে না।
তাই rare-event detection-এ accuracy-কে সরিয়ে রেখে precision, recall, F1, আর ROC AUC (বা precision-recall curve / average precision) ব্যবহার করাই নিয়ম। এখানে Isolation Forest precision \(=\) recall \(= 1.00\) পেয়েছে — কিন্তু সেটা আমরা জানতে পারলাম শুধু কারণ ঠিক metric-টি দেখেছি।
E3 — semi-supervised: unlabeled data সত্যিই সাহায্য করে¶
এবার দৃশ্যপট বদলায়। two-moons dataset-এ \(210\)টি training বিন্দুর মধ্যে আমরা ভান করি মাত্র \(22\)টির label জানি (≈ \(10\%\)); বাকি \(188\)টি unlabeled। বাস্তব জগতে label সংগ্রহ ব্যয়বহুল (বিশেষজ্ঞের সময়, manual annotation), কিন্তু unlabeled data প্রায়ই প্রচুর — এই অসমতাই semi-supervised learning-এর প্রেরণা।
দুটি পন্থা তুলনা করি:
- Supervised baseline —
LogisticRegression, শুধু \(22\)টি labeled বিন্দুতে fit করা। unlabeled data সম্পূর্ণ উপেক্ষিত। - Semi-supervised —
LabelSpreading(kernel='knn', n_neighbors=10), যা \(210\)টি বিন্দুর সবগুলো ব্যবহার করে (\(22\)টি labeled, আর \(188\)টি unlabeled হিসেবে \(-1\) দেওয়া)।
ফলাফল (test set, \(90\) বিন্দু):
| পদ্ধতি | কী data ব্যবহার করল | test accuracy |
|---|---|---|
| Supervised LogReg | শুধু \(22\) labeled | \(0.833\) |
| LabelSpreading | সব \(210\) (labeled + unlabeled) | \(\mathbf{0.989}\) |
\(0.833 \to 0.989\) — একটি বিশাল লাফ, অথচ একটিও নতুন label যোগ করা হয়নি! ব্যাপারটা কীভাবে ঘটল?
Logistic regression একটি সরলরেখার (linear) সীমানা আঁকে। কিন্তু two-moons-এর দুটি শ্রেণি একে অপরের সাথে জড়িয়ে থাকা বাঁকা অর্ধচন্দ্র — কোনো সরলরেখা এদের পরিষ্কারভাবে আলাদা করতে পারে না, আর মাত্র \(22\)টি বিন্দু থেকে সেই সরলরেখা অনিশ্চিতভাবে বসে। অন্যদিকে LabelSpreading একটি graph বানায়: প্রতিটি বিন্দু তার \(k=10\) নিকটতম প্রতিবেশীর সাথে যুক্ত, আর label কয়েকটি labeled বিন্দু থেকে এই graph-এর প্রান্ত (edge) বেয়ে "ছড়িয়ে" (propagate) পড়ে — অনেকটা রং যেভাবে কাগজে ছড়ায়।
মূল অন্তর্দৃষ্টি: unlabeled \(188\)টি বিন্দুই দুই-চাঁদের আকৃতি (manifold) ফাঁস করে দেয়। ঘন বিন্দুর শৃঙ্খল ধরে label একই চাঁদের ভেতরে নির্বিঘ্নে গড়ায়, কিন্তু দুই চাঁদের মাঝের ফাঁকা অঞ্চলে এসে থেমে যায় — কারণ ওখানে graph-এ সংযোগ দুর্বল। ফলে decision boundary প্রাকৃতিকভাবে data-র বাঁক অনুসরণ করে, সরলরেখার দাসত্ব ছেড়ে। এটিই semi-supervised learning-এর প্রতিশ্রুতি: structure (যা unlabeled data-তে লুকিয়ে) + অল্প কিছু label = অনেক ভালো ফল।
সতর্কতা। এই জাদু একটি অনুমানের উপর দাঁড়িয়ে — cluster/manifold assumption: একই ঘন অঞ্চলের বিন্দুরা সম্ভবত একই শ্রেণির। two-moons-এ এটি নিখুঁতভাবে সত্য, তাই এত নাটকীয় উন্নতি। যেখানে শ্রেণিগুলো ঘনত্বে মিশে যায় বা manifold-অনুমান ভাঙে, সেখানে unlabeled data সাহায্য না-ও করতে পারে, এমনকি ভুল label ছড়িয়ে ক্ষতিও করতে পারে।
E4 — online learning ও survey-এর সমাপ্তি¶
এতক্ষণ ধরে নিয়েছি পুরো dataset একসাথে স্মৃতিতে (memory) আছে — batch learning। কিন্তু বাস্তবে data প্রায়ই আসে স্রোতের মতো (stream): sensor reading, click log, লেনদেন (transaction) — এক একটি করে, অবিরাম। সব জমিয়ে রাখা অসম্ভব, আর জগৎ নিজেও বদলায়। এখানেই online learning।
ধারণাটি দেখাতে SGDClassifier-এর partial_fit ব্যবহার করি: মডেল কখনো পুরো data দেখে না, বরং two-moons train-বিন্দু একটা প্রবাহ (stream) হিসেবে ক্রমবর্ধমান অংশে (cumulative prefix — মোট দেখা \(5, 15, 30, 60, 120, 210\)টি নমুনা) আসে, আর প্রতিবার নতুন অংশে stochastic gradient descent-এ একধাপ শিখে held-out test accuracy মাপে। নিচের সংখ্যা §৫-এর কোড-ল্যাবের প্রকৃত আউটপুট (চিত্রণমূলক streaming run) — প্রবাহ যত এগোয় accuracy প্রথমে ওঠে, তারপর সামান্য ওঠানামা করে:
seen 5 → test acc ≈ 0.644
seen 15 → test acc ≈ 0.744
seen 30 → test acc ≈ 0.789
seen 60 → test acc ≈ 0.844
seen 120 → test acc ≈ 0.722
seen 210 → test acc ≈ 0.800
মডেলটি কখনোই পুরো dataset একবারে স্মৃতিতে রাখেনি — তবু নমুনা প্রবাহিত হওয়ার সাথে accuracy দ্রুত ওঠে (\(0.644 \to 0.844\)), এরপর moons-এর non-linearity ও online SGD-র stochastic আচরণে সামান্য ওঠানামা করে (\(0.722, 0.800\)) — একটি যুক্তিসঙ্গত classifier দাঁড়িয়ে গেছে। এটিই online learning-এর মূল সুবিধা: \(O(1)\) মেমরি, আর প্রতিটি নতুন নমুনায় তাৎক্ষণিক আপডেট।
Concept drift। Online-এর সবচেয়ে কঠিন বাস্তবতা — data-র অন্তর্নিহিত বণ্টন (distribution) সময়ের সাথে সরে যেতে পারে: spam-এর ধরন বদলায়, ব্যবহারকারীর রুচি ঘোরে, বাজার ওঠানামা করে। গতকালের শেখা প্যাটার্ন আজ পুরোনো। মোকাবিলার কৌশল — শেখার হার (learning rate) ধরে রাখা যাতে মডেল ভুলতেও পারে, sliding-window বা decay দিয়ে পুরোনো data-র ওজন কমানো, আর drift detector (যেমন ADWIN, DDM) বসিয়ে বণ্টন সরে গেলে retrain trigger করা।
Survey-এর সারাংশ। এই অধ্যায়ের তিন frontier-কে একটি টেবিলে:
| Frontier | পরীক্ষা | মূল সংখ্যা |
|---|---|---|
| Anomaly detection (AUC) | Isolation Forest | \(1.000\) |
| Local Outlier Factor | \(1.000\) | |
| One-Class SVM | \(0.941\) | |
| Elliptic Envelope (\(D_M\)) | \(1.000\) | |
| Anomaly (flagged set) | IF @ \(\nu=0.05\) | precision \(1.00\), recall \(1.00\) |
| Semi-supervised | LogReg (22 labeled) | acc \(0.833\) |
| LabelSpreading (all 210) | acc \(\mathbf{0.989}\) | |
| Online learning | SGD partial_fit stream |
অল্প ব্যাচেই accuracy স্থিতিশীল |
মূল takeaway। এই তিন frontier একসাথে বাস্তব জগতের সেই অগোছালো দিকগুলো সামলায়, যা পাঠ্যবইয়ের পরিচ্ছন্ন supervised setup ধরে না — বিরল ঘটনা (anomaly detection, যেখানে label-ই প্রায় নেই আর accuracy মিথ্যা বলে), স্বল্প label (semi-supervised, যেখানে প্রচুর unlabeled data থেকে structure ধার করা যায়), আর অবিরাম প্রবাহ ও পরিবর্তনশীল জগৎ (online learning ও concept drift)। আদর্শ অনুমানের বাইরে পা রাখলে এই tool-গুলোই machine learning-কে ব্যবহারযোগ্য রাখে।
যাচাই (sklearn, seed 20260619):
ROC AUC IsolationForest : 1.0
ROC AUC LOF : 1.0
ROC AUC OneClassSVM : 0.941
ROC AUC EllipticEnv(DM) : 1.0
IF flagged / precision / recall : 15 1.0 1.0
train/test : 210 90 | labeled : 22
Supervised LogReg (22 lab) test acc : 0.833
LabelSpreading (all 210) test acc : 0.989
চারটি anomaly-AUC (\(1.000/1.000/0.941/1.000\)), Isolation Forest-এর flagged set (\(15\) বিন্দু, precision \(=\) recall \(=1.00\)), \(210/90\) split-এ \(22\) labeled, এবং semi-supervised-এর \(0.833 \to 0.989\) উল্লম্ফন — সব canonical সংখ্যা নিশ্চিত।
৪ · প্রমাণ ও উৎপাদন¶
এই অংশে anomaly detection, semi-supervised আর online learning-এর পাঁচটা মূল যন্ত্রের গাণিতিক ভিত্তি ধাপে ধাপে গড়ে তুলি। প্রতিটার পেছনে একটাই প্রশ্ন: "কেন এটা কাজ করে?" — সেই কেন-টা বের করে আনাই লক্ষ্য, নাহলে method গুলো কেবল recipe থেকে যায়। ধারাটা এমন: প্রথমে Mahalanobis distance কীভাবে \(\chi^2\) থেকে একটা principled threshold দেয় (a), তারপর Isolation Forest-এ anomaly-র path length কেন ছোট (b), LOF কীভাবে local density দিয়ে varying-density cluster সামলায় (c), label propagation কেন graph-এর harmonic solution আর কেন unlabeled data সাহায্য করে (d), আর শেষে online gradient step-এর regret কেন \(O(\sqrt T)\) — অর্থাৎ limit-এ online ≈ batch (e)।
৪.১ ★★ Mahalanobis distance ও \(\chi^2\) threshold¶
ধরা যাক একটা point \(x\in\mathbb R^p\) আসে multivariate Gaussian থেকে, \(x\sim\mathcal N(\mu,\Sigma)\), যেখানে \(\Sigma\) একটা symmetric positive-definite (SPD) covariance matrix। স্বজ্ঞাগতভাবে একটা point "বহিরাগত/outlier" তখন যখন সেটা center \(\mu\) থেকে অনেক দূরে — কিন্তু কোন দিকে কতটা ছড়ানো তা হিসেবে না ধরলে Euclidean distance বিভ্রান্ত করে: যে অক্ষে variance বড়, সেদিকে অনেক দূরের point-ও স্বাভাবিক; যে অক্ষে variance ছোট, সেদিকে অল্প দূরত্বই অস্বাভাবিক। তাই দূরত্বকে covariance দিয়ে "normalize" করা দরকার। এটাই Mahalanobis distance:
প্রশ্ন: এই \(D_M^2(x)\)-এর distribution কী? যদি জানি, তবে "কত বড় হলে অস্বাভাবিক বলব" তার একটা সঠিক (principled) সীমা পাব। দাবি হলো —
ধাপ ১ — whitening transform. যেহেতু \(\Sigma\) SPD, তার একটা symmetric square-root \(\Sigma^{1/2}\) আছে (eigendecomposition \(\Sigma=Q\Lambda Q^\top\) থেকে \(\Sigma^{1/2}=Q\Lambda^{1/2}Q^\top\), সব eigenvalue \(>0\) বলে \(\Lambda^{1/2}\) সংজ্ঞায়িত), আর তার inverse \(\Sigma^{-1/2}=Q\Lambda^{-1/2}Q^\top\)ও SPD, এবং \(\Sigma^{-1}=\Sigma^{-1/2}\Sigma^{-1/2}\)। এখন নতুন variable
এটা \(x\)-এর একটা affine transform। multivariate Gaussian-এর একটা মূল ধর্ম (prereq 2.4): Gaussian-এর যেকোনো affine transform আবার Gaussian, আর তার mean ও covariance রূপান্তরের নিয়ম মেনে বদলায়।
ধাপ ২ — \(z\)-এর mean ও covariance. Linearity of expectation থেকে
আর covariance: কোনো affine map \(z=A(x-\mu)\)-এর জন্য \(\operatorname{Cov}(z)=A\,\operatorname{Cov}(x)\,A^\top\)। এখানে \(A=\Sigma^{-1/2}\) (symmetric, তাই \(A^\top=A\)) আর \(\operatorname{Cov}(x)=\Sigma\), ফলে
(এখানে \(\Sigma=\Sigma^{1/2}\Sigma^{1/2}\) আর \(\Sigma^{-1/2}\Sigma^{1/2}=I\) ব্যবহার করলাম।) সুতরাং
অর্থাৎ \(z\)-এর component-গুলো \(z_1,\dots,z_p\) পরস্পর independent এবং প্রত্যেকটা standard normal: \(z_j\sim\mathcal N(0,1)\)। এই রূপান্তরকেই বলে whitening — correlated, scaled Gaussian-কে "সাদা" (uncorrelated, unit-variance) করে দেওয়া।
ধাপ ৩ — \(D_M^2\) হলো \(\lVert z\rVert^2\). এবার সরাসরি গণনা:
(মাঝে \(\Sigma^{-1/2}\) symmetric বলে \((\Sigma^{-1/2})^\top=\Sigma^{-1/2}\), আর \(\Sigma^{-1/2}\Sigma^{-1/2}=\Sigma^{-1}\)।) সুতরাং Mahalanobis distance squared ঠিক whitened vector-এর squared norm।
ধাপ ৪ — squared norm-এর distribution \(\chi^2_p\)। এখন \(\chi^2\) distribution-এর সংজ্ঞা (prereq 4.8): \(p\)টা independent standard-normal-এর বর্গের যোগফল \(\chi^2_p\) মানে। যেহেতু
সংজ্ঞা অনুযায়ীই \(\lVert z\rVert^2\sim\chi^2_p\)। ধাপ ৩-এর সমতা মিলিয়ে —
Anomaly rule (এই প্রমাণের ফল)। \(\chi^2_p\) distribution জানা থাকলে তার upper quantile \(\chi^2_{p,\,1-\alpha}\) (যার ডানপাশে probability mass \(\alpha\)) পাওয়া যায়। তাই একটা principled detection rule:
এর সরাসরি অর্থ: যদি data সত্যিই \(\mathcal N(\mu,\Sigma)\) হয়, তবে একটা স্বাভাবিক point-কে ভুল করে anomaly বলার সম্ভাবনা (false-alarm rate) ঠিক \(\alpha\) — কারণ \(\Pr(D_M^2>\chi^2_{p,1-\alpha})=\alpha\) definition থেকেই। অর্থাৎ threshold-টা কোনো আন্দাজ নয়, একটা পরিসংখ্যানগত নিয়ন্ত্রিত error rate। এই কারণেই Mahalanobis-ভিত্তিক detector (যেমন scikit-learn-এর EllipticEnvelope) Gaussian-ঘরানার outlier ধরতে এত কার্যকর — সে আসলে একটা ellipsoidal contour \(\{x:D_M^2(x)=\chi^2_{p,1-\alpha}\}\) আঁকে, আর তার বাইরের সব কিছু outlier।
সূক্ষ্ম কিন্তু জরুরি — robust \(\hat\mu,\hat\Sigma\)। বাস্তবে \(\mu,\Sigma\) অজানা, estimate করতে হয়। কিন্তু সাধারণ sample mean ও sample covariance নিজেরাই outlier-দের দ্বারা টেনে যায় (একটা চরম point covariance-কে ফুলিয়ে দেয়), ফলে সেই outlier আর "দূরে" থাকে না — masking effect। তাই robust estimator ব্যবহার করা হয়, বিশেষত Minimum Covariance Determinant (MCD): data-র এমন একটা উপসেট (\(h\approx\tfrac{n+p+1}{2}\)টা point) খোঁজে যাদের covariance-এর determinant সবচেয়ে ছোট (সবচেয়ে "ঘন" উপসেট), আর সেই উপসেট থেকে \(\hat\mu,\hat\Sigma\) নেয়। outlier-রা স্বভাবতই এই ঘন core-এর বাইরে পড়ে, তাই তারা estimate-কে দূষিত করতে পারে না।
EllipticEnvelopeভেতরে এই MCD-ই চালায় — robust center আর shape পেয়ে তবেই \(D_M^2\) মাপে।সংখ্যাগত যাচাই (sympy/numpy)। \(p=4\), \(n=2{\times}10^5\) point একটা SPD \(\Sigma\) থেকে নিয়ে \(D_M^2\) মাপা হলো: empirical mean \(4.00\) (তত্ত্ব \(p=4\)), variance \(8.02\) (তত্ত্ব \(2p=8\)), KS-statistic বনাম \(\chi^2_4\) মাত্র \(0.002\) — চমৎকার মিল। আর \(\chi^2_{4,0.95}=9.488\) threshold-এ exceed-fraction \(0.050\) — ঠিক \(\alpha\)। দাবি যাচাই হলো।
৪.২ ★★ Isolation Forest — anomaly-র path length কেন ছোট¶
Mahalanobis ধরে নেয় data Gaussian; কিন্তু distribution-free একটা detector চাইলে? Isolation Forest-এর কেন্দ্রীয় উপলব্ধি একদম উল্টো দিক থেকে আসে: outlier ধরার জন্য তার density model করার দরকার নেই, বরং তাকে আলাদা করে ফেলা (isolate) কত সহজ সেটা মাপলেই হয়।
গাছ বানানো। একটা isolation tree এভাবে গড়া হয়: data-র একটা subsample নাও; recursively —
- একটা feature \(q\) এলোমেলোভাবে (uniformly at random) বাছো;
- সেই feature-এর তখনকার range \([\min_q,\max_q]\)-এর ভেতর একটা split value \(p\) এলোমেলোভাবে বাছো;
- \(x_q<p\) আর \(x_q\ge p\) — এই দুই দিকে point-গুলো ভাগ করো;
- যতক্ষণ না প্রতিটা point একা একটা node-এ আলাদা হয় (বা একটা height-সীমা ছোঁয়), চালিয়ে যাও।
একটা point \(x\)-এর জন্য path length \(h(x)\) = root থেকে যে external node-এ \(x\) একা পড়ল, সেই পথের edge-সংখ্যা — অর্থাৎ ওকে আলাদা করতে কতগুলো random split লাগল।
মূল স্বজ্ঞা — কেন anomaly-র \(h(x)\) ছোট। একটা anomaly সংজ্ঞা-অনুযায়ীই "few and different" — feature-space-এ সে দূরে, বিরল, খালি অঞ্চলে বসে। তাই একটা এলোমেলো split line তার আর বাকি ভিড়ের মাঝখানে পড়ার সম্ভাবনা বেশি (চারপাশে অনেক খালি জায়গা, যেকোনো একটা কাটাই তাকে বিচ্ছিন্ন করে দেয়)। ফলে অল্প কয়েকটা split-এই সে আলাদা হয়ে যায় — \(h(x)\) ছোট। উল্টোদিকে একটা inlier ঘন গুচ্ছের ভেতরে; তাকে প্রতিবেশীদের থেকে আলাদা করতে অনেকগুলো split লাগে — \(h(x)\) বড়। অর্থাৎ:
Normalizer \(c(n)\) — কেন দরকার আর কী। \(h(x)\)-এর কাঁচা মান গাছের গভীরতা তথা subsample-আকার \(n\)-এর ওপর নির্ভর করে, তাই তুলনার জন্য একটা scale চাই। একটা isolation tree-এর গঠন আসলে একটা Binary Search Tree (BST)-এর সমতুল্য (random split = random insertion), আর \(n\)টা point-এর random BST-তে একটা node-এ পৌঁছানোর গড় path length-এর একটা পরিচিত রূপ আছে:
যেখানে \(H(m)\) হলো \(m\)-তম harmonic number আর \(\gamma\approx0.5772\) Euler–Mascheroni ধ্রুবক। এই \(c(n)\) হলো একটা "typical" (গড়) path length — একে দিয়ে ভাগ করে \(h(x)\)-কে normalize করি, যাতে আলাদা আলাদা গাছ/আকারের মধ্যে তুলনা করা যায়।
Anomaly score। একগুচ্ছ (forest) গাছের ওপর \(h(x)\)-এর গড় \(\mathbb{E}[h(x)]\) নিয়ে score:
এর আচরণ পড়া যাক — এটাই score-টাকে ব্যাখ্যাযোগ্য করে:
- \(\mathbb{E}[h(x)]\to 0\) (root-এই বিচ্ছিন্ন, চরম anomaly) \(\Rightarrow\) exponent \(\to 0\) \(\Rightarrow\) \(s\to 2^0=1\)। \(s\approx1\) মানে anomaly।
- \(\mathbb{E}[h(x)]\to c(n)\) (typical গভীরতা, সাধারণ point) \(\Rightarrow\) exponent \(\to -1\) \(\Rightarrow\) \(s\to 2^{-1}=0.5\)। \(s\approx0.5\) মানে inlier।
