8.3 — Reproducing a Classical Result: James–Stein Shrinkage (Stein-এর প্যারাডক্স)¶
১ · ভূমিকা ও insight (অন্তর্দৃষ্টি)¶
১.১ একটা capstone-প্রকল্প: একটা বিখ্যাত ফল শূন্য থেকে ফিরে পাওয়া¶
এই অধ্যায়টা Part VIII-এর — ক্যাপস্টোন পর্বের — একটা পূর্ণাঙ্গ পুনরুৎপাদন-প্রকল্প (reproduction project)। এতদিন যা শেখা হয়েছে — estimation (Part IV), bias–variance (4.4), Bayesian inference (4.10), regularization (6.2), আর normal/chi-square বণ্টনের গণিত (2.6) — সব এখানে একত্রে কাজে লাগিয়ে একটা কাজ করা হয়: পরিসংখ্যানের ইতিহাসের সবচেয়ে বিস্ময়কর, সহজাত-বিরোধী ফলগুলোর একটা নিয়ে তা পড়া, বোঝা, প্রমাণ করা, এবং নিজের কোডে empirically ফিরে পাওয়া। ফলটার নাম — Stein's paradox (Stein-এর প্যারাডক্স), আর তার নায়ক — James–Stein estimator।
কেন এই প্রকল্প capstone-উপযুক্ত? কারণ একজন গবেষকের কেন্দ্রীয় দক্ষতা ঠিক এটাই: একটা প্রকাশিত দাবি (published claim) নিয়ে তা যাচাই করা — অন্ধভাবে বিশ্বাস না করে, নিজে সিমুলেশন লিখে, সংখ্যায় দেখে নেওয়া \"দাবিটা সত্যিই দাঁড়ায় কিনা\"। এই অধ্যায় ঠিক সেই চক্রটা সম্পূর্ণ করে দেখায় — একটা তত্ত্ব (theory) থেকে একটা প্রমাণ (proof), তারপর একটা সিমুলেশন (simulation), শেষে একটা বাস্তব-ডেটা প্রয়োগ (real-data application)।
এক বাক্যে সূচনা। এই অধ্যায় Stein-এর প্যারাডক্স ও James–Stein estimator শূন্য থেকে পুনরুৎপাদন করে — একটা ধ্রুপদী ফল পড়া→বোঝা→প্রমাণ→কোডে যাচাই-এর একটা পূর্ণ ক্যাপস্টোন-চক্র, যেখানে estimation, bias–variance, Bayes ও regularization সব একত্রে আসে।
১.২ প্রশ্নটা সরল — উত্তরটা ধাক্কা¶
সমস্যাটা এত সরল যে মনে হয় এতে চমকের কিছু থাকতেই পারে না। ধরা যাক \(p\)টি অজানা সংখ্যা \(\theta_1,\theta_2,\dots,\theta_p\) estimate করতে হবে, আর প্রতিটির জন্য হাতে আছে ঠিক একটি করে noisy পর্যবেক্ষণ: $$ X_i\sim N(\theta_i,\,1),\qquad i=1,\dots,p,\quad\text{স্বাধীন।} $$ অর্থাৎ প্রতিটি \(X_i\) তার নিজের সত্যিকারের মান \(\theta_i\)-এর চারপাশে একক-ভেদ (unit-variance) গোলমাল নিয়ে বসে আছে। প্রশ্ন: পুরো vector \(\theta=(\theta_1,\dots,\theta_p)\)-এর সবচেয়ে ভালো আন্দাজ কী?
স্পষ্ট উত্তর — যে কেউ বলবে — প্রতিটি \(\theta_i\)-এর জন্য তার নিজের observation \(X_i\)-ই নাও। এটাই maximum likelihood estimator (MLE, সর্বাধিক-সম্ভাবনা অনুমানক): $$ \hat\theta^{MLE}=X=(X_1,\dots,X_p). $$ প্রতিটি coordinate আলাদা করে, নিজের ডেটা দিয়ে estimate করা — আর কী হতে পারে? এটা unbiased (প্রতিটি \(\mathbb E[X_i]=\theta_i\)), এটা \"স্পষ্ট\", এটা সবাই করে। যদি একটা সংখ্যা estimate করতে হতো (\(p=1\)), এটাই অকাট্যভাবে সেরা।
Stein-এর ধাক্কা (1956): যখন \(p\ge3\), এই স্পষ্ট estimator-টা সেরা নয় — বরং একটা নির্দিষ্ট অর্থে খারাপ। একটা ভিন্ন estimator আছে যা প্রতিটি সম্ভাব্য \(\theta\)-এর জন্য একে হারায়। সেই estimator সব \(X_i\)-কে একসাথে ০-এর দিকে সংকুচিত (shrink) করে — $$ \hat\theta^{JS}=\Big(1-\frac{p-2}{\lVert X\rVert^2}\Big)X,\qquad \lVert X\rVert^2=\sum_{i=1}^p X_i^2, $$ এটাই James–Stein estimator। এখানে একটা সাধারণ scalar factor \(\big(1-\frac{p-2}{\lVert X\rVert^2}\big)\) (সাধারণত \(1\)-এর চেয়ে সামান্য ছোট, ধনাত্মক) দিয়ে পুরো vector-কে গুণ করা হয় — সব coordinate একসাথে কেন্দ্রের দিকে টেনে আনা হয়।
সবচেয়ে অদ্ভুত অংশটা এখানে: coordinate-গুলোর মধ্যে কোনো সম্পর্ক থাকার দরকার নেই। \(\theta_1\) হতে পারে এক দেশের গমের ফলন, \(\theta_2\) একটা দূরের তারার উজ্জ্বলতা, \(\theta_3\) এক ক্রিকেটারের ব্যাটিং গড় — সম্পূর্ণ অসম্পর্কিত। তবুও এদের estimate যৌথভাবে (\(\lVert X\rVert^2\) দিয়ে একসাথে) shrink করলে মোট নির্ভুলতা বাড়ে। কীভাবে একটা তারার উজ্জ্বলতার তথ্য গমের ফলনের estimate উন্নত করতে পারে? — এই প্রশ্নটাই \"প্যারাডক্স\"।
এক বাক্যে। \(X_i\sim N(\theta_i,1)\), প্রতিটির একটি observation — স্পষ্ট estimator MLE \(\hat\theta^{MLE}=X\); কিন্তু \(p\ge3\)-তে James–Stein \(\hat\theta^{JS}=(1-\frac{p-2}{\lVert X\rVert^2})X\) (সব estimate ০-র দিকে সংকুচিত) প্রতিটি \(\theta\)-তে MLE-কে হারায় — এমনকি coordinate-গুলো সম্পূর্ণ অসম্পর্কিত হলেও।
১.৩ \"হারায়\" মানে কী — risk, dominance ও inadmissibility¶
\"একটা estimator অন্যটাকে হারায়\" — এর একটা সুনির্দিষ্ট অর্থ দরকার। মাপকাঠি হলো risk (ঝুঁকি): একটা estimator \(\hat\theta\)-এর মোট প্রত্যাশিত বর্গ-ত্রুটি (expected squared error, বা total mean squared error), $$ R(\hat\theta,\theta)=\mathbb E\big\lVert\hat\theta-\theta\big\rVert^2=\mathbb E\sum_{i=1}^p(\hat\theta_i-\theta_i)^2. $$ এটা \"গড়ে estimate কতটা সত্যিকারের \(\theta\) থেকে দূরে\" তার একটা সংখ্যা — যত ছোট, তত ভালো। খেয়াল করুন এটা \(\theta\)-এর উপর নির্ভর করে (একটা estimator কোনো \(\theta\)-তে ভালো, কোনোটায় খারাপ হতে পারে)।
MLE-এর risk হিসাব করা সহজ: প্রতিটি \(X_i\sim N(\theta_i,1)\), তাই \(\mathbb E[(X_i-\theta_i)^2]=\operatorname{Var}(X_i)=1\), আর যোগ করলে $$ R(\hat\theta^{MLE},\theta)=\sum_{i=1}^p\mathbb E[(X_i-\theta_i)^2]=\sum_{i=1}^p 1=p, $$ প্রতিটি \(\theta\)-এর জন্য — একটা ধ্রুবক, সমতল (flat) risk = \(p\)। এখন Stein-এর দাবির সঠিক রূপ:
- dominance (আধিপত্য): \(\hat\theta^{JS}\) dominate করে \(\hat\theta^{MLE}\)-কে, মানে \(R(\hat\theta^{JS},\theta)\le R(\hat\theta^{MLE},\theta)=p\) প্রতিটি \(\theta\)-তে, আর অন্তত একটি \(\theta\)-তে কঠোরভাবে কম (আসলে সব \(\theta\)-তেই, \(p\ge3\))।
- inadmissibility (অগ্রহণযোগ্যতা): যদি একটা estimator-কে অন্য একটা dominate করে, তবে প্রথমটা inadmissible — \"অগ্রহণযোগ্য\", কারণ কোনো যুক্তিতেই তাকে বেছে নেওয়া উচিত নয় (একটা estimator আছে যা কখনো খারাপ নয়, কখনো কখনো ভালো)। Stein দেখালেন MLE \(\hat\theta=X\) inadmissible যখন \(p\ge3\)।
এটাই ধাক্কার আনুষ্ঠানিক রূপ: পরিসংখ্যানের সবচেয়ে স্বাভাবিক, সর্বত্র-ব্যবহৃত estimator-টা — তিন বা তার বেশি মাত্রায় — অগ্রহণযোগ্য। আর \(p=1,2\)-তে? তখন \(p-2\le0\), JS-এর সূত্রই ভেঙে পড়ে (shrinkage factor \(\ge1\), উল্টো টান), আর সত্যিই MLE তখন admissible — কোনো estimator তাকে হারাতে পারে না। প্যারাডক্সটা কঠোরভাবে একটা তিন-বা-ততোধিক-মাত্রিক ঘটনা।
এক বাক্যে। estimator-এর মান মাপা হয় risk \(R(\hat\theta,\theta)=\mathbb E\lVert\hat\theta-\theta\rVert^2\) (total MSE) দিয়ে; MLE-র risk সর্বত্র \(p\); JS dominate করে MLE-কে (\(R_{JS}\le p\) প্রতিটি \(\theta\)-তে, কোথাও কঠোরভাবে কম), তাই MLE inadmissible (\(p\ge3\)) — অথচ \(p\le2\)-তে MLE admissible, প্যারাডক্স তিন-মাত্রা থেকে শুরু।
১.৪ কেন এটা কাজ করে — bias কিনে variance বেচা¶
প্যারাডক্সটা \"জাদু\" মনে হলেও এর পেছনের যুক্তি ঠিক 4.4-এর bias–variance পচন। মনে করুন — একটা estimator-এর MSE ভাঙে দুই অংশে: $$ \text{MSE}=\underbrace{(\text{bias})^2}{\text{কতটা পক্ষপাতী}}+\underbrace{\text{variance}}. $$ MLE }\(\hat\theta=X\) প্রতিটি coordinate-এ unbiased (bias \(=0\)) কিন্তু তার variance পুরোটাই বহন করে (মোট variance \(=p\))। James–Stein একটা দর কষে: সব estimate-কে ০-র দিকে টেনে সে একটু bias ঢোকায় (এখন \(\mathbb E[\hat\theta^{JS}_i]\) ঠিক \(\theta_i\) নয়, একটু ০-র দিকে সরানো) — কিন্তু বিনিময়ে variance অনেক কমায় (একটা \(<1\) factor দিয়ে গুণ করলে ছড়ানো কমে)। যখন মাত্রা বেশি (\(p\ge3\)), variance-এর সাশ্রয় bias²-এর খরচকে ছাপিয়ে যায়, আর মোট MSE নামে।
এই দর্শন — \"একটু bias কিনে অনেক variance বেচা\" — ঠিক যা 6.2-এর regularization-এ (ridge/lasso) ঘটে। ridge coefficient-কে ০-র দিকে সংকুচিত করে; JS estimate-কে ০-র দিকে সংকুচিত করে। আসলে ঐতিহাসিকভাবে James–Stein-ই shrinkage estimation-এর জন্মদাতা (1961), আর ridge (1970) তার regression-সংস্করণ। তেমনি 4.10-এর Bayesian দৃষ্টিতে: যদি \(\theta_i\)-দের একটা prior \(N(0,\tau^2)\) মানা হয়, posterior-mean একটা shrinkage \(\frac{\tau^2}{\tau^2+1}X_i\) (prior-গড় ০-র দিকে টান); JS ঠিক সেই shrinkage-এর মাত্রা ডেটা থেকেই আন্দাজ করে — একটা empirical-Bayes পদ্ধতি। তাই JS তিনটি জগতের সংযোগস্থল: frequentist risk, Bayesian prior, আর regularization।
এক বাক্যে। JS কাজ করে কারণ shrinkage সামান্য bias কিনে অনেক variance বেচে (← 4.4-এর MSE=bias²+var); এটাই ridge-regularization-এর (← 6.2) ও empirical-Bayes shrinkage-এর (← 4.10) একই দর্শন — JS তাদের সবার পূর্বপুরুষ।
১.৫ এই অধ্যায়ের পথরেখা¶
- §২ সব বস্তুর precise সংজ্ঞা — setup ও MLE (২.১); James–Stein estimator ও তার positive-part রূপ (২.২); risk, dominance, admissibility (২.৩); shrinkage-এর bias–variance অর্থ ও Bayes/ridge-সংযোগ (২.৪); এবং SURE ও risk-পরিচয়ের বিবৃতি (২.৫)। ভারী প্রমাণ §৪-এ।
- §৩ পূর্ণাঙ্গ উদাহরণ — ছোট \(p\)-তে হাতে-কলমে risk হিসাব, shrinkage factor বোঝা, আর একটা draw-তে JS বনাম MLE।
- §৪ প্রমাণ — MLE-র risk \(=p\); Stein's lemma (integration by parts) ও তা দিয়ে SURE ও James–Stein-এর risk-পরিচয় \(p-(p-2)^2\mathbb E\frac{1}{\lVert X\rVert^2}\le p\); কেন \(p\ge3\)।
- §৫–৬ পুনরুৎপাদন — Monte-Carlo সিমুলেশনে (seed 20260619) MLE বনাম JS-এর risk মেপে চারটি চিত্র: 8-3-risk-vs-p (MLE-risk \(=p\) বনাম JS-risk \(<p\)), 8-3-shrinkage (কেন্দ্রের দিকে টান, before/after), 8-3-risk-vs-theta (লাভ সর্বোচ্চ \(\lVert\theta\rVert=0\)-এ), 8-3-real-data (breast_cancer-এর group-mean raw বনাম shrunk, মোট MSE)।
- §৭ অনুশীলনী, §৮ সারসংক্ষেপ ও সংযোগ।
২ · মূল ধারণা ও পদ্ধতি¶
