7.7 — Conditional Expectation (আংশিক তথ্যের নিচে সেরা অনুমান)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
১.১ যেখানে আমরা দাঁড়িয়ে — 2.2-এর conditional expectation (শর্তাধীন প্রত্যাশা), আর তার এক গোপন crack (ফাটল)¶
পরিসংখ্যানের গোটা ভবন একটা সহজ প্রশ্নের উপর দাঁড়িয়ে: আংশিক তথ্য হাতে এলে একটা অজানা রাশি সম্পর্কে আমাদের সেরা অনুমান কী হবে? রোগীর রক্তচাপ জানা থাকলে তার হৃদরোগের ঝুঁকি কত? আজকের আবহাওয়া দেখে আগামীকালের তাপমাত্রার সেরা প্রাক্কলন কী? একটা স্টকের গতকালের দাম জানলে আজকের প্রত্যাশিত দাম? — এই সব প্রশ্নের গাণিতিক উত্তর একটিমাত্র বস্তু: conditional expectation (শর্তাধীন প্রত্যাশা)।
2.2-এ আমরা এর সাথে প্রথম পরিচিত হয়েছিলাম, কিন্তু স্বজ্ঞাগতভাবে ও সীমিত আকারে। সেখানে যখন \(Y\) একটা discrete random variable, তখন একটা নির্দিষ্ট মান \(Y=y\) পেলে আমরা \(X\)-এর শর্তাধীন প্রত্যাশা লিখেছিলাম $$ \mathbb E[X\mid Y=y]\;=\;\sum_x x\;\mathbb P(X=x\mid Y=y)\;=\;\sum_x x\,\frac{\mathbb P(X=x,\,Y=y)}{\mathbb P(Y=y)}, $$ এবং এর উপর গড়েছিলাম law of total expectation \(\mathbb E[X]=\sum_y\mathbb E[X\mid Y=y]\,\mathbb P(Y=y)\) — "প্রতিটি পরিস্থিতিতে সেরা অনুমান, তারপর সেই পরিস্থিতিগুলোর উপর গড়"। এটি স্বজ্ঞার সাথে সম্পূর্ণ মেলে: \(Y=y\) জানা মানে নমুনাক্ষেত্র \(\Omega\)-কে \(\{Y=y\}\)-অংশে সীমিত করা, আর সেই সীমিত জগতে \(X\)-এর সাধারণ গড় নেওয়া।
কিন্তু এই সংজ্ঞার ভেতরে একটা গোপন ফাটল আছে — হরে বসে থাকা \(\mathbb P(Y=y)\)। যতক্ষণ \(Y\) discrete এবং \(\mathbb P(Y=y)>0\), ততক্ষণ সব ঠিক। কিন্তু \(Y\) যদি continuous হয় — যেমন তাপমাত্রা, রক্তচাপ, দাম, যা প্রকৃত পরিসংখ্যানে প্রায় সর্বত্র — তখন প্রতিটি নির্দিষ্ট মানের সম্ভাবনা ঠিক শূন্য: \(\mathbb P(Y=y)=0\) সব \(y\)-তে। তখন উপরের ভগ্নাংশটা হয়ে যায় \(0/0\) — সম্পূর্ণ অর্থহীন। অথচ স্বজ্ঞা স্পষ্ট বলে যে "রক্তচাপ ঠিক \(120\) হলে প্রত্যাশিত ঝুঁকি" একটা সুসংজ্ঞ, অর্থবহ সংখ্যা হওয়া উচিত। তাহলে 2.2-এর সংজ্ঞা কোথায় ব্যর্থ, আর কীভাবে তাকে উদ্ধার করা যায়?
এক বাক্যে সূচনা। 2.2 দিয়েছিল \(\mathbb E[X\mid Y=y]=\sum_x x\,\mathbb P(X=x\mid Y=y)\), কিন্তু সেটি কেবল \(\mathbb P(Y=y)>0\) হলেই খাটে — continuous \(Y\)-তে \(\mathbb P(Y=y)=0\) হওয়ায় \(0/0\)-তে ভেঙে পড়ে; এই অধ্যায় একটা sub-σ-algebra \(\mathcal G\)-কে "তথ্য" ধরে \(\mathbb E[X\mid\mathcal G]\)-এর কঠোর, সর্বত্র-বৈধ সংজ্ঞা গড়ে — আংশিক তথ্যের নিচে \(X\)-এর সেরা অনুমান।
১.২ মূল মোড় — তথ্যকে σ-algebra হিসেবে দেখা, একটিমাত্র মান হিসেবে নয়¶
ফাটলটা সারানোর চাবি একটা দৃষ্টিভঙ্গির পরিবর্তন — যা পুরো measure-তাত্ত্বিক সম্ভাব্যতার প্রাণ। ভুলটা ছিল আমরা "\(Y\)-র একটামাত্র মান \(y\)"-এর উপর শর্ত আরোপ করার চেষ্টা করছিলাম, যা একটা probability-শূন্য ঘটনা। বদলে, প্রশ্ন করি: \(Y\) আমাদের আসলে কী তথ্য দেয়? — সে \(\Omega\)-কে \(\{Y=y\}\)-level-set-গুলোতে ভাগ করে, এবং আমাদের জানায় আমরা কোন level-set-এ আছি। অর্থাৎ \(Y\)-র দেওয়া তথ্য মানে "\(Y\) সম্পর্কে যেকোনো প্রশ্নের" সংগ্রহ — যা ঠিক 7.3-এর generated σ-algebra \(\sigma(Y)=\{Y^{-1}(B):B\in\mathcal B\}\)।
এখানেই সিদ্ধান্তকারী সাধারণীকরণ: তথ্যের একক একটামাত্র মান নয়, একটা sub-σ-algebra \(\mathcal G\subseteq\mathcal F\)। একটা \(\mathcal G\) হলো "যেসব ঘটনা সম্পর্কে আমরা ইতিমধ্যে জানি সত্য না মিথ্যা"-র সংগ্রহ — আমাদের বর্তমান জ্ঞানের পূর্ণ ভাণ্ডার। কয়েকটা চেনা চরম:
- \(\mathcal G=\{\emptyset,\Omega\}\) — কোনো তথ্য নেই (trivial σ-algebra)। তখন সেরা অনুমান শুধু সামগ্রিক গড়: \(\mathbb E[X\mid\mathcal G]=\mathbb E[X]\), একটা ধ্রুবক।
- \(\mathcal G=\mathcal F\) — সম্পূর্ণ তথ্য। তখন \(X\) নিজেই জানা: \(\mathbb E[X\mid\mathcal G]=X\)।
- \(\mathcal G=\sigma(Y)\) — \(Y\) জানা, কিন্তু আর কিছু নয়। এটিই \(\mathbb E[X\mid Y]\), যা পুরোনো \(\mathbb E[X\mid Y=y]\)-কে ধারণ করে কিন্তু \(\mathbb P(Y=y)=0\)-ফাটল ছাড়াই।
এই পরিবর্তনের সৌন্দর্য: একটা নির্দিষ্ট মানে শর্ত আরোপ (\(\mathbb P=0\)-সমস্যা) এড়িয়ে, আমরা পুরো σ-algebra-র উপর শর্ত আরোপ করি — আর σ-algebra-তে level-set-গুলো একসাথে থাকে, কোনো একটাকে আলাদা করে "শূন্য সম্ভাবনায়" বিচ্ছিন্ন করতে হয় না। সবচেয়ে স্বাভাবিকভাবে, \(\mathbb E[X\mid\mathcal G]\) আর একটা সংখ্যা নয়, বরং একটা random variable — একটা ফাংশন যা প্রতিটি \(\omega\)-তে বলে "এই \(\omega\)-তে \(\mathcal G\) যতটুকু তথ্য দেয়, তার ভিত্তিতে \(X\)-এর সেরা অনুমান কত"। continuous \(Y\)-তে এটি হয়ে ওঠে একটা মসৃণ regression curve, discrete-এ একটা সিঁড়ি-ফাংশন — দুই-ই এক সংজ্ঞার দুই মুখ।
এক বাক্যে মূল মোড়। একটামাত্র মান \(Y=y\) (probability-শূন্য) নয়, "তথ্য"-কে ধরা হয় একটা sub-σ-algebra \(\mathcal G\subseteq\mathcal F\) দিয়ে — আমাদের জানা-ঘটনার পূর্ণ সংগ্রহ — আর \(\mathbb E[X\mid\mathcal G]\) হয়ে ওঠে একটা random variable (একটা সংখ্যা নয়) যা প্রতিটি ফলাফলে \(\mathcal G\)-তথ্যের নিচে \(X\)-এর সেরা অনুমান দেয়; \(\mathcal G=\{\emptyset,\Omega\}\) দেয় \(\mathbb E[X]\), \(\mathcal G=\mathcal F\) দেয় \(X\)।
১.৩ সংজ্ঞা-ধর্মটা কী — দুই শর্ত যা "সেরা অনুমান"-কে আঁটোসাঁটো করে¶
তথ্য = sub-σ-algebra মেনে নিলে, \(\mathbb E[X\mid\mathcal G]\)-কে কীসে চেনা যাবে? উত্তর — দুটো শর্ত, যারা একসঙ্গে "আংশিক তথ্যের নিচে সেরা অনুমান"-কে নির্ভুলভাবে ধরে। ধরা যাক \(X\in L^1\) (অর্থাৎ \(\mathbb E\lvert X\rvert<\infty\))। তখন \(Z=\mathbb E[X\mid\mathcal G]\) হলো সেই random variable যা—
- \(\mathcal G\)-measurable — অর্থাৎ \(Z\) কেবল \(\mathcal G\)-তে থাকা তথ্য ব্যবহার করে; \(\mathcal G\) যা জানে না, তার উপর \(Z\) নির্ভর করতে পারে না। (একটা অনুমান যদি আমাদের জ্ঞানের বাইরের কিছুর উপর নির্ভর করত, সেটা তো অনুমানই নয়।)
- averaging property (গড়-মিল) — প্রতিটি \(\mathcal G\)-ঘটনা \(G\in\mathcal G\)-র উপর \(Z\) ও \(X\)-এর মোট গড় হুবহু মেলে: $$ \int_G Z\,d\mathbb P\;=\;\int_G X\,d\mathbb P\qquad\text{সব }G\in\mathcal G. $$
দ্বিতীয় শর্তটাই হৃদয়। এটা বলে: \(\mathcal G\) দিয়ে যত মোটা দানায় (coarse) আমরা জগৎকে দেখতে পারি, তত দানায় \(Z\) আর \(X\)-কে আলাদা করা যায় না — তাদের যেকোনো \(\mathcal G\)-অঞ্চলের উপর সমষ্টি এক। অন্য কথায়, \(Z\) হলো \(X\)-এর সেই রূপ যা প্রতিটি "\(\mathcal G\)-চোখে দৃশ্যমান অঞ্চলে" \(X\)-এর গড়মান ধরে রাখে — তথ্য না-হারিয়ে যতটা smoothing করা যায়, ঠিক ততটা। \(\mathcal G=\sigma(\text{একটা partition})\) হলে এর অর্থ আক্ষরিক: \(Z\) প্রতিটি partition-ব্লকে ধ্রুবক, আর সেই ধ্রুবক = ঐ ব্লকে \(X\)-এর গড় (চিত্র 7-7-partition-averaging)। আর এই দুই শর্ত \(Z\)-কে a.s. অনন্যভাবে নির্ধারণ করে — দুটো random variable দুই-ই শর্ত মানলে তারা almost surely সমান (§৪-এ 7.4-এর a.e.-অনন্যতা-যুক্তি দিয়ে প্রমাণ)।
লক্ষণীয়, এই সংজ্ঞায় \(\mathbb P(Y=y)\) কোথাও নেই — তাই continuous \(Y\)-তেও তা নির্বিঘ্নে খাটে। কিন্তু এমন একটা \(Z\) কি সত্যিই থাকে? হ্যাঁ — আর তার দুই প্রমাণ সরাসরি 7.5 থেকে: হয় Radon–Nikodym (\(\nu(G)=\int_G X\,d\mathbb P\) measure-টা \(\mathbb P\ll\), তাই density আছে), নয় \(L^2\)-projection (\(X\in L^2\) হলে \(Z=\) \(X\)-এর projection \(L^2(\mathcal G)\)-তে)। অস্তিত্বের এই দুই ইঞ্জিন ১.৪-এ ও §২-৩-এ খুলব।
এক বাক্যে সংজ্ঞা-ধর্ম। \(\mathbb E[X\mid\mathcal G]\) হলো সেই a.s.-অনন্য random variable \(Z\) যা (১) \(\mathcal G\)-measurable (কেবল \(\mathcal G\)-তথ্য ব্যবহার করে) এবং (২) averaging property \(\int_G Z\,d\mathbb P=\int_G X\,d\mathbb P\) সব \(G\in\mathcal G\)-তে মেটায় (\(X\in L^1\)) — কোথাও \(\mathbb P(Y=y)\) নেই, তাই continuous শর্তেও খাটে; অস্তিত্ব আসে Radon–Nikodym বা \(L^2\)-projection (7.5) থেকে।
১.৪ তিন বড় পুরস্কার — regression, Bayesian updating, martingale¶
এই একটিমাত্র বস্তু কেন আধুনিক সম্ভাব্যতার সবচেয়ে কেন্দ্রীয় বস্তু — তার তিনটে কারণ, যারা পরিসংখ্যান ও সম্ভাব্যতার তিন বিশাল শাখার গোড়া।
-
পুরস্কার ১ — সেরা অনুমান = regression। এটি সবচেয়ে ব্যবহারিক মুখ। \(X\in L^2\) হলে \(\mathbb E[X\mid\mathcal G]\) হলো ঠিক সেই \(\mathcal G\)-measurable random variable \(Z\) যা mean squared error \(\mathbb E[(X-Z)^2]\)-কে সর্বনিম্ন করে — অর্থাৎ \(\mathcal G\)-তথ্য দিয়ে গড়া সব সম্ভাব্য অনুমানের মধ্যে গাণিতিকভাবে সেরা (minimum-MSE) predictor। এটিই regression-এর প্রকৃত সংজ্ঞা: \(\mathbb E[Y\mid X]\) হলো \(Y\)-এর সেরা (\(L^2\)-অর্থে) প্রাক্কলন \(X\)-এর ফাংশন হিসেবে — bivariate scatter-এ যে regression curve আমরা আঁকি (চিত্র 7-7-bivariate-regression)। 5.1-এর linear regression এখন তার একটা বিশেষ রূপ বলে ধরা পড়ে — যেখানে আমরা সব \(\mathcal G\)-measurable ফাংশনের বদলে কেবল রৈখিক ফাংশনের মধ্যে সেরাটা খুঁজি (একটা ছোট subspace-এ projection)। তাই "আজকের মেশিন-লার্নিং যা শেখে — input দিয়ে output-এর শর্তাধীন গড়" আসলে এই \(\mathbb E[X\mid\mathcal G]\)-ই।
-
পুরস্কার ২ — Bayesian updating। শর্তাধীন সম্ভাবনা \(\mathbb P(A\mid\mathcal G):=\mathbb E[\mathbf 1_A\mid\mathcal G]\) — একটা ঘটনার indicator-এর শর্তাধীন প্রত্যাশা — হলো "নতুন তথ্য \(\mathcal G\) পাওয়ার পর \(A\)-এর হালনাগাদ সম্ভাবনা"-র কঠোর রূপ। এটিই Bayesian inference-এর হৃৎপিণ্ড: prior থেকে posterior-এ যাওয়া মানে ঠিক একটা শর্তাধীন প্রত্যাশা নেওয়া। 2.2-এর Bayes' theorem ছিল এর discrete ছায়া; measure-তাত্ত্বিক \(\mathbb P(A\mid\mathcal G)\) তাকে continuous parameter-ও observation-এ বৈধ করে — আধুনিক Bayesian পরিসংখ্যানের সম্পূর্ণ ভিত্তি।
-
পুরস্কার ৩ — martingale (7.8)। সবচেয়ে গভীর কাঠামোগত মুখ। একটা martingale হলো এমন একটা random process \((X_n)\) যেখানে "এ-পর্যন্ত-জানা তথ্য \(\mathcal F_n\) দিয়ে পরের ধাপের সেরা অনুমান = বর্তমান মান": \(\mathbb E[X_{n+1}\mid\mathcal F_n]=X_n\) — একটা ন্যায্য খেলার (fair game) গাণিতিক সংজ্ঞা, যেখানে কোনো পক্ষপাত নেই। সম্ভাব্যতার অন্যতম শক্তিশালী যন্ত্র — martingale convergence theorem (7.9), optional stopping, concentration — সবই এই \(\mathbb E[\cdot\mid\mathcal F_n]\)-এর উপর গড়া। শর্তাধীন প্রত্যাশা ছাড়া martingale বিবৃতই করা যায় না।
এক বাক্যে পুরস্কার। \(\mathbb E[X\mid\mathcal G]\)-এর তিন কেন্দ্রীয় ভূমিকা — (১) সেরা \(L^2\) predictor / regression (minimum-MSE অনুমান, 5.1-এর linear regression তার রৈখিক বিশেষ রূপ); (২) Bayesian updating \(\mathbb P(A\mid\mathcal G)=\mathbb E[\mathbf 1_A\mid\mathcal G]\) (prior→posterior); (৩) martingale \(\mathbb E[X_{n+1}\mid\mathcal F_n]=X_n\) (7.8 — ন্যায্য খেলা, এবং 7.9-এর convergence-তত্ত্বের ভিত্তি)।
১.৫ এই অধ্যায়ের পথরেখা¶
- §২ সব মূল বস্তুর precise সংজ্ঞা ও বিবৃতি — তথ্য হিসেবে sub-σ-algebra (২.১); কঠোর সংজ্ঞা (\(\mathcal G\)-measurable + averaging) ও a.s.-অনন্যতা (২.২); অস্তিত্ব দুই পথে — Radon–Nikodym ও \(L^2\)-projection (২.৩); \(\mathbb E[X\mid Y]=g(Y)\) ও \(\mathbb P(A\mid\mathcal G)\) (২.৪); calculus-ধর্ম — linearity, tower, pull-out, independence, monotonicity (২.৫); conditional Jensen, conditional MCT/Fatou/DCT, \(L^p\)-contraction (২.৬); সেরা \(L^2\) predictor / regression (২.৭); conditional variance ও law of total variance (২.৮); regular conditional distribution (২.৯)। ভারী প্রমাণ §৪-এ স্থগিত, স্পষ্ট forward pointer সহ।
- §৪ ভারী প্রমাণ — অস্তিত্ব (Radon–Nikodym দিয়ে সাধারণ \(L^1\)-ক্ষেত্রে, \(L^2\)-projection দিয়ে \(L^2\)-ক্ষেত্রে এবং দুই সংজ্ঞার সমতা) ও a.s.-অনন্যতা; tower ও pull-out (averaging-property থেকে সরাসরি, প্রথমে indicator তারপর simple-function-এ); independence, monotonicity; conditional Jensen (convex ফাংশনের supporting-line ও pull-out দিয়ে); conditional convergence theorems; এবং best-\(L^2\)-predictor (Pythagoras / orthogonality দিয়ে) ও law of total variance।
- §৫–৬ simulation ও চিত্র (seed 20260619) — 7-7-partition-averaging (discrete \(\mathcal G=\sigma(\text{partition})\)-এ \(\mathbb E[X\mid\mathcal G]\) প্রতিটি ব্লকে \(X\)-এর গড় — averaging চোখে দেখা), 7-7-bivariate-regression (\((X,Y)\) scatter-এ \(\mathbb E[Y\mid X=x]\)-curve = regression), 7-7-l2-projection (\(X\)-কে \(L^2(\mathcal G)\)-তে orthogonal projection — residual ⊥, সেরা MSE), এবং 7-7-total-variance (মোট ভেদাঙ্ক = between-group + within-group)।
এর পরে Part VII এগোয়: 7.8 filtration ও martingale — যেখানে \(\mathbb E[X_{n+1}\mid\mathcal F_n]\) কেন্দ্রীয়; 7.9 martingale convergence theorem ও SLLN-এর দ্বিতীয় প্রমাণ; এবং 7.10 — rigorous central limit theorem-এর দিকে।
এক বাক্যে পথরেখা। §২ সংজ্ঞা ও বিবৃতি (sub-σ-algebra + averaging-সংজ্ঞা + দুই-পথ অস্তিত্ব + \(\mathbb E[X\mid Y]=g(Y)\) + সব ধর্ম + best-\(L^2\)-predictor + law of total variance) → §৪ প্রমাণ (অস্তিত্ব via RN ও projection, tower/pull-out via averaging, conditional Jensen, Pythagoras) → §৫–৬ চার চিত্র (seed 20260619); আর এই শর্তাধীন-প্রত্যাশা-ভিত্তির উপর Part VII গড়ে 7.8 (martingale) → 7.9 (martingale convergence) → 7.10 (rigorous CLT)।
২ · মূল ধারণা ও সংজ্ঞা¶
এই বিভাগে এ অধ্যায়ের সব formal বস্তুর precise সংজ্ঞা ও বিবৃতি দিই — প্রতিটি প্রতীক প্রথম ব্যবহারেই খুলে। কাঠামো §১-এর সুতো ধরে: প্রথমে তথ্য হিসেবে sub-σ-algebra (২.১); তারপর কঠোর সংজ্ঞা (\(\mathcal G\)-measurable + averaging) ও a.s.-অনন্যতা (২.২) এবং অস্তিত্ব দুই পথে (২.৩); তারপর \(\mathbb E[X\mid Y]=g(Y)\) ও শর্তাধীন সম্ভাবনা (২.৪); তারপর calculus-ধর্ম — linearity/tower/pull-out/independence/monotonicity (২.৫) এবং conditional Jensen ও convergence theorems ও contraction (২.৬); তারপর সেরা \(L^2\) predictor / regression (২.৭) ও conditional variance ও law of total variance (২.৮); শেষে regular conditional distribution (২.৯)। ভারী প্রমাণগুলো §৪-এ — এখানে কেবল বিবৃতি ও অন্তর্দৃষ্টি, স্পষ্ট forward pointer সহ।
জুড়ে আমরা একটা probability space \((\Omega,\mathcal F,\mathbb P)\) ধরে কাজ করি, random variable বলতে measurable \(X:\Omega\to\mathbb R\) (7.3); মনে রাখি \(\mathbb E[X]=\int_\Omega X\,d\mathbb P\) (7.4) এবং \(X\in L^1\iff\mathbb E\lvert X\rvert<\infty\), \(X\in L^2\iff\mathbb E[X^2]<\infty\)। 7.5-এর Radon–Nikodym theorem ও \(L^2\)-projection theorem এবং 7.4-এর MCT/Fatou/DCT নিঃশব্দে ধরে নেওয়া। প্রতিটি সমতা — \(\mathbb E[X\mid\mathcal G]=\cdots\) — by default a.s. (almost surely) অর্থে বোঝা, যেহেতু conditional expectation কেবল a.s.-অনন্যভাবে সংজ্ঞায়িত।
২.১ তথ্য হিসেবে sub-σ-algebra¶
প্রথম ইট — "তথ্য" বস্তুটাকে গণিতে বসানো। স্বজ্ঞা: তথ্য মানে "আমরা কোন কোন প্রশ্নের উত্তর ইতিমধ্যে জানি"। আর একটা ঘটনা-সম্পর্কিত প্রশ্নের উত্তর জানা মানে সেই ঘটনাটা আমাদের জ্ঞান-সংগ্রহে থাকা। এই সংগ্রহ একটা σ-algebra হওয়া স্বাভাবিক — কারণ যদি \(A\)-এর উত্তর জানি তবে \(A^c\)-এরও জানি, আর গণনাযোগ্য কয়েকটা জানা ঘটনার \(\cup\)-ও জানা।
সংজ্ঞা (sub-σ-algebra = তথ্য)। একটা sub-σ-algebra (উপ-σ-বীজগণিত) হলো \(\mathcal G\subseteq\mathcal F\) যা নিজেও একটা σ-algebra (অর্থাৎ \(\Omega\in\mathcal G\), complement-এ বদ্ধ, গণনাযোগ্য union-এ বদ্ধ)। একে আমরা ভাবি আংশিক তথ্য হিসেবে: \(G\in\mathcal G\) ঠিক সেইসব ঘটনা যাদের সত্য-মিথ্যা "আমরা জানি"। একটা random variable \(Z\) \(\mathcal G\)-measurable হলে বলি \(Z\) "\(\mathcal G\)-তথ্য দিয়ে নির্ধারিত" — তার প্রতিটি মান কেবল \(\mathcal G\)-ঘটনার উপর নির্ভর করে।
দুটো চেনা উৎস থেকে \(\mathcal G\) আসে:
- একটা random variable (বা vector) থেকে: \(\mathcal G=\sigma(Y)=\{Y^{-1}(B):B\in\mathcal B\}\) — "\(Y\)-এর মান জানা" তথ্য। এখানেই \(\mathbb E[X\mid Y]:=\mathbb E[X\mid\sigma(Y)]\)।
- একটা partition থেকে: \(\Omega\)-কে গণনাযোগ্য অসংলগ্ন ব্লকে \(\{B_1,B_2,\dots\}\) ভাগ করলে \(\mathcal G=\sigma(B_1,B_2,\dots)\) — "আমরা কোন ব্লকে আছি তা জানা"। এটিই 2.2-এর discrete শর্তের কঠোর রূপ, এবং সবচেয়ে স্বচ্ছ চিত্র (7-7-partition-averaging)।
দুই চরম মনে রাখা ভালো, কারণ সব ধর্মের sanity-check এদের উপরেই: \(\mathcal G=\{\emptyset,\Omega\}\) ("কোনো তথ্য নেই") এবং \(\mathcal G=\mathcal F\) ("সম্পূর্ণ তথ্য")। আর একটা মৌলিক একঘেয়েমি-নিয়ম: \(\mathcal H\subseteq\mathcal G\) মানে "\(\mathcal H\) কম তথ্য, \(\mathcal G\) বেশি তথ্য" — এই nested কাঠামোই tower property ও martingale-এর filtration-এর ভিত্তি।
এক বাক্যে। "তথ্য"-র গাণিতিক একক হলো একটা sub-σ-algebra \(\mathcal G\subseteq\mathcal F\) — আমাদের জানা-ঘটনার পূর্ণ সংগ্রহ; \(\sigma(Y)\) ("\(Y\) জানা") ও partition-জনিত \(\mathcal G\) ("কোন ব্লকে আছি জানা") তার প্রধান দুই উৎস, আর \(\{\emptyset,\Omega\}\) (তথ্যহীন) ও \(\mathcal F\) (পূর্ণ তথ্য) দুই চরম।
২.২ কঠোর সংজ্ঞা — \(\mathcal G\)-measurable + averaging, এবং a.s.-অনন্যতা¶
এবার মূল সংজ্ঞা, পূর্ণ আকারে। §১.৩-এর দুই শর্তকে formally বসাই।
সংজ্ঞা (conditional expectation, \(X\in L^1\))। ধরা যাক \(X\in L^1(\Omega,\mathcal F,\mathbb P)\) এবং \(\mathcal G\subseteq\mathcal F\) একটা sub-σ-algebra। তখন \(\mathcal G\)-এর সাপেক্ষে \(X\)-এর conditional expectation (শর্তাধীন প্রত্যাশা), লেখা \(\mathbb E[X\mid\mathcal G]\), হলো এমন যেকোনো random variable \(Z\) যা— 1. (\(\mathcal G\)-measurability) \(Z\) একটা \(\mathcal G\)-measurable random variable, এবং 2. (averaging / partial-averaging property) $$ \int_G Z\,d\mathbb P\;=\;\int_G X\,d\mathbb P\qquad\text{সব }G\in\mathcal G. $$ এমন একটা \(Z\) থাকে (২.৩) এবং তা a.s. অনন্য — কোনো দুটো এমন \(Z,Z'\) থাকলে \(Z=Z'\) a.s.। তাই \(\mathbb E[X\mid\mathcal G]\) একটা সুসংজ্ঞ random variable, "a.s.-সমতা পর্যন্ত" বুঝে।
দুটো শর্তের ভূমিকা আলাদা করে দেখা দরকার। শর্ত ১ নিশ্চিত করে অনুমানটা শুধু আমাদের জ্ঞানের উপর দাঁড়িয়ে — \(\mathcal G\) যা জানে না তার উপর নয়। শর্ত ২ নিশ্চিত করে অনুমানটা নিরপেক্ষ (unbiased) প্রতিটি \(\mathcal G\)-অঞ্চলে: \(G\)-এর উপর \(Z\)-এর মোট ভর ঠিক \(X\)-এর মোট ভরের সমান, তাই কোনো \(\mathcal G\)-দৃশ্যমান অঞ্চলে \(Z\) পদ্ধতিগতভাবে \(X\)-কে বেশি বা কম অনুমান করে না। (শর্ত ২-এ \(G=\Omega\) বসালেই পাই \(\mathbb E[Z]=\mathbb E[X]\) — অর্থাৎ conditional expectation নেওয়ায় সামগ্রিক গড় বদলায় না; এটি ২.৫-এর "\(\mathbb E[\mathbb E[X\mid\mathcal G]]=\mathbb E[X]\)"-এর বীজ।)
a.s.-অনন্যতা কেন। ধরা যাক \(Z,Z'\) দুই-ই শর্ত মানে। তখন \(Z-Z'\) \(\mathcal G\)-measurable এবং সব \(G\in\mathcal G\)-তে \(\int_G(Z-Z')\,d\mathbb P=0\)। বিশেষত \(G=\{Z-Z'>0\}\in\mathcal G\) নিলে একটা অঋণাত্মক random variable-এর integral শূন্য, তাই (7.4) সেখানে \(Z-Z'=0\) a.s.; একইভাবে \(\{Z-Z'<0\}\)-এও। সুতরাং \(Z=Z'\) a.s. (সম্পূর্ণ যুক্তি §৪)। এই a.s.-অনন্যতাই কারণ আমরা সারা অধ্যায়ে "=" বলতে "a.s.-=" বুঝি।
একটা সতর্কতা: সংজ্ঞাটা একটা নির্দিষ্ট সূত্র দেয় না — শুধু একটা চরিত্রায়ণ দেয় ("যে \(Z\) এই দুই শর্ত মানে, সে-ই")। তাই বহু গণনায় কৌশল হলো একটা স্বাভাবিক candidate \(Z\) আঁচ করে নিয়ে যাচাই করা যে সে দুই শর্ত মানে — তাহলে a.s.-অনন্যতা থেকেই সে-ই উত্তর। এই "guess-and-verify" পদ্ধতি tower ও pull-out-এর প্রমাণে (§৪) বারবার ফিরবে।
এক বাক্যে। \(X\in L^1\)-এর জন্য \(\mathbb E[X\mid\mathcal G]\) হলো সেই a.s.-অনন্য random variable \(Z\) যা (১) \(\mathcal G\)-measurable ও (২) averaging property \(\int_G Z\,d\mathbb P=\int_G X\,d\mathbb P\) (\(\forall G\in\mathcal G\)) মেটায় — অনন্যতা আসে "\(\mathcal G\)-measurable + সব \(G\)-তে integral শূন্য ⇒ a.s. শূন্য" থেকে, আর গণনার মূল কৌশল candidate guess করে দুই শর্ত verify করা।
২.৩ অস্তিত্ব — দুই পথ: Radon–Nikodym ও \(L^2\)-projection¶
সংজ্ঞা সুন্দর, কিন্তু এমন \(Z\) আদৌ থাকে কেন? — দুটো স্বাধীন প্রমাণ, দুই-ই 7.5 থেকে, প্রতিটি একটা ভিন্ন স্বজ্ঞা দেয়। (পূর্ণ প্রমাণ §৪; এখানে কাঠামো ও স্বজ্ঞা।)