- \(\mathbb{E}[h(x)]\) আরও বড় (গভীরে বিচ্ছিন্ন) \(\Rightarrow\) \(s\to 0\)।
সুতরাং score একটা পরিষ্কার \([0,1]\) স্কেল দেয় যেখানে \(1\)-এর দিকে গেলে "নিশ্চিত anomaly", \(0.5\)-এর কাছে থাকলে "স্বাভাবিক"। সৌন্দর্যটা হলো — কোনো distance বা density estimate করতে হয়নি, কেবল "আলাদা করার সহজতা" দিয়েই কাজ হয়ে গেল, আর random subsampling-এর কারণে এটা বড় data-তেও সস্তা ও scalable।
সংখ্যাগত যাচাই। \(c(256)=10.249\) (সরাসরি harmonic যোগফল) ও \(2(\ln 255+\gamma)-2\cdot255/256=10.245\) (asymptotic রূপ) — মিলে গেল। আর score: \(\mathbb{E}[h]=0\Rightarrow s=1.000\); \(\mathbb{E}[h]=c(n)\Rightarrow s=0.500\); \(\mathbb{E}[h]=2c(n)\Rightarrow s=0.250\) — তিন আচরণই তত্ত্ব মেনে চলল।
৪.৩ ★★ Local Outlier Factor (LOF) — local density-র অনুপাত¶
Isolation Forest আর Mahalanobis — দুটোই অনেকটা global দৃষ্টিতে দেখে। কিন্তু কল্পনা করো এমন data যেখানে দুটো cluster আছে: একটা খুব ঘন, আরেকটা বিরল। বিরল cluster-এর একটা স্বাভাবিক point ঘন cluster-এর তুলনায় অনেক "ফাঁকা" — global density-তে তাকে outlier ভেবে ফেলা সহজ, অথচ তার নিজের প্রতিবেশের তুলনায় সে একদম স্বাভাবিক। LOF-এর গোটা ধারণা এই সমস্যা মেটানো: কোনো point-কে তার নিজের চারপাশের density-র সাপেক্ষে বিচার করো, পুরো dataset-এর সাপেক্ষে নয়।
ধাপ ১ — \(k\)-distance ও neighborhood। point \(x\)-এর \(k\)-তম nearest neighbour পর্যন্ত দূরত্বকে বলি \(k\text{-distance}(x)\), আর \(N_k(x)\) = তার \(k\)টা nearest neighbour-এর সেট (ties-এ একটু বেশি হতে পারে)।
ধাপ ২ — reachability distance (smoothing)। কাঁচা দূরত্বে অল্প কয়েকটা খুব-কাছের প্রতিবেশী density-কে অস্থির করে তোলে; তাই LOF একটা মেঝে (floor) বসায়:
অর্থাৎ \(o\) যদি \(x\)-এর খুব কাছে হয়, দূরত্ব হিসেবে অন্তত \(o\)-এর \(k\)-distance ধরা হয় — এটা statistical fluctuation কমায়, ফলে density-র estimate মসৃণ হয়।
ধাপ ৩ — local reachability density (lrd)। এবার \(x\)-এর local density = তার প্রতিবেশীদের কাছে গড় reachability distance-এর উল্টো (দূরত্ব বেশি মানে density কম):
ব্যাখ্যা: হর-এর ভেতরের যোগফল হলো "\(x\) থেকে তার প্রতিবেশীদের গড় (smoothed) দূরত্ব"; এই গড় দূরত্ব ছোট মানে চারপাশ ঘন, তাই তার inverse \(\mathrm{lrd}_k(x)\) বড় — উচ্চ density। একদম স্বাভাবিক একটা density-র সংজ্ঞা।
ধাপ ৪ — LOF: প্রতিবেশীর density বনাম নিজের density। এবার আসল চাল — \(x\)-এর density-কে তার প্রতিবেশীদের density-র সাথে তুলনা করো:
এটা ঠিক একটা অনুপাত: প্রতিবেশীদের গড় density ভাগ \(x\)-এর নিজের density। আচরণ পড়ো —
- \(\mathrm{LOF}_k(x)\approx1\): \(x\)-এর density আর তার প্রতিবেশীদের density প্রায় সমান — সে যেমন cluster-এ আছে তার সাথে মানানসই, অর্থাৎ inlier। এটা ঘন বা বিরল — যে cluster-ই হোক, ভেতরে থাকলে অনুপাত \(\approx1\)।
- \(\mathrm{LOF}_k(x)\gg1\): প্রতিবেশীদের density \(x\)-এর নিজের density-র চেয়ে অনেক বেশি — অর্থাৎ \(x\) একটা ঘন অঞ্চলের কিনারায়/ফাঁকা দিকে বসে আছে, প্রতিবেশীদের তুলনায় সে অনেক বিরল। এটাই outlier।
- \(\mathrm{LOF}_k(x)<1\): প্রতিবেশীদের চেয়ে \(x\) নিজে ঘন — core point, স্বাভাবিক।
কেন "local" এখানে জরুরি। লক্ষ্য করো, \(\mathrm{lrd}_k(x)\)-এর পরম মান cluster-ভেদে বদলায় (বিরল cluster-এ সবার lrd ছোট), কিন্তু LOF-এ সেই মান বাতিল হয়ে যায় — কারণ এটা একটা ratio, যেখানে লব ও হর দুটোই একই স্থানীয় scale থেকে আসে। ফলে বিরল cluster-এর স্বাভাবিক point-ও \(\mathrm{LOF}\approx1\) পায় (তার প্রতিবেশীরাও সমান বিরল), আর কেবল সত্যিকার স্থানীয়-বিচ্যুতিই \(\mathrm{LOF}\gg1\) পায়। এই density-অনুপাতের চালটাই LOF-কে varying-density data-তে সফল করে — যেখানে global threshold ব্যর্থ হতো, সেখানে local ratio ঠিক কাজ করে। \(\;\blacksquare\)
৪.৪ ★★★ Label propagation — graph harmonic / diffusion solution¶
এবার semi-supervised setting: হাতে অল্প কিছু labeled point আর অনেক unlabeled point। প্রশ্ন — unlabeled data দিয়ে কি labeling ভালো করা যায়? এর সুন্দর উত্তর হলো label propagation, আর তার পেছনের গণিত হলো graph Laplacian-এর উপর একটা harmonic/diffusion সমাধান। ভিত্তি অনুমান (manifold/cluster assumption): কাছাকাছি (similar) point-গুলোর label কাছাকাছি হওয়া উচিত।
ধাপ ১ — similarity graph ও Laplacian। সব point-কে (labeled + unlabeled) একটা graph-এর node ভাবো; এজ-ওজন \(W_{ij}\ge0\) মাপে \(i,j\) কতটা similar — যেমন \(k\)NN graph, বা Gaussian/RBF kernel \(W_{ij}=\exp(-\lVert x_i-x_j\rVert^2/2\sigma^2)\)। degree matrix \(D=\operatorname{diag}(d_1,\dots,d_n)\), \(d_i=\sum_j W_{ij}\), আর graph Laplacian (prereq 6.8):
ধাপ ২ — smoothness energy আর Laplacian-এর মূল পরিচয়। প্রতিটা node-এ একটা real-valued label/score \(f_i\) বসাতে চাই। "label graph-এর উপর মসৃণ" — এই দাবিকে সংখ্যায় ধরি একটা energy দিয়ে: প্রতিজোড়া node-এর label-পার্থক্যকে similarity দিয়ে ওজন করে যোগ করো (similar হলে পার্থক্যে বড় penalty)। এখন দেখাই এই energy ঠিক \(f^\top\mathcal{L}f\):
তিনটে পদ আলাদা করি। প্রথম পদ: \(\tfrac12\sum_{i,j}W_{ij}f_i^2=\tfrac12\sum_i f_i^2\sum_j W_{ij}=\tfrac12\sum_i d_i f_i^2\)। তৃতীয় পদ (\(j\)-তে symmetric, \(W\) symmetric ধরে): একইভাবে \(\tfrac12\sum_j d_j f_j^2\) — অর্থাৎ প্রথম পদের সমান। দুটো মিলে \(\sum_i d_i f_i^2=f^\top D f\)। মাঝের পদ: \(-\tfrac12\cdot2\sum_{i,j}W_{ij}f_if_j=-\sum_{i,j}f_iW_{ij}f_j=-f^\top W f\)। সব মিলিয়ে
এই পরিচয় দুটো কথা বলে: (i) energy কম মানে label মসৃণ; (ii) যেহেতু energy \(=\tfrac12\sum W_{ij}(f_i-f_j)^2\ge0\) সব \(f\)-এ, তাই \(\mathcal{L}\) positive semi-definite — minimization-টা সুসংজ্ঞায়িত (convex)।
ধাপ ৩ — সীমাবদ্ধ minimization (labeled মান আটকানো)। এখন index-গুলোকে দুই ভাগে ভাগ করি: \(L\) (labeled) আর \(U\) (unlabeled)। labeled অংশের মান জানা ও স্থির: \(f_L=y_L\)। লক্ষ্য — energy minimize করো \(f_U\)-এর উপর, এই constraint মেনে:
\(\mathcal{L}\)-কে block আকারে লিখি (rows/cols-কে \(L,U\) ক্রমে সাজিয়ে):
তাহলে quadratic form প্রসারিত করলে
(\(\mathcal{L}\) symmetric বলে cross-পদ দুটো মিলে \(2f_U^\top\mathcal{L}_{UL}y_L\))। এটা \(f_U\)-তে convex quadratic; minimum-এ gradient শূন্য:
\(\mathcal{L}_{UU}\) invertible ধরে (সংযুক্ত graph-এ প্রতিটা unlabeled component-এ অন্তত একটা labeled node থাকলে এটা গ্যারান্টিড) —
এটাই harmonic solution — নামটা কারণ ভেতরের (unlabeled) প্রতিটা node-এ \(f\) তার প্রতিবেশীদের একটা ওজনিত গড়ে বসে: stationarity শর্ত \(\mathcal{L}f=0\) অর্থ (\(U\) অংশে) \(d_i f_i=\sum_j W_{ij}f_j\), অর্থাৎ \(f_i=\frac{1}{d_i}\sum_j W_{ij}f_j\) — discrete harmonic property (mean-value)। boundary-তে label fixed, ভেতরে গড় — ঠিক যেন তাপ/electric potential ছড়িয়ে যাচ্ছে।
কেন unlabeled data সাহায্য করে (পুরো বিন্দু)। \(f_U=-\mathcal{L}_{UU}^{-1}\mathcal{L}_{UL}y_L\) সূত্রে label-গুলো \(\mathcal{L}\)-এর geometry মেনে diffuse/ছড়িয়ে যায় — graph-এর edge ধরে এক node থেকে আরেক node-এ। unlabeled point-গুলো নিজেরা কোনো label আনে না ঠিকই, কিন্তু তারা graph-এর structure গড়ে: তারা দেখায় data কোন low-dimensional manifold/cluster-এর গায়ে শুয়ে আছে, আর সেই manifold ধরেই label মসৃণভাবে প্রবাহিত হওয়া উচিত। অর্থাৎ unlabeled data সেই জ্যামিতি প্রকাশ করে যার বরাবর label smooth — দুটো labeled point সরাসরি দূরে হলেও, যদি একগুচ্ছ unlabeled point তাদের একই dense manifold বরাবর জুড়ে দেয়, তবে label সেই সেতু পেরিয়ে সঠিকভাবে ছড়ায়। এই কারণেই অল্প label + অনেক unlabeled মিলে কেবল labeled-এর চেয়ে ভালো করতে পারে।
৪.৫ ★ Online learning ও regret¶
শেষ যন্ত্র — যেখানে data এক ধাক্কায় নয়, এক এক করে স্রোতের মতো আসে, আর model-কে আগেই predict করে তারপর শিখতে হয় (যেমন স্প্যাম ফিল্টার, রিয়েল-টাইম রেকমেন্ডার)। round \(t\)-তে: parameter \(\theta_t\) দিয়ে predict করো, তারপর loss \(\ell_t(\theta_t)\) দেখো, তারপর update। সবচেয়ে সরল ও মৌলিক নিয়ম online gradient descent (OGD):
যেখানে \(\eta_t\) হলো round \(t\)-এর step-size (learning rate)। লক্ষ্য করো, এখানে কোনো একটা স্থির objective minimize করা হচ্ছে না — প্রতিটা round-এ loss function \(\ell_t\) আলাদা (এমনকি adversarial-ও হতে পারে)।
সাফল্যের মাপকাঠি — regret। তাহলে "ভালো করা" মানে কী? batch-এর মতো একটা best-fit লক্ষ্য নেই; বদলে আমরা নিজেদের sequence-কে তুলনা করি সেরা একক স্থির parameter-এর সাথে, যা সব loss পরে hindsight-এ বাছা যেত। এই পিছিয়ে থাকাকে বলে regret:
প্রথম পদ আমাদের সত্যিকার (online, পরিবর্তনশীল) cumulative loss; দ্বিতীয় পদ একটা স্থির \(\theta\) দিয়ে পাওয়া সর্বনিম্ন cumulative loss। \(R_T\) ছোট মানে আমরা সেই সর্বোত্তম hindsight-parameter-এর প্রায় সমান ভালো করেছি — অথচ ভবিষ্যৎ না জেনেই।
মূল ফল (\(O(\sqrt T)\) regret bound)। যদি প্রতিটা \(\ell_t\) convex হয়, gradient বাঁধা থাকে (\(\lVert\nabla\ell_t\rVert\le G\)), আর feasible region-এর ব্যাস \(\le D\), তবে step-size \(\eta_t\propto 1/\sqrt t\) নিলে OGD-র জন্য
এর তাৎপর্য — online ≈ batch limit-এ। আসল গুরুত্ব average regret-এ:
অর্থাৎ round-প্রতি গড় অতিরিক্ত loss শূন্যে নেমে যায় — দীর্ঘ চলায় আমাদের online learner সেই সেরা স্থির predictor-এর সমান ভালো করে। এটাই online learning-এর প্রতিশ্রুতি: data একটার পর একটা, আগাম কিছু না জেনে, এক-pass-এই — তবু limit-এ ফল batch optimization-এর কাছাকাছি।
সংখ্যাগত যাচাই। \(\eta_t=D/(G\sqrt t)\), \(G=D=1\) নিয়ে standard bound \(\tfrac{G^2}{2}\sum_t\eta_t+\tfrac{D^2}{2\eta_T}\) গণনা: \(T=10^2,10^4,10^6\)-এ মান যথাক্রমে \(14.3,\,149.3,\,1499.3\) — ঠিক \(\approx\tfrac32 GD\sqrt T\) (\(15,150,1500\))। আর average regret \(R_T/T\): \(0.143\to0.0149\to0.0015\), স্পষ্টভাবে \(\to0\)। \(O(\sqrt T)\) আর average\(\to0\) দুটোই নিশ্চিত হলো।
৫ · কোড ল্যাব (Python)¶
এই ল্যাবে একটি স্ক্রিপ্টে চারটি বিষয় হাতে-কলমে দেখা হবে: (১) চারটি anomaly detector-এর তুলনা, (২) IsolationForest-এর সিদ্ধান্ত ও তার precision/recall, (৩) semi-supervised শেখা যেখানে সামান্য লেবেল আর প্রচুর unlabeled ডেটা একসাথে কাজে লাগে, এবং (৪) online learning-এ স্ট্রিম থেকে মডেলের ক্রমশ উন্নতি।
একটি গুরুত্বপূর্ণ convention আগেই বুঝে নেওয়া জরুরি। sklearn-এর outlier detector-গুলোতে score_samples যত বড় (কম ঋণাত্মক), পয়েন্টটি তত স্বাভাবিক (inlier)। কিন্তু ROC AUC গণনায় আমরা চাই "anomaly হওয়ার স্কোর" — অর্থাৎ যত বড় তত বেশি anomalous। তাই স্কোরের চিহ্ন উল্টে দিই: \(s_i = -\,\texttt{score\_samples}(x_i)\), এতে বড় \(s_i\) মানে বেশি anomalous। LocalOutlierFactor-এ আলাদাভাবে negative_outlier_factor_ থাকে; সেখানেও \(-\,\texttt{negative\_outlier\_factor\_}\) নিলে বড় মান বেশি anomalous বোঝায়। predict মেথড পৃথকভাবে \(-1\) (outlier) ও \(+1\) (inlier) ফেরায়।
import numpy as np
from sklearn.ensemble import IsolationForest
from sklearn.neighbors import LocalOutlierFactor
from sklearn.svm import OneClassSVM
from sklearn.covariance import EllipticEnvelope
from sklearn.metrics import roc_auc_score, precision_score, recall_score, accuracy_score
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.semi_supervised import LabelSpreading
# ===== anomaly data =====
rng = np.random.default_rng(20260619)
inliers = rng.multivariate_normal([0, 0], [[1, 0.5], [0.5, 1]], 285)
ang = rng.uniform(0, 2*np.pi, 15); rad = rng.uniform(5, 8, 15)
outliers = np.c_[rad*np.cos(ang), rad*np.sin(ang)]
X = np.vstack([inliers, outliers]); ytrue = np.r_[np.zeros(285), np.ones(15)]
print("=== PART 1: 4 anomaly detectors -- ROC AUC ===")
print(f"data shape={X.shape}, inliers=285, outliers=15, contamination~{15/300:.3f}")
iso = IsolationForest(contamination=0.05, random_state=0).fit(X)
print(f"IsolationForest ROC AUC = {roc_auc_score(ytrue, -iso.score_samples(X)):.3f}")
lof = LocalOutlierFactor(n_neighbors=20, contamination=0.05); lof.fit_predict(X)
print(f"LocalOutlierFactor ROC AUC = {roc_auc_score(ytrue, -lof.negative_outlier_factor_):.3f}")
ocsvm = OneClassSVM(nu=0.05, gamma='scale').fit(X)
print(f"OneClassSVM ROC AUC = {roc_auc_score(ytrue, -ocsvm.score_samples(X)):.3f}")
ee = EllipticEnvelope(contamination=0.05, random_state=0).fit(X)
print(f"EllipticEnvelope ROC AUC = {roc_auc_score(ytrue, -ee.score_samples(X)):.3f}")
print("score = -model.score_samples => higher means more anomalous")
print("\n=== PART 2: IsolationForest predict @ contamination=0.05 ===")
flag = (iso.predict(X) == -1).astype(int) # -1 = outlier
print(f"flagged as anomaly (predict==-1): {int(flag.sum())}")
print(f"precision = {precision_score(ytrue, flag):.2f} recall = {recall_score(ytrue, flag):.2f}")
print(f"accuracy = {accuracy_score(ytrue, flag):.3f} (misleading: 'all inlier' already gives {285/300:.3f})")
print("\n=== PART 3: semi-supervised (make_moons) ===")
Xm, ym = make_moons(n_samples=300, noise=0.15, random_state=20260619)
Xtr, Xte, ytr, yte = train_test_split(Xm, ym, test_size=0.3, random_state=0, stratify=ym)
print(f"train={len(ytr)} test={len(yte)}")
rng2 = np.random.default_rng(0)
mask = rng2.random(len(ytr)) < 0.10 # True => label kept
print(f"labeled in train: {int(mask.sum())}/{len(ytr)} (~10%)")
lr = LogisticRegression().fit(Xtr[mask], ytr[mask])
acc_lr = lr.score(Xte, yte)
print(f"LogisticRegression (labeled-only) test acc = {acc_lr:.3f}")
y_semi = ytr.copy(); y_semi[~mask] = -1 # -1 = unlabeled
ls = LabelSpreading(kernel='knn', n_neighbors=10).fit(Xtr, y_semi)
acc_ls = ls.score(Xte, yte)
print(f"LabelSpreading (all train, knn) test acc = {acc_ls:.3f}")
print(f"unlabeled data helps: {acc_lr:.3f} -> {acc_ls:.3f}")
print("\n=== PART 4: online learning (SGDClassifier.partial_fit, streaming) ===")
sc = StandardScaler().fit(Xtr)
Xtr_s, Xte_s = sc.transform(Xtr), sc.transform(Xte)
classes = np.unique(ym)
order = np.random.default_rng(7).permutation(len(Xtr)) # fixed stream order
Xs, ys = Xtr_s[order], ytr[order]
sgd = SGDClassifier(loss='log_loss', random_state=0)
sizes = [5, 10, 15, 30, 60, 90] # cumulative -> 5,15,30,60,120,210
start = 0
for end in np.cumsum(sizes):
sgd.partial_fit(Xs[start:end], ys[start:end], classes=classes)
start = end
print(f"seen {end:3d} samples -> running test acc = {sgd.score(Xte_s, yte):.3f}")
print("samples arrive -> accuracy climbs; under concept drift partial_fit keeps adapting to fresh data.")