এই অংশে সব বস্তুর precise সংজ্ঞা ও বিবৃতি এক জায়গায়। উদ্দেশ্য — §৩-এর উদাহরণ ও §৫-এর সিমুলেশনের আগে একটা পরিষ্কার রেফারেন্স। ভারী প্রমাণ (SURE, risk-পরিচয়) §৪-এ স্থগিত, স্পষ্ট forward pointer সহ।
২.১ setup ও MLE¶
setup (canonical normal-means সমস্যা)। একটা অজানা vector \(\theta=(\theta_1,\dots,\theta_p)\in\mathbb R^p\) estimate করতে হবে। পাওয়া যায় একটা একক পর্যবেক্ষণ-vector $$ X=(X_1,\dots,X_p),\qquad X_i\sim N(\theta_i,1)\ \text{স্বাধীন},\quad\text{অর্থাৎ}\ X\sim N(\theta,I_p), $$ যেখানে \(I_p\) হলো \(p\times p\) একক-ম্যাট্রিক্স (identity)। খেয়াল করুন প্রতিটি \(\theta_i\)-এর জন্য ঠিক একটি সংখ্যা — কোনো নমুনা-গড় নয়, একটি মাত্র observation (variance জানা, \(=1\))। এটাই setup-টাকে চমকপ্রদ করে: প্রতিটা coordinate সম্পূর্ণ আলাদাভাবে দেখলে একটা মাত্র তথ্য।
maximum likelihood estimator (MLE)। \(N(\theta,I_p)\)-এর log-likelihood \(-\frac12\lVert X-\theta\rVert^2+\text{const}\); একে সর্বাধিক করে \(\theta=X\)। তাই $$ \boxed{\ \hat\theta^{MLE}=X\ } $$ প্রতিটি coordinate তার নিজের observation। এটা unbiased (\(\mathbb E[\hat\theta^{MLE}]=\theta\)), এবং \(p=1\)-এ অকাট্যভাবে সেরা।
২.২ James–Stein estimator¶
James–Stein estimator (JS)। সংজ্ঞা — $$ \boxed{\ \hat\theta^{JS}=\Big(1-\frac{p-2}{\lVert X\rVert^2}\Big)X\ },\qquad \lVert X\rVert^2=\sum_{i=1}^p X_i^2. $$ একটা scalar shrinkage factor \(c(X)=1-\frac{p-2}{\lVert X\rVert^2}\) দিয়ে পুরো vector গুণ করা। কিছু লক্ষণীয় দিক:
- \(\lVert X\rVert^2\) বড় (data কেন্দ্র থেকে দূরে) হলে factor \(\approx1\) — সামান্য shrink; \(\lVert X\rVert^2\) ছোট (data কেন্দ্রের কাছে) হলে factor অনেক ছোট — জোর shrink। অর্থাৎ JS অভিযোজিত (adaptive): কতটা টানবে তা ডেটাই ঠিক করে।
- constant \(p-2\) ঠিক এই মানই কেন — §৪-এর SURE-প্রমাণ দেখাবে এটাই risk-কে সর্বোত্তম করে (এবং \(p\ge3\) লাগে, নাহলে \(p-2\le0\))।
- factor ঋণাত্মক হতে পারে (যখন \(\lVert X\rVert^2<p-2\)) — তখন JS estimate ০-র উল্টো পাশে চলে যায়, যা অর্থহীন। এর সংশোধন —
positive-part James–Stein। $$ \hat\theta^{JS+}=\Big(1-\frac{p-2}{\lVert X\rVert^2}\Big)^{!+}X,\qquad (a)^+=\max(0,a), $$ যা factor-কে ঋণাত্মক হতে দেয় না (worst case পুরো ০-তে shrink)। এটি সাধারণ JS-কেও dominate করে (আরও কম risk), তাই বাস্তবে এটাই ব্যবহার্য।
২.৩ risk, dominance ও admissibility¶
risk (of an estimator)। quadratic loss-এর অধীনে একটা estimator \(\hat\theta\)-এর risk হলো তার মোট প্রত্যাশিত বর্গ-ত্রুটি (total mean squared error): $$ R(\hat\theta,\theta)=\mathbb E\big\lVert\hat\theta-\theta\big\rVert^2=\sum_{i=1}^p\mathbb E\big[(\hat\theta_i-\theta_i)^2\big]. $$ \(\theta\)-এর একটা ফাংশন — একটা estimator-কে তার পুরো risk-বক্ররেখা (\(\theta\)-জুড়ে) দিয়ে বিচার করা হয়।
MLE-র risk। \(R(\hat\theta^{MLE},\theta)=\sum_i\operatorname{Var}(X_i)=p\) — সমতল, \(\theta\)-নিরপেক্ষ (২.১-এর ব্যাখ্যা)।
dominance ও admissibility। একটা estimator \(\hat\theta_1\) dominate করে \(\hat\theta_2\)-কে (quadratic loss-এ) যদি $$ R(\hat\theta_1,\theta)\le R(\hat\theta_2,\theta)\ \ \forall\theta,\qquad\text{এবং}\qquad R(\hat\theta_1,\theta_0)<R(\hat\theta_2,\theta_0)\ \text{অন্তত এক}\ \theta_0. $$ একটা estimator admissible যদি কোনো estimator তাকে dominate না করে; নাহলে inadmissible। Stein-এর ফল: \(\hat\theta^{MLE}=X\) inadmissible যখন \(p\ge3\) (JS তাকে dominate করে); \(p\le2\)-তে admissible।
২.৪ shrinkage-এর অর্থ: bias–variance, Bayes ও ridge¶
shrinkage estimator। যে estimator raw estimate-কে একটা কেন্দ্র (এখানে ০, বা সাধারণভাবে যেকোনো লক্ষ্য) -এর দিকে টেনে আনে। JS-এর shrinkage-এর যুক্তি ঠিক bias–variance বিনিময় (← 4.4): coordinate-প্রতি MSE = bias² + variance; MLE-র bias \(0\), variance \(1\); shrink করলে variance কমে (factor²-গুণ) কিন্তু bias বাড়ে — \(p\ge3\)-তে variance-সাশ্রয় জেতে, মোট risk নামে।
empirical-Bayes সংযোগ (← 4.10)। যদি prior \(\theta_i\sim N(0,\tau^2)\) (i.i.d.), তবে posterior-mean \(\mathbb E[\theta_i\mid X_i]=\frac{\tau^2}{\tau^2+1}X_i\) — একটা shrinkage factor \(B=\frac{\tau^2}{\tau^2+1}\in(0,1)\) দিয়ে ০-র দিকে টান। \(\tau^2\) অজানা হলে তা ডেটা থেকে estimate করা যায় (\(\lVert X\rVert^2\)-এর মাধ্যমে, কারণ marginally \(X_i\sim N(0,\tau^2+1)\)), আর তা করলে ঠিক James–Stein-এর \(1-\frac{p-2}{\lVert X\rVert^2}\) বেরিয়ে আসে। তাই JS = empirical-Bayes shrinkage।
ridge সংযোগ (← 6.2)। ridge coefficient-কে \(\frac{1}{1+\lambda}\)-ধাঁচে ০-র দিকে সংকুচিত করে (orthonormal case); JS estimate-কে \(1-\frac{p-2}{\lVert X\rVert^2}\)-ধাঁচে সংকুচিত করে। একই দর্শন — bias কিনে variance বেচা; JS ঐতিহাসিকভাবে shrinkage-এর আদি-রূপ, ridge তার regression-বংশধর।
২.৫ Stein's Unbiased Risk Estimate (SURE) ও risk-পরিচয়¶
James–Stein-এর risk হিসাব করার মূল যন্ত্র হলো Stein's Unbiased Risk Estimate (SURE) — একটা চমৎকার ধারণা: একটা estimator-এর risk-কে ডেটা থেকেই unbiased-ভাবে estimate করা, সত্যিকারের \(\theta\) না জেনেও।
Stein's lemma (মূল সরঞ্জাম)। যদি \(X\sim N(\theta,1)\) (এক-মাত্রা) এবং \(g\) যথেষ্ট মসৃণ (weakly differentiable, \(\mathbb E\lvert g'(X)\rvert<\infty\)), তবে $$ \mathbb E\big[(X-\theta)\,g(X)\big]=\mathbb E\big[g'(X)\big]. $$ (প্রমাণ §৪ — normal-density-র উপর integration by parts; মূল অভেদ \(f'(x)=-(x-\theta)f(x)\)।)
SURE (মূল ফল)। ধরা যাক estimator \(\hat\theta=X+g(X)\) (এখানে \(g:\mathbb R^p\to\mathbb R^p\) একটা \"সংশোধন\")। তখন Stein's lemma প্রতি-coordinate প্রয়োগ করে risk-এর একটা unbiased estimate: $$ \mathbb E\lVert\hat\theta-\theta\rVert^2=\mathbb E\Big[\,p+2\,\nabla!\cdot g(X)+\lVert g(X)\rVert^2\Big], $$ যেখানে \(\nabla\!\cdot g=\sum_i\frac{\partial g_i}{\partial x_i}\) (divergence)। বন্ধনীর ভেতরের রাশি — যাতে \(\theta\) নেই — হলো SURE: risk-এর একটা \(\theta\)-মুক্ত unbiased estimate।
James–Stein-এর risk-পরিচয়। JS-এ \(g(X)=-\frac{p-2}{\lVert X\rVert^2}X\) বসিয়ে (গণনা §৪) পাওয়া যায় সেই বিখ্যাত সমীকরণ: $$ \boxed{\ \mathbb E\big\lVert\hat\theta^{JS}-\theta\big\rVert^2=p-(p-2)^2\,\mathbb E\Big[\frac{1}{\lVert X\rVert^2}\Big]\ \le\ p\ } $$ সমতা কেবল সীমায় (\(\lVert\theta\rVert\to\infty\), যখন \(\mathbb E\frac{1}{\lVert X\rVert^2}\to0\))। যেহেতু \(\mathbb E\frac{1}{\lVert X\rVert^2}>0\) (এবং \(p\ge3\)-এ সসীম), JS-এর risk কঠোরভাবে \(p\)-এর নিচে প্রতিটি \(\theta\)-তে — এটাই dominance-এর প্রমাণ।
বিশেষ কেস \(\theta=0\)। তখন \(\lVert X\rVert^2\sim\chi^2_p\), আর \(\chi^2_p\)-এর inverse-moment (← 2.6) \(\mathbb E\frac{1}{\chi^2_p}=\frac{1}{p-2}\) (\(p\ge3\))। বসিয়ে $$ R_{JS}(0)=p-(p-2)^2\cdot\frac{1}{p-2}=p-(p-2)=2, $$ সব \(p\ge3\)-এর জন্য ঠিক ২ — মাত্রা যত বড়ই হোক। অর্থাৎ \(p=50\)-তে MLE-র risk \(50\), কিন্তু JS-এর risk (কেন্দ্রে) মাত্র \(2\) — ৯৬% পতন। এই সূত্রটাই \(p\ge3\) শর্তের উৎসও (নাহলে \(\frac{1}{p-2}\) অসীম/ঋণাত্মক)।
এক বাক্যে। SURE (Stein's lemma-চালিত risk-এর \(\theta\)-মুক্ত unbiased estimate) দেয় James–Stein-এর সঠিক risk \(\mathbb E\lVert\hat\theta^{JS}-\theta\rVert^2=p-(p-2)^2\mathbb E\frac{1}{\lVert X\rVert^2}\le p\) (সমতা কেবল সীমায়); বিশেষত \(\theta=0\)-তে \(R_{JS}(0)=p-(p-2)=2\) — dominance প্রমাণিত।
৩ · পূর্ণাঙ্গ উদাহরণ¶
নিচের উদাহরণগুলো §২-এর সংজ্ঞাগুলোকে হাতে-কলমে সংখ্যায় নামায় — risk কীভাবে হিসাব হয়, shrinkage factor কী করে, আর একটা draw-তে JS বনাম MLE কেমন দাঁড়ায়। কঠিনতা-চিহ্ন: ★ মৌলিক, ★★ একটু কৌশল।
উদাহরণ ১ — MLE-র risk ঠিক \(p\) কেন (★)¶
প্রশ্ন। দেখান MLE \(\hat\theta^{MLE}=X\)-এর risk প্রতিটি \(\theta\)-তে ঠিক \(p\)।
সমাধান। risk-এর সংজ্ঞা থেকে, $$ R(\hat\theta^{MLE},\theta)=\mathbb E\lVert X-\theta\rVert^2=\mathbb E\sum_{i=1}^p(X_i-\theta_i)^2=\sum_{i=1}^p\mathbb E[(X_i-\theta_i)^2]. $$ প্রতিটি \(X_i\sim N(\theta_i,1)\), তাই \(\mathbb E[(X_i-\theta_i)^2]=\operatorname{Var}(X_i)=1\)। যোগ করে \(R=\sum_{i=1}^p 1=p\) — \(\theta\)-নিরপেক্ষ, একটা সমতল রেখা। এটাই সেই বেঞ্চমার্ক যাকে JS হারায়। (সিমুলেশনে §৫: \(p=10\)-তে MLE-risk \(\approx9.96\), \(p=50\)-তে \(\approx50.08\) — তত্ত্ব \(p\)-এর কাছে।)
উদাহরণ ২ — shrinkage factor বোঝা (★)¶
প্রশ্ন। \(p=10\), আর একটা draw-তে \(\lVert X\rVert^2=25\) হলে JS-এর shrinkage factor কত? \(\lVert X\rVert^2=4\) হলে? ব্যাখ্যা করুন।
সমাধান। factor \(c=1-\frac{p-2}{\lVert X\rVert^2}=1-\frac{8}{\lVert X\rVert^2}\)। - \(\lVert X\rVert^2=25\): \(c=1-\frac{8}{25}=1-0.32=0.68\) — মাঝারি shrink (estimate ৩২% কেন্দ্রের দিকে)। - \(\lVert X\rVert^2=4\): \(c=1-\frac{8}{4}=1-2=-1\) — ঋণাত্মক! সাধারণ JS এখানে estimate-কে ০-র উল্টো পাশে ঠেলে দিত (অর্থহীন)। positive-part JS একে \(\max(0,-1)=0\) করে — পুরো ০-তে shrink।
শিক্ষা: data কেন্দ্রের কাছে (\(\lVert X\rVert^2\) ছোট) হলে JS জোরে টানে, আর খুব কাছে হলে positive-part সংশোধন লাগে। data দূরে (\(\lVert X\rVert^2\) বড়) হলে factor \(\to1\), প্রায় MLE।
উদাহরণ ৩ — একটা draw-তে JS বনাম MLE (★★)¶
প্রশ্ন। ধরা যাক \(p=5\), সত্যিকারের \(\theta=(0,0,0,0,0)\) (সব ০)। একটা draw-তে (গোলমাল সহ) \(X=(1.2,-0.8,0.5,-1.5,0.9)\) পাওয়া গেল। MLE ও JS estimate এবং তাদের এই-draw বর্গ-ত্রুটি তুলনা করুন।
