7.6 — Independence, Kolmogorov 0–1 Law ও Strong Law of Large Numbers (স্বাধীনতার গভীর ফল)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
১.১ যেখানে আমরা দাঁড়িয়ে — সব পরিসংখ্যানের নিচে একটাই অনুমান: স্বাধীনতা¶
প্রায় সমগ্র পরিসংখ্যান যে একটা নীরব অনুমানের উপর দাঁড়িয়ে আছে, সেটি হলো independence (স্বাধীনতা)। যখন আমরা বলি "\(X_1,\dots,X_n\) একটা iid নমুনা" — independent and identically distributed — তখন আমরা ধরে নিচ্ছি প্রতিটি observation আগেরগুলোর কোনো ছাপ বহন করে না: একটা coin-এর আগের toss পরের toss-কে প্রভাবিত করে না, একজন উত্তরদাতার মত পরের জনের থেকে আলাদা ও অসংলগ্ন। এই একটিমাত্র কাঠামোগত অনুমানের উপরেই দাঁড়িয়ে আছে law of large numbers (গড় সত্যিকারের mean-এর দিকে যায়), central limit theorem (যোগফল bell-curve-আকার নেয়), maximum likelihood (likelihood একটা গুণফল \(\prod f(x_i)\)-তে ভাঙে), bootstrap, hypothesis testing — কার্যত যা-কিছু আমরা data থেকে শিখি।
2.2-এ আমরা এই স্বাধীনতার সাথে প্রথম পরিচিত হয়েছিলাম — কিন্তু স্বজ্ঞাগতভাবে, ঘটনার ভাষায়: দুটো ঘটনা \(A,B\) স্বাধীন যদি \(\mathbb P(A\cap B)=\mathbb P(A)\,\mathbb P(B)\) — অর্থাৎ একটার ঘটা অন্যটার সম্ভাবনা বদলায় না। সেখান থেকে iid random variable-এর ধারণাটাকে কাজ চালানোর মতো করে ধরে নিয়েছিলাম, কিন্তু কয়েকটা গভীর প্রশ্ন অমীমাংসিত রেখে: "দুটো random variable স্বাধীন" — এর কঠোর মানে কী, যখন তারা continuous এবং অসংখ্য মান নিতে পারে? "একটা অসীম অনুক্রম \(X_1,X_2,\dots\) সবাই-পরস্পর-স্বাধীন" — এটা কীভাবে আঁটোসাঁটোভাবে সংজ্ঞায়িত করব? আর সবচেয়ে আকর্ষণীয়: এই স্বাধীনতা থেকে কি কোনো চমকপ্রদ ফল বেরোয় — যা স্বজ্ঞা একা দিতে পারত না?
এই অধ্যায়ের কাজ ঠিক সেটাই: Part VII-এ গড়া measure-তাত্ত্বিক ভিত্তির (σ-algebra, random variable, integral) উপর দাঁড়িয়ে স্বাধীনতাকে কঠোর করা — শুধু ঘটনার নয়, σ-algebra ও random variable-এর স্বাধীনতা — এবং তারপর সেই কঠোর সংজ্ঞা থেকে এমন তিনটে গভীর ফল ফসল তোলা যা পরিসংখ্যানের ভিত্তি ধরে রাখে।
এক বাক্যে সূচনা। 2.2 দিয়েছিল ঘটনার স্বাধীনতা (\(\mathbb P(A\cap B)=\mathbb P(A)\mathbb P(B)\)) ও iid-এর স্বজ্ঞা; এই অধ্যায় তাকে σ-algebra ও random variable-এর জন্য কঠোর করে এবং তার থেকে তিন গভীর ফল তোলে — Borel–Cantelli, Kolmogorov 0–1 law, ও কঠোর SLLN (\(\bar X_n\to\mu\) almost surely)।
১.২ কেন স্বাধীনতাকে কঠোর করতে হবে — σ-algebra-র ভাষাই কেন ঠিক ভাষা¶
2.2-এর ঘটনা-ভিত্তিক সংজ্ঞা কাজ চালায়, কিন্তু random variable-এ পৌঁছালে সে অপ্রতুল হয়ে পড়ে। "\(X\) ও \(Y\) স্বাধীন" বলতে আমরা চাই — \(X\)-সম্পর্কে যেকোনো প্রশ্ন আর \(Y\)-সম্পর্কে যেকোনো প্রশ্ন পরস্পর-স্বাধীন: \(\{X\in B\}\) আর \(\{Y\in C\}\) স্বাধীন হোক সব Borel set \(B,C\)-র জন্য, শুধু \(\{X\le x\}\)-জাতীয় নয়। কিন্তু "\(X\)-সম্পর্কে সব প্রশ্ন"-এর সংগ্রহ তো ঠিক একটা বস্তু যা আমরা 7.3-এ চিনেছি — generated σ-algebra \(\sigma(X)=\{X^{-1}(B):B\in\mathcal B\}\), \(X\) যত তথ্য বহন করে তার সম্পূর্ণ ভাণ্ডার। তাই স্বাধীনতার স্বাভাবিক, পূর্ণ-সাধারণ রূপ ঘটনা নিয়ে নয়, σ-algebra নিয়ে: \(\sigma(X)\) ও \(\sigma(Y)\) যেন "তথ্য হিসেবে" পরস্পর-অসংলগ্ন।
এই σ-algebra-ভাষার তিনটে সিদ্ধান্তকারী সুবিধা, যা পুরো অধ্যায়কে সম্ভব করে:
- এক ছাতার নিচে সব। "ঘটনা স্বাধীন", "random variable স্বাধীন", "random vector স্বাধীন", এমনকি "একটা গোটা প্রক্রিয়ার অতীত ও ভবিষ্যৎ স্বাধীন" — সব এক সংজ্ঞায় ধরা পড়ে: কতগুলো σ-algebra স্বাধীন কিনা। ঘটনা \(A\) ⟷ σ-algebra \(\{\emptyset,A,A^c,\Omega\}\); random variable \(X\) ⟷ \(\sigma(X)\) — তাই আলাদা সংজ্ঞার দরকার নেই।
- π-system criterion — যাচাই সহজ হয়। σ-algebra বিশাল (অসংখ্য set), তাই সরাসরি সব \(A_i\in\mathcal F_i\)-তে \(\mathbb P(\bigcap A_i)=\prod\mathbb P(A_i)\) যাচাই অসম্ভব মনে হয়। কিন্তু 7.2-এর π–λ theorem একটা অলৌকিক সংক্ষিপ্তকরণ দেয়: একটা generating π-system-এ (যেমন \(\{X\le x\}\)-জাতীয় ঘটনা, যা \(\cap\)-এ বদ্ধ এবং \(\sigma(X)\) জন্ম দেয়) স্বাধীনতা মিললেই তা পুরো σ-algebra-য় ছড়িয়ে পড়ে। তাই random variable-এর স্বাধীনতা যাচাই করতে শুধু CDF-স্তরে — \(\mathbb P(X\le x,Y\le y)=F_X(x)F_Y(y)\) — দেখলেই চলে।
- tail σ-algebra সম্ভব হয়। σ-algebra-র ভাষাই আমাদের "asymptotic তথ্য"-কে একটা বস্তু হিসেবে ধরতে দেয় — \(\mathcal T=\bigcap_n\sigma(X_n,X_{n+1},\dots)\), যে তথ্য সসীম-সংখ্যক \(X_i\) ভুলে গেলেও অটুট। এই tail σ-algebra ছাড়া Kolmogorov 0–1 law বিবৃতই করা যায় না।
মোদ্দা কথা: σ-algebra হলো "তথ্য"-এর সঠিক গাণিতিক একক, আর স্বাধীনতা মূলত তথ্যের অসংলগ্নতা। তাই স্বাধীনতাকে σ-algebra-র ভাষায় বলা মানে তাকে তার স্বাভাবিক, সবচেয়ে শক্তিশালী রূপে বলা।
এক বাক্যে কেন কঠোর। "\(X\) স্বাধীন" মানে \(X\)-এর সব তথ্য (= \(\sigma(X)\)) অন্যের সব তথ্য থেকে অসংলগ্ন, তাই স্বাধীনতার সঠিক ভাষা ঘটনা নয় σ-algebra; এর তিন পুরস্কার — সব-ধরনের স্বাধীনতা এক ছাতায়, π-system criterion-এ সহজ যাচাই (CDF-স্তরেই), আর tail σ-algebra ও 0–1 law সম্ভব হওয়া।
১.৩ এই অধ্যায়ের তিন প্রাপ্তি — Borel–Cantelli, 0–1 law, ও কঠোর SLLN¶
কঠোর স্বাধীনতা একবার হাতে এলে তা থেকে তিনটে গভীর ফল ফসল ওঠে — এই অধ্যায়ের আসল পুরস্কার, এবং একে অপরের সিঁড়ি।
-
প্রাপ্তি ১ — Borel–Cantelli lemma: অসীম-বার কখন ঘটে? একটা অসীম অনুক্রম ঘটনা \(A_1,A_2,\dots\) — তাদের মধ্যে অসীম-সংখ্যক ঘটবে কিনা (\(A_n\) "infinitely often", সংক্ষেপে i.o.) — এই asymptotic প্রশ্নের আশ্চর্য-সরল উত্তর দেয় দুই Borel–Cantelli lemma। BC-I: যদি সম্ভাবনার যোগফল \(\sum_n\mathbb P(A_n)\) অভিসারী হয়, তবে \(\mathbb P(A_n\text{ i.o.})=0\) — অসীম-বার ঘটার সম্ভাবনা শূন্য, এবং এর জন্য কোনো স্বাধীনতা লাগে না। BC-II: যদি \(A_n\)-গুলো স্বাধীন হয় এবং \(\sum_n\mathbb P(A_n)\) অপসারী হয়, তবে উল্টোটা — \(\mathbb P(A_n\text{ i.o.})=1\), প্রায় নিশ্চিতভাবে অসীম-বার ঘটে। দুইয়ে মিলে স্বাধীন ঘটনার জন্য একটা পরিষ্কার শূন্য-এক বিভাজন: \(\sum\mathbb P(A_n)\) অভিসারী হলে i.o.-সম্ভাবনা \(0\), অপসারী হলে \(1\) — মাঝামাঝি কিছু নেই।
-
প্রাপ্তি ২ — Kolmogorov 0–1 law: tail event দৈবহীন। এবার একটা চমকপ্রদ ফল। কিছু ঘটনা প্রকৃতিগতভাবে asymptotic — সসীম-সংখ্যক \(X_i\)-র মান বদলালেও তাদের সত্য-মিথ্যা বদলায় না; যেমন "\(\sum_n X_n\) অভিসারী হয় কিনা", বা "\(\limsup_n\bar X_n>c\) কিনা" — প্রথম দশ-হাজার পদ বদলে দিলেও উত্তর একই। এদের বলে tail event, আর তাদের সংগ্রহ tail σ-algebra \(\mathcal T=\bigcap_n\sigma(X_n,X_{n+1},\dots)\)। Kolmogorov 0–1 law বলে: যদি \(X_n\)-গুলো স্বাধীন হয়, তবে প্রতিটি tail event-এর সম্ভাবনা হয় ঠিক \(0\), নয় ঠিক \(1\) — কখনো \(0.5\) নয়! অর্থাৎ যেকোনো সত্যিকারের asymptotic প্রশ্নের উত্তর পূর্বনির্ধারিত (deterministic), দৈবতা সম্পূর্ণ নিঃশেষিত; সমতুল্যভাবে, প্রতিটি tail random variable (যেমন \(\limsup\bar X_n\)) almost surely একটা ধ্রুবক। এটিই বলে দেয় কেন SLLN-এ সীমাটা একটা নির্দিষ্ট সংখ্যা (\(\mu\)) হওয়াই স্বাভাবিক।
-
প্রাপ্তি ৩ — মুকুটমণি: কঠোর SLLN। এই অধ্যায়ের শিরোমণি। 3.3-এ আমরা weak law পেয়েছিলাম — \(\bar X_n\xrightarrow{P}\mu\), অর্থাৎ গড় mean-এর কাছে থাকার সম্ভাবনা \(1\)-এর দিকে যায়, কিন্তু কোনো একটা নির্দিষ্ট নমুনা-পথ নিজে অভিসারী হবে তার নিশ্চয়তা ছিল না। Strong law (SLLN) এই নিশ্চয়তাই দেয়: $$ X_1,X_2,\dots\ \text{iid},\quad \mathbb E\lvert X\rvert<\infty \quad\Longrightarrow\quad \bar X_n=\frac1n\sum_{i=1}^n X_i\ \xrightarrow{\ \text{a.s.}\ }\ \mu=\mathbb E[X]. $$ মানে — প্রায় প্রতিটি নমুনা-পথ (probability-\(1\) একটা set-এ) সত্যিকারভাবে \(\mu\)-তে গিয়ে পৌঁছায় ও সেখানে থেকে যায়, ফেরত আসে না। আর hypothesis-টা চমকপ্রদভাবে দুর্বল: variance লাগে না, শুধু \(\mathbb E\lvert X\rvert<\infty\) (\(X\in L^1\)) — first moment থাকলেই যথেষ্ট। এটি 3.3-এর convergence-in-probability-কে almost-sure convergence-এ উন্নীত করে, পরিসংখ্যানের সবচেয়ে মৌলিক প্রতিশ্রুতি — "যথেষ্ট data নিলে গড় সত্যিকারের mean-ই দেয়" — কে তার কঠোরতম রূপে প্রতিষ্ঠা করে।
এক বাক্যে প্রাপ্তি। তিন উপহার — Borel–Cantelli (I: \(\sum\mathbb P(A_n)<\infty\Rightarrow\) i.o. সম্ভাবনা \(0\), স্বাধীনতা ছাড়া; II: স্বাধীন ও \(\sum\mathbb P(A_n)=\infty\Rightarrow\) i.o. সম্ভাবনা \(1\) — শূন্য-এক বিভাজন); Kolmogorov 0–1 law (স্বাধীন \(X_n\)-এ প্রতিটি tail event \(0\) বা \(1\), tail RV a.s. ধ্রুবক); আর কঠোর SLLN (\(\mathbb E\lvert X\rvert<\infty\Rightarrow\bar X_n\to\mu\) a.s., variance ছাড়াই) — 3.3-এর weak law-এর a.s.-উন্নয়ন।
১.৪ "গড় সত্যিই অভিসারী হয়, almost surely" — 3.3-এর প্রতিশ্রুতি কেন এবার পূর্ণ¶
এই অধ্যায়ের কেন্দ্রীয় উন্নয়নটা — weak থেকে strong — কেন এত গুরুত্বপূর্ণ, তা একটা ছবিতে ধরা যাক। কল্পনা করো অসংখ্য সমান্তরাল-জগৎ, প্রতিটিতে একই পরীক্ষা অসীম-বার চলছে: জগৎ \(\omega\)-তে নমুনা \(X_1(\omega),X_2(\omega),\dots\) এবং তাদের চলমান গড়ের একটা পথ \(n\mapsto\bar X_n(\omega)\)।
- 3.3-এর weak law যা বলেছিল। একটা নির্দিষ্ট বড় \(n\)-এ তাকালে, অধিকাংশ জগতে \(\bar X_n\) \(\mu\)-র কাছে — অর্থাৎ \(\mathbb P(\lvert\bar X_n-\mu\rvert>\varepsilon)\to 0\)। কিন্তু এটি প্রতিটি জগতের পথ নিয়ে কিছু বলে না: হতে পারত যে প্রতিটি জগৎই অসীম-বার \(\mu\) থেকে দূরে ছিটকে যায় (যদিও প্রতি মুহূর্তে দূরে-থাকা জগতের ভগ্নাংশ ছোট হয়ে আসে) — তখনও weak law সত্য থাকত, অথচ কোনো একটা পথ "অভিসারী" বলা যেত না। convergence-in-probability পথ সম্পর্কে নীরব।
- SLLN যা বলে — অনেক বেশি। SLLN প্রতিটি জগতের গোটা পথের ভবিষ্যৎ নিয়ে কথা বলে: প্রায় প্রতিটি জগতে (\(\omega\)-set-এর probability \(1\)) পথ \(\bar X_n(\omega)\) একটা সাধারণ অনুক্রম হিসেবে \(\mu\)-তে অভিসারী — একটা মুহূর্ত থেকে চিরকালের জন্য \(\mu\)-র যত-কাছে-চাও তত-কাছে থেকে যায়, আর কখনো বড় বিচ্যুতিতে ফেরে না। অর্থাৎ "ছিটকে দূরে যাওয়া" শুধু কমে না, একসময় সম্পূর্ণ থেমে যায় (প্রায় নিশ্চিতভাবে)।
এই পার্থক্যই almost-sure convergence-কে strictly শক্তিশালী করে: a.s. ⇒ in probability, কিন্তু উল্টোটা নয়। বাস্তব পরিসংখ্যানে এটিই সেই গভীর আশ্বাস — যখন তুমি একটামাত্র জগতে (তোমার একটামাত্র দীর্ঘ data-সংগ্রহে) বাস করো, SLLN বলে যে এই পথটাই (probability \(1\)) সত্যিকারের mean-এ পৌঁছাবে, শুধু "ভাগ্য ভালো থাকলে অধিকাংশ ক্ষেত্রে" নয়। আর Borel–Cantelli ও 0–1 law হলো ঠিক সেই যন্ত্র যা এই a.s.-বিবৃতি প্রমাণ করতে লাগে — কারণ "অসীম-বার বড় বিচ্যুতি ঘটে কিনা" (\(\{\lvert\bar X_n-\mu\rvert>\varepsilon\ \text{i.o.}\}\)) একটা i.o.-প্রশ্ন, আর "\(\bar X_n\) অভিসারী" একটা tail-event।
এক বাক্যে উন্নয়ন। 3.3-এর weak law বলত "প্রতিটি বড় \(n\)-এ অধিকাংশ পথ \(\mu\)-র কাছে", কিন্তু SLLN বলে "প্রায় প্রতিটি পথ একসময় চিরতরে \(\mu\)-তে গুটিয়ে আসে" — এই পথ-ভিত্তিক, almost-sure নিশ্চয়তাই (a.s. ⇒ in probability, উল্টোটা নয়) পরিসংখ্যানের আসল আশ্বাস, আর তা প্রমাণে লাগে Borel–Cantelli ও 0–1 law।
১.৫ এই অধ্যায়ের পথরেখা¶
- §২ সব মূল বস্তুর precise সংজ্ঞা ও বিবৃতি — স্বাধীনতা (ঘটনা / σ-algebra / random variable, সসীম ও যথেচ্ছ পরিবার — ২.১–২.২) ও π-system criterion এবং iid ⇔ product (২.৩); \(\limsup A_n=\{A_n\text{ i.o.}\}\) (২.৪); Borel–Cantelli I ও II-এর বিবৃতি (২.৫); tail σ-algebra \(\mathcal T\) ও tail event-উদাহরণ (২.৬); Kolmogorov 0–1 law (২.৭); Kolmogorov maximal inequality ও three-series theorem-এর বিবৃতি (২.৮); এবং কঠোর SLLN ও Cauchy-necessity (২.৯)। ভারী প্রমাণ §৪-এ স্থগিত, স্পষ্ট forward pointer সহ।
- §৪ ভারী প্রমাণ — π-system criterion (π–λ theorem, 7.2 থেকে); BC-I (MCT দিয়ে \(\mathbb E[\sum_n\mathbf 1_{A_n}]=\sum_n\mathbb P(A_n)<\infty\Rightarrow\sum\mathbf 1_{A_n}<\infty\) a.s.); BC-II (স্বাধীনতা ও \(1-x\le e^{-x}\) দিয়ে \(\mathbb P(\bigcap_{n\ge N}A_n^c)=0\)); Kolmogorov 0–1 law (\(\mathcal T\) নিজে নিজের সাথে স্বাধীন, তাই \(\mathbb P(T)=\mathbb P(T)^2\)); Kolmogorov maximal inequality ও তা দিয়ে SLLN-এর প্রমাণ (Etemadi-র truncation \(X_k\mathbf 1_{\{\lvert X_k\rvert\le k\}}\) + subsequence + monotonicity যুক্তি), সঙ্গে Cauchy-necessity (BC-II দিয়ে \(\lvert X_n\rvert>n\) i.o.)।
- §৫–৬ simulation ও চিত্র (seed 20260619) — 7-6-slln-paths (একাধিক চলমান-গড় পথ \(\bar X_n\) কীভাবে \(n\) বাড়লে ঘন হয়ে \(\mu\)-র চারপাশে গুটিয়ে আসে — a.s.-অভিসারণ চোখে দেখা), 7-6-borel-cantelli (স্বাধীন \(A_n\)-এ \(\mathbb P(A_n)=1/n\) বনাম \(1/n^2\) — divergent-এ i.o. ঘটে, convergent-এ থেমে যায়), 7-6-cauchy-no-slln (standard Cauchy নমুনায় \(\bar X_n\) স্থির না হয়ে বুনোভাবে দোলে — \(\mathbb E\lvert X\rvert=\infty\), SLLN ভাঙা), এবং 7-6-tail-01-law (একটা tail-জাতীয় ঘটনার empirical সম্ভাবনা বহু run-এ \(0\) বা \(1\)-এর দিকে জমাট বাঁধে)।
এর পরে Part VII এগোয়: 7.8 filtration ও martingale — যেখানে স্বাধীনতার শিথিল রূপ (martingale difference) আসে; 7.9 martingale convergence theorem, যা SLLN-কে দ্বিতীয়, আরও গভীর পথে প্রমাণ করে; এবং 7.10 — স্বাধীন যোগফলের সূক্ষ্মতর আচরণ, rigorous central limit theorem-এর দিকে।
এক বাক্যে পথরেখা। §২ সংজ্ঞা ও বিবৃতি (স্বাধীনতা + π-system criterion + \(\limsup A_n\) + Borel–Cantelli I/II + tail σ-algebra + 0–1 law + SLLN) → §৪ প্রমাণ (π–λ criterion, BC via MCT ও \(1-x\le e^{-x}\), 0–1 law via self-independence, Etemadi-র SLLN) → §৫–৬ চার চিত্র (seed 20260619); আর এই স্বাধীনতা-ভিত্তির উপর Part VII গড়ে 7.8 (martingale) → 7.9 (martingale convergence, SLLN-এর দ্বিতীয় প্রমাণ) → 7.10 (rigorous CLT)।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে এ অধ্যায়ের সব formal বস্তুর precise সংজ্ঞা ও বিবৃতি দিই — প্রতিটি প্রতীক প্রথম ব্যবহারেই খুলে। কাঠামো §১-এর সুতো ধরে: প্রথমে স্বাধীনতা — ঘটনার পুনরাবৃত্তি ও σ-algebra-র স্বাধীনতা (২.১), random variable ও যথেচ্ছ পরিবার (২.২), π-system criterion ও iid/product (২.৩); তারপর asymptotic ভাষা — \(\limsup A_n\) ও "i.o." (২.৪); তারপর দুই Borel–Cantelli lemma-র বিবৃতি (২.৫); তারপর tail σ-algebra ও উদাহরণ (২.৬) এবং Kolmogorov 0–1 law (২.৭); তারপর Kolmogorov maximal inequality ও three-series theorem (২.৮); শেষে কঠোর SLLN ও তার necessity (২.৯)। ভারী প্রমাণগুলো §৪-এ — এখানে কেবল বিবৃতি ও অন্তর্দৃষ্টি, স্পষ্ট forward pointer সহ।
জুড়ে আমরা একটা probability space \((\Omega,\mathcal F,\mathbb P)\) ধরে কাজ করি, এবং random variable বলতে measurable \(X:\Omega\to\mathbb R\) (7.3); মনে রাখি \(\mathbb E[X]=\int_\Omega X\,d\mathbb P\) (7.4) এবং \(X\in L^1\iff\mathbb E\lvert X\rvert<\infty\)। 7.2-এর π-system / λ-system ও π–λ theorem এবং product measure নিঃশব্দে ধরে নেওয়া।
২.১ স্বাধীনতা — ঘটনা থেকে σ-algebra¶
শুরু করি 2.2-এর চেনা ঘটনা-স্বাধীনতা থেকে, তারপর সঙ্গে সঙ্গে তাকে σ-algebra-র স্তরে তুলি — কারণ ওটাই হবে আমাদের কাজের একক।
প্রথমে স্মরণ: কতগুলো ঘটনা \(A_1,\dots,A_n\) পরস্পর (mutually) স্বাধীন বলা হয় যদি প্রতিটি উপ-সংগ্রহের জন্য সম্ভাবনা গুণফলে ভাঙে।
সংজ্ঞা (ঘটনার পারস্পরিক স্বাধীনতা)। ঘটনা \(A_1,\dots,A_n\in\mathcal F\) পরস্পর-স্বাধীন (mutually independent) যদি প্রতিটি উপসেট \(I\subseteq\{1,\dots,n\}\)-এর জন্য $$ \mathbb P\Big(\bigcap_{i\in I}A_i\Big)\;=\;\prod_{i\in I}\mathbb P(A_i). $$ (এখানে প্রতিটি উপসেট জরুরি: শুধু জোড়ায়-জোড়ায় (pairwise) \(\mathbb P(A_i\cap A_j)=\mathbb P(A_i)\mathbb P(A_j)\) মিললেই পারস্পরিক স্বাধীনতা আসে না — 2.2-এর সেই সতর্কতা এখানেও বহাল, এবং ২.৩-এ একটা ক্লাসিক প্রতিউদাহরণে ফিরবে।)
এবার মূল পদক্ষেপ — ঘটনা থেকে σ-algebra। ধারণাটা: কতগুলো sub-σ-algebra স্বাধীন মানে তাদের থেকে যে-কোনো ঘটনা বেছে নিলেই গুণফল-নিয়ম মেটে।
সংজ্ঞা (σ-algebra-র স্বাধীনতা)। sub-σ-algebra \(\mathcal F_1,\dots,\mathcal F_n\subseteq\mathcal F\) স্বাধীন যদি যেকোনো নির্বাচনে \(A_i\in\mathcal F_i\) (\(i=1,\dots,n\)) $$ \mathbb P\Big(\bigcap_{i=1}^n A_i\Big)\;=\;\prod_{i=1}^n\mathbb P(A_i). $$ (যেহেতু প্রতিটি \(\mathcal F_i\)-তে \(\Omega\) আছে এবং \(A_i=\Omega\) বসালে সেই index উধাও হয়ে যায় — \(\mathbb P(\Omega)=1\) — এই একটা শর্তই স্বয়ংক্রিয়ভাবে সব উপ-নির্বাচনকে ঢেকে দেয়; তাই σ-algebra-র ক্ষেত্রে "প্রতিটি উপসেট" আলাদা করে লেখার দরকার নেই।)
এই সংজ্ঞা ঘটনা-স্বাধীনতাকে বিশেষ ক্ষেত্র হিসেবে ফিরিয়ে দেয়: একটা ঘটনা \(A\)-কে তার ক্ষুদ্রতম σ-algebra \(\sigma(A)=\{\emptyset,A,A^c,\Omega\}\)-র সাথে মিলিয়ে দিলে, "ঘটনা \(A_1,\dots,A_n\) স্বাধীন" আর "σ-algebra \(\sigma(A_1),\dots,\sigma(A_n)\) স্বাধীন" একই কথা হয়ে দাঁড়ায় (পরীক্ষা করলে দেখা যায় \(A_i\) ও \(A_i^c\) উভয় বাছাই একই গুণফল-শর্তে নেমে আসে)।
এক বাক্যে। ঘটনা \(A_1,\dots,A_n\) পারস্পরিক-স্বাধীন মানে প্রতিটি উপসংগ্রহে \(\mathbb P(\bigcap A_i)=\prod\mathbb P(A_i)\) (pairwise যথেষ্ট নয়), আর এর পূর্ণ-সাধারণ রূপ — sub-σ-algebra \(\mathcal F_1,\dots,\mathcal F_n\) স্বাধীন যদি যেকোনো \(A_i\in\mathcal F_i\) বাছাইতেই গুণফল-নিয়ম মেটে — যা ঘটনা-স্বাধীনতাকে \(\sigma(A)=\{\emptyset,A,A^c,\Omega\}\)-এর মাধ্যমে বিশেষ ক্ষেত্র হিসেবে ধরে।
২.২ random variable-এর স্বাধীনতা ও যথেচ্ছ পরিবার¶
σ-algebra-র স্বাধীনতা হাতে থাকায় random variable-এর স্বাধীনতা এখন এক লাইনে আসে — কারণ একটা random variable-এর "সব তথ্য" হলো তার generated σ-algebra \(\sigma(X)=\{X^{-1}(B):B\in\mathcal B\}\) (7.3)।
সংজ্ঞা (random variable-এর স্বাধীনতা)। random variable \(X_1,\dots,X_n\) স্বাধীন যদি তাদের generated σ-algebra \(\sigma(X_1),\dots,\sigma(X_n)\) স্বাধীন — সমতুল্যভাবে, যেকোনো Borel set \(B_1,\dots,B_n\in\mathcal B\)-র জন্য $$ \mathbb P\big(X_1\in B_1,\dots,X_n\in B_n\big)\;=\;\prod_{i=1}^n\mathbb P(X_i\in B_i). $$ (একই ধারণা random vector-এও খাটে — তখন \(\sigma(X_i)\) মানে সেই vector-এর generated σ-algebra; তাই "দুটো random vector স্বাধীন"-ও একই সংজ্ঞা।)
এবার অসীম দিকে যাওয়া — পরিসংখ্যানে আমরা প্রায়ই একটা অসীম অনুক্রম \(X_1,X_2,\dots\) (বা যেকোনো index-পরিবার) নিয়ে কাজ করি, এবং তাদের সবাইকে "পরস্পর-স্বাধীন" বলতে চাই। কৌশলটা স্ট্যান্ডার্ড: অসীম পরিবারের স্বাধীনতা মানে তার প্রতিটি সসীম উপ-পরিবার স্বাধীন।
সংজ্ঞা (যথেচ্ছ পরিবারের স্বাধীনতা)। σ-algebra-র একটা পরিবার \((\mathcal F_i)_{i\in I}\) (বা random variable-এর পরিবার \((X_i)_{i\in I}\)) স্বাধীন যদি তার প্রতিটি সসীম উপ-পরিবার স্বাধীন হয় (উপরের অর্থে)। বিশেষত একটা অসীম অনুক্রম \(X_1,X_2,\dots\) স্বাধীন যদি প্রতিটি \(n\)-এ \(X_1,\dots,X_n\) স্বাধীন হয়।
