7.5 — \(L^p\) Space, Hilbert Space ও Radon–Nikodym Theorem (integrable ফাংশনের জ্যামিতি)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
১.১ যেখানে 7.4 থেমেছিল — হাতে একটা integral, কিন্তু জ্যামিতি এখনও নেই¶
আগের অধ্যায়ে (7.4) আমরা একটা শক্তিশালী যন্ত্র গড়েছিলাম — Lebesgue integral \(\int f\,d\mu\), যা সব measurable ফাংশনে কাজ করে এবং limit-এর সঙ্গে সুন্দর আচরণ করে (MCT/Fatou/DCT)। সেই অধ্যায়ের শেষে একটা বিশেষ শ্রেণি আলাদা করেছিলাম — integrable ফাংশন, \(L^1=\{f:\int\lvert f\rvert\,d\mu<\infty\}\) — যাদের "মোট আকার" সসীম। আর একটা সূক্ষ্ম-কিন্তু-গভীর উপলব্ধি দিয়ে শেষ করেছিলাম: integration-তত্ত্বে একটা ফাংশন আসলে আচরণ করে তার a.e.-সমতা-শ্রেণি (almost-everywhere equivalence class) হিসেবে — কারণ \(f=g\) a.e. হলে \(\int f=\int g\), তাই measure-শূন্য set-এ মান বদলালে integral গায়ে মাখে না।
কিন্তু একটা প্রশ্ন তখন খোলা রয়ে গিয়েছিল। আমাদের হাতে এখন অসংখ্য integrable ফাংশন — কিন্তু তারা কি নিছক একটা স্তূপ, নাকি তাদের মধ্যে গঠন (structure) আছে? দুটো ফাংশন "কাছাকাছি" না "দূরে" — সেটা মাপা যায় কি? একটা ফাংশন থেকে আরেকটার দিকে কি কোনো "কোণ" বা "দিক" আছে? একটা ফাংশনকে কি অন্যদের একটা সংগ্রহের উপর "প্রক্ষেপণ" (project) করা যায় — যেমন \(\mathbb R^3\)-এ একটা vector-কে একটা সমতলে ফেলা যায়?
এই অধ্যায়ের কাজ ঠিক সেটাই: 7.4-এর integral-কে আঠা হিসেবে ব্যবহার করে integrable ফাংশনদের একটা জ্যামিতিক জগতে সাজানো — যেখানে norm (দৈর্ঘ্য), distance (দূরত্ব), inner product / orthogonality (কোণ) আর সবচেয়ে গুরুত্বপূর্ণভাবে projection (প্রক্ষেপণ) — এই সব জ্যামিতিক ধারণা অর্থবহ হয়ে ওঠে। ফাংশনগুলো আর বিচ্ছিন্ন বস্তু থাকে না; তারা হয়ে ওঠে একটা সুবিশাল (অসীম-মাত্রিক) vector space-এর "বিন্দু", যেখানে \(\mathbb R^n\)-এর চেনা জ্যামিতি প্রায় হুবহু খাটে।
এক বাক্যে সূচনা। 7.4 দিয়েছিল integral \(\int f\,d\mu\) আর \(L^1\); এই অধ্যায় সেই integral-কে ভিত্তি করে integrable ফাংশনদের একটা জ্যামিতিক জগতে (\(L^p\), \(L^2\)) সাজায় — যেখানে দৈর্ঘ্য, দূরত্ব, কোণ ও প্রক্ষেপণ অর্থবহ, আর সঙ্গে আসে "কঠোর pdf" (Radon–Nikodym derivative)।
১.২ কেন জ্যামিতি — দৈর্ঘ্য, দূরত্ব, কোণ, প্রক্ষেপণ¶
কেন ফাংশনদের জ্যামিতিকভাবে দেখতে চাই — এতে লাভ কী? উত্তরটা একটা চেনা সাদৃশ্যে। \(\mathbb R^n\)-এ (0.5-এর linear algebra) আমরা vector নিয়ে যা যা করি, তার প্রায় সবই দাঁড়িয়ে আছে দুটো সরঞ্জামের উপর — norm (দৈর্ঘ্য \(\lVert x\rVert\)) ও inner product (অন্তঃগুণফল \(\langle x,y\rangle\)):
- দৈর্ঘ্য থেকে দূরত্ব ও convergence। \(\lVert x-y\rVert\) দুই vector-এর দূরত্ব; এর থেকেই "\(x_n\to x\)" মানে \(\lVert x_n-x\rVert\to 0\) — limit-যুক্তির গোড়া। ফাংশন-জগতে এর অনুরূপ চাই: \(\lVert f_n-f\rVert\to 0\) মানে "\(f_n\) ক্রমে \(f\)-এর কাছে আসছে" — যা estimator-এর consistency, approximation, ও series-অভিসারণের ভাষা।
- inner product থেকে কোণ ও orthogonality। \(\langle x,y\rangle=0\) মানে \(x\perp y\) (লম্ব); আর \(\langle x,y\rangle/(\lVert x\rVert\lVert y\rVert)\) হলো তাদের মধ্যবর্তী কোণের cosine। পরিসংখ্যানে এটাই uncorrelatedness-এর জ্যামিতি — দুই কেন্দ্রিত random variable orthogonal মানে তাদের covariance শূন্য।
- projection — সবচেয়ে দামি। \(\mathbb R^3\)-এ একটা vector \(v\)-কে একটা সমতল \(W\)-এর উপর ফেললে যে \(\hat v\in W\) পাই, সে \(W\)-এর মধ্যে \(v\)-এর নিকটতম বিন্দু, আর অবশিষ্ট \(v-\hat v\) সমতলটার সাথে লম্ব। এই একই ছবি — "একটা সংগ্রহের মধ্যে নিকটতম প্রতিরূপ, residual লম্ব" — পরিসংখ্যানের দুটো স্তম্ভের গোড়ায়: least squares (data-কে একটা model-space-এ projection) আর conditional expectation \(\mathbb E[X\mid\mathcal G]\) (একটা random variable-কে \(\mathcal G\)-measurable ফাংশনের space-এ projection — 7.7)।
মোদ্দা কথা: জ্যামিতি কোনো অলংকার নয়, এটি যুক্তির যন্ত্র। একবার integrable ফাংশনদের একটা norm ও inner product দিয়ে সাজাতে পারলে, \(\mathbb R^n\)-এ vector নিয়ে গড়া পুরো স্বজ্ঞা-ভাণ্ডার — দূরত্ব, কোণ, লম্ব, নিকটতম-বিন্দু — অবিকল ফাংশনে আনা যায়, শুধু মাত্রা এখন সসীম \(n\) নয়, অসীম।
এক বাক্যে কেন জ্যামিতি। norm দেয় দৈর্ঘ্য-দূরত্ব-convergence, inner product দেয় কোণ-orthogonality, আর projection দেয় "নিকটতম প্রতিরূপ, residual লম্ব" — যা least squares ও conditional expectation-এর গোড়া; তাই integrable ফাংশনদের জ্যামিতিক জগতে তোলা মানে \(\mathbb R^n\)-এর পুরো যুক্তি-ভাণ্ডার অসীম-মাত্রায় পাওয়া।
১.৩ এই অধ্যায়ের চার প্রাপ্তি — space, অসমতা, Hilbert-জ্যামিতি, density¶
7.4-এর integral-কে ভিত্তি করে আমরা চারটে বস্তু পাব — এই অধ্যায়ের আসল পুরস্কার, আর Part VII-এর বাকিটার যন্ত্র।
-
প্রাপ্তি ১ — \(L^p\) space ও তার norm। integral দিয়ে দৈর্ঘ্য মাপি: \(\lVert f\rVert_p=(\int\lvert f\rvert^p\,d\mu)^{1/p}\) (\(1\le p<\infty\)), আর \(L^p\) হলো সেই সব (a.e.-শ্রেণির) ফাংশন যাদের এই দৈর্ঘ্য সসীম। \(p=1\) ফিরিয়ে দেয় চেনা \(L^1\); \(p=2\) দেয় "শক্তি/ভেদাঙ্ক"-এর space (square-integrable); আর চরম \(p=\infty\) দেয় essential supremum দিয়ে মাপা \(L^\infty\) (a.e.-সীমাবদ্ধ ফাংশন)। এই \(L^p\)-গুলোই হবে আমাদের জ্যামিতিক মঞ্চ।
-
প্রাপ্তি ২ — চার কর্মঘোড়া-অসমতা। এই norm-গুলোকে চালু রাখতে চারটে অসমতা লাগে, যারা পরিসংখ্যানের সর্বত্র ফিরে আসে: Hölder (\(\int\lvert fg\rvert\le\lVert f\rVert_p\lVert g\rVert_q\), \(\tfrac1p+\tfrac1q=1\)) — দুই ফাংশনের গুণফল কীভাবে আলাদা-আলাদা দৈর্ঘ্যে আবদ্ধ; Minkowski — ত্রিভুজ-অসমতা, যা ছাড়া \(\lVert\cdot\rVert_p\) আদৌ norm-ই নয়; Jensen (convex \(\varphi\)-তে \(\varphi(\mathbb E[X])\le\mathbb E[\varphi(X)]\)) — 3.1-এর সাধারণীকরণ, যা variance-এর অঋণাত্মকতা থেকে শুরু করে বহু মৌলিক বাউন্ডের জনক; আর Cauchy–Schwarz (\(p=q=2\)) — covariance-এর সীমা ও correlation \(\in[-1,1]\)-এর গোড়া।
-
প্রাপ্তি ৩ — completeness ও \(L^2\) Hilbert-জ্যামিতি। এই space-গুলো নিছক norm-যুক্ত নয়, complete — মানে কোনো Cauchy অনুক্রম মাঝপথে "ফাঁকে পড়ে" হারিয়ে যায় না, সবসময় space-এর ভেতরেই একটা limit-এ পৌঁছায় (Riesz–Fischer theorem ⇒ \(L^p\) একটা Banach space)। আর \(p=2\)-তে বাড়তি উপহার: একটা inner product \(\langle f,g\rangle=\int fg\,d\mu\), যা \(L^2\)-কে একটা Hilbert space বানায় — অসীম-মাত্রিক ইউক্লিডীয় জ্যামিতির পূর্ণ রূপ। তার মুকুটমণি projection theorem: যেকোনো closed subspace-এ একটা বিন্দুর নিকটতম প্রতিরূপ আছে এবং একমাত্র, residual subspace-এর সাথে লম্ব — ঠিক ১.২-এর ছবি, কিন্তু অসীম-মাত্রায় প্রমাণিত।
-
প্রাপ্তি ৪ — Radon–Nikodym ও "কঠোর pdf"। শেষে একটা সম্পূর্ণ ভিন্ন কিন্তু সমান-গভীর ফল: কখন একটা measure \(\nu\)-কে আরেকটা \(\mu\)-এর সাপেক্ষে একটা density দিয়ে লেখা যায়? উত্তর Radon–Nikodym theorem — যদি \(\nu\ll\mu\) (absolute continuity: \(\mu(A)=0\Rightarrow\nu(A)=0\)) এবং σ-finite, তবে একটা অঋণাত্মক \(f=\tfrac{d\nu}{d\mu}\) আছে যাতে \(\nu(A)=\int_A f\,d\mu\), আর সে a.e.-অনন্য। এটাই density/pdf-এর কঠোর, সর্বজনীন সংজ্ঞা (\(f_X=\tfrac{dP_X}{d\lambda}\)), likelihood ratio \(\tfrac{dP}{dQ}\)-এর ভিত্তি, এবং (projection-এর পাশাপাশি) conditional expectation-এর অস্তিত্ব-ইঞ্জিন; সঙ্গে Lebesgue decomposition \(\nu=\nu_{ac}+\nu_{sing}\) যা যেকোনো measure-কে "density-অংশ + singular-অংশ"-এ ভাঙে।
এক বাক্যে প্রাপ্তি। চার উপহার — \(L^p\) space ও norm \(\lVert f\rVert_p\) (\(L^1,L^2,L^\infty\) সহ); চার অসমতা (Hölder, Minkowski, Jensen, Cauchy–Schwarz); completeness (Riesz–Fischer ⇒ Banach) ও \(L^2\) Hilbert-জ্যামিতি (inner product + projection theorem); আর Radon–Nikodym density \(\tfrac{d\nu}{d\mu}\) (কঠোর pdf + Lebesgue decomposition) — যা সরাসরি 7.7-এর conditional expectation ও least squares-এ গড়ায়।
১.৪ দুই মুকুটমণির পরিসংখ্যান-মূল্য — projection ও RN-derivative¶
এই অধ্যায়ের দুটো ফল আলাদা করে দাগিয়ে রাখার মতো, কারণ পরের অধ্যায়গুলো সরাসরি এদের উপর দাঁড়িয়ে।
projection theorem ⇒ conditional expectation ও least squares। কল্পনা করো random variable-দের একটা \(L^2\)-জগৎ, যেখানে \(\lVert X-Y\rVert_2^2=\mathbb E[(X-Y)^2]\) হলো দুই random variable-এর "বর্গ-দূরত্ব"। এখন একটা \(\sigma\)-algebra \(\mathcal G\)-এর "জানা তথ্য" দিয়ে যত random variable তৈরি করা যায় (অর্থাৎ \(\mathcal G\)-measurable, square-integrable ফাংশন) — তারা একটা closed subspace \(L^2(\mathcal G)\) গড়ে। তাহলে conditional expectation \(\mathbb E[X\mid\mathcal G]\) আসলে কী? — সে ঠিক \(X\)-এর projection এই subspace-এ: \(\mathcal G\)-তথ্য দিয়ে গড়া যত random variable, তাদের মধ্যে \(X\)-এর নিকটতম (minimum mean-squared-error) প্রতিরূপ, যার residual \(X-\mathbb E[X\mid\mathcal G]\) পুরো \(L^2(\mathcal G)\)-এর সাথে orthogonal। এই একই projection-ছবি least squares regression-এও — data-vector-কে predictor-দের span-এ ফেলা, residual ⊥ predictors (normal equations)। অর্থাৎ আজকের projection theorem 7.7-এর conditional expectation ও পরিসংখ্যানের least-squares-পুরো-সাম্রাজ্যের জ্যামিতিক ভিত্তি।
Radon–Nikodym derivative ⇒ pdf ও likelihood। "একটা random variable \(X\)-এর pdf \(f_X\)" — এতদিন এটা ছিল একটা সূত্র (\(P(a<X\le b)=\int_a^b f_X\)), কিন্তু কেন এমন একটা \(f_X\) থাকে, বা কখন থাকে না, তা ছিল ধোঁয়াশা। Radon–Nikodym পরিষ্কার করে: \(f_X\) হলো ঠিক \(\tfrac{dP_X}{d\lambda}\) — \(X\)-এর law \(P_X\)-এর Lebesgue measure \(\lambda\)-সাপেক্ষে density, এবং সে থাকে যদি ও কেবল যদি \(P_X\ll\lambda\) (continuous বণ্টন)। তেমনি likelihood ratio \(\tfrac{dP}{dQ}\) — দুই hypothesis-এর তুলনা, Neyman–Pearson lemma, importance sampling, আর পরে (7.8) measure-পরিবর্তন/martingale — সবই একটা Radon–Nikodym derivative; আর conditional expectation-এর সাধারণ (non-\(L^2\)) অস্তিত্বও RN থেকেই আসে। এক কথায়, RN-derivative হলো পরিসংখ্যানের "density" শব্দটার কঠোর মেরুদণ্ড।
এক বাক্যে মূল্য। \(L^2\)-projection theorem হলো conditional expectation \(\mathbb E[X\mid\mathcal G]\) ও least-squares-এর জ্যামিতি (নিকটতম প্রতিরূপ, residual ⊥), আর Radon–Nikodym derivative \(\tfrac{d\nu}{d\mu}\) হলো pdf \(f_X=\tfrac{dP_X}{d\lambda}\) ও likelihood ratio \(\tfrac{dP}{dQ}\)-এর কঠোর রূপ — দুই-ই সরাসরি 7.7-এ গড়ায়।
১.৫ এই অধ্যায়ের পথরেখা¶
- §২ সব মূল বস্তুর precise সংজ্ঞা ও বিবৃতি — \(L^p\) norm ও space (a.e.-শ্রেণি) এবং \(L^\infty\)/ess sup (২.১–২.২); চার অসমতা Hölder, Minkowski, Jensen, Cauchy–Schwarz-এর বিবৃতি, সমতা-শর্ত ও ব্যবহার (২.৩–২.৪); completeness ও Riesz–Fischer (⇒ Banach) (২.৫); \(L^2\)-এর inner product, orthogonality, projection theorem, orthonormal basis (২.৬–২.৭); absolute continuity \(\nu\ll\mu\), Radon–Nikodym ও Lebesgue decomposition (২.৮); এবং পরিসংখ্যান-প্রয়োগ — pdf, likelihood ratio, conditional-expectation পূর্বাভাস (২.৯)। ভারী প্রমাণ §৪-এ স্থগিত, স্পষ্ট forward pointer সহ।
- §৪ ভারী প্রমাণ — Young's inequality ⇒ Hölder ⇒ Minkowski; Jensen (supporting-line/convexity থেকে); Riesz–Fischer (absolutely-convergent-series criterion দিয়ে completeness); projection theorem (parallelogram law + completeness দিয়ে নিকটতম বিন্দুর অস্তিত্ব ও orthogonality); এবং Radon–Nikodym (\(L^2\)-projection-ভিত্তিক von Neumann প্রমাণ, σ-finite ক্ষেত্রে) সহ a.e.-অনন্যতা ও Lebesgue decomposition।
- §৫–৬ simulation ও চিত্র (seed 20260619) — 7-5-lp-norms (\(\lVert f\rVert_p\) কীভাবে \(p\)-র সাথে বদলায়, এবং \(\mathbb R^2\)-এ \(p=1,2,\infty\) unit ball-এর আকার), 7-5-holder-young (Young's \(ab\le\tfrac{a^p}{p}+\tfrac{b^q}{q}\)-এর ক্ষেত্রফল-ছবি ও সমতা কখন), 7-5-l2-projection (একটা closed subspace-এ নিকটতম বিন্দু ও residual ⊥ — conditional-expectation-এর ছবি), এবং 7-5-radon-nikodym (density \(f=\tfrac{d\nu}{d\mu}\) কীভাবে \(\nu(A)=\int_A f\,d\mu\) পুনর্গঠন করে)।
এর পরে Part VII এগোয়: 7.6 এই \(L^p\)-কাঠামো ও integrability দিয়ে moment ও SLLN; 7.7 projection theorem ও Radon–Nikodym দুই-ই ব্যবহার করে conditional expectation \(\mathbb E[X\mid\mathcal G]\)-কে \(L^2\)-projection / RN-derivative হিসেবে; 7.9 \(L^2\)-bounded martingale ও তাদের convergence; এবং 7.10 — শেষমেশ rigorous CLT-র দিকে।
এক বাক্যে পথরেখা। §২ সংজ্ঞা ও বিবৃতি (\(L^p\) + চার অসমতা + Riesz–Fischer + \(L^2\) projection + Radon–Nikodym) → §৪ প্রমাণ (Young⇒Hölder⇒Minkowski, Riesz–Fischer, projection theorem, Radon–Nikodym via projection) → §৫–৬ চার চিত্র (seed 20260619); আর এই জ্যামিতি-ভিত্তির উপর Part VII গড়ে 7.6 (SLLN) → 7.7 (conditional expectation = \(L^2\)-projection/RN-derivative) → 7.9 (\(L^2\) martingale), rigorous CLT-র পথে।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে এ অধ্যায়ের সব formal বস্তুর precise সংজ্ঞা ও বিবৃতি দিই — প্রতিটি প্রতীক প্রথম ব্যবহারেই খুলে। কাঠামো §১-এর সুতো ধরে: প্রথমে \(L^p\) space ও তার norm এবং চরম \(L^\infty\)/ess sup (২.১–২.২); তারপর চার কর্মঘোড়া-অসমতা — Hölder ও Minkowski (২.৩), Jensen ও Cauchy–Schwarz (২.৪); তারপর completeness ও Riesz–Fischer (২.৫); তারপর \(L^2\)-এর Hilbert-জ্যামিতি — inner product ও orthogonality (২.৬), projection theorem ও orthonormal basis (২.৭); তারপর absolute continuity, Radon–Nikodym ও Lebesgue decomposition (২.৮); শেষে পরিসংখ্যান-প্রয়োগ (২.৯)। ভারী প্রমাণগুলো §৪-এ — এখানে কেবল বিবৃতি ও insight (অন্তর্দৃষ্টি), স্পষ্ট forward pointer সহ।
জুড়ে আমরা একটা সাধারণ measure space \((\Omega,\mathcal F,\mu)\) ধরে কাজ করি (যখন \(\mu=\mathbb P\) probability, তখন বিশেষ ক্ষেত্র — random variable ও expectation)। 7.4-এর সব ধর্ম — linearity, monotonicity, \(\lvert\int f\rvert\le\int\lvert f\rvert\), এবং "\(f=g\) a.e. ⇒ \(\int f=\int g\)" — নিঃশব্দে ধরে নেওয়া।
২.১ \(L^p\) norm ও \(L^p\) space — দৈর্ঘ্য দিয়ে সাজানো ফাংশন-জগৎ¶
জ্যামিতির প্রথম ইট — দৈর্ঘ্য। 7.4-এর integral হাতে থাকায় একটা ফাংশনের "আকার" মাপার একটা গোটা পরিবার পাই, একটা parameter \(p\) দিয়ে সূচিত।
সংজ্ঞা (\(L^p\) norm ও space, \(1\le p<\infty\))। একটা measurable \(f:\Omega\to\mathbb R\) (বা \(\mathbb C\))-এর \(L^p\) norm (এল-পি নর্ম, \(p\)-নর্ম) হলো $$ \lVert f\rVert_p\;:=\;\Big(\int_\Omega\lvert f\rvert^p\,d\mu\Big)^{1/p}\;\in\;[0,\infty], $$ এবং \(L^p\) space (এল-পি স্পেস) হলো সেই সব ফাংশনের সংগ্রহ যাদের এই norm সসীম: $$ L^p(\mu)\;:=\;\big{\,f\ \text{measurable}\ :\ \lVert f\rVert_p<\infty\,\big}\;=\;\Big{f:\int_\Omega\lvert f\rvert^p\,d\mu<\infty\Big}. $$ (এখানে "norm" বলার পূর্ণ যৌক্তিকতা — বিশেষত ত্রিভুজ-অসমতা — আসে Minkowski থেকে, ২.৩; আর \(p=1\) ফিরিয়ে দেয় 7.4-এর চেনা \(L^1\)।)
কেন \(p\)-ঘাত ও তারপর \(p\)-মূল? — যাতে scaling ঠিক থাকে: একটা ধ্রুবক \(c\)-তে গুণ করলে দৈর্ঘ্যও ঠিক \(\lvert c\rvert\) গুণ হয় (\(\lVert cf\rVert_p=\lvert c\rvert\,\lVert f\rVert_p\)), ঠিক \(\mathbb R^n\)-এর Euclidean দৈর্ঘ্যের মতো। তিনটে \(p\) পরিসংখ্যানে বিশেষভাবে গুরুত্বপূর্ণ:
- \(p=1\): \(\lVert f\rVert_1=\int\lvert f\rvert\,d\mu\) — "মোট আকার" বা "মোট absolute ভর"; random variable-এ \(\mathbb E\lvert X\rvert\) (mean absolute deviation-এর জগৎ)।
- \(p=2\): \(\lVert f\rVert_2=(\int f^2\,d\mu)^{1/2}\) — "শক্তি/বর্গমূল-গড়-বর্গ"; random variable-এ \(\sqrt{\mathbb E[X^2]}\), আর কেন্দ্রিত হলে standard deviation। এই \(p=2\)-ই inner product বহন করে (২.৬) — তাই সবচেয়ে জ্যামিতিক।
- \(p=\infty\): আলাদা সংজ্ঞা লাগে (২.২) — "সর্বোচ্চ মান" (a.e.-অর্থে)।
একটা সতর্কতা গোড়াতেই: \(\lVert f\rVert_p\) আসলে একটা semi-norm-এর মতো আচরণ করে যতক্ষণ না আমরা একটা সূক্ষ্ম সমস্যা সারাই — সেটি ২.২-এর শেষে।
এক বাক্যে। \(\lVert f\rVert_p=(\int\lvert f\rvert^p\,d\mu)^{1/p}\) একটা ফাংশনের "দৈর্ঘ্য" মাপে, আর \(L^p\) হলো সসীম-দৈর্ঘ্যের ফাংশনদের জগৎ — \(p=1\) মোট ভর, \(p=2\) শক্তি (একমাত্র inner-product বহনকারী), \(p=\infty\) সর্বোচ্চ মান।
২.২ \(L^\infty\) ও essential supremum; এবং কেন \(L^p\) আসলে a.e.-শ্রেণির space¶
\(L^\infty\) ও ess sup। \(p\to\infty\) সীমায় \(\lVert f\rVert_p\) যেদিকে যায় তা হলো \(f\)-এর "সর্বোচ্চ মান" — কিন্তু একটা সূক্ষ্ম মোচড়ে: measure-শূন্য set-এ \(f\) যত বড়ই হোক, তা গোনা হয় না (কারণ integral-জগতে measure-শূন্য set অদৃশ্য, 7.4)। তাই দরকার "প্রায়-সর্বত্র সর্বোচ্চ" — essential supremum।
সংজ্ঞা (essential supremum ও \(L^\infty\))। measurable \(f\)-এর essential supremum (অত্যাবশ্যক ঊর্ধ্বসীমা) হলো $$ \lVert f\rVert_\infty\;:=\;\operatorname{ess\,sup}{\omega}\lvert f(\omega)\rvert\;:=\;\inf\big{M\ge 0\ :\ \lvert f\rvert\le M\ \ \mu\text{-a.e.}\big}, $$ অর্থাৎ এমন সবচেয়ে ছোট ছাদ \(M\) যা একটা measure-শূন্য set বাদ দিয়ে \(\lvert f\rvert\)-কে আটকে রাখে; আর $$ L^\infty(\mu)\;:=\;\big{f\ \text{measurable}\ :\ \lVert f\rVert\infty<\infty\big} $$ হলো essentially bounded* (অত্যাবশ্যকভাবে সীমাবদ্ধ) ফাংশনদের space। (সাধারণ \(\sup\)-এর সাথে পার্থক্য কেবল measure-শূন্য set-এ: যেমন \(\mathbf 1_{\mathbb Q}\)-এর \(\sup=1\) কিন্তু \(\operatorname{ess\,sup}=0\), যেহেতু \(\lambda(\mathbb Q)=0\)।)
কেন \(L^p\) আসলে a.e.-সমতা-শ্রেণির space। এবার ২.১-এ ইশারা-করা সমস্যাটা। একটা "norm"-এর একটা আবশ্যিক ধর্ম — \(\lVert f\rVert=0\) হলে \(f\) অবশ্যই শূন্য। কিন্তু 7.4-এর ধর্ম ৪ বলে \(\int\lvert f\rvert^p\,d\mu=0\iff\lvert f\rvert^p=0\) a.e. \(\iff f=0\) a.e. — অর্থাৎ \(\lVert f\rVert_p=0\) মানে \(f\) প্রায়-সর্বত্র শূন্য, কিন্তু একটা measure-শূন্য set-এ অশূন্য হতে পারে (যেমন \(f=\mathbf 1_{\mathbb Q}\)-এর \(\lVert f\rVert_p=0\) অথচ \(f\not\equiv 0\))। তাই কঠোর অর্থে \(\lVert\cdot\rVert_p\) আলাদা ফাংশনকে আলাদা করতে পারে না।
সমাধান (যা 7.4-এর শেষ উপলব্ধিরই পরিণতি): আমরা দুটো ফাংশনকে একই ধরি যদি তারা a.e. সমান, \(f\sim g\iff f=g\ \mu\text{-a.e.}\) — এবং \(L^p\)-এর সদস্য বলতে বুঝি এই সমতা-শ্রেণি (equivalence class), একক ফাংশন নয়।