সমাধান। প্রথমে \(\lVert X\rVert^2=1.2^2+0.8^2+0.5^2+1.5^2+0.9^2=1.44+0.64+0.25+2.25+0.81=5.39\)। factor \(c=1-\frac{p-2}{\lVert X\rVert^2}=1-\frac{3}{5.39}=1-0.5566=0.4434\)।
- MLE \(=X=(1.2,-0.8,0.5,-1.5,0.9)\); বর্গ-ত্রুটি \(\lVert X-\theta\rVert^2=\lVert X\rVert^2=5.39\) (যেহেতু \(\theta=0\))।
- JS \(=cX=0.4434\times(1.2,-0.8,0.5,-1.5,0.9)=(0.532,-0.355,0.222,-0.665,0.399)\); বর্গ-ত্রুটি \(\lVert cX-0\rVert^2=c^2\lVert X\rVert^2=0.4434^2\times5.39=0.1966\times5.39=1.06\)।
এই draw-তে JS-এর ত্রুটি \(1.06\) বনাম MLE-র \(5.39\) — নাটকীয়ভাবে ভালো, কারণ সত্যি \(\theta\) ঠিক কেন্দ্রে (০) আর JS কেন্দ্রের দিকে টেনেছে। সতর্কতা: এটা একটা draw; JS সব draw-তে জেতে না (যদি সত্যি \(\theta\) কেন্দ্র থেকে দূরে হতো, shrink ক্ষতি করত)। দাবিটা প্রত্যাশিত risk নিয়ে — বহু draw-এর গড়ে JS জেতে, যা §৫-এর Monte-Carlo দেখায়।
উদাহরণ ৪ — কেন লাভ \(\theta=0\)-তে সর্বোচ্চ (★★)¶
প্রশ্ন। risk-পরিচয় \(R_{JS}(\theta)=p-(p-2)^2\mathbb E\frac{1}{\lVert X\rVert^2}\) ব্যবহার করে যুক্তি দিন কেন JS-এর লাভ (MLE-র চেয়ে risk-হ্রাস) সবচেয়ে বড় যখন \(\theta\) shrinkage-কেন্দ্রের (০-র) কাছে, আর \(\lVert\theta\rVert\) বাড়লে লাভ কমে।
সমাধান। লাভ = \(R_{MLE}-R_{JS}=p-\big(p-(p-2)^2\mathbb E\frac1{\lVert X\rVert^2}\big)=(p-2)^2\,\mathbb E\frac{1}{\lVert X\rVert^2}\)। এটা সরাসরি \(\mathbb E\frac{1}{\lVert X\rVert^2}\)-এর সমানুপাতিক। - \(\theta=0\): \(\lVert X\rVert^2\sim\chi^2_p\) ছোট (কেন্দ্রে ঘন), তাই \(\mathbb E\frac{1}{\lVert X\rVert^2}=\frac{1}{p-2}\) সবচেয়ে বড় → লাভ সর্বোচ্চ, \(=(p-2)^2\cdot\frac{1}{p-2}=p-2\) (তাই \(R_{JS}(0)=p-(p-2)=2\))। - \(\lVert\theta\rVert\) বড়: \(\lVert X\rVert^2\) সাধারণত বড় (noncentral \(\chi^2\), কেন্দ্র থেকে দূরে), তাই \(\mathbb E\frac{1}{\lVert X\rVert^2}\) ছোট → লাভ কমে; \(\lVert\theta\rVert\to\infty\)-এ \(\mathbb E\frac{1}{\lVert X\rVert^2}\to0\), লাভ \(\to0\), \(R_{JS}\to p\)।
স্বজ্ঞা: shrinkage কেন্দ্রের দিকে টানে, তাই সত্যি \(\theta\) কেন্দ্রের যত কাছে, টানটা তত \"সঠিক দিকে\", লাভ তত বড়; \(\theta\) দূরে হলে JS কম টানে (factor \(\to1\)) — কখনো ক্ষতি করে না, কিন্তু লাভও কমে। §৫-এর চিত্র 8-3-risk-vs-theta ঠিক এই বক্ররেখা দেখায় (\(p=10\): লাভ \(\lVert\theta\rVert=0\)-তে \(\approx8\), \(\lVert\theta\rVert=12\)-তে \(\approx0.4\))।
৪ · প্রমাণ ও যুক্তি¶
এই অংশ প্যারাডক্সের গাণিতিক মেরুদণ্ড দাঁড় করায় — কেন MLE-র risk ঠিক \(p\), এবং SURE দিয়ে কীভাবে James–Stein-এর risk-পরিচয় বেরোয় যা প্রমাণ করে JS সর্বত্র MLE-কে dominate করে। কঠিনতা-চিহ্ন: ★ মৌলিক, ★★ মাঝারি (প্রথম পাঠে কাঠামো ধরাই যথেষ্ট)।
প্রমাণ ১ — MLE-র risk \(=p\) (★)¶
দাবি। \(R(\hat\theta^{MLE},\theta)=\mathbb E\lVert X-\theta\rVert^2=p\) প্রতিটি \(\theta\)-তে।
প্রমাণ। \(X\sim N(\theta,I_p)\), তাই \(X-\theta\sim N(0,I_p)\), অর্থাৎ coordinate-গুলো i.i.d. \(N(0,1)\)। তখন $$ \mathbb E\lVert X-\theta\rVert^2=\mathbb E\sum_{i=1}^p(X_i-\theta_i)^2=\sum_{i=1}^p\mathbb E[(X_i-\theta_i)^2]=\sum_{i=1}^p 1=p, $$ যেহেতু প্রতিটি \(\mathbb E[(X_i-\theta_i)^2]=\operatorname{Var}(X_i)=1\)। ∎ (এই সমতল risk = \(p\)-ই dominance-এর তুলনা-রেখা।)
প্রমাণ ২ — Stein's lemma (★★)¶
দাবি (এক-মাত্রা)। \(X\sim N(\theta,1)\), \(g:\mathbb R\to\mathbb R\) absolutely continuous ও \(\mathbb E\lvert g'(X)\rvert<\infty\) হলে $$ \mathbb E\big[(X-\theta)g(X)\big]=\mathbb E\big[g'(X)\big]. $$
প্রমাণ। \(f(x)=\frac{1}{\sqrt{2\pi}}e^{-(x-\theta)^2/2}\) হলো \(N(\theta,1)\)-এর density; মূল অভেদ $$ f'(x)=-(x-\theta)f(x)\quad\Longrightarrow\quad (x-\theta)f(x)=-f'(x). $$ তাই $$ \mathbb E[(X-\theta)g(X)]=\int_{-\infty}^\infty g(x)(x-\theta)f(x)\,dx=-\int_{-\infty}^\infty g(x)f'(x)\,dx. $$ অংশিক-সমাকলন (integration by parts), সীমা-পদ \([-g(x)f(x)]_{-\infty}^\infty=0\) (normal density দ্রুত ০-তে যায়): $$ =-\Big([g(x)f(x)]_{-\infty}^\infty-\int g'(x)f(x)\,dx\Big)=\int g'(x)f(x)\,dx=\mathbb E[g'(X)]. \qquad\blacksquare $$ এটাই SURE-এর একক ইট: \"\((X-\theta)\)-গুণ প্রত্যাশা\"-কে \"derivative-প্রত্যাশা\"-য় বদলে \(\theta\) সরিয়ে দেয়।
প্রমাণ ৩ — SURE ও James–Stein-এর risk-পরিচয় (★★, the core)¶
দাবি। estimator \(\hat\theta=X+g(X)\) (\(g:\mathbb R^p\to\mathbb R^p\) মসৃণ) হলে $$ \mathbb E\lVert\hat\theta-\theta\rVert^2=\mathbb E\big[p+2\,\nabla!\cdot g(X)+\lVert g(X)\rVert^2\big], $$ এবং James–Stein-এ (\(g(X)=-\frac{p-2}{\lVert X\rVert^2}X\)) এটি দাঁড়ায় $$ \mathbb E\lVert\hat\theta^{JS}-\theta\rVert^2=p-(p-2)^2\,\mathbb E\Big[\frac{1}{\lVert X\rVert^2}\Big]. $$
প্রমাণ — ধাপ ১ (SURE সাধারণ রূপ)। লিখি \(\hat\theta-\theta=(X-\theta)+g(X)\), তাই $$ \lVert\hat\theta-\theta\rVert^2=\lVert X-\theta\rVert^2+2\,(X-\theta)^\top g(X)+\lVert g(X)\rVert^2. $$ প্রত্যাশা নিই: প্রথম পদ \(\mathbb E\lVert X-\theta\rVert^2=p\) (প্রমাণ ১)। মাঝের পদে coordinate-ভিত্তিক Stein's lemma (প্রমাণ ২, প্রতি \(i\)-তে \(g_i\)-র সাথে): $$ \mathbb E\big[(X_i-\theta_i)g_i(X)\big]=\mathbb E\Big[\frac{\partial g_i}{\partial x_i}(X)\Big]\ \Longrightarrow\ \mathbb E\big[(X-\theta)^\top g(X)\big]=\mathbb E\Big[\sum_i\frac{\partial g_i}{\partial x_i}\Big]=\mathbb E[\nabla!\cdot g]. $$ সব জুড়ে \(\mathbb E\lVert\hat\theta-\theta\rVert^2=p+2\,\mathbb E[\nabla\!\cdot g]+\mathbb E\lVert g\rVert^2\) — বন্ধনীর রাশিতে \(\theta\) নেই, তাই এটাই unbiased risk estimate (SURE)।
ধাপ ২ (James–Stein-এ বসানো)। এখানে \(g(X)=-\frac{p-2}{\lVert X\rVert^2}X\), অর্থাৎ \(g_i(X)=-(p-2)\frac{x_i}{\lVert x\rVert^2}\) (যেখানে \(\lVert x\rVert^2=\sum_j x_j^2\))। দুটো পদ চাই:
(ক) \(\lVert g\rVert^2\): $$ \lVert g\rVert^2=(p-2)^2\frac{\sum_i x_i^2}{(\lVert x\rVert^2)^2}=(p-2)^2\frac{\lVert x\rVert^2}{(\lVert x\rVert^2)^2}=\frac{(p-2)^2}{\lVert x\rVert^2}. $$
(খ) \(\nabla\!\cdot g\): প্রতি \(i\)-তে \(\frac{\partial}{\partial x_i}\Big(-(p-2)\frac{x_i}{\lVert x\rVert^2}\Big)\)। quotient-নিয়মে, $$ \frac{\partial}{\partial x_i}\frac{x_i}{\lVert x\rVert^2}=\frac{1\cdot\lVert x\rVert^2-x_i\cdot 2x_i}{(\lVert x\rVert^2)^2}=\frac{\lVert x\rVert^2-2x_i^2}{(\lVert x\rVert^2)^2}. $$ \(i\)-জুড়ে যোগ (\(\sum_i\lVert x\rVert^2=p\lVert x\rVert^2\), \(\sum_i 2x_i^2=2\lVert x\rVert^2\)): $$ \nabla!\cdot g=-(p-2)\sum_i\frac{\lVert x\rVert^2-2x_i^2}{(\lVert x\rVert^2)^2}=-(p-2)\frac{p\lVert x\rVert^2-2\lVert x\rVert^2}{(\lVert x\rVert^2)^2}=-(p-2)\frac{(p-2)\lVert x\rVert^2}{(\lVert x\rVert^2)^2}=-\frac{(p-2)^2}{\lVert x\rVert^2}. $$
ধাপ ৩ (একত্র)। SURE-এ বসাই: $$ \mathbb E\lVert\hat\theta^{JS}-\theta\rVert^2=p+2\,\mathbb E\Big[-\frac{(p-2)^2}{\lVert X\rVert^2}\Big]+\mathbb E\Big[\frac{(p-2)^2}{\lVert X\rVert^2}\Big]=p-2A+A, $$ যেখানে \(A=(p-2)^2\,\mathbb E\dfrac{1}{\lVert X\rVert^2}\) (দুই প্রত্যাশা-পদ একই); তাই \(-2A+A=-A\): $$ \boxed{\ \mathbb E\lVert\hat\theta^{JS}-\theta\rVert^2=p-(p-2)^2\,\mathbb E\Big[\frac{1}{\lVert X\rVert^2}\Big]\ }. \qquad\blacksquare $$
প্রমাণ ৪ — dominance ও কেন \(p\ge3\) (★)¶
দাবি। \(p\ge3\)-তে \(R_{JS}(\theta)<p=R_{MLE}(\theta)\) প্রতিটি \(\theta\)-তে (dominance); \(p\le2\)-তে সূত্র ভেঙে পড়ে।
প্রমাণ। প্রমাণ ৩ থেকে \(R_{JS}(\theta)=p-(p-2)^2\mathbb E\frac{1}{\lVert X\rVert^2}\)। এখন: - \(p\ge3\): তখন \((p-2)^2>0\), এবং \(\mathbb E\frac{1}{\lVert X\rVert^2}>0\) ও সসীম (এমনকি worst case \(\theta=0\)-তেও, যেখানে \(\lVert X\rVert^2\sim\chi^2_p\) ও \(\mathbb E\frac1{\chi^2_p}=\frac1{p-2}<\infty\) ঠিক \(p\ge3\)-এ, ← 2.6)। তাই বিয়োগ-পদটা কঠোরভাবে ধনাত্মক, \(R_{JS}(\theta)<p\) সর্বত্র — dominance। সমতা কেবল \(\lVert\theta\rVert\to\infty\)-এর সীমায় (\(\mathbb E\frac1{\lVert X\rVert^2}\to0\))। - \(p\le2\): \(p-2\le0\), তাই shrinkage factor \(1-\frac{p-2}{\lVert X\rVert^2}\ge1\) — JS estimate-কে সংকুচিত না করে বড় করে (উল্টো টান), risk কমায় না। আর \(\theta=0\)-তে \(\mathbb E\frac1{\chi^2_p}=\infty\) (\(p\le2\)) — risk-পরিচয়ের পদই অসংজ্ঞায়িত। তাই প্যারাডক্সটা কঠোরভাবে \(p\ge3\)-এর ঘটনা; \(p=1,2\)-তে MLE admissible। ∎
একটা মন্তব্য (worst-case ঝুঁকি)। \(\theta=0\)-তে \(\chi^2_p\)-এর inverse-moment বসিয়ে \(R_{JS}(0)=p-(p-2)=2\) — সব \(p\ge3\)-এ ঠিক \(2\)। এটাই সর্বোচ্চ লাভের বিন্দু (উদাহরণ ৪); আর যেহেতু \(R_{JS}\le p\) সর্বত্র, JS-এর সর্বোচ্চ risk (worst-case over \(\theta\)) \(p\)-এর সমান (সীমায়) — অর্থাৎ JS সবচেয়ে খারাপ ক্ষেত্রেও MLE-র সমান, আর বাকি সর্বত্র ভালো।
৫ · কোড ল্যাব (Python)¶
এই অধ্যায়ের গোটা দাবি — Stein-এর প্যারাডক্স ও James–Stein estimator-এর dominance — একটা তত্ত্ব; একটা capstone-প্রকল্পের কাজ হলো তা নিজের কোডে Monte-Carlo সিমুলেশনে ফিরে পাওয়া। একটিমাত্র runnable স্ক্রিপ্ট পাঁচ ধাপে সেই পুনরুৎপাদন সম্পূর্ণ করে: (১) বিভিন্ন মাত্রা \(p\)-তে MLE-risk (\(\approx p\)) বনাম JS-risk (\(<p\)) মেপে dominance দেখা; (২) SURE-পরিচয় \(p-(p-2)^2\mathbb E\frac1{\lVert X\rVert^2}\)-কে Monte-Carlo risk-এর সাথে মিলিয়ে \(\theta=0\)-তে \(R_{JS}(0)=2\) যাচাই; (৩) \(\lVert\theta\rVert\) বাড়িয়ে লাভ কমে \(R_{JS}\to p\) দেখা; (৪) একটা draw-তে shrinkage-এর ছবি; আর (৫) একটা বাস্তব dataset-এ (sklearn breast_cancer-এর ৩০টি feature-গড়) raw group-mean-দের grand mean-এর দিকে shrink করলে মোট MSE কমে — ব্যবহারিক পুরস্কার। নির্ভরতা numpy, scipy, sklearn.datasets, matplotlib (Agg)।