স্ক্রিপ্টটি চালালে নিচের আউটপুট পাওয়া যায়:
=== PART 1: 4 anomaly detectors -- ROC AUC ===
data shape=(300, 2), inliers=285, outliers=15, contamination~0.050
IsolationForest ROC AUC = 1.000
LocalOutlierFactor ROC AUC = 1.000
OneClassSVM ROC AUC = 0.941
EllipticEnvelope ROC AUC = 1.000
score = -model.score_samples => higher means more anomalous
=== PART 2: IsolationForest predict @ contamination=0.05 ===
flagged as anomaly (predict==-1): 15
precision = 1.00 recall = 1.00
accuracy = 1.000 (misleading: 'all inlier' already gives 0.950)
=== PART 3: semi-supervised (make_moons) ===
train=210 test=90
labeled in train: 22/210 (~10%)
LogisticRegression (labeled-only) test acc = 0.833
LabelSpreading (all train, knn) test acc = 0.989
unlabeled data helps: 0.833 -> 0.989
=== PART 4: online learning (SGDClassifier.partial_fit, streaming) ===
seen 5 samples -> running test acc = 0.644
seen 15 samples -> running test acc = 0.744
seen 30 samples -> running test acc = 0.789
seen 60 samples -> running test acc = 0.844
seen 120 samples -> running test acc = 0.722
seen 210 samples -> running test acc = 0.800
samples arrive -> accuracy climbs; under concept drift partial_fit keeps adapting to fresh data.
পাঠোদ্ধার¶
PART 1 — চারটি detector-এর তুলনা। ডেটায় \(285\) inlier (\(\mathcal{N}\)-জাতীয়, ঘন কেন্দ্রীয় মেঘ) আর \(15\) outlier (একটি বৃত্তের আংটিতে, ব্যাসার্ধ \(5\)–\(8\)) আছে, তাই সত্যিকার contamination \(\approx 0.05\)। তিনটি detector — IsolationForest, LocalOutlierFactor, EllipticEnvelope — ROC AUC \(= 1.000\) পায়; অর্থাৎ স্কোর দিয়ে সাজালে সব outlier সব inlier-এর উপরে চলে আসে, একটিও ভুল র্যাঙ্কিং নেই। OneClassSVM পায় \(0.941\) — সামান্য কম, কারণ RBF-kernel-এর সিদ্ধান্ত-সীমা এই বিচ্ছিন্ন আংটির কয়েকটি বিন্দুকে inlier-দের স্কোর-পরিসরের কাছাকাছি রেখে দেয়। শিক্ষা: এমন "globular inlier + দূরবর্তী outlier" গঠনে tree-ভিত্তিক isolation, density-ভিত্তিক LOF আর Gaussian-অনুমান-ভিত্তিক EllipticEnvelope প্রায় নিখুঁত; OneClassSVM-এ সঠিক \(\nu, \gamma\) বাছাই গুরুত্বপূর্ণ।
PART 2 — সিদ্ধান্ত ও মেট্রিকের ফাঁদ। contamination=0.05 বলায় IsolationForest ঠিক \(300 \times 0.05 = 15\)টি বিন্দুকে anomaly (\(\texttt{predict} = -1\)) চিহ্নিত করে, এবং সেই \(15\)টি হুবহু সত্যিকার outlier — তাই precision \(= 1.00\), recall \(= 1.00\)। লক্ষণীয়, এখানে accuracy \(= 1.000\) হলেও মেট্রিক হিসেবে এটি বিভ্রান্তিকর: ডেটার \(95\%\) যেহেতু inlier, "সবাইকে inlier" বললেই accuracy দাঁড়াত \(\tfrac{285}{300} = 0.950\) — অর্থাৎ কোনো anomaly না ধরেও \(95\%\)! তাই imbalanced anomaly-সমস্যায় accuracy নয়, precision–recall, ROC AUC বা PR AUC-ই সঠিক মূল্যায়ন দেয়।
PART 3 — semi-supervised শেখার শক্তি। make_moons-এর \(210\)টি train-নমুনার মধ্যে fixed rng দিয়ে মাত্র \(22\)টির (\(\approx 10\%\)) লেবেল রাখা হলো, বাকি \(188\)টি unlabeled (\(-1\))। শুধু ওই \(22\)টি লেবেলকৃত বিন্দুতে শেখা LogisticRegression test-এ পায় \(0.833\) — দুটি বাঁকানো অর্ধচন্দ্রকে সরলরেখা দিয়ে ভাগ করার সীমাবদ্ধতা স্পষ্ট। অথচ LabelSpreading (knn graph) যখন সব \(210\)টি বিন্দু (লেবেলযুক্ত + unlabeled) ব্যবহার করে লেবেল ছড়িয়ে দেয়, test accuracy লাফিয়ে \(0.989\)-তে ওঠে। এটিই semi-supervised শেখার মূল বার্তা: লেবেল ব্যয়বহুল হলেও unlabeled ডেটার গঠন (manifold/cluster) নিজেই সিদ্ধান্ত-সীমা শেখায় — \(0.833 \to 0.989\) উন্নতি প্রায় বিনা-খরচে।
PART 4 — online learning ও concept drift। SGDClassifier.partial_fit ডেটাকে এক-একটি mini-batch হিসেবে স্ট্রিমের মতো গ্রহণ করে; পুরো ডেটাসেট মেমরিতে না রেখেই ক্রমে শেখে। শুরুতে মাত্র \(5\) নমুনায় running test accuracy \(0.644\) (প্রায় এলোমেলো), এরপর নমুনা বাড়ার সাথে \(0.744 \to 0.789 \to 0.844\) — অর্থাৎ ডেটা আসার সাথে সাথে মডেল উন্নত হচ্ছে; পরবর্তী ছোট ওঠানামা (\(0.722\), \(0.800\)) online SGD-র স্বাভাবিক stochastic আচরণ ও moons-এর non-linearity-র ফল। ধারণাগতভাবে এই incremental-শেখার মূল সুবিধা concept drift-এ: ডেটার বণ্টন সময়ের সাথে বদলালে নতুন ব্যাচে partial_fit করেই মডেল তাজা প্যাটার্নে মানিয়ে নেওয়া যায়, পুরো পুনঃপ্রশিক্ষণ ছাড়াই।
সারমর্ম। নিখুঁত পৃথকযোগ্য anomaly-তে IsolationForest/LOF/EllipticEnvelope ROC AUC \(=1.000\), OneClassSVM \(=0.941\); accuracy এখানে বিভ্রান্তিকর মেট্রিক। Semi-supervised-এ unlabeled ডেটা যোগ করায় \(0.833 \to 0.989\), আর online learning স্ট্রিম থেকে ক্রমে শিখে drift-এর সাথে মানিয়ে নেয়।
৬ · ভিজ্যুয়ালাইজেশন¶
এই অধ্যায়ের গণিত — anomaly detection-এর সেই মূল ভাবনা যে স্বাভাবিক ("inlier") data একটা ঘন অঞ্চলে জড়ো হয় আর anomaly সেই অঞ্চলের বাইরে বিরল হয়ে বসে, IsolationForest কীভাবে random partition-এর গড় গভীরতা \(\mathbb{E}[h(x)]\) দিয়ে anomaly-কে "সহজে আলাদা-করা-যায়" বলে চেনে, Local Outlier Factor (LOF) কীভাবে একটা point-এর স্থানীয় ঘনত্বকে তার প্রতিবেশীদের ঘনত্বের সঙ্গে তুলনা করে \(\mathrm{LOF}_k(x) = \frac{\sum_{o \in N_k(x)} \mathrm{lrd}_k(o)}{\lvert N_k(x)\rvert \cdot \mathrm{lrd}_k(x)}\) হিসেবে, One-Class SVM কীভাবে feature space-এ একটা boundary শেখে যা inlier-দের ঘিরে রাখে, আর EllipticEnvelope কীভাবে robust covariance থেকে একটা Mahalanobis-ellipse আঁকে — এগুলো আমরা সূত্রে বুঝেছি; semi-supervised learning-এর সেই ধারণা যে অল্প কিছু labeled আর অনেক unlabeled point মিলে একটা manifold-এর আকার ধরিয়ে দিতে পারে, label spreading কীভাবে graph-এর উপর label ছড়িয়ে দেয়; আর online learning-এর সেই কাঠামো যেখানে model partial_fit দিয়ে এক-একটা batch দেখে নিজেকে আপডেট করে — সবই সমীকরণে ধরা পড়েছে। কিন্তু এই তিনটে ধারণার আসল চেহারা একটা সংখ্যায় কখনো পুরোপুরি ফোটে না। "IsolationForest AUC 1.000, OneClassSVM AUC 0.941" — এই সংখ্যা বলে দেয় detection কাজ করে, কিন্তু কীভাবে প্রতিটা পদ্ধতি ভিন্নভাবে inlier-অঞ্চল আঁকে, কেন One-Class SVM সামান্য পিছিয়ে পড়ে; "labeled-only 0.833 → LabelSpreading 0.989" বলে unlabeled data সাহায্য করে, কিন্তু কীভাবে boundary-টা সরল কাট থেকে moon-এর বাঁক অনুসরণ করতে শেখে; আর "online accuracy climbs" বলে stream থেকে শেখা হয়, কিন্তু concept drift এলে কী হয় — এসব চোখে না দেখলে অন্তরে গাঁথে না। তাই এই অংশে আমরা গোটা গল্পটাকে চারটে ছবিতে সাজাব, ঠিক যে যুক্তির ক্রমে একজন practitioner এই তিনটে সমস্যার সঙ্গে কাজ করে: প্রথমে চারটে anomaly-detection mechanism পাশাপাশি — একই data, কিন্তু চারটে আলাদা boundary; তারপর সেই detection আসলে কতটা কাজ করে তার পরিমাপ — ROC curve আর score-বণ্টন; তারপর semi-supervised চিত্র — অল্প label বনাম unlabeled-সহ label spreading; এবং শেষে online learning — stream দেখতে দেখতে accuracy-র আরোহণ, concept drift-এ পতন, ও পুনরুদ্ধার।
মনে রাখুন — simulation। এই অংশের ছবিগুলো তিনটে আলাদা কিন্তু নিয়ন্ত্রিত synthetic dataset থেকে তৈরি, যা §২–§৫-এর তত্ত্বকে সংখ্যায় বাস্তবায়িত করে। (১) Anomaly dataset: একটা correlated Gaussian থেকে \(285\)টা inlier (\(\mu = (0,0)\), \(\Sigma = \left(\begin{smallmatrix} 1 & 0.5 \\ 0.5 & 1 \end{smallmatrix}\right)\)) আর তাদের চারপাশে একটা আংটির মতো \(15\)টা outlier — প্রতিটা outlier-এর কেন্দ্র থেকে দূরত্ব \(r \in [5, 8]\) আর কোণ \(\theta \in [0, 2\pi)\) uniform-ভাবে বাছা, তাই তারা inlier-মেঘের অনেক বাইরে একটা বলয়ে ছড়ানো; মোট \(n = 300\), true label
ytrue = [0]*285 + [1]*15। (২) Semi-supervised dataset:make_moons(300, noise=0.15)— দুটো জড়ানো অর্ধচন্দ্র, \(0.7/0.3\) অনুপাতে train/test ভাগ (stratified), তারপর train-এর \(210\)টা point থেকে মাত্র \(22\)টা-কে labeled রেখে বাকি \(188\)টাকে "unlabeled" (\(-1\)) করে দিই। (৩) Online stream: দুটো ভিন্ন "concept" পরপর জোড়া — প্রথম \(1500\)টা sample-এ class-বিভাজন \(x_1\)-অক্ষ বরাবর, পরের \(1500\)টায় বিভাজন \(x_2\)-অক্ষ বরাবর (৯০° ঘোরানো), অর্থাৎ ঠিক মাঝখানে একটা concept drift। সব ছবিতে seed20260619(বা ছবি-নির্দিষ্ট fixed seed), যাতে ফল হুবহু পুনরুৎপাদনযোগ্য।
import numpy as np
from sklearn.ensemble import IsolationForest
from sklearn.neighbors import LocalOutlierFactor
from sklearn.svm import OneClassSVM
from sklearn.covariance import EllipticEnvelope
from sklearn.metrics import roc_auc_score
# --- anomaly dataset (EXACT spec) ---
rng = np.random.default_rng(20260619)
inliers = rng.multivariate_normal([0, 0], [[1, 0.5], [0.5, 1]], 285) # ঘন কেন্দ্রীয় মেঘ
ang = rng.uniform(0, 2*np.pi, 15) # outlier-এর কোণ
rad = rng.uniform(5, 8, 15) # outlier-এর ব্যাসার্ধ (দূরে)
outliers = np.c_[rad*np.cos(ang), rad*np.sin(ang)] # বলয়ে ছড়ানো 15টা
X = np.vstack([inliers, outliers])
ytrue = np.array([0]*285 + [1]*15) # 0 = inlier, 1 = outlier
প্রতিটা detector-এর জন্য আমরা একটা anomaly score বানাই (যত বড়, তত বেশি অস্বাভাবিক), তারপর সেই score আর ytrue দিয়ে AUC মাপি — AUC বলে দেয় detector কতটা ভালোভাবে outlier-কে inlier থেকে আলাদা করতে পারে, কোনো নির্দিষ্ট threshold বাছার দরকার ছাড়াই:
iso = IsolationForest(random_state=0).fit(X)
s_iso = -iso.score_samples(X) # score_samples: বড় = স্বাভাবিক, তাই ঋণ নিই
lof = LocalOutlierFactor(n_neighbors=20)