সংজ্ঞা (\(L^p\) = a.e.-সমতা-শ্রেণির space)। \(L^p(\mu)\)-কে আনুষ্ঠানিকভাবে সংজ্ঞায়িত করি a.e.-সমতা-শ্রেণির space হিসেবে — অর্থাৎ \(f\) ও \(g\) একই উপাদান যদি \(f=g\) \(\mu\)-a.e.। এই সংজ্ঞায় \(\lVert f\rVert_p=0\iff f=0\) (শ্রেণি হিসেবে শূন্য), তাই \(\lVert\cdot\rVert_p\) একটা প্রকৃত norm, আর \(L^p\) একটা normed vector space (যোগ ও scalar-গুণ a.e.-শ্রেণিতে well-defined; বদ্ধতা আসে Minkowski থেকে, ২.৩)।
ব্যবহারে আমরা যথারীতি "\(f\in L^p\)" লিখব আর একক ফাংশনের মতোই কথা বলব — কিন্তু মনে রাখতে হবে point-wise মান একটা measure-শূন্য set-এ অর্থহীন; যা অর্থবহ তা হলো integral, norm, ও a.e.-ধর্ম।
এক বাক্যে। \(\lVert f\rVert_\infty=\operatorname{ess\,sup}\lvert f\rvert\) (measure-শূন্য set উপেক্ষা করে সর্বোচ্চ) দেয় \(L^\infty\); আর যেহেতু \(\lVert f\rVert_p=0\) মানে কেবল \(f=0\) a.e., \(L^p\)-কে নিতে হয় a.e.-সমতা-শ্রেণির space হিসেবে — তবেই \(\lVert\cdot\rVert_p\) একটা প্রকৃত norm।
২.৩ Hölder ও Minkowski — গুণফল ও যোগফলের দুই স্তম্ভ-অসমতা¶
\(\lVert\cdot\rVert_p\)-কে "norm" বলার অধিকার ও \(L^p\)-এর গোটা বীজগণিত দাঁড়িয়ে আছে দুটো অসমতার উপর। দুটোই গভীরভাবে যুক্ত — Hölder প্রথমে, তারপর তা থেকে Minkowski (প্রমাণ §৪)। প্রথমে একটা সংজ্ঞা: \(1\le p,q\le\infty\)-কে conjugate exponents (অনুবন্ধী সূচক) বলি যদি \(\tfrac1p+\tfrac1q=1\) (যেমন \(p=2\Rightarrow q=2\); \(p=1\Rightarrow q=\infty\); \(p=3\Rightarrow q=\tfrac32\))।
উপপাদ্য (Hölder's inequality — বিবৃতি; প্রমাণ §৪)। ধরা যাক \(1\le p,q\le\infty\) conjugate (\(\tfrac1p+\tfrac1q=1\)), আর \(f\in L^p,\ g\in L^q\)। তবে \(fg\in L^1\) এবং $$ \int_\Omega\lvert fg\rvert\,d\mu\;\le\;\lVert f\rVert_p\,\lVert g\rVert_q,\qquad\text{সমতুল্যভাবে}\qquad \lVert fg\rVert_1\le\lVert f\rVert_p\lVert g\rVert_q. $$ সমতা ঘটে যখন \(\lvert f\rvert^p\) ও \(\lvert g\rvert^q\) a.e. সমানুপাতিক। (প্রমাণের বীজ Young's inequality \(ab\le\tfrac{a^p}{p}+\tfrac{b^q}{q}\) — চিত্র 7-5-holder-young।)
কীভাবে পড়তে হয়। Hölder বলে দুই ফাংশনের গুণফলের "মোট আকার" তাদের আলাদা-আলাদা \(p\)- ও \(q\)-দৈর্ঘ্য দিয়ে আবদ্ধ — যেন গুণফলের আকার নিয়ন্ত্রণ করতে দুজনের দৈর্ঘ্য "ভাগ করে নেয়" (\(\tfrac1p+\tfrac1q=1\))। এটি \(\mathbb R^n\)-এর dot-product-বাউন্ডেরই integral-সংস্করণ, আর \(p=q=2\)-তে সরাসরি Cauchy–Schwarz দেয় (২.৪)। পরিসংখ্যানে এর ব্যবহার অজস্র — moment-দের সম্পর্ক, \(L^p\subseteq L^r\) অন্তর্ভুক্তি (finite measure-এ), covariance-বাউন্ড — সবই Hölder।
উপপাদ্য (Minkowski's inequality — বিবৃতি; প্রমাণ §৪)। ধরা যাক \(1\le p\le\infty\) আর \(f,g\in L^p\)। তবে \(f+g\in L^p\) এবং $$ \lVert f+g\rVert_p\;\le\;\lVert f\rVert_p+\lVert g\rVert_p. $$ অর্থাৎ \(\lVert\cdot\rVert_p\) ত্রিভুজ-অসমতা মানে। (১-মাত্রায় এটি সাধারণ \(\lvert a+b\rvert\le\lvert a\rvert+\lvert b\rvert\)-এর সাধারণীকরণ; প্রমাণ Hölder-নির্ভর।)
Minkowski-ই সেই অনুপস্থিত টুকরো যা \(\lVert\cdot\rVert_p\)-কে একটা প্রকৃত norm করে তোলে — কারণ ত্রিভুজ-অসমতা norm-এর তিন স্বতঃসিদ্ধের তৃতীয়টি (অন্য দুটো — \(\lVert f\rVert_p\ge 0\) এবং \(\lVert cf\rVert_p=\lvert c\rvert\lVert f\rVert_p\) — সরাসরি)। সঙ্গে এটি প্রমাণ করে \(f,g\in L^p\Rightarrow f+g\in L^p\), অর্থাৎ \(L^p\) যোগের অধীনে বদ্ধ — তাই সত্যিই একটা vector space (২.২)। মোদ্দা: Hölder আঁটে গুণফল, Minkowski আঁটে যোগফল, আর এই দুইয়ের জোরেই \(L^p\)-এর জ্যামিতি দাঁড়ায়।
এক বাক্যে। Hölder (\(\int\lvert fg\rvert\le\lVert f\rVert_p\lVert g\rVert_q\), conjugate \(p,q\)) গুণফলের আকার দুই দৈর্ঘ্য দিয়ে আঁটে আর Cauchy–Schwarz-এর জনক; Minkowski (\(\lVert f+g\rVert_p\le\lVert f\rVert_p+\lVert g\rVert_p\)) ত্রিভুজ-অসমতা দিয়ে \(\lVert\cdot\rVert_p\)-কে প্রকৃত norm ও \(L^p\)-কে vector space বানায়।
২.৪ Jensen ও Cauchy–Schwarz — convexity ও inner-product থেকে দুই অসমতা¶
আরও দুটো অসমতা, যারা 3.1-এর পরিচিত মুখ — কিন্তু এখন সম্পূর্ণ-সাধারণ measure/integral-ভাষায়।
উপপাদ্য (Jensen's inequality — বিবৃতি; প্রমাণ §৪)। ধরা যাক \((\Omega,\mathcal F,\mathbb P)\) একটা probability space (\(\mathbb P(\Omega)=1\)), \(X\in L^1(\mathbb P)\) একটা random variable যার মান একটা ব্যবধি \(I\)-তে, আর \(\varphi:I\to\mathbb R\) একটা convex (উত্তল) ফাংশন। তবে $$ \varphi\Big(\int_\Omega X\,d\mathbb P\Big)\;\le\;\int_\Omega\varphi(X)\,d\mathbb P,\qquad\text{অর্থাৎ}\qquad \varphi\big(\mathbb E[X]\big)\le\mathbb E\big[\varphi(X)\big]. $$ (concave \(\varphi\)-তে অসমতা উল্টো; সমতা ঘটে যখন \(\varphi\) ব্যবহৃত পরিসরে রৈখিক, বা \(X\) a.s. ধ্রুবক। প্রমাণের বীজ — \(\varphi\)-এর গ্রাফের নিচে \(\mathbb E[X]\)-বিন্দুতে একটা supporting line।)
কেন এত শক্তিশালী। Jensen এক ঝটকায় বহু পরিচিত বাউন্ড দেয়: \(\varphi(x)=x^2\) নিলে \((\mathbb E X)^2\le\mathbb E[X^2]\) — অর্থাৎ \(\mathrm{Var}(X)\ge 0\); \(\varphi(x)=\lvert x\rvert\) দিলে \(\lvert\mathbb E X\rvert\le\mathbb E\lvert X\rvert\); \(\varphi=-\log\) দিলে AM–GM ও KL-divergence-এর অঋণাত্মকতা; আর \(L^p\)-norm-দের একঘাতিতা (\(p\le r\Rightarrow\lVert X\rVert_p\le\lVert X\rVert_r\) probability-তে)। 3.1-এ এটি discrete/elementary রূপে দেখা হয়েছিল; এখানে একই অসমতা যেকোনো distribution-এ, integral হিসেবে। লক্ষণীয় — Jensen-এ measure probability হওয়া আবশ্যিক (\(\mathbb P(\Omega)=1\)), কারণ "গড়" ধারণাটা মোট-ভর-\(1\)-এর উপর দাঁড়ানো।
উপপাদ্য (Cauchy–Schwarz inequality — বিবৃতি; প্রমাণ §৪)। \(f,g\in L^2(\mu)\)-এর জন্য \(fg\in L^1\) এবং $$ \Big\lvert\int_\Omega fg\,d\mu\Big\rvert\;\le\;\int_\Omega\lvert fg\rvert\,d\mu\;\le\;\lVert f\rVert_2\,\lVert g\rVert_2,\qquad\text{অর্থাৎ}\qquad \lvert\langle f,g\rangle\rvert\le\lVert f\rVert_2\lVert g\rVert_2. $$ সমতা ঘটে যখন \(f,g\) a.e. রৈখিকভাবে নির্ভরশীল (\(g=cf\) a.e.)। (এটি ঠিক Hölder-এর \(p=q=2\) ক্ষেত্র, এবং \(L^2\)-এর inner product-এর — ২.৬ — মৌলিক অসমতা।)
Cauchy–Schwarz হলো \(L^2\)-জ্যামিতির ভিত্তি-অসমতা: এটিই নিশ্চিত করে যে "কোণের cosine" \(\tfrac{\langle f,g\rangle}{\lVert f\rVert_2\lVert g\rVert_2}\in[-1,1]\) — অর্থাৎ inner product থেকে সত্যিই একটা কোণ সংজ্ঞায়িত করা যায়। পরিসংখ্যানে এটি সরাসরি দেয় \(\lvert\mathrm{Cov}(X,Y)\rvert\le\sigma_X\sigma_Y\), তাই correlation \(\rho\in[-1,1]\) — সব association-পরিমাপের সীমা।
এক বাক্যে। Jensen (\(\varphi\) convex ⇒ \(\varphi(\mathbb E X)\le\mathbb E[\varphi(X)]\), probability measure-এ) এক সূত্রে \(\mathrm{Var}\ge 0\)/AM–GM/moment-একঘাতিতা দেয়; Cauchy–Schwarz (\(\lvert\langle f,g\rangle\rvert\le\lVert f\rVert_2\lVert g\rVert_2\), Hölder-এর \(p=q=2\)) দেয় কোণ-cosine \(\in[-1,1]\), তাই correlation \(\rho\in[-1,1]\)।
২.৫ Completeness ও Riesz–Fischer — \(L^p\) একটা Banach space¶
জ্যামিতি গড়ার পরের অপরিহার্য প্রশ্ন — এই space-টা কি "ফুটো", নাকি "সম্পূর্ণ"? অর্থাৎ একটা অনুক্রম যদি নিজের সদস্যদের সাথে ক্রমে কাছাকাছি আসতে থাকে (Cauchy), সে কি space-এর ভেতরেই একটা limit-এ পৌঁছায়, নাকি একটা "ফাঁকে" পড়ে অদৃশ্য হয়? এই ধর্মই completeness — limit-যুক্তির নিরাপত্তা।
সংজ্ঞা (Cauchy অনুক্রম, completeness, Banach space)। \(L^p\)-এ একটা অনুক্রম \((f_n)\) Cauchy যদি \(\lVert f_n-f_m\rVert_p\to 0\) (\(n,m\to\infty\))। একটা normed space complete (পূর্ণ) যদি প্রতিটি Cauchy অনুক্রম space-এরই কোনো উপাদানে অভিসারী হয় (\(\exists f\in L^p\) যাতে \(\lVert f_n-f\rVert_p\to 0\))। একটা complete normed vector space-কে বলে Banach space (বানাখ স্পেস)।
স্বজ্ঞা: \(\mathbb Q\) (মূলদ সংখ্যা) "ফুটো" — \(1,1.4,1.41,1.414,\dots\) একে অপরের কাছে আসে (Cauchy) কিন্তু limit \(\sqrt2\) \(\mathbb Q\)-এর বাইরে। \(\mathbb R\) "সম্পূর্ণ" — তাই \(\mathbb R\)-এ calculus চলে। ফাংশন-জগতেও আমরা একই নিরাপত্তা চাই: একটা approximation-অনুক্রম যেন একটা প্রকৃত ফাংশনে পৌঁছায়, হাওয়ায় মিলিয়ে না যায়। সুসংবাদ — \(L^p\) সম্পূর্ণ:
উপপাদ্য (Riesz–Fischer — বিবৃতি; প্রমাণ §৪)। প্রতিটি \(1\le p\le\infty\)-এর জন্য \(L^p(\mu)\) complete, অর্থাৎ একটা Banach space। আরও — যদি \(\lVert f_n-f\rVert_p\to 0\), তবে \((f_n)\)-এর একটা উপ-অনুক্রম \(f_{n_k}\to f\) point-wise a.e.। (প্রমাণের কৌশল — absolutely-convergent series criterion: \(\sum_k\lVert f_{k+1}-f_k\rVert_p<\infty\) দেখিয়ে MCT/DCT দিয়ে point-wise limit গড়া।)
এর তাৎপর্য বিশাল। completeness ছাড়া "\(f_n\to f\) in \(L^p\)" বলে কোনো \(f\)-এর অস্তিত্ব নিশ্চিত করা যেত না — তখন series, Fourier-প্রসারণ, estimator-limit, martingale-limit — কিছুই দাঁড়াত না। Riesz–Fischer-ই \(L^p\)-কে এমন একটা মঞ্চ বানায় যেখানে "limit নিয়ে কথা বলা নিরাপদ"। বিশেষত \(p=2\)-তে এই completeness + inner product (২.৬) মিলে \(L^2\)-কে দেয় তার পূর্ণ মর্যাদা — Hilbert space (২.৭), যেখানে projection theorem-ও completeness-এর উপরই দাঁড়ায়।
এক বাক্যে। Riesz–Fischer: প্রতিটি \(L^p\) complete (Cauchy ⇒ অভিসারী, একটা উপ-অনুক্রম point-wise a.e.), তাই একটা Banach space — যা limit/series/approximation-যুক্তিকে নিরাপদ করে, আর \(L^2\)-কে Hilbert-মর্যাদা দেওয়ার পূর্বশর্ত।
২.৬ \(L^2\)-এর inner product ও orthogonality — কোণ ফিরে এল¶
এখন এ অধ্যায়ের জ্যামিতিক হৃদয় — \(p=2\)। শুধু \(L^2\)-তেই norm-টা একটা inner product থেকে জন্মায়, আর তখনই ফাংশন-জগতে "কোণ" ও "লম্ব" সংজ্ঞায়িত করা যায় — অসীম-মাত্রিক ইউক্লিডীয় জ্যামিতি।
সংজ্ঞা (\(L^2\) inner product; orthogonality)। \(f,g\in L^2(\mu)\)-এর inner product (অন্তঃগুণফল) হলো $$ \langle f,g\rangle\;:=\;\int_\Omega f\,g\,d\mu\qquad(\text{complex হলে }\textstyle\int f\bar g\,d\mu), $$ যা Cauchy–Schwarz (২.৪) দিয়ে সসীম ও well-defined। এটি (i) bilinear/linear, (ii) symmetric, (iii) \(\langle f,f\rangle=\lVert f\rVert_2^2\ge 0\) এবং \(=0\iff f=0\) (a.e.-শ্রেণিতে) — অর্থাৎ একটা প্রকৃত inner product, আর তা থেকেই norm \(\lVert f\rVert_2=\sqrt{\langle f,f\rangle}\)। দুই ফাংশন orthogonal (লম্ব), লেখা \(f\perp g\), যদি \(\langle f,g\rangle=0\)।
এটি 0.5-এর dot product \(\langle x,y\rangle=x^\top y=\sum_i x_iy_i\)-এর সরাসরি ফাংশন-সংস্করণ — "যোগ" এখন "integral", মাত্রা এখন অসীম। আর এর সাথে আসে \(\mathbb R^n\)-এর সব চেনা জ্যামিতিক অভেদ, অবিকল:
- Pythagoras: \(f\perp g\Rightarrow\lVert f+g\rVert_2^2=\lVert f\rVert_2^2+\lVert g\rVert_2^2\)।
- parallelogram law: \(\lVert f+g\rVert_2^2+\lVert f-g\rVert_2^2=2\lVert f\rVert_2^2+2\lVert g\rVert_2^2\) (যা projection theorem-এর প্রমাণে চাবি — §৪)।
পরিসংখ্যান-অনুবাদ। random variable-দের \(L^2(\mathbb P)\)-তে এই inner product হলো \(\langle X,Y\rangle=\mathbb E[XY]\)। কেন্দ্রিত (\(\mathbb E[X]=\mathbb E[Y]=0\)) হলে \(\langle X,Y\rangle=\mathrm{Cov}(X,Y)\), \(\lVert X\rVert_2^2=\mathrm{Var}(X)\), আর orthogonality \(=\) uncorrelatedness (\(\mathrm{Cov}=0\))। তখন variance-এর additivity (\(\mathrm{Var}(X+Y)=\mathrm{Var}(X)+\mathrm{Var}(Y)\) যখন uncorrelated) ঠিক Pythagoras। অর্থাৎ পরিসংখ্যানের covariance-জ্যামিতি আর \(L^2\)-জ্যামিতি একই বস্তু।
এক বাক্যে। \(L^2\)-এ inner product \(\langle f,g\rangle=\int fg\,d\mu\) (random variable-এ \(\mathbb E[XY]\)) ফিরিয়ে আনে কোণ ও orthogonality (\(f\perp g\iff\langle f,g\rangle=0\), পরিসংখ্যানে uncorrelatedness), Pythagoras ও parallelogram সহ — \(\mathbb R^n\)-জ্যামিতির অসীম-মাত্রিক রূপ।
২.৭ Hilbert space ও Projection Theorem — নিকটতম বিন্দু, residual লম্ব¶
inner product (২.৬) আর completeness (২.৫) একসাথে \(L^2\)-কে দেয় তার পূর্ণ নাম — Hilbert space — আর তার সবচেয়ে দামি ফল projection theorem, যা ১.৪-এ প্রতিশ্রুত conditional-expectation-জ্যামিতির ভিত্তি।
সংজ্ঞা (Hilbert space)। একটা Hilbert space (হিলবার্ট স্পেস) হলো একটা inner-product space যা সেই inner-product-জাত norm-এ complete। বিশেষত \(L^2(\mu)\) একটা Hilbert space (inner product ২.৬ + Riesz–Fischer completeness ২.৫)।
উপপাদ্য (Projection Theorem — বিবৃতি; প্রমাণ §৪)। ধরা যাক \(H\) একটা Hilbert space (যেমন \(L^2\)) আর \(M\subseteq H\) একটা closed subspace (বদ্ধ উপ-স্পেস)। তবে প্রতিটি \(f\in H\)-এর জন্য একটা একমাত্র \(\hat f\in M\) আছে যা \(M\)-এর মধ্যে \(f\)-এর নিকটতম বিন্দু: $$ \lVert f-\hat f\rVert\;=\;\min_{g\in M}\lVert f-g\rVert, $$ এবং এই \(\hat f\) স্বতন্ত্রভাবে চিহ্নিত orthogonality শর্ত দিয়ে — residual পুরো \(M\)-এর সাথে লম্ব: $$ f-\hat f\;\perp\;M,\qquad\text{অর্থাৎ}\qquad \langle f-\hat f,\;g\rangle=0\ \ \forall g\in M. $$ এই \(\hat f=P_M f\)-কে বলে \(M\)-এ \(f\)-এর orthogonal projection; চিত্র 7-5-l2-projection।
কীভাবে পড়তে হয়। এটি অবিকল ১.২-এর \(\mathbb R^3\)-ছবি — vector-কে সমতলে ফেলা, পায়ের তলায় লম্ব — কিন্তু এখন \(H\) অসীম-মাত্রিক, আর "\(M\) closed" শর্তটাই (completeness-এর সাথে মিলে) নিশ্চিত করে নিকটতম বিন্দুটা সত্যিই থাকে (নয়তো infimum-টা অধরা থেকে যেতে পারত, যেমন \(\mathbb Q\)-তে \(\sqrt2\))। দুটো বৈশিষ্ট্য — "নিকটতম" আর "residual ⊥" — আসলে সমতুল্য: যে বিন্দুতে residual লম্ব, সেই বিন্দুই নিকটতম (Pythagoras দিয়ে দেখা যায়)। এই দ্বৈত রূপই পরিসংখ্যানে দুই মুখে দেখা দেয় — "minimum mean-squared error" (নিকটতম) আর "residual ⊥ predictors / normal equations" (orthogonality)।
orthonormal basis (সংক্ষেপে)। \(\mathbb R^n\)-এর মতো \(L^2\)-তেও একটা orthonormal system \(\{e_k\}\) (\(\langle e_i,e_j\rangle=\delta_{ij}\)) নিয়ে কাজ করা যায়; যদি এটি complete (orthonormal basis) হয়, তবে প্রতিটি \(f\in L^2\) লেখা যায় \(f=\sum_k\langle f,e_k\rangle e_k\) (Fourier-প্রসারণ) সঙ্গে Parseval \(\lVert f\rVert_2^2=\sum_k\lvert\langle f,e_k\rangle\rvert^2\) — এবং একটা subspace-এ projection মানে কেবল সেই basis-অংশটুকু রাখা। (Fourier series, orthogonal polynomial, PCA-র অসীম-মাত্রিক আত্মীয় — সবই এই কাঠামো।)
এক বাক্যে। \(L^2\) একটা Hilbert space, আর projection theorem বলে যেকোনো closed subspace \(M\)-এ \(f\)-এর একটা একমাত্র নিকটতম \(\hat f=P_Mf\) আছে যার residual \(f-\hat f\perp M\) — "নিকটতম" ও "residual লম্ব" সমতুল্য, ঠিক \(\mathbb R^n\)-এর projection, যা least squares ও conditional expectation (7.7)-এর জ্যামিতি।
২.৮ Absolute continuity, Radon–Nikodym ও Lebesgue decomposition — কঠোর density¶
এবার অধ্যায়ের দ্বিতীয় বড় স্তম্ভ, জ্যামিতি থেকে সরে measure-দের সম্পর্কে। প্রশ্ন: কখন একটা measure \(\nu\)-কে আরেকটা \(\mu\)-এর সাপেক্ষে একটা density ফাংশন দিয়ে প্রকাশ করা যায় — যেমন pdf \(f_X\) probability-কে length-এর সাপেক্ষে প্রকাশ করে? প্রথমে যে শর্ত এটিকে সম্ভব করে:
সংজ্ঞা (absolute continuity, \(\nu\ll\mu\))। দুটো measure \(\mu,\nu\) একই \((\Omega,\mathcal F)\)-তে। \(\nu\)-কে \(\mu\)-এর সাপেক্ষে absolutely continuous (সম্পূর্ণ অবিচ্ছিন্ন) বলি, লেখা \(\nu\ll\mu\), যদি $$ \mu(A)=0\ \Longrightarrow\ \nu(A)=0\qquad(\forall A\in\mathcal F), $$ অর্থাৎ \(\mu\) যেখানে কোনো ভর দেখে না, \(\nu\)-ও সেখানে শূন্য। (স্বজ্ঞা: \(\nu\) "\(\mu\)-এর চোখেই দেখে" — \(\mu\)-null যা, \(\nu\)-এর কাছেও তা শূন্য; বিপরীত ধারণা — \(\mu,\nu\) mutually singular \(\mu\perp\nu\) — যখন তারা দুটো disjoint set-এ বাস করে।)
এই শর্তই Radon–Nikodym-এর চাবি — কারণ যদি \(\nu(A)=\int_A f\,d\mu\) হতো, তবে \(\mu(A)=0\) সরাসরি \(\nu(A)=0\) দিত (শূন্য set-এ integral শূন্য); তাই \(\nu\ll\mu\) একটা আবশ্যিক শর্ত। চমকপ্রদভাবে, σ-finite ক্ষেত্রে এটি যথেষ্টও:
উপপাদ্য (Radon–Nikodym — বিবৃতি; প্রমাণ §৪)। ধরা যাক \(\mu,\nu\) σ-finite measure \((\Omega,\mathcal F)\)-তে এবং \(\nu\ll\mu\)। তবে একটা measurable density \(f:\Omega\to[0,\infty)\) আছে যাতে $$ \nu(A)\;=\;\int_A f\,d\mu\qquad(\forall A\in\mathcal F), $$ এবং এই \(f\) \(\mu\)-a.e. অনন্য। একে বলে Radon–Nikodym derivative (র্যাডন–নিকোডিম অন্তরজ), লেখা $$ f\;=\;\frac{d\nu}{d\mu}. $$ (চিত্র 7-5-radon-nikodym দেখায় density \(f\) কীভাবে \(\nu(A)=\int_A f\,d\mu\) পুনর্গঠন করে; প্রমাণ §৪-এ — একটা মার্জিত পথ ঠিক ২.৭-এর \(L^2\)-projection ব্যবহার করে, von Neumann-এর কৌশলে।)
কীভাবে পড়তে হয়। এটি 7.4-এর ২.৪-এর পর্যবেক্ষণের উল্টো দিক: সেখানে দেখেছিলাম যেকোনো অঋণাত্মক \(f\) থেকে \(\nu(A)=\int_A f\,d\mu\) একটা measure বানায়; Radon–Nikodym বলে — উল্টোটাও সত্য, অর্থাৎ \(\nu\ll\mu\) (σ-finite) হলে সব এমন measure আসলে এক-একটা density থেকেই আসে। প্রতীক \(\tfrac{d\nu}{d\mu}\) ইচ্ছাকৃতভাবে derivative-এর মতো — এটি সত্যিই একটা "measure-পরিবর্তনের হার", আর chain-rule-সদৃশ নিয়ম মানে (\(\tfrac{d\nu}{d\mu}\cdot\tfrac{d\mu}{d\rho}=\tfrac{d\nu}{d\rho}\))।
শেষে, যে measure \(\mu\)-এর সাপেক্ষে absolutely continuous নয়, তাকেও একটা পরিষ্কার ভাগে ফেলা যায়:
উপপাদ্য (Lebesgue decomposition — বিবৃতি; প্রমাণ §৪)। σ-finite \(\mu,\nu\)-এর জন্য \(\nu\)-কে একমাত্রভাবে দুই টুকরোয় ভাঙা যায় $$ \nu\;=\;\nu_{ac}+\nu_{sing},\qquad \nu_{ac}\ll\mu,\quad \nu_{sing}\perp\mu, $$ অর্থাৎ একটা absolutely-continuous অংশ (density আছে, \(\nu_{ac}(A)=\int_A f\,d\mu\)) আর একটা singular অংশ (একটা \(\mu\)-null set-এ কেন্দ্রীভূত — যেমন discrete atom বা Cantor-ধরনের)।
এটিই ব্যাখ্যা করে কেন কিছু বণ্টনের "density নেই" — তাদের একটা singular অংশ আছে (discrete mass, বা Cantor-বণ্টন)। মিশ্র বণ্টন (যেমন censored data — কিছু ভর একটা বিন্দুতে, বাকিটা মসৃণ) ঠিক \(\nu_{ac}+\nu_{sing}\) রূপে ধরা পড়ে।
এক বাক্যে। \(\nu\ll\mu\) (\(\mu\)-null ⇒ \(\nu\)-null) হলে σ-finite ক্ষেত্রে Radon–Nikodym দেয় একটা a.e.-অনন্য density \(\tfrac{d\nu}{d\mu}\ge 0\) যাতে \(\nu(A)=\int_A f\,d\mu\) — অর্থাৎ "কঠোর pdf"; আর Lebesgue decomposition \(\nu=\nu_{ac}+\nu_{sing}\) যেকোনো measure-কে density-অংশ ও singular-অংশে ভাঙে।