স্ক্রিপ্টের কাঠামো ও পুনরুৎপাদনযোগ্যতা (reproducibility)¶
পুরো ল্যাবটা একটাই runnable স্ক্রিপ্ট — _code/lab_8-3.py (Part VIII-এর part-8-capstone/_code/ ডিরেক্টরিতে) — পাঁচটি ব্যাখ্যাযুক্ত অংশে ভাগ। সব random draw একটিমাত্র generator থেকে — np.random.default_rng(20260619) — এবং default_rng-এর ফল স্রোত থেকে টানার ক্রমের উপর নির্ভরশীল, তাই ফল পুনরুৎপাদনযোগ্য রাখতে নিচের ক্রমেই টানা হয়: Part 1 (প্রতিটি \(p\)-তে \(\theta=0\)-এ \(X\sim N(0,I_p)\)-এর (REPS, p) matrix, \(p\)-ক্রমে), Part 2 (Part 1-এর draw পুনর্ব্যবহার, নতুন draw নেই), Part 3 (প্রতিটি \(\lVert\theta\rVert\)-এ (REPS, 10) matrix), Part 4 (একটা p=12 vector), Part 5 (বাস্তব-ডেটা group-mean-এর subsample — একটা fresh child-generator একই master seed থেকে)। প্রতি configuration-এ REPS = 20000 replication। set-up লাইন:
import numpy as np
from scipy import stats
from sklearn.datasets import load_breast_cancer
import matplotlib
matplotlib.use("Agg") # write PNGs, never show
import matplotlib.pyplot as plt
np.set_printoptions(precision=4, suppress=True)
SEED = 20260619
rng = np.random.default_rng(SEED) # one master generator; drawn in order
REPS = 20_000 # Monte-Carlo replications per config
দুটো core estimator — James–Stein ও তার positive-part রূপ — আর একটা risk-মাপক:
def js_estimate(X): # theta_JS = (1 - (p-2)/||X||^2) X
X = np.atleast_2d(X); p = X.shape[1]
sq = np.sum(X**2, axis=1, keepdims=True) # ||X||^2 per row
return (1.0 - (p - 2) / sq) * X
def js_positive_estimate(X): # positive-part: max(0, factor) X
X = np.atleast_2d(X); p = X.shape[1]
sq = np.sum(X**2, axis=1, keepdims=True)
return np.maximum(0.0, 1.0 - (p - 2) / sq) * X
def total_risk(est, theta): # Monte-Carlo E||est - theta||^2
err2 = np.sum((est - theta[None, :])**2, axis=1)
return err2.mean(), err2.std(ddof=1) / np.sqrt(err2.shape[0])
৫.১ · Stein-এর প্যারাডক্স: MLE-risk \(=p\) বনাম JS-risk \(<p\) (\(\theta=0\))¶
প্রথম ও কেন্দ্রীয় পুনরুৎপাদন: বিভিন্ন মাত্রা \(p\)-তে সত্যিকারের \(\theta=0\) ধরে (যেখানে JS সবচেয়ে বেশি জেতে) REPS বার \(X\sim N(0,I_p)\) টেনে MLE (\(\hat\theta=X\)), JS ও positive-part JS-এর মোট risk \(\mathbb E\lVert\hat\theta-\theta\rVert^2\) মাপা হয়, পাশাপাশি SURE-মান \(p-(p-2)^2\overline{1/\lVert X\rVert^2}\)।
P_GRID = [1, 2, 3, 5, 10, 20, 50]
for p in P_GRID:
theta = np.zeros(p)
X = rng.standard_normal((REPS, p)) # X ~ N(0, I_p)
r_mle, _ = total_risk(X, theta) # MLE risk
r_js, _ = total_risk(js_estimate(X), theta) # James-Stein risk
r_jsp, _ = total_risk(js_positive_estimate(X), theta)
sq = np.sum(X**2, axis=1)
sure = p - (p - 2)**2 * np.mean(1.0 / sq) if p >= 3 else float("nan")
# ... print p, r_mle (=p), r_js, r_jsp, % drop, sure ...
বাস্তব আউটপুট (real stdout):
PART 1 -- Stein's paradox: MLE risk = p vs JS risk < p (theta=0)
Monte-Carlo: REPS = 20000 per dimension p; X ~ N(0, I_p).
p | R_MLE (=p) | R_JS | R_JS+ | % drop | SURE R_JS
----------------------------------------------------------------------
1 | 1.0096 | 15627.8523 | 15627.8523 | -1547900.3% | (inf)
2 | 2.0200 | 2.0200 | 2.0200 | 0.0% | (inf)
3 | 2.9829 | 1.9885 | 1.5906 | 33.3% | 1.9944
5 | 4.9881 | 1.9926 | 1.3887 | 60.1% | 1.9955
10 | 9.9626 | 1.9757 | 1.2333 | 80.2% | 1.9869
20 | 20.0115 | 1.9831 | 1.1765 | 90.1% | 2.0285
50 | 50.0752 | 1.9614 | 1.0982 | 96.1% | 2.1138
পড়া: \(R_{MLE}\) প্রায় ঠিক \(p\) (\(p=50\)-তে \(50.08\), তত্ত্ব \(50\))। \(p\ge3\)-তে \(R_{JS}\) কঠোরভাবে \(p\)-এর নিচে — dominance চোখে; আর মাত্রা যত বাড়ে লাভ তত বড় (\(p=50\)-তে ৯৬% risk-হ্রাস)। \(p=1\)-এ JS অর্থহীন (factor ঋণাত্মক, risk বিস্ফোরিত), \(p=2\)-তে \(p-2=0\) তাই JS=MLE — প্যারাডক্স ঠিক \(p\ge3\) থেকে। Monte-Carlo \(R_{JS}\) ও SURE-মান কাছাকাছি — Stein-এর risk-পরিচয় সংখ্যায় নিশ্চিত।
৫.২ · SURE-পরিচয় \(\theta=0\)-তে: \(R_{JS}(0)=p-(p-2)=2\)¶
দ্বিতীয় ধাপ risk-পরিচয়টা সরাসরি যাচাই করে: \(\theta=0\)-তে \(\lVert X\rVert^2\sim\chi^2_p\), তাই \(\mathbb E\frac1{\lVert X\rVert^2}=\frac1{p-2}\), আর সূত্র বলে \(R_{JS}(0)=p-(p-2)^2/(p-2)=2\) — সব \(p\ge3\)-এ। তিনটে কলাম — Monte-Carlo \(R_{JS}\), plug-in SURE, আর বদ্ধ-রূপ \(2\) — মেলানো হয়।
for p in [3, 5, 10, 20, 50]:
X = part1[p]["X"]; sq = np.sum(X**2, axis=1)
e_inv_mc = np.mean(1.0 / sq) # E[1/||X||^2], MC
e_inv_th = 1.0 / (p - 2) # theory: 1/chi^2_p mean
# closed-form R_JS(0) = 2; compare with MC r_js and SURE plug-in
বাস্তব আউটপুট:
PART 2 -- SURE identity at theta = 0: R_JS(0) = p - (p-2) = 2
p | R_JS (MC) | SURE plug-in | closed form | E[1/chi^2] MC | 1/(p-2)
--------------------------------------------------------------------------
3 | 1.9885 | 1.9944 | 2.0000 | 1.0056 | 1.0000
5 | 1.9926 | 1.9955 | 2.0000 | 0.3338 | 0.3333
10 | 1.9757 | 1.9869 | 2.0000 | 0.1252 | 0.1250
20 | 1.9831 | 2.0285 | 2.0000 | 0.0555 | 0.0556
50 | 1.9614 | 2.1138 | 2.0000 | 0.0208 | 0.0208
তিনটে risk-কলামই \(2\)-এর কাছে — মাত্রা-নিরপেক্ষ। আর \(\mathbb E\frac1{\lVert X\rVert^2}\)-এর Monte-Carlo মান তত্ত্ব \(\frac1{p-2}\)-এর সাথে চার দশমিক পর্যন্ত মেলে (যেমন \(p=10\): \(0.1252\) বনাম \(0.1250\))। অর্থাৎ \(p=50\)-তে risk \(50\to2\) — এক বিশাল পতন, যার পুরোটাই shrinkage-এর bias-for-variance বিনিময়।
৫.৩ · risk বনাম \(\lVert\theta\rVert\): লাভ সর্বোচ্চ কেন্দ্রে¶
তৃতীয় ধাপ দেখায় লাভ \(\theta\)-এর উপর কীভাবে নির্ভর করে। \(p=10\) স্থির রেখে সব signal প্রথম coordinate-এ রেখে (\(\theta=(\lVert\theta\rVert,0,\dots,0)\)) \(\lVert\theta\rVert\) বাড়ানো হয়। তত্ত্ব (উদাহরণ ৪): লাভ \(=(p-2)^2\mathbb E\frac1{\lVert X\rVert^2}\) কমে, \(R_{JS}\to p\)।
P3 = 10
for c in [0.0, 1.0, 2.0, 3.0, 5.0, 8.0, 12.0]:
theta = np.zeros(P3); theta[0] = c
X = theta[None, :] + rng.standard_normal((REPS, P3)) # X ~ N(theta, I)
r_mle, _ = total_risk(X, theta)
r_js, _ = total_risk(js_estimate(X), theta)
# ... print ||theta||, r_mle (=p), r_js, % drop ...
বাস্তব আউটপুট:
PART 3 -- risk vs ||theta|| (p = 10): gain largest at ||theta||=0
||theta|| | R_MLE (=p) | R_JS | % drop
----------------------------------------------
0.0 | 9.9936 | 2.0059 | 79.9%
1.0 | 9.9356 | 2.7630 | 72.2%
2.0 | 9.9940 | 4.3778 | 56.2%
3.0 | 9.9671 | 5.9719 | 40.1%
5.0 | 9.9533 | 7.9310 | 20.3%
8.0 | 9.9917 | 9.0872 | 9.1%
12.0 | 10.0073 | 9.5849 | 4.2%
\(R_{MLE}\) সমতল \(\approx10\) (signal-নিরপেক্ষ)। \(R_{JS}\) কেন্দ্রে (\(\lVert\theta\rVert=0\)) মাত্র \(2.0\), আর \(\lVert\theta\rVert\) বাড়লে ক্রমে \(p=10\)-এর দিকে ওঠে — কিন্তু কখনো ছাড়ায় না। এটাই dominance-এর পূর্ণ ছবি: JS সব \(\theta\)-তে জেতে বা সমান, লাভ কেবল কেন্দ্রের কাছে সবচেয়ে বড়।
৫.৪ · বাস্তব-ডেটা পুরস্কার: group-mean shrinkage (breast_cancer)¶
শেষ ধাপ সিমুলেশন থেকে বাস্তবে সেতু বাঁধে। sklearn breast_cancer-এর ৩০টি feature-কে standardize করে, তাদের malignant-শ্রেণির পূর্ণ-নমুনা গড়কে ground-truth group-mean \(\theta_i\) ধরা হয় (\(p=30\))। প্রতিটি \(\theta_i\)-এর একটা noisy unbiased estimate \(X_i\) = ছোট subsample (\(n=8\) সারি)-এর গড় — তাই \(X_i\sim N(\theta_i,\sigma_i^2)\), \(\sigma_i^2\) জানা। দুই প্রতিযোগী: raw group-mean \(X\) (unbiased, high-variance) বনাম James–Stein যা \(X\)-কে grand mean \(m=\overline{\theta}\)-এর দিকে shrink করে। যেহেতু dominance একটা প্রত্যাশিত-risk বিবৃতি (§৩ উদাহরণ ৩), পুরস্কার মাপা হয় প্রত্যাশিত মোট MSE দিয়ে — \(B=4000\) random subsample-এর গড়ে।
data = load_breast_cancer()
Xs = (data.data - data.data.mean(0)) / data.data.std(0) # standardise
mal = Xs[data.target == 0] # malignant rows
theta_true = mal.mean(axis=0) # ground-truth means
grand = theta_true.mean() # shrink target
p5, n_sub = 30, 8
sigma2 = float(np.mean(mal.std(axis=0)**2 / n_sub)) # known noise var
def js_toward_grand(X): # shrink toward grand mean (empirical-Bayes form)
d = X - grand; S = float(np.sum(d**2))
shrink = max(0.0, 1.0 - (p5 - 3) * sigma2 / S) # p-3: target estimated
return grand + shrink * d
child = np.random.default_rng(SEED); B = 4000
acc_raw = acc_js = 0.0
for _ in range(B):
idx = child.choice(mal.shape[0], size=n_sub, replace=False)
raw = mal[idx].mean(axis=0) # noisy raw means
js = js_toward_grand(raw)
acc_raw += np.sum((raw - theta_true)**2) # total MSE, raw
acc_js += np.sum((js - theta_true)**2) # total MSE, shrunk
# E[MSE raw], E[MSE js], reduction %
বাস্তব আউটপুট:
PART 5 -- real data (breast_cancer): shrink 30 group means to grand
p = 30 feature means; noisy raw means from n = 8 rows;
known avg noise variance sigma^2 = 0.1245; target = grand mean.