পথ ১ — Radon–Nikodym (সাধারণ \(X\in L^1\))। একটা set-function বানাই: \(\mathcal G\)-ঘটনার উপর \(X\)-এর মোট ভর, $$ \nu(G)\;:=\;\int_G X\,d\mathbb P,\qquad G\in\mathcal G. $$ ধরা যাক প্রথমে \(X\ge 0\)। তখন \(\nu\) হলো \((\Omega,\mathcal G)\)-এর উপর একটা (সসীম) measure, এবং স্পষ্টতই \(\mathbb P(G)=0\Rightarrow\nu(G)=0\) — অর্থাৎ \(\nu\ll\mathbb P\big\rvert_{\mathcal G}\) (absolutely continuous)। তাই Radon–Nikodym theorem (7.5) একটা \(\mathcal G\)-measurable density \(Z=\tfrac{d\nu}{d\mathbb P}\ge 0\) দেয় যাতে \(\nu(G)=\int_G Z\,d\mathbb P\) সব \(G\in\mathcal G\)-তে — যা ঠিক averaging property। সাধারণ \(X\)-এ \(X=X^+-X^-\) ভেঙে দুই অংশে প্রয়োগ করে যোগ করি। এই পথের সৌন্দর্য: এটি পূর্ণ সাধারণ (\(X\in L^1\) যথেষ্ট, square-integrability লাগে না), এবং স্পষ্ট করে দেয় conditional expectation মূলত একটা density — \(\mathbb E[X\mid\mathcal G]=\tfrac{d\nu}{d\mathbb P}\big\rvert_{\mathcal G}\), একটা Radon–Nikodym derivative।
পথ ২ — \(L^2\)-orthogonal projection (যখন \(X\in L^2\))। এই পথটা কম সাধারণ কিন্তু সবচেয়ে জ্যামিতিক ও স্বজ্ঞাবাহী। \(X\in L^2\) ধরি। \(\mathcal G\)-measurable, square-integrable random variable-দের সংগ্রহ $$ L^2(\mathcal G)\;:=\;{\,Z\in L^2:\ Z\ \text{is}\ \mathcal G\text{-measurable}\,} $$ হলো Hilbert space \(L^2(\mathcal F)\)-এর একটা closed subspace (7.5)। projection theorem (7.5) বলে \(X\)-এর একটা অনন্য নিকটতম বিন্দু \(\hat X\in L^2(\mathcal G)\) আছে, এবং residual \(X-\hat X\) পুরো \(L^2(\mathcal G)\)-এর সাথে orthogonal: \(\mathbb E[(X-\hat X)Z]=0\) সব \(Z\in L^2(\mathcal G)\)-তে। বিশেষত \(Z=\mathbf 1_G\) (\(G\in\mathcal G\)) নিলে \(\mathbb E[(X-\hat X)\mathbf 1_G]=0\), অর্থাৎ \(\int_G\hat X\,d\mathbb P=\int_G X\,d\mathbb P\) — আবার averaging property। তাই \(\hat X=\mathbb E[X\mid\mathcal G]\)। এই পথ একসাথে দেখায় conditional expectation = \(L^2\)-projection এবং (২.৭-এর) সেরা predictor — কারণ projection মানেই নিকটতম, অর্থাৎ minimum \(\mathbb E[(X-Z)^2]\)।
দুই পথ \(L^2\)-তে একই \(Z\) দেয় (a.s.-অনন্যতা থেকে), তাই সংজ্ঞা সঙ্গতিপূর্ণ; \(L^1\setminus L^2\)-এ কেবল RN-পথ খাটে, এবং সাধারণ \(L^1\)-conditional expectation \(L^2\)-গুলোর \(L^1\)-সীমা হিসেবেও পাওয়া যায়।
এক বাক্যে। \(\mathbb E[X\mid\mathcal G]\)-এর অস্তিত্ব দুই পথে — Radon–Nikodym (\(\nu(G)=\int_G X\,d\mathbb P\ll\mathbb P\big\rvert_{\mathcal G}\)-এর density, সাধারণ \(X\in L^1\)-এ, conditional expectation = একটা RN-derivative) এবং \(L^2\)-projection (\(X\in L^2\) হলে \(L^2(\mathcal G)\) closed subspace-এ \(X\)-এর নিকটতম বিন্দু, residual ⊥, যা একসাথে অস্তিত্ব ও সেরা-predictor দেয়) — দুই-ই 7.5 থেকে, \(L^2\)-এ একই উত্তরে মেলে।
২.৪ \(\mathbb E[X\mid Y]=g(Y)\) এবং শর্তাধীন সম্ভাবনা¶
এবার সংজ্ঞাটাকে চেনা \(Y\)-শর্তে ফিরিয়ে আনি, এবং দেখি কীভাবে এটি 2.2/2.6-এর সূত্র পুনরুদ্ধার করে।
\(\mathbb E[X\mid Y]\) আসলে \(Y\)-এর একটা ফাংশন। যখন \(\mathcal G=\sigma(Y)\), তখন একটা মৌলিক measurability-ফল কাজে লাগে।
Doob–Dynkin lemma (factorization)। একটা random variable \(Z\) \(\sigma(Y)\)-measurable হয় যদি ও কেবল যদি \(Z=g(Y)\) কোনো measurable ফাংশন \(g:\mathbb R\to\mathbb R\)-এর জন্য। সুতরাং $$ \mathbb E[X\mid Y]\;:=\;\mathbb E[X\mid\sigma(Y)]\;=\;g(Y)\quad\text{কোনো measurable }g\text{-র জন্য}, $$ এবং সেই \(g(y)\)-কেই আমরা স্বজ্ঞায় "\(\mathbb E[X\mid Y=y]\)" বলি — কিন্তু এবার তা averaging property দিয়ে সংজ্ঞায়িত, \(\mathbb P(Y=y)\) ছাড়াই।
এটি 2.2-এর সাথে পুরো সঙ্গতিপূর্ণ। discrete \(Y\)-তে averaging property যাচাই করলে দেখা যায় \(g(y)=\sum_x x\,\mathbb P(X=x\mid Y=y)\) — হুবহু পুরোনো সূত্র। continuous \((X,Y)\)-তে (joint density \(f_{X,Y}\), 2.6) averaging property মেটে যখন $$ g(y)\;=\;\mathbb E[X\mid Y=y]\;=\;\int_{\mathbb R} x\,f_{X\mid Y}(x\mid y)\,dx,\qquad f_{X\mid Y}(x\mid y)=\frac{f_{X,Y}(x,y)}{f_Y(y)}, $$ অর্থাৎ measure-তাত্ত্বিক সংজ্ঞা ঠিক 2.6-এর চেনা conditional-density-সূত্রকেই পুনরুদ্ধার করে — কিন্তু এখন \(f_Y(y)=0\) যেখানে সেখানেও পুরো বস্তুটা (\(g(Y)\) একটা random variable হিসেবে) সুসংজ্ঞ থাকে। তাই \(\mathbb E[Y\mid X=x]\) হলো ঠিক সেই regression curve যা bivariate scatter-এ আমরা আঁকি (চিত্র 7-7-bivariate-regression)।
শর্তাধীন সম্ভাবনা। একটা ঘটনার শর্তাধীন সম্ভাবনা এখন কেবল একটা বিশেষ conditional expectation।
সংজ্ঞা (শর্তাধীন সম্ভাবনা)। ঘটনা \(A\in\mathcal F\)-এর জন্য \(\mathcal G\)-সাপেক্ষে শর্তাধীন সম্ভাবনা $$ \mathbb P(A\mid\mathcal G)\;:=\;\mathbb E[\mathbf 1_A\mid\mathcal G], $$ একটা \([0,1]\)-মান random variable (a.s.)। এটি \(A\)-এর "হালনাগাদ সম্ভাবনা \(\mathcal G\) জানার পর" — Bayesian updating-এর কঠোর রূপ, এবং (২.৯-এর) regular conditional distribution-এর বিল্ডিং-ব্লক।
এক বাক্যে। \(\mathcal G=\sigma(Y)\) হলে Doob–Dynkin lemma অনুযায়ী \(\mathbb E[X\mid Y]=g(Y)\) একটা measurable ফাংশন, যার \(g(y)=\mathbb E[X\mid Y=y]\) ঠিক 2.2-এর discrete সূত্র ও 2.6-এর \(\int x\,f_{X\mid Y}(x\mid y)\,dx\) (regression curve) পুনরুদ্ধার করে — \(\mathbb P(Y=y)\) ছাড়াই; আর শর্তাধীন সম্ভাবনা \(\mathbb P(A\mid\mathcal G)=\mathbb E[\mathbf 1_A\mid\mathcal G]\) Bayesian updating-এর কঠোর রূপ।
২.৫ calculus-ধর্ম — linearity, tower, pull-out, independence, monotonicity¶
conditional expectation-কে কাজে লাগানোর জন্য কয়েকটা বীজগাণিতিক নিয়ম দরকার, যা সাধারণ expectation-এর নিয়মগুলোর শক্তিশালী সাধারণীকরণ। সব সমতা a.s., \(X,Y\in L^1\) (বা যথাযথ integrability)। প্রমাণ §৪।
ধর্মাবলি (অংশ ১)। ধরা যাক \(\mathcal H\subseteq\mathcal G\subseteq\mathcal F\)। 1. (linearity) \(\mathbb E[aX+bY\mid\mathcal G]=a\,\mathbb E[X\mid\mathcal G]+b\,\mathbb E[Y\mid\mathcal G]\) (\(a,b\in\mathbb R\))। 2. (total expectation) \(\mathbb E\big[\mathbb E[X\mid\mathcal G]\big]=\mathbb E[X]\) — conditional expectation নিলে সামগ্রিক গড় বদলায় না (averaging-এ \(G=\Omega\))। 3. (tower / iterated expectation) \(\mathbb E\big[\mathbb E[X\mid\mathcal G]\,\big\rvert\,\mathcal H\big]=\mathbb E[X\mid\mathcal H]\) — ছোট তথ্যই জেতে: পরপর দুটো conditioning-এ ফল ঠিক ছোট σ-algebra-র conditioning। (ধর্ম ২ এর বিশেষ রূপ, \(\mathcal H=\{\emptyset,\Omega\}\)।) 4. (pull-out / "take out what is known") \(Y\) \(\mathcal G\)-measurable (ও \(XY\in L^1\)) হলে $$ \mathbb E[YX\mid\mathcal G]\;=\;Y\,\mathbb E[X\mid\mathcal G]. $$ বিশেষত \(Y\) নিজে \(\mathcal G\)-measurable হলে \(\mathbb E[Y\mid\mathcal G]=Y\) (যা জানা, তা অনুমানের দরকার নেই)। 5. (independence) \(X\) যদি \(\mathcal G\) থেকে স্বাধীন হয় (\(\sigma(X)\perp\!\!\!\perp\mathcal G\)), তবে \(\mathbb E[X\mid\mathcal G]=\mathbb E[X]\) — অপ্রাসঙ্গিক তথ্য অনুমান বদলায় না। 6. (monotonicity) \(X\le Y\) a.s. ⇒ \(\mathbb E[X\mid\mathcal G]\le\mathbb E[Y\mid\mathcal G]\) a.s.; এবং \(\big\lvert\mathbb E[X\mid\mathcal G]\big\rvert\le\mathbb E\big[\lvert X\rvert\,\big\rvert\,\mathcal G\big]\)।
এই ছয়টার মধ্যে tower ও pull-out সবচেয়ে বেশি ব্যবহৃত। tower-এর স্বজ্ঞা: কম-সূক্ষ্ম তথ্যে নামার সময় বেশি-সূক্ষ্ম তথ্যের অনুমান "গড় হয়ে" মিলিয়ে যায় — এটিই martingale (7.8)-এর সংজ্ঞার গাণিতিক মেরুদণ্ড। pull-out-এর স্বজ্ঞা: \(Y\) যদি ইতিমধ্যে \(\mathcal G\)-তে জানা থাকে, তবে শর্তাধীন গড়ের ভেতরে সে একটা ধ্রুবকের মতো — তাই বাইরে টেনে আনা যায়। এই দুই নিয়মই বেশিরভাগ conditional-expectation গণনার কাজ চালায়।
এক বাক্যে। conditional expectation মানে linearity, \(\mathbb E[\mathbb E[X\mid\mathcal G]]=\mathbb E[X]\), tower \(\mathbb E[\mathbb E[X\mid\mathcal G]\mid\mathcal H]=\mathbb E[X\mid\mathcal H]\) (ছোট তথ্য জেতে), pull-out \(\mathbb E[YX\mid\mathcal G]=Y\,\mathbb E[X\mid\mathcal G]\) (\(Y\) \(\mathcal G\)-measurable — যা জানা তা বের করে আনা), independence (\(X\perp\!\!\!\perp\mathcal G\Rightarrow\mathbb E[X\mid\mathcal G]=\mathbb E[X]\)) ও monotonicity — সবই a.s.।
২.৬ conditional Jensen, conditional convergence theorems, ও \(L^p\)-contraction¶
সাধারণ expectation-এর গভীর অসমতা ও limit-উপপাদ্যগুলোর প্রতিটিরই একটা শর্তাধীন রূপ আছে — কারণ \(\mathbb E[\cdot\mid\mathcal G]\) একটা positive, linear, normalized অপারেটর যা সাধারণ integral-এর মতো আচরণ করে। প্রমাণ §৪।
ধর্মাবলি (অংশ ২ — অসমতা ও limit)। 7. (conditional Jensen) \(\varphi:\mathbb R\to\mathbb R\) convex ও \(X,\varphi(X)\in L^1\) হলে $$ \varphi\big(\mathbb E[X\mid\mathcal G]\big)\;\le\;\mathbb E\big[\varphi(X)\,\big\rvert\,\mathcal G\big]\qquad\text{a.s.} $$ (3.1/7.5-এর Jensen-এর শর্তাধীন রূপ; \(\varphi(t)=\lvert t\rvert,\,t^2\) বিশেষভাবে কাজে লাগে।) 8. (\(L^p\)-contraction) \(1\le p\le\infty\)-এর জন্য \(\big\lVert\mathbb E[X\mid\mathcal G]\big\rVert_p\le\lVert X\rVert_p\) — conditioning কখনো \(L^p\)-norm বাড়ায় না (7-এ \(\varphi(t)=\lvert t\rvert^p\) থেকে)। অর্থাৎ \(\mathbb E[\cdot\mid\mathcal G]\) একটা contraction; বিশেষত \(L^2\)-তে এটি ঠিক orthogonal projection (norm কমায়, residual ⊥)। 9. (conditional MCT) \(0\le X_n\uparrow X\) a.s. ⇒ \(\mathbb E[X_n\mid\mathcal G]\uparrow\mathbb E[X\mid\mathcal G]\) a.s. 10. (conditional Fatou) \(X_n\ge 0\) ⇒ \(\mathbb E[\liminf_n X_n\mid\mathcal G]\le\liminf_n\mathbb E[X_n\mid\mathcal G]\) a.s. 11. (conditional DCT) \(X_n\to X\) a.s. ও \(\lvert X_n\rvert\le W\in L^1\) ⇒ \(\mathbb E[X_n\mid\mathcal G]\to\mathbb E[X\mid\mathcal G]\) a.s. (ও \(L^1\)-এ)।
conditional Jensen-টা আলাদা করে দামি: \(\varphi(t)=t^2\) বসালে পাই \((\mathbb E[X\mid\mathcal G])^2\le\mathbb E[X^2\mid\mathcal G]\) — যা ২.৮-এর conditional variance-কে অঋণাত্মক রাখে; আর \(\varphi(t)=\lvert t\rvert\) দেয় ধর্ম ৬-এর triangle-রূপ। conditional convergence theorems-গুলো martingale convergence (7.9)-এর প্রমাণে অপরিহার্য।
এক বাক্যে। সাধারণ integral-এর সব গভীর ফলের শর্তাধীন রূপ আছে — conditional Jensen \(\varphi(\mathbb E[X\mid\mathcal G])\le\mathbb E[\varphi(X)\mid\mathcal G]\), \(L^p\)-contraction \(\lVert\mathbb E[X\mid\mathcal G]\rVert_p\le\lVert X\rVert_p\) (conditioning norm বাড়ায় না; \(L^2\)-এ orthogonal projection), এবং conditional MCT/Fatou/DCT — সবই a.s., আর martingale-তত্ত্বের যন্ত্র।
২.৭ সেরা \(L^2\) predictor — এটাই regression¶
এবার §১.৪-এর প্রথম পুরস্কারটা formally। conditional expectation কেন "সেরা অনুমান" — তার সঠিক, পরিমাপযোগ্য অর্থ।
উপপাদ্য (best \(L^2\) predictor)। \(X\in L^2\) হলে, সব \(\mathcal G\)-measurable \(Z\in L^2\)-র মধ্যে \(\mathbb E[(X-Z)^2]\) সর্বনিম্ন হয় ঠিক \(Z=\mathbb E[X\mid\mathcal G]\)-তে (a.s.-অনন্য minimizer): $$ \mathbb E[X\mid\mathcal G]\;=\;\arg\min_{\substack{Z\ \mathcal G\text{-measurable}\ Z\in L^2}}\ \mathbb E\big[(X-Z)^2\big]. $$ অর্থাৎ \(\mathbb E[X\mid\mathcal G]\) হলো \(\mathcal G\)-তথ্য দিয়ে \(X\)-এর minimum mean-squared-error অনুমান। সমতুল্যভাবে (Pythagoras), যেকোনো \(\mathcal G\)-measurable \(Z\in L^2\)-র জন্য $$ \underbrace{\mathbb E[(X-Z)^2]}{\text{মোট ত্রুটি}}\;=\;\underbrace{\mathbb E\big[(X-\mathbb E[X\mid\mathcal G])^2\big]}. $$}}\;+\;\underbrace{\mathbb E\big[(\mathbb E[X\mid\mathcal G]-Z)^2\big]}_{\ge 0
এটি সরাসরি ২.৩-এর projection-ছবি থেকে আসে: \(\mathbb E[X\mid\mathcal G]\) হলো \(X\)-এর projection \(L^2(\mathcal G)\)-তে, আর projection মানেই subspace-এর মধ্যে নিকটতম বিন্দু (চিত্র 7-7-l2-projection)। এর তাৎপর্য বিশাল:
- এটিই regression-এর সংজ্ঞা। \(\mathbb E[Y\mid X]\) হলো \(X\)-এর ফাংশন হিসেবে \(Y\)-এর সেরা (\(L^2\)) প্রাক্কলন — পরিসংখ্যান ও মেশিন-লার্নিং যাকে "regression function" বলে। কোনো model-অনুমান ছাড়াই, এটিই তাত্ত্বিকভাবে অর্জনযোগ্য সেরা predictor।
- 5.1-এর linear regression একটা বিশেষ রূপ। সেখানে আমরা সব \(\mathcal G\)-measurable ফাংশনের বদলে কেবল \(X\)-এর রৈখিক ফাংশন \(\{a+bX\}\)-এর মধ্যে সেরাটা খুঁজি — অর্থাৎ একটা ছোট subspace-এ projection (best linear predictor)। তাই \(\mathbb E[Y\mid X]\) যদি রৈখিক হয়, তবে দুটো মিলে যায়; নইলে linear regression হলো এই সেরা predictor-এর রৈখিক আনুমানিক।
এক বাক্যে। \(X\in L^2\)-এ \(\mathbb E[X\mid\mathcal G]\) হলো সব \(\mathcal G\)-measurable \(Z\)-র মধ্যে \(\mathbb E[(X-Z)^2]\)-এর অনন্য minimizer — অর্থাৎ minimum-MSE সেরা অনুমান, যা projection-ছবি (Pythagoras) থেকে আসে; এটিই regression (\(\mathbb E[Y\mid X]\) = regression function), আর 5.1-এর linear regression তার রৈখিক-subspace বিশেষ রূপ।
২.৮ conditional variance ও law of total variance¶
best predictor-এর সঙ্গী ধারণা — অনুমানের পরও যে অনিশ্চয়তা থাকে তা মাপা, এবং মোট অনিশ্চয়তাকে "ব্যাখ্যাত + অব্যাখ্যাত" অংশে ভাঙা।
সংজ্ঞা (conditional variance)। \(X\in L^2\)-এর জন্য \(\mathcal G\)-সাপেক্ষে conditional variance (শর্তাধীন ভেদাঙ্ক) $$ \operatorname{Var}(X\mid\mathcal G)\;:=\;\mathbb E\big[(X-\mathbb E[X\mid\mathcal G])^2\,\big\rvert\,\mathcal G\big]\;=\;\mathbb E[X^2\mid\mathcal G]-\big(\mathbb E[X\mid\mathcal G]\big)^2, $$ একটা অঋণাত্মক (conditional Jensen, ২.৬) \(\mathcal G\)-measurable random variable — "\(\mathcal G\) জানার পরও \(X\)-এ যত অনিশ্চয়তা বাকি"।
উপপাদ্য (law of total variance / variance decomposition)। \(X\in L^2\) হলে $$ \operatorname{Var}(X)\;=\;\underbrace{\mathbb E\big[\operatorname{Var}(X\mid\mathcal G)\big]}{\text{within-group: অব্যাখ্যাত}}\;+\;\underbrace{\operatorname{Var}\big(\mathbb E[X\mid\mathcal G]\big)}. $$}
এর স্বজ্ঞা পরিসংখ্যানের কেন্দ্রে: মোট ভেদাঙ্ক দুই ভাগে ভাঙে — (i) within-group \(\mathbb E[\operatorname{Var}(X\mid\mathcal G)]\), প্রতিটি \(\mathcal G\)-পরিস্থিতির ভেতরে গড় অবশিষ্ট-ভেদাঙ্ক (যা \(\mathcal G\) ব্যাখ্যা করতে পারে না), এবং (ii) between-group \(\operatorname{Var}(\mathbb E[X\mid\mathcal G])\), \(\mathcal G\)-পরিস্থিতি-ভেদে সেরা-অনুমান নিজে কতটা দোলে (যা \(\mathcal G\) ব্যাখ্যা করে)। এটিই regression-এ "explained vs unexplained variance", ANOVA-র sum-of-squares-বিভাজন, এবং \(R^2\)-এর তাত্ত্বিক ভিত্তি (চিত্র 7-7-total-variance)। লক্ষণীয় ফল: \(\operatorname{Var}(\mathbb E[X\mid\mathcal G])\le\operatorname{Var}(X)\) — অর্থাৎ conditioning সবসময় ভেদাঙ্ক কমায় বা সমান রাখে (Rao–Blackwell-এর বীজ)।
এক বাক্যে। \(\operatorname{Var}(X\mid\mathcal G)=\mathbb E[X^2\mid\mathcal G]-(\mathbb E[X\mid\mathcal G])^2\) হলো \(\mathcal G\)-জানার-পরও-বাকি অনিশ্চয়তা, আর law of total variance \(\operatorname{Var}(X)=\mathbb E[\operatorname{Var}(X\mid\mathcal G)]+\operatorname{Var}(\mathbb E[X\mid\mathcal G])\) মোট ভেদাঙ্ককে অব্যাখ্যাত (within) ও ব্যাখ্যাত (between) অংশে ভাঙে — regression-এর explained/unexplained variance ও \(R^2\)-এর ভিত্তি।
২.৯ regular conditional distribution (সংক্ষেপে)¶
শেষ একটা সূক্ষ্মতা, পূর্ণতার জন্য। \(\mathbb P(A\mid\mathcal G)\) (২.৪) প্রতিটি নির্দিষ্ট \(A\)-তে একটা random variable, a.s.-সংজ্ঞায়িত। স্বাভাবিক ইচ্ছা: প্রতিটি ফলাফল \(\omega\)-তে এটিকে একটা সম্পূর্ণ probability measure \(\mu_\omega(\cdot)\) হিসেবে পেতে — যাতে \(A\mapsto\mathbb P(A\mid\mathcal G)(\omega)\) সত্যিই একটা measure হয় (সব \(A\)-তে একসাথে), নিছক প্রতিটি \(A\)-তে আলাদা random variable নয়। সমস্যা: প্রতিটি \(A\)-র a.s.-ব্যতিক্রম-set আলাদা, আর অগণিত \(A\)-র union measure-শূন্য না-ও থাকতে পারে — তাই countable-additivity সব \(\omega\)-তে একসাথে নিশ্চিত নয়।
সংজ্ঞা (regular conditional distribution, RCD)। \(X\)-এর \(\mathcal G\)-সাপেক্ষে একটা regular conditional distribution হলো একটা map \((\omega,B)\mapsto\kappa(\omega,B)\) (একটা Markov kernel) যেখানে (i) প্রতিটি স্থির \(\omega\)-তে \(B\mapsto\kappa(\omega,B)\) একটা probability measure \(\mathbb R\)-এ, (ii) প্রতিটি স্থির \(B\in\mathcal B\)-তে \(\omega\mapsto\kappa(\omega,B)\) একটা \(\mathcal G\)-measurable random variable, এবং (iii) \(\kappa(\cdot,B)=\mathbb P(X\in B\mid\mathcal G)\) a.s. সব \(B\)-তে।
অস্তিত্ব। \(X\) একটা Polish space-এ মান নিলে (যেমন \(\mathbb R,\mathbb R^d\) — সব বাস্তব ক্ষেত্র) এমন একটা RCD থাকে। তখন conditional expectation একটা সত্যিকারের গড় হিসেবে লেখা যায়, \(\mathbb E[h(X)\mid\mathcal G](\omega)=\int h(x)\,\kappa(\omega,dx)\) — অর্থাৎ "\(\omega\)-তে \(X\)-এর শর্তাধীন বণ্টন" বস্তুটা গাণিতিকভাবে বৈধ। এটি ঠিক সেই কাঠামো যা Bayesian posterior-কে একটা প্রকৃত বণ্টন হিসেবে অর্থ দেয়, এবং 7.8-এ disintegration ও conditioning-এর ভিত্তি। (পূর্ণ নির্মাণ §৪-এ সংক্ষেপে।)
এক বাক্যে। regular conditional distribution হলো একটা Markov kernel \(\kappa(\omega,\cdot)\) — প্রতিটি \(\omega\)-তে একটা সত্যিকারের probability measure যা a.s. \(\mathbb P(X\in\cdot\mid\mathcal G)\) ধরে — যা \(X\) Polish space-এ মান নিলে থাকে, এবং "\(\omega\)-তে \(X\)-এর শর্তাধীন বণ্টন"-কে (তাই Bayesian posterior-কে) একটা বৈধ বণ্টন বানায়।
৩ · পূর্ণাঙ্গ উদাহরণ¶
§১–২-এ conditional expectation (শর্তাধীন প্রত্যাশা) \(\mathbb E[X\mid\mathcal G]\)-এর গোটা স্থাপত্য গড়া হয়েছে — সংজ্ঞা দুই শর্তে: (ক) ফলটি \(\mathcal G\)-পরিমাপযোগ্য (measurable), আর (খ) প্রতিটি \(G\in\mathcal G\)-এর উপর গড় মেলে, \(\int_G\mathbb E[X\mid\mathcal G]\,d\mathbb P=\int_G X\,d\mathbb P\); অস্তিত্ব আসে Radon–Nikodym (রাদোঁ–নিকোদিম) উপপত্তি বা \(L^2\)-এ orthogonal projection (লম্ব-অভিক্ষেপ) থেকে; আর হাতিয়ার-সম্ভার: tower property (স্তর-নিয়ম) \(\mathbb E[\mathbb E[X\mid\mathcal G]\mid\mathcal H]=\mathbb E[X\mid\mathcal H]\) যখন \(\mathcal H\subseteq\mathcal G\), pull-out (টেনে-বার) \(\mathbb E[YX\mid\mathcal G]=Y\,\mathbb E[X\mid\mathcal G]\) যখন \(Y\) হলো \(\mathcal G\)-পরিমাপযোগ্য, independence (স্বাধীনতা) \(X\perp\mathcal G\Rightarrow\mathbb E[X\mid\mathcal G]=\mathbb E[X]\), এবং conditional Jensen (শর্তাধীন ইয়েনসেন)। আর সবচেয়ে চমকপ্রদ মুখ — \(\mathbb E[X\mid Y]\) হলো \(X\)-এর best \(L^2\) predictor (সেরা \(L^2\)-ভবিষ্যদ্বক্তা), যা ঠিক regression (রিগ্রেশন, 5.1)-এর সঙ্গে মিলে যায়, আর তার সঙ্গী conditional variance (শর্তাধীন ভেদ) ও law of total variance (সম্পূর্ণ-ভেদের নিয়ম)। এই অংশের উদ্দেশ্য সেই বিমূর্ত কাঠামোকে হাতে-কলমে, কংক্রিট সংখ্যা ও কংক্রিট সিমুলেশন দিয়ে ছুঁয়ে দেখা — finite partition-এ শর্তাধীন প্রত্যাশা কীভাবে নিছক "atom-এর গড়" হয়ে দাঁড়ায়, tower কীভাবে "ধাপে-ধাপে গড় নেওয়া", bivariate normal-এ শর্তাধীন প্রত্যাশা কীভাবে হুবহু রিগ্রেশন-রেখা হয়ে আত্মপ্রকাশ করে, কেন সব ভবিষ্যদ্বক্তার মধ্যে এটিই সেরা, কীভাবে স্বাধীনতা ও pull-out হিসাব সহজ করে, আর কীভাবে মোট তারতম্য "ভেতরের" আর "মধ্যেকার" দুই টুকরোয় ভাগ হয়ে রিগ্রেশনের \(R^2\)-পরিচয় দেয়। ছয়টি উদাহরণে প্রতিটি ধাপ ধৈর্য ধরে কষব — কোনো হিসাব লুকানো থাকবে না — তারপর প্রতিটির শেষে "কী শিখলাম" বলে মূল শিক্ষাটা গুটিয়ে আনব। কষ্টের স্তর শিরোনামে তারা দিয়ে চিহ্নিত: ★ = সরাসরি, সংজ্ঞা প্রয়োগ করলেই হয় · ★★ = কিছু কৌশল বা সতর্ক যুক্তি লাগে। প্রতিটি ইংরেজি পরিভাষা প্রথম ব্যবহারে বাংলায় খুলে দেওয়া হবে। সব সিমুলেশন একই বীজে (seed np.random.default_rng(20260619)) চালানো, যাতে সংখ্যাগুলো পুনরুৎপাদনযোগ্য থাকে।
উদাহরণ ১ — finite partition-এ শর্তাধীন প্রত্যাশা = atom-এর গড় (★)¶
সেটআপ। একটা নিরপেক্ষ পাশা (fair die) ছোড়া হলো — ফল \(X\in\{1,2,3,4,5,6\}\), প্রতিটি মুখের সম্ভাবনা \(\tfrac16\), তাই \(\mathbb E[X]=\tfrac{1+2+\dots+6}{6}=\tfrac{21}{6}=3.5\)। এখন কম তথ্যওয়ালা একটা \(\sigma\)-বীজগণিত নিই: কেবল জোড়/বিজোড় (even/odd) জানি, পুরো সংখ্যাটা নয়। অর্থাৎ $$ \mathcal G=\sigma\big({\text{even}}\big)=\big{\varnothing,\ {2,4,6},\ {1,3,5},\ \Omega\big}. $$ এই \(\mathcal G\)-এর atom (পরমাণু, সবচেয়ে ছোট অশূন্য ঘটনা) দুটি: \(G_{\text{even}}=\{2,4,6\}\) আর \(G_{\text{odd}}=\{1,3,5\}\)। প্রশ্ন: "জোড় না বিজোড়" — এই টুকু জেনে \(X\)-এর সেরা অনুমান \(\mathbb E[X\mid\mathcal G]\) কী?