২.৯ পরিসংখ্যান-প্রয়োগ — pdf, likelihood ratio, ও conditional-expectation পূর্বাভাস¶
এ অধ্যায়ের বিমূর্ত যন্ত্রগুলো — projection ও Radon–Nikodym — সরাসরি কোথায় ফসল ফলায়, তা গুছিয়ে রাখা যাক; বিস্তারিত আসবে 7.6–7.7-এ।
-
pdf = Radon–Nikodym derivative। একটা continuous random variable \(X\)-এর probability density function আসলে \(f_X=\tfrac{dP_X}{d\lambda}\) — \(X\)-এর law \(P_X\) (7.3-এর pushforward)-এর Lebesgue measure \(\lambda\)-সাপেক্ষে RN-derivative। এটি থাকে যদি ও কেবল যদি \(P_X\ll\lambda\) (continuous বণ্টন); discrete \(X\)-এর জন্য \(P_X\perp\lambda\) (singular), তাই pdf নেই — বরং counting measure-এর সাপেক্ষে density (pmf)। অর্থাৎ "pdf আছে কিনা" প্রশ্নটার কঠোর উত্তর Radon–Nikodym-এই।
-
likelihood ratio \(\tfrac{dP}{dQ}\)। দুই candidate বণ্টন \(P,Q\)-এর তুলনায় likelihood ratio হলো RN-derivative \(\Lambda=\tfrac{dP}{dQ}\) (যখন \(P\ll Q\))। এটি Neyman–Pearson lemma (সবচেয়ে শক্তিশালী test), importance sampling (\(\mathbb E_P[h]=\mathbb E_Q[h\,\tfrac{dP}{dQ}]\)), এবং পরে (7.8) change of measure / martingale-এর কেন্দ্রীয় বস্তু — সবই একটা Radon–Nikodym derivative।
-
conditional expectation = \(L^2\)-projection / RN-derivative (7.7-এর পূর্বাভাস)। \(\mathbb E[X\mid\mathcal G]\)-কে দুইভাবে দেখা যায়, এবং দুটোই এ অধ্যায়ের ফল: (i) জ্যামিতিক — \(X\in L^2\)-এর projection closed subspace \(L^2(\mathcal G)\)-তে (২.৭), অর্থাৎ \(\mathcal G\)-তথ্য দিয়ে গড়া নিকটতম (least-squares) প্রতিরূপ, residual ⊥ \(L^2(\mathcal G)\); (ii) measure-তাত্ত্বিক — সাধারণ \(L^1\)-ক্ষেত্রে এর অস্তিত্ব আসে Radon–Nikodym থেকে (একটা signed measure \(A\mapsto\int_A X\,d\mathbb P\)-এর \(\mathbb P\!\restriction_{\mathcal G}\)-সাপেক্ষে derivative)। তাই 7.5-এর দুই মুকুটমণিই 7.7-এ এক বিন্দুতে মেলে।
এক বাক্যে প্রয়োগ। pdf \(f_X=\tfrac{dP_X}{d\lambda}\) ও likelihood ratio \(\tfrac{dP}{dQ}\) হলো Radon–Nikodym derivative (density-র কঠোর রূপ, NP-lemma/importance-sampling-এর ভিত্তি), আর conditional expectation \(\mathbb E[X\mid\mathcal G]\) হলো একই সাথে \(L^2\)-projection ও RN-derivative — তাই এ অধ্যায়ের জ্যামিতি ও density সরাসরি 7.7-এ গড়ায়।
৩ · পূর্ণাঙ্গ উদাহরণ¶
§১–২-এ আমরা \(L^p\)-জগতের গোটা কাঠামো গড়েছি — \(L^p\) norm (এল-পি নর্ম, "আকার-মাপক") \(\lVert f\rVert_p=\big(\int\lvert f\rvert^p\,d\mu\big)^{1/p}\) থেকে শুরু করে দুই স্তম্ভ-অসমতা — Hölder (হ্যোল্ডার) \(\int\lvert fg\rvert\le\lVert f\rVert_p\lVert g\rVert_q\) (\(\tfrac1p+\tfrac1q=1\)) ও তার ত্রিভুজ-জোড়া Minkowski (মিন্কফ্স্কি) \(\lVert f+g\rVert_p\le\lVert f\rVert_p+\lVert g\rVert_p\) — হয়ে Jensen (ইয়েনসেন) উত্তলতা-অসমতা, completeness (পূর্ণতা) যা \(L^p\)-কে Banach space (বানাখ স্পেস, পূর্ণ নর্মযুক্ত স্থান) বানায়, \(L^2\)-এর Hilbert (হিলবার্ট) অন্তঃগুণন-গঠন ও তার projection theorem (অভিক্ষেপ উপপাদ্য), এবং শেষে absolute continuity (পরম অবিচ্ছিন্নতা) ও Radon–Nikodym (রাদোঁ–নিকোদিম) density। এই অংশের উদ্দেশ্য সেই বিমূর্ত কাঠামোকে হাতে-কলমে, কংক্রিট সংখ্যা দিয়ে ছুঁয়ে দেখা — প্রতিটি অসমতা সত্যিই কোন সংখ্যায় কতটা ধরা পড়ে, projection কীভাবে "গড়" হয়ে দাঁড়ায়, RN-density কীভাবে চেনা pdf-এ নামে। ছয়টি উদাহরণে প্রতিটি ধাপ ধৈর্য ধরে কষব — কোনো হিসাব লুকানো থাকবে না — তারপর প্রতিটির শেষে "কী শিখলাম" বলে মূল শিক্ষাটা গুটিয়ে আনব। কষ্টের স্তর শিরোনামে তারা দিয়ে চিহ্নিত: ★ = সরাসরি, সংজ্ঞা প্রয়োগ করলেই হয় · ★★ = কিছু কৌশল বা সতর্ক যুক্তি লাগে। প্রতিটি ইংরেজি পরিভাষা প্রথম ব্যবহারে বাংলায় খুলে দেওয়া হবে। জুড়ে \(\lambda\) মানে \([0,1]\)-এর উপর Lebesgue measure (লেবেগ পরিমাপ) — যেহেতু \(\lambda([0,1])=1\), এটি একটি probability measure (সম্ভাবনা পরিমাপ), তাই \(\int_0^1(\cdot)\,d\lambda\)-কে নিশ্চিন্তে expectation (প্রত্যাশা) \(\mathbb E[\cdot]\) বলে পড়া যায়।
উদাহরণ ১ — \(L^p\) norm ও \(p\)-এর সাথে বৃদ্ধি (★)¶
সেটআপ। \(L^p\) norm-টা আসলে কত — এটা একটা কংক্রিট ফাংশনে গুনে দেখা যাক। নিই \([0,1]\)-এর উপর সবচেয়ে সরল অ-ধ্রুবক ফাংশন $$ f(x)=x ,\qquad x\in[0,1] . $$ \(\lambda\) এখানে probability measure বলে \(\lVert f\rVert_p\) আসলে random variable \(X\sim\text{Uniform}(0,1)\)-এর জন্য \(\big(\mathbb E[\lvert X\rvert^p]\big)^{1/p}\) — যাকে statistics-এ \(p\)-th moment-এর \(p\)-মূল বলা চলে। সংজ্ঞা থেকে $$ \lVert f\rVert_p=\Big(\int_0^1 \lvert x\rvert^{\,p}\,d\lambda\Big)^{1/p}=\Big(\int_0^1 x^{p}\,dx\Big)^{1/p} . $$
হাতে কষা। ভেতরের integral সরাসরি: \(\int_0^1 x^p\,dx=\big[\tfrac{x^{p+1}}{p+1}\big]_0^1=\tfrac{1}{p+1}\)। তাই বদ্ধ-রূপ (closed form) $$ \boxed{\;\lVert f\rVert_p=\Big(\frac{1}{p+1}\Big)^{1/p}\;} $$ এবার বিভিন্ন \(p\)-তে মান বসাই। প্রতিটি একটা একক \(\tfrac{1}{p+1}\)-এর \(p\)-তম মূল:
| \(p\) | \(\dfrac{1}{p+1}\) | \(\lVert f\rVert_p=\big(\tfrac{1}{p+1}\big)^{1/p}\) |
|---|---|---|
| \(1\) | \(\tfrac12\) | \(0.5000\) |
| \(2\) | \(\tfrac13\) | \(0.5774\) |
| \(3\) | \(\tfrac14\) | \(0.6300\) |
| \(4\) | \(\tfrac15\) | \(0.6687\) |
| \(10\) | \(\tfrac1{11}\) | \(0.7868\) |
| \(\infty\) | — | \(1.0000\) |
কয়েকটা ধাপ মিলিয়ে দেখি। \(p=1\): \(\lVert f\rVert_1=\tfrac12=0.5\) — এটা ঠিক \(\mathbb E[X]=\int_0^1 x\,dx\), গড়। \(p=2\): \(\lVert f\rVert_2=(1/3)^{1/2}=1/\sqrt3\approx 0.5774\) — এটাই \(\sqrt{\mathbb E[X^2]}\), যাকে RMS (root-mean-square, বর্গ-গড়-মূল) বলে। \(p=4\): \((1/5)^{1/4}=5^{-1/4}\approx 0.6687\)।
\(p=\infty\) প্রান্ত। \(L^\infty\) norm হলো essential supremum (অত্যাবশ্যিক ঊর্ধ্বসীমা) — null set উপেক্ষা করে সর্বোচ্চ মান: $$ \lVert f\rVert_\infty=\operatorname*{ess\,sup}_{x\in[0,1]}\lvert x\rvert=1 . $$ (\(f(x)=x\) একটানা বাড়ছে \(1\) পর্যন্ত; \(\{x=1\}\) একটা single point, measure \(0\), কিন্তু তার যেকোনো ডানপাশের পরিবেশের measure ধনাত্মক, তাই \(\sup=1\) essential অর্থেও \(1\)।) লক্ষণীয়, \(\big(\tfrac{1}{p+1}\big)^{1/p}\to 1\) যখন \(p\to\infty\) — সংখ্যাটা ঠিক \(1\)-তে গিয়ে মেলে, কারণ সর্বজনীনভাবে \(\lVert f\rVert_p\to\lVert f\rVert_\infty\)।
মূল পর্যবেক্ষণ — \(p\) বাড়লে norm বাড়ে। টেবিলে স্পষ্ট: \(0.5<0.5774<0.63<0.6687<0.7868<1.0\) — \(\lVert f\rVert_p\) একঘাতীভাবে বাড়ছে (monotone increasing in \(p\))। এটা দৈবাৎ নয়; probability measure-এর উপর সর্বদা সত্য: \(0<q\le p\) হলে \(\lVert f\rVert_q\le\lVert f\rVert_p\)। সংক্ষিপ্ত কারণ — Jensen বা power-mean অসমতা: \(\mu\) মোট-ভর \(1\) হওয়ায় বড় ঘাত বড় মানগুলোকে অসমানুপাতিক বেশি ওজন দেয়, তাই গড়-আকার বাড়ে।
এর সরাসরি ফল একটা inclusion (অন্তর্ভুক্তি): probability space-এ $$ p\ge q \;\Longrightarrow\; L^p\subseteq L^q , $$ অর্থাৎ \(\lVert f\rVert_p<\infty\) হলে \(\lVert f\rVert_q<\infty\)-ও — বড় \(p\)-তে integrable হওয়া কঠিনতর শর্ত, তাই সেটি ছোট \(q\)-কে আপনিই দেয়। statistics-এ এর অর্থ গভীর: finite variance (\(L^2\)) থাকলে finite mean (\(L^1\)) আপনিই থাকে, কিন্তু উল্টোটা নয় — মোটা-লেজা (heavy-tailed) বণ্টনে \(\mathbb E[X]\) থাকলেও \(\mathbb E[X^2]=\infty\) হতে পারে। (সতর্কতা: এই inclusion কেবল finite-measure স্পেসে; \(\mathbb R\)-এর Lebesgue measure-এ \(L^p\subseteq L^q\) ভাঙে।)
কী শিখলাম। probability measure-এর উপর \(L^p\) norm \(p\)-এর সাথে একঘাতীভাবে বাড়ে: \(f(x)=x\)-এ \(\lVert f\rVert_p=(1/(p+1))^{1/p}\) দিল \(p=1,2,3,4,10,\infty\to 0.5,\,0.5774,\,0.63,\,0.6687,\,0.7868,\,1.0\) — \(p=1\) গড় (\(\tfrac12\)), \(p=2\) RMS (\(1/\sqrt3\)), \(p=\infty\) ess sup (\(1\))। ফলে \(p\ge q\Rightarrow L^p\subseteq L^q\) (finite measure-এ): বড় \(p\)-তে integrability ছোট \(q\)-কে বিনামূল্যে দেয়, তাই finite variance (\(L^2\)) থাকলে finite mean (\(L^1\)) আপনিই থাকে — উল্টোটা নয়। norm আসলে "গড়-আকার", আর ঘাত যত বড়, বড় মানগুলো তত বেশি ওজন পায়।
উদাহরণ ২ — Cauchy–Schwarz হাতে যাচাই (★)¶
সেটআপ। Cauchy–Schwarz (কোশি–শোয়ার্জ) অসমতা হলো Hölder-এর \(p=q=2\) বিশেষ রূপ এবং \(L^2\) Hilbert space-এর হৃৎপিণ্ড: $$ \lvert\langle f,g\rangle\rvert\;\le\;\lVert f\rVert_2\,\lVert g\rVert_2 , \qquad \langle f,g\rangle=\int f\,g\,d\lambda . $$ এটা একটা কংক্রিট জোড়ায় সংখ্যায় যাচাই করি। নিই \([0,1]\)-এর উপর $$ f(x)=x,\qquad g(x)=x^2 . $$
বাঁ পক্ষ — inner product (অন্তঃগুণন)। $$ \langle f,g\rangle=\int_0^1 x\cdot x^2\,dx=\int_0^1 x^3\,dx=\Big[\frac{x^4}{4}\Big]_0^1=\frac14=0.25 . $$
ডান পক্ষ — দুই norm। উদাহরণ ১-এর বদ্ধ-রূপ \(\lVert x^k\rVert_2=\big(\int_0^1 x^{2k}\,dx\big)^{1/2}=(2k+1)^{-1/2}\) ব্যবহার করি: $$ \lVert f\rVert_2=\lVert x\rVert_2=\Big(\int_0^1 x^2\,dx\Big)^{1/2}=\frac{1}{\sqrt3},\qquad \lVert g\rVert_2=\lVert x^2\rVert_2=\Big(\int_0^1 x^4\,dx\Big)^{1/2}=\frac{1}{\sqrt5} . $$ গুণফল: $$ \lVert f\rVert_2\,\lVert g\rVert_2=\frac{1}{\sqrt3}\cdot\frac{1}{\sqrt5}=\frac{1}{\sqrt{15}}\approx 0.2582 . $$
তুলনা। পাশাপাশি রাখি: $$ \underbrace{0.25}{\langle f,g\rangle}\;\le\;\underbrace{0.2582}\qquad\checkmark $$ অসমতা মানছে — এবং কঠোরভাবে (strict): \(0.25<0.2582\), সমতা নয়। কারণ Cauchy–Schwarz-এ সমতা ঠিক তখনই হয় যখন \(f,g\) একে অপরের ধ্রুবক-গুণিতক (linearly dependent, "সমান্তরাল ভেক্টর")। এখানে \(g=x^2\) কোনো ধ্রুবক \(c\)-এর জন্য \(c\cdot x\) নয় (একটা সরলরেখা আর একটা প্যারাবোলা), তাই তারা সমান্তরাল নয় — ফাঁক থাকবেই। সংখ্যায় সেই ফাঁক \(0.2582-0.25=0.0082\)।
ভৌমিতিক পাঠ। \(L^2\)-এ ফাংশনগুলো ভেক্টর, \(\langle f,g\rangle\) তাদের "ডট-গুণন", আর \(\cos\theta=\dfrac{\langle f,g\rangle}{\lVert f\rVert_2\lVert g\rVert_2}\) তাদের মধ্যবর্তী কোণ। এখানে \(\cos\theta=\dfrac{0.25}{0.2582}\approx 0.968\), তাই \(\theta\approx 14.5^\circ\) — \(f\) আর \(g\) প্রায় একই দিকে (ছোট কোণ), কিন্তু ঠিক এক রেখায় নয়, তাই Cauchy–Schwarz কঠোর। statistics-এ এই \(\cos\theta\)-ই correlation (সহসম্বন্ধ): \(\lvert\rho\rvert\le 1\) আসলে Cauchy–Schwarz-এরই ছদ্মবেশ।
কী শিখলাম। Cauchy–Schwarz \(\lvert\langle f,g\rangle\rvert\le\lVert f\rVert_2\lVert g\rVert_2\) হলো Hölder-এর \(p=q=2\) রূপ। \(f=x,\,g=x^2\) on \([0,1]\)-এ বাঁ পক্ষ \(\int_0^1 x^3=0.25\), ডান পক্ষ \(\tfrac1{\sqrt3}\cdot\tfrac1{\sqrt5}=\tfrac1{\sqrt{15}}=0.2582\) — অসমতা কঠোরভাবে মানে (\(0.25<0.2582\)), কারণ \(x\) ও \(x^2\) সমান্তরাল নয় (সমতা কেবল linear dependence-এ)। গভীর বার্তা: \(\langle f,g\rangle/(\lVert f\rVert_2\lVert g\rVert_2)\) হলো দুই ফাংশন-ভেক্টরের কোণের কোসাইন (এখানে \(\cos\theta\approx 0.968\)) — আর সেটাই statistics-এ correlation, তাই \(\lvert\rho\rvert\le 1\) নিজেই Cauchy–Schwarz।
উদাহরণ ৩ — Jensen ও কেন variance \(\ge 0\) (★)¶
সেটআপ। Jensen's inequality (ইয়েনসেনের অসমতা) বলে: \(\varphi\) একটি convex (উত্তল) ফাংশন হলে $$ \varphi\big(\mathbb E[X]\big)\;\le\;\mathbb E\big[\varphi(X)\big] . $$ স্বজ্ঞা: উত্তল বক্ররেখায় গড়-বিন্দু সবসময় বক্ররেখার নিচে ঝোলা জ্যা (chord)-এর উপরে নয়, বরং বক্ররেখাটা গড়কে নিচে টেনে রাখে — তাই "ফাংশনের গড়" \(\ge\) "গড়ের ফাংশন"। সবচেয়ে চেনা উত্তল ফাংশন \(\varphi(x)=x^2\) নিয়ে এটা সংখ্যায় দেখি, \(X\sim\text{Uniform}(0,1)\)-এ।
দুই পক্ষ কষা। ডান পক্ষ — ফাংশনের গড়: $$ \mathbb E[\varphi(X)]=\mathbb E[X^2]=\int_0^1 x^2\,dx=\frac13\approx 0.3333 . $$ বাঁ পক্ষ — গড়ের ফাংশন: $$ \varphi(\mathbb E[X])=\big(\mathbb E[X]\big)^2=\Big(\int_0^1 x\,dx\Big)^2=\Big(\frac12\Big)^2=\frac14=0.25 . $$ তুলনা: $$ \underbrace{0.25}{(\mathbb E X)^2}\;\le\;\underbrace{0.3333}\qquad\checkmark $$ Jensen মানছে — কঠোরভাবে, কারণ \(x^2\) কঠোর-উত্তল (strictly convex) এবং \(X\) অ-ধ্রুবক (nondegenerate)।
ফাঁকটাই variance। এই অসমতার ফাঁক কী? ঠিক $$ \mathbb E[X^2]-(\mathbb E X)^2=\frac13-\frac14=\frac{4-3}{12}=\frac{1}{12}\approx 0.0833 . $$ আর এটা তো variance (ভেদাঙ্ক)-এরই সংজ্ঞা: $$ \operatorname{Var}(X)=\mathbb E[X^2]-(\mathbb E X)^2=\frac{1}{12} . $$ (\(\text{Uniform}(0,1)\)-এর জানা variance \(\tfrac{1}{12}\) — মিলে গেল।) অর্থাৎ এই বিশেষ ক্ষেত্রে $$ \text{Jensen-এর ফাঁক}\;(\varphi=x^2)\;=\;\operatorname{Var}(X)\;\ge\;0 . $$
গভীর সমতুল্যতা। তাই \(\varphi(x)=x^2\)-এ Jensen অসমতা \(\Leftrightarrow\) \(\operatorname{Var}(X)\ge 0\) — দুটো একই বিবৃতির দুই মুখ। variance যে অঋণাত্মক (যা আমরা Part I থেকে স্বতঃসিদ্ধের মতো ধরে এসেছি) তার আসল কারণ \(x^2\)-এর উত্তলতা। সমতা (\(\operatorname{Var}=0\)) ঠিক তখন যখন \(X\) একটা ধ্রুবকে কেন্দ্রীভূত — কোনো ছড়ানো নেই।
আরেকটি মুখ — \(\log\) ও AM–GM। Jensen শুধু \(x^2\)-এ আটকে নেই। \(\varphi(x)=-\log x\) উত্তল (অর্থাৎ \(\log\) concave/অবতল), তাই ধনাত্মক \(X\)-এ Jensen দেয় \(\log\mathbb E[X]\ge\mathbb E[\log X]\) — এক্সপোনেনশিয়াল নিলে $$ \mathbb E[X]\;\ge\;\exp\big(\mathbb E[\log X]\big) , $$ অর্থাৎ arithmetic mean \(\ge\) geometric mean (AM–GM, সমান্তর গড় \(\ge\) গুণোত্তর গড়) — বিচ্ছিন্ন \(n\)-টি মানে \(\tfrac1n\sum x_i\ge\big(\prod x_i\big)^{1/n}\)। একই উত্তলতা-যুক্তি, ভিন্ন \(\varphi\), আরেকটা চিরচেনা অসমতা।
কী শিখলাম। Jensen (\(\varphi\) উত্তল): \(\varphi(\mathbb E X)\le\mathbb E[\varphi(X)]\)। \(\varphi(x)=x^2,\,X\sim U(0,1)\)-এ \((\mathbb E X)^2=\tfrac14=0.25\le\mathbb E[X^2]=\tfrac13=0.3333\), আর ফাঁকটা ঠিক \(\operatorname{Var}(X)=\tfrac1{12}=0.0833\) — তাই "\(x^2\)-এ Jensen" \(\Leftrightarrow\) "\(\operatorname{Var}\ge 0\)": variance-এর অঋণাত্মকতার আসল উৎস \(x^2\)-এর উত্তলতা। \(\varphi=-\log\) নিলে একই যুক্তি AM–GM (\(\mathbb E[X]\ge e^{\mathbb E[\log X]}\)) দেয়। মূল বার্তা: বহু চেনা statistics-অসমতা আসলে একটিমাত্র উত্তলতা-নীতির বিশেষ রূপ।
উদাহরণ ৪ — \(L^2\) projection = best constant predictor (★★)¶
সেটআপ। \(L^2\) একটা Hilbert space, আর Hilbert space-এর সবচেয়ে কাজের অস্ত্র projection theorem: একটা বদ্ধ উপস্থান (closed subspace) \(M\)-এর উপর যেকোনো \(f\)-এর নিকটতম বিন্দু \(\hat f\in M\) একক ও বিদ্যমান, এবং তার বৈশিষ্ট্য — residual (অবশেষ) \(f-\hat f\) পুরো \(M\)-এর উপর লম্ব (orthogonal): \(\langle f-\hat f,\,m\rangle=0\ \forall m\in M\)। এই বিমূর্ত উপপাদ্যটা statistics-এ কী দাঁড়ায়, সবচেয়ে সরল \(M\)-এ দেখি।
ধরা যাক \(M=\operatorname{span}\{1\}\) — সব ধ্রুবক ফাংশন (\(L^2[0,1]\)-এর এক-মাত্রিক উপস্থান)। প্রশ্ন: \(f(x)=x\)-কে এই \(M\)-এ অভিক্ষিপ্ত করলে কোন ধ্রুবক \(c\) পাই? অর্থাৎ $$ \min_{c\in\mathbb R}\;\lVert f-c\rVert_2^2=\min_{c}\int_0^1 (x-c)^2\,dx . $$
পথ ১ — orthogonality (লম্বতা) থেকে। projection theorem বলে best \(\hat f=c\cdot 1\)-এ residual \(x-c\) লম্ব হবে \(M\)-এর জনক \(1\)-এর উপর: $$ \langle x-c,\,1\rangle=0 \;\Longrightarrow\; \int_0^1 (x-c)\cdot 1\,dx=0 \;\Longrightarrow\; \int_0^1 x\,dx-c\int_0^1 1\,dx=0 . $$ অর্থাৎ \(\tfrac12-c\cdot 1=0\), তাই \(c=\tfrac12\)। আরও পরিষ্কারভাবে, এক-মাত্রিক projection-এর সূত্র সরাসরি: $$ \hat c=\frac{\langle f,1\rangle}{\langle 1,1\rangle} =\frac{\int_0^1 x\cdot 1\,dx}{\int_0^1 1\cdot 1\,dx} =\frac{1/2}{1} =\frac12 . $$
পথ ২ — ক্যালকুলাসে যাচাই। \(\phi(c)=\int_0^1(x-c)^2\,dx\) minimize করি। \(\phi(c)=\int_0^1(x^2-2cx+c^2)\,dx=\tfrac13-2c\cdot\tfrac12+c^2=\tfrac13-c+c^2\)। অবকলন: \(\phi'(c)=-1+2c=0\Rightarrow c=\tfrac12\) (এবং \(\phi''=2>0\), সত্যিই minimum)। দুই পথ একই উত্তর \(c=\tfrac12\) দিল।
মূল অভেদ — best constant = mean। লক্ষ করুন $$ \hat c=\frac12=\int_0^1 x\,dx=\mathbb E[X] . $$ অর্থাৎ \(f(x)=x\)-এর \(L^2\)-নিকটতম ধ্রুবক ঠিক তার গড়। এটা দৈবাৎ নয়; সর্বজনীন সত্য: যেকোনো \(X\in L^2\)-এর best constant predictor (যে ধ্রুবক \(c\) mean-squared error \(\mathbb E[(X-c)^2]\) ন্যূনতম করে) হলো \(c=\mathbb E[X]\)। কারণ ঠিক উপরের লম্বতা: \(\mathbb E[(X-c)\cdot 1]=0\Rightarrow c=\mathbb E[X]\)। mean হলো ধ্রুবক-জগতে \(X\)-এর ছায়া (projection)।
residual সত্যিই লম্ব — যাচাই। \(c=\tfrac12\)-এ residual \(r(x)=x-\tfrac12\)। লম্বতা মানে \(\int_0^1 r\,d\lambda=0\): $$ \int_0^1\Big(x-\frac12\Big)\,dx=\frac12-\frac12=0 \qquad\checkmark $$ অর্থাৎ residual \(1\)-এর উপর লম্ব — projection theorem-এর শর্ত আক্ষরিকভাবে মিলল। আর সেই minimum-error স্বয়ং: \(\phi(\tfrac12)=\tfrac13-\tfrac12+\tfrac14=\tfrac{1}{12}=\operatorname{Var}(X)\) — best constant দিয়েও যে অবশিষ্ট ভুল থাকে, তা ঠিক variance (উদাহরণ ৩-এর সঙ্গে মিল)।
সামনে যা আসছে — conditional expectation। এখানে আমরা \(X\)-কে এক-মাত্রিক \(\operatorname{span}\{1\}\)-এ অভিক্ষিপ্ত করে mean পেলাম। ৭.৭-এ এই একই projection-চিন্তা সাধারণীকৃত হবে: \(X\)-কে অভিক্ষিপ্ত করা হবে বড়, \(\sigma(Y)\)-পরিমাপযোগ্য ফাংশনের উপস্থানে — আর সেই projection-ই হবে conditional expectation (শর্তাধীন প্রত্যাশা) \(\mathbb E[X\mid Y]\), "\(Y\) জানার পর \(X\)-এর best guess"। অর্থাৎ "\(\mathbb E[X]\) = best constant" আর "\(\mathbb E[X\mid Y]\) = best \(Y\)-নির্ভর অনুমান" একই Hilbert-projection-এর দুই স্তর।
কী শিখলাম। \(L^2\) একটি Hilbert space; projection theorem বলে subspace \(M\)-এর নিকটতম বিন্দুতে residual \(M\)-এর উপর লম্ব। \(f(x)=x\)-কে \(\operatorname{span}\{1\}\) (ধ্রুবক)-এ অভিক্ষিপ্ত করলে best \(c=\langle x,1\rangle/\langle 1,1\rangle=\tfrac12=\mathbb E[X]\), আর residual \(x-\tfrac12\perp 1\) (\(\int_0^1(x-\tfrac12)=0\)) — orthogonality ও ক্যালকুলাস দুই পথেই। গভীর বার্তা: mean হলো \(X\)-এর \(L^2\)-best constant predictor (variance ন্যূনতমকারী), অর্থাৎ ধ্রুবক-জগতে \(X\)-এর projection; আর ৭.৭-এ একই চিন্তা বড় subspace-এ বাড়লে projection হয়ে দাঁড়াবে conditional expectation \(\mathbb E[X\mid Y]\)।
উদাহরণ ৫ — Radon–Nikodym density (★★)¶