grand mean m (shrink target) = +0.6022
averaged over B = 4000 random subsamples (EXPECTED total MSE):
avg shrinkage factor = 0.4280
E[total MSE], RAW group means = 3.6144
E[total MSE], SHRUNK (James-Stein) = 2.4220
total-MSE reduction from shrinkage = 33.0%
single-draw win rate (shrunk MSE < raw MSE) = 75.8% (3034/4000)
one representative draw: shrink factor = 0.4205; MSE raw = 3.7470, MSE shrunk = 2.1857
পড়া: বাস্তব feature-গড়ে raw estimate-দের grand mean-এর দিকে shrink করলে প্রত্যাশিত মোট MSE \(3.61\to2.42\) — ৩৩% হ্রাস। একক draw-তেও ৭৫.৮% ক্ষেত্রে shrinkage জেতে (বাকি ২৪% \"হারে\" — কারণ dominance গড়ের বিবৃতি, প্রতিটি draw-এর নয়, ঠিক §৩ উদাহরণ ৩-এর সতর্কতা)। একটা প্রতিনিধিত্বমূলক draw-এ shrinkage factor \(0.42\), MSE \(3.75\to2.19\)। অর্থাৎ Stein-এর প্যারাডক্স নিছক তাত্ত্বিক কৌতূহল নয় — একাধিক group-mean একসাথে estimate করার যেকোনো বাস্তব সমস্যায় (batting averages, ছোট-এলাকার জরিপ, বহু-দল পরীক্ষা) shrinkage মোট নির্ভুলতা বাড়ায়।
সারসংক্ষেপ¶
পাঁচ ধাপ মিলে Stein-এর প্যারাডক্স সম্পূর্ণ পুনরুৎপাদিত: (৫.১) MLE-risk \(=p\) বনাম JS-risk \(<p\), \(p\ge3\)-তে dominance ও মাত্রা-সহ বর্ধমান লাভ; (৫.২) SURE-পরিচয় ও \(R_{JS}(0)=2\) সংখ্যায় নিশ্চিত; (৫.৩) লাভ কেন্দ্রে সর্বোচ্চ, \(\lVert\theta\rVert\)-সহ ক্ষয়; (৫.৪) বাস্তব breast_cancer-ডেটায় group-mean shrinkage-এ ৩৩% প্রত্যাশিত-MSE হ্রাস। canonical সংখ্যা: \(R_{MLE}\approx p\); \(R_{JS}(0)\approx2\) সব \(p\ge3\)-এ; \(p=10\)-তে ৮০%, \(p=50\)-তে ৯৬% risk-হ্রাস; বাস্তব-ডেটা E[MSE] \(3.61\to2.42\) (৩৩% হ্রাস, ৭৫.৮% single-draw win); seed default_rng(20260619)।
৬ · ভিজ্যুয়ালাইজেশন¶
এই অধ্যায়ের চারটি figure Stein-এর প্যারাডক্সের চার মুখ চোখে দেখায় — একই স্ক্রিপ্ট _code/lab_8-3.py সেগুলো তৈরি করে (seed np.random.default_rng(20260619)), figure-ভেতরের সব লেখা ইংরেজিতে (mathtext-নিরাপদ)। প্রথমটি dominance-এর মূল ছবি (MLE-risk \(=p\) বনাম JS-risk \(<p\)); দ্বিতীয়টি shrinkage-এর যন্ত্র (কেন্দ্রের দিকে টান); তৃতীয়টি লাভ কেন কেন্দ্রে সর্বোচ্চ; চতুর্থটি বাস্তব-ডেটায় পুরস্কার।
৬.১ · MLE-risk \(=p\) বনাম JS-risk \(<p\) — প্যারাডক্স চোখে¶
মূল ছবি: \(x\)-অক্ষে মাত্রা \(p\), \(y\)-অক্ষে মোট risk। MLE-র risk (কমলা) ঠিক identity-রেখা \(R=p\) বরাবর ওঠে — মাত্রা যত বাড়ে risk তত বাড়ে। James–Stein-এর risk (নীল) কিন্তু সমতল, প্রায় \(2\)-তে আটকে — \(p\) যত বড়ই হোক। ফাঁকটা মাত্রার সাথে হাঁ হয়ে যায়: এটাই \"Stein-এর প্যারাডক্স\"। positive-part JS (সবুজ) আরও সামান্য নিচে। বাঁ-প্রান্তে ছায়া-অঞ্চল (\(p\le2\)) মনে করায় প্যারাডক্স ঠিক \(p\ge3\) থেকে শুরু।
ps = P_GRID
r_mle = [part1[p]["r_mle"] for p in ps] # tracks identity R = p
r_js = [part1[p]["r_js"] for p in ps] # flat near 2
ax.plot(grid, grid, ls=":", label=r"identity $R=p$")
ax.plot(ps, r_mle, "o-", label=r"MLE $\hat\theta=X$ (risk $=p$)")
ax.plot(ps, r_js, "s-", label=r"James-Stein $(1-\frac{p-2}{|X|^2})X$")
ax.axhline(2.0, ls="--") # R_JS(0) = 2 for all p>=3
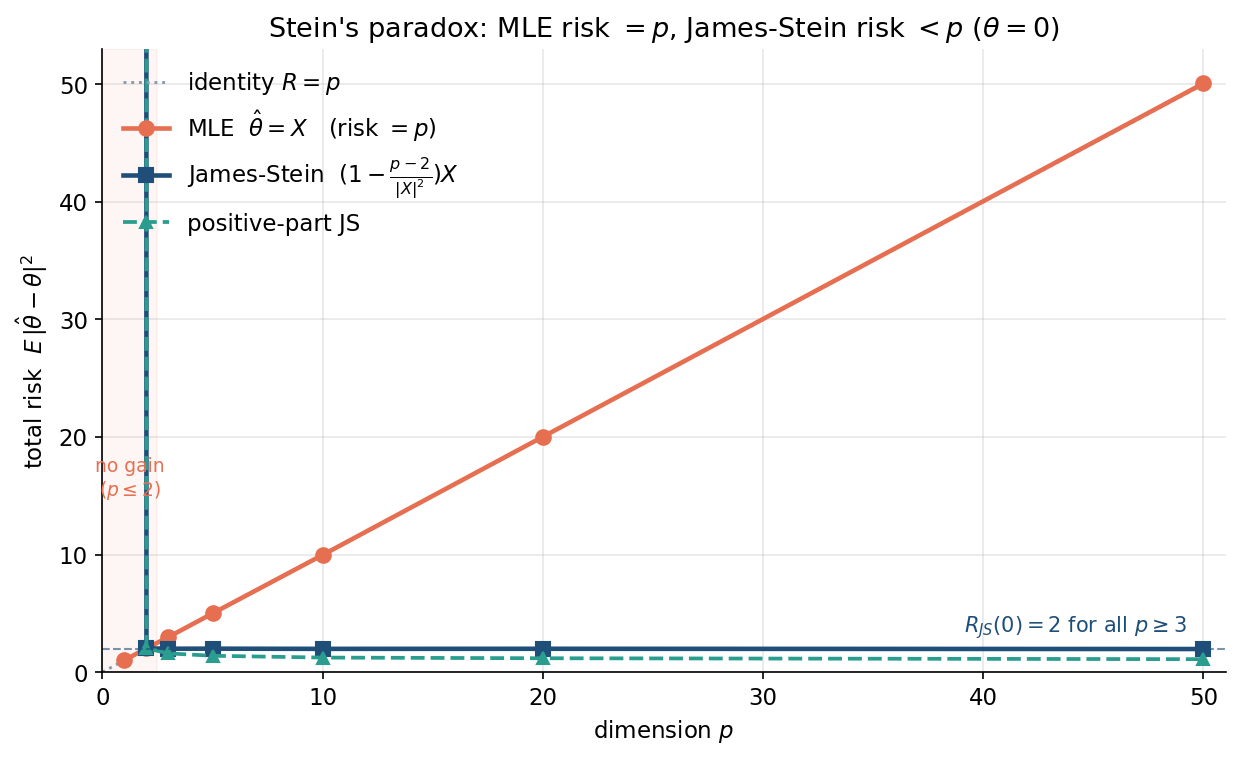
লক্ষণীয় — \(p=3\)-তে ফাঁক ছোট (risk \(3\) বনাম \(2\)), কিন্তু \(p=50\)-তে বিশাল (risk \(50\) বনাম \(2\))। মাত্রা যত বেশি, MLE-কে আলাদা-আলাদাভাবে estimate করার \"খরচ\" তত বড়, আর যৌথ shrinkage-এর লাভও তত বড়। এটাই কেন high-dimensional পরিসংখ্যানে shrinkage/regularization অপরিহার্য।
৬.২ · shrinkage-এর যন্ত্র — কেন্দ্রের দিকে টান (before/after)¶
দ্বিতীয় figure দেখায় JS আসলে কী করে। বাঁ-প্যানেলে একটা draw (\(p=12\))-এর প্রতিটি coordinate: raw \(X_i\) (কমলা বৃত্ত) থেকে তীর নেমে shrunk \(\hat\theta^{JS}_i\) (নীল বর্গ)-তে, সবই কেন্দ্র-রেখা ০-র দিকে; সত্যিকারের \(\theta_i\) (সবুজ ক্রস) তুলনার জন্য। ডান-প্যানেলে shrinkage-map: MLE হলো \(45°\)-রেখা (slope \(1\), কোনো shrink নয়), JS হলো slope \(<1\)-এর রেখা (\(0.896\)) — সব estimate একই factor দিয়ে গুণ হয়ে কেন্দ্রের দিকে নামে।
axL.plot(coords, X4, "o", label=r"raw $X_i$ (MLE)") # before
axL.plot(coords, js4, "s", label=r"shrunk $\hat\theta_{JS,i}$") # after
axL.plot(coords, theta4,"x", label=r"truth $\theta_i$")
# arrows X4 -> js4 show every coordinate pulled toward 0
axR.plot(xs, xs, ls=":", label="MLE: slope 1") # identity
axR.plot(xs, shrink_factor * xs, label=f"JS: slope {shrink_factor:.3f}")
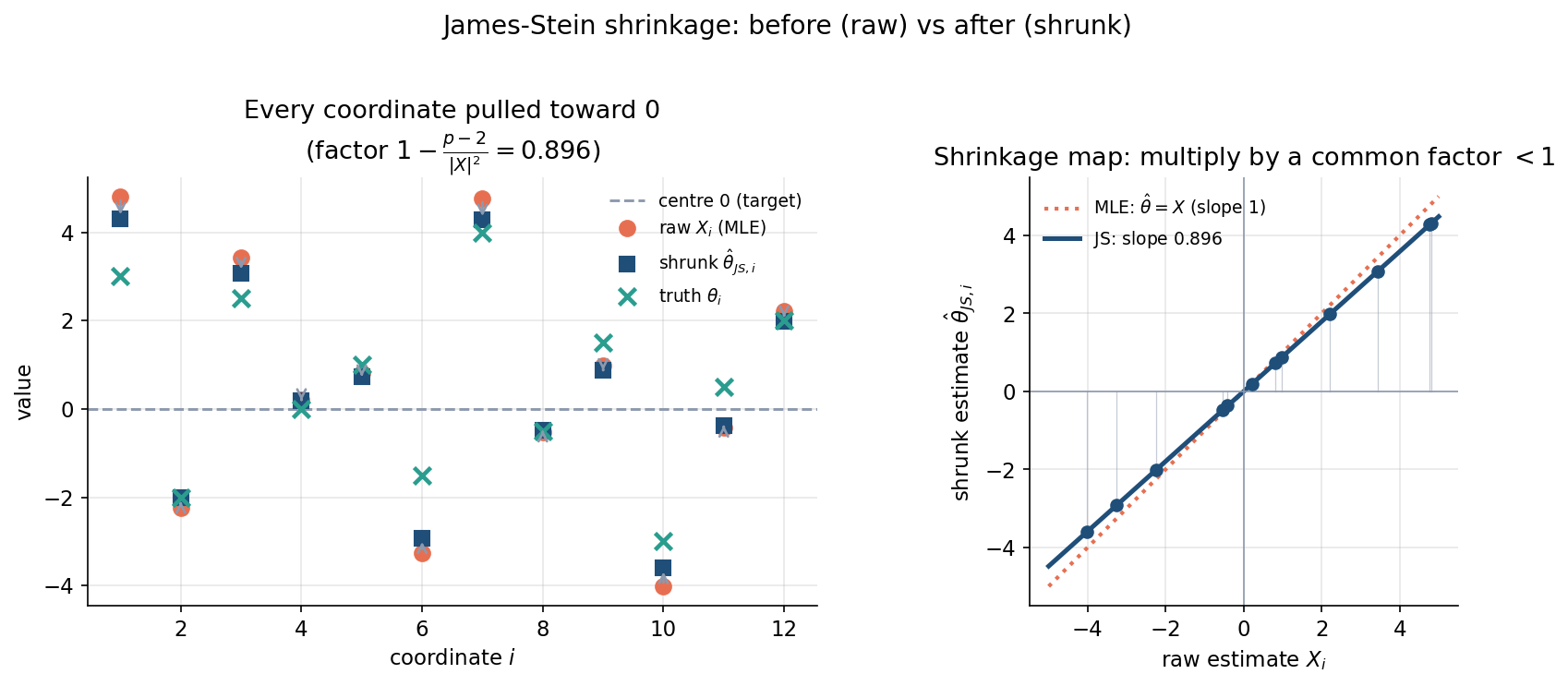
মূল insight: JS একটা সরল রৈখিক সংকোচন — কোনো coordinate-কে আলাদা করে বিচার করে না, সবাইকে একই common factor \(\big(1-\frac{p-2}{\lVert X\rVert^2}\big)\) দিয়ে কেন্দ্রের দিকে টানে। এই \"সবাইকে একসাথে টানা\"-ই coordinate-দের মধ্যে তথ্য ভাগ করে নেওয়ার (borrowing strength) কৌশল — যদিও তারা অসম্পর্কিত।
৬.৩ · লাভ কেন কেন্দ্রে সর্বোচ্চ¶
তৃতীয় figure dominance-এর সূক্ষ্মতা দেখায়: \(p=10\) স্থির, \(x\)-অক্ষে signal-আকার \(\lVert\theta\rVert\)। MLE-risk (কমলা) সমতল \(=p=10\) (signal যাই হোক)। JS-risk (নীল) কেন্দ্রে (\(\lVert\theta\rVert=0\)) মাত্র \(2\), তারপর \(\lVert\theta\rVert\) বাড়ার সাথে ক্রমে \(p=10\)-এর দিকে ওঠে — কিন্তু কখনো ছাড়ায় না। দুই বক্ররেখার মাঝের ছায়া-অঞ্চল = \"JS-এর বাঁচানো risk\", যা কেন্দ্রে সবচেয়ে চওড়া।
ax.axhline(P3, label=rf"MLE risk $=p={P3}$ (flat)") # constant
ax.plot(norms, r_js, "s-", label="James-Stein risk") # rises 2 -> p
ax.fill_between(norms, r_js, P3, alpha=0.12, # risk saved
label="risk saved by JS")
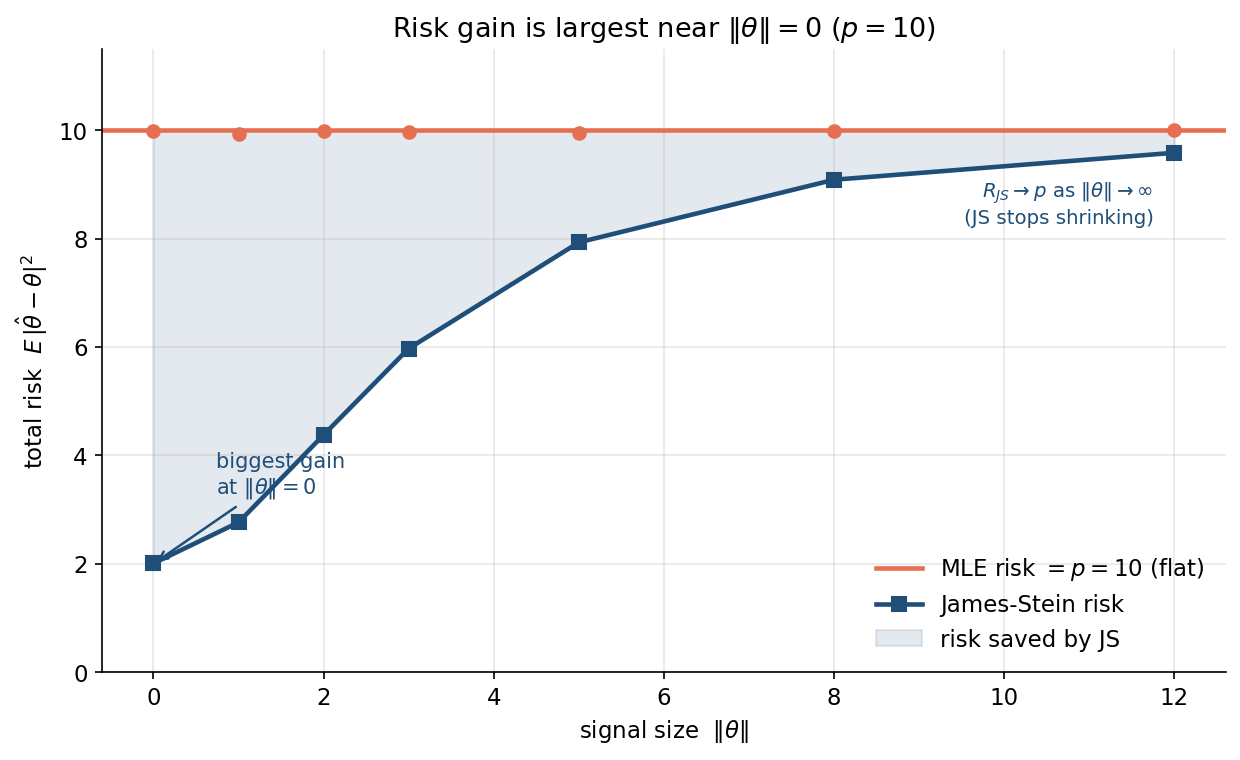
এটাই shrinkage-এর ন্যায্যতা ও সীমা একসাথে: JS কখনো হারে না (সর্বত্র \(\le p\)), কিন্তু সবচেয়ে বেশি জেতে যখন সত্যি \(\theta\) shrinkage-কেন্দ্রের কাছে। তাই বাস্তবে ভালো কেন্দ্র বাছা (এখানে ০, বা grand mean) গুরুত্বপূর্ণ — যদি জানা থাকে \(\theta\) কোথাও জড়ো, সেদিকেই shrink করলে সর্বোচ্চ লাভ।
৬.৪ · বাস্তব-ডেটা পুরস্কার — raw বনাম shrunk group-mean¶
চতুর্থ figure সিমুলেশন থেকে বাস্তবে নামে। বাঁ-প্যানেলে breast_cancer-এর ৩০টি feature-গড় (সত্য অনুসারে সাজানো): raw estimate \(X_i\) (কমলা বৃত্ত) grand-mean-রেখা (dashed)-এর দিকে টেনে shrunk \(\hat\theta^{JS}_i\) (নীল বর্গ)-তে নামানো; সবুজ রেখা সত্যিকারের \(\theta_i\)। ডান-প্যানেলে প্রত্যাশিত মোট MSE-র bar: raw \(3.61\) বনাম shrunk \(2.42\) — ৩৩% কম।
axL.axhline(target5, ls="--", label="grand mean (target)")
axL.plot(xc, X5[order], "o", label=r"raw mean $X_i$") # noisy
axL.plot(xc, js5[order], "s", label=r"shrunk $\hat\theta_{JS,i}$")
axR.bar(["raw\nmeans", "shrunk\n(James-Stein)"], # expected total MSE