ধাপ ১ — কেন এটি প্রতিটি atom-এ ধ্রুব। সংজ্ঞার প্রথম শর্ত: \(\mathbb E[X\mid\mathcal G]\) হতে হবে \(\mathcal G\)-পরিমাপযোগ্য। কিন্তু \(\mathcal G\)-এর তথ্য তো কেবল "কোন atom-এ পড়েছি" — তার সূক্ষ্মতর কিছু \(\mathcal G\) আলাদা করতে পারে না। তাই যেকোনো \(\mathcal G\)-পরিমাপযোগ্য function প্রতিটি atom-এর ভেতরে একই মান ধরতে বাধ্য — সে একটা ধাপ-অপেক্ষক (step function), atom-প্রতি একটা ধ্রুবক। ধরা যাক সেই দুই ধ্রুবক \(a\) (জোড়ের উপর) ও \(b\) (বিজোড়ের উপর): $$ \mathbb EX\mid\mathcal G=\begin{cases}a,&\omega\in{2,4,6}\[2pt] b,&\omega\in{1,3,5}.\end{cases} $$
ধাপ ২ — averaging শর্ত \(a,b\) ঠিক করে দেয়। সংজ্ঞার দ্বিতীয় শর্ত: প্রতিটি \(G\in\mathcal G\)-এর উপর \(\int_G\mathbb E[X\mid\mathcal G]\,d\mathbb P=\int_G X\,d\mathbb P\)। \(G=G_{\text{even}}\) নিই। বাঁ পাশ — ধ্রুবক \(a\) গুণ atom-এর ভর: $$ \int_{G_{\text{even}}}\mathbb E[X\mid\mathcal G]\,d\mathbb P=a\cdot\mathbb P({2,4,6})=a\cdot\tfrac12. $$ ডান পাশ — atom-এর ভেতর \(X\)-এর প্রকৃত মান যোগ করে ভর দিয়ে: $$ \int_{G_{\text{even}}}X\,d\mathbb P=\sum_{k\in{2,4,6}}k\cdot\tfrac16=\tfrac{2+4+6}{6}=\tfrac{12}{6}=2. $$ দুই পাশ সমান করে: \(a\cdot\tfrac12=2\Rightarrow a=4\)। হুবহু একইভাবে \(G_{\text{odd}}\)-এ: \(b\cdot\tfrac12=\tfrac{1+3+5}{6}=\tfrac{9}{6}=1.5\Rightarrow b=3\)। অর্থাৎ $$ \boxed{\ \mathbb E[X\mid\mathcal G]=4\ \text{(জোড়ে)},\qquad \mathbb E[X\mid\mathcal G]=3\ \text{(বিজোড়ে)}.\ } $$ লক্ষণীয়, \(a=4\) ঠিক জোড়-মুখগুলোর গড় \(\tfrac{2+4+6}{3}=4\), আর \(b=3\) ঠিক বিজোড়-মুখগুলোর গড় \(\tfrac{1+3+5}{3}=3\)। finite partition-এ শর্তাধীন প্রত্যাশা মানেই প্রতিটি atom-এর ভেতরে \(X\)-এর সাধারণ গড় — কারণ \(\mathbb P\) atom-এর ভেতর সমভাবে বিলানো, তাই "ভর-ওজনে গড়" = "সরল গড়"।
ধাপ ৩ — সংজ্ঞা সরাসরি যাচাই (\(G=\)even-এ)। উপরের হিসাবটাই আসলে যাচাই, কিন্তু গুটিয়ে দেখি — defining property \(\int_{G}\mathbb E[X\mid\mathcal G]=\int_{G}X\) সত্যিই ধরছে কিনা \(G=\{2,4,6\}\)-তে: $$ \underbrace{4\times\tfrac12}{=\,2}\;=\;\underbrace{2\cdot\tfrac16+4\cdot\tfrac16+6\cdot\tfrac16}\quad\checkmark $$ দুই পাশ \(2\)-তে মিলল। (একই কাজ \(\Omega\)-তে করলে \(4\cdot\tfrac12+3\cdot\tfrac12=3.5=\mathbb E[X]\) — পরের উদাহরণের tower-এর বীজ এখানেই।)
একটি কোডে দেখা। atom-গড় হিসেবে গুনে দেখি — বিশ্লেষিত মান \(4\) ও \(3\) পাওয়া উচিত:
import numpy as np
faces = np.array([1, 2, 3, 4, 5, 6])
even = faces[faces % 2 == 0] # {2,4,6}
odd = faces[faces % 2 == 1] # {1,3,5}
print("E[X|even] =", even.mean()) # 4.0
print("E[X|odd] =", odd.mean()) # 3.0
print("E[X] =", faces.mean()) # 3.5
কী শিখলাম। finite partition \(\mathcal G\)-এর উপর শর্তাধীন প্রত্যাশা হলো একটা ধাপ-অপেক্ষক — প্রতিটি atom-এ ধ্রুব, আর সেই ধ্রুবক = atom-এর ভেতর \(X\)-এর গড়। পাশার জোড়/বিজোড়-এ তা \(4\) (জোড়) ও \(3\) (বিজোড়), কারণ \(\mathcal G\)-পরিমাপযোগ্যতা atom-এর ভেতর মান ধ্রুব হতে বাধ্য করে, আর averaging শর্ত \(\int_G\mathbb E[X\mid\mathcal G]=\int_G X\) সেই ধ্রুবককে atom-গড়ে বেঁধে দেয় (\(4\times\tfrac12=2=\int_{\text{even}}X\))। স্বজ্ঞা: শর্তাধীন প্রত্যাশা মানে "যতটুকু জানি, তাতে \(X\)-এর সেরা একক-সংখ্যা আন্দাজ" — আর গুচ্ছ-পর্যায়ে সেই সেরা আন্দাজ হলো গুচ্ছের গড়। এই ছবিটাই পরের সব উদাহরণের ভিত্তি।
উদাহরণ ২ — tower property হাতে: ধাপে-ধাপে গড় (★)¶
সেটআপ। উদাহরণ ১-এর পাশা ও \(\mathcal G=\sigma(\{\text{even}\})\) ধরে রাখি, যেখানে পেয়েছি \(\mathbb E[X\mid\mathcal G]=4\) (জোড়), \(3\) (বিজোড়)। tower property (ওরফে law of total expectation, সম্পূর্ণ-প্রত্যাশার নিয়ম) বলে: শর্তাধীন প্রত্যাশার আবার প্রত্যাশা নিলে শর্তটা মুছে যায়, $$ \mathbb E\big[\mathbb E[X\mid\mathcal G]\big]=\mathbb E[X]. $$ আরও সাধারণভাবে, দুটি স্তর \(\mathcal H\subseteq\mathcal G\) হলে মোটাটাই জেতে: \(\mathbb E\big[\mathbb E[X\mid\mathcal G]\mid\mathcal H\big]=\mathbb E[X\mid\mathcal H]\)। এখানে দুটোই হাতে দেখাই।
কষা ১ — সাধারণ tower। \(\mathbb E[X\mid\mathcal G]\) একটা random variable যার মান \(4\) ঘটে যখন পাশা জোড় (সম্ভাবনা \(\tfrac12\)), আর \(3\) ঘটে যখন বিজোড় (সম্ভাবনা \(\tfrac12\))। তার সাধারণ প্রত্যাশা: $$ \mathbb E\big[\mathbb E[X\mid\mathcal G]\big]=4\cdot\mathbb P(\text{even})+3\cdot\mathbb P(\text{odd})=4\cdot\tfrac12+3\cdot\tfrac12=2+1.5=3.5. $$ আর সরাসরি \(\mathbb E[X]=3.5\) (উদাহরণ ১)। দুই পাশ \(3.5\)-তে মিলল — tower ধরল। ছবিটা: প্রথমে প্রতিটি গুচ্ছের ভেতরে গড় নাও (\(4\) ও \(3\)), তারপর সেই গুচ্ছ-গড়গুলোর গড় নাও (গুচ্ছ-ওজনে) — ফল মূল সামগ্রিক গড়ই। তাই tower-কে বলা যায় "ধাপে-ধাপে গড় নেওয়া (averaging in stages)": এক ধাপে সব না মিশিয়ে আগে উপগোষ্ঠীতে গড়, পরে গোষ্ঠীগুলোর উপর গড় — উত্তর একই।
কষা ২ — মোটা স্তরে নামা (\(\mathcal H\) তুচ্ছ)। এবার সবচেয়ে মোটা \(\sigma\)-বীজগণিত নিই, তুচ্ছ (trivial) \(\mathcal H=\{\varnothing,\Omega\}\) — যা "কিছুই জানি না"। যেকোনো random variable-কে \(\mathcal H\)-এ শর্তাধীন করা মানে নিছক তার ধ্রুব প্রত্যাশা: \(\mathbb E[Z\mid\mathcal H]=\mathbb E[Z]\)। যেহেতু \(\mathcal H\subseteq\mathcal G\) (তুচ্ছ-বীজ সব কিছুর ভেতর), tower খাটে: $$ \mathbb E\big[\mathbb E[X\mid\mathcal G]\mid\mathcal H\big]=\mathbb E\big[\mathbb E[X\mid\mathcal G]\big]=3.5=\mathbb E[X]=\mathbb E[X\mid\mathcal H]. $$ অর্থাৎ সূক্ষ্ম স্তর \(\mathcal G\) পেরিয়ে মোটা স্তর \(\mathcal H\)-এ নামলে \(\mathbb E[X\mid\mathcal H]\)-ই ফিরে আসে — "মোটাটাই জেতে": পরপর দুই শর্তে যেটি কম তথ্যওয়ালা, ফল সেটিই নির্ধারণ করে। এটিই tower-এর সাধারণ রূপ, আর \(\mathcal H\) তুচ্ছ হলে তা ঠিক কষা ১-এ ফিরে দাঁড়ায়।
একটি কোডে দেখা।
import numpy as np
ce = np.array([4, 3]) # E[X|G]: জোড়ে 4, বিজোড়ে 3
pr = np.array([0.5, 0.5]) # P(even), P(odd)
print("E[E[X|G]] =", (ce * pr).sum()) # 3.5 == E[X]
কী শিখলাম। tower property: \(\mathbb E[\mathbb E[X\mid\mathcal G]]=\mathbb E[X]\) — শর্তাধীন প্রত্যাশার গড় নিলে শর্ত মুছে মূল গড়ই ফেরে; পাশায় \(4\cdot\tfrac12+3\cdot\tfrac12=3.5=\mathbb E[X]\)। আর স্তরে-স্তরে (\(\mathcal H\subseteq\mathcal G\)) সংস্করণে "মোটাটাই জেতে": \(\mathbb E[\mathbb E[X\mid\mathcal G]\mid\mathcal H]=\mathbb E[X\mid\mathcal H]\), এবং \(\mathcal H\) তুচ্ছ হলে আবার \(\mathbb E[X]=3.5\)। স্বজ্ঞা: tower মানে "ধাপে-ধাপে গড়" — উপগোষ্ঠীতে আগে গড়, পরে গোষ্ঠীগুলোর উপর গড়; পরিসংখ্যানে এই একটা সূত্রই বারবার ফেরে (mixture-এর গড়, hierarchical মডেল, conditioning দিয়ে প্রত্যাশা ভাঙা)।
উদাহরণ ৩ — bivariate normal: শর্তাধীন প্রত্যাশা = রিগ্রেশন-রেখা (★★)¶
সেটআপ। এবার অবিচ্ছিন্ন (continuous) জগৎ। \((X,Y)\) একটা standard bivariate normal (প্রমাণ দ্বি-চলক স্বাভাবিক) — দুটোরই প্রান্তিক বণ্টন \(N(0,1)\), আর সহগ-সম্পর্ক (correlation) \(\rho=0.6\)। এখানে দুটো প্রশ্ন: \(Y=y\) জানলে \(X\)-এর সেরা অনুমান \(\mathbb E[X\mid Y=y]\) কী, আর সেই অনুমানের চারপাশে অবশিষ্ট অনিশ্চয়তা \(\operatorname{Var}(X\mid Y)\) কত?
ধাপ ১ — \(X\)-কে \(Y\)-এর সাপেক্ষে ভাঙা। যেকোনো প্রমাণ bivariate normal-কে এভাবে লেখা যায়: $$ X=\rho\,Y+\sqrt{1-\rho^2}\;Z,\qquad Z\sim N(0,1),\ Z\perp Y. $$ যাচাই: এই \(X\)-এর ভেদ \(\rho^2\operatorname{Var}(Y)+(1-\rho^2)\operatorname{Var}(Z)=\rho^2+(1-\rho^2)=1\) ✓ (প্রমাণ প্রান্তিক), আর \(\operatorname{Cov}(X,Y)=\rho\operatorname{Var}(Y)=\rho\), তাই \(\operatorname{corr}(X,Y)=\rho\) ✓। এই ভাঙনটাই মূল চাবি — \(X\)-এর "\(Y\)-নির্ভর অংশ" \(\rho Y\) আর "\(Y\)-স্বাধীন গোলমাল" \(\sqrt{1-\rho^2}\,Z\) পরিষ্কার আলাদা।
ধাপ ২ — শর্তাধীন প্রত্যাশা। \(Y=y\) স্থির ধরে প্রত্যাশা নিই। \(Z\perp Y\) বলে \(\mathbb E[Z\mid Y=y]=\mathbb E[Z]=0\) (independence rule), আর \(\rho y\) অংশটা \(Y\)-পরিমাপযোগ্য বলে pull-out-এ অপরিবর্তিত: $$ \mathbb E[X\mid Y=y]=\rho y+\sqrt{1-\rho^2}\;\underbrace{\mathbb E[Z\mid Y=y]}_{=\,0}=\rho y=\boxed{0.6\,y}. $$ এটি \(y\)-এর একটা সরলরেখা, ঢাল \(\rho=0.6\), intercept \(0\) — হুবহু 5.1-এর রিগ্রেশন-রেখা (প্রমাণ-মার্জিনে \(\hat\beta=\operatorname{Cov}(X,Y)/\operatorname{Var}(Y)=\rho\))। অর্থাৎ যে "সেরা রেখা" 5.1-এ data-মেঘের ভেতর দিয়ে টানা হতো, measure-তত্ত্বে সেটিই \(\mathbb E[X\mid Y]\) — শর্তাধীন প্রত্যাশা = রিগ্রেশন function-এর প্রকৃত পরিচয়।
ধাপ ৩ — শর্তাধীন ভেদ। \(Y=y\) স্থির হলে \(X-\rho y=\sqrt{1-\rho^2}\,Z\), তাই $$ \operatorname{Var}(X\mid Y=y)=(1-\rho^2)\operatorname{Var}(Z)=1-\rho^2=1-0.36=\boxed{0.64}. $$ লক্ষণীয়, এটি \(y\)-নিরপেক্ষ — normal-এ শর্তাধীন ছড়ানো সব \(y\)-তে একই (homoscedastic, সমভেদ)। আর \(1-\rho^2=0.64\) মানে: \(Y\) জানার পরও \(X\)-এর মূল ভেদ \(1\)-এর \(64\%\) অনিশ্চয়তা থেকেই গেল, \(\rho\) যত বড় ততই কম থাকে।
ধাপ ৪ — সিমুলেশনে যাচাই। ভাঙন-সূত্র দিয়ে \(10^6\) নমুনা টেনে slope ও \(\mathbb E[X\mid Y\approx1]\) মাপি:
import numpy as np
rng = np.random.default_rng(20260619)
rho, n = 0.6, 10**6
Y = rng.standard_normal(n)
Z = rng.standard_normal(n)
X = rho*Y + np.sqrt(1 - rho**2)*Z # standard bivariate normal, corr=0.6
slope = np.cov(X, Y, bias=True)[0, 1] / Y.var()
print("নমুনা slope :", round(slope, 4)) # 0.6008 ≈ rho
m = np.abs(Y - 1.0) < 0.02
print("E[X | Y≈1] :", round(X[m].mean(), 4)) # 0.6014 ≈ rho*1
print("Var(X | Y≈1) :", round(X[m].var(), 4)) # ≈ 0.64
সিমুলেশনের slope \(0.6008\) আর \(Y\approx1\)-এর স্লাইসে \(X\)-গড় \(0.6014\) — দুটোই তত্ত্বের \(0.6\)-এর গায়ে, আর স্লাইসের ভেতর \(X\)-এর ভেদ \(\approx0.64\), ঠিক \(1-\rho^2\)। অর্থাৎ "\(Y=1\) জানলে \(X\) গড়ে \(0.6\)-এর আশেপাশে, \(0.8\) মানের চারপাশে ছড়িয়ে (\(\sqrt{0.64}=0.8\))" — শর্তাধীন বণ্টন \(N(0.6,\,0.64)\)।
কী শিখলাম। প্রমাণ bivariate normal-এ (\(\rho=0.6\)) শর্তাধীন প্রত্যাশা \(\mathbb E[X\mid Y=y]=\rho y=0.6y\) — একটা সরলরেখা, যা হুবহু 5.1-এর রিগ্রেশন-রেখা। এটিই শর্তাধীন প্রত্যাশার আসল মুখ: রিগ্রেশন function \(=\mathbb E[X\mid Y]\)। শর্তাধীন ভেদ \(\operatorname{Var}(X\mid Y)=1-\rho^2=0.64\), \(y\)-নিরপেক্ষ (সমভেদ)। মূল কৌশল \(X=\rho Y+\sqrt{1-\rho^2}\,Z\) ভাঙন — independence rule \(Z\)-অংশকে শূন্য করে, pull-out \(\rho Y\)-কে অটুট রাখে। সিমুলেশনে slope \(0.6008\) ও \(\mathbb E[X\mid Y\approx1]=0.6014\) তত্ত্বের \(0.6\)-কে নিশ্চিত করল। গভীর বার্তা: data-চালিত যে "সেরা রেখা" Part V-এ আঁকা হতো, measure-তত্ত্ব দেখায় তা আসলে একটা প্রত্যাশা — শর্তাধীন প্রত্যাশা।
উদাহরণ ৪ — সেরা \(L^2\)-ভবিষ্যদ্বক্তা: রিগ্রেশন কেন জেতে (★★)¶
সেটআপ। একই \(\rho=0.6\) bivariate normal। এখন মৌলিক প্রশ্ন: \(Y\) থেকে \(X\) আন্দাজ করতে চাই, ভবিষ্যদ্বক্তা \(g(Y)\) — যেকোনো (এমনকি বক্র) function। "ভালো" মানে mean squared error (MSE, গড়-বর্গ-ত্রুটি) \(\mathbb E[(X-g(Y))^2]\) ছোট। দাবি: সব \(g\)-এর মধ্যে \(g^\star(Y)=\mathbb E[X\mid Y]\) এই MSE সবচেয়ে ছোট করে — শর্তাধীন প্রত্যাশা হলো সেরা \(L^2\)-ভবিষ্যদ্বক্তা।
ধাপ ১ — কেন (অভিক্ষেপ-যুক্তি)। যেকোনো \(g(Y)\)-তে ত্রুটিকে দুই টুকরোয় ভাঙি, \(\mu(Y):=\mathbb E[X\mid Y]\) মাঝে গুঁজে: $$ \mathbb E\big[(X-g(Y))^2\big]=\underbrace{\mathbb E\big[(X-\mu(Y))^2\big]}{\text{অপসারণযোগ্য নয়}}+\underbrace{\mathbb E\big[(\mu(Y)-g(Y))^2\big]}. $$ আড়াআড়ি পদ \(2\,\mathbb E[(X-\mu(Y))(\mu(Y)-g(Y))]\) শূন্য হয়, কারণ \(\mu(Y)-g(Y)\) হলো \(Y\)-পরিমাপযোগ্য আর শর্তাধীন প্রত্যাশার সংজ্ঞায় অবশিষ্ট \(X-\mu(Y)\) যেকোনো \(Y\)-পরিমাপযোগ্য রাশির সঙ্গে লম্ব (orthogonal, tower দিয়ে \(\mathbb E[(X-\mu(Y))h(Y)]=0\))। দ্বিতীয় পদ \(\ge0\), আর শূন্য হয় কেবল \(g=\mu\)-তে — তাই \(g^\star=\mu(Y)=\mathbb E[X\mid Y]\)-ই একমাত্র minimizer। এটি ঠিক \(L^2\)-এ \(X\)-কে "\(Y\)-পরিমাপযোগ্য function-দের subspace"-এ লম্ব-অভিক্ষেপ, যেমন 5.1-এ OLS ছিল column space-এ অভিক্ষেপ।
ধাপ ২ — দুই ভবিষ্যদ্বক্তার MSE কষা। এখানে \(\mu(Y)=\rho Y\)। তার MSE: $$ \mathbb E\big[(X-\rho Y)^2\big]=\mathbb E\big[(1-\rho^2)Z^2\big]=1-\rho^2=0.64. $$ এবার তুলনায় সবচেয়ে ভালো ধ্রুব (constant) ভবিষ্যদ্বক্তা — যা \(Y\) একেবারেই দেখে না। সেরা ধ্রুব হলো \(\mathbb E[X]=0\), আর তার MSE: $$ \mathbb E\big[(X-0)^2\big]=\operatorname{Var}(X)=1. $$ তফাত পরিষ্কার: রিগ্রেশন \(0.64\) বনাম ধ্রুব \(1\) — রিগ্রেশন কঠোরভাবে ভালো। আর কতটা ভালো? ঠিক $$ 1-0.64=0.36=\rho^2=\operatorname{Var}\big(\mathbb E[X\mid Y]\big), $$ অর্থাৎ শর্তাধীন প্রত্যাশা সেরা ধ্রুবকে হারায় ঠিক \(\operatorname{Var}(\mathbb E[X\mid Y])=\rho^2=0.36\) পরিমাণ — যা \(Y\) "ব্যাখ্যা করে দেওয়া" তারতম্য।
ধাপ ৩ — সিমুলেশনে।
import numpy as np
rng = np.random.default_rng(20260619)
rho, n = 0.6, 10**6
Y = rng.standard_normal(n)
Z = rng.standard_normal(n)
X = rho*Y + np.sqrt(1 - rho**2)*Z
mse_reg = np.mean((X - rho*Y)**2) # E[X|Y] = rho*Y
mse_const = np.mean((X - 0.0)**2) # সেরা ধ্রুব = E[X] = 0
print("MSE(rho*Y) :", round(mse_reg, 4)) # 0.6410
print("MSE(ধ্রুব 0) :", round(mse_const, 4)) # 1.0017
print("লাভ (rho^2) :", round(mse_const - mse_reg, 4)) # ≈ 0.36
সিমুলেশন তত্ত্বকে মিলিয়ে দিল: \(0.6410\) বনাম \(1.0017\), পার্থক্য \(\approx0.36\)। \(Y\) ব্যবহার করায় গড়-বর্গ-ত্রুটি \(1\) থেকে \(0.64\)-এ নামল — এই \(0.36\) লাভই "\(Y\) কতটা সাহায্য করল" তার মাপ।
কী শিখলাম। সব ভবিষ্যদ্বক্তা \(g(Y)\)-এর মধ্যে \(\mathbb E[X\mid Y]\) গড়-বর্গ-ত্রুটি \(\mathbb E[(X-g(Y))^2]\) সবচেয়ে ছোট করে — শর্তাধীন প্রত্যাশা = সেরা \(L^2\)-ভবিষ্যদ্বক্তা, যা \(L^2\)-এ লম্ব-অভিক্ষেপ ছাড়া কিছু নয় (5.1-এর OLS-জ্যামিতির ঠিক ছায়া)। \(\rho=0.6\)-এ \(\rho Y\)-এর MSE \(0.64\) (MC \(0.6410\)), সেরা ধ্রুব \(0\)-এর MSE \(1\) (MC \(1.0017\)) — রিগ্রেশন কঠোরভাবে জেতে, আর জেতার মাপ ঠিক \(\operatorname{Var}(\mathbb E[X\mid Y])=\rho^2=0.36\)। মূল কৌশল: ত্রুটিকে "অপসারণযোগ্য নয়" + "\(\ge0\)" দুই পদে ভাঙা, যেখানে আড়াআড়ি পদ orthogonality-তে শূন্য। স্বজ্ঞা: জানা-তথ্য \(Y\) ব্যবহার করলে ত্রুটি কমে ঠিক ততটা, যতটা \(Y\) \(X\)-এর তারতম্য ব্যাখ্যা করে।
উদাহরণ ৫ — স্বাধীনতা ও pull-out: হিসাব সহজ করার দুই নিয়ম (★)¶
সেটআপ। শর্তাধীন প্রত্যাশার দুটি কাজের-নিয়ম এখানে কংক্রিটে যাচাই করি — (ক) independence rule: তথ্য যদি \(X\) সম্পর্কে কিছুই না বলে, শর্ত মূল্যহীন; (খ) pull-out: যা ইতিমধ্যে "জানা" (\(\mathcal G\)-পরিমাপযোগ্য), তাকে প্রত্যাশার বাইরে টেনে আনা যায়।
কষা ১ — independence rule। ধরা যাক \(X\perp\mathcal G\) — অর্থাৎ \(\mathcal G\)-এর তথ্য \(X\) সম্পর্কে কিছুই বলে না। তখন $$ \mathbb E[X\mid\mathcal G]=\mathbb E[X]\quad(\text{একটা ধ্রুবক}). $$ কংক্রিট: দুটি স্বাধীন পাশা, \(X\) = প্রথম পাশার মুখ, \(\mathcal G=\sigma(W)\) যেখানে \(W\) = দ্বিতীয় পাশার মুখ। যেহেতু \(X\perp W\), দ্বিতীয় পাশা জানা প্রথম পাশা সম্পর্কে কিছুই বলে না, তাই $$ \mathbb E[X\mid W=w]=\mathbb E[X]=3.5\qquad\text{প্রতিটি } w\in{1,\dots,6}\text{-এর জন্য}. $$ যাচাই (সংজ্ঞা): \(\{W=w\}\)-এর উপর \(\int_{\{W=w\}}X\,d\mathbb P=\mathbb E[X]\,\mathbb P(W=w)\) (স্বাধীনতায় joint ভাঙে), যা ঠিক ধ্রুবক \(3.5\) গুণ \(\mathbb P(W=w)\) — তাই \(\mathbb E[X\mid W]=3.5\)। "যে তথ্য কিছু বলে না, তাকে শর্তে ধরা আর না-ধরা সমান।"
কষা ২ — pull-out। নিয়ম: \(Y\) যদি \(\mathcal G\)-পরিমাপযোগ্য হয়, তবে $$ \mathbb E[YX\mid\mathcal G]=Y\,\mathbb E[X\mid\mathcal G]. $$ স্বজ্ঞা: \(\mathcal G\) জানলে \(Y\) আর "দৈব" নয়, একটা জানা ধ্রুবক — তাই প্রত্যাশার বাইরে টেনে আনা যায়। উদাহরণ ১-এর পাশা ও \(\mathcal G=\sigma(\{\text{even}\})\) নিই, আর \(Y=\mathbf 1\{\text{even}\}\) (জোড় হলে \(1\), নয়তো \(0\)) — এটি \(\mathcal G\)-পরিমাপযোগ্য। বাঁ পাশ \(\mathbb E[YX\mid\mathcal G]\) আর ডান পাশ \(Y\,\mathbb E[X\mid\mathcal G]\) atom-ভিত্তিক কষি:
জোড় atom-এ (\(Y=1\)): \(YX=X\), তাই \(\mathbb E[YX\mid\mathcal G]=\mathbb E[X\mid\mathcal G]=4\); আর \(Y\,\mathbb E[X\mid\mathcal G]=1\cdot4=4\) — মিলল। বিজোড় atom-এ (\(Y=0\)): \(YX=0\), তাই \(\mathbb E[YX\mid\mathcal G]=0\); আর \(Y\,\mathbb E[X\mid\mathcal G]=0\cdot3=0\) — মিলল।
দুই atom-এ দুই পাশ মিলল, তাই \(\mathbb E[YX\mid\mathcal G]=Y\,\mathbb E[X\mid\mathcal G]\) সর্বত্র। (পাশে: এই \(YX\)-এর সাধারণ প্রত্যাশা tower-এ \(4\cdot\tfrac12+0\cdot\tfrac12=2\), যা সরাসরি \(\mathbb E[X\,\mathbf 1\{\text{even}\}]=\tfrac{2+4+6}{6}=2\) — আবার মিলল।)
একটি কোডে দেখা।
import numpy as np
faces = np.array([1, 2, 3, 4, 5, 6])
ce = np.where(faces % 2 == 0, 4, 3) # E[X|G]: জোড়ে 4, বিজোড়ে 3
Yind = (faces % 2 == 0).astype(int) # Y = 1{even}, G-পরিমাপযোগ্য
lhs = np.where(faces % 2 == 0, 4, 0) # E[YX|G]: জোড়ে 4, বিজোড়ে 0
print("pull-out মেলে:", np.array_equal(lhs, Yind * ce)) # True
কী শিখলাম। দুটি কাজের-নিয়ম। Independence: \(X\perp\mathcal G\) হলে \(\mathbb E[X\mid\mathcal G]=\mathbb E[X]\) — দুই স্বাধীন পাশায় একটার মুখ জেনে অন্যটার শর্তাধীন গড় নিছক \(3.5\), কারণ ও-তথ্য কিছুই বলে না। Pull-out: \(\mathcal G\)-পরিমাপযোগ্য \(Y\)-কে বাইরে টানা যায়, \(\mathbb E[YX\mid\mathcal G]=Y\,\mathbb E[X\mid\mathcal G]\) — \(Y=\mathbf 1\{\text{even}\}\)-এ দুই পাশই atom-ভেদে \(4,0\), মিলে যায়। স্বজ্ঞা: শর্তাধীন প্রত্যাশা "ইতিমধ্যে যা জানি তা ধ্রুবকের মতো, যা জানি না তা গড়ে দেওয়ার বিষয়" — এই দুই নিয়ম হিসাবে বারবার লাগে, পরের law of total variance-ও এদের উপরই দাঁড়ায়।
উদাহরণ ৬ — সম্পূর্ণ-ভেদের নিয়ম: মোট ছড়ানো = ভেতরের + মধ্যেকার (★★)¶
সেটআপ। আবার \(\rho=0.6\) bivariate normal। law of total variance (সম্পূর্ণ-ভেদের নিয়ম) বলে মোট ভেদ ঠিক দুই টুকরোয় ভাঙে: $$ \operatorname{Var}(X)=\underbrace{\mathbb E\big[\operatorname{Var}(X\mid Y)\big]}{\text{ভেতরের (within)}}+\underbrace{\operatorname{Var}\big(\mathbb E[X\mid Y]\big)}. $$ প্রথম পদ = "}\(Y\) জানার পরও বাকি থাকা গড় অনিশ্চয়তা" (অব্যাখ্যাত, unexplained); দ্বিতীয় পদ = "\(Y\) বদলালে গড়টা নিজেই কতটা নড়ে" (ব্যাখ্যাত, explained)।
ধাপ ১ — দুই পদ কষা। উদাহরণ ৩ থেকে \(\mathbb E[X\mid Y]=\rho Y\) আর \(\operatorname{Var}(X\mid Y)=1-\rho^2\) (সব \(y\)-তে ধ্রুব)। তাই $$ \mathbb E\big[\operatorname{Var}(X\mid Y)\big]=\mathbb E[1-\rho^2]=1-\rho^2=0.64, $$ $$ \operatorname{Var}\big(\mathbb E[X\mid Y]\big)=\operatorname{Var}(\rho Y)=\rho^2\operatorname{Var}(Y)=\rho^2=0.36. $$ যোগ করি: $$ 0.64+0.36=1=\operatorname{Var}(X)\quad\checkmark $$ মোট ভেদ \(1\) ঠিক \(0.64\) (ভেতরের) + \(0.36\) (মধ্যেকার)-এ ভাঙল।
ধাপ ২ — \(R^2\)-এর সঙ্গে যোগসূত্র। "ব্যাখ্যাত ভগ্নাংশ" = মধ্যেকার / মোট: $$ \frac{\operatorname{Var}(\mathbb E[X\mid Y])}{\operatorname{Var}(X)}=\frac{0.36}{1}=0.36=\rho^2=R^2. $$ এটিই 5.1-এর \(R^2\) আর ANOVA (variance-বিশ্লেষণ)-এর মূল পরিচয়: মোট তারতম্য = ব্যাখ্যাত (between-group) + অব্যাখ্যাত (within-group), আর \(R^2=\rho^2\) = \(Y\) যে ভগ্নাংশ ব্যাখ্যা করে। এখানে \(Y\) \(X\)-এর \(36\%\) তারতম্য ব্যাখ্যা করে, বাকি \(64\%\) অব্যাখ্যাত গোলমাল।
ধাপ ৩ — সিমুলেশনে। \(Y\)-কে সরু বিনে (bin) ভেঙে within ও between ভেদ আলাদা মাপি — যোগফল মোট ভেদ দেওয়া উচিত:
import numpy as np
rng = np.random.default_rng(20260619)
rho, n = 0.6, 10**6
Y = rng.standard_normal(n)
Z = rng.standard_normal(n)
X = rho*Y + np.sqrt(1 - rho**2)*Z
bins = np.linspace(-4, 4, 81) # Y-কে সরু বিনে ভাগ
idx = np.digitize(Y, bins)
within = np.array([X[idx == k].var() for k in np.unique(idx) if (idx == k).sum() > 50])
between = np.array([X[idx == k].mean() for k in np.unique(idx) if (idx == k).sum() > 50])
wts = np.array([(idx == k).sum() for k in np.unique(idx) if (idx == k).sum() > 50], float)
wts /= wts.sum()
print("E[Var(X|Y)] (ভেতরের) :", round((within * wts).sum(), 3)) # ≈ 0.64
print("Var(E[X|Y]) (মধ্যেকার):", round(np.cov(between, aweights=wts), 3)) # ≈ 0.36