স্বাধীনতার একটা অপরিহার্য, প্রায়ই-নীরবে-ব্যবহৃত পরিণতি: স্বাধীন random variable-দের পৃথক ফাংশনও স্বাধীন থাকে। যদি \(X_1,\dots,X_n\) স্বাধীন এবং \(g_1,\dots,g_n\) measurable হয়, তবে \(g_1(X_1),\dots,g_n(X_n)\)-ও স্বাধীন (কারণ \(\sigma(g_i(X_i))\subseteq\sigma(X_i)\))। আরও সাধারণভাবে, একটা স্বাধীন অনুক্রমকে অসংলগ্ন (disjoint) ব্লকে ভাগ করে প্রতিটি ব্লকের যেকোনো (measurable) ফাংশন নিলে সেই ফাংশনগুলোও পরস্পর-স্বাধীন — যেমন \(X_1+X_2\) আর \(X_3X_4\) স্বাধীন। এই "ব্লক-স্বাধীনতা"ই tail σ-algebra ও 0–1 law-এর প্রমাণে কাজে লাগবে।
এক বাক্যে। random variable \(X_1,\dots,X_n\) স্বাধীন মানে তাদের \(\sigma(X_i)\)-গুলো স্বাধীন (⇔ সব Borel \(B_i\)-তে \(\mathbb P(\bigcap\{X_i\in B_i\})=\prod\mathbb P(X_i\in B_i)\)), একটা অসীম পরিবার স্বাধীন যদি তার প্রতিটি সসীম উপ-পরিবার স্বাধীন হয়, এবং স্বাধীন চলকের (অসংলগ্ন-ব্লকের) measurable ফাংশনও স্বাধীন থাকে।
২.৩ π-system criterion এবং iid ⇔ product measure¶
আগের সংজ্ঞাগুলো "সব Borel \(B_i\)"-তে যাচাই চায় — কার্যত অসম্ভব, কারণ Borel σ-algebra বিশাল। এখানেই 7.2-এর π–λ theorem একটা নাটকীয় সরলীকরণ দেয়: জন্মদাতা (generating) π-system-এ যাচাই-ই যথেষ্ট।
স্মরণ (7.2): একটা সংগ্রহ \(\mathcal P\) একটা π-system যদি তা সসীম ছেদে (finite intersection) বদ্ধ (\(A,B\in\mathcal P\Rightarrow A\cap B\in\mathcal P\)); আর \(\sigma(\mathcal P)\) হলো তার generated σ-algebra।
উপপাদ্য (π-system criterion — স্বাধীনতা যাচাইয়ের সংক্ষিপ্তকরণ)। ধরা যাক \(\mathcal P_1,\dots,\mathcal P_n\) প্রতিটি একটি π-system এবং \(\mathcal F_i=\sigma(\mathcal P_i)\)। যদি গুণফল-নিয়ম কেবল π-system-এর সদস্যদের উপর মেটে — অর্থাৎ যেকোনো \(A_i\in\mathcal P_i\)-র জন্য \(\mathbb P(\bigcap_i A_i)=\prod_i\mathbb P(A_i)\) — তবে তা পুরো \(\mathcal F_1,\dots,\mathcal F_n\)-এও মেটে, অর্থাৎ \(\mathcal F_i\)-গুলো স্বাধীন। (প্রমাণ §৪ — π–λ theorem ধাপে-ধাপে প্রয়োগ করে।)
এই criterion-ই random variable-এর স্বাধীনতা যাচাইকে হাতের নাগালে আনে। লক্ষ করি \(\{X\le x\}\)-জাতীয় ঘটনার সংগ্রহ \(\{\{X\le x\}:x\in\mathbb R\}\) একটা π-system (\(\{X\le x\}\cap\{X\le y\}=\{X\le\min(x,y)\}\)) এবং তা \(\sigma(X)\) জন্ম দেয়। তাই:
ফলাফল (CDF-স্তরে যাচাই)। \(X_1,\dots,X_n\) স্বাধীন যদি ও কেবল যদি তাদের যৌথ CDF গুণফলে ভাঙে: $$ \mathbb P\big(X_1\le x_1,\dots,X_n\le x_n\big)\;=\;\prod_{i=1}^n F_{X_i}(x_i)\qquad\forall\,(x_1,\dots,x_n)\in\mathbb R^n. $$ (density থাকলে এটি \(f_{X_1,\dots,X_n}(x_1,\dots,x_n)=\prod_i f_{X_i}(x_i)\)-র সমতুল্য — যৌথ density factor হওয়াই স্বাধীনতা।)
এর সাহায্যে এখন pairwise-বনাম-mutual-এর সেই ক্লাসিক ফাঁকটা পরিষ্কার করা যায়: দুটো স্বাধীন fair-coin \(\{0,1\}\) আর তাদের XOR — তিনটি জোড়ায়-জোড়ায় স্বাধীন, কিন্তু তৃতীয়টি প্রথম দুটোর deterministic ফাংশন, তাই \(\mathbb P\)(তিনটি একসাথে) গুণফলে ভাঙে না — পারস্পরিক স্বাধীনতা ব্যর্থ (§৪/§৩-এ বিস্তারিত)।
অবশেষে iid ও product measure। এই অধ্যায়ের নায়ক হলো iid অনুক্রম — independent and identically distributed: \(X_1,X_2,\dots\) পরস্পর-স্বাধীন এবং সবার একই বণ্টন \(P_X\) (একই law)। স্বাধীনতা ঠিক বলে দেয় যে অনুক্রমটির যৌথ law হলো প্রতিটি coordinate-এর law-এর product measure (7.2):
সংজ্ঞা/ফলাফল (iid ⇔ product law)। \((X_i)_{i\ge 1}\) iid \(\sim P_X\) হওয়া সমতুল্য — অনুক্রম-vector \((X_1,X_2,\dots)\)-এর law \(\prod\)-space \(\mathbb R^{\mathbb N}\)-তে হলো product measure \(\bigotimes_{i\ge 1}P_X\) (যার অস্তিত্ব ও uniqueness 7.2-এর extension/product-নির্মাণ নিশ্চিত করে)। অর্থাৎ iid নমুনা = একটা product probability space-এর coordinate map।
এক বাক্যে। π–λ theorem-এর জোরে স্বাধীনতা যাচাই করতে generating π-system-ই যথেষ্ট — তাই random variable-এর জন্য CDF (বা density) factor হওয়াই (\(\mathbb P(\bigcap\{X_i\le x_i\})=\prod F_{X_i}(x_i)\)) স্বাধীনতার সমতুল্য; আর iid অনুক্রম মানে ঠিক যৌথ law = product measure \(\bigotimes_i P_X\)।
২.৪ \(\limsup A_n\) — "অসীম-বার ঘটে" (infinitely often)¶
স্বাধীনতার গভীর ফলগুলো সবই asymptotic — "অনুক্রমটা শেষমেশ কী করে" নিয়ে। এই প্রশ্নের ভাষা গড়তে দরকার ঘটনার অনুক্রমের \(\limsup\) — যা ঠিক ধরে "অসীম-সংখ্যক \(A_n\) ঘটে" ব্যাপারটা।
সংজ্ঞা (\(\limsup A_n\) ও "infinitely often")। ঘটনার অনুক্রম \((A_n)_{n\ge 1}\)-এর limit superior: $$ \limsup_{n}A_n\;:=\;\bigcap_{N=1}^{\infty}\ \bigcup_{n\ge N}A_n\;=\;{\omega:\omega\in A_n\ \text{অসীম-সংখ্যক}\ n\text{-এর জন্য}}, $$ যাকে সংক্ষেপে \(\{A_n\ \text{i.o.}\}\) (infinitely often, "অসীম-বার") লেখা হয়। স্বজ্ঞা: \(\omega\in\limsup A_n\) মানে যত বড় \(N\)-ই নাও, তার পরেও (\(n\ge N\)) অন্তত একটা \(A_n\) ঘটে \(\omega\)-তে — অর্থাৎ \(A_n\)-গুলো \(\omega\)-তে কখনো পুরোপুরি থামে না।
এর দ্বৈত ধারণাও কাজে লাগে — "শেষমেশ সবসময় ঘটে":
$$ \liminf_{n}A_n\;:=\;\bigcup_{N=1}^{\infty}\ \bigcap_{n\ge N}A_n\;=\;{\omega:\omega\in A_n\ \text{সব যথেষ্ট-বড়}\ n\text{-এর জন্য}}\;=\;{A_n\ \text{eventually}}. $$ (দ্বৈততা: \((\limsup A_n)^c=\liminf A_n^c\) — "অসীম-বার \(A_n\) ঘটে"-র অস্বীকার হলো "শেষমেশ সবসময় \(A_n^c\) ঘটে"।)
কেন এই ধারণাটাই ঠিক যন্ত্র? — কারণ পরিসংখ্যানের প্রায় সব asymptotic প্রশ্ন i.o.-ভাষায় বসে। "\(\bar X_n\) কি \(\mu\) থেকে \(\varepsilon\)-এর বেশি দূরে অসীম-বার যায়?" = \(\{\lvert\bar X_n-\mu\rvert>\varepsilon\ \text{i.o.}\}\); এই ঘটনার সম্ভাবনা \(0\) হলে (প্রতিটি \(\varepsilon\)-এর জন্য) ঠিক \(\bar X_n\to\mu\) a.s. পাওয়া যায় — তাই SLLN-প্রমাণ মূলত একটা i.o.-সম্ভাবনা \(0\) দেখানোর খেলা, আর সেটাই Borel–Cantelli-র এলাকা।
এক বাক্যে। \(\limsup_n A_n=\bigcap_N\bigcup_{n\ge N}A_n=\{A_n\ \text{i.o.}\}\) ধরে "অসীম-সংখ্যক \(A_n\) ঘটে" (এবং দ্বৈত \(\liminf A_n=\{A_n\ \text{eventually}\}\)), আর পরিসংখ্যানের asymptotic প্রশ্ন — যেমন "\(\bar X_n\) কি বারবার \(\mu\) থেকে দূরে যায়" — ঠিক এই i.o.-ভাষায় বসে।
২.৫ Borel–Cantelli lemma I ও II¶
এবার দুই Borel–Cantelli lemma — "\(\{A_n\ \text{i.o.}\}\)-এর সম্ভাবনা \(0\) না \(1\)" প্রশ্নের দুই দিকের উত্তর। দুটোই কেবল সম্ভাবনার যোগফল \(\sum_n\mathbb P(A_n)\)-এর উপর নির্ভর করে।
প্রথমটি — সরল, শক্তিশালী, এবং কোনো স্বাধীনতা ছাড়াই খাটে।
উপপাদ্য (Borel–Cantelli I)। যেকোনো ঘটনা-অনুক্রম \((A_n)\)-এর জন্য (স্বাধীনতা লাগে না): $$ \sum_{n=1}^\infty\mathbb P(A_n)<\infty\quad\Longrightarrow\quad \mathbb P\big(A_n\ \text{i.o.}\big)=\mathbb P\big(\limsup_n A_n\big)=0. $$ স্বজ্ঞা: সম্ভাবনার যোগফল সসীম হলে \(\sum_n\mathbf 1_{A_n}\)-এর প্রত্যাশা সসীম (\(\mathbb E[\sum\mathbf 1_{A_n}]=\sum\mathbb P(A_n)<\infty\), MCT), তাই \(\sum_n\mathbf 1_{A_n}<\infty\) a.s. — অর্থাৎ প্রায় প্রতিটি \(\omega\)-তে কেবল সসীম-সংখ্যক \(A_n\) ঘটে। (প্রমাণ §৪।)
দ্বিতীয়টি উল্টোমুখী, কিন্তু এর জন্য স্বাধীনতা অপরিহার্য।
উপপাদ্য (Borel–Cantelli II)। যদি \((A_n)\) স্বাধীন ঘটনা-অনুক্রম হয়, তবে: $$ \sum_{n=1}^\infty\mathbb P(A_n)=\infty\quad\Longrightarrow\quad \mathbb P\big(A_n\ \text{i.o.}\big)=1. $$ স্বজ্ঞা: স্বাধীনতায় "কোনোটাই-ঘটল-না" সম্ভাবনা গুণফলে ভাঙে — \(\mathbb P(\bigcap_{n\ge N}A_n^c)=\prod_{n\ge N}(1-\mathbb P(A_n))\), আর \(1-x\le e^{-x}\) ব্যবহার করলে এটি \(\le\exp(-\sum_{n\ge N}\mathbb P(A_n))=e^{-\infty}=0\); সব \(N\)-এ শূন্য মানে i.o. ঘটার সম্ভাবনা \(1\)। (প্রমাণ §৪।)
দুটোকে একসাথে রাখলে স্বাধীন ঘটনার জন্য একটা পরিচ্ছন্ন শূন্য-এক বিভাজন ফুটে ওঠে — কোনো ধূসর অঞ্চল নেই:
পরিণতি (Borel–Cantelli শূন্য-এক বিভাজন)। \((A_n)\) স্বাধীন হলে $$ \mathbb P\big(A_n\ \text{i.o.}\big)\;=\;\begin{cases}0 & \text{যদি}\ \sum_n\mathbb P(A_n)<\infty,\[2pt] 1 & \text{যদি}\ \sum_n\mathbb P(A_n)=\infty.\end{cases} $$ অর্থাৎ স্বাধীন ঘটনার ক্ষেত্রে "অসীম-বার ঘটা"-র সম্ভাবনা কেবল \(0\) বা \(1\) হতে পারে — এটিই Kolmogorov 0–1 law-এর (২.৭) একটা পূর্বাভাস, কারণ \(\{A_n\ \text{i.o.}\}\) আসলে একটা tail event (২.৬)।
একটা ক্লাসিক প্রয়োগ-ছবি: স্বাধীন \(A_n\)-এ \(\mathbb P(A_n)=1/n\) হলে \(\sum 1/n=\infty\), তাই \(A_n\) অসীম-বার ঘটে (a.s.); কিন্তু \(\mathbb P(A_n)=1/n^2\) হলে \(\sum 1/n^2<\infty\), তাই একসময় চিরতরে থেমে যায় (a.s.) — চিত্র 7-6-borel-cantelli ঠিক এই বৈপরীত্য দেখাবে।
এক বাক্যে। BC-I (\(\sum\mathbb P(A_n)<\infty\Rightarrow\) i.o.-সম্ভাবনা \(0\)) কোনো স্বাধীনতা ছাড়াই খাটে, BC-II (স্বাধীন ও \(\sum\mathbb P(A_n)=\infty\Rightarrow\) i.o.-সম্ভাবনা \(1\)) স্বাধীনতা দাবি করে, আর দুয়ে মিলে স্বাধীন ঘটনার জন্য একটা শূন্য-এক বিভাজন — যোগফল অভিসারী না অপসারী, সেই অনুযায়ী \(0\) বা \(1\)।
২.৬ tail σ-algebra ও tail event — "যা সসীম শুরু ভুললেও বদলায় না"¶
Kolmogorov 0–1 law-এ পৌঁছানোর আগে শেষ উপকরণ — tail σ-algebra, যা ধরে "একদম দূরের, asymptotic তথ্য"। স্বজ্ঞা: কিছু ঘটনা প্রথম যত-খুশি পদ (\(X_1,\dots,X_k\)) বদলে দিলেও অপরিবর্তিত থাকে — তারা কেবল "লেজের" (\(X_{k+1},X_{k+2},\dots\)) উপর নির্ভর করে।
সংজ্ঞা (tail σ-algebra ও tail event)। random variable-অনুক্রম \((X_n)_{n\ge 1}\)-এর জন্য, \(n\)-তম tail σ-algebra \(\mathcal T_n:=\sigma(X_n,X_{n+1},X_{n+2},\dots)\) (অর্থাৎ \(n\) থেকে শুরু করে সব \(X_i\)-র তথ্য)। tail σ-algebra হলো এদের ছেদ: $$ \mathcal T\;:=\;\bigcap_{n=1}^{\infty}\sigma(X_n,X_{n+1},\dots)\;=\;\bigcap_{n=1}^\infty\mathcal T_n. $$ \(\mathcal T\)-র সদস্য ঘটনাকে বলে tail event, আর \(\mathcal T\)-measurable random variable-কে tail random variable। সংজ্ঞা অনুযায়ী একটা tail event \(T\) প্রতিটি \(\mathcal T_n\)-তে থাকে — অর্থাৎ প্রথম \(n-1\)টা চলক (\(X_1,\dots,X_{n-1}\)) সম্পূর্ণ বাদ দিয়েও \(T\) প্রকাশ করা যায়, যেকোনো \(n\)-এর জন্য। তাই সসীম-সংখ্যক \(X_i\)-র মান বদলালে tail event-এর সত্য-মিথ্যা বদলায় না।
কয়েকটা গুরুত্বপূর্ণ উদাহরণ — যারা ঠিক পরিসংখ্যানের asymptotic প্রশ্ন:
- \(\{\sum_n X_n\ \text{converges}\}\) — অসীম যোগফলের অভিসৃতি। প্রথম \(k\)টা পদ বদলালে যোগফল একটা সসীম পরিমাণে সরে কিন্তু অভিসৃতি-প্রশ্নের উত্তর বদলায় না, তাই এটি tail event। (এর সম্ভাবনা \(0\) না \(1\) — তা ঠিক করে three-series theorem, ২.৮।)
- \(\{\limsup_n\bar X_n>c\}\) এবং \(\{\bar X_n\ \text{converges}\}\) — চলমান গড়ের asymptotic আচরণ। যেহেতু \(\bar X_n=\frac1n\sum_{i=1}^n X_i\)-তে প্রথম \(k\) পদের অবদান \(\frac1n\sum_{i\le k}X_i\to 0\), প্রথম-পদ-পরিবর্তন \(\limsup\bar X_n\) বা অভিসৃতি-প্রশ্নে কোনো ছাপ ফেলে না — দুটোই tail। (এই কারণেই SLLN-এর সীমা একটা tail random variable।)
- \(\{X_n>c\ \text{i.o.}\}\) এবং সাধারণভাবে যেকোনো \(\{A_n\ \text{i.o.}\}\) যেখানে \(A_n\in\sigma(X_n)\) — i.o.-ঘটনা সর্বদা tail (সসীম-সংখ্যক পদ ফেললে "অসীম-বার ঘটা" অপরিবর্তিত)। তাই BC-II-র \(\{A_n\ \text{i.o.}\}\)-ও tail।
এক বাক্যে। tail σ-algebra \(\mathcal T=\bigcap_n\sigma(X_n,X_{n+1},\dots)\) ধরে সেই তথ্য যা সসীম-সংখ্যক \(X_i\) বদলালেও অটুট — যেমন \(\{\sum X_n\ \text{converges}\}\), \(\{\limsup\bar X_n>c\}\), \(\{\bar X_n\ \text{converges}\}\), ও যেকোনো \(\{A_n\ \text{i.o.}\}\) — যা ঠিক পরিসংখ্যানের asymptotic প্রশ্নগুলোর গাণিতিক রূপ।
২.৭ Kolmogorov 0–1 law — tail event দৈবহীন¶
এবার এই অধ্যায়ের প্রথম "চমক" — Kolmogorov-এর শূন্য-এক সূত্র। বিবৃতিটা সংক্ষিপ্ত কিন্তু পরিণতি গভীর: স্বাধীন চলকের জগতে কোনো সত্যিকারের asymptotic প্রশ্নের উত্তর আদৌ দৈব নয় — তা আগে থেকেই নির্ধারিত।
উপপাদ্য (Kolmogorov 0–1 law)। ধরা যাক \(X_1,X_2,\dots\) স্বাধীন random variable, এবং \(\mathcal T=\bigcap_n\sigma(X_n,X_{n+1},\dots)\) তাদের tail σ-algebra। তবে \(\mathcal T\) trivial — অর্থাৎ $$ \text{প্রতিটি tail event}\ T\in\mathcal T:\quad \mathbb P(T)\in{0,1}, $$ এবং সমতুল্যভাবে, প্রতিটি tail random variable \(Y\) (\(\mathcal T\)-measurable) almost surely একটা ধ্রুবক (\(\exists\,c:\mathbb P(Y=c)=1\))। (প্রমাণ §৪ — কৌশলের মূল: ব্লক-স্বাধীনতা ব্যবহার করে দেখানো যে \(\mathcal T\) নিজের সাথেই স্বাধীন, তাই যেকোনো \(T\in\mathcal T\)-এর জন্য \(\mathbb P(T)=\mathbb P(T\cap T)=\mathbb P(T)^2\), যার সমাধান কেবল \(0\) বা \(1\)।)
এর তাৎপর্য কয়েক স্তরে:
- দৈবতা নিঃশেষিত। "\(\sum X_n\) অভিসারী?", "\(\bar X_n\) অভিসারী?", "\(X_n>n\) অসীম-বার?" — এদের প্রতিটির উত্তর স্বাধীন-জগতে \(0\) বা \(1\), কোনো \(0.5\) নেই। অর্থাৎ asymptotic ভাগ্য বলে কিছু নেই; হয় প্রায়-নিশ্চিতভাবে ঘটে, নয় প্রায়-নিশ্চিতভাবে ঘটে না।
- সীমা একটা সংখ্যা। যেহেতু \(\limsup\bar X_n\) ও \(\liminf\bar X_n\) দুটোই tail random variable, প্রতিটিই a.s. ধ্রুবক — তাই যদি \(\bar X_n\) আদৌ a.s. অভিসারী হয়, তার সীমা অবশ্যই একটা নির্দিষ্ট ধ্রুবক। 0–1 law তাই SLLN-এর "সীমাটা \(\mu\)-জাতীয় একটা সংখ্যা" — এই কাঠামোটা আগেভাগেই নিশ্চিত করে (যদিও সংখ্যাটা ঠিক \(\mu\), তা SLLN-এর নিজস্ব হিসাব)।
- BC শূন্য-এক বিভাজনের ব্যাখ্যা। ২.৫-এ স্বাধীন \(A_n\)-এ \(\mathbb P(A_n\ \text{i.o.})\in\{0,1\}\) পেয়েছিলাম — এখন বোঝা যায় কেন: \(\{A_n\ \text{i.o.}\}\) একটা tail event (২.৬), তাই 0–1 law-ই তার সম্ভাবনাকে \(0\)/\(1\)-এ বাঁধে; BC-II শুধু কোনটা (\(\sum\mathbb P(A_n)\)-এর উপর) তা বলে দেয়।
এক বাক্যে। স্বাধীন \(X_n\)-এর tail σ-algebra \(\mathcal T\) trivial (Kolmogorov 0–1 law) — প্রতিটি tail event-এর সম্ভাবনা \(0\) বা \(1\), প্রতিটি tail random variable a.s. ধ্রুবক — তাই কোনো সত্যিকারের asymptotic প্রশ্নই দৈব নয়, এবং \(\bar X_n\) অভিসারী হলে তার সীমা বাধ্যতই একটা নির্দিষ্ট সংখ্যা।
২.৮ Kolmogorov maximal inequality ও three-series theorem (বিবৃতি)¶
SLLN-এ পৌঁছানোর পথে দুটো শক্ত যন্ত্র লাগে, যাদের এখানে কেবল বিবৃতি দিই (একটি §৪-এর SLLN-প্রমাণে সরাসরি কাজে লাগবে; অন্যটি \(\{\sum X_n\ \text{converges}\}\)-tail-event-এর সম্ভাবনা ঠিক করে)।
প্রথমটি Chebyshev-এর (3.1) একটা শক্তিশালী, "সর্বোচ্চ-পর্যন্ত" সংস্করণ — শুধু শেষ যোগফল \(S_n\) নয়, পুরো পথের সর্বোচ্চ আংশিক-যোগফলকে বাঁধে।
উপপাদ্য (Kolmogorov maximal inequality)। ধরা যাক \(X_1,\dots,X_n\) স্বাধীন, \(\mathbb E[X_k]=0\) ও \(\operatorname{Var}(X_k)=\mathbb E[X_k^2]<\infty\), এবং আংশিক-যোগফল \(S_k=X_1+\dots+X_k\)। তবে প্রতিটি \(\varepsilon>0\)-র জন্য $$ \mathbb P\Big(\max_{1\le k\le n}\lvert S_k\rvert\ge\varepsilon\Big)\;\le\;\frac{\operatorname{Var}(S_n)}{\varepsilon^2}\;=\;\frac{1}{\varepsilon^2}\sum_{k=1}^n\operatorname{Var}(X_k). $$ (লক্ষ করি ডান পাশ ঠিক Chebyshev-এর বাউন্ড — কিন্তু বাঁ পাশে \(\lvert S_n\rvert\)-এর বদলে \(\max_k\lvert S_k\rvert\); এই "সর্বোচ্চ-নিয়ন্ত্রণ"ই আংশিক-যোগফল-পথের অভিসৃতি প্রমাণে অপরিহার্য, এবং এটিই SLLN-এর Etemadi-পরবর্তী/Kolmogorov-মূল প্রমাণের ইঞ্জিন। এটি 7.8-এর martingale maximal inequality-র পূর্বসূরি।)
দ্বিতীয়টি — স্বাধীন চলকের যোগফল কখন অভিসারী হয় তার সম্পূর্ণ (যদি-ও-কেবল-যদি) মানদণ্ড, তিনটি series-এর অভিসৃতির ভাষায়।
উপপাদ্য (Kolmogorov three-series theorem — বিবৃতি)। \(X_1,X_2,\dots\) স্বাধীন। একটা ধ্রুবক \(A>0\) স্থির করে truncation \(X_k^A:=X_k\mathbf 1_{\{\lvert X_k\rvert\le A\}}\) নিই। তবে \(\sum_n X_n\) a.s. অভিসারী হয় যদি ও কেবল যদি নিচের তিনটি series-ই অভিসারী হয়: $$ \text{(i)}\ \sum_n\mathbb P(\lvert X_n\rvert>A),\qquad \text{(ii)}\ \sum_n\mathbb E[X_n^A],\qquad \text{(iii)}\ \sum_n\operatorname{Var}(X_n^A). $$ (0–1 law অনুযায়ী \(\{\sum X_n\ \text{converges}\}\) একটা tail event, তাই তার সম্ভাবনা \(0\) বা \(1\)-ই হতে পারত — three-series theorem ঠিক বলে দেয় কোনটা, এবং কীসের উপর তা নির্ভর করে। SLLN-এর শাস্ত্রীয় Kolmogorov-প্রমাণে \(\sum (X_k-\mu)/k\)-এর অভিসৃতি এর থেকে আসে, তারপর Kronecker's lemma।)
এক বাক্যে। Kolmogorov maximal inequality Chebyshev-কে \(\lvert S_n\rvert\) থেকে \(\max_{k\le n}\lvert S_k\rvert\)-এ উন্নীত করে (পথ-সর্বোচ্চ নিয়ন্ত্রণ — SLLN-এর ইঞ্জিন), আর three-series theorem স্বাধীন \(\sum X_n\)-এর a.s.-অভিসৃতির পূর্ণ মানদণ্ড দেয় (truncation-এর তিন series), যা tail-event \(\{\sum X_n\ \text{converges}\}\)-এর \(0\)/\(1\) ঠিক করে।
২.৯ Strong Law of Large Numbers (SLLN) — মুকুটমণি ও তার ধার¶
অবশেষে এই অধ্যায়ের শিরোমণি। সব যন্ত্র — স্বাধীনতা, Borel–Cantelli, 0–1 law, maximal inequality — একত্র হয়ে যে ফল দেয়, তা পরিসংখ্যানের সবচেয়ে মৌলিক প্রতিশ্রুতির কঠোরতম রূপ।
উপপাদ্য (Strong Law of Large Numbers — Kolmogorov)। ধরা যাক \(X_1,X_2,\dots\) iid এবং \(\mathbb E\lvert X_1\rvert<\infty\) (অর্থাৎ \(X_1\in L^1\)), \(\mu:=\mathbb E[X_1]\)। তবে চলমান গড় $$ \bar X_n\;=\;\frac1n\sum_{i=1}^n X_i\ \xrightarrow{\ \text{a.s.}\ }\ \mu\qquad(n\to\infty), $$ অর্থাৎ \(\mathbb P\big(\lim_{n\to\infty}\bar X_n=\mu\big)=1\) — প্রায় প্রতিটি নমুনা-পথ সত্যিকারভাবে \(\mu\)-তে অভিসারী। (প্রমাণ §৪ — Etemadi-র truncation \(X_k\mathbf 1_{\{\lvert X_k\rvert\le k\}}\), subsequence \(n_k\approx\alpha^k\) বরাবর অভিসৃতি (Chebyshev+BC-I), এবং monotonicity দিয়ে ফাঁক ভরাট; অথবা Kolmogorov-এর maximal-inequality + Kronecker-পথ।)
কয়েকটা কথা বিবৃতিটার ভার বোঝাতে:
- 3.3-এর উপর উন্নয়ন। 3.3 দিয়েছিল weak law \(\bar X_n\xrightarrow{P}\mu\) (Chebyshev দিয়ে, এবং সসীম variance লাগত)। SLLN দুই দিক থেকেই কঠোরভাবে বেশি: (ক) convergence-mode — almost sure (পথ-ভিত্তিক, চিরস্থায়ী), শুধু in-probability নয়; (খ) hypothesis — কেবল \(\mathbb E\lvert X\rvert<\infty\), variance বা higher moment লাগে না। মনে রাখি a.s. ⇒ in probability (১.৪), তাই SLLN তার ভেতরেই 3.3-এর weak law ধারণ করে।
- first moment-ই সঠিক দাগ। hypothesis \(\mathbb E\lvert X\rvert<\infty\) কেবল যথেষ্ট নয়, আবশ্যকও — তাই দাগটা ঠিক জায়গায়।
উপপাদ্য (SLLN-এর necessity — Cauchy-প্রতিউদাহরণ)। যদি \(X_1,X_2,\dots\) iid এবং \(\mathbb E\lvert X_1\rvert=\infty\), তবে \(\bar X_n\) a.s. অভিসারী নয়; বরং \(\limsup_n\lvert\bar X_n\rvert=\infty\) a.s. (এমনকি \(\limsup_n\lvert X_n\rvert/n=\infty\) a.s.)। (কারণ-স্কেচ §৪/§৩: \(\mathbb E\lvert X\rvert=\infty\Rightarrow\sum_n\mathbb P(\lvert X_n\rvert>n)=\infty\); স্বাধীনতায় BC-II দেয় \(\lvert X_n\rvert>n\) অসীম-বার — তাই \(X_n/n\not\to 0\), যা \(\bar X_n\)-অভিসৃতির সাথে অসঙ্গত।)