সেটআপ। Radon–Nikodym theorem বলে: যদি measure \(P\) measure \(\lambda\)-এর প্রতি absolutely continuous (পরম-অবিচ্ছিন্ন) হয় — লেখা \(P\ll\lambda\), অর্থ "\(\lambda(A)=0\Rightarrow P(A)=0\)" — তবে একটি অঋণাত্মক measurable density (ঘনত্ব) \(\frac{dP}{d\lambda}\) থাকে যাতে $$ P(A)=\int_A \frac{dP}{d\lambda}\,d\lambda \qquad\forall A . $$ এই \(\frac{dP}{d\lambda}\)-কে Radon–Nikodym derivative (RN-অবকলজ) বলে। দেখি এটা ঠিক চেনা pdf-এই নামে। নিই \([0,\infty)\)-এর উপর $$ \frac{dP}{d\lambda}(x)=e^{-x},\qquad x\ge 0 , $$ যা Exponential(1) (সূচকীয়) বণ্টনের density।
ধাপ ১ — এটা বৈধ probability measure কি? (মোট ভর \(1\))। RN-density একটি প্রকৃত probability দেয় কেবল যদি সমগ্র স্পেসে integral \(1\) হয়: $$ P([0,\infty))=\int_0^\infty e^{-x}\,d\lambda=\int_0^\infty e^{-x}\,dx =\big[-e^{-x}\big]_0^\infty =\big(0\big)-\big(-1\big) =1 \qquad\checkmark $$ (\(x\to\infty\)-এ \(e^{-x}\to 0\), \(x=0\)-এ \(-e^{-0}=-1\)।) মোট ভর \(1\) — তাই \(P\) একটি বৈধ probability measure, আর \(e^{-x}\) একটি বৈধ pdf।
ধাপ ২ — একটা ঘটনার সম্ভাবনা: \(P([0,1])\)। RN-সূত্রে \(A=[0,1]\) বসাই: $$ P([0,1])=\int_0^1 e^{-x}\,d\lambda=\int_0^1 e^{-x}\,dx =\big[-e^{-x}\big]_0^1 =\big(-e^{-1}\big)-\big(-1\big) =1-e^{-1} . $$ সংখ্যায়: $$ P([0,1])=1-e^{-1}\approx 1-0.3679=0.6321 . $$ অর্থাৎ একটা Exponential(1)-চলক প্রথম এক-একক সময়ের মধ্যে "ঘটে যাওয়ার" সম্ভাবনা \(\approx 63.21\%\) — এটাই exponential-এর চেনা CDF \(F(1)=1-e^{-1}\), এখন RN-density-এর integral হিসেবে।
ধাপ ৩ — density IS the pdf। খেয়াল করুন আমরা আলাদা করে কোনো "pdf"-এর সংজ্ঞা টানিনি; RN-derivative \(\frac{dP}{d\lambda}\) স্বয়ংই সেই বস্তু যাকে Part II–III-এ pdf বলেছি। অর্থাৎ "pdf" মানে আসলে "\(\lambda\)-এর সাপেক্ষে আইনের (law-এর) Radon–Nikodym derivative" — এটাই density-র কঠোর (rigorous) সংজ্ঞা। density থাকা \(=P\ll\lambda\) হওয়া; যেমন একটা discrete বণ্টন (point mass-যুক্ত) \(\lambda\)-এর প্রতি absolutely continuous নয় (single point-এর \(\lambda\)-measure \(0\) অথচ \(P>0\)), তাই তার \(\lambda\)-density নেই — এই জন্যই discrete বণ্টনের pdf থাকে না, pmf থাকে।
আরেক RN-derivative — likelihood ratio। \(\frac{dP}{d\lambda}\)-ই একমাত্র RN-derivative নয়। দুটো probability measure \(P,Q\)-এর মধ্যে \(P\ll Q\) হলে \(\frac{dP}{dQ}\)-ও একটা RN-derivative — আর সেটাই statistics-এর likelihood ratio (সম্ভাব্যতা-অনুপাত): $$ \frac{dP}{dQ}(x)=\frac{f_P(x)}{f_Q(x)} \quad(\text{যেখানে দুজনেরই }\lambda\text{-density আছে}). $$ এই অনুপাতই hypothesis testing-এর (Neyman–Pearson) ভিত্তি এবং change-of-measure-এর হাতিয়ার (যেমন finance-এ risk-neutral measure)। অর্থাৎ pdf আর likelihood ratio — দুটোই একই RN-যন্ত্রের ফসল, কেবল হর-measure আলাদা (\(\lambda\) বনাম \(Q\))।
কী শিখলাম। \(P\ll\lambda\) হলে Radon–Nikodym একটি density \(\frac{dP}{d\lambda}\) দেয় যাতে \(P(A)=\int_A\frac{dP}{d\lambda}\,d\lambda\)। \(\frac{dP}{d\lambda}=e^{-x}\) on \([0,\infty)\) (Exp(1))-এ যাচাই: মোট ভর \(\int_0^\infty e^{-x}=1\) (বৈধ pdf), আর \(P([0,1])=1-e^{-1}=0.6321\)। মূল উপলব্ধি: pdf-টা স্বয়ং একটা RN-derivative — "density" মানে আসলে law-এর \(\lambda\)-সাপেক্ষ RN-অবকলজ, তাই \(P\ll\lambda\) না হলে (যেমন discrete বণ্টন) pdf থাকে না। আর হর বদলে \(\frac{dP}{dQ}\) নিলে পাই likelihood ratio — hypothesis testing ও change-of-measure-এর ভিত্তি।
উদাহরণ ৬ — Hölder/Minkowski একটা ছোট উদাহরণে (★★)¶
সেটআপ। \(L^p\)-জগতের দুই মৌলিক অসমতা — Hölder (গুণফল-আবদ্ধক) আর Minkowski (ত্রিভুজ-অসমতা) — একটাই ছোট জোড়ায় সংখ্যায় যাচাই করি, যাতে দুটো একসঙ্গে হাতে ধরা যায়। আগের মতোই \([0,1]\)-এর উপর $$ f(x)=x,\qquad g(x)=x^2 . $$
অংশ ক — Hölder (\(p=q=2\))। Hölder: \(\int\lvert fg\rvert\,d\lambda\le\lVert f\rVert_p\lVert g\rVert_q\) যেখানে \(\tfrac1p+\tfrac1q=1\)। সবচেয়ে symmetric বাছাই \(p=q=2\) (যেহেতু \(\tfrac12+\tfrac12=1\)) — এটা ঠিক Cauchy–Schwarz, কিন্তু এখন absolute value-যুক্ত integrand দিয়ে। বাঁ পক্ষ (\(f,g\ge 0\) বলে \(\lvert fg\rvert=fg\)): $$ \int_0^1\lvert x\cdot x^2\rvert\,dx=\int_0^1 x^3\,dx=\frac14=0.25 . $$ ডান পক্ষ (উদাহরণ ২-এর মান): \(\lVert f\rVert_2\lVert g\rVert_2=\tfrac{1}{\sqrt3}\cdot\tfrac{1}{\sqrt5}=\tfrac{1}{\sqrt{15}}\approx 0.2582\)। $$ 0.25\le 0.2582 \qquad\checkmark $$ Hölder মানছে। (অন্য বৈধ জোড়াও কাজ করত, যেমন \(p=1,q=\infty\): \(\int_0^1\lvert fg\rvert=0.25\le\lVert fg\rVert\)... বরং সরল কেস \(\int\lvert fg\rvert\le\lVert f\rVert_1\lVert g\rVert_\infty\) নিলে \(g=x^2\)-এ \(\lVert g\rVert_\infty=1\), \(\lVert f\rVert_1=\int_0^1 x=\tfrac12\), ডান পক্ষ \(0.5\ge 0.25\) — এটিও মানে, তবে \(p=q=2\) আঁটসাঁট সীমা দেয়।)
অংশ খ — Minkowski (ত্রিভুজ-অসমতা)। Minkowski: \(\lVert f+g\rVert_p\le\lVert f\rVert_p+\lVert g\rVert_p\) — এটাই \(\lVert\cdot\rVert_p\)-কে প্রকৃত norm বানায় (ত্রিভুজ-অসমতা ছাড়া "দূরত্ব" অর্থহীন)। \(p=2\)-তে যাচাই করি \(f+g=x+x^2\)। বাঁ পক্ষ — যোগফলের norm: $$ \lVert f+g\rVert_2^2=\int_0^1 (x+x^2)^2\,dx=\int_0^1\big(x^2+2x^3+x^4\big)\,dx =\frac13+2\cdot\frac14+\frac15=\frac13+\frac12+\frac15 . $$ সাধারণ হর \(30\): \(\tfrac13=\tfrac{10}{30},\ \tfrac12=\tfrac{15}{30},\ \tfrac15=\tfrac{6}{30}\), যোগে \(\tfrac{31}{30}\approx 1.0333\)। তাই $$ \lVert f+g\rVert_2=\sqrt{\tfrac{31}{30}}\approx 1.0165 . $$ ডান পক্ষ — দুই norm-এর যোগ: $$ \lVert f\rVert_2+\lVert g\rVert_2=\frac{1}{\sqrt3}+\frac{1}{\sqrt5}\approx 0.5774+0.4472=1.0246 . $$ তুলনা: $$ \underbrace{1.0165}{\lVert f+g\rVert_2}\;\le\;\underbrace{1.0246}\qquad\checkmark $$ Minkowski মানছে — এবং কঠোরভাবে (\(1.0165<1.0246\)), কারণ সমতা কেবল তখন যখন \(f,g\) একই দিকে (একে অপরের অঋণাত্মক-গুণিতক); এখানে \(x\) ও \(x^2\) তা নয়, তাই ফাঁক \(\approx 0.008\)।
দুই অসমতার সম্পর্ক। লক্ষণীয়, Minkowski-র প্রমাণটাই Hölder-নির্ভর: \(\lVert f+g\rVert_p^p=\int\lvert f+g\rvert^p\)-কে \(\lvert f+g\rvert^{p}\le\lvert f\rvert\,\lvert f+g\rvert^{p-1}+\lvert g\rvert\,\lvert f+g\rvert^{p-1}\) ভেঙে প্রতিটি পদে Hölder লাগালেই ত্রিভুজ-অসমতা বেরোয়। অর্থাৎ Hölder মৌলিক, Minkowski তার ফল — আর Minkowski-ই \(L^p\)-কে একটা normed space, এবং completeness-সহ Banach space বানানোর শেষ পেরেক।
কী শিখলাম। \(f=x,\,g=x^2\) on \([0,1]\)-এ দুই স্তম্ভ-অসমতা যাচাই হলো। Hölder (\(p=q=2\)): \(\int_0^1\lvert fg\rvert=0.25\le\lVert f\rVert_2\lVert g\rVert_2=\tfrac{1}{\sqrt{15}}=0.2582\)। Minkowski (\(p=2\)): \(\lVert f+g\rVert_2=\sqrt{31/30}=1.0165\le\lVert f\rVert_2+\lVert g\rVert_2=0.5774+0.4472=1.0246\) — দুটোই কঠোরভাবে মানে (linear dependence না থাকায়)। মূল বার্তা: Hölder মৌলিক, Minkowski তার ফল (Hölder দিয়েই প্রমাণিত), আর Minkowski-র ত্রিভুজ-অসমতাই \(\lVert\cdot\rVert_p\)-কে প্রকৃত norm — তাই \(L^p\)-কে normed তথা (completeness-সহ) Banach space — বানায়।
৪ · প্রমাণ ও উৎপাদন¶
এই অংশে §২-এর সংজ্ঞাগুলো থেকে \(L^p\)-তত্ত্বের কাঠামোটাকে ধাপে ধাপে উৎপাদন (derive) করা হয় — দুটি স্তম্ভ-অসমতা (Young, তা থেকে Hölder, তা থেকে Minkowski) দিয়ে শুরু করে, Jensen হয়ে, এবং শেষ তিন গভীর উপপাদ্যে — \(L^p\)-এর completeness (Riesz–Fischer), Hilbert projection ও Radon–Nikodym — যেখানে আগের অসমতাগুলো এবং 7.4-এর convergence theorem (MCT/DCT) যন্ত্র হিসেবে খাটে। প্রতিটি প্রমাণে কেন প্রতিটি পদক্ষেপ বৈধ — কোন সংজ্ঞা, কোন পূর্ববর্তী ফল (7.2-এর measure-ধর্ম, 7.4-এর MCT/DCT, এ-অংশেরই আগের অসমতা), বা কোন বীজগাণিতিক অভেদ ব্যবহৃত হচ্ছে — তা স্পষ্ট করে বলা হয়েছে। প্রতিটি প্রমাণের শিরোনামে কঠিনতা-চিহ্ন (difficulty tag):
- ★ — মৌলিক, প্রথম পাঠেই বোঝা উচিত।
- ★★ — মাঝারি, একটু কৌশল লাগে।
- ★★★ — গভীর, প্রথম পাঠে কিছু অংশ এড়িয়ে যাওয়া যায় (যথাস্থানে চিহ্নিত)।
স্মরণ — মূল সংজ্ঞা (§২ থেকে)। গোটা অংশে \((\Omega,\mathcal F,\mu)\) একটি measure space। একটি measurable \(f:\Omega\to\mathbb R\) (বা \(\mathbb C\))-এর জন্য, \(1\le p<\infty\) হলে,
আর \(\lVert f\rVert_\infty:=\operatorname*{ess\,sup}\lvert f\rvert\) (\(\mu\)-essential supremum)। conjugate exponent (অনুবন্ধী সূচক) \(q\) হলো \(\frac1p+\frac1q=1\) মেনে চলা সংখ্যা (\(1<p<\infty\) হলে \(1<q<\infty\); \(p=1\) হলে \(q=\infty\))। কারিগরি সূক্ষ্মতা: \(\lVert f\rVert_p=0\) মানে \(f=0\) a.e. (প্রমাণ-৬, 7.4 থেকে), \(f\equiv 0\) নয়; তাই \(L^p\)-এর উপাদানগুলো আসলে a.e.-সমতার শ্রেণি (equivalence class) — এই কথাটা প্রমাণ ২-এর শেষে স্পষ্ট হবে।
এ-অংশের যুক্তি-শৃঙ্খল একমুখী: প্রমাণ ১ (Young⇒Hölder) দাঁড়ায় কেবল \(\log\)-এর অবতলতা ও 7.4-এর monotonicity-র উপর; প্রমাণ ২ (Minkowski) দাঁড়ায় প্রমাণ ১-এর উপর; প্রমাণ ৪ (completeness) প্রমাণ ২ + 7.4-এর MCT/DCT ব্যবহার করে; প্রমাণ ৫ (projection) completeness-কে; আর প্রমাণ ৬ (Radon–Nikodym) প্রমাণ ৫-এর Riesz representation-কে ইঞ্জিন বানায়। তাই Hölder–Minkowski জোড়াই (প্রমাণ ১–২) এ-অধ্যায়ের ভিত্তি-ইট।
প্রমাণ ১ — Young + Hölder (★★)¶
দাবি। ধরা যাক \(1<p<\infty\) এবং \(\frac1p+\frac1q=1\)।
- (Young's inequality) যেকোনো \(a,b\ge 0\)-এর জন্য $$ ab\ \le\ \frac{a^p}{p}+\frac{b^q}{q}, $$ সমতা ⟺ \(a^p=b^q\)।
- (Hölder's inequality) measurable \(f,g\)-এর জন্য $$ \int_\Omega\lvert fg\rvert\,d\mu\ \le\ \lVert f\rVert_p\,\lVert g\rVert_q . $$ বিশেষ ক্ষেত্রে \(p=q=2\) এটি Cauchy–Schwarz \(\int\lvert fg\rvert\,d\mu\le\lVert f\rVert_2\lVert g\rVert_2\)।
ধাপ ১ — Young, \(\log\)-এর অবতলতা থেকে। \(a=0\) বা \(b=0\) হলে বাঁ পাশ \(0\le\) ডান পাশ, তুচ্ছ; তাই ধরি \(a,b>0\)। মূল হাতিয়ার: \(\log\) ফাংশনটি \((0,\infty)\)-তে concave (অবতল) — কারণ \((\log x)''=-1/x^2<0\)। concavity-র সংজ্ঞা বলে, যেকোনো দুই বিন্দু \(u,v>0\) ও যেকোনো ওজন \(\lambda\in[0,1]\)-এর জন্য $$ \log\bigl(\lambda u+(1-\lambda)v\bigr)\ \ge\ \lambda\log u+(1-\lambda)\log v. $$ এখন বেছে নিই \(u=a^p\), \(v=b^q\), এবং \(\lambda=\frac1p\) (তাই \(1-\lambda=\frac1q\), যেহেতু \(\frac1p+\frac1q=1\))। বসিয়ে পাই $$ \log\Bigl(\frac{a^p}{p}+\frac{b^q}{q}\Bigr)\ \ge\ \frac1p\log(a^p)+\frac1q\log(b^q)=\log a+\log b=\log(ab), $$ যেখানে শেষ ধাপে \(\frac1p\cdot p\log a=\log a\) ও \(\frac1q\cdot q\log b=\log b\) ব্যবহৃত। \(\log\) কঠোরভাবে বর্ধমান (increasing), তাই দুই পাশে exponential নিলে অসমতার দিক অটুট থাকে: $$ \frac{a^p}{p}+\frac{b^q}{q}\ \ge\ ab. $$ সমতা ঘটে ঠিক তখনই যখন concavity-অসমতায় সমতা, অর্থাৎ \(u=v\), অর্থাৎ \(a^p=b^q\) (কারণ \(\log\) কঠোরভাবে অবতল হলে supporting-line-এ স্পর্শ কেবল এক বিন্দুতে)। ∎(ধাপ ১)
ধাপ ২ — অবক্ষয়ী (degenerate) ক্ষেত্রগুলো আলাদা করা। Hölder প্রমাণে তিনটি সীমান্ত-পরিস্থিতি আগেই সরিয়ে রাখি। (i) যদি \(\lVert f\rVert_p=0\), তবে \(f=0\) a.e. (প্রমাণ-৬, 7.4), তাই \(fg=0\) a.e. এবং বাঁ পাশ \(\int\lvert fg\rvert=0=\) ডান পাশ; একই যুক্তি \(\lVert g\rVert_q=0\)-তে। (ii) যদি \(\lVert f\rVert_p=\infty\) বা \(\lVert g\rVert_q=\infty\), ডান পাশ \(\infty\) (যেহেতু অন্য গুণনীয়কটি \(>0\) ধরা যায়, নইলে (i)), অসমতা স্বয়ংক্রিয়। সুতরাং ধরে নিই \(0<\lVert f\rVert_p<\infty\) এবং \(0<\lVert g\rVert_q<\infty\) — তবেই আসল কাজ।
ধাপ ৩ — normalize করে Young pointwise লাগানো। সংজ্ঞা দিই $$ \hat f:=\frac{f}{\lVert f\rVert_p},\qquad \hat g:=\frac{g}{\lVert g\rVert_q}. $$ এদের গড়ে নেওয়া হলো এমনভাবে যে \(\lVert\hat f\rVert_p=1\) ও \(\lVert\hat g\rVert_q=1\), অর্থাৎ $$ \int\lvert\hat f\rvert^p\,d\mu=\frac{1}{\lVert f\rVert_p^{\,p}}\int\lvert f\rvert^p\,d\mu=1, \qquad \int\lvert\hat g\rvert^q\,d\mu=1. \tag{N} $$ এবার প্রতিটি বিন্দু \(\omega\)-তে Young (ধাপ ১) প্রয়োগ করি \(a=\lvert\hat f(\omega)\rvert\), \(b=\lvert\hat g(\omega)\rvert\) নিয়ে: $$ \lvert\hat f(\omega)\,\hat g(\omega)\rvert\ \le\ \frac{\lvert\hat f(\omega)\rvert^p}{p}+\frac{\lvert\hat g(\omega)\rvert^q}{q}\qquad\text{সব }\omega\text{-তে}. $$ এটি দুই measurable অঋণাত্মক ফাংশনের মধ্যে একটি pointwise অসমতা।
ধাপ ৪ — integrate ও (N) বসানো। 7.4-এর monotonicity ও linearity দিয়ে দুই পাশ integrate করি: $$ \int\lvert\hat f\hat g\rvert\,d\mu\ \le\ \frac1p\int\lvert\hat f\rvert^p\,d\mu+\frac1q\int\lvert\hat g\rvert^q\,d\mu \ \overset{(N)}{=}\ \frac1p\cdot 1+\frac1q\cdot 1=1, $$ যেখানে শেষ সমতা (N)-এর দুই normalize-শর্ত এবং \(\frac1p+\frac1q=1\) থেকে। অর্থাৎ \(\int\lvert\hat f\hat g\rvert\,d\mu\le 1\)।
ধাপ ৫ — scale ফিরিয়ে আনা। সংজ্ঞা থেকে \(\lvert\hat f\hat g\rvert=\dfrac{\lvert fg\rvert}{\lVert f\rVert_p\,\lVert g\rVert_q}\), তাই উপরের অসমতাকে \(\lVert f\rVert_p\lVert g\rVert_q\) দিয়ে গুণ করলে $$ \int\lvert fg\rvert\,d\mu\ \le\ \lVert f\rVert_p\,\lVert g\rVert_q . $$ \(p=q=2\) বসালে \(\frac12+\frac12=1\), তাই এটিই Cauchy–Schwarz। ∎
এক বাক্যে: \(\log\)-এর অবতলতা সরাসরি Young \(ab\le\frac{a^p}{p}+\frac{b^q}{q}\) দেয়; এরপর \(f,g\)-কে নিজ নিজ norm দিয়ে ভাগ করে (\(\hat f,\hat g\)) Young-কে বিন্দুতে বিন্দুতে লাগিয়ে integrate করলে ডান পাশ ঠিক \(\frac1p+\frac1q=1\) হয়, আর scale ফিরিয়ে আনলেই Hölder — যার \(p=q=2\) রূপ Cauchy–Schwarz।
প্রমাণ ২ — Minkowski (ত্রিভুজ-অসমতা \(\lVert\cdot\rVert_p\)-এ) (★★)¶
দাবি (Minkowski's inequality)। \(1\le p<\infty\) এবং \(f,g\in L^p(\mu)\) হলে \(f+g\in L^p(\mu)\) এবং $$ \lVert f+g\rVert_p\ \le\ \lVert f\rVert_p+\lVert g\rVert_p . $$ ফলস্বরূপ \(\lVert\cdot\rVert_p\) হলো \(L^p\)-এর উপর একটি norm (a.e.-শ্রেণিতে নামালে)।
ধাপ ১ — \(p=1\) ও সীমান্ত-ক্ষেত্র। \(p=1\) হলে এটি কেবল pointwise ত্রিভুজ-অসমতা \(\lvert f+g\rvert\le\lvert f\rvert+\lvert g\rvert\) integrate করা: \(\int\lvert f+g\rvert\le\int\lvert f\rvert+\int\lvert g\rvert\) (7.4 monotonicity+linearity)। তাই নিচে ধরি \(1<p<\infty\)। এছাড়া যদি \(\lVert f+g\rVert_p=0\) অসমতা তুচ্ছ; দেখাব এটি সসীমও।
ধাপ ২ — \(f+g\in L^p\) (closure যাচাই)। স্থির বিন্দুতে দুই সংখ্যার যোগের convexity-অসমতা: \(t\mapsto t^p\) (\(p\ge 1\)) উত্তল, তাই \(\bigl(\frac{x+y}{2}\bigr)^p\le\frac{x^p+y^p}{2}\), যা \(x,y\ge 0\)-তে দেয় $$ \lvert f+g\rvert^p\le\bigl(\lvert f\rvert+\lvert g\rvert\bigr)^p\le 2^{p-1}\bigl(\lvert f\rvert^p+\lvert g\rvert^p\bigr). $$ integrate করে \(\int\lvert f+g\rvert^p\le 2^{p-1}(\lVert f\rVert_p^p+\lVert g\rVert_p^p)<\infty\), অর্থাৎ \(f+g\in L^p\)। তাই \(\lVert f+g\rVert_p<\infty\) — এখন বাকি কেবল কড়া ধ্রুবকটা (\(2^{p-1}\) নয়, \(1\)) আনা।
ধাপ ৩ — মূল বীজগাণিতিক ভাঙন। pointwise লিখি, \(\lvert f+g\rvert\le\lvert f\rvert+\lvert g\rvert\) ব্যবহার করে: $$ \lvert f+g\rvert^p=\lvert f+g\rvert\cdot\lvert f+g\rvert^{p-1} \ \le\ \lvert f\rvert\,\lvert f+g\rvert^{p-1}+\lvert g\rvert\,\lvert f+g\rvert^{p-1}. \tag{∗} $$ এখন (∗)-এর দুই পদে আলাদা আলাদা Hölder (প্রমাণ ১) লাগাব — সূচক জোড়া \(p\) ও \(q=\frac{p}{p-1}\) (লক্ষ করি \(\frac1p+\frac1q=\frac1p+\frac{p-1}{p}=1\), ঠিক conjugate)।
ধাপ ৪ — Hölder দুই পদে। প্রথম পদে \(f\)-কে \(L^p\)-ভাগে, \(\lvert f+g\rvert^{p-1}\)-কে \(L^q\)-ভাগে বসাই: $$ \int\lvert f\rvert\,\lvert f+g\rvert^{p-1}\,d\mu \ \le\ \lVert f\rVert_p\,\Bigl(\int\lvert f+g\rvert^{(p-1)q}\,d\mu\Bigr)^{1/q} =\lVert f\rVert_p\,\Bigl(\int\lvert f+g\rvert^{p}\,d\mu\Bigr)^{1/q}, $$ যেখানে \((p-1)q=(p-1)\cdot\frac{p}{p-1}=p\) ব্যবহৃত হলো — ঠিক এই সরলীকরণের জন্যই \(q=\frac{p}{p-1}\) বাছা। একইভাবে দ্বিতীয় পদে $$ \int\lvert g\rvert\,\lvert f+g\rvert^{p-1}\,d\mu\ \le\ \lVert g\rVert_p\,\Bigl(\int\lvert f+g\rvert^{p}\,d\mu\Bigr)^{1/q}. $$ দুটো (∗)-এ যোগ করে, ডান পাশে অভিন্ন গুণনীয়ক \(\bigl(\int\lvert f+g\rvert^p\bigr)^{1/q}\) বের করে আনি: $$ \int\lvert f+g\rvert^p\,d\mu\ \le\ \bigl(\lVert f\rVert_p+\lVert g\rVert_p\bigr)\Bigl(\int\lvert f+g\rvert^{p}\,d\mu\Bigr)^{1/q}. $$
ধাপ ৫ — গুণনীয়ক বাতিল করে শেষ। ধরি \(\int\lvert f+g\rvert^p\,d\mu=:S\), যা ধাপ ২ থেকে সসীম ও \(>0\) (নইলে তুচ্ছ)। উপরের অসমতা \(S\le(\lVert f\rVert_p+\lVert g\rVert_p)\,S^{1/q}\)। দুই পাশে \(S^{1/q}\) (ধনাত্মক, সসীম) দিয়ে ভাগ করি — এখানেই ধাপ ২-এর "সসীম" শর্ত অপরিহার্য, নইলে \(\infty/\infty\) হতো: $$ S^{\,1-\frac1q}\ \le\ \lVert f\rVert_p+\lVert g\rVert_p. $$ কিন্তু \(1-\frac1q=\frac1p\), তাই বাঁ পাশ \(S^{1/p}=\bigl(\int\lvert f+g\rvert^p\bigr)^{1/p}=\lVert f+g\rVert_p\)। অর্থাৎ $$ \lVert f+g\rVert_p\ \le\ \lVert f\rVert_p+\lVert g\rVert_p . \qquad\blacksquare $$
ধাপ ৬ — কেন এটি একটি norm (a.e.-শ্রেণিতে)। norm-এর তিন স্বীকার্য যাচাই করি: (i) absolute homogeneity \(\lVert\alpha f\rVert_p=\lvert\alpha\rvert\,\lVert f\rVert_p\) সংজ্ঞা থেকে সরাসরি (\(\int\lvert\alpha f\rvert^p=\lvert\alpha\rvert^p\int\lvert f\rvert^p\)); (ii) triangle inequality — এইমাত্র প্রমাণিত Minkowski; (iii) positive-definiteness \(\lVert f\rVert_p=0\Rightarrow f=0\) — কিন্তু প্রমাণ-৬ (7.4) বলে \(\lVert f\rVert_p=0\Rightarrow\lvert f\rvert^p=0\) a.e. \(\Rightarrow f=0\) a.e. মাত্র, সর্বত্র নয়। তাই কড়া অর্থে \(\lVert\cdot\rVert_p\) কেবল একটি seminorm। সমাধান: \(f\sim g\iff f=g\) a.e. সম্পর্কে ভাগ করে নিই — এই quotient space \(L^p(\mu)=\mathcal L^p/\!\sim\)-এ \(\lVert\cdot\rVert_p\) পূর্ণ-অর্থে একটি norm, কারণ এখন "\(\lVert[f]\rVert_p=0\)" মানে \([f]\) হলো শূন্য-শ্রেণি। এজন্যই \(L^p\)-এর উপাদান সবসময় a.e.-সমতার শ্রেণি (প্রমাণ ৪-এও এই শ্রেণি-দৃষ্টিভঙ্গি লাগবে)। ∎
এক বাক্যে: \(\lvert f+g\rvert^p\le\lvert f\rvert\lvert f+g\rvert^{p-1}+\lvert g\rvert\lvert f+g\rvert^{p-1}\) ভেঙে প্রতিটি পদে সূচক \(q=\frac{p}{p-1}\)-এ Hölder লাগালে অভিন্ন গুণনীয়ক \((\int\lvert f+g\rvert^p)^{1/q}\) বেরোয়, যা বাতিল করলেই ত্রিভুজ-অসমতা — আর a.e.-শ্রেণিতে নামালে \(\lVert\cdot\rVert_p\) পূর্ণ norm।