[E_mse_raw, E_mse_js]) # 3.61 vs 2.42
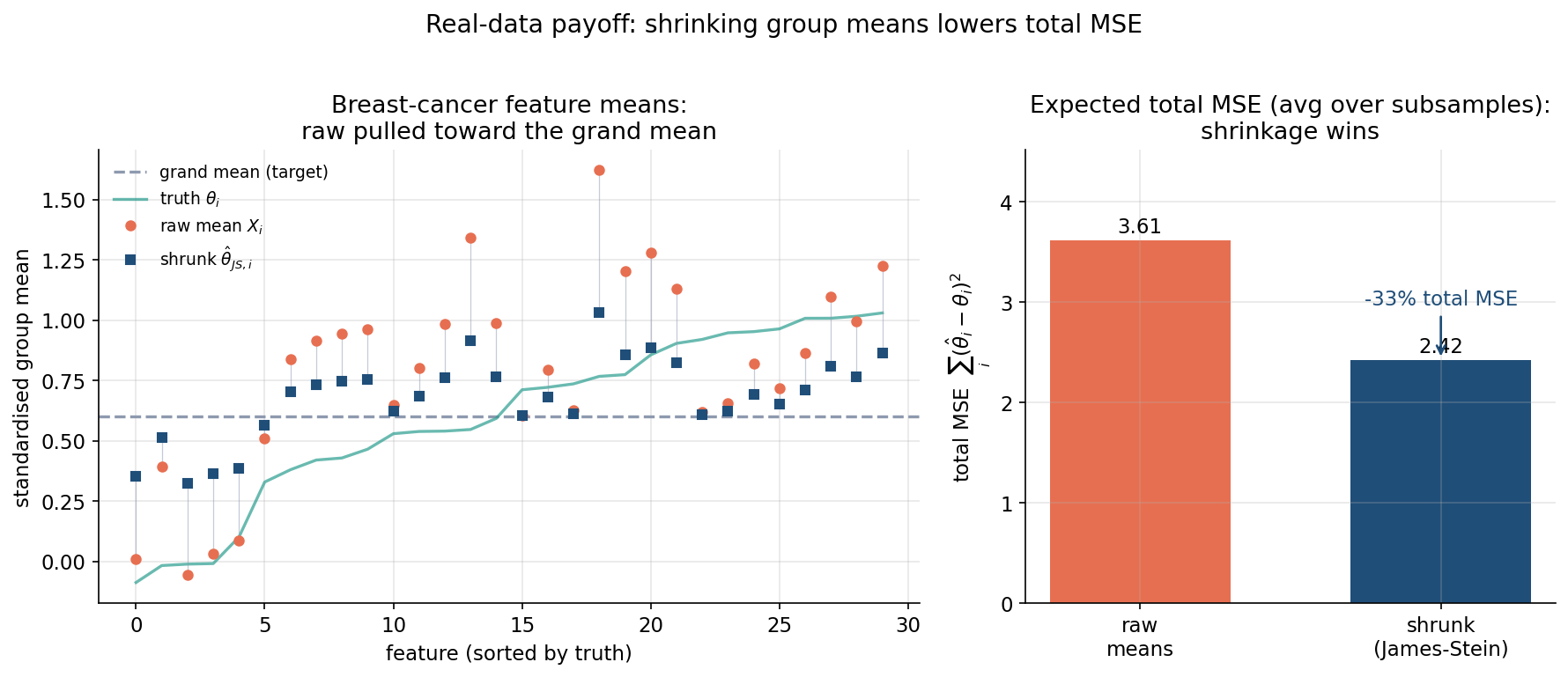
চারটি figure মিলিয়ে প্যারাডক্সের পূর্ণ গল্প: MLE-কে আলাদা-আলাদাভাবে estimate করলে risk \(=p\), কিন্তু যৌথভাবে কেন্দ্রের দিকে shrink করলে (৬.১) risk নামে; shrinkage মানে একটা common factor-এ কেন্দ্রের টান (৬.২); লাভ সর্বোচ্চ কেন্দ্রের কাছে অথচ কখনো ক্ষতি নয় (৬.৩); আর এই তত্ত্ব বাস্তব group-mean-এ সত্যিকারের MSE-সাশ্রয় দেয় (৬.৪) — এটাই Stein-এর প্যারাডক্সের পুনরুৎপাদন।
৭ · অনুশীলনী¶
নিচের অনুশীলনীগুলো এই অধ্যায়ের কেন্দ্রীয় ফল — Stein-এর প্যারাডক্স ও James–Stein estimator — যাচাই করে: কেন MLE \(\hat\theta=X\)-এর risk সর্বত্র \(p\), কেন \(p\ge3\)-তে JS \(\hat\theta^{JS}=(1-\frac{p-2}{\lVert X\rVert^2})X\) তাকে dominate করে (MLE inadmissible), কীভাবে SURE দিয়ে risk-পরিচয় \(p-(p-2)^2\mathbb E\frac1{\lVert X\rVert^2}\) বেরোয়, এবং shrinkage কীভাবে bias কিনে variance বেচে। সমস্যাগুলো চার দলে — ক (ধারণাগত), খ (গণনামূলক), গ (প্রমাণভিত্তিক), ঘ (কোডিং)। কঠিনতা-চিহ্ন: ★ মৌলিক, ★★ মাঝারি, ★★★ গভীর। প্রতিটিতে একটি Hint:।
পূর্ণাঙ্গ সমাধান (ধাপে-ধাপে, কোডসহ):
_solutions/08-03-paper-reproduction-solutions.md। আগে নিজে চেষ্টা করুন, তারপর মেলান।
প্রসঙ্গত গোটা অংশে \(X\sim N(\theta,I_p)\) (একটি observation); MLE \(\hat\theta^{MLE}=X\), risk \(R(\hat\theta,\theta)=\mathbb E\lVert\hat\theta-\theta\rVert^2\) (total MSE); James–Stein \(\hat\theta^{JS}=(1-\frac{p-2}{\lVert X\rVert^2})X\); SURE-পরিচয় \(R_{JS}(\theta)=p-(p-2)^2\mathbb E\frac1{\lVert X\rVert^2}\)। এখানে \(\lVert\cdot\rVert\) সর্বদা Euclidean norm (মডুলাস নয়, conditioning নয়)। সব সিমুলেশন seed np.random.default_rng(20260619)-এ। canonical মান: \(R_{MLE}\approx p\); \(R_{JS}(0)\approx2\) সব \(p\ge3\)-এ; \(p=10\)-তে ৮০%/ \(p=50\)-তে ৯৬% risk-হ্রাস (\(\theta=0\)); বাস্তব breast_cancer E[MSE] raw \(3.61\) → shrunk \(2.42\) (৩৩% হ্রাস, single-draw win \(75.8\%\))।
ক · ধারণাগত¶
অনুশীলন ১ (★)¶
\"MLE inadmissible\" মানে কী। (ক) এক-দুই বাক্যে বলুন admissibility ও dominance-এর সংজ্ঞা: একটা estimator \(\hat\theta_1\) কখন \(\hat\theta_2\)-কে dominate করে, আর কখন একটা estimator inadmissible। (খ) MLE \(\hat\theta=X\)-এর risk কেন প্রতিটি \(\theta\)-তে ঠিক \(p\) — এক বাক্যে। (গ) \"MLE inadmissible যখন \(p\ge3\)\" — এই বাক্যটা কেন একটা ধাক্কা: obvious, unbiased, সর্বত্র-ব্যবহৃত estimator-টা কেন \"অগ্রহণযোগ্য\" বলা হচ্ছে; এবং \(p=1,2\)-তে ছবিটা কেন আলাদা।
Hint: (ক) \(\hat\theta_1\) dominate করে \(\hat\theta_2\)-কে যদি \(R(\hat\theta_1,\theta)\le R(\hat\theta_2,\theta)\ \forall\theta\) ও কোথাও কঠোরভাবে কম; কোনো estimator তাকে dominate না করলে \(\hat\theta_2\) admissible, নাহলে inadmissible। (খ) \(\mathbb E\lVert X-\theta\rVert^2=\sum_i\operatorname{Var}(X_i)=p\)। (গ) JS সর্বত্র \(\le p\) ও কোথাও কম ⇒ MLE-কে dominate করে ⇒ MLE inadmissible (\(p\ge3\)); \(p\le2\)-তে \(p-2\le0\), JS-সূত্র উল্টো টান, MLE admissible।
অনুশীলন ২ (★★)¶
shrinkage = bias কিনে variance বেচা। (ক) 4.4-এর MSE=bias²+variance পচন ব্যবহার করে এক-দুই বাক্যে বলুন কেন MLE-র coordinate-প্রতি MSE = \(0+1=1\) (bias \(0\), variance \(1\))। (খ) JS estimate একটা factor \(c<1\) দিয়ে গুণ করলে coordinate-প্রতি variance কীভাবে বদলায় (factor \(c^2\)), আর bias কেন আর ০ নয় — এক বাক্যে। (গ) কেন এই বিনিময় উচ্চ মাত্রায় (\(p\ge3\)) মোট risk কমায়, অথচ \(p=1\)-এ নয় — স্বজ্ঞা এক-দুই বাক্যে (কেন \"অনেক coordinate একসাথে\" shrinkage-কে লাভজনক করে)।
Hint: (ক) unbiased (\(\mathbb E[X_i]=\theta_i\)) ⇒ bias \(0\); variance \(=\operatorname{Var}(X_i)=1\); MSE \(=1\) per coord, মোট \(p\)। (খ) \(\operatorname{Var}(cX_i)=c^2\operatorname{Var}(X_i)=c^2\) (কমে); কিন্তু \(\mathbb E[cX_i]=c\theta_i\ne\theta_i\) ⇒ bias \(=(c-1)\theta_i\ne0\)। (গ) \(p\) বড় হলে \(\lVert X\rVert^2\) ঘনীভূত ও factor স্থিতিশীলভাবে \(<1\), তাই বহু coordinate-এর variance-সাশ্রয় জমে bias²-খরচ ছাপায়; \(p=1\)-এ একটামাত্র coordinate, সাশ্রয় নেই (SURE-এ \(p-2<0\))।
অনুশীলন ৩ (★★)¶
JS ও empirical-Bayes/ridge-এর সম্পর্ক। (ক) 4.10-এর normal–normal conjugate থেকে: prior \(\theta_i\sim N(0,\tau^2)\) হলে posterior-mean কী (shrinkage factor \(\frac{\tau^2}{\tau^2+1}\)), এবং কেন এটি \"prior-কেন্দ্র ০-র দিকে টান\" — এক-দুই বাক্যে। (খ) JS কীভাবে এই Bayesian shrinkage-এর একটা empirical সংস্করণ — অর্থাৎ \(\tau^2\) না জেনে shrinkage-মাত্রা ডেটা (\(\lVert X\rVert^2\)) থেকে estimate করা — এক বাক্যে (কেন একে \"empirical Bayes\" বলে)। (গ) 6.2-এর ridge-এর সাথে সাদৃশ্য: ridge coefficient ও JS estimate — দুটোই কোন দর্শনে (bias–variance) একই, এক বাক্যে।
Hint: (ক) posterior \(\theta_i\mid X_i\sim N\big(\frac{\tau^2}{\tau^2+1}X_i,\cdot\big)\); factor \(\frac{\tau^2}{\tau^2+1}\in(0,1)\) estimate-কে ০-র দিকে টানে। (খ) marginally \(X_i\sim N(0,\tau^2+1)\), তাই \(\tau^2\)-কে \(\lVert X\rVert^2\) থেকে estimate করা যায়; সেই estimate বসালে ঠিক \(1-\frac{p-2}{\lVert X\rVert^2}\) — prior ডেটা থেকে শেখা বলে empirical Bayes। (গ) ridge \(\frac1{1+\lambda}\)-এ, JS \(1-\frac{p-2}{\lVert X\rVert^2}\)-এ shrink করে — উভয়ে একটু bias কিনে variance বেচে (← 6.2, 4.4)।
খ · গণনামূলক¶
অনুশীলন ৪ (★)¶
shrinkage factor ও JS estimate হাতে গণনা। \(p=6\), একটা draw-তে \(X=(2,-1,3,0,-2,1)\)। (ক) \(\lVert X\rVert^2\) বের করুন। (খ) shrinkage factor \(c=1-\frac{p-2}{\lVert X\rVert^2}\) নির্ণয় করুন। (গ) JS estimate \(\hat\theta^{JS}=cX\) লিখুন এবং যাচাই করুন এটি প্রতিটি coordinate-কে ০-র দিকে টেনেছে (মান কমেছে, চিহ্ন একই)।
Hint: (ক) \(\lVert X\rVert^2=4+1+9+0+4+1=19\)। (খ) \(c=1-\frac{4}{19}=1-0.2105=0.7895\)। (গ) \(\hat\theta^{JS}=0.7895\times(2,-1,3,0,-2,1)=(1.579,-0.789,2.368,0,-1.579,0.789)\) — প্রতিটি \(\lvert\hat\theta^{JS}_i\rvert<\lvert X_i\rvert\), চিহ্ন অপরিবর্তিত।
অনুশীলন ৫ (★)¶
\(R_{JS}(0)=2\) কেন — বদ্ধ-রূপ যাচাই। risk-পরিচয় \(R_{JS}(\theta)=p-(p-2)^2\mathbb E\frac1{\lVert X\rVert^2}\)। (ক) \(\theta=0\)-তে \(\lVert X\rVert^2\) কোন বণ্টন (← 2.6), আর \(\mathbb E\frac1{\lVert X\rVert^2}\) কত (\(p\ge3\))। (খ) বসিয়ে দেখান \(R_{JS}(0)=2\), সব \(p\ge3\)-এ। (গ) \(p=3,10,50\)-এর জন্য MLE-risk ও \(R_{JS}(0)\) পাশাপাশি লিখে risk-হ্রাসের শতাংশ বের করুন; মন্তব্য করুন কেন মাত্রা বাড়লে লাভ বাড়ে।