এর জীবন্ত উদাহরণ standard Cauchy বণ্টন (\(f(x)=\frac{1}{\pi(1+x^2)}\)): এর \(\mathbb E\lvert X\rvert=\infty\) (লেজ এত মোটা যে first moment-ই অস্তিত্বহীন), তাই SLLN ভাঙে। আশ্চর্যজনকভাবে এখানে \(\bar X_n\) মোটেও স্থির হয় না — বরং \(\bar X_n\) নিজেই আবার standard Cauchy বণ্টিত (যেকোনো \(n\)-এ!), তাই বড় নমুনাতেও বুনোভাবে দোলে, কখনো \(\mu\)-জাতীয় কিছুতে গোছায় না। চিত্র 7-6-cauchy-no-slln ঠিক এই "অভিসৃতি-হীন দোলা" দেখাবে — SLLN-এর hypothesis কেন সত্যিই দরকার তার নিখুঁত প্রতিচ্ছবি, ঠিক যেমন 7.4-এর moving-spike দেখিয়েছিল DCT-র dominating-\(g\) কেন দরকার।
এক বাক্যে। SLLN বলে iid ও \(\mathbb E\lvert X\rvert<\infty\) হলে \(\bar X_n\to\mu\) almost surely (3.3-এর weak law-কে পথ-ভিত্তিক a.s.-অভিসৃতিতে উন্নীত, variance ছাড়াই), আর \(\mathbb E\lvert X\rvert=\infty\) (Cauchy) হলে BC-II দিয়ে \(\lvert X_n\rvert>n\) i.o., তাই \(\bar X_n\) a.s. অভিসারী নয় — অর্থাৎ first-moment-শর্তটা ঠিক ধারালো, যথেষ্ট-ও আবশ্যক-ও।
৩ · পূর্ণাঙ্গ উদাহরণ¶
§১–২-এ আমরা স্বাধীনতা (independence)-র গোটা স্থাপত্য গড়েছি — ঘটনার স্বাধীনতা \(\mathbb P(A\cap B)=\mathbb P(A)\mathbb P(B)\) থেকে শুরু করে \(\sigma\)-algebra (\(\sigma\)-বীজগণিত)-এর স্বাধীনতা ও random variable-এর স্বাধীনতা, এবং সেগুলো যাচাইয়ের সহজ চাবি \(\pi\)-system criterion (\(\pi\)-জগৎ-মানদণ্ড) যা বলে generator-এ factorization দেখালেই গোটা \(\sigma\)-বীজগণিত জুড়ে তা ছড়িয়ে যায়। তারপর এসেছে দুই যমজ Borel–Cantelli (বোরেল–ক্যান্টেলি) উপপত্তি — প্রথমটি (\(\sum\mathbb P(A_n)<\infty\Rightarrow\) a.s. সসীম-অনেক ঘটে) কোনো স্বাধীনতা ছাড়াই, দ্বিতীয়টি (স্বাধীন ও \(\sum\mathbb P(A_n)=\infty\Rightarrow\) a.s. অসীম-অনেক ঘটে) স্বাধীনতা-সহ। তারপর tail \(\sigma\)-algebra (লেজ-\(\sigma\)-বীজগণিত) \(\mathcal T=\bigcap_n\sigma(X_n,X_{n+1},\dots)\) ও তার চমকপ্রদ Kolmogorov 0–1 law (কোলমোগরভ ০–১ নিয়ম) — স্বাধীন ক্রমে যেকোনো tail-ঘটনার সম্ভাবনা হয় ঠিক \(0\), নয় ঠিক \(1\), কখনো মাঝামাঝি নয়। এবং শেষে সেই সবের মুকুট SLLN (Strong Law of Large Numbers, বৃহৎ-সংখ্যার সবল নিয়ম) — \(\mathbb E\lvert X\rvert<\infty\) হলে \(\bar X_n\to\mathbb E[X]\) almost surely (প্রায়-নিশ্চিতভাবে), কেবল বণ্টনে নয়। এই অংশের উদ্দেশ্য সেই বিমূর্ত কাঠামোকে হাতে-কলমে, কংক্রিট সংখ্যা ও কংক্রিট সিমুলেশন দিয়ে ছুঁয়ে দেখা — factorization সত্যিই কোথায় ভাঙে, বিরল ঘটনা কখন থেমে যায় আর কখন চিরকাল চলে, একটা tail-ঘটনা কীভাবে দৈবকে হারিয়ে দিয়ে নির্ধারিত হয়ে দাঁড়ায়, গড় কীভাবে সত্যিকারের গড়ে গিয়ে স্থির হয়, আর কোথায় সেই স্থিরতা একেবারেই আসে না। ছয়টি উদাহরণে প্রতিটি ধাপ ধৈর্য ধরে কষব — কোনো হিসাব লুকানো থাকবে না — তারপর প্রতিটির শেষে "কী শিখলাম" বলে মূল শিক্ষাটা গুটিয়ে আনব। কষ্টের স্তর শিরোনামে তারা দিয়ে চিহ্নিত: ★ = সরাসরি, সংজ্ঞা প্রয়োগ করলেই হয় · ★★ = কিছু কৌশল বা সতর্ক যুক্তি লাগে। প্রতিটি ইংরেজি পরিভাষা প্রথম ব্যবহারে বাংলায় খুলে দেওয়া হবে। সব সিমুলেশন একই বীজে (seed np.random.default_rng(20260619)) চালানো, যাতে সংখ্যাগুলো পুনরুৎপাদনযোগ্য থাকে।
উদাহরণ ১ — দুই RV স্বাধীন কিনা, factorization দিয়ে (★)¶
সেটআপ। দুটি discrete random variable \(X,Y\) স্বাধীন (independent) ঠিক তখনই যখন তাদের joint pmf (যৌথ ভর-অপেক্ষক, probability mass function) marginal-দের গুণফলে ভেঙে যায়: $$ \mathbb P(X=i,\,Y=j)=\mathbb P(X=i)\,\mathbb P(Y=j)\qquad\text{সব } i,j\text{-এর জন্য}. $$ এটি কেবল একটি-দুটি জোড়ায় নয়, প্রতিটি \((i,j)\)-তে ধরতে হবে। প্রথমে একটা সত্যিকারের স্বাধীন জোড়া কষি, তারপর একটা ফাঁদ দেখাই যেখানে marginal-গুলো ঠিকঠাক মেলে অথচ joint মেলে না।
কষা ১ — স্বাধীন জোড়া। ধরা যাক \(X\in\{0,1\}\), \(Y\in\{0,1\}\) আর joint pmf-টা এই \(2\times2\) ছকে দেওয়া:
| \(\mathbb P(X{=}i,Y{=}j)\) | \(Y=0\) | \(Y=1\) | সারি-যোগ \(\mathbb P(X{=}i)\) |
|---|---|---|---|
| \(X=0\) | \(0.12\) | \(0.28\) | \(0.40\) |
| \(X=1\) | \(0.18\) | \(0.42\) | \(0.60\) |
| স্তম্ভ-যোগ \(\mathbb P(Y{=}j)\) | \(0.30\) | \(0.70\) | \(1.00\) |
marginal বের করি ধার বরাবর যোগ করে: \(\mathbb P(X=0)=0.12+0.28=0.40\), \(\mathbb P(X=1)=0.60\); \(\mathbb P(Y=0)=0.12+0.18=0.30\), \(\mathbb P(Y=1)=0.70\)। এবার চারটি কোষেই গুণফল-পরীক্ষা: $$ \begin{aligned} \mathbb P(X{=}0)\mathbb P(Y{=}0)&=0.40\times0.30=0.12=\mathbb P(X{=}0,Y{=}0)\ \checkmark\ \mathbb P(X{=}0)\mathbb P(Y{=}1)&=0.40\times0.70=0.28=\mathbb P(X{=}0,Y{=}1)\ \checkmark\ \mathbb P(X{=}1)\mathbb P(Y{=}0)&=0.60\times0.30=0.18=\mathbb P(X{=}1,Y{=}0)\ \checkmark\ \mathbb P(X{=}1)\mathbb P(Y{=}1)&=0.60\times0.70=0.42=\mathbb P(X{=}1,Y{=}1)\ \checkmark \end{aligned} $$ চারটিই মিলল, তাই \(X\perp Y\)। লক্ষণীয়, পুরো ছকটাই আসলে একটা rank-one (এক-ক্রমের) ম্যাট্রিক্স — বাইরের গুণফল (outer product) \(\begin{psmallmatrix}0.40\\0.60\end{psmallmatrix}\begin{psmallmatrix}0.30&0.70\end{psmallmatrix}\); স্বাধীনতা মানেই joint-table-টা marginal-ভেক্টরদ্বয়ের outer product।
কষা ২ — ফাঁদ: marginal মেলে, joint মেলে না। এবার একই marginal (\(X\): \(0.40,0.60\); \(Y\): \(0.30,0.70\)) রেখে কোষগুলো একটু নাড়ি:
| \(\mathbb P(X{=}i,Y{=}j)\) | \(Y=0\) | \(Y=1\) | সারি-যোগ |
|---|---|---|---|
| \(X=0\) | \(0.20\) | \(0.20\) | \(0.40\) |
| \(X=1\) | \(0.10\) | \(0.50\) | \(0.60\) |
| স্তম্ভ-যোগ | \(0.30\) | \(0.70\) | \(1.00\) |
marginal হুবহু আগের মতোই (সারি-যোগ \(0.40,0.60\); স্তম্ভ-যোগ \(0.30,0.70\))। কিন্তু \((0,0)\)-কোষে: $$ \mathbb P(X{=}0,Y{=}0)=0.20\neq 0.12=\mathbb P(X{=}0)\mathbb P(Y{=}0). $$ একটিমাত্র কোষ ভাঙলেই স্বাধীনতা ভাঙে — তাই এখানে \(X\not\perp Y\), যদিও আলাদা-আলাদা দেখলে \(X\) ও \(Y\) অবিকল আগের বণ্টন। শিক্ষা: marginal স্বাধীনতা ঠিক করে না; joint-ই শেষ কথা। স্বজ্ঞায়: marginal কেবল ছকের দুই ধার (প্রান্ত-যোগফল) বলে, কিন্তু ভেতরের ভর কীভাবে বিলি হলো — \(X\) জানলে \(Y\) সম্পর্কে কিছু আঁচ করা যায় কিনা — সেটা বলে না। এখানে \(X=1\) জানা থাকলে \(Y=1\)-এর শর্তাধীন সম্ভাবনা \(\tfrac{0.50}{0.60}=0.833\), অথচ \(X=0\) হলে তা \(\tfrac{0.20}{0.40}=0.50\) — দুটো আলাদা, তাই \(X\) সত্যিই \(Y\) সম্পর্কে তথ্য বহন করে, অর্থাৎ পরাধীনতা।
\(\sigma(X)\perp\sigma(Y)\)-এর সঙ্গে যোগসূত্র। \(X\) binary বলে \(\sigma(X)=\{\varnothing,\{X{=}0\},\{X{=}1\},\Omega\}\), অনুরূপ \(\sigma(Y)\)। random variable-দ্বয়ের স্বাধীনতার আসল সংজ্ঞা হলো তাদের generate-করা \(\sigma\)-বীজগণিতের স্বাধীনতা: \(\sigma(X)\)-এর প্রতিটি ঘটনা \(\sigma(Y)\)-এর প্রতিটি ঘটনার সঙ্গে স্বাধীন। উপরের চারটি কোষ-সমতাই ঠিক এই দাবি — কারণ \(\{X{=}i\}\) আর \(\{Y{=}j\}\) atom-গুলো একটা \(\pi\)-system গড়ে যা \(\sigma(X),\sigma(Y)\)-কে generate করে, তাই atom-পর্যায়ে factorization পেলে \(\pi\)-system criterion তা গোটা \(\sigma(X)\times\sigma(Y)\) জুড়ে তুলে দেয়। অর্থাৎ চারটি সংখ্যা-পরীক্ষা = অসীম-অনেক ঘটনার স্বাধীনতা।
কী শিখলাম। discrete \(X,Y\) স্বাধীন ঠিক তখনই যখন joint pmf প্রতিটি কোষে marginal-দের গুণফল হয় — joint-table হয় rank-one outer product (যেমন \(0.40\,\&\,0.60\) আর \(0.30\,\&\,0.70\) থেকে \(0.12,0.28,0.18,0.42\))। একটিমাত্র কোষ গুণফল না-মিললেই (যেমন \(0.20\neq0.12\)) স্বাধীনতা যায়, এমনকি marginal হুবহু এক থাকলেও — তাই marginal নয়, joint-ই নির্ণায়ক। আর এই কোষ-সমতাগুলোই হলো \(\sigma(X)\perp\sigma(Y)\): atom-পর্যায়ের factorization \(\pi\)-system criterion-এর জোরে গোটা \(\sigma\)-বীজগণিত জুড়ে স্বাধীনতা দেয়, তাই কয়েকটা সংখ্যা যাচাই করলেই random variable-দুটির পূর্ণ স্বাধীনতা প্রমাণ হয়ে যায়।
উদাহরণ ২ — Borel–Cantelli I: বিরল ঘটনা শেষমেশ থেমে যায় (★)¶
সেটআপ। একটা ঘটনা-ক্রম \(A_1,A_2,\dots\) ধরে নাও যেখানে \(n\)-তম ঘটনার সম্ভাবনা \(\mathbb P(A_n)=1/n^2\)। প্রথম Borel–Cantelli lemma বলে: যদি সম্ভাবনাগুলোর যোগফল \(\sum_n\mathbb P(A_n)<\infty\) (সসীম) হয়, তবে $$ \mathbb P\big(A_n\text{ infinitely often}\big)=\mathbb P\Big(\limsup_n A_n\Big)=0, $$ অর্থাৎ প্রায়-নিশ্চিতভাবে কেবল সসীম-অনেক \(A_n\) ঘটে। এখানে স্বাধীনতার কোনো দরকার নেই — শুধু যোগফল সসীম হলেই হবে। ("\(A_n\) i.o." = infinitely often = "অসীম-বার ঘটে"; \(\limsup_n A_n=\bigcap_N\bigcup_{n\ge N}A_n\) = "যত দূরেই যাও, তার পরেও আরও একটা ঘটে"।)
যোগফল কষা। \(\mathbb P(A_n)=1/n^2\)-এর যোগফল হলো বিখ্যাত Basel series: $$ \sum_{n=1}^\infty\frac1{n^2}=\frac{\pi^2}{6}\approx 1.6449<\infty . $$ সসীম — তাই BC-I সরাসরি লাগে, এবং উপসংহার: \(\mathbb P(A_n\text{ i.o.})=0\)।
কেন যোগফল সসীম হলেই থেমে যায় — এক লাইনের যুক্তি। "\(n\ge N\)-এর মধ্যে অন্তত একটা ঘটে" ঘটনার সম্ভাবনা subadditivity (উপ-যোগাত্মকতা) দিয়ে চাপা পড়ে লেজের যোগফলে: $$ \mathbb P\Big(\bigcup_{n\ge N}A_n\Big)\le\sum_{n\ge N}\mathbb P(A_n)=\sum_{n\ge N}\frac1{n^2}\xrightarrow[N\to\infty]{}0 . $$ যেহেতু পুরো যোগফল সসীম, তার লেজ \(N\to\infty\)-তে \(0\)-তে নামে; তাই "\(N\)-এর পরেও কিছু ঘটে" ঘটনার সম্ভাবনা \(0\) — মানে এক জায়গার পর আর কিছুই ঘটে না (a.s.)।
সিমুলেশন। \(n=1\) থেকে \(10^5\) পর্যন্ত প্রতিটি \(A_n\)-কে স্বাধীনভাবে সম্ভাবনা \(1/n^2\)-তে "ঘটাই/ঘটাই না", তারপর মোট কয়টা ঘটল গুনি:
import numpy as np
rng = np.random.default_rng(20260619)
N = 10**5
n = np.arange(1, N+1)
occurred = rng.random(N) < 1.0/n**2 # A_n ঘটল কি?
print("মোট ঘটনা সংখ্যা:", occurred.sum()) # ≈ 2
print("শেষ ঘটনার সূচক :", np.where(occurred)[0].max()+1) # ছোট n-এ আটকে
কী শিখলাম। Borel–Cantelli I: \(\sum_n\mathbb P(A_n)<\infty\) হলে \(\mathbb P(A_n\text{ i.o.})=0\) — কোনো স্বাধীনতা ছাড়াই, কেবল subadditivity দিয়ে লেজের যোগফল শূন্যে নামানো থেকে। \(\mathbb P(A_n)=1/n^2\)-এ যোগফল \(\pi^2/6\approx1.6449<\infty\), তাই a.s. কেবল সসীম-অনেক ঘটনা ঘটে; সিমুলেশনে \(n\le10^5\)-এ মোটে ≈২টি, আর গণনা saturate করে। স্বজ্ঞা: ঘটনা যথেষ্ট-বিরল হলে (যোগফল মিলে গেলে) একসময় তারা একেবারেই থেমে যায় — অসীম-বার ঘটার "জ্বালানি" ফুরিয়ে যায়। পরের উদাহরণে দেখব, যোগফল অসীম হলে আর স্বাধীনতা থাকলে ঠিক উল্টোটা ঘটে।
উদাহরণ ৩ — Borel–Cantelli II: স্বাধীন ও যথেষ্ট-ঘন ঘটনা চিরকাল ঘটে (★★)¶
সেটআপ। এবার ঘটনাগুলো স্বাধীন (independent), আর সম্ভাবনা \(\mathbb P(A_n)=1/n\)। দ্বিতীয় Borel–Cantelli lemma বলে: যদি \(A_n\)-গুলো স্বাধীন হয় এবং \(\sum_n\mathbb P(A_n)=\infty\) (অপসারী) হয়, তবে $$ \mathbb P\big(A_n\text{ infinitely often}\big)=1, $$ অর্থাৎ প্রায়-নিশ্চিতভাবে অসীম-অনেক \(A_n\) ঘটে। লক্ষ করো দুটো শর্তই অপরিহার্য — স্বাধীনতা ছাড়া কেবল \(\sum=\infty\) যথেষ্ট নয় (একই ঘটনা \(A_n=A\) বারবার নিলে \(\sum=\infty\) অথচ "i.o." কেবল \(A\)-র উপর নির্ভর করে)।
যোগফল কষা। \(\mathbb P(A_n)=1/n\)-এর যোগফল হলো harmonic series (হারমোনিক ধারা): $$ \sum_{n=1}^\infty\frac1n=\infty\qquad(\text{ধীরে, কিন্তু সীমাহীন — } \textstyle\sum_{n\le N}\tfrac1n\approx\ln N). $$ অপসারী, আর ঘটনাগুলো স্বাধীন — দুই শর্তই মিলল, তাই BC-II লাগে: \(\mathbb P(A_n\text{ i.o.})=1\)।
কেন স্বাধীনতা + অপসারিতা \(1\) দেয় — যুক্তির কঙ্কাল। "\(n\ge N\)-এর কোনোটিই ঘটে না" ঘটনার সম্ভাবনা, স্বাধীনতা ব্যবহার করে, গুণফলে ভাঙে; তারপর \(1-x\le e^{-x}\) অসমতা দিয়ে: $$ \mathbb P\Big(\bigcap_{n=N}^{M}A_n^{\,c}\Big)=\prod_{n=N}^{M}\big(1-\mathbb P(A_n)\big)\le\exp!\Big(-!!\sum_{n=N}^{M}\mathbb P(A_n)\Big)\xrightarrow[M\to\infty]{}e^{-\infty}=0 . $$ যেহেতু লেজের যোগফল \(\sum_{n\ge N}1/n=\infty\), ঘাত-চিহ্নের ভেতরটা \(-\infty\), তাই "\(N\)-এর পর কিছুই ঘটে না"-র সম্ভাবনা \(0\) — অর্থাৎ "\(N\)-এর পর অন্তত একটা ঘটে" সম্ভাবনা \(1\), সব \(N\)-এর জন্য, মানে অসীম-বার ঘটে। এখানেই স্বাধীনতা গুণফল-রূপটা সম্ভব করল — BC-I-এ যা লাগেনি।
সিমুলেশন। \(n=1\) থেকে \(10^5\), প্রতিটি \(A_n\) স্বাধীনভাবে সম্ভাবনা \(1/n\)-তে:
import numpy as np
rng = np.random.default_rng(20260619)
N = 10**5
n = np.arange(1, N+1)
occurred = rng.random(N) < 1.0/n # স্বাধীন A_n
print("মোট ঘটনা সংখ্যা:", occurred.sum()) # ≈ 8, আর বাড়তেই থাকে
print("ln(N) =", round(np.log(N), 2)) # ≈ 11.5 — তাত্ত্বিক প্রবণতা
উদাহরণ ২-এর সঙ্গে তীক্ষ্ণ বৈসাদৃশ্য। দুটো ক্ষেত্রেই সম্ভাবনা \(0\)-র দিকে নামছে, তবু ভাগ্য সম্পূর্ণ বিপরীত:
| \(\mathbb P(A_n)\) | \(\sum\mathbb P(A_n)\) | স্বাধীন? | \(\mathbb P(A_n\text{ i.o.})\) | |
|---|---|---|---|---|
| উদাহরণ ২ (BC-I) | \(1/n^2\) | \(\pi^2/6\approx1.6449\) (সসীম) | লাগে না | \(0\) |
| উদাহরণ ৩ (BC-II) | \(1/n\) | \(\infty\) (অপসারী) | লাগে | \(1\) |
\(1/n^2\) আর \(1/n\) — দুই প্রতিবেশী ক্রম, একটির যোগফল সসীম, অপরটির অসীম। এই একটিমাত্র পার্থক্য (সাথে স্বাধীনতা) উত্তরকে \(0\) থেকে \(1\)-এ উল্টে দেয়। কোনো মাঝামাঝি নেই — যা পরের উদাহরণে 0–1 law আরও সাধারণভাবে ব্যাখ্যা করবে।
কী শিখলাম। Borel–Cantelli II: ঘটনাগুলো স্বাধীন এবং \(\sum_n\mathbb P(A_n)=\infty\) হলে \(\mathbb P(A_n\text{ i.o.})=1\) — অসীম-অনেক ঘটে। \(\mathbb P(A_n)=1/n\)-এ harmonic series \(\sum1/n=\infty\), তাই a.s. অসীম-বার ঘটে; সিমুলেশনে \(n\le10^5\)-এ ≈৮টি, আর গণনা saturate না করে \(\ln N\)-এর হারে বাড়তেই থাকে। মূল কৌশল: স্বাধীনতা "কিছুই ঘটে না"-কে গুণফলে ভাঙতে দেয়, আর \(1-x\le e^{-x}\) অপসারী যোগফলকে \(e^{-\infty}=0\)-এ ফেলে। সবচেয়ে বড় শিক্ষা — উদাহরণ ২-এর সাথে মিলিয়ে: \(1/n^2\) (যোগফল সসীম) দেয় \(0\), \(1/n\) (যোগফল অসীম, স্বাধীন) দেয় \(1\) — স্বাধীনতা + অপসারিতা মিলে সম্ভাবনাকে ঠিক উল্টো মেরুতে নিয়ে যায়।
উদাহরণ ৪ — tail event ও Kolmogorov 0–1 law (★★)¶
সেটআপ। \(\varepsilon_1,\varepsilon_2,\dots\) স্বাধীন random sign (দৈব-চিহ্ন), প্রতিটি \(\pm1\) সমান সম্ভাবনায়। বিচার্য ঘটনা: $$ B=\Big{\textstyle\sum_{n=1}^\infty\dfrac{\varepsilon_n}{n}\ \text{converges (অভিসৃত হয়)}\Big}. $$ দাবি দুটো ধাপে: (ক) \(B\) একটা tail event (লেজ-ঘটনা) — তাই Kolmogorov 0–1 law অনুসারে \(\mathbb P(B)\in\{0,1\}\); (খ) আসলে \(\mathbb P(B)=1\) (a.s. অভিসৃত)।
(ক) কেন \(B\) tail-পরিমাপযোগ্য। tail \(\sigma\)-algebra হলো \(\mathcal T=\bigcap_{N}\sigma(\varepsilon_N,\varepsilon_{N+1},\dots)\) — যে-সব ঘটনা কোনো সসীম উপসর্গের (finite prefix) উপর নির্ভর করে না। মূল পর্যবেক্ষণ: একটা ধারার অভিসারিতা তার প্রথম যে-কটা পদ বদলালেও বদলায় না। কারণ যেকোনো \(N\)-এর জন্য $$ \sum_{n=1}^\infty\frac{\varepsilon_n}{n}\ \text{অভিসৃত}\quad\Longleftrightarrow\quad \sum_{n=N}^\infty\frac{\varepsilon_n}{n}\ \text{অভিসৃত}, $$ যেহেতু দুই ধারার পার্থক্য একটা সসীম যোগফল \(\sum_{n<N}\varepsilon_n/n\) — যা সর্বদা সসীম, তাই অভিসারিতা-প্রশ্নে কোনো প্রভাব ফেলে না। অর্থাৎ \(B\) প্রতিটি লেজ-\(\sigma\)-বীজগণিত \(\sigma(\varepsilon_N,\varepsilon_{N+1},\dots)\)-এ পড়ে (যেহেতু \(\sum_{n\ge N}\varepsilon_n/n\) কেবল \(\varepsilon_N,\varepsilon_{N+1},\dots\)-এর উপর নির্ভর), তাই তাদের ছেদ \(\mathcal T\)-তেও পড়ে। \(B\) tail-পরিমাপযোগ্য।
0–1 law প্রয়োগ। \(\varepsilon_n\)-গুলো স্বাধীন, আর \(B\in\mathcal T\) — তাই Kolmogorov 0–1 law সরাসরি লাগে: $$ \mathbb P(B)\in{0,1}. $$ গভীর কথা: \(B\) একটা দৈব-ঘটনা মনে হলেও তার সম্ভাবনা নির্ধারিত (deterministic) — হয় প্রায়-সব নমুনা-পথ অভিসৃত, নয় প্রায়-কোনোটিই নয়; "অর্ধেক ক্ষেত্রে অভিসৃত হয়" বলে কিছু হতে পারে না। এটাই 0–1 law-এর বিস্ময়: tail-ঘটনা \(B\) স্বাধীন ক্রমের সব পদের উপর নির্ভর করে, অথচ কোনো একক পদ তার ভাগ্য বদলাতে পারে না — তাই \(B\) একই সাথে \(\sigma(\varepsilon_1,\dots)\)-পরিমাপযোগ্য ও তার নিজের থেকে স্বাধীন; কিন্তু একটা ঘটনা নিজের থেকে স্বাধীন হলে \(\mathbb P(B)=\mathbb P(B\cap B)=\mathbb P(B)^2\), যার সমাধান কেবল \(0\) বা \(1\)। এই এক-লাইনের সমীকরণই 0–1 law-এর হৃৎপিণ্ড।
(খ) কোন দিকে — \(0\) না \(1\)? 0–1 law বলে দেয় উত্তর \(0\) বা \(1\), কিন্তু কোনটা সেটা বলতে আলাদা যুক্তি লাগে। এখানে \(\mathbb E[\varepsilon_n/n]=0\) আর পদগুলোর variance-যোগফল সসীম: $$ \sum_{n=1}^\infty\operatorname{Var}!\Big(\frac{\varepsilon_n}{n}\Big)=\sum_{n=1}^\infty\frac1{n^2}=\frac{\pi^2}{6}\approx1.6449<\infty . $$ স্বাধীন, শূন্য-গড়, সসীম-variance-যোগফল পদের ধারা a.s. অভিসৃত হয় (Kolmogorov-র two-series / one-series উপপাদ্য)। তাই এখানে \(\mathbb P(B)=1\) — random sign সত্ত্বেও \(\sum\varepsilon_n/n\) প্রায়-নিশ্চিতভাবে একটা (এলোমেলো, কিন্তু সসীম) মানে গিয়ে থামে। লক্ষণীয়, এখানে আবার সেই \(\sum1/n^2=\pi^2/6\) ফিরে এল — কিন্তু এবার variance-যোগফল হিসেবে।
সতর্কতা — চিহ্ন না থাকলে। \(\varepsilon_n\) বাদ দিয়ে নিরেট \(\sum 1/n\) নিলে সেটি অপসারী (\(=\infty\))। random sign-ই এখানে আংশিক-যোগফলকে দোলাতে-দোলাতে থিতু করে — variance সসীম থাকায় দোলন নিয়ন্ত্রণে। এটাই দেখায় 0–1 law "কোন মান" বলে না, কেবল "মাঝামাঝি কিছু নয়" বলে; প্রকৃত মান ঠিক করতে পদের গঠন (এখানে variance-যোগফল) খতিয়ে দেখতে হয়।
কী শিখলাম। একটা ঘটনা tail event যদি তা কোনো সসীম উপসর্গ বদলালেও অপরিবর্তিত থাকে — যেমন \(\{\sum\varepsilon_n/n\text{ অভিসৃত}\}\), কারণ প্রথম কটা পদ বাদ দেওয়ায় শুধু একটা সসীম যোগফল সরে, অভিসারিতা অটুট। স্বাধীন ক্রমে Kolmogorov 0–1 law এমন ঘটনার সম্ভাবনাকে \(\{0,1\}\)-এ বাঁধে — দৈব-দেখতে প্রশ্নের উত্তর আসলে নির্ধারিত। এখানে variance-যোগফল \(\sum1/n^2=\pi^2/6<\infty\) হওয়ায় উত্তর \(1\) (a.s. অভিসৃত)। মূল বার্তা দুই স্তরের: 0–1 law বলে দেয় উত্তর প্রান্তিক (\(0\) বা \(1\), মাঝামাঝি নয়), কিন্তু কোন প্রান্ত তা ঠিক করতে আলাদা বিশ্লেষণ লাগে — আর SLLN-ই (পরের উদাহরণ) এমন একটা tail-ঘটনার বিখ্যাততম দৃষ্টান্ত যেখানে উত্তর \(1\)।
উদাহরণ ৫ — SLLN কাজে: গড় সত্যিকারের গড়ে গিয়ে থামে (★)¶
সেটআপ। \(X_1,X_2,\dots\) স্বাধীন ও সমবণ্টিত (i.i.d., independent and identically distributed), \(\mathbb E\lvert X\rvert<\infty\)। SLLN বলে নমুনা-গড় (sample mean) প্রায়-নিশ্চিতভাবে সত্যিকারের গড়ে যায়: $$ \bar X_n=\frac1n\sum_{i=1}^n X_i\ \xrightarrow{\ \text{a.s.}\ }\ \mathbb E[X]. $$ "a.s." মানে কেবল বণ্টনে নয় — প্রায়-প্রতিটি নমুনা-পথ ধরে গড়ের ক্রম \(\mathbb E[X]\)-এ গিয়ে থিতু হয়। আর "\(\bar X_n\to\mu\)" একটা tail event (প্রথম কটা \(X_i\) বদলালে limit বদলায় না), তাই 0–1 law-এর সাথেও মিলে যায় — SLLN বলছে সেই tail-সম্ভাবনাটা \(1\)।
কষা ১ — \(X_i\sim\text{Exp}(1)\)। exponential বণ্টন (rate \(1\))-এর গড় \(\mathbb E[X]=1\), তাই SLLN বলে \(\bar X_n\to1\)। সিমুলেশনে ক্রমবর্ধমান \(n\)-এ গড় দেখি:
import numpy as np
rng = np.random.default_rng(20260619)
X = rng.exponential(1.0, size=10**6) # Exp(1): সত্যিকারের গড় = 1
for n in [10, 100, 10**3, 10**4, 10**5, 10**6]:
print(f"n={n:>7}: মানে = {X[:n].mean():.4f}")