প্রমাণ ৩ — Jensen's inequality (★★)¶
দাবি (Jensen)। ধরা যাক \((\Omega,\mathcal F,\mathbb P)\) একটি probability space (\(\mathbb P(\Omega)=1\)), \(\varphi:\mathbb R\to\mathbb R\) একটি convex (উত্তল) ফাংশন, এবং \(f\in L^1(\mathbb P)\) যেন \(\varphi(f)\)-এর integral-ও অর্থবহ। তবে, \(m:=\int_\Omega f\,d\mathbb P=\mathbb E[f]\) ধরলে, $$ \varphi\Bigl(\int_\Omega f\,d\mathbb P\Bigr)=\varphi(m)\ \le\ \int_\Omega\varphi(f)\,d\mathbb P=\mathbb E[\varphi(f)]. $$ সংক্ষেপে: \(\varphi(\mathbb E f)\le\mathbb E\varphi(f)\) — "উত্তল ফাংশন গড়ের ভেতরে ঢুকলে ছোট হয়"।
ধাপ ১ — কেন probability measure লাগে। এখানে \(\mathbb P(\Omega)=1\) অপরিহার্য, কারণ আমরা \(\int 1\,d\mathbb P=1\) ব্যবহার করব দুই জায়গায় — \(m\)-কে "ভারিত গড়" হিসেবে অর্থবহ করতে, এবং ধ্রুবক \(\varphi(m)\)-কে integrate করলে \(\int\varphi(m)\,d\mathbb P=\varphi(m)\) পেতে। সাধারণ measure-এ (\(\mu(\Omega)\ne 1\)) এ-রূপ মিথ্যা।
ধাপ ২ — supporting line (সহায়ক-রেখা) অস্তিত্ব। উত্তলতার একটি মৌলিক ফল: প্রতিটি অভ্যন্তরীণ বিন্দু \(m\)-এ একটি supporting line আছে — একটি ঢাল \(c\) (geometrically, \(m\)-এ \(\varphi\)-এর কোনো subderivative; \(\varphi\) অন্তরকলনযোগ্য হলে \(c=\varphi'(m)\)) যেন $$ \varphi(t)\ \ge\ \varphi(m)+c\,(t-m)\qquad\text{সব }t\in\mathbb R\text{-এর জন্য}. \tag{S} $$ কেন এটি থাকে: উত্তল ফাংশনের ক্ষেত্রে বাঁ-অন্তরকলজ \(\varphi'_-(m)\) ও ডান-অন্তরকলজ \(\varphi'_+(m)\) দুটোই বিদ্যমান এবং \(\varphi'_-(m)\le\varphi'_+(m)\); এদের মাঝের যেকোনো \(c\) নিলে, উত্তলতার "ক্রমবর্ধমান-ঢাল" ধর্ম থেকে \(t>m\)-এ slope \(\ge c\) ও \(t<m\)-এ slope \(\le c\) — দুই দিকেই (S) পাওয়া যায়। (S)-ই Jensen-এর গোটা ইঞ্জিন: গ্রাফ তার যেকোনো স্পর্শ-রেখার উপরে থাকে।
ধাপ ৩ — \(t=f(\omega)\) বসিয়ে integrate। (S)-তে প্রতিটি বিন্দু \(\omega\)-তে \(t=f(\omega)\) বসাই — এটি বৈধ কারণ (S) সব বাস্তবে সত্য: $$ \varphi(f(\omega))\ \ge\ \varphi(m)+c\,(f(\omega)-m)\qquad\text{সব }\omega. $$ এটি দুই measurable ফাংশনের একটি pointwise অসমতা; 7.4-এর monotonicity দিয়ে দুই পাশ \(\mathbb P\)-integrate করি, আর ডান পাশে linearity: $$ \int\varphi(f)\,d\mathbb P\ \ge\ \int\bigl[\varphi(m)+c(f-m)\bigr]d\mathbb P=\varphi(m)\underbrace{\int 1\,d\mathbb P}{=1}+c\Bigl(\underbrace{\int f\,d\mathbb P}\Bigr). $$ ডান পাশের বন্ধনী }-m\underbrace{\int 1\,d\mathbb P}_{=1\(=m-m\cdot 1=0\), তাই দ্বিতীয় পদ অদৃশ্য, আর প্রথম পদ \(\varphi(m)\cdot 1=\varphi(m)\)। সুতরাং $$ \int\varphi(f)\,d\mathbb P\ \ge\ \varphi(m)=\varphi\Bigl(\int f\,d\mathbb P\Bigr). \qquad\blacksquare $$ এখানে probability-শর্তটি ঠিক দুই \(\int 1\,d\mathbb P=1\)-এ কাজে লাগল — supporting line-এর রৈখিক পদ গড়-নেওয়ায় হুবহু বাতিল হলো।
টীকা — conditional সংস্করণ (7.7-এর পূর্বাভাস)। একই supporting-line যুক্তি hub করে আরও শক্তিশালী conditional Jensen — যেখানে সাধারণ \(\mathbb E\)-র বদলে একটি sub-σ-algebra \(\mathcal G\)-র সাপেক্ষে conditional expectation \(\mathbb E[\,\cdot\mid\mathcal G]\) বসে: $$ \varphi\bigl(\mathbb E[f\mid\mathcal G]\bigr)\ \le\ \mathbb E\bigl[\varphi(f)\mid\mathcal G\bigr]\quad\text{a.e.} $$ (এখানে \(\mid\) মানে conditioning, \(\lvert\cdot\rvert\) নয়।) এর প্রমাণে (S)-তে \(m\)-এর জায়গায় random-variable \(\mathbb E[f\mid\mathcal G]\) বসাতে হয় এবং ঢাল \(c\)-ও \(\mathcal G\)-measurable করে বাছতে হয় — পূর্ণ বিস্তারিত 7.7-এ, যখন conditional expectation-এর সংজ্ঞা ও ধর্ম হাতে থাকবে। আপাতত শুধু এটুকু মনে রাখা — Jensen-এর গাঁথুনি (graph তার স্পর্শ-রেখার উপরে) দুই ক্ষেত্রেই অভিন্ন।
এক বাক্যে: উত্তল \(\varphi\)-এর গ্রাফ \(m=\int f\,d\mathbb P\)-এর supporting line \(\varphi(t)\ge\varphi(m)+c(t-m)\)-এর উপরে থাকে, তাই \(t=f\) বসিয়ে integrate করলে রৈখিক পদ (probability-শর্তে) বাতিল হয়ে \(\mathbb E\varphi(f)\ge\varphi(\mathbb E f)\) — যার conditional রূপ 7.7-এ আসবে।
প্রমাণ ৪ — Riesz–Fischer: \(L^p\) পূর্ণ (★★★, কাঠামোবদ্ধ)¶
দাবি (Riesz–Fischer)। \(1\le p<\infty\)-এর জন্য \(\bigl(L^p(\mu),\lVert\cdot\rVert_p\bigr)\) একটি complete normed space, অর্থাৎ একটি Banach space — এর প্রতিটি Cauchy অনুক্রম \(L^p\)-এর কোনো উপাদানে অভিসৃত হয়।
স্বীকৃতি — গভীরতম ধাপগুলো চিহ্নিত (প্রথম পাঠে এড়ানো যায়)। নিচের মূল কৌশল — "absolutely convergent ⇒ convergent" মানদণ্ড, এবং তা completeness-এর সমতুল্য — পরিষ্কারভাবে দেওয়া হলো। ধাপ ৩ (MCT দিয়ে \(g\in L^p\)) ও ধাপ ৪ (DCT দিয়ে \(L^p\)-অভিসৃতি) হলো সবচেয়ে যান্ত্রিক অংশ; প্রথম পাঠে এদের বিবৃতি মেনে নিয়ে এগোনো যায়, ফিরে এসে কষা যায়।
ধাপ ০ — মানদণ্ড: "series-পূর্ণতা ⟺ completeness"। সরাসরি Cauchy অনুক্রম নিয়ে কাজ না করে একটা সমতুল্য, কিন্তু কাজে-সহজ বিবৃতি প্রমাণ করব:
(★) মানদণ্ড। একটি normed space complete ⟺ তার প্রতিটি absolutely convergent series convergent — অর্থাৎ \(\sum_k\lVert f_k\rVert<\infty\) হলে আংশিক-যোগফল \(\sum_{k=1}^N f_k\) space-এরই কোনো উপাদানে অভিসৃত হয়।
কেন সমতুল্য (★★, রূপরেখা)। (⇒) complete ধরলে, \(\sum_k\lVert f_k\rVert<\infty\)-এ আংশিক-যোগফল \(S_N\) Cauchy (কারণ \(\lVert S_N-S_M\rVert\le\sum_{k=M+1}^N\lVert f_k\rVert\to 0\) লেজ-যোগফল হিসেবে), তাই অভিসৃত। (⇐) ধরা যাক প্রতিটি absolutely convergent series convergent, এবং \((h_n)\) একটি Cauchy অনুক্রম। Cauchy বলে একটি উপ-অনুক্রম \((h_{n_k})\) বাছা যায় যেন \(\lVert h_{n_{k+1}}-h_{n_k}\rVert\le 2^{-k}\); তখন \(f_k:=h_{n_{k+1}}-h_{n_k}\)-এ \(\sum_k\lVert f_k\rVert\le\sum_k 2^{-k}=1<\infty\), তাই telescoping series \(\sum_k f_k=\lim_K h_{n_{K+1}}-h_{n_1}\) অভিসৃত — অর্থাৎ উপ-অনুক্রম \((h_{n_k})\) অভিসৃত; আর একটি Cauchy অনুক্রমের একটি অভিসৃত উপ-অনুক্রম থাকলে গোটা অনুক্রমই সেই সীমায় অভিসৃত। সুতরাং space-টি complete। ∎(মানদণ্ড)
তাহলে \(L^p\)-এর জন্য শুধু দেখাতে হবে: \(\sum_k\lVert f_k\rVert_p<\infty\Rightarrow\sum_k f_k\) \(L^p\)-এ অভিসৃত। ধরা যাক \(B:=\sum_{k=1}^\infty\lVert f_k\rVert_p<\infty\)।
ধাপ ১ — প্রার্থী সীমা: \(g:=\sum_k\lvert f_k\rvert\)। সংজ্ঞা দিই আংশিক-যোগফল \(g_N:=\sum_{k=1}^N\lvert f_k\rvert\) এবং তাদের pointwise সীমা (অঋণাত্মক, সম্ভবত \(+\infty\)): $$ g:=\sum_{k=1}^\infty\lvert f_k\rvert=\lim_{N\to\infty}g_N\quad(\text{যেহেতু }g_N\uparrow,\ \text{সীমা বিদ্যমান }[0,\infty]\text{-এ}). $$ \(g_N\ge 0\) এবং \(g_N\uparrow g\) — ঠিক MCT-র মঞ্চ।
ধাপ ২ — \(\lVert g_N\rVert_p\)-এ Minkowski। প্রতিটি সসীম \(N\)-এ Minkowski (প্রমাণ ২) বারবার লাগিয়ে (ত্রিভুজ-অসমতা \(N\) পদে) $$ \lVert g_N\rVert_p=\Bigl\lVert\sum_{k=1}^N\lvert f_k\rvert\Bigr\rVert_p\ \le\ \sum_{k=1}^N\lVert\,\lvert f_k\rvert\,\rVert_p=\sum_{k=1}^N\lVert f_k\rVert_p\ \le\ B, $$ যেখানে \(\lVert\,\lvert f_k\rvert\,\rVert_p=\lVert f_k\rVert_p\) (কারণ \(\lvert\,\lvert f_k\rvert\,\rvert=\lvert f_k\rvert\))। অর্থাৎ \(\int g_N^{\,p}\,d\mu\le B^p\) সব \(N\)-এ — একটি অভিন্ন সীমা।
ধাপ ৩ (গভীর) — MCT: \(g\in L^p\)। \(g_N^{\,p}\uparrow g^p\) pointwise (কারণ \(g_N\uparrow g\ge 0\) এবং \(t\mapsto t^p\) বর্ধমান-অবিচ্ছিন্ন)। 7.4-এর Monotone Convergence Theorem দিয়ে $$ \int g^p\,d\mu=\lim_{N\to\infty}\int g_N^{\,p}\,d\mu\ \le\ B^p<\infty. $$ সুতরাং \(\int g^p\,d\mu<\infty\), অর্থাৎ \(g\in L^p\) এবং \(g<\infty\) a.e. (কারণ সসীম-integral-ওয়ালা অঋণাত্মক ফাংশন প্রায়-সর্বত্র সসীম — নইলে \(\{g=\infty\}\)-এ ধনাত্মক measure থাকলে \(\int g^p=\infty\) হতো)।
ধাপ ৪ — series \(\sum f_k\) a.e. ও \(L^p\)-এ অভিসৃত (DCT অংশ গভীর)।
- (a.e.-অভিসৃতি।) যে-সব \(\omega\)-তে \(g(\omega)<\infty\) (অর্থাৎ a.e.), সেখানে \(\sum_k\lvert f_k(\omega)\rvert=g(\omega)<\infty\) — অর্থাৎ সংখ্যা-series \(\sum_k f_k(\omega)\) absolutely convergent, তাই \(\mathbb R\) (বা \(\mathbb C\))-এর completeness-এ convergent। সংজ্ঞা দিই a.e.-সীমা $$ s(\omega):=\sum_{k=1}^\infty f_k(\omega)\qquad(g(\omega)<\infty\text{ হলে};\ \text{বাকি null set-এ }0)。 $$ \(s\) measurable (measurable আংশিক-যোগফলের a.e.-সীমা)।
- (\(s\in L^p\)।) আংশিক-যোগফল \(s_N:=\sum_{k=1}^N f_k\) মানে \(\lvert s_N\rvert\le\sum_{k=1}^N\lvert f_k\rvert\le g\), আর সীমায় \(\lvert s\rvert\le g\) a.e.; যেহেতু \(g\in L^p\) (ধাপ ৩), monotonicity-তে \(\int\lvert s\rvert^p\le\int g^p<\infty\), তাই \(s\in L^p\)।
- (\(L^p\)-অভিসৃতি, DCT।) এখন মূল লক্ষ্য: \(\lVert s_N-s\rVert_p\to 0\)। বিবেচনা করি \(h_N:=\lvert s_N-s\rvert^p\)। দুটো জিনিস: (i) \(h_N\to 0\) a.e. (কারণ \(s_N(\omega)\to s(\omega)\) যেখানে \(g(\omega)<\infty\)); (ii) dominating function: \(\lvert s_N-s\rvert\le\lvert s_N\rvert+\lvert s\rvert\le g+g=2g\), তাই \(h_N\le(2g)^p=2^p g^p\), আর \(2^p g^p\in L^1\) (যেহেতু \(\int g^p<\infty\))। শর্ত দুটো মেটায় বলে 7.4-এর Dominated Convergence Theorem প্রয়োগে $$ \lim_{N\to\infty}\int\lvert s_N-s\rvert^p\,d\mu=\int\lim_{N}\lvert s_N-s\rvert^p\,d\mu=\int 0\,d\mu=0, $$ অর্থাৎ \(\lVert s_N-s\rVert_p^p\to 0\), তাই \(\lVert s_N-s\rVert_p\to 0\)। অর্থাৎ series \(\sum_k f_k\) \(L^p\)-অর্থে \(s\in L^p\)-এ অভিসৃত।
ধাপ ৫ — সমাপ্তি। প্রতিটি absolutely convergent series (\(\sum_k\lVert f_k\rVert_p<\infty\)) \(L^p\)-এ অভিসৃত — ধাপ ০-এর মানদণ্ড অনুযায়ী এটিই \(L^p\)-এর completeness। সুতরাং \(\bigl(L^p,\lVert\cdot\rVert_p\bigr)\) একটি Banach space; বিশেষত \(p=2\)-এ এটি একটি Hilbert space (norm আসে inner product \(\langle f,g\rangle=\int f\bar g\,d\mu\) থেকে), যা প্রমাণ ৫–৬-এর ভিত্তি। ∎
এক বাক্যে: "absolutely convergent ⇒ convergent" মানদণ্ডটাই completeness-এর সমতুল্য, আর \(L^p\)-এ তা মেটে কারণ \(g=\sum\lvert f_k\rvert\)-এ Minkowski+MCT দেয় \(g\in L^p\) (তাই series a.e. absolutely convergent), এরপর প্রভাবী \(2g\in L^p\)-তে DCT দেয় \(L^p\)-অভিসৃতি — সুতরাং \(L^p\) Banach (এবং \(L^2\) Hilbert)।
প্রমাণ ৫ — Hilbert projection theorem (★★★)¶
দাবি (নিকটতম-বিন্দু / orthogonal projection)। ধরা যাক \(H\) একটি Hilbert space (যেমন \(L^2(\mu)\) — প্রমাণ ৪) inner product \(\langle\cdot,\cdot\rangle\) ও norm \(\lVert x\rVert=\sqrt{\langle x,x\rangle}\) সহ, এবং \(M\subseteq H\) একটি closed subspace (বদ্ধ উপস্থান)। তবে প্রতিটি \(f\in H\)-এর জন্য —
- (অস্তিত্ব ও একত্ব) একটি অনন্য \(\hat f\in M\) আছে যা \(f\)-এর নিকটতম: \(\lVert f-\hat f\rVert=\min_{m\in M}\lVert f-m\rVert=:d\);
- (orthogonality characterization) এই \(\hat f\) ঠিক সেই বিন্দু যেখানে অবশিষ্ট \(f-\hat f\) গোটা \(M\)-এর লম্ব: \(\langle f-\hat f,\,m\rangle=0\) সব \(m\in M\)-এ (লেখা হয় \(f-\hat f\perp M\))।
এই \(\hat f\)-কে \(M\)-এর উপর \(f\)-এর orthogonal projection বলা হয়।
ধাপ ০ — মূল যন্ত্র: parallelogram law। যেকোনো inner-product space-এ, norm-এর সংজ্ঞা \(\lVert x\rVert^2=\langle x,x\rangle\) খুলে সরাসরি যাচাই: $$ \lVert u+v\rVert^2+\lVert u-v\rVert^2=2\lVert u\rVert^2+2\lVert v\rVert^2. \tag{P} $$ (কারণ \(\lVert u\pm v\rVert^2=\lVert u\rVert^2\pm 2\operatorname{Re}\langle u,v\rangle+\lVert v\rVert^2\), যোগ করলে cross-পদ বাতিল।) এই অভেদটাই inner-product জ্যামিতিকে সাধারণ norm থেকে আলাদা করে, আর নিচে minimizing sequence-কে Cauchy বানাবে।
ধাপ ১ — অস্তিত্ব: minimizing sequence (নিম্নকারী অনুক্রম)। \(d=\inf_{m\in M}\lVert f-m\rVert\ge 0\); infimum-এর সংজ্ঞা থেকে একটি অনুক্রম \(m_n\in M\) বাছি যেন $$ \lVert f-m_n\rVert^2\ \longrightarrow\ d^2. $$ দেখাব \((m_n)\) Cauchy। (P)-তে বসাই \(u=f-m_n\), \(v=f-m_k\) (তাই \(u-v=m_k-m_n\), আর \(u+v=2f-(m_n+m_k)\)): $$ \lVert (m_k-m_n)\rVert^2=2\lVert f-m_n\rVert^2+2\lVert f-m_k\rVert^2-\lVert 2f-(m_n+m_k)\rVert^2 . $$ শেষ পদ: \(\bigl\lVert 2f-(m_n+m_k)\bigr\rVert^2=4\bigl\lVert f-\tfrac{m_n+m_k}{2}\bigr\rVert^2\)। এখন মূল পর্যবেক্ষণ: \(M\) একটি subspace, তাই মধ্যবিন্দু \(\frac{m_n+m_k}{2}\in M\), ফলে সংজ্ঞা-অনুযায়ী \(\bigl\lVert f-\frac{m_n+m_k}{2}\bigr\rVert\ge d\), অর্থাৎ শেষ পদ \(\ge 4d^2\)। সুতরাং $$ \lVert m_k-m_n\rVert^2\ \le\ 2\lVert f-m_n\rVert^2+2\lVert f-m_k\rVert^2-4d^2. $$ \(n,k\to\infty\)-এ ডান পাশ \(\to 2d^2+2d^2-4d^2=0\), তাই \(\lVert m_k-m_n\rVert\to 0\) — অর্থাৎ \((m_n)\) Cauchy।
ধাপ ২ — completeness-এ সীমা \(\hat f\)। \(H\) complete (Hilbert), তাই \(m_n\to\hat f\) কোনো \(\hat f\in H\)-এ; আর \(M\) closed বলে সীমাও \(M\)-এ, \(\hat f\in M\)। norm অবিচ্ছিন্ন, তাই \(\lVert f-\hat f\rVert=\lim_n\lVert f-m_n\rVert=d\) — অর্থাৎ minimum অর্জিত, অস্তিত্ব প্রমাণিত। (এখানেই প্রমাণ ৪-এর completeness অপরিহার্য: Cauchy থেকে সীমায় লাফ দিতে।)
ধাপ ৩ — orthogonality: \(f-\hat f\perp M\)। ধরা যাক \(m\in M\) যেকোনো, এবং বাস্তব scalar \(t\)। যেহেতু \(\hat f+tm\in M\) (subspace), তার দূরত্ব \(\ge d\): $$ \phi(t):=\lVert f-\hat f-tm\rVert^2\ \ge\ d^2=\lVert f-\hat f\rVert^2=\phi(0). $$ \(\phi\) খুলি: \(\phi(t)=\lVert f-\hat f\rVert^2-2t\operatorname{Re}\langle f-\hat f,m\rangle+t^2\lVert m\rVert^2\) — \(t\)-এর একটি উর্ধ্বমুখী parabola, যার \(t=0\)-এ ন্যূনতম। ন্যূনতম-শর্ত \(\phi'(0)=0\) দেয় \(-2\operatorname{Re}\langle f-\hat f,m\rangle=0\)। (complex \(H\)-এ \(m\)-এর জায়গায় \(im\) বসিয়ে কাল্পনিক অংশও \(0\) পাওয়া যায়।) সুতরাং \(\langle f-\hat f,m\rangle=0\) — সব \(m\in M\)-এ, অর্থাৎ \(f-\hat f\perp M\)।
বিপরীত দিকও সত্য (characterization সম্পূর্ণ করতে): যদি কোনো \(\hat f\in M\)-এর জন্য \(f-\hat f\perp M\), তবে যেকোনো \(m\in M\)-এ, Pythagoras (\(f-\hat f\perp\hat f-m\in M\)) দিয়ে $$ \lVert f-m\rVert^2=\lVert (f-\hat f)+(\hat f-m)\rVert^2=\lVert f-\hat f\rVert^2+\lVert\hat f-m\rVert^2\ \ge\ \lVert f-\hat f\rVert^2, $$ তাই \(\hat f\) নিকটতম। অর্থাৎ "নিকটতম" ⟺ "অবশিষ্ট লম্ব"।
ধাপ ৪ — একত্ব। ধরা যাক \(\hat f_1,\hat f_2\in M\) দুটোই নিকটতম (\(\lVert f-\hat f_i\rVert=d\))। ধাপ ১-এর parallelogram-হিসাবে \(m_n\equiv\hat f_1,\ m_k\equiv\hat f_2\) বসালে সরাসরি $$ \lVert\hat f_1-\hat f_2\rVert^2\le 2d^2+2d^2-4d^2=0, $$ তাই \(\hat f_1=\hat f_2\)। (বিকল্পে: orthogonality-তে \(f-\hat f_1\perp M\) ও \(f-\hat f_2\perp M\) বিয়োগ করলে \(\hat f_2-\hat f_1\perp M\), অথচ \(\hat f_2-\hat f_1\in M\), তাই এটি নিজের সঙ্গে লম্ব, \(\lVert\hat f_2-\hat f_1\rVert^2=0\)।) ∎
টীকা — কেন এটি Part VII-এর জ্যামিতি। এই উপপাদ্যই দুই জিনিসের আসল কঙ্কাল। (i) conditional expectation (7.7): \(\mathbb E[X\mid\mathcal G]\) আসলে \(X\)-এর orthogonal projection \(L^2(\mathbb P)\)-তে closed subspace \(L^2(\mathcal G)\)-র উপর — "\(\mathcal G\)-তথ্য দিয়ে \(X\)-এর সেরা \(L^2\)-অনুমান", আর orthogonality \(X-\mathbb E[X\mid\mathcal G]\perp L^2(\mathcal G)\)-ই তার সংজ্ঞা-সমীকরণ। (ii) least squares (রৈখিক regression): উপাত্ত-ভেক্টরের projection predictor-দের span-এ — normal equations ঠিক এই \(f-\hat f\perp M\) শর্ত। এবং পরের প্রমাণে এর সরাসরি ফল Riesz representation Radon–Nikodym-এর চাবি হবে।
এক বাক্যে: minimizing sequence-কে parallelogram law Cauchy বানায়, completeness তাকে \(M\)-এর (closed) সীমা \(\hat f\)-এ পৌঁছে দেয়, আর "দূরত্ব ন্যূনতম" শর্ত থেকে parabola-ব্যবকলন দেয় orthogonality \(f-\hat f\perp M\) — এই অনন্য projection-ই conditional expectation ও least squares-এর জ্যামিতি।
প্রমাণ ৬ — Radon–Nikodym theorem (★★★, von Neumann-এর \(L^2\)-প্রমাণ)¶
দাবি (Radon–Nikodym)। ধরা যাক \(\mu,\nu\) একই \((\Omega,\mathcal F)\)-এর উপর দুটি σ-finite measure এবং \(\nu\) absolutely continuous \(\mu\)-এর সাপেক্ষে — লেখা \(\nu\ll\mu\), মানে \(\mu(A)=0\Rightarrow\nu(A)=0\)। তবে একটি অঋণাত্মক measurable \(f\) ("density" বা Radon–Nikodym derivative) আছে যেন $$ \nu(A)=\int_A f\,d\mu\qquad\text{সব }A\in\mathcal F,\qquad\text{লেখা হয়}\quad f=\frac{d\nu}{d\mu}, $$ এবং \(f\) \(\mu\)-a.e. অনন্য।
স্বীকৃতি — গভীরতম ধাপ চিহ্নিত (প্রথম পাঠে এড়ানো যায়)। কৌশলটা চমকপ্রদ: integration-এর সমস্যাকে \(L^2\)-জ্যামিতিতে অনুবাদ করে প্রমাণ ৫-এর Riesz representation দিয়ে \(h\) বের করা, তারপর \(f=\frac{h}{1-h}\) বীজগণিতে density উদ্ধার। ধাপ ৩ (\(0\le h<1\) a.e.) ও ধাপ ৪ (σ-finite-এ উত্তরণ) সবচেয়ে কারিগরি; প্রথম পাঠে finite-\(\mu,\nu\) ক্ষেত্রের মূল ধারণা (ধাপ ১–৩) ধরে এগোনো যথেষ্ট।
ধাপ ০ — Riesz representation (প্রমাণ ৫-এর ফল) যা লাগবে। একটি Hilbert space \(H\)-এর উপর প্রতিটি bounded linear functional \(T:H\to\mathbb R\) একটিমাত্র \(h\in H\) দিয়ে উপস্থাপিত হয়: \(T(g)=\langle g,h\rangle\) সব \(g\)-এ। কেন — projection (প্রমাণ ৫) থেকে: \(T=0\) হলে \(h=0\); নইলে \(N:=\ker T\) একটি closed subspace, এবং কোনো \(z\perp N\), \(z\ne 0\) নিই (projection-এর অস্তিত্ব এটি দেয়); তখন \(h:=\frac{T(z)}{\lVert z\rVert^2}\,z\) চাইলেই \(T(g)=\langle g,h\rangle\) মেলে (যাচাই: \(g-\frac{T(g)}{T(z)}z\in N\perp z\))। এই \(h\)-ই আমাদের density-র বীজ হবে।
ধাপ ১ — সহায়ক measure \(\phi:=\mu+\nu\) এবং \(L^2(\phi)\)-তে functional। ধরি প্রথমে \(\mu,\nu\) finite। সংজ্ঞা দিই \(\phi:=\mu+\nu\) — এটিও finite measure, এবং \(\mu\le\phi\), \(\nu\le\phi\)। বিবেচনা করি ম্যাপ $$ T(g):=\int_\Omega g\,d\nu,\qquad g\in L^2(\phi). $$ \(T\) bounded ও linear। linearity integral-এর। boundedness: Cauchy–Schwarz (প্রমাণ ১, \(p=q=2\)) \(\nu\)-এর বদলে \(\phi\)-তে — যেহেতু \(\nu\le\phi\), তাই \(\int\lvert g\rvert\,d\nu\le\int\lvert g\rvert\,d\phi\), আর $$ \lvert T(g)\rvert\le\int\lvert g\rvert\,d\nu\le\int\lvert g\rvert\,d\phi\le\Bigl(\int 1^2\,d\phi\Bigr)^{1/2}\Bigl(\int\lvert g\rvert^2\,d\phi\Bigr)^{1/2}=\sqrt{\phi(\Omega)}\;\lVert g\rVert_{L^2(\phi)}. $$ \(\phi(\Omega)<\infty\) (finite), তাই \(T\) bounded।