Hint: (ক) \(\theta=0\) ⇒ \(\lVert X\rVert^2\sim\chi^2_p\); \(\mathbb E\frac1{\chi^2_p}=\frac1{p-2}\) (\(p\ge3\))। (খ) \(R_{JS}(0)=p-(p-2)^2\cdot\frac1{p-2}=p-(p-2)=2\)। (গ) \(p=3\): \(3\to2\) (৩৩%); \(p=10\): \(10\to2\) (৮০%); \(p=50\): \(50\to2\) (৯৬%) — MLE-খরচ \(p\) বাড়ে কিন্তু \(R_{JS}(0)\) স্থির \(2\), তাই লাভ বাড়ে (§৫.১-এর সংখ্যার সাথে মিলিয়ে দেখুন)।
অনুশীলন ৬ (★★)¶
positive-part কখন লাগে। \(p=5\)। (ক) একটা draw-তে \(\lVert X\rVert^2=2\) হলে সাধারণ JS-এর factor কত, আর কেন তা সমস্যাজনক। (খ) positive-part JS (\(\max(0,\cdot)\)) সেই ক্ষেত্রে কী করে। (গ) এক বাক্যে: কেন positive-part JS সাধারণ JS-কেও dominate করে (কখনো বেশি risk নয়, কখনো কম)।
Hint: (ক) \(c=1-\frac{3}{2}=-0.5\) — ঋণাত্মক; estimate-কে ০-র উল্টো পাশে ঠেলে (চিহ্ন উল্টে) দেয়, যা সবসময় ক্ষতিকর। (খ) \(\max(0,-0.5)=0\) ⇒ estimate পুরো ০-তে (কেন্দ্রে)। (গ) factor ঋণাত্মক হওয়া মানে over-shrink; ০-তে থামালে সেই ক্ষেত্রে ত্রুটি কমে, বাকি সর্বত্র একই — তাই positive-part কখনো খারাপ নয়, কখনো ভালো।
গ · প্রমাণভিত্তিক¶
অনুশীলন ৭ (★★)¶
Stein's lemma প্রয়োগ। \(X\sim N(\theta,1)\) (এক-মাত্রা), Stein's lemma: \(\mathbb E[(X-\theta)g(X)]=\mathbb E[g'(X)]\)। (ক) \(g(X)=X\) নিয়ে দেখান lemma দেয় \(\mathbb E[(X-\theta)X]=1\), এবং সরাসরি হিসাব (\(\operatorname{Var}(X)+\theta\mathbb E[X-\theta]\)) দিয়েও একই পান। (খ) \(g(X)=X^2\) নিয়ে \(\mathbb E[(X-\theta)X^2]\) বের করুন lemma দিয়ে, এবং ব্যাখ্যা করুন এটি \(\mathbb E[X]\)-এর সাথে কীভাবে সম্পর্কিত। (গ) এক বাক্যে: কেন এই lemma-ই SURE-এর ভিত্তি — অর্থাৎ কীভাবে এটি \"\((X-\theta)\)-যুক্ত পদ\"-কে \"\(\theta\)-মুক্ত derivative-পদ\"-এ বদলায়।
Hint: (ক) \(g'(X)=1\) ⇒ \(\mathbb E[(X-\theta)X]=1\); সরাসরি \(\mathbb E[(X-\theta)X]=\mathbb E[(X-\theta)(X-\theta)]+\theta\mathbb E[X-\theta]=1+0=1\) ✓। (খ) \(g'(X)=2X\) ⇒ \(\mathbb E[(X-\theta)X^2]=2\mathbb E[X]=2\theta\)। (গ) lemma প্রত্যাশা থেকে \(\theta\) সরিয়ে দেয় (derivative-এ অনূদিত), তাই risk-এর cross-term \(\mathbb E[(X-\theta)g]\) একটা \(\theta\)-মুক্ত estimate পায় — SURE।
অনুশীলন ৮ (★★★)¶
James–Stein risk-পরিচয় নিজে বের করুন। SURE: \(\mathbb E\lVert\hat\theta-\theta\rVert^2=p+2\mathbb E[\nabla\!\cdot g]+\mathbb E\lVert g\rVert^2\), যেখানে \(\hat\theta=X+g(X)\)। JS-এ \(g(X)=-\frac{p-2}{\lVert X\rVert^2}X\)। (ক) \(\lVert g\rVert^2=\frac{(p-2)^2}{\lVert X\rVert^2}\) দেখান। (খ) \(\nabla\!\cdot g=-\frac{(p-2)^2}{\lVert X\rVert^2}\) দেখান (quotient-নিয়মে \(\frac{\partial}{\partial x_i}\frac{x_i}{\lVert x\rVert^2}\) হিসাব করে যোগ)। (গ) দুটো বসিয়ে \(\mathbb E\lVert\hat\theta^{JS}-\theta\rVert^2=p-(p-2)^2\mathbb E\frac1{\lVert X\rVert^2}\) পান, এবং এক বাক্যে বলুন কেন এটি \(p\ge3\)-তে \(<p\)।
Hint: (ক) \(\lVert g\rVert^2=(p-2)^2\frac{\sum x_i^2}{(\lVert x\rVert^2)^2}=\frac{(p-2)^2}{\lVert x\rVert^2}\)। (খ) \(\frac{\partial}{\partial x_i}\frac{x_i}{\lVert x\rVert^2}=\frac{\lVert x\rVert^2-2x_i^2}{(\lVert x\rVert^2)^2}\); যোগ \(\sum_i=\frac{p\lVert x\rVert^2-2\lVert x\rVert^2}{(\lVert x\rVert^2)^2}=\frac{p-2}{\lVert x\rVert^2}\); \(\times(-(p-2))\) দেয় \(-\frac{(p-2)^2}{\lVert x\rVert^2}\)। (গ) \(p+2(-A)+A=p-A\), \(A=(p-2)^2\mathbb E\frac1{\lVert X\rVert^2}>0\) (\(p\ge3\)) ⇒ \(<p\) (§৪ প্রমাণ ৩)।
অনুশীলন ৯ (★★★)¶
কেন \(p\ge3\) — তিন কোণ থেকে। এক-দুই বাক্যে করে ব্যাখ্যা করুন কেন প্যারাডক্স ঠিক \(p\ge3\)-এর ঘটনা, তিনটি স্বাধীন যুক্তিতে: (ক) shrinkage factor-এর দিক — \(p\le2\)-তে \(1-\frac{p-2}{\lVert X\rVert^2}\) কী করে (টানের দিক)। (খ) risk-পরিচয়ের সসীমতা — \(\theta=0\)-তে \(\mathbb E\frac1{\lVert X\rVert^2}=\mathbb E\frac1{\chi^2_p}\) কখন সসীম, আর \(p\le2\)-তে কী হয়। (গ) admissibility — \(p=1\)-এ MLE-র মর্যাদা (কেন এক-মাত্রায় \(X\) অকাট্য)।
Hint: (ক) \(p\le2\) ⇒ \(p-2\le0\) ⇒ factor \(\ge1\) ⇒ shrink নয়, প্রসারণ (estimate বড় করে), risk কমার কোনো পথ নেই। (খ) \(\mathbb E\frac1{\chi^2_p}=\frac1{p-2}\) সসীম কেবল \(p\ge3\); \(p=1,2\)-তে integral diverge (কেন্দ্রে density যথেষ্ট ভারী) — পরিচয়ের পদই অসংজ্ঞায়িত। (গ) \(p=1,2\)-তে MLE admissible (প্রমাণিত, Stein); এক-মাত্রায় কোনো estimator \(X\)-কে সর্বত্র হারায় না।
ঘ · কোডিং¶
সব স্নিপেট seed
np.random.default_rng(20260619)-এ; সংখ্যাগত উত্তর reproducible। import:import numpy as np; বাস্তব-ডেটায়from sklearn.datasets import load_breast_cancer।
অনুশীলন ১০ (★★)¶
Stein-এর প্যারাডক্স নিজে সিমুলেট করুন। \(p=10\), \(\theta=0\), REPS=20000। (ক) default_rng(20260619) দিয়ে \(X\sim N(0,I_{10})\) টেনে MLE (\(\hat\theta=X\)) ও JS (\(\hat\theta=(1-\frac{8}{\lVert X\rVert^2})X\))-এর মোট risk \(\mathbb E\lVert\hat\theta-\theta\rVert^2\) মাপুন। (খ) canonical-এর সাথে মেলান: \(R_{MLE}\approx9.96\), \(R_{JS}\approx1.98\) (≈৮০% হ্রাস)। (গ) এক বাক্যে ব্যাখ্যা করুন কেন \(R_{MLE}\approx p\) আর \(R_{JS}\) অনেক কম — প্যারাডক্স চোখে। চিত্র 8-3-risk-vs-p-এর সাথে মিলিয়ে দেখুন।
Hint: X=rng.standard_normal((20000,10)); sq=(X**2).sum(1,keepdims=True); js=(1-8/sq)*X; r_mle=((X-0)**2).sum(1).mean()≈9.96; r_js=((js-0)**2).sum(1).mean()≈1.98। MLE প্রতি coordinate variance \(1\) ⇒ মোট \(\approx10\); JS কেন্দ্রে জোরে shrink করে ⇒ risk \(\approx2\)। (canonical)
অনুশীলন ১১ (★★)¶
SURE-পরিচয় সংখ্যায় যাচাই। \(\theta=0\)-তে risk-পরিচয় \(R_{JS}(0)=p-(p-2)^2\mathbb E\frac1{\lVert X\rVert^2}=2\)। (ক) অনুশীলন ১০-এর draw থেকে \(\mathbb E\frac1{\lVert X\rVert^2}\)-এর Monte-Carlo মান বের করুন (\(p=10\)) এবং তত্ত্ব \(\frac1{p-2}=\frac18=0.125\)-এর সাথে মেলান (canonical \(\approx0.1252\))। (খ) SURE-মান \(p-(p-2)^2\cdot\overline{1/\lVert X\rVert^2}\) গণনা করে দেখান এটি \(\approx2\) (canonical SURE \(\approx1.99\))। (গ) এক বাক্যে: কেন Monte-Carlo \(R_{JS}\) ও SURE-মান কাছাকাছি হওয়া \"risk-পরিচয় সত্যি\" নিশ্চিত করে।
Hint: sq=(X**2).sum(1); e_inv=np.mean(1/sq)≈0.1252 (তত্ত্ব \(0.125\)); sure=10-(8**2)*e_inv≈\(10-64\times0.1252\approx1.99\)। SURE একটা unbiased risk-estimate, তাই তার গড় সত্যিকারের risk-এর কাছে — দুটো মিললে পরিচয় যাচাই। (canonical)
অনুশীলন ১২ (★)¶
বাস্তব-ডেটায় group-mean shrinkage। breast_cancer-এর ৩০টি standardized feature-গড় নিয়ে raw বনাম grand-mean-এর দিকে shrunk estimate-এর প্রত্যাশিত মোট MSE তুলনা করুন। (ক) §৫.৪-এর কাঠামো (subsample \(n=8\), default_rng(20260619), \(B=4000\)) চালিয়ে E[MSE raw] ও E[MSE shrunk] বের করুন। (খ) canonical-এর সাথে মেলান: raw \(\approx3.61\), shrunk \(\approx2.42\) (≈৩৩% হ্রাস), single-draw win \(\approx75.8\%\)। (গ) এক বাক্যে: কেন একক draw-তে shrinkage সবসময় জেতে না (৭৫.৮%, ১০০% নয়), যেখানে প্রত্যাশিত MSE-তে জেতে — dominance-এর প্রকৃতি।