ছোট \(n\)-এ গড় বেশ এলোমেলো (\(n=10\)-এ মোটে \(0.5194\), প্রায় অর্ধেক), কিন্তু \(n\) বাড়ার সঙ্গে তা দৃঢ়ভাবে \(1\)-এর দিকে গুটিয়ে আসে — \(n=10^6\)-এ \(1.0007\), লক্ষ্যের প্রায় গায়ে। লক্ষণীয়, অভিসরণ মসৃণ নয় (\(0.9710\) থেকে \(0.9603\)-এ সামান্য নামাও দেখা যায়) — SLLN প্রতিটি ধাপে কাছে-যাওয়ার নিশ্চয়তা দেয় না, কেবল সীমায় গিয়ে থামার a.s. নিশ্চয়তা দেয়।
কষা ২ — \(X_i\sim\text{Bernoulli}(0.3)\)। সত্যিকারের গড় \(\mathbb E[X]=0.3\) (সাফল্যের সম্ভাবনা)। \(n=10^6\)-এ:
rng = np.random.default_rng(20260619)
B = (rng.random(10**6) < 0.3).astype(float) # Bernoulli(0.3)
print(f"n=10^6: মানে = {B.mean():.4f}") # ≈ 0.2999
কী শিখলাম। SLLN: i.i.d. \(X_i\)-তে \(\mathbb E\lvert X\rvert<\infty\) হলে \(\bar X_n\to\mathbb E[X]\) প্রায়-নিশ্চিতভাবে — empirical গড় সত্যিকারের গড়কে ধরে ফেলে। \(\text{Exp}(1)\)-এ (\(\mathbb E[X]=1\)) গড় \(0.5194\to0.9710\to\dots\to1.0007\) (\(n=10\) থেকে \(10^6\)), আর \(\text{Bernoulli}(0.3)\)-এ \(\bar X_{10^6}=0.2999\to0.3\)। ছোট \(n\)-এ অস্থির, বড় \(n\)-এ দৃঢ়; অভিসরণ মসৃণ নয় কিন্তু সীমায় নিশ্চিত। গভীর বার্তা: "\(\bar X_n\to\mu\)" একটা tail-ঘটনা যার সম্ভাবনা \(1\) — তাই SLLN আসলে Kolmogorov 0–1 law-এর জগতেরই বাসিন্দা, আর Bernoulli-রূপে এটি "আপেক্ষিক কম্পাঙ্ক সম্ভাবনায় স্থির হয়" দাবিটাকেই সবল করে তোলে। তবে এ সবের প্রাণভোমরা শর্ত \(\mathbb E\lvert X\rvert<\infty\) — পরের উদাহরণে দেখব সেটি ভাঙলে গোটা ছবিই ভেঙে পড়ে।
উদাহরণ ৬ — কখন SLLN ভাঙে: Cauchy (★★)¶
সেটআপ। SLLN-এর একমাত্র নিঃশর্ত-অপরিহার্য অনুমান হলো \(\mathbb E\lvert X\rvert<\infty\)। সেটি ভাঙলে কী হয়? Cauchy বণ্টন (standard Cauchy) ঠিক সেই প্রতি-উদাহরণ। এর pdf \(f(x)=\dfrac{1}{\pi(1+x^2)}\), আর গুরুত্বপূর্ণভাবে $$ \mathbb E\lvert X\rvert=\int_{-\infty}^{\infty}\frac{\lvert x\rvert}{\pi(1+x^2)}\,dx=\infty , $$ কারণ বড় \(\lvert x\rvert\)-এ integrand \(\sim\dfrac{1}{\pi\lvert x\rvert}\), আর \(\int^\infty\frac{dx}{x}\) অপসারী (সেই harmonic-জাতীয় লেজ আবার!)। যেহেতু গড়ই সংজ্ঞায়িত নয়, \(\bar X_n\) কোনো নির্দিষ্ট সংখ্যায় থিতু হওয়ার "লক্ষ্য"ই নেই — SLLN প্রযোজ্য নয়।
কষা — running mean ঘোরে, থামে না। Cauchy থেকে নমুনা টেনে ক্রমবর্ধমান \(n\)-এ গড় দেখি:
import numpy as np
rng = np.random.default_rng(20260619)
C = rng.standard_cauchy(size=10**6) # Cauchy: গড় অসংজ্ঞায়িত
for n in [10**2, 10**4, 10**6]:
print(f"n={n:>7}: running mean = {C[:n].mean():.3f}")
কোনো অভিসরণ নেই: \(n=100\)-এ \(1.126\), \(n=10^4\)-এ \(0.851\), \(n=10^6\)-এ এমনকি ঋণাত্মক \(-0.173\) — \(n\) লক্ষ-কোটি গুণ বাড়লেও গড় স্থির হওয়ার বদলে এদিক-ওদিক ঘুরতে (wander) থাকে। কারণ Cauchy-র heavy tail (ভারী-লেজ) মাঝে-মাঝে এমন বিশাল মান ছোড়ে যে একটিমাত্র চরম নমুনা গোটা চলমান-গড়কে এক ঝটকায় টেনে সরিয়ে দেয়; আর যত \(n\) বাড়ে, তত বড় চরম-মানের সম্ভাবনাও বাড়ে — তাই দোলন কখনো প্রশমিত হয় না। (গাণিতিকভাবে: Cauchy-র একটা চমক — \(X_i\) i.i.d. Cauchy হলে \(\bar X_n\)-ও হুবহু একই Cauchy বণ্টনের, তাই \(n\) বাড়লেও \(\bar X_n\) মোটেই সরু হয় না।)
Exp(1)-এর সঙ্গে তীব্র বৈসাদৃশ্য। একই কোড-কাঠামোয় দুই বণ্টনের ভাগ্য সম্পূর্ণ বিপরীত:
| বণ্টন | \(\mathbb E\lvert X\rvert\) | SLLN? | \(\bar X_n\)-এর আচরণ |
|---|---|---|---|
| \(\text{Exp}(1)\) | \(1<\infty\) | প্রযোজ্য | \(\to 1\)-এ থিতু (\(1.0007\) at \(10^6\)) |
| \(\text{Cauchy}\) | \(\infty\) | প্রযোজ্য নয় | চিরকাল ঘোরে (\(-0.173\) at \(10^6\)) |
পার্থক্যের গোড়ায় ঠিক একটি শর্ত: SLLN-এর একমাত্র শর্ত হলো \(\mathbb E\lvert X\rvert<\infty\) (গড় সসীমভাবে সংজ্ঞায়িত)। \(\text{Exp}(1)\)-এ \(\mathbb E\lvert X\rvert=1<\infty\), তাই \(\bar X_n\) প্রায়-নিশ্চিতভাবে সত্য গড় \(1\)-এ থিতু হয়। কিন্তু standard Cauchy distribution-এ \(\mathbb E\lvert X\rvert=\int_{-\infty}^{\infty}\frac{\lvert x\rvert}{\pi(1+x^2)}\,dx=\infty\) — গড়ই অস্তিত্বহীন। SLLN-এর অনুমানই ভাঙে, তাই উপসংহারও ভাঙে: \(\bar X_n\) কোনো সংখ্যায় থিতু না হয়ে চিরকাল লাফাতে থাকে (\(n=10^2,10^4,10^6\)-এ \(1.126, 0.851, -0.173\) — কোনো প্রবণতা নেই)। আসলে Cauchy-র একটি চমৎকার ধর্ম: \(\bar X_n\)-এর distribution আবার standard Cauchy — অর্থাৎ \(10^6\)টি নমুনার গড় একটিমাত্র নমুনার চেয়ে এক বিন্দুও বেশি নিখুঁত নয়।
কী শিখলাম (crack of SLLN)। SLLN জাদু নয় — তার মেরুদণ্ড \(\mathbb E\lvert X\rvert<\infty\)। heavy-tailed Cauchy-তে এই শর্ত ভাঙে, গড় অস্তিত্বহীন, আর empirical mean কখনোই থিতু হয় না। তাই বাস্তব data-তে 'গড় নিচ্ছি, নিশ্চয়ই converge করবে' — এই অনুমান heavy tail-এ বিপজ্জনক।
৪ · প্রমাণ ও উৎপাদন¶
এই অংশে §২-এর সংজ্ঞা থেকে শুরু করে অধ্যায়ের ছয়টি স্তম্ভ-ফল ধাপে ধাপে উৎপাদন (derive) করা হয় — দুই দিক থেকে। একদিকে মাপ-তত্ত্বের যন্ত্র (measure-theoretic machinery): independence কীভাবে generator-পরিবার থেকে গোটা σ-algebra-তে ছড়ায় (π-system criterion), আর তা থেকে Kolmogorov-এর 0–1 সূত্র — যা বলে tail-ঘটনার সম্ভাব্যতা কেবল \(0\) বা \(1\) হতে পারে। অন্যদিকে সীমা-আচরণের যন্ত্র (limit machinery): দুই Borel–Cantelli lemma (\(A_n\) ঘটনাগুলো অসীমবার ঘটে কি না তার দুই-মুখী মানদণ্ড) এবং strong law of large numbers (SLLN) — প্রথমে সসীম চতুর্থ আঘূর্ণে (4th moment) পরিষ্কার Cantelli-পথে, তারপর কেবল \(\mathbb E\lvert X\rvert<\infty\)-তে Kolmogorov-এর maximal inequality হয়ে সাধারণ রূপের রূপরেখা। প্রতিটি প্রমাণে কেন প্রতিটি পদক্ষেপ বৈধ — কোন সংজ্ঞা, কোন পূর্ববর্তী ফল (7.2-এর Dynkin π–λ ও measure-ধর্ম, 7.3-এর independence ও random variable, 7.4-এর monotone convergence/Tonelli, এ-অংশেরই আগের lemma), বা কোন বীজগাণিতিক অভেদ ব্যবহৃত হচ্ছে — তা স্পষ্ট করা হয়েছে। প্রতিটি প্রমাণের শিরোনামে কঠিনতা-চিহ্ন (difficulty tag):
- ★ — মৌলিক, প্রথম পাঠেই বোঝা উচিত।
- ★★ — মাঝারি, একটু কৌশল লাগে।
- ★★★ — গভীর, প্রথম পাঠে কিছু অংশ এড়িয়ে যাওয়া যায় (যথাস্থানে চিহ্নিত)।
স্মরণ — মূল সংজ্ঞা (§২ থেকে)। গোটা অংশে \((\Omega,\mathcal F,\mathbb P)\) একটি probability space (\(\mathbb P(\Omega)=1\))। দুটি ঘটনা \(A,B\) স্বাধীন (independent) যদি \(\mathbb P(A\cap B)=\mathbb P(A)\,\mathbb P(B)\)। দুটি sub-σ-algebra \(\mathcal G_1,\mathcal G_2\subseteq\mathcal F\) স্বাধীন (লিখি \(\mathcal G_1\perp\mathcal G_2\)) যদি \(\mathbb P(A\cap B)=\mathbb P(A)\mathbb P(B)\) সব \(A\in\mathcal G_1,\,B\in\mathcal G_2\)-এর জন্য। random variable পরিবার \((X_n)\) স্বাধীন যদি তাদের জন্ম-দেওয়া σ-algebra-গুলো \(\sigma(X_n)\) পরস্পর (পরিবার-অর্থে) স্বাধীন। একটি ঘটনা-অনুক্রম \((A_n)_{n\ge 1}\)-এর জন্য limsup (উপরিসীমা-ঘটনা)
কারণ একটি ফলাফল \(\omega\) এতে থাকে ⟺ প্রতিটি \(N\)-এর জন্য কোনো \(n\ge N\)-তে \(\omega\in A_n\) ⟺ \(\omega\) অসীম-সংখ্যক \(A_n\)-তে আছে। শেষ মূল-বস্তু: tail σ-algebra (লেজ-সিগমা-বীজগণিত) — random variable অনুক্রম \((X_n)\)-এর জন্য
যেখানে \(\sigma(X_m,X_{m+1},\dots)\) হলো "\(m\)-তম থেকে পরের সব \(X\)-যা জানায়" সবচেয়ে ছোট σ-algebra। \(\mathcal T\)-তে থাকা ঘটনা প্রথম \(m-1\)টি চলক বদলালেও বদলায় না — যেকোনো \(m\)-এর জন্য — তাই এরা "অসীম-দূরের লেজ"-এর তথ্য (যেমন \(\{\lim_n \bar X_n\) exists\(\}\), \(\{\sum X_n\) converges\(\}\), \(\{\limsup X_n>c\}\))।
এ-অংশের যুক্তি-শৃঙ্খল: প্রমাণ ১ (π-system criterion) দাঁড়ায় কেবল 7.2-এর Dynkin π–λ-র উপর; প্রমাণ ২ (Borel–Cantelli I) স্বাধীনতা ছাড়াই কেবল 7.2-এর countable subadditivity ও convergent series-এর tail থেকে; প্রমাণ ৩ (Borel–Cantelli II) independence + \(1-x\le e^{-x}\); প্রমাণ ৪ (Kolmogorov 0–1) প্রমাণ ১-কে ইঞ্জিন বানায়; প্রমাণ ৫ (4th-moment SLLN) প্রমাণ ২ (Borel–Cantelli I)-কে; আর প্রমাণ ৬ (maximal inequality + সাধারণ SLLN) প্রমাণ ৫-এর সীমাবদ্ধতা ভাঙার রূপরেখা। তাই প্রমাণ ১ (π-system) এ-অধ্যায়ের চাবি-ইট — independence-এর গোটা স্থাপত্য তার উপর দাঁড়ায়।
প্রমাণ ১ — π-system independence criterion (★★)¶
দাবি। ধরা যাক \(\mathcal P_1,\mathcal P_2\subseteq\mathcal F\) দুটি π-system (পাই-সিস্টেম: সসীম intersection-বদ্ধ, অর্থাৎ \(A,B\in\mathcal P_i\Rightarrow A\cap B\in\mathcal P_i\); 7.2-এর সংজ্ঞা)। যদি এরা স্বাধীন হয় —
তবে তাদের জন্ম-দেওয়া σ-algebra-ও স্বাধীন: \(\sigma(\mathcal P_1)\perp\sigma(\mathcal P_2)\)।
কেন এটি জরুরি। বাস্তবে স্বাধীনতা সবসময় ছোট, পরিচিত পরিবারে যাচাই করা যায় — যেমন দুটি random variable-এর জন্য \(\{X\le x\}\) ও \(\{Y\le y\}\) ray-ঘটনা (এরা π-system), অথবা একটা প্রক্রিয়ার "প্রথম \(n\)" বনাম "পরের সব"-এর cylinder-ঘটনা। কিন্তু আমাদের দরকার গোটা \(\sigma(X)\) ও \(\sigma(Y)\)-এর স্বাধীনতা। এই lemma সেই ফাঁক ভরাট করে: π-system-এ মিললেই σ-algebra-তে মেলে — ঠিক যেমন 7.2-এ π–λ measure-uniqueness দিয়েছিল ("π-system-এ মিললে measure সর্বত্র মেলে")।
ধাপ ১ — একটি \(A\) স্থির করে একটি good-set শ্রেণি গড়া। প্রথমে একটি স্থির \(A\in\mathcal P_1\) নিই, এবং সংজ্ঞা দিই সেই সব ঘটনার শ্রেণি যেগুলো \(A\)-এর সঙ্গে product-সূত্র মানে:
দাবির শর্ত বলছে \(\mathcal P_2\subseteq\mathcal D_A\) (কারণ সব \(B\in\mathcal P_2\)-এ product-সূত্র ধরা আছে, আর \(A\in\mathcal P_1\))। লক্ষ্য: দেখানো \(\sigma(\mathcal P_2)\subseteq\mathcal D_A\) — তাহলেই \(A\)-এর সাথে গোটা \(\sigma(\mathcal P_2)\) স্বাধীন।
ধাপ ২ — \(\mathcal D_A\) একটি λ-system। 7.2-এর তিন λ-স্বীকার্য (Dynkin system) যাচাই করি:
- (λ1) \(\Omega\in\mathcal D_A\): \(\mathbb P(A\cap\Omega)=\mathbb P(A)=\mathbb P(A)\cdot 1=\mathbb P(A)\mathbb P(\Omega)\), যেহেতু \(\mathbb P(\Omega)=1\)। ✓ (এখানেই probability measure লাগে — \(\mathbb P(\Omega)=1\)।)
- (λ2) proper-difference-বদ্ধ: ধরা যাক \(B_1,B_2\in\mathcal D_A\) এবং \(B_1\subseteq B_2\)। তখন \(A\cap(B_2\setminus B_1)=(A\cap B_2)\setminus(A\cap B_1)\) এবং \(A\cap B_1\subseteq A\cap B_2\), তাই সসীম ভর বিয়োগ (7.2 monotonicity, finite measure) বৈধ: $$ \mathbb P\bigl(A\cap(B_2\setminus B_1)\bigr)=\mathbb P(A\cap B_2)-\mathbb P(A\cap B_1)=\mathbb P(A)\mathbb P(B_2)-\mathbb P(A)\mathbb P(B_1), $$ যেখানে দুই পদেই \(\mathcal D_A\)-সদস্যতা বসানো হলো। ডান পাশ \(=\mathbb P(A)\bigl(\mathbb P(B_2)-\mathbb P(B_1)\bigr)=\mathbb P(A)\,\mathbb P(B_2\setminus B_1)\)। কাজেই \(B_2\setminus B_1\in\mathcal D_A\)। ✓
- (λ3) ক্রমবর্ধমান গণনাযোগ্য union-বদ্ধ: ধরা যাক \(B_n\in\mathcal D_A\) ও \(B_n\uparrow B\) (অর্থাৎ \(B_n\subseteq B_{n+1}\), \(B=\bigcup_n B_n\))। তখন \(A\cap B_n\uparrow A\cap B\)-ও, তাই 7.2-এর নিচ-থেকে-ধারাবাহিকতা (continuity from below) দুই বার লাগিয়ে: $$ \mathbb P(A\cap B)=\lim_n\mathbb P(A\cap B_n)=\lim_n\mathbb P(A)\mathbb P(B_n)=\mathbb P(A)\lim_n\mathbb P(B_n)=\mathbb P(A)\mathbb P(B). $$ কাজেই \(B\in\mathcal D_A\)। ✓
তিনটিই ধরায় \(\mathcal D_A\) একটি λ-system।
ধাপ ৩ — π–λ দিয়ে \(\sigma(\mathcal P_2)\) গিলে ফেলা। \(\mathcal P_2\) একটি π-system এবং \(\mathcal P_2\subseteq\mathcal D_A\) (ধাপ ১), আর \(\mathcal D_A\) একটি λ-system (ধাপ ২)। 7.2-এর Dynkin π–λ theorem সরাসরি দেয় \(\sigma(\mathcal P_2)\subseteq\mathcal D_A\)। অর্থাৎ:
এই ধাপ-৩-ই lemma-র প্রাণ: একটি ছোট, সরল মানদণ্ড (π-system-এ product-সূত্র) একটি λ-system-কে "ভরে" দেয়, আর λ-system যা একটি π-system ধারণ করে সে গোটা generated σ-algebra ধারণ করে।
ধাপ ৪ — দ্বিতীয় চলকেও একই যুক্তি (symmetry / bootstrap)। এবার (†) থেকে আমরা প্রথম পরিবারকে প্রসারিত করব। একটি স্থির \(B\in\sigma(\mathcal P_2)\) নিই, এবং সংজ্ঞা দিই
(†) ঠিক বলছে \(\mathcal P_1\subseteq\mathcal D'_B\) (যেকোনো \(A\in\mathcal P_1\)-এ product-সূত্র এখন সব \(B\in\sigma(\mathcal P_2)\)-এ ধরা)। ধাপ ২-এর হুবহু একই তিন-স্বীকার্য-যাচাই (ভূমিকায় \(A\) ও \(B\)-এর ভূমিকা অদলবদল) দেখায় \(\mathcal D'_B\)-ও একটি λ-system। যেহেতু \(\mathcal P_1\) π-system, π–λ আবার দেয় \(\sigma(\mathcal P_1)\subseteq\mathcal D'_B\), অর্থাৎ
এটিই \(\sigma(\mathcal P_1)\perp\sigma(\mathcal P_2)\)। ∎
বহু-পরিবার সংস্করণ (multi-family version)। ঠিক একই দুই-ধাপ bootstrap (\(n\) পরিবারে একে একে) প্রমাণ করে: যদি \(\mathcal P_1,\dots,\mathcal P_n\) এমন π-system হয় যে প্রতিটি \(\{A_1,\dots,A_n\}\) (যেখানে \(A_i\in\mathcal P_i\)) পারস্পরিক-স্বাধীনতা-সূত্র
মানে, তবে \(\sigma(\mathcal P_1),\dots,\sigma(\mathcal P_n)\) পারস্পরিক স্বাধীন। আরও সাধারণভাবে গণনাযোগ্য বা অগণনীয় সংগ্রহের জন্য — যেহেতু independence-এর সংজ্ঞাই কেবল সসীম উপ-সংগ্রহ ছোঁয় — একই ফল প্রতিটি সসীম উপ-পরিবারে প্রয়োগ করলে পাওয়া যায়। এই multi-family রূপ-ই প্রমাণ ৪-এ Kolmogorov 0–1 সূত্রে সরাসরি লাগবে।
এক বাক্যে: একটি \(A\) স্থির রেখে \(\{B:\mathbb P(A\cap B)=\mathbb P(A)\mathbb P(B)\}\) একটি λ-system হয় যা π-system \(\mathcal P_2\) ধারণ করে, তাই Dynkin π–λ দিয়ে সে \(\sigma(\mathcal P_2)\) ধারণ করে; দ্বিতীয় চলকে একই যুক্তি bootstrap করলে \(\sigma(\mathcal P_1)\perp\sigma(\mathcal P_2)\) — আর সসীম-উপপরিবারে পুনরাবৃত্তিতে বহু-পরিবার রূপ।
প্রমাণ ২ — Borel–Cantelli lemma I (★)¶
দাবি (প্রথম Borel–Cantelli lemma)। যেকোনো ঘটনা-অনুক্রম \((A_n)\)-এর জন্য, স্বাধীনতা লাগে না, কেবল
স্বজ্ঞা: যদি ঘটনাগুলোর সম্ভাব্যতার যোগফল সসীম হয় (অর্থাৎ গড়ে সসীম-সংখ্যক ঘটনা ঘটে — কারণ \(\mathbb E[\sum_n\mathbf 1_{A_n}]=\sum_n\mathbb P(A_n)<\infty\), 7.4 Tonelli), তবে "অসীমবার ঘটা" একটি শূন্য-সম্ভাব্যতার ব্যতিক্রম।
ধাপ ১ — সংজ্ঞা খুলে monotone tail। সংজ্ঞা থেকে \(\limsup_n A_n=\bigcap_{N\ge 1}\bigl(\bigcup_{n\ge N}A_n\bigr)\)। লিখি \(B_N:=\bigcup_{n\ge N}A_n\)। লক্ষ করি \(B_1\supseteq B_2\supseteq B_3\supseteq\cdots\) (বড় \(N\)-এ কম পদের union, তাই ছোট ঘটনা), অর্থাৎ \(B_N\downarrow\bigcap_N B_N=\limsup_n A_n\)। যেহেতু \(\mathbb P(B_1)\le 1<\infty\) (finite measure), 7.2-এর উপর-থেকে-ধারাবাহিকতা (continuity from above) বৈধ:
ধাপ ২ — প্রতিটি tail-কে যোগফল-লেজ দিয়ে বাঁধা। যেকোনো স্থির \(N\)-এ, 7.2-এর countable subadditivity (\(\mathbb P\)-এর গণনাযোগ্য union-অসমতা) সরাসরি দেয়:
ধাপ ৩ — convergent series-এর লেজ শূন্যে যায়। ধরা শর্ত \(\sum_{n\ge 1}\mathbb P(A_n)<\infty\) — একটি অভিসৃত অঋণাত্মক ধারা। যেকোনো অভিসৃত ধারার লেজ-যোগফল শূন্যে নামে: \(\sum_{n\ge N}\mathbb P(A_n)\to 0\) যখন \(N\to\infty\) (কারণ এটি \(\sum_{n\ge 1}\mathbb P(A_n)-\sum_{n=1}^{N-1}\mathbb P(A_n)\), আর আংশিক-যোগফল পূর্ণ-যোগফলে অভিসৃত)। (2) দিয়ে \(0\le\mathbb P(B_N)\le\sum_{n\ge N}\mathbb P(A_n)\to 0\), তাই sandwich-এ \(\mathbb P(B_N)\to 0\)। (1)-এ বসিয়ে \(\mathbb P(\limsup_n A_n)=0\)। ∎
লক্ষণীয়: কোথাও \(A_n\)-দের স্বাধীনতা ব্যবহৃত হয়নি — এটি সম্পূর্ণ সাধারণ lemma, কেবল additivity ও convergence-এর উপর দাঁড়ানো। (উল্টোপথ — যোগফল অসীম হলে i.o. — সাধারণভাবে মিথ্যা; সেটির জন্য independence লাগে, প্রমাণ ৩।)
এক বাক্যে: \(\sum_n\mathbb P(A_n)<\infty\) হলে countable subadditivity দিয়ে \(\mathbb P(\bigcup_{n\ge N}A_n)\le\sum_{n\ge N}\mathbb P(A_n)\), আর অভিসৃত ধারার লেজ \(N\to\infty\)-এ শূন্যে নামে — তাই \(\mathbb P(A_n\text{ i.o.})=0\), কোনো স্বাধীনতা ছাড়াই।
প্রমাণ ৩ — Borel–Cantelli lemma II (★★)¶
দাবি (দ্বিতীয় Borel–Cantelli lemma)। যদি \((A_n)\) ঘটনাগুলো স্বাধীন (independent) হয় এবং
এটি প্রমাণ ২-এর প্রায়-বিপরীত: independence থাকলে আর যোগফল-শর্ত (\(<\infty\) বনাম \(=\infty\)) একটি শূন্য-এক dichotomy তৈরি করে — সম্ভাব্যতা ঠিক \(0\) বা ঠিক \(1\), মাঝে কিছু নয়।
ধাপ ১ — পরিপূরক ঘটনায় অনুবাদ। \(\mathbb P(\limsup A_n)=1\) দেখানো সমতুল্য তার পরিপূরক \(\mathbb P\bigl((\limsup A_n)^c\bigr)=0\) দেখানোর সঙ্গে। De Morgan-এ পরিপূরক নিই:
(\(C_N\) = "\(N\)-তম থেকে আর কখনো \(A_n\) ঘটে না"।) countable subadditivity বলে \(\mathbb P(\bigcup_N C_N)\le\sum_N\mathbb P(C_N)\), তাই প্রতিটি \(N\)-এ \(\mathbb P(C_N)=0\) দেখালেই যথেষ্ট (গণনাযোগ্য শূন্য-ঘটনার union আবার শূন্য)।
ধাপ ২ — সসীম intersection-এ independence ভাঙা। একটি স্থির \(N\) নিই এবং একটি বড় \(M\ge N\) নিই। \(A_n\)-রা স্বাধীন হলে তাদের পরিপূরক \(A_n^c\)-ও স্বাধীন (independence একটি family-ধর্ম যা পরিপূরকে টেকে — \(\sigma(A_n)=\{\varnothing,A_n,A_n^c,\Omega\}\) অপরিবর্তিত)। তাই সসীম product-সূত্র সরাসরি প্রয়োগযোগ্য:
ধাপ ৩ — মূল বিশ্লেষণিক বাঁধন \(1-x\le e^{-x}\)। এখানে গোটা প্রমাণের চাবি একটি মৌলিক অসমতা: যেকোনো বাস্তব \(x\)-এর জন্য \(1-x\le e^{-x}\) (কারণ \(g(x)=e^{-x}-(1-x)\)-এ \(g(0)=0\), \(g'(x)=1-e^{-x}\), যা \(x>0\)-তে \(>0\) ও \(x<0\)-তে \(<0\), তাই \(x=0\) একটি ন্যূনতম ⇒ \(g\ge 0\))। প্রতিটি গুণনীয়কে \(x=\mathbb P(A_n)\in[0,1]\) বসিয়ে:
(এই rewriting-ই গুণফলকে যোগফলে নামায় — যেখানে আমাদের অপসারী শর্ত \(\sum=\infty\) কামড় বসাতে পারে।)
ধাপ ৪ — \(M\to\infty\) এবং monotone tail। ধরা শর্তে \(\sum_{n=N}^{\infty}\mathbb P(A_n)=\infty\) (একটি সসীম-প্রথম-অংশ বাদ দিলে অসীম-যোগফল অসীমই থাকে), তাই \(\sum_{n=N}^{M}\mathbb P(A_n)\to\infty\) যখন \(M\to\infty\), কাজেই (4)-এর ডান পাশ \(\exp(-\infty^{+})\to 0\)। বাঁ পাশে, \(\bigcap_{n=N}^{M}A_n^c\downarrow\bigcap_{n=N}^{\infty}A_n^c=C_N\) যখন \(M\uparrow\infty\) (বড় \(M\)-এ বেশি শর্ত, ছোট ঘটনা), তাই 7.2-এর উপর-থেকে-ধারাবাহিকতা দেয়
কাজেই \(\mathbb P(C_N)=0\) প্রতিটি \(N\)-এ। ধাপ ১-এ ফিরে \(\mathbb P\bigl((\limsup A_n)^c\bigr)\le\sum_N\mathbb P(C_N)=0\), অর্থাৎ \(\mathbb P(\limsup_n A_n)=1\)। ∎
দুই lemma একসাথে (Borel–Cantelli zero–one dichotomy)। স্বাধীন ঘটনাদের জন্য: \(\sum\mathbb P(A_n)<\infty\Rightarrow\mathbb P(\text{i.o.})=0\) (প্রমাণ ২), আর \(\sum\mathbb P(A_n)=\infty\Rightarrow\mathbb P(\text{i.o.})=1\) (প্রমাণ ৩) — অর্থাৎ "অসীমবার ঘটা" ঘটনার সম্ভাব্যতা সবসময় \(0\) বা \(1\), কখনো মাঝামাঝি নয়। এই \(0\)/\(1\)-আচরণ আকস্মিক নয়; এর গভীর কারণ পরের প্রমাণ — \(\{A_n\text{ i.o.}\}\) আসলে একটি tail ঘটনা (\(\sigma(A_n)\)-অনুক্রমের), আর Kolmogorov 0–1 সূত্র সব tail ঘটনাকে \(0\)/\(1\)-এ বাধ্য করে।
এক বাক্যে: independence-এ \(\mathbb P(\bigcap_{n=N}^M A_n^c)=\prod(1-\mathbb P(A_n))\le\exp(-\sum_{n=N}^M\mathbb P(A_n))\) (\(1-x\le e^{-x}\) থেকে), আর \(\sum=\infty\) হলে \(M\to\infty\)-এ এটি \(0\) — তাই "কখনো না-ঘটা" শূন্য-সম্ভাব্য, অর্থাৎ \(\mathbb P(A_n\text{ i.o.})=1\)।
প্রমাণ ৪ — Kolmogorov 0–1 law (★★★)¶