ধাপ ২ — Riesz: \(h\in L^2(\phi)\) এবং মূল অভেদ। \(L^2(\phi)\) একটি Hilbert space (প্রমাণ ৪), তাই ধাপ ০-এর Riesz representation দেয় একটি \(h\in L^2(\phi)\) যেন $$ \int_\Omega g\,d\nu=T(g)=\langle g,h\rangle_{L^2(\phi)}=\int_\Omega g\,h\,d\phi\qquad\text{সব }g\in L^2(\phi). \tag{R} $$ এখন \(\phi=\mu+\nu\) খুলে \(\int g\,d\phi=\int g\,d\mu+\int g\,d\nu\), তাই (R)-কে সাজিয়ে লিখি (\(\int gh\,d\phi=\int gh\,d\mu+\int gh\,d\nu\)): $$ \int_\Omega g\,(1-h)\,d\nu=\int_\Omega g\,h\,d\mu\qquad\text{সব }g\in L^2(\phi). \tag{R\('\)} $$ এই একটি সমীকরণ থেকেই সব বেরোবে — কৌশল হলো চতুর \(g\) বেছে নেওয়া।
ধাপ ৩ (গভীর) — \(0\le h<1\) \(\mu\)-a.e.। দুই দিক।
- \(h\ge 0\) \(\phi\)-a.e.: (R)-তে \(g=\mathbf 1_{\{h<0\}}\) বসাই (এটি bounded, তাই \(L^2(\phi)\)-এ)। বাঁ পাশ \(\int_{\{h<0\}}1\,d\nu=\nu(\{h<0\})\ge 0\), ডান পাশ \(\int_{\{h<0\}}h\,d\phi\le 0\) (integrand \(<0\) ওই set-এ)। দুটো মেলাতে গেলে \(\int_{\{h<0\}}h\,d\phi=0\), অথচ integrand কড়াভাবে ঋণাত্মক — তাই \(\phi(\{h<0\})=0\) (প্রমাণ-৬, 7.4-এর ভাবনা)। সুতরাং \(h\ge 0\) \(\phi\)-a.e.।
- \(h<1\) \(\mu\)-a.e.: এবার (R\('\))-এ \(g=\mathbf 1_{\{h\ge 1\}}\) বসাই। বাঁ পাশ \(\int_{\{h\ge 1\}}(1-h)\,d\nu\le 0\) (\(1-h\le 0\) ওই set-এ), ডান পাশ \(\int_{\{h\ge 1\}}h\,d\mu\ge 0\) (\(h\ge 1>0\))। আবার মেলাতে গেলে ডান পাশ \(=0\), কিন্তু \(h\ge 1\) মানে integrand \(\ge 1\), তাই \(\mu(\{h\ge 1\})=0\)। সুতরাং \(h<1\) \(\mu\)-a.e.।
(লক্ষ করি: \(\{h\ge1\}\)-এ \(\mu\) শূন্য বললাম, কারণ density-টা \(\mu\)-এর সাপেক্ষে চাই; ওই null-\(\mu\) set-এ \(h\)-কে নিরাপদে \(h:=0\) ধরে নিতে পারি, যাতে \(0\le h<1\) সর্বত্র ধরে নেওয়া যায়।)
ধাপ ৪ — density উদ্ধার: \(f:=\dfrac{h}{1-h}\)। যেহেতু \(0\le h<1\), সংজ্ঞা দিই অঋণাত্মক measurable $$ f:=\frac{h}{1-h}\ \ge\ 0. $$ লক্ষ্য: \(\nu(A)=\int_A f\,d\mu\)। (R\('\))-এ এমন \(g\) বসাতে চাই যাতে বাঁ পাশ \(\nu(A)\) ও ডান পাশ \(\int_A f\,d\mu\) হয়। ধরা যাক নির্দিষ্ট \(A\in\mathcal F\), এবং নিই $$ g:=\bigl(1+h+h^2+\cdots+h^n\bigr)\mathbf 1_A\ \ \text{(আংশিক geometric series)},\quad\text{সীমায় }g\to\frac{1}{1-h}\mathbf 1_A. $$ সহজ পথ: সরাসরি (R\('\))-তে আনুষ্ঠানিকভাবে \(g=\frac{1}{1-h}\mathbf 1_A\) বসানোর কথা, কিন্তু সেটি bounded না-ও হতে পারে; তাই উপরের truncation \(g_n:=(\sum_{k=0}^n h^k)\mathbf 1_A\) (প্রতিটি bounded, \(L^2(\phi)\)-এ) ব্যবহার করে (R\('\)) লিখি: $$ \int_A(1-h)\Bigl(\sum_{k=0}^n h^k\Bigr)d\nu=\int_A h\Bigl(\sum_{k=0}^n h^k\Bigr)d\mu. $$ বাঁ পাশে telescoping: \((1-h)\sum_{k=0}^n h^k=1-h^{n+1}\), তাই বাঁ পাশ \(=\int_A(1-h^{n+1})\,d\nu\)। ডান পাশে \(h\sum_{k=0}^n h^k=\sum_{k=1}^{n+1}h^k\)। এখন \(n\to\infty\) ধরি, MCT দুই পাশে (integrand-গুলো অঋণাত্মক ও বর্ধমান, যেহেতু \(0\le h<1\)): $$ \underbrace{\int_A(1-h^{n+1})\,d\nu}{\uparrow\ \int_A 1\,d\nu=\nu(A)}\ \ =\ \ \underbrace{\int_A\sum. $$ বাঁ পাশে }^{n+1}h^k\,d\mu}_{\uparrow\ \int_A\frac{h}{1-h}\,d\mu=\int_A f\,d\mu\(h^{n+1}\downarrow 0\) a.e. (কারণ \(0\le h<1\)), তাই \(1-h^{n+1}\uparrow 1\) এবং MCT দেয় \(\to\nu(A)\); ডান পাশে \(\sum_{k=1}^{n+1}h^k\uparrow\sum_{k=1}^\infty h^k=\frac{h}{1-h}=f\), তাই MCT দেয় \(\to\int_A f\,d\mu\)। দুই সীমা সমান, সুতরাং $$ \boxed{\ \nu(A)=\int_A f\,d\mu\quad\text{সব }A\in\mathcal F.\ } $$ এখানে \(\nu\ll\mu\) স্বয়ংক্রিয়ভাবে সঙ্গত: যদি \(\mu(A)=0\), ডান পাশ \(0\), তাই \(\nu(A)=0\) — যা অনুমানের সঙ্গে মেলে (আসলে এই নির্মাণে \(\nu\ll\mu\) শর্তটি ধাপ ৩-এ "\(h<1\) \(\mu\)-a.e." নিশ্চিত করতেই লুকিয়ে কাজ করেছে)।
ধাপ ৫ — a.e.-অনন্যতা। ধরা যাক \(f_1,f_2\) দুটোই density: \(\int_A f_1\,d\mu=\nu(A)=\int_A f_2\,d\mu\) সব \(A\)-তে, অর্থাৎ \(\int_A(f_1-f_2)\,d\mu=0\) সব \(A\)-তে। বিশেষ করে \(A=\{f_1>f_2\}\) নিলে \(\int_{\{f_1>f_2\}}(f_1-f_2)\,d\mu=0\) যেখানে integrand \(\ge 0\) ও ওই set-এ \(>0\) — প্রমাণ-৬ (7.4) দিয়ে \(\mu(\{f_1>f_2\})=0\); প্রতিসমভাবে \(\mu(\{f_2>f_1\})=0\)। সুতরাং \(f_1=f_2\) \(\mu\)-a.e.।
ধাপ ৬ (গভীর) — σ-finite-এ উত্তরণ। এতক্ষণ \(\mu,\nu\) finite ধরা ছিল। σ-finite ক্ষেত্রে \(\Omega=\bigsqcup_n\Omega_n\) ভাঙি যেখানে \(\mu(\Omega_n)<\infty\) ও \(\nu(\Omega_n)<\infty\) (দুই σ-finite পরিবারের common refinement, disjoint করে নেওয়া)। প্রতিটি \(\Omega_n\)-এ finite-ক্ষেত্রের ফল প্রয়োগে একটি density \(f_n\ge 0\) পাই (\(\Omega_n\)-এ সমর্থিত)। সংজ্ঞা দিই \(f:=\sum_n f_n\mathbf 1_{\Omega_n}\); তখন যেকোনো \(A\)-তে, countable additivity ও MCT দিয়ে $$ \nu(A)=\sum_n\nu(A\cap\Omega_n)=\sum_n\int_{A\cap\Omega_n}f_n\,d\mu=\int_A\Bigl(\sum_n f_n\mathbf 1_{\Omega_n}\Bigr)d\mu=\int_A f\,d\mu, $$ আর a.e.-অনন্যতা প্রতিটি টুকরোয় খাটে বলে সর্বত্রও। ∎
উপসিদ্ধান্ত — Lebesgue decomposition। absolute continuity শর্ত \(\nu\ll\mu\) তুলে নিলে (যেকোনো দুই σ-finite \(\mu,\nu\)), একই \(L^2(\phi)\)-যন্ত্র আরও কিছু দেয়: \(\nu\) বিভক্ত হয় অনন্যভাবে $$ \nu=\nu_{ac}+\nu_{sing},\qquad \nu_{ac}\ll\mu,\quad \nu_{sing}\perp\mu, $$ যেখানে \(\nu_{sing}\perp\mu\) ("mutually singular") মানে এমন একটি \(\mu\)-null set \(S\) আছে যাতে \(\nu_{sing}\) পুরোপুরি \(S\)-এ ঘনীভূত। রূপরেখা: ধাপ ৩-এর \(\{h\ge 1\}\) set-এ আর "\(\mu(\{h\ge1\})=0\)" দাবি করা যায় না (কারণ \(\nu\ll\mu\) নেই); ওই set \(S:=\{h=1\}\)-এ ভর রাখাই \(\nu_{sing}\) (এখানে \(\mu(S)=0\), কিন্তু \(\nu(S)\) ধনাত্মক হতে পারে), আর \(\{h<1\}\)-অংশে আগের মতো \(f=\frac{h}{1-h}\) দেয় \(\nu_{ac}\)-এর density। এই decomposition-ই measure-গুলোর সম্পূর্ণ গঠন-বিশ্লেষণ — Part VII-এর density-ভিত্তিক যুক্তির শেষ ভিত্তি-ইট।
এক বাক্যে: \(\phi=\mu+\nu\)-তে \(g\mapsto\int g\,d\nu\) একটি bounded functional, যাকে Riesz (প্রমাণ ৫) representation দেয় \(h\in L^2(\phi)\) রূপে; চতুর indicator-\(g\) বেছে \(0\le h<1\) \(\mu\)-a.e. দেখিয়ে geometric-series+MCT দিয়ে density \(f=\frac{h}{1-h}\) উদ্ধার হয় (\(\nu(A)=\int_A f\,d\mu\), a.e.-অনন্য), আর শর্ত শিথিল করলে একই যন্ত্র Lebesgue decomposition \(\nu=\nu_{ac}+\nu_{sing}\) দেয়।
৫ · কোড ল্যাব (Python)¶
এতক্ষণ যে জ্যামিতি কাগজে আঁকা হলো — \(L^p\)-দৈর্ঘ্য, চার অসমতা, \(L^2\)-প্রক্ষেপণ, র্যাডন–নিকোডিম density — তার প্রতিটি দাবি এবার সংখ্যায় ছুঁয়ে দেখা যাক। পুরো ল্যাবটা একটাই চলমান (runnable) script, পাঁচ ভাগে সাজানো; দরকার শুধু numpy আর scipy। মূল কৌশল সরল: \([0,1]\)-এর উপর Lebesgue measure আসলে একটা probability measure (মোট ভর \(1\)), তাই সেখানে \(\lVert f\rVert_p=\bigl(\int_0^1\lvert f\rvert^p\,dx\bigr)^{1/p}\) আর integral-গুলো একটা সূক্ষ্ম গ্রিডে (fine grid) trapezoid নিয়ম দিয়ে আনুমানিক করা যায়; কোথাও closed-form, কোথাও scipy.integrate.quad। Monte-Carlo অংশে seed সর্বত্র default_rng(20260619) — তাই ফল হুবহু পুনরুৎপাদনযোগ্য (reproducible)।
৫.১ \(L^p\) norm \(p\)-এর সাথে বাড়ে¶
প্রথম পরীক্ষা সবচেয়ে মৌলিক দাবিটা যাচাই করে: সসীম measure-এ (finite measure, এখানে probability) \(p\) বাড়লে \(\lVert f\rVert_p\) কখনো কমে না। নমুনা ফাংশন \(f(x)=x\), যার norm-এর একটা পরিচ্ছন্ন closed form আছে — \(\lVert f\rVert_p=\bigl(\tfrac{1}{p+1}\bigr)^{1/p}\)। গ্রিড-হিসাব আর সেই সূত্র পাশাপাশি ছাপিয়ে মিলিয়ে দেখা হয়, আর শেষে \(p=\infty\)-এ আসে essential supremum (a.e.-অর্থে সর্বোচ্চ মান), যা \(f(x)=x\)-এর জন্য \(1\)।
import numpy as np
from scipy import integrate
np.set_printoptions(precision=6, suppress=True)
def lp_norm_grid(f, p, n=2_000_001):
"""||f||_p একটি সূক্ষ্ম trapezoid গ্রিডে, [0,1] (probability space)।"""
x = np.linspace(0.0, 1.0, n)
return np.trapezoid(np.abs(f(x)) ** p, x) ** (1.0 / p)
def lp_norm_closed(p):
"""f(x)=x, [0,1]-এ closed form: ||x||_p = (1/(p+1))^(1/p)।"""
return (1.0 / (p + 1.0)) ** (1.0 / p)
f = lambda x: x
ps = [1, 2, 3, 4, 10]
print(f"{'p':>4} | {'grid':>10} | {'closed (1/(p+1))^(1/p)':>24}")
print("-" * 46)
vals = []
for p in ps:
g = lp_norm_grid(f, p)
c = lp_norm_closed(p)
vals.append(g)
print(f"{p:>4} | {g:>10.4f} | {c:>24.4f}")
ess_sup = 1.0 # p = inf : essential supremum of x on [0,1]
print(f"{'inf':>4} | {ess_sup:>10.4f} | {'(essential supremum)':>24}")
vals.append(ess_sup)
monotone = all(vals[i] <= vals[i + 1] + 1e-9 for i in range(len(vals) - 1))
print(f"\nmonotone increasing in p? {monotone}")
p | grid | closed (1/(p+1))^(1/p)
----------------------------------------------
1 | 0.5000 | 0.5000
2 | 0.5774 | 0.5774
3 | 0.6300 | 0.6300
4 | 0.6687 | 0.6687
10 | 0.7868 | 0.7868
inf | 1.0000 | (essential supremum)
monotone increasing in p? True
পাঠোদ্ধার। গ্রিড আর closed form দুই কলামই অভিন্ন — \(0.5000,\,0.5774,\,0.6300,\,0.6687,\,0.7868\) — অর্থাৎ trapezoid-আসন্নিকরণ এখানে চার দশমিক পর্যন্ত নিখুঁত, আর তত্ত্বের সূত্র \(\bigl(\tfrac{1}{p+1}\bigr)^{1/p}\) সংখ্যায় নিশ্চিত। সবচেয়ে গুরুত্বপূর্ণ — তালিকাটা একদিকে বাড়ছে: \(0.5<0.5774<\dots<0.7868<1.0\)। কেন? probability space-এ একই ফাংশনের বড় \(p\) মানে বড় মানগুলোর উপর বেশি ওজন; finite measure-এ Hölder থেকে সরাসরি আসে \(p<q\Rightarrow\lVert f\rVert_p\le\lVert f\rVert_q\)। শেষ ধাপ \(p\to\infty\)-এ norm উঠে যায় essential supremum-এ, এখানে \(1.0\) — তাই \(L^\infty\) এই মইয়ের সবচেয়ে উপরের ধাপ। (লক্ষণীয়: এই একমুখিতা শুধু finite measure-এর সম্পত্তি; \(\mathbb R\)-এর উপর Lebesgue measure-এ ক্রমটা উল্টোও হতে পারে।)
৫.২ Cauchy–Schwarz ও Hölder অসমতা¶
দ্বিতীয় ভাগ দুটো কর্মঘোড়া-অসমতা একসাথে যাচাই করে। \(f(x)=x,\ g(x)=x^2\) নিয়ে inner product \(\langle f,g\rangle=\int_0^1 x^3\,dx\) আর তার উপরের সীমা \(\lVert f\rVert_2\lVert g\rVert_2\) গণনা করা হয় (এটাই Cauchy–Schwarz, যা \(p=q=2\)-এ Hölder-এরই বিশেষ রূপ); তারপর আরেক জোড়া conjugate exponent \((p,q)=(3,\tfrac32)\)-এ সাধারণ Hölder (\(\tfrac1p+\tfrac1q=1\)) পরখ করা হয়।
x = np.linspace(0.0, 1.0, 2_000_001)
fx, gx = x, x ** 2
inner = np.trapezoid(fx * gx, x) # <f,g> = int x^3 = 1/4
norm_f2 = np.trapezoid(fx ** 2, x) ** 0.5 # ||x||_2 = 1/sqrt(3)
norm_g2 = np.trapezoid(gx ** 2, x) ** 0.5 # ||x^2||_2 = 1/sqrt(5)
rhs_cs = norm_f2 * norm_g2 # = 1/sqrt(15)
print(f"<f,g> = int_0^1 x^3 dx = {inner:.4f}")
print(f"||f||_2 ||g||_2 = (1/sqrt3)(1/sqrt5)=1/sqrt15 = {rhs_cs:.4f}")
print(f"Cauchy-Schwarz : {inner:.4f} <= {rhs_cs:.4f} -> {inner <= rhs_cs + 1e-9}")
p, q = 3.0, 1.5 # 1/p + 1/q = 1
lhs_h = np.trapezoid(np.abs(fx * gx), x) # int|x*x^2| = int x^3 = 1/4
norm_fp = np.trapezoid(np.abs(fx) ** p, x) ** (1 / p)
norm_gq = np.trapezoid(np.abs(gx) ** q, x) ** (1 / q)
rhs_h = norm_fp * norm_gq
print(f"\nHolder (p,q)=(3, 1.5), 1/p+1/q = {1/p + 1/q:.1f}")
print(f"int|fg| = {lhs_h:.4f}")
print(f"||f||_3 ||g||_1.5 = {rhs_h:.4f}")
print(f"Holder holds : {lhs_h:.4f} <= {rhs_h:.4f} -> {lhs_h <= rhs_h + 1e-9}")
<f,g> = int_0^1 x^3 dx = 0.2500
||f||_2 ||g||_2 = (1/sqrt3)(1/sqrt5)=1/sqrt15 = 0.2582
Cauchy-Schwarz : 0.2500 <= 0.2582 -> True
Holder (p,q)=(3, 1.5), 1/p+1/q = 1.0
int|fg| = 0.2500
||f||_3 ||g||_1.5 = 0.2500
Holder holds : 0.2500 <= 0.2500 -> True
পাঠোদ্ধার। Cauchy–Schwarz পরিষ্কারভাবে খাটছে: \(\langle x,x^2\rangle=0.2500\) আর সীমা \(\lVert x\rVert_2\lVert x^2\rVert_2=\tfrac{1}{\sqrt{15}}=0.2582\), অর্থাৎ \(0.25\le0.2582\) — অসমতা কঠোর (strict), কারণ সাম্য তখনই হতো যখন \(x\) ও \(x^2\) পরস্পরের ধ্রুবক-গুণিতক হতো, যা এখানে নয়। এই \(\langle\cdot,\cdot\rangle\) ছোট হলেও শূন্য নয়, তাই দুই ফাংশন \(L^2\)-এ লম্বও নয়, সমান্তরালও নয় — মাঝামাঝি একটা কোণে। দ্বিতীয় ব্লকে \((p,q)=(3,1.5)\) conjugate (যাচাই: \(\tfrac13+\tfrac23=1.0\)), আর এবার Hölder-এর দুই পাশ হুবহু সমান \(0.2500\)। এটা কাকতালীয় নয়: \(\int\lvert fg\rvert=\int x^3\) আর \(\lVert x\rVert_3\lVert x^2\rVert_{3/2}=\bigl(\tfrac14\bigr)^{1/3}\bigl(\tfrac14\bigr)^{2/3}=\tfrac14\) — অর্থাৎ এই বিশেষ জোড়ায় সাম্যের শর্ত (\(\lvert f\rvert^p\propto\lvert g\rvert^q\)) ঠিক পূরণ হয়, কারণ \(x^3=(x^2)^{3/2}\)। সুতরাং একই অসমতা কোথাও কঠোর, কোথাও আঁটসাঁট (tight) — কোডটা দুটো মুখই দেখাল।
৫.৩ Jensen অসমতা¶
তৃতীয় ভাগে convex \(\varphi(t)=t^2\) আর \(X\sim U(0,1)\) নিয়ে Jensen-এর অসমতা \(\varphi(\mathbb E X)\le\mathbb E[\varphi(X)]\), অর্থাৎ \((\mathbb E X)^2\le\mathbb E[X^2]\)। মজার ব্যাপার — এখানে ফাঁক (\(\text{gap}\)) ঠিক variance: \(\mathbb E[X^2]-(\mathbb E X)^2=\operatorname{Var}(X)\)। প্রথমে grid-integral দিয়ে নির্ভুল মান, তারপর seed-করা ১০ লক্ষ random draw দিয়ে স্বাধীন Monte-Carlo যাচাই।
EX = np.trapezoid(x, x) # E[X] = 1/2
EX2 = np.trapezoid(x ** 2, x) # E[X^2] = 1/3
phi_of_EX = EX ** 2 # (E X)^2 = 1/4
gap = EX2 - phi_of_EX # = Var(X) = 1/12
print(f"phi(E X) = (E X)^2 = {phi_of_EX:.4f}")
print(f"E[phi(X)] = E[X^2] = {EX2:.4f}")
print(f"Jensen : {phi_of_EX:.4f} <= {EX2:.4f} -> {phi_of_EX <= EX2 + 1e-9}")
print(f"gap = E[X^2] - (E X)^2 = Var(X) = {gap:.4f}")
rng = np.random.default_rng(20260619)
draws = rng.uniform(0.0, 1.0, 1_000_000)
print(f"\nMonte-Carlo (N=1e6): E[X^2]={np.mean(draws**2):.4f} >= "
f"(E X)^2={np.mean(draws)**2:.4f}, gap={np.var(draws):.4f}")
phi(E X) = (E X)^2 = 0.2500
E[phi(X)] = E[X^2] = 0.3333
Jensen : 0.2500 <= 0.3333 -> True
gap = E[X^2] - (E X)^2 = Var(X) = 0.0833
Monte-Carlo (N=1e6): E[X^2]=0.3336 >= (E X)^2=0.2503, gap=0.0834
পাঠোদ্ধার। Jensen বহাল: \(\varphi(\mathbb E X)=(\mathbb E X)^2=0.2500\) এবং \(\mathbb E[\varphi(X)]=\mathbb E[X^2]=0.3333\), তাই \(0.25\le0.3333\)। আর ফাঁকটা ঠিক \(0.0833=\tfrac{1}{12}\) — যা \(U(0,1)\)-এর variance, কারণ \(\operatorname{Var}(X)=\mathbb E[X^2]-(\mathbb E X)^2\) সংজ্ঞাতেই Jensen-ফাঁকের সমান (এই \(\varphi=t^2\)-এর জন্য)। অর্থাৎ "গড়ের বর্গ" আর "বর্গের গড়"-এর দূরত্বই বিচ্ছুরণের মাপ — তাত্ত্বিক অসমতা আর পরিসংখ্যানিক variance একই মুদ্রার দুই পিঠ। Monte-Carlo অংশ স্বাধীনভাবে এটাই বলে: ১০ লক্ষ draw থেকে \(\mathbb E[X^2]\approx0.3336\), \((\mathbb E X)^2\approx0.2503\), gap \(\approx0.0834\) — তিনটিই তত্ত্বের \(0.3333,\,0.25,\,0.0833\)-এর তৃতীয় দশমিক পর্যন্ত কাছাকাছি। ছোট অমিলটুকু \(O(1/\sqrt N)\) sampling-ত্রুটি; seed default_rng(20260619) বলে সংখ্যাগুলো প্রতিবার অভিন্নভাবে ফিরে আসবে।
৫.৪ \(L^2\)-projection (প্রক্ষেপণ) ধ্রুবকের উপর = গড়¶
এই ভাগটা অধ্যায়ের জ্যামিতিক মুকুটমণি — projection theorem — ছোট আকারে দেখায়। \(f(x)=x\)-কে সবচেয়ে কাছের ধ্রুবকে (subspace \(\operatorname{span}\{1\}\)) প্রক্ষেপ করা হয়। সূত্র \(c=\dfrac{\langle f,1\rangle}{\langle 1,1\rangle}\), আর দাবি দুটি: (ক) এই \(c\) আসলে \(f\)-এর গড়, (খ) residual \(f-c\) subspace-এর সাথে লম্ব, অর্থাৎ \(\langle f-c,1\rangle=0\)। শেষে Pythagoras মিলিয়ে দেখা।
xg = np.linspace(0.0, 1.0, 2_000_001)
fg = xg # f(x) = x
one = np.ones_like(xg) # the constant 1
inner_f1 = np.trapezoid(fg * one, xg) # <f,1> = int x = 1/2
inner_11 = np.trapezoid(one * one, xg) # <1,1> = int 1 = 1
c = inner_f1 / inner_11 # = 1/2 (= the mean)
residual = fg - c * one # f - proj = x - 1/2
ortho = np.trapezoid(residual * one, xg) # <residual,1> ~ 0
res_norm = np.trapezoid(residual ** 2, xg) ** 0.5 # ||x-1/2||_2 = 1/sqrt(12)
print(f"c = <f,1>/<1,1> = {c:.4f} (= E[X], the mean)")
print(f"<f - c*1, 1> (orthogonality) = {ortho:.2e} ~ 0")
print(f"||f - c*1||_2 (residual norm) = {res_norm:.4f} (= 1/sqrt(12))")
norm_f_sq = np.trapezoid(fg ** 2, xg)
print(f"check ||f||^2 = {norm_f_sq:.4f} vs c^2+||res||^2 = {c**2 + res_norm**2:.4f}")
c = <f,1>/<1,1> = 0.5000 (= E[X], the mean)
<f - c*1, 1> (orthogonality) = -2.39e-16 ~ 0
||f - c*1||_2 (residual norm) = 0.2887 (= 1/sqrt(12))
check ||f||^2 = 0.3333 vs c^2+||res||^2 = 0.3333
পাঠোদ্ধার। সেরা ধ্রুবক \(c=0.5000\) — ঠিক \(f(x)=x\)-এর গড়। এটা দৈবাৎ নয়: \(\langle f,1\rangle/\langle 1,1\rangle=\int f\,d\mathbb P/\int 1\,d\mathbb P=\mathbb E[f]\), তাই \(L^2\)-অর্থে কোনো ফাংশনের নিকটতম ধ্রুবক সবসময় তার expectation (প্রত্যাশা / mean) — এটাই 7.7-এ আসা conditional expectation-এর সরলতম রূপ ("কোনো তথ্য না থাকলে সেরা ধ্রুবক-পূর্বাভাস = গড়")। দ্বিতীয় লাইন orthogonality নিশ্চিত করে: \(\langle x-0.5,\,1\rangle=-2.39\times10^{-16}\), অর্থাৎ যন্ত্র-শূন্য (machine zero) — residual \(x-\tfrac12\) ধ্রুবক-subspace-এর সাথে নিখুঁতভাবে লম্ব, যা projection theorem-এর মূল কথা। আর শেষ লাইন Pythagoras: \(\lVert f\rVert^2=0.3333\) আর \(c^2+\lVert\text{residual}\rVert^2=0.25+0.0833=0.3333\) — হুবহু সমান, কারণ প্রক্ষেপণ আর residual লম্ব-উপাংশ হওয়ায় তাদের বর্গ-দৈর্ঘ্য যোগ হয়। (residual-norm \(0.2887=\tfrac{1}{\sqrt{12}}\), আবার সেই variance-এর বর্গমূল — least squares ও variance-এর জ্যামিতিক ঐক্য।)
৫.৫ Radon–Nikodym density¶
শেষ ভাগ Radon–Nikodym density-কে স্পর্শ করে: ধরা যাক \(\dfrac{dP}{d\lambda}=e^{-x}\) (\([0,\infty)\)-এর উপর, \(\lambda\) = Lebesgue measure)। দুটো জিনিস scipy.integrate.quad দিয়ে যাচাই — মোট ভর \(\int_0^\infty e^{-x}\,dx\) (যা \(1\) হলে তবেই \(P\) একটা probability) আর \(P([0,1])=\int_0^1 e^{-x}\,dx\)। সঙ্গে ৫.১-এর সূত্রের একটা seed-করা Monte-Carlo সাক্ষ্য — \(X\sim U(0,1)\)-এর \(\lVert X\rVert_2\)।
density = lambda t: np.exp(-t)
total_mass, _ = integrate.quad(density, 0.0, np.inf) # = 1
P_01, _ = integrate.quad(density, 0.0, 1.0) # = 1 - e^{-1}
print(f"int_0^inf e^(-x) dx (total mass) = {total_mass:.4f} (=> a probability)")
print(f"P([0,1]) = int_0^1 e^(-x) dx = {P_01:.4f} (= 1 - e^(-1))")