print("মোট Var(X) :", round(X.var(), 4)) # 1.0017
সিমুলেশনে ভেতরের পদ \(\approx0.64\), মধ্যেকার \(\approx0.36\), আর মোট ভেদ \(1.0017\) — তিনটিই তত্ত্বে মিলল, \(0.64+0.36=1\)।
কী শিখলাম। law of total variance: \(\operatorname{Var}(X)=\mathbb E[\operatorname{Var}(X\mid Y)]+\operatorname{Var}(\mathbb E[X\mid Y])\) — মোট ছড়ানো = ভেতরের (within, অব্যাখ্যাত) + মধ্যেকার (between, ব্যাখ্যাত)। \(\rho=0.6\) normal-এ \(1=0.64+0.36\): \(Y\) জানার পরও \(0.64\) অনিশ্চয়তা বাকি, আর \(Y\)-নির্ভর গড় নিজে \(0.36\) নড়ে। এই \(\dfrac{0.36}{1}=\rho^2=R^2\) ঠিক 5.1-এর \(R^2\) ও ANOVA-পরিচয় — ব্যাখ্যাত-ভগ্নাংশ। স্বজ্ঞা: একটা চলকের মোট তারতম্যকে "যা গোষ্ঠী-জানলে ব্যাখ্যা হয়" আর "যা তবু বাকি" — এই দুই ভাগে চিরকাল ভাঙা যায়, আর শর্তাধীন প্রত্যাশা ও শর্তাধীন ভেদ ঠিক সেই দুই টুকরোর নাম। গোটা পরিসংখ্যানিক মডেলিং (regression, ANOVA, mixed model) এই একটাই পচন-পরিচয়ের উপর দাঁড়িয়ে।
৪ · প্রমাণ ও উৎপাদন¶
এই অংশে §২-এর সংজ্ঞা থেকে conditional expectation (শর্তাধীন প্রত্যাশা) \(\mathbb E[X\mid\mathcal G]\)-এর গোটা তত্ত্বটাকে ধাপে ধাপে উৎপাদন (derive) করা হয় — প্রথমে তার অস্তিত্ব ও a.s.-একত্ব (existence and almost-sure uniqueness) দুই স্বাধীন পথে (একদিকে 7.5-এর \(L^2\) projection, অন্যদিকে 7.5-এর Radon–Nikodym density), তারপর তার চার মৌলিক ধর্ম — tower (পুনরাবৃত্ত প্রত্যাশা), pull-out (জানা-জিনিস বাইরে আনা), conditional Jensen, এবং best \(L^2\) predictor-পরিচয় — আর শেষে এক সরাসরি ফসল, law of total variance (মোট ভেদাঙ্কের সূত্র)। প্রতিটি প্রমাণে কেন প্রতিটি পদক্ষেপ বৈধ — কোন সংজ্ঞা, কোন পূর্ববর্তী ফল (7.4-এর MCT/DCT ও monotonicity, 7.5-এর Hilbert projection ও Radon–Nikodym, এ-অংশেরই আগের ধর্ম), বা কোন বীজগাণিতিক অভেদ ব্যবহৃত হচ্ছে — তা স্পষ্ট করা হয়েছে। প্রতিটি প্রমাণের শিরোনামে কঠিনতা-চিহ্ন (difficulty tag):
- ★ — মৌলিক, প্রথম পাঠেই বোঝা উচিত।
- ★★ — মাঝারি, একটু কৌশল লাগে।
- ★★★ — গভীর, প্রথম পাঠে কিছু অংশ এড়িয়ে যাওয়া যায় (যথাস্থানে চিহ্নিত)।
স্মরণ — সংজ্ঞা ও সংকেত (§২ থেকে)। গোটা অংশে \((\Omega,\mathcal F,\mathbb P)\) একটি probability space (\(\mathbb P(\Omega)=1\)), \(\mathcal G\subseteq\mathcal F\) একটি sub-σ-algebra (উপ-সিগমা-বীজগণিত, "আংশিক তথ্য"), এবং \(X\in L^1(\mathcal F)\) — অর্থাৎ \(\mathbb E\lvert X\rvert=\int_\Omega\lvert X\rvert\,d\mathbb P<\infty\)। conditional expectation \(\mathbb E[X\mid\mathcal G]\) হলো এমন যেকোনো random variable \(Z\) যা দুটি শর্ত মানে:
(এখানে \(\mid\) মানে conditioning — শর্তাধীনতা — কখনোই \(\lvert\cdot\rvert\) নয়।) (CE-1) বলে \(Z\) কেবল \(\mathcal G\)-এর তথ্যেই গড়া ("\(\mathcal G\) যা জানায় তার বাইরে \(Z\) কিছু জানে না"); (CE-2) বলে \(\mathcal G\)-এর প্রতিটি ঘটনায় \(Z\)-এর "মোট ভর" ঠিক \(X\)-এর মোট ভরের সমান। লক্ষণীয় — সংজ্ঞাটা একটি শ্রেণি (a.e.-equivalence class) বেঁধে দেয়, একটিমাত্র ফাংশন নয়; তাই "\(\mathbb E[X\mid\mathcal G]\)" সবসময় "a version of \(\mathbb E[X\mid\mathcal G]\)" — দুই version a.s. সমান (প্রমাণ ১)। এই a.e.-শ্রেণির দৃষ্টিভঙ্গি গোটা অংশে চুপিচুপি কাজ করবে, ঠিক যেমন 7.5-এ \(L^p\)-উপাদান a.e.-শ্রেণি ছিল। নিচে \(X\ge 0\) বললে বোঝাব "a.s. অঋণাত্মক", আর \(\mathbb E[X\mid\mathcal G]\ge 0\) ইত্যাদি অসমতা সর্বত্র "a.s." অর্থে।
এ-অংশের যুক্তি-শৃঙ্খল একমুখী: প্রমাণ ১ (\(Z\)-এর অস্তিত্ব ও একত্ব) গোটা তত্ত্বের ভিত্তি-ইট — এ ছাড়া \(\mathbb E[X\mid\mathcal G]\) লেখাই অর্থহীন; তা দাঁড়ায় কেবল 7.5-এর projection ও Radon–Nikodym-এর উপর। প্রমাণ ২ (tower) ও প্রমাণ ৩ (pull-out) সরাসরি (CE-1)–(CE-2) যাচাই করে প্রমাণ ১-এর একত্ব-অংশকে ইঞ্জিন বানায়। প্রমাণ ৪ (Jensen) pull-out-নয়, কিন্তু conditional linearity ও monotonicity (যা প্রমাণ ১ থেকেই বেরোয়) ব্যবহার করে। প্রমাণ ৫ (best predictor) pull-out + tower-এর সরাসরি ফল, আর প্রমাণ ৬ (total variance) প্রমাণ ৫-এর Pythagoras + tower-এর এক-লাইনের ফসল। তাই প্রমাণ ১-ই গাঁথুনির কেন্দ্র।
আগে একবার — দুটি ছোট অথচ বারবার-লাগা মৌলিক fact (প্রমাণ ১ থেকে আসবে, এখানে আগাম নাম দিয়ে রাখি):
- (Linearity, রৈখিকতা) \(\mathbb E[aX+bY\mid\mathcal G]=a\,\mathbb E[X\mid\mathcal G]+b\,\mathbb E[Y\mid\mathcal G]\) a.s. — কারণ ডান পাশ \(\mathcal G\)-measurable এবং (CE-2) integral-এর linearity থেকে দুই পাশে মেলে, তাই একত্ব-অংশে এটিই version।
- (Monotonicity, একঘাতিতা) \(X\le Y\) a.s. \(\Rightarrow\ \mathbb E[X\mid\mathcal G]\le\mathbb E[Y\mid\mathcal G]\) a.s. — কারণ \(W:=\mathbb E[Y\mid\mathcal G]-\mathbb E[X\mid\mathcal G]=\mathbb E[Y-X\mid\mathcal G]\) এবং \(G=\{W<0\}\in\mathcal G\) নিলে \(\int_G W=\int_G(Y-X)\ge 0\), অথচ \(W<0\) ওই set-এ — তাই \(\mathbb P(W<0)=0\) (প্রমাণ-৬, 7.4-এর ভাবনা)। বিশেষত \(X\ge 0\Rightarrow\mathbb E[X\mid\mathcal G]\ge 0\) a.s।
এই দুই fact-এর প্রমাণ আসলে প্রমাণ ১-এর একত্ব-যন্ত্রেরই (নিচে ★ চিহ্নিত "একত্ব-লেমা") পুনঃপ্রয়োগ; নিচে যেখানে দরকার সেখানে নাম ধরে ডাকা হবে।
প্রমাণ ১ — \(\mathbb E[X\mid\mathcal G]\)-এর অস্তিত্ব ও a.s.-একত্ব (★★★)¶
দাবি। প্রতিটি \(X\in L^1(\Omega,\mathcal F,\mathbb P)\)-এর জন্য একটি random variable \(Z\) আছে যা (CE-1)–(CE-2) মানে, এবং এমন \(Z\) \(\mathbb P\)-a.s. অনন্য — অর্থাৎ \(Z_1,Z_2\) দুটোই (CE-1)–(CE-2) মানলে \(Z_1=Z_2\) a.s.। এই \(Z\)-কেই \(\mathbb E[X\mid\mathcal G]\) বলা হয়।
স্বীকৃতি — গভীরতম ধাপ চিহ্নিত (প্রথম পাঠে এড়ানো যায়)। দুই স্বাধীন নির্মাণ-পথ দেওয়া হলো — পথ-(ক) Hilbert projection (\(X\in L^2\)-এ জ্যামিতিক, সবচেয়ে স্বচ্ছ) আর পথ-(খ) Radon–Nikodym (যেকোনো \(X\ge 0\)-এ density-ভিত্তিক)। প্রথম পাঠে পথ-(ক)-ই যথেষ্ট; পথ-(খ) ও "\(L^2\to L^1\) সম্প্রসারণ" (ধাপ ৪) হলো সবচেয়ে কারিগরি, যা \(L^2\)-এর বাইরে যাওয়ার সম্পূর্ণতা দেয়। একত্ব-অংশ (ধাপ ০) কিন্তু দুই পথেই অভিন্ন এবং সবচেয়ে বেশি ব্যবহৃত — এটি প্রথম পাঠেই আত্মস্থ করা জরুরি।
ধাপ ০ — একত্ব-লেমা (★, গোটা অংশের কর্মঘোড়া)। প্রথমে একত্ব, কারণ এটিই বারবার লাগবে। ধরা যাক \(Z_1,Z_2\) দুটোই \(\mathcal G\)-measurable এবং \(\int_G Z_1\,d\mathbb P=\int_G Z_2\,d\mathbb P\) সব \(G\in\mathcal G\)-তে (অর্থাৎ দুটোই (CE-2) মানে — তাই উভয়ের integral \(\int_G X\)-এর সমান, ফলে পরস্পর-সমান)। বিয়োগ করে: \(\int_G (Z_1-Z_2)\,d\mathbb P=0\) সব \(G\in\mathcal G\)। এখন মূল কৌশল — পরীক্ষক-set হিসেবে \(G:=\{Z_1>Z_2\}\) বাছি। এটি \(\mathcal G\)-তে আছে কারণ \(Z_1,Z_2\) দুটোই \(\mathcal G\)-measurable, তাই \(\{Z_1-Z_2>0\}\in\mathcal G\)। ওই \(G\)-তে \(Z_1-Z_2>0\) (কড়াভাবে ধনাত্মক), অথচ \(\int_G(Z_1-Z_2)\,d\mathbb P=0\) — একটি অঋণাত্মক ফাংশনের integral শূন্য মানে সে a.e. শূন্য (প্রমাণ-৬, 7.4)। তাই \(\mathbb P(Z_1>Z_2)=\mathbb P(G)=0\)। প্রতিসমভাবে \(H:=\{Z_2>Z_1\}\in\mathcal G\) নিয়ে \(\mathbb P(Z_2>Z_1)=0\)। সুতরাং \(\mathbb P(Z_1\ne Z_2)=0\), অর্থাৎ \(Z_1=Z_2\) a.s.। ∎(একত্ব-লেমা)
এই লেমার দু'টি ব্যবহার আলাদা করে চেনা ভালো: (i) একত্ব — দুই version মেলে; (ii) monotonicity/ধনাত্মকতা — \(\int_G W\ge 0\) সব \(G\in\mathcal G\)-তে এবং \(W\) \(\mathcal G\)-measurable হলে \(W\ge 0\) a.s. (একই \(G=\{W<0\}\)-যুক্তি)। এই (ii)-রূপ নিচে বহুবার লাগবে।
এবার অস্তিত্ব — দুই পথে।
ধাপ ১ — পথ-(ক): \(L^2\) projection (★★, জ্যামিতিক হৃৎপিণ্ড)। প্রথমে ধরি \(X\in L^2(\Omega,\mathcal F,\mathbb P)\) (শক্ত শর্ত; ধাপ ৪-এ শিথিল হবে)। বিবেচনা করি $$ L^2(\mathcal G)\ :=\ \bigl{\,Z\in L^2(\Omega,\mathcal F,\mathbb P):\ Z\ \text{হলো }\mathcal G\text{-measurable}\,\bigr}. $$ দাবি: \(L^2(\mathcal G)\) হলো Hilbert space \(L^2(\mathcal F)\)-এর একটি closed subspace। subspace হওয়া স্পষ্ট (\(\mathcal G\)-measurable ফাংশনের রৈখিক সমাহারও \(\mathcal G\)-measurable)। closed হওয়া: ধরা যাক \(Z_n\in L^2(\mathcal G)\) এবং \(Z_n\to Z\) in \(L^2\)। 7.5-এর Riesz–Fischer-প্রমাণে দেখা গেছে \(L^2\)-অভিসৃতি একটি a.e.-অভিসারী উপ-অনুক্রম \(Z_{n_k}\to Z\) দেয়; প্রতিটি \(Z_{n_k}\) \(\mathcal G\)-measurable, আর measurable ফাংশনের a.e.-সীমা (একটি \(\mathcal G\)-measurable null set বাদ দিয়ে, complete করে নিলে) \(\mathcal G\)-measurable (7.3) — তাই \(Z\)-এর একটি \(\mathcal G\)-measurable version আছে, অর্থাৎ \(Z\in L^2(\mathcal G)\)। সুতরাং subspace-টি closed।
এখন 7.5-এর Hilbert projection theorem প্রয়োগ করি: closed subspace \(L^2(\mathcal G)\)-এর উপর \(X\)-এর একটি অনন্য orthogonal projection আছে, $$ Z\ :=\ \Pi_{\mathcal G}X\ \in\ L^2(\mathcal G),\qquad\text{যা characterized হয় }\ \langle X-Z,\,W\rangle=0\ \ \forall\,W\in L^2(\mathcal G), $$ যেখানে \(\langle A,B\rangle=\int_\Omega AB\,d\mathbb P=\mathbb E[AB]\) (\(L^2(\mathcal F)\)-এর inner product)। অর্থাৎ অবশিষ্ট \(X-Z\) গোটা \(L^2(\mathcal G)\)-এর লম্ব (orthogonal)। এই \(Z\) ঠিক (CE-1)–(CE-2) মানে কিনা যাচাই করি:
- (CE-1): সংজ্ঞা-অনুযায়ী \(Z=\Pi_{\mathcal G}X\in L^2(\mathcal G)\), তাই \(\mathcal G\)-measurable। ✓
- (CE-2): যেকোনো \(G\in\mathcal G\)-এর জন্য indicator \(\mathbf 1_G\) একটি bounded \(\mathcal G\)-measurable ফাংশন, তাই \(\mathbf 1_G\in L^2(\mathcal G)\) (probability space-এ \(\int\mathbf 1_G^2\,d\mathbb P=\mathbb P(G)\le 1<\infty\))। orthogonality-তে \(W=\mathbf 1_G\) বসাই: $$ 0=\langle X-Z,\mathbf 1_G\rangle=\int_\Omega (X-Z)\mathbf 1_G\,d\mathbb P=\int_G X\,d\mathbb P-\int_G Z\,d\mathbb P, $$ অর্থাৎ \(\int_G Z=\int_G X\) সব \(G\in\mathcal G\)-তে। ✓
সুতরাং \(X\in L^2\)-এর জন্য \(Z=\Pi_{\mathcal G}X\) একটি বৈধ \(\mathbb E[X\mid\mathcal G]\) — conditional expectation আসলে \(L^2(\mathcal G)\)-এর উপর \(X\)-এর লম্ব প্রক্ষেপণ। এই এক বাক্যেই Part VII-এর গোটা জ্যামিতি: "\(\mathcal G\)-তথ্য দিয়ে \(X\)-এর সেরা \(L^2\)-অনুমান", আর \(X-\mathbb E[X\mid\mathcal G]\perp L^2(\mathcal G)\)-ই তার সংজ্ঞা-সমীকরণ (প্রমাণ ৫-এ এটিই "best predictor" দেবে)।
ধাপ ২ — পথ-(খ): Radon–Nikodym (\(X\ge 0\), ★★★)। এবার একটি সম্পূর্ণ স্বাধীন পথ, যা \(L^2\) ছাড়াই সরাসরি \(L^1\)-এ কাজ করে। প্রথমে ধরি \(X\ge 0\) এবং \(X\in L^1\) (তাই \(\mathbb E[X]<\infty\))। সংজ্ঞা দিই \((\Omega,\mathcal G)\)-এর উপর একটি set-function: $$ \nu(G)\ :=\ \int_G X\,d\mathbb P\qquad(G\in\mathcal G). $$ দাবি: \(\nu\) হলো \((\Omega,\mathcal G)\)-এর উপর একটি finite measure এবং \(\nu\ll\mathbb P\big\rvert_{\mathcal G}\)।
- \(\nu\) একটি measure: \(\nu(\varnothing)=0\); আর countable additivity আসে 7.4-এর integral-এর countable additivity থেকে — disjoint \(G_k\in\mathcal G\)-এ \(\int_{\bigsqcup_k G_k}X\,d\mathbb P=\sum_k\int_{G_k}X\,d\mathbb P\) (MCT-র ফল, যেহেতু \(X\ge 0\); অর্থাৎ \(X\,d\mathbb P\) একটি measure)। ✓
- finite: \(\nu(\Omega)=\int_\Omega X\,d\mathbb P=\mathbb E[X]<\infty\)। ✓
- absolute continuity \(\nu\ll\mathbb P\big\rvert_{\mathcal G}\): ধরা যাক \(G\in\mathcal G\) এবং \(\mathbb P(G)=0\)। তবে \(X\mathbf 1_G=0\) a.s. (কারণ ওই null-set-এর বাইরে \(\mathbf 1_G=0\)), তাই \(\nu(G)=\int_G X\,d\mathbb P=\int_\Omega X\mathbf 1_G\,d\mathbb P=0\)। অর্থাৎ \(\mathbb P\big\rvert_{\mathcal G}\)-null set \(\nu\)-null। ✓
দুই measure-ই \((\Omega,\mathcal G)\)-তে finite (তাই σ-finite), আর \(\nu\ll\mathbb P\big\rvert_{\mathcal G}\) — তাই 7.5-এর Radon–Nikodym theorem একটি অঋণাত্মক \(\mathcal G\)-measurable density দেয় (লক্ষণীয় — RN-derivative-টা যে base-space-এ থিওরেম প্রয়োগ হয়, সেই \(\mathcal G\)-সাপেক্ষেই measurable): $$ Z\ :=\ \frac{d\nu}{d\mathbb P\big\rvert_{\mathcal G}}\ \ge 0,\qquad \nu(G)=\int_G Z\,d\bigl(\mathbb P\big\rvert_{\mathcal G}\bigr)=\int_G Z\,d\mathbb P\quad\forall\,G\in\mathcal G. $$ এই \(Z\)-ই (CE-1)–(CE-2): (CE-1) — RN-derivative \(\mathcal G\)-measurable; (CE-2) — উপরের সমীকরণ ঠিক \(\int_G Z=\nu(G)=\int_G X\)। ✓ তাই \(\mathbb E[X\mid\mathcal G]=\dfrac{d\nu}{d\mathbb P\rvert_{\mathcal G}}\) — conditional expectation আসলে একটি Radon–Nikodym density। এ-ই 7.1-এ প্রতিশ্রুত "শূন্য-সম্ভাবনার শর্তে naive \(0/0\) এড়িয়ে conditional-কে নির্ভুল অর্থ দেওয়া": ভাগ নয়, density।
ধাপ ৩ — চিহ্নিত \(X\)-কে ভাঙা (\(X\ge 0\) থেকে সাধারণ \(L^1\))। এবার যেকোনো \(X\in L^1(\mathcal F)\) (চিহ্ন-যুক্ত)। লিখি \(X=X^+-X^-\) যেখানে \(X^+=\max(X,0)\ge 0\), \(X^-=\max(-X,0)\ge 0\), এবং \(\mathbb E[X^\pm]\le\mathbb E\lvert X\rvert<\infty\) (তাই দুটোই ধাপ ২-এর আওতায়)। সংজ্ঞা দিই $$ \mathbb E[X\mid\mathcal G]\ :=\ \mathbb E[X^+\mid\mathcal G]-\mathbb E[X^-\mid\mathcal G], $$ দুটোই ধাপ ২ থেকে বিদ্যমান ও \(\mathcal G\)-measurable, আর উভয়ই a.s. সসীম (যেহেতু \(\mathbb E\,\mathbb E[X^\pm\mid\mathcal G]=\mathbb E[X^\pm]<\infty\), তাই \(\mathbb E[X^\pm\mid\mathcal G]<\infty\) a.s.) — বিয়োগ অর্থবহ। (CE-2) integral-এর linearity-তে মেলে: \(\int_G\mathbb E[X\mid\mathcal G]=\int_G X^+-\int_G X^-=\int_G X\)। সুতরাং সাধারণ \(X\in L^1\)-এর জন্যও অস্তিত্ব প্রতিষ্ঠিত — এবং ধাপ ০-এর একত্ব-লেমায় এটি a.s. অনন্য।
ধাপ ৪ (গভীর) — দুই পথের সঙ্গতি, ও \(L^2\)-পথের \(L^1\)-সম্প্রসারণ। দুই পথ একই বস্তু দেয়: \(X\in L^2\cap L^1\) হলে ধাপ ১-এর \(\Pi_{\mathcal G}X\) ও ধাপ ২–৩-এর density-নির্মাণ দুটোই (CE-1)–(CE-2) মানে, তাই একত্ব-লেমায় a.s. সমান। তাই কোন পথে নির্মাণ হলো তা irrelevant — বস্তুটা একটাই a.e.-শ্রেণি। শুধু পথ-(ক) দিয়ে \(L^1\)-এ পৌঁছাতে চাইলে density-পথের বিকল্প আছে density/monotone limit: যেকোনো \(X\ge 0,\ X\in L^1\)-এর জন্য truncation \(X_n:=\min(X,n)\in L^\infty\subseteq L^2\) নিই; \(X_n\uparrow X\), তাই \(X_n^+=X_n\) এবং monotonicity-fact (ধাপ ০-(ii)) থেকে \(\mathbb E[X_n\mid\mathcal G]\) অঋণাত্মক ও অ-হ্রাসমান in \(n\) a.s., তাই a.s.-সীমা \(Z:=\lim_n\mathbb E[X_n\mid\mathcal G]\in[0,\infty]\) আছে; conditional MCT (নিচের টীকা) দেয় (CE-2): \(\int_G Z=\lim_n\int_G\mathbb E[X_n\mid\mathcal G]=\lim_n\int_G X_n=\int_G X\) (শেষ ধাপ সাধারণ MCT, \(X_n\uparrow X\))। বিশেষত \(\int_\Omega Z=\mathbb E[X]<\infty\), তাই \(Z<\infty\) a.s.; এবং \(Z\) \(\mathcal G\)-measurable (measurable-সীমা)। এরপর চিহ্ন-যুক্ত \(X\)-এ ধাপ ৩-এর মতো \(X^+-X^-\) ভাঙন। সুতরাং projection-পথও পুরো \(L^1\) ঢাকে — RN ছাড়াই। ∎
টীকা — conditional MCT (উপরে ব্যবহৃত, আলাদা করে রাখা)। \(0\le Y_n\uparrow Y\) a.s. ও \(Y\in L^1\) হলে \(\mathbb E[Y_n\mid\mathcal G]\uparrow\mathbb E[Y\mid\mathcal G]\) a.s.। কারণ: monotonicity-তে \(W_n:=\mathbb E[Y_n\mid\mathcal G]\) অ-হ্রাসমান, তাই a.s.-সীমা \(W_\infty\) আছে এবং \(\mathcal G\)-measurable; প্রতিটি \(G\in\mathcal G\)-তে সাধারণ MCT দুইবার দেয় \(\int_G W_\infty=\lim_n\int_G W_n=\lim_n\int_G Y_n=\int_G Y\), তাই একত্ব-লেমায় \(W_\infty=\mathbb E[Y\mid\mathcal G]\) a.s.। (এই conditional-MCT প্রমাণ ৪-এও লাগবে।)
এক বাক্যে: একত্ব আসে এক চাল থেকে — \(G=\{Z_1>Z_2\}\in\mathcal G\) নিলে \(\int_G(Z_1-Z_2)=0\) অথচ integrand \(>0\), তাই \(Z_1=Z_2\) a.s.; আর অস্তিত্ব দুই পথে — \(X\in L^2\)-এ \(\mathbb E[X\mid\mathcal G]=\Pi_{\mathcal G}X\) (closed subspace \(L^2(\mathcal G)\)-এ লম্ব প্রক্ষেপণ, \(\langle X-Z,\mathbf 1_G\rangle=0\) ⇒ (CE-2)), আর \(X\ge 0\)-এ \(\mathbb E[X\mid\mathcal G]=\frac{d\nu}{d\mathbb P\rvert_{\mathcal G}}\) (\(\nu(G)=\int_G X\)-এর RN-density), শেষে \(X=X^+-X^-\) ও monotone-limit দিয়ে পুরো \(L^1\)-এ সম্প্রসারিত।
প্রমাণ ২ — tower / iterated expectation (★★)¶
দাবি (tower property, পুনরাবৃত্ত প্রত্যাশা)। ধরা যাক \(\mathcal H\subseteq\mathcal G\subseteq\mathcal F\) — দুই স্তরের আংশিক তথ্য, যেখানে \(\mathcal H\) আরও মোটা (কম তথ্য)। তবে \(X\in L^1\)-এর জন্য $$ \mathbb E\bigl[\,\mathbb E[X\mid\mathcal G]\,\big\rvert\,\mathcal H\,\bigr]\ =\ \mathbb E[X\mid\mathcal H]\quad\text{a.s.} $$ স্বজ্ঞা: "আগে সূক্ষ্ম তথ্য \(\mathcal G\) দিয়ে গড়, তারপর মোটা তথ্য \(\mathcal H\) দিয়ে গড় — ফল ঠিক সরাসরি \(\mathcal H\) দিয়ে গড়ের সমান"; মোটা চালুনিই শেষ কথা বলে।
ধাপ ১ — কৌশল: একত্ব-লেমায় পরিচয় যাচাই। সংজ্ঞা দিই \(Z:=\mathbb E[X\mid\mathcal G]\) (প্রমাণ ১) এবং \(V:=\mathbb E[Z\mid\mathcal H]\)। লক্ষ্য: \(V=\mathbb E[X\mid\mathcal H]\) a.s.। যেহেতু \(\mathbb E[X\mid\mathcal H]\) হলো \(\mathcal H\)-শর্তের (CE-1)–(CE-2)-এর অনন্য সমাধান (ধাপ ০, একত্ব-লেমা), শুধু দেখাতে হবে \(V\) নিজেই সেই দুই শর্ত মানে। অর্থাৎ যাচাই করব: (i) \(V\) হলো \(\mathcal H\)-measurable, এবং (ii) \(\int_H V\,d\mathbb P=\int_H X\,d\mathbb P\) সব \(H\in\mathcal H\)-তে।
ধাপ ২ — (i) \(\mathcal H\)-measurability। \(V=\mathbb E[Z\mid\mathcal H]\) — সংজ্ঞা-অনুযায়ীই (প্রমাণ ১-এর (CE-1)) এটি \(\mathcal H\)-measurable। ✓ (এখানে কোনো খাটুনি নেই; conditional expectation সবসময় শর্ত-σ-algebra-measurable।)
ধাপ ৩ — (ii) integral-শর্ত, দুই ধাপে চালুনি নামানো। যেকোনো \(H\in\mathcal H\) নিই। যেহেতু \(\mathcal H\subseteq\mathcal G\), এই \(H\) \(\mathcal G\)-তেও আছে: \(H\in\mathcal G\)। এখন দুই ধাপ: $$ \int_H V\,d\mathbb P\ \overset{(a)}{=}\ \int_H Z\,d\mathbb P\ \overset{(b)}{=}\ \int_H X\,d\mathbb P. $$ - (a) \(V=\mathbb E[Z\mid\mathcal H]\)-এর (CE-2) (\(Z\)-কে base random variable ধরে, \(\mathcal H\)-শর্তে): \(\int_H V=\int_H Z\) সব \(H\in\mathcal H\)-তে — সরাসরি সংজ্ঞা। - (b) \(Z=\mathbb E[X\mid\mathcal G]\)-এর (CE-2) (\(\mathcal G\)-শর্তে): \(\int_G Z=\int_G X\) সব \(G\in\mathcal G\)-তে; এখানে \(G=H\) বসানো বৈধ ঠিক কারণ \(H\in\mathcal G\) (এ-ই \(\mathcal H\subseteq\mathcal G\)-শর্তের একমাত্র, কিন্তু অপরিহার্য, ব্যবহার)।
সুতরাং \(\int_H V=\int_H X\) সব \(H\in\mathcal H\)-তে — (ii) প্রমাণিত। (i)+(ii) মিলে \(V\) হলো \(\mathcal H\)-শর্তের (CE-1)–(CE-2)-এর একটি সমাধান, তাই একত্ব-লেমায় \(V=\mathbb E[X\mid\mathcal H]\) a.s.। \(\blacksquare\)
ধাপ ৪ — বিশেষ ক্ষেত্র: total expectation। \(\mathcal H=\{\varnothing,\Omega\}\) (তুচ্ছ σ-algebra, "কোনো তথ্য নেই") নিই। তখন একটি \(\mathcal H\)-measurable ফাংশন মানে একটি ধ্রুবক, আর সংজ্ঞা থেকে \(\mathbb E[Y\mid\{\varnothing,\Omega\}]=\mathbb E[Y]\) (ধ্রুবক, যার মান (CE-2)-তে \(G=\Omega\) দিয়ে \(\int_\Omega Y\,d\mathbb P=\mathbb E[Y]\))। tower বসিয়ে পাই law of total / iterated expectation: $$ \mathbb E\bigl[\,\mathbb E[X\mid\mathcal G]\,\bigr]\ =\ \mathbb E[X]. $$ অর্থাৎ conditional expectation নেওয়া "গড়-অক্ষুণ্ণ" (mean-preserving) — \(\mathcal G\)-চালুনির ভেতর-বাইরে গড় একই। এটি প্রমাণ ৫–৬-এ সরাসরি লাগবে।
এক বাক্যে: \(V:=\mathbb E[\mathbb E[X\mid\mathcal G]\mid\mathcal H]\) স্পষ্টতই \(\mathcal H\)-measurable, আর প্রতিটি \(H\in\mathcal H\subseteq\mathcal G\)-তে দুই-ধাপ (CE-2) দেয় \(\int_H V=\int_H \mathbb E[X\mid\mathcal G]=\int_H X\) (দ্বিতীয় সমতা বৈধ কারণ \(H\in\mathcal G\)), তাই একত্ব-লেমায় \(V=\mathbb E[X\mid\mathcal H]\) — আর \(\mathcal H\) তুচ্ছ নিলে \(\mathbb E[\mathbb E[X\mid\mathcal G]]=\mathbb E[X]\)।
প্রমাণ ৩ — pull-out: জানা-জিনিস বাইরে আনা (★★)¶
দাবি (pull-out / "taking out what is known")। ধরা যাক \(Y\) হলো \(\mathcal G\)-measurable, এবং integrability নিশ্চিত — যেমন \(Y\) bounded ও \(X\in L^1\), অথবা \(X,Y\in L^2\) (তখন Cauchy–Schwarz-এ \(YX\in L^1\))। তবে $$ \mathbb E[\,YX\mid\mathcal G\,]\ =\ Y\,\mathbb E[X\mid\mathcal G]\quad\text{a.s.} $$ স্বজ্ঞা: \(\mathcal G\) যদি \(Y\)-কে "জানে" (সে \(\mathcal G\)-measurable), তবে \(\mathcal G\)-শর্তে \(Y\) একটি ধ্রুবকের মতো — তাই গড়ের বাইরে টেনে আনা যায়।
কৌশল — standard machine (মানক যন্ত্র)। measure theory-র চিরাচরিত চার-ধাপ আরোহণ: indicator → simple → অঋণাত্মক (MCT) → সাধারণ। প্রতিটি ধাপে দেখাব \(W:=Y\,\mathbb E[X\mid\mathcal G]\) হলো \(YX\)-এর জন্য (CE-1)–(CE-2)-এর সমাধান, তাই একত্ব-লেমায় \(\mathbb E[YX\mid\mathcal G]=W\)।