দাবি (Kolmogorov-এর শূন্য-এক সূত্র)। ধরা যাক \((X_n)_{n\ge 1}\) একটি স্বাধীন random variable অনুক্রম, এবং \(\mathcal T=\bigcap_{m\ge 1}\sigma(X_m,X_{m+1},\dots)\) তার tail σ-algebra। তবে প্রতিটি tail ঘটনা \(A\in\mathcal T\)-এর জন্য
ফলস্বরূপ প্রতিটি tail random variable (যেমন \(\limsup_n X_n\), \(\liminf_n\bar X_n\), বা \(\{\sum X_n\) converges\(\}\)-এর indicator) a.s. ধ্রুবক (almost surely constant)।
স্বজ্ঞা — চমকপ্রদ: একটি ঘটনা যা "অসীম-দূরের লেজ"-এর উপর নির্ভর করে (প্রথম যত-খুশি চলক বদলালেও বদলায় না), অথচ সব চলকের জন্ম-দেওয়া σ-algebra-র ভেতরেই বাস করে — এমন ঘটনা কেবল \(0\) বা \(1\) হতে বাধ্য, কারণ সে নিজের থেকেই স্বাধীন হয়ে পড়ে।
ধাপ ১ — \(\mathcal T\) প্রথম \(n\) চলক থেকে স্বাধীন। স্থির করি যেকোনো \(n\ge 1\)। সংজ্ঞা থেকে
কারণ ডান পাশের σ-algebra-টি (\(m=n+1\)-এর পদ) intersection-এর একটি সদস্য, আর intersection সব সদস্যের ভেতরেই থাকে। এখন \((X_k)\) স্বাধীন বলে "প্রথম \(n\)টি" \(\{X_1,\dots,X_n\}\) আর "পরের সব" \(\{X_{n+1},X_{n+2},\dots\}\) — দুই গুচ্ছ পরস্পর স্বাধীন; কঠোরভাবে, \(\sigma(X_1,\dots,X_n)\perp\sigma(X_{n+1},X_{n+2},\dots)\)।
(এটি নিজেই প্রমাণ ১-এর একটি প্রয়োগ: cylinder-ঘটনা \(\{X_1\in B_1,\dots,X_n\in B_n\}\) একটি π-system যা \(\sigma(X_1,\dots,X_n)\) generate করে, আর "লেজ-cylinder" \(\{X_{n+1}\in B_{n+1},\dots,X_{n+j}\in B_{n+j}\}\) একটি π-system যা \(\sigma(X_{n+1},\dots)\) generate করে; এদের product-সূত্র independence-এর সংজ্ঞা থেকে সরাসরি — তাই প্রমাণ ১ দিয়ে σ-algebra-দ্বয় স্বাধীন।)
যেহেতু \(\mathcal T\subseteq\sigma(X_{n+1},X_{n+2},\dots)\), একটি ছোট σ-algebra সবসময় তার ধারক-এর স্বাধীনতা উত্তরাধিকারসূত্রে পায়, তাই
ধাপ ২ — π-system criterion দিয়ে গোটা σ-algebra-তে তোলা। (5) সব \(n\)-এ ধরে। সংজ্ঞা দিই বর্ধমান union
লক্ষ করি \(\mathcal A\) একটি π-system: যদি \(A\in\sigma(X_1,\dots,X_n)\) ও \(B\in\sigma(X_1,\dots,X_m)\), তবে \(n'=\max(n,m)\) নিলে দুটোই \(\sigma(X_1,\dots,X_{n'})\)-তে আছে (σ-algebra-গুলো বাসা-বাঁধা/nested), তাই \(A\cap B\in\sigma(X_1,\dots,X_{n'})\subseteq\mathcal A\) — intersection-বদ্ধ। আর এই π-system গোটা "অতীত+ভবিষ্যৎ" σ-algebra generate করে:
কারণ প্রতিটি \(X_k\) বাঁ পাশে measurable (যেকোনো \(n\ge k\)-তে), আর ডান পাশ এই সবকটিকে ধারণকারী সবচেয়ে ছোট σ-algebra। এখন (5) ঠিক বলছে \(\mathcal T\) আর π-system \(\mathcal A\) স্বাধীন (যেকোনো \(A\in\mathcal T\) আর \(C\in\mathcal A\)-এ \(C\) কোনো \(\sigma(X_1,\dots,X_n)\)-তে থাকে, তাই product-সূত্র (5)-এ ধরা)। প্রমাণ ১ (π-system criterion — \(\mathcal T\) ও \(\mathcal A\) উভয়ে; \(\mathcal T\) নিজেই σ-algebra তাই π-system) তখন দেয়
ধাপ ৩ — \(\mathcal T\) নিজের থেকে স্বাধীন ⇒ \(0\)/\(1\)। কিন্তু সংজ্ঞা থেকে প্রতিটি \(\sigma(X_m,X_{m+1},\dots)\subseteq\sigma(X_1,X_2,\dots)\), তাই তাদের intersection-ও:
(6)-এ ডান পাশ \(\mathcal T\)-কে ধারণ করে, আর একটি σ-algebra তার যেকোনো sub-σ-algebra থেকে স্বাধীন থাকলে বিশেষত নিজের থেকেও স্বাধীন: \(\mathcal T\perp\mathcal T\)। অর্থাৎ যেকোনো \(A\in\mathcal T\)-কে \(\mathcal T\)-এর দুই কপিতে রেখে product-সূত্র লাগাই —
তাই \(p:=\mathbb P(A)\) মানে \(p=p^2\), অর্থাৎ \(p(1-p)=0\), যার একমাত্র সমাধান \(p\in\{0,1\}\)। ∎
ফল — tail random variable a.s. ধ্রুবক। ধরা যাক \(Y\) একটি \(\mathcal T\)-measurable random variable (tail RV)। তখন প্রতিটি \(t\)-এ ঘটনা \(\{Y\le t\}\in\mathcal T\), তাই তার CDF \(F_Y(t)=\mathbb P(Y\le t)\in\{0,1\}\) — একটি \(\{0,1\}\)-মানের, অ-হ্রাসমান, ডান-অবিচ্ছিন্ন function। এমন function অবশ্যই একটি \(c\)-তে \(0\) থেকে \(1\)-এ লাফ দেয় (\(c=\inf\{t:F_Y(t)=1\}\)), অর্থাৎ \(\mathbb P(Y=c)=1\) — \(Y\) a.s. ধ্রুবক। বিশেষ করে: \(\limsup_n X_n\), \(\liminf_n X_n\) a.s. ধ্রুবক; "\(\sum X_n\) converges", "\(\bar X_n\) একটি সীমায় অভিসৃত" — এসব tail ঘটনার সম্ভাব্যতা \(0\) বা \(1\)। এটিই প্রমাণ ২–৩-এর Borel–Cantelli dichotomy-র অন্তর্নিহিত কারণ (\(\{A_n\text{ i.o.}\}\) একটি tail ঘটনা যখন \(A_n\in\sigma(X_n)\) ও \(X_n\) স্বাধীন), এবং পরের SLLN-এর জন্য একটি বড় স্বস্তি: \(\bar X_n\)-এর সীমা যদি থাকে, সেটি অবশ্যই একটি ধ্রুবক — এখন কেবল দেখাতে হবে সেই ধ্রুবক \(\mu\)।
এক বাক্যে: \(\mathcal T\subseteq\sigma(X_{n+1},\dots)\) প্রতিটি \(n\)-এ প্রথম-\(n\)-চলক থেকে স্বাধীন, তাই π-system criterion (প্রমাণ ১) দিয়ে \(\mathcal T\perp\sigma(X_1,X_2,\dots)\supseteq\mathcal T\), অর্থাৎ \(\mathcal T\perp\mathcal T\) ⇒ \(\mathbb P(A)=\mathbb P(A)^2\in\{0,1\}\) — সব tail RV a.s. ধ্রুবক।
প্রমাণ ৫ — SLLN under finite 4th moment (★★★, পরিষ্কার পথ)¶
দাবি (Cantelli-র SLLN, 4th-moment রূপ)। ধরা যাক \(X_1,X_2,\dots\) iid (independent and identically distributed), গড় \(\mu:=\mathbb E[X_1]\), এবং সসীম চতুর্থ আঘূর্ণ \(K:=\mathbb E[X_1^4]<\infty\)। ধরি \(\bar X_n:=\frac1n\sum_{i=1}^n X_i\)। তবে
অর্থাৎ \(\mathbb P\bigl(\lim_n\bar X_n=\mu\bigr)=1\) — strong law (a.s. অভিসরণ, কেবল probability-তে নয়)।
ধাপ ০ — WLOG কেন্দ্রায়ন। \(Y_i:=X_i-\mu\) ধরলে \(\mathbb E[Y_i]=0\), \(\bar Y_n=\bar X_n-\mu\), এবং \(\mathbb E[Y_1^4]<\infty\) (কারণ \((X-\mu)^4\)-এর প্রসারে সব পদ \(\mathbb E[X^j]\) (\(j\le 4\)) সসীম — Lyapunov/Hölder: \(\mathbb E[X^4]<\infty\Rightarrow\mathbb E\lvert X\rvert^j<\infty\) সব \(j\le 4\), 7.5)। তাই সাধারণতা না হারিয়ে ধরি \(\mu=0\); দেখাব \(\bar X_n\to 0\) a.s.। লিখি \(S_n:=\sum_{i=1}^n X_i\), তাই \(\bar X_n=S_n/n\)।
ধাপ ১ — \(\mathbb E[S_n^4]\)-এর বিস্তার এবং বিজোড়-পদ অন্তর্ধান। চতুর্থ ঘাত খুলি:
প্রতিটি পদ চারটি সূচক \((i,j,k,l)\)-এর একটি multiset। iid + স্বাধীনতা দিয়ে এক পদ factorize হয় স্বতন্ত্র সূচকের আঘূর্ণে। মূল পর্যবেক্ষণ: যদি কোনো সূচক (ধরি \(i\)) বাকি তিনটির কোনোটির সমান না হয়, তবে \(X_i\) অন্যদের থেকে স্বাধীন, তাই
যেহেতু \(\mathbb E[X_i]=0\) (ধাপ ০)। অর্থাৎ যেসব পদে অন্তত একটি সূচক "একা" (একবার মাত্র) আসে, তারা সব শূন্য — এতে অন্তর্ভুক্ত সব "বিজোড়-গঠনের" পদ (\(X_i^3X_j\) ধরনের, এবং \(X_i^2X_jX_k\) ধরনের যেখানে \(j\ne k\) এবং কোনোটাই বারবার নয়)। বেঁচে থাকে কেবল দুই ধরনের পদ:
- সব চার সূচক সমান (\(i=j=k=l\)): এমন পদ \(\mathbb E[X_i^4]=K\), সংখ্যায় \(n\)টি (প্রতিটি \(i\))। অবদান \(n\,K\)।
- দুই-জোড়া সমান (\(i=j\ne k=l\) ধরনের): এমন পদ \(\mathbb E[X_i^2X_k^2]=\mathbb E[X_i^2]\mathbb E[X_k^2]=(\mathbb E[X^2])^2=:\sigma^4\) (স্বাধীনতায় factorize; \(\sigma^2:=\mathbb E[X^2]=\operatorname{Var}(X)\))। কয়টি এমন পদ? চারটি অবস্থান \((i,j,k,l)\)-কে দুই জোড়ায় ভাগ করার উপায় সরাসরি গুনি: জোড়া-করার তিন রকম pairing \(\{(ij)(kl),(ik)(jl),(il)(jk)\}\), প্রতিটিতে দুই স্বতন্ত্র মান বাছার উপায় \(n(n-1)\), তাই \(3\,n(n-1)\)টি পদ। অবদান \(3n(n-1)\sigma^4\)।
(একটি সূক্ষ্মতা: "তিন সমান, এক আলাদা" \(X_i^3X_j\) (\(i\ne j\)) পদে \(\mathbb E[X_i^3X_j]=\mathbb E[X_i^3]\mathbb E[X_j]=\mathbb E[X_i^3]\cdot 0=0\) — তাই উপরের "একা সূচক" নিয়মেই ঢাকা পড়ে।) সব মিলিয়ে:
ডান পাশ একটি \(n\)-এর দ্বিঘাত বহুপদী, তাই \(\mathbb E[S_n^4]=O(n^2)\) — এটিই মূল লাভ: চতুর্থ ঘাত \(n^4\)-এর মতো বাড়ে না (যেমন নির্ভরশীল হলে হতে পারত), মাত্র \(n^2\)-এর মতো, কারণ cross-পদের বেশিরভাগই শূন্য।
ধাপ ২ — \(\bar X_n\)-এর চতুর্থ আঘূর্ণ summable। \(\bar X_n=S_n/n\), তাই \(\mathbb E[\bar X_n^4]=\mathbb E[S_n^4]/n^4\)। (7) বসিয়ে:
যেখানে \(n-1\le n\) ব্যবহার করে ঢিলেঢালা কিন্তু যথেষ্ট বাঁধন। সুতরাং \(\mathbb E[\bar X_n^4]=O(1/n^2)\), এবং তাই
ধাপ ৩ — যোগফল-অদলবদল ও a.s. সসীমতা (Tonelli)। সব পদ অঋণাত্মক (\(\bar X_n^4\ge 0\)), তাই 7.4-এর Tonelli theorem (monotone convergence-এর ফল) যোগফল ও integral বিনিময় করতে দেয়:
একটি অঋণাত্মক random variable-এর integral সসীম হলে সেটি a.s. সসীম (নইলে অসীম-মান একটি ধনাত্মক-ভর set-এ থাকত, integral অসীম করে দিত)। কাজেই
ধাপ ৪ — সসীম ধারার পদ শূন্যে যায় ⇒ \(\bar X_n\to 0\)। একটি অভিসৃত ধারার সাধারণ পদ অবশ্যই শূন্যে নামে (necessary condition for convergence)। তাই a.s.-ভাবে \(\bar X_n^4\to 0\), অর্থাৎ \(\bar X_n\to 0\) a.s.। কেন্দ্রায়ন ফিরিয়ে (\(\bar X_n=\bar X_n^{\text{মূল}}-\mu\)) পাই
(সংযোগ — কেন এটি "strong"। \(\bar X_n^4\to 0\) a.s. সরাসরি a.s. অভিসরণ দেয়, কেবল probability-তে নয়; বিকল্প-দৃষ্টিতে (8) দিয়ে \(\mathbb P(\lvert\bar X_n\rvert>\varepsilon)\le\mathbb E[\bar X_n^4]/\varepsilon^4\le C/(n^2\varepsilon^4)\) — Markov, 3.1 — তাই \(\sum_n\mathbb P(\lvert\bar X_n\rvert>\varepsilon)<\infty\), এবং প্রমাণ ২ (Borel–Cantelli I) দেয় \(\mathbb P(\lvert\bar X_n\rvert>\varepsilon\text{ i.o.})=0\) প্রতিটি \(\varepsilon\)-এ; সব rational \(\varepsilon\downarrow 0\) নিলে \(\bar X_n\to 0\) a.s.। দুই পথই একই গন্তব্য, আর দ্বিতীয়টি Borel–Cantelli I-এর গুরুত্ব স্পষ্ট করে।)
সাধারণ উপপাদ্য (Kolmogorov-এর SLLN)। 4th-moment অনুমান কৃত্রিম — এটি কেবল প্রমাণ সহজ করে। প্রকৃত উপপাদ্য বহু দুর্বল:
Kolmogorov SLLN। \(X_1,X_2,\dots\) iid এবং \(\mathbb E\lvert X_1\rvert<\infty\) হলে \(\bar X_n\to\mu=\mathbb E[X_1]\) a.s.; বিপরীতে, \(\mathbb E\lvert X_1\rvert=\infty\) হলে \(\limsup_n\lvert\bar X_n\rvert=\infty\) a.s. (কোনো সসীম সীমায় a.s. অভিসরণ অসম্ভব)।
অর্থাৎ প্রথম আঘূর্ণ সসীম হওয়াই a.s.-অভিসরণের ঠিক-ঠিক (iff) শর্ত — variance বা 4th moment লাগে না। কিন্তু \(\mathbb E[X^4]\) ছাড়া উপরের পরিষ্কার পথ ভেঙে পড়ে: (7)-এর মতো পদ-গণনা আর কাজ করে না, কারণ \(X\)-এর উচ্চ-ঘাত অসীম হতে পারে। তাই \(\mathbb E\lvert X\rvert<\infty\)-তে প্রমাণ লাগে দুই বাড়তি যন্ত্র — truncation (কেটে-ছেঁটে \(X\)-কে সসীম-variance বানানো) এবং Kolmogorov-এর maximal inequality (আংশিক-যোগফলের সর্বোচ্চ-বিচ্যুতি বাঁধা) — যা পরের প্রমাণ ৬-এ রূপরেখা-আকারে দেওয়া হলো।
এক বাক্যে: \(\mu=0\) ধরে \(\mathbb E[S_n^4]\)-এর প্রসারে বিজোড়-সূচকের সব cross-পদ (\(\mathbb E[X]=0\)-তে) মরে গিয়ে \(\mathbb E[S_n^4]=nK+3n(n-1)\sigma^4=O(n^2)\) থাকে, তাই \(\mathbb E[\bar X_n^4]=O(1/n^2)\) summable ⇒ (Tonelli) \(\sum_n\bar X_n^4<\infty\) a.s. ⇒ \(\bar X_n^4\to 0\) ⇒ \(\bar X_n\to\mu\) a.s.; সাধারণ রূপ কেবল \(\mathbb E\lvert X\rvert<\infty\)-তে সত্য কিন্তু truncation+maximal inequality দরকার।
প্রমাণ ৬ — Kolmogorov maximal inequality + সাধারণ SLLN-এর পথ (★★, রূপরেখা — প্রথম পাঠে এড়ানো যায়)¶
পাঠ-নির্দেশ: এই অংশটি একটি রূপরেখা (sketch) — সাধারণ (\(\mathbb E\lvert X\rvert<\infty\)) SLLN-এর প্রমাণ-কৌশলের মানচিত্র, পূর্ণ ε-δ বিস্তারিত নয়। প্রথম পাঠে নিশ্চিন্তে এড়িয়ে যাওয়া যায়; দরকার কেবল প্রমাণ ৫-এর উপসংহার ও এই নিচের একটি বাক্স-করা অসমতা মনে রাখা। পূর্ণ প্রমাণ Klenke (অধ্যায় ৫)-এ।
প্রমাণ ৫-এর সীমাবদ্ধতা ছিল: cross-পদ-গণনা কেবল উচ্চ আঘূর্ণ সসীম হলে চলে। সাধারণ পথে দুটি যন্ত্র এই বাধা ভাঙে।
যন্ত্র ১ — Kolmogorov-এর maximal inequality (★★)। ধরা যাক \(X_1,\dots,X_n\) স্বাধীন, প্রতিটির \(\mathbb E[X_i]=0\) ও \(\operatorname{Var}(X_i)<\infty\); \(S_k:=\sum_{i=1}^k X_i\) আংশিক-যোগফল। তবে যেকোনো \(t>0\)-এর জন্য
এটি Chebyshev-এর শক্তিশালী সংস্করণ: সাধারণ Chebyshev (3.1) কেবল শেষ যোগফল \(S_n\)-কে বাঁধে — \(\mathbb P(\lvert S_n\rvert\ge t)\le\operatorname{Var}(S_n)/t^2\); কিন্তু maximal inequality পুরো পথের সর্বোচ্চ \(\max_{k\le n}\lvert S_k\rvert\)-কেও একই ডান-পাশ দিয়ে বাঁধে। গভীর কারণ: \(\{S_k\}_{k}\) একটি martingale (7.9), এবং এটি Doob-এর maximal inequality-র একটি বিশেষ রূপ।
প্রমাণের মূল কৌশল (রূপরেখা)। "প্রথমবার \(\lvert S_k\rvert\) স্তর \(t\) ছোঁয়" সেই সময়টি স্থির করো — stopping time \(\tau=\min\{k:\lvert S_k\rvert\ge t\}\) — এবং ঘটনাটিকে disjoint টুকরোয় ভাঙো \(\{\tau=k\}\) অনুযায়ী। প্রতিটি টুকরোয় \(S_n=S_k+(S_n-S_k)\) লিখে, \(S_k\) (\(\mathbf 1_{\{\tau=k\}}\)-সহ) প্রথম \(k\) চলকের উপর নির্ভরশীল, আর increment \(S_n-S_k\) পরের চলকের — স্বাধীনতা দিয়ে cross-পদ মরে যায়, তাই \(\mathbb E[S_n^2\mathbf 1_{\{\tau=k\}}]\ge t^2\,\mathbb P(\tau=k)\)। সব \(k\)-এ যোগ করে \(\operatorname{Var}(S_n)=\mathbb E[S_n^2]\ge t^2\,\mathbb P(\tau\le n)=t^2\,\mathbb P(\max_k\lvert S_k\rvert\ge t)\) — পুনর্বিন্যাসেই বাক্স-করা অসমতা। ∎(রূপরেখা)
যন্ত্র ২ — truncation (কেটে-ছাঁটা)। \(\mathbb E\lvert X\rvert<\infty\) হলেও \(\operatorname{Var}(X)=\infty\) হতে পারে, তাই maximal inequality সরাসরি লাগে না। সমাধান — চলককে \(n\)-এ কেটে দাও:
এই কর্তিত \(X_n'\) আবদ্ধ, তাই সব আঘূর্ণ সসীম — maximal inequality প্রয়োগযোগ্য।
সাধারণ SLLN-এর পথ (Klenke-র যুক্তির মানচিত্র)। চারটি পদ:
-
কর্তন প্রায় ক্ষতিহীন (truncation harmless)। যেহেতু \(\mathbb E\lvert X\rvert<\infty\), একটি স্ট্যান্ডার্ড হিসাব দেয় \(\sum_{n\ge 1}\mathbb P(X_n\ne X_n')=\sum_n\mathbb P(\lvert X_n\rvert>n)=\sum_n\mathbb P(\lvert X_1\rvert>n)\le\mathbb E\lvert X_1\rvert<\infty\) (layer-cake/Tonelli, 7.4)। তাই প্রমাণ ২ (Borel–Cantelli I) দিয়ে a.s. কেবল সসীম-সংখ্যকবার \(X_n\ne X_n'\) — অর্থাৎ \(X_n\) ও \(X_n'\)-এর গড় একই সীমায় যায়; মূল-চলক বাদ দিয়ে কর্তিত-চলক নিয়ে কাজ করলেই চলে।
-
কর্তিত গড় তার প্রত্যাশায় যায় (maximal inequality)। \(\sum_n \operatorname{Var}(X_n')/n^2<\infty\) দেখানো যায় (কর্তনের কারণে variance বাড়ে কিন্তু \(n^2\)-ভাগে summable থাকে — আবার \(\mathbb E\lvert X\rvert<\infty\) থেকে)। তারপর Kolmogorov maximal inequality (যন্ত্র ১, কেন্দ্রিত \(X_n'-\mathbb E[X_n']\)-এ) দিয়ে দেখানো যায় \(\frac1n\sum_{i=1}^n(X_i'-\mathbb E[X_i'])\to 0\) a.s.। (এই ধাপটির আদর্শ মোড়ক Kolmogorov-এর three-series / one-series theorem বা Kronecker-এর lemma — উভয়েই maximal inequality থেকে \(\sum_n (X_n'-\mathbb E[X_n'])/n\)-এর a.s. অভিসরণ বের করে, যা Kronecker দিয়ে গড়-অভিসরণে নামে।)
-
কর্তিত প্রত্যাশা সত্যিকার গড়ে যায় (deterministic)। dominated convergence (7.4) দিয়ে \(\mathbb E[X_n']=\mathbb E[X_1\mathbf 1_{\{\lvert X_1\rvert\le n\}}]\to\mathbb E[X_1]=\mu\) যখন \(n\to\infty\), তাই তাদের Cesàro গড় \(\frac1n\sum_{i=1}^n\mathbb E[X_i']\to\mu\)-ও (একটি অভিসৃত অনুক্রমের গড় একই সীমায় যায়)।
-
জোড়া দাও। পদ ২+৩: \(\bar X_n'=\frac1n\sum X_i'\to\mu\) a.s.; পদ ১: \(\bar X_n\) ও \(\bar X_n'\)-এর সীমা অভিন্ন। কাজেই \(\bar X_n\to\mu\) a.s.। ∎(রূপরেখা)
এই পথ-ই দেখায় কেন SLLN-এ মাত্র \(\mathbb E\lvert X\rvert<\infty\) যথেষ্ট: truncation সসীম-variance ফিরিয়ে আনে, maximal inequality পথ-সর্বোচ্চ নিয়ন্ত্রণ করে, আর Borel–Cantelli I (প্রমাণ ২) কর্তনের ভুল গোনা শূন্য করে দেয়। লক্ষণীয় — এই গোটা যন্ত্রপাতি 7.9-এর martingale তত্ত্বের পূর্বাভাস: maximal inequality martingale-এর, আর "আংশিক-যোগফল a.s. অভিসৃত" Doob/martingale-convergence-এর সুরে বাঁধা।
এক বাক্যে (রূপরেখা): Kolmogorov-এর maximal inequality \(\mathbb P(\max_{k\le n}\lvert S_k\rvert\ge t)\le\operatorname{Var}(S_n)/t^2\) (martingale/Chebyshev-এর পথ-সংস্করণ) + কর্তন \(X_n'=X_n\mathbf 1_{\{\lvert X_n\rvert\le n\}}\) + Borel–Cantelli I মিলে সাধারণ SLLN দেয় কেবল \(\mathbb E\lvert X\rvert<\infty\)-তে — পূর্ণ বিস্তারিত Klenke-তে, এখানে শুধু মানচিত্র।
৫ · কোড ল্যাব (Python)¶
এই অধ্যায়ের তিনটি মূল ফল—Borel–Cantelli lemma, Kolmogorov 0–1 law ও strong law of large numbers (SLLN)—সবই asymptotic, অর্থাৎ "\(n\to\infty\)-তে শেষমেশ কী ঘটে" নিয়ে। কাগজে-কলমে এরা বিমূর্ত, কিন্তু simulation-এ এদের প্রতিটি দাবি সংখ্যায় চোখে দেখা যায়: গড় সত্যিই এক বিন্দুতে গুটিয়ে আসে, Cauchy-তে সেই গুটিয়ে আসা ভেঙে পড়ে, বিরল ঘটনা থেমে যায় বা চিরকাল ঘটতে থাকে—সমষ্টি (\(\sum\mathbb P(A_n)\)) অভিসারী না অপসারী, ঠিক তার উপর নির্ভর করে। এই ল্যাবে একটিমাত্র runnable স্ক্রিপ্ট (numpy-নির্ভর, কোনো বাড়তি library নয়) চারটি অংশে এই দাবিগুলো একে একে যাচাই করে।
স্ক্রিপ্টের কাঠামো ও পুনরুৎপাদনযোগ্যতা (reproducibility)¶
পুরো ল্যাবে একটিমাত্র random generator ব্যবহার হয়—np.random.default_rng(20260619)—এবং সব নমুনা সেই একই স্রোত (stream) থেকে টানা হয়। কিন্তু default_rng-এর ফলাফল স্রোত থেকে টানার ক্রমের উপর নির্ভরশীল: একই seed হলেও আগে-পরে টানলে আলাদা সংখ্যা আসে। তাই হুবহু একই ফল পেতে নিচের ক্রমেই (এবং ঠিক এই আকারে) স্রোত নিঃশেষ করতে হয়—
X = rng.exponential(1.0, 10**6)— SLLN, \(\text{Exp}(1)\);B = (rng.random(10**6) < 0.3)— SLLN, \(\text{Bernoulli}(0.3)\);C = rng.standard_cauchy(10**6)— যেখানে SLLN ভাঙে (Cauchy);U1 = rng.random(10**5), তারপর \(1/n^2\)-এর সাথে তুলনা — Borel–Cantelli I;U2 = rng.random(10**5), তারপর \(1/n\)-এর সাথে তুলনা — Borel–Cantelli II।
স্ক্রিপ্টের শুরুতেই এই পাঁচটি নমুনা এই ক্রমে একবারে টেনে নেওয়া হয়, পরে বিশ্লেষণ করা হয়—তাই ক্রম স্থির ও ফল পুনরুৎপাদনযোগ্য।
import numpy as np
np.set_printoptions(precision=4, suppress=True)
# একটিমাত্র generator, একবার seed; নিচের প্রতিটি draw এই একই স্রোত থেকে টানে।
rng = np.random.default_rng(20260619)
# পুরো স্রোত আগেভাগে, canonical ক্রমে টেনে নাও; তারপর বিশ্লেষণ।
N = 10**6
X = rng.exponential(1.0, N) # (1) Exp(1): E[X]=1
B = (rng.random(N) < 0.3) # (2) Bernoulli(0.3): E[X]=0.3
C = rng.standard_cauchy(N) # (3) Cauchy: E|X|=infinity, কোনো mean নেই
M = 10**5
U1 = rng.random(M) # (4) Borel-Cantelli I-এর জন্য
U2 = rng.random(M) # (5) Borel-Cantelli II-এর জন্য
def running_mean_at(samples, ns):
"""চলমান গড় S_n/n, ns-এর প্রতিটি সূচকে পড়ে নেওয়া (1-based n)।"""
csum = np.cumsum(samples)
return {n: csum[n - 1] / n for n in ns}
এখানে running_mean_at হলো মূল কর্মী-ফাংশন: একবার np.cumsum দিয়ে আংশিক-যোগফল \(S_n=\sum_{i\le n}X_i\) বানিয়ে নিলে, যেকোনো \(n\)-এ চলমান গড় (running mean) \(\bar X_n=S_n/n\) এক ভাগে পড়ে নেওয়া যায়। SLLN ঠিক এই \(\bar X_n\)-এরই a.s. অভিসরণের দাবি।
৫.১ · SLLN — গড় সত্যিকারের গড়ে গিয়ে থামে¶
SLLN বলে: \(X_1,X_2,\dots\) iid এবং \(\mathbb E\lvert X\rvert<\infty\) হলে \(\bar X_n\to\mu=\mathbb E[X]\) almost surely। এটি 3.3-এর weak/\(L^2\)-LLN-এর চেয়ে কঠোর—সেখানে কেবল probability-তে অভিসরণ ছিল, এখানে প্রায়-নিশ্চিতভাবে (গোটা পথ ধরে) অভিসরণ। যাচাইয়ে দুটি বণ্টন নেওয়া হয়: \(\text{Exp}(1)\) (যার \(\mu=1\)) ও \(\text{Bernoulli}(0.3)\) (যার \(\mu=0.3\))। \(\text{Exp}(1)\)-এর চলমান গড় \(n=10\) থেকে \(10^6\) পর্যন্ত ছ-টি ধাপে ছাপা হয়, আর Bernoulli-র পূর্ণ \(10^6\)-নমুনার গড় দেখা হয়।