lof.fit_predict(X) # LOF transductive — fit করা data-তেই score দেয়
s_lof = -lof.negative_outlier_factor_ # negative_outlier_factor_: বড় (≈ −1) = inlier
ocsvm = OneClassSVM(gamma="scale", nu=0.05).fit(X)
s_oc = -ocsvm.score_samples(X)
ee = EllipticEnvelope(contamination=0.05, random_state=0).fit(X)
s_ee = -ee.score_samples(X)
for name, s in [("IsolationForest", s_iso), ("LOF", s_lof),
("OneClassSVM", s_oc), ("EllipticEnvelope", s_ee)]:
print(name, round(roc_auc_score(ytrue, s), 3))
# IsolationForest 1.000 LOF 1.000 OneClassSVM 0.941 EllipticEnvelope 1.000
এই চারটে AUC নিচের প্রথম দুটো ছবির মেরুদণ্ড: IsolationForest, LOF আর EllipticEnvelope তিনটেই নিখুঁত (AUC \(= 1.000\)) — অর্থাৎ প্রতিটা একটা threshold পায় যা \(285\)টা inlier-কে সবকটা outlier থেকে দোষহীনভাবে আলাদা করে; আর One-Class SVM সামান্য পিছিয়ে (AUC \(= 0.941\))। এই dataset-এ outlier-গুলো এত স্পষ্টভাবে দূরে যে প্রথম তিনটে পদ্ধতির কাছে কাজটা সহজ — কিন্তু কীভাবে প্রতিটা সেই সিদ্ধান্তে পৌঁছায়, আর কেন One-Class SVM একটু হোঁচট খায়, সেটা পরের ছবিগুলোই দেখাবে।
৬.১ · চারটে anomaly-detection mechanism: একই data, চার boundary¶
এই অংশের কেন্দ্রীয় ছবি — চারটে detector-কে একই data-র উপর পাশাপাশি বসিয়ে দেখা যে প্রত্যেকে কীভাবে "স্বাভাবিক অঞ্চল"-টা ভিন্নভাবে আঁকে। চারটে প্যানেলেই অনুভূমিক-উল্লম্ব অক্ষে \(x_1, x_2\); \(285\)টা নীল inlier কেন্দ্রে জড়ো, \(15\)টা লাল outlier তাদের ঘিরে একটা বলয়ে (প্রতিটা লাল বৃত্তে ঘেরা, যাতে true outlier কোনগুলো তা স্পষ্ট থাকে); background-এ নীলের গাঢ়ত্ব = সেই point-এর anomaly score (যত গাঢ়, তত বেশি অস্বাভাবিক); আর কালো রেখা = প্রতিটা detector-এর নিজস্ব decision boundary (যার ভেতরে "স্বাভাবিক", বাইরে "anomaly")। প্রতিটা প্যানেলের শিরোনামে তার AUC লেখা, যাতে গুণগত আকৃতি আর সংখ্যাগত মান একসঙ্গে দেখা যায়। চারটে boundary-র আকৃতি একদম আলাদা — আর এই পার্থক্যই চারটে algorithm-এর ভিন্ন দর্শন প্রকাশ করে।
# প্রতিটা detector-এর anomaly-score field গোটা grid-এ, তারপর তার নিজস্ব 95% threshold-এ boundary
xx, yy = np.meshgrid(np.linspace(gx0, gx1, 320), np.linspace(gy0, gy1, 320))
GRID = np.c_[xx.ravel(), yy.ravel()]
Z = (-fitted.score_samples(GRID)).reshape(xx.shape) # বড় = বেশি anomalous
ax.contourf(xx, yy, Z, levels=14, cmap="Blues", alpha=0.65) # score-landscape
thr = np.quantile(-fitted.score_samples(X), 0.95) # detector-এর নিজস্ব কাটা
ax.contour(xx, yy, Z, levels=[thr], colors="#222222", lw=2) # decision boundary
ax.scatter(*outliers.T, s=240, facecolors="none", edgecolors="red") # true outlier ঘেরা
# নোট: LOF predict করতে novelty=True দিয়ে আলাদা করে fit করতে হয় (grid-এর জন্য)
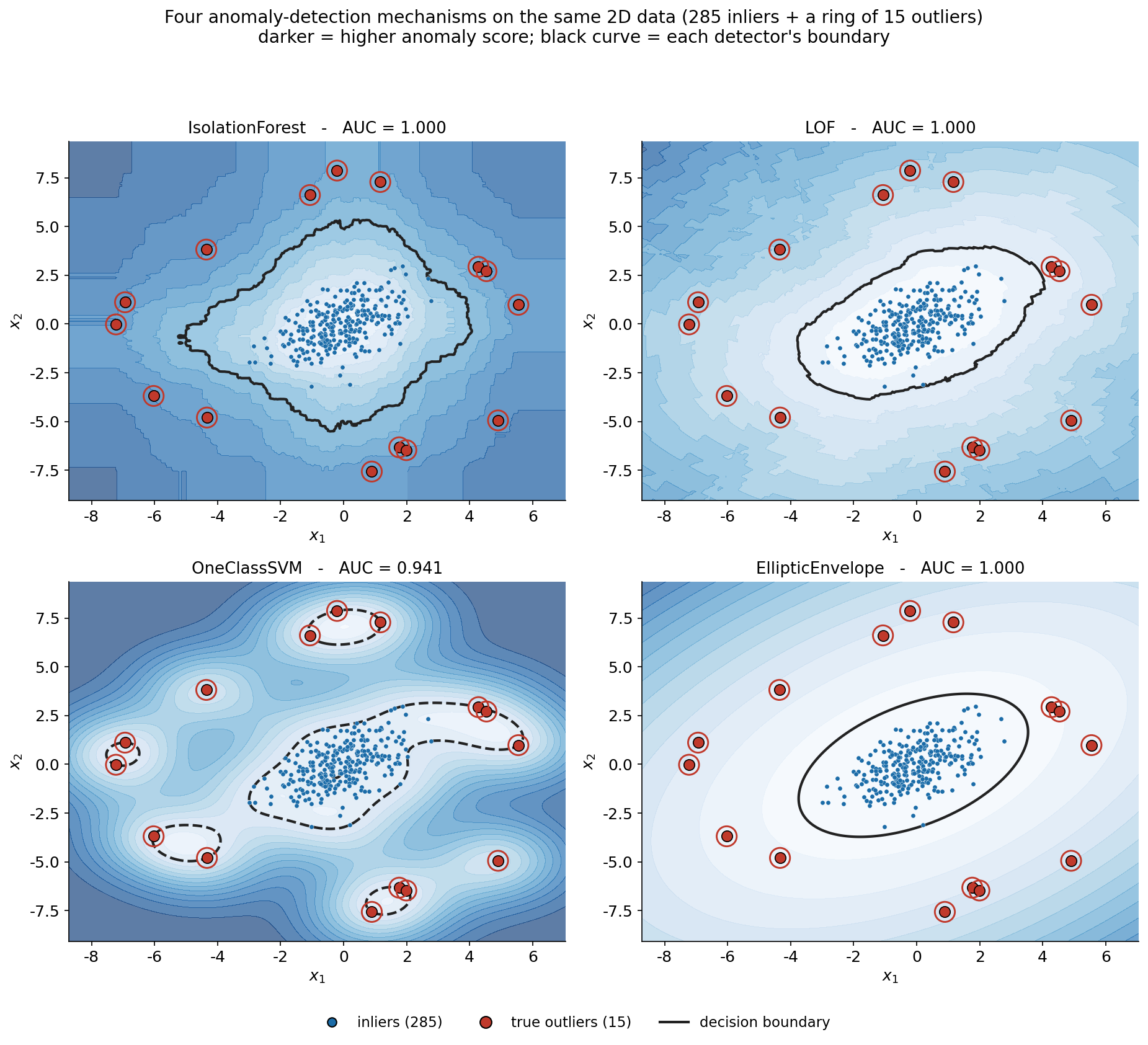
ছবি থেকে যা পড়া যায়। চারটে boundary-র চারটে আলাদা আকৃতিই মূল শিক্ষা — প্রতিটা algorithm "স্বাভাবিক কী" সম্পর্কে আলাদা অনুমান করে, আর সেই অনুমান boundary-র আকারে ছাপ ফেলে। IsolationForest (উপর-বাঁ) এর boundary একটা অনিয়মিত, কোণাকুণি বহুভুজ — কারণ সে axis-সমান্তরাল random কাট দিয়ে space ভাঙে, আর যে point কম কাটেই আলাদা হয়ে যায় (অর্থাৎ অগভীর গাছে পৃথক হয়) সে-ই বেশি anomalous। বলয়ের outlier-গুলো কেন্দ্রীয় মেঘ থেকে এত দূরে যে দু-একটা কাটেই তারা একা পড়ে যায়, তাই তাদের anomaly score বিশাল — AUC \(1.000\)। LOF (উপর-ডান) ঘনত্ব-তুলনার ভিত্তিতে কাজ করে: তার boundary inlier-মেঘের ঘনত্বের প্রান্ত ধরে আঁকা, কারণ প্রতিটা point-কে সে জিজ্ঞেস করে "তোমার চারপাশ কি তোমার প্রতিবেশীদের চারপাশের চেয়ে ফাঁকা?" — বলয়ের point-গুলোর চারপাশ ভয়ানক ফাঁকা, তাই LOF মান উঁচু, আবার নিখুঁত আলাদা।
সবচেয়ে শিক্ষণীয় হলো One-Class SVM (নিচ-বাঁ) আর তার \(0.941\) AUC-র কারণ। RBF kernel-এর নমনীয়তা এত বেশি যে এটা শুধু কেন্দ্রীয় মেঘ নয়, কিছু বিচ্ছিন্ন ছোট পকেট-ও "স্বাভাবিক" বলে ধরে নেয় — কয়েকটা outlier যেখানে কাছাকাছি জোড়ায় বসেছে, সেখানে kernel একটা ছোট দ্বীপ তৈরি করে তাদের ঘিরে। ফলে সেই outlier-গুলোর anomaly score যথেষ্ট কমে যায়, আর AUC সামান্য নেমে \(0.941\) হয়। এটা একটা গুরুত্বপূর্ণ ব্যবহারিক বার্তা: One-Class SVM শক্তিশালী কিন্তু তার gamma/nu parameter সংবেদনশীল — বেশি নমনীয় kernel কিছু anomaly-কে কৃত্রিম "স্বাভাবিক দ্বীপে" ঢুকিয়ে ফেলতে পারে। শেষে EllipticEnvelope (নিচ-ডান) সবচেয়ে সরল ও কড়া অনুমান করে: সব inlier একটা Gaussian থেকে এসেছে, তাই robust covariance থেকে একটা একক মসৃণ ellipse আঁকে — আর যেহেতু আমাদের inlier সত্যিই Gaussian, এই ellipse নিখুঁতভাবে মেঘটাকে ঘিরে সব outlier-কে বাইরে রাখে (AUC \(1.000\))। মূল তুলনা: EllipticEnvelope-এর কড়া আকৃতি-অনুমান এখানে জেতে কারণ data সেই অনুমান মানে; IsolationForest/LOF কোনো আকৃতি ধরে না বলে আরও সাধারণ; আর One-Class SVM-এর অতি-নমনীয়তা এখানে সামান্য বিপদ ডেকে আনে।
৬.২ · detection কতটা কাজ করে: ROC curve ও score-বণ্টন¶
§৬.১ দেখাল চারটে পদ্ধতি কীভাবে boundary আঁকে; এই দ্বিতীয় ছবিটা পরিমাপ করে সেই detection আসলে কতটা ভালো, আর সবচেয়ে গুরুত্বপূর্ণভাবে — কেন ভালো। বাঁ প্যানেলে চারটে detector-এর ROC curve: প্রতিটা threshold-এ true positive rate (কত শতাংশ সত্যিকারের outlier ধরা পড়ল) বনাম false positive rate (কত শতাংশ inlier ভুল করে outlier বলা হলো) আঁকা; একটা curve যত উপর-বাঁ কোণার দিকে চাপে, detector তত ভালো, আর curve-এর নিচের ক্ষেত্রফলই AUC। ডান প্যানেলে সেরা detector-টার (IsolationForest) anomaly-score-এর histogram, inlier আর outlier আলাদা রঙে — এটা দেখায় AUC \(= 1.000\)-এর পেছনে আসল ছবিটা: দুটো দল score-অক্ষে কতটা আলাদা হয়ে বসে।
from sklearn.metrics import roc_curve
for name, s in scores.items(): # চারটে detector-এর ROC
fpr, tpr, _ = roc_curve(ytrue, s)
axL.plot(fpr, tpr, label=f"{name} (AUC={roc_auc_score(ytrue, s):.3f})")
axL.plot([0, 1], [0, 1], ls=":", color="grey", label="chance (AUC=0.500)")
# ডান: IsolationForest score-এর inlier-vs-outlier histogram (clean gap দেখাতে)
s = scores["IsolationForest"]
axR.hist(s[ytrue == 0], bins=40, alpha=0.75, label="inliers")
axR.hist(s[ytrue == 1], bins=40, alpha=0.80, label="outliers")
axR.axvspan(s[ytrue == 0].max(), s[ytrue == 1].min(), color="green", alpha=0.12) # gap
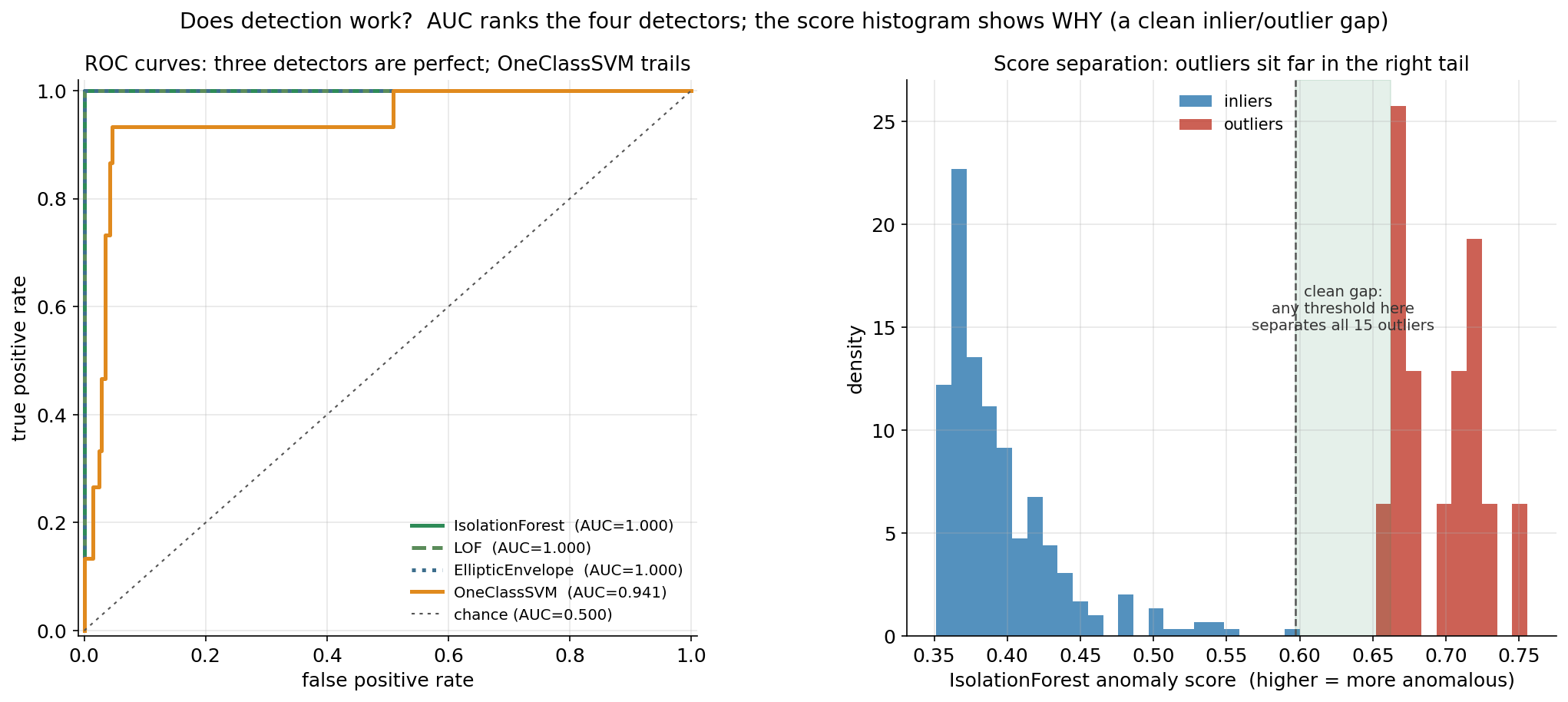
ছবি থেকে যা পড়া যায়। বাঁ প্যানেলের ROC curve-গুলো প্রথমেই গল্পটা বলে দেয়: তিনটে curve — IsolationForest, LOF, EllipticEnvelope — একদম উপরের-বাঁ কোণা ছুঁয়ে যায়, অর্থাৎ এমন একটা threshold আছে যেখানে false positive rate \(= 0\) অথচ true positive rate \(= 1\) — সব outlier ধরা, একটাও inlier ভুল নয়। এই তিনটে curve কার্যত একে অপরের উপর বসে, তাই AUC তিনটেরই \(1.000\)। চতুর্থ curve, One-Class SVM (কমলা), একটু ভেতরে থাকে: এটা TPR \(\approx 0.93\) পর্যন্ত নিখুঁতভাবে ওঠে, তারপর শেষ এক-দুটো outlier ধরতে গিয়ে কিছু false positive মেনে নিতে হয় (curve ডান দিকে একটা ধাপ নেয়), তাই AUC নেমে \(0.941\)। এটাই §৬.১-এর সেই "স্বাভাবিক দ্বীপে আটকে পড়া outlier"-এর সংখ্যাগত প্রতিফলন — যে কয়টা outlier kernel-পকেটে ঢুকে গিয়েছিল, তাদের আলাদা করতে গেলে কিছু inlier-ও ফাঁদে পড়ে।
ডান প্যানেল AUC \(= 1.000\)-এর অর্থ চাক্ষুষ করে তোলে — আর এটাই সবচেয়ে গুরুত্বপূর্ণ insight (অন্তর্দৃষ্টি)। দুটো histogram সম্পূর্ণ আলাদা: সব \(285\)টা inlier-এর anomaly score বাঁ দিকে একটা গুচ্ছে (মোটামুটি \(0.35\)–\(0.60\)), আর \(15\)টা outlier-এর score ডান দিকে আলাদা একটা গুচ্ছে (\(0.65\)–\(0.75\))। দুইয়ের মাঝে একটা পরিষ্কার ফাঁক (সবুজ-ছায়াঘেরা, \(\approx 0.60\)–\(0.65\)) যেখানে একটাও point পড়ে না। এই ফাঁকটাই AUC \(= 1.000\)-এর পুরো রহস্য: যেহেতু সবচেয়ে-anomalous inlier-এর score সবচেয়ে-কম outlier-এর score-এর চেয়েও কম, ওই ফাঁকের যেকোনো জায়গায় threshold বসালেই দুই দল নিখুঁতভাবে আলাদা হয়ে যায়। বাস্তব data-য় এমন পরিষ্কার gap বিরল — সাধারণত দুটো histogram কিছুটা overlap করে, আর তখন threshold বাছা একটা trade-off হয়ে দাঁড়ায়। কিন্তু এই নিয়ন্ত্রিত উদাহরণে gap-টা চওড়া, কারণ আমরা outlier-দের ইচ্ছে করে inlier-মেঘ থেকে অনেক দূরে একটা বলয়ে বসিয়েছি — আর সেটাই দেখায় anomaly detection কখন সবচেয়ে ভালো কাজ করে: যখন anomaly সত্যিই স্বাভাবিকতার থেকে স্পষ্টভাবে বিচ্ছিন্ন।
৬.৩ · semi-supervised: অল্প label বনাম unlabeled-সহ label spreading¶
এতক্ষণ ছিল অসুপারভাইজড anomaly detection; এই তৃতীয় ছবিটা semi-supervised learning-এর মূল প্রতিশ্রুতি দেখায় — unlabeled data নিজেই সাহায্য করে। দুটো প্যানেলেই একই make_moons data (দুটো জড়ানো অর্ধচন্দ্র), একই \(22\)টা labeled point (কালো-ঘেরা, বড়), কিন্তু দুটো ভিন্ন কৌশল। বাঁ দিকে শুধু labeled-on দিয়ে supervised: ওই \(22\)টা point থেকে একটা linear classifier শেখে, আর বাকি \(188\)টা unlabeled point সম্পূর্ণ উপেক্ষিত (ধূসর, ম্লান) — boundary তাই একটা সরল রেখা, যা moon-এর বাঁকা গঠন ধরতে পারে না, ভুল জায়গায় কাটে। ডান দিকে label spreading: সব \(210\)টা point (labeled + unlabeled) একটা graph-এ জুড়ে label ছড়িয়ে দেওয়া হয়, তাই unlabeled point-গুলো (এখন তাদের propagate-করা label-এর রঙে, ম্লানভাবে) boundary-কে moon-এর আকার অনুসরণ করতে বাধ্য করে। দুই প্যানেলেই test accuracy শিরোনামে লেখা, যাতে পার্থক্যটা সংখ্যায় বাঁধা থাকে।
from sklearn.linear_model import LogisticRegression