ধাপ ১ — \(Y=\mathbf 1_{G_0}\), \(G_0\in\mathcal G\) (মূল ধাপ)। এখানে \(W=\mathbf 1_{G_0}\mathbb E[X\mid\mathcal G]\)। - (CE-1): \(\mathbf 1_{G_0}\) \(\mathcal G\)-measurable (\(G_0\in\mathcal G\)) এবং \(\mathbb E[X\mid\mathcal G]\) \(\mathcal G\)-measurable, তাই গুণফল \(W\) \(\mathcal G\)-measurable। ✓ - (CE-2): যেকোনো \(G\in\mathcal G\)-তে — লক্ষণীয় \(G\cap G_0\in\mathcal G\) (দুই \(\mathcal G\)-set-এর intersection) — $$ \int_G W\,d\mathbb P=\int_G \mathbf 1_{G_0}\,\mathbb E[X\mid\mathcal G]\,d\mathbb P=\int_{G\cap G_0}\mathbb E[X\mid\mathcal G]\,d\mathbb P\overset{(\ast)}{=}\int_{G\cap G_0}X\,d\mathbb P=\int_G \mathbf 1_{G_0}X\,d\mathbb P=\int_G (YX)\,d\mathbb P, $$ যেখানে \((\ast)\) হলো \(\mathbb E[X\mid\mathcal G]\)-এর (CE-2), test-set \(G\cap G_0\in\mathcal G\) দিয়ে। ✓ তাই indicator-ক্ষেত্রে \(\mathbb E[\mathbf 1_{G_0}X\mid\mathcal G]=\mathbf 1_{G_0}\mathbb E[X\mid\mathcal G]\) a.s.।
ধাপ ২ — \(Y\) simple (সরল), \(\mathcal G\)-measurable। ধরা যাক \(Y=\sum_{i=1}^m c_i\mathbf 1_{G_i}\), \(G_i\in\mathcal G\), \(c_i\in\mathbb R\)। conditional linearity (ধাপ ০-পরবর্তী fact) ও ধাপ ১ মিলিয়ে: $$ \mathbb E[YX\mid\mathcal G]=\mathbb E\Bigl[\textstyle\sum_i c_i\mathbf 1_{G_i}X\,\Big\rvert\,\mathcal G\Bigr]=\sum_i c_i\,\mathbb E[\mathbf 1_{G_i}X\mid\mathcal G]=\sum_i c_i\mathbf 1_{G_i}\,\mathbb E[X\mid\mathcal G]=Y\,\mathbb E[X\mid\mathcal G]. $$
ধাপ ৩ — \(Y\ge 0\), \(X\ge 0\) (MCT-আরোহণ)। ধরি আপাতত \(Y\ge 0\) ও \(X\ge 0\)। 7.3-এর simple-approximation: \(\mathcal G\)-measurable simple \(Y_n\uparrow Y\) (\(0\le Y_n\), অ-হ্রাসমান)। তখন \(Y_nX\uparrow YX\) (যেহেতু \(X\ge 0\))। ধাপ ২ দেয় \(\mathbb E[Y_nX\mid\mathcal G]=Y_n\mathbb E[X\mid\mathcal G]\)। দুই পাশে \(n\to\infty\): $$ \mathbb E[YX\mid\mathcal G]\overset{(c)}{=}\lim_n\mathbb E[Y_nX\mid\mathcal G]=\lim_n Y_n\,\mathbb E[X\mid\mathcal G]=Y\,\mathbb E[X\mid\mathcal G], $$ যেখানে \((c)\) হলো conditional MCT (প্রমাণ ১-এর টীকা — \(Y_nX\uparrow YX\in L^1\)), আর শেষ সমতা \(Y_n\uparrow Y\) ও \(\mathbb E[X\mid\mathcal G]\ge 0\) (monotonicity-fact, যেহেতু \(X\ge 0\)) থেকে pointwise।
ধাপ ৪ — সাধারণ চিহ্ন। যেকোনো (integrable) \(X=X^+-X^-\), \(Y=Y^+-Y^-\) ভেঙে ধাপ ৩ চারটি অঋণাত্মক জোড়ায় প্রয়োগ করি, তারপর conditional linearity দিয়ে জোড়ো: $$ \mathbb E[YX\mid\mathcal G]=\mathbb E[(Y^+-Y^-)(X^+-X^-)\mid\mathcal G]=(Y^+-Y^-)\,\mathbb E[X\mid\mathcal G]=Y\,\mathbb E[X\mid\mathcal G], $$ (integrability — \(Y\) bounded বা \(X,Y\in L^2\) — নিশ্চিত করে প্রতিটি \(\mathbb E[Y^\pm X^\pm\mid\mathcal G]\) সসীম, তাই বিয়োগ অর্থবহ)। \(\blacksquare\)
উপসিদ্ধান্ত — \(\mathcal G\)-measurable \(Y\) "নিজের শর্তে নিজেই"। বিশেষ করে \(X=1\) বসালে \(\mathbb E[Y\mid\mathcal G]=Y\) a.s. যখন \(Y\) \(\mathcal G\)-measurable (ও integrable) — "\(\mathcal G\) যা জানে, তার গড় নেওয়ার কিছু নেই"। এটি pull-out-এরই সীমা-রূপ এবং প্রমাণ ৫–৬-এ লাগবে।
এক বাক্যে: indicator \(Y=\mathbf 1_{G_0}\)-এ (CE-2)-র test-set \(G\cap G_0\in\mathcal G\) নিয়েই \(\mathbb E[\mathbf 1_{G_0}X\mid\mathcal G]=\mathbf 1_{G_0}\mathbb E[X\mid\mathcal G]\) বেরোয়; এরপর linearity (simple) → conditional MCT (অঋণাত্মক) → \(\pm\)-ভাঙন (সাধারণ) চারধাপের মানক যন্ত্রে \(\mathbb E[YX\mid\mathcal G]=Y\mathbb E[X\mid\mathcal G]\) — আর \(\mathcal G\)-measurable \(Y\) তার নিজের শর্তে অপরিবর্তিত।
প্রমাণ ৪ — conditional Jensen (★★)¶
দাবি (conditional Jensen's inequality)। ধরা যাক \(\varphi:\mathbb R\to\mathbb R\) একটি convex (উত্তল) ফাংশন, এবং \(X\in L^1\) যেন \(\varphi(X)\in L^1\)-ও। তবে $$ \varphi\bigl(\mathbb E[X\mid\mathcal G]\bigr)\ \le\ \mathbb E\bigl[\varphi(X)\mid\mathcal G\bigr]\quad\text{a.s.} $$ এটি 7.5-এর সাধারণ Jensen-এর শর্তাধীন সংস্করণ — সেখানে ধ্রুবক \(\mathbb E[X]\) ছিল, এখানে random variable \(\mathbb E[X\mid\mathcal G]\)।
ধাপ ১ — উত্তল ফাংশনের গণনাযোগ্য (countable) supporting-line পরিবার। 7.5-এর প্রমাণ ৩-এ দেখা গেছে, একটি উত্তল \(\varphi\)-এর প্রতিটি বিন্দুতে একটি supporting line (সহায়ক-রেখা) আছে। মূল পর্যবেক্ষণ: একটি উত্তল ফাংশন তার supporting line-গুলোর উপরিসীমা (upper envelope), এবং এই পরিবারকে একটি গণনাযোগ্য পরিবারে নামানো যায় — $$ \varphi(t)\ =\ \sup_{k\in\mathbb N}\,\bigl(a_k t+b_k\bigr)\qquad\text{সব }t\in\mathbb R, $$ যেখানে \((a_k,b_k)\) হলো মূলদ (rational) বিন্দু \(q_k\in\mathbb Q\)-তে নেওয়া supporting line-এর ঢাল-ছেদ। কেন গণনাযোগ্য যথেষ্ট: প্রতিটি \(t\) ও \(\varepsilon>0\)-এ একটি মূলদ \(q\) আছে \(t\)-এর এত কাছে যে \(q\)-এর supporting line \(t\)-এ \(\varphi(t)-\varepsilon\)-এর বেশি দেয় (উত্তল ফাংশন অবিচ্ছিন্ন, তাই supporting-line ঢাল-ছেদ \(q\)-তে অবিচ্ছিন্নভাবে বদলায়); \(\sup\) নিলে সমতা। প্রতিটি রেখা \(\ell_k(t):=a_kt+b_k\)-এর জন্য, supporting-line-ধর্ম বলে \(\varphi(s)\ge\ell_k(s)\) সব \(s\)-এ।
ধাপ ২ — একটি স্থির রেখায় conditional monotonicity+linearity। স্থির \(k\) ধরি। যেহেতু \(\varphi(X)\ge a_kX+b_k\) a.s. (supporting-line, \(s=X\) বসিয়ে — সব \(\omega\)-তে সত্য), conditional monotonicity (ধাপ ০-fact) প্রয়োগ করি: $$ \mathbb E[\varphi(X)\mid\mathcal G]\ \ge\ \mathbb E[a_kX+b_k\mid\mathcal G]\ \overset{\text{linearity}}{=}\ a_k\,\mathbb E[X\mid\mathcal G]+b_k\quad\text{a.s.} $$ (এখানে \(b_k\) ধ্রুবকের conditional expectation \(b_k\), আর \(\mathbb E[a_kX\mid\mathcal G]=a_k\mathbb E[X\mid\mathcal G]\) — linearity, বা pull-out ধ্রুবক-\(Y\)-তে।) সুতরাং প্রতিটি \(k\)-এর জন্য একটি a.s.-অসমতা পেলাম: $$ \mathbb E[\varphi(X)\mid\mathcal G]\ \ge\ a_k\,\mathbb E[X\mid\mathcal G]+b_k\qquad\text{a.s., প্রতি স্থির }k. \tag{J\(_k\)} $$
ধাপ ৩ — সব \(k\)-এ supremum নেওয়া (এখানেই "গণনাযোগ্য" অপরিহার্য)। (J\(_k\))-এর প্রতিটি একটি \(\mathbb P\)-null exceptional set \(N_k\) বাদে সত্য। গণনাযোগ্য পরিবার বলে মিলিত exceptional set \(N:=\bigcup_k N_k\)-ও null (\(\mathbb P(N)\le\sum_k\mathbb P(N_k)=0\), countable subadditivity) — অগণনীয় হলে এই ধাপ ভেঙে পড়ত। তাই \(N\)-এর বাইরে (অর্থাৎ a.s.) একসঙ্গে সব \(k\)-তে (J\(_k\)) সত্য, ফলে ডান পাশে \(k\)-এর উপর supremum নেওয়া বৈধ: $$ \mathbb E[\varphi(X)\mid\mathcal G]\ \ge\ \sup_{k}\Bigl(a_k\,\mathbb E[X\mid\mathcal G]+b_k\Bigr)\ \overset{(\dagger)}{=}\ \varphi\bigl(\mathbb E[X\mid\mathcal G]\bigr)\quad\text{a.s.,} $$ যেখানে \((\dagger)\) হলো ধাপ ১-এর অভেদ \(\varphi(t)=\sup_k(a_kt+b_k)\), কিন্তু এবার \(t\)-এর জায়গায় random variable \(\mathbb E[X\mid\mathcal G](\omega)\) বসানো — প্রতিটি \(\omega\)-তে (যেখানে সব (J\(_k\)) ধরে) এটি বৈধ একটি বাস্তব-সংখ্যা-অভেদ। এ-ই দাবি। \(\blacksquare\)
উপসিদ্ধান্ত — \(L^p\)-সংকোচন (contraction)। \(p\ge 1\)-এ \(\varphi(t)=\lvert t\rvert^p\) উত্তল; conditional Jensen দেয় \(\bigl\lvert\mathbb E[X\mid\mathcal G]\bigr\rvert^p\le\mathbb E[\lvert X\rvert^p\mid\mathcal G]\) a.s.। দুই পাশে (নিঃশর্ত) প্রত্যাশা নিয়ে tower (প্রমাণ ২, ধাপ ৪) প্রয়োগ: $$ \mathbb E\bigl[\lvert\mathbb E[X\mid\mathcal G]\rvert^p\bigr]\ \le\ \mathbb E\bigl[\,\mathbb E[\lvert X\rvert^p\mid\mathcal G]\,\bigr]=\mathbb E[\lvert X\rvert^p], $$ অর্থাৎ \(\bigl\lVert\mathbb E[X\mid\mathcal G]\bigr\rVert_p\le\lVert X\rVert_p\) — conditional expectation একটি \(L^p\)-সংকোচন (norm বাড়ায় না), তাই \(L^p\)-এ একটি bounded (আসলে contraction) operator। বিশেষত \(p=2\)-এ এটিই প্রমাণ ১-এর projection-এর norm-সংকোচন (লম্ব প্রক্ষেপণ লম্বার্ধক্য বাড়ায় না), এবং প্রমাণ ৫-এর "best predictor"-এর সঙ্গে সঙ্গতিপূর্ণ।
এক বাক্যে: উত্তল \(\varphi=\sup_k(a_kt+b_k)\)-এর প্রতিটি সহায়ক-রেখায় conditional monotonicity+linearity দেয় \(\mathbb E[\varphi(X)\mid\mathcal G]\ge a_k\mathbb E[X\mid\mathcal G]+b_k\) a.s.; গণনাযোগ্য পরিবার বলে সব \(k\) একসঙ্গে a.s. ধরে, তাই supremum নিয়ে \(\varphi(\mathbb E[X\mid\mathcal G])\le\mathbb E[\varphi(X)\mid\mathcal G]\) — যার \(\varphi=\lvert\cdot\rvert^p\) রূপ tower-সহযোগে \(L^p\)-সংকোচন \(\lVert\mathbb E[X\mid\mathcal G]\rVert_p\le\lVert X\rVert_p\) দেয়।
প্রমাণ ৫ — সেরা \(L^2\) পূর্বাভাস = conditional expectation (★★)¶
দাবি (best \(L^2\) predictor)। ধরা যাক \(X\in L^2(\mathcal F)\)। তবে সব \(\mathcal G\)-measurable \(Z\in L^2\)-এর মধ্যে \(\mathbb E[(X-Z)^2]\) ন্যূনতম হয় ঠিক \(Z=\mathbb E[X\mid\mathcal G]\)-তে (a.s.)। সমতুল্যভাবে, প্রতিটি এমন \(Z\)-এর জন্য Pythagorean বিভাজন: $$ \mathbb E[(X-Z)^2]\ =\ \underbrace{\mathbb E\bigl[(X-\mathbb E[X\mid\mathcal G])^2\bigr]}{\text{অপসারণযোগ্য নয় (irreducible)}}\ +\ \underbrace{\mathbb E\bigl[(\mathbb E[X\mid\mathcal G]-Z)^2\bigr]}. \tag{}Z=\mathbb E[X\mid\mathcal G]\text{-এ }0\(\Pi\)} $$ এটিই "regression = conditional expectation"-এর গাণিতিক হৃৎপিণ্ড।
ধাপ ০ — সংকেত ও কেন \(L^2\)। লিখি \(m:=\mathbb E[X\mid\mathcal G]\) (প্রমাণ ১; \(X\in L^2\) বলে \(m=\Pi_{\mathcal G}X\in L^2\), ও \(L^2\)-সংকোচন প্রমাণ ৪ থেকে \(\lVert m\rVert_2\le\lVert X\rVert_2<\infty\))। \(\mathbb E[(X-Z)^2]\) মানে \(L^2\)-দূরত্বের বর্গ, তাই প্রশ্নটা ঠিক "\(L^2(\mathcal G)\)-এ \(X\)-এর নিকটতম বিন্দু" — যার উত্তর প্রমাণ ১-এর projection-এই লুকানো; নিচে তা conditional-ধর্ম দিয়ে স্বয়ংসম্পূর্ণভাবে দেখাই।
ধাপ ১ — মাঝে \(m\) ঢুকিয়ে বর্গ ভাঙা। যেকোনো \(\mathcal G\)-measurable \(Z\in L^2\)-এর জন্য pointwise লিখি \(X-Z=(X-m)+(m-Z)\), বর্গ করি ও প্রত্যাশা নিই (তিন পদই integrable: \(X,m,Z\in L^2\)): $$ \mathbb E[(X-Z)^2]=\mathbb E[(X-m)^2]+2\,\underbrace{\mathbb E\bigl[(X-m)(m-Z)\bigr]}_{=:\,C\ \text{(cross term)}}+\mathbb E[(m-Z)^2]. \tag{∗} $$ পুরো দাবিটা দাঁড়ায় একটি জিনিসে: cross term \(C=0\)।
ধাপ ২ — cross term বিলোপ (pull-out + tower)। মূল পর্যবেক্ষণ: \(m-Z\) হলো \(\mathcal G\)-measurable (\(m\) ও \(Z\) দুটোই \(\mathcal G\)-measurable)। তাই tower (প্রমাণ ২, ধাপ ৪ — নিঃশর্ত প্রত্যাশা = \(\mathbb E[\,\cdot\mid\mathcal G]\)-এর প্রত্যাশা) দিয়ে ভেতরে \(\mathcal G\)-শর্ত ঢোকাই, তারপর pull-out (প্রমাণ ৩) দিয়ে \(\mathcal G\)-measurable গুণনীয়ক \((m-Z)\) বাইরে আনি: $$ C=\mathbb E\bigl[(X-m)(m-Z)\bigr]\overset{\text{tower}}{=}\mathbb E\Bigl[\,\mathbb E\bigl[(X-m)(m-Z)\,\big\rvert\,\mathcal G\bigr]\Bigr]\overset{\text{pull-out}}{=}\mathbb E\Bigl[(m-Z)\,\mathbb E[X-m\mid\mathcal G]\Bigr]. $$ এখন ভেতরের conditional: \(\mathbb E[X-m\mid\mathcal G]=\mathbb E[X\mid\mathcal G]-\mathbb E[m\mid\mathcal G]=m-m=0\) a.s. — কারণ \(\mathbb E[X\mid\mathcal G]=m\) (সংজ্ঞা) এবং \(\mathbb E[m\mid\mathcal G]=m\) (\(m\) \(\mathcal G\)-measurable, প্রমাণ ৩-এর উপসিদ্ধান্ত)। সুতরাং বন্ধনীর ভেতর \(0\), তাই \(C=\mathbb E[(m-Z)\cdot 0]=0\)। ✓
ধাপ ৩ — Pythagoras ও minimizer। \(C=0\) বসিয়ে (∗) থেকে সরাসরি (\(\Pi\)): $$ \mathbb E[(X-Z)^2]=\mathbb E[(X-m)^2]+\mathbb E[(m-Z)^2]. $$ ডান পাশের প্রথম পদ \(Z\)-নিরপেক্ষ (ধ্রুবক), দ্বিতীয় পদ \(\mathbb E[(m-Z)^2]\ge 0\) সবসময়, এবং \(=0\) ⟺ \(m-Z=0\) a.s. ⟺ \(Z=m\) a.s. (প্রমাণ-৬, 7.4 — অঋণাত্মক বর্গের প্রত্যাশা শূন্য মানে a.s.-শূন্য)। সুতরাং বাঁ পাশ ন্যূনতম হয় ঠিক \(Z=m=\mathbb E[X\mid\mathcal G]\)-তে, এবং সেই ন্যূনতম মান \(\mathbb E[(X-\mathbb E[X\mid\mathcal G])^2]\)। \(\blacksquare\)
ব্যাখ্যা — কেন regression = conditional expectation। "\(X\)-কে \(\mathcal G\)-তথ্য দিয়ে গড়-বর্গ-ত্রুটি (mean squared error) ন্যূনতম রেখে পূর্বাভাস" — এর নিঃশর্ত সেরা সমাধান (কোনো রৈখিকতা-অনুমান ছাড়া) হলো \(\mathbb E[X\mid\mathcal G]\), যাকে regression function বলে। parametric/linear regression (Part V) আসলে এই সেরা পূর্বাভাসকে একটি ছোট subspace-এ (যেমন \(\{a+bW\}\)) সীমিত করে আনুমানিক করা; \(\mathcal G=\sigma(W)\) নিলে সত্যিকারের লক্ষ্য সবসময় \(\mathbb E[X\mid W]\)। আর (\(\Pi\))-এর প্রথম পদ — irreducible error — যত-তথ্যই থাক ছেঁটে ফেলা যায় না; এটি প্রমাণ ৬-এ "ব্যাখ্যা-না-করা ভেদাঙ্ক"-এর রূপ নেবে।
এক বাক্যে: \(X-Z=(X-m)+(m-Z)\) ভেঙে cross term \(\mathbb E[(X-m)(m-Z)]\)-কে tower দিয়ে \(\mathcal G\)-ভেতরে নিয়ে pull-out করলে \(\mathbb E[X-m\mid\mathcal G]=0\) বলে তা বিলুপ্ত হয়, ফলে Pythagoras \(\mathbb E[(X-Z)^2]=\mathbb E[(X-m)^2]+\mathbb E[(m-Z)^2]\) — যার ডান পদ কেবল \(Z=m=\mathbb E[X\mid\mathcal G]\)-এ শূন্য, তাই সেরা \(L^2\)-পূর্বাভাসই conditional expectation (= regression function)।
প্রমাণ ৬ — law of total variance (★)¶
দাবি (মোট ভেদাঙ্কের সূত্র)। ধরা যাক \(X\in L^2\)। conditional variance (শর্তাধীন ভেদাঙ্ক) সংজ্ঞা দিই $$ \operatorname{Var}(X\mid\mathcal G)\ :=\ \mathbb E\bigl[X^2\mid\mathcal G\bigr]-\bigl(\mathbb E[X\mid\mathcal G]\bigr)^2\ \ (\ge 0\ \text{a.s.}), $$ (অঋণাত্মকতা ঠিক conditional Jensen, প্রমাণ ৪, \(\varphi(t)=t^2\)-এ)। তবে $$ \operatorname{Var}(X)\ =\ \mathbb E\bigl[\operatorname{Var}(X\mid\mathcal G)\bigr]\ +\ \operatorname{Var}\bigl(\mathbb E[X\mid\mathcal G]\bigr). $$ ভাষায়: মোট ভেদাঙ্ক = (গড় শর্তাধীন-ভেদাঙ্ক) + (শর্তাধীন-গড়ের ভেদাঙ্ক) = "within-group" + "between-group" বিচ্ছুরণ।
ধাপ ১ — দুই সংকেত ও tower দিয়ে গড় মেলানো। লিখি \(m:=\mathbb E[X\mid\mathcal G]\)। দুটো মৌলিক tower-ফল (প্রমাণ ২, ধাপ ৪) আগেই নোট করি: $$ \mathbb E[m]=\mathbb E\bigl[\mathbb E[X\mid\mathcal G]\bigr]=\mathbb E[X]=:\mu,\qquad \mathbb E\bigl[\mathbb E[X^2\mid\mathcal G]\bigr]=\mathbb E[X^2]. \tag{T} $$ অর্থাৎ শর্তাধীন-গড় \(m\)-এর গড় হলো সাধারণ গড় \(\mu\), আর \(\mathbb E[X^2\mid\mathcal G]\)-এর গড় \(\mathbb E[X^2]\) — দুটোই "চালুনির ভেতর-বাইরে গড় এক"।
ধাপ ২ — ডান পাশের প্রথম পদ: \(\mathbb E[\operatorname{Var}(X\mid\mathcal G)]\)। সংজ্ঞা ও (T) দিয়ে সরাসরি: $$ \mathbb E\bigl[\operatorname{Var}(X\mid\mathcal G)\bigr]=\mathbb E\bigl[\mathbb E[X^2\mid\mathcal G]\bigr]-\mathbb E\bigl[m^2\bigr]\overset{(T)}{=}\mathbb E[X^2]-\mathbb E[m^2]. \tag{A} $$
ধাপ ৩ — ডান পাশের দ্বিতীয় পদ: \(\operatorname{Var}(m)\)। variance-এর সংজ্ঞা \(\operatorname{Var}(m)=\mathbb E[m^2]-(\mathbb E[m])^2\), আর (T)-তে \(\mathbb E[m]=\mu\): $$ \operatorname{Var}\bigl(\mathbb E[X\mid\mathcal G]\bigr)=\mathbb E[m^2]-\mu^2. \tag{B} $$
ধাপ ৪ — যোগ করে \(\mathbb E[m^2]\) বাতিল। (A)+(B): $$ \mathbb E\bigl[\operatorname{Var}(X\mid\mathcal G)\bigr]+\operatorname{Var}(m)=\bigl(\mathbb E[X^2]-\mathbb E[m^2]\bigr)+\bigl(\mathbb E[m^2]-\mu^2\bigr)=\mathbb E[X^2]-\mu^2. $$ কিন্তু \(\mathbb E[X^2]-\mu^2=\mathbb E[X^2]-(\mathbb E[X])^2=\operatorname{Var}(X)\) — variance-এর সংজ্ঞা। সুতরাং $$ \operatorname{Var}(X)=\mathbb E\bigl[\operatorname{Var}(X\mid\mathcal G)\bigr]+\operatorname{Var}\bigl(\mathbb E[X\mid\mathcal G]\bigr). \qquad\blacksquare $$ (লক্ষণীয় — মাঝের \(\mathbb E[m^2]\) ঠিক বিপরীত চিহ্নে দুই পদে এসে কাটল; এ-ই Pythagoras-এরই variance-রূপ — প্রমাণ ৫-এর (\(\Pi\))-তে \(Z=\mu\) ধ্রুবক বসালে হুবহু একই বিভাজন।)
ব্যাখ্যা — \(R^2\) ও ব্যাখ্যাকৃত ভেদাঙ্ক (explained variance)। \(\mathcal G=\sigma(W)\) নিলে সূত্রটা পরিসংখ্যানের কেন্দ্রীয় রূপ পায়: $$ \underbrace{\operatorname{Var}(X)}{\text{মোট}}=\underbrace{\mathbb E[\operatorname{Var}(X\mid W)]}. $$ দ্বিতীয় পদ — predictor }}+\underbrace{\operatorname{Var}(\mathbb E[X\mid W])}_{\text{ব্যাখ্যাকৃত (explained)}\(\mathbb E[X\mid W]\)-এর নিজস্ব বিচ্ছুরণ — হলো "\(W\) যতটুকু \(X\)-এর ওঠানামা ব্যাখ্যা করে"; প্রথম পদ প্রমাণ ৫-এর irreducible error-এর গড়। এদের অনুপাত $$ R^2\ :=\ \frac{\operatorname{Var}(\mathbb E[X\mid W])}{\operatorname{Var}(X)}\ =\ 1-\frac{\mathbb E[\operatorname{Var}(X\mid W)]}{\operatorname{Var}(X)}\ \in[0,1], $$ ঠিক regression-এর coefficient of determination \(R^2\)-এর জনসংখ্যা-রূপ (population analogue) — "মোট ভেদাঙ্কের কত ভগ্নাংশ \(W\) ব্যাখ্যা করে"। তাই law of total variance শুধু একটি অভেদ নয়, পুরো explained-vs-unexplained বিশ্লেষণের measure-তাত্ত্বিক ভিত্তি, এবং Part V-এর ANOVA-বিভাজনের (\(SS_{\text{total}}=SS_{\text{within}}+SS_{\text{between}}\)) সঠিক জনসংখ্যা-প্রতিরূপ।
এক বাক্যে: \(\mathbb E[\operatorname{Var}(X\mid\mathcal G)]=\mathbb E[X^2]-\mathbb E[m^2]\) আর \(\operatorname{Var}(m)=\mathbb E[m^2]-\mu^2\) — যোগ করলে \(\mathbb E[m^2]\) কাটাকাটি গিয়ে \(\operatorname{Var}(X)=\mathbb E[X^2]-\mu^2\), অর্থাৎ মোট ভেদাঙ্ক = (within) শর্তাধীন-ভেদাঙ্কের গড় + (between) শর্তাধীন-গড়ের ভেদাঙ্ক, যার অনুপাতই regression-এর \(R^2\)।
৫ · কোড ল্যাব (Python)¶
এই অধ্যায়ের কেন্দ্রীয় বস্তু conditional expectation (শর্তাধীন প্রত্যাশা) \(\mathbb E[X\mid\mathcal G]\) পুরোপুরি বিমূর্ত: এটি কোনো একটিমাত্র সংখ্যা নয়, বরং একটি \(\mathcal G\)-measurable random variable — "\(\mathcal G\) যতটুকু তথ্য দেয়, ঠিক ততটুকু দিয়ে গড়া \(X\)-এর সেরা অনুমান"। কিন্তু সংজ্ঞাটি যত বিমূর্তই হোক, তার প্রতিটি দাবি simulation-এ সংখ্যায় চোখে দেখা যায়: সসীম partition-এ \(\mathbb E[X\mid\mathcal G]\) স্রেফ atom-ভিত্তিক গড়ে নেমে আসে; jointly normal উপাত্তে সেটি হুবহু regression line-এ মিলে যায়; সব function-এর মধ্যে এই অনুমানই mean squared error (গড় বর্গ-ত্রুটি) সর্বনিম্ন করে; আর মোট ভেদাঙ্ক (variance) ঠিক দুই টুকরোয় — "ভিতরের" আর "বাইরের" — ভেঙে যায়। এই ল্যাবে একটিমাত্র runnable স্ক্রিপ্ট (শুধু numpy-নির্ভর, বাড়তি কোনো library নয়) চারটি অংশে এই চারটি মুখ একে একে যাচাই করে।
স্ক্রিপ্টের কাঠামো ও পুনরুৎপাদনযোগ্যতা (reproducibility)¶
Part 1 (পাশা) সম্পূর্ণ বদ্ধ-রূপে (closed-form) — কোনো random draw নেই, তাই এটি random স্রোত (stream) স্পর্শ করে না। Part 2–4-এর জন্য একটিমাত্র generator ব্যবহার হয়—np.random.default_rng(20260619)—এবং দুটি নমুনা সেই একই স্রোত থেকে টানা হয়। কিন্তু default_rng-এর ফলাফল স্রোত থেকে টানার ক্রমের উপর নির্ভরশীল: একই seed হলেও আগে-পরে টানলে আলাদা সংখ্যা আসে। তাই হুবহু canonical সংখ্যা (\(0.6008\), \(0.6014\), \(0.6410\), \(1.0017\)) পেতে নিচের ঠিক এই ক্রমেই স্রোত টানতে হয়—
Y = rng.standard_normal(10**6)— শর্তদাতা চলক (conditioning variable), আগে টানা;X = 0.6*Y + np.sqrt(1 - 0.36)*rng.standard_normal(10**6)— শর্তাধীন চলক, \(Z_2\) পরে টানা।
এই দুই লাইনেই standard marginal (প্রান্তিক বণ্টন \(\mathcal N(0,1)\)) ও correlation \(\rho=0.6\)-এর bivariate normal গড়ে ওঠে: \(Y=Z_1\), তারপর \(X=\rho Y+\sqrt{1-\rho^2}\,Z_2\)। এর ফলে বিশ্লেষণিকভাবে (analytically) \(\mathbb E[X\mid Y=y]=\rho y=0.6y\) এবং \(\operatorname{Var}(X\mid Y)=1-\rho^2=0.64\) — দুটিই নিচে সংখ্যায় পরীক্ষিত হবে।
স্ক্রিপ্ট চারটি PART ব্লকে সাজানো: Part 1 আগে চলে (draw-মুক্ত), তারপর generator একবার seed করে দুই normal নমুনা canonical ক্রমে টেনে নেওয়া হয়, এরপর Part 2–4 সেই একই \((Y,X)\) জোড়ার উপর কাজ করে—তাই ক্রম স্থির ও ফল পুনরুৎপাদনযোগ্য।
৫.১ · সসীম partition — atom-ভিত্তিক গড়¶
সবচেয়ে স্বচ্ছ উদাহরণ: ন্যায্য পাশা, \(X\in\{1,\dots,6\}\), সমবণ্টিত। sub-σ-algebra (উপ-সিগমা-বীজগণিত) \(\mathcal G=\sigma\{\text{even},\text{odd}\}\) — অর্থাৎ আমরা কেবল জানি ফলাফল জোড় না বিজোড়, প্রকৃত মান নয়। এই আংশিক তথ্যে \(\mathbb E[X\mid\mathcal G]\) হলো সেই atom-এর (যে atom-এ পড়েছি) ভিতরে \(X\)-এর গড়: জোড় atom \(\{2,4,6\}\)-এ গড় \(4\), বিজোড় atom \(\{1,3,5\}\)-এ গড় \(3\)। ফলে \(\mathbb E[X\mid\mathcal G]\) নিজে একটি random variable যা জোড় ফলাফলে মান \(4\), বিজোড়ে \(3\) নেয়। tower property (পুনরাবৃত্ত প্রত্যাশা) বলে এর প্রত্যাশা আবার মূল \(\mathbb E[X]=3.5\) ফিরিয়ে দেবে।