# =====================================================================
# PART 1 -- SLLN. চলমান গড় a.s.-ভাবে E[X]-এ যায়।
# Exp(1) -> 1 এবং Bernoulli(0.3) -> 0.3.
# =====================================================================
ns = [10, 100, 10**3, 10**4, 10**5, 10**6]
rm_exp = running_mean_at(X, ns)
print("Exp(1), E[X] = 1 :")
print(f"{'n':>9} | {'running mean Xbar_n':>20}")
print("-" * 33)
for n in ns:
print(f"{n:>9} | {rm_exp[n]:>20.4f}")
xbar_bern = B[: 10**6].mean() # Bernoulli(0.3), পূর্ণ 1e6 নমুনা
print(f"\nBernoulli(0.3), E[X] = 0.3 : Xbar_(1e6) = {xbar_bern:.4f}")
err_exp = abs(rm_exp[10**6] - 1.0)
err_bern = abs(xbar_bern - 0.3)
print(f"\n|Xbar_(1e6) - 1| (Exp) = {err_exp:.4f} -> converged")
print(f"|Xbar_(1e6) - 0.3| (Bernoulli) = {err_bern:.4f} -> converged")
Exp(1), E[X] = 1 :
n | running mean Xbar_n
---------------------------------
10 | 0.5194
100 | 0.9710
1000 | 0.9603
10000 | 0.9841
100000 | 0.9978
1000000 | 1.0007
Bernoulli(0.3), E[X] = 0.3 : Xbar_(1e6) = 0.2999
|Xbar_(1e6) - 1| (Exp) = 0.0007 -> converged
|Xbar_(1e6) - 0.3| (Bernoulli) = 0.0001 -> converged
পাঠোদ্ধার (read-off)।
- চলমান গড় \(\mu=1\)-এ গুটিয়ে আসে। \(n=10\)-এ \(\bar X_{10}=0.5194\)—সত্যিকারের গড় \(1\) থেকে অনেক দূরে, কারণ অল্প নমুনায় ওঠানামা প্রবল। কিন্তু \(n\) বাড়তে বাড়তে \(0.9710\to0.9603\to0.9841\to0.9978\to\mathbf{1.0007}\)—\(10^6\)-এ ভুল মাত্র \(0.0007\)। লক্ষণীয়, অভিসরণ একঘেয়ে নয় (\(0.9710\) থেকে \(0.9603\)-এ সামান্য নামে): SLLN ধাপে-ধাপে কমার দাবি করে না, শুধু সীমায় \(\to\mu\)।
- Bernoulli-ও একই গল্প। \(\bar X_{10^6}=\mathbf{0.2999}\), প্রকৃত \(0.3\) থেকে ভুল মাত্র \(0.0001\)। দুই ভিন্ন বণ্টন, ভিন্ন \(\mu\)—কিন্তু একই আচরণ: গড় তার প্রত্যাশায় গিয়ে থামে।
- কেন এটি "strong"। এখানে আমরা একটিই নমুনা-পথের চলমান গড় দেখছি, এবং সেটিই \(\mu\)-তে স্থির হচ্ছে—এটাই almost-sure অভিসরণের চাক্ষুষ রূপ ("যে-কোনো একটি বাস্তবায়নে গড় থিতু হয়"), নিছক "অনেক পুনরাবৃত্তির গড়ে কাছে আসে" (probability-তে অভিসরণ) নয়।
৫.২ · Cauchy — যেখানে SLLN ভাঙে¶
SLLN-এর একমাত্র শর্ত \(\mathbb E\lvert X\rvert<\infty\), এবং সেটি আবশ্যকও: শর্ত ভাঙলে অভিসরণও ভাঙে। standard Cauchy বণ্টনের ঘনত্ব \(f(x)=\dfrac{1}{\pi(1+x^2)}\) লেজ এত মোটা যে \(\mathbb E\lvert X\rvert=\int\dfrac{\lvert x\rvert}{\pi(1+x^2)}\,dx=\infty\)—কোনো (সসীম) mean নেই। ফলে চলমান গড় কোথাও থিতু হয় না; বরং প্রতিবার এক বিরাট outlier এসে গোটা গড়কে নতুন জায়গায় ছুঁড়ে দেয়। নিচে \(n=10^2,10^4,10^6\)-এ Cauchy-গড় ছাপা হলো—Part 1-এর শান্ত অভিসরণের ঠিক বিপরীত।
# =====================================================================
# PART 2 -- Cauchy-তে SLLN ভাঙে। E|X| = infinity, তাই SLLN-এর
# hypothesis লঙ্ঘিত; চলমান গড় কখনো থিতু হয় না।
# =====================================================================
ns_c = [10**2, 10**4, 10**6]
rm_cauchy = running_mean_at(C, ns_c)
print(f"{'n':>9} | {'running mean Xbar_n':>20}")
print("-" * 33)
for n in ns_c:
print(f"{n:>9} | {rm_cauchy[n]:>20.3f}")
span = max(rm_cauchy.values()) - min(rm_cauchy.values())
print(f"\nrange across these n = {span:.3f} (wanders, no convergence)")
print("contrast Part 1: Exp(1) mean pinned near 1.0; here it drifts wildly.")
n | running mean Xbar_n
---------------------------------
100 | 1.126
10000 | 0.851
1000000 | -0.173
range across these n = 1.299 (wanders, no convergence)
contrast Part 1: Exp(1) mean pinned near 1.0; here it drifts wildly.
পাঠোদ্ধার।
- গড় থিতু হওয়ার বদলে দোলে। \(n=10^2\)-এ \(1.126\), \(n=10^4\)-এ \(0.851\), \(n=10^6\)-এ \(\mathbf{-0.173}\)—নমুনা \(10^4\) গুণ বাড়িয়েও গড় কোনো এক বিন্দুর দিকে গুটিয়ে আসে না, বরং চিহ্নও বদলে ফেলে (ধনাত্মক থেকে ঋণাত্মক)। তিন ধাপের বিস্তার (range) \(1.299\)—Part 1-এ \(10^6\)-এ ভুল ছিল মাত্র \(0.0007\)।
- এটি দুর্ভাগ্য নয়, নিয়ম। Cauchy-র একটি চমকপ্রদ ধর্ম: \(\bar X_n\)-এর বণ্টন আবার ঠিক একই standard Cauchy (\(n\)-নিরপেক্ষ)—তাই গড় নিয়ে কোনো নমুনা যোগ করলেও তা "শান্ত" হয় না, প্রতিটি \(n\)-এ সমান বুনো থাকে। বড় sample বেশি তথ্য দেয় না, কারণ প্রতিবার এক নতুন বিশাল outlier আগের সবটুকু গড় উল্টে দেয়।
- সংযোগ। Part 1 বনাম Part 2 মিলে দেখায় \(\mathbb E\lvert X\rvert<\infty\) শর্তটি SLLN-এ আলংকারিক নয়, নির্ণায়ক: শর্ত মানলে গড় a.s. থামে (\(\text{Exp}\), Bernoulli), শর্ত ভাঙলে \(\limsup_n\lvert\bar X_n\rvert=\infty\) a.s.—কোনো সীমাই নেই (Cauchy)।
৫.৩ · Borel–Cantelli I বনাম II — সমষ্টিই ভাগ্য ঠিক করে¶
দুই Borel–Cantelli lemma স্বাধীন ঘটনার অসীম অনুক্রমে "অসীম-বার ঘটে" (\(A_n\) i.o.) ঘটনার সম্ভাবনা সম্পূর্ণরূপে নির্ধারণ করে, এবং তা নির্ভর করে একটিমাত্র সংখ্যার উপর—\(\sum_n\mathbb P(A_n)\):
- BC-I (স্বাধীনতা লাগে না): \(\sum_n\mathbb P(A_n)<\infty\Rightarrow\mathbb P(A_n\text{ i.o.})=0\)—অর্থাৎ a.s. কেবল সসীম-সংখ্যক \(A_n\) ঘটে, গণনা একসময় থেমে যায়।
- BC-II (স্বাধীন হলে): \(\sum_n\mathbb P(A_n)=\infty\Rightarrow\mathbb P(A_n\text{ i.o.})=1\)—অর্থাৎ a.s. অসীম-সংখ্যক \(A_n\) ঘটে, গণনা চিরকাল বাড়ে।
যাচাইয়ে দুটি স্বাধীন ঘটনা-অনুক্রম: \(\mathbb P(A_n)=1/n^2\) (BC-I, কারণ \(\sum 1/n^2=\pi^2/6<\infty\)) ও \(\mathbb P(A_n)=1/n\) (BC-II, কারণ \(\sum 1/n=\infty\))। স্বাধীন indicator \(\mathbf 1_{A_n}\) বানানো হয় U < p তুলনায়—\(U\sim\text{Uniform}(0,1)\) হলে \(\mathbb P(U<p)=p\), ঠিক যা চাই।
# =====================================================================
# PART 3 -- স্বাধীন ঘটনা A_n-এ Borel-Cantelli I বনাম II।
# I : P(A_n)=1/n^2, sum = pi^2/6 < infinity -> A_n i.o.-র prob 0
# (কেবল সসীম-সংখ্যক A_n ঘটে; চলমান গণনা থেমে যায়/saturate)।
# II: P(A_n)=1/n, sum = infinity -> A_n i.o.-র prob 1
# (অসীম-সংখ্যক A_n ঘটে; গণনা বাড়তেই থাকে ~ ln n)।
# =====================================================================
n_idx = np.arange(1, M + 1) # n = 1 .. 1e5
# --- BC-I : P(A_n) = 1/n^2 ---
p1 = 1.0 / n_idx**2
occ1 = U1 < p1 # স্বাধীন indicator 1{A_n ঘটে}
count1 = int(occ1.sum())
sum_p1 = p1.sum()
print("BC-I : P(A_n) = 1/n^2")
print(f" sum_(n=1..1e5) 1/n^2 = {sum_p1:.4f}")
print(f" pi^2/6 = {np.pi**2 / 6:.4f} (finite => i.o. prob 0)")
print(f" # occurrences (n<=1e5) = {count1} (saturates: finitely many)")
# --- BC-II : P(A_n) = 1/n ---
p2 = 1.0 / n_idx
occ2 = U2 < p2 # স্বাধীন indicator
count2 = int(occ2.sum())
print("\nBC-II : P(A_n) = 1/n")
print(f" sum_(n=1..1e5) 1/n = {p2.sum():.4f} (diverges ~ ln n => i.o. prob 1)")
print(f" # occurrences (n<=1e5) = {count2} (keeps growing with n)")
# BC-II-র সঞ্চিত গণনা বনাম ln n, কয়েকটি দিগন্তে
print("\n cumulative BC-II count vs ln(n) :")
cum2 = np.cumsum(occ2)
print(f" {'n':>9} | {'count<=n':>9} | {'ln n':>8}")
print(" " + "-" * 32)
for n in [10**2, 10**3, 10**4, 10**5]:
print(f" {n:>9} | {int(cum2[n - 1]):>9} | {np.log(n):>8.2f}")
BC-I : P(A_n) = 1/n^2
sum_(n=1..1e5) 1/n^2 = 1.6449
pi^2/6 = 1.6449 (finite => i.o. prob 0)
# occurrences (n<=1e5) = 2 (saturates: finitely many)
BC-II : P(A_n) = 1/n
sum_(n=1..1e5) 1/n = 12.0901 (diverges ~ ln n => i.o. prob 1)
# occurrences (n<=1e5) = 8 (keeps growing with n)
cumulative BC-II count vs ln(n) :
n | count<=n | ln n
--------------------------------
100 | 4 | 4.61
1000 | 5 | 6.91
10000 | 7 | 9.21
100000 | 8 | 11.51
পাঠোদ্ধার।
- BC-I — সমষ্টি সসীম, গণনা থেমে যায়। \(\sum_{n\le10^5}1/n^2=\mathbf{1.6449}\), যা ঠিক \(\pi^2/6=1.6449\) (বিখ্যাত Basel-যোগফল)। সমষ্টি সসীম, তাই BC-I বলে \(A_n\) i.o.-র সম্ভাবনা \(0\)—simulation-এ \(10^5\) পর্যন্ত মাত্র ২ বার \(A_n\) ঘটেছে, এবং কার্যত সবই খুব ছোট \(n\)-এ (যেখানে \(1/n^2\) বড়)। বড় \(n\)-এ \(\mathbb P(A_n)=1/n^2\) এত ছোট যে আর কখনো ঘটে না: গণনা saturate করে।
- BC-II — সমষ্টি অসীম, গণনা বাড়তেই থাকে। \(\sum_{n\le10^5}1/n=12.0901\) (\(\approx\ln(10^5)+\gamma\), harmonic series-এর ধীর অপসরণ)। সমষ্টি অপসারী, তাই BC-II বলে \(A_n\) i.o.-র সম্ভাবনা \(1\)—\(10^5\) পর্যন্ত ৮ বার \(A_n\) ঘটেছে, এবং থামার লক্ষণ নেই।
- বৃদ্ধির হার \(\sim\ln n\)। সঞ্চিত গণনা \(4\to5\to7\to\mathbf{8}\) (\(n=10^2,10^3,10^4,10^5\))। প্রত্যাশিত গণনা \(\sum_{k\le n}1/k\approx\ln n\), তাই প্রতিবার \(n\) ১০ গুণ হলে গণনা বাড়ে মোটামুটি ধ্রুবক \(\ln 10\approx2.3\)—ধীর কিন্তু অসীমে অভিমুখী। এটাই BC-I বনাম II-এর মর্ম: ঘটনাগুলো "একটু কম বিরল" (\(1/n\) বনাম \(1/n^2\)) হওয়ায় সম্ভাবনা \(0\) থেকে লাফিয়ে \(1\)-এ চলে যায়—মাঝামাঝি কিছু নেই।
৫.৪ · Kolmogorov 0–1 law-এর আস্বাদ — tail event-এর সম্ভাবনা \(0\) বা \(1\)¶
Kolmogorov 0–1 law বলে: স্বাধীন \(X_n\) হলে প্রতিটি tail event-এর সম্ভাবনা হয় \(0\), নয় \(1\)—কখনো মাঝামাঝি নয়। tail event সেই ঘটনা যা সসীম-সংখ্যক \(X_i\) বদলালেও বদলায় না। একটি ধ্রুপদী উদাহরণ: \(\varepsilon_n=\pm1\) স্বাধীন ন্যায্য (fair) চিহ্ন হলে, ঘটনা \(\bigl\{\sum_n \varepsilon_n/n\text{ অভিসারী}\bigr\}\)—কারণ প্রথম কয়েকটি \(\varepsilon_n\) বদলালে আংশিক-যোগফল সরে যায় বটে, কিন্তু অভিসারী কিনা সেই প্রশ্নের উত্তর বদলায় না (সীমা থাকা/না-থাকা লেজের উপর নির্ভর)। 0–1 law বলে এর সম্ভাবনা \(\{0,1\}\)-এ; আর যেহেতু \(\sum\operatorname{Var}(\varepsilon_n/n)=\sum 1/n^2=\pi^2/6<\infty\), Kolmogorov-এর two-series theorem দেয় a.s. অভিসরণ—তাই অভিসারী পথের ভগ্নাংশ \(\approx1\) হওয়া উচিত। নিচে ৪০০০টি স্বাধীন পথ গড়ে এই tail event-এর empirical সম্ভাবনা মাপা হয় (লেজের অর্ধেকে আংশিক-যোগফলের দোলন ক্ষুদ্র কিনা দেখে)।
# =====================================================================
# PART 4 -- Kolmogorov 0-1 law-এর আস্বাদ। ঘটনা
# { sum_n eps_n / n অভিসারী }, eps_n = +-1 স্বাধীন ন্যায্য চিহ্ন,
# একটি TAIL event: সসীম-সংখ্যক চিহ্ন বদলালে ধারা অভিসারী কিনা বদলায় না।
# 0-1 law তার সম্ভাবনাকে {0,1}-এ বাঁধে; sum 1/n^2 < infinity হওয়ায়
# two-series theorem a.s. অভিসরণ দেয় -> অভিসারী পথের ভগ্নাংশ ~ 1।
# =====================================================================
n_paths, n_terms = 4000, 20000
signs = rng.integers(0, 2, size=(n_paths, n_terms)) * 2 - 1 # +-1, ন্যায্য
weights = 1.0 / np.arange(1, n_terms + 1)
partial = np.cumsum(signs * weights, axis=1) # আংশিক-যোগফল
# Cauchy-লেজ নির্ণায়ক: লেজের অর্ধেকে আংশিক-যোগফলের দোলন ক্ষুদ্র হলে
# ধারা অভিসারী। সসীম truncation-এ উদার threshold।
tail = partial[:, n_terms // 2:]
tail_osc = tail.max(axis=1) - tail.min(axis=1) # লেজের দোলন
frac_converge = float(np.mean(tail_osc < 0.05))
print(f"independent fair signs eps_n=+-1, weights 1/n, {n_paths} paths")
print(f"sum_n Var = sum 1/n^2 = pi^2/6 = {np.pi**2 / 6:.4f} < infinity")
print(f"fraction of paths with tail oscillation < 0.05 = {frac_converge:.4f}")
print("(a tail event under the 0-1 law: probability collapses to ~1, not in-between)")
independent fair signs eps_n=+-1, weights 1/n, 4000 paths
sum_n Var = sum 1/n^2 = pi^2/6 = 1.6449 < infinity
fraction of paths with tail oscillation < 0.05 = 1.0000
পাঠোদ্ধার।
- ভগ্নাংশ \(\mathbf{1.0000}\)—মাঝামাঝি কিছু নেই। ৪০০০টি স্বাধীন পথের প্রতিটিরই লেজে আংশিক-যোগফলের দোলন \(0.05\)-এর নিচে: সবাই অভিসারী। empirical সম্ভাবনা \(1.0000\)—ঠিক যেমন 0–1 law ভবিষ্যদ্বাণী করে। এটি \(0.5\) বা \(0.7\)-এর মতো কোনো "মাঝারি" সংখ্যায় থামত না: একটি প্রকৃত tail event-এর সম্ভাবনা শুধু \(0\) বা \(1\) হতে পারে।
- কেন এখানে \(1\) (\(0\) নয়)? ভ্যারিয়েন্সের যোগফল \(\sum 1/n^2=\pi^2/6=\mathbf{1.6449}\) সসীম—Kolmogorov two-series theorem অনুযায়ী এটিই a.s. অভিসরণের যথেষ্ট শর্ত। তুলনায় ওজন যদি \(1/\sqrt n\) হতো (\(\sum 1/n=\infty\)), একই 0–1 law সম্ভাবনাকে \(0\)-তে বাঁধত (a.s. অপসারী)। অর্থাৎ 0–1 law শুধু বলে উত্তর \(\{0,1\}\)-এ; কোনটি তা ঠিক করে যোগফলটি সসীম না অসীম—আবারও সেই একই "সমষ্টিই ভাগ্য" সুর (৫.৩-এর মতো)।
- সংযোগ। এই tail-event আচরণই Borel–Cantelli-র (৫.৩) সাধারণীকরণ: সেখানে \(\{A_n\text{ i.o.}\}\)-ও একটি tail event ছিল, আর তার সম্ভাবনাও \(0\)/\(1\)-এ পড়েছিল (\(\sum\mathbb P(A_n)\)-ভেদে)। 0–1 law এই "শূন্য-এক বিভাজন"-কে সব tail event-এ সম্প্রসারিত করে।
সারসংক্ষেপ¶
চারটি অংশ একসুতোয় গাঁথে এই অধ্যায়ের যুক্তি-শৃঙ্খল—স্বাধীনতা → Borel–Cantelli → 0–1 law → SLLN:
| অংশ | দাবি | মূল সংখ্যা |
|---|---|---|
| ৫.১ | SLLN: \(\bar X_n\to\mu\) a.s. (\(\mathbb E\lvert X\rvert<\infty\)) | \(\text{Exp}(1)\to\mathbf{1.0007}\); \(\text{Bernoulli}(0.3)\to\mathbf{0.2999}\) |
| ৫.২ | \(\mathbb E\lvert X\rvert=\infty\) হলে SLLN ভাঙে | Cauchy গড় \(\mathbf{1.126\to0.851\to-0.173}\) (দোলে) |
| ৫.৩ | BC-I বনাম II: সমষ্টিই i.o.-সম্ভাবনা ঠিক করে | \(\sum 1/n^2=\pi^2/6=\mathbf{1.6449}\), গণনা \(\mathbf{2}\) (থামে) বনাম \(\mathbf{8}\sim\ln n\) (বাড়ে) |
| ৫.৪ | 0–1 law: tail event-এর সম্ভাবনা \(0\) বা \(1\) | অভিসারী পথের ভগ্নাংশ \(\mathbf{1.0000}\) |
একই গল্প বারবার ফিরে আসে: স্বাধীন ঘটনার অসীম অনুক্রমে "শেষমেশ কী ঘটে" তা মাঝামাঝি কোনো সম্ভাবনায় ঝোলে না—একটিমাত্র সংখ্যা (\(\sum\mathbb P(A_n)\) অথবা \(\sum\operatorname{Var}\), সসীম না অসীম) সব ঠিক করে দেয়। Borel–Cantelli এই বিভাজন দেয় \(\{A_n\text{ i.o.}\}\)-এর জন্য (৫.৩); Kolmogorov 0–1 law তা সব tail event-এ বাড়ায় (৫.৪); আর SLLN এই যন্ত্রপাতিরই চূড়ান্ত ফসল—\(\mathbb E\lvert X\rvert<\infty\) হলে চলমান গড় a.s. থিতু হয় (৫.১), শর্ত ভাঙলেই দোলে (৫.২)। তিনটি বিমূর্ত উপপাদ্য, একটিমাত্র seed (20260619)—সবই সংখ্যায় ধরা পড়ল।
৬ · ভিজ্যুয়ালাইজেশন¶
এই অধ্যায়ের প্রতিটি বড় ফলাফল — strong law of large numbers (SLLN), Borel–Cantelli-র দুই lemma-র dichotomy, এবং Kolmogorov-এর 0–1 law — একটা সাধারণ সুরে বাঁধা: একটা infinite sequence-এর "শেষ-আচরণ" (limiting behaviour) প্রায়ই deterministic, যদিও প্রতিটা পদ random। কথাটা সূত্রে পড়লে বিমূর্ত শোনায়; কিন্তু running mean-এর path যখন চোখের সামনে একটা সরু funnel-এ গুটিয়ে এসে \(\mu\)-তে বসে যায়, কিংবা একটা tail-event-এর indicator যখন হাজারটা স্বাধীন simulation-এ পুরোপুরি \(1\)-এর গায়ে স্তূপীকৃত হয়, তখন এই "randomness থেকে নিশ্চয়তা" ব্যাপারটা অন্তরে গাঁথে। তাই এই অংশে চারটে ছবি, ঠিক সেই যুক্তির ক্রমে যেভাবে তত্ত্বটা গড়ে ওঠে: প্রথমে SLLN-এর মূল প্রতিশ্রুতি (\(\bar X_n\to\mu\) almost surely), তারপর সেই almost-sure-ত্বের যন্ত্র — Borel–Cantelli-র \(\sum\mathbb P(A_n)\) finite-বনাম-infinite বিভাজন, তারপর একটা সতর্কবার্তা যেখানে SLLN ভেঙে পড়ে (Cauchy, কারণ \(\mathbb E\lvert X\rvert=\infty\)), এবং শেষে সবচেয়ে গভীর বার্তা — Kolmogorov-এর 0–1 law, যা বলে tail event-এর probability কেবল \(0\) বা \(1\) হতে পারে, মাঝামাঝি কিছু নয়।