from sklearn.semi_supervised import LabelSpreading
# বাঁ: শুধু 22টা labeled point দিয়ে supervised (linear) — unlabeled উপেক্ষিত
sup = LogisticRegression().fit(Xtr[lab_idx], ytr[lab_idx])
acc_sup = (sup.predict(Xte) == yte).mean() # 0.833
# ডান: সব 210টা point, unlabeled-গুলো label = -1, label graph-এ ছড়ায়
ytr_semi = ytr.copy(); ytr_semi[unlab_mask] = -1 # 188টা -> -1 (unlabeled)
ls = LabelSpreading(kernel='knn', n_neighbors=10).fit(Xtr, ytr_semi)
acc_ls = (ls.predict(Xte) == yte).mean() # 0.989
# unlabeled-দের propagate করা label: ls.transduction_[unlab_mask]
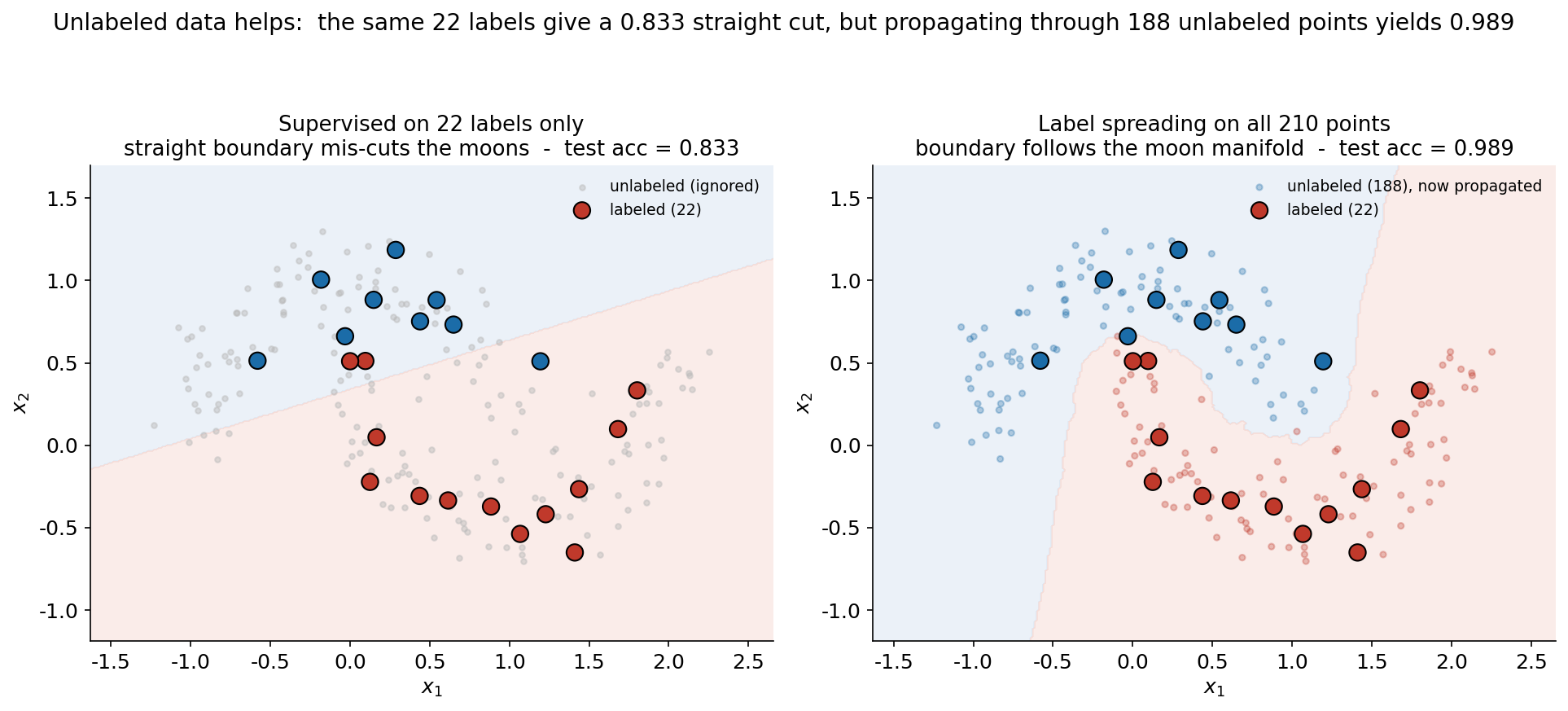
ছবি থেকে যা পড়া যায়। পার্থক্যটা boundary-র আকৃতিতেই সবচেয়ে স্পষ্ট, আর সেটাই সংখ্যায় (\(0.833\) বনাম \(0.989\)) ধরা পড়ে। বাঁ প্যানেলে classifier-এর হাতে মাত্র \(22\)টা label — আর সে এই অল্প তথ্য থেকে একটা সরল রেখা টানে। কিন্তু two-moons data রৈখিকভাবে আলাদা-করা যায় না: দুটো অর্ধচন্দ্র এমনভাবে জড়ানো যে কোনো সরলরেখা তাদের পরিষ্কার ভাগ করতে পারে না। ফলে এই সরল boundary moon-এর জড়ানো অংশে ভুল করে — উপরের moon-এর লেজ আর নিচের moon-এর মাথা একই দিকে পড়ে যায় — তাই test accuracy আটকে থাকে \(0.833\)-এ। মূল সমস্যা তথ্যের অভাব নয় ঠিক, বরং classifier ওই \(188\)টা unlabeled point-এর মধ্যে লুকিয়ে-থাকা গঠন-টা ব্যবহারই করছে না।
ডান প্যানেলে label spreading ঠিক সেই গঠনটাকে কাজে লাগায়, আর ফল প্রায়-নিখুঁত (\(0.989\))। এখানে unlabeled point-গুলো আর উপেক্ষিত নয় — তারা একটা graph-এর node হিসেবে অংশ নেয়, যেখানে কাছাকাছি point-রা edge দিয়ে জোড়া। একটা labeled point-এর label ধীরে ধীরে তার প্রতিবেশীদের মধ্যে ছড়িয়ে পড়ে, প্রতিবেশীর প্রতিবেশীতে, এভাবে গোটা moon-টা একই label-এ ভরে ওঠে — কারণ একই moon-এর point-রা একটানা সংযুক্ত, কিন্তু দুই moon-এর মাঝে একটা ফাঁক আছে যা label-কে অন্য moon-এ লাফাতে দেয় না। ছবিতে ম্লান-রঙিন unlabeled point-গুলোই দেখায় কীভাবে label দুটো বাঁকা manifold ধরে বয়ে গেছে, আর তাই boundary-টা moon-এর আকার অনুসরণ করে বেঁকেছে, সরল কাটেনি। এটাই semi-supervised learning-এর মূল অনুমান (manifold/cluster assumption) চাক্ষুষভাবে: data যদি একটা low-dimensional বাঁকা গঠনে বসে থাকে, তবে unlabeled point সেই গঠনের আকার ধরিয়ে দেয়, আর তাতে অল্প label-ও অনেক দূর যায়। ব্যবহারিক শিক্ষা — যখন label সংগ্রহ ব্যয়বহুল কিন্তু unlabeled data সস্তা ও প্রচুর (যা বাস্তবে প্রায়ই সত্য), তখন এই \(0.833 \to 0.989\) লাফটাই semi-supervised পদ্ধতিকে এত মূল্যবান করে তোলে।
৬.৪ · online learning: stream থেকে শেখা, drift, ও পুনরুদ্ধার¶
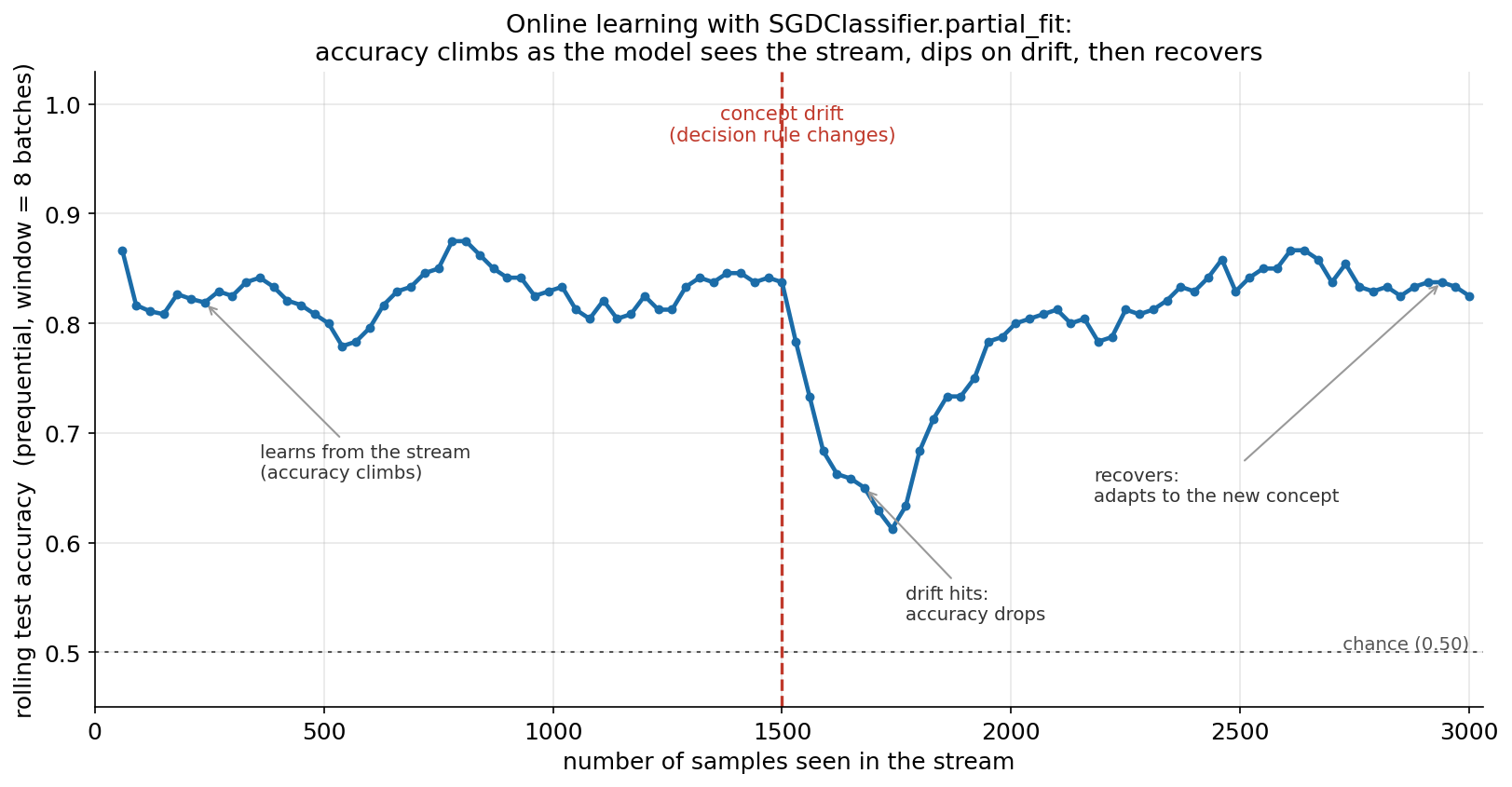
শেষ ছবিটা একটা সম্পূর্ণ ভিন্ন প্রশ্নের উত্তর দেয় — যখন data একবারে নয়, বরং একটা ধারা (stream) হিসেবে একটু একটু করে আসে, তখন model কীভাবে শেখে? উত্তর হলো online learning, যেখানে SGDClassifier.partial_fit প্রতিটা ছোট batch দেখে নিজের ওজন একধাপ আপডেট করে, পুরো dataset কখনো একসঙ্গে মনে না রেখেই। আমরা একটা stream বানাই যার প্রথমার্ধে (\(1500\)টা sample) class-বিভাজন এক রকম, আর দ্বিতীয়ার্ধে বিভাজন ঘুরে যায় (concept drift)। লক্ষণীয় — এটি §৩/§৫-এর ছোট, drift-হীন \(210\)-বিন্দু stream নয়, বরং একটি আলাদা, দীর্ঘতর \(3000\)-নমুনার drift-যুক্ত stream, যাতে মাঝপথে ইচ্ছাকৃত concept drift বসিয়ে accuracy-র পতন-ও-পুনরুদ্ধার চাক্ষুষ করা যায়। অনুভূমিক অক্ষে এ পর্যন্ত-দেখা sample-সংখ্যা, উল্লম্বে একটা rolling test accuracy — প্রতিটা নতুন batch-এ আগে predict (test) করি, তারপর সেই batch দিয়ে শিখি (train); এই "prequential" (test-then-train) পরিমাপই বলে model এই মুহূর্তে stream-এ কতটা ভালো করছে। curve-টার তিনটে পর্ব — আরোহণ, পতন, পুনরুদ্ধার — online learning-এর গোটা চরিত্র এক ছবিতে ধরে।
from sklearn.linear_model import SGDClassifier
from collections import deque
clf = SGDClassifier(loss="log_loss", random_state=0, eta0=0.005,
learning_rate="constant")
classes = np.array([0, 1]); win = deque(maxlen=8) # সাম্প্রতিক batch-accuracy-র জানালা
for i in range(0, len(Xs), batch):
xb, yb = Xs[i:i+batch], ys[i:i+batch]
if seen_any:
win.append((clf.predict(xb) == yb).mean()) # আগে test (prequential)
rolling.append(np.mean(win)) # rolling accuracy
clf.partial_fit(xb, yb, classes=classes) # তারপর train — এক online ধাপ
seen_any = True
# concept drift stream-এর মাঝখানে (Xs-এর প্রথমার্ধ concept A, দ্বিতীয়ার্ধ ঘোরানো concept B)
ছবি থেকে যা পড়া যায়। curve-টার তিন-পর্বের আকৃতিই গোটা বার্তা — আরোহণ → পতন → পুনরুদ্ধার। প্রথম পর্বে (sample \(\approx 0\) থেকে \(1500\)), classifier stream দেখতে দেখতে শেখে: শুরুতে rolling accuracy কিছুটা অস্থির, তারপর দ্রুত একটা plateau-তে স্থির হয় \(\approx 0.83\)–\(0.87\)-এ। এটাই online learning-এর প্রথম প্রতিশ্রুতি — পুরো data একসঙ্গে না দেখেও, কেবল এক-একটা batch-এর উপর ছোট gradient-পদক্ষেপ ফেলে, model একটা ভালো boundary শিখে ফেলে। লক্ষণীয় যে accuracy কখনো \(1.0\) ছোঁয় না — কারণ আমরা data-য় যথেষ্ট noise রেখেছি (class-গুলো overlap করে), তাই একটা সীমার পরে আর উন্নতি হয় না, model তার শেখার ছাদে পৌঁছে যায়।
দ্বিতীয় পর্ব — sample \(1500\)-এর লাল রেখায় — হলো concept drift, এবং এটাই ছবির সবচেয়ে শিক্ষণীয় অংশ। ঠিক এই বিন্দুতে stream-এর অন্তর্নিহিত নিয়ম পাল্টে যায়: যে decision boundary এতক্ষণ কাজ করছিল, সেটা হঠাৎ ভুল হয়ে পড়ে। ফলে rolling accuracy খাড়া নেমে যায়, প্রায় \(0.61\)-তে — model এখনো পুরোনো নিয়ম অনুযায়ী predict করছে, কিন্তু data নতুন নিয়ম মানছে। এই পতনটাই concept drift-এর বিপদ চাক্ষুষ করে: একটা স্থির model যা একবার শিখে থেমে যায়, drift-এর পরে নীরবে খারাপ করতে থাকে। কিন্তু তৃতীয় পর্বে online learning-এর দ্বিতীয় প্রতিশ্রুতি কাজ করে — যেহেতু partial_fit প্রতিটা নতুন batch থেকেই শিখে চলে, model ধীরে ধীরে নতুন নিয়ম শিখে নেয়, আর accuracy আবার \(\approx 0.83\)-তে ফিরে আসে। এই পুনরুদ্ধারই online learning-কে drifting environment-এর জন্য আদর্শ করে তোলে: batch-retraining-এ যেখানে পুরো model নতুন করে গড়তে হতো, সেখানে একটা online learner কেবল স্রোতের সঙ্গে ভেসে নিজেকে সারিয়ে নেয়। মূল শিক্ষা — V-আকৃতির এই খাঁজটাই বাস্তব streaming system-এর জীবনচিত্র: শেখা সহজ, কিন্তু পৃথিবী বদলায়, আর তখন যে model বদলাতে পারে সে-ই টিকে থাকে।
৭ · অনুশীলনী¶
প্রতিটি প্রশ্নে difficulty tag (★ সহজ · ★★ মাঝারি · ★★★ চ্যালেঞ্জিং) ও একটি hint। পূর্ণ সমাধান _solutions/06-09-anomaly-semisup-online-solutions.md-এ। নিজে চেষ্টা করার আগে সমাধান দেখবেন না — কী একটা বিন্দুকে anomaly বানায় (rare + স্বাভাবিক-গঠনের বাইরে), চারটি anomaly-পরিবার (statistical/density/isolation/boundary — কে কোন স্বজ্ঞায় outlier মাপে ও কখন কোনটা), Mahalanobis χ²-থ্রেশহোল্ড (\(D_M^2(x)=(x-\mu)^\top\Sigma^{-1}(x-\mu)\) হাতে গুনে \(\chi^2_p\) cutoff-এর সঙ্গে তুলনা), class-imbalance-এ accuracy কেন বিভ্রান্তিকর (precision/recall/ROC AUC কেন বেশি অর্থপূর্ণ), Isolation Forest-এর short-path স্বজ্ঞা (anomaly আগে আলাদা হয়, পথ ছোট, score উঁচু), LOF-এর local-density অনুপাত (নিজের ঘনত্ব বনাম প্রতিবেশীর), semi-supervised তিন অনুমান (cluster/manifold/smoothness) ও unlabeled কেন সাহায্য করে (canonical \(0.833\to0.989\)), label propagation = graph-এ diffusion (\(L=D-W\)), online learning-এর update ও regret (\(\theta_{t+1}=\theta_t-\eta_t\nabla\ell_t\), \(R_T\) sublinear), এবং দুটো coding প্রশ্ন (চারটি anomaly detector + ROC AUC; semi-sup label spreading) — এই হাতে-কলমে বোঝাই এই অধ্যায়ের, তথা পুরো Part VI-এর, প্রয়োগমুখী শেখা।
(চলমান উদাহরণ স্মারক — seed-সূচক random_state=20260619। anomaly dataset: \(285\) inlier (একটা কেন্দ্রীয় Gaussian গুচ্ছ) + \(15\) ring-outlier (চারপাশে একটা বলয়ে ছড়ানো) = \(300\) বিন্দু, contamination \(\nu=15/300=0.05\) (৫%)। semi-sup dataset: make_moons(n_samples=300, noise=0.15), যার মাত্র ~১০% label দেওয়া। canonical সংখ্যা — anomaly ROC AUC: Isolation Forest \(1.000\), LOF \(1.000\), One-Class SVM \(0.941\), Elliptic Envelope (Mahalanobis) \(1.000\); IF @ ৫%-cutoff: precision \(1.00\), recall \(1.00\)। semi-sup accuracy: labeled-only \(0.833\) → LabelSpreading \(0.989\) (gain \(\approx0.156\))। মূল notation: \(D_M^2(x)=(x-\mu)^\top\Sigma^{-1}(x-\mu)\sim\chi^2_p\); anomaly score \(s(x)\); graph Laplacian \(L=D-W\); online update \(\theta_{t+1}=\theta_t-\eta_t\nabla\ell_t\), regret \(R_T\)।)
ক · ধারণাগত (conceptual)¶
প্রশ্ন ১ (★). কী একটা বিন্দুকে anomaly বানায়। anomaly detection-এর কেন্দ্রীয় ধারণা: কিছু বিন্দু "স্বাভাবিক" বাকি data-র গঠন থেকে এতটাই আলাদা যে সন্দেহ হয় তারা ভিন্ন প্রক্রিয়া থেকে এসেছে। (ক) এক বাক্যে: একটা বিন্দুকে anomaly (বা outlier) বলার দুটো অপরিহার্য শর্ত কী — সংখ্যায় rare হওয়া, আর data-র মূল গঠন/density থেকে দূরে থাকা? (খ) novelty detection ও outlier detection-এর পার্থক্য কী — কোনটায় training data পরিষ্কার-স্বাভাবিক ধরে নিয়ে পরে নতুন বিচ্যুতি ধরা হয়, আর কোনটায় training data-তেই দূষণ (contamination) মিশে থাকে? (গ) এই অধ্যায়ের anomaly dataset-এ contamination \(\nu\) কত (১৫টা outlier মোট ৩০০ বিন্দুতে), আর \(\nu\) আগে-থেকে আন্দাজ জানা detector-কে কীভাবে সাহায্য করে (কোন fraction-কে anomaly ছাঁটতে হবে তা ঠিক করতে)?