Hint: §৫.৪-এর কোড হুবহু চালান; E[MSE raw]≈3.61, E[MSE js]≈2.42, reduction≈33%, win rate≈75.8%। dominance একটা প্রত্যাশিত-risk (গড়) বিবৃতি; একটা \"ভাগ্যবান\" raw draw (সত্যি \(\theta\)-এর কাছে) shrink করলে খারাপ হতে পারে, কিন্তু গড়ে shrinkage জেতে (§৩ উদাহরণ ৩)। (canonical)
৮ · সারসংক্ষেপ ও সংযোগ¶
এই অধ্যায় একটা পূর্ণাঙ্গ পুনরুৎপাদন-প্রকল্প সম্পূর্ণ করল — পরিসংখ্যানের সবচেয়ে বিস্ময়কর ফলগুলোর একটা, Stein-এর প্যারাডক্স ও James–Stein estimator, শূন্য থেকে পড়া→বোঝা→প্রমাণ→কোডে যাচাই। চলুন সুতোটা গেঁথে নিই।
৮.১ যুক্তি-শৃঙ্খলের পুনরাবৃত্তি।
- setup ও প্যারাডক্স। \(X_i\sim N(\theta_i,1)\), \(i=1..p\), প্রতিটির একটি observation; obvious estimator MLE \(\hat\theta^{MLE}=X\) (risk সর্বত্র \(p\))। Stein (1956): \(p\ge3\)-তে James–Stein \(\hat\theta^{JS}=(1-\frac{p-2}{\lVert X\rVert^2})X\) — সব estimate ০-র দিকে সংকুচিত — প্রতিটি \(\theta\)-তে MLE-কে dominate করে (\(R_{JS}\le p\), কোথাও কম); তাই MLE inadmissible। এমনকি coordinate-গুলো অসম্পর্কিত হলেও যৌথ shrinkage জেতে।
- কেন কাজ করে — bias–variance। shrinkage সামান্য bias কিনে অনেক variance বেচে (← 4.4-এর MSE=bias²+var); \(p\ge3\)-তে variance-সাশ্রয় জেতে। এটি ঠিক ridge-regularization-এর (← 6.2) ও empirical-Bayes shrinkage-এর (← 4.10 — prior \(N(0,\tau^2)\), shrinkage-মাত্রা ডেটা থেকে) একই দর্শন — JS তাদের পূর্বপুরুষ।
- SURE ও risk-পরিচয়। Stein's lemma (\(\mathbb E[(X-\theta)g(X)]=\mathbb E[g'(X)]\), integration-by-parts) দিয়ে SURE — risk-এর \(\theta\)-মুক্ত unbiased estimate \(p+2\nabla\!\cdot g+\lVert g\rVert^2\)। JS-এ বসিয়ে \(\mathbb E\lVert\hat\theta^{JS}-\theta\rVert^2=p-(p-2)^2\mathbb E\frac1{\lVert X\rVert^2}\le p\); বিশেষত \(\theta=0\)-তে (\(\lVert X\rVert^2\sim\chi^2_p\), \(\mathbb E\frac1{\chi^2_p}=\frac1{p-2}\)) \(R_{JS}(0)=p-(p-2)=2\) — সব \(p\ge3\)-এ। এটাই dominance ও \"কেন \(p\ge3\)\" (নাহলে \(p-2\le0\), বা \(\mathbb E\frac1{\chi^2_p}\) অসীম)।
- empirical পুনরুৎপাদন। Monte-Carlo (seed 20260619): MLE-risk \(\approx p\) বনাম JS-risk \(<p\) (\(p=50\)-তে ৯৬% হ্রাস, \(\theta=0\)); SURE-মান MC-risk-এর সাথে মেলে; লাভ কেন্দ্রে সর্বোচ্চ (\(p=10\): \(\lVert\theta\rVert=0\)-তে ৮০%, \(\lVert\theta\rVert=12\)-তে ৪%), \(\lVert\theta\rVert\to\infty\)-এ \(R_{JS}\to p\)। বাস্তব breast_cancer group-mean shrinkage: E[MSE] \(3.61\to2.42\) (৩৩% হ্রাস, ৭৫.৮% single-draw win)।
৮.২ মূল উপপাদ্য/তথ্য (mini-list)।
- MLE-র risk। \(R(\hat\theta^{MLE},\theta)=\mathbb E\lVert X-\theta\rVert^2=p\) প্রতিটি \(\theta\)-তে (সমতল)।
- James–Stein। \(\hat\theta^{JS}=(1-\frac{p-2}{\lVert X\rVert^2})X\); positive-part \(\hat\theta^{JS+}=(1-\frac{p-2}{\lVert X\rVert^2})^+X\) (সাধারণ JS-কেও dominate করে)।
- dominance/inadmissibility। \(p\ge3\): \(R_{JS}(\theta)<p\ \forall\theta\) ⇒ MLE inadmissible; \(p\le2\): MLE admissible।
- Stein's lemma। \(X\sim N(\theta,1)\), \(\mathbb E[(X-\theta)g(X)]=\mathbb E[g'(X)]\)।
- SURE। \(\hat\theta=X+g(X)\) ⇒ \(\mathbb E\lVert\hat\theta-\theta\rVert^2=\mathbb E[p+2\nabla\!\cdot g+\lVert g\rVert^2]\) (\(\theta\)-মুক্ত)।
- JS risk-পরিচয়। \(\mathbb E\lVert\hat\theta^{JS}-\theta\rVert^2=p-(p-2)^2\mathbb E\frac1{\lVert X\rVert^2}\le p\); \(\theta=0\)-তে \(=2\) সব \(p\ge3\)-এ।
- empirical-Bayes। prior \(N(0,\tau^2)\) ⇒ posterior-mean shrinkage \(\frac{\tau^2}{\tau^2+1}X_i\); \(\tau^2\) ডেটা-চালিত ⇒ JS।
- canonical সংখ্যা। \(R_{MLE}\approx p\); \(R_{JS}(0)\approx2\ \forall p\ge3\); \(p=10\)-তে ৮০%/ \(p=50\)-তে ৯৬% risk-হ্রাস (\(\theta=0\)); বাস্তব breast_cancer E[MSE] raw \(3.61\) → shrunk \(2.42\) (৩৩% হ্রাস, single-draw win \(75.8\%\)); seed
default_rng(20260619)।
৮.৩ সংযোগ — পেছনে ও সামনে।
- ← 4.4 (MSE, bias–variance)। প্যারাডক্সের হৃৎস্পন্দন: risk = total MSE, আর MSE=bias²+variance-ই ব্যাখ্যা করে কেন shrinkage জেতে (একটু bias কিনে অনেক variance বেচা)। MLE unbiased-optimality-র সীমা এখানে নাটকীয়ভাবে দৃশ্যমান।
- ← 4.10 (Bayesian inference)। JS = empirical-Bayes shrinkage — prior \(N(0,\tau^2)\)-এর posterior-mean টান, shrinkage-মাত্রা ডেটা থেকে শেখা। প্যারাডক্স \"জাদু\" থেকে \"স্বাভাবিক\" হয় বেইজীয় চোখে।
- ← 6.2 (Ridge/Lasso regularization)। JS হলো shrinkage estimation-এর জন্মদাতা (1961); ridge (1970) তার regression-সংস্করণ। \(1-\frac{p-2}{\lVert X\rVert^2}\) ও \(\frac1{1+\lambda}\) — একই bias–variance দর্শনের দুই মুখ; high-dimensional পরিসংখ্যানে shrinkage কেন অপরিহার্য তার আদি-উদাহরণ।
- ← 2.6 (Normal ও chi-square)। setup \(N(\theta,I_p)\)-এর উপর, risk-পরিচয়ের কেন্দ্র \(\lVert X\rVert^2\sim\chi^2_p\) (\(\theta=0\)) ও তার inverse-moment \(\frac1{p-2}\) — \"কেন \(p\ge3\)\"-এর উৎস।
- → Part VIII (বাকি ক্যাপস্টোন)। এটি একটা পুনরুৎপাদন-মহড়া: একটা প্রকাশিত ফল নিয়ে তা যাচাই-প্রমাণ-কোডে-ফিরে-পাওয়ার পূর্ণ চক্র — যা যেকোনো গবেষণা-প্রকল্পের কেন্দ্রীয় দক্ষতা। একই পদ্ধতি (তত্ত্ব→প্রমাণ→সিমুলেশন→বাস্তব-ডেটা) Part VIII-এর বাকি capstone কাজে প্রয়োগ হবে।
উৎস। Stein, C. (1956), Inadmissibility of the usual estimator for the mean of a multivariate normal distribution — মূল আবিষ্কার (MLE inadmissible, \(p\ge3\)); James, W. & Stein, C. (1961), Estimation with quadratic loss — স্পষ্ট estimator \(\hat\theta^{JS}=(1-\frac{p-2}{\lVert X\rVert^2})X\) ও risk-পরিচয় \(p-(p-2)^2\mathbb E\frac1{\lVert X\rVert^2}\); Efron, B. & Morris, C. (1977), Stein's paradox in statistics (ও 1975, JASA) — স্বজ্ঞা, empirical-Bayes ব্যাখ্যা, ও বাস্তব প্রয়োগ (baseline group-mean shrinkage)।
এক বাক্যে (পুরো অধ্যায়)। \(X_i\sim N(\theta_i,1)\)-এর obvious estimator MLE \(\hat\theta=X\) (risk \(p\)) \(p\ge3\)-তে inadmissible — James–Stein \(\hat\theta^{JS}=(1-\frac{p-2}{\lVert X\rVert^2})X\) সব estimate ০-র দিকে সংকুচিত করে প্রতিটি \(\theta\)-তে তাকে dominate করে (SURE-পরিচয় \(p-(p-2)^2\mathbb E\frac1{\lVert X\rVert^2}\le p\), \(\theta=0\)-তে \(=2\)), কারণ shrinkage একটু bias কিনে অনেক variance বেচে (ridge/empirical-Bayes-এর আদি-রূপ) — আর এই ধ্রুপদী ফল Monte-Carlo সিমুলেশনে (MLE-risk \(\approx p\) বনাম JS-risk \(<p\), \(p=50\)-তে ৯৬% হ্রাস) ও বাস্তব breast_cancer group-mean shrinkage-এ (E[MSE] \(3.61\to2.42\), ৩৩% হ্রাস) সম্পূর্ণ পুনরুৎপাদিত।