মনে রাখুন — simulation। নিচের চারটে ছবিই একটিমাত্র স্ক্রিপ্ট (
_code/figs_7-6.py) থেকে তৈরি, যাnp.random.default_rng(20260619)দিয়ে seed করা — অর্থাৎ ফলাফল পুনরুৎপাদনযোগ্য (reproducible)। in-figure সব লেখা ইংরেজিতে (Bengali-font rendering সমস্যা এড়াতে), আর figure-এর label-এ matplotlib-এর সীমাবদ্ধতার জন্য\lvert\cdot\rvert-এর বদলে সাধারণ|ব্যবহৃত হয়েছে; ব্যাখ্যা বাংলায়। এখানে কোনো বাস্তব dataset নেই — সবই synthetic random draw, যেগুলো §২–§৫-এ প্রমাণিত theorem-গুলোকে সংখ্যায় ও ছবিতে জীবন্ত করে।
৬.১ · SLLN: running mean কীভাবে \(\mu\)-তে গুটিয়ে আসে¶
এই অধ্যায়ের কেন্দ্রীয় ছবি। strong law বলে: i.i.d. sample \(X_1,X_2,\dots\) যদি \(\mathbb E\lvert X_1\rvert<\infty\) মানে, তবে running mean \(\bar X_n=\frac1n\sum_{i=1}^n X_i\) প্রায় নিশ্চিতভাবে (almost surely) \(\mu=\mathbb E[X_1]\)-তে অভিসরণ করে — শুধু distribution-এ নয়, প্রতিটা একক random path ধরেই। এটা দেখাতে \(X\sim\text{Exp}(1)\) নেওয়া হয়েছে (যার \(\mu=1\), \(\sigma=1\)), এবং \(10\)টা স্বাধীন path আঁকা হয়েছে; অনুভূমিক অক্ষ \(n\) (log scale, যাতে শুরুর তোলপাড় আর শেষের স্থিতি দুটোই এক ছবিতে ধরা যায়)। শুরুতে (\(n\) ছোট) path-গুলো ছড়িয়ে-ছিটিয়ে — কোনোটা \(2\)-এর ওপরে, কোনোটা \(0.3\)-এ — কিন্তু \(n\) বাড়তেই তারা একটা সরু funnel-এ গুটিয়ে এসে \(\mu=1\) (ভাঙা কালো রেখা)-র গায়ে বসে যায়। ধূসর বিন্দুরেখা দুটো হলো \(\mu\pm\sigma/\sqrt n\), অর্থাৎ \(\bar X_n\)-এর তাত্ত্বিক standard-error funnel: যেহেতু \(\text{sd}(\bar X_n)=\sigma/\sqrt n\to0\), funnel নিজেই সংকুচিত হয়, আর সব path তার ভেতরে বন্দি হয়ে almost-sure convergence-এর চাক্ষুষ প্রমাণ দেয়। লক্ষণীয়: funnel \(1/\sqrt n\) হারে সরু হয় (এটা মূলত CLT-র scale), কিন্তু SLLN আরও জোরালো — সে বলে প্রতিটা path-ই limit-এ গিয়ে স্থির হয়, কেবল গড়ে নয়।
N, n_paths, mu = 50_000, 10, 1.0
n = np.arange(1, N + 1)
for k in range(n_paths):
x = rng.exponential(scale=1.0, size=N) # Exp(1): mean 1, var 1
running = np.cumsum(x) / n # Xbar_n
ax.plot(n, running, lw=1.0, alpha=0.75, color=plt.cm.viridis(k / n_paths))
ax.plot(n, mu + 1/np.sqrt(n), color=GREY, ls=":") # +/- standard-error funnel
ax.plot(n, mu - 1/np.sqrt(n), color=GREY, ls=":")
ax.axhline(mu, color="black", ls="--") # the limit mu = 1
ax.set_xscale("log")
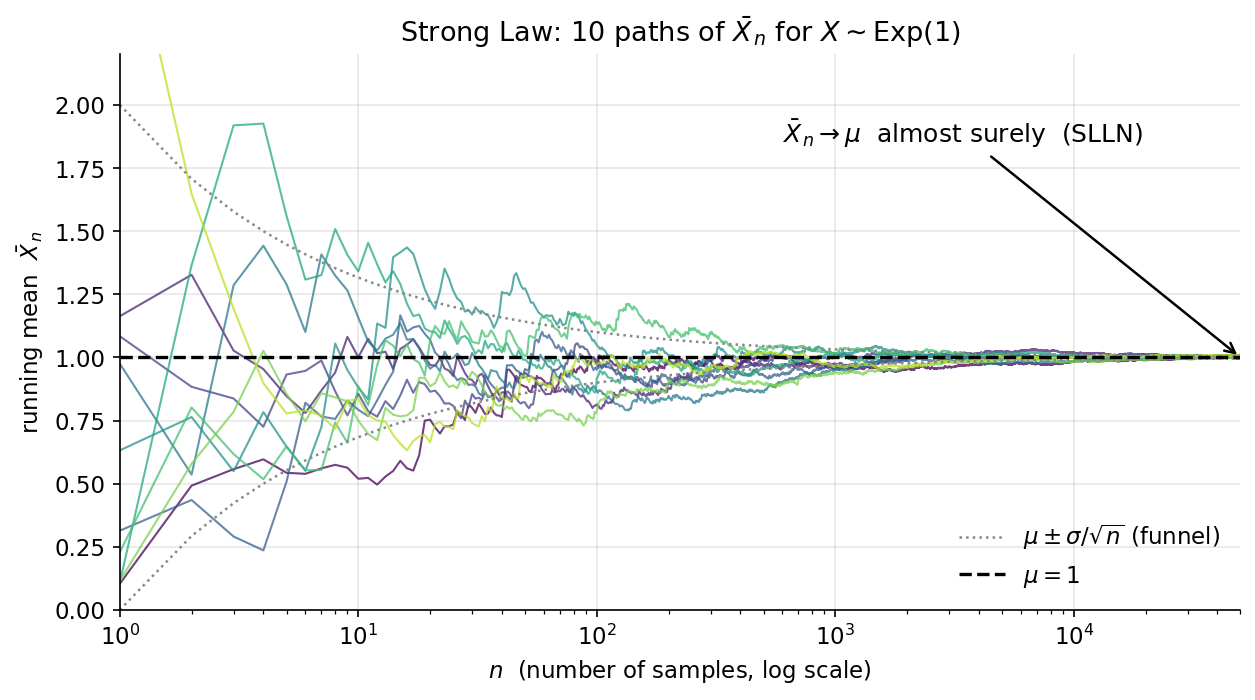
৬.২ · Borel–Cantelli: \(\sum\mathbb P(A_n)\) finite বনাম infinite¶
SLLN-এর "almost surely" শব্দটার পেছনের যন্ত্র Borel–Cantelli-র দুই lemma। প্রশ্নটা সবসময় এক: একটা ঘটনার ক্রম \(A_1,A_2,\dots\) কি infinitely often (i.o.) ঘটবে, নাকি একটা পর্যায়ের পর আর ঘটবেই না? উত্তর লুকিয়ে আছে \(\sum_n\mathbb P(A_n)\)-এর মধ্যে, আর ছবিটা ঠিক এই dichotomy-টাই দুই panel-এ দেখায়। বাঁ panel: \(\mathbb P(A_n)=1/n^2\), তাই \(\sum\mathbb P(A_n)=\pi^2/6<\infty\) — finite। প্রথম Borel–Cantelli lemma (BC-I) বলে তখন \(\mathbb P(A_n\text{ i.o.})=0\), অর্থাৎ ঘটনাটা কেবল finitely many বার ঘটে। ছবিতে cumulative occurrence-count একটা নিচু level-এ (এখানে \(1\)) উঠে থেমে যায় (saturates) — log-x অক্ষে \(n\) হাজারে পৌঁছালেও আর একটাও নতুন occurrence যোগ হয় না। ডান panel: \(\mathbb P(A_n)=1/n\) এবং ঘটনাগুলো স্বাধীন (independent), তাই \(\sum\mathbb P(A_n)=\infty\) — divergent। দ্বিতীয় lemma (BC-II, যেটার জন্য independence অপরিহার্য) বলে তখন \(\mathbb P(A_n\text{ i.o.})=1\), ঘটনাটা infinitely often ঘটে। ছবিতে count-টা কোনো ceiling ছাড়াই \(\ln n\) হারে (ধূসর reference রেখা) বাড়তেই থাকে। এই দুই panel পাশাপাশি রাখলেই পুরো সিদ্ধান্ত-নিয়মটা এক নজরে: \(\sum\mathbb P\) finite হলে "শেষমেশ থেমে যায়", infinite (ও independent) হলে "চিরকাল ঘটে যায়"।
n = np.arange(1, 4001)
# LEFT: P(A_n)=1/n^2 => sum < infinity => i.o. probability 0 (BC-I)
occL = (rng.uniform(size=4000) < 1/n**2).astype(int)
cumL = np.cumsum(occL) # saturates at a finite level
# RIGHT: P(A_n)=1/n, independent => sum = infinity => i.o. probability 1 (BC-II)
occR = (rng.uniform(size=4000) < 1/n).astype(int)
cumR = np.cumsum(occR) # grows like ln n, no ceiling
axR.plot(n, np.log(n), ls="--") # ln n reference
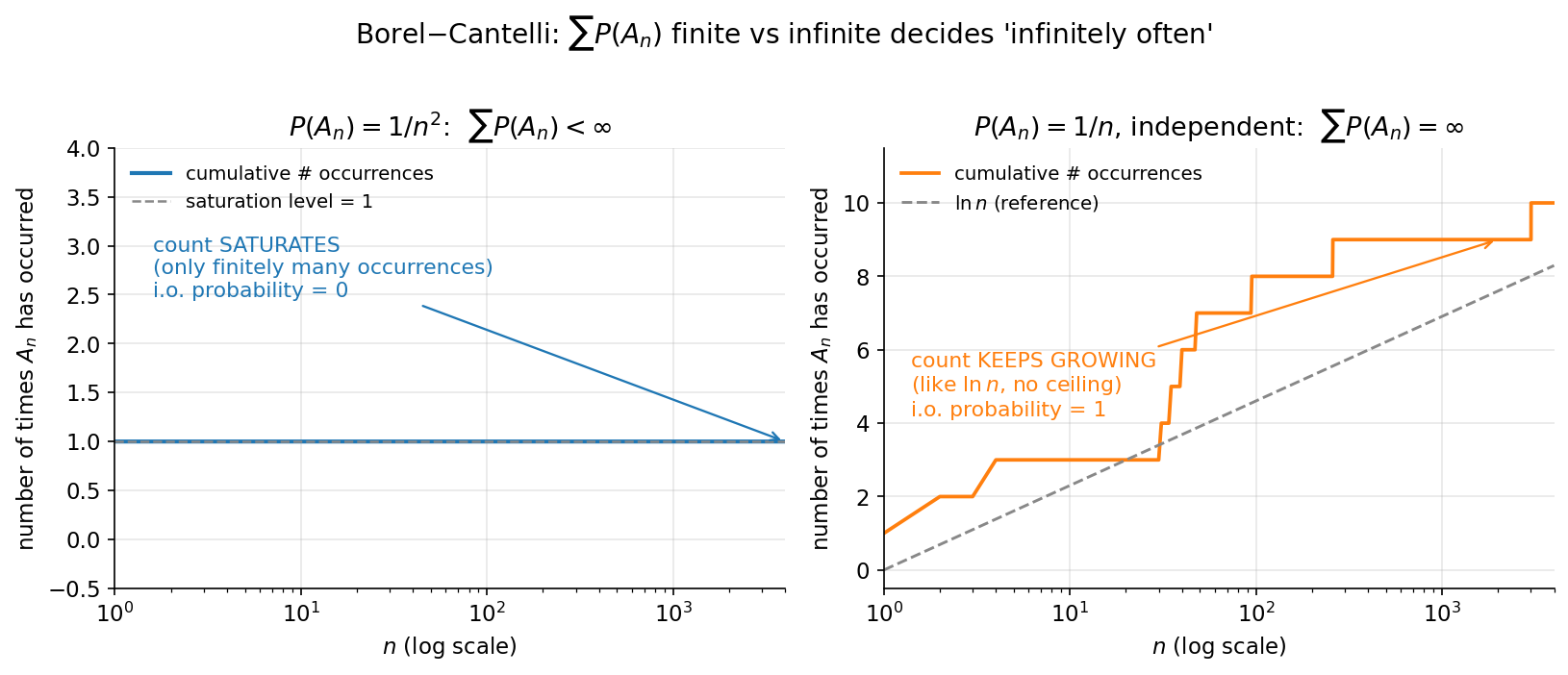
৬.৩ · Cauchy: যেখানে SLLN ভেঙে পড়ে¶
SLLN-এর শর্ত \(\mathbb E\lvert X_1\rvert<\infty\) নিছক টেকনিক্যাল খুঁটিনাটি নয় — এটা ভাঙলে গোটা law-ই উবে যায়। সবচেয়ে নিখুঁত counterexample হলো standard Cauchy distribution, যার ঘনত্ব \(f(x)=\frac{1}{\pi(1+x^2)}\) এতই ভারী-লেজ (heavy-tailed) যে \(\mathbb E\lvert X\rvert=\int\frac{\lvert x\rvert}{\pi(1+x^2)}\,dx=\infty\) — গড় সংজ্ঞায়িতই নয়। ফলে running mean কোনো limit-এ বসে না; বরং একটা চমকপ্রদ তথ্য: \(n\) সংখ্যক Cauchy-র গড় নিজেও আবার ঠিক একটা standard Cauchy! তাই যতই sample জমাও, \(\bar X_n\)-এর spread একটুও কমে না। ছবিতে \(3\)টা স্বাধীন path আঁকা হয়েছে (log-x অক্ষে \(n\)), এবং প্রতিটাই বুনোভাবে লাফায় — মাঝে মাঝে একটা বিশাল outlier এসে গড়টাকে হঠাৎ \(15\) কি \(20\)-তে ছুঁড়ে দেয়, তারপর ধীরে নামে, আবার অন্য একটা outlier আবার ছুঁড়ে দেয়। কোনো অনুভূমিক limit-রেখা নেই (§৬.১-এর \(\mu\)-রেখার বিপরীতে), কারণ অভিসরণের কোনো গন্তব্যই নেই। বিন্দুরেখায় শুধু \(0\) চিহ্নিত — সেটা limit নয়, নিছক চোখের জন্য reference। বার্তাটা স্পষ্ট: finite mean ছাড়া SLLN-এর কোনো ভিত্তি নেই, গড় চিরকাল ঘুরে বেড়ায়।
N, n_paths = 50_000, 3
n = np.arange(1, N + 1)
for k in range(n_paths):
x = rng.standard_cauchy(size=N) # heavy tails: E|X| = infinity
running = np.cumsum(x) / n # mean of n Cauchys is again Cauchy!
ax.plot(n, running, lw=1.1, label=f"path {k+1}")
ax.axhline(0.0, color=GREY, ls=":") # reference 0, NOT a limit
ax.set_xscale("log") # NO horizontal limit line is drawn
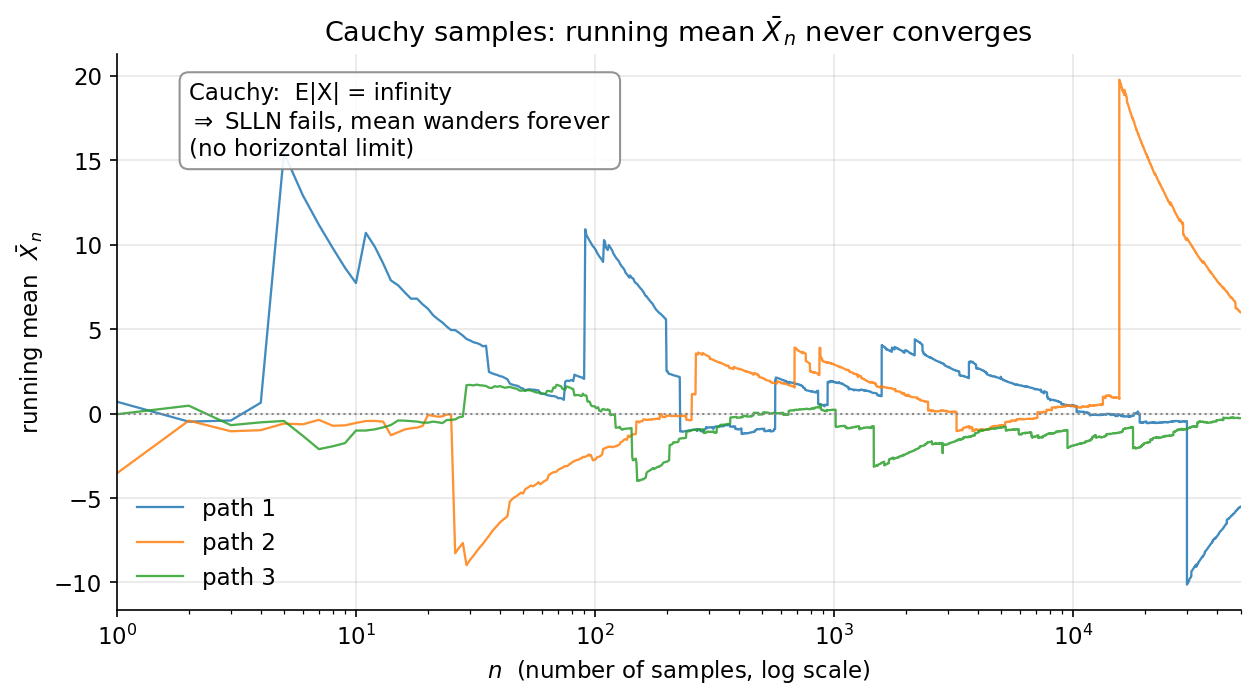
৬.৪ · Kolmogorov-এর 0–1 law: tail event deterministic¶
এই অধ্যায়ের গভীরতম ফলাফল, আর ছবিটা তাকে দুই দৃষ্টিকোণে ধরে। বাঁ panel একটা schematic: tail \(\sigma\)-algebra-র সংজ্ঞা \(\mathcal T=\bigcap_{m}\sigma(X_m,X_{m+1},\dots)\) মানে "যা যেকোনো finite prefix বাদ দিলেও টিকে থাকে"। ছবিতে ধূসর বিন্দুগুলো (\(X_1,\dots,X_4\)) হলো বাদ-দেওয়া prefix, আর নীল বিন্দুগুলো (\(X_5,X_6,\dots\)) হলো অবশিষ্ট লেজ — একটা tail event কেবল এই লেজের ওপর নির্ভর করে, sequence-এর কোনো নির্দিষ্ট finite অংশের ওপর নয়। Kolmogorov-এর 0–1 law বলে: i.i.d. (বা শুধু independent) sequence-এর জন্য যেকোনো tail event-এর probability হয় \(0\), নয় \(1\) — কোনো \(0.5\) বা \(0.7\) অসম্ভব। ডান panel এটাকে সংখ্যায় দেখায়। একটা সত্যিকারের tail event বেছে নেওয়া হয়েছে: \(\{\bar X_N\approx\mu\}\), অর্থাৎ "running mean শেষমেশ \(\mu=1\)-এ পৌঁছায়" — এটা সত্যিই tail \(\sigma\)-algebra-তে পড়ে (কারণ শুরুর যেকোনো কয়টা পদ বদলালে limit একটুও বদলায় না)। \(2000\)টা স্বাধীন simulation চালিয়ে প্রতিটার জন্য indicator \(\mathbf 1\{\bar X_N\approx\mu\}\) গণনা করা হয়েছে। SLLN যেহেতু এই event-কে almost sure করে, 0–1 law বাধ্য করে \(\mathbb P=1\) — এবং histogram-এ সব \(2000\)টা mass একটামাত্র bar-এ, ঠিক \(1\)-এর গায়ে, স্তূপীকৃত (empirical \(P=1.000\)); \(0\)-এর ঘরে একটাও নেই। কোনো ঘণ্টা-আকৃতি, কোনো ছড়ানো বিতরণ নয় — tail event-এর "randomness" বলে কিছু থাকে না, সে deterministic।
n_sims, N = 2000, 20_000
nn = np.arange(1, N + 1)
indicators = np.empty(n_sims)
for s in range(n_sims):
x = rng.exponential(scale=1.0, size=N)
xbar = np.cumsum(x) / nn
indicators[s] = 1.0 if abs(xbar[-1] - 1.0) < 0.05 else 0.0 # tail-event 1_T
p1 = indicators.mean() # empirical P -> 1.000 (Kolmogorov 0-1)
axB.hist(indicators, bins=np.linspace(-0.1, 1.1, 13)) # all mass piles at 1
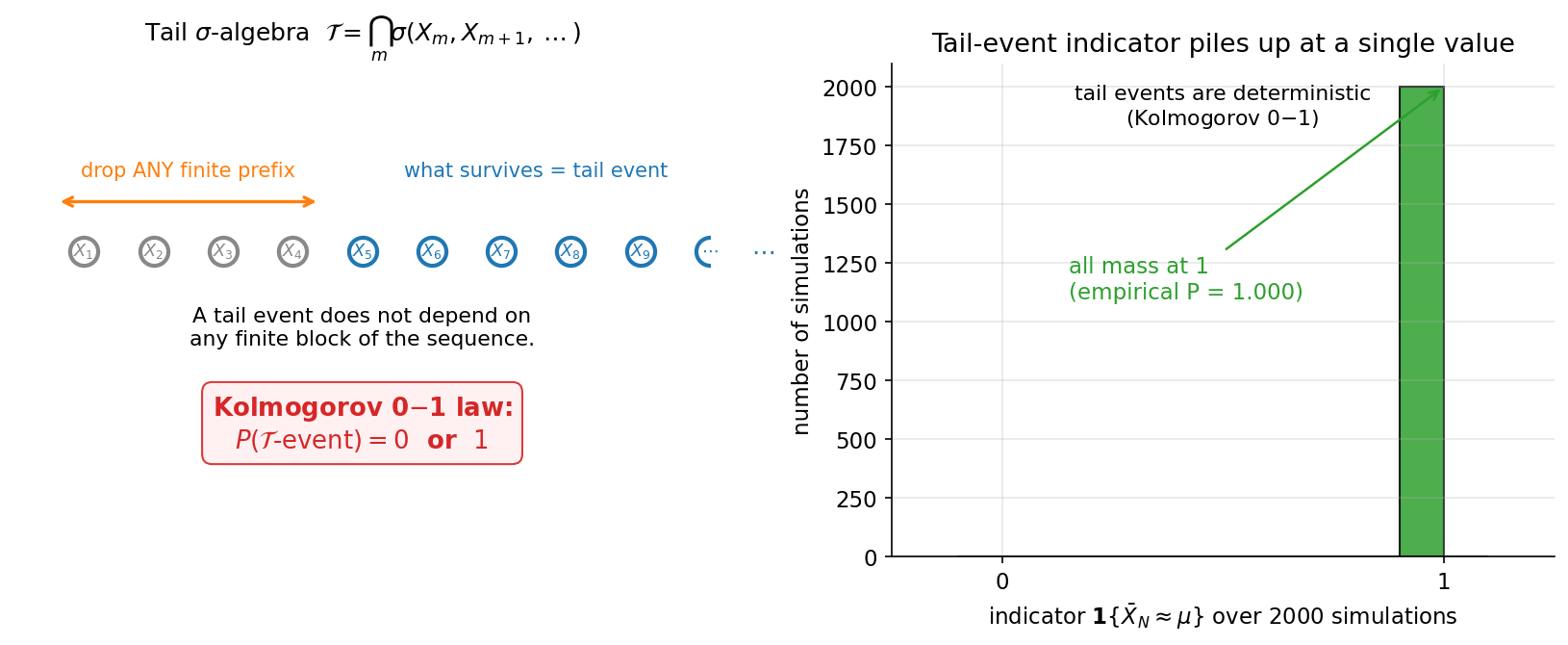
৭ · অনুশীলনী¶
নিচের অনুশীলনীগুলো অধ্যায়ের চারটি স্তম্ভ যাচাই করে: স্বাধীনতা (independence) — ঘটনা / σ-algebra / random variable, পারস্পরিক বনাম জোড়ায়, ও π-system criterion; দুই Borel–Cantelli lemma (BC-I — স্বাধীনতা ছাড়া; BC-II — স্বাধীন, অপসারী-যোগফল) ও "\(A_n\) i.o."-এর শূন্য-এক বিভাজন; tail σ-algebra ও Kolmogorov 0–1 law; এবং কঠোর SLLN (\(\mathbb E\lvert X\rvert<\infty\Rightarrow\bar X_n\to\mu\) a.s., Cauchy-necessity সহ)। সমস্যাগুলো চার দলে সাজানো — ক (ধারণাগত), খ (গণনামূলক), গ (প্রমাণভিত্তিক), ঘ (কোডিং)। প্রতিটির শিরোনামে কঠিনতা-চিহ্ন (difficulty tag): ★ মৌলিক, ★★ মাঝারি, ★★★ গভীর। প্রতিটিতে একটি Hint: দেওয়া আছে।
পূর্ণাঙ্গ সমাধান (ধাপে-ধাপে):
_solutions/07-06-independence-zero-one-slln-solutions.md। আগে নিজে চেষ্টা করুন, তারপর মেলান।
প্রসঙ্গত গোটা অংশে \((\Omega,\mathcal F,\mathbb P)\) একটি probability space; random variable বলতে measurable \(X:\Omega\to\mathbb R\) (7.3), এবং \(\mathbb E[X]=\int_\Omega X\,d\mathbb P\) (7.4), \(X\in L^1\iff\mathbb E\lvert X\rvert<\infty\)। "i.o." = infinitely often ("অসীম-বার"), \(\limsup_n A_n=\bigcap_N\bigcup_{n\ge N}A_n=\{A_n\ \text{i.o.}\}\); tail σ-algebra \(\mathcal T=\bigcap_m\sigma(X_m,X_{m+1},\dots)\)। সব সিমুলেশন seed np.random.default_rng(20260619)-এ চালানো।
ক · ধারণাগত¶
অনুশীলন ১ (★)¶
দুই স্বাধীন fair coin \(X_1,X_2\in\{0,1\}\) আর তাদের XOR \(X_3=X_1\oplus X_2\) নিন। (ক) দেখান (যুক্তিতে, পূর্ণ কষা §৩-এ) যে \(X_1,X_2,X_3\) জোড়ায়-জোড়ায় (pairwise) স্বাধীন — যেকোনো দুটো নিলে স্বাধীন। (খ) এবার ব্যাখ্যা করুন কেন তিনটি একসাথে পারস্পরিক (mutual) স্বাধীন নয় — অর্থাৎ কেন \(\mathbb P(X_1\in B_1,X_2\in B_2,X_3\in B_3)\) সব নির্বাচনে গুণফলে ভাঙে না। (গ) এক বাক্যে: pairwise থেকে mutual স্বাধীনতা আসে না — এই ফাঁকটা কেন σ-algebra-র স্বাধীনতা-সংজ্ঞায় "প্রতিটি উপসেট"/"যেকোনো নির্বাচন" দাবি করতেই হয়, তা বলুন।
Hint: \(X_3\) প্রথম দুটোর একটি deterministic ফাংশন, তাই \(X_3\)-এর মান \(X_1,X_2\) জানলে নিশ্চিত — তিনটি একসাথে "স্বাধীন" হতে পারে না। যেমন \(\mathbb P(X_1{=}0,X_2{=}0,X_3{=}1)=0\) অথচ গুণফল \(\tfrac12\cdot\tfrac12\cdot\tfrac12=\tfrac18\ne0\)। জোড়ায় ঠিক থাকে কারণ যেকোনো দুটো coordinate স্বাধীন uniform জোড়া। (← 2.2-এর সতর্কতা)
অনুশীলন ২ (★)¶
একটি স্বাধীন অনুক্রম \(X_1,X_2,\dots\)-এ tail σ-algebra \(\mathcal T=\bigcap_m\sigma(X_m,X_{m+1},\dots)\)। (ক) নিজের ভাষায় বলুন একটি tail event কী — অর্থাৎ কোন বৈশিষ্ট্যে একটি ঘটনা \(\mathcal T\)-তে পড়ে। (খ) নিচের কোনগুলো tail event, কোনগুলো নয় — প্রতিটির জন্য এক বাক্যে কারণ দিন: (i) \(\{\sum_n X_n\ \text{converges}\}\); (ii) \(\{\limsup_n \bar X_n>c\}\); (iii) \(\{X_1>0\}\); (iv) \(\{\sum_{n=1}^{100}X_n>5\}\)। (গ) Kolmogorov 0–1 law ব্যবহার করে বলুন কেন একটি tail event-এর সম্ভাবনা \(0.5\) হতে পারে না — অর্থাৎ কেন tail event "দৈবহীন/নির্ধারিত (deterministic)"।
Hint: tail event = যা কোনো সসীম-সংখ্যক \(X_i\) বদলালেও বদলায় না। (i),(ii) প্রথম যত-খুশি পদ বদলালে অপরিবর্তিত (অভিসারিতা ও \(\limsup\) লেজ-নির্ভর); (iii),(iv) কেবল সসীম-সংখ্যক \(X_i\)-র উপর নির্ভর — সেগুলো বদলালেই বদলায়, তাই tail নয়। 0–1 law: স্বাধীন হলে \(\mathcal T\perp\mathcal T\), তাই \(\mathbb P(A)=\mathbb P(A)^2\in\{0,1\}\)।
অনুশীলন ৩ (★★)¶
দুই Borel–Cantelli lemma-র মধ্যে একটা গঠনগত অসমতা আছে: BC-I-এ স্বাধীনতা লাগে না, কিন্তু BC-II-তে অপরিহার্য। (ক) ব্যাখ্যা করুন BC-I-এর প্রমাণে ঠিক কোন একটি measure-ধর্ম (স্বাধীনতা নয়) "\(N\)-এর পর কিছু ঘটে" সম্ভাবনাকে লেজ-যোগফলে চাপা দেয় — তাই কোনো স্বাধীনতা ছাড়াই \(\mathbb P(A_n\ \text{i.o.})=0\)। (খ) BC-II-তে স্বাধীনতা ঠিক কোথায় ঢোকে — অর্থাৎ "\(N\)-এর পর কিছুই ঘটে না"-কে কীসে রূপান্তর করতে স্বাধীনতা লাগে। (গ) একটি প্রতিউদাহরণ দিয়ে দেখান BC-II স্বাধীনতা ছাড়া মিথ্যা: এমন (নির্ভরশীল) ঘটনা-অনুক্রম তৈরি করুন যেখানে \(\sum_n\mathbb P(A_n)=\infty\) অথচ \(\mathbb P(A_n\ \text{i.o.})=0\)।
Hint: (ক) countable subadditivity — \(\mathbb P(\bigcup_{n\ge N}A_n)\le\sum_{n\ge N}\mathbb P(A_n)\), আর অভিসৃত ধারার লেজ \(\to0\)। (খ) স্বাধীনতা "\(\bigcap_{n=N}^M A_n^c\)"-কে গুণফলে ভাঙে, তারপর \(1-x\le e^{-x}\) দিয়ে \(\exp(-\sum)=0\)। (গ) একই ঘটনা বারবার: \(A_n=A\) সব \(n\)-এ (\(0<\mathbb P(A)<1\)) — তখন \(\sum\mathbb P(A_n)=\infty\), কিন্তু \(\{A_n\ \text{i.o.}\}=A\), তাই সম্ভাবনা \(\mathbb P(A)<1\) (এমনকি ছোট \(A\)-তে \(\ll1\))।
খ · গণনামূলক¶
অনুশীলন ৪ (★)¶
তিনটি ঘটনা-অনুক্রমের জন্য \(\sum_n\mathbb P(A_n)\) অভিসারী না অপসারী যাচাই করে Borel–Cantelli দিয়ে i.o.-ভাগ্য নির্ণয় করুন (যেখানে স্বাধীনতা প্রয়োজন, ধরে নিন ঘটনাগুলো স্বাধীন)। (ক) \(\mathbb P(A_n)=1/n^2\); (খ) \(\mathbb P(A_n)=1/n\); (গ) \(\mathbb P(A_n)=1/(n\log n)\) (\(n\ge2\))। প্রতিটির জন্য (i) যোগফলের অভিসারিতা/অপসারিতা ও তার মান বা বৃদ্ধি-হার লিখুন, (ii) প্রযোজ্য lemma (BC-I না BC-II) বলুন, (iii) উপসংহার \(\mathbb P(A_n\ \text{i.o.})\) = \(0\) না \(1\) লিখুন।
Hint: \(\sum 1/n^2=\pi^2/6\approx1.6449<\infty\) ⇒ BC-I ⇒ \(0\)। \(\sum 1/n=\infty\) (বৃদ্ধি \(\approx\ln N\)) ⇒ স্বাধীন ⇒ BC-II ⇒ \(1\)। \(\sum 1/(n\log n)\): integral test-এ \(\int^{}\frac{dx}{x\log x}=\log\log x\to\infty\), তাই অপসারী (অতি-ধীর, \(\sim\log\log N\)) ⇒ BC-II ⇒ \(1\)।
অনুশীলন ৫ (★★)¶
ঠিক \(1/n^2\) আর \(1/n\)-এর মাঝের সীমারেখা ছুঁতে \(\mathbb P(A_n)=1/(n\log n)\) (\(n\ge2\)) কেস (অনুশীলন ৪গ)-কে যাচাই করুন গণনায়। (ক) integral test দিয়ে দেখান \(\sum_{n\ge2}\frac1{n\log n}\) অপসারী (substitution \(u=\log x\))। (খ) আংশিক-যোগফলের বৃদ্ধি-হার \(\sum_{2\le n\le N}\frac1{n\log n}\approx\log\log N\) — \(N=10^3,10^6\)-এ আনুমানিক মান বের করুন এবং মন্তব্য করুন এটি \(\sum 1/n\approx\ln N\)-এর চেয়ে কত ধীরে বাড়ে। (গ) উপসংহার: ঘটনাগুলো স্বাধীন হলে \(\mathbb P(A_n\ \text{i.o.})\) কত, এবং সেটি \(1/n^2\) (থামে) বনাম \(1/n\) (চলে) স্পেকট্রামে কোথায় বসে।
Hint: (ক) \(\int_2^\infty\frac{dx}{x\log x}=[\log\log x]_2^\infty=\infty\) — তাই অপসারী, integral test-এ। (খ) \(\log\log 10^3\approx\log(6.91)\approx1.93\); \(\log\log 10^6\approx\log(13.8)\approx2.62\) — তুলনায় \(\ln10^3\approx6.9,\ \ln10^6\approx13.8\), অর্থাৎ \(\log\log\) অনেক ধীর। (গ) অপসারী + স্বাধীন ⇒ BC-II ⇒ \(1\); তাই "\(1/n\)-জাতীয়" (চলে), যদিও সীমারেখার একদম গা ঘেঁষে।
অনুশীলন ৬ (★★)¶