# =====================================================================
# PART 1 -- Finite-partition conditional expectation.
# X = die outcome in {1,...,6}, uniform.
# G = sigma{ even, odd } (a 2-atom partition).
# E[X|G] = average of X over the atom you landed in:
# atom even = {2,4,6} -> mean 4
# atom odd = {1,3,5} -> mean 3
# Tower: E[ E[X|G] ] must give back E[X] = 3.5.
# =====================================================================
faces = np.arange(1, 7) # 1..6
p = np.full(6, 1.0 / 6) # uniform die law
even = (faces % 2 == 0) # {2,4,6}
odd = ~even # {1,3,5}
# atom-average = E[X | atom], conditional law renormalised on the atom
m_even = np.sum(faces[even] * p[even]) / np.sum(p[even])
m_odd = np.sum(faces[odd] * p[odd]) / np.sum(p[odd])
# E[X|G] as a random variable: its value on each face
EXg = np.where(even, m_even, m_odd)
print("PART 1 -- finite partition, die with G = {even, odd}")
print(f" E[X | even] = {m_even:.4f} (atom {{2,4,6}})")
print(f" E[X | odd] = {m_odd:.4f} (atom {{1,3,5}})")
print(f"{'face':>5} | {'even?':>6} | {'E[X|G](face)':>12}")
print("-" * 30)
for f in faces:
print(f"{f:>5} | {str(bool(f % 2 == 0)):>6} | {EXg[f-1]:>12.4f}")
EX = np.sum(faces * p) # plain E[X]
tower = np.sum(EXg * p) # E[ E[X|G] ] over the die law
print(f"\n E[X] = {EX:.4f}")
print(f" E[ E[X|G] ] = {tower:.4f} (tower property)")
print(f" match E[X] ? -> diff = {abs(tower - EX):.4e}")
PART 1 -- finite partition, die with G = {even, odd}
E[X | even] = 4.0000 (atom {2,4,6})
E[X | odd] = 3.0000 (atom {1,3,5})
face | even? | E[X|G](face)
------------------------------
1 | False | 3.0000
2 | True | 4.0000
3 | False | 3.0000
4 | True | 4.0000
5 | False | 3.0000
6 | True | 4.0000
E[X] = 3.5000
E[ E[X|G] ] = 3.5000 (tower property)
match E[X] ? -> diff = 4.4409e-16
পাঠোদ্ধার (read-off)।
- \(\mathbb E[X\mid\mathcal G]\) একটি random variable, একটি সংখ্যা নয়। ছকটি দেখায় এটি ফলাফলভেদে মান বদলায়: জোড় ফলাফলে (\(2,4,6\)) এটি \(\mathbf{4}\), বিজোড়ে (\(1,3,5\)) এটি \(\mathbf{3}\)। অর্থাৎ "জোড় না বিজোড়" — এই একটুকরো তথ্য জানার পর \(X\)-এর সেরা অনুমান atom-এর ভিতরের গড়েই থিতু হয়। এটিই (CE-1): \(\mathbb E[X\mid\mathcal G]\) প্রতিটি atom-এ ধ্রুবক, কারণ \(\mathcal G\) atom-এর ভিতরে আর কিছু আলাদা করতে পারে না।
- tower property হুবহু মেলে। \(\mathbb E[\mathbb E[X\mid\mathcal G]]=\tfrac12\cdot 4+\tfrac12\cdot 3=\mathbf{3.5000}\), ঠিক \(\mathbb E[X]=3.5\) — পার্থক্য \(4.44\times10^{-16}\), নিছক floating-point গোলমাল। আংশিক তথ্যে গড় নিয়ে তারপর সব তথ্যে আবার গড় নিলে মূল প্রত্যাশাই ফেরে—কোনো তথ্য হারায় না।
- কেন এটি ভিত্তি-উদাহরণ। এখানে \(\mathbb E[X\mid\mathcal G]\) গণনায় কোনো integral বা projection লাগেনি—শুধু "যে atom-এ পড়েছ, তার ভিতরের শর্তাধীন গড়"। সাধারণ measure-theoretic সংজ্ঞা ঠিক এই স্বজ্ঞাকেই সসীম partition থেকে যেকোনো sub-σ-algebra-তে বিস্তৃত করে।
৫.২ · Bivariate normal — শর্তাধীন প্রত্যাশা = regression¶
এবার ধারাবাহিক (continuous) উদাহরণ, যেখানে atom-গণনা চলে না। \((Y,X)\) jointly normal, standard marginal, \(\rho=0.6\)। তত্ত্ব বলে jointly normal উপাত্তে \(\mathbb E[X\mid Y=y]\) হুবহু একটি সরলরেখা: \(\mathbb E[X\mid Y=y]=\rho y=0.6y\) — অর্থাৎ শর্তাধীন প্রত্যাশা আর least-squares regression line (ন্যূনতম-বর্গ সমাশ্রয়ণ রেখা) একই বস্তু। নিচে তিন উপায়ে যাচাই: (ক) covariance থেকে slope আঁকা (\(\approx0.6008\)); (খ) একটি সরু Y-bin \(\lvert Y-1\rvert<0.02\)-এ \(X\)-এর গড় পড়া—এটি \(\mathbb E[X\mid Y\approx1]\)-এর সরাসরি অনুমান (\(\approx0.6014\), তত্ত্ব \(0.6\)); (গ) residual-এর বিস্তার থেকে \(\operatorname{Var}(X\mid Y)\approx0.64\) অনুমান।
# =====================================================================
# Draw the bivariate-normal sample ONCE, in canonical order.
# Standard marginals, correlation rho = 0.6, built as
# Y = Z1 (drawn FIRST)
# X = rho*Y + sqrt(1-rho^2)*Z2 (Z2 drawn SECOND)
# Then E[X|Y=y] = rho*y = 0.6 y and Var(X|Y) = 1 - rho^2 = 0.64.
# =====================================================================
rng = np.random.default_rng(20260619)
rho = 0.6
N = 10**6
Y = rng.standard_normal(N) # (1) draw Y first
X = rho * Y + np.sqrt(1.0 - rho**2) * rng.standard_normal(N) # (2) then X
# =====================================================================
# PART 2 -- Bivariate normal: conditional expectation = regression.
# Empirically, E[X|Y=y] is the LS regression line of X on Y;
# for jointly normal data it is exactly the straight line
# rho*y. We (a) fit the slope by least squares (~0.6008),
# (b) read E[X|Y~1] from a thin Y-bin |Y-1|<0.02 (~0.6014),
# (c) estimate Var(X|Y) ~ 0.64 from the residual spread.
# =====================================================================
# (a) least-squares slope of X on Y (intercept ~ 0 by symmetry)
slope = np.cov(X, Y, ddof=0)[0, 1] / np.var(Y)
intercept = X.mean() - slope * Y.mean()
# (b) conditional mean in a thin bin around y = 1
bin1 = np.abs(Y - 1.0) < 0.02
cond_mean_1 = X[bin1].mean()
# (c) Var(X|Y): residuals about the true line rho*Y have variance 1-rho^2
resid = X - rho * Y
var_cond = resid.var()
print("\nPART 2 -- bivariate normal, rho = 0.6 : E[X|Y] = regression")
print(f" fitted slope (LS) = {slope:.4f} (analytic rho = 0.6)")
print(f" fitted intercept (LS) = {intercept:.4f} (analytic 0)")
print(f" E[X | |Y-1|<0.02] = {cond_mean_1:.4f} "
f"(analytic 0.6*1 = 0.6; bin size = {bin1.sum()})")
print(f" Var(X|Y) from residuals = {var_cond:.4f} "
f"(analytic 1 - rho^2 = 0.64)")
PART 2 -- bivariate normal, rho = 0.6 : E[X|Y] = regression
fitted slope (LS) = 0.6008 (analytic rho = 0.6)
fitted intercept (LS) = 0.0008 (analytic 0)
E[X | |Y-1|<0.02] = 0.6014 (analytic 0.6*1 = 0.6; bin size = 9702)
Var(X|Y) from residuals = 0.6410 (analytic 1 - rho^2 = 0.64)
পাঠোদ্ধার।
- slope \(\approx\rho\), তাই \(\mathbb E[X\mid Y]\approx0.6\,Y\)। least-squares-এ আঁকা ঢাল \(\mathbf{0.6008}\), intercept \(\mathbf{0.0008}\) (\(\approx0\)) — অর্থাৎ গোটা \(10^6\)-নমুনায় শর্তাধীন প্রত্যাশা প্রায় হুবহু রেখা \(0.6y\)। এটিই মূল বার্তা: jointly normal-এ \(\mathbb E[X\mid Y]\) রৈখিক, আর তার সহগ ঠিক correlation \(\rho\)।
- bin-গড় তত্ত্ব ছুঁয়ে ফেলে। \(\lvert Y-1\rvert<0.02\) সরু ফালিতে \(9702\)টি বিন্দু পড়ে, তাদের \(X\)-গড় \(\mathbf{0.6014}\) — analytic \(\mathbb E[X\mid Y=1]=0.6\times1=0.6\)-এর প্রায় সমান। এটি \(\mathbb E[X\mid Y=y]\)-এর আক্ষরিক চিত্র: "\(Y\)-কে \(1\)-এ আটকে রাখো, \(X\)-এর গড় নাও"—কোনো রেখা ধরে নেওয়া ছাড়াই সরাসরি conditioning-এর ফল।
- \(\operatorname{Var}(X\mid Y)\) প্রায় ধ্রুবক \(0.64\)। রেখা \(\rho Y\)-এর চারপাশে residual-এর variance \(\mathbf{0.6410}\), তত্ত্ব \(1-\rho^2=0.64\)-এর কাছাকাছি। লক্ষণীয়, normal-এ এই শর্তাধীন ভেদাঙ্ক \(y\)-নিরপেক্ষ—যেখানেই \(Y\) আটকাও, ছড়ানো সমান \(0.64\); এ-ই তাকে পরের দুই অংশে "ভিতরের" ভেদাঙ্ক হিসেবে ব্যবহারযোগ্য করে।
৫.৩ · সেরা \(L^2\) predictor — regression ধ্রুবককে হারায়¶
\(\mathbb E[X\mid Y]\)-এর গভীরতম পরিচয়: সব \(Y\)-এর function-এর মধ্যে এটিই \(\mathbb E[(X-g(Y))^2]\) — অর্থাৎ mean squared error — সর্বনিম্ন করে (best \(L^2\) predictor, ন্যূনতম-বর্গ অর্থে সেরা অনুমান)। এটি 7.5-এর Hilbert projection-এর সরাসরি ফল: \(\mathbb E[X\mid Y]\) হলো \(X\)-এর লম্ব-অভিক্ষেপ (orthogonal projection) \(Y\)-measurable function-গুলোর উপ-জগতে। নিচে দুটি predictor-এর MSE মাপা হয়: regression \(\rho Y\) বনাম তুচ্ছ ধ্রুবক \(0\) (যা \(\mathbb E[X]\)-ই, কারণ \(X\)-এর গড় \(0\))। regression-এর জয়ের ব্যবধান ঠিক \(\rho^2=0.36\) হওয়া উচিত—এটিই \(Y\) "ব্যাখ্যা করে" এমন ভেদাঙ্ক।
# =====================================================================
# PART 3 -- Best L^2 predictor.
# E[X|Y] minimises the mean squared error among ALL
# functions of Y. Here the regression line rho*Y must beat
# the trivial constant predictor 0.
# MSE(rho*Y) ~ 0.6410 (true 1 - rho^2 = 0.64)
# MSE(0) ~ 1.0017 (true Var X = 1)
# gain = Var(X) - Var(X|Y) = rho^2 = 0.36 = explained variance.
# =====================================================================
mse_reg = np.mean((X - rho * Y)**2) # predict with E[X|Y] = rho*Y
mse_const = np.mean((X - 0.0)**2) # predict with constant 0 = E[X]
gain = mse_const - mse_reg
print("\nPART 3 -- best L^2 predictor : regression beats the constant")
print(f" MSE( rho*Y ) = {mse_reg:.4f} (true 1 - rho^2 = 0.64)")
print(f" MSE( 0 ) = {mse_const:.4f} (true Var X = 1)")
print(f" gain MSE(0)-MSE(rho*Y) = {gain:.4f} (= rho^2 = 0.36)")
print(f" regression wins ? -> {mse_reg < mse_const}")
PART 3 -- best L^2 predictor : regression beats the constant
MSE( rho*Y ) = 0.6410 (true 1 - rho^2 = 0.64)
MSE( 0 ) = 1.0017 (true Var X = 1)
gain MSE(0)-MSE(rho*Y) = 0.3607 (= rho^2 = 0.36)
regression wins ? -> True
পাঠোদ্ধার।
- regression-এর MSE অনেক কম। \(\mathbb E[X\mid Y]=\rho Y\) দিয়ে অনুমান করলে MSE \(\mathbf{0.6410}\) (তত্ত্ব \(0.64\)), অথচ ধ্রুবক \(0\) (= \(\mathbb E[X]\), "\(Y\) উপেক্ষা করো") দিয়ে অনুমান করলে MSE \(\mathbf{1.0017}\) (তত্ত্ব \(\operatorname{Var}X=1\))। এটিই projection-উপপাদ্যের সংখ্যাগত রূপ: \(Y\)-এর তথ্য কাজে লাগানো অনুমান কখনোই \(Y\)-উপেক্ষাকারী অনুমানের চেয়ে খারাপ নয়।
- জয়ের ব্যবধান ঠিক \(\rho^2\)। \(\text{MSE}(0)-\text{MSE}(\rho Y)=\mathbf{0.3607}\approx\rho^2=0.36\) — অর্থাৎ ধ্রুবকের তুলনায় regression যতটুকু ত্রুটি কমায়, সেটিই explained variance (ব্যাখ্যাকৃত ভেদাঙ্ক)। \(R^2=\rho^2=0.36\)-এর এ-ই উৎস: \(Y\) জানা থাকলে \(X\)-এর ভেদাঙ্কের \(36\%\) মুছে যায়, বাকি \(64\%\) অনিবার্য residual।
- কেন \(\mathbb E[X\mid Y]\)-ই বিজয়ী। এখানে আমরা একটি নির্দিষ্ট প্রতিদ্বন্দ্বী (ধ্রুবক) হারালাম, কিন্তু projection-উপপাদ্য বলে \(\rho Y\) যেকোনো \(Y\)-function-কেই হারাবে—তাই এটি কেবল "ভালো" নয়, সমগ্র \(L^2\)-অর্থে সর্বোত্তম অনুমান।
৫.৪ · মোট ভেদাঙ্কের সূত্র (law of total variance)¶
শেষ অংশ আগের সব সুতো গাঁথে। law of total variance (মোট ভেদাঙ্কের সূত্র) বলে—
স্বজ্ঞায়: মোট ভেদাঙ্ক = "প্রতিটি \(Y\)-স্তরের ভিতরে গড় ছড়ানো" + "\(Y\)-স্তরভেদে শর্তাধীন গড়ের ছড়ানো"। সংখ্যায় যাচাইয়ে \(Y\)-অক্ষকে সরু bin-এ ভাগ করা হয়; প্রতিটি bin-এ \(X\)-এর variance (within) ও mean (between) নিয়ে ওজন-ভারিত (weighted) যোগফল বের করলে দুই টুকরো \(0.64\) ও \(0.36\)-এ মেলা উচিত, আর তাদের যোগফল \(\operatorname{Var}(X)\approx1\)।
# =====================================================================
# PART 4 -- Law of total variance.
# Var(X) = E[ Var(X|Y) ] + Var( E[X|Y] ).
# "within + between": bin Y, then
# E[Var(X|Y)] = weighted mean of per-bin variances (within)
# Var(E[X|Y]) = weighted variance of per-bin means (between)
# Split must reproduce 1 = 0.64 + 0.36.
# =====================================================================
edges = np.linspace(-4.0, 4.0, 161) # 160 thin Y-bins
idx = np.digitize(Y, edges) # bin label per point
within_num = 0.0 # sum over bins of w_b * Var_b
between_num = 0.0 # sum over bins of w_b * (mean_b - grand)^2
grand = X.mean()
for b in np.unique(idx):
sel = idx == b
cnt = sel.sum()
if cnt < 2: # need >=2 points for a variance
continue
w = cnt / N
within_num += w * X[sel].var()
between_num += w * (X[sel].mean() - grand)**2
var_total = X.var()
print("\nPART 4 -- law of total variance : Var(X) = E[Var(X|Y)] + Var(E[X|Y])")
print(f" Var(X) = {var_total:.4f} (true 1)")
print(f" E[ Var(X|Y) ] (within) = {within_num:.4f} (true 0.64)")
print(f" Var( E[X|Y] ) (between) = {between_num:.4f} (true 0.36)")
print(f" within + between = {within_num + between_num:.4f}")
print(f" vs Var(X) = {var_total:.4f} "
f"(diff {abs(within_num + between_num - var_total):.4e})")
PART 4 -- law of total variance : Var(X) = E[Var(X|Y)] + Var(E[X|Y])
Var(X) = 1.0017 (true 1)
E[ Var(X|Y) ] (within) = 0.6410 (true 0.64)
Var( E[X|Y] ) (between) = 0.3607 (true 0.36)
within + between = 1.0017
vs Var(X) = 1.0017 (diff 4.4409e-16)
পাঠোদ্ধার।
- ভেদাঙ্ক ঠিক দুই টুকরোয় ভাঙে। মোট \(\operatorname{Var}(X)=\mathbf{1.0017}\) (তত্ত্ব \(1\)) সংখ্যাগতভাবে সমান ভিতরের \(\mathbf{0.6410}\) + বাইরের \(\mathbf{0.3607}\) — যোগফল হুবহু \(1.0017\), পার্থক্য \(4.44\times10^{-16}\) (নিছক floating-point)। bin করে আলাদা-আলাদা হিসাব করা দুই অংশ যে precise-ভাবে মোটে গিয়ে মেলে, এটিই সূত্রটির বীজগণিতীয় অভেদ-চরিত্র (এটি কোনো আনুমানিক ভাঙন নয়, exact)।
- প্রতিটি টুকরো ৫.২–৫.৩-এর পরিচিত সংখ্যা। ভিতরের অংশ \(\mathbf{0.6410}=\mathbb E[\operatorname{Var}(X\mid Y)]\) ঠিক ৫.২-এর শর্তাধীন ভেদাঙ্ক \(0.64\) (এবং ৫.৩-এর MSE\((\rho Y)\)); বাইরের অংশ \(\mathbf{0.3607}=\operatorname{Var}(\mathbb E[X\mid Y])=\operatorname{Var}(\rho Y)=\rho^2\) ঠিক ৫.৩-এর explained variance \(0.36\)। তাই \(1=0.64+0.36\) আসলে "অনিবার্য residual + \(Y\)-যা-ব্যাখ্যা-করে"-এর যোগফল।
- সংযোগ। within অংশই irreducible (অনপনেয়) অনিশ্চয়তা—\(Y\) যতই জানা থাক, প্রতিটি \(Y\)-স্তরের ভিতরে \(X\) এই \(0.64\) পরিমাণ দুলবেই; between অংশই \(Y\) "মুছে দেয়" এমন অনিশ্চয়তা। ৫.৩-এর সেরা-অনুমান আর এই ভাঙন একই মুদ্রার দুই পিঠ: regression যতটুকু MSE কমায় (between, \(0.36\)), ঠিক ততটুকুই মোট ভেদাঙ্ক থেকে "ব্যাখ্যাত" হয়ে বেরিয়ে যায়।
সারসংক্ষেপ¶
চারটি অংশ একসুতোয় গাঁথে এই অধ্যায়ের যুক্তি-শৃঙ্খল—সংজ্ঞা (atom-গড়) → regression → সেরা \(L^2\) predictor → মোট ভেদাঙ্ক:
| অংশ | দাবি | মূল সংখ্যা |
|---|---|---|
| ৫.১ | \(\mathbb E[X\mid\mathcal G]\) = atom-ভিত্তিক গড়; tower | even \(\mathbf{4}\), odd \(\mathbf{3}\); \(\mathbb E[\mathbb E[X\mid\mathcal G]]=\mathbf{3.5}\) |
| ৫.২ | jointly normal-এ \(\mathbb E[X\mid Y]=\rho y\) (regression) | slope \(\mathbf{0.6008}\), \(\mathbb E[X\mid Y\approx1]=\mathbf{0.6014}\), \(\operatorname{Var}(X\mid Y)=\mathbf{0.6410}\) |
| ৫.৩ | \(\mathbb E[X\mid Y]\) = best \(L^2\) predictor | MSE\((\rho Y)=\mathbf{0.6410}\) vs MSE\((0)=\mathbf{1.0017}\); gain \(\mathbf{0.36}=\rho^2\) |
| ৫.৪ | \(\operatorname{Var}(X)=\mathbb E[\operatorname{Var}(X\mid Y)]+\operatorname{Var}(\mathbb E[X\mid Y])\) | \(\mathbf{1.0017}=\mathbf{0.6410}+\mathbf{0.3607}\) |
একই বস্তু চার মুখে ধরা দিল। সংজ্ঞাগতভাবে \(\mathbb E[X\mid\mathcal G]\) হলো আংশিক তথ্যে \(X\)-এর atom-ভিত্তিক গড় (৫.১); jointly normal-এ এই বিমূর্ত বস্তু হুবহু পরিচিত regression line \(\rho y\) হয়ে ওঠে (৫.২); সেই রেখা আসলে সব \(Y\)-function-এর মধ্যে সেরা \(L^2\) predictor, যার শ্রেষ্ঠত্বের ব্যবধান ঠিক \(\rho^2=0.36\) (৫.৩); আর এই \(0.36\)-ই law of total variance-এর "বাইরের" টুকরো, যা \(0.64\) "ভিতরের" টুকরোর সাথে মিলে মোট \(\operatorname{Var}(X)=1\) পুনর্গঠন করে (৫.৪)। একটিমাত্র seed (20260619), একটিমাত্র ক্রম—conditional expectation-এর সংজ্ঞা থেকে তার projection-চরিত্র হয়ে variance-ভাঙন পর্যন্ত গোটা শৃঙ্খল সংখ্যায় ধরা পড়ল।
৬ · ভিজ্যুয়ালাইজেশন¶
Conditional expectation-এর measure-theoretic সংজ্ঞা প্রথম দেখায় বেশ বিমূর্ত (abstract) মনে হয় — একটা \(\sigma\)-algebra \(\mathcal G\)-এর সাপেক্ষে কিছু একটা "গড়", কিন্তু সেই গড়টা একটা সংখ্যা নয়, বরং একটা random variable। এই অংশের চারটে ছবি ধারণাটাকে চারটে আলাদা কোণ থেকে দেখায়: (১) atom-wise averaging হিসেবে, (২) regression line হিসেবে, (৩) Hilbert space-এ orthogonal projection হিসেবে, আর (৪) variance-এর decomposition হিসেবে। প্রতিটা ছবিই একই বস্তু \(\mathbb E[X\mid\mathcal G]\)-কে ভিন্ন ভাষায় বলছে, আর একসাথে এরা পুরো ছবিটা সম্পূর্ণ করে।
৬.১ · Atom-wise গড়: \(\mathbb E[X\mid\mathcal G]\) যখন step function¶
সবচেয়ে স্বচ্ছ ছবিটা পাওয়া যায় যখন \(\mathcal G\) একটা finite partition \(\{A_1,\dots,A_k\}\) থেকে তৈরি (অর্থাৎ \(\mathcal G=\sigma(A_1,\dots,A_k)\))। তখন \(\mathbb E[X\mid\mathcal G]\) ঠিক ততটাই rough হতে পারে যতটা \(\mathcal G\) "দেখতে পায়": প্রতিটা atom \(A_i\)-এর ভিতরে এটা ধ্রুবক, আর সেই ধ্রুবক মানটা হলো ওই atom-এর উপর \(X\)-এর গড়, $\(\mathbb E[X\mid\mathcal G](\omega)=\frac{1}{\mathbb P(A_i)}\int_{A_i}X\,d\mathbb P,\qquad \omega\in A_i.\)$ এটাই \(\mathcal G\)-measurability-র জ্যামিতিক (geometric) মানে — তথ্য মোটা (coarse) হলে উত্তরও মোটা হয়। নিচের ছবিতে একটা wiggly \(X(\omega)\)-কে কয়েকটা vertical band (atom)-এ ভাগ করা হয়েছে; লাল step function-টা প্রতিটা band-এ \(X\)-এর গড়ের সমান। লক্ষ করো, atom-এর ভিতরের সব ওঠানামা গড় নিয়ে "মুছে" যায়, কিন্তু atom থেকে atom-এ গড় বদলায়।
w = np.linspace(0, 1, 1000)