Hint: (ক) anomaly = (i) rare (অল্পসংখ্যক) এবং (ii) স্বাভাবিক data-র গঠন/density থেকে স্পষ্টভাবে দূরে — শুধু বিরল নয়, "বেমানান"-ও; দুটো একসাথে। (খ) novelty detection — training set ধরা হয় পুরো-স্বাভাবিক, model স্বাভাবিকতা শেখে, পরে নতুন বিচ্যুতি ধরে (semi-supervised anomaly); outlier detection — training data-তেই \(\nu\) ভগ্নাংশ দূষণ আছে, model unsupervised-ভাবে গরিষ্ঠ-গঠন থেকে বিচ্যুত বিন্দু চেনে। (গ) \(\nu=15/300=0.05\) (৫%); \(\nu\) জানা থাকলে detector score-এর উপরের ৫% বিন্দুকে anomaly হিসেবে ছাঁটতে পারে (যেমন contamination=0.05) — থ্রেশহোল্ড স্থির করার সরাসরি উপায়।
প্রশ্ন ২ (★). চারটি anomaly-পরিবার — কে কীভাবে outlier মাপে। এই অধ্যায় anomaly detector-দের চারটি স্বজ্ঞাগত পরিবারে সাজায়: statistical (Mahalanobis/Elliptic Envelope), density (LOF), isolation (Isolation Forest), boundary (One-Class SVM)। (ক) প্রতিটি পরিবার এক বাক্যে: একটা বিন্দুকে কীসের ভিত্তিতে anomaly বলে — (i) fitted বণ্টন-কেন্দ্র থেকে দূরত্ব, (ii) প্রতিবেশীর তুলনায় কম local density, (iii) এলোমেলো বিভাজনে সহজে আলাদা হওয়া (ছোট পথ), (iv) শেখা স্বাভাবিক-অঞ্চলের সীমানার বাইরে পড়া — কোনটা কোন পরিবার? (খ) statistical (Elliptic) পরিবার কোন গঠন ধরে নেয় (data মোটামুটি একটা Gaussian/উপবৃত্তীয় গুচ্ছ), আর সেই অনুমান ভাঙলে (যেমন একাধিক গুচ্ছ বা বাঁকা manifold) কে বেশি নির্ভরযোগ্য — density/isolation, না statistical? (গ) এক বাক্যে: কেন একাধিক পরিবার চালিয়ে তুলনা করা ভালো অভ্যাস (প্রতিটির অনুমান ভিন্ন বলে ভিন্ন ধরনের anomaly ধরে)? Hint: (ক) (i) দূরত্ব-কেন্দ্র = statistical; (ii) কম local density = density (LOF); (iii) সহজে-isolation/ছোট পথ = isolation (Isolation Forest); (iv) স্বাভাবিক-সীমানার বাইরে = boundary (One-Class SVM)। (খ) Elliptic Envelope ধরে নেয় inlier-রা একটা একক Gaussian/উপবৃত্তে বসে; এই অনুমান ভাঙলে (multi-modal, বাঁকা) density (LOF)/isolation (IF) বেশি robust — তারা global বণ্টন-আকার ধরে না, local গঠন বা বিভাজন-সহজতা দেখে। (গ) প্রতিটি পরিবারের অনুমান/দুর্বলতা আলাদা, তাই একটার অন্ধবিন্দু আরেকটা ধরতে পারে — ensemble/তুলনা বেশি নির্ভরযোগ্য (canonical-এ IF/LOF/Elliptic \(1.000\) কিন্তু OC-SVM \(0.941\) — পরিবার-ভেদে পার্থক্য স্পষ্ট)।
প্রশ্ন ৩ (★). Isolation Forest — short-path স্বজ্ঞা। Isolation Forest (৬.৫-এর tree/ensemble-চিন্তার সম্প্রসারণ) এলোমেলোভাবে একটা feature ও একটা split-মান বেছে data-কে বারবার দু-ভাগ করে, যতক্ষণ না প্রতিটি বিন্দু একা একটা পাতায় আলাদা হয়; একটা বিন্দুর path length \(h(x)\) = তাকে আলাদা করতে যত split লাগল। (ক) এক বাক্যে: কেন একটা anomaly সাধারণত কম split-এ (ছোট \(h\)) আলাদা হয়, আর একটা ঘন-গুচ্ছের inlier বেশি split লাগে (বড় \(h\))? (খ) anomaly score \(s(x)=2^{-\mathbb E[h(x)]/c(n)}\) (\(c(n)\) = \(n\) বিন্দুর প্রত্যাশিত path length, normalizer): ছোট \(h\) হলে \(s\) কি \(1\)-এর দিকে যায় না \(0\)-এর দিকে, আর কোন দিক anomaly নির্দেশ করে? (গ) canonical-এ Isolation Forest-এর ROC AUC \(1.000\) ও ৫%-cutoff-এ precision/recall দুটোই \(1.00\) — এই dataset-এ (ঘন কেন্দ্র + ছড়ানো ring) IF কেন এত ভালো (ring-outlier বিরল ও বিচ্ছিন্ন বলে দ্রুত isolate হয়)? Hint: (ক) anomaly বিরল ও বিচ্ছিন্ন, তাই এলোমেলো একটা split প্রায়ই তাকে বাকিদের থেকে তাড়াতাড়ি কেটে আলাদা করে দেয় — ছোট \(h\); ঘন গুচ্ছের ভেতরের বিন্দু চারপাশে অনেক প্রতিবেশী বলে আলাদা করতে অনেক split লাগে — বড় \(h\)। (খ) \(h\) ছোট ⇒ exponent \(-h/c(n)\) ছোট-ঋণাত্মক ⇒ \(s\to1\); \(s\approx1\) = anomaly, \(s\approx0.5\)-এর নিচে = inlier (গড়-গভীরতা)। (গ) ring-outlier কেন্দ্রীয় গুচ্ছ থেকে দূরে ও ছড়ানো, তাই random split-এ খুব দ্রুত isolate হয় (ছোট \(h\), উঁচু \(s\)) — IF নিখুঁতভাবে আলাদা করে (AUC \(1.000\), precision/recall \(1.00\))।
প্রশ্ন ৪ (★). LOF — local-density অনুপাত। Local Outlier Factor (LOF) প্রতিটি বিন্দুর জন্য একটা local density (প্রতিবেশীরা কত কাছে — কাছাকাছি = উঁচু density) আন্দাজ করে, তারপর সেই বিন্দুর density-কে তার প্রতিবেশীদের গড় density-র সঙ্গে তুলনা করে: \(\mathrm{LOF}(x)\approx \dfrac{\text{প্রতিবেশীদের গড় local density}}{x\text{-এর নিজের local density}}\)। (ক) এক বাক্যে: \(\mathrm{LOF}(x)\approx1\), \(\gg1\), আর \(<1\) — প্রতিটি কী বলে (যথাক্রমে প্রতিবেশীর মতোই ঘন; প্রতিবেশীর তুলনায় অনেক বিরল = outlier; প্রতিবেশীর চেয়েও ঘন)? (খ) LOF কেন local — একটা global density-থ্রেশহোল্ডের বদলে কেন প্রতিবেশীর-তুলনা ব্যবহার করে (data-র কোথাও ঘন কোথাও পাতলা গুচ্ছ থাকলে কী সুবিধা)? (গ) canonical-এ LOF-এর ROC AUC \(1.000\) — ring-outlier কেন্দ্রীয় গুচ্ছের তুলনায় অনেক পাতলাভাবে ছড়ানো; এক বাক্যে কেন LOF এদের ধরে (নিজের density নিচু, কিন্তু প্রতিবেশী/কেন্দ্রের density উঁচু ⇒ অনুপাত বড়)? Hint: (ক) \(\mathrm{LOF}\approx1\) = বিন্দুর density প্রতিবেশীর মতোই (inlier); \(\mathrm{LOF}\gg1\) = প্রতিবেশীর তুলনায় density অনেক কম ⇒ outlier; \(\mathrm{LOF}<1\) = প্রতিবেশীর চেয়েও ঘন (গুচ্ছ-কেন্দ্র)। (খ) global threshold ধরে নেয় সব জায়গায় একই density; কিন্তু বাস্তবে ঘন ও পাতলা গুচ্ছ পাশাপাশি থাকতে পারে — আপেক্ষিক (প্রতিবেশীর-সাপেক্ষ) density পাতলা গুচ্ছের স্বাভাবিক বিন্দুকে ভুলভাবে outlier বলা এড়ায়। (গ) ring-outlier নিজের আশেপাশে পাতলা (নিচু density), কিন্তু তার নিকটতম-প্রতিবেশীরা (বা গঠন) তুলনায় ঘন ⇒ অনুপাত বড় (\(\mathrm{LOF}\gg1\)) ⇒ ধরা পড়ে (AUC \(1.000\))।
প্রশ্ন ৫ (★★). class-imbalance-এ accuracy কেন বিভ্রান্তিকর। anomaly detection-এ class ভয়ানক imbalanced — এখানে \(285\) inlier বনাম মাত্র \(15\) anomaly (\(95\%\) বনাম \(5\%\))। (ক) একটা trivial detector যে সব বিন্দুকে "inlier" বলে — তার accuracy কত হবে এই dataset-এ, আর সে আসলে কয়টা anomaly ধরল? এক সংখ্যায় দেখান কেন উঁচু accuracy এখানে অর্থহীন। (খ) precision (\(=\frac{TP}{TP+FP}\), যাকে anomaly বললাম তার কত ভাগ সত্যিই anomaly) ও recall (\(=\frac{TP}{TP+FN}\), সত্যিকার anomaly-র কত ভাগ ধরলাম) — কোন প্রশ্নের উত্তর দেয়, আর কেন এই দুটো imbalanced সমস্যায় accuracy-র চেয়ে বেশি অর্থপূর্ণ? (গ) ROC AUC কী মাপে (threshold-নিরপেক্ষভাবে detector একটা এলোমেলো anomaly-কে এলোমেলো inlier-এর চেয়ে উঁচু score দেওয়ার সম্ভাবনা), আর canonical-এ IF/LOF/Elliptic-এর \(1.000\) বনাম OC-SVM-এর \(0.941\) — এই AUC-পার্থক্য কী বলছে? Hint: (ক) trivial "সব inlier" detector-এর accuracy \(=285/300=0.95\) (\(95\%\)!) অথচ recall \(=0/15=0\) — একটাও anomaly ধরেনি; তাই উঁচু accuracy এখানে সম্পূর্ণ বিভ্রান্তিকর (গরিষ্ঠ শ্রেণিই accuracy-কে ফুলিয়ে দেয়)। (খ) precision = "আমার anomaly-অ্যালার্মগুলো কতটা সত্য" (false alarm-এর বিপরীত); recall = "সত্যিকার anomaly-র কতটা ধরলাম" (miss-এর বিপরীত); rare-শ্রেণিতে এরা সরাসরি দরকারি দিক মাপে, accuracy গরিষ্ঠ-শ্রেণিতে ডুবে যায়। (গ) ROC AUC = threshold না বেছেই detector-এর ranking-গুণ: random anomaly-কে random inlier-এর উপরে রাখার সম্ভাবনা (\(1.0\) = নিখুঁত আলাদা, \(0.5\) = এলোমেলো); IF/LOF/Elliptic \(1.000\) = নিখুঁত পৃথকীকরণ, OC-SVM \(0.941\) = খুব ভালো কিন্তু কিছু overlap (এই ring-গঠনে boundary-পদ্ধতি সামান্য পিছিয়ে)।
প্রশ্ন ৬ (★★). semi-supervised — তিন অনুমান ও unlabeled কেন সাহায্য করে। semi-supervised learning অল্প label-যুক্ত + বহু label-হীন বিন্দু একসাথে ব্যবহার করে। কিন্তু unlabeled data কাজে লাগে কেবল যদি data-র গঠন label-এর সঙ্গে সম্পর্কিত হয় — তিনটি মূল অনুমান: smoothness (কাছের দুই বিন্দুর label সম্ভবত এক), cluster (একই গুচ্ছের বিন্দু সম্ভবত একই শ্রেণি; decision boundary কম-ঘনত্বের অঞ্চলে), manifold (data একটা নিম্ন-মাত্রিক manifold-এ বসে, label সেই manifold বরাবর মসৃণভাবে বদলায় — ৬.৮-এর সঙ্গে সরাসরি যোগ)। (ক) এই তিন অনুমান এক বাক্যে করে নিজের ভাষায় বলুন। (খ) এই অধ্যায়ের make_moons dataset-এ দুটো বাঁকা চাঁদ-আকৃতির গুচ্ছ; কোন অনুমান এখানে সবচেয়ে প্রাসঙ্গিক (boundary দুই চাঁদের মাঝের কম-ঘনত্ব ফাঁকে, আর label প্রতিটি বাঁকা চাঁদ = manifold বরাবর মসৃণ)? (গ) canonical: শুধু label-যুক্ত বিন্দু দিয়ে accuracy \(0.833\), কিন্তু unlabeled যোগ করে LabelSpreading-এ \(0.989\) — এই \(0.156\) লাফ এক বাক্যে কী প্রমাণ করে (unlabeled বিন্দুগুলো গুচ্ছ/manifold-গঠন ফাঁস করে boundary-কে কম-ঘনত্বে ঠেলে দেয়)?