iid \(X_1,X_2,\dots\), প্রতিটি \(X_i\in\{0,1\}\) সমান-সম্ভাবনায় (\(\mathbb P(X_i{=}1)=\tfrac12\)) — অর্থাৎ fair-coin অনুক্রম। নিম্নলিখিত গড়গুলোর a.s. সীমা SLLN দিয়ে নির্ণয় করুন এবং প্রতিটি ক্ষেত্রে \(\mathbb E\lvert\cdot\rvert<\infty\) যাচাই করুন। (ক) \(\bar X_n=\frac1n\sum_{i=1}^n X_i\); (খ) \(\frac1n\sum_{i=1}^n X_iX_{i+1}\) (পরপর দুই coin-এর গুণফল); (গ) \(\frac1n\sum_{i=1}^n (2X_i-1)^2\)। প্রতিটির জন্য প্রযোজ্য random variable (\(X_i\), \(Y_i=X_iX_{i+1}\), বা \(Z_i=(2X_i-1)^2\))-এর mean বের করে সীমা লিখুন।
Hint: (ক) \(\mathbb E[X_i]=\tfrac12\) ⇒ \(\bar X_n\to\tfrac12\) a.s.। (খ) \(Y_i=X_iX_{i+1}\in\{0,1\}\), \(\mathbb E[Y_i]=\mathbb P(X_i{=}1,X_{i+1}{=}1)=\tfrac14\); \(Y_i\)-রা স্বাধীন নয় (পাশাপাশি overlap) কিন্তু identically distributed ও stationary-ergodic, SLLN-এর ergodic রূপে \(\to\tfrac14\) a.s. (সহজ যুক্তি: জোড়/বিজোড় ব্লকে ভাঙুন)। (গ) \((2X_i-1)\in\{-1,1\}\), তাই \((2X_i-1)^2=1\) ধ্রুবক ⇒ গড় ঠিক \(1\), সীমা \(1\)।
গ · প্রমাণভিত্তিক¶
অনুশীলন ৭ (★★)¶
Borel–Cantelli lemma I প্রমাণ করুন। যেকোনো ঘটনা-অনুক্রম \((A_n)\)-এর জন্য (স্বাধীনতা ছাড়াই) দেখান: $$ \sum_{n=1}^\infty\mathbb P(A_n)<\infty\quad\Longrightarrow\quad \mathbb P\big(\limsup_n A_n\big)=\mathbb P(A_n\ \text{i.o.})=0. $$ (ক) \(B_N:=\bigcup_{n\ge N}A_n\) লিখে দেখান \(B_N\downarrow\limsup_n A_n\), এবং continuity-from-above (7.2) প্রয়োগ করে \(\mathbb P(\limsup A_n)=\lim_N\mathbb P(B_N)\) পান। (খ) countable subadditivity দিয়ে \(\mathbb P(B_N)\le\sum_{n\ge N}\mathbb P(A_n)\) দেখান। (গ) অভিসৃত ধারার লেজ \(\to0\) ব্যবহার করে উপসংহার টানুন।
Hint: (ক) বড় \(N\)-এ কম পদের union, তাই \(B_1\supseteq B_2\supseteq\cdots\) এবং \(\bigcap_N B_N=\limsup A_n\); \(\mathbb P(B_1)\le1<\infty\) তাই continuity-from-above বৈধ। (খ) σ-additivity-র subadditive রূপ। (গ) \(\sum_{n\ge N}\mathbb P(A_n)=\big(\sum_{n\ge1}-\sum_{n=1}^{N-1}\big)\mathbb P(A_n)\to0\); sandwich-এ \(\mathbb P(B_N)\to0\)।
অনুশীলন ৮ (★★★)¶
দেখান \(\{\sum_n X_n\ \text{converges}\}\) একটি tail event (যখন \(X_1,X_2,\dots\) স্বাধীন), তাই Kolmogorov 0–1 law-এ তার সম্ভাবনা \(0\) বা \(1\)। (ক) প্রতিটি \(N\ge1\)-এর জন্য যুক্তি দিন কেন $$ \sum_{n=1}^\infty X_n\ \text{অভিসৃত}\quad\Longleftrightarrow\quad \sum_{n=N}^\infty X_n\ \text{অভিসৃত}, $$ অর্থাৎ অভিসারিতা প্রথম \(N-1\)টি পদের উপর নির্ভর করে না। (খ) এ থেকে দেখান ঘটনাটি প্রতিটি \(\sigma(X_N,X_{N+1},\dots)\)-এ পড়ে, তাই \(\mathcal T=\bigcap_N\sigma(X_N,\dots)\)-তেও। (গ) এক বাক্যে: 0–1 law প্রয়োগ করে কী উপসংহার, এবং এটি কীভাবে SLLN-এর "\(\bar X_n\to\) ধ্রুবক"-কে স্বাভাবিক করে তোলে।
Hint: (ক) দুই ধারার পার্থক্য সসীম যোগফল \(\sum_{n<N}X_n\) — সর্বদা সসীম, তাই অভিসারিতা-প্রশ্নে নিরপেক্ষ। (খ) \(\sum_{n\ge N}X_n\) কেবল \(X_N,X_{N+1},\dots\)-এর measurable ফাংশন (আংশিক-যোগফলের limit), তাই ঘটনাটি \(\sigma(X_N,\dots)\)-measurable; সব \(N\)-এ সত্য বলে ছেদ \(\mathcal T\)-তেও। (গ) \(\mathbb P\in\{0,1\}\); আর "\(\bar X_n\) অভিসৃত"-ও tail, তাই সীমা থাকলে তা a.s. ধ্রুবক — SLLN শুধু দেখায় ধ্রুবকটা \(\mu\)।
অনুশীলন ৯ (★★)¶
0–1 law-এর হৃৎপিণ্ড: \(\mathbb P(A)=\mathbb P(A)^2\Rightarrow\mathbb P(A)\in\{0,1\}\)। ধরা যাক একটি ঘটনা \(A\) এমন যে সে নিজের থেকে স্বাধীন — অর্থাৎ \(\mathbb P(A\cap A)=\mathbb P(A)\,\mathbb P(A)\)। (ক) এই সমীকরণ থেকে বীজগণিতে দেখান \(\mathbb P(A)\in\{0,1\}\)। (খ) Kolmogorov 0–1 law-এর প্রমাণে এই "নিজের-থেকে-স্বাধীনতা" কোথা থেকে আসে — সংক্ষেপে যুক্তি-শৃঙ্খল দিন (কেন \(\mathcal T\perp\mathcal T\))। (গ) এটি ব্যবহার করে দেখান একটি tail random variable \(Y\) (যেমন \(\limsup_n X_n\)) a.s. ধ্রুবক — অর্থাৎ এর CDF \(F_Y\) একটি \(\{0,1\}\)-মানের ধাপ।
Hint: (ক) \(p=p^2\Rightarrow p(1-p)=0\Rightarrow p\in\{0,1\}\)। (খ) \(\mathcal T\subseteq\sigma(X_{n+1},\dots)\) প্রতিটি \(n\)-এ, তাই \(\mathcal T\perp\sigma(X_1,\dots,X_n)\) সব \(n\)-এ; π-system criterion দিয়ে \(\mathcal T\perp\sigma(X_1,X_2,\dots)\supseteq\mathcal T\), অর্থাৎ \(\mathcal T\perp\mathcal T\)। (গ) \(\{Y\le t\}\in\mathcal T\) ⇒ \(F_Y(t)\in\{0,1\}\); এমন অ-হ্রাসমান ডান-অবিচ্ছিন্ন \(\{0,1\}\)-function একটি \(c\)-তে লাফায়, তাই \(\mathbb P(Y=c)=1\)।
ঘ · কোডিং¶
অনুশীলন ১০ (★★)¶
SLLN অভিসরণ বনাম Cauchy non-convergence — পাশাপাশি। seed np.random.default_rng(20260619) ও \(N=10^6\) দিয়ে: (ক) \(X_i\sim\text{Exp}(1)\) (\(\mathbb E[X]=1\)) নমুনায় চলমান-গড় \(\bar X_n\) ছাপুন \(n=10,10^2,10^3,10^4,10^5,10^6\)-এ এবং দেখান তা \(1\)-এর দিকে গুটিয়ে আসে (\(n=10^6\)-এ \(\approx1.0007\))। (খ) standard Cauchy (\(\mathbb E\lvert X\rvert=\infty\)) নমুনায় একই \(n\)-গুলোয় \(\bar X_n\) ছাপুন এবং দেখান তা স্থির না হয়ে ঘুরতে থাকে (canonical: \(\approx1.126,\ 0.851,\ -0.173\) at \(n=10^2,10^4,10^6\) — এমনকি চিহ্ন বদলায়)। (গ) দুই আচরণের পার্থক্যের গোড়ায় কোন একটি শর্ত — এক বাক্যে কোডের comment-এ লিখুন।
Hint: rng=np.random.default_rng(20260619); X=rng.exponential(1.0,size=10**6) তারপর X[:n].mean(); নতুন cell-এ আবার seed দিয়ে rng.standard_cauchy(size=10**6)। Exp-এ \(\mathbb E\lvert X\rvert=1<\infty\) (SLLN লাগে), Cauchy-তে \(=\infty\) (SLLN ভাঙে — \(\bar X_n\) নিজেও হুবহু Cauchy থাকে, সরু হয় না)।
অনুশীলন ১১ (★★)¶
Borel–Cantelli I বনাম II — occurrence-count সিমুলেশন। seed 20260619, \(N=10^5\), \(n=1,\dots,N\) দিয়ে: (ক) স্বাধীন \(A_n\) সম্ভাবনা \(1/n^2\)-তে ঘটিয়ে মোট কতবার ঘটল গুনুন — দেখান গণনা একটি ছোট সংখ্যায় (≈২) saturate করে, আর শেষ-ঘটনার সূচক ছোট \(n\)-এ আটকে (BC-I, \(\sum1/n^2=\pi^2/6\approx1.6449<\infty\))। (খ) স্বাধীন \(A_n\) সম্ভাবনা \(1/n\)-তে ঘটিয়ে গুনুন — দেখান গণনা saturate করে না, ইতিমধ্যে ≈৮, আর মোটামুটি \(\ln N\approx11.5\)-এর হারে বাড়ে (BC-II, \(\sum1/n=\infty\))। (গ) দুই ফলাফল এক টেবিলে রেখে মন্তব্য করুন — কেন প্রতিবেশী \(1/n^2\) ও \(1/n\) ভাগ্যকে \(0\) বনাম \(1\)-এ উল্টে দেয়।
Hint: n=np.arange(1,N+1); occ=rng.random(N)<1.0/n**2; occ.sum() এবং np.where(occ)[0].max()+1; পুনরায় seed দিয়ে <1.0/n। প্রত্যাশিত: BC-I count ≈২ (saturate), BC-II count ≈৮ (বাড়ন্ত, \(\sim\ln N\))।
অনুশীলন ১২ (★★★)¶
একটি tail event-এর সম্ভাবনা empirical-ভাবে \(0\) বা \(1\)-এ জমাট। seed 20260619 দিয়ে বহু স্বাধীন run-এ একটি tail-জাতীয় ঘটনার আপেক্ষিক কম্পাঙ্ক আনুমান করুন এবং দেখান তা \(\{0,1\}\)-এর দিকে যায়, \(0.5\)-এ নয়। (ক) iid fair-coin \(X_i\in\{0,1\}\)-এ ঘটনা \(C=\{\bar X_n\to\tfrac12\}\) — প্রতিটি run-এ বড় \(n\) (\(=10^5\))-এ \(\lvert\bar X_n-\tfrac12\rvert<0.01\) কিনা দেখে, \(200\) run-এ কত ভগ্নাংশ "সফল" গুনুন; দেখান তা \(\approx1.0\) (SLLN ⇒ tail-সম্ভাবনা \(1\))। (খ) তুলনায় একটি non-tail ঘটনা \(\{X_1=1\}\)-এর আপেক্ষিক কম্পাঙ্ক বের করুন — দেখান তা \(\approx0.5\) (tail নয়, তাই 0–1 law খাটে না)। (গ) এক বাক্যে: কেন (ক) \(\{0,1\}\)-এ জমাট অথচ (খ) \(0.5\)-এ — পার্থক্যটা tail বনাম non-tail।
Hint: প্রতি run-এ x=(rng.random(10**5)<0.5); hit=abs(x.mean()-0.5)<0.01; \(200\) run-এ np.mean(hits)\(\approx1.0\)। \(\{X_1=1\}\)-এ first=x[0]; গড় \(\approx0.5\)। (ক) tail event (লেজ-নির্ভর, প্রথম পদে নয়) ⇒ 0–1 law ⇒ এখানে \(1\); (খ) প্রথম পদ-নির্ভর ⇒ tail নয় ⇒ সম্ভাবনা \(\tfrac12\) থাকে।
৮ · সারসংক্ষেপ ও সংযোগ¶
এই অধ্যায়ে আমরা 2.2-এর স্বজ্ঞাগত ঘটনা-স্বাধীনতাকে measure-তাত্ত্বিকভাবে কঠোর করেছি — শুধু ঘটনার নয়, σ-algebra ও random variable-এরও স্বাধীনতা — এবং তার থেকে তিনটি গভীর ফল তুলেছি: Borel–Cantelli, Kolmogorov 0–1 law, ও কঠোর SLLN।
১. স্বাধীনতা ও π-system criterion। sub-σ-algebra \(\mathcal F_1,\dots,\mathcal F_n\) স্বাধীন যদি যেকোনো \(A_i\in\mathcal F_i\) বাছাইতে \(\mathbb P(\bigcap A_i)=\prod\mathbb P(A_i)\); random variable \(X_i\) স্বাধীন যদি \(\sigma(X_i)\)-গুলো স্বাধীন (⇔ সব Borel \(B_i\)-তে যৌথ সম্ভাবনা factorize); একটি অসীম পরিবার স্বাধীন যদি তার প্রতিটি সসীম উপ-পরিবার স্বাধীন। পারস্পরিক (mutual) ≠ জোড়ায় (pairwise) — তিন XOR-coin জোড়ায় স্বাধীন অথচ পারস্পরিক নয়। π-system criterion (7.2-এর π–λ থেকে): একটি generating π-system-এ factorization মিললেই তা পুরো σ-algebra-য় ছড়ায় — তাই random variable-এর স্বাধীনতা CDF-স্তরেই (\(\mathbb P(\bigcap\{X_i\le x_i\})=\prod F_{X_i}(x_i)\)) যাচাই করা যায়, আর iid ⇔ যৌথ law = product measure \(\bigotimes_i P_X\)।
২. Borel–Cantelli I ও II। \(\limsup_n A_n=\bigcap_N\bigcup_{n\ge N}A_n=\{A_n\ \text{i.o.}\}\) ধরে "অসীম-সংখ্যক \(A_n\) ঘটে"। BC-I: \(\sum_n\mathbb P(A_n)<\infty\Rightarrow\mathbb P(A_n\ \text{i.o.})=0\) — কোনো স্বাধীনতা ছাড়াই (countable subadditivity + লেজ\(\to0\))। BC-II: \(A_n\) স্বাধীন ও \(\sum_n\mathbb P(A_n)=\infty\Rightarrow\mathbb P(A_n\ \text{i.o.})=1\) (গুণফল + \(1-x\le e^{-x}\))। দুইয়ে মিলে স্বাধীন ঘটনার জন্য একটি শূন্য-এক বিভাজন: \(\sum\mathbb P(A_n)\) অভিসারী হলে \(0\), অপসারী হলে \(1\) — মাঝামাঝি কিছু নেই। canonical: \(1/n^2\) (\(\sum=\pi^2/6\approx1.6449\)) দেয় \(0\), ≈২ ঘটনায় saturate; \(1/n\) (\(\sum=\infty\)) দেয় \(1\), ≈৮ ঘটনা ও \(\sim\ln N\) হারে বৃদ্ধি; সীমারেখার \(1/(n\log n)\) (\(\sum\sim\log\log N=\infty\)) দেয় \(1\)।
৩. tail σ-algebra ও Kolmogorov 0–1 law। \(\mathcal T=\bigcap_m\sigma(X_m,X_{m+1},\dots)\) — যে ঘটনা সসীম-সংখ্যক \(X_i\) বদলালেও বদলায় না (যেমন \(\{\sum X_n\ \text{converges}\}\), \(\{\limsup\bar X_n>c\}\))। Kolmogorov 0–1 law: স্বাধীন \(X_n\) হলে প্রতিটি tail event-এর \(\mathbb P\in\{0,1\}\), প্রতিটি tail random variable a.s. ধ্রুবক। হৃৎপিণ্ড: \(\mathcal T\perp\mathcal T\) (π-system criterion দিয়ে), তাই \(\mathbb P(A)=\mathbb P(A)^2\Rightarrow\mathbb P(A)\in\{0,1\}\)। এটিই Borel–Cantelli-র শূন্য-এক বিভাজনের অন্তর্নিহিত কারণ, এবং বলে দেয় কেন SLLN-এ সীমা একটি নির্দিষ্ট ধ্রুবক হওয়াই স্বাভাবিক।
৪. কঠোর SLLN। iid ও \(\mathbb E\lvert X\rvert<\infty\Rightarrow\bar X_n=\frac1n\sum_{i=1}^n X_i\xrightarrow{\text{a.s.}}\mu=\mathbb E[X]\) — 3.3-এর weak law (\(\xrightarrow{P}\))-কে almost-sure অভিসরণে উন্নীত, variance ছাড়াই (শুধু first moment)। Necessity: \(\mathbb E\lvert X\rvert=\infty\) হলে (যেমন Cauchy) \(\limsup_n\lvert\bar X_n\rvert=\infty\) a.s. — কোনো সসীম a.s. সীমা নেই; তাই \(\mathbb E\lvert X\rvert<\infty\) যথেষ্ট ও আবশ্যক (iff)। canonical: \(\text{Exp}(1)\)-এ \(\bar X_n\to1\) (\(n=10^6\)-এ \(1.0007\)), \(\text{Bernoulli}(0.3)\)-এ \(\to0.2999\); Cauchy-তে \(\bar X_n\) ঘোরে (\(1.126,\ 0.851,\ -0.173\))। প্রমাণ-যন্ত্র: truncation (\(X_n\mathbf 1_{\{\lvert X_n\rvert\le n\}}\)) + Kolmogorov maximal inequality (\(\mathbb P(\max_{k\le n}\lvert S_k\rvert\ge t)\le\operatorname{Var}(S_n)/t^2\)) + Borel–Cantelli I; সহজ পথে সসীম 4th moment-এ Cantelli।
মূল উপপাদ্য/তথ্য (mini-list)। - σ-algebra-র স্বাধীনতা: \(\mathcal F_1,\dots,\mathcal F_n\) স্বাধীন \(\iff\) যেকোনো \(A_i\in\mathcal F_i\)-তে \(\mathbb P(\bigcap_i A_i)=\prod_i\mathbb P(A_i)\)। - π-system criterion: π-system \(\mathcal P_i\)-তে factorization \(\Rightarrow\) \(\sigma(\mathcal P_1),\dots,\sigma(\mathcal P_n)\) স্বাধীন (তাই CDF-স্তরে যাচাই-ই যথেষ্ট)। - \(\limsup A_n\) / i.o.: \(\limsup_n A_n=\bigcap_N\bigcup_{n\ge N}A_n=\{A_n\ \text{i.o.}\}\)। - Borel–Cantelli I: \(\sum_n\mathbb P(A_n)<\infty\Rightarrow\mathbb P(A_n\ \text{i.o.})=0\) (স্বাধীনতা লাগে না)। - Borel–Cantelli II: \((A_n)\) স্বাধীন ও \(\sum_n\mathbb P(A_n)=\infty\Rightarrow\mathbb P(A_n\ \text{i.o.})=1\)। - tail σ-algebra: \(\mathcal T=\bigcap_{m\ge1}\sigma(X_m,X_{m+1},\dots)\)। - Kolmogorov 0–1 law: \((X_n)\) স্বাধীন \(\Rightarrow\) \(\forall A\in\mathcal T:\ \mathbb P(A)\in\{0,1\}\); tail RV a.s. ধ্রুবক (\(\mathbb P(A)=\mathbb P(A)^2\))। - SLLN: iid, \(\mathbb E\lvert X\rvert<\infty\Rightarrow\bar X_n\to\mu\) a.s.; \(\mathbb E\lvert X\rvert=\infty\Rightarrow\limsup\lvert\bar X_n\rvert=\infty\) a.s. - Kolmogorov maximal inequality: স্বাধীন, শূন্য-গড়, \(S_k=\sum_{i\le k}X_i\)-এ \(\mathbb P(\max_{k\le n}\lvert S_k\rvert\ge t)\le\operatorname{Var}(S_n)/t^2\)।
পেছনের সংযোগ: - ← 2.2 (Independence ও conditional probability): সেখানকার ঘটনা-স্বাধীনতা \(\mathbb P(A\cap B)=\mathbb P(A)\mathbb P(B)\) ও pairwise-বনাম-mutual সতর্কতা এখানে σ-algebra ও random variable-এর কঠোর স্বাধীনতায় (π-system criterion সহ) উন্নীত। - ← 3.3 (Law of large numbers): সেখানকার weak LLN (\(\bar X_n\xrightarrow{P}\mu\), Chebyshev দিয়ে, সসীম variance-এ) এখানে strong-এ উন্নীত — \(\bar X_n\to\mu\) a.s., কেবল \(\mathbb E\lvert X\rvert<\infty\)-তে (a.s. ⇒ in probability, উল্টোটা নয়)। - ← 3.1 (Markov, Chebyshev): Kolmogorov maximal inequality হলো Chebyshev-এর পথ-সংস্করণ (পুরো \(\max_{k\le n}\lvert S_k\rvert\)-কে একই ডান-পাশে বাঁধে); আর BC-I-এর Markov-পথ (\(\mathbb P(\lvert\bar X_n\rvert>\varepsilon)\le\mathbb E[\bar X_n^4]/\varepsilon^4\)) SLLN-প্রমাণে। - ← 7.2 (π–λ ও product measure): π-system criterion ও iid ⇔ product-law সরাসরি 7.2-এর Dynkin π–λ ও product-নির্মাণের উপর দাঁড়ায়।
সামনের সংযোগ: - → 7.8 (Filtration ও martingale): এখানকার Kolmogorov maximal inequality আসলে Doob-এর maximal inequality-র বিশেষ রূপ (\(\{S_k\}\) একটি martingale); স্বাধীনতার শিথিল রূপ (martingale difference) সেখানে আসে। - → 7.9 (Martingale convergence): SLLN-কে দ্বিতীয়, আরও গভীর পথে (martingale convergence theorem দিয়ে) প্রমাণ করে। - → 7.10 (Rigorous CLT): স্বাধীন যোগফলের সূক্ষ্মতর আচরণ — SLLN-এর (\(\bar X_n\to\mu\)) পরের স্তর, \(\sqrt n(\bar X_n-\mu)\)-এর বণ্টন-সীমা।
উৎস: Klenke, Probability Theory: A Comprehensive Course, অধ্যায় ২ (Independence) ও অধ্যায় ৫ (Borel–Cantelli, 0–1 law, Strong Law) — σ-algebra ও random variable-এর স্বাধীনতা ও π-system criterion, \(\limsup A_n\) ও দুই Borel–Cantelli lemma, tail σ-algebra ও Kolmogorov 0–1 law, Kolmogorov maximal inequality ও three-series theorem, এবং কঠোর SLLN (Etemadi-র truncation-প্রমাণ) সহ Cauchy-necessity-র আদর্শ উপস্থাপনা।
এক বাক্যে: 2.2-এর ঘটনা-স্বাধীনতাকে σ-algebra ও random variable-এর জন্য কঠোর করে (π-system criterion দিয়ে CDF-স্তরে যাচাই) তিন গভীর ফল ওঠে — Borel–Cantelli (\(\sum\mathbb P(A_n)\) অভিসারী/অপসারী-ভেদে i.o. \(0\)/\(1\)), Kolmogorov 0–1 law (tail event \(0\)/\(1\), \(\mathbb P(A)=\mathbb P(A)^2\)), ও কঠোর SLLN (\(\mathbb E\lvert X\rvert<\infty\Rightarrow\bar X_n\to\mu\) a.s., Cauchy-তে ভাঙে) — যা 3.3-এর weak law-কে a.s.-এ উন্নীত করে আর 7.8–7.10-এর martingale ও CLT-তে গড়