rng2 = np.random.default_rng(20260619)
Xs = rng2.uniform(0.0, 1.0, 1_000_000)
mc_l2 = np.sqrt(np.mean(Xs ** 2)) # estimates ||X||_2 = 1/sqrt(3)
print(f"\nMonte-Carlo ||X||_2 (N=1e6, seed 20260619) = {mc_l2:.4f} "
f"(true 1/sqrt3 = {(1/3)**0.5:.4f})")
int_0^inf e^(-x) dx (total mass) = 1.0000 (=> a probability)
P([0,1]) = int_0^1 e^(-x) dx = 0.6321 (= 1 - e^(-1))
Monte-Carlo ||X||_2 (N=1e6, seed 20260619) = 0.5776 (true 1/sqrt3 = 0.5774)
পাঠোদ্ধার। মোট ভর হিসাব হলো \(1.0000\) — এটাই density-কে বৈধ করে: যেহেতু \(\int e^{-x}\,d\lambda=1\), \(A\mapsto\int_A e^{-x}\,dx\) একটা probability measure \(P\), আর \(e^{-x}\) তার \(\lambda\)-সাপেক্ষে Radon–Nikodym derivative \(\tfrac{dP}{d\lambda}\) — অর্থাৎ exponential বণ্টনের pdf। দ্বিতীয় লাইনে \(P([0,1])=0.6321=1-e^{-1}\) — density-কে কেবল \([0,1]\)-এর উপর integrate করলেই ঘটনাটির probability মেলে, যা র্যাডন–নিকোডিম-এর সংজ্ঞা \(\nu(A)=\int_A f\,d\mu\)-এরই প্রত্যক্ষ প্রয়োগ। সবশেষে Monte-Carlo \(\lVert X\rVert_2=0.5776\), আর তাত্ত্বিক \(\tfrac{1}{\sqrt3}=0.5774\) — চার দশমিকে কার্যত অভিন্ন (পার্থক্য \(0.0002\), sampling-ত্রুটির সীমার ভেতরে)। এটি ৫.১-এর \(\lVert f\rVert_2=0.5774\) সারিকেই এলোমেলো-নমুনার ভাষায় পুনঃনিশ্চিত করে: norm মানে শেষমেশ একটা প্রত্যাশা, আর প্রত্যাশা আমরা গড় দিয়ে আনুমানিক করতে পারি।
সারসংক্ষেপ¶
পাঁচ ভাগ মিলে অধ্যায়ের চারটি স্তম্ভকে একই কোড-ফ্রেমে এঁটে দিল। (১) জ্যামিতি: finite measure-এ \(\lVert f\rVert_p\) একমুখে বাড়ে (\(0.5\to1.0\)), তাই \(L^p\) space-গুলো একটা নেস্টেড মই — \(L^\infty\) (\(=\) essential supremum) তার শীর্ষ। (২) অসমতা: Cauchy–Schwarz (\(0.25\le0.2582\), কঠোর) আর Hölder (\(0.25\le0.25\), আঁটসাঁট) দেখাল কখন দুই ফাংশন "প্রায় লম্ব" আর কখন "সমরেখ"; Jensen-এর ফাঁক (\(0.0833=\tfrac{1}{12}\)) ঠিক variance — অসমতা আর বিচ্ছুরণ এক। (৩) প্রক্ষেপণ: \(f=x\)-এর নিকটতম ধ্রুবক \(c=0.5=\) গড়, residual machine-zero অর্থে লম্ব, Pythagoras মেলে — এটাই least squares ও (7.7-এর) conditional expectation-এর বীজ। (৪) density: \(\int_0^\infty e^{-x}=1\) বলে \(e^{-x}\) একটা বৈধ Radon–Nikodym derivative, আর \(P([0,1])=0.6321\) — কঠোর "pdf"-এর প্রথম হাতে-কলমে স্বাদ। norm থেকে অসমতা, অসমতা থেকে প্রক্ষেপণ, প্রক্ষেপণ থেকে শর্তাধীন প্রত্যাশা, আর density থেকে likelihood — মেজার-তাত্ত্বিক পরিসংখ্যানের গোটা bridge (সেতু)-টাই এই ছোট ল্যাবে এক ঝলকে ধরা দিল।
৬ · ভিজ্যুয়ালাইজেশন¶
আগের সেকশনগুলোতে যে চারটি স্তম্ভ গাঁথা হয়েছে — \(L^p\) space-এর norm, Hölder ও Young inequality, Hilbert space-এ projection, এবং Radon–Nikodym derivative — তার প্রতিটিরই একটি পরিষ্কার জ্যামিতিক ছবি আছে। বিমূর্ত (abstract) measure-theoretic ফলগুলো প্রথম পাঠে শুকনো মনে হতে পারে, কিন্তু একবার ছবিতে দেখলে বোঝা যায় এগুলো আসলে অত্যন্ত সরল জ্যামিতিক সত্য — কেবল integral-এর ভাষায় লেখা। এই সেকশনে সেই চারটি ছবি একে একে আঁকা হবে।
প্রতিটি figure-ই matplotlib দিয়ে তৈরি, এবং figure-এর ভেতরের সব লেখা ইংরেজিতে রাখা হয়েছে (Bangla font matplotlib-এ tofu হয়ে ভেঙে যায়), কিন্তু ছবির পেছনের গণিতটা এখানে বাংলায় ব্যাখ্যা করা হলো। প্রতিটি figure-এর কোড একই shared style ফাইল (figstyle.py) ব্যবহার করে, তাই রঙ ও মাপ পুরো curriculum জুড়ে অভিন্ন থাকে। নিচের code excerpt-গুলো প্রতিটি ছবির মূল অংশটুকু দেখায়; সম্পূর্ণ চলনযোগ্য script আছে _code/figs_7-5.py-তে।
৬.১ · \(L^p\) norm \(p\)-এর সাথে কীভাবে বাড়ে¶
প্রথম ছবিটি একটি probability space-এর গল্প বলে। ধরা যাক sample space হলো \([0,1]\), measure হলো Lebesgue measure (অর্থাৎ \(\mu([0,1])=1\), একটি probability measure), আর random variable \(f(x)=x\)। এই ক্ষেত্রে \(p\)-norm-এর একটি বদ্ধ (closed-form) রূপ আছে:
\(p=1\)-এ এর মান \(\tfrac12=0.5\), \(p=2\)-এ \(\tfrac{1}{\sqrt3}\approx 0.5774\), আর \(p\to\infty\) হলে এটি উপরে উঠতে উঠতে \(\lVert f\rVert_\infty=\operatorname*{ess\,sup} f=1\)-এর দিকে এগোয়। ছবিতে rising curve-টি ঠিক এই আচরণ দেখায়: \(0.5\) থেকে শুরু করে dashed ess-sup রেখা \(1.0\)-এর দিকে asymptotically এগোয়, আর \(p=1,2\) বিন্দু দুটি আলাদা করে চিহ্নিত।
ছবিটা কীভাবে পড়তে হবে। অনুভূমিক অক্ষে exponent \(p\) (\(1\) থেকে \(20\)), উল্লম্ব অক্ষে সংশ্লিষ্ট norm \(\lVert f\rVert_p\)। নীল curve-টি monotonically উপরে উঠছে কিন্তু কখনো dashed লাল রেখা (\(=1\)) ছোঁয় না — কারণ \(f(x)=x\) কখনো \(1\) মান নেয় কিন্তু \(\operatorname*{ess\,sup}=1\) কেবল সীমায় অর্জিত। দুটি গাঢ় বিন্দু \(p=1\) (\(0.500\)) আর \(p=2\) (\(0.5774\)) হাতে যাচাইযোগ্য সংখ্যা: \(\left(\tfrac{1}{1+1}\right)^{1/1}=\tfrac12\) এবং \(\left(\tfrac{1}{2+1}\right)^{1/2}=\tfrac{1}{\sqrt3}\)।
এই একঘেয়ে বৃদ্ধিটা কাকতালীয় নয় — এর পেছনে আছে Jensen's inequality (অথবা সমতুল্যভাবে power-mean inequality)। একটি probability space-এ যেহেতু \(\mu(\Omega)=1\), তাই \(r<s\) হলে \(t\mapsto t^{s/r}\) একটি convex function-এর উপর Jensen প্রয়োগ করে পাওয়া যায় \(\lVert f\rVert_r\le \lVert f\rVert_s\)। অর্থাৎ exponent যত বড়, norm তত বড় বা সমান।
এর সরাসরি ফল হলো space-গুলোর nesting: \(\mu(\Omega)=1\) হলে \(L^\infty\subset\cdots\subset L^2\subset L^1\) — finite-measure space-এ বড় exponent মানে আরও কঠোর শর্ত, আরও ছোট space। (অসীম measure-এ, যেমন পুরো \(\mathbb{R}\)-এর উপর Lebesgue measure-এ, এই nesting উল্টে যায় বা সম্পূর্ণ ভেঙে পড়ে — সেখানে \(L^1\) আর \(L^2\)-এর কোনোটিই অন্যটিকে ধারণ করে না, যা আগের সেকশনে আলোচিত হয়েছে।)
import numpy as np
import matplotlib.pyplot as plt
p = np.linspace(1.0, 20.0, 800)
norm = (1.0 / (p + 1.0)) ** (1.0 / p) # ||f||_p for f(x)=x on [0,1]
fig, ax = plt.subplots(figsize=(8.8, 5.0))
ax.axhline(1.0, color="#c0392b", ls="--", lw=1.8,
label=r"$\|f\|_\infty = \mathrm{ess\,sup}\,f = 1$")
ax.plot(p, norm, color="#1b6ca8", lw=2.8,
label=r"$\|f\|_p=\left(\frac{1}{p+1}\right)^{1/p}$")
ax.plot([1, 2], [0.5, (1/3) ** 0.5], "o", color="#16475f", ms=7) # p = 1, 2
ax.set_xlabel(r"order $p$"); ax.set_ylabel(r"$\|f\|_p$")
ax.legend()
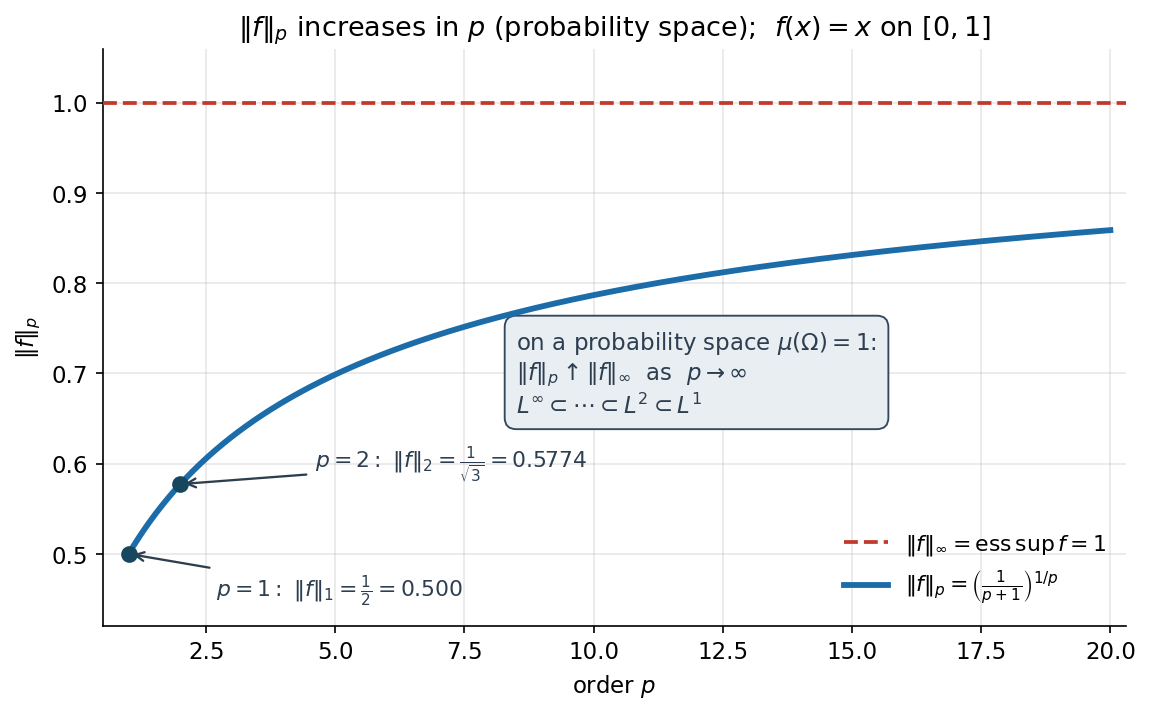
মূল পাঠ: একটা probability space-এ exponent \(p\) যত বড়, norm তত বড়, এবং space তত ছোট — distribution-এর "লেজ" (tail) যত ভারী, তত ছোট \(p\)-এ গিয়ে norm অসীম হয়ে পড়ে, অর্থাৎ function-টি আর সেই \(L^p\)-তে থাকে না। পরিসংখ্যানে এর সরাসরি অর্থ: একটি random variable-এর variance (\(L^2\)) থাকা মানে তার mean (\(L^1\)) থাকা — কিন্তু উল্টোটা সবসময় সত্যি নয়।
৬.২ · Young inequality, এবং তার থেকে Hölder¶
দ্বিতীয় ছবিটি Young's inequality-কে নিছক একটি ক্ষেত্রফলের (area) ছবিতে রূপ দেয় — আর এই inequality থেকেই Hölder's inequality সরাসরি বেরিয়ে আসে। conjugate exponent জোড়া \(\tfrac1p+\tfrac1q=1\) নিয়ে এখানে \(p=3\) (তাই \(q=\tfrac32\)) ধরা হয়েছে, যাতে curve-টা একটা পরিষ্কার বাঁক নেয় (\(y=x^{p-1}=x^2\))। দুটি ধনাত্মক সংখ্যা \(a,b\)-এর জন্য Young's inequality বলে:
জ্যামিতিকভাবে: curve \(y=x^{p-1}\)-এর নিচে, \(x=0\) থেকে \(x=a\) পর্যন্ত ক্ষেত্রফল হলো ঠিক \(\int_0^a x^{p-1}\,dx=\tfrac{a^p}{p}\) (ছবিতে নীল)। আবার ওই একই curve-এর বাঁ দিকে, \(y=0\) থেকে \(y=b\) পর্যন্ত ক্ষেত্রফল (inverse function-এর integral) হলো \(\int_0^b y^{1/(p-1)}\,dy=\tfrac{b^q}{q}\) (ছবিতে বালি-রঙা)। এই দুই ক্ষেত্রফল একসাথে সবসময় \(a\times b\) মাপের আয়তক্ষেত্রটিকে ঢেকে ফেলে।
সমতা ঠিক তখনই হয়, যখন \(b=a^{p-1}\), অর্থাৎ বিন্দু \((a,b)\) ঠিক curve-এর উপরে পড়ে — তখন দুই ক্ষেত্রফল হুবহু আয়তক্ষেত্রটিকে টালির মতো ভরে দেয়, কোনো overlap বা ফাঁক থাকে না। ছবিতে ইচ্ছে করে \(a=1.4,\,b=1.3\) নেওয়ায় বিন্দুটি curve-এর সামান্য নিচে, তাই দুই ক্ষেত্রফলের যোগফল আয়তক্ষেত্র ছাড়িয়ে যায় — strict inequality চোখে দেখা যায়।
ছবিটা কীভাবে পড়তে হবে। নীল curve \(y=x^{p-1}\) পুরো সমতলটিকে দুই ভাগে ভাগ করে। নীল shading হলো curve-এর নিচের অংশ (\(x\)-অক্ষ পর্যন্ত), যার মান \(\tfrac{a^p}{p}\); বালি-রঙা shading হলো curve-এর বাঁ অংশ (\(y\)-অক্ষ পর্যন্ত), যার মান \(\tfrac{b^q}{q}\)। লাল আয়তক্ষেত্রটি (\(a\times b\)) এই দুই রঙিন অঞ্চলের ভেতরে সম্পূর্ণ ঢাকা পড়ে যায় — সেটাই \(ab\le \tfrac{a^p}{p}+\tfrac{b^q}{q}\)-এর প্রত্যক্ষ চিত্র। সংখ্যায় যাচাই: এখানে \(\tfrac{a^p}{p}=\tfrac{1.4^3}{3}\approx 0.915\) আর \(\tfrac{b^q}{q}=\tfrac{1.3^{1.5}}{1.5}\approx 0.988\), যাদের যোগফল \(\approx 1.903\), কিন্তু \(ab=1.82\) — ফাঁকটাই strictness।
এই pointwise অসমতাটাকে \(f,g\)-এর মান বসিয়ে integrate করলেই Hölder পাওয়া যায়: \(\lvert f g\rvert\le \tfrac{\lvert f\rvert^p}{p}+\tfrac{\lvert g\rvert^q}{q}\), আর norm দিয়ে normalize করে (\(f\to f/\lVert f\rVert_p\), \(g\to g/\lVert g\rVert_q\)) দুই পাশ integrate করলে \(\lVert fg\rVert_1\le \lVert f\rVert_p\,\lVert g\rVert_q\)। বিশেষ ক্ষেত্রে \(p=q=2\) ধরলে এটিই Cauchy–Schwarz inequality \(\lVert fg\rVert_1\le \lVert f\rVert_2\,\lVert g\rVert_2\) — যেটি statistics-এ correlation coefficient \(\lvert\rho\rvert\le 1\)-এর ভিত্তি।
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
pexp, a, b = 3.0, 1.4, 1.3 # q = pexp/(pexp-1) = 3/2
fig, ax = plt.subplots(figsize=(8.8, 5.0))
xa = np.linspace(0, a, 300) # area under curve = a^p / p
ax.fill_between(xa, 0, xa ** (pexp - 1), color="#5b93bf", alpha=0.55)
yb = np.linspace(0, b, 300) # area left of curve = b^q / q
ax.fill_betweenx(yb, 0, yb ** (1 / (pexp - 1)), color="#f3e2c7", alpha=0.75)
x = np.linspace(0, 1.9, 600)
ax.plot(x, x ** (pexp - 1), color="#1b6ca8", lw=2.8) # y = x^{p-1}
ax.add_patch(Rectangle((0, 0), a, b, fill=False, edgecolor="#c0392b", lw=2.0))
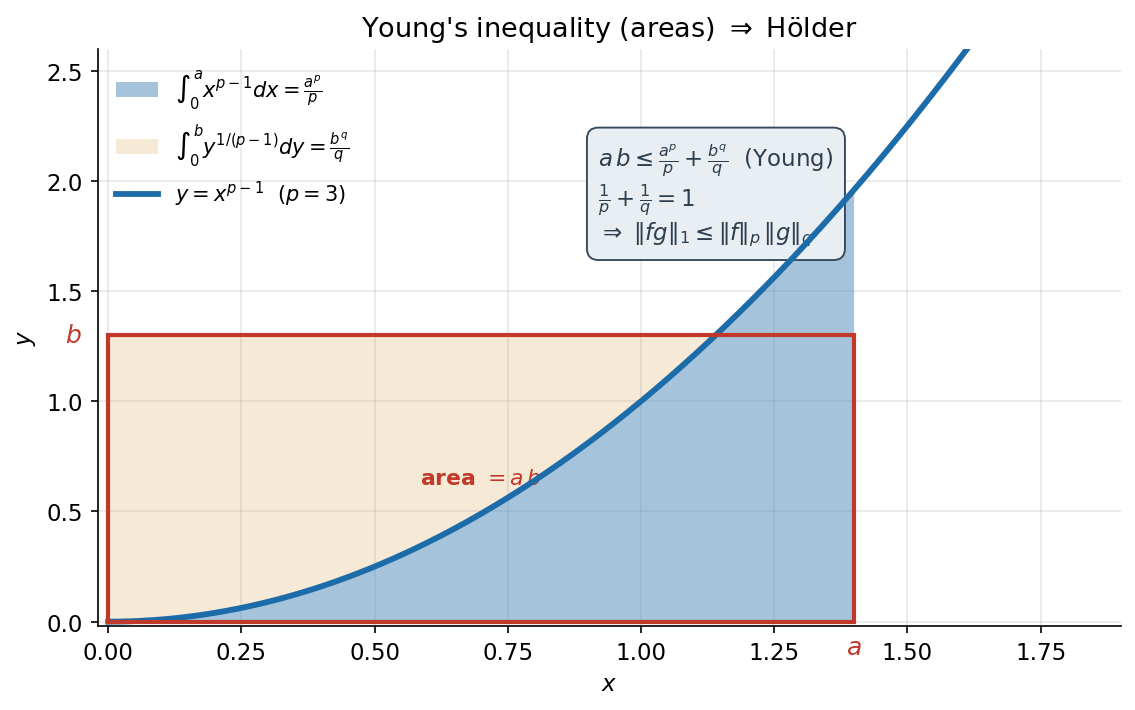
মূল পাঠ: Hölder কোনো জাদু নয় — এটি একটি সাধারণ ক্ষেত্রফলের অসমতা, integrate করলে যা \(L^p\)–\(L^q\) duality-তে রূপ নেয়। এই duality-ই বলে দেয় কেন \(L^p\)-এর dual space হলো \(L^q\) (যেখানে \(1\le p<\infty\)): \(g\in L^q\) প্রতিটি \(f\mapsto\int fg\) রূপের bounded linear functional তৈরি করে, আর তার norm ঠিক \(\lVert g\rVert_q\)।
৬.৩ · Hilbert space-এ projection: নিকটতম বিন্দু¶
তৃতীয় ছবিটি \(L^2\)-এর সবচেয়ে গুরুত্বপূর্ণ জ্যামিতিক সত্যটি দেখায় — Hilbert projection theorem। একটি Hilbert space \(H\)-এ যদি \(M\) একটি closed subspace হয় এবং \(f\in H\) একটি বিন্দু (vector) হয়, তবে \(M\)-এর মধ্যে \(f\)-এর সবচেয়ে কাছের একটি ও কেবল একটিই বিন্দু \(\hat f\) থাকে, এবং তার characterizing বৈশিষ্ট্য হলো: residual \(f-\hat f\) পুরো \(M\)-এর উপর লম্ব (orthogonal),
ছবিতে \(M\)-কে একটি রেখা হিসেবে আঁকা হয়েছে (সমতলে এটি একটি \(1\)-মাত্রিক subspace), বিন্দু \(f\) রেখার বাইরে, আর তার পা-এর লম্ব \(\hat f=P_M f\) ঠিক রেখার উপর। residual vector \(f-\hat f\) dashed দেখানো হয়েছে, আর \(\hat f\) বিন্দুতে একটি right-angle marker বসিয়ে দেখানো হয়েছে যে \(f-\hat f\) সত্যিই \(M\)-এর লম্ব। লক্ষণীয় যে \(f\) থেকে \(M\)-এর অন্য যেকোনো বিন্দুতে পৌঁছাতে গেলে একটি সমকোণী ত্রিভুজের কর্ণ পেরোতে হয় — Pythagoras বলে সেই দূরত্ব সবসময় লম্ব-দূরত্বের চেয়ে বড়, তাই \(\hat f\)-ই নিকটতম।
ছবিটা কীভাবে পড়তে হবে। নীল তীর হলো মূল vector \(f\) (origin থেকে), গাঢ় নীল তীর হলো তার projection \(\hat f=P_M f\) (রেখার উপর), আর dashed লাল তীর হলো residual \(f-\hat f\)। মূল পরীক্ষাটা হলো \(\hat f\)-বিন্দুর ছোট বর্গাকার marker: এটি জানায় residual আর রেখা \(M\)-এর মধ্যে কোণ ঠিক \(90^\circ\)। সংখ্যায় formula হলো \(\hat f=(f\cdot u)\,u\) যেখানে \(u\) হলো \(M\)-এর একক দিক-vector; এতে নিশ্চিতভাবে \((f-\hat f)\cdot u=0\) হয়। এই inner product শূন্য হওয়াটাই "orthogonality" — এবং এটাই গোটা projection ছবির একমাত্র শর্ত যা সব প্রয়োগে অপরিবর্তিত থাকে।
এই একটিমাত্র ছবি statistics-এর দুটি বিশাল ধারণাকে একসূত্রে বাঁধে। প্রথমত, যদি \(M\) হয় কোনো sub-\(\sigma\)-algebra \(\mathcal{G}\)-তে measurable square-integrable function-দের space, তবে \(\hat f\) ঠিক conditional expectation \(\mathbb{E}[f\mid \mathcal{G}]\) — অর্থাৎ conditional expectation মানে \(L^2\)-এ একটি orthogonal projection, আর orthogonality শর্ত \((f-\hat f)\perp M\)-ই হলো tower property ও সব conditioning-নিয়মের উৎস।
দ্বিতীয়ত, যদি \(M\) হয় design matrix \(X\)-এর column space, তবে \(\hat f=X\hat\beta\) হলো least squares fit, residual-এর লম্বতা \(X^\top(y-X\hat\beta)=0\)-ই হলো normal equations, আর fitted value \(\hat y\) হলো \(y\)-এর projection। এক জ্যামিতি, বহু প্রয়োগ — এটাই orthogonality principle।
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import FancyArrowPatch
u = np.array([1.0, 0.42]); u /= np.linalg.norm(u) # direction of subspace M
f = np.array([2.6, 2.55])
fhat = np.dot(f, u) * u # projection P_M f = (f·u) u
fig, ax = plt.subplots(figsize=(8.8, 5.0))
t = np.linspace(-1.2, 4.2, 2); line = np.outer(t, u)
ax.plot(line[:, 0], line[:, 1], color="#2e6f9e", lw=2.6) # the line M
ax.add_patch(FancyArrowPatch((0, 0), f, arrowstyle="-|>", color="#1b6ca8"))
ax.add_patch(FancyArrowPatch((0, 0), fhat, arrowstyle="-|>", color="#16475f"))
ax.add_patch(FancyArrowPatch(fhat, f, arrowstyle="-|>", # residual ⟂ M
color="#c0392b", ls="--"))
ax.set_aspect("equal")
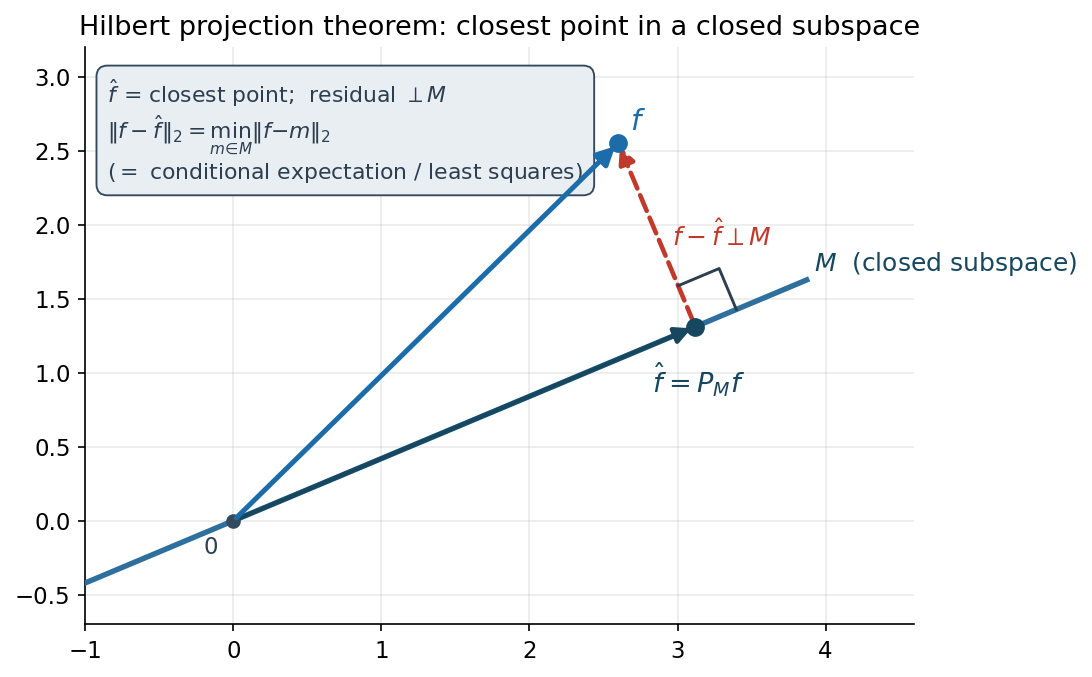
মূল পাঠ: closed subspace-এ নিকটতম বিন্দু = orthogonal projection, এবং residual সবসময় subspace-এর লম্ব। conditional expectation আর least squares — দুটোই এই একই projection-এর মুখোশ পরা চেহারা। closed হওয়াটা অপরিহার্য: subspace বন্ধ না হলে minimum-টি আদৌ অর্জিত নাও হতে পারে।
৬.৪ · Radon–Nikodym derivative: density দিয়ে পুনর্ভার¶
চতুর্থ ছবিটি Radon–Nikodym theorem-এর হৃদয়টা দেখায় — density কাকে বলে। যদি একটি measure \(\nu\) আরেকটি (\(\sigma\)-finite) measure \(\mu\)-এর সাপেক্ষে absolutely continuous হয় (\(\nu\ll\mu\), অর্থাৎ \(\mu(A)=0\) হলেই \(\nu(A)=0\)), তবে এমন একটি অঋণাত্মক measurable function \(f\ge 0\) থাকে যে প্রতিটি measurable set \(A\)-এর জন্য
এই \(f\)-কেই বলা হয় Radon–Nikodym derivative বা density। ছবিতে base measure \(\mu\) হলো length (Lebesgue measure), আর density নেওয়া হয়েছে \(f=e^{-x}\) — exponential distribution-এর density। একটি interval \(A=[a,b]\)-এর নতুন measure \(\nu(A)\) হলো ঠিক curve-এর নিচে, \(A\)-এর উপরে যে ক্ষেত্রফল (ছবিতে সবুজে shaded), অর্থাৎ \(\int_A e^{-x}\,dx\)। অন্তর্নিহিত ভাবনাটি হলো reweighting (পুনর্ভার): base measure-এর প্রতিটি ক্ষুদ্র টুকরো \(d\mu\)-কে \(f\) দিয়ে গুণ করে নতুন measure \(d\nu=f\,d\mu\) বানানো হচ্ছে — যেখানে \(f\) বড়, সেখানে ভর বেশি জমে, যেখানে \(f\) ছোট, সেখানে কম।
ছবিটা কীভাবে পড়তে হবে। অনুভূমিক অক্ষ হলো base space \(\Omega\) (এখানে \([0,\infty)\)-এর একটি অংশ), উল্লম্ব অক্ষ হলো density-র মান \(\tfrac{d\nu}{d\mu}(x)=e^{-x}\)। নিচে লাল দ্বিমুখী তীরটি base set \(A=[a,b]=[1,\,2.5]\) চিহ্নিত করে — এই অংশটুকুর "length" হলো base measure \(\mu(A)=1.5\)। কিন্তু নতুন measure \(\nu(A)\) সেই দৈর্ঘ্য নয়, বরং সবুজ shaded অঞ্চলের ক্ষেত্রফল: \(\nu([1,2.5])=\int_1^{2.5}e^{-x}\,dx=e^{-1}-e^{-2.5}\approx 0.2858\)। লক্ষ করুন density যেখানে নেমে গেছে (ডান দিকে), সেখানে একই দৈর্ঘ্যের set অনেক কম \(\nu\)-ভর পায় — এটাই reweighting-এর দৃশ্যরূপ।
density-টি \(\mu\)-almost-everywhere অর্থে একক (unique): দুটি density যদি একই \(\nu\) দেয়, তবে তারা \(\mu\)-a.e. সমান। derivative-এর সাধারণ calculus-নিয়মগুলোও বজায় থাকে — যেমন chain rule \(\tfrac{d\nu}{d\lambda}=\tfrac{d\nu}{d\mu}\cdot\tfrac{d\mu}{d\lambda}\) (যখন \(\nu\ll\mu\ll\lambda\)), যা importance sampling ও change-of-variable হিসাবের মেরুদণ্ড।
এই একটিমাত্র উপপাদ্য পুরো probability theory-কে concrete করে তোলে: probability density function (pdf) মানেই Lebesgue measure-এর সাপেক্ষে একটি Radon–Nikodym derivative, probability mass function (pmf) মানে counting measure-এর সাপেক্ষে একই জিনিস; likelihood ratio মানে দুই measure-এর derivative-এর অনুপাত \(\tfrac{d\nu}{d\mu}\); আর change of measure (যেমন Girsanov theorem বা importance sampling) মানে এক density দিয়ে আরেক density-তে রূপান্তর। continuous আর discrete distribution-এর কৃত্রিম বিভাজন এখানে মিলিয়ে যায় — দুটোই কেবল ভিন্ন base measure-এর সাপেক্ষে density।
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 5, 800)
f = np.exp(-x) # density f = dν/dμ = e^{-x}
fig, ax = plt.subplots(figsize=(8.8, 5.0))
ax.plot(x, f, color="#1b6ca8", lw=2.8,
label=r"$f=\frac{d\nu}{d\mu}=e^{-x}$")
a0, a1 = 1.0, 2.5 # the set A = [a, b]
xa = np.linspace(a0, a1, 300)
ax.fill_between(xa, 0, np.exp(-xa), color="#cfe2cf", # ν(A) = ∫_A f dμ
label=r"$\nu(A)=\int_A f\,d\mu$")
ax.legend()
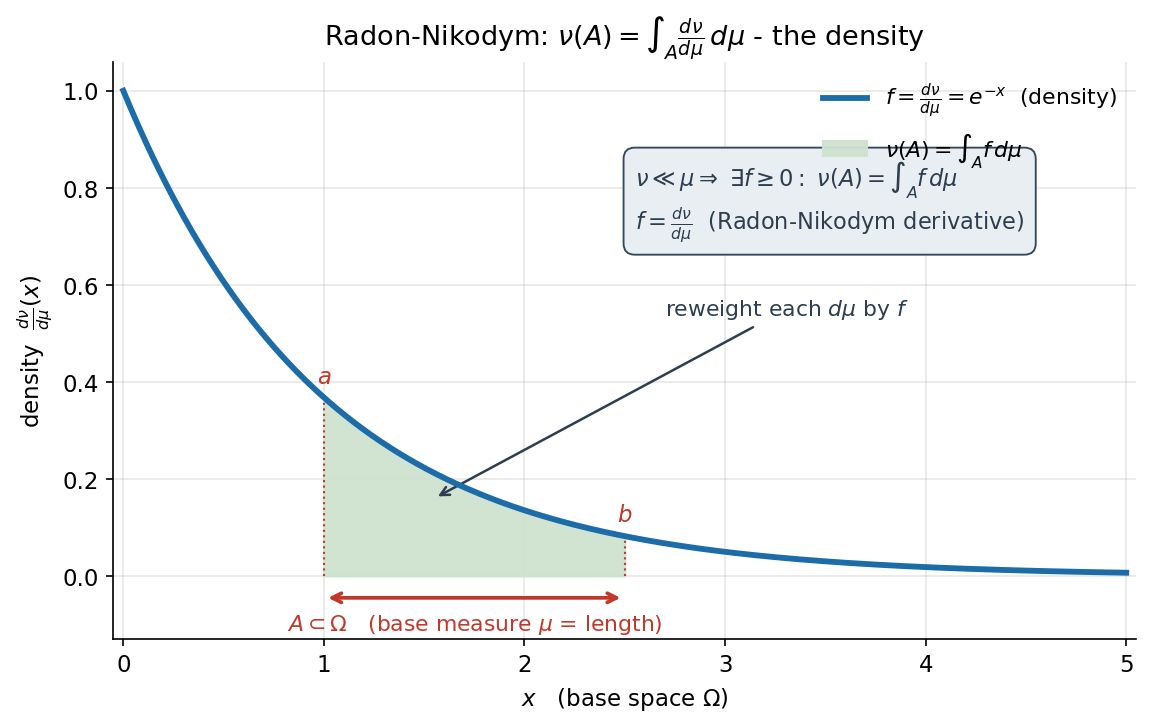
মূল পাঠ: density মানে একটি measure-কে আরেকটির সাপেক্ষে পুনর্ভার করার নিয়ম। \(\nu(A)=\int_A \tfrac{d\nu}{d\mu}\,d\mu\) — এই একটি সূত্রের মধ্যেই pdf, pmf, likelihood, আর change of measure সব লুকিয়ে আছে। absolute continuity (\(\nu\ll\mu\)) শর্তটাই density-র অস্তিত্বের চাবিকাঠি: \(\mu\) যেখানে কোনো ভর দেয় না, \(\nu\)-ও সেখানে নিঃশব্দ থাকতে বাধ্য।
৭ · অনুশীলনী¶
নিচের অনুশীলনীগুলো অধ্যায়ের চারটি স্তম্ভ যাচাই করে: \(L^p\) space ও norm (এর geometry ও \(L^p\subseteq L^q\) inclusion), চার কর্মঘোড়া-অসমতা (Hölder, Minkowski, Jensen, Cauchy–Schwarz), \(L^2\) Hilbert-জ্যামিতি ও projection theorem (নিকটতম বিন্দু, residual ⊥), এবং absolute continuity ও Radon–Nikodym density (\(\nu\ll\mu\Rightarrow\tfrac{d\nu}{d\mu}\))। সমস্যাগুলো চার দলে সাজানো — ক (ধারণাগত), খ (গণনামূলক), গ (প্রমাণভিত্তিক), ঘ (কোডিং)। প্রতিটির শিরোনামে কঠিনতা-চিহ্ন (difficulty tag): ★ মৌলিক, ★★ মাঝারি, ★★★ গভীর। প্রতিটিতে একটি Hint: দেওয়া আছে।