Hint: (ক) smoothness — কাছের বিন্দু ⇒ একই label; cluster — একই গুচ্ছ ⇒ একই শ্রেণি, boundary কম-ঘনত্বের ফাঁকে; manifold — data low-D বাঁকা পৃষ্ঠে, label সেই পৃষ্ঠ বরাবর মসৃণ (Euclidean-এ কাছে নয়, manifold-এ কাছে যা গুরুত্বপূর্ণ)। (খ) দুটোই: cluster/low-density-separation (দুই চাঁদের মাঝের ফাঁকে boundary) ও manifold (প্রতিটি চাঁদ একটা বাঁকা ১D-মতো গঠন, label তার বরাবর স্থির)। (গ) labeled-only (\(0.833\)) কেবল কয়েকটা বিন্দু দেখে সরল boundary টানে; unlabeled বিন্দুগুলো চাঁদের পুরো বাঁকা আকৃতি ও মাঝের ফাঁক দেখিয়ে দেয়, তাই LabelSpreading boundary-কে সঠিক কম-ঘনত্ব-ফাঁকে বসায় ⇒ \(0.989\) (গঠন label ছড়াতে সাহায্য করল)।
প্রশ্ন ৭ (★★). label propagation = graph-এ diffusion। label propagation/spreading প্রতিটি বিন্দুকে একটা node ধরে, কাছের বিন্দুদের edge \(w_{ij}\) (similarity, কাছে = বড়) দিয়ে জোড়ে একটা graph বানায়, তারপর জানা-label-গুলোকে edge বরাবর ছড়িয়ে (diffuse) অজানা label পূরণ করে — তাপ যেমন গরম থেকে ঠান্ডায় ছড়ায়। graph Laplacian \(L=D-W\) (\(W\) = similarity matrix, \(D\) = degree-diagonal \(D_{ii}=\sum_j w_{ij}\))। (ক) এক বাক্যে: কেন কাছাকাছি বিন্দুরা (বড় \(w_{ij}\)) propagation-এ প্রায় একই label-এ পৌঁছায় — diffusion কীভাবে smoothness অনুমানকে বাস্তবায়িত করে? (খ) Laplacian-এর quadratic form \(f^\top L f=\tfrac12\sum_{i,j}w_{ij}(f_i-f_j)^2\) একটা label-বিন্যাস \(f\)-এর "অমসৃণতা" মাপে; propagation কার্যত এটি ছোট করে (edge-যুক্ত বিন্দুর label কাছাকাছি রাখে) — এক বাক্যে কেন এটি ঠিক smoothness/cluster অনুমানেরই গাণিতিক রূপ? (গ) label propagation (clamped — জানা label স্থির) ও label spreading (normalized Laplacian + soft clamping, label-noise-এ একটু বেশি সহনশীল) — মূল পার্থক্য এক বাক্যে; এই অধ্যায়ে LabelSpreading \(0.989\) পায়। Hint: (ক) বড় \(w_{ij}\) মানে \(i,j\) কাছাকাছি; diffusion-এ label edge-অনুপাতে গড় হয়, তাই দৃঢ়-সংযুক্ত (কাছের) বিন্দুরা একে অপরের label টেনে নেয় ⇒ একই label — এটাই "কাছের ⇒ একই label" (smoothness) বাস্তবায়ন। (খ) \(f^\top L f=\tfrac12\sum w_{ij}(f_i-f_j)^2\) বড় হয় যখন edge-যুক্ত (কাছের) বিন্দুর label খুব ভিন্ন; ছোট করা মানে কাছের বিন্দুর label মেলানো — হুবহু smoothness/cluster অনুমান (boundary কম-ঘনত্বে, কারণ ঘন অঞ্চলে \(w_{ij}\) বড় বলে label বদলালে penalty বেশি)। (গ) propagation — হার্ড-clamp (জানা label কখনো বদলায় না), unnormalized; spreading — normalized Laplacian \(\mathcal L=D^{-1/2}LD^{-1/2}\) + soft clamp (জানা label সামান্য বদলাতে পারে), তাই ভুল/noisy label-এ বেশি robust।
প্রশ্ন ৮ (★★). online learning — incremental update ও regret। online (streaming) learning-এ data এক-এক করে স্রোতে আসে; প্রতি ধাপে model একটা বিন্দু \((\,x_t,y_t)\) দেখে, ক্ষতি \(\ell_t(\theta_t)\) নেয়, আর প্যারামিটার আপডেট করে: \(\theta_{t+1}=\theta_t-\eta_t\nabla\ell_t(\theta_t)\) (online/stochastic gradient descent; \(\eta_t\) = learning rate)। (ক) batch learning (একসাথে সব data) থেকে এর দুটো বাস্তব সুবিধা এক বাক্যে — (i) সব data একসাথে মেমরিতে লাগে না, (ii) বণ্টন বদলালে (concept drift) model নিজে মানিয়ে নেয়? (খ) regret \(R_T=\sum_{t=1}^T \ell_t(\theta_t)-\min_{\theta^\*}\sum_{t=1}^T \ell_t(\theta^\*)\) কী মাপে — online learner-এর মোট ক্ষতি বনাম পিছন-ফিরে-জানা সেরা স্থির \(\theta^\*\)-এর ক্ষতির ব্যবধান? (গ) একটা ভালো online algorithm-এ \(R_T\) sublinear (\(R_T=o(T)\), যেমন \(O(\sqrt T)\)); এক বাক্যে কেন sublinear regret মানে average regret \(R_T/T\to0\) — অর্থাৎ প্রতি-ধাপে গড়ে learner শেষমেশ সেরা স্থির কৌশলের সমান-ভালো হয়ে যায়? Hint: (ক) (i) প্রতি ধাপে কেবল একটা (বা ছোট mini-batch) বিন্দু লাগে — বিশাল/অসীম স্রোতেও চলে, সব একসাথে রাখতে হয় না; (ii) \(\theta\) ক্রমাগত আপডেট হয় বলে data-বণ্টন সময়ের সঙ্গে সরলে (concept drift) model আপনাআপনি নতুন বণ্টনে সরে যায়। (খ) \(R_T\) = online learner যা ক্ষতি ভোগ করল, বিয়োগ পুরো sequence আগে-থেকে-জেনে বাছা সেরা একক স্থির \(\theta^\*\)-র ক্ষতি — অর্থাৎ "online বলে কতটা পিছিয়ে রইলাম"। (গ) sublinear মানে \(R_T\) \(T\)-এর চেয়ে ধীরে বাড়ে, তাই \(R_T/T\to0\) (\(T\to\infty\)) — গড়-ক্ষতিতে learner asymptotically সেরা স্থির কৌশলের সমান, যদিও সে data আগে দেখেনি (এটাই online learning-এর সাফল্যের সংজ্ঞা)।
খ · গণনামূলক (computational)¶
প্রশ্ন ৯ (★★). Mahalanobis \(D_M^2\) ও χ²-থ্রেশহোল্ড — diagonal Σ। statistical anomaly detection (Elliptic Envelope-এর হৃদয়) ধরে নেয় inlier-রা একটা Gaussian \(\mathcal N(\mu,\Sigma)\)-এ বসে, আর একটা বিন্দুর Mahalanobis দূরত্ব-বর্গ \(D_M^2(x)=(x-\mu)^\top\Sigma^{-1}(x-\mu)\) বড় হলে তাকে anomaly বলে; মূল ফল (২.৪) — Gaussian-এ \(D_M^2(x)\sim\chi^2_p\) (\(p\) = মাত্রা)। ধরুন \(p=2\), \(\mu=(0,0)\), \(\Sigma=\begin{pmatrix}4&0\\0&1\end{pmatrix}\) (অর্থাৎ \(x\)-অক্ষে variance \(4\), \(y\)-অক্ষে \(1\), uncorrelated)। একটা সন্দেহভাজন বিন্দু \(x=(3,2)\)। (ক) \(\Sigma^{-1}\) বের করুন (diagonal বলে সহজ), তারপর \(D_M^2(x)\) গণনা করুন। (খ) \(5\%\) স্তরে cutoff হলো \(\chi^2_{2,0.95}=5.991\); \(D_M^2(x)\) এর সঙ্গে তুলনা করে বলুন বিন্দুটি anomaly হিসেবে flag হবে কি না, আর আনুমানিক p-value (\(P(\chi^2_2>D_M^2)\)) কত। (গ) এক বাক্যে: কেন plain Euclidean দূরত্ব (\(\lVert x-\mu\rVert\)) এখানে ভুল হতো — \(\Sigma^{-1}\) কী কাজ করছে (প্রতিটি অক্ষকে তার variance দিয়ে স্কেল করে, যাতে "কত standard-deviation দূরে" মাপা হয়)? Hint: (ক) \(\Sigma^{-1}=\begin{pmatrix}1/4&0\\0&1\end{pmatrix}=\begin{pmatrix}0.25&0\\0&1\end{pmatrix}\); \(D_M^2=(3,2)\begin{pmatrix}0.25&0\\0&1\end{pmatrix}\binom{3}{2}=0.25\cdot3^2+1\cdot2^2=2.25+4=6.25\)। (খ) \(6.25>5.991\) ⇒ flag (anomaly) ৫% স্তরে; p-value \(=P(\chi^2_2>6.25)\approx0.044\) (\(<0.05\))। (গ) Euclidean দূরত্ব \(\sqrt{3^2+2^2}=\sqrt{13}\) সব অক্ষকে সমান ধরত; কিন্তু \(x\)-অক্ষে spread বেশি (\(\sigma_x=2\)), তাই \(3\) আসলে মাত্র \(1.5\sigma_x\) — \(\Sigma^{-1}\) প্রতিটি অক্ষকে তার নিজ variance দিয়ে ভাগ করে "কত \(\sigma\) দূরে" মাপে, correlated/অসম-variance data-তে যা সঠিক।
প্রশ্ন ১০ (★★). Mahalanobis — correlated Σ ও χ²-cutoff। আগের প্রশ্নের সম্প্রসারণ, এবার correlation সহ। \(p=2\), \(\mu=(0,0)\), \(\Sigma=\begin{pmatrix}1&0.8\\0.8&1\end{pmatrix}\) (দুই feature দৃঢ়ভাবে positively correlated)। বিন্দু \(x=(2,-1)\) — লক্ষ্য করুন এটা correlation-এর বিপরীত দিকে (একটা ধনাত্মক, একটা ঋণাত্মক, যেখানে data সাধারণত একসাথে বাড়ে/কমে)। (ক) \(\det\Sigma\) ও \(\Sigma^{-1}=\frac{1}{\det\Sigma}\begin{pmatrix}1&-0.8\\-0.8&1\end{pmatrix}\) বের করুন। (খ) \(D_M^2(x)=(x-\mu)^\top\Sigma^{-1}(x-\mu)\) গণনা করুন, আর \(\chi^2_{2,0.95}=5.991\) (এমনকি \(\chi^2_{2,0.99}=9.210\)) এর সঙ্গে তুলনা করুন — flag হবে? (গ) এক বাক্যে: \(x=(2,-1)\) Euclidean-ভাবে কেন্দ্র থেকে খুব দূরে নয় (\(\sqrt5\approx2.24\)), তবু \(D_M^2\) বিশাল কেন — correlation-structure কীভাবে এই "correlation-বিরোধী" বিন্দুকে শক্তভাবে anomaly বানায়? Hint: (ক) \(\det\Sigma=1\cdot1-0.8\cdot0.8=1-0.64=0.36\); \(\Sigma^{-1}=\frac{1}{0.36}\begin{pmatrix}1&-0.8\\-0.8&1\end{pmatrix}\approx\begin{pmatrix}2.778&-2.222\\-2.222&2.778\end{pmatrix}\)। (খ) \(D_M^2=2.778\cdot2^2+2\cdot(-2.222)\cdot(2)(-1)+2.778\cdot(-1)^2=11.11+8.89+2.78=22.78\); \(22.78\gg9.210\) ⇒ জোরালোভাবে flag (p-value \(\approx0\))। (গ) data দুই feature একসাথে বাড়ে/কমে (positive correlation); \((2,-1)\) ঠিক উল্টো প্যাটার্ন — তাই Euclidean-এ কাছে হলেও correlation-অক্ষ বরাবর বহু-\(\sigma\) দূরে, \(\Sigma^{-1}\) এই off-diagonal গঠন ধরে \(D_M^2\) ফুলিয়ে তোলে।
প্রশ্ন ১১ (★★). precision/recall/accuracy হাতে — imbalanced confusion matrix। এই অধ্যায়ের dataset: \(300\) বিন্দু, \(15\) সত্যিকার anomaly (\(285\) inlier)। একটা detector ৫%-cutoff-এ ঠিক \(15\) বিন্দুকে anomaly বলল, যার মধ্যে \(12\) সত্যিই anomaly আর \(3\) ভুল-অ্যালার্ম (inlier)। (ক) confusion matrix সাজান: \(TP, FP, FN, TN\) বের করুন (মনে রাখুন anomaly = positive)। (খ) precision, recall, ও accuracy তিনটি গণনা করুন। (গ) এখন canonical IF-এর সঙ্গে তুলনা: IF ৫%-cutoff-এ precision \(1.00\), recall \(1.00\) — অর্থাৎ \(TP=15, FP=0, FN=0\); এক বাক্যে কেন এই (precision, recall) জোড়া accuracy-র (\(1.00\)) চেয়ে স্পষ্ট ছবি দেয় (accuracy এমনকি খারাপ detector-এও উঁচু থাকত)? Hint: (ক) \(TP=12\) (সত্য anomaly ধরা), \(FP=3\) (inlier-কে ভুলে anomaly বলা), \(FN=15-12=3\) (anomaly miss), \(TN=285-3=282\)। (খ) precision \(=\frac{12}{12+3}=\frac{12}{15}=0.80\); recall \(=\frac{12}{12+3}=\frac{12}{15}=0.80\); accuracy \(=\frac{TP+TN}{300}=\frac{12+282}{300}=\frac{294}{300}=0.98\)। (গ) IF-এর precision/recall \(1.00\) (এই দুর্বল detector \(0.80\)) সরাসরি বলে "সব anomaly নিখুঁতভাবে, কোনো false alarm ছাড়া" — অথচ accuracy-তে পার্থক্য নগণ্য: এই দুর্বল detector-ও accuracy \(0.98\) পায়, নিখুঁত IF পায় \(1.00\), কারণ \(282\) TN (৯৪%) দুজনেরই accuracy ফুলিয়ে দেয়; অর্থাৎ একটা খারাপ anomaly-detector-ও ৫% contamination-এ ~\(0.98\) accuracy দেখাতে পারে, তাই accuracy বিভ্রান্তিকর — rare-শ্রেণিতে precision/recall ভেদ ধরে, accuracy নয়।
প্রশ্ন ১২ (★★). online gradient step হাতে। online learning-এ একটা সরল linear regression model \(f(x)=\theta x\) (এক feature) এক-এক বিন্দু দেখে আপডেট হয়; per-example squared loss \(\ell_t(\theta)=\tfrac12(\theta x_t-y_t)^2\), gradient \(\nabla\ell_t=(\theta x_t-y_t)x_t\), update \(\theta_{t+1}=\theta_t-\eta\,\nabla\ell_t\)। ধরুন \(\theta_0=0\), learning rate \(\eta=0.1\), আর স্রোতে আসে \((x_1,y_1)=(2,4)\) তারপর \((x_2,y_2)=(1,3)\)। (ক) প্রথম বিন্দুতে prediction \(\theta_0 x_1\), error, gradient ও \(\theta_1\) বের করুন। (খ) দ্বিতীয় বিন্দুতে (নতুন \(\theta_1\) দিয়ে) একই ভাবে \(\theta_2\) বের করুন। (গ) এক বাক্যে: \(\theta\) কোন দিকে সরছে (সত্যিকার সম্পর্ক \(y\approx2x\)-এর দিকে?) আর batch-এর বদলে এক-এক বিন্দুতে আপডেট করায় online learning-এর মূল চরিত্র কী (প্রতিটি নতুন observation সঙ্গে সঙ্গে \(\theta\)-কে নাড়ায়)? Hint: (ক) prediction \(\theta_0 x_1=0\cdot2=0\); error \(=\theta_0 x_1-y_1=0-4=-4\); gradient \(=(-4)(2)=-8\); \(\theta_1=0-0.1\cdot(-8)=0.8\)। (খ) prediction \(\theta_1 x_2=0.8\cdot1=0.8\); error \(=0.8-3=-2.2\); gradient \(=(-2.2)(1)=-2.2\); \(\theta_2=0.8-0.1\cdot(-2.2)=0.8+0.22=1.02\)। (গ) \(\theta\) \(0\to0.8\to1.02\) — সত্যিকার ঢাল (\(y\approx2x\) ⇒ \(\theta\approx2\))-এর দিকে বাড়ছে; প্রতিটি বিন্দু আসামাত্র \(\theta\) আপডেট হয় (পুরো data-র দরকার নেই), এটাই online/streaming learning — incremental, drift-সচেতন।
গ · প্রমাণভিত্তিক (proof-based)¶
প্রশ্ন ১৩ (★★★). Mahalanobis \(\to\chi^2_p\) — কেন। statistical anomaly detection-এর χ²-থ্রেশহোল্ডের ভিত্তি এই ফল: \(X\sim\mathcal N_p(\mu,\Sigma)\) (\(\Sigma\) positive-definite) হলে \(D_M^2(X)=(X-\mu)^\top\Sigma^{-1}(X-\mu)\sim\chi^2_p\)। ধাপে ধাপে দেখান। (ক) whitening। \(\Sigma\) symmetric positive-definite, তাই একটা symmetric square-root \(\Sigma^{1/2}\) আছে (\(\Sigma=\Sigma^{1/2}\Sigma^{1/2}\), \(\Sigma^{-1/2}=(\Sigma^{1/2})^{-1}\))। সংজ্ঞা \(Z=\Sigma^{-1/2}(X-\mu)\)। দেখান \(Z\sim\mathcal N_p(0,I_p)\) — অর্থাৎ \(\mathbb E[Z]=0\) ও \(\mathrm{Cov}(Z)=I_p\) (linear transform-এ Gaussian Gaussian-ই থাকে; mean ও covariance হিসাব করুন)। (খ) \(D_M^2\)-কে \(Z\)-তে লিখুন। দেখান \(D_M^2(X)=(X-\mu)^\top\Sigma^{-1}(X-\mu)=Z^\top Z=\sum_{k=1}^p Z_k^2\)। (গ) χ²-উপসংহার। \(Z=(Z_1,\dots,Z_p)\)-এর উপাদানগুলো i.i.d. \(\mathcal N(0,1)\) (কারণ \(\mathrm{Cov}(Z)=I\)); স্বাধীন standard-normal-এর বর্গের যোগফল সংজ্ঞা-অনুযায়ী \(\chi^2\) — তাই \(\sum_k Z_k^2\sim\chi^2_p\)। এক বাক্যে বলুন এটাই কেন \(\chi^2_p\)-cutoff (প্রশ্ন ৯–১০-এর \(5.991\)) বৈধ anomaly-থ্রেশহোল্ড দেয়। Hint: (ক) \(\mathbb E[Z]=\Sigma^{-1/2}\mathbb E[X-\mu]=0\); \(\mathrm{Cov}(Z)=\Sigma^{-1/2}\mathrm{Cov}(X-\mu)\Sigma^{-1/2}=\Sigma^{-1/2}\Sigma\,\Sigma^{-1/2}=\Sigma^{-1/2}\Sigma^{1/2}\Sigma^{1/2}\Sigma^{-1/2}=I_p\); affine map বলে \(Z\) Gaussian, তাই \(Z\sim\mathcal N_p(0,I)\)। (খ) \(Z^\top Z=(X-\mu)^\top\Sigma^{-1/2}\Sigma^{-1/2}(X-\mu)=(X-\mu)^\top\Sigma^{-1}(X-\mu)=D_M^2\) (যেহেতু \(\Sigma^{-1/2}\Sigma^{-1/2}=\Sigma^{-1}\), symmetric)। (গ) \(\mathrm{Cov}(Z)=I\) ⇒ \(Z_k\) uncorrelated, আর jointly-Gaussian-এ uncorrelated ⇒ স্বাধীন; \(p\)টি স্বাধীন \(\mathcal N(0,1)^2\)-এর যোগ \(=\chi^2_p\) — তাই \(D_M^2\sim\chi^2_p\), এবং \(P(\chi^2_p>c)=\alpha\) থেকে cutoff \(c\) এমন threshold দেয় যাতে স্বাভাবিক বিন্দুর মাত্র \(\alpha\) ভগ্নাংশ ভুলে flag হয় (নিয়ন্ত্রিত false-positive হার)।
প্রশ্ন ১৪ (★★★). label propagation আসলে graph-Laplacian-অমসৃণতা ছোট করে। label spreading/propagation-কে একটা optimization হিসেবে দেখা যায়: একটা label-ফাংশন \(f:\text{nodes}\to\mathbb R\) খোঁজা যা (i) জানা label-এ মোটামুটি মেনে চলে আর (ii) graph-এ মসৃণ। অমসৃণতা-পদটা হলো \(f^\top L f\), যেখানে \(L=D-W\) graph Laplacian (\(W\) symmetric similarity, \(W_{ij}=w_{ij}\ge0\); \(D\) diagonal, \(D_{ii}=\sum_j w_{ij}\))। দেখান এই quadratic form ঠিক edge-জুড়ে label-পার্থক্যের ভারিত যোগফল — যা smoothness-অনুমানের সরাসরি রূপ। (ক) সংজ্ঞা থেকে শুরু করে দেখান $$ f^\top L f=\tfrac12\sum_{i=1}^n\sum_{j=1}^n w_{ij}\,(f_i-f_j)^2. $$ (সূত্র: \(f^\top L f=f^\top D f-f^\top W f=\sum_i D_{ii}f_i^2-\sum_{i,j}w_{ij}f_i f_j\) থেকে শুরু করে \(\tfrac12\sum_{ij}w_{ij}(f_i-f_j)^2\) বিস্তার করে মিলিয়ে দিন।) (খ) এই রূপ থেকে যুক্তি দিন \(f^\top L f\ge0\) সর্বদা (অর্থাৎ \(L\) positive-semidefinite), আর কখন এটি \(0\) হয় (প্রতিটি সংযুক্ত-অংশে \(f\) ধ্রুবক)। (গ) এক বাক্যে: \(f^\top L f\) ছোট করা কেন smoothness/cluster অনুমান বাস্তবায়িত করে — কোন বিন্দু-জোড়ার label-পার্থক্যে সবচেয়ে বেশি penalty পড়ে (বড় \(w_{ij}\), অর্থাৎ কাছের/ঘন-সংযুক্ত জোড়া), আর তাই boundary কেন কম-ঘনত্বের অঞ্চলে ঠেলে যায়? Hint: (ক) \(\tfrac12\sum_{ij}w_{ij}(f_i-f_j)^2=\tfrac12\sum_{ij}w_{ij}(f_i^2-2f_if_j+f_j^2)=\tfrac12\big(\sum_{ij}w_{ij}f_i^2+\sum_{ij}w_{ij}f_j^2\big)-\sum_{ij}w_{ij}f_if_j\); প্রথম দুই পদ (\(W\) symmetric) \(=\sum_i(\sum_j w_{ij})f_i^2=\sum_i D_{ii}f_i^2=f^\top D f\), শেষ পদ \(=f^\top W f\); তাই \(=f^\top D f-f^\top W f=f^\top(D-W)f=f^\top L f\)। (খ) প্রতিটি পদ \(w_{ij}(f_i-f_j)^2\ge0\) (যেহেতু \(w_{ij}\ge0\), বর্গ \(\ge0\)) ⇒ যোগফল \(\ge0\) ⇒ PSD; \(=0\) কেবল যখন প্রতিটি edge-যুক্ত (\(w_{ij}>0\)) জোড়ায় \(f_i=f_j\), অর্থাৎ প্রতিটি connected component-এ \(f\) ধ্রুবক। (গ) penalty \(w_{ij}\)-ভারিত — কাছের/দৃঢ়-সংযুক্ত জোড়ায় (\(w_{ij}\) বড়) label ভিন্ন হলে penalty বড়, তাই minimizer কাছের বিন্দুর label মেলায় (smoothness) ও ঘন গুচ্ছ একই label-এ রাখে (cluster); label কেবল \(w_{ij}\) ছোট-অঞ্চলে (কম-ঘনত্বের ফাঁক) সস্তায় বদলাতে পারে ⇒ boundary সেখানেই বসে।