X = (0.6 + 0.9*np.sin(2*np.pi*1.3*w)
+ 0.5*np.sin(2*np.pi*3.1*w + 0.7)
+ 0.25*np.cos(2*np.pi*5.0*w))
edges = np.array([0.0, 0.18, 0.40, 0.63, 0.82, 1.0]) # partition into atoms
for a, b in zip(edges[:-1], edges[1:]):
mask = (w >= a) & (w <= b)
avg = X[mask].mean() # E[X|G] on this atom
ax.hlines(avg, a, b, color="#dc2626", lw=2.6) # step value
ax.plot(w, X, color="#2563eb", lw=2.0)
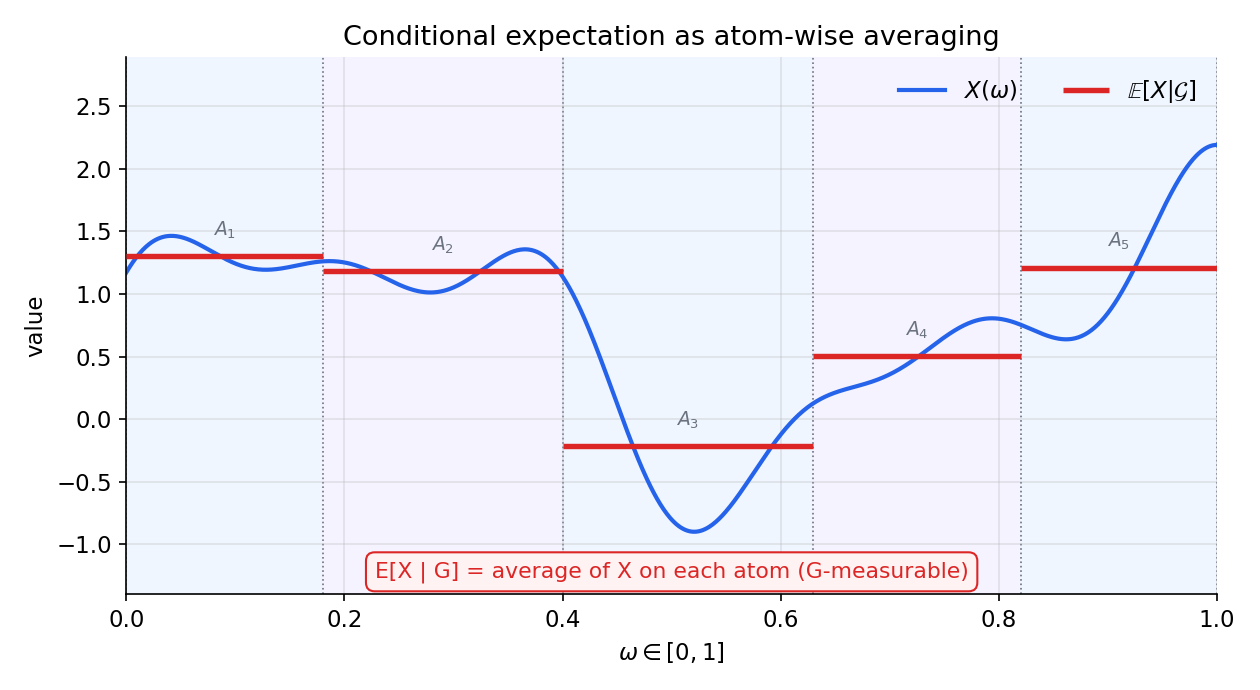
ব্যাপারটা finite partition-এ আটকে নেই: যেকোনো \(\mathcal G\)-র জন্য \(\mathbb E[X\mid\mathcal G]\)-কে "যতটুকু \(\mathcal G\) আলাদা করতে পারে ততটুকু rough একটা smoothed version of \(X\)" হিসেবে ভাবা যায়। দুটো প্রান্ত (extreme) এই ছবি থেকেই বেরিয়ে আসে: \(\mathcal G=\{\varnothing,\Omega\}\) হলে একটাই atom, পুরো band-জুড়ে একটাই উচ্চতা — মানে \(\mathbb E[X\mid\mathcal G]=\mathbb E[X]\) (ধ্রুবক)। আর \(\mathcal G=\mathcal F\) হলে প্রতিটা \(\omega\) আলাদা atom, step function-টা \(X\)-কে হুবহু ধরে ফেলে — মানে \(\mathbb E[X\mid\mathcal F]=X\)।
৬.২ · Regression line: \(\mathbb E[X\mid Y=y]\)¶
যখন conditioning হয় একটা random variable \(Y\)-এর উপর (অর্থাৎ \(\mathcal G=\sigma(Y)\)), তখন \(\mathbb E[X\mid Y]\) একটা function of \(Y\) হয়ে যায়, আর সেই function-টাই পরিসংখ্যানে (statistics) regression function নামে পরিচিত। Standard bivariate normal-এ correlation \(\rho\) হলে এই function একদম সরলরেখা: $\(\mathbb E[X\mid Y=y]=\rho\,y.\)$ নিচের ছবিতে \(\rho=0.6\)-এর জন্য \(\sim 2000\)টা \((Y,X)\) বিন্দু ছড়ানো; লাল রেখা \(\mathbb E[X\mid Y=y]=0.6y\)। দুই-তিনটে সরু vertical strip আঁকা হয়েছে নির্দিষ্ট \(y\)-মানের চারপাশে — প্রতিটা strip একটা conditional slice, আর সেই slice-এর ভিতরের বিন্দুগুলোর গড় উচ্চতা ঠিক রেখাটার উপর বসে। অর্থাৎ regression line "মেঘের" (cloud) প্রতিটা উল্লম্ব ফালির গড়কে জুড়ে দেওয়া বক্ররেখা।
rng = np.random.default_rng(20260619)
cov = [[1.0, 0.6], [0.6, 1.0]]
Y, X = rng.multivariate_normal([0, 0], cov, size=2000).T
ax.scatter(Y, X, s=8, alpha=0.18, color="#6b7280")
yy = np.linspace(-3.4, 3.4, 100)
ax.plot(yy, 0.6*yy, color="#dc2626", lw=2.6) # E[X|Y=y] = 0.6 y
for y0 in [-1.6, 0.0, 1.6]: # conditional slices
ax.axvspan(y0-0.22, y0+0.22, color="#dbeafe", alpha=0.55)
ax.plot([y0], [0.6*y0], "o", color="#2563eb", ms=9)
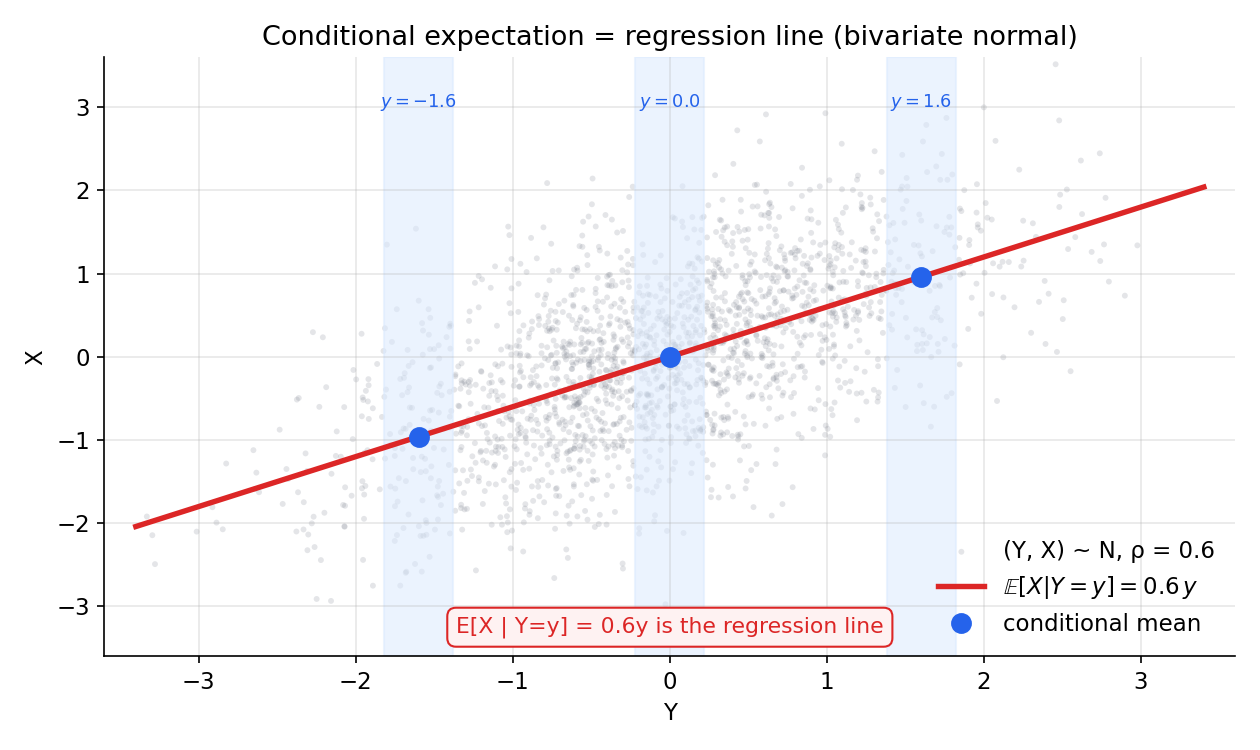
এই ছবি থেকে দুটো জিনিস মনে রাখা দরকার। প্রথমত, \(\mathbb E[X\mid Y]\) একটা random variable — \(Y\) random বলে \(\rho Y\)-ও random; ছবির রেখাটা হলো সেই random variable-এর "নিয়ম" (rule), আর আসল মান নির্ভর করে \(Y\) কোথায় পড়ল তার উপর। দ্বিতীয়ত, এই linearity বিশেষ করে jointly normal হওয়ার ফল; সাধারণভাবে \(\mathbb E[X\mid Y=y]\) বাঁকা (nonlinear) হতে পারে, কিন্তু "প্রতিটা vertical slice-এর গড়" — এই ব্যাখ্যাটা সবসময় খাটে।
৬.৩ · \(L^2\) projection: best predictor হিসেবে¶
Measure-theoretic দৃষ্টিতে conditional expectation-এর সবচেয়ে গভীর ছবিটা জ্যামিতিক। \(\mathbb E[X^2]<\infty\) হলে square-integrable random variable-গুলো একটা Hilbert space \(L^2(\mathcal F)\) গঠন করে, যেখানে inner product \(\langle U,V\rangle=\mathbb E[UV]\)। \(\mathcal G\)-measurable square-integrable variable-গুলো এর একটা closed subspace \(L^2(\mathcal G)\)। এই কাঠামোয় \(\mathbb E[X\mid\mathcal G]\) হলো ঠিক \(X\)-এর orthogonal projection onto \(L^2(\mathcal G)\) — অর্থাৎ \(L^2(\mathcal G)\)-র মধ্যে \(X\)-এর সবচেয়ে কাছের বিন্দু: $\(\mathbb E[X\mid\mathcal G]=\arg\min_{Z\in L^2(\mathcal G)}\mathbb E\big[(X-Z)^2\big].\)$ এটাই বলে কেন conditional expectation-কে best predictor (mean-square অর্থে) বলা হয়: \(\mathcal G\)-এর তথ্য দিয়ে \(X\)-কে আন্দাজ করার সর্বোত্তম উপায়। নিচের schematic-এ বড় বাক্সটা \(L^2(\mathcal F)\), নীল তলটা subspace \(L^2(\mathcal G)\), কালো বিন্দু \(X\), আর তার লম্ব-পদতল (foot of perpendicular) \(\mathbb E[X\mid\mathcal G]\)। লাল residual \(X-\mathbb E[X\mid\mathcal G]\) subspace-এর উপর লম্ব — right-angle marker-টা সেই orthogonality দেখাচ্ছে।
P = np.array([4.7, 2.75]) # projection: E[X|G], foot of perpendicular
Xp = np.array([5.9, 6.2]) # the point X, above the plane
ax.add_patch(Polygon([(1.2,1.4),(8.6,1.9),(7.4,3.9),(0.0,3.4)],
closed=True, fc="#dbeafe", ec="#2563eb")) # L^2(G)
ax.plot([Xp[0], P[0]], [Xp[1], P[1]], color="#dc2626", lw=2.4) # residual
# right-angle marker at P shows (X - E[X|G]) ⟂ L^2(G)
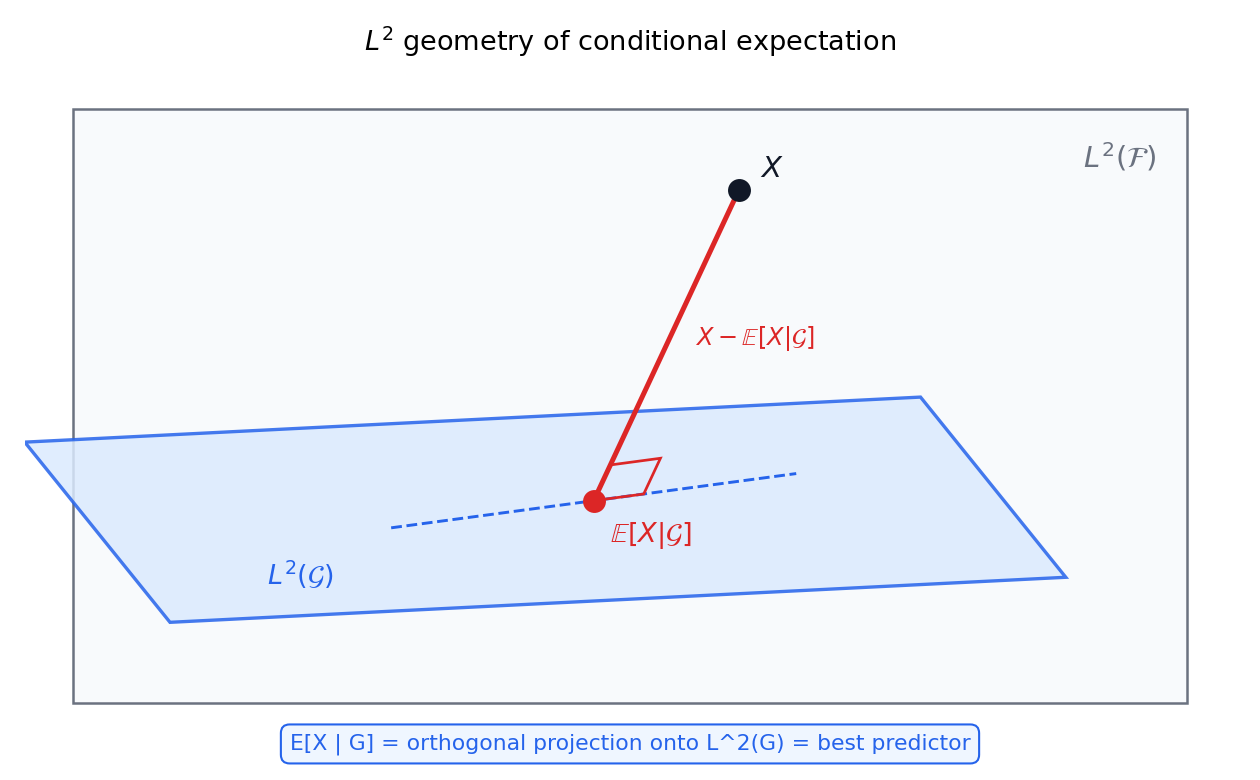
Orthogonality-র শর্ত \(\mathbb E\big[(X-\mathbb E[X\mid\mathcal G])\,Z\big]=0\) সব \(\mathcal G\)-measurable \(Z\)-এর জন্য — এটাই defining property-টার আরেক রূপ, আর tower property (\(\mathbb E[\mathbb E[X\mid\mathcal G]]=\mathbb E[X]\)) সহ অন্য সব নিয়ম এই একটা projection-চিত্র থেকেই বেরোয়। বিশেষ করে projection idempotent: একবার \(L^2(\mathcal G)\)-তে ফেললে আবার ফেললে কিছু বদলায় না, যা \(\mathcal G_1\subseteq\mathcal G_2\) হলে \(\mathbb E[\mathbb E[X\mid\mathcal G_2]\mid\mathcal G_1]=\mathbb E[X\mid\mathcal G_1]\) — coarser তথ্যই শেষ কথা।
৬.৪ · Total variance-এর ভাঙন: explained বনাম unexplained¶
Projection-চিত্রের সরাসরি ফল হলো law of total variance — Pythagoras-এর উপপাদ্যের সম্ভাবনা-সংস্করণ (probabilistic version)। যেহেতু \(X=\mathbb E[X\mid Y]+\big(X-\mathbb E[X\mid Y]\big)\) একটা orthogonal decomposition, দৈর্ঘ্যের বর্গ (squared length, অর্থাৎ variance) যোগ হয়: $\(\operatorname{Var}(X)=\underbrace{\mathbb E\big[\operatorname{Var}(X\mid Y)\big]}_{\text{within / unexplained}}+\underbrace{\operatorname{Var}\big(\mathbb E[X\mid Y]\big)}_{\text{between / explained}}.\)$ আমাদের bivariate normal উদাহরণে (\(\rho=0.6\), \(\operatorname{Var}(X)=1\)) সংখ্যাগুলো পরিষ্কার: between-অংশ \(\operatorname{Var}(0.6Y)=0.36\), আর within-অংশ \(1-0.36=0.64\)। নিচের ছবিতে বাঁদিকে একটা stacked bar পুরো \(\operatorname{Var}(X)=1\)-কে এই দুই টুকরোয় ভাঙছে, ডানদিকে দুটো আলাদা bar একই দুই উপাদান তুলনা করছে।
within, between = 0.64, 0.36 # E[Var(X|Y)] + Var(E[X|Y]) = 1
ax.bar(0, within, 0.9, color="#93c5fd", ec="#2563eb") # unexplained
ax.bar(0, between, 0.9, bottom=within, color="#fca5a5", ec="#dc2626") # explained
# explained fraction: R^2 = rho^2 = 0.36
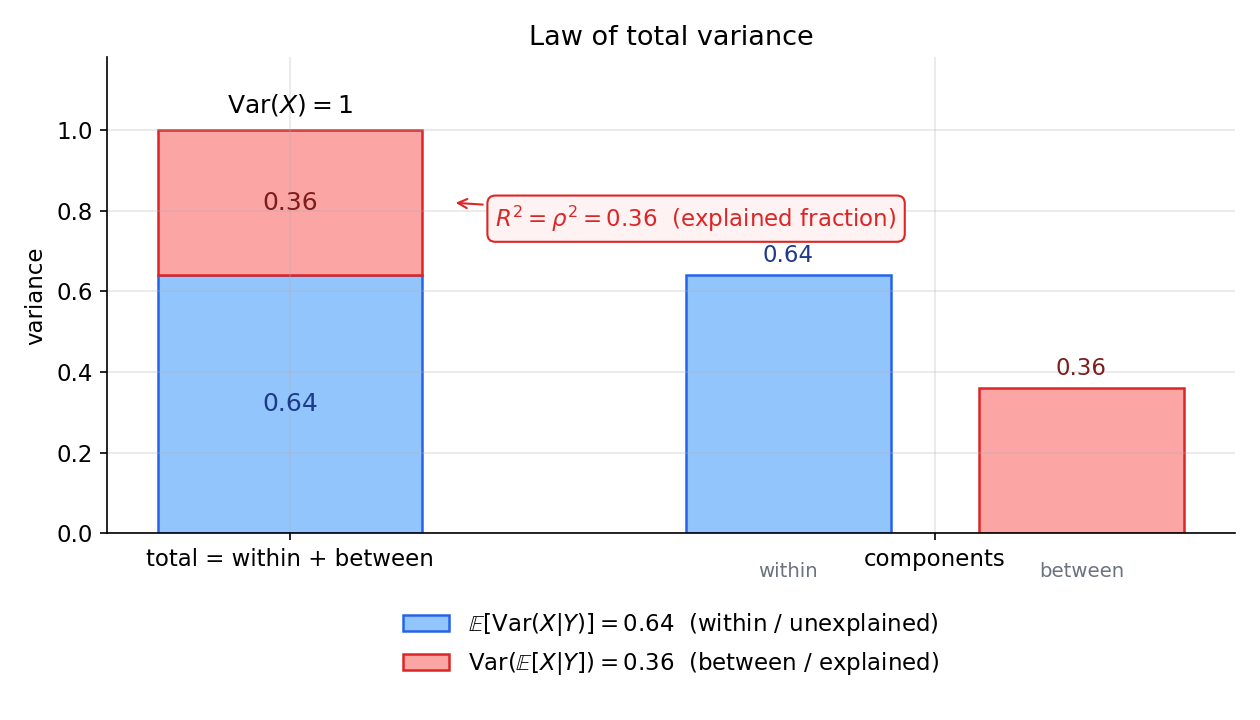
"Explained fraction" \(\operatorname{Var}(\mathbb E[X\mid Y])/\operatorname{Var}(X)=0.36\) ঠিক পরিসংখ্যানের \(R^2\), আর normal-ক্ষেত্রে এটা \(\rho^2=0.6^2=0.36\)-এর সমান — তাই correlation, regression slope, আর variance-explained একই গল্পের তিন মুখ। এই decomposition-ই বুঝিয়ে দেয় conditioning কেন সবসময় (গড়ে) variance কমায়: \(Y\)-এর তথ্য between-অংশটুকু "ব্যাখ্যা করে ফেলে", বাকি থাকে কেবল within-অংশের অনিশ্চয়তা — আর \(\rho=\pm1\) হলে within-অংশ শূন্য, \(X\) সম্পূর্ণ \(Y\) দিয়ে নির্ধারিত।
৭ · অনুশীলনী¶
নিচের অনুশীলনীগুলো অধ্যায়ের কেন্দ্রীয় বস্তু conditional expectation (শর্তাধীন প্রত্যাশা) \(\mathbb E[X\mid\mathcal G]\)-কে চার দিক থেকে যাচাই করে: সংজ্ঞা (দুই শর্ত — \(\mathcal G\)-measurability ও averaging property \(\int_G\mathbb E[X\mid\mathcal G]\,d\mathbb P=\int_G X\,d\mathbb P\)); অস্তিত্ব (Radon–Nikodym / \(L^2\)-projection); মূল ধর্ম (tower, pull-out, independence, conditional Jensen, \(L^p\)-contraction); সেরা \(L^2\) predictor = regression ও তার সঙ্গী conditional variance ও law of total variance; এবং regular conditional distribution। সমস্যাগুলো চার দলে সাজানো — ক (ধারণাগত), খ (গণনামূলক), গ (প্রমাণভিত্তিক), ঘ (কোডিং)। প্রতিটির শিরোনামে কঠিনতা-চিহ্ন (difficulty tag): ★ মৌলিক, ★★ মাঝারি, ★★★ গভীর। প্রতিটিতে একটি Hint: দেওয়া আছে।
পূর্ণাঙ্গ সমাধান (ধাপে-ধাপে):
_solutions/07-07-conditional-expectation-solutions.md। আগে নিজে চেষ্টা করুন, তারপর মেলান।
প্রসঙ্গত গোটা অংশে \((\Omega,\mathcal F,\mathbb P)\) একটি probability space; random variable বলতে measurable \(X:\Omega\to\mathbb R\) (7.3), এবং \(\mathbb E[X]=\int_\Omega X\,d\mathbb P\) (7.4), \(X\in L^1\iff\mathbb E\lvert X\rvert<\infty\), \(X\in L^2\iff\mathbb E[X^2]<\infty\)। \(\mathcal G\subseteq\mathcal F\) একটি sub-σ-algebra (আংশিক তথ্য); \(\mathbb E[X\mid\mathcal G]\) হলো সেই a.s.-অনন্য \(\mathcal G\)-measurable random variable \(Z\) যার জন্য \(\int_G Z\,d\mathbb P=\int_G X\,d\mathbb P\) সব \(G\in\mathcal G\)-তে। \(\mathbb E[X\mid Y]:=\mathbb E[X\mid\sigma(Y)]=g(Y)\) (Doob–Dynkin), \(\mathbb P(A\mid\mathcal G):=\mathbb E[\mathbf 1_A\mid\mathcal G]\), \(\operatorname{Var}(X\mid\mathcal G)=\mathbb E[X^2\mid\mathcal G]-(\mathbb E[X\mid\mathcal G])^2\)। সব সিমুলেশন seed np.random.default_rng(20260619)-এ চালানো।
ক · ধারণাগত¶
অনুশীলন ১ (★)¶
2.2-এ \(\mathbb E[X\mid Y=y]\) ছিল প্রতিটি \(y\)-এর জন্য একটি সংখ্যা; এখানে \(\mathbb E[X\mid\mathcal G]\) একটি random variable (দৈব চলক), নিছক সংখ্যা নয়। (ক) এক-দুই বাক্যে ব্যাখ্যা করুন কেন এটি random variable হতেই হয় — সংজ্ঞার কোন শর্ত (\(\mathcal G\)-measurability) একে \(\omega\)-এর function বানায়, এবং "প্রতিটি atom/স্লাইসে আলাদা গড়" ছবিটা কীভাবে এই random-ভাব তৈরি করে। (খ) কখন \(\mathbb E[X\mid\mathcal G]\) অধঃপতিত হয়ে একটিমাত্র ধ্রুব সংখ্যায় নামে — অর্থাৎ কোন দুই চরম \(\mathcal G\)-তে (\(\mathcal G=\{\varnothing,\Omega\}\) বনাম \(\mathcal G=\mathcal F\)) তা যথাক্রমে ধ্রুবক \(\mathbb E[X]\) ও স্বয়ং \(X\) হয়, এবং কেন। (গ) এক বাক্যে: \(\mathbb E[X\mid Y=y]\) (সংখ্যা, \(y\)-এর function) আর \(\mathbb E[X\mid Y]\) (random variable, \(\omega\)-এর function \(g(Y(\omega))\))-এর সম্পর্ক কী।
Hint: \(\mathcal G\)-measurable মানে মান কেবল "\(\mathcal G\) কোন atom/স্লাইসে রেখেছে" তার উপর নির্ভর করে, আর সেই atom নিজেই দৈব — তাই \(\mathbb E[X\mid\mathcal G](\omega)\) দৈব। চরমে: \(\mathcal G=\{\varnothing,\Omega\}\) কিছুই আলাদা করে না ⇒ ধ্রুবক \(=\mathbb E[X]\); \(\mathcal G=\mathcal F\) সব জানে ⇒ \(=X\)। আর \(\mathbb E[X\mid Y]=g(Y)\) যেখানে \(g(y)=\mathbb E[X\mid Y=y]\) — সংখ্যাগুলোকে \(Y\)-তে বসিয়ে random variable। (← 2.2)
অনুশীলন ২ (★)¶
\(\mathbb E[X\mid\mathcal G]\)-এর সংজ্ঞা ঠিক দুটি শর্তে দাঁড়ায়। (ক) দুটি শর্ত হুবহু লিখুন: (i) measurability-শর্ত, (ii) averaging/integral-শর্ত (\(G\) কোন সংগ্রহে চলে তা সহ)। (খ) ব্যাখ্যা করুন কেন একটিমাত্র শর্ত যথেষ্ট নয় — অর্থাৎ শুধু "\(\mathcal G\)-measurable" দাবি করলে অসংখ্য প্রার্থী থাকে (যেমন ধ্রুবক \(0\)-ও \(\mathcal G\)-measurable), আর শুধু "averaging" দাবি করলে \(X\) নিজেও মেলে; দুটি একসঙ্গে কী আঁটোসাঁটো করে। (গ) এক বাক্যে: averaging-শর্তে \(G\)-কে কেন সব \(G\in\mathcal G\)-তে চাইতে হয়, শুধু \(G=\Omega\)-তে (\(\mathbb E[Z]=\mathbb E[X]\)) নয় — অর্থাৎ \(G=\Omega\) একা কেন দুর্বল।
Hint: (i) \(Z\) \(\mathcal G\)-measurable; (ii) \(\int_G Z\,d\mathbb P=\int_G X\,d\mathbb P\) সব \(G\in\mathcal G\)। শুধু (i): \(0,\ \tfrac12X\)-জাতীয় বহু \(\mathcal G\)-measurable মেলে না-গড়ে; শুধু (ii) measurability ছাড়া: \(X\) নিজেই মেলে কিন্তু তা \(\mathcal G\) "জানে না"। \(G=\Omega\) একা শুধু মোট গড় বাঁধে — atom-ভেদে বণ্টন বাঁধে না; "সব \(G\)" প্রতিটি atom-এ আলাদা করে গড় মেলায়, তাই \(Z\) অনন্য (a.s.)। (← §২.২)
অনুশীলন ৩ (★★)¶
\(\mathbb E[X\mid\mathcal G]\) যে \(X\)-এর সেরা \(L^2\) predictor (best \(L^2\) predictor) — অর্থাৎ সব \(\mathcal G\)-measurable \(Z\)-এর মধ্যে \(\mathbb E[(X-Z)^2]\)-কে minimize করে — এটিই "শর্তাধীন প্রত্যাশা = regression" পরিচয়ের গোড়া। (ক) জ্যামিতিক ভাষায় বলুন: \(L^2\)-এ \(\mathbb E[(X-Z)^2]=\lVert X-Z\rVert_2^2\) মানে দূরত্ব-বর্গ, আর \(\{Z:\ Z\ \mathcal G\text{-measurable},\ Z\in L^2\}=L^2(\mathcal G)\) একটি closed subspace — তাই minimizer ঠিক \(X\)-এর orthogonal projection \(L^2(\mathcal G)\)-তে; কেন এই projection-ই \(\mathbb E[X\mid\mathcal G]\) (7.5-এর projection theorem-এর কোন বৈশিষ্ট্য মেলে)। (খ) ব্যাখ্যা করুন কেন এতে কোনো রৈখিকতা-অনুমান নেই — \(\mathbb E[X\mid Y]\) সব (এমনকি বক্র) function \(g(Y)\)-এর মধ্যে সেরা, আর 5.1-এর linear regression কেবল এর \(g(Y)=a+bY\)-রূপ সীমাবদ্ধ আনুমান। (গ) এক বাক্যে: residual \(X-\mathbb E[X\mid\mathcal G]\) কেন প্রতিটি \(\mathcal G\)-measurable \(Z\)-এর সাথে orthogonal (\(\mathbb E[(X-\mathbb E[X\mid\mathcal G])Z]=0\)), এবং এটি কীভাবে "জানা-তথ্যে আর কিছু নিংড়ে নেওয়ার নেই" বলে।
Hint: (ক) projection theorem (7.5): closed subspace-এ নিকটতম বিন্দু \(\hat X\) অনন্য ও residual \(X-\hat X\perp\) subspace; এখানে subspace \(=L^2(\mathcal G)\), আর normal equation \(\mathbb E[(X-Z)\mathbf 1_G]=0\ \forall G\) ঠিক averaging-শর্ত, তাই \(\hat X=\mathbb E[X\mid\mathcal G]\)। (খ) \(\mathcal G\)-measurable function-এর space-এ সব \(g(Y)\) পড়ে, রৈখিক উপ-space ছোট। (গ) orthogonality = "\(Z\)-তথ্যের সাথে error-এর correlation শূন্য" — সেরা-হওয়ার সমার্থক। (← 7.5, ← 5.1)
খ · গণনামূলক¶
অনুশীলন ৪ (★)¶
একটি দৈব চলক \(X\) ও একটি finite partition \(\mathcal G=\sigma(\{G_1,G_2,G_3\})\)-এ \(\mathbb E[X\mid\mathcal G]\) atom-গড় হিসেবে বের করুন (§২ ও §৩-উদাহরণ ১-এর নিয়ম: atom-এ ধ্রুব = atom-গড়)। দুই কেস:
(ক) সমভর atom। নিরপেক্ষ পাশা \(X\in\{1,\dots,6\}\), প্রতিটি \(\tfrac16\); \(\mathcal G\) কেবল "জোড়/বিজোড় (even/odd)" জানে: atom \(\{2,4,6\}\) ও \(\{1,3,5\}\)। (i) দুই atom-এ \(\mathbb E[X\mid\mathcal G]\)-এর মান বের করুন; (ii) tower দিয়ে \(\mathbb E[\mathbb E[X\mid\mathcal G]]\) বের করে দেখান তা \(\mathbb E[X]\)-এ ফেরে।
(খ) অসমভর atom (discrete joint pmf)। যৌথ pmf: \((X,Y)\)-এ \(X\in\{0,1,2\}\), \(Y\in\{a,b\}\), আর $$ \begin{array}{c|cc} & Y=a & Y=b\\hline X=0 & 0.10 & 0.20\ X=1 & 0.30 & 0.05\ X=2 & 0.10 & 0.25 \end{array} $$ \(\mathcal G=\sigma(Y)\) ধরে (i) \(\mathbb E[X\mid Y=a]\) ও \(\mathbb E[X\mid Y=b]\) বের করুন (atom-এ conditional pmf \(\mathbb P(X=x\mid Y=y)=\mathbb P(X=x,Y=y)/\mathbb P(Y=y)\) দিয়ে); (ii) tower \(\mathbb E[\mathbb E[X\mid Y]]=\mathbb E[X]\) যাচাই করুন।
Hint: (ক-i) সমভর বলে atom-গড় = সরল গড়: জোড়ে \(\tfrac{2+4+6}{3}=4\), বিজোড়ে \(\tfrac{1+3+5}{3}=3\); (ক-ii) \(4\cdot\tfrac12+3\cdot\tfrac12=3.5=\mathbb E[X]\) ✓। (খ) marginals: \(\mathbb P(Y=a)=0.5,\ \mathbb P(Y=b)=0.5\); \(\mathbb E[X\mid Y=a]=\frac{0\cdot0.10+1\cdot0.30+2\cdot0.10}{0.5}\), একইভাবে \(Y=b\); tower-এ ওজন \(\mathbb P(Y=a),\mathbb P(Y=b)\) দিয়ে গড়।
অনুশীলন ৫ (★★)¶
standard bivariate normal \((X,Y)\) — দুটোরই marginal \(N(0,1)\), correlation \(\rho=0.6\) (§৩-উদাহরণ ৩-এর সেটআপ)। বিভাজন \(X=\rho Y+\sqrt{1-\rho^2}\,Z\), \(Z\sim N(0,1)\), \(Z\perp Y\) ব্যবহার করে: (ক) \(\mathbb E[X\mid Y=y]\) একটি \(y\)-এর function হিসেবে বের করুন — দেখান এটি একটি সরলরেখা, এবং তার ঢাল ও intercept লিখুন (independence rule \(\mathbb E[Z\mid Y]=\mathbb E[Z]=0\) ও pull-out দিয়ে)। (খ) \(\operatorname{Var}(X\mid Y=y)\) বের করুন এবং মন্তব্য করুন কেন তা \(y\)-নিরপেক্ষ (homoscedastic, সমভেদ)। (গ) এক বাক্যে: এই \(\mathbb E[X\mid Y=y]\)-রেখা ঠিক 5.1-এর কোন বস্তু — অর্থাৎ "শর্তাধীন প্রত্যাশা = regression function"-এর সংখ্যাগত নিশ্চিতকরণ।
Hint: \(X=\rho Y+\sqrt{1-\rho^2}Z\) ⇒ \(\mathbb E[X\mid Y=y]=\rho y+\sqrt{1-\rho^2}\cdot 0=\rho y=0.6y\) (ঢাল \(\rho=0.6\), intercept \(0\)); \(\operatorname{Var}(X\mid Y=y)=(1-\rho^2)\operatorname{Var}(Z)=1-\rho^2=0.64\), \(y\)-নিরপেক্ষ কারণ noise-পদ \(Y\)-স্বাধীন। রেখাটি ঠিক population regression line \(\hat\beta=\operatorname{Cov}(X,Y)/\operatorname{Var}(Y)=\rho\)।
অনুশীলন ৬ (★★)¶
একই \(\rho=0.6\) bivariate normal-এ law of total variance (সম্পূর্ণ-ভেদের নিয়ম) \(\operatorname{Var}(X)=\mathbb E[\operatorname{Var}(X\mid Y)]+\operatorname{Var}(\mathbb E[X\mid Y])\) প্রয়োগ করে মোট ভেদকে ব্যাখ্যাকৃত (explained) ও অব্যাখ্যাত (unexplained) অংশে ভাঙুন। (ক) অনুশীলন ৫-এর ফল ব্যবহার করে দুই পদ আলাদা করে কষুন: \(\mathbb E[\operatorname{Var}(X\mid Y)]\) (unexplained / within) ও \(\operatorname{Var}(\mathbb E[X\mid Y])\) (explained / between)। (খ) যোগফল \(=\operatorname{Var}(X)=1\) যাচাই করুন এবং সংখ্যা দুটি লিখুন। (গ) ব্যাখ্যাকৃত ভগ্নাংশ \(\operatorname{Var}(\mathbb E[X\mid Y])/\operatorname{Var}(X)\) বের করুন এবং দেখান এটি ঠিক \(\rho^2\) — অর্থাৎ regression-এর \(R^2\)।
Hint: \(\operatorname{Var}(X\mid Y)=1-\rho^2=0.64\) ধ্রুব, তাই \(\mathbb E[\operatorname{Var}(X\mid Y)]=0.64\) (unexplained); \(\mathbb E[X\mid Y]=\rho Y\), তাই \(\operatorname{Var}(\rho Y)=\rho^2\operatorname{Var}(Y)=\rho^2=0.36\) (explained)। যোগ \(0.64+0.36=1=\operatorname{Var}(X)\) ✓; ব্যাখ্যাকৃত ভগ্নাংশ \(0.36/1=0.36=\rho^2=R^2\)।
গ · প্রমাণভিত্তিক¶
অনুশীলন ৭ (★★)¶