পূর্ণাঙ্গ সমাধান (ধাপে-ধাপে):
_solutions/07-05-lp-spaces-hilbert-radon-nikodym-solutions.md। আগে নিজে চেষ্টা করুন, তারপর মেলান।
প্রসঙ্গত গোটা অংশে \((\Omega,\mathcal F,\mu)\) একটি measure space; \(\lambda\) মানে সংশ্লিষ্ট অন্তরের উপর Lebesgue measure, এবং \([0,1]\)-এর উপর \(\lambda\) একটি probability measure বলে \(\int_0^1(\cdot)\,d\lambda\)-কে নিশ্চিন্তে \(\mathbb E[\cdot]\) (\(X\sim U(0,1)\)) পড়া যায়। inner product \(\langle f,g\rangle=\int fg\,d\mu\), norm \(\lVert f\rVert_p=\big(\int\lvert f\rvert^p\,d\mu\big)^{1/p}\)।
ক · ধারণাগত¶
অনুশীলন ১ (★)¶
একটি probability space-এ (\(\mu(\Omega)=1\)) দেখানো হয় যে \(p\ge q>0\) হলে \(L^p\subseteq L^q\) — অর্থাৎ বড় \(p\)-তে integrable হওয়া কঠিনতর শর্ত, এবং তা ছোট \(q\)-কে আপনিই দেয়। (ক) স্বজ্ঞাগতভাবে ব্যাখ্যা করুন কেন \(\mu(\Omega)=1\) হলে \(\lVert f\rVert_q\le\lVert f\rVert_p\) (\(q\le p\)) — অর্থাৎ norm কেন \(p\)-এর সাথে একঘাতীভাবে বাড়ে। (খ) এর সরাসরি statistics-ফল লিখুন: কেন finite variance (\(L^2\)) থাকলে finite mean (\(L^1\)) আপনিই থাকে, কিন্তু উল্টোটা সবসময় নয়। (গ) কোথায় এই inclusion ভাঙে — একটি শব্দে measure-শর্তটি বলুন।
Hint: মোট-ভর \(1\) হওয়ায় বড় ঘাত বড় মানগুলোকে অসমানুপাতিক বেশি ওজন দেয় (power-mean/Jensen)। heavy-tailed বণ্টনে \(\mathbb E\lvert X\rvert<\infty\) অথচ \(\mathbb E[X^2]=\infty\) সম্ভব। inclusion কেবল finite-measure space-এ; \(\mathbb R\)-এর Lebesgue measure-এ (\(\mu(\mathbb R)=\infty\)) ভাঙে।
অনুশীলন ২ (★★)¶
absolute continuity \(\nu\ll\mu\)-এর সংজ্ঞা হলো "\(\mu(A)=0\Rightarrow\nu(A)=0\)"। (ক) এই সংজ্ঞাটি নিজের ভাষায় লিখুন এবং ব্যাখ্যা করুন কেন এটি Radon–Nikodym theorem-এর জন্য আবশ্যিক — অর্থাৎ density \(f=\tfrac{d\nu}{d\mu}\) থাকলে \(\nu(A)=\int_A f\,d\mu\) থেকে \(\nu\ll\mu\) কেন স্বয়ংক্রিয়ভাবে বেরোয়, তাই \(\nu\ll\mu\) ছাড়া density থাকতেই পারে না। (খ) একটি কংক্রিট ব্যর্থতা দিন: কেন একটি discrete বণ্টন (যেমন point mass \(\delta_0\)) Lebesgue measure \(\lambda\)-এর সাপেক্ষে absolutely continuous নয়, তাই তার \(\lambda\)-density (pdf) থাকে না — কেবল pmf থাকে।
Hint: \(\nu(A)=\int_A f\,d\mu\)-এ যদি \(\mu(A)=0\) হয়, integrand-এর domain measure-শূন্য, তাই integral \(0\) — এই দিকটাই "density ⇒ absolute continuity"। উল্টোদিকে \(\delta_0(\{0\})=1\) অথচ \(\lambda(\{0\})=0\) — null set-এ ভর, তাই \(\delta_0\not\ll\lambda\)।
অনুশীলন ৩ (★★)¶
সব \(L^p\) (\(1\le p<\infty\)) Banach space (complete normed space), কিন্তু কেবল \(L^2\) একটি Hilbert space। (ক) ব্যাখ্যা করুন ঠিক কোন বাড়তি গঠন \(L^2\)-কে অন্য \(L^p\) থেকে আলাদা করে — অর্থাৎ কোন একটি বস্তু \(p=2\)-তেই কেবল norm থেকে স্বাভাবিকভাবে জন্মায়, আর কেন। (খ) সেই গঠন থেকে দুটো জ্যামিতিক ধারণা আসে যা সাধারণ Banach space-এ নেই — সেগুলোর নাম দিন এবং এক বাক্যে projection theorem বিবৃত করুন। (গ) এক বাক্যে বলুন কেন এই projection-ই 7.7-এর conditional expectation-এর জ্যামিতিক ভিত্তি।
Hint: \(\langle f,g\rangle=\int fg\,d\mu\) — inner product (কোণ ও orthogonality), যা \(\lVert f\rVert_2^2=\langle f,f\rangle\) দেয়; অন্য \(p\)-তে এমন bilinear form নেই (parallelogram law মানে না)। projection: closed subspace-এ নিকটতম বিন্দু একক ও বিদ্যমান, residual subspace-এর সাথে orthogonal। \(\mathbb E[X\mid\mathcal G]\) = \(X\)-এর projection \(L^2(\mathcal G)\)-তে।
খ · গণনামূলক¶
অনুশীলন ৪ (★)¶
\([0,1]\)-এর উপর \(f(x)=x\) ধরুন (যেহেতু \(\lambda([0,1])=1\), এটি \(X\sim U(0,1)\))। বদ্ধ-রূপ \(\lVert f\rVert_p=\big(\tfrac{1}{p+1}\big)^{1/p}\) ব্যবহার করে (বা সরাসরি integral কষে) \(\lVert f\rVert_p\) নির্ণয় করুন \(p=1,2,4\)-এর জন্য, এবং \(\lVert f\rVert_\infty\) আলাদা করে বের করুন। চার মান চার-দশমিকে লিখুন এবং পরীক্ষা করুন তারা monotone increasing কিনা। \(p=1\) ও \(p=2\) মান দুটিকে statistics-ভাষায় কী বলে — তাও লিখুন।
Hint: \(\int_0^1 x^p\,dx=\tfrac1{p+1}\)। \(p=1\Rightarrow\tfrac12\) (mean), \(p=2\Rightarrow(1/3)^{1/2}=1/\sqrt3\) (RMS), \(p=4\Rightarrow5^{-1/4}\), \(p=\infty\Rightarrow\operatorname{ess\,sup}\lvert x\rvert=1\)। প্রত্যাশিত: \(0.5,\,0.5774,\,0.6687,\,1.0\)।
অনুশীলন ৫ (★★)¶
\([0,1]\)-এর উপর \(f(x)=x,\ g(x)=x^2\) ধরুন। (ক) Cauchy–Schwarz \(\lvert\langle f,g\rangle\rvert\le\lVert f\rVert_2\lVert g\rVert_2\) সংখ্যায় যাচাই করুন — দুই পক্ষ আলাদা করে কষে দেখান অসমতা কঠোরভাবে (\(<\)) মানে, এবং সমতা না-হওয়ার কারণ এক বাক্যে বলুন। (খ) Jensen (\(\varphi(x)=x^2\)) যাচাই করুন \(X\sim U(0,1)\)-এ — দুই পক্ষ কষে দেখান \((\mathbb E X)^2\le\mathbb E[X^2]\), এবং দেখান অসমতার ফাঁকটা ঠিক \(\operatorname{Var}(X)\)।
Hint: (ক) \(\langle f,g\rangle=\int_0^1 x^3=\tfrac14=0.25\); \(\lVert f\rVert_2\lVert g\rVert_2=\tfrac1{\sqrt3}\cdot\tfrac1{\sqrt5}=\tfrac1{\sqrt{15}}=0.2582\); \(0.25<0.2582\) (\(x,x^2\) linearly independent)। (খ) \((\mathbb E X)^2=\tfrac14=0.25\), \(\mathbb E[X^2]=\tfrac13=0.3333\), ফাঁক \(\tfrac13-\tfrac14=\tfrac1{12}=0.0833=\operatorname{Var}\)।
অনুশীলন ৬ (★★)¶
\(f(x)=x\)-কে \(L^2[0,1]\)-এ ধ্রুবক ফাংশনের subspace \(M=\operatorname{span}\{1\}\)-এ project করুন। (ক) projection-সূত্র \(\hat c=\tfrac{\langle f,1\rangle}{\langle 1,1\rangle}\) ব্যবহার করে best constant \(\hat c\) নির্ণয় করুন এবং দেখান এটি ঠিক \(\mathbb E[X]\)। (খ) residual \(r(x)=f(x)-\hat c\) লিখুন এবং যাচাই করুন \(r\perp 1\) (অর্থাৎ \(\int_0^1 r\,d\lambda=0\))। (গ) সর্বনিম্ন বর্গ-ত্রুটি \(\lVert f-\hat c\rVert_2^2=\min_c\int_0^1(x-c)^2\,dx\) কষুন এবং দেখান এটি ঠিক \(\operatorname{Var}(X)\)।
Hint: \(\hat c=\tfrac{\int_0^1 x\,dx}{\int_0^1 1\,dx}=\tfrac{1/2}{1}=\tfrac12=\mathbb E[X]\)। \(r=x-\tfrac12\), \(\int_0^1(x-\tfrac12)\,dx=\tfrac12-\tfrac12=0\) ✓। \(\min\)-error \(=\tfrac13-\tfrac12+\tfrac14=\tfrac1{12}=\operatorname{Var}(X)\)।
গ · প্রমাণভিত্তিক¶
অনুশীলন ৭ (★★)¶
Young's inequality থেকে Cauchy–Schwarz উৎপাদন করুন। Young বলে ধনাত্মক \(a,b\) ও conjugate exponents \(\tfrac1p+\tfrac1q=1\)-এ \(ab\le\tfrac{a^p}{p}+\tfrac{b^q}{q}\)। (ক) \(p=q=2\) নিয়ে দেখান \(ab\le\tfrac{a^2+b^2}{2}\) (AM–GM)। (খ) এই point-wise অসমতাকে \(\lVert f\rVert_2\lVert g\rVert_2\ne 0\) ধরে normalize-করা \(a=\tfrac{\lvert f\rvert}{\lVert f\rVert_2},\ b=\tfrac{\lvert g\rvert}{\lVert g\rVert_2}\)-এ প্রয়োগ করে integrate করুন, এবং উপসংহারে Cauchy–Schwarz \(\int\lvert fg\rvert\le\lVert f\rVert_2\lVert g\rVert_2\) বের করুন। (গ) সমতা কখন — সংক্ষেপে বলুন।
Hint: \((a-b)^2\ge0\Rightarrow ab\le\tfrac{a^2+b^2}2\)। normalize-করা \(a,b\) বসিয়ে integrate করলে ডান পাশ \(\tfrac12\big(\tfrac{\int f^2}{\lVert f\rVert_2^2}+\tfrac{\int g^2}{\lVert g\rVert_2^2}\big)=\tfrac12(1+1)=1\), বাঁ পাশ \(\tfrac{\int\lvert fg\rvert}{\lVert f\rVert_2\lVert g\rVert_2}\)। সমতা ⇔ \(a=b\) a.e. ⇔ \(\lvert f\rvert,\lvert g\rvert\) সমানুপাতিক (linear dependence)।
অনুশীলন ৮ (★★★)¶
Jensen's inequality প্রমাণ করুন supporting line দিয়ে। ধরুন \(\varphi:\mathbb R\to\mathbb R\) convex এবং \(X\in L^1(\mathbb P)\) একটি random variable, \(m=\mathbb E[X]\)। (ক) convexity থেকে যুক্তি দিন কেন \(m\)-বিন্দুতে একটি supporting line \(\ell(x)=\varphi(m)+s(x-m)\) আছে যা \(\varphi(x)\ge\ell(x)\) সর্বত্র (এখানে \(s\) একটি subgradient)। (খ) উভয় পাশে \(\mathbb E[\cdot]\) নিয়ে দেখান \(\mathbb E[\varphi(X)]\ge\varphi(m)=\varphi(\mathbb E X)\)। (গ) সমতা কখন — এক বাক্যে।
Hint: convex ফাংশনের প্রতিটি বিন্দুতে অন্তত একটি tangent/support line আছে যা পুরো graph-এর নিচে থাকে (← 3.1)। \(\mathbb E[\ell(X)]=\varphi(m)+s(\mathbb E X-m)=\varphi(m)\) যেহেতু \(\mathbb E X-m=0\); আর \(\varphi(X)\ge\ell(X)\)-এ \(\mathbb E\) নিলেই ফল। সমতা ⇔ \(X\) ধ্রুবক a.s. (বা \(\varphi\) সেই span-এ affine)।
অনুশীলন ৯ (★★)¶
Radon–Nikodym derivative-এর a.e.-অনন্যতা প্রমাণ করুন। ধরুন \(f_1,f_2\ge0\) measurable এবং উভয়ই \(\nu(A)=\int_A f_1\,d\mu=\int_A f_2\,d\mu\) সব \(A\in\mathcal F\)-এ (\(\mu\) σ-finite)। প্রমাণ করুন \(f_1=f_2\) \(\mu\)-a.e. (ক) \(A=\{f_1>f_2\}\) নিন (σ-finite-এ finite-measure অংশে সীমাবদ্ধ করে) এবং দেখান \(\int_A(f_1-f_2)\,d\mu=0\)। (খ) integrand \(A\)-তে কঠোর-ধনাত্মক, তাই 7.4-এর ধর্ম ("\(h\ge0,\int h=0\Rightarrow h=0\) a.e.") প্রয়োগ করে \(\mu(A)=0\) সিদ্ধ করুন; symmetric ভাবে \(\{f_2>f_1\}\)-ও measure-শূন্য।
Hint: \(\int_A f_1=\int_A f_2\) থেকে \(\int_A(f_1-f_2)\,d\mu=0\)। \(A\)-তে \(f_1-f_2>0\), তাই অঋণাত্মক integrand-এর integral শূন্য মানে integrand \(=0\) a.e. on \(A\) — কিন্তু সেখানে তা \(>0\), তাই \(\mu(A)=0\)। (σ-finite: \(\Omega=\bigcup\Omega_n\), \(\mu(\Omega_n)<\infty\), প্রতিটিতে আলাদা করে।)
ঘ · কোডিং¶
অনুশীলন ১০ (★)¶
\(\lVert f\rVert_p\) বনাম \(p\) — monotone যাচাই। Python-এ \(f(x)=x\) on \([0,1]\)-এর জন্য analytic মান \(\big(\tfrac{1}{p+1}\big)^{1/p}\) এবং একটি numerical integral (যেমন scipy.integrate.quad-এ \(\int_0^1 x^p\,dx\) তুলে \(1/p\)-ঘাত) দুই-ভাবেই \(p=1,2,3,4,10\)-এর জন্য পাশাপাশি ছাপুন। দেখান উভয় কলাম \(0.5,0.5774,0.63,0.6687,0.7868\)-এর কাছাকাছি এবং \(p\) বাড়লে মান একঘাতীভাবে বাড়ে (এবং \(p\to\infty\) সীমায় \(\lVert f\rVert_\infty=1\)-এর দিকে যায়)।
Hint: norm = (1/(p+1))**(1/p); numerical: val,_ = quad(lambda x: x**p, 0, 1); val**(1/p)। np.diff দিয়ে monotone নিশ্চিত (সব পার্থক্য \(>0\))।
অনুশীলন ১১ (★★)¶
একটি vector-কে subspace-এ project করুন ও residual ⊥ যাচাই করুন। numpy-তে একটি ফাংশনকে \([0,1]\)-এর সূক্ষ্ম grid-এ discretize করে \(L^2\)-projection কষুন: \(f(x)=x\)-কে ধ্রুবক subspace \(\operatorname{span}\{1\}\)-এ project করে দেখান best \(\hat c\approx 0.5=\mathbb E[X]\), এবং residual \(r=f-\hat c\)-এর সাথে \(\mathbf 1\)-এর discrete inner product (\(\langle r,1\rangle=\int_0^1 r\,d\lambda\)) \(\approx 0\)। বাড়তি: একই কোডে \(f\)-কে \(\operatorname{span}\{1,x\}\)-এ project করলে residual \(\approx 0\) (কারণ \(f\) ইতিমধ্যেই subspace-এ) — তা দেখান।
Hint: x=np.linspace(0,1,N); c_hat=np.trapz(f,x)/np.trapz(np.ones_like(x),x); r=f-c_hat; ortho=np.trapz(r*1,x)। \(\hat c\to0.5\), ortho\(\to0\)। দুই-মাত্রিক basis \(\{1,x\}\)-এ Gram-matrix সমাধান বা np.linalg.lstsq ব্যবহার করুন।
অনুশীলন ১২ (★★)¶
Radon–Nikodym density যাচাই + একটি \(L^2\)-norm Monte-Carlo। (ক) \(\tfrac{dP}{d\lambda}(x)=e^{-x}\) on \([0,\infty)\) (Exp(1)) density-টি analytic ও numerical দুই-ভাবে integrate করে দেখান (i) মোট ভর \(\int_0^\infty e^{-x}\,dx=1\) (বৈধ pdf) এবং (ii) \(P([0,1])=\int_0^1 e^{-x}\,dx=1-e^{-1}\approx 0.6321\) — অর্থাৎ density সত্যিই measure পুনর্গঠন করে। (খ) numpy.random.default_rng(20260619) ও \(N=10^6\) নমুনা দিয়ে \(X\sim U(0,1)\)-এর \(\lVert X\rVert_2=\sqrt{\mathbb E[X^2]}\) Monte-Carlo-তে আনুমান করুন এবং দেখান ফল \(\approx 0.5776\) (analytic \(1/\sqrt3=0.5774\))।
Hint: (ক) quad(lambda x: np.exp(-x), 0, np.inf) → 1.0; quad(..., 0, 1) → 1-np.exp(-1)। (খ) rng=np.random.default_rng(20260619); x=rng.uniform(0,1,10**6); est=np.sqrt(np.mean(x**2)) → seed-এ \(0.5776\), analytic \(1/\sqrt3=0.5774\)।
৮ · সারসংক্ষেপ ও সংযোগ¶
এই অধ্যায়ে আমরা 7.4-এর Lebesgue integral-কে আঠা হিসেবে ব্যবহার করে integrable ফাংশনদের একটা জ্যামিতিক জগতে (\(L^p\), \(L^2\)) সাজিয়েছি — যেখানে দৈর্ঘ্য, দূরত্ব, কোণ ও প্রক্ষেপণ অর্থবহ — এবং density-র কঠোর রূপ Radon–Nikodym derivative পেয়েছি।
১. \(L^p\) space ও norm — সসীম-দৈর্ঘ্যের ফাংশন-জগৎ। \(\lVert f\rVert_p=\big(\int\lvert f\rvert^p\,d\mu\big)^{1/p}\) (\(1\le p<\infty\)) ও \(\lVert f\rVert_\infty=\operatorname{ess\,sup}\lvert f\rvert\) একটি ফাংশনের "আকার" মাপে; \(L^p\) হলো সসীম-norm-এর (a.e.-শ্রেণির) ফাংশনদের space। \(\lVert f\rVert_p=0\iff f=0\) a.e. — তাই \(L^p\) আসলে a.e.-সমতা-শ্রেণির space। canonical: \(f(x)=x\) on \([0,1]\)-এ \(\lVert f\rVert_p=(1/(p+1))^{1/p}\) দিল \(p=1,2,3,4,10,\infty\to 0.5,\,0.5774,\,0.63,\,0.6687,\,0.7868,\,1.0\) — monotone increasing in \(p\), তাই probability space-এ \(p\ge q\Rightarrow L^p\subseteq L^q\) (finite variance ⇒ finite mean, উল্টোটা নয়)।
২. চার কর্মঘোড়া-অসমতা। Hölder \(\int\lvert fg\rvert\le\lVert f\rVert_p\lVert g\rVert_q\) (\(\tfrac1p+\tfrac1q=1\), Young থেকে); Minkowski \(\lVert f+g\rVert_p\le\lVert f\rVert_p+\lVert g\rVert_p\) (ত্রিভুজ-অসমতা — যা \(\lVert\cdot\rVert_p\)-কে প্রকৃত norm বানায়, Hölder থেকে উৎপাদিত); Jensen \(\varphi(\mathbb E X)\le\mathbb E[\varphi(X)]\) (\(\varphi\) convex — supporting line থেকে, ← 3.1); Cauchy–Schwarz \(\lvert\langle f,g\rangle\rvert\le\lVert f\rVert_2\lVert g\rVert_2\) (\(p=q=2\))। canonical: \(f=x,g=x^2\)-এ Cauchy–Schwarz \(0.25\le 0.2582=1/\sqrt{15}\) (কঠোর); Jensen (\(x^2\)) ফাঁক \(=\operatorname{Var}=\tfrac1{12}=0.0833\) — তাই "\(x^2\)-এ Jensen" \(\Leftrightarrow\) "\(\operatorname{Var}\ge0\)"।
৩. completeness ও \(L^2\) Hilbert-জ্যামিতি। Riesz–Fischer theorem: প্রতিটি \(L^p\) complete (Cauchy অনুক্রম মাত্রই অভিসারী) ⇒ একটি Banach space। আর \(p=2\)-তে বাড়তি উপহার — inner product \(\langle f,g\rangle=\int fg\,d\mu\), যা \(L^2\)-কে একটি Hilbert space বানায়। তার মুকুটমণি projection theorem: যেকোনো closed subspace-এ একটি বিন্দুর নিকটতম প্রতিরূপ একক ও বিদ্যমান, residual subspace-এর সাথে orthogonal। canonical: \(f(x)=x\)-কে \(\operatorname{span}\{1\}\)-এ project ⇒ best \(c=\langle x,1\rangle/\langle1,1\rangle=0.5=\mathbb E[X]\), residual \(x-\tfrac12\perp1\), min-error \(=\operatorname{Var}=\tfrac1{12}\)।
৪. Radon–Nikodym ও কঠোর density। \(\nu\ll\mu\) (absolute continuity: \(\mu(A)=0\Rightarrow\nu(A)=0\)) এবং σ-finite হলে Radon–Nikodym theorem একটি অঋণাত্মক density \(f=\tfrac{d\nu}{d\mu}\) দেয় (a.e.-অনন্য) যাতে \(\nu(A)=\int_A f\,d\mu\)। এটাই pdf-এর কঠোর রূপ \(f_X=\tfrac{dP_X}{d\lambda}\) ও likelihood ratio \(\tfrac{dP}{dQ}\)-এর ভিত্তি; সঙ্গে Lebesgue decomposition \(\nu=\nu_{ac}+\nu_{sing}\)। canonical: \(\tfrac{dP}{d\lambda}=e^{-x}\) (Exp(1))-এ মোট ভর \(1\) (বৈধ pdf), \(P([0,1])=1-e^{-1}=0.6321\); \(L^2\)-norm Monte-Carlo \(\lVert X\rVert_2=0.5776\) (\(X\sim U(0,1)\), seed 20260619)।
মূল সংজ্ঞা/উপপাদ্য (mini-list)। - \(L^p\) norm / space: \(\lVert f\rVert_p=(\int\lvert f\rvert^p\,d\mu)^{1/p}\); \(L^p=\{f:\lVert f\rVert_p<\infty\}\) (a.e.-শ্রেণি); \(\lVert f\rVert_\infty=\operatorname{ess\,sup}\lvert f\rvert\)। - Hölder: \(\int\lvert fg\rvert\,d\mu\le\lVert f\rVert_p\lVert g\rVert_q\), \(\tfrac1p+\tfrac1q=1\)। - Minkowski: \(\lVert f+g\rVert_p\le\lVert f\rVert_p+\lVert g\rVert_p\) (\(\Rightarrow\lVert\cdot\rVert_p\) একটি norm)। - Jensen: \(\varphi\) convex \(\Rightarrow\varphi(\mathbb E X)\le\mathbb E[\varphi(X)]\)। - Cauchy–Schwarz: \(\lvert\langle f,g\rangle\rvert\le\lVert f\rVert_2\lVert g\rVert_2\) (\(p=q=2\))। - Riesz–Fischer: \(L^p\) complete \(\Rightarrow\) Banach space; \(L^2\) inner-product \(\Rightarrow\) Hilbert space। - projection theorem: closed subspace \(M\)-এ নিকটতম \(\hat f\) একক; \(f-\hat f\perp M\)। - absolute continuity: \(\nu\ll\mu\iff(\mu(A)=0\Rightarrow\nu(A)=0)\)। - Radon–Nikodym: \(\nu\ll\mu\), σ-finite \(\Rightarrow\exists\,f=\tfrac{d\nu}{d\mu}\ge0\) (a.e.-অনন্য), \(\nu(A)=\int_A f\,d\mu\)। - Lebesgue decomposition: \(\nu=\nu_{ac}+\nu_{sing}\) (\(\nu_{ac}\ll\mu\), \(\nu_{sing}\perp\mu\))।
পেছনের সংযোগ: - ← 7.4 (Lebesgue integral ও \(L^1\)): \(L^1\)-কে সাধারণীকরণ করে \(L^p\); integral-এর linearity/monotonicity/triangle (\(\lvert\int f\rvert\le\int\lvert f\rvert\)) চার অসমতার প্রতিটি ধাপে, এবং MCT/DCT Riesz–Fischer ও Radon–Nikodym-এর প্রমাণে। - ← 3.1 (Markov, Chebyshev, Jensen): সেখানকার elementary Jensen ও Cauchy–Schwarz এখানে সাধারণ measure space-এ integral-ভাষায় ও পূর্ণ \(L^p\)-কাঠামোয় পুনঃপ্রতিষ্ঠিত (supporting-line যুক্তি একই)। - ← 2.5 (Expectation, variance, moments): \(\lVert X\rVert_2^2=\mathbb E[X^2]\), আর কেন্দ্রিত হলে variance = squared distance from mean — Jensen ফাঁক ও projection min-error দুই-ই variance-এ নামে।
সামনের সংযোগ: - → 7.7 (Conditional expectation): \(\mathbb E[X\mid\mathcal G]\) = \(X\)-এর \(L^2\)-projection \(L^2(\mathcal G)\)-তে (নিকটতম প্রতিরূপ, residual ⊥), এবং তার সাধারণ (non-\(L^2\)) অস্তিত্ব Radon–Nikodym derivative থেকে — দুই মুকুটমণিই সেখানে একসাথে কাজে লাগে। - → 7.9 (\(L^2\)-bounded martingale): \(L^2\)-জ্যামিতি ও orthogonality-র উপর দাঁড়িয়ে martingale-convergence; orthogonal increment-এর Pythagoras।
উৎস: Klenke, Probability Theory: A Comprehensive Course, অধ্যায় ৭ (\(L^p\) spaces, inequalities, Hilbert space, Radon–Nikodym) — \(L^p\)-norm ও Riesz–Fischer completeness, Hölder/Minkowski/Jensen, \(L^2\)-projection theorem, এবং absolute continuity ও Radon–Nikodym (σ-finite) সহ Lebesgue decomposition-এর আদর্শ উপস্থাপনা।
এক বাক্যে: 7.4-এর integral integrable ফাংশনদের একটা জ্যামিতিক জগতে তোলে — \(L^p\) (Banach) ও \(L^2\) (Hilbert, projection theorem), চার অসমতা (Hölder/Minkowski/Jensen/Cauchy–Schwarz) দিয়ে সেই geometry আঁটা থাকে, আর Radon–Nikodym derivative \(\tfrac{d\nu}{d\mu}\) density-কে কঠোর রূপ দেয় — যা সরাসরি 7.7-এর conditional expectation (\(L^2\)-projection / RN-derivative)