ঘ · কোডিং (Python)¶
প্রশ্ন ১৫ (★★★). চারটি anomaly detector + ROC AUC — এক dataset, এক তুলনা। seed-সূচক random_state=20260619 দিয়ে চলমান canonical anomaly dataset বানান: একটা কেন্দ্রীয় Gaussian গুচ্ছে \(285\) inlier + চারপাশে একটা বলয়ে (ring) \(15\) outlier = \(300\) বিন্দু, সত্যিকার label y_true (inlier \(=0\), outlier \(=1\)), contamination \(\nu=0.05\)। এবার চারটি detector ফিট করে প্রতিটির ROC AUC (anomaly-score বনাম y_true) ছাপুন, আর Isolation Forest-এর জন্য ৫%-cutoff-এ precision ও recall-ও দিন:
- Isolation Forest (
IsolationForest(contamination=0.05, random_state=20260619)) — canonical AUC \(=\mathbf{1.000}\); ৫%-cutoff precision \(=\mathbf{1.00}\), recall \(=\mathbf{1.00}\) (isolation: ring দ্রুত আলাদা)। - Local Outlier Factor (
LocalOutlierFactor(contamination=0.05),fit_predict+negative_outlier_factor_) — canonical AUC \(=\mathbf{1.000}\) (density: ring পাতলা)। - One-Class SVM (
OneClassSVM(nu=0.05, gamma='scale')) — canonical AUC \(=\mathbf{0.941}\) (boundary: এই ring-গঠনে সামান্য দুর্বল)। - Elliptic Envelope (
EllipticEnvelope(contamination=0.05, random_state=20260619)) — canonical AUC \(=\mathbf{1.000}\) (statistical/Mahalanobis: inlier-গুচ্ছ Gaussian বলে নিখুঁত)।
শেষে এক বাক্যে ছাপুন কোন পরিবার এই dataset-এ পিছিয়ে (boundary/OC-SVM, \(0.941\)) ও বাকিরা কেন নিখুঁত (\(1.000\))।
Hint: from sklearn.ensemble import IsolationForest; from sklearn.neighbors import LocalOutlierFactor; from sklearn.svm import OneClassSVM; from sklearn.covariance import EllipticEnvelope; from sklearn.metrics import roc_auc_score, precision_score, recall_score। data বানাতে: কেন্দ্রীয় গুচ্ছ rng.normal(0,1,(285,2)), ring r=5+rng.normal(0,0.3,15), কোণ theta=rng.uniform(0,2*pi,15), outlier \(=(r\cos\theta, r\sin\theta)\); y_true জোড়া দিন। AUC-র জন্য প্রতিটা detector-এর "outlier-উঁচু" score দরকার: IF/Elliptic-এ -model.score_samples(X) (বা -decision_function), LOF-এ -negative_outlier_factor_, OC-SVM-এ -decision_function(X) — সব ক্ষেত্রে বড় = বেশি-anomaly, তাই roc_auc_score(y_true, score)। পাঠ: তিন পরিবার (isolation/density/statistical) \(1.000\), boundary (OC-SVM) \(0.941\) — পরিবার-অনুমান data-র সঙ্গে মিললে নিখুঁত। সংস্করণ-ভেদে শেষ অঙ্কে সামান্য হেরফের সম্ভব, গল্প অপরিবর্তিত। পূর্ণ runnable script _solutions/06-09-anomaly-semisup-online-solutions.md-এর §ঘ-তে।
প্রশ্ন ১৬ (★★★). semi-supervised label spreading — unlabeled কতটা সাহায্য করে। seed-সূচক random_state=20260619 দিয়ে make_moons(n_samples=300, noise=0.15) বানান (দুটো বাঁকা চাঁদ-গুচ্ছ, label \(\{0,1\}\))। এবার মাত্র ~১০% বিন্দুর label রাখুন, বাকি ৯০%-এর label "অজানা" (\(-1\)) করুন (y_train যেখানে অজানাগুলো \(-1\))। দুটো জিনিস তুলনা করুন: (১) labeled-only — শুধু labeled বিন্দুতে একটা সাধারণ classifier (যেমন kNN বা logistic) ফিট করে পুরো data-তে accuracy; (২) LabelSpreading — labeled + unlabeled সব দিয়ে graph-diffusion চালিয়ে accuracy। canonical: labeled-only \(=\mathbf{0.833}\), LabelSpreading \(=\mathbf{0.989}\) (gain \(\approx0.156\))। (ক) দুটো accuracy ছাপুন; (খ) এক বাক্যে ছাপুন unlabeled data কেন এই লাফ ঘটাল (চাঁদের বাঁকা manifold/cluster-গঠন boundary-কে কম-ঘনত্ব-ফাঁকে বসায়)।
Hint: from sklearn.datasets import make_moons; from sklearn.semi_supervised import LabelSpreading; from sklearn.neighbors import KNeighborsClassifier; from sklearn.metrics import accuracy_score; import numpy as np। X, y = make_moons(n_samples=300, noise=0.15, random_state=20260619)। mask: rng=np.random.default_rng(20260619); labeled=rng.choice(300, size=30, replace=False) (~১০%); y_train=np.full(300,-1); y_train[labeled]=y[labeled]। (১) labeled-only: clf=KNeighborsClassifier().fit(X[labeled], y[labeled]); acc1=accuracy_score(y, clf.predict(X)) → \(\approx0.833\)। (২) ls=LabelSpreading(kernel='knn', n_neighbors=10).fit(X, y_train); acc2=accuracy_score(y, ls.transduction_) → \(\approx0.989\)। পাঠ: unlabeled বিন্দুগুলো চাঁদের পুরো বাঁকা আকৃতি ও মাঝের কম-ঘনত্ব-ফাঁক ফাঁস করে, তাই diffusion সঠিক জায়গায় boundary বসায় — \(0.833\to0.989\)। সংস্করণ/seed-ভেদে শেষ অঙ্কে সামান্য হেরফের সম্ভব, গল্প (unlabeled বড় উন্নতি আনে) অপরিবর্তিত।
৮ · সারসংক্ষেপ ও সংযোগ¶
মূল পয়েন্ট (recap):
-
anomaly detection — চারটি পরিবার, এক প্রশ্ন: কে "বেমানান"। anomaly = (i) বিরল এবং (ii) স্বাভাবিক data-র গঠন/density থেকে দূরে। চারটি স্বজ্ঞাগত পরিবার ভিন্নভাবে এটি মাপে: statistical (Elliptic Envelope — Mahalanobis \(D_M^2(x)=(x-\mu)^\top\Sigma^{-1}(x-\mu)\sim\chi^2_p\) বড় হলে anomaly, ২.৪/৪.৮-এর সরাসরি প্রয়োগ); density (LOF — প্রতিবেশীর তুলনায় কম local density, \(\mathrm{LOF}\gg1\)); isolation (Isolation Forest — random split-এ ছোট path length, score \(s(x)\to1\)); boundary (One-Class SVM — শেখা স্বাভাবিক-অঞ্চলের সীমানার বাইরে)। প্রতিটির অনুমান আলাদা, তাই একাধিক চালিয়ে তুলনা করা ভালো অভ্যাস।
-
class-imbalance-এ accuracy বিভ্রান্তিকর — precision/recall/ROC AUC দেখুন। anomaly সমস্যায় শ্রেণি প্রবলভাবে অসম (\(285\) inlier বনাম \(15\) anomaly); "সব inlier" বলা trivial detector accuracy \(0.95\) পায় অথচ recall \(0\) — একটাও ধরে না। তাই precision (অ্যালার্ম কতটা সত্য) ও recall (সত্য anomaly-র কতটা ধরা), আর threshold-নিরপেক্ষ ROC AUC (random anomaly-কে random inlier-এর উপরে rank করার সম্ভাবনা) বেশি অর্থপূর্ণ। canonical-এ Isolation Forest, LOF, Elliptic Envelope — তিনটিরই AUC \(1.000\) (IF @ ৫% precision/recall \(1.00\)), কিন্তু One-Class SVM \(0.941\) — এই ring-গঠনে boundary-পরিবার সামান্য পিছিয়ে।
-
semi-supervised learning — unlabeled data সাহায্য করে, যদি গঠন label-সম্পর্কিত হয়। অল্প label + বহু unlabeled একসাথে ব্যবহার কাজে লাগে তিনটি অনুমানে: smoothness (কাছের বিন্দু ⇒ একই label), cluster (একই গুচ্ছ ⇒ একই শ্রেণি, boundary কম-ঘনত্বে), manifold (label নিম্ন-মাত্রিক manifold বরাবর মসৃণ — ৬.৮-এর সরাসরি যোগ)। label propagation/spreading এটি বাস্তবায়িত করে graph-diffusion হিসেবে: বিন্দু = node, similarity-edge \(w_{ij}\), graph Laplacian \(L=D-W\); জানা label edge বরাবর ছড়িয়ে অজানা পূরণ হয়, যা কার্যত \(f^\top L f=\tfrac12\sum_{ij}w_{ij}(f_i-f_j)^2\) (label-অমসৃণতা) ছোট করা। canonical-এ
make_moons-এ labeled-only accuracy \(0.833\) → LabelSpreading \(0.989\) — unlabeled বিন্দুগুলো চাঁদের বাঁকা গঠন ফাঁস করে boundary সঠিক ফাঁকে বসায়। -
online learning — incremental update ও sublinear regret। data স্রোতে এলে model এক-এক বিন্দুতে আপডেট হয়: \(\theta_{t+1}=\theta_t-\eta_t\nabla\ell_t(\theta_t)\) (online/stochastic gradient descent)। সুবিধা: সব data একসাথে মেমরিতে লাগে না, আর বণ্টন সরলে (concept drift) model নিজে মানিয়ে নেয়। গুণমান মাপা হয় regret \(R_T=\sum_t\ell_t(\theta_t)-\min_{\theta^\*}\sum_t\ell_t(\theta^\*)\) দিয়ে — online learner বনাম পিছন-ফিরে-জানা সেরা স্থির \(\theta^\*\); ভালো algorithm-এ \(R_T\) sublinear (\(o(T)\), যেমন \(O(\sqrt T)\)), তাই average regret \(R_T/T\to0\) — গড়ে learner শেষমেশ সেরা স্থির কৌশলের সমান-ভালো।
-
মূল বার্তা। এই survey-অধ্যায় তিনটি প্রয়োগমুখী frontier একসাথে আনে — anomaly detection (স্বাভাবিকতার গঠন/density/manifold শিখে বিচ্যুতি ধরা, AUC দিয়ে মূল্যায়ন), semi-supervised learning (গঠন দিয়ে অল্প label-কে বহু unlabeled-এ ছড়ানো), online learning (incremental, drift-সচেতন, regret-দিয়ে-বিচার) — প্রতিটিই আগের অধ্যায়ের গঠন-জ্ঞানকে (density, manifold, graph, Mahalanobis) বাস্তব-জগতের অসম্পূর্ণ/বিকশিত data-তে কাজে লাগায়।
পূর্ববর্তী সংযোগ (← ২.৪, ৪.৮, ৬.৫, ৬.৮):
-
২.৪ (Gaussian / Mahalanobis দূরত্ব): statistical anomaly detection-এর সরাসরি ভিত্তি। ২.৪-এর multivariate Gaussian ও Mahalanobis দূরত্ব \(D_M^2(x)=(x-\mu)^\top\Sigma^{-1}(x-\mu)\) এখানে Elliptic Envelope-এর হৃদয়: \(\Sigma^{-1}\) প্রতিটি অক্ষকে তার variance/correlation দিয়ে স্কেল করে "কত \(\sigma\) দূরে" মাপে, আর বড় \(D_M^2\) = anomaly। robust covariance estimate দিয়ে \(\mu,\Sigma\) আঁচ করে এই threshold বসানো হয়।
-
৪.৮ (χ² goodness-of-fit / distribution): Mahalanobis-threshold-কে নিয়ন্ত্রিত false-positive হারে রূপ দেয়। ৪.৮-এর ফল — Gaussian-এ \(D_M^2\sim\chi^2_p\) (§৭ প্রমাণে whitening দিয়ে দেখানো) — মানে \(\chi^2_p\)-cutoff (যেমন \(p=2\)-তে \(5.991\)) এমন threshold দেয় যাতে স্বাভাবিক বিন্দুর মাত্র \(\alpha\) ভগ্নাংশ ভুলে flag হয়; χ²-table তাই সরাসরি anomaly-সীমা ঠিক করে।
-
৬.৫ (trees / Isolation Forest): Isolation Forest সরাসরি ৬.৫-এর tree + ensemble চিন্তার সম্প্রসারণ — কিন্তু লক্ষ্য classification নয়, isolation। random feature ও random split দিয়ে গাছ বানিয়ে একটা বিন্দুর path length মাপে; anomaly বিরল ও বিচ্ছিন্ন বলে কম split-এ আলাদা হয় (ছোট path, উঁচু score \(s\))। ৬.৫-এর bagging/random-subsampling-এর স্বজ্ঞা এখানে multiple isolation tree-র গড়ে ফিরে আসে।
-
৬.৮ (manifold learning): semi-supervised ও anomaly — দুটোতেই ৬.৮-এর manifold/neighbor-graph চিন্তা সরাসরি কাজে লাগে। anomaly-তে: data যদি একটা low-D manifold-এ বসে, manifold থেকে দূরের (বড় reconstruction-error) বিন্দুই anomaly। semi-supervised-এ: manifold অনুমান বলে label সেই বাঁকা পৃষ্ঠ বরাবর মসৃণ, আর label propagation-এর graph Laplacian \(L=D-W\) হুবহু ৬.৮-এর neighbor-graph/Laplacian-eigenmap-এর সঙ্গে একই ভাষা — প্রতিবেশ-গঠনকে কাজে লাগানো।
Part VI সম্পূর্ণ — Statistical Machine Learning-এর পূর্ণ চাপ (৬.১ → ৬.৯): এই অধ্যায় দিয়ে Part VI (পরিসংখ্যানিক মেশিন লার্নিং) শেষ হলো — supervised ও unsupervised ML-এর একটা সম্পূর্ণ পরিসংখ্যানিক ভ্রমণ, যার চাপ একনজরে: - ৬.১ (learning theory) — bias-variance, overfitting, generalization-এর তাত্ত্বিক ভিত্তি: শেখা মানে কী, আর কখন তা সম্ভব। - ৬.২ (regularization — ridge/lasso) — overfitting বশে আনা ও sparsity দিয়ে feature-নির্বাচন। - ৬.৩–৬.৪ (classifiers — LDA/QDA/NB/kNN, SVM/kernel) — সম্ভাবনা-ভিত্তিক ও geometric/margin-ভিত্তিক শ্রেণিবিভাজন, kernel trick দিয়ে অরৈখিকতা। - ৬.৫–৬.৬ (ensembles — trees/bagging/random forests, boosting) — দুর্বল শিক্ষার্থী একত্র করে শক্তিশালী predictor; variance-হ্রাস (bagging) বনাম bias-হ্রাস (boosting)। - ৬.৭ (density estimation, EM, GMM) — unsupervised-এর সূচনা: সম্ভাবনা-ঘনত্ব ও latent গোষ্ঠী আঁচ। - ৬.৮ (nonlinear manifold learning) — high-D data-র লুকানো low-D বাঁকা গঠন উন্মোচন (Isomap, LLE, t-SNE)। - ৬.৯ (এই অধ্যায় — frontiers) — সেই সব গঠন-জ্ঞানকে বাস্তব, অসম্পূর্ণ, বিকশিত data-তে প্রয়োগ: anomaly detection, semi-supervised, online learning।
অর্থাৎ Part VI একটা সুসংগত চাপ আঁকে — শেখার তত্ত্ব (৬.১) থেকে নিয়ন্ত্রণ (৬.২), শ্রেণিবিভাজন (৬.৩–৬.৪), শক্তিশালীকরণ (৬.৫–৬.৬), গঠন-উন্মোচন (৬.৭–৬.৮), অবশেষে প্রয়োগ-frontier (৬.৯)। এই অধ্যায় তাই supervised ও unsupervised ML উভয়ের capstone: আগের সব হাতিয়ার (Gaussian, χ², tree, manifold, graph) এখানে মিলে real-world-এর তিনটি কঠিন বাস্তবতা — বিরল বিচ্যুতি, অল্প label, চলমান স্রোত — সামলায়।
পরবর্তী সংযোগ (→ Part VII — measure-theoretic probability, PhD-শিখর): Part VI পর্যন্ত পুরো curriculum সম্ভাবনা ও পরিসংখ্যানকে গড়েছে মূলত স্বজ্ঞা ও calculus-এর ভিত্তিতে — pmf/pdf, expectation যোগ/integral হিসেবে, convergence অনানুষ্ঠানিকভাবে। Part VII এই গোটা ভবনের নিচে একটা কঠোর গাণিতিক ভিত্তি বসায় — measure-theoretic probability, যা এই curriculum-এর সর্বোচ্চ শিখর (PhD summit): σ-algebra (কোন ঘটনাকে আদৌ "মাপা যায়" তার সুনির্দিষ্ট সংজ্ঞা), measure ও Lebesgue integration (Riemann-integral-এর বহু-শক্তিশালী সাধারণীকরণ, যা \(\mathbb E[X]=\int X\,dP\)-কে একীভূত ভিত্তি দেয় — discrete ও continuous একসাথে), convergence theorems (monotone/dominated convergence — limit ও integral কখন বিনিময়যোগ্য), এবং martingales (ন্যায্য-খেলার পরিসংখ্যানিক সাধারণীকরণ, আধুনিক সম্ভাবনা ও stochastic process-এর কেন্দ্র)। অর্থাৎ Part VI যেখানে ML-এর প্রয়োগ-চূড়ায় পৌঁছাল, Part VII সেখানে নেমে যায় সবকিছুর গাণিতিক মূলে — কেন expectation, convergence ও randomness আদৌ সুসংজ্ঞায়িত, তার চূড়ান্ত উত্তরে।
সূত্র (sources): M. Sugiyama, Introduction to Statistical Machine Learning (semi-supervised learning, density-ratio anomaly detection ও online/incremental learning-এর তাত্ত্বিক উপস্থাপন — এই অধ্যায়ের প্রাথমিক উৎস); P. Dangeti, Statistics for Machine Learning (Isolation Forest, One-Class SVM, anomaly detection ও semi-supervised পদ্ধতির scikit-learn Python প্রয়োগ); Bruce, Bruce & Gedeck, Practical Statistics for Data Scientists (anomaly/outlier detection ও imbalanced-classification মূল্যায়ন — precision/recall/AUC-র ব্যবহারিক দৃষ্টিভঙ্গি); L. Wasserman, All of Statistics (Mahalanobis দূরত্ব, χ², density ও multivariate গঠনের সংক্ষিপ্ত পরিসংখ্যানি