tower property (iterated expectation) প্রমাণ করুন — সংজ্ঞা থেকে। \(\mathcal H\subseteq\mathcal G\subseteq\mathcal F\) এবং \(X\in L^1\) হলে দেখান: $$ \mathbb E\big[\,\mathbb E[X\mid\mathcal G]\,\big\rvert\,\mathcal H\,\big]=\mathbb E[X\mid\mathcal H]\qquad(\text{a.s.}), $$ এবং বিশেষ ক্ষেত্র \(\mathcal H=\{\varnothing,\Omega\}\)-এ \(\mathbb E[\mathbb E[X\mid\mathcal G]]=\mathbb E[X]\)। (ক) লিখুন কী দেখাতে হবে: \(W:=\mathbb E[X\mid\mathcal G]\) ধরে দেখান \(\mathbb E[W\mid\mathcal H]\) এবং \(\mathbb E[X\mid\mathcal H]\) একই defining property মেটায়। (খ) যেকোনো \(H\in\mathcal H\) নিন; যেহেতু \(\mathcal H\subseteq\mathcal G\), তাই \(H\in\mathcal G\)-ও — এই অন্তর্ভুক্তি ব্যবহার করে দেখান \(\int_H W\,d\mathbb P=\int_H X\,d\mathbb P\)। (গ) a.s.-অনন্যতা প্রয়োগ করে উপসংহার টানুন, এবং \(\mathcal H=\{\varnothing,\Omega\}\) বসিয়ে \(\mathbb E[\mathbb E[X\mid\mathcal G]]=\mathbb E[X]\) পান।
Hint: (ক) \(\mathbb E[X\mid\mathcal H]\) হলো সেই \(\mathcal H\)-measurable \(V\) যার \(\int_H V=\int_H X\ \forall H\in\mathcal H\); দেখাতে হবে \(V=\mathbb E[W\mid\mathcal H]\) এই শর্ত মেটায়। (খ) \(\mathbb E[W\mid\mathcal H]\)-এর defining property: \(\int_H\mathbb E[W\mid\mathcal H]=\int_H W\); আর \(W=\mathbb E[X\mid\mathcal G]\)-এর defining property (\(H\in\mathcal G\) বলে প্রযোজ্য): \(\int_H W=\int_H X\); চেইন করুন। (গ) দুই দিক একই: \(\int_H\mathbb E[W\mid\mathcal H]=\int_H X=\int_H\mathbb E[X\mid\mathcal H]\) সব \(H\)-তে, আর দুটোই \(\mathcal H\)-measurable ⇒ a.s. সমান।
অনুশীলন ৮ (★★)¶
pull-out (taking out what is known) প্রমাণ করুন — indicator-ক্ষেত্রে। \(X\in L^1\), \(G_0\in\mathcal G\), এবং \(Y=\mathbf 1_{G_0}\) (যা \(\mathcal G\)-measurable) হলে সংজ্ঞা থেকে দেখান: $$ \mathbb E[\,\mathbf 1_{G_0}X\mid\mathcal G\,]=\mathbf 1_{G_0}\,\mathbb E[X\mid\mathcal G]\qquad(\text{a.s.}). $$ (ক) ডান পাশের প্রার্থী \(Z:=\mathbf 1_{G_0}\mathbb E[X\mid\mathcal G]\) যে \(\mathcal G\)-measurable, তা যুক্তি দিন (দুই \(\mathcal G\)-measurable-এর গুণফল)। (খ) যেকোনো \(G\in\mathcal G\) নিয়ে দেখান \(\int_G Z\,d\mathbb P=\int_G\mathbf 1_{G_0}X\,d\mathbb P\) — মূল কৌশল: \(\int_G\mathbf 1_{G_0}(\cdot)=\int_{G\cap G_0}(\cdot)\), আর \(G\cap G_0\in\mathcal G\) বলে \(\mathbb E[X\mid\mathcal G]\)-এর defining property প্রয়োগযোগ্য। (গ) a.s.-অনন্যতায় উপসংহার দিন, এবং এক বাক্যে বলুন কীভাবে এই indicator-ক্ষেত্র থেকে সাধারণ \(\mathcal G\)-measurable \(Y\) (simple → measurable, MCT) পর্যন্ত বাড়ানো যায়।
Hint: (খ) \(\int_G\mathbf 1_{G_0}\mathbb E[X\mid\mathcal G]\,d\mathbb P=\int_{G\cap G_0}\mathbb E[X\mid\mathcal G]\,d\mathbb P\overset{\text{def}}{=}\int_{G\cap G_0}X\,d\mathbb P=\int_G\mathbf 1_{G_0}X\,d\mathbb P\) — মাঝের সমতা \(G\cap G_0\in\mathcal G\)-তে defining property। (গ) indicator ⇒ simple function (linearity) ⇒ অঋণাত্মক measurable (monotone limit, conditional MCT) ⇒ সাধারণ \(Y\) (\(Y=Y^+-Y^-\))।
অনুশীলন ৯ (★★)¶
স্বাধীনতা হলে \(\mathbb E[X\mid\mathcal G]=\mathbb E[X]\) প্রমাণ করুন। \(X\in L^1\) এবং \(X\perp\!\!\!\perp\mathcal G\) (\(X\) ও \(\mathcal G\) স্বাধীন) হলে দেখান \(\mathbb E[X\mid\mathcal G]=\mathbb E[X]\) a.s. — অর্থাৎ যে তথ্য কিছু বলে না, তাকে শর্তে ধরা অর্থহীন। (ক) প্রার্থী হিসেবে ধ্রুবক \(Z\equiv\mathbb E[X]\) নিন; যুক্তি দিন কেন একটি ধ্রুবক সর্বদা \(\mathcal G\)-measurable। (খ) যেকোনো \(G\in\mathcal G\) নিয়ে দেখান \(\int_G\mathbb E[X]\,d\mathbb P=\int_G X\,d\mathbb P\) — মূল ধাপ: \(\int_G X\,d\mathbb P=\mathbb E[X\,\mathbf 1_G]=\mathbb E[X]\,\mathbb E[\mathbf 1_G]\) (স্বাধীনতায় product-এ ভাঙে, কারণ \(X\perp\mathbf 1_G\)), আর \(\mathbb E[\mathbf 1_G]=\mathbb P(G)\)। (গ) a.s.-অনন্যতায় উপসংহার দিন, এবং তা §৩-উদাহরণ ৫-এর "দুই স্বাধীন পাশা"-র সাথে মেলান।
Hint: (ক) ধ্রুবক \(c\)-এর জন্য \(\{c\le t\}\in\{\varnothing,\Omega\}\subseteq\mathcal G\) — তাই measurable। (খ) \(X\perp\!\!\!\perp\mathcal G\Rightarrow X\perp\!\!\!\perp\mathbf 1_G\) (কারণ \(\mathbf 1_G\) \(\mathcal G\)-measurable), তাই \(\mathbb E[X\mathbf 1_G]=\mathbb E[X]\mathbb P(G)\); বাঁ পাশ \(\int_G\mathbb E[X]\,d\mathbb P=\mathbb E[X]\mathbb P(G)\) — মিলে গেল। (গ) তাই \(Z=\mathbb E[X]\) সংজ্ঞা মেটায়, a.s.-অনন্যতায় \(\mathbb E[X\mid\mathcal G]=\mathbb E[X]\)।
ঘ · কোডিং¶
অনুশীলন ১০ (★★)¶
\(\mathbb E[X\mid Y]\) binning দিয়ে আনুমান — slope \(0.6\) ফিরে পাওয়া। seed np.random.default_rng(20260619), \(N=200{,}000\) নমুনায় standard bivariate normal \((X,Y)\) (\(\rho=0.6\)) তৈরি করে (\(X=\rho Y+\sqrt{1-\rho^2}Z\)): (ক) \(Y\)-অক্ষকে সমান bin-এ ভাগ করে প্রতিটি bin-এ \(X\)-এর গড় নিয়ে empirical \(\widehat{\mathbb E}[X\mid Y=y]\) আঁকুন/ছাপুন — দেখান bin-গড়গুলো \(y\)-এর সাথে প্রায়-রৈখিক, ঢাল \(\approx0.6\)। (খ) একটি সরু স্লাইস \(\lvert Y-1\rvert<0.05\)-এ \(X\)-এর গড় বের করে দেখান তা \(\approx\rho\cdot 1=0.6\) (canonical \(0.6014\)), আর সেই স্লাইসে \(X\)-এর ভেদ \(\approx 1-\rho^2=0.64\)। (গ) np.polyfit(Y, X, 1) দিয়ে সরাসরি slope বের করুন — canonical \(0.6008\); এক বাক্যে কোড-comment-এ লিখুন কেন এই slope ঠিক \(\mathbb E[X\mid Y]\)-এর ঢাল।
Hint:
import numpy as np
rng = np.random.default_rng(20260619)
N, rho = 200_000, 0.6
Y = rng.standard_normal(N)
Z = rng.standard_normal(N)
X = rho*Y + np.sqrt(1-rho**2)*Z
# (গ) সরাসরি slope
slope = np.polyfit(Y, X, 1)[0] # ≈ 0.6008 == E[X|Y]-এর ঢাল (= rho)
# (খ) Y≈1 স্লাইস
m = np.abs(Y - 1.0) < 0.05
print(round(slope,4), round(X[m].mean(),4), round(X[m].var(),4)) # 0.6008 0.6014 ~0.64
np.digitize দিয়ে bin করে প্রতি bin-এ X.mean()) ⇒ \(\widehat{\mathbb E}[X\mid Y]\)-এর সিঁড়ি, যা রেখা \(0.6y\)-কে অনুসরণ করে।
অনুশীলন ১১ (★★)¶
সেরা-predictor MSE অসমতা সংখ্যায় যাচাই। একই seed 20260619, \(N=200{,}000\), \(\rho=0.6\) নমুনায় তিন predictor-এর গড়-বর্গ-ত্রুটি (MSE) \(\mathbb E[(X-g(Y))^2]\) তুলনা করুন: (ক) regression \(g(Y)=\rho Y=\mathbb E[X\mid Y]\) — দেখান MSE \(\approx 1-\rho^2=0.64\) (canonical \(0.6410\)); (খ) সেরা ধ্রুব \(g\equiv\mathbb E[X]=0\) — দেখান MSE \(\approx\operatorname{Var}(X)=1\) (canonical \(1.0017\)); (গ) দেখান পার্থক্য (লাভ) \(\approx\rho^2=0.36=\operatorname{Var}(\mathbb E[X\mid Y])\), এবং নিশ্চিত করুন regression-এর MSE কঠোরভাবে ছোট — অর্থাৎ \(\mathbb E[X\mid Y]\) সত্যিই সেরা।
Hint:
import numpy as np
rng = np.random.default_rng(20260619)
N, rho = 200_000, 0.6
Y = rng.standard_normal(N); Z = rng.standard_normal(N)
X = rho*Y + np.sqrt(1-rho**2)*Z
mse_reg = np.mean((X - rho*Y)**2) # ≈ 0.6410 (= 1-rho^2)
mse_const = np.mean((X - 0.0)**2) # ≈ 1.0017 (= Var X)
print(round(mse_reg,4), round(mse_const,4), round(mse_const-mse_reg,4)) # 0.6410 1.0017 ~0.36
অনুশীলন ১২ (★★★)¶
law of total variance সংখ্যায় — \(0.64+0.36=1\)। একই seed 20260619, \(N=200{,}000\), \(\rho=0.6\) নমুনায় \(\operatorname{Var}(X)=\mathbb E[\operatorname{Var}(X\mid Y)]+\operatorname{Var}(\mathbb E[X\mid Y])\)-এর তিন পদই empirical-ভাবে আনুমান করে যোগফল যাচাই করুন। (ক) \(Y\)-কে bin-এ ভাগ করে প্রতি bin-এ \(X\)-এর within-variance নিন, bin-ভরে ওজন দিয়ে গড় করে \(\widehat{\mathbb E[\operatorname{Var}(X\mid Y)]}\approx 0.64\) পান (unexplained)। (খ) প্রতি bin-এ \(X\)-এর গড় (= \(\widehat{\mathbb E[X\mid Y]}\)) নিয়ে তার ভর-ওজনিত ভেদ \(\widehat{\operatorname{Var}(\mathbb E[X\mid Y])}\approx 0.36\) পান (explained)। (গ) দুই যোগ করে দেখান \(\approx\operatorname{Var}(X)\approx 1\) (canonical \(0.64+0.36=1\)), এবং explained/total \(\approx 0.36=\rho^2=R^2\) ছাপুন।
Hint:
import numpy as np
rng = np.random.default_rng(20260619)
N, rho = 200_000, 0.6
Y = rng.standard_normal(N); Z = rng.standard_normal(N)
X = rho*Y + np.sqrt(1-rho**2)*Z
edges = np.quantile(Y, np.linspace(0,1,51)) # ~50 সমভর bin
idx = np.clip(np.digitize(Y, edges[1:-1]), 0, 49)
within, means, w = [], [], []
for b in range(50):
xb = X[idx==b]
if xb.size:
within.append(xb.var()); means.append(xb.mean()); w.append(xb.size)
w = np.array(w, float); w /= w.sum()
E_var = np.sum(w*np.array(within)) # ≈ 0.64 (unexplained)
mbar = np.sum(w*np.array(means))
Var_E = np.sum(w*(np.array(means)-mbar)**2) # ≈ 0.36 (explained)
print(round(E_var,3), round(Var_E,3), round(E_var+Var_E,3), round(Var_E/X.var(),3))
# ≈ 0.64 0.36 1.00 0.36 (= rho^2 = R^2)
৮ · সারসংক্ষেপ ও সংযোগ¶
এই অধ্যায়ে 2.2-এর elementary শর্তাধীন প্রত্যাশা \(\mathbb E[X\mid Y=y]\) (যা \(\mathbb P(Y=y)=0\)-এ ভেঙে পড়ত) measure-তাত্ত্বিকভাবে কঠোর করা হয়েছে: তথ্যকে একটি sub-σ-algebra \(\mathcal G\subseteq\mathcal F\) দিয়ে ধরে \(\mathbb E[X\mid\mathcal G]\)-কে "আংশিক তথ্যের নিচে \(X\)-এর সেরা অনুমান" হিসেবে সংজ্ঞায়িত করা হয়েছে — continuous শর্তেও যা খাটে।
১. সংজ্ঞা ও অস্তিত্ব। \(X\in L^1\) হলে \(\mathbb E[X\mid\mathcal G]\) হলো সেই a.s.-অনন্য \(\mathcal G\)-measurable random variable \(Z\) যার averaging property \(\int_G Z\,d\mathbb P=\int_G X\,d\mathbb P\) সব \(G\in\mathcal G\)-তে মেটে — দুই শর্ত (\(\mathcal G\)-measurability + গড়-মিল) একসঙ্গে একে আঁটোসাঁটো করে। অস্তিত্ব দুই পথে (7.5): (i) Radon–Nikodym — \(\nu(G)=\int_G X\,d\mathbb P\ll\mathbb P\), তাই \(\mathbb E[X\mid\mathcal G]=\tfrac{d\nu}{d\mathbb P}\big\rvert_{\mathcal G}\); (ii) \(L^2\)-orthogonal projection — \(X\in L^2\) হলে \(\mathbb E[X\mid\mathcal G]\) ঠিক \(X\)-এর projection \(L^2(\mathcal G)\)-তে (residual ⊥ subspace)। Doob–Dynkin: \(\mathbb E[X\mid Y]=g(Y)\) একটি measurable function; শর্তাধীন সম্ভাবনা \(\mathbb P(A\mid\mathcal G)=\mathbb E[\mathbf 1_A\mid\mathcal G]\)।
২. ধর্মাবলি। linearity; \(\mathbb E[\mathbb E[X\mid\mathcal G]]=\mathbb E[X]\); tower/iterated \(\mathbb E[\mathbb E[X\mid\mathcal G]\mid\mathcal H]=\mathbb E[X\mid\mathcal H]\) (\(\mathcal H\subseteq\mathcal G\) — "ধাপে-ধাপে গড়, মোটাটাই জেতে"); pull-out (যা জানা তা বের করে আনা) \(\mathbb E[YX\mid\mathcal G]=Y\,\mathbb E[X\mid\mathcal G]\) (\(Y\) \(\mathcal G\)-measurable); independence \(X\perp\!\!\!\perp\mathcal G\Rightarrow\mathbb E[X\mid\mathcal G]=\mathbb E[X]\); monotonicity; conditional Jensen \(\varphi(\mathbb E[X\mid\mathcal G])\le\mathbb E[\varphi(X)\mid\mathcal G]\) (\(\varphi\) convex); conditional MCT/Fatou/DCT; \(L^p\)-contraction \(\lVert\mathbb E[X\mid\mathcal G]\rVert_p\le\lVert X\rVert_p\)।
৩. সেরা \(L^2\) predictor = regression। \(\mathbb E[X\mid\mathcal G]\) সব \(\mathcal G\)-measurable \(Z\)-এর মধ্যে \(\mathbb E[(X-Z)^2]\)-কে minimize করে — এটিই regression (কোনো রৈখিকতা-অনুমান ছাড়া), আর 5.1-এর linear regression তার \(g(Y)=a+bY\)-রূপ সীমিত আনুমান। bivariate normal (\(\rho=0.6\))-এ \(\mathbb E[X\mid Y=y]=\rho y=0.6y\) — একটি সরলরেখা, হুবহু population regression line; \(\operatorname{Var}(X\mid Y)=1-\rho^2=0.64\) (\(y\)-নিরপেক্ষ, homoscedastic)। সিমুলেশনে slope \(0.6008\), \(\mathbb E[X\mid Y\approx1]=0.6014\); regression-MSE \(0.6410\) বনাম সেরা-ধ্রুব-MSE \(1.0017\) — regression কঠোরভাবে জেতে।
৪. conditional variance ও law of total variance। \(\operatorname{Var}(X)=\mathbb E[\operatorname{Var}(X\mid\mathcal G)]+\operatorname{Var}(\mathbb E[X\mid\mathcal G])\) — মোট ভেদ = অব্যাখ্যাত (within, \(\mathbb E[\operatorname{Var}]\)) + ব্যাখ্যাকৃত (between, \(\operatorname{Var}(\mathbb E)\))। bivariate normal-এ \(1=0.64+0.36\), আর ব্যাখ্যাকৃত ভগ্নাংশ \(0.36=\rho^2=R^2\) — regression-এর \(R^2\)-এর প্রকৃত পরিচয়। সঙ্গে regular conditional distribution — সমগ্র শর্তাধীন বণ্টন \(\mathbb P(X\in\cdot\mid\mathcal G)(\omega)\) একটি সত্যিকার probability measure হিসেবে (নিয়মিত শর্তে), যা শর্তাধীন density ও প্রত্যাশাকে এক ছাতার নিচে আনে।
মূল সংজ্ঞা/উপপাদ্য (mini-list)। - সংজ্ঞা: \(\mathbb E[X\mid\mathcal G]\) = a.s.-অনন্য \(\mathcal G\)-measurable \(Z\) যাতে \(\int_G Z\,d\mathbb P=\int_G X\,d\mathbb P\ \forall G\in\mathcal G\) (\(X\in L^1\))। - অস্তিত্ব: Radon–Nikodym derivative \(\tfrac{d\nu}{d\mathbb P}\big\rvert_{\mathcal G}\) (\(\nu(G)=\int_G X\,d\mathbb P\)); \(X\in L^2\)-এ \(L^2(\mathcal G)\)-তে orthogonal projection। - Doob–Dynkin: \(\mathbb E[X\mid\sigma(Y)]=g(Y)\) কোনো measurable \(g\)-তে; \(\mathbb P(A\mid\mathcal G)=\mathbb E[\mathbf 1_A\mid\mathcal G]\)। - tower: \(\mathcal H\subseteq\mathcal G\Rightarrow\mathbb E[\mathbb E[X\mid\mathcal G]\mid\mathcal H]=\mathbb E[X\mid\mathcal H]\); \(\mathbb E[\mathbb E[X\mid\mathcal G]]=\mathbb E[X]\)। - pull-out: \(Y\) \(\mathcal G\)-measurable, \(XY\in L^1\Rightarrow\mathbb E[YX\mid\mathcal G]=Y\,\mathbb E[X\mid\mathcal G]\)। - independence: \(X\perp\!\!\!\perp\mathcal G\Rightarrow\mathbb E[X\mid\mathcal G]=\mathbb E[X]\)। - conditional Jensen: \(\varphi\) convex \(\Rightarrow\varphi(\mathbb E[X\mid\mathcal G])\le\mathbb E[\varphi(X)\mid\mathcal G]\); ফলস্বরূপ \(L^p\)-contraction \(\lVert\mathbb E[X\mid\mathcal G]\rVert_p\le\lVert X\rVert_p\)। - best \(L^2\) predictor: \(\mathbb E[X\mid\mathcal G]=\arg\min_{Z\ \mathcal G\text{-meas}}\mathbb E[(X-Z)^2]\) — Pythagoras \(\mathbb E[(X-Z)^2]=\mathbb E[(X-\mathbb E[X\mid\mathcal G])^2]+\mathbb E[(\mathbb E[X\mid\mathcal G]-Z)^2]\)। - law of total variance: \(\operatorname{Var}(X)=\mathbb E[\operatorname{Var}(X\mid\mathcal G)]+\operatorname{Var}(\mathbb E[X\mid\mathcal G])\)।
পেছনের সংযোগ: - ← 2.2 (Independence ও conditional probability): সেখানকার \(\mathbb E[X\mid Y=y]=\sum_x x\,\mathbb P(X=x\mid Y=y)\) ও law of total expectation এখানে continuous শর্তে (σ-algebra দিয়ে) কঠোর; স্বাধীনতা-ধর্ম \(X\perp\!\!\!\perp\mathcal G\Rightarrow\mathbb E[X\mid\mathcal G]=\mathbb E[X]\)-ও সেখানকার ঘটনা-স্বাধীনতা থেকেই। - ← 2.6 (Joint distribution, covariance): bivariate \((X,Y)\)-এ \(\mathbb E[Y\mid X=x]=\int y\,f_{Y\mid X}(y\mid x)\,dy\) — regression curve — এখানকার density-formula-র চেনা মুখ; covariance ও \(\operatorname{Var}\) law of total variance-এর ভাষা। - ← 5.1 (Linear regression): সেখানকার OLS "সেরা রেখা" আসলে \(\mathbb E[X\mid Y]\)-এর রৈখিক subspace-এ সীমিত আনুমান; population regression line \(\hat\beta=\operatorname{Cov}/\operatorname{Var}=\rho\) ঠিক \(\mathbb E[X\mid Y=y]=\rho y\), আর \(R^2=\rho^2\) ঠিক law of total variance-এর ব্যাখ্যাকৃত ভগ্নাংশ। - ← 7.5 (\(L^p\)/Hilbert/Radon–Nikodym): \(L^2\)-projection theorem ও Radon–Nikodym theorem এই অধ্যায়ের অস্তিত্ব-ইঞ্জিন; \(\langle X,Y\rangle=\mathbb E[XY]\)-এর orthogonality conditional expectation-এর residual ⊥ subspace। - ← 7.4 (Lebesgue integral): \(\mathbb E[X]=\int_\Omega X\,d\mathbb P\) ও MCT/Fatou/DCT — averaging property ও conditional convergence theorem-এর ভাষা; "\(\int_G Z=\int_G X\ \forall G\Rightarrow Z=Z'\) a.s." a.s.-অনন্যতা দেয়।
সামনের সংযোগ: - → 7.8 (Filtration ও martingale): martingale হলো ঠিক \(\mathbb E[X_{n+1}\mid\mathcal F_n]=X_n\) — এই অধ্যায়ের conditional expectation-ই তার সংজ্ঞার ভিত্তি; tower ও pull-out সেখানে কর্মঘোড়া। - → 7.9 (Martingale convergence): conditional expectation-এর \(L^p\)-contraction ও tower martingale convergence theorem-এর প্রস্তুতি; Bayesian updating ও filtering-এর কঠোর রূপ।
উৎস: Klenke, Probability Theory: A Comprehensive Course, অধ্যায় ৮ (Conditional Expectations) — sub-σ-algebra-ভিত্তিক \(\mathbb E[X\mid\mathcal G]\)-এর সংজ্ঞা (averaging property), Radon–Nikodym ও \(L^2\)-projection দিয়ে অস্তিত্ব ও a.s.-অনন্যতা, \(\mathbb E[X\mid Y]=g(Y)\) (Doob–Dynkin factorization), সব মূল ধর্ম (linearity, tower, pull-out, independence, monotonicity, conditional Jensen, conditional convergence theorems, \(L^p\)-contraction), best-\(L^2\)-predictor ও conditional variance, law of total variance, এবং regular conditional distribution-এর আদর্শ, কঠোর উপস্থাপনা — সরাসরি 7.8-এর martingale-এর প্রস্তুতি।
এক বাক্যে: তথ্যকে একটি sub-σ-algebra \(\mathcal G\) দিয়ে ধরে \(\mathbb E[X\mid\mathcal G]\) = সেই a.s.-অনন্য \(\mathcal G\)-measurable random variable যার গড় প্রতিটি \(G\in\mathcal G\)-তে \(X\)-এর সাথে মেলে (অস্তিত্ব Radon–Nikodym / \(L^2\)-projection-এ) — tower, pull-out ও independence যার কর্মঘোড়া, যা সব \(\mathcal G\)-measurable অনুমানের মধ্যে সেরা \(L^2\) predictor (= regression), আর law of total variance (\(\operatorname{Var}X=\mathbb E[\operatorname{Var}(X\mid\mathcal G)]+\operatorname{Var}(\mathbb E[X\mid\mathcal G])\), bivariate normal-এ \(1=0.64+0.36\), \(R^2=\rho^2\)) যাকে ব্যাখ্যাকৃত ও অব্যাখ্যাত ভেদে ভাঙে — এই বস্তুই 7.